fast autoaugment
1.0.0
Implementação oficial de rápida auto -agrupamento em Pytorch.
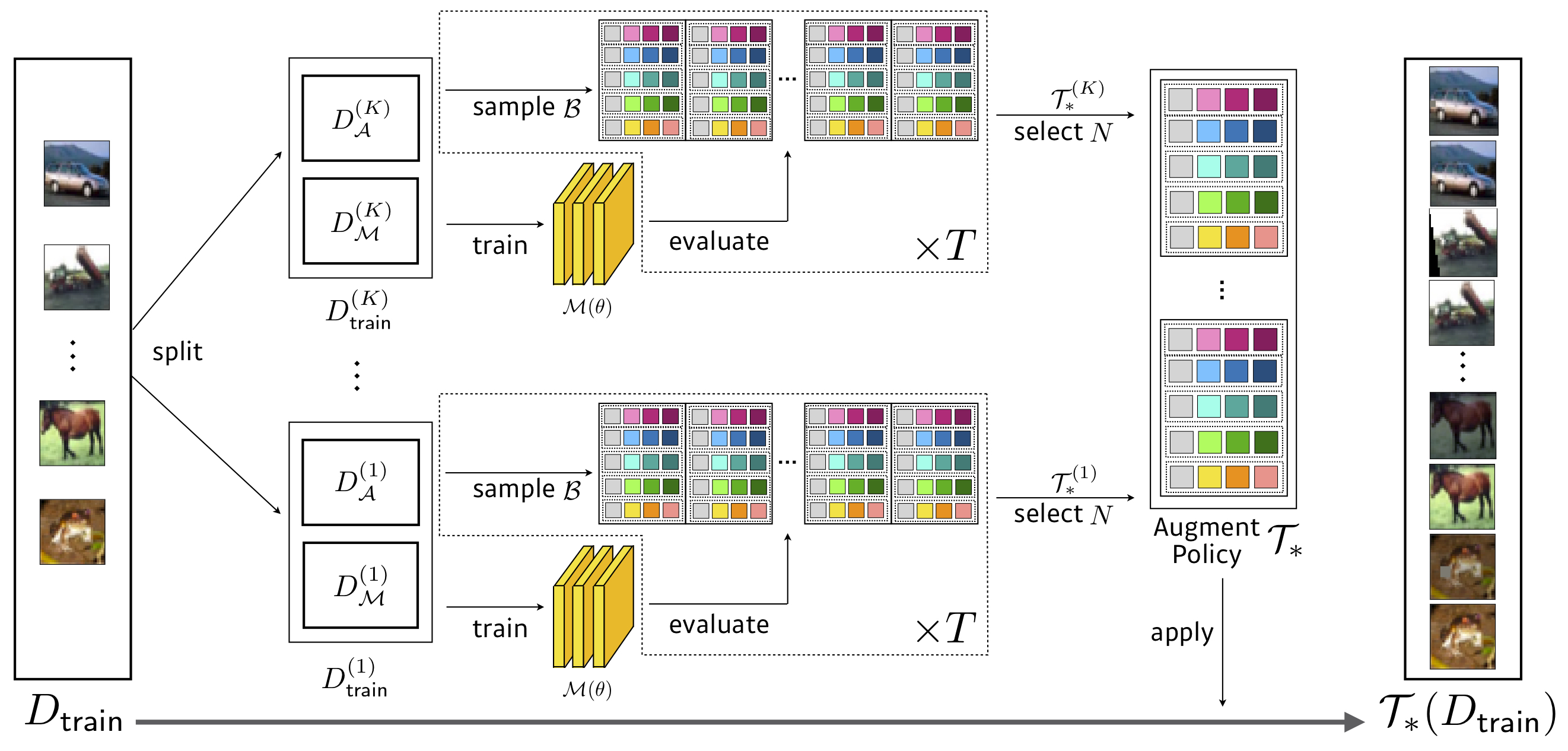
Pesquisa: 3,5 Horas de GPU (1428x mais rápido que o AutoAgment) , WRESNET-40X2 em CIFAR-10 reduzido
| Modelo (CIFAR-10) | Linha de base | Recortar | Autoaugment | Rápido Autoaugment (transferência/direto) | |
|---|---|---|---|---|---|
| Larga-ressente-40-2 | 5.3 | 4.1 | 3.7 | 3.6 / 3.7 | Download |
| Loja de resistência 28-10 | 3.9 | 3.1 | 2.6 | 2.7 / 2.7 | Download |
| Shake-shake (26 2x32d) | 3.6 | 3.0 | 2.5 | 2.7 / 2.5 | Download |
| Shake-shake (26 2x96D) | 2.9 | 2.6 | 2.0 | 2.0 / 2.0 | Download |
| Shake-shake (26 2x112d) | 2.8 | 2.6 | 1.9 | 2.0 / 1.9 | Download |
| Piramidnet+shakedrop | 2.7 | 2.3 | 1.5 | 1.8 / 1.7 | Download |
| Modelo (CIFAR-100) | Linha de base | Recortar | Autoaugment | Rápido Autoaugment (transferência/direto) | |
|---|---|---|---|---|---|
| Larga-ressente-40-2 | 26.0 | 25.2 | 20.7 | 20.7 / 20.6 | Download |
| Loja de resistência 28-10 | 18.8 | 18.4 | 17.1 | 17.3 / 17.3 | Download |
| Shake-shake (26 2x96D) | 17.1 | 16.0 | 14.3 | 14.9 / 14.6 | Download |
| Piramidnet+shakedrop | 14.0 | 12.2 | 10.7 | 11.9 / 11.7 | Download |
Pesquisa: 450 Horas de GPU (33x mais rápido que o AutoAgment) , Resnet-50 em ImageNet reduzido
| Modelo | Linha de base | Autoaugment | Rápido Autoaugment (TOP1/TOP5) | |
|---|---|---|---|---|
| Resnet-50 | 23.7 / 6.9 | 22.4 / 6.2 | 22.4 / 6.3 | Download |
| Resnet-200 | 21.5 / 5.8 | 20.0 / 5.0 | 19.4 / 4.7 | Download |
Notas
Realizamos experimentos adicionais com eficientes.
| Modelo | Linha de base | Autoaugment | Nossa linha de base (lote) | +Rápido aa | |
|---|---|---|---|---|---|
| B0 | 23.2 | 22.7 | 22.96 | 22.68 |
Pesquisa: 1,5 horas de GPU
| Linha de base | Autoaug / Our | Rápido Autoaugment | |
|---|---|---|---|
| Wide-RESNET28X10 | 1.5 | 1.1 | 1.1 |
Realizamos experimentos sob
Leia o documento de Ray para construir um cluster de raios adequado: https://github.com/ray-project/ray e execute o search.py com o endereço Redis do mestre.
$ python search.py -c confs/wresnet40x2_cifar10_b512.yaml --dataroot ... --redis ...
Você pode treinar arquiteturas de rede no CIFAR-10 /100 e imagenet com nossas políticas pesquisadas.
$ export PYTHONPATH=$PYTHONPATH:$PWD
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet40x2_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar10
$ python FastAutoAugment/train.py -c confs/wresnet28x10_cifar10_b512.yaml --aug fa_reduced_cifar10 --dataset cifar100
...
$ python FastAutoAugment/train.py -c confs/resnet50_b512.yaml --aug fa_reduced_imagenet
$ python FastAutoAugment/train.py -c confs/resnet200_b512.yaml --aug fa_reduced_imagenet
Ao adicionar argumentos-apenas-eventos e--salvar, você pode testar modelos treinados sem treinamento.
Se você deseja treinar com multi-gpu/nó, use torch.distributed.launch como
$ python -m torch.distributed.launch --nproc_per_node={num_gpu_per_node} --nnodes={num_node} --master_addr={master} --master_port={master_port} --node_rank={0,1,2,...,num_node} FastAutoAugment/train.py -c confs/efficientnet_b4.yaml --aug fa_reduced_imagenetSe você usar este código em sua pesquisa, cite nosso artigo.
@inproceedings{lim2019fast,
title={Fast AutoAugment},
author={Lim, Sungbin and Kim, Ildoo and Kim, Taesup and Kim, Chiheon and Kim, Sungwoong},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2019}
}
Aumentamos o tamanho do lote e adaptamos a taxa de aprendizado de acordo para aumentar o treinamento. Caso contrário, definimos outros hiperparâmetros iguais ao agrupamento automático, se possível. Para os hiperparâmetros desconhecidos, seguimos os valores das referências originais ou as sintonizamos para corresponder às performances da linha de base.


