External Attention pytorch
1.0.0

简体中文 | English
Hello,大家好,我是小马
For 小白(Like Me): 最近在读论文的时候会发现一个问题,有时候论文核心思想非常简单,核心代码可能也就十几行。但是打开作者release的源码时,却发现提出的模块嵌入到分类、检测、分割等任务框架中,导致代码比较冗余,对于特定任务框架不熟悉的我,很难找到核心代码,导致在论文和网络思想的理解上会有一定困难。
For 进阶者(Like You): 如果把Conv、FC、RNN这些基本单元看做小的Lego积木,把Transformer、ResNet这些结构看成已经搭好的Lego城堡。那么本项目提供的模块就是一个个具有完整语义信息的Lego组件。让科研工作者们避免反复造轮子,只需思考如何利用这些“Lego组件”,搭建出更多绚烂多彩的作品。
For 大神(May Be Like You): 能力有限,不喜轻喷!!!
For All: 本项目致力于实现一个既能让深度学习小白也能搞懂,又能服务科研和工业社区的代码库。
直接通过 pip 安装
pip install fightingcv-attention或克隆该仓库
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorchimport torch
from torch import nn
from torch.nn import functional as F
# 使用 pip 方式
from fightingcv_attention.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)import torch
from torch import nn
from torch.nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)Attention Series
1. External Attention Usage
2. Self Attention Usage
3. Simplified Self Attention Usage
4. Squeeze-and-Excitation Attention Usage
5. SK Attention Usage
6. CBAM Attention Usage
7. BAM Attention Usage
8. ECA Attention Usage
9. DANet Attention Usage
10. Pyramid Split Attention (PSA) Usage
11. Efficient Multi-Head Self-Attention(EMSA) Usage
12. Shuffle Attention Usage
13. MUSE Attention Usage
14. SGE Attention Usage
15. A2 Attention Usage
16. AFT Attention Usage
17. Outlook Attention Usage
18. ViP Attention Usage
19. CoAtNet Attention Usage
20. HaloNet Attention Usage
21. Polarized Self-Attention Usage
22. CoTAttention Usage
23. Residual Attention Usage
24. S2 Attention Usage
25. GFNet Attention Usage
26. Triplet Attention Usage
27. Coordinate Attention Usage
28. MobileViT Attention Usage
29. ParNet Attention Usage
30. UFO Attention Usage
31. ACmix Attention Usage
32. MobileViTv2 Attention Usage
33. DAT Attention Usage
34. CrossFormer Attention Usage
35. MOATransformer Attention Usage
36. CrissCrossAttention Attention Usage
37. Axial_attention Attention Usage
Backbone Series
1. ResNet Usage
2. ResNeXt Usage
3. MobileViT Usage
4. ConvMixer Usage
5. ShuffleTransformer Usage
6. ConTNet Usage
7. HATNet Usage
8. CoaT Usage
9. PVT Usage
10. CPVT Usage
11. PIT Usage
12. CrossViT Usage
13. TnT Usage
14. DViT Usage
15. CeiT Usage
16. ConViT Usage
17. CaiT Usage
18. PatchConvnet Usage
19. DeiT Usage
20. LeViT Usage
21. VOLO Usage
22. Container Usage
23. CMT Usage
24. EfficientFormer Usage
25. ConvNeXtV2 Usage
MLP Series
1. RepMLP Usage
2. MLP-Mixer Usage
3. ResMLP Usage
4. gMLP Usage
5. sMLP Usage
6. vip-mlp Usage
Re-Parameter(ReP) Series
1. RepVGG Usage
2. ACNet Usage
3. Diverse Branch Block(DDB) Usage
Convolution Series
1. Depthwise Separable Convolution Usage
2. MBConv Usage
3. Involution Usage
4. DynamicConv Usage
5. CondConv Usage
Pytorch implementation of "Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"
Pytorch implementation of "Attention Is All You Need---NIPS2017"
Pytorch implementation of "Squeeze-and-Excitation Networks---CVPR2018"
Pytorch implementation of "Selective Kernel Networks---CVPR2019"
Pytorch implementation of "CBAM: Convolutional Block Attention Module---ECCV2018"
Pytorch implementation of "BAM: Bottleneck Attention Module---BMCV2018"
Pytorch implementation of "ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"
Pytorch implementation of "Dual Attention Network for Scene Segmentation---CVPR2019"
Pytorch implementation of "EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"
Pytorch implementation of "ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"
Pytorch implementation of "SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"
Pytorch implementation of "MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"
Pytorch implementation of "Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"
Pytorch implementation of "A2-Nets: Double Attention Networks---NIPS2018"
Pytorch implementation of "An Attention Free Transformer---ICLR2021 (Apple New Work)"
Pytorch implementation of VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24" 【论文解析】
Pytorch implementation of Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23 【论文解析】
Pytorch implementation of CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09 【论文解析】
Pytorch implementation of Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral 【论文解析】
Pytorch implementation of Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02 【论文解析】
Pytorch implementation of Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26 【论文解析】
Pytorch implementation of Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021
Pytorch implementation of S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02 【论文解析】
Pytorch implementation of Global Filter Networks for Image Classification---arXiv 2021.07.01
Pytorch implementation of Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021
Pytorch implementation of Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021
Pytorch implementation of MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05
Pytorch implementation of Non-deep Networks---ArXiv 2021.10.20
Pytorch implementation of UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29
Pytorch implementation of Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06
Pytorch implementation of On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14
Pytorch implementation of CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022
Pytorch implementation of Aggregating Global Features into Local Vision Transformer
Pytorch implementation of CCNet: Criss-Cross Attention for Semantic Segmentation
Pytorch implementation of Axial Attention in Multidimensional Transformers
"Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"
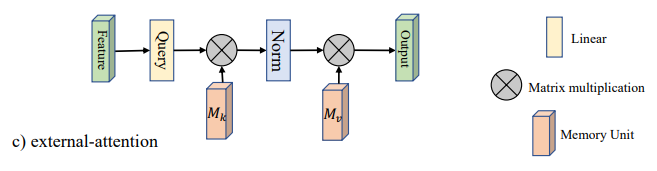
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)"Attention Is All You Need"
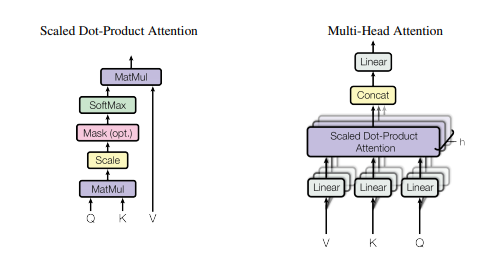
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)None
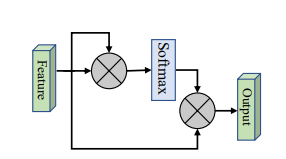
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)"Squeeze-and-Excitation Networks"
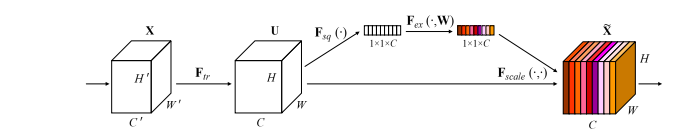
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)"Selective Kernel Networks"
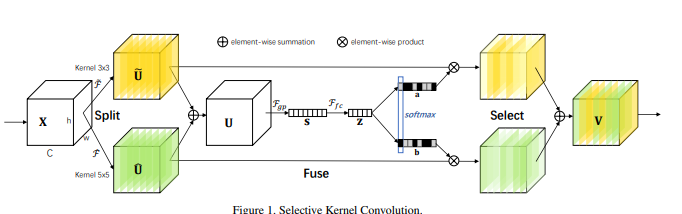
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)"CBAM: Convolutional Block Attention Module"
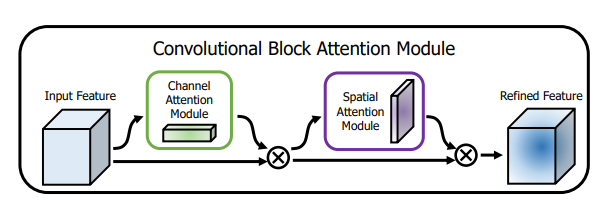
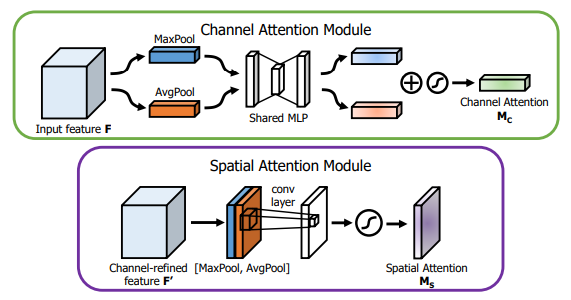
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)"BAM: Bottleneck Attention Module"
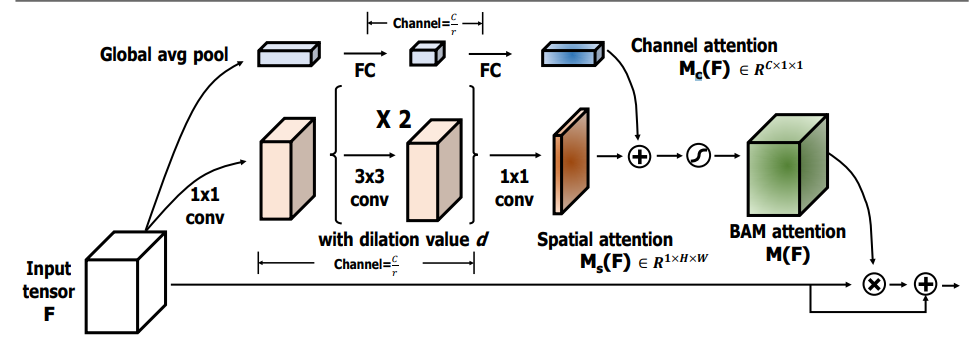
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)"ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"
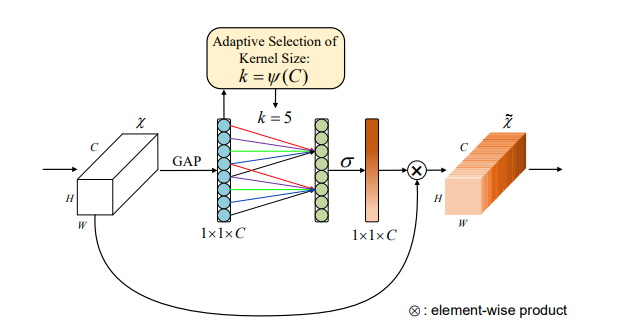
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)"Dual Attention Network for Scene Segmentation"
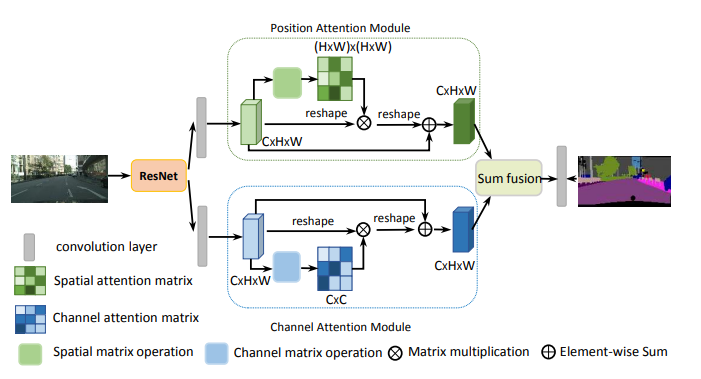
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)"EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"
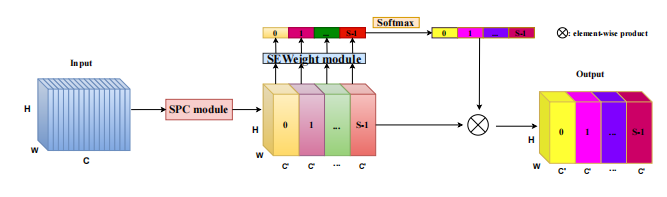
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)"ResT: An Efficient Transformer for Visual Recognition"
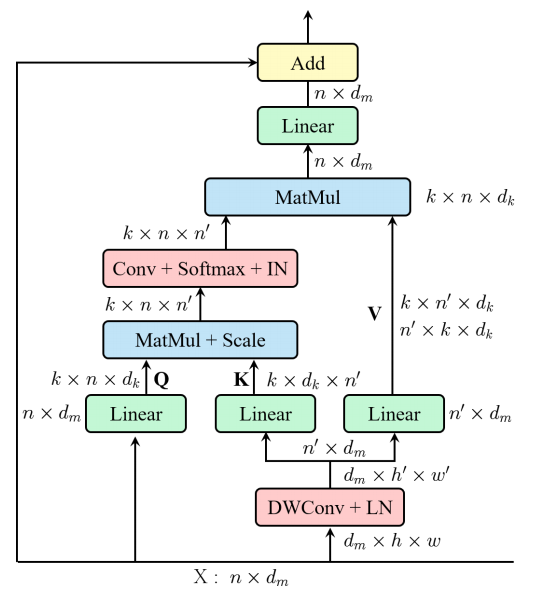
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
"SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"
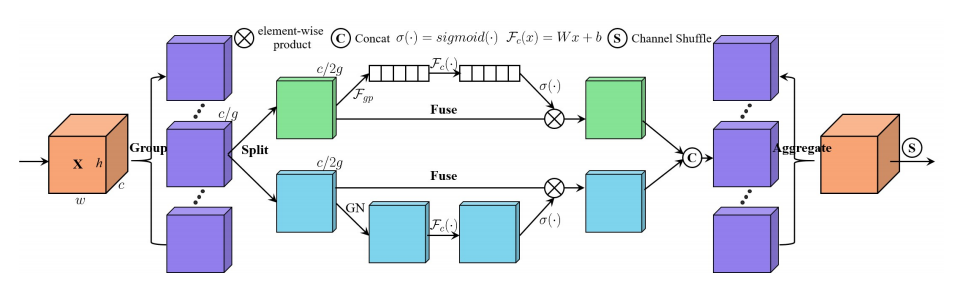
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
"MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
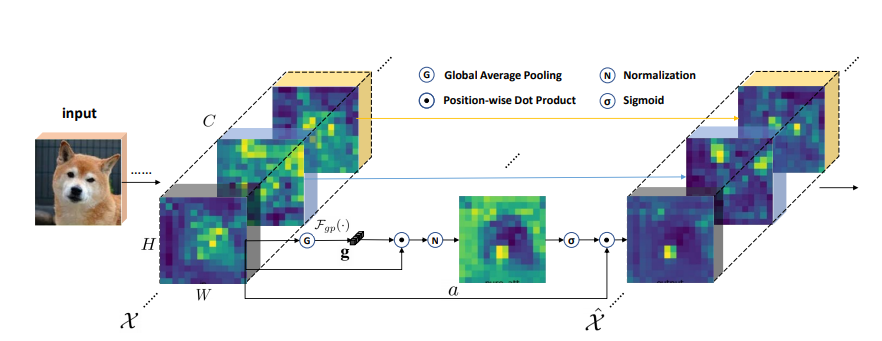
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)A2-Nets: Double Attention Networks
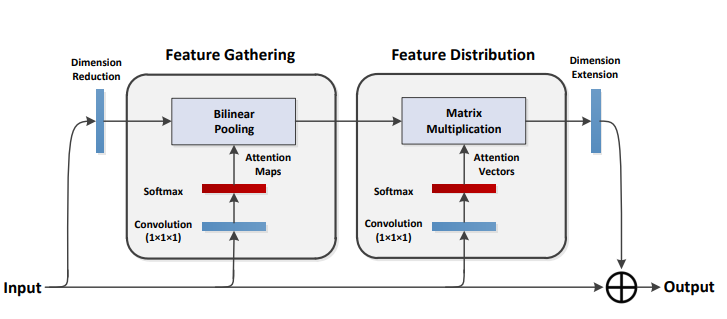
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)An Attention Free Transformer
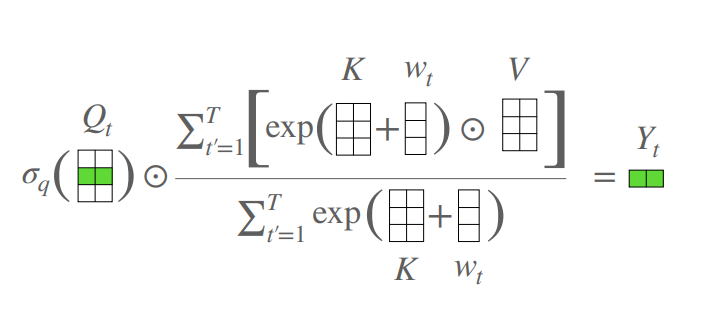
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)VOLO: Vision Outlooker for Visual Recognition"
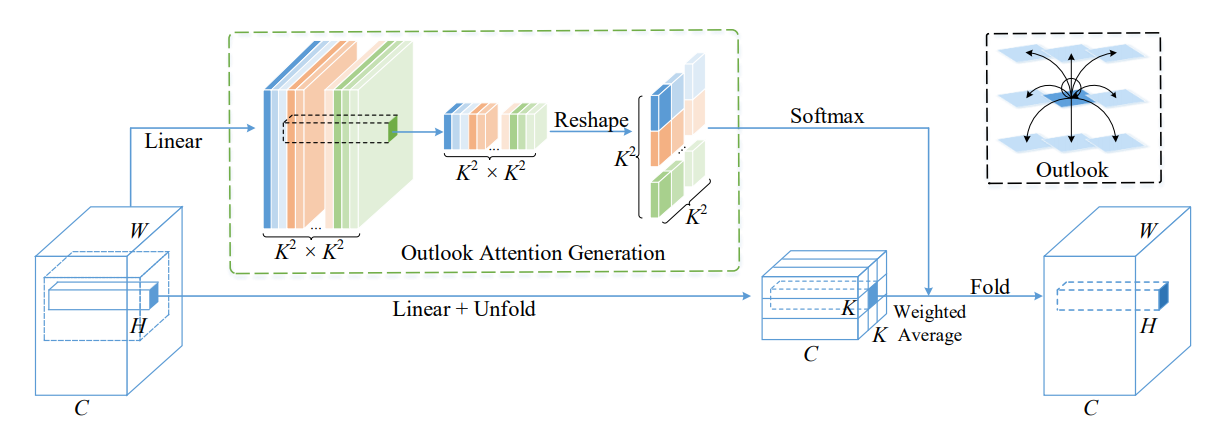
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"
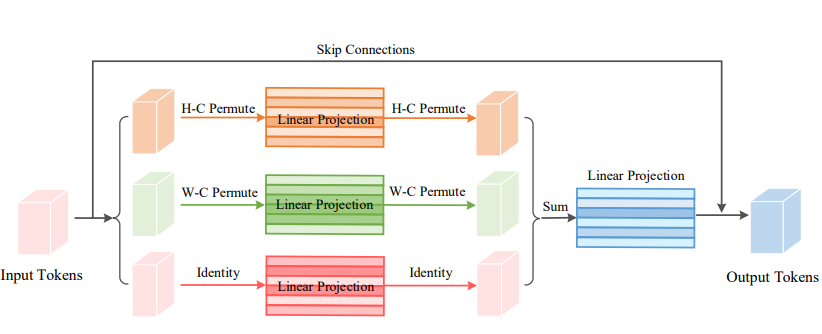
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)CoAtNet: Marrying Convolution and Attention for All Data Sizes"
None
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)Scaling Local Self-Attention for Parameter Efficient Visual Backbones"
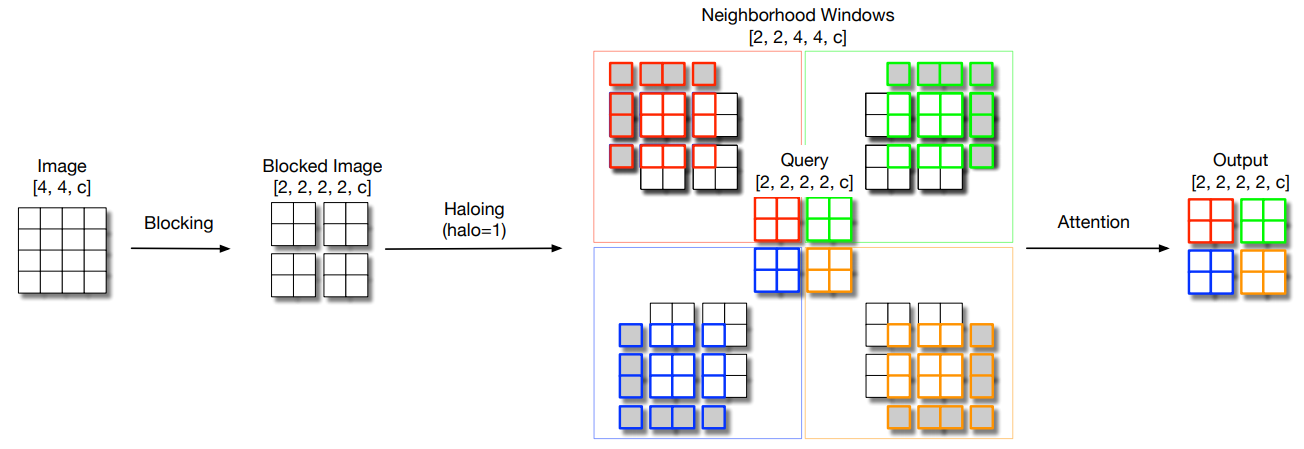
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)Polarized Self-Attention: Towards High-quality Pixel-wise Regression"
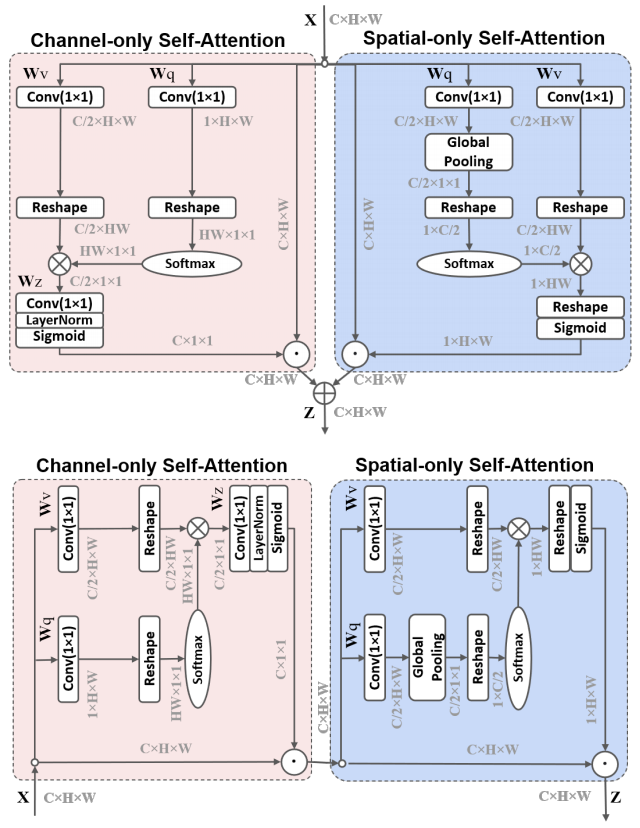
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26
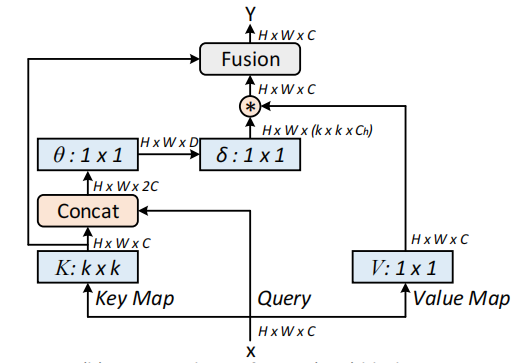
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021
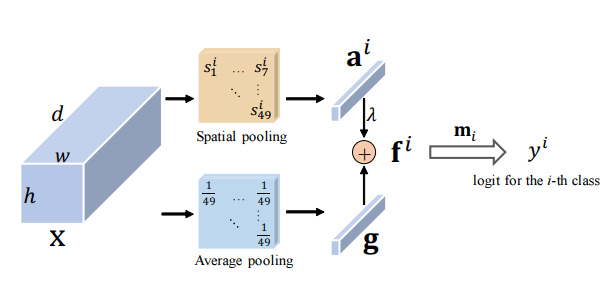
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02
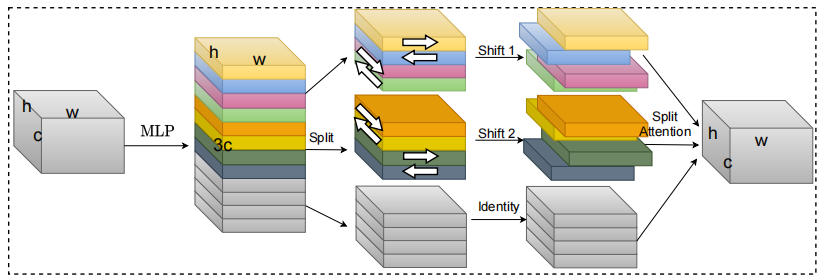
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)Global Filter Networks for Image Classification---arXiv 2021.07.01
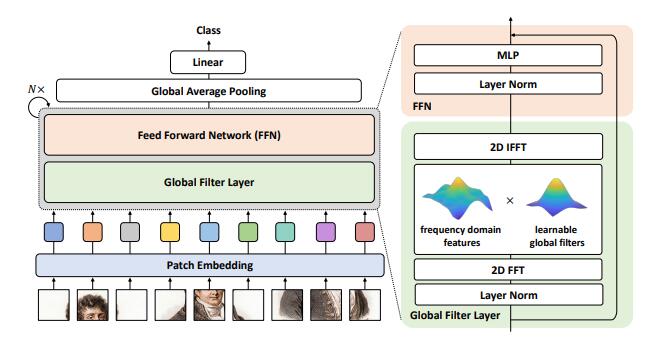
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021
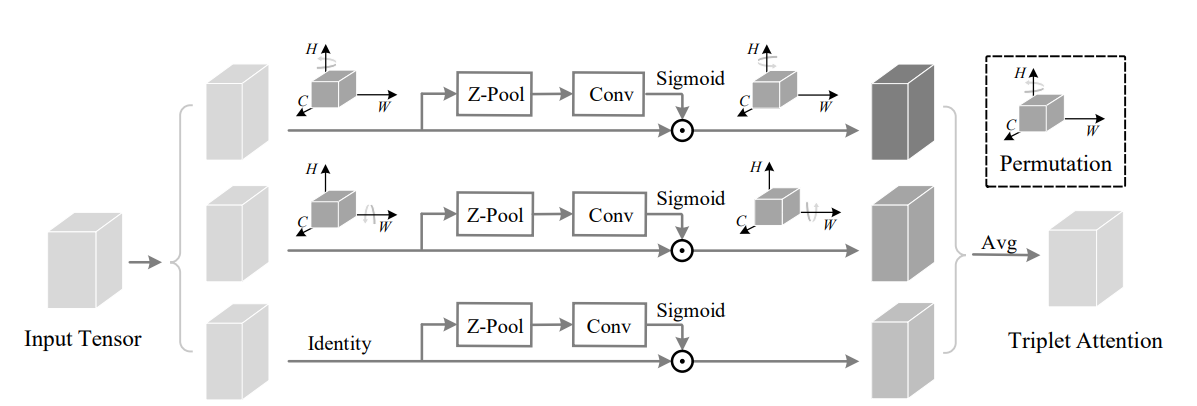
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)Coordinate Attention for Efficient Mobile Network Design---CVPR 2021
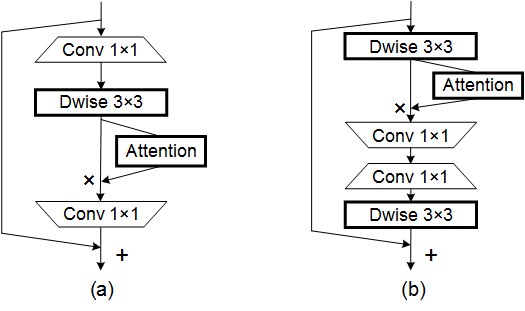
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05
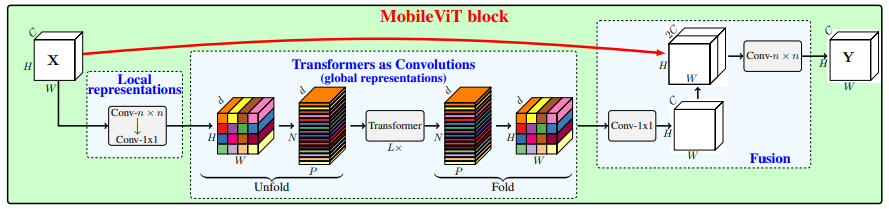
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
Non-deep Networks---ArXiv 2021.10.20
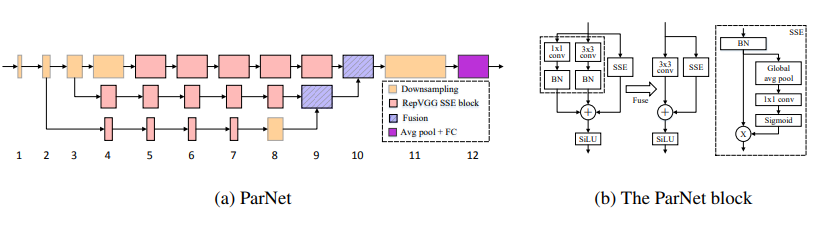
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
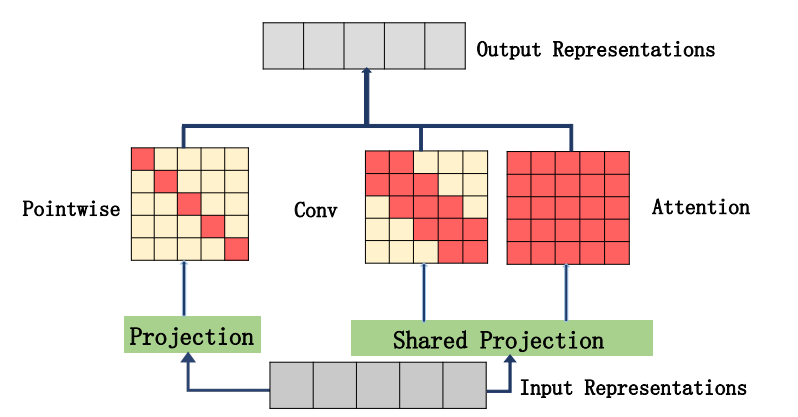
On the Integration of Self-Attention and Convolution
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
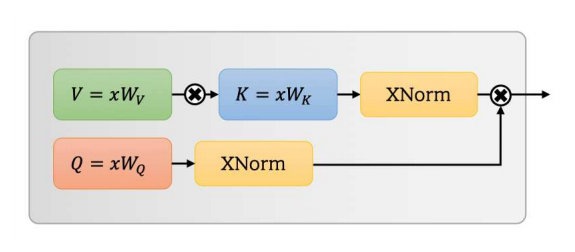
Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06
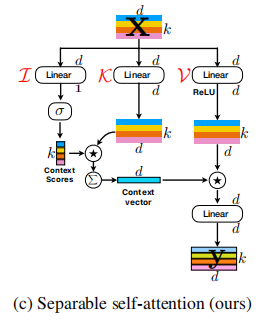
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
Vision Transformer with Deformable Attention---CVPR2022
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
Aggregating Global Features into Local Vision Transformer
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
CCNet: Criss-Cross Attention for Semantic Segmentation
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
Axial Attention in Multidimensional Transformers
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
Pytorch implementation of "Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"
Pytorch implementation of "Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"
Pytorch implementation of MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05
Pytorch implementation of Patches Are All You Need?---ICLR2022 (Under Review)
Pytorch implementation of Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07
Pytorch implementation of ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27
Pytorch implementation of Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15
Pytorch implementation of Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26
Pytorch implementation of Conditional Positional Encodings for Vision Transformers
Pytorch implementation of Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021
Pytorch implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021
Pytorch implementation of Transformer in Transformer---NeurIPS 2021
Pytorch implementation of DeepViT: Towards Deeper Vision Transformer
Pytorch implementation of Incorporating Convolution Designs into Visual Transformers
Pytorch implementation of ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Pytorch implementation of Augmenting Convolutional networks with attention-based aggregation
Pytorch implementation of Going deeper with Image Transformers---ICCV 2021 (Oral)
Pytorch implementation of Training data-efficient image transformers & distillation through attention---ICML 2021
Pytorch implementation of LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
Pytorch implementation of VOLO: Vision Outlooker for Visual Recognition
Pytorch implementation of Container: Context Aggregation Network---NeuIPS 2021
Pytorch implementation of CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022
Pytorch implementation of Vision Transformer with Deformable Attention---CVPR 2022
Pytorch implementation of EfficientFormer: Vision Transformers at MobileNet Speed
Pytorch implementation of ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders
"Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"
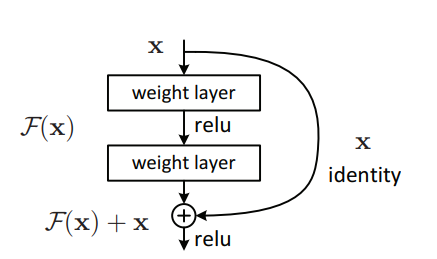
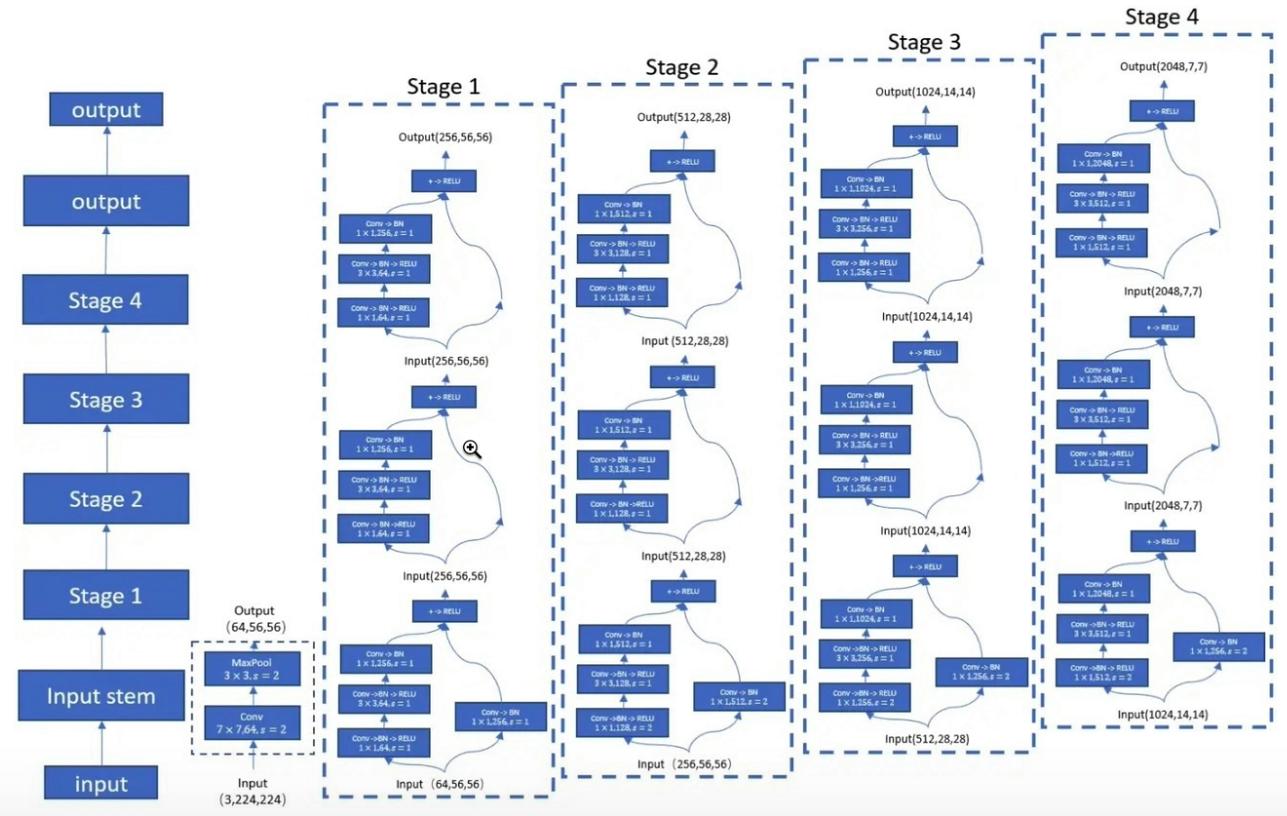
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)"Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"
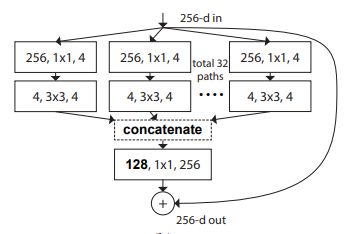
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05
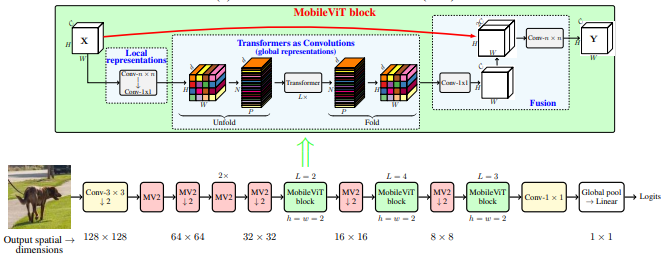
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)Patches Are All You Need?---ICLR2022 (Under Review)
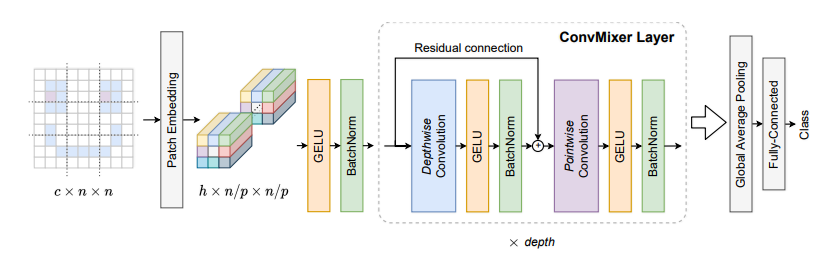
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
ConTNet: Why not use convolution and transformer at the same time?
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
Vision Transformers with Hierarchical Attention
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
Co-Scale Conv-Attentional Image Transformers
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])PVT v2: Improved Baselines with Pyramid Vision Transformer
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)Conditional Positional Encodings for Vision Transformers
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)Rethinking Spatial Dimensions of Vision Transformers
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)Transformer in Transformer
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)DeepViT: Towards Deeper Vision Transformer
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)Incorporating Convolution Designs into Visual Transformers
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)Going deeper with Image Transformers
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)Augmenting Convolutional networks with attention-based aggregation
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)Training data-efficient image transformers & distillation through attention
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)VOLO: Vision Outlooker for Visual Recognition
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)Container: Context Aggregation Network
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)CMT: Convolutional Neural Networks Meet Vision Transformers
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)EfficientFormer: Vision Transformers at MobileNet Speed
from model.backbone.EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders
from model.backbone.convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__":
model = convnextv2_atto()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)Pytorch implementation of "RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"
Pytorch implementation of "MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"
Pytorch implementation of "ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"
Pytorch implementation of "Pay Attention to MLPs---arXiv 2021.05.17"
Pytorch implementation of "Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"
"RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"
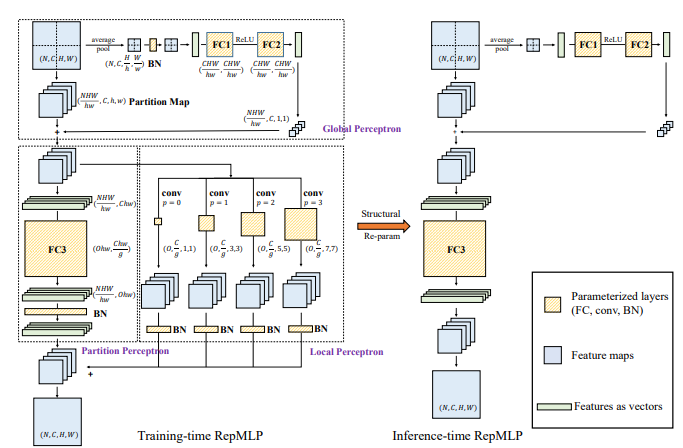
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())"MLP-Mixer: An all-MLP Architecture for Vision"
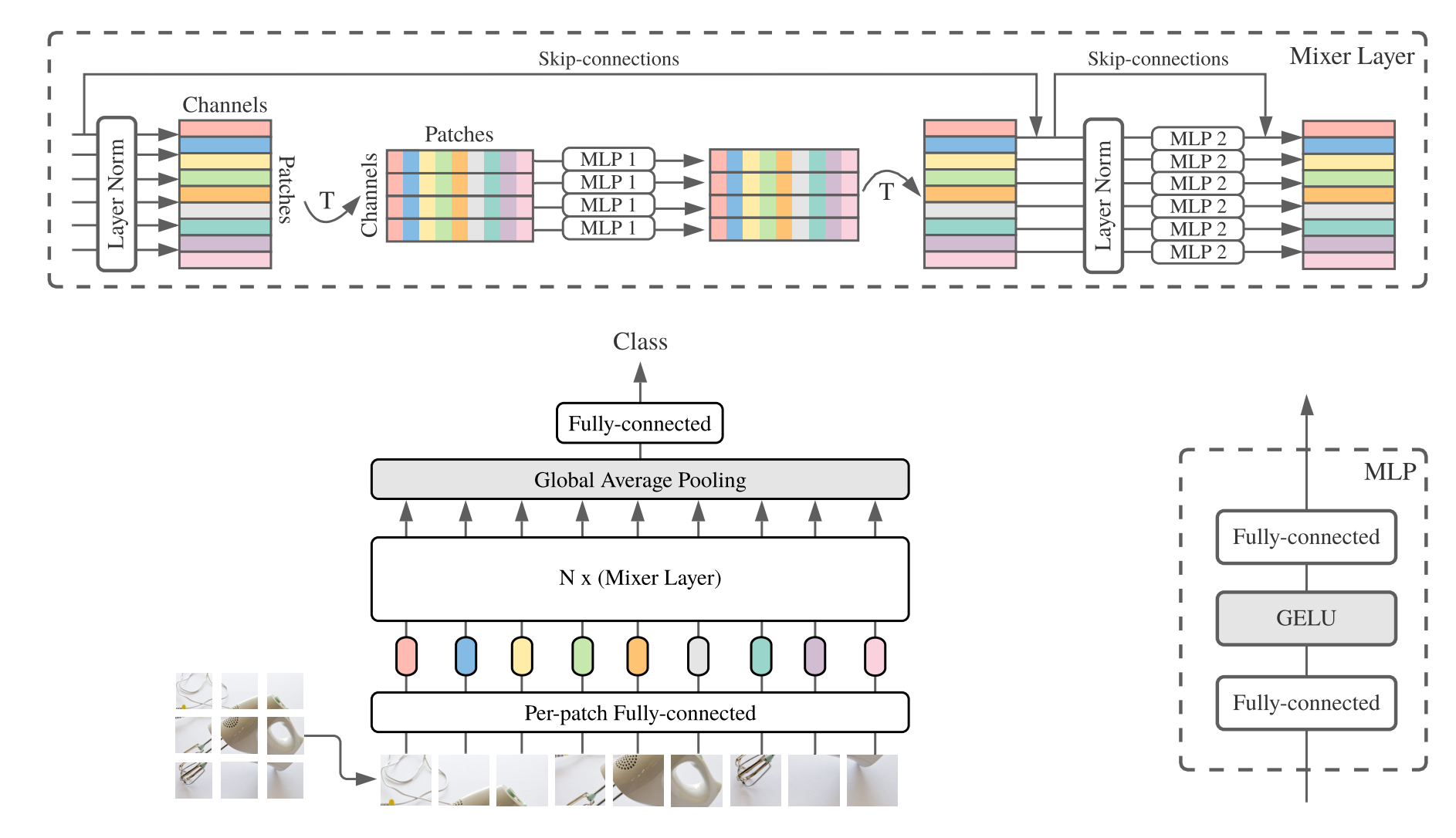
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)"ResMLP: Feedforward networks for image classification with data-efficient training"

from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num"Pay Attention to MLPs"
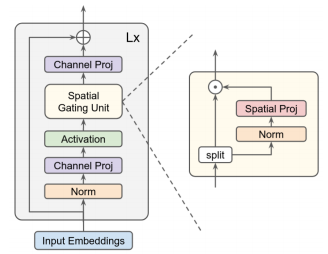
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)"Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"
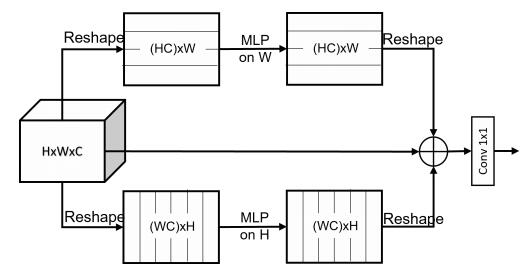
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)"Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)Pytorch implementation of "RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"
Pytorch implementation of "ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"
Pytorch implementation of "Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"
"RepVGG: Making VGG-style ConvNets Great Again"
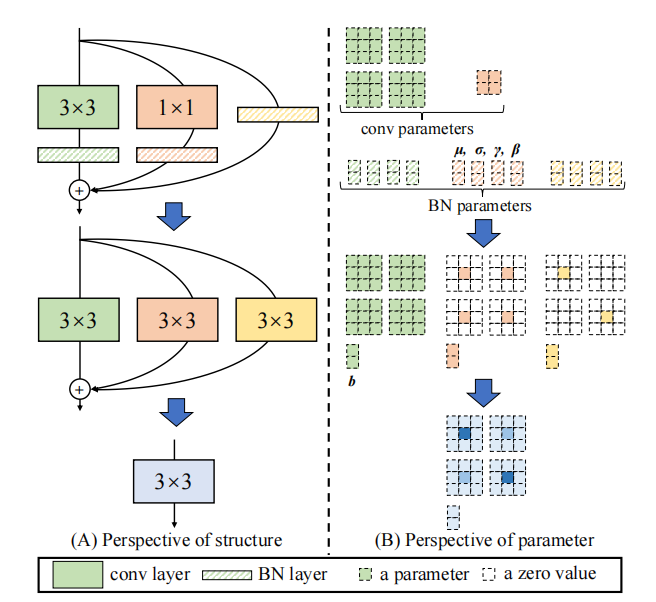
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())"ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"
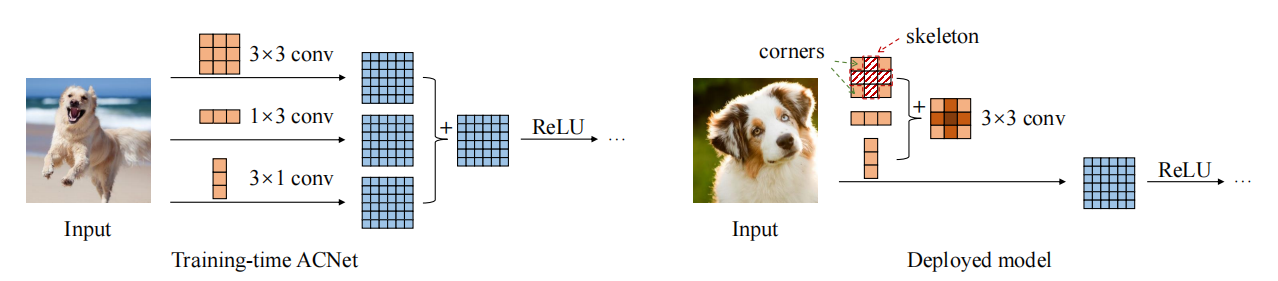
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())"Diverse Branch Block: Building a Convolution as an Inception-like Unit"
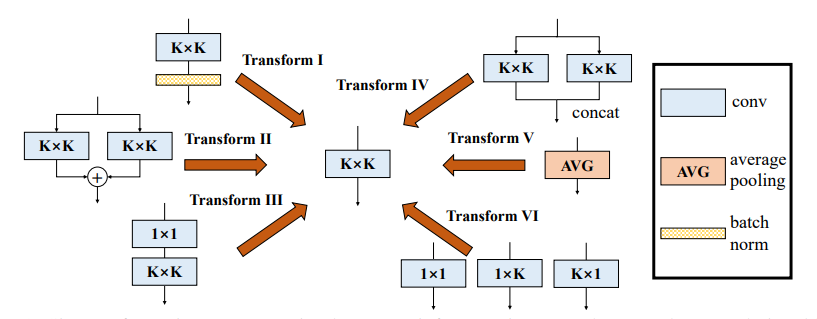
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())Pytorch implementation of "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"
Pytorch implementation of "Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"
Pytorch implementation of "Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"
Pytorch implementation of "Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"
Pytorch implementation of "CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"
"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"
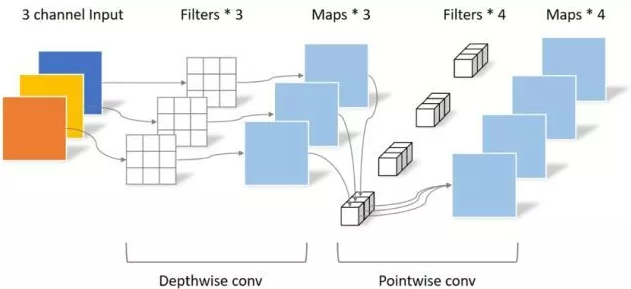
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)"Efficientnet: Rethinking model scaling for convolutional neural networks"
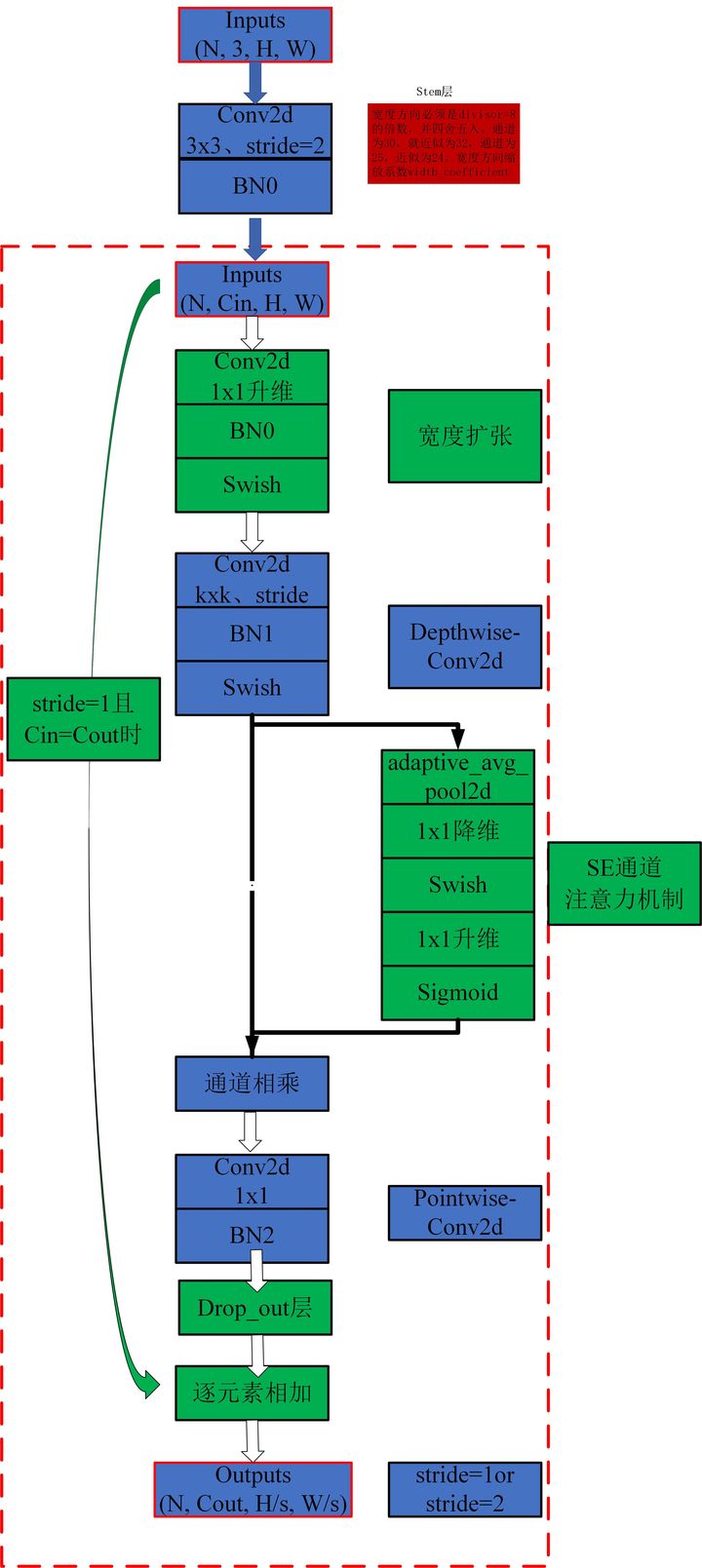
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
"Involution: Inverting the Inherence of Convolution for Visual Recognition"
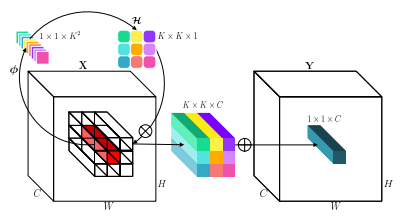
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)"Dynamic Convolution: Attention over Convolution Kernels"
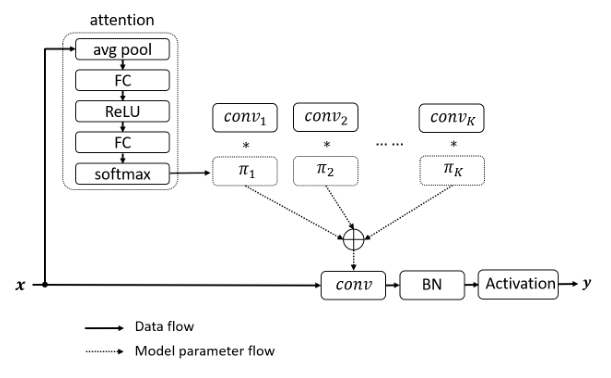
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64"CondConv: Conditionally Parameterized Convolutions for Efficient Inference"
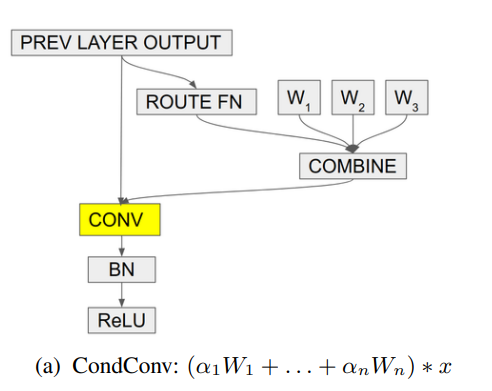
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)重磅!!!作为项目补充,更多论文层面的解析,可以关注新开源的项目 FightingCV-Paper-Reading ,里面汇集和整理了各大顶会顶刊的论文解析
重磅!!! 最近为大家整理了网上的各种AI相关的视频教程和必读论文 FightingCV-Course
重磅!!!最近全新开源了一个 YOLOAir 目标检测代码库 ,里面集成了多种YOLO模型,包括YOLOv5, YOLOv7,YOLOR, YOLOX,YOLOv4, YOLOv3以及其他YOLO模型,还包括多种现有Attention机制。
ECCV2022论文汇总:ECCV2022-Paper-List


