External Attention pytorch
1.0.0

ภาษาจีนง่ายๆ | ภาษาอังกฤษ
สวัสดีทุกคนฉันคือ Xiaoma
สำหรับ Xiaobai (เช่นฉัน): เมื่อเร็ว ๆ นี้ฉันจะพบปัญหาเมื่อฉันอ่านกระดาษ บางครั้งแนวคิดหลักของกระดาษนั้นง่ายมากและรหัสหลักอาจเป็นเพียงโหลบรรทัด อย่างไรก็ตามเมื่อฉันเปิดซอร์สโค้ดของการเปิดตัวของผู้เขียนฉันพบว่าโมดูลที่เสนอนั้นถูกฝังอยู่ในกรอบงานเช่นการจำแนกประเภทการตรวจจับและการแบ่งส่วนซึ่งนำไปสู่รหัสที่ค่อนข้างซ้ำซ้อน ฉันไม่คุ้นเคยกับกรอบงานเฉพาะและ เป็นเรื่องยากสำหรับฉันที่จะค้นหารหัสหลัก ซึ่งนำไปสู่ความยากลำบากในการทำความเข้าใจเอกสารและแนวคิดเครือข่าย
สำหรับขั้นสูง (เช่นคุณ): หากคุณถือว่าหน่วยพื้นฐานเช่น Conv, FC และ RNN เป็นหน่วยการสร้างเลโก้ขนาดเล็กและโครงสร้างเช่นหม้อแปลงและ resnet เป็นปราสาทเลโก้ที่ถูกสร้างขึ้น จากนั้นโมดูลที่จัดทำโดยโครงการนี้เป็นส่วนประกอบเลโก้ที่มีข้อมูลความหมายที่สมบูรณ์ ให้นักวิจัยทางวิทยาศาสตร์หลีกเลี่ยงการทำล้อซ้ำ ๆ เพียง แค่คิดเกี่ยวกับวิธีการใช้ "องค์ประกอบเลโก้" เหล่านี้เพื่อสร้างผลงานที่มีสีสันมากขึ้น
สำหรับอาจารย์ (อาจเป็นเหมือนคุณ): ฉันมีความสามารถที่ จำกัด และ ไม่อยากฉีดเบา ๆ ! - -
สำหรับทุกคน: โครงการนี้มุ่งมั่นที่จะใช้ฐานรหัสที่ ช่วยให้สามเณรการเรียนรู้ลึกสามารถเข้าใจ และ ให้บริการการวิจัยทางวิทยาศาสตร์และชุมชนอุตสาหกรรม
ติดตั้งโดยตรงผ่าน PIP
pip install fightingcv-attentionหรือโคลนที่เก็บ
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )ชุดความสนใจ
1. การใช้ความสนใจภายนอก
2. การใช้ความสนใจในตนเอง
3. การใช้ความสนใจในตนเองง่ายขึ้น
4. การใช้ความสนใจแบบบีบและกระตุ้น
5. การใช้ความสนใจ SK
6. การใช้ความสนใจ CBAM
7. การใช้ความสนใจ BAM
8. การใช้ความสนใจของ ECA
9. การใช้ความสนใจของ Danet
10. การใช้พีระมิดแยกความสนใจ (PSA)
11. การใช้งานด้วยตนเองหลายหัว (EMSA) ที่มีประสิทธิภาพ
12. การใช้ความสนใจแบบสับเปลี่ยน
13. การใช้ความสนใจของ Muse
14. การใช้ความสนใจ SGE
15. การใช้ความสนใจ A2
16. การใช้ความสนใจท้ายท้าย
17. การใช้ความสนใจของ Outlook
18. การใช้ความสนใจวีไอพี
19. การใช้ความสนใจของ Coatnet
20. การใช้ Halonet ความสนใจ
21. การใช้ความพยายามด้วยตนเองแบบโพลาไรซ์
22. การใช้ Cotattention
23. การใช้ความสนใจที่เหลืออยู่
24. การใช้ความสนใจ S2
25. การใช้ความสนใจของ GFNET
26. การใช้ Triplet Attention
27. ประสานงานการใช้ความสนใจ
28. การใช้ความสนใจของ Mobilevit
29. การใช้ความสนใจของนกแก้ว
30. การใช้ความสนใจของยูเอฟโอ
31. การใช้ความสนใจของ Acmix
32. Mobilevitv2 การใช้ความสนใจ
33. การใช้ความสนใจของ DAT
34. การใช้ความสนใจ crossformer
35. การใช้ความสนใจของ Moatransformer
36. การใช้ความสนใจ Crisscrossattention
37. การใช้ความสนใจ Axial_Attention
ซีรีส์ Backbone
1. การใช้งาน resnet
2. การใช้งาน resnext
3. การใช้งาน Mobilevit
4. การใช้งาน convmixer
5. การใช้งาน shuffletransformer
6. การใช้งาน contnet
7. การใช้งาน Hatnet
8. การใช้เสื้อโค้ท
9. การใช้งาน PVT
10. การใช้งาน CPVT
11. การใช้หลุม
12. การใช้ CrossVit
13. การใช้งานทีเอ็นที
14. การใช้งาน DVIT
15. การใช้งาน Ceit
16. ตัดสินการใช้งาน
17. การใช้งาน Cait
18. การใช้งาน PatchConvnet
19. การใช้งาน deit
20. การใช้งาน Levit
21. การใช้ Volo
22. การใช้งานคอนเทนเนอร์
23. การใช้งาน CMT
24. การใช้งานที่มีประสิทธิภาพ
25. การใช้งาน convnextv2
ซีรี่ส์ MLP
1. การใช้งาน repmlp
2. การใช้งาน MLP-Mixer
3. การใช้งาน resmlp
4. การใช้งาน GMLP
5. การใช้ SMLP
6. การใช้ VIP-MLP
ซีรี่ส์ RE-PARAMETER (Rep)
1. การใช้งาน repvgg
2. การใช้งาน ACNET
3. การใช้งานสาขาสาขาที่หลากหลาย (DDB)
ซีรีย์ Convolution
1. การใช้งานแบบแยกส่วนที่แยกออกได้
2. การใช้งาน mbconv
3. การใช้งานที่เกี่ยวข้อง
4. การใช้งาน DynamicConv
5. การใช้งาน condconv
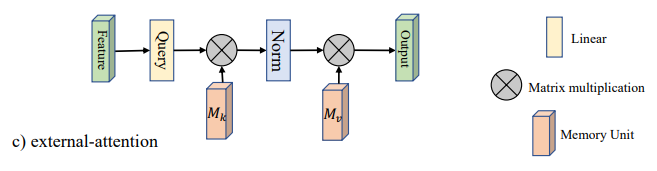
การใช้งาน Pytorch ของ "Beyond Selfention: ความสนใจภายนอกโดยใช้สองชั้นเชิงเส้นสำหรับงานภาพ --- Arxiv 2021.05.05"
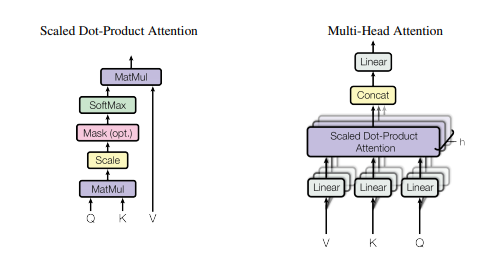
การใช้ Pytorch ของ "ความสนใจคือสิ่งที่คุณต้องการ --- NIPS2017"
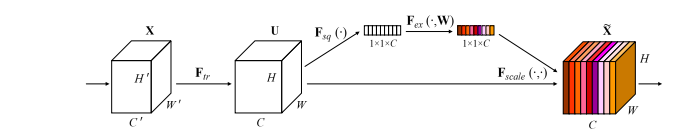
การใช้งาน Pytorch ของ "เครือข่ายการบีบและการกระตุ้น --- CVPR2018"
การใช้งาน Pytorch ของ "Selective Kernel Networks --- CVPR2019"
การใช้งาน Pytorch ของ "CBAM: โมดูลความสนใจบล็อก convolutional --- ECCV2018"
การใช้งาน Pytorch ของ "BAM: Module Module Bottleneck --- BMCV2018"
การใช้งาน Pytorch ของ "ECA-NET: ความสนใจของช่องทางที่มีประสิทธิภาพสำหรับเครือข่ายประสาทเชิงลึก --- CVPR2020"
การใช้งาน Pytorch ของ "เครือข่ายความสนใจแบบคู่สำหรับการแบ่งส่วนฉาก --- CVPR2019"
การใช้งาน Pytorch ของ "Epsanet: บล็อกปิรามิดที่มีประสิทธิภาพแยกความสนใจในเครือข่ายประสาท Convolutional --- Arxiv 2021.05.30"
การใช้งาน Pytorch ของ "REST: หม้อแปลงที่มีประสิทธิภาพสำหรับการจดจำภาพ --- Arxiv 2021.05.28"
การใช้งาน Pytorch ของ "SA-NET: Shuffle Intentent สำหรับ Neural Networks ที่ลึกล้ำ --- ICASSP 2021"
การใช้งาน Pytorch ของ "Muse: ความสนใจหลายระดับแบบขนานสำหรับลำดับการเรียนรู้ลำดับ --- Arxiv 2019.11.17"
การใช้งาน Pytorch ของ "การปรับปรุงกลุ่มเชิงพื้นที่อย่างชาญฉลาด: การปรับปรุงการเรียนรู้คุณสมบัติความหมายในเครือข่าย Convolutional --- Arxiv 2019.05.23"
การใช้งาน Pytorch ของ "A2-Nets: Double Attention Networks --- NIPS2018"
การใช้งาน Pytorch ของ "A Stated Free Transformer --- ICLR2021 (งานใหม่ของ Apple)"
การใช้ Pytorch ของ Volo: Vision Outlooker สำหรับการจดจำภาพ --- Arxiv 2021.06.24 "[การวิเคราะห์กระดาษ]
การใช้ Pytorch ของการแทรกซึมของการมองเห็น: สถาปัตยกรรม MLP แบบซึมผ่านได้สำหรับการจดจำภาพ --- Arxiv 2021.06.23 [การวิเคราะห์กระดาษ]
การใช้งาน Pytorch ของ Coatnet: แต่งงานกับความสนใจและความสนใจสำหรับขนาดข้อมูลทั้งหมด --- Arxiv 2021.06.09 [การวิเคราะห์กระดาษ]
การใช้ Pytorch ในการปรับขนาดการควบคุมตนเองในท้องถิ่นสำหรับพารามิเตอร์ที่มีประสิทธิภาพในการมองเห็นแบ็คโบน --- CVPR2021 ช่องปาก [การวิเคราะห์กระดาษ]
การใช้ Pytorch ของการตั้งใจด้วยตนเองแบบโพลาไรซ์: ไปสู่การถดถอยพิกเซลคุณภาพสูง --- อาร์กซ์ 2021.07.02 [การวิเคราะห์กระดาษ]
การใช้งาน Pytorch ของเครือข่ายหม้อแปลงบริบทสำหรับการจดจำภาพ --- Arxiv 2021.07.26 [การวิเคราะห์กระดาษ]
การใช้ Pytorch ของความสนใจที่เหลือ: วิธีที่ง่าย แต่มีประสิทธิภาพสำหรับการจดจำหลายฉลาก --- ICCV2021
การใช้งาน Pytorch ของS²-MLPV2: ปรับปรุงสถาปัตยกรรม MLP เชิงพื้นที่-กะสำหรับการมองเห็น --- arxiv 2021.08.02 [การวิเคราะห์กระดาษ]
การใช้งาน Pytorch ของเครือข่ายตัวกรองทั่วโลกสำหรับการจำแนกรูปภาพ --- Arxiv 2021.07.01
การใช้ Pytorch ของการหมุนเพื่อเข้าร่วม: โมดูลความสนใจ triplet convolutional --- WACV 2021
การใช้ Pytorch ของความสนใจพิกัดสำหรับการออกแบบเครือข่ายมือถือที่มีประสิทธิภาพ --- CVPR 2021
การใช้งาน Pytorch ของ Mobilevit: น้ำหนักเบา, พรรณนาวิสัยทัศน์ทั่วไป, และทแยงมุมที่เป็นมิตรกับมือถือ --- Arxiv 2021.10.05
การใช้งาน Pytorch ของเครือข่ายที่ไม่ลึก --- Arxiv 2021.10.20
การใช้งาน Pytorch ของ UFO-VIT: หม้อแปลง Linear Vision Performance Performance โดยไม่ต้องใช้ Softmax --- Arxiv 2021.09.29
การใช้งาน Pytorch ของการใช้งานด้วยตนเองที่แยกกันไม่ออกสำหรับหม้อแปลงวิสัยทัศน์มือถือ --- Arxiv 2022.06.06
Pytorch การดำเนินการในการบูรณาการความตั้งใจและการควบคุมตนเอง --- Arxiv 2022.03.14
การใช้ Pytorch ของ crossformer: หม้อแปลงไฟฟ้าที่หลากหลายขึ้นอยู่กับการเข้าร่วมข้ามระดับ --- ICLR 2022
การใช้งาน Pytorch ของการรวมคุณสมบัติระดับโลกในหม้อแปลงวิสัยทัศน์ท้องถิ่น
การใช้ Pytorch ของ CCNET: ความสนใจข้ามครอสสำหรับการแบ่งส่วนความหมาย
การใช้ Pytorch ของความสนใจตามแนวแกนในหม้อแปลงหลายมิติ
"นอกเหนือจากความตั้งใจของตนเอง: ความสนใจภายนอกโดยใช้สองชั้นเชิงเส้นสำหรับงานภาพ"
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"ความสนใจคือสิ่งที่คุณต้องการ"
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )ไม่มี
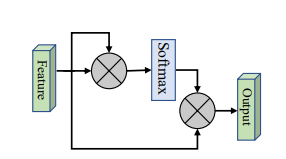
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"เครือข่ายการบีบและเร่งปฏิกิริยา"
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Selective Kernel Networks"
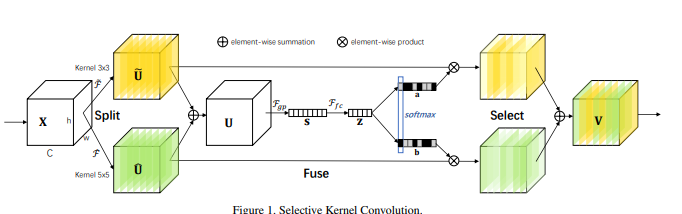
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: โมดูลความสนใจบล็อก convolutional"
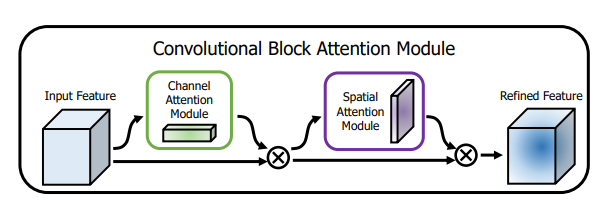
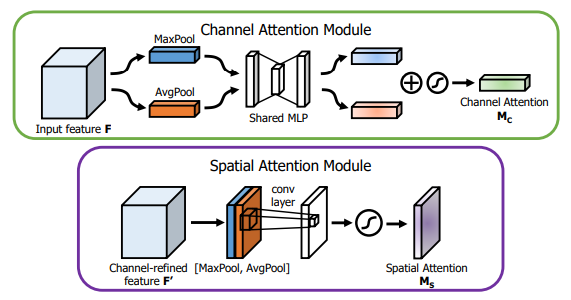
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"BAM: โมดูลความสนใจคอขวด"
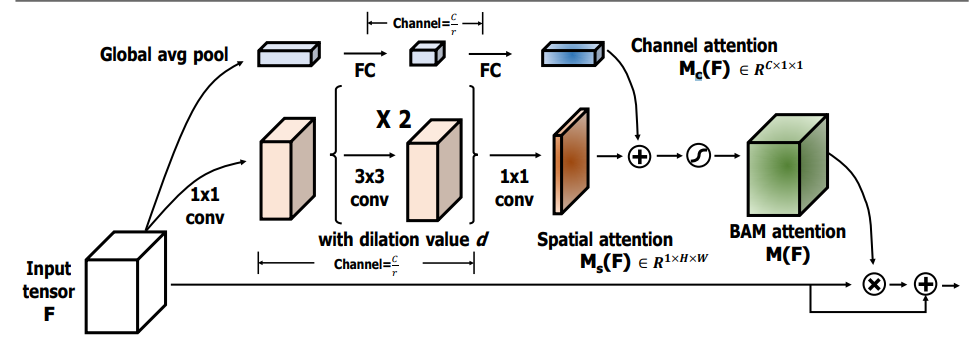
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: ความสนใจของช่องทางที่มีประสิทธิภาพสำหรับเครือข่ายประสาทที่ลึกล้ำ"
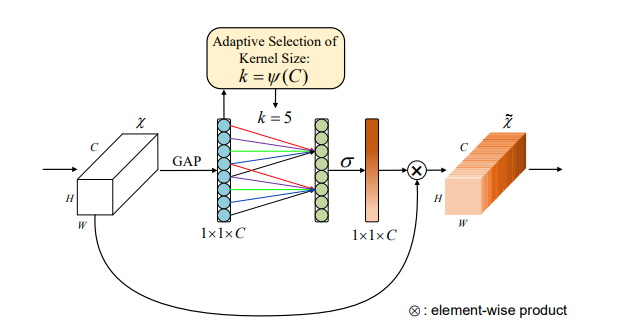
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"เครือข่ายความสนใจแบบคู่สำหรับการแบ่งส่วนฉาก"
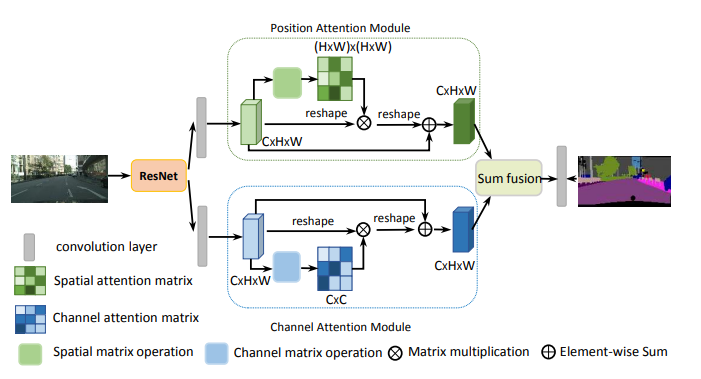
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet: บล็อกปิรามิดที่มีประสิทธิภาพแยกความสนใจในเครือข่ายประสาท Convolutional"
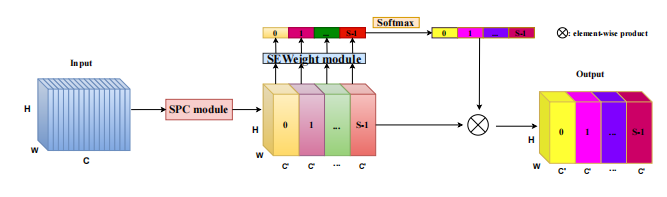
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"REST: หม้อแปลงที่มีประสิทธิภาพสำหรับการจดจำภาพ"
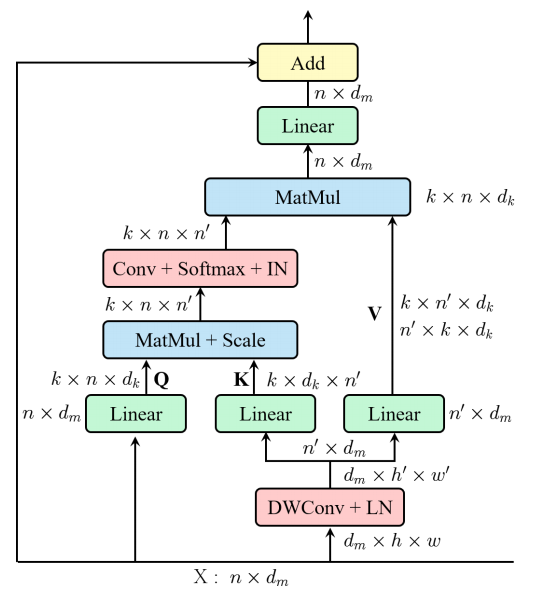
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: Shuffle Intentent สำหรับเครือข่ายประสาทที่ลึกล้ำ"
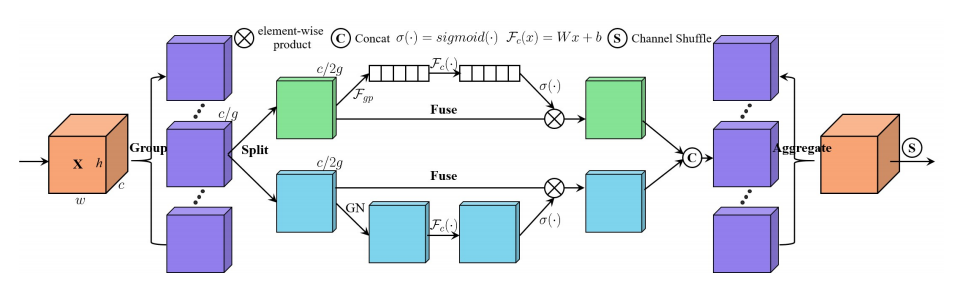
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse: ความสนใจหลายระดับแบบขนานสำหรับลำดับการเรียนรู้ลำดับ"
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )การปรับปรุงกลุ่มเชิงพื้นที่อย่างชาญฉลาด: การปรับปรุงการเรียนรู้คุณสมบัติความหมายในเครือข่าย convolutional
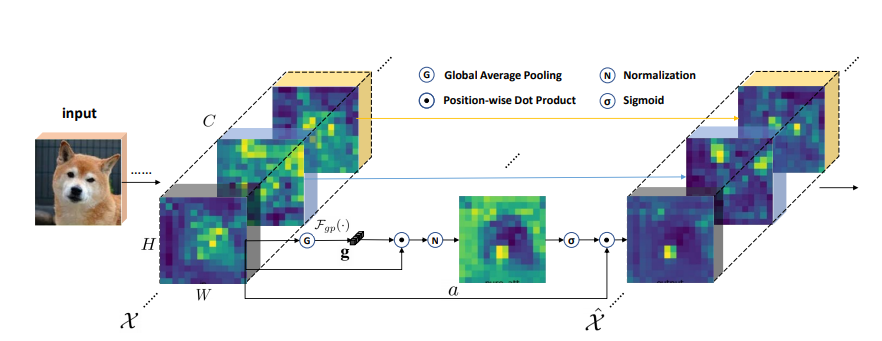
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Nets: เครือข่ายความสนใจสองเท่า
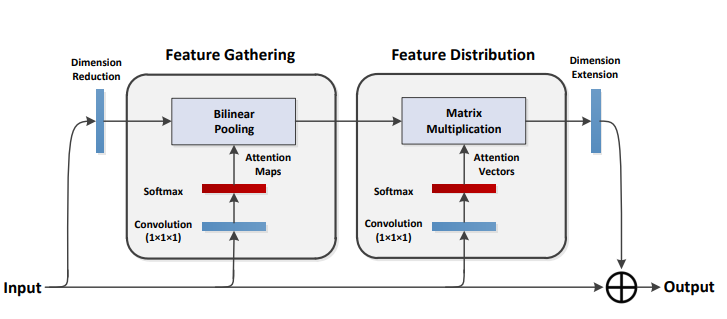
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )หม้อแปลงที่ปราศจากความสนใจ
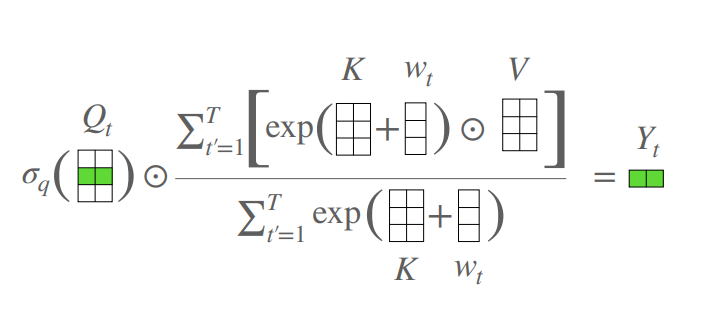
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo: Vision Outlooker สำหรับการจดจำภาพ "
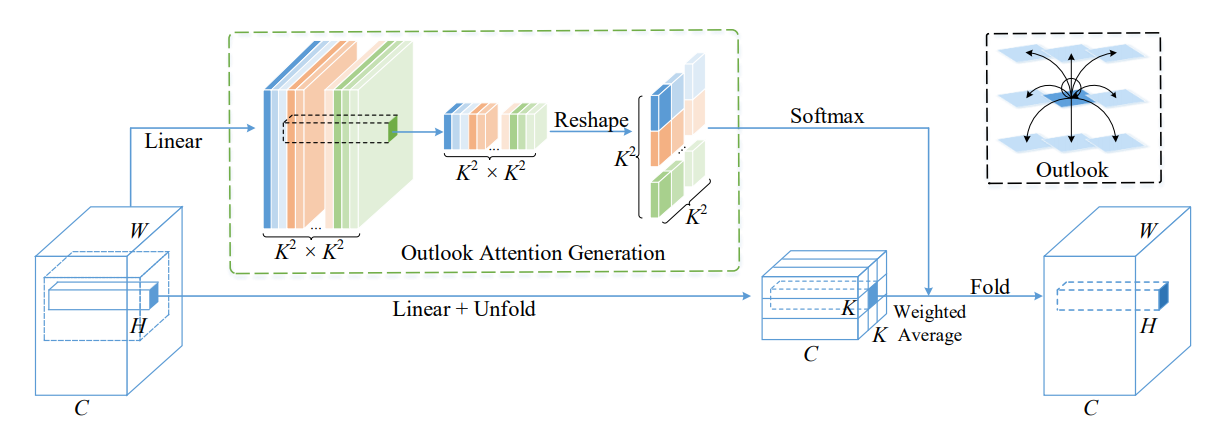
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Vision Permutator: สถาปัตยกรรม MLP ที่อนุญาตสำหรับการจดจำภาพ "
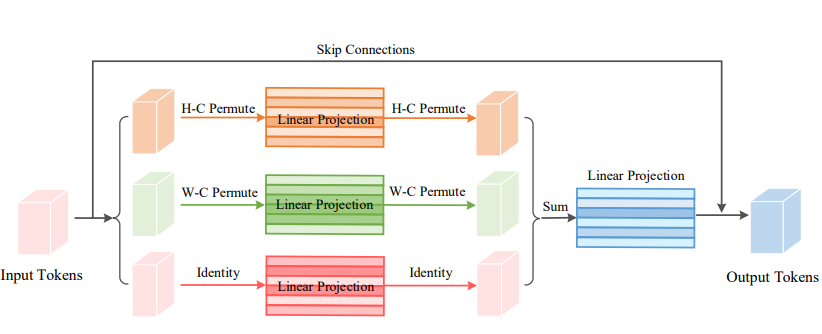
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: แต่งงานกับความสนใจและความสนใจสำหรับทุกขนาดข้อมูล "
ไม่มี
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )ปรับขนาดการควบคุมตนเองในท้องถิ่นสำหรับพารามิเตอร์ที่มีประสิทธิภาพในการมองเห็น "
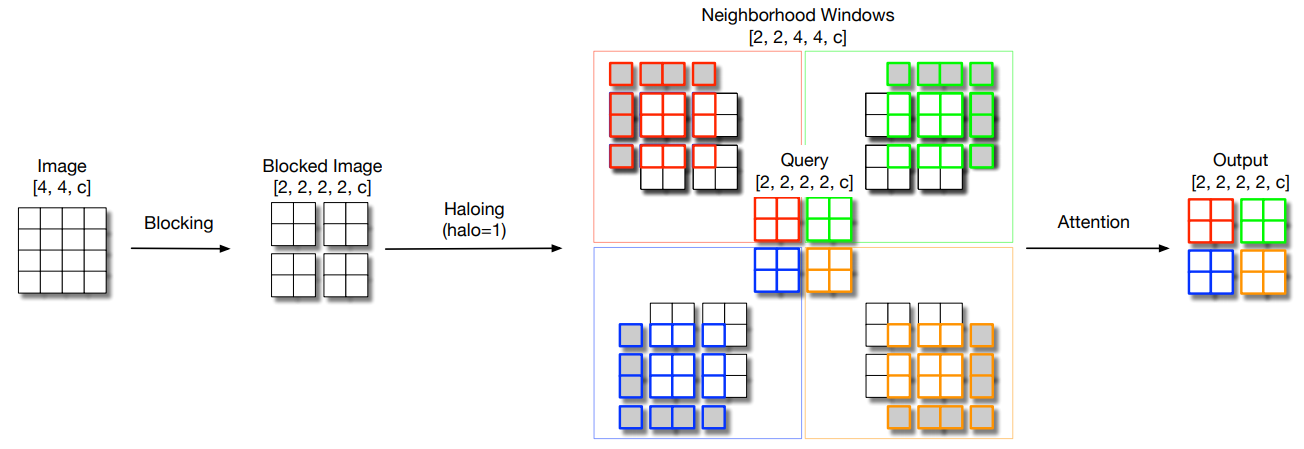
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )ความตั้งใจของตนเองแบบโพลาไรซ์: ไปสู่การถดถอยพิกเซลคุณภาพสูง "
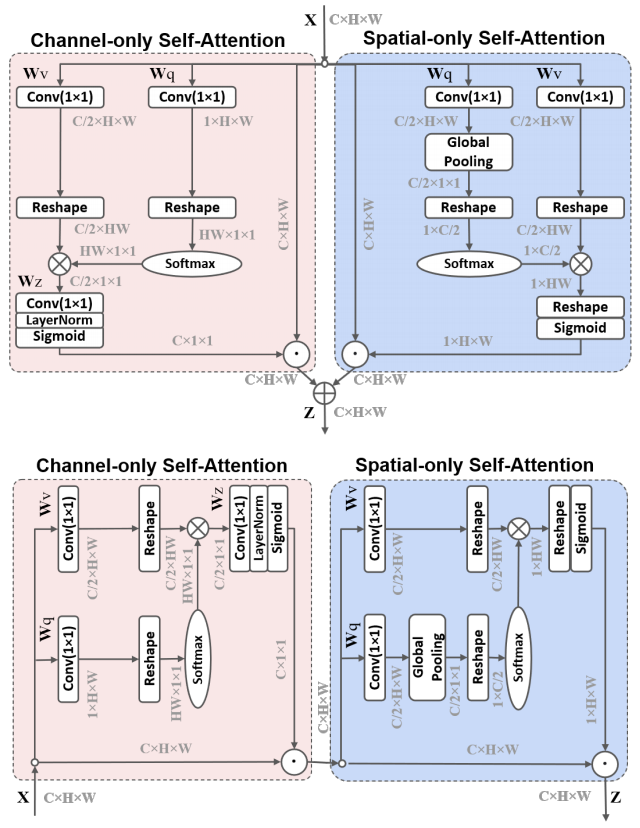
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
เครือข่ายหม้อแปลงบริบทสำหรับการจดจำภาพ --- Arxiv 2021.07.26
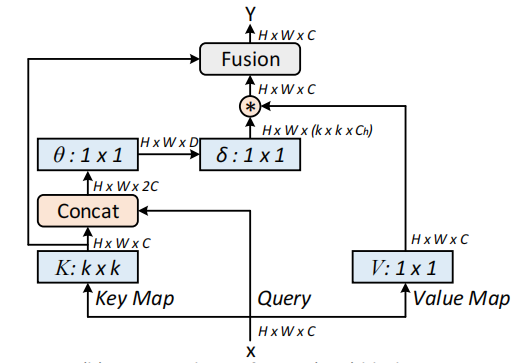
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
ความสนใจที่เหลืออยู่: วิธีที่ง่าย แต่มีประสิทธิภาพสำหรับการจดจำหลายฉลาก --- ICCV2021
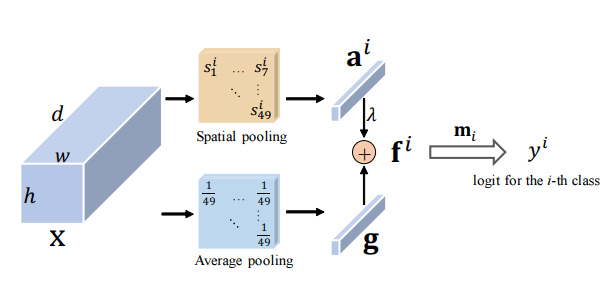
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: ปรับปรุงสถาปัตยกรรม MLP เชิงพื้นที่เพื่อการมองเห็น --- Arxiv 2021.08.02
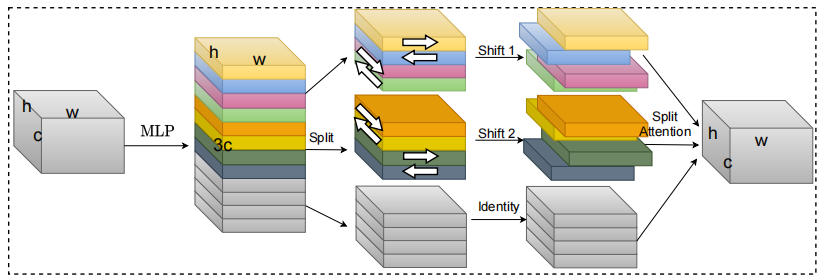
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Global Filter Networks สำหรับการจำแนกรูปภาพ --- Arxiv 2021.07.01
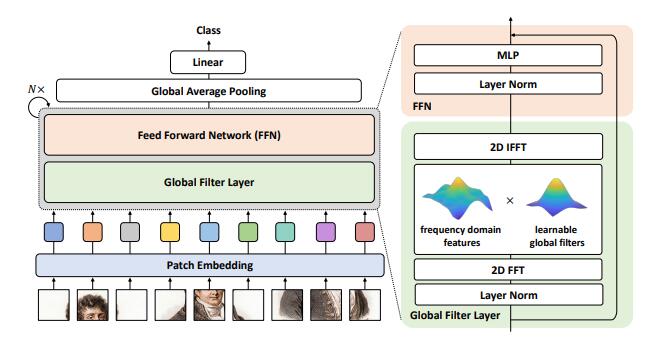
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )หมุนเพื่อเข้าร่วม: โมดูลความสนใจ triplet convolutional --- CVPR 2021
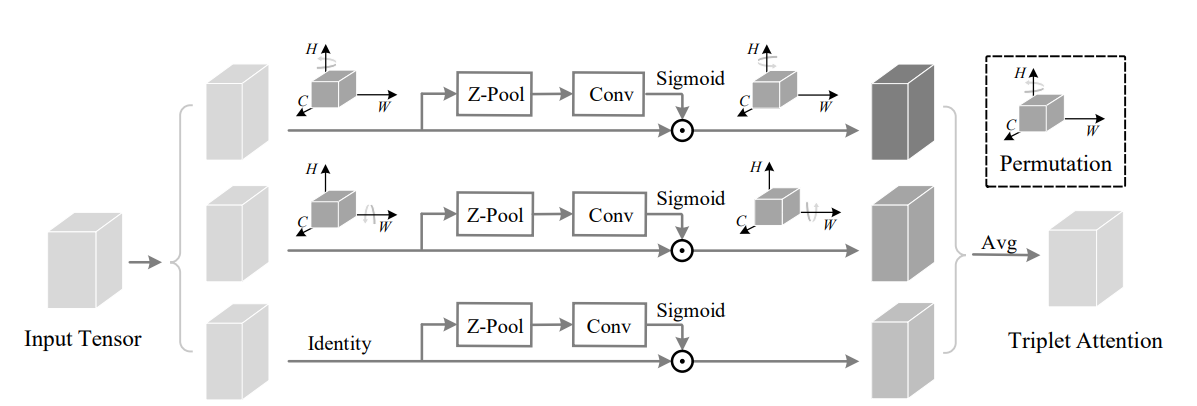
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )ประสานความสนใจสำหรับการออกแบบเครือข่ายมือถือที่มีประสิทธิภาพ --- CVPR 2021
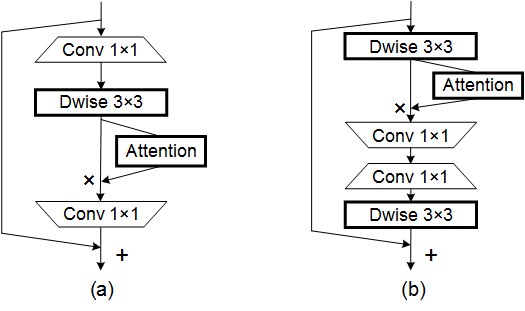
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )Mobilevit: น้ำหนักเบา, อเนกประสงค์และหม้อแปลงวิสัยทัศน์ที่เป็นมิตรกับมือถือ --- Arxiv 2021.10.05
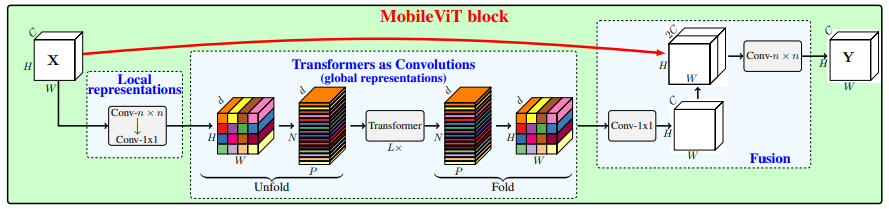
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
เครือข่ายที่ไม่ลึก --- Arxiv 2021.10.20
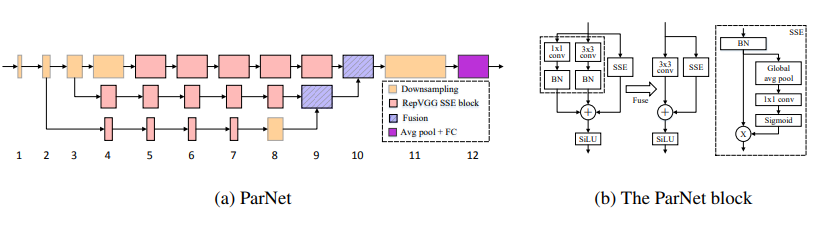
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT: Transformer Vision Linear Vision ที่มีประสิทธิภาพสูงโดยไม่มี Softmax --- Arxiv 2021.09.29
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
เกี่ยวกับการบูรณาการการดูแลตนเองและการประชุม
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
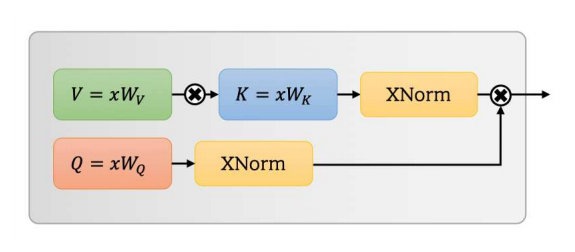
ความตั้งใจของตนเองที่แยกกันไม่ออกสำหรับหม้อแปลงวิสัยทัศน์มือถือ --- Arxiv 2022.06.06
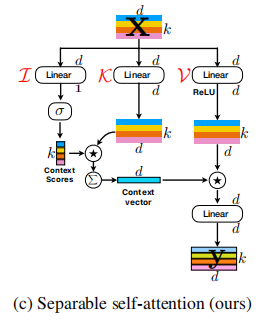
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
หม้อแปลงวิสัยทัศน์ด้วยความสนใจที่ผิดรูป --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer: หม้อแปลงวิสัยทัศน์อเนกประสงค์ที่เพิ่มขึ้นบน cross-scale attentent --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
การรวมคุณสมบัติระดับโลกเข้ากับหม้อแปลงวิสัยทัศน์ท้องถิ่น
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: ความสนใจข้ามข้ามสำหรับการแบ่งส่วนความหมาย
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
ความสนใจตามแนวแกนในหม้อแปลงหลายมิติ
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
การใช้ Pytorch ของ "การเรียนรู้ที่เหลืออยู่ลึกสำหรับการจดจำภาพ --- CVPR2016 กระดาษที่ดีที่สุด"
การใช้งาน Pytorch ของ
การใช้งาน Pytorch ของ Mobilevit: น้ำหนักเบา, อเนกประสงค์, และหม้อแปลงวิสัยทัศน์ที่เป็นมิตรกับมือถือ --- Arxiv 2020.10.05
การใช้งาน Pytorch ของแพตช์คือสิ่งที่คุณต้องการหรือไม่ --- ICLR2022 (อยู่ระหว่างการตรวจสอบ)
การใช้ Pytorch ของหม้อแปลงสับเปลี่ยน: ทบทวนการสับเปลี่ยนเชิงพื้นที่สำหรับหม้อแปลงวิสัยทัศน์ --- อาร์กซิฟ 2021.06.07
การใช้งาน Pytorch ของ ContNet: ทำไมไม่ใช้ Convolution และ Transformer ในเวลาเดียวกัน --- Arxiv 2021.04.27
การใช้ Pytorch ของหม้อแปลงวิสัยทัศน์ด้วยความสนใจแบบลำดับชั้น --- Arxiv 2022.06.15
การใช้งาน Pytorch ของ Transformers Image Conv-Attentional Co-conv-Attentional --- Arxiv 2021.08.26
การใช้ Pytorch ของการเข้ารหัสตำแหน่งตามเงื่อนไขสำหรับหม้อแปลงวิสัยทัศน์
การใช้ Pytorch ของการทบทวนมิติเชิงพื้นที่ของหม้อแปลงวิสัยทัศน์ --- ICCV 2021
การใช้ Pytorch ของ CrossVit: Cross-Attention Multi-Scale Vision Transformer สำหรับการจำแนกภาพ --- ICCV 2021
การใช้ Pytorch ของ Transformer ใน Transformer --- Neurips 2021
การใช้ Pytorch ของ DeepVit: ไปสู่ Transwis Vision Transformer
การใช้งาน Pytorch ของการรวมการออกแบบ convolution เข้ากับหม้อแปลงภาพ
การใช้ Pytorch ของ Convit: การปรับปรุงหม้อแปลงวิสัยทัศน์ด้วยอคติอุปนัยแบบนิ่มนวล
การใช้งาน Pytorch ของการเพิ่มเครือข่าย convolutional ด้วยการรวมความสนใจ
การใช้งาน Pytorch ของการก้าวลึกลงไปด้วย Image Transformers --- ICCV 2021 (ปากเปล่า)
การใช้งาน Pytorch ของการฝึกอบรมการฝึกอบรมภาพและการกลั่นด้วยข้อมูลที่มีประสิทธิภาพผ่านความสนใจ --- ICML 2021
การใช้ Pytorch ของ Levit: A Vision Transformer ในเสื้อผ้าของ Convnet เพื่อการอนุมานที่เร็วขึ้น
การใช้ Pytorch ของ Volo: Vision Outlooker สำหรับการจดจำภาพ
การใช้งาน Pytorch ของคอนเทนเนอร์: เครือข่ายการรวมบริบท --- Neuips 2021
การใช้งาน Pytorch ของ CMT: เครือข่ายประสาท Convolutional พบกับ Vision Transformers --- CVPR 2022
การใช้ Pytorch ของหม้อแปลงวิสัยทัศน์ด้วยความสนใจที่ผิดรูป --- CVPR 2022
การใช้ Pytorch ของ EfficientFormer: Vision Transformers ที่ความเร็ว Mobilenet
การใช้ Pytorch ของ ConvNextv2: การออกแบบร่วมและการปรับสัดส่วนการควบคุมด้วยตัวออกแบบหน้ากาก
"การเรียนรู้ที่เหลืออยู่ลึกสำหรับการจดจำภาพ --- CVPR2016 กระดาษที่ดีที่สุด"
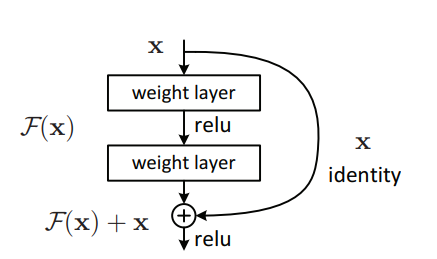
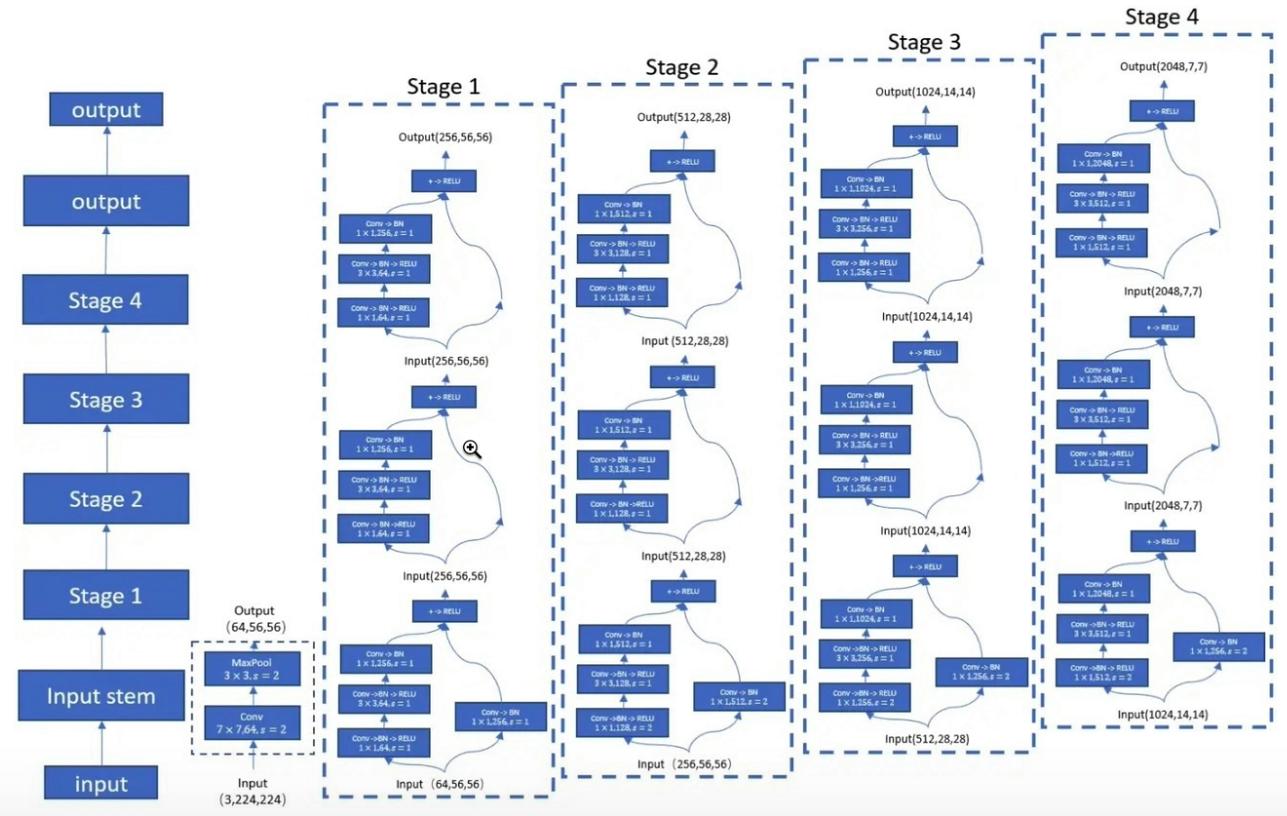
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"การเปลี่ยนแปลงที่เหลือรวมสำหรับเครือข่ายประสาทลึก --- CVPR2017"
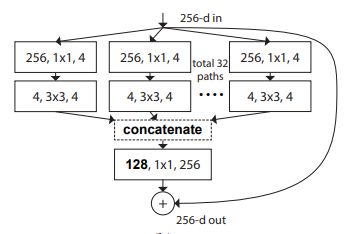
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
Mobilevit: น้ำหนักเบา, อเนกประสงค์และหม้อแปลงวิสัยทัศน์ที่เป็นมิตรกับมือถือ --- Arxiv 2020.10.05
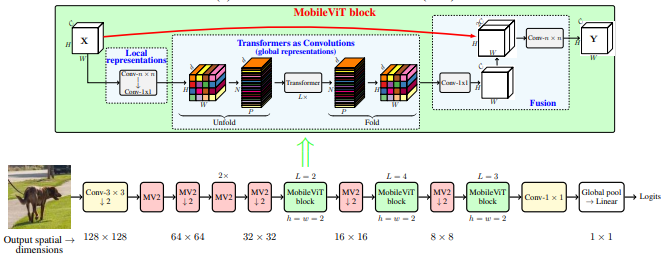
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )แพตช์คือสิ่งที่คุณต้องการหรือไม่ --- ICLR2022 (อยู่ระหว่างการตรวจสอบ)
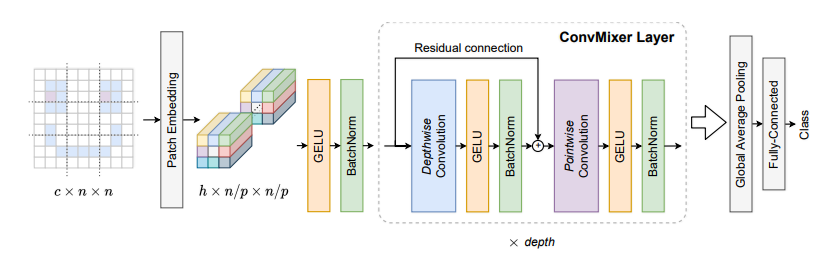
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Shuffle Transformer: ทบทวนการสับเปลี่ยนเชิงพื้นที่สำหรับหม้อแปลงวิสัยทัศน์
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
ContNet: ทำไมไม่ใช้ Convolution และ Transformer ในเวลาเดียวกัน?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
หม้อแปลงวิสัยทัศน์ด้วยความสนใจแบบลำดับชั้น
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
หม้อแปลงภาพร่วมกันในระดับ
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])Pvt V2: Baselines ที่ได้รับการปรับปรุงด้วย Pyramid Vision Transformer
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )การเข้ารหัสตำแหน่งตามเงื่อนไขสำหรับหม้อแปลงวิสัยทัศน์
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )ทบทวนมิติเชิงพื้นที่ของหม้อแปลงวิสัยทัศน์
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit: หม้อแปลงวิสัยทัศน์หลายระดับการแทรกแซงสำหรับการจำแนกรูปภาพ
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )หม้อแปลงในหม้อแปลง
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )DeepVit: ไปสู่หม้อแปลงวิสัยทัศน์ที่ลึกซึ้งยิ่งขึ้น
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )ผสมผสานการออกแบบ convolution เข้ากับหม้อแปลงภาพ
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Convit: ปรับปรุงการมองเห็น Transformers ด้วยอคติอุปนัย
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )ลึกลงไปกับหม้อแปลงภาพ
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )การเพิ่มเครือข่าย convolutional ด้วยการรวมความสนใจ
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )การฝึกอบรมการฝึกอบรมภาพและการกลั่นด้วยความสนใจ
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: หม้อแปลงวิสัยทัศน์ในเสื้อผ้าของ Convnet เพื่อการอนุมานที่เร็วขึ้น
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo: Vision Outlooker สำหรับการจดจำภาพ
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )คอนเทนเนอร์: เครือข่ายการรวมบริบท
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: เครือข่ายประสาท Convolutional พบกับ Vision Transformers
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )EfficientFormer: Vision Transformers ที่ความเร็ว Mobilenet
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )Convnextv2: การออกแบบร่วมและปรับสัดส่วน convnets ด้วย masked autoencoders
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )การใช้งาน Pytorch ของ "RepMLP: การตั้งค่าการโน้มน้าวใจใหม่ในเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์สำหรับการจดจำภาพ --- Arxiv 2021.05.05"
การใช้งาน Pytorch ของ "MLP-Mixer: สถาปัตยกรรม All-MLP สำหรับ Vision --- Arxiv 2021.05.17"
การใช้งาน Pytorch ของ "Resmlp: เครือข่าย Feedforward สำหรับการจำแนกภาพด้วยการฝึกอบรมที่มีประสิทธิภาพด้านข้อมูล --- Arxiv 2021.05.07"
การใช้งาน Pytorch ของ "ให้ความสนใจกับ MLPS --- Arxiv 2021.05.17"
การใช้งาน Pytorch ของ "Sparse MLP สำหรับการจดจำภาพ: ความตั้งใจด้วยตนเองจำเป็นจริงหรือไม่ --- Arxiv 2021.09.12"
"RepMLP: การทำให้เกิดการโน้มน้าวใจอีกครั้งในเลเยอร์ที่เชื่อมต่ออย่างเต็มรูปแบบสำหรับการจดจำภาพ"
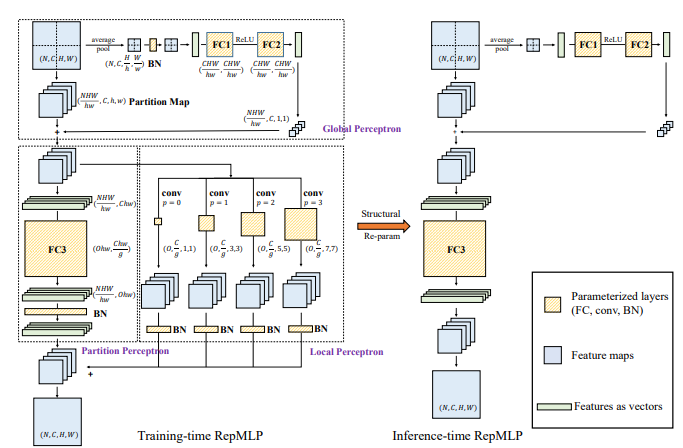
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-MIXER: สถาปัตยกรรม All-MLP สำหรับการมองเห็น"
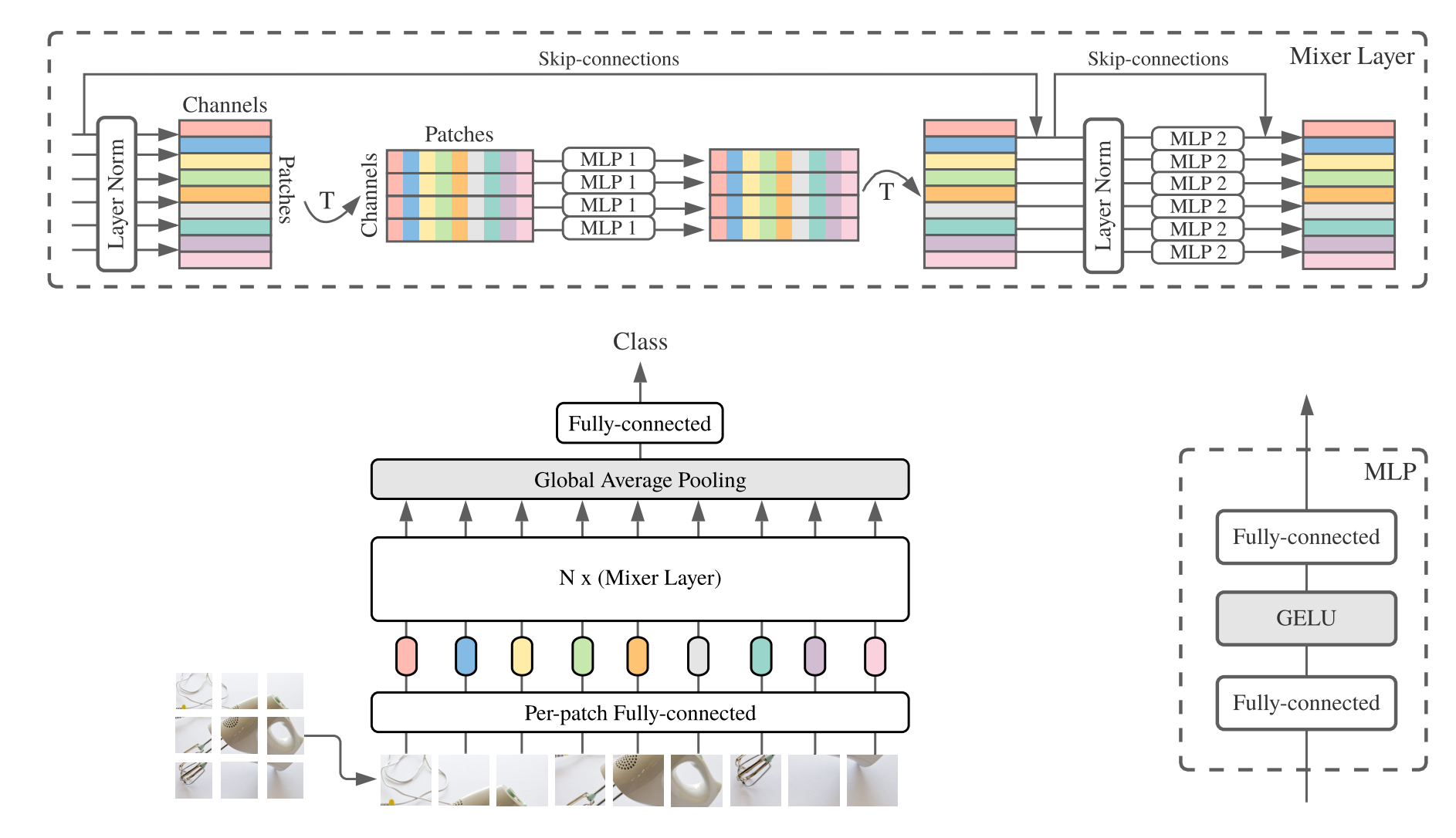
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"RESMLP: เครือข่าย FeedForward สำหรับการจำแนกรูปภาพด้วยการฝึกอบรมที่ประหยัดข้อมูล"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"ให้ความสนใจกับ MLPS"
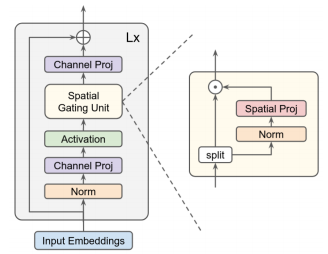
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"Sparse MLP สำหรับการจดจำภาพ: ความตั้งใจด้วยตนเองจำเป็นจริง ๆ หรือไม่?"
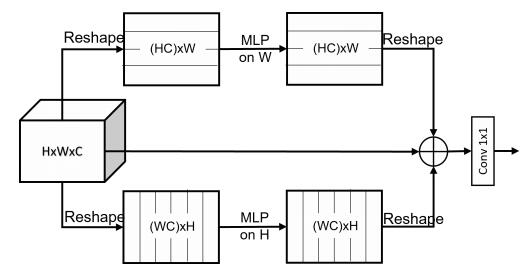
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Vision Permutator: สถาปัตยกรรม MLP ที่สามารถซึมผ่านได้สำหรับการจดจำภาพ"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )การใช้งาน Pytorch ของ "Repvgg: การสร้าง convnets สไตล์ VGG นั้นยอดเยี่ยมอีกครั้ง ---- CVPR2021"
การใช้งาน Pytorch ของ "ACNET: เสริมสร้างโครงกระดูกเคอร์เนลสำหรับ CNN ที่ทรงพลังผ่านบล็อก convolution แบบอสมมาตร --- ICCV2019"
การใช้งาน Pytorch ของ "Branch Block ที่หลากหลาย: การสร้าง convolution เป็นหน่วยที่เหมือนก่อตั้ง --- CVPR2021"
"Repvgg: การสร้างความมั่นใจในสไตล์ VGG อีกครั้ง"
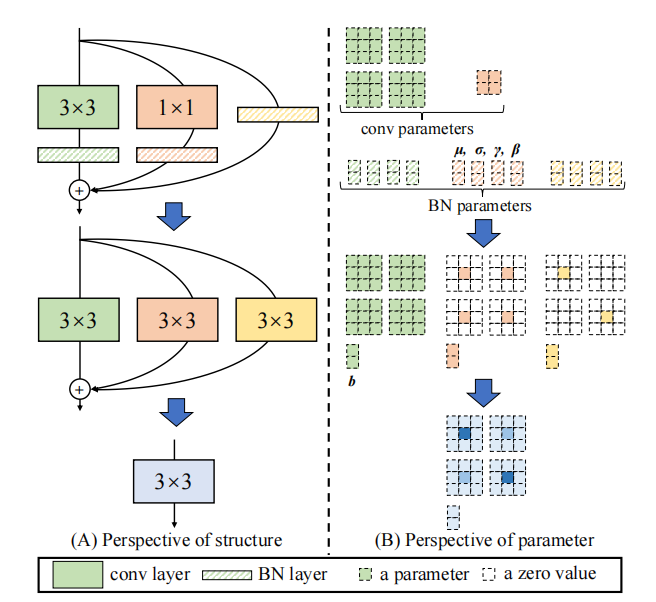
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"ACNET: เสริมความแข็งแกร่งของโครงกระดูกเคอร์เนลสำหรับ CNN ที่ทรงพลังผ่านบล็อก convolution แบบไม่สมมาตร"
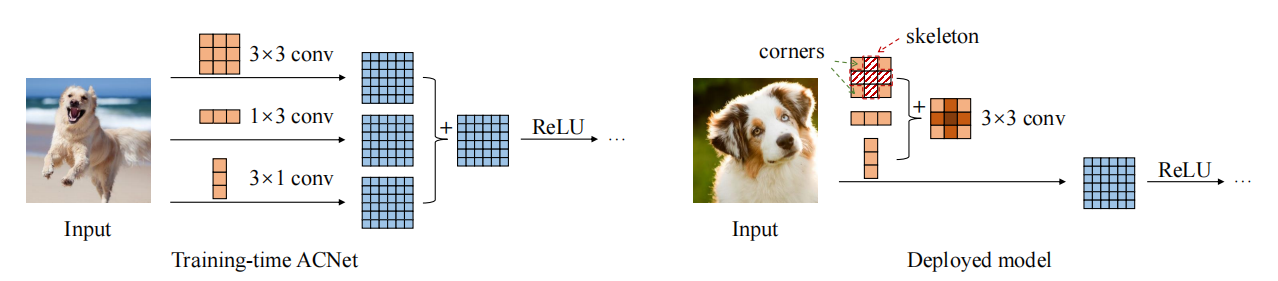
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"บล็อกสาขาที่หลากหลาย: การสร้างความเชื่อมั่นเป็นหน่วยเหมือนเริ่มต้น"
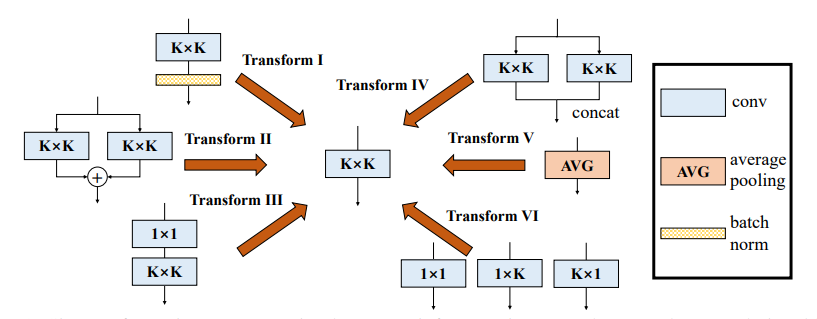
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())การใช้งาน Pytorch ของ "Mobilenets: เครือข่ายประสาท Convolutional ที่มีประสิทธิภาพสำหรับแอพพลิเคชั่น Mobile Vision --- CVPR2017"
การใช้งาน Pytorch ของ "EfficientNet: Rethinking Model Scaling สำหรับ Neural Networks Convolutional --- PMLR2019"
การใช้ Pytorch ของ "การมีส่วนร่วม: การพลิกผันการสืบทอดของ convolution สำหรับการจดจำภาพ ---- CVPR2021"
การใช้งาน Pytorch ของ "Dynamic Convolution: ให้ความสนใจกับเมล็ดพันธุ์-CVPR2020 ORAL"
การใช้ Pytorch ของ "condConv: convolutions พารามิเตอร์แบบมีเงื่อนไขสำหรับการอนุมานที่มีประสิทธิภาพ --- Neurips2019"
"Mobilenets: Neural Neural Neural ที่มีประสิทธิภาพสำหรับแอพพลิเคชั่น Vision Mobile"
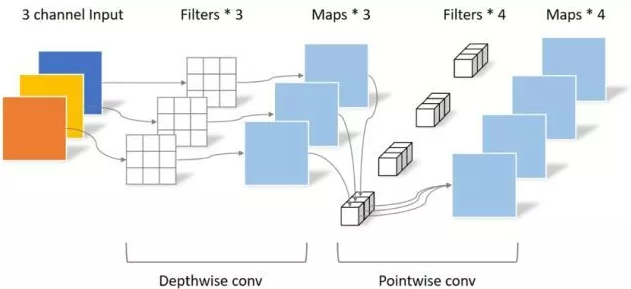
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"EfficientNet: Rethinking Model Scaling สำหรับ Neural Networks Convolutional"
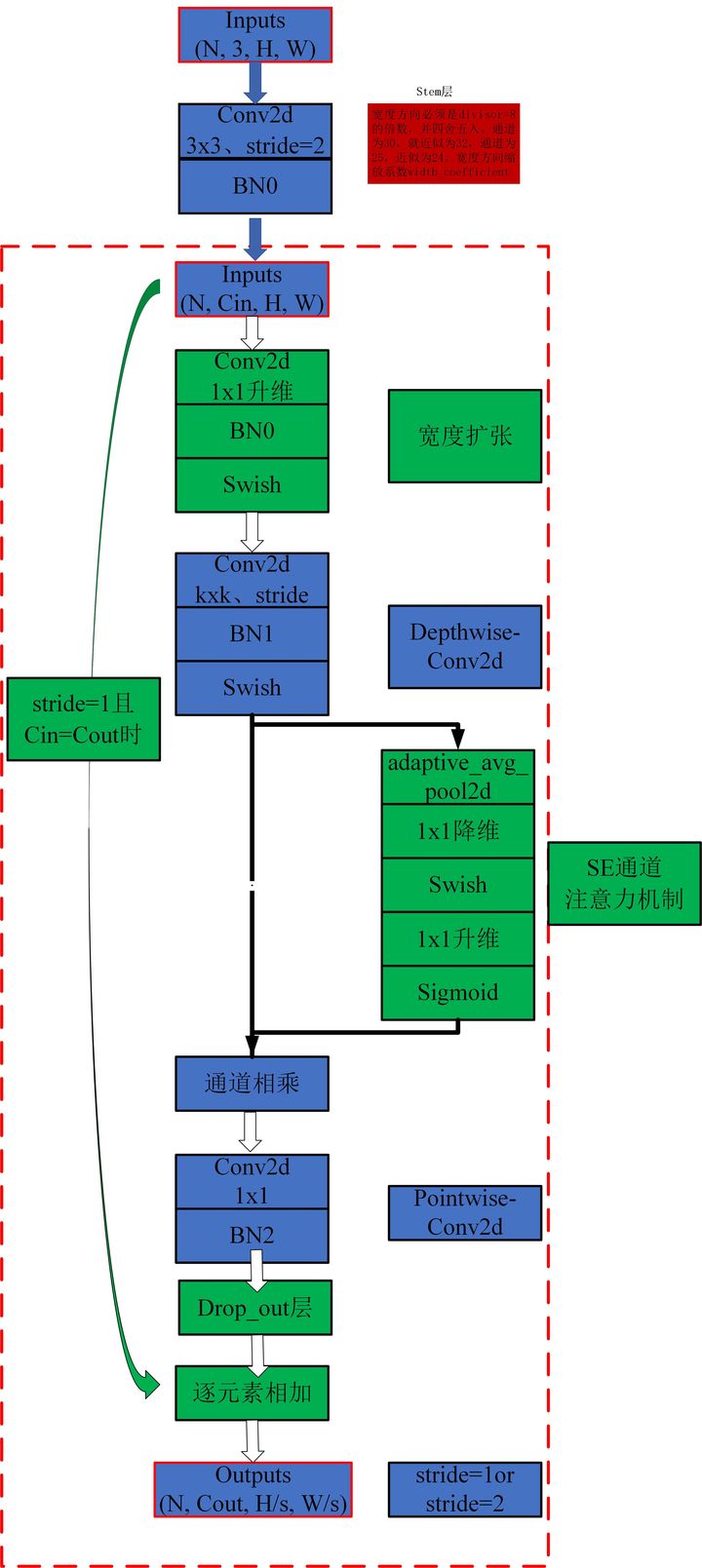
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"การมีส่วนร่วม: การพลิกผันการสืบทอดของการโน้มน้าวใจสำหรับการจดจำภาพ"
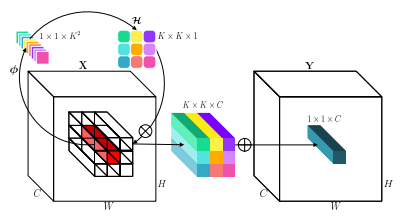
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"Dynamic Convolution: ให้ความสนใจกับเมล็ดพันธุ์"
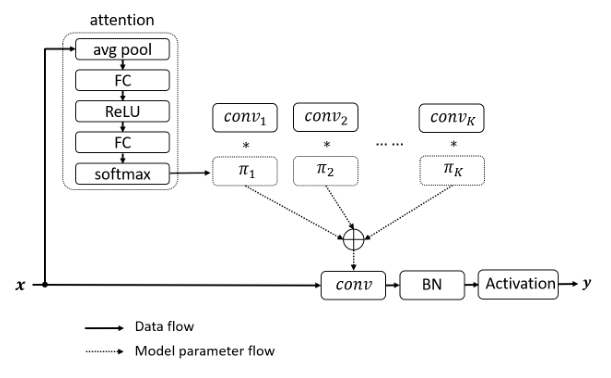
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"CondConv: convolutions พารามิเตอร์แบบมีเงื่อนไขสำหรับการอนุมานที่มีประสิทธิภาพ"
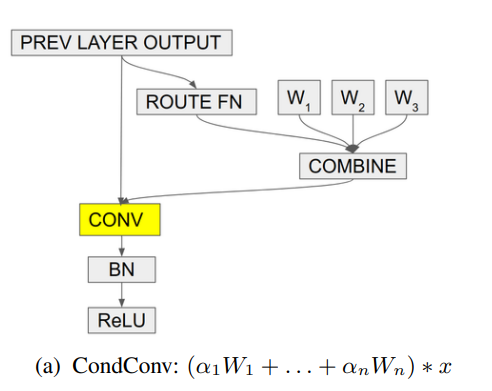
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )ข่าวใหญ่! - - ในฐานะที่เป็นส่วนเสริมของโครงการคุณสามารถให้ความสนใจกับโครงการ FightingCV-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper-Paper
ข่าวใหญ่! - - เมื่อเร็ว ๆ นี้ฉันได้รวบรวมบทเรียนวิดีโอที่เกี่ยวข้องกับ AI และเอกสารที่ต้องอ่านบนอินเทอร์เน็ต FightingCV-Course
ข่าวใหญ่! - - เมื่อเร็ว ๆ นี้ห้องสมุดการตรวจจับวัตถุ Yoloair ใหม่ได้เปิดขึ้นซึ่งรวมโมเดล YOLO ที่หลากหลายรวมถึง YOLOV5, YOLOV7, YOLOR, YOLOX, YOLOV4, YOLOV3 และรุ่น YOLO อื่น ๆ รวมถึงกลไกความสนใจที่มีอยู่
ECCV2022 PAPER SUMMARY: ECCV2022-PAPER-LIST


