External Attention pytorch
1.0.0

Chinois simplifié | Anglais
Bonjour à tous, je suis Xiaoma
Pour Xiaobai (comme moi): Récemment, je trouverai un problème lorsque j'ai lu un article. Parfois, l'idée principale du papier est très simple, et le code central peut être seulement une douzaine de lignes. Cependant, lorsque j'ai ouvert le code source de la version de l'auteur, j'ai constaté que le module proposé était intégré dans des cadres de tâches tels que la classification, la détection et la segmentation, ce qui a conduit à un code relativement redondant. Je ne connais pas les cadres de tâches spécifiques et il est difficile pour moi de trouver le code de base , ce qui conduit à certaines difficultés à comprendre les articles et les idées de réseau.
Pour avancé (comme vous): si vous considérez des unités de base telles que Conv, FC et RNN comme de petits blocs de construction Lego, et des structures telles que Transformer et Resnet en tant que châteaux LEGO qui ont été construits. Ensuite, les modules fournis par ce projet sont des composants LEGO avec des informations sémantiques complètes. Laissez les chercheurs scientifiques éviter de faire des roues à plusieurs reprises , réfléchissez à la façon d'utiliser ces "composants LEGO" pour construire des œuvres plus colorées.
Pour Master (peut-être comme vous): J'ai une capacité limitée et je n'aime pas les gicler légèrement ! ! !
Pour tous: ce projet s'engage à mettre en œuvre une base de code qui permet aux novices d'apprentissage en profondeur de comprendre et de servir la recherche scientifique et les communautés industrielles .
Installez directement via PIP
pip install fightingcv-attentionOu cloner le référentiel
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Séries d'attention
1. Utilisation de l'attention externe
2. Utilisation de l'attention de soi
3. Utilisation simplifiée de l'attention de soi
4. Utilisation de l'attention de la pression et de l'excitation
5. Utilisation de l'attention SK
6. Utilisation de l'attention CBAM
7. Utilisation de l'attention de Bam
8. Utilisation de l'attention ECA
9. Utilisation de l'attention de Danet
10. Utilisation de l'attention de la pyramide (PSA)
11. Utilisation efficace de l'auto-assertion multi-tête (EMSA)
12. Mélanger l'utilisation de l'attention
13. Utilisation de l'attention de la muse
14. Utilisation de l'attention SGE
15. A2 Utilisation de l'attention
16. Utilisation de l'attention arrière
17. Utilisation de l'attention des perspectives
18. Utilisation de l'attention VIP
19. Utilisation de l'attention du manteau
20. Utilisation de l'attention de Halonet
21. Utilisation de l'auto-attention polarisée
22. Utilisation de la cotatétention
23. Utilisation de l'attention résiduelle
24. S2 Utilisation de l'attention
25. Utilisation de l'attention GFNET
26. Utilisation de l'attention du triplet
27. Coordonner l'utilisation de l'attention
28. Utilisation de l'attention sur mobile
29. Utilisation de l'attention de Parnet
30. Utilisation de l'attention d'OVNI
31. Utilisation de l'attention Acmix
32. MobileVitv2 Utilisation de l'attention
33. Utilisation de l'attention des données
34. Utilisation de l'attention de la transition
35. Utilisation de l'attention de Moatransformateur
36. Utilisation de l'attention entrecrrossive
37. Axial_attention Utilisation de l'attention
Série de squelette
1. Utilisation de la resnet
2. Utilisation de Resnext
3. Utilisation du mobile
4. Utilisation Convmixer
5. Utilisation de shuffletransformateur
6. Utilisation de contnet
7. Utilisation du Hatnet
8. Utilisation du manteau
9. Utilisation du Pvt
10. Utilisation du CPVT
11. Utilisation de la fosse
12. Utilisation des visitaires
13. Utilisation de TNT
14. Utilisation du DVIT
15. Utilisation de CEIT
16. Utilisation de la condamnation
17. Utilisation de CAIT
18. Utilisation de PatchConvnet
19. Utilisation du Deit
20. Utilisation de lévites
21. Utilisation de Volo
22. Utilisation des conteneurs
23. Utilisation CMT
24. Utilisation efficace
25. Utilisation Convnextv2
Série MLP
1. Utilisation du REPMLP
2. Utilisation du MLP-MIXER
3. Utilisation de RESMLP
4. Utilisation GMLP
5. Utilisation SMLP
6. Utilisation VIP-MLP
Série de re-paramètre (représentant)
1. Utilisation du repvgg
2. Utilisation acnet
3. Utilisation diversifiée du bloc de branche (DDB)
Série Convolution
1. Utilisation de la convolution séparable dans le sens de la profondeur
2. Utilisation MBCONV
3. Utilisation de l'involution
4. Utilisation de DynamicConv
5. Utilisation condconv
Pytorch Implémentation de "Beyond Auto-Aimation: Attention externe en utilisant deux couches linéaires pour les tâches visuelles --- Arxiv 2021.05.05"
La mise en œuvre de Pytorch de "l'attention est tout ce dont vous avez besoin --- NIPS2017"
Implémentation Pytorch des "réseaux de compression et d'excitation --- CVPR2018"
Pytorch Implémentation de "réseaux de noyau sélectifs --- CVPR2019"
Pytorch Implémentation de "CBAM: Module d'attention du bloc convolutionnel --- ECCV2018"
Pytorch Implémentation de "BAM: Module d'attention d'étranglement --- BMCV2018"
Mise en œuvre de Pytorch de "ECA-NET: ATTENTION EFFICATEUR DE LA CHANSE pour les réseaux de neurones convolutionnels profonds --- CVPR2020"
Pytorch Implémentation de "réseau de double attention pour la segmentation des scènes --- CVPR2019"
Pytorch Implémentation de "Epsanet: un bloc d'attention de la pyramide efficace sur le réseau neuronal convolutionnel --- Arxiv 2021.05.30"
Pytorch Implémentation de "REST: un transformateur efficace pour la reconnaissance visuelle --- Arxiv 2021.05.28"
Mise en œuvre de Pytorch de "SA-NET: Shuffle Atention pour les réseaux de neurones convolutionnels profonds --- ICASSP 2021"
Pytorch Mise en œuvre de "Muse: une attention multi-échelle parallèle pour l'apprentissage de la séquence à la séquence --- Arxiv 2019.11.17"
Pytorch Implémentation de "Spatial Group-Wise Amélioration: Amélioration de l'apprentissage des fonctionnalités sémantiques dans les réseaux convolutionnels --- ARXIV 2019.05.23"
Pytorch Implémentation de "A2-NETS: Double Attention Networks --- NIPS2018"
Implémentation Pytorch d'un "Transformateur sans attention --- ICLR2021 (Apple New Work)"
Pytorch Implémentation de Volo: Vision Outlooker pour la reconnaissance visuelle --- Arxiv 2021.06.24 "[Analyse du papier]
Implémentation de Pytorch du permutator de la vision: une architecture permanent de type MLP pour la reconnaissance visuelle --- Arxiv 2021.06.23 [Analyse du papier]
Pytorch Implémentation de CoatNet: Mariant la convolution et l'attention pour toutes les tailles de données --- Arxiv 2021.06.09 [Analyse du papier]
Pytorch Implémentation de l'échelle de l'auto-agence d'auto-agence locale pour les squelettes visuelles efficaces par les paramètres --- CVPR2021 ORAL [Analyse du papier]
Pytorch Mise en œuvre de l'auto-agence polarisée: vers une régression par pixel de haute qualité --- Arxiv 2021.07.02 [Analyse du papier]
Pytorch Implémentation de réseaux de transformateurs contextuels pour la reconnaissance visuelle --- Arxiv 2021.07.26 [Analyse du papier]
Pytorch Implémentation de l'attention résiduelle: une méthode simple mais efficace pour la reconnaissance multi-étiquettes --- ICCV2021
Implémentation de Pytorch de S²-MLPV2: Amélioration de l'architecture MLP à décalage spatial pour la vision --- Arxiv 2021.08.02 [Analyse du papier]
Pytorch Implémentation de réseaux de filtres globaux pour la classification d'images --- Arxiv 2021.07.01
Pytorch Implémentation de Rotate pour y assister: Module d'attention du triplet convolutionnel --- WACV 2021
Pytorch Implémentation de l'attention des coordonnées pour une conception efficace du réseau mobile --- CVPR 2021
Implémentation de Pytorch de Mobilevit: Transformateur de vision à usage général, à usage général et à usage mobile --- Arxiv 2021.10.05
Pytorch Implémentation de réseaux non profonds --- Arxiv 2021.10.20
Pytorch Implémentation d'UFO-VIT: Transformateur de vision linéaire haute performance sans softmax --- Arxiv 2021.09.29
Pytorch Implémentation de l'auto-agence d'auto-agence séparable pour les transformateurs de vision mobile --- Arxiv 2022.06.06
Pytorch Mise en œuvre de l'intégration de l'auto-attention et de la convolution --- Arxiv 2022.03.14
Implémentation de Pytorch de CrossFormer: un transformateur de vision polyvalent chargée à l'échelle croisée --- ICLR 2022
Pytorch Implémentation des fonctionnalités globales agrégées dans un transformateur de vision local
Pytorch Implémentation de CCNET: attention croisée pour la segmentation sémantique
Pytorch Implémentation de l'attention axiale dans les transformateurs multidimensionnels
"Au-delà de l'attention: l'attention externe en utilisant deux couches linéaires pour les tâches visuelles"
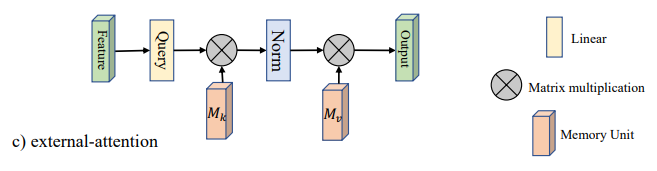
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"L'attention est tout ce dont vous avez besoin"
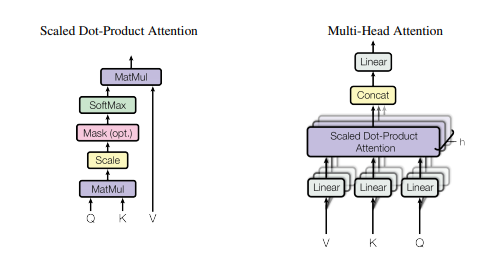
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Aucun
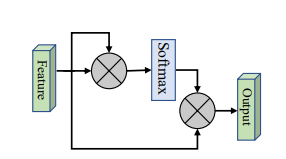
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Réseaux de compression et d'excitation"
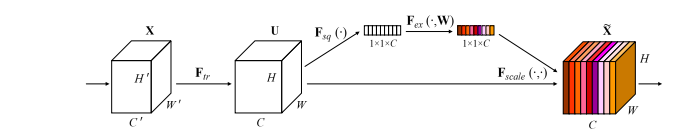
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Réseaux de noyau sélectifs"
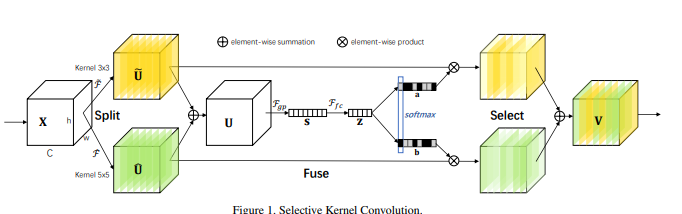
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: module d'attention du bloc convolutionnel"
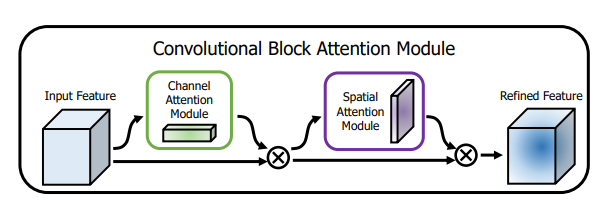
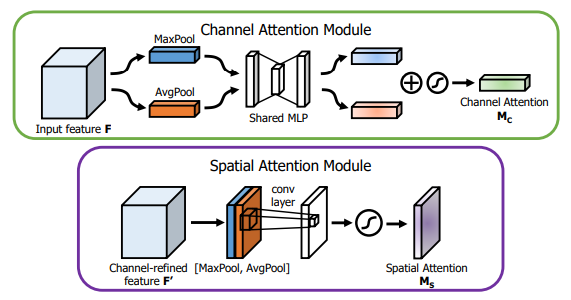
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"Bam: module d'attention goulot d'étranglement"
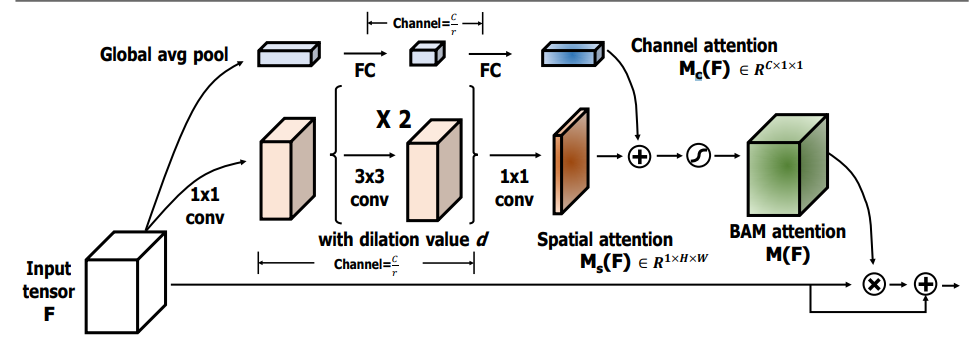
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: une attention efficace du canal pour les réseaux de neurones convolutionnels profonds"
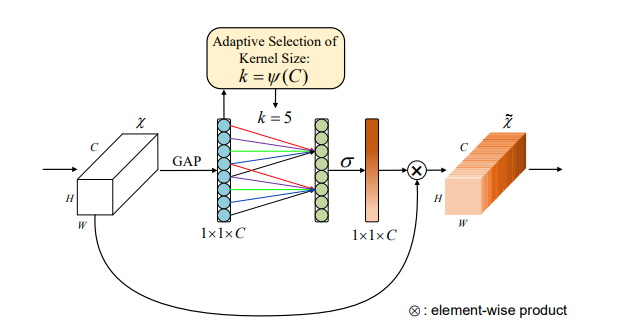
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"Réseau à double attention pour la segmentation des scène"
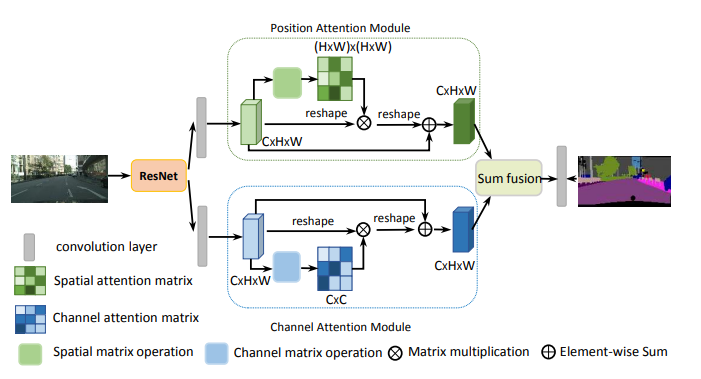
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet: un bloc d'attention de la pyramide efficace sur le réseau neuronal convolutionnel"
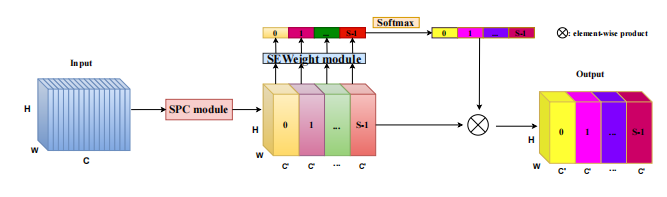
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"Repos: un transformateur efficace pour la reconnaissance visuelle"
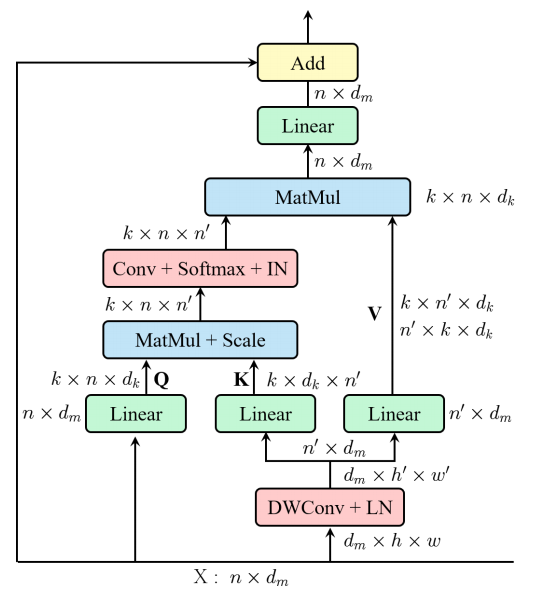
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: SHUFFLET ASENTANT POUR LES NEAURS NEURALS CONVOLUTIONNELS SUPPORTS"
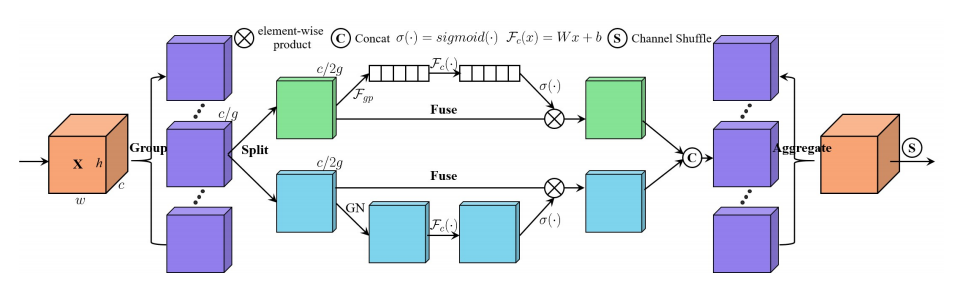
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse: l'attention à plusieurs échelles parallèles pour l'apprentissage des séquences"
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Amélioration du groupe spatial: Amélioration de l'apprentissage des fonctionnalités sémantiques dans les réseaux convolutionnels
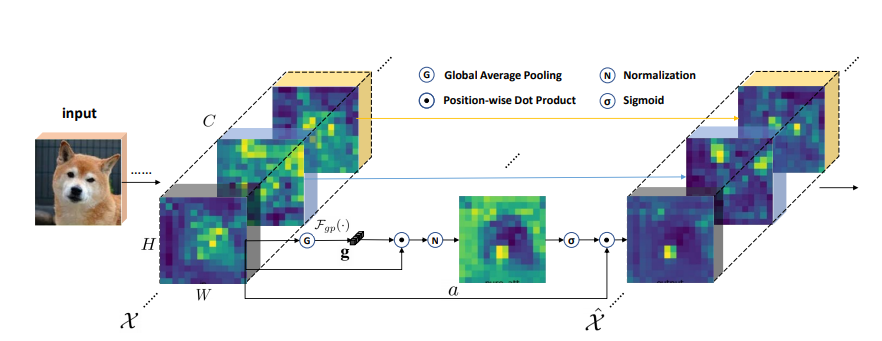
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2 nets: réseaux à double attention
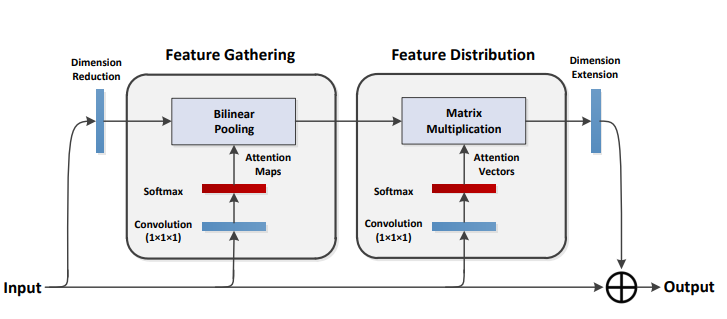
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Un transformateur sans attention
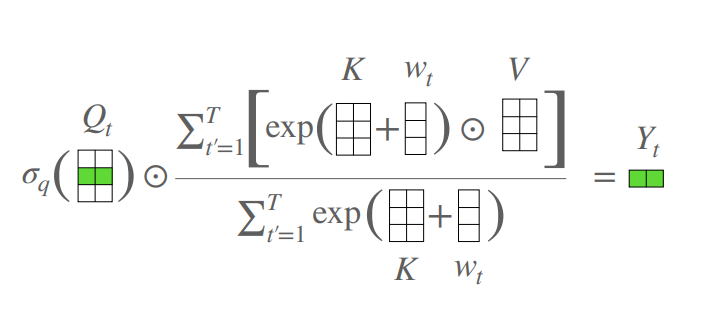
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo: Vision Outlooker pour la reconnaissance visuelle "
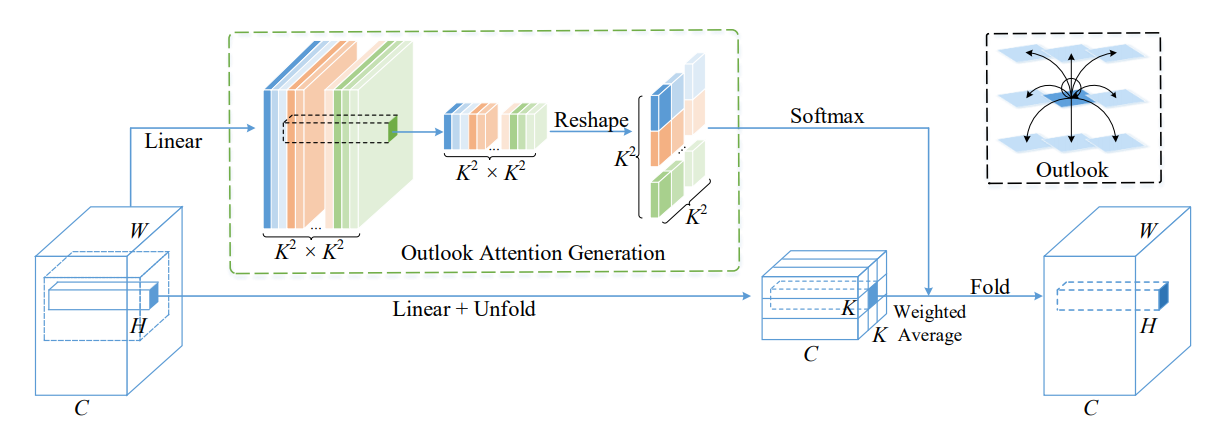
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Vision Permutator: une architecture de type MLP permutable pour la reconnaissance visuelle "
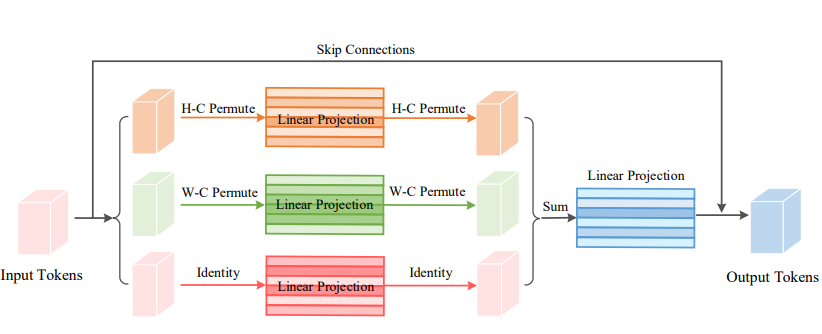
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: épouser la convolution et l'attention pour toutes les tailles de données "
Aucun
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Mise à l'échelle de l'auto-attention locale pour les squelette visuel efficace des paramètres "
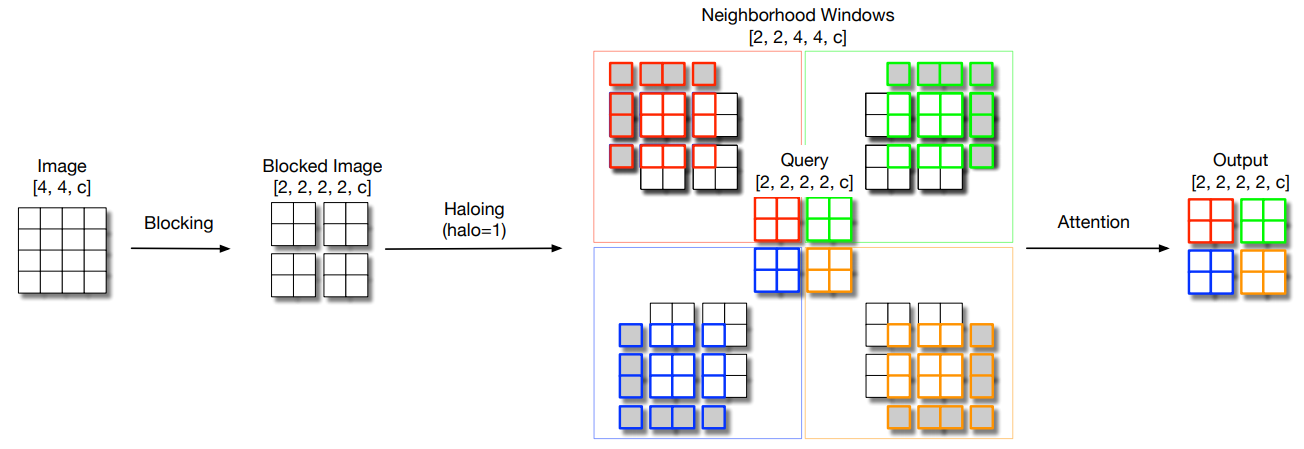
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Aménagement polarisé: vers une régression par pixel de haute qualité "
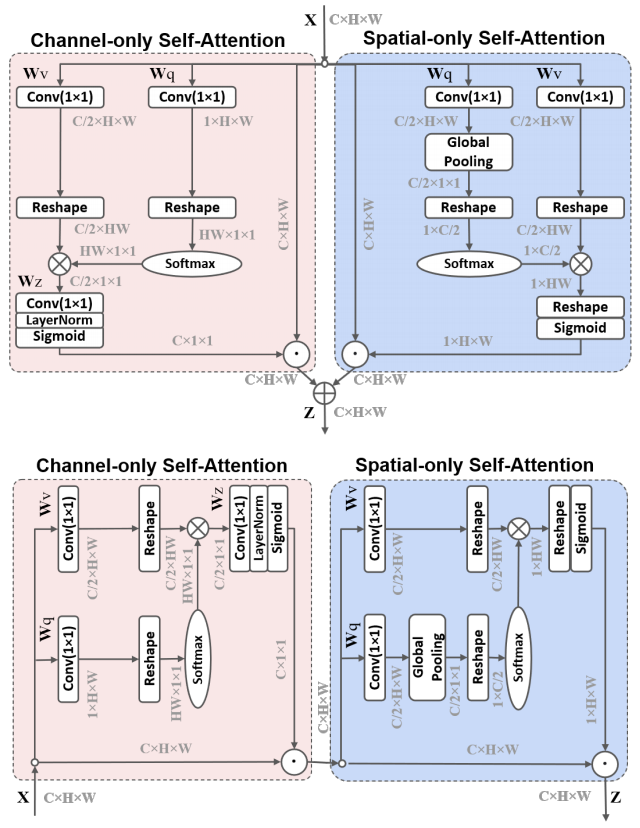
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Réseaux de transformateurs contextuels pour la reconnaissance visuelle --- Arxiv 2021.07.26
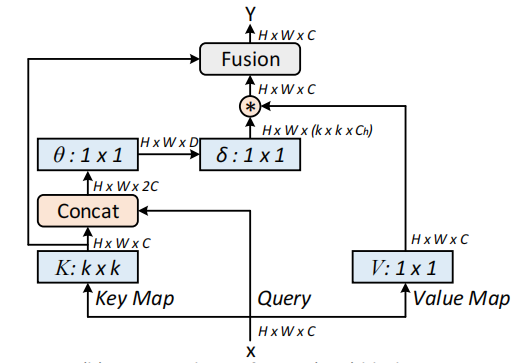
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Attention résiduelle: une méthode simple mais efficace pour la reconnaissance multi-étiquettes --- ICCV2021
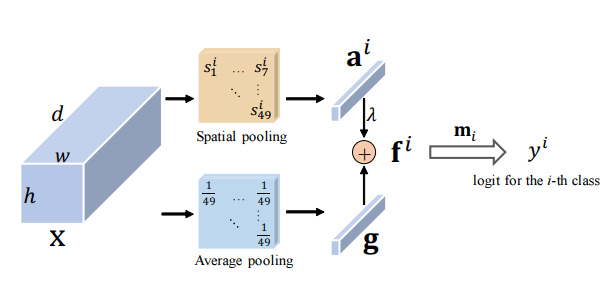
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: Amélioration de l'architecture MLP à décalage spatial pour la vision --- Arxiv 2021.08.02
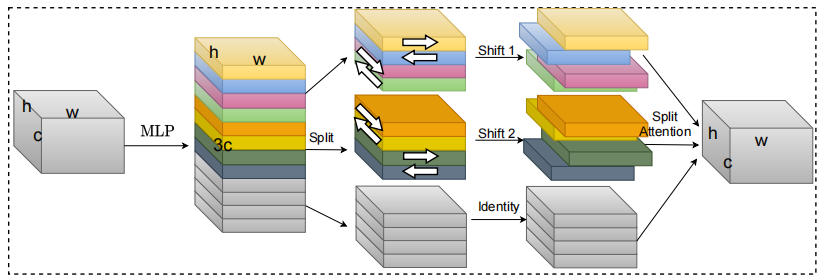
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Réseaux de filtrage mondial pour la classification des images --- Arxiv 2021.07.01
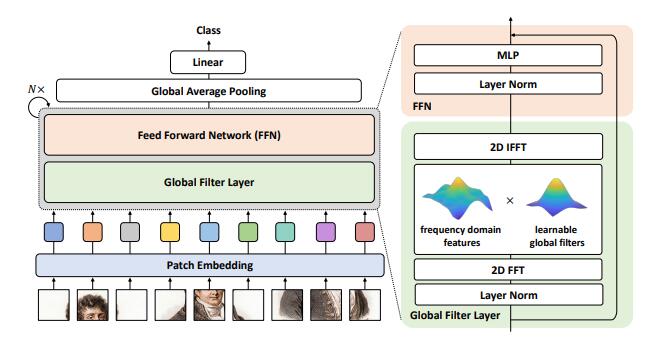
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )Tourner pour assister: Module de l'attention du triplet convolutionnel --- CVPR 2021
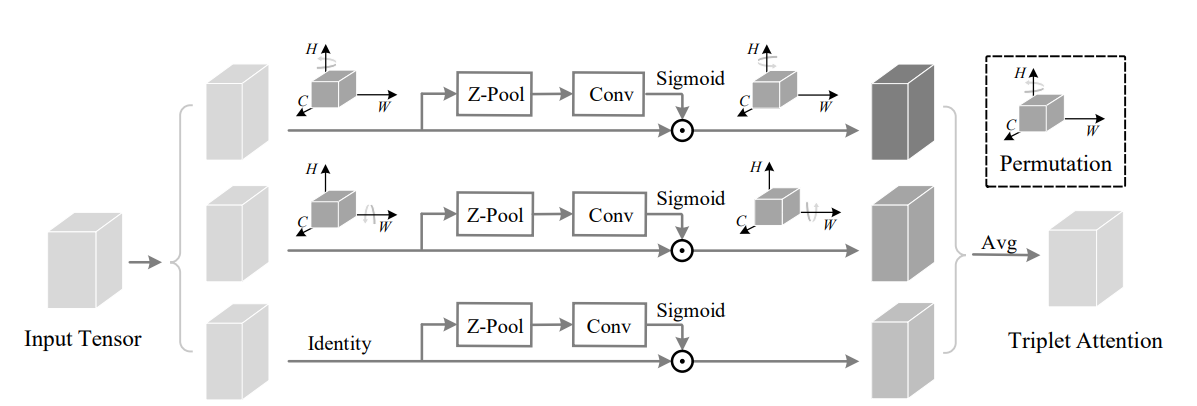
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Coordonner l'attention pour une conception efficace de réseau mobile --- CVPR 2021
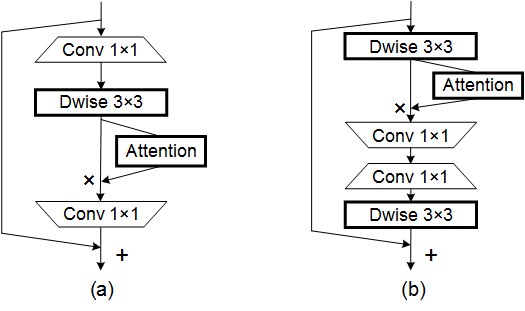
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )Mobilevit: Transformateur de vision de poids léger, à usage général et mobile --- Arxiv 2021.10.05
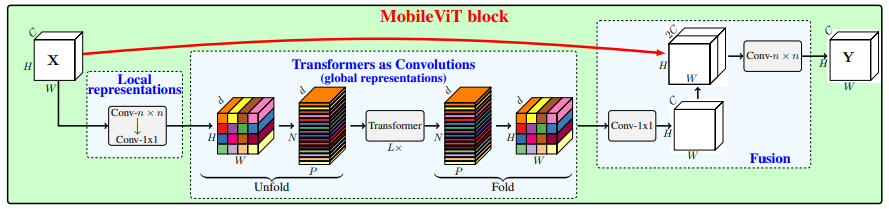
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Réseaux non profonds --- Arxiv 2021.10.20
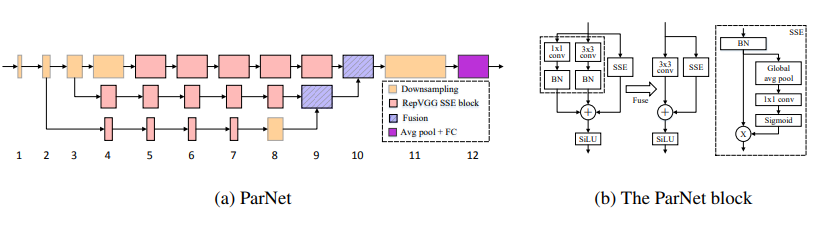
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT: Transformateur de vision linéaire haute performance sans softmax --- Arxiv 2021.09.29
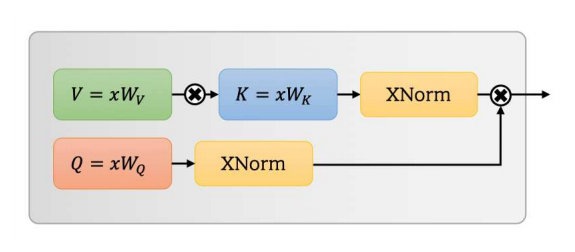
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
Sur l'intégration de l'addition et de la convolution
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
Aménagement auto-séparable pour les transformateurs de vision mobile --- Arxiv 2022.06.06
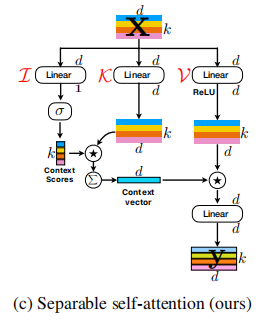
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Transformateur de vision avec une attention déformable --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
CrossFormer: un transformateur de vision polyvalent chargée à l'étude croisée --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Agréger les fonctionnalités globales dans le transformateur de vision local
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: attention croisée pour la segmentation sémantique
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Attention axiale dans les transformateurs multidimensionnels
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Mise en œuvre de Pytorch de "l'apprentissage résiduel profond pour la reconnaissance d'image --- CVPR2016 Meilleur papier"
Pytorch Implémentation de "transformations résiduelles agrégées pour les réseaux de neurones profonds --- CVPR2017"
Pytorch Implémentation de Mobilevit: Transformateur de vision à usage général, à usage général et à usage mobile --- Arxiv 2020.10.05
La mise en œuvre de Pytorch des correctifs est tout ce dont vous avez besoin? --- ICLR2022 (en cours d'examen)
Pytorch Implémentation de Shuffle Transformer: Repenser Spatial Shuffle pour Vision Transformer --- Arxiv 2021.06.07
Pytorch Implémentation de contnet: pourquoi ne pas utiliser la convolution et le transformateur en même temps? --- Arxiv 2021.04.27
Pytorch Mise en œuvre des transformateurs de vision avec une attention hiérarchique --- Arxiv 2022.06.15
Pytorch Mise en œuvre des transformateurs d'image Conv-Atentional co-échelle --- Arxiv 2021.08.26
Pytorch Implémentation des encodages positionnels conditionnels pour les transformateurs de vision
Mise en œuvre de Pytorch de repenser les dimensions spatiales des transformateurs de vision --- ICCV 2021
Pytorch Implémentation de Crossvit: Transformateur de vision multi-échelle de l'attention pour la classification d'images --- ICCV 2021
Implémentation de Pytorch du transformateur dans Transformer --- Neirips 2021
Pytorch Mise en œuvre de Deepvit: Vers Deep Vision Transformateur
Mise en œuvre de Pytorch de l'incorporation de conceptions de convolution dans les transformateurs visuels
Pytorch Mise en œuvre de Conconstor: Amélioration des transformateurs de vision avec des biais inductifs convolutionnels doux
Mise en œuvre de Pytorch des réseaux convolutionnels augmentants avec une agrégation basée sur l'attention
Implémentation de Pytorch de l'aller plus loin avec les transformateurs d'image --- ICCV 2021 (oral)
Pytorch Mise en œuvre des transformateurs d'images éconergétiques de formation et distillation par l'attention --- ICML 2021
Pytorch Implémentation de Levit: un transformateur de vision dans les vêtements de Convnet pour une inférence plus rapide
Pytorch Implémentation de Volo: Vision Outlooker pour la reconnaissance visuelle
Pytorch Implémentation du conteneur: Réseau d'agrégation de contexte --- Neups 2021
Pytorch Implémentation de CMT: Réseaux de neurones convolutionnels Rencontrez Vision Transformers --- CVPR 2022
Pytorch Mise en œuvre du transformateur de vision avec une attention déformable --- CVPR 2022
Pytorch Implémentation de EfficientFormer: Vision Transformers à Mobilenet Speed
Pytorch Implémentation de ConvNextV2: Co-conception et mise à l'échelle des convaints avec autoencoders masqués
"Apprentissage résiduel profond pour la reconnaissance d'image --- CVPR2016 Meilleur papier"
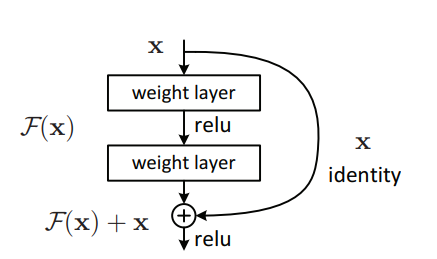
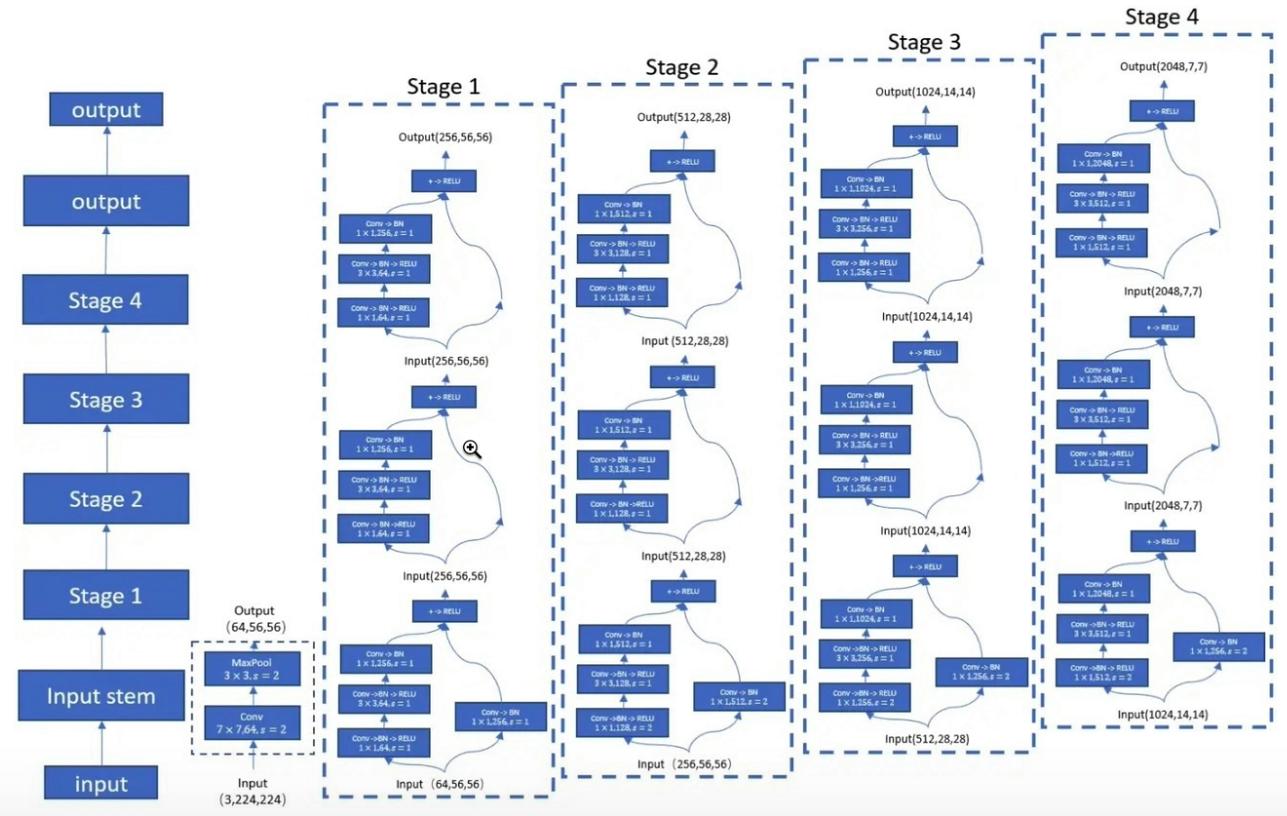
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"Transformations résiduelles agrégées pour les réseaux de neurones profonds --- CVPR2017"
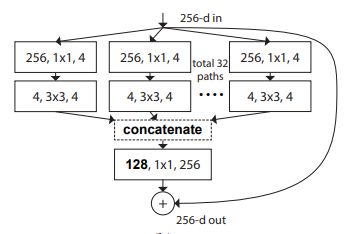
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
Mobilevit: Transformateur de vision de poids léger, à usage général et à usage mobile --- Arxiv 2020.10.05
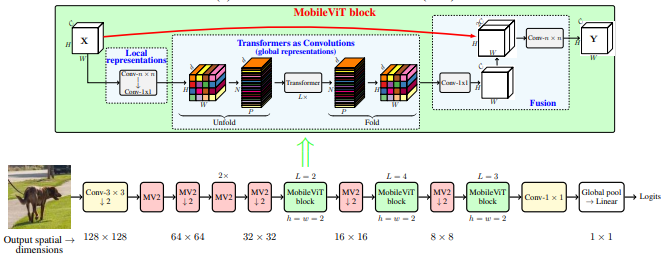
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Les correctifs sont tout ce dont vous avez besoin? --- ICLR2022 (en cours d'examen)
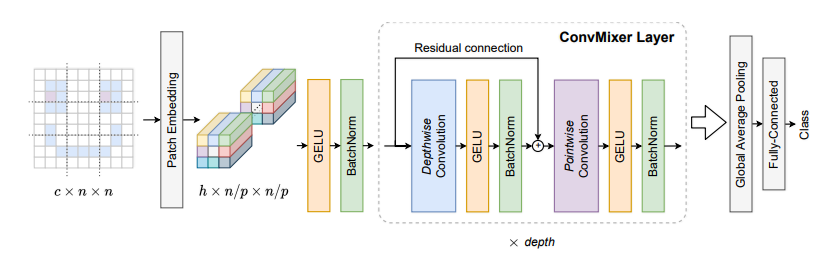
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Transformateur de shuffle: repenser le shuffle spatial pour le transformateur de vision
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
Contnet: Pourquoi ne pas utiliser Convolution and Transformer en même temps?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Transformers de vision avec une attention hiérarchique
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Transformateurs d'image conv-conservateurs co-échelle
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: Bâlines améliorées avec transformateur de vision pyramidale
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Encodages positionnels conditionnels pour les transformateurs de vision
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Repenser les dimensions spatiales des transformateurs de vision
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )Crossvit: Transformateur de vision multi-échelle transformateur pour la classification de l'image
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Transformateur dans le transformateur
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )Deepvit: vers un transformateur de vision plus profond
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Incorporer les conceptions de convolution dans les transformateurs visuels
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Conconvention: Amélioration des transformateurs de vision avec des biais inductifs convolutionnels doux
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Aller plus profondément avec les transformateurs d'image
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Augmenter les réseaux convolutionnels avec une agrégation basée sur l'attention
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Transformeurs d'image économes en matière de données et distillation par l'attention
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Lévit: un transformateur de vision dans les vêtements de Convnet pour une inférence plus rapide
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo: Vision Outlooker pour la reconnaissance visuelle
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Conteneur: réseau d'agrégation de contexte
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: Les réseaux de neurones convolutionnels rencontrent des transformateurs de vision
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )EfficientFormer: Vision Transformers à Mobilenet Speed
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )ConvNextV2: Co-conception et mise à l'échelle des convaints avec des autoencoders masqués
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Pytorch Implémentation de "REPMLP: Re-paramétriseur de convolutions en couches entièrement connectées pour la reconnaissance d'image --- Arxiv 2021.05.05"
Pytorch Implémentation de "MLP-MIXER: Une architecture All-MLP pour la vision --- Arxiv 2021.05.17"
Implémentation de Pytorch de "RESMLP: réseaux de restauration pour la classification d'image avec une formation économe en données --- ARXIV 2021.05.07"
Mise en œuvre de Pytorch de "prêter attention aux MLP --- Arxiv 2021.05.17"
Pytorch Implémentation de "MLP clairsemé pour la reconnaissance d'image: l'auto-attention est-elle vraiment nécessaire? --- ARXIV 2021.09.12"
"REPMLP: re-paamètre des convolutions en couches entièrement connectées pour la reconnaissance d'image"
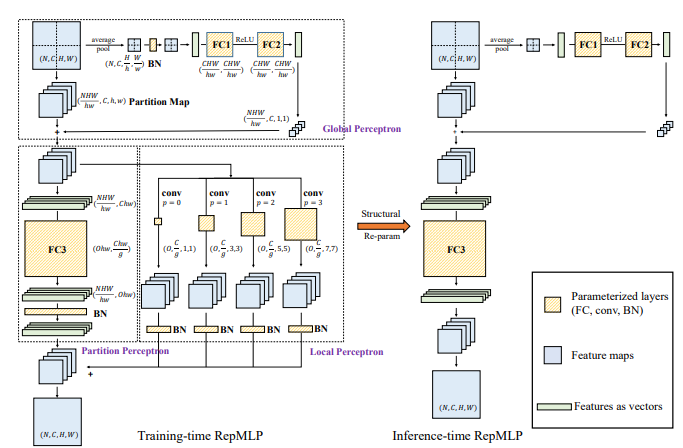
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-mixer: une architecture All-MLP pour la vision"
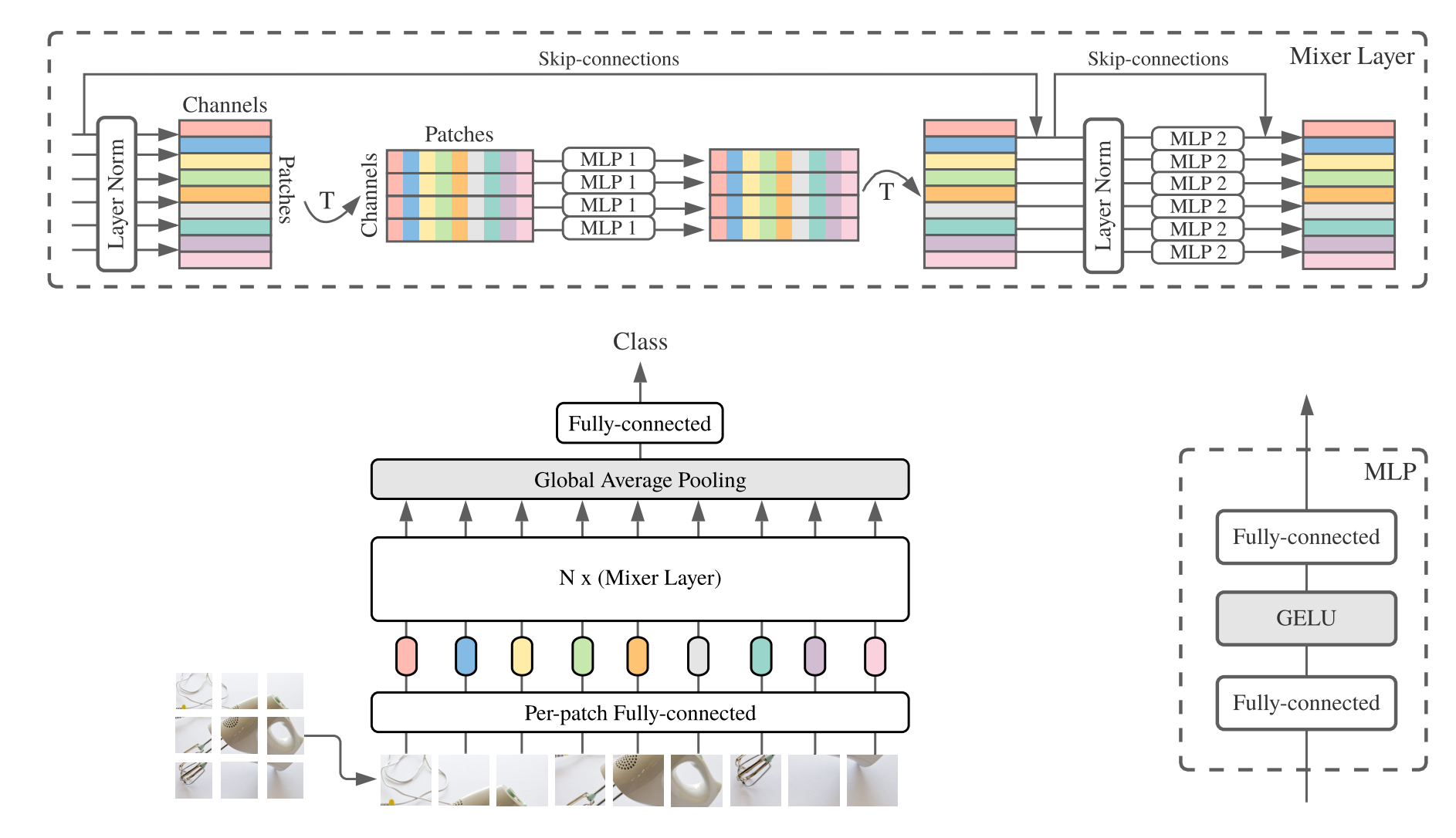
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"RESMLP: réseaux de restauration pour la classification d'images avec une formation économe en données"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Faites attention aux MLP"
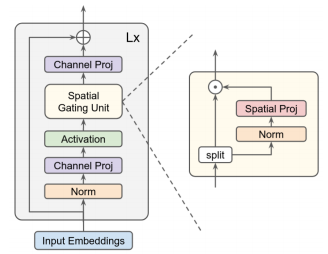
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"MLP clairsemé pour la reconnaissance de l'image: l'auto-attention est-elle vraiment nécessaire?"
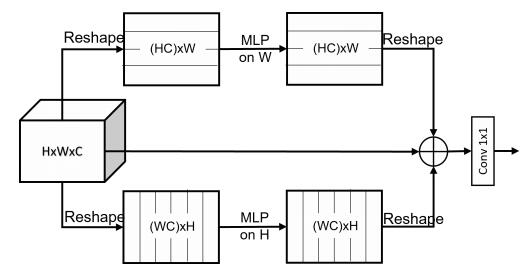
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Vision Permutator: une architecture de type MLP permutable pour la reconnaissance visuelle"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Pytorch Implémentation de "Repvgg: Rendre à nouveau des convaints de style VGG ---- CVPR2021"
Pytorch Implémentation de "ACNET: renforcement des squelettes du noyau pour un CNN puissant via des blocs de convolution asymétrique --- ICCV2019"
Pytorch Implémentation de "Bloc de branche diversifié: construire une convolution en tant qu'unité de création --- CVPR2021"
"Repvgg: rendre les convaints de style VGG à nouveau à nouveau"
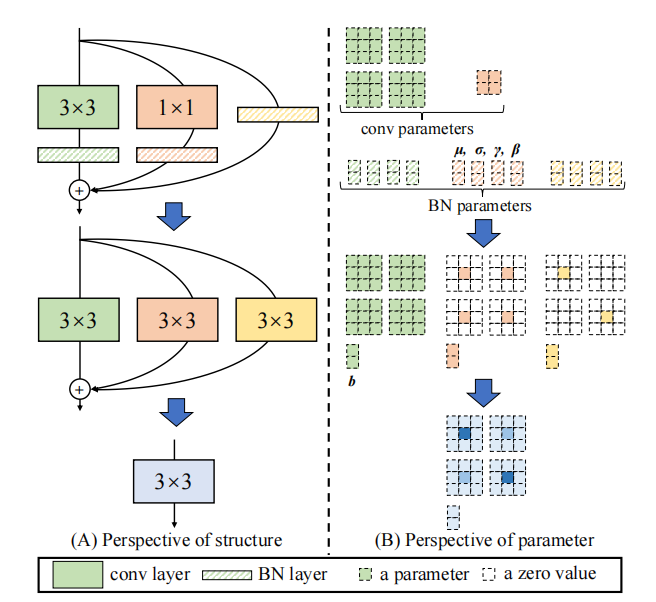
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"ACNET: renforcement des squelettes du noyau pour un CNN puissant via des blocs de convolution asymétrique"
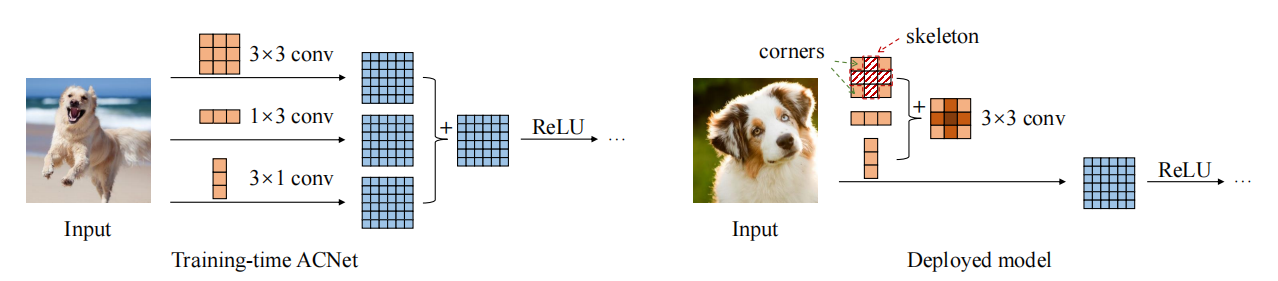
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"Bloc de branche diversifié: construire une convolution comme une unité de création"
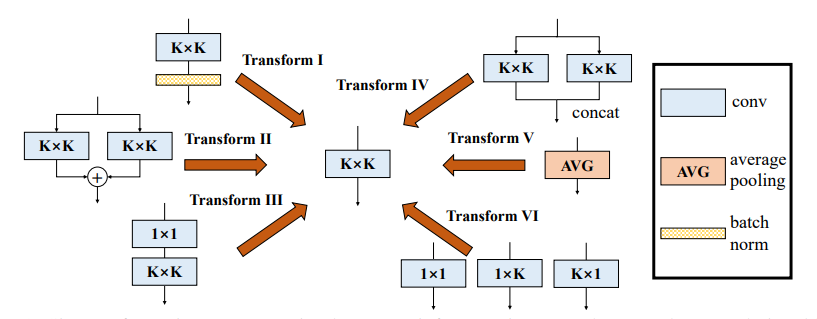
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Pytorch Implémentation de "Mobilenets: réseaux de neurones convolutionnels efficaces pour les applications de vision mobile --- CVPR2017"
Mise en œuvre de Pytorch de "EfficientNet: Repenser la mise à l'échelle du modèle pour les réseaux de neurones convolutionnels --- PMLR2019"
Pytorch Implémentation de "Involution: inverser l'inhérence de la convolution pour la reconnaissance visuelle ---- CVPR2021"
Pytorch Implémentation de "Convolution dynamique: attention sur les noyaux de convolution --- CVPR2020 ORAL"
Pytorch Implémentation de "CONDCONV: Convolutions paramétrées conditionnelles pour une inférence efficace --- NIRIPS2019"
"Mobilenets: réseaux de neurones convolutionnels efficaces pour les applications de vision mobile"
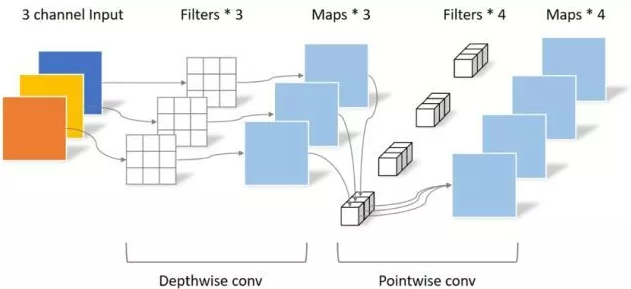
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"EfficientNet: Repenser la mise à l'échelle du modèle pour les réseaux de neurones convolutionnels"
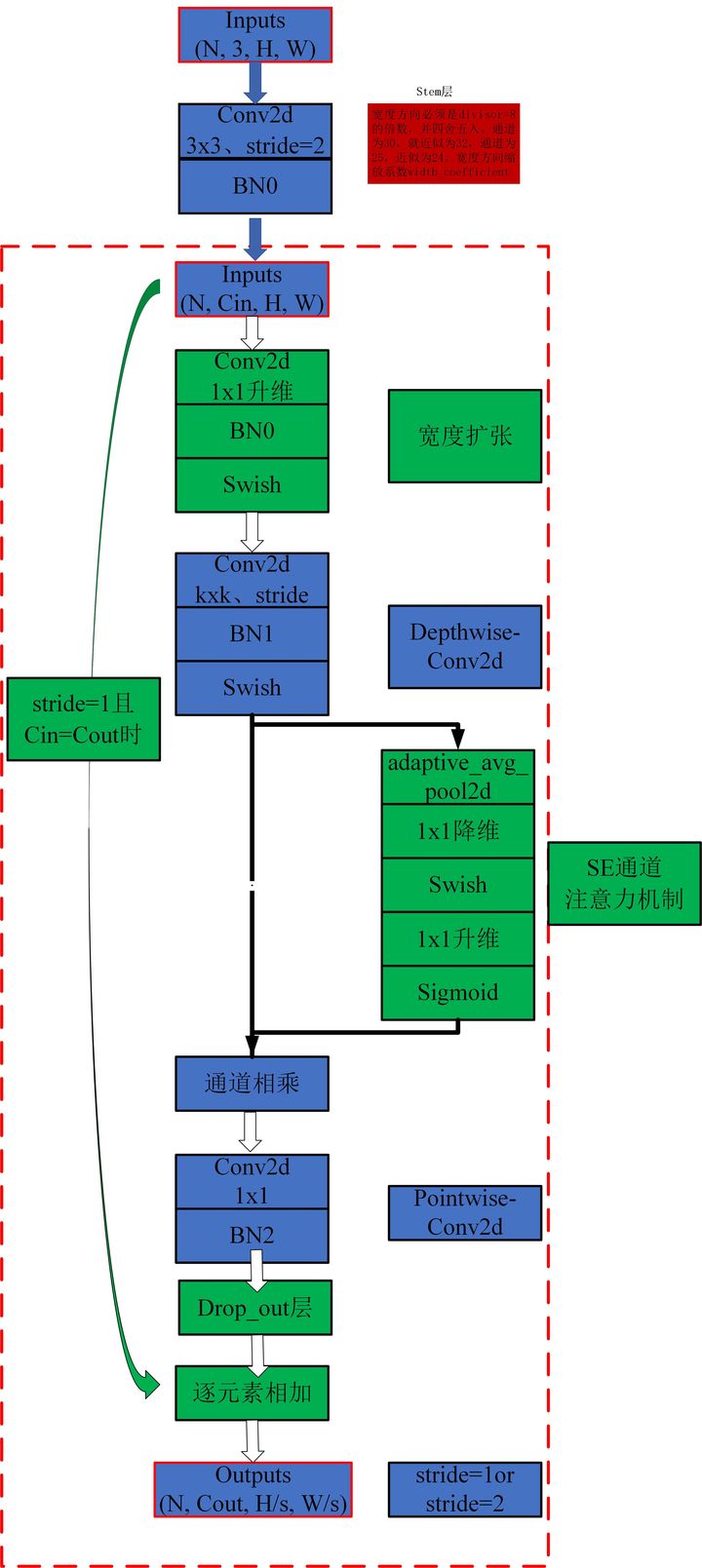
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"Involution: inverser l'inhérence de la convolution pour la reconnaissance visuelle"
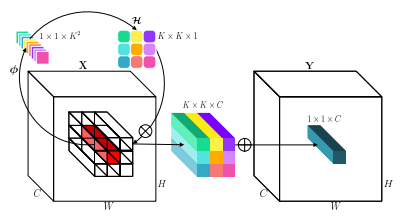
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"Convolution dynamique: attention sur les noyaux de convolution"
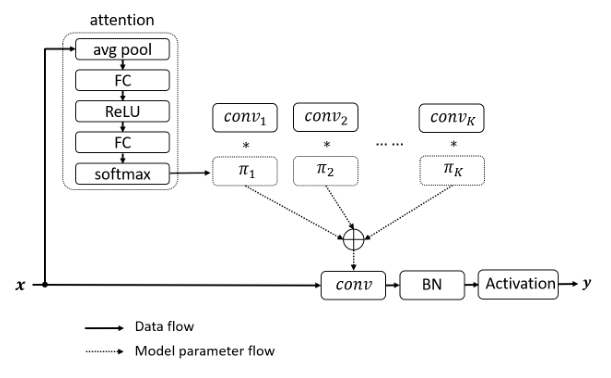
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"CONDCONV: Convolutions paramétrées conditionnelles pour une inférence efficace"
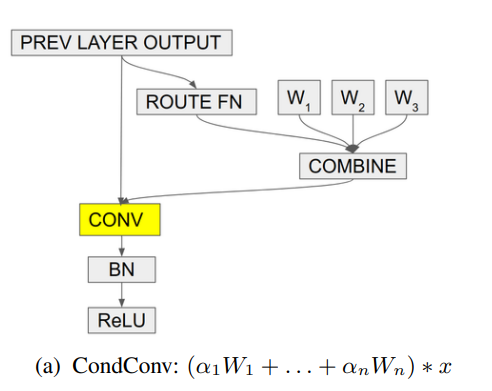
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )Grande nouvelle! ! ! En complément du projet, vous pouvez prêter attention au projet nouvellement open source FightingCV-Paper Reading , qui recueille et organise l'analyse papier des principales conférences et revues.
Grande nouvelle! ! ! Récemment, j'ai compilé divers tutoriels vidéo liés à l'IA et à lire des articles sur le cours de combat Internet
Grande nouvelle! ! ! Récemment, une nouvelle bibliothèque de code de détection d'objets Yoloair a été ouverte, qui intègre une variété de modèles Yolo, notamment Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 et d'autres modèles Yolo, ainsi qu'une variété de mécanismes d'attention existants.
ECCV2022 Résumé du papier: ECCV2022-PAPER-LIST


