External Attention pytorch
1.0.0

Chino simplificado | Inglés
Hola a todos, soy Xiaoma
Para Xiaobai (como yo): Recientemente, encontraré un problema cuando lea un artículo. A veces, la idea central del documento es muy simple, y el código central puede ser solo una docena de líneas. Sin embargo, cuando abrí el código fuente de la versión del autor, descubrí que el módulo propuesto estaba integrado en marcos de tareas como clasificación, detección y segmentación, lo que condujo a un código relativamente redundante. No estoy familiarizado con los marcos de tareas específicos y es difícil para mí encontrar el código central , lo que lleva a ciertas dificultades para comprender los documentos e ideas de red.
Para avanzado (como usted): si considera unidades básicas como Conv, FC y RNN como pequeños bloques de construcción LEGO, y estructuras como Transformer y Resnet como castillos de Lego que se han construido. Luego, los módulos proporcionados por este proyecto son componentes LEGO con información semántica completa. Deje que los investigadores científicos eviten hacer ruedas repetidamente , solo piense en cómo usar estos "componentes LEGO" para construir obras más coloridas.
Para el maestro (puede ser como tú): ¡ tengo una habilidad limitada y no me gusta chorrear ligeramente ! ! !
Para todos: este proyecto se compromete a implementar una base de código que permita a los novatos de aprendizaje profundo comprender y servir a la investigación científica y a las comunidades industriales .
Instalar directamente a través de PIP
pip install fightingcv-attentionO clonar el repositorio
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Serie de atención
1. Uso de atención externa
2. Uso de autoholección
3. Uso de atención propia simplificada
4. Uso de atención de compresión y excitación
5. Uso de atención de SK
6. Uso de atención de CBAM
7. Uso de atención de BAM
8. Uso de atención ECA
9. Uso de atención danética
10. Uso de atención de la división de pirámide (PSA)
11. Uso eficiente de autoatención de múltiples cabezas (EMSA)
12. Uso de atención de arrastre
13. Uso de atención de musa
14. Uso de atención de SGE
15. Uso de atención A2
16. Uso de atención de popa
17. Uso de atención de Outlook
18. Uso de atención VIP
19. Uso de atención de Coatnet
20. Uso de atención de Halonet
21. Uso de autoatención polarizada
22. Uso de la cotización
23. Uso de atención residual
24. Uso de atención S2
25. Uso de atención de GFNET
26. Uso de atención del triplete
27. Coordinar el uso de la atención
28. Uso de atención de MobileVit
29. Uso de atención de Parnet
30. Uso de la atención de ovnis
31. Uso de atención de Acmix
32. Uso de atención MobileVITV2
33. Uso de atención
34. Uso de atención de Crossformer
35. Uso de atención de Moatransformer
36. Uso de atención de atención entrecruzada
37. Uso de atención Axial_Attention
Serie
1. Uso de resnet
2. Uso de resnext
3. Uso de MobileVit
4. Uso de Convmixer
5. Uso de Shuffletransformer
6. Uso de contnet
7. Uso de Hatnet
8. Uso de abrigo
9. Uso de PVT
10. Uso de CPVT
11. Uso de pozo
12. Uso de CrossVit
13. Uso de TNT
14. Uso del DVIT
15. Uso de CEIT
16. Uso convicto
17. Uso de Cait
18. Uso de PatchConvnet
19. Uso de Deit
20. Uso de Levit
21. Uso de Volo
22. Uso del contenedor
23. Uso de CMT
24. Uso eficiente del formador
25. Uso de convNextV2
Serie MLP
1. Uso de Repmlp
2. Uso de MLP-Mixer
3. Uso de resmlp
4. Uso de GMLP
5. Uso de SMLP
6. Uso VIP-MLP
Serie de re-parámetro (representante)
1. Uso de Repvgg
2. Uso de ACNET
3. Uso de un bloque de sucursal diverso (DDB)
Serie de convoluciones
1. Uso de convolución separable en profundidad
2. Uso de MBConv
3. Uso de la invención
4. Uso de DynamicConv
5. Uso de condconv
Implementación de Pytorch de "Más allá de la autoatención: atención externa que usa dos capas lineales para tareas visuales --- ARXIV 2021.05.05"
Implementación de Pytorch de "La atención es todo lo que necesita --- NIPS2017"
Implementación de Pytorch de "redes de compresión y excitación --- CVPR2018"
Implementación de Pytorch de "Redes de kernel selectivas --- CVPR2019"
Implementación de Pytorch de "CBAM: Módulo de atención del bloque de convoluciones --- ECCV2018"
Implementación de Pytorch de "Bam: módulo de atención de cuello de botella --- BMCV2018"
Implementación de Pytorch de "ECA-NET: atención de canal eficiente para redes neuronales convolucionales profundas --- CVPR2020"
Implementación de Pytorch de "Red de doble atención para la segmentación de escenas --- CVPR2019"
Implementación de Pytorch de "Epsanet: un bloque eficiente de atención de la pirámide en la red neuronal convolucional --- ARXIV 2021.05.30"
Implementación de Pytorch de "REST: un transformador eficiente para el reconocimiento visual --- ARXIV 2021.05.28"
Implementación de Pytorch de "SA-Net: Shuffle atento para redes neuronales convolucionales profundas --- ICASSP 2021"
Implementación de Pytorch de "Muse: Atención paralela a múltiples escala para la secuencia al aprendizaje de secuencias --- ARXIV 2019.11.17"
Implementación de Pytorch de "Mejora espacial de grupo: Mejora del aprendizaje de características semánticas en redes convolucionales --- ARXIV 2019.05.23"
Implementación de Pytorch de "A2-Nets: redes de doble atención --- NIPS2018"
Implementación de Pytorch de "Un transformador sin atención --- ICLR2021 (Apple New Work)"
Implementación de Pytorch de VOLO: Vision Outchlooker para el reconocimiento visual --- ARXIV 2021.06.24 "[Análisis en papel]
Implementación de Pytorch de Vision Permutator: una arquitectura similar a MLP permutable para el reconocimiento visual --- ARXIV 2021.06.23 [Análisis en papel]
Implementación de Pytorch de Coatnet: Casando la convolución y la atención para todos los tamaños de datos --- ARXIV 2021.06.09 [Análisis en papel]
Implementación de Pytorch de escala de autoeficiencia local para parámetros backbones visuales eficientes --- CVPR2021 oral [análisis en papel]
Implementación de Pytorch de autoatención polarizada: hacia la regresión de píxeles de alta calidad --- ARXIV 2021.07.02 [Análisis en papel]
Implementación de Pytorch de redes de transformadores contextuales para el reconocimiento visual --- ARXIV 2021.07.26 [Análisis en papel]
Implementación de Pytorch de atención residual: un método simple pero efectivo para el reconocimiento de múltiples etiquetas --- ICCV2021
Implementación de Pytorch de S²-MLPV2: Arquitectura MLP de cambio espacial mejorado para la visión --- ARXIV 2021.08.02 [Análisis de papel]
Implementación de Pytorch de redes de filtro global para la clasificación de imágenes --- ARXIV 2021.07.01
Implementación de Pytorch de Rotate para asistir: Módulo de atención de triplete convolucional --- WACV 2021
Implementación de Pytorch de la atención de coordenadas para el diseño eficiente de la red móvil --- CVPR 2021
Implementación de Pytorch de MobileVit: Transformador de visión Light-Weight, General-Purpose and Mobile-admitente --- ARXIV 2021.10.05
Implementación de Pytorch de redes no profundas --- ARXIV 2021.10.20
Implementación de Pytorch de UFO-VIT: Transformador de visión lineal de alto rendimiento sin Softmax --- ARXIV 2021.09.29
Implementación de Pytorch de autoatención separable para transformadores de visión móvil --- ARXIV 2022.06.06
Implementación de Pytorch de la integración de la autoatención y la convolución --- ARXIV 2022.03.14
Implementación de Pytorch de Crossformer: un transformador de visión versátil que depende de la atención a la escala transversal --- ICLR 2022
Implementación de Pytorch de las características globales agregadas en el transformador de visión local
Implementación de Pytorch de CCNET: atención cruzada para la segmentación semántica
Implementación de Pytorch de atención axial en transformadores multidimensionales
"Más allá de la autoatención: atención externa utilizando dos capas lineales para tareas visuales"
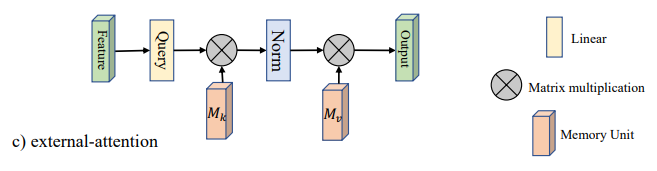
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"La atención es todo lo que necesitas"
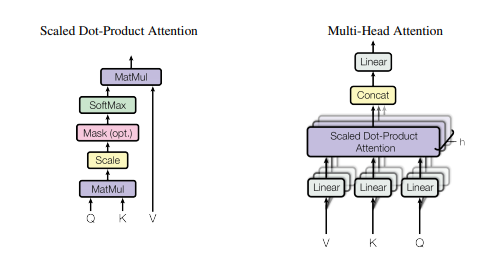
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Ninguno
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Redes de compresión y excitación"
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Redes de núcleo selectivas"
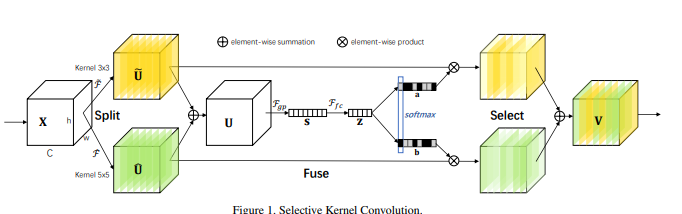
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: módulo de atención del bloque de convoluciones"
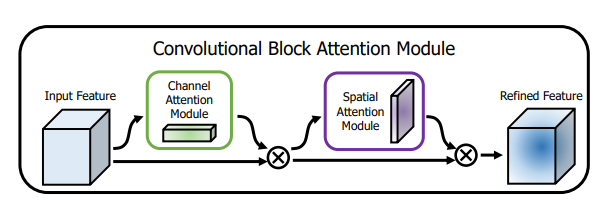
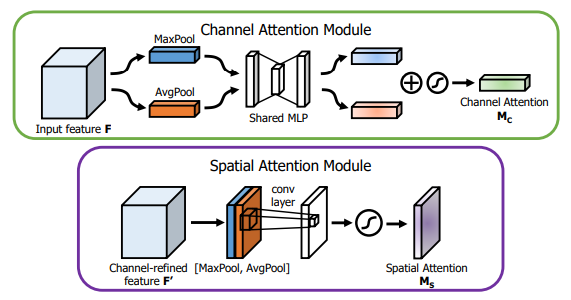
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"Bam: módulo de atención de cuello de botella"
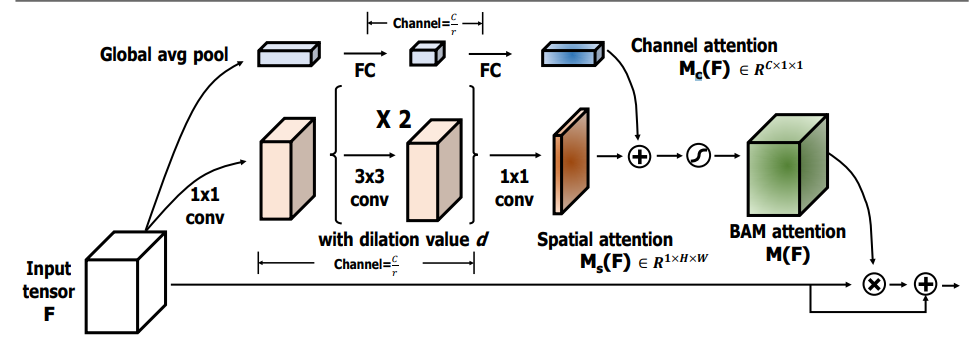
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: atención de canal eficiente para redes neuronales convolucionales profundas"
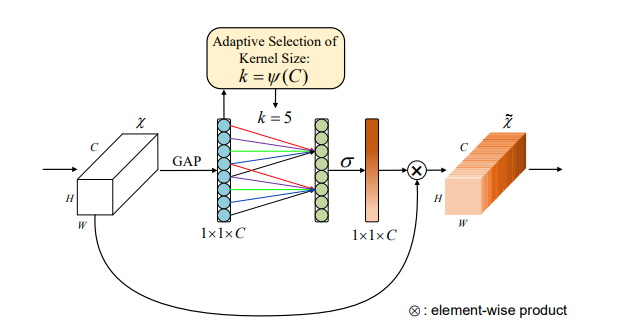
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"Red de doble atención para la segmentación de escenas"
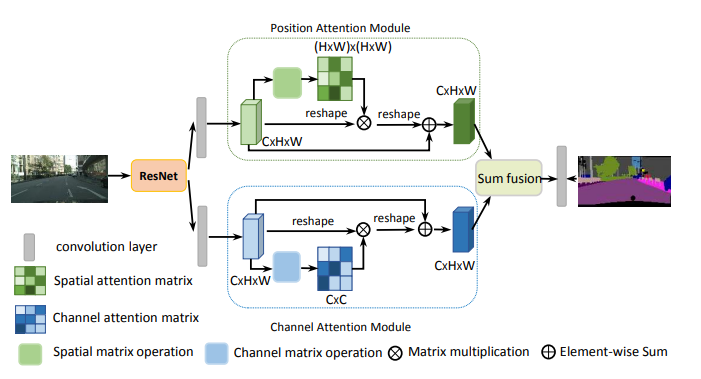
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet: un bloque eficiente de atención de la pirámide en la red neuronal convolucional"
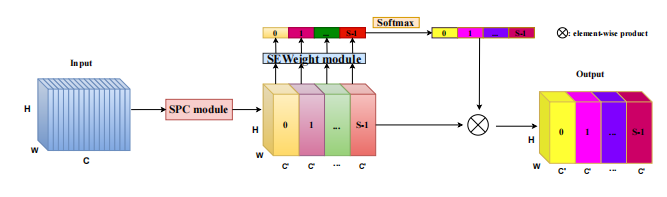
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"Descanso: un transformador eficiente para el reconocimiento visual"
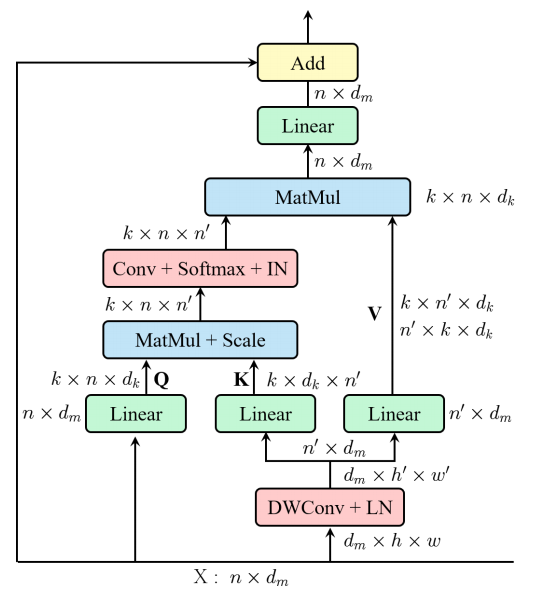
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: Atento para las redes neuronales convolucionales profundas"
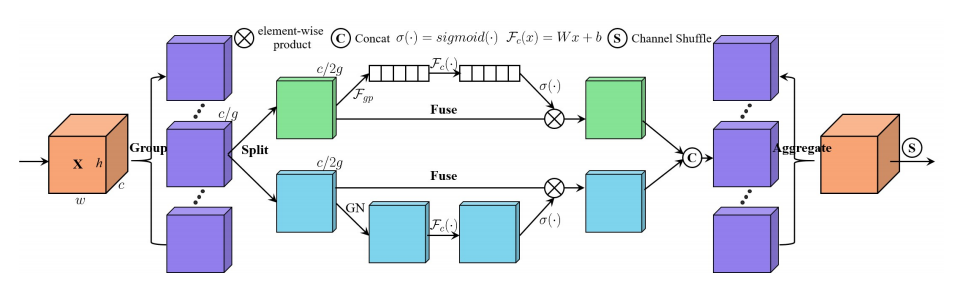
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse: Atención paralela a múltiples a escala para secuencia a secuencia aprendizaje"
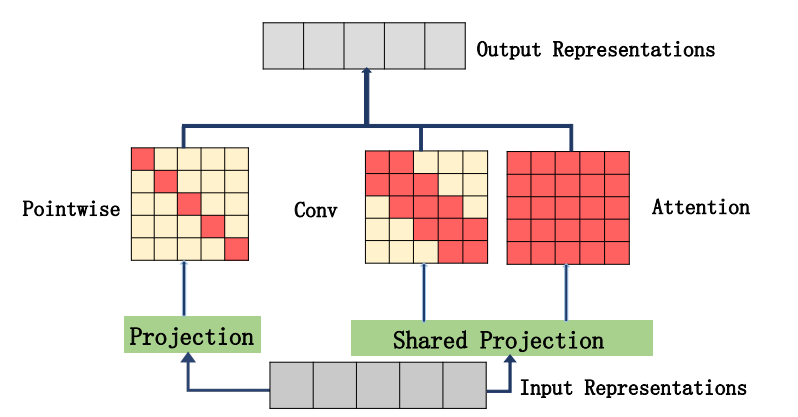
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Mejora espacial en forma de grupo: Mejora del aprendizaje de características semánticas en redes convolucionales
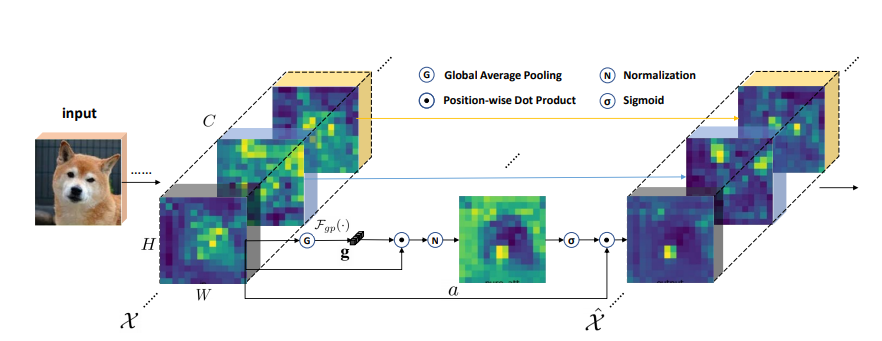
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2 Nets: redes de doble atención
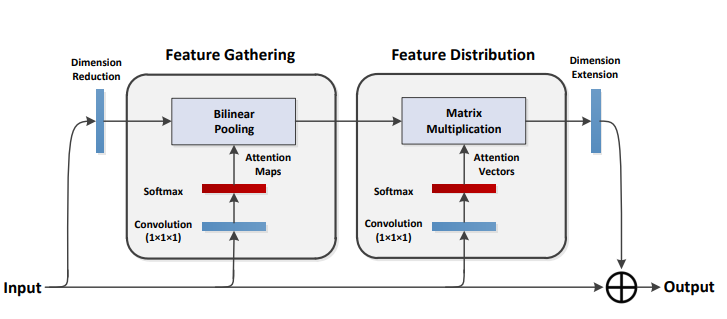
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Un transformador sin atención
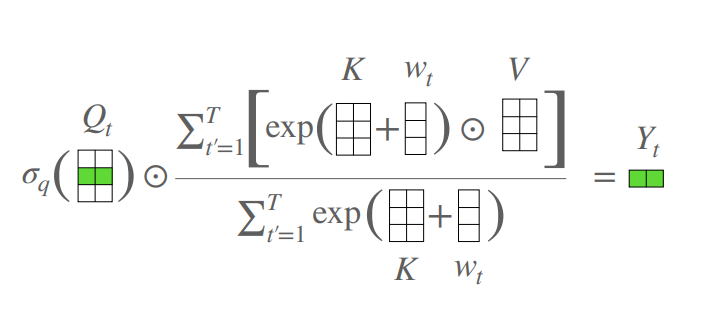
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )VOLO: Vision Outlooker para el reconocimiento visual "
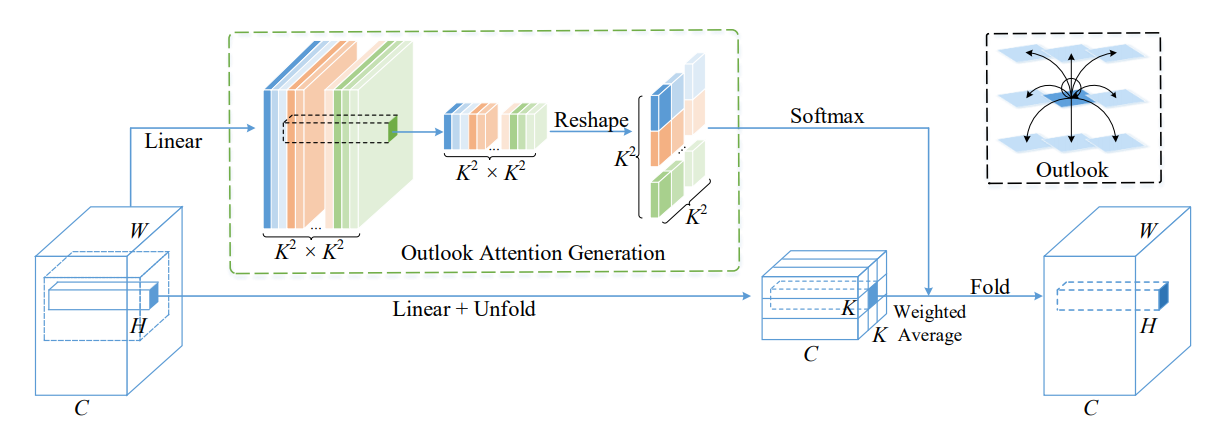
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Permutador de visión: una arquitectura similar a MLP permutable para el reconocimiento visual "
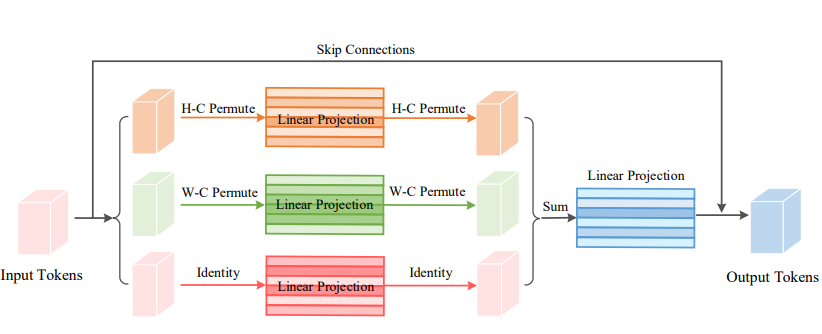
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: Casando la convolución y la atención para todos los tamaños de datos "
Ninguno
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Escala de autoeficiencia local para parámetros de backbones visuales eficientes "
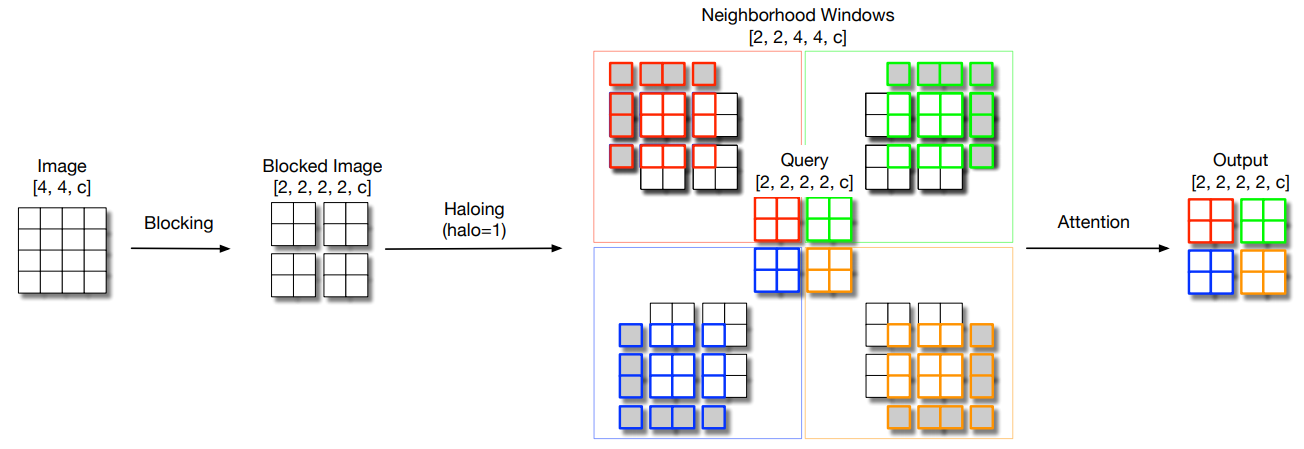
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Autoatención polarizada: hacia la regresión de píxeles de alta calidad "
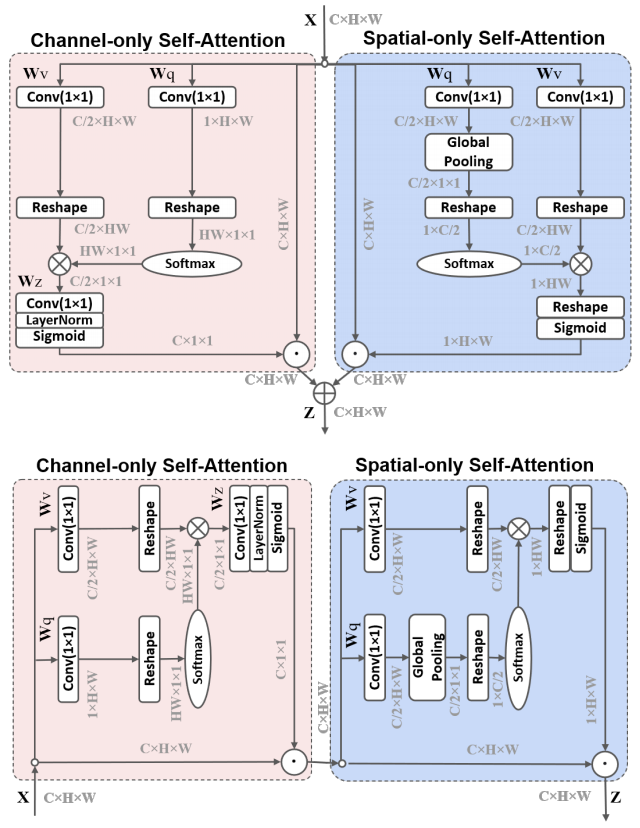
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Redes de transformadores contextuales para el reconocimiento visual --- ARXIV 2021.07.26
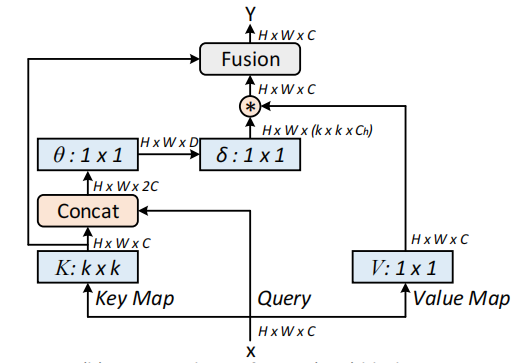
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Atención residual: un método simple pero efectivo para el reconocimiento de múltiples etiquetas --- ICCV2021
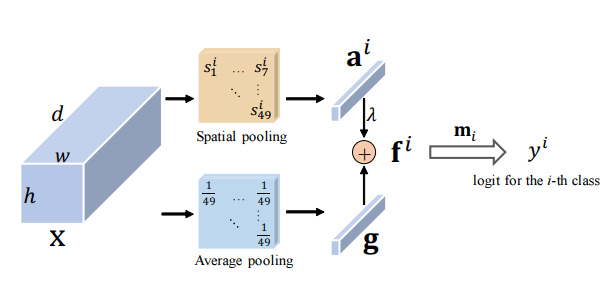
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: Arquitectura MLP de cambio espacial mejorado para la visión --- ARXIV 2021.08.02
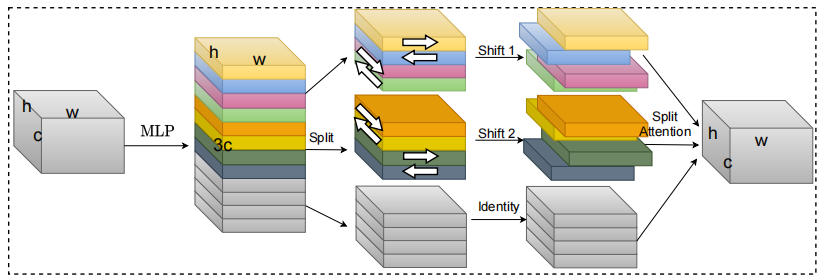
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Redes de filtro global para la clasificación de imágenes --- ARXIV 2021.07.01
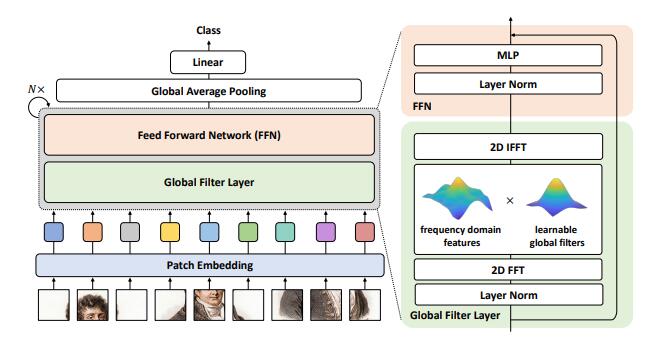
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )Gire para asistir: Módulo de atención de triplete convolucional --- CVPR 2021
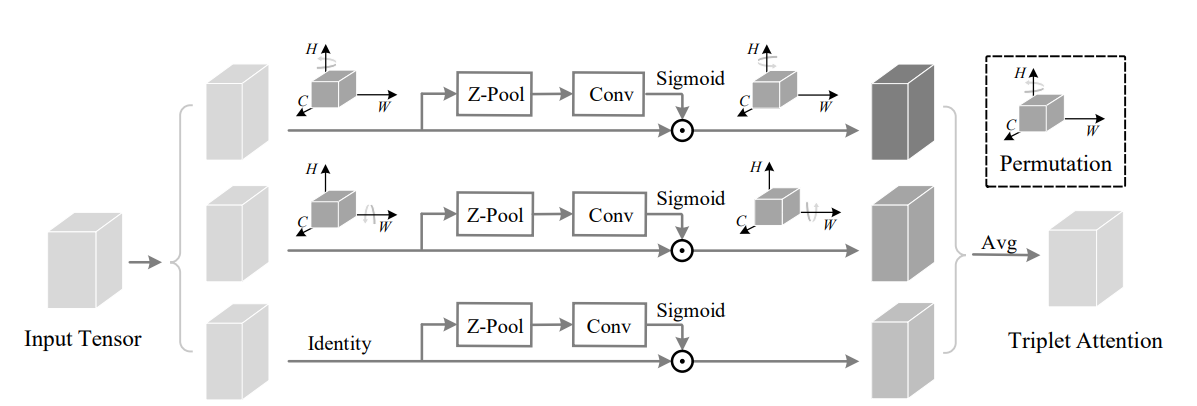
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Coordinar la atención para un diseño eficiente de red móvil --- CVPR 2021
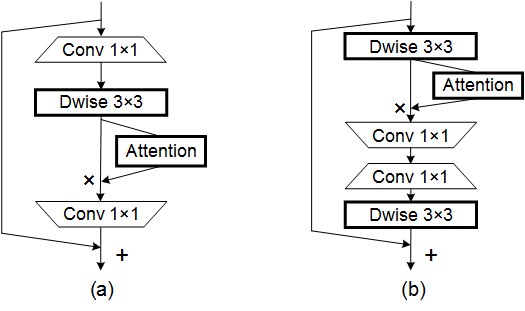
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit: transformador de visión ligero, de propósito general y amigable para dispositivos móviles --- ARXIV 2021.10.05
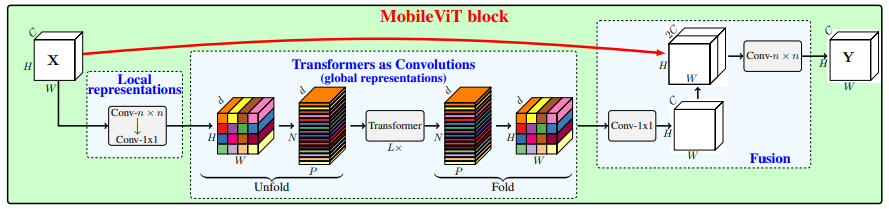
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Redes no profundas --- ARXIV 2021.10.20
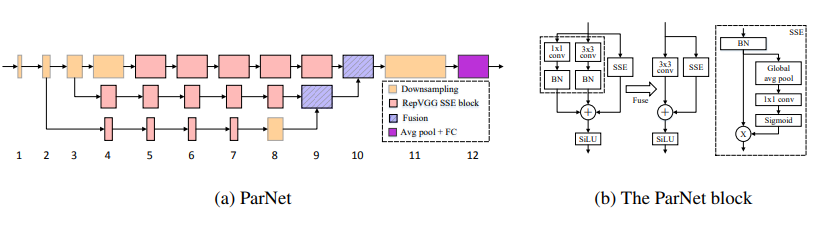
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT: Transformador de visión lineal de alto rendimiento sin Softmax --- ARXIV 2021.09.29
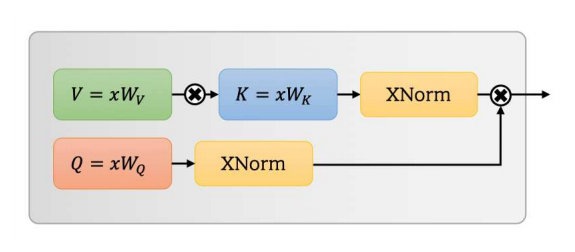
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
Sobre la integración de la autoatención y la convolución
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
Autoatención separable para transformadores de visión móvil --- ARXIV 2022.06.06
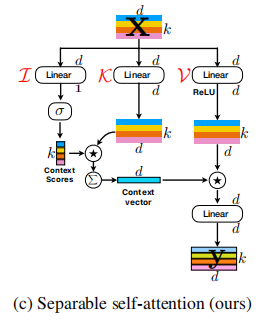
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Transformador de visión con atención deformable --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer: un transformador de visión versátil que depende de la atención a la escala a través de la escala --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Agregando las características globales en el transformador de visión local
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: atención cruzada para la segmentación semántica
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Atención axial en transformadores multidimensionales
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Implementación de Pytorch de "aprendizaje residual profundo para el reconocimiento de imágenes --- CVPR2016 Mejor documento"
Implementación de Pytorch de "Transformaciones residuales agregadas para redes neuronales profundas --- CVPR2017"
Implementación de Pytorch de MobileVit: Transformador de visión Ligero, de propósito general y amigable para dispositivos móviles --- ARXIV 2020.10.05
La implementación de Pytorch de parches es todo lo que necesita? --- ICLR2022 (bajo revisión)
Implementación de Pytorch de Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer --- ARXIV 2021.06.07
Implementación de Pytorch de Contnet: ¿Por qué no usar la convolución y el transformador al mismo tiempo? --- ARXIV 2021.04.27
Implementación de Pytorch de transformadores de visión con atención jerárquica --- ARXIV 2022.06.15
Implementación de Pytorch de transformadores de imagen convencionales de la escala co-escala --- ARXIV 2021.08.26
Implementación de Pytorch de codificaciones posicionales condicionales para transformadores de visión
Implementación de Pytorch de replanteamiento de dimensiones espaciales de transformadores de visión --- ICCV 2021
Implementación de Pytorch de CrossVit: Transformador de visión multiescala de atención cruzada para la clasificación de imágenes --- ICCV 2021
Implementación de Pytorch de Transformer en Transformer --- Neurips 2021
Implementación de Pytorch de DeepVit: Hacia un transformador de visión más profundo
Implementación de Pytorch de incorporar diseños de convolución en transformadores visuales
Implementación de Pytorch de convicto: Mejora de los transformadores de visión con sesgos inductivos convolucionales suaves
Implementación de Pytorch del aumento de las redes convolucionales con agregación basada en la atención
Implementación de Pytorch de ir más profundo con los transformadores de imagen --- ICCV 2021 (oral)
Implementación de Pytorch de la capacitación de transformadores de imágenes eficientes en datos y destilación a través de la atención --- ICML 2021
Implementación de Pytorch de Levit: un transformador de visión en la ropa de Convnet para una inferencia más rápida
Implementación de Pytorch de VOLO: Vision Outlooker para el reconocimiento visual
Implementación de Pytorch del contenedor: Red de agregación de contexto --- Neuips 2021
Implementación de Pytorch de CMT: las redes neuronales convolucionales cumplen con los transformadores de la visión --- CVPR 2022
Implementación de Pytorch del transformador de visión con atención deformable --- CVPR 2022
Implementación de Pytorch de formador eficiente: transformadores de visión a la velocidad de MobileNet
Implementación de Pytorch de ConvNextV2: Codsigning y escala Convnets con autoencoders enmascarados
"Aprendizaje residual profundo para el reconocimiento de imágenes --- CVPR2016 Mejor papel"
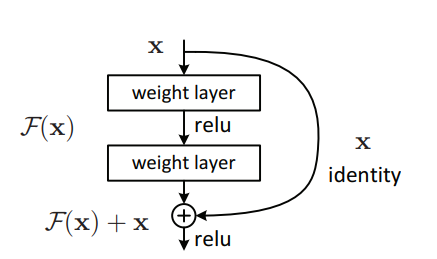
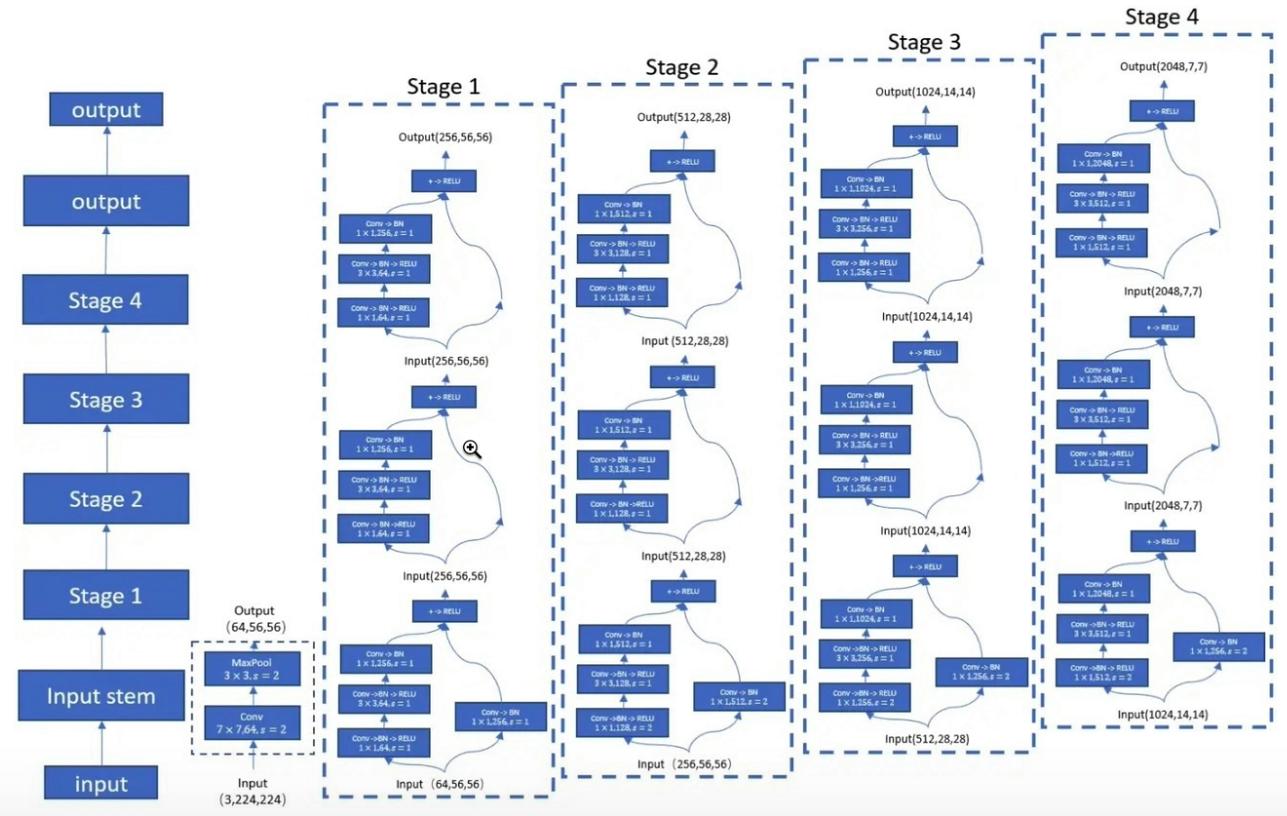
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"Transformaciones residuales agregadas para redes neuronales profundas --- CVPR2017"
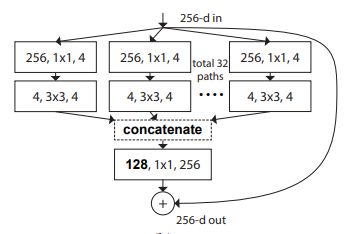
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit: transformador de visión ligero, de propósito general y amigable para dispositivos móviles --- ARXIV 2020.10.05
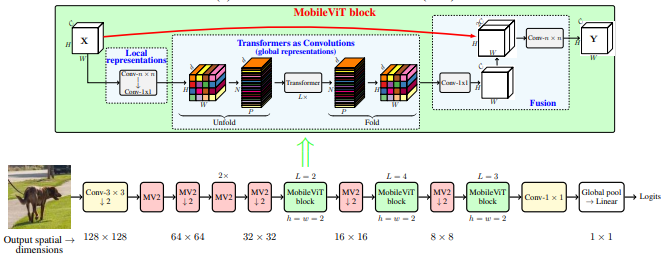
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Los parches son todo lo que necesita? --- ICLR2022 (bajo revisión)
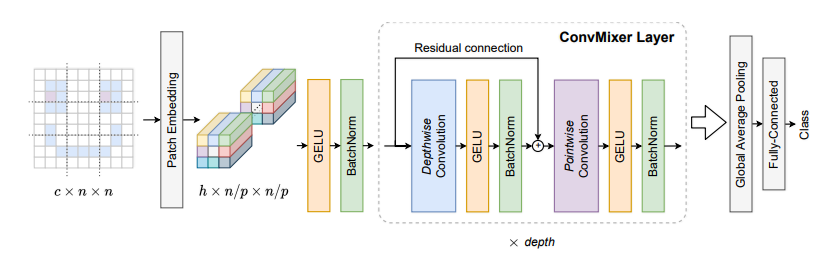
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Transformador de Shuffle: Repensar la baraja espacial para la visión Transformer
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
Contnet: ¿Por qué no usar convolución y transformador al mismo tiempo?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Transformadores de visión con atención jerárquica
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Transformadores de imagen convencionales de co-escala
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: líneas de base mejoradas con transformador de visión piramidal
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Codificaciones posicionales condicionales para transformadores de visión
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Repensar las dimensiones espaciales de los transformadores de la visión
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit: Transformador de visión multiescala de atención cruzada para la clasificación de imágenes
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Transformador en Transformer
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )Deepvit: hacia el transformador de visión más profundo
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Incorporando diseños de convolución en transformadores visuales
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Convito: Mejora de los transformadores de visión con sesgos inductivos convolucionales suaves
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Profundizar con los transformadores de imágenes
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Aumento de redes convolucionales con agregación basada en la atención
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Transformadores de imágenes y destilación de Imagen eficientes en datos a través de la atención
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: un transformador de visión en la ropa de Convnet para una inferencia más rápida
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )VOLO: Vision Outlooker para el reconocimiento visual
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Contenedor: Red de agregación de contexto
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: las redes neuronales convolucionales cumplen con los transformadores de la visión
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )Formador eficiente: transformadores de visión a la velocidad de MobileNet
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )ConvNextV2: Codsignar y escalar convnets con autoencoders enmascarados
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Implementación de Pytorch de "RepMLP: re-parametrizar convoluciones en capas totalmente conectadas para el reconocimiento de imágenes --- ARXIV 2021.05.05"
Implementación de Pytorch de "MLP-Mixer: una arquitectura All-MLP para la visión --- ARXIV 2021.05.17"
Implementación de Pytorch de "Resmlp: FeedForward Networks para la clasificación de imágenes con capacitación eficiente en datos --- ARXIV 2021.05.07"
Implementación de Pytorch de "Presta atención a MLP --- ARXIV 2021.05.17"
Implementación de Pytorch de "MLP escaso para el reconocimiento de imágenes: ¿es realmente necesaria la autoatición? --- ARXIV 2021.09.12"
"RepMLP: re-parametrizar convoluciones en capas totalmente conectadas para el reconocimiento de imágenes"
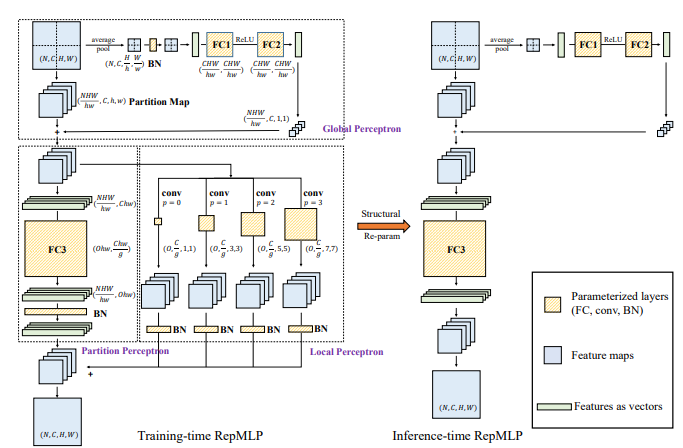
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-Mixer: una arquitectura All-MLP para la visión"
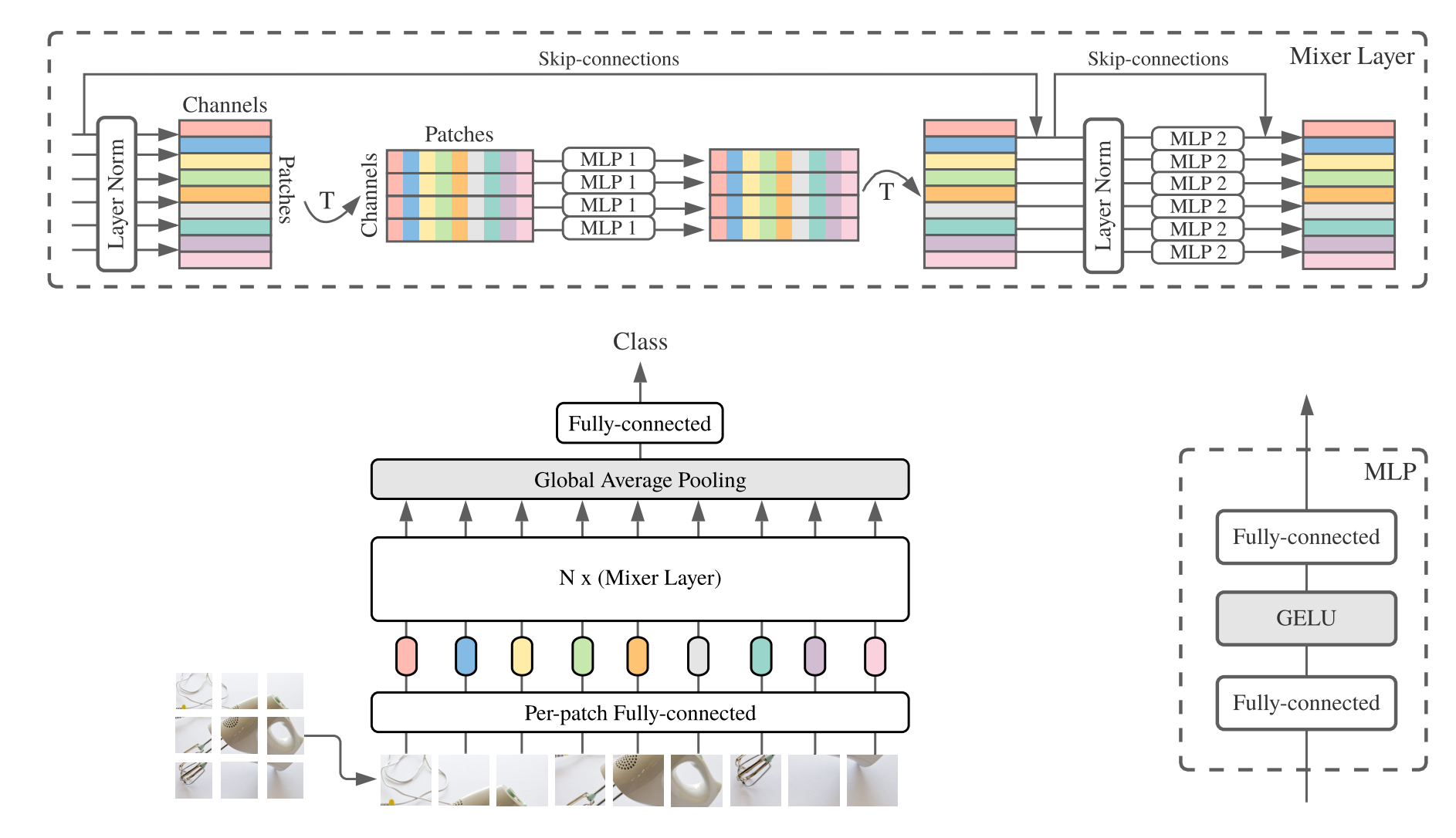
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"Resmlp: FeedForward Networks para la clasificación de imágenes con capacitación eficiente en datos"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Presta atención a los MLP"
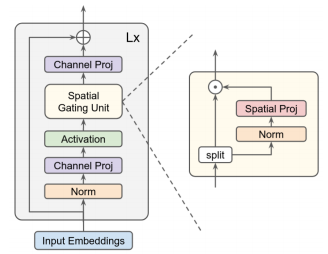
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"MLP escaso para el reconocimiento de imágenes: ¿es realmente necesaria la autoatición?"
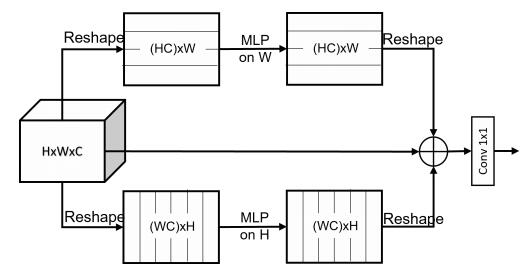
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Vision Permutator: una arquitectura similar a MLP permutable para el reconocimiento visual"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Implementación de Pytorch de "Repvgg: Hacer convnets de estilo VGG bien nuevamente ---- CVPR2021"
Implementación de Pytorch de "ACNET: Fortalecimiento de los esqueletos del núcleo para potentes CNN a través de bloques de convolución asimétrica --- ICCV2019"
Implementación de Pytorch de "Bloque de sucursal diverso: construir una convolución como una unidad de inicio --- CVPR2021"
"Repvgg: hacer que los convnets de estilo VGG sean geniales de nuevo"
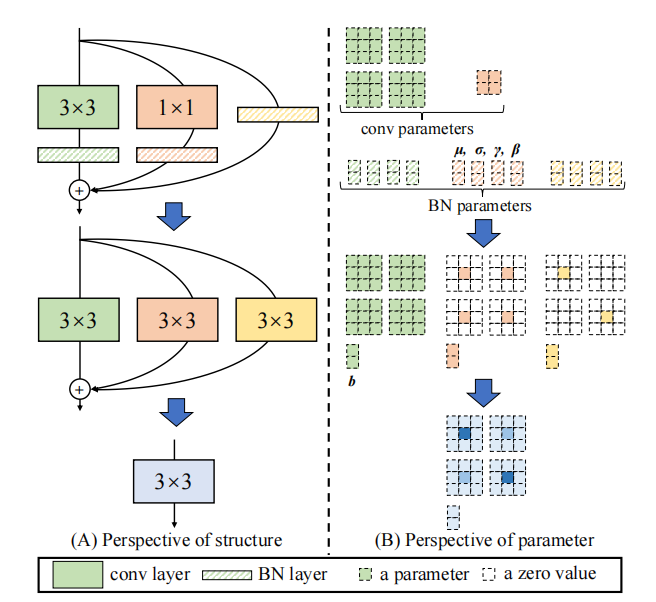
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"ACNET: fortalecer los esqueletos del núcleo para potentes CNN a través de bloques de convolución asimétricos"
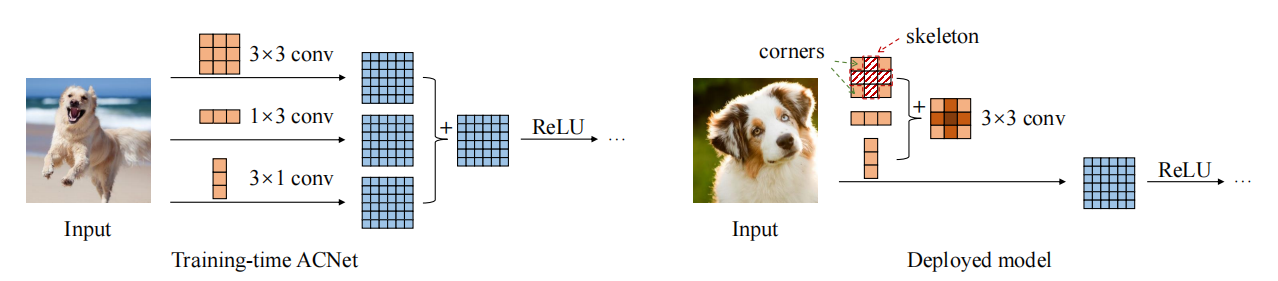
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"Bloque de sucursal diverso: construir una convolución como unidad de inicio"
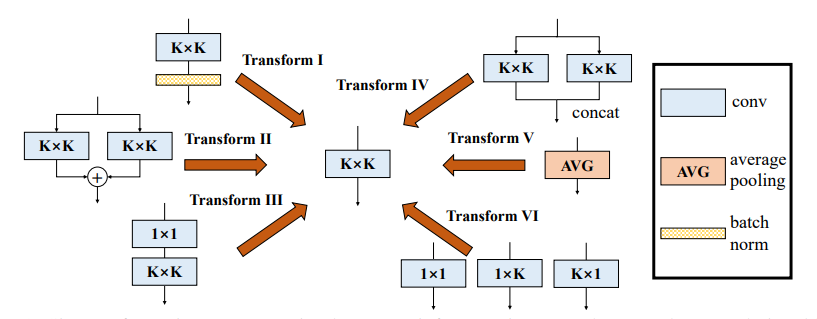
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Implementación de Pytorch de "MobileNets: redes neuronales convolucionales eficientes para aplicaciones de visión móvil --- CVPR2017"
Implementación de Pytorch de "EficeTient NET: Repensar la escala del modelo para redes neuronales convolucionales --- PMLR2019"
Implementación de Pytorch de "Involucencia: invertir la inherencia de la convolución para el reconocimiento visual ---- CVPR2021"
Implementación de Pytorch de "Convolución dinámica: atención sobre los núcleos de la convolución --- CVPR2020 oral"
Implementación de Pytorch de "Condconv: convoluciones parametrizadas condicionalmente para inferencia eficiente --- neurips2019"
"MobileNets: redes neuronales convolucionales eficientes para aplicaciones de visión móvil"
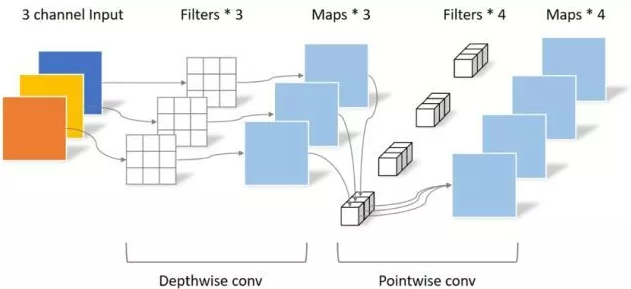
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
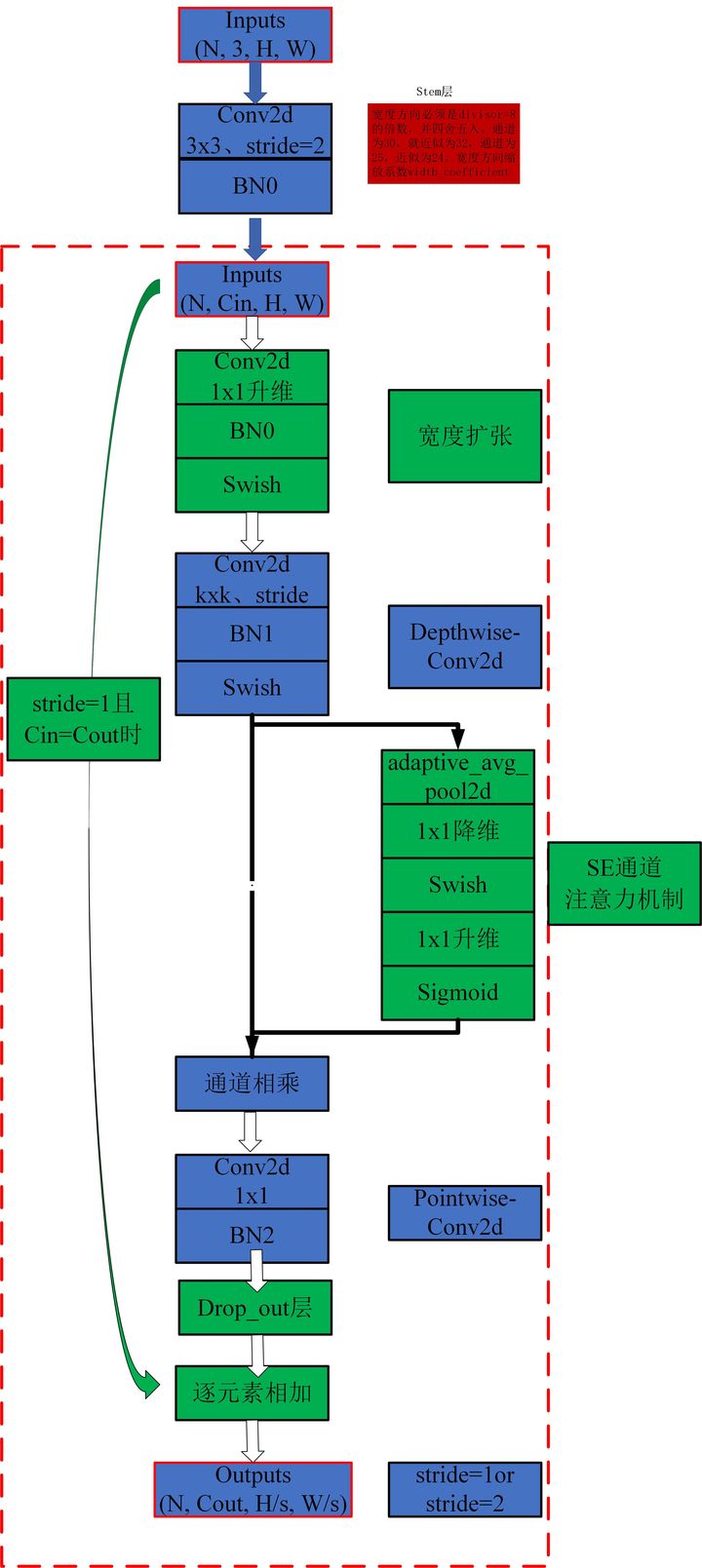
print ( out . shape )"EficeTnet: repensar la escala del modelo para redes neuronales convolucionales"
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
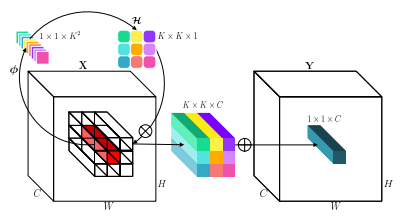
"Involucra: invertir la inherencia de la convolución para el reconocimiento visual"
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
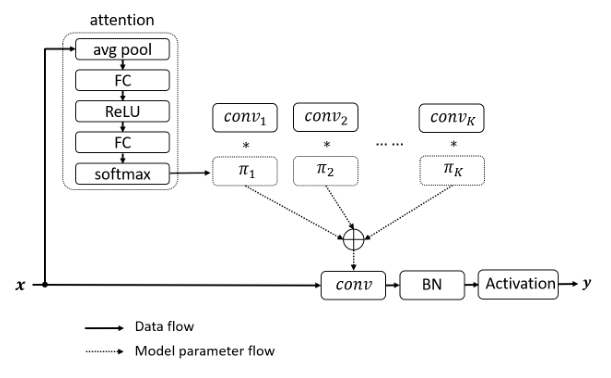
print ( out . shape )"Convolución dinámica: atención sobre los núcleos de convolución"
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
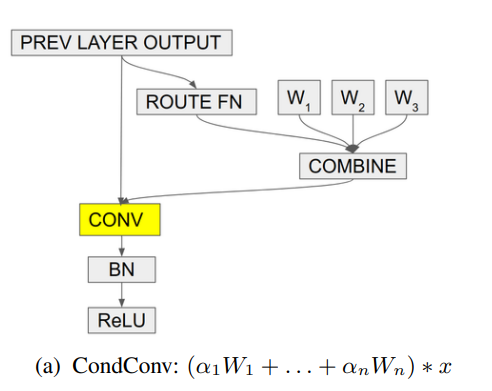
print ( out . shape ) # 2,32,64,64"Condconv: convoluciones parametrizadas condicionalmente para una inferencia eficiente"
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )¡Grandes noticias! ! ! Como suplemento del proyecto, puede prestar atención al proyecto de código recientemente abierto FightCV-Paper-Reading , que recopila y organiza el análisis en papel de principales conferencias y revistas.
¡Grandes noticias! ! ! Recientemente, he compilado varios videos tutoriales relacionados con la IA y documentos de lectura obligada en el curso de FightingCV de Internet
¡Grandes noticias! ! ! Recientemente, se ha abierto una nueva biblioteca de código de detección de objetos Yoloair , que integra una variedad de modelos Yolo, incluidos Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 y otros modelos de Yolo, así como una variedad de mecanismos de atención existentes.
Resumen del documento ECCV2022: ECCV2022-Paper-List


