External Attention pytorch
1.0.0

Упрощенный китайский | Английский
Привет всем, я Xiaoma
Для Xiaobai (как и я): Недавно я найду проблему, когда прочитаю газету. Иногда основная идея статьи очень проста, а базовый код может составлять всего дюжину строк. Однако, когда я открыл исходный код выпуска автора, я обнаружил, что предлагаемый модуль был встроен в структуры задач, такие как классификация, обнаружение и сегментация, что привело к относительно избыточному коду. Я не знаком с конкретными структурами задач, и мне трудно найти основной код , который приводит к определенным трудностям в понимании документов и идей сети.
Для Advanced (как вы): если вы рассматриваете основные подразделения, такие как Conv, FC и RNN как небольшие строительные блоки LEGO, а также такие структуры, как трансформатор и Resnet, как построенные замки Lego. Тогда модули, предоставленные этим проектом, являются компонентами LEGO с полной семантической информацией. Позвольте научным исследователям избегать создания колес неоднократно , просто подумайте о том, как использовать эти «компоненты LEGO», чтобы построить более красочные работы.
Для Master (может быть похожим на вас): у меня есть ограниченная способность, и я не люблю легкомысленно вплеснуть ! ! !
Для всех: этот проект стремится внедрить кодовую базу, которая позволяет новичкам глубокого обучения понимать и обслуживать научные исследования и промышленные сообщества .
Установить прямо через PIP
pip install fightingcv-attentionИли клонировать репозиторий
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Серия внимания
1. Использование внешнего внимания
2. Использование самостоятельного внимания
3. Упрощенное использование внимания самостоятельно
4. Выжимание и извлечение использования внимания
5. Внимание SK
6. Использование внимания CBAM
7. Использование внимания BAM
8. Использование внимания ECA
9. Использование внимания.
10. Использование пирамиды (PSA)
11. Эффективное использование с мульти-годом (EMSA)
12. Потащите внимание использования внимания
13. Muse Использование внимания
14. SGE Использование внимания
15. A2 Использование внимания
16. КОМПУСКИ
17. Использование внимания Outlook
18. Использование внимания VIP
19. Использование внимания Coatnet
20. Использование внимания Halonet
21. Поляризованное использование самопринятия
22. Использование котатирования
23. Использование остаточного внимания
24. S2 Использование внимания
25. Использование внимания GFNet
26. Использование внимания триплета
27. Координируйте использование внимания
28. Использование внимания мобильной связи
29. Использование внимания Parnet
30. Использование внимания НЛО
31. Использование внимания ACMIX
32. Мобильныйв. Использование внимания
33. Использование внимания DAT
34. Использование внимания Crossformer
35. Использование внимания Moatransformer
36. Крестное внимание использование внимания
37. Использование внимания Axial_Attention
Серия магистралей
1. Использование Resnet
2. Resnext Использование
3. Мобильное использование
4. Convmixer Использование
5. Shuffletransformer Использование
6. Использование Contnet
7. Использование Hatnet
8. Использование покрытия
9. Использование PVT
10. Использование CPVT
11. Использование ям
12. Использование CrossVit
13. Использование TNT
14. Использование DVIT
15. CEIT Использование
16. Использование осуждения
17. Использование Кейт
18. Использование PatchConvnet
19. DEIT Использование
20. Использование Левита
21. Использование Воло
22. Использование контейнера
23. Использование CMT
24. Эффективное использование
25. Использование Convnextv2
Серия MLP
1. Использование Repmlp
2. Использование MLP-Mixer
3. Resmlp Использование
4. Использование GMLP
5. Использование SMLP
6. Использование VIP-MLP
Серия повторного парараметра (Rep)
1. Использование Репвгга
2. Использование ACNET
3. Использование разнообразного филиала (DDB)
Серия свертки
1. Глубиное отдельное использование свертки
2. Использование MBConv
3. Использование инволюции
4. Использование DynamicConv
5. Использование CondConv
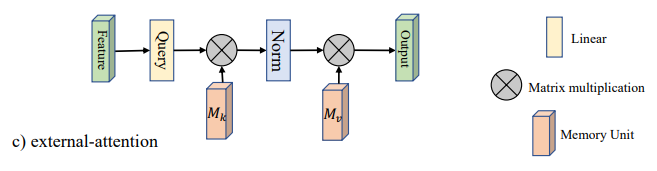
Реализация Pytorch "Beyond Self Cantention: внешнее внимание с использованием двух линейных слоев для визуальных задач-A arxiv 2021.05.05"
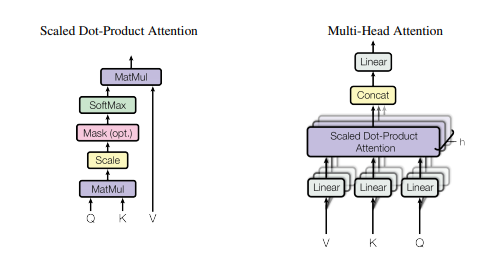
Реализация Pytorch "Внимание-это все, что вам нужно --- NIPS2017"
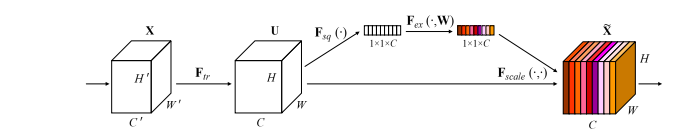
Реализация Pytorch "Squeeze и Excation Networks --- CVPR2018"
Реализация Pytorch "Селективные сети ядра --- CVPR2019"
Реализация Pytorch "CBAM: модуль внимания CONLORTAL --- ECCV2018"
Реализация Pytorch "BAM: узкое внимание модуля внимания --- BMCV2018"
Внедрение Pytorch "ECA-NET: эффективное внимание канала для глубоких сверточных нейронных сетей --- CVPR2020"
Реализация Pytorch "сеть двойного внимания для сегментации сцен-CVPR2019"
Реализация Pytorch "Epsanet: эффективный блок расщепления пирамиды в сверточной нейронной сети-A arxiv 2021.05.30"
Реализация Pytorch "REST: эффективный трансформатор для визуального распознавания --- ARXIV 2021.05.28"
Реализация Pytorch "SA-NET: Shuffle Attent для глубоких сверточных нейронных сетей --- ICASSP 2021"
Реализация Pytorch "Muse: параллельное многомасштабное внимание для последовательности для изучения последовательности --- ARXIV 2019.11.17"
Реализация Pytorch "Spatial Group Shower Anhrance: улучшение семантического обучения функциям в сверточных сетях --- ARXIV 2019.05.23"
Реализация Pytorch "A2 Nets: Double внимания сетей --- NIPS2018"
Реализация Pytorch "Без внимания трансформатора --- ICLR2021 (Apple New Work)"
Реализация Pytorch Volo: Vision Outlooker для визуального распознавания --- arxiv 2021.06.24 "[Анализ бумаги]
Реализация Pytorch Persutator: проницаемая MLP-подобная архитектура для визуального распознавания-A arxiv 2021.06.23 [Анализ бумаги]
Реализация Pytorch CoatNet: жениться на свертке и внимание для всех размеров данных --- ARXIV 2021.06.09 [Анализ бумаги]
Реализация Pytorch масштабирования локального самостоятельного приспособления для эффективных параметров визуальных костей --- CVPR2021 Пероральный [Анализ бумаги]
Реализация Pytorch поляризованного самостоятельного приспособления: к высококачественной регрессии пикселей-ARXIV 2021.07.02 [Анализ бумаги]
Реализация Pytorch контекстных трансформаторных сетей для визуального распознавания-A arxiv 2021.07.26 [Анализ бумаги]
Реализация остаточного внимания Pytorch: простой, но эффективный метод для распознавания с несколькими маркировкой --- ICCV2021
Реализация Pytorch S2-MLPV2: улучшенная архитектура MLP-пространственного сдвига для зрения --- ARXIV 2021.08.02 [Анализ бумаги]
Реализация Pytorch глобальных фильтров для классификации изображений --- ARXIV 2021.07.01
Реализация Pytorch для посещения: модуль свертки триплета --- WACV 2021
Реализация Pytorch Координаты для эффективного дизайна мобильной сети --- CVPR 2021
Реализация Pytorch MobileVIT: легкий, общий и мобильный трансформатор Vision Transformer --- ARXIV 2021.10.05
Реализация Pytorch неглубоких сетей --- arxiv 2021.10.20
Реализация Pytorch UFO-VIT: высокопроизводительный линейный видение трансформатор без SoftMax --- ARXIV 2021.09.29
Реализация Pytorch Scretable Self Canting для трансформаторов мобильного зрения --- ARXIV 2022.06.06
Реализация Pytorch по интеграции самоуправления и свертки-A arxiv 2022.03.14
Реализация Pytorch Crossformer: универсальный вид трансформатора зрения, касающийся кросс-масштабного внимания --- ICLR 2022
Реализация Pytorch агрегирующих глобальных функций в локальный видение трансформатор
Реализация Pytorch CCnet: КРИСС КОССОВОЙ ВНИМАНИЕ для семантической сегментации
Реализация аксиального внимания Pytorch в многомерных трансформаторах
«Помимо самостоятельного присмотра: внешнее внимание, используя два линейных слоя для визуальных задач»
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )«Внимание - это все, что вам нужно»
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Никто
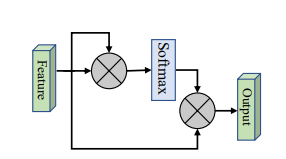
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Сетки сжимания и извлечения"
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Селективные сети ядра"
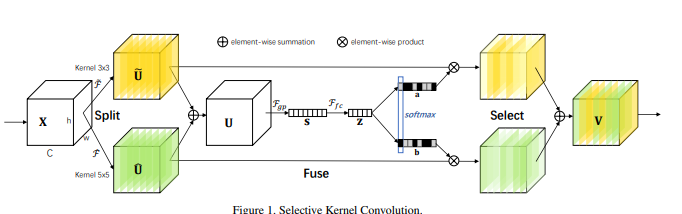
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: Модуль с розационным вниманием"
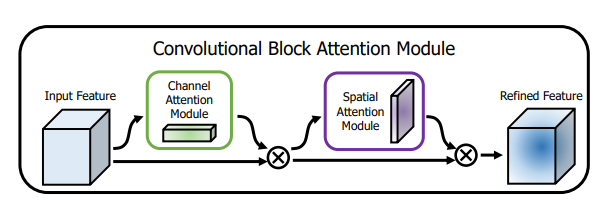
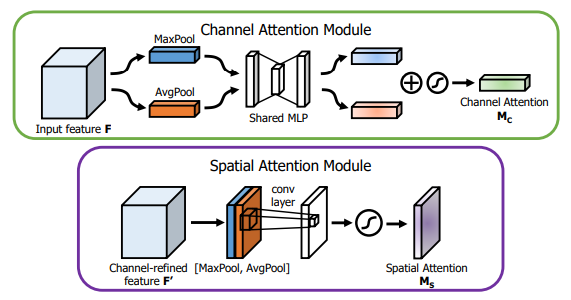
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"Бэм: модуль внимания на место"
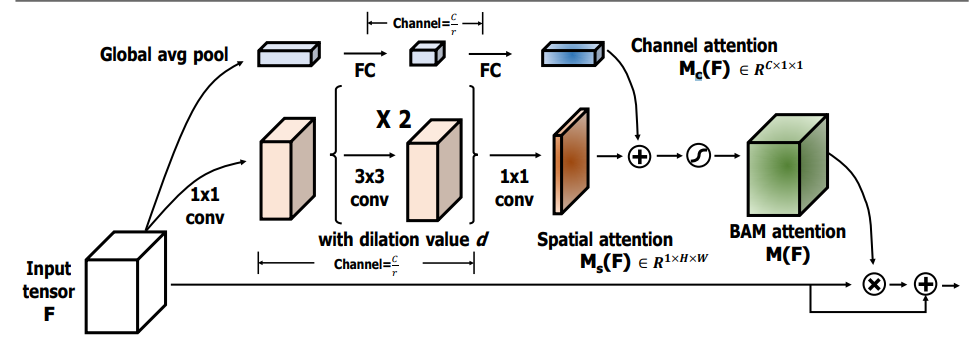
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )«ECA-Net: эффективное внимание канала для глубоких сверточных нейронных сетей»
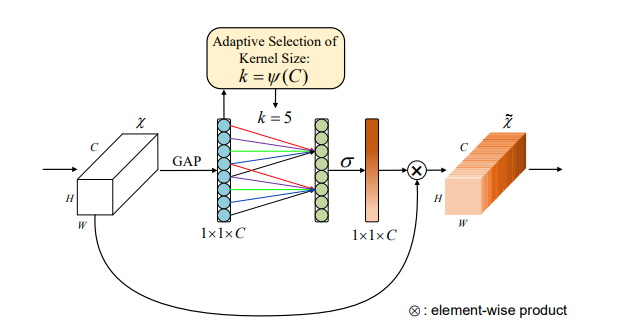
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )«Сеть двойного внимания для сегментации сцены»
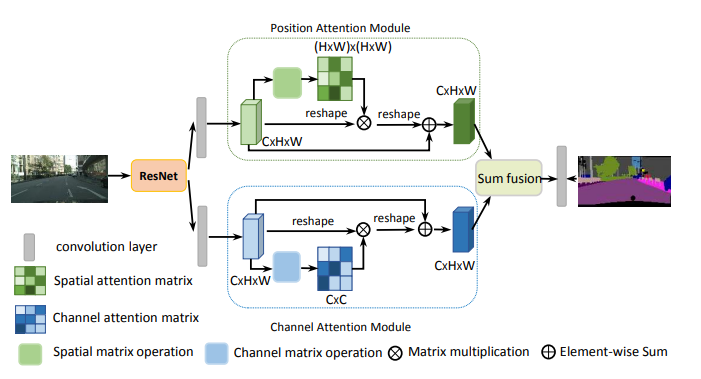
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )«Epsanet: эффективный блок разделителя пирамиды на сверточной нейронной сети»
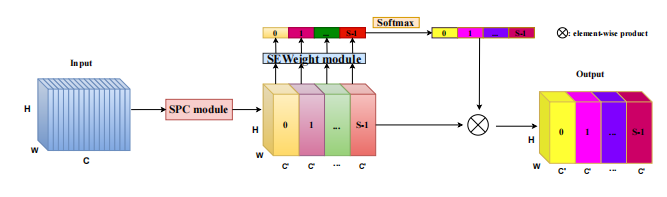
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )«Отдых: эффективный трансформатор для визуального распознавания»
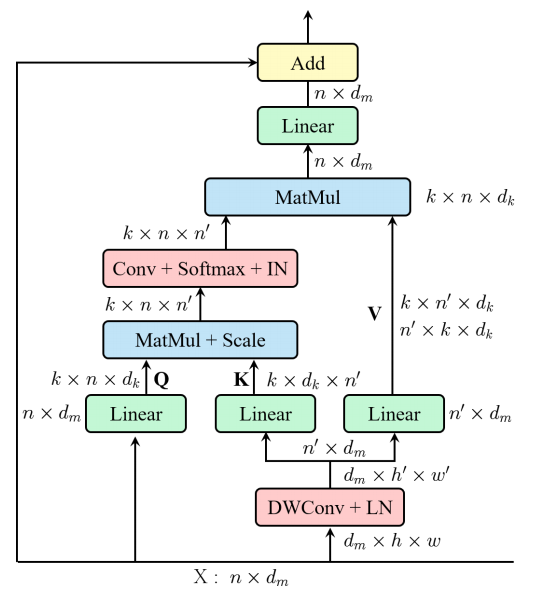
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
«SA-Net: уравновешенность внимательно для глубоких сверточных нейронных сетей»
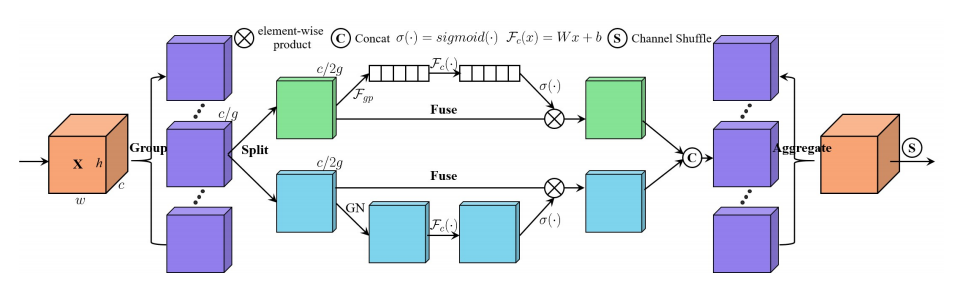
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
«Muse: параллельное многомасштабное внимание для последовательности для последовательности обучения»
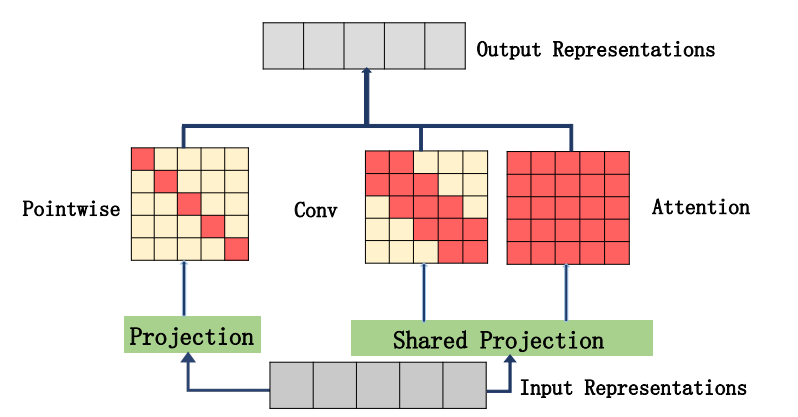
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Пространственное групповое улучшение: улучшение семантического обучения функциям в сверточных сетях
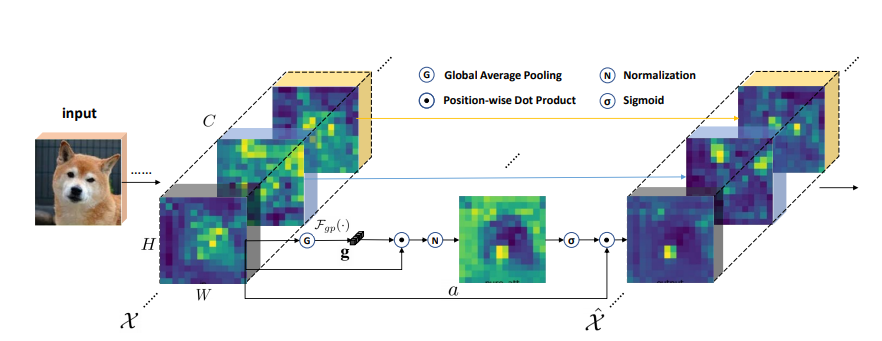
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-сети: двойные сети внимания
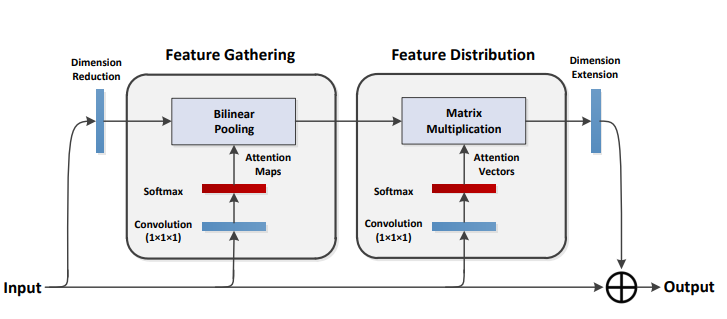
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Трансформатор без внимания
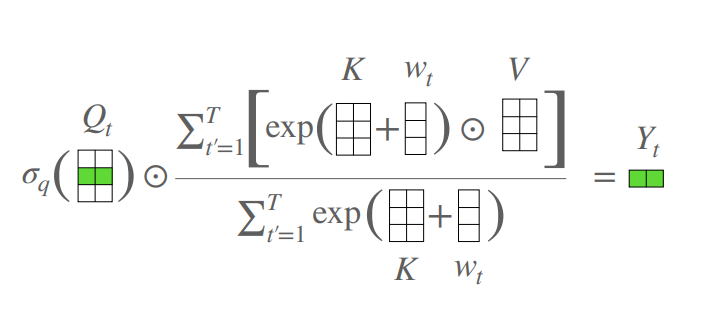
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo: Vision Outlooker для визуального распознавания »
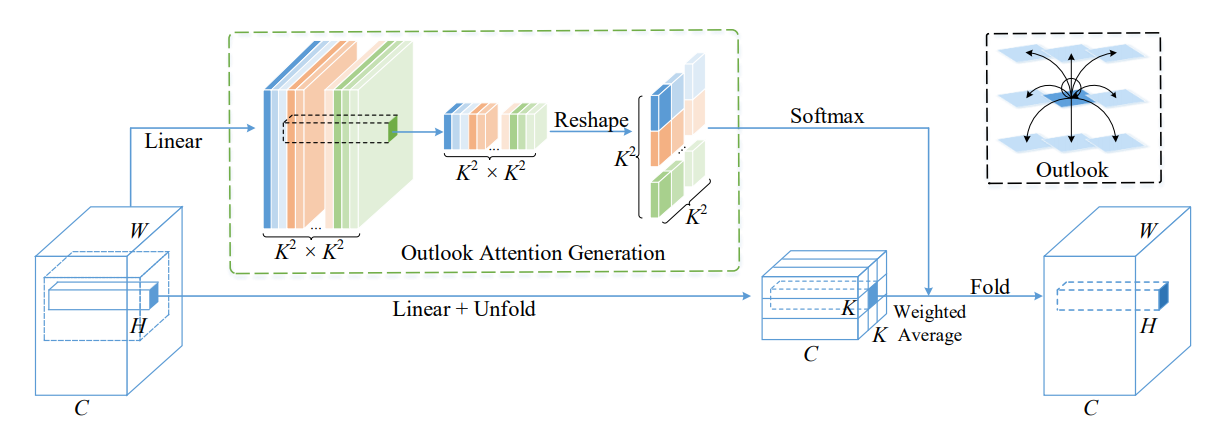
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Просмотчик Vision: проницаемая MLP-подобная архитектура для визуального распознавания »
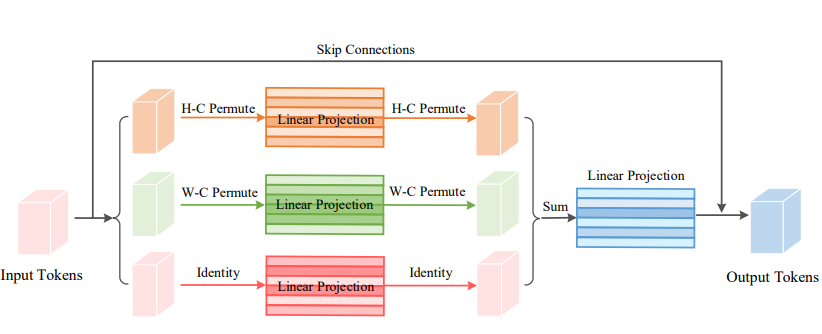
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: жениться на свертке и внимании всех размеров данных »
Никто
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Масштабирование локального самостоятельного присмотра за эффективными визуальными костями параметров "
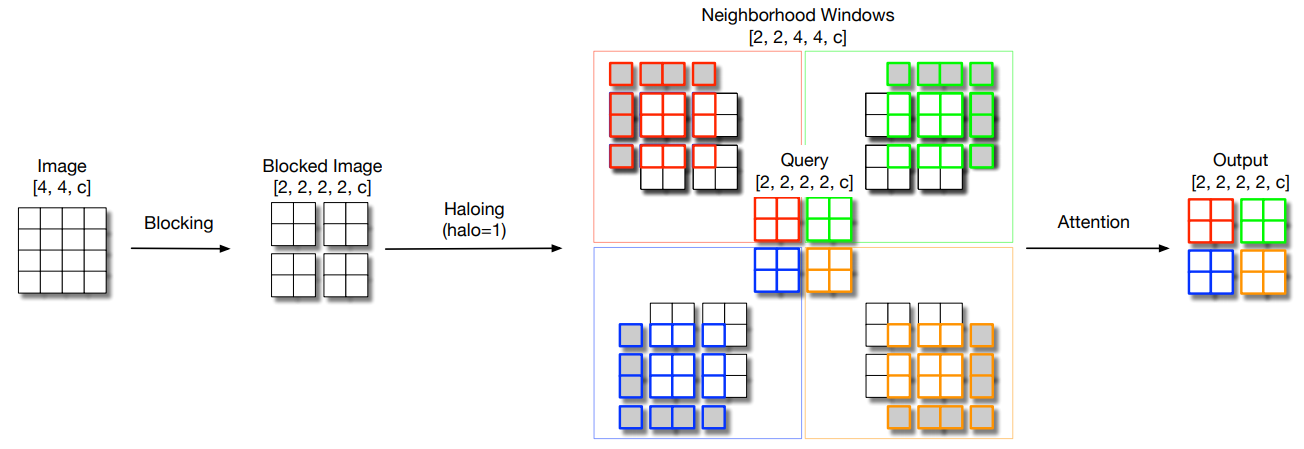
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Поляризованное самоуничтожение: к высококачественной пиксельной регрессии »
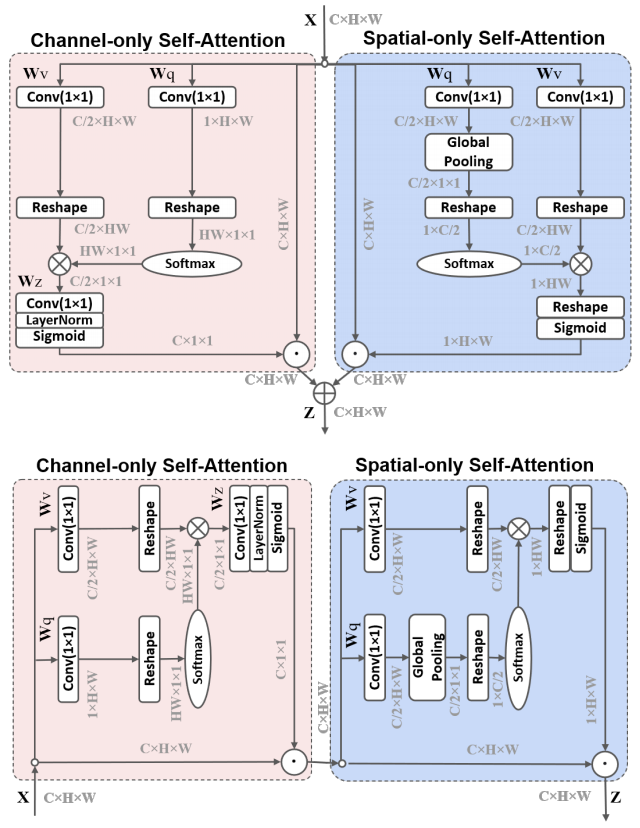
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Контекстуальные сети трансформаторов для визуального распознавания --- arxiv 2021.07.26
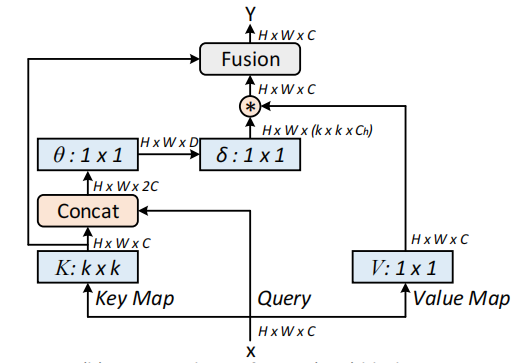
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Остатовое внимание: простой, но эффективный метод для распознавания мульти-маршрута --- ICCV2021
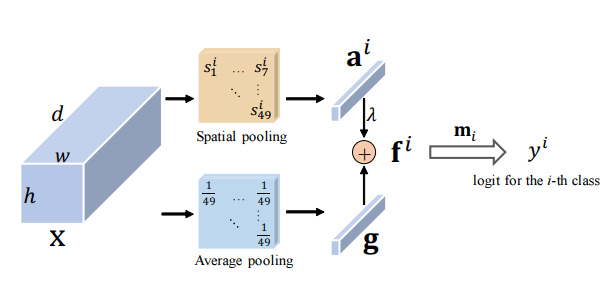
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: улучшенная архитектура MLP-пространственного сдвига для зрения --- ARXIV 2021.08.02
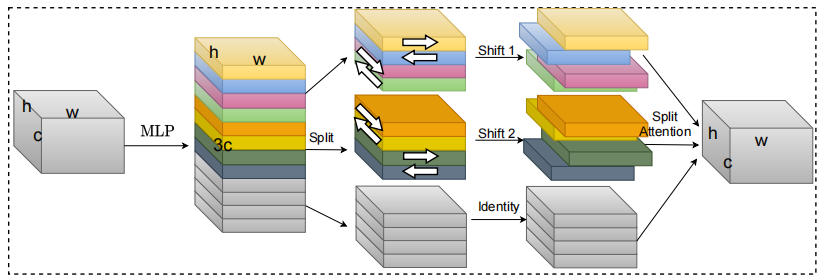
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Глобальные сети фильтров для классификации изображений --- ARXIV 2021.07.01
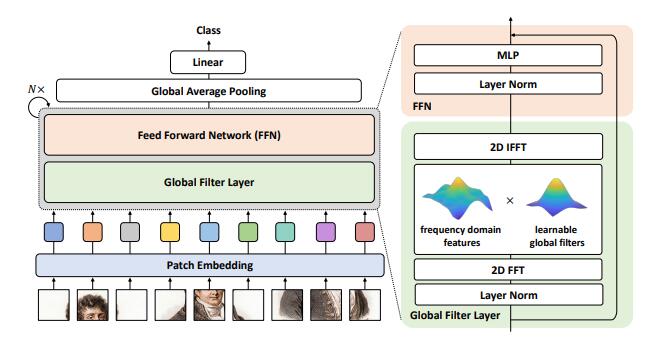
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )Поверните, чтобы посетить: модуль свертки триплета --- CVPR 2021
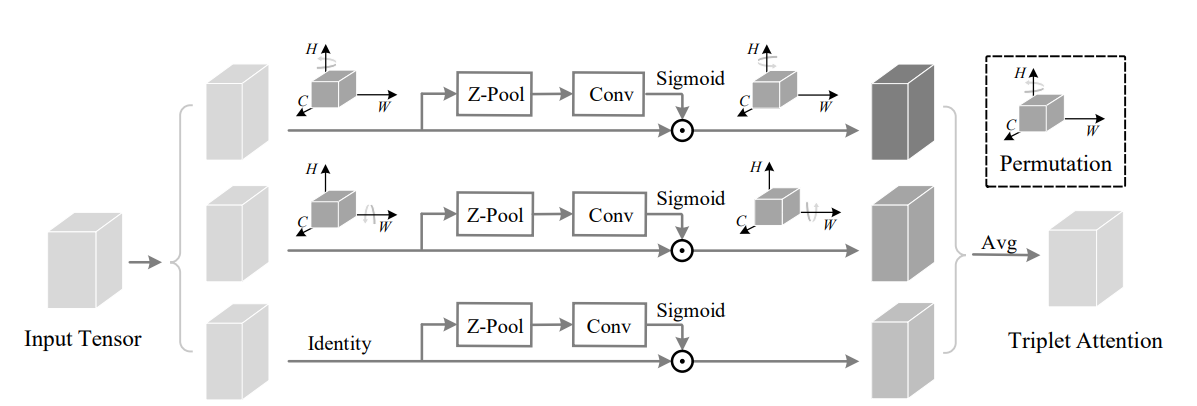
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Координировать внимание для эффективного дизайна мобильной сети --- CVPR 2021
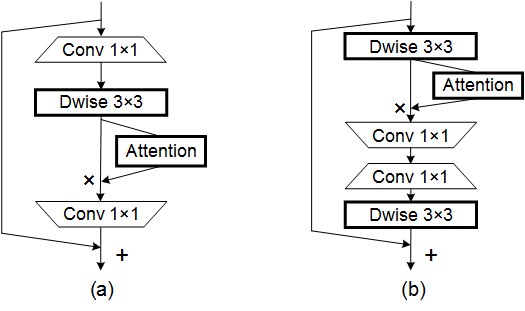
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit: легкий, общий назначен и мобильный вид Vision Transformer --- arxiv 2021.10.05
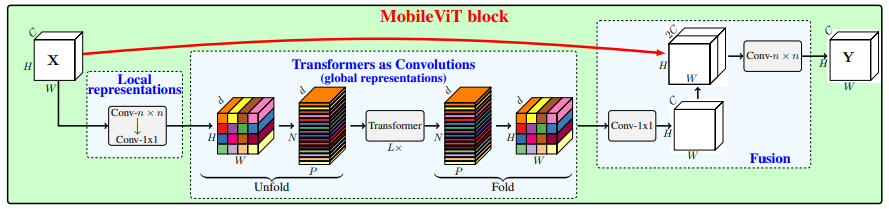
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Нестуопубличные сети --- arxiv 2021.10.20
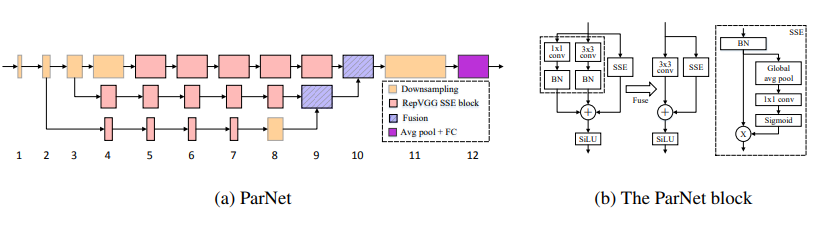
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT: высокопроизводительный линейный вид видения без SoftMax --- ARXIV 2021.09.29
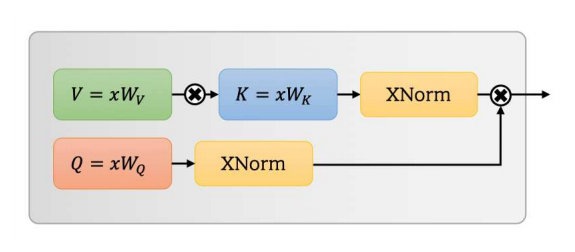
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
Об интеграции самоуправления и свертки
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
Разделяемое самопринятие для трансформаторов мобильного зрения --- arxiv 2022.06.06
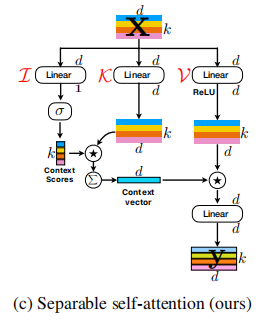
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Трансформатор зрения с деформируемым вниманием --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer: Универсальный вид трансформатора зрения, зависящий от кросс-масштабного внимания --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Агрегация глобальных функций в локальный видение трансформатор
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: КРИСС-КОССОВОЕ ВНИМАНИЕ для семантической сегментации
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Осевое внимание в многомерных трансформаторах
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Реализация Pytorch "глубокое остаточное обучение для распознавания изображений-CVPR2016 Лучшая статья"
Внедрение Pytorch "агрегированных остаточных преобразований для глубоких нейронных сетей --- CVPR2017"
Реализация Pytorch MobileVIT: легкий, общий и мобильный трансформатор Vision Transformer --- arxiv 2020.10.05
Реализация патчей Pytorch-все, что вам нужно?
Реализация Pytorch Transformer: Переосмысление пространственного перетасовки для Vision Transformer --- Arxiv 2021.06.07
Реализация Pytorch Contnet: Почему бы не использовать свертку и трансформатор одновременно? --- arxiv 2021.04.27
Реализация Pytorch трансформеров зрения с иерархическим вниманием --- Arxiv 2022.06.15
Реализация Pytorch коннусолюционных трансформаторов изображений-A arxiv 2021.08.26
Реализация Pytorch условных позиционных кодировки для трансформаторов зрения
Реализация Pytorch переосмысления пространственных измерений трансформаторов зрения --- ICCV 2021
Реализация Pytorch Crossvit: многомасштабный трансформатор зрения для классификации изображений --- ICCV 2021
Реализация Pytorch Transformer в Transformer --- Neurips 2021
Реализация Pytorch Deepvit: к более глубокому трансформатору зрения
Реализация Pytorch включала проекты свертки в визуальные трансформаторы
Реализация Pytorch Convit: улучшение трансформеров зрения с мягкими сверточными индуктивными предубеждениями
Внедрение Pytorch дополнения сверточных сетей с агрегацией, основанной на внимании, на основе внимания
Реализация Pytorch о том, как глубже с трансформаторами изображений --- ICCV 2021 (устный)
Реализация Pytorch учебных трансформаторов и дистилляции изображений с помощью данных-ICML 2021
Реализация Pytorch Levit: Vision Transformer в одежде Convnet для более быстрого вывода
Реализация Pytorch Volo: Vision Outlooker для визуального распознавания
Реализация контейнера Pytorch: сеть агрегации контекста --- Neuips 2021
Реализация Pytorch CMT: сверточные нейронные сети соответствуют трансформаторам видения --- CVPR 2022
Реализация Pytorch Transformer с деформируемым вниманием --- CVPR 2022
Pytorch Реализация эффективности: трансформаторы зрения на скорости Mobilenet
ПИТОРЧ ВЕДУЩЕНИЕ УНУТА
"Глубокое остаточное обучение для распознавания изображений --- лучшая бумага CVPR2016"
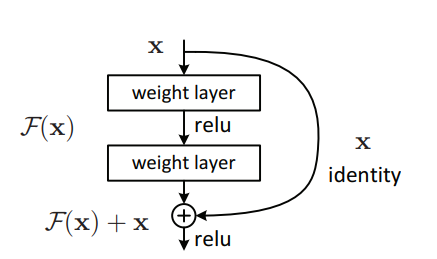
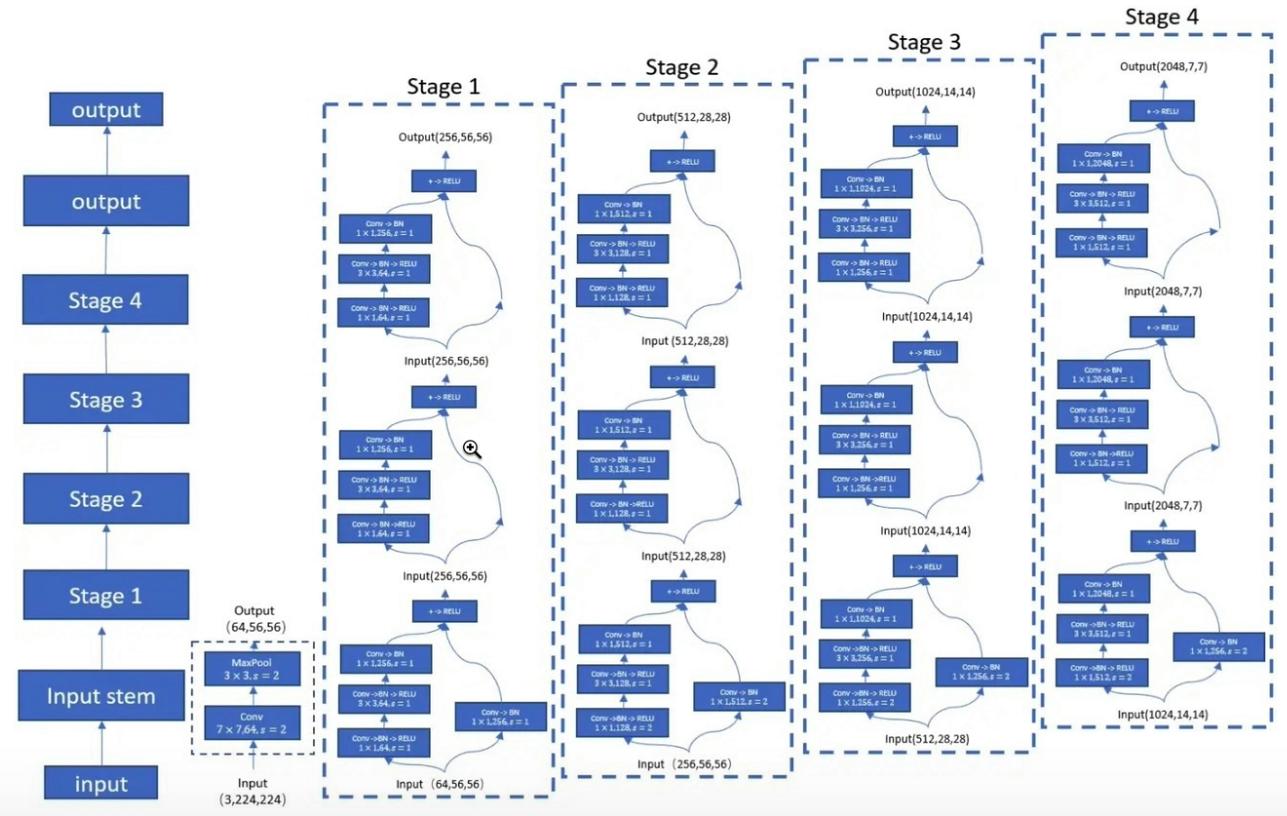
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )«Совокупные остаточные преобразования для глубоких нейронных сетей --- CVPR2017»
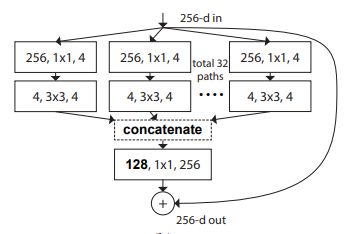
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVIT: легкий, общий и мобильный трансформатор Vision Transformer --- arxiv 2020.10.05
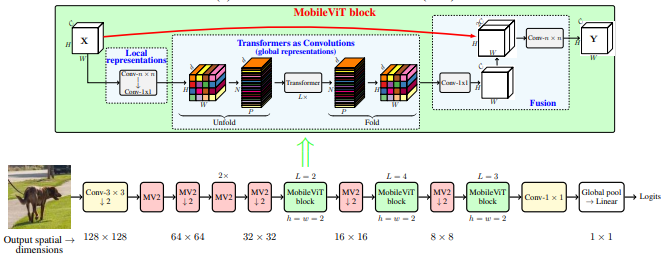
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Патчи-это все, что вам нужно? --- ICLR2022 (под рассмотрением)
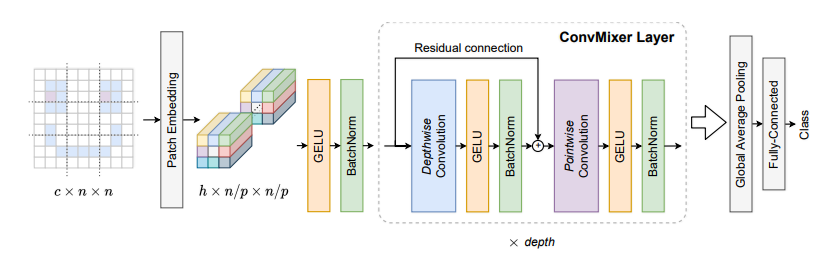
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Шафма трансформатора: переосмысление пространственного перетасовки для трансформатора зрения
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
Contnet: Почему бы не использовать свертку и трансформатор одновременно?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Трансформеры зрения с иерархическим вниманием
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Совместные конвурронные трансформаторы изображений
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])Pvt V2: улучшенные базовые показатели с трансформатором Pyramid Vision
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Условные позиционные кодировки для трансформаторов зрения
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Переосмысление пространственных измерений трансформаторов зрения
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit: многомасштабное видение трансформатора по перекрестному взаимодействию для классификации изображений
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Трансформатор в трансформаторе
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )Deepvit: к более глубокому визуальному трансформатору
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Включение проектов свертки в визуальные трансформаторы
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Convit: улучшение трансформаторов зрения с мягкими сверточными индуктивными уклонами
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Подойдя глубже с трансформаторами изображений
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Расширение сверточных сетей с агрегацией, основанной на внимании
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Обучение данных, экономически эффективные трансформаторы изображений и дистилляция с помощью внимания
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Левит: трансформатор видения в одежде Convnet для более быстрого вывода
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo: Vision Outlooker для визуального распознавания
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Контейнер: сеть агрегации контекста
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: сверточные нейронные сети встречаются с трансформаторами зрения
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )Effectiformer: Vision Transformers у Mobilenet Speed
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )Urvenextv2: совместное проектирование и масштабирование Convnets с помощью маскированных автоходоров
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Реализация Pytorch "Repmlp: повторный параметеризацию свертков в полностью подключенные слои для распознавания изображений --- arxiv 2021.05.05"
Реализация Pytorch "MLP-Mixer: архитектура All-MLP для зрения --- Arxiv 2021.05.17"
Реализация Pytorch "RESMLP: сетей пищи для классификации изображений с эффективным обучением --- ARXIV 2021.05.07"
Реализация Pytorch "Обратите внимание на MLP --- ARXIV 2021.05.17"
Реализация Pytorch "Sparse MLP для распознавания изображений: действительно ли это приспосабливается? --- arxiv 2021.09.12"
«RepMLP: повторный параметрирующий сверток в полностью подключенные слои для распознавания изображений»
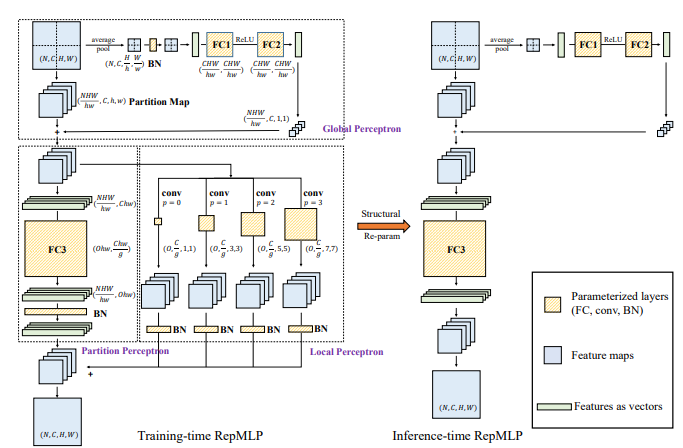
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())«MLP-Mixer: архитектура All-MLP для видения»
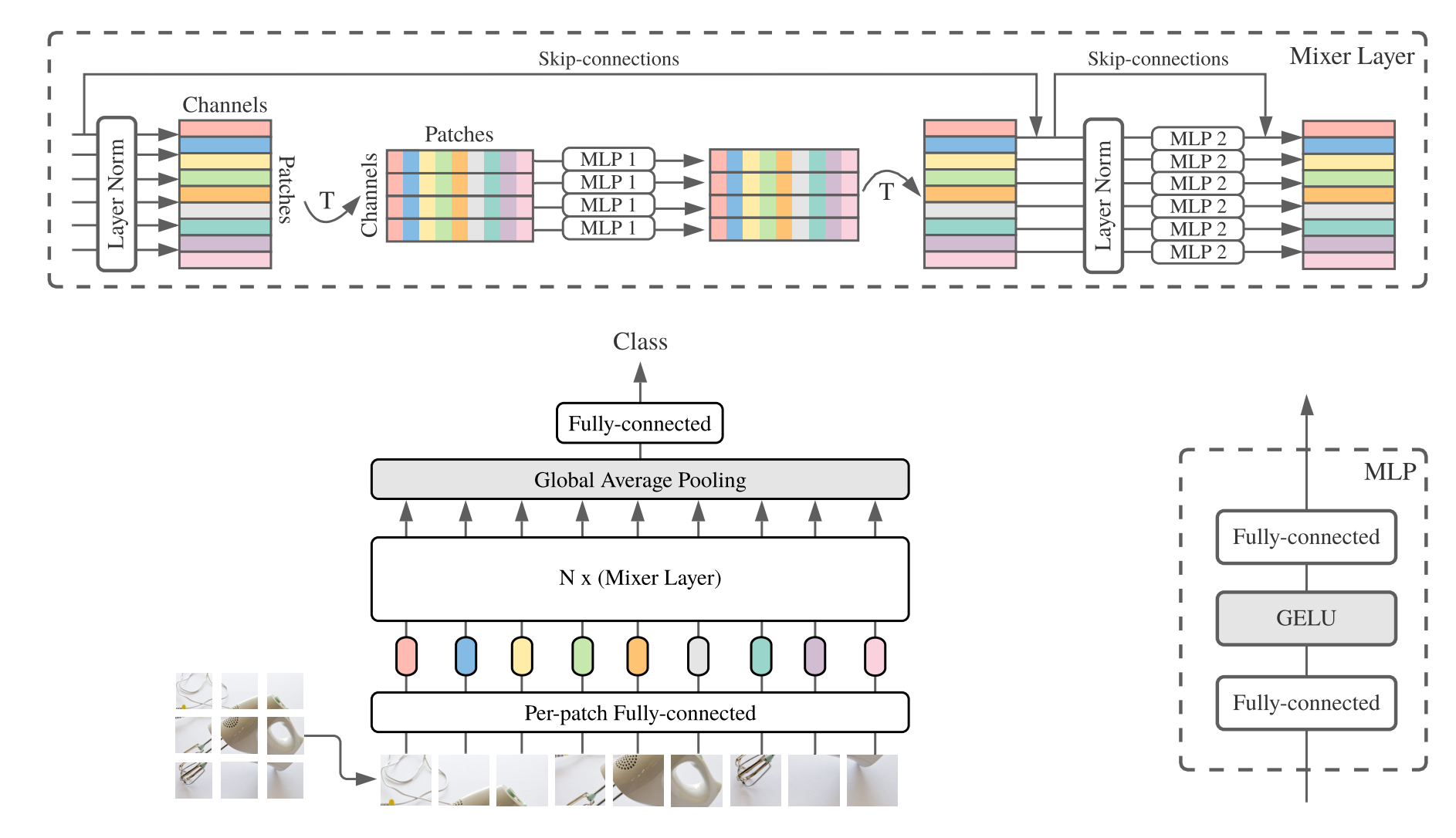
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"RESMLP: сети приправочных соединений для классификации изображений с учетом эффективного обучения"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Обратите внимание на MLP"
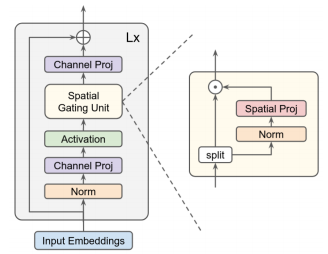
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"Sparse MLP для распознавания изображений: действительно ли самопринимание действительно необходимо?"
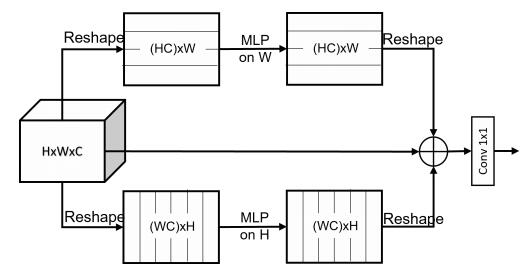
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )«Перестатор зрения: пересеченная архитектура MLP для визуального распознавания»
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Реализация Pytorch "Repvgg: снова создает VGG-стиль отличным ---- CVPR2021"
Реализация Pytorch "ACNet: укрепление скелетов ядра для мощных CNN через асимметричные свертывающие блоки --- ICCV2019"
Реализация Pytorch "Разнообразие блока филиала: строительство свертки в качестве начального блока-CVPR2021"
"Repvgg: снова создает VGG в стиле VGG
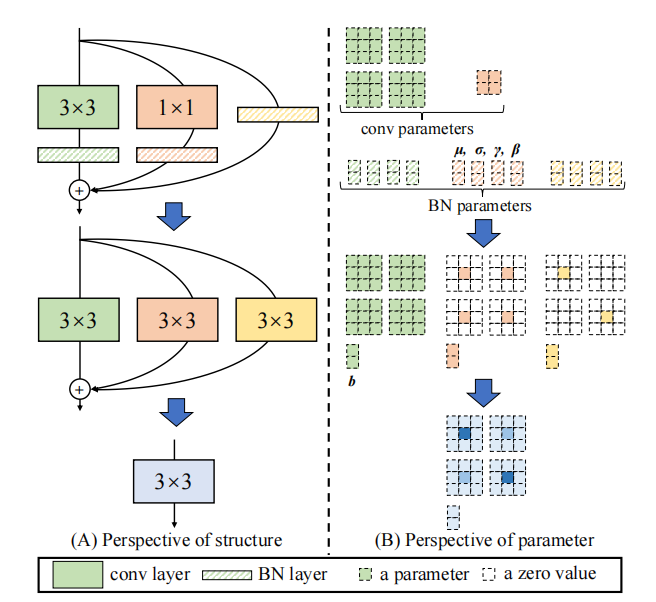
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())«ACNet: укрепление скелетов ядра для мощных CNN через асимметричные свертывающие блоки»
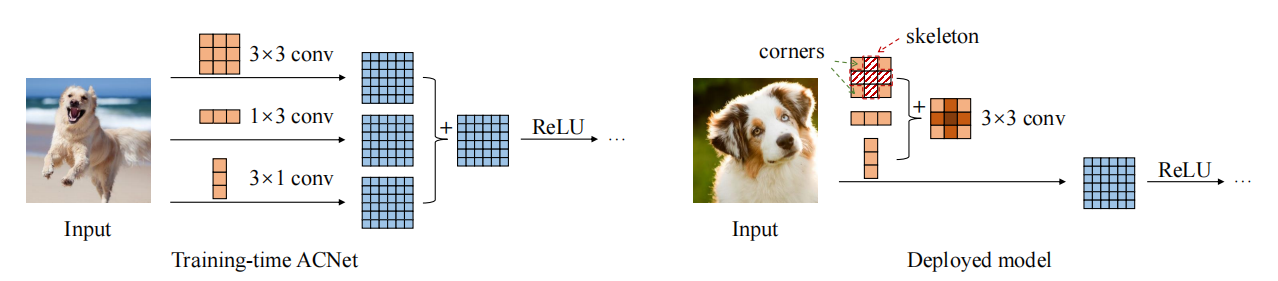
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())«Разнообразие блока филиала: строительство свертки в качестве начального подразделения»
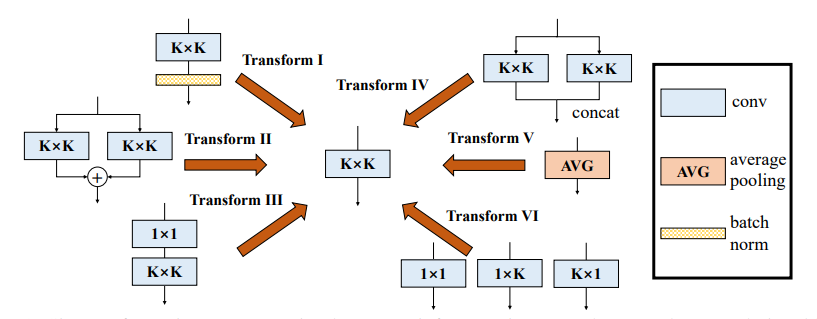
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Внедрение Pytorch "Mobilenets: Эффективные сверточные нейронные сети для приложений мобильного зрения --- CVPR2017"
Реализация Pytorch "EffureTintNet: переосмысление масштабирования модели для сверточных нейронных сетей --- PMLR2019"
Реализация Pytorch «Инволюция: инвертирование присутствия свертки для визуального распознавания ---- CVPR2021»
Реализация Pytorch "Динамическая свертка: внимание к ядрам свертки --- оральный CVPR2020"
Реализация Pytorch "condConv: условные параметризованные сверлочки для эффективного вывода-neurips2019"
«Mobilenets: эффективные сверточные нейронные сети для приложений мобильного зрения»
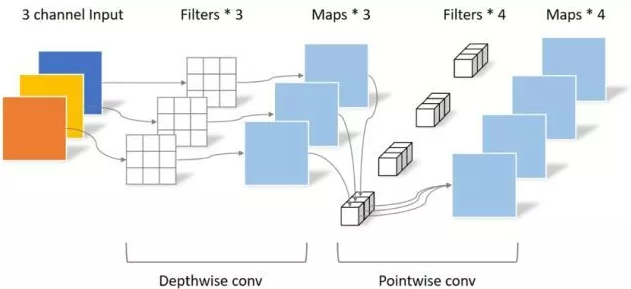
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )«Эффективное сечение: переосмысление масштабирования модели для сверточных нейронных сетей»
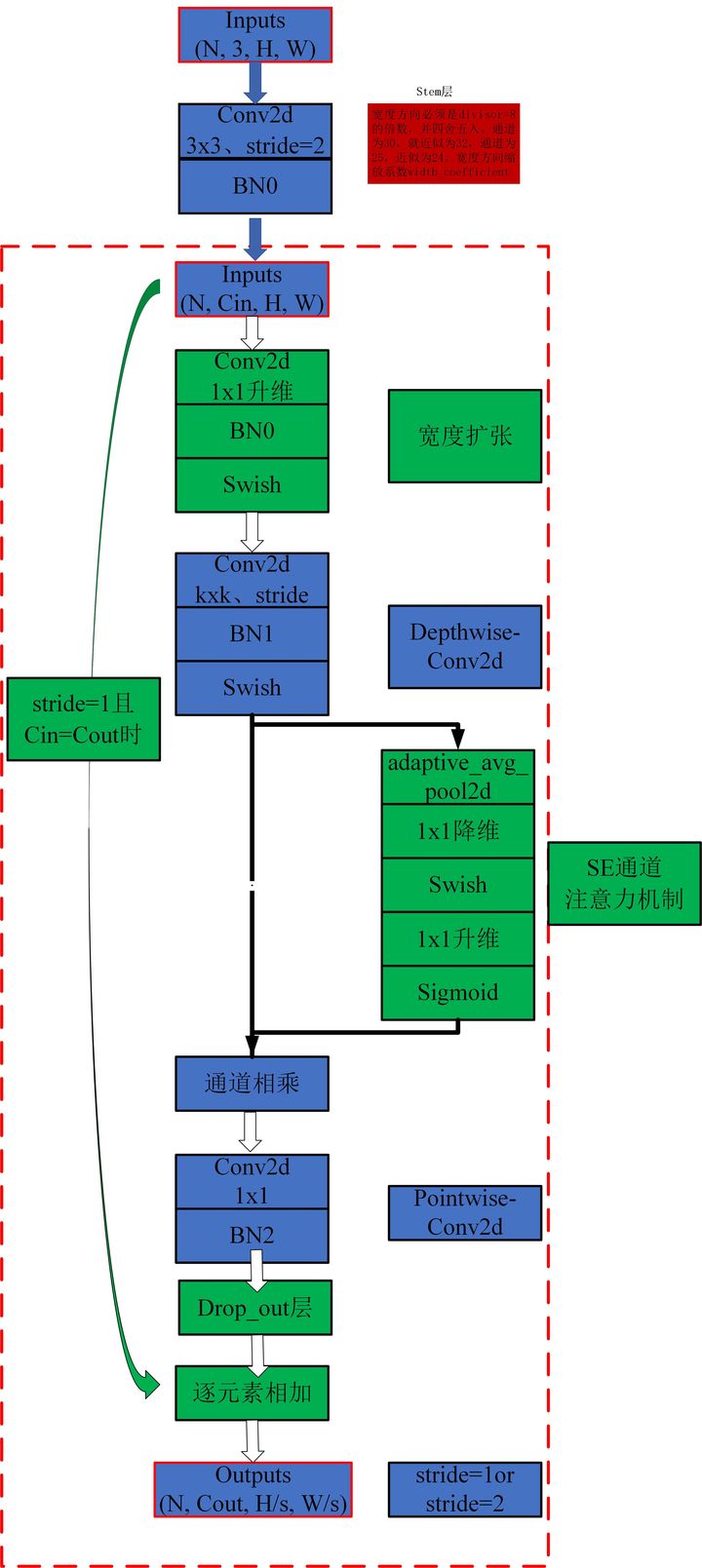
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
«Инволюция: инвертирование присутствия свертки для визуального признания»
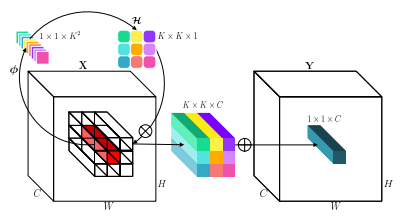
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )«Динамическая свертка: внимание к ядрам свертки»
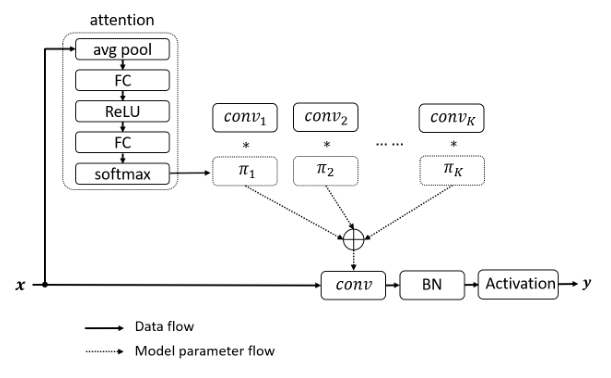
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64«ConDCONV: условно параметризованные сверлочки для эффективного вывода»
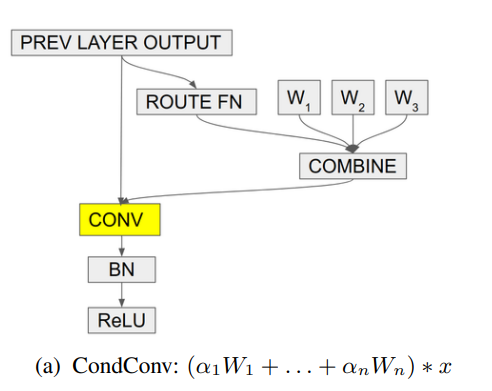
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )Большие новости! ! ! В качестве дополнения к проекту, вы можете обратить внимание на недавно с открытым исходным кодом , чтение Paper-Paper , которая собирает и организует газетный анализ основных конференций и журналов.
Большие новости! ! ! Недавно я собрал различные видеоуроки, связанные с ИИ, и обязательные документы в Интернете FightingCv-Course
Большие новости! ! ! Недавно была открыта новая библиотека кодов обнаружения объектов YOLOAIR , которая интегрирует различные модели YOLO, включая Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 и другие модели Yolo, а также различные механизмы внимания.
ECCV2022 Сводка бумаги: ECCV2022-List-List


