External Attention pytorch
1.0.0

تبسيط الصينية | إنجليزي
مرحبا بالجميع ، أنا شياووما
بالنسبة إلى Xiaobai (مثلي): في الآونة الأخيرة ، سأجد مشكلة عندما أقرأ ورقة. في بعض الأحيان تكون الفكرة الأساسية للورقة بسيطة للغاية ، وقد يكون الرمز الأساسي فقط عشرات الخطوط. ومع ذلك ، عندما فتحت الكود المصدري لإصدار المؤلف ، وجدت أن الوحدة النمطية المقترحة تم تضمينها في أطر العمل مثل التصنيف والاكتشاف والتجزئة ، مما أدى إلى رمز زائد نسبيًا. لست على دراية بأطر عمل محددة ومن الصعب بالنسبة لي العثور على الكود الأساسي ، مما يؤدي إلى بعض الصعوبات في فهم الأوراق وأفكار الشبكة.
من أجل المتقدم (مثلك): إذا كنت تعتبر الوحدات الأساسية مثل Conv و FC و RNN كبنات بناء صغيرة LEGO ، والهياكل مثل Transformer و Resnet كقلاع LEGO التي تم بناؤها. ثم الوحدات النمطية التي يوفرها هذا المشروع هي مكونات LEGO مع معلومات دلالية كاملة. دع الباحثين العلميين يتجنبون صنع العجلات مرارًا وتكرارًا ، فقط فكر في كيفية استخدام هذه "مكونات LEGO" لبناء أعمال أكثر ملونة.
بالنسبة إلى Master (قد يكون مثلك): لدي قدرة محدودة ولا أحب أن أقوم بخفة ! ! !
للجميع: يلتزم هذا المشروع بتنفيذ قاعدة رمز تتيح للمبتدئين في التعلم العميق فهم وخدمة البحوث العلمية والمجتمعات الصناعية .
تثبيت مباشرة من خلال PIP
pip install fightingcv-attentionأو استنساخ المستودع
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )سلسلة الانتباه
1. استخدام الاهتمام الخارجي
2. استخدام انتباه الذات
3. تبسيط استخدام انتباه الذات
4.
5. استخدام الانتباه SK
6. استخدام انتباه CBAM
7. استخدام انتباه بام
8. استخدام انتباه ECA
9. استخدام الانتباه الدانيت
10. استخدام الاهتمام الهرم (PSA)
11. استخدام فعال متعدد الرؤوس (EMSA)
12. استخدام الاهتمام بالانتباه
13. استخدام انتباه موس
14. استخدام الانتباه SGE
15. استخدام الانتباه A2
16. استخدام الانتباه بعد
17. استخدام الانتباه في التوقعات
18. استخدام الانتباه لكبار الشخصيات
19. استخدام الانتباه مع Coatnet
20. استخدام انتباه الهالونيت
21. استخدام الاستقطاب الذاتي
22. استخدام Cotattention
23. استخدام الاهتمام المتبقي
24. استخدام الانتباه S2
25. استخدام انتباه GFNET
26. استخدام الانتباه الثلاثي
27. تنسيق استخدام الانتباه
28. استخدام الاهتمام بالهاتف المحمول
29. استخدام انتباه Parnet
30. استخدام الانتباه UFO
31. استخدام الانتباه Acmix
32. استخدام الانتباه MobileVitv2
33. استخدام انتباه دات
34. استخدام الانتباه المتقاطع
35.
36. استخدام انتباه Crisscrossattent
37. استخدام انتباه Axial_attention
سلسلة العمود الفقري
1. استخدام RESNET
2. الاستخدام RESNEXT
3. استخدام MobileVit
4. الاستخدام القادم
5. استخدام Shuffletransformer
6. الاستخدام contnet
7. استخدام Hatnet
8. استخدام المعطف
9. الاستخدام الجندي
10. استخدام CPVT
11. استخدام الحفرة
12. استخدام Crossvit
13. استخدام TNT
14. استخدام DVIT
15. استخدام CEIT
16. الاستخدام الدنيوي
17. استخدام Cait
18
19. استخدام الاستخدام
20. استخدام الليفيت
21. استخدام فولو
22. استخدام الحاوية
23. استخدام CMT
24. الاستخدام الفعال
25. الاستخدام Convnextv2
سلسلة MLP
1. repmlp الاستخدام
2. استخدام MLP-mixer
3. استخدام Resmlp
4. استخدام GMLP
5. استخدام SMLP
6. استخدام VIP-MLP
سلسلة المعلمة (Rep)
1. repvgg استخدام
2. استخدام ACNET
3. استخدام كتلة فرع متنوعة (DDB)
سلسلة الالتصاف
1. استخدام الالتواء القابل للفصل عمقًا
2. الاستخدام MBConv
3. الاستخدام الجانبي
4. استخدام DynamicConv
5. الاستخدام condconv
تنفيذ Pytorch لـ "Beyond Enthenention: الاهتمام الخارجي باستخدام طبقتين خطيتين للمهام المرئية --- Arxiv 2021.05.05"
تنفيذ Pytorch لـ "الانتباه هو كل ما تحتاجه --- NIPS2017"
تنفيذ Pytorch لـ "شبكات الضغط والإثارة --- CVPR2018"
تنفيذ Pytorch لـ "شبكات kernel الانتقائية --- CVPR2019"
تنفيذ Pytorch لـ "CBAM: وحدة الانتباه التنازلية --- ECCV2018"
Pytorch تطبيق "BAM: وحدة الانتباه عنق الزجاجة --- BMCV2018"
تنفيذ Pytorch لـ "ECA-NET: اهتمام قناة فعال للشبكات العصبية التلافيفية العميقة --- CVPR2020"
تنفيذ Pytorch لـ "شبكة الانتباه المزدوجة لتجزئة المشهد --- CVPR2019"
تنفيذ Pytorch لـ "Epsanet: كتلة انتباه هرم فعالة على الشبكة العصبية التلافيفية --- Arxiv 2021.05.30"
تنفيذ Pytorch لـ "REST: محول فعال للتعرف المرئي --- ARXIV 2021.05.28"
تنفيذ Pytorch لـ "SA-NET: خلط ورق اللعب للشبكات العصبية التلافيفية العميقة --- ICASSP 2021"
تنفيذ Pytorch لـ "Muse: Parallel Multi-Scale Lungion for Sequence to Sequence Learning --- Arxiv 2019.11.17"
تنفيذ Pytorch لـ "تعزيز المجموعة المكانية: تحسين تعلم الميزة الدلالية في الشبكات التلافيفية --- ARXIV 2019.05.23"
تنفيذ Pytorch لـ "A2-Nets: Double Lunction Networks --- NIPS2018"
تنفيذ Pytorch لـ "محول خالي من الانتباه --- ICLR2021 (Apple New Work)"
Pytorch تطبيق Volo: Vision Outlooker للتعرف البصري --- Arxiv 2021.06.24 "[تحليل الورق]
PYTORCH تنفيذ الرؤية الباهتة: بنية تشبه MLP القابلية للاحتفال بالتعرف المرئي --- ARXIV 2021.06.23 [تحليل الورق]
Pytorch تطبيق Coatnet: الزواج من الالتفاف والاهتمام لجميع أحجام البيانات --- Arxiv 2021.06.09 [تحليل الورق]
تنفيذ Pytorch لتوسيع نطاق الالتحاق الذاتي المحلي للمعلمة البصرية البصرية الفعالة --- CVPR2021 عن طريق الفم [تحليل الورق]
تنفيذ Pytorch للتراجع الذاتي المستقطب: نحو الانحدار عالي الجودة بكسل --- Arxiv 2021.07.02 [تحليل الورق]
تنفيذ Pytorch لشبكات المحولات السياقية للتعرف المرئي --- ARXIV 2021.07.26 [تحليل الورق]
تنفيذ Pytorch للانتباه المتبقي: طريقة بسيطة ولكنها فعالة للتعرف على العلامات المتعددة --- ICCV2021
تنفيذ Pytorch لـ S²-MLPV2: تحسين بنية MLP المكانية للرؤية --- ARXIV 2021.08.02 [تحليل الورق]
تنفيذ Pytorch لشبكات التصفية العالمية لتصنيف الصور --- ARXIV 2021.07.01
تنفيذ Pytorch للتناوب للحضور: وحدة الانتباه الثلاثي التلافييل --- WACV 2021
تنفيذ Pytorch للتنسيق لتصميم شبكة الهاتف المحمول الفعال --- CVPR 2021
Pytorch تطبيق MobileVit: محول الرؤية الخفيف والغرض العام ، وصديق للهاتف المحمول --- Arxiv 2021.10.05
تنفيذ Pytorch للشبكات غير العميقة --- Arxiv 2021.10.20
تنفيذ Pytorch لـ UFO-Vit: محول الرؤية الخطي عالي الأداء بدون softmax --- Arxiv 2021.09.29
تنفيذ Pytorch للتراجع الذاتي القابل للفصل لمحولات الرؤية المتنقلة --- Arxiv 2022.06.06
تنفيذ Pytorch على دمج الاهتمام الذاتي والالتواء --- ARXIV 2022.03.14
Pytorch تطبيق CrossFormer: محول رؤية متعدد الاستخدامات يتوقف على العواقب عبر نطاق --- ICLR 2022
تنفيذ Pytorch لتجميع الميزات العالمية في محول الرؤية المحلية
تنفيذ Pytorch لـ CCNET: اهتمام Criss-Cross للتجزئة الدلالية
تنفيذ Pytorch للاهتمام المحوري في المحولات متعددة الأبعاد
"ما وراء الاهتمام الذاتي: الاهتمام الخارجي باستخدام طبقتين خطين للمهام البصرية"
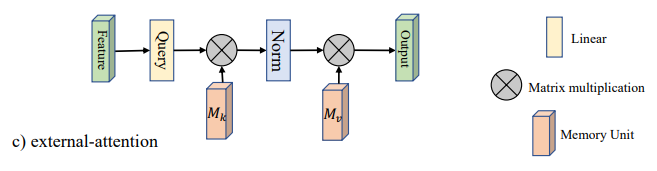
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"الاهتمام هو كل ما تحتاجه"
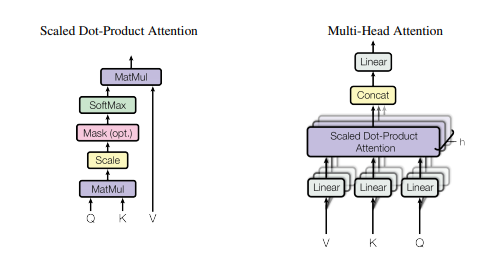
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )لا أحد
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"شبكات الضغط والإثبات"
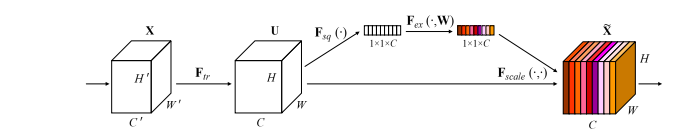
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"شبكات kernel الانتقائية"
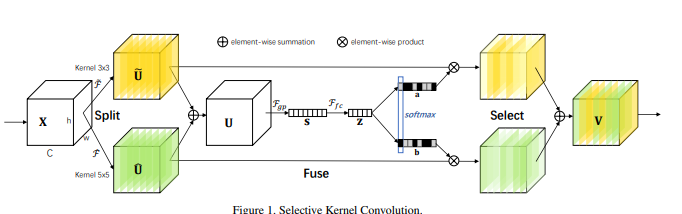
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: وحدة انتباه الكتلة التلافيفية"
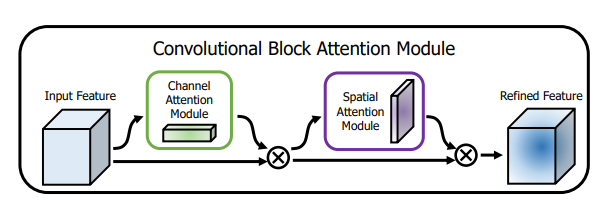
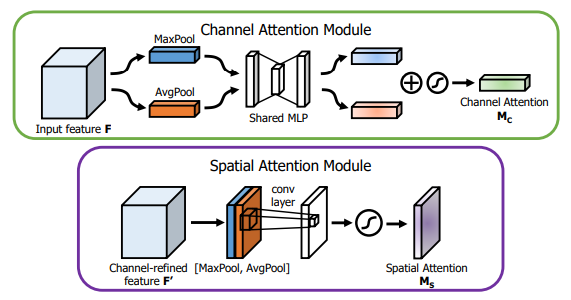
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"بام: وحدة انتباه عنق الزجاجة"
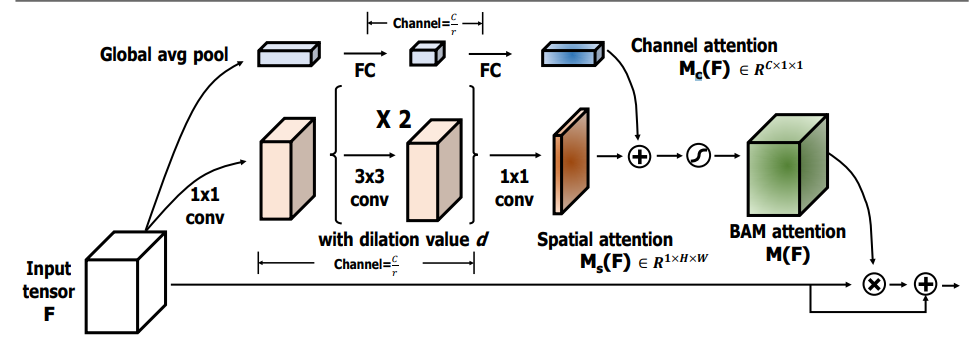
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: اهتمام قناة فعال للشبكات العصبية التلافيفية العميقة"
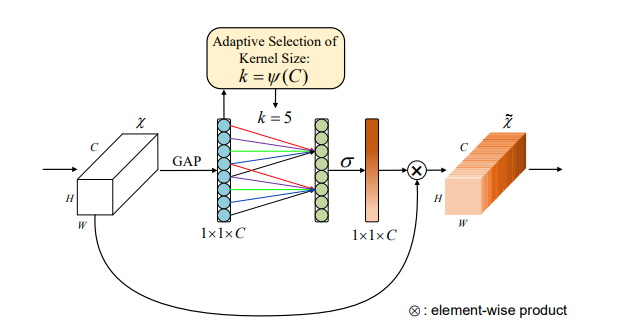
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"شبكة الانتباه المزدوجة لتجزئة المشهد"
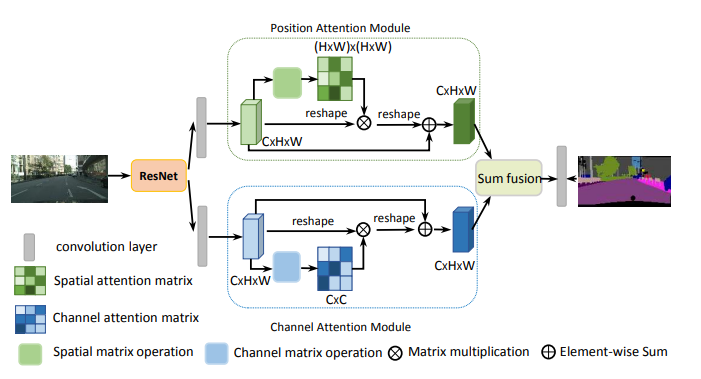
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"إبسانيت: كتلة انتباه هرم فعالة على الشبكة العصبية التلافيفية"
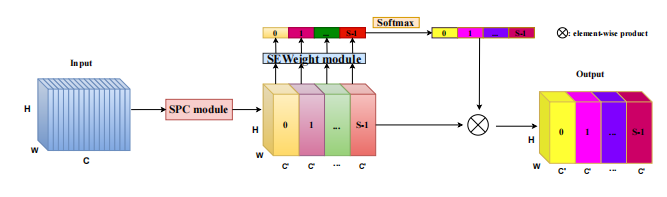
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"بقية: محول فعال للاعتراف البصري"
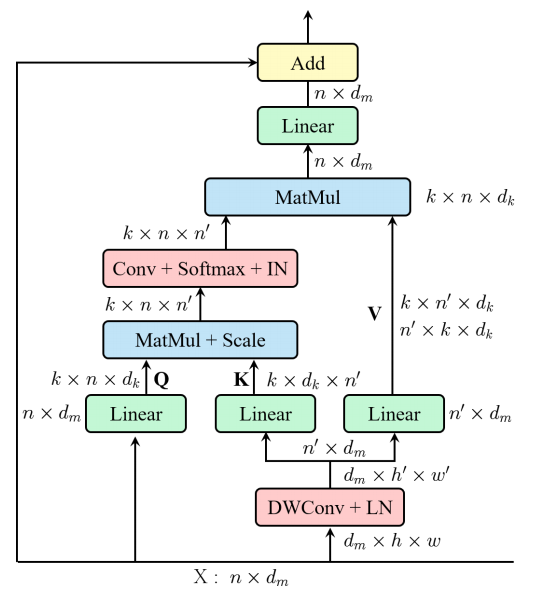
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: خلط خلط الاكتتاب للشبكات العصبية التلافيفية العميقة"
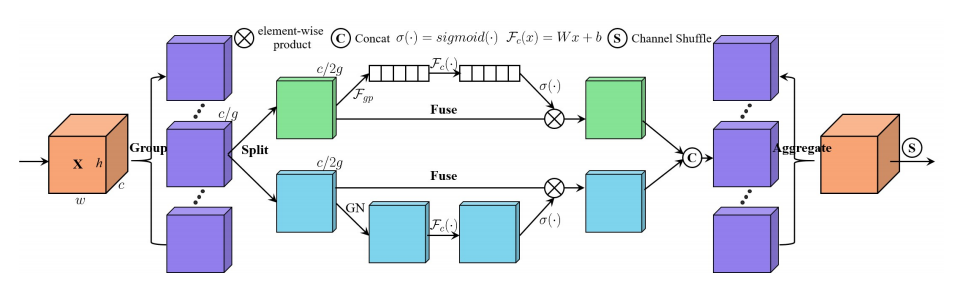
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"موسى: اهتمام متوازي متعدد النطاق للتسلسل إلى التسلسل التعلم"
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )تعزيز المجموعة المكانية: تحسين تعلم الميزة الدلالية في الشبكات التلافيفية
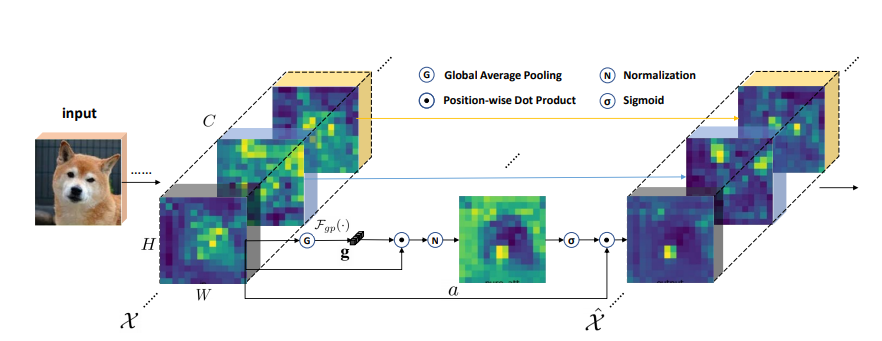
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Nets: شبكات الاهتمام المزدوجة
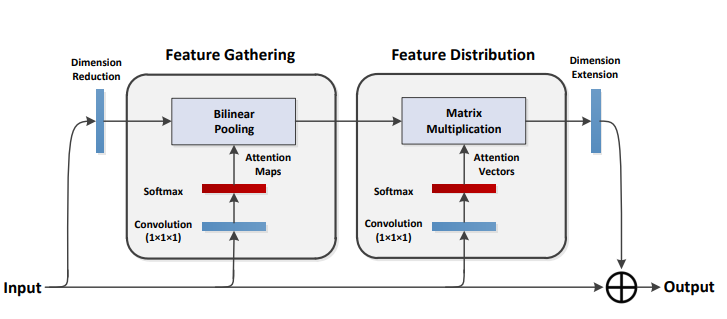
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )محول خالي من الاهتمام
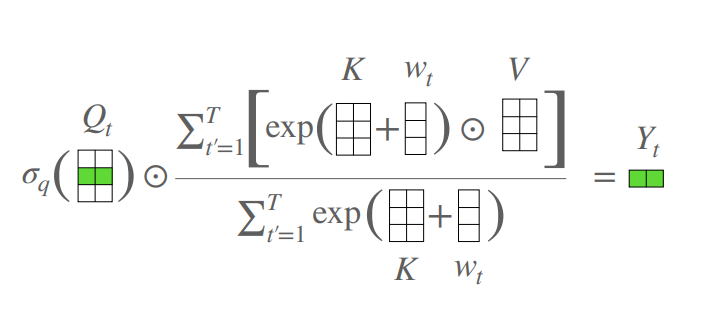
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )VOLO: Vision Outlooker للاعتراف البصري "
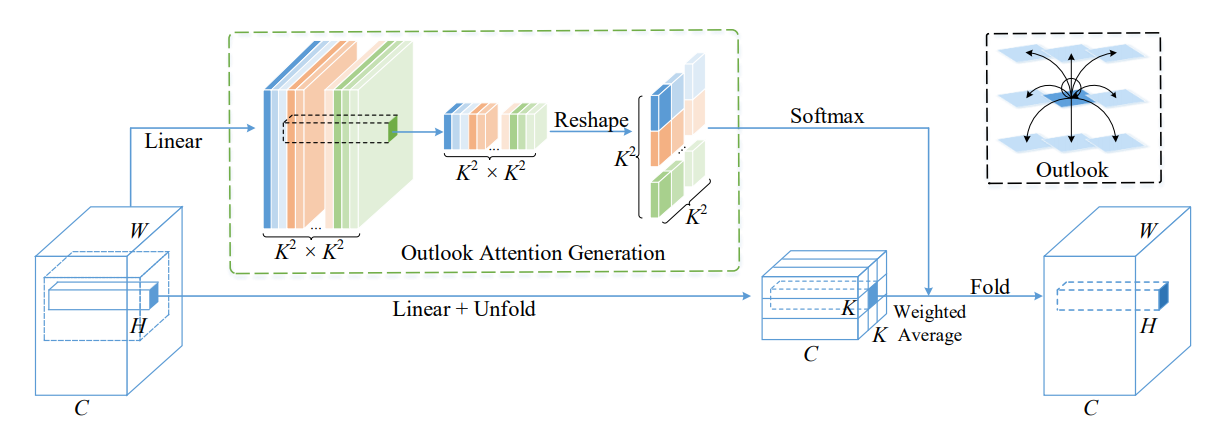
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )الرؤية الباهظة: بنية تشبه MLP قابلة للتطبيق للاعتراف البصري "
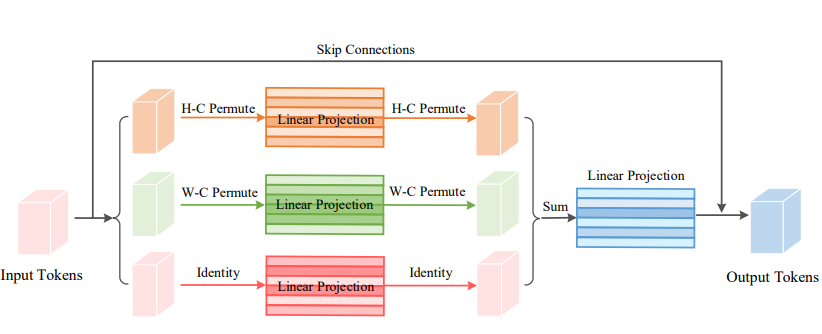
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: الزواج من الالتفاف والاهتمام لجميع أحجام البيانات "
لا أحد
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )توسيع نطاق الالتحاق الذاتي المحلي للمعلمة ذات الكفاءة البصرية في العمود الفقري "
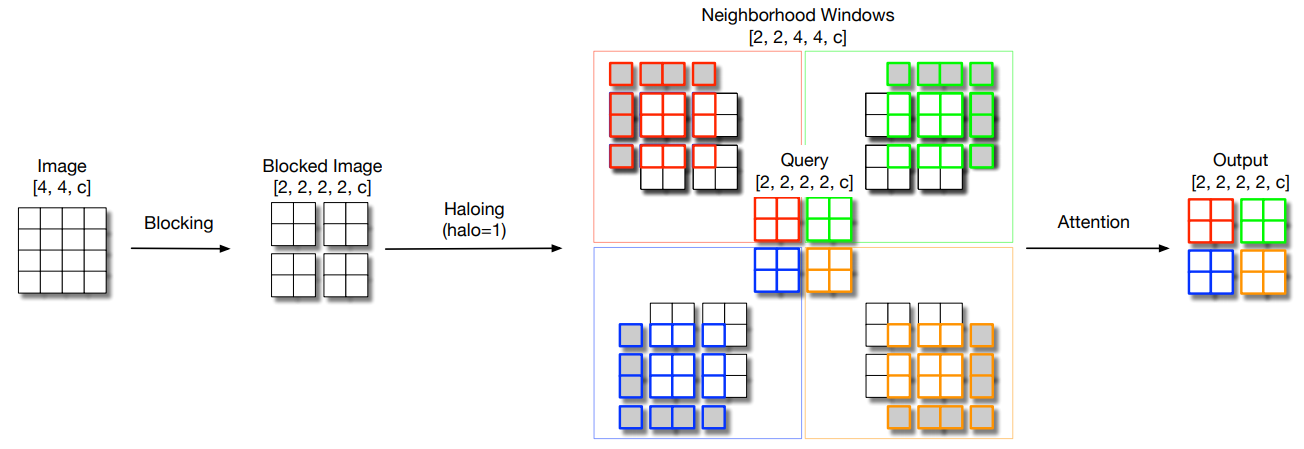
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )الاستقطاب الذاتي المستقطب: نحو الانحدار عالي الجودة بكسل "
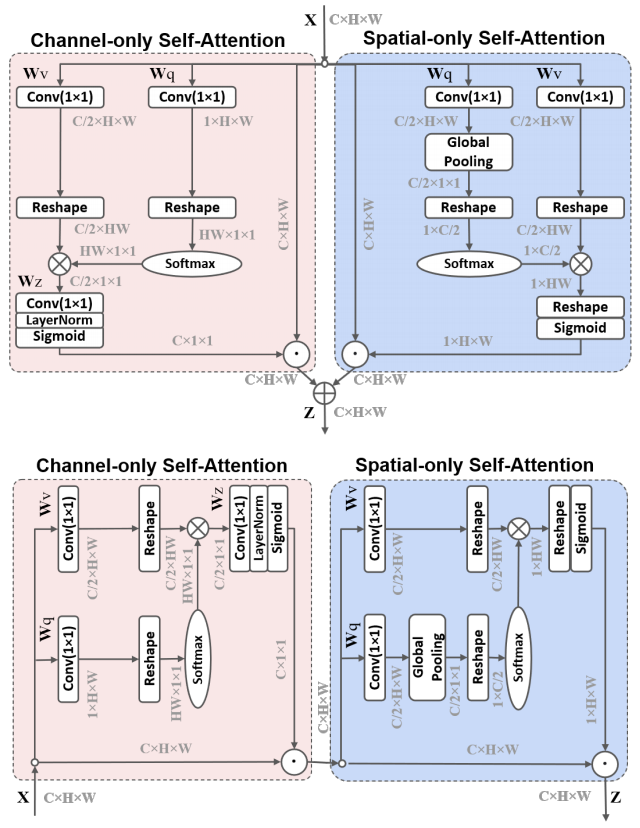
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
شبكات المحولات السياقية للتعرف المرئي --- ARXIV 2021.07.26
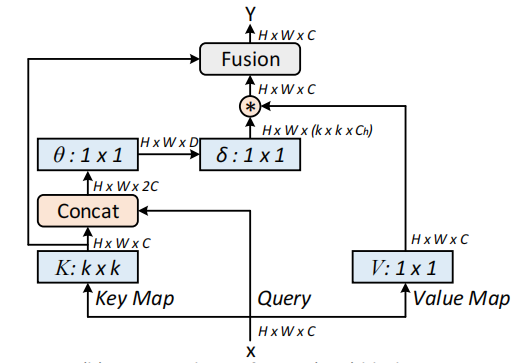
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
الاهتمام المتبقي: طريقة بسيطة ولكنها فعالة للتعرف على العطلة --- ICCV2021
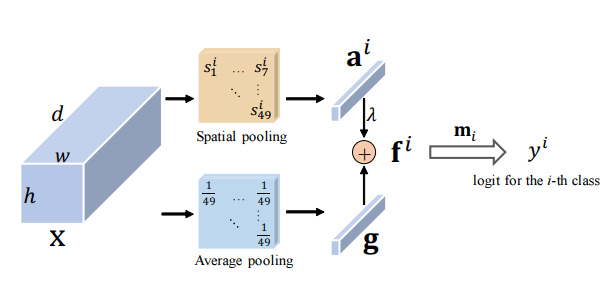
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: تحسين بنية MLP المكانية للرؤية --- ARXIV 2021.08.02
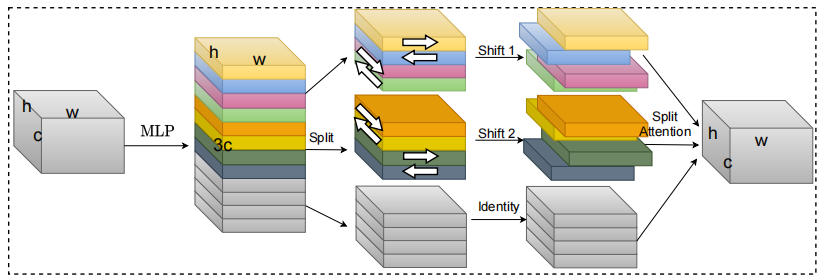
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )شبكات التصفية العالمية لتصنيف الصور --- ARXIV 2021.07.01
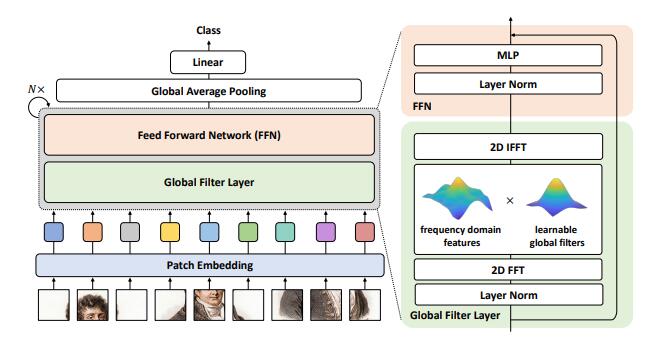
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )تدوير للحضور: وحدة الانتباه الثلاثي التنازلي --- CVPR 2021
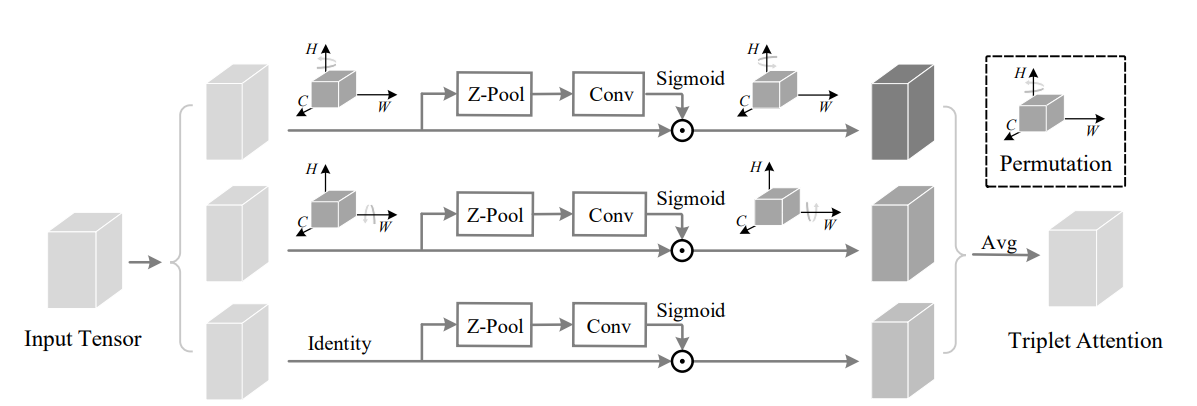
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )تنسيق الانتباه لتصميم شبكة الهاتف المحمول الفعال --- CVPR 2021
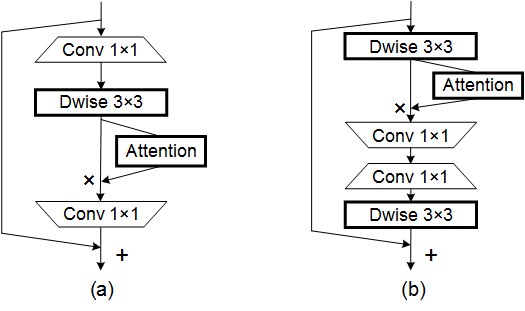
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit: محول الرؤية الخفيفة والخفيفة ، والأغراض العامة ، وصديق للهاتف المحمول --- Arxiv 2021.10.05
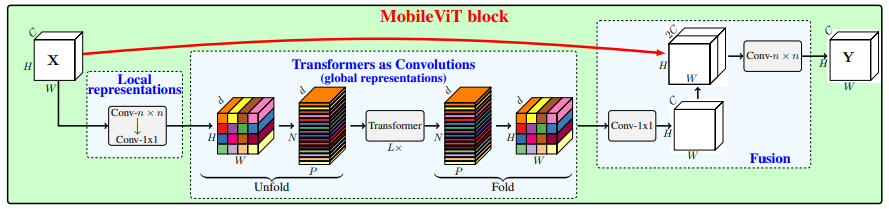
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
شبكات غير عميقة --- ARXIV 2021.10.20
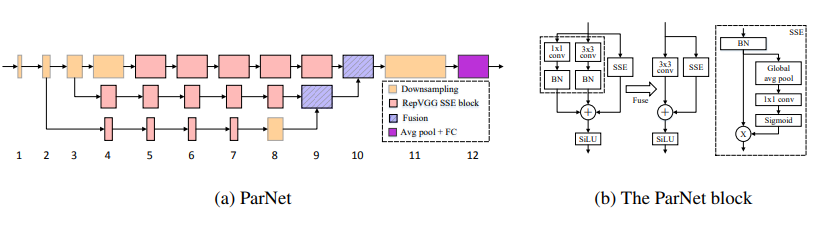
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-Vit: محول الرؤية الخطي عالي الأداء بدون softmax --- Arxiv 2021.09.29
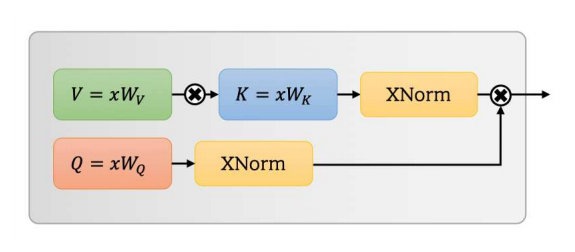
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
على دمج الاهتمام الذاتي والالتواء
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
الاهتمام الذاتي القابل للفصل لمحولات الرؤية المتنقلة --- Arxiv 2022.06.06
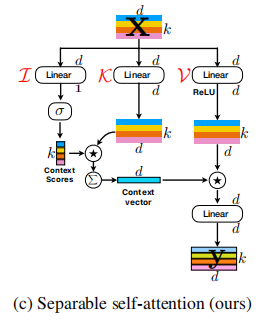
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
محول الرؤية مع اهتمام مشوه --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
CrossFormer: محول رؤية متعدد الاستخدامات يتوقف على العواقب المتقاطعة --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
تجميع الميزات العالمية في محول الرؤية المحلية
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: اهتمام متقاطع للتجزئة الدلالية
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
الاهتمام المحوري في المحولات متعددة الأبعاد
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
تنفيذ Pytorch لـ "التعلم المتبقي العميق للتعرف على الصور --- CVPR2016 أفضل ورقة"
تنفيذ Pytorch لـ "التحولات المتبقية المجمعة للشبكات العصبية العميقة --- CVPR2017"
Pytorch تطبيق MobileVit: محول الرؤية الخفيف والغرض العام ، وصديق للهاتف المحمول --- Arxiv 2020.10.05
تنفيذ Pytorch للبقع هل كل ما تحتاجه؟ --- ICLR2022 (قيد المراجعة)
تنفيذ Pytorch لمحول خلط ورق اللعب: إعادة التفكير في خلط ورق اللعب المكاني لمحول الرؤية --- Arxiv 2021.06.07
Pytorch تطبيق Contnet: لماذا لا تستخدم الالتفاف والمحول في نفس الوقت؟ --- Arxiv 2021.04.27
تنفيذ Pytorch لمحولات الرؤية مع الاهتمام الهرمي --- ARXIV 2022.06.15
تنفيذ Pytorch لمحولات الصور المقنعة المشتركة --- Arxiv 2021.08.26
تنفيذ Pytorch للترميزات الموضعية الشرطية لمحولات الرؤية
تنفيذ Pytorch لإعادة التفكير في الأبعاد المكانية لمحولات الرؤية --- ICCV 2021
Pytorch تطبيق Crossvit: محول رؤية متعدد النطاق لتصنيف الصور --- ICCV 2021
تنفيذ Pytorch للمحول في المحول --- Neups 2021
تنفيذ Pytorch من DeepVit: نحو محول الرؤية الأعمق
تنفيذ Pytorch لدمج تصميمات الالتفاف في المحولات البصرية
تنفيذ Pytorch للمشاركة: تحسين محولات الرؤية مع التحيزات الاستقرائية التنازلية الناعمة
تنفيذ Pytorch لزيادة الشبكات التلافيفية مع التجميع القائم على الانتباه
تنفيذ Pytorch من التعمق مع محولات الصور --- ICCV 2021 (عن طريق الفم)
تنفيذ Pytorch لتدريب محولات الصور الموفرة للبيانات والتقطير من خلال الانتباه --- ICML 2021
تنفيذ Pytorch لـ Levit: محول رؤية في ملابس Convnet من أجل الاستدلال الأسرع
تطبيق Pytorch of Volo: Vision Outlooker للاعتراف البصري
تنفيذ Pytorch للحاوية: شبكة تجميع السياق --- Neuips 2021
تنفيذ Pytorch لـ CMT: الشبكات العصبية التلافيفية تلبي محولات الرؤية --- CVPR 2022
تنفيذ Pytorch لمحول الرؤية مع اهتمام مشوه --- CVPR 2022
تنفيذ Pytorch من الكفاءة: محولات الرؤية في سرعة Mobilenet
تنفيذ Pytorch لـ Convnextv2: التصميم المشترك وتوسيع نطاق المقنعين مع أدوات التوصيل التلقائية المقنعة
"التعلم المتبقي العميق للتعرف على الصور --- CVPR2016 أفضل ورقة"
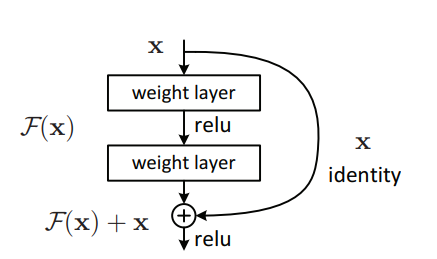
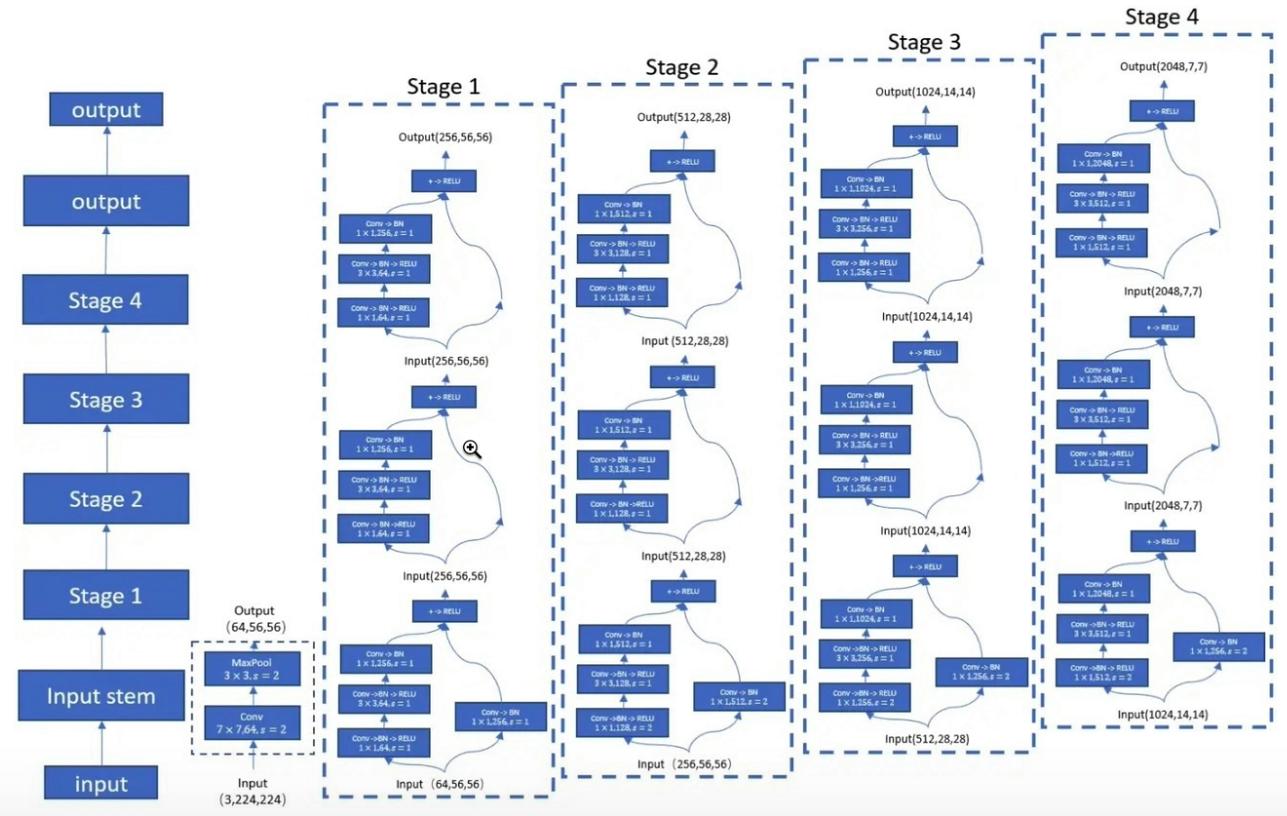
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"التحولات المتبقية المجمعة للشبكات العصبية العميقة --- CVPR2017"
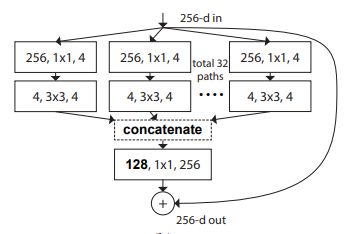
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit: محول الرؤية الخفيف الوزن ، والأغراض العامة ، وصديقه للهاتف المحمول --- Arxiv 2020.10.05
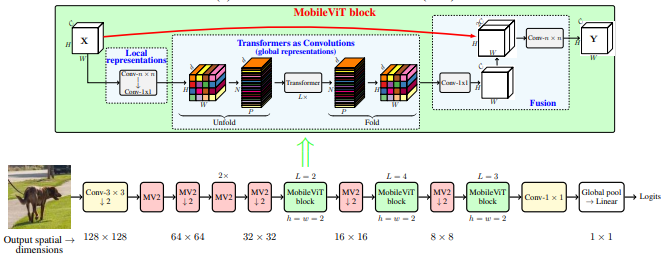
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )بقع كل ما تحتاجه؟ --- ICLR2022 (قيد المراجعة)
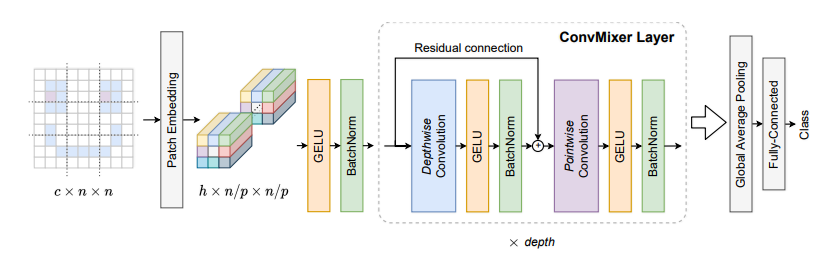
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
محول خلط ورق اللعب: إعادة التفكير في خلط ورق اللعب المكاني لمحول الرؤية
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
Contnet: لماذا لا تستخدم الالتفاف والمحول في نفس الوقت؟
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
محولات الرؤية مع الاهتمام الهرمي
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
محولات الصور المقنعة على نطاق واسع
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: محسّن خطوط الأساس مع محول رؤية الهرم
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )الترميزات الموضعية الشرطية لمحولات الرؤية
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )إعادة التفكير في الأبعاد المكانية لمحولات الرؤية
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )Crossvit: محول رؤية متعدد النطاقات لتصنيف الصور
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )محول في المحول
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )DeepVit: نحو محول الرؤية الأعمق
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )دمج تصاميم الالتفاف في المحولات البصرية
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )دخول: تحسين محولات الرؤية مع التحيزات الاستقرائية التنازلية الناعمة
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )التعمق مع محولات الصور
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )زيادة الشبكات التلافيفية مع تجميع القائمة على الانتباه
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )تدريب محولات الصور الموفرة للبيانات والتقطير من خلال الاهتمام
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: محول رؤية في ملابس Convnet من أجل الاستدلال الأسرع
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )VOLO: Vision Outlooker للاعتراف البصري
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )الحاوية: شبكة تجميع السياق
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: تلبي الشبكات العصبية التلافيفية محولات الرؤية
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )كفاءة: محولات الرؤية في سرعة Mobilenet
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )Convnextv2: التصميم المشترك وتوسيع نطاق المقنعين مع أدوات تلقائية مقنعة
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )تنفيذ Pytorch لـ "repmlp: إعادة تدوير الملاحظات في طبقات متصلة بالكامل للتعرف على الصور --- Arxiv 2021.05.05"
تنفيذ Pytorch لـ "MLP-mixer: AN ALL-MLP Architecture for Vision --- ARXIV 2021.05.17"
تنفيذ Pytorch لـ "resmlp: شبكات Feedforward لتصنيف الصور مع التدريب الموفرة للبيانات --- ARXIV 2021.05.07"
تنفيذ Pytorch من "الانتباه إلى MLPs --- ARXIV 2021.05.17"
تنفيذ Pytorch لـ "MLP المتفرق للتعرف على الصور: هل الاهتمام الذاتي ضروري حقًا؟ --- Arxiv 2021.09.12"
"repmlp: إعادة تدوير الملاحظات في طبقات متصلة بالكامل للتعرف على الصور"
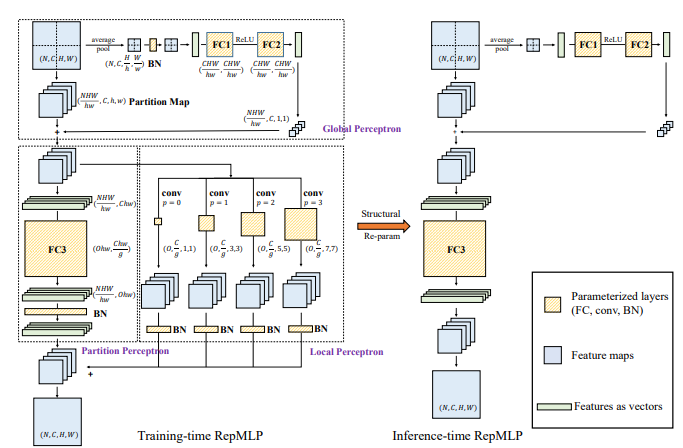
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-Mixer: A Coll-MLP Architecture for Vision"
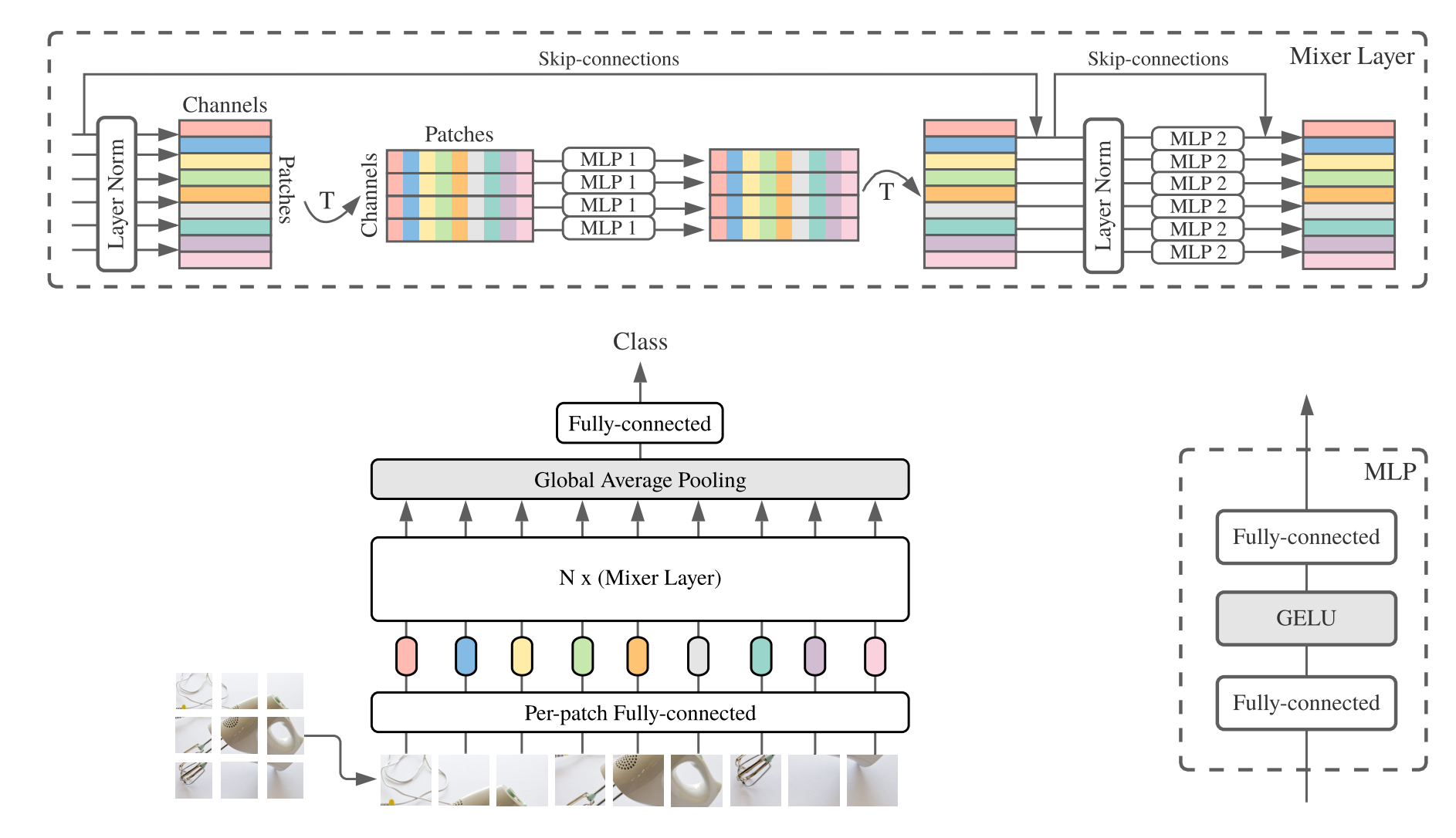
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"Resmlp: شبكات Feedforward لتصنيف الصور مع التدريب الموفرة للبيانات"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"انتبه إلى MLPs"
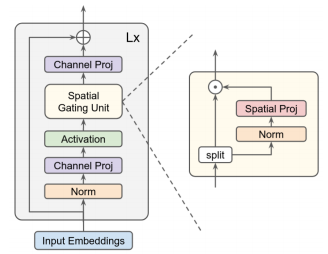
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"MLP متناثر للتعرف على الصور: هل الاهتمام الذاتي ضروري حقًا؟"
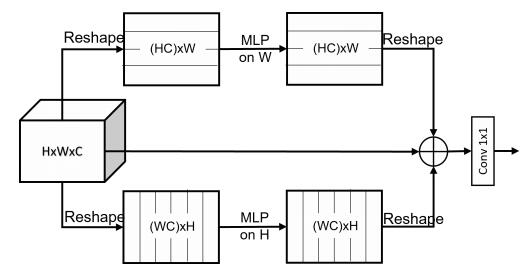
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"الرؤية الباهظة: بنية تشبه MLP التي لا تشوبهي معها للتعرف البصري"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )تنفيذ Pytorch لـ "Repvgg: جعل مقاطعات على غرار VGG رائعة مرة أخرى ---- CVPR2021"
تنفيذ Pytorch لـ "ACNET: تعزيز الهياكل العظمية لـ kernel لـ CNN القوية عبر كتل الالتصاف غير المتماثلة --- ICCV2019"
تنفيذ Pytorch لـ "كتلة فرع متنوعة: بناء إيلاء كوحدة تشبه البدء --- CVPR2021"
"repvgg: جعل مقنعات على غرار VGG رائعة مرة أخرى"
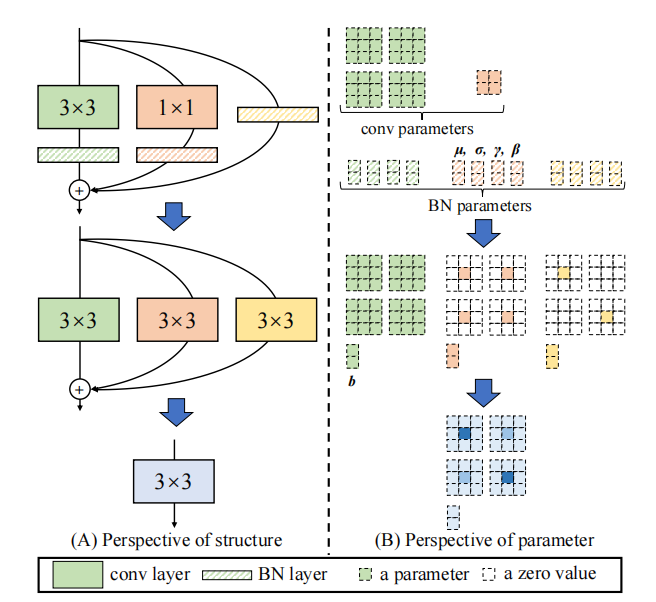
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"Acnet: تعزيز الهياكل العظمية kernel لـ CNN القوية عبر كتل الالتفاف غير المتماثلة"
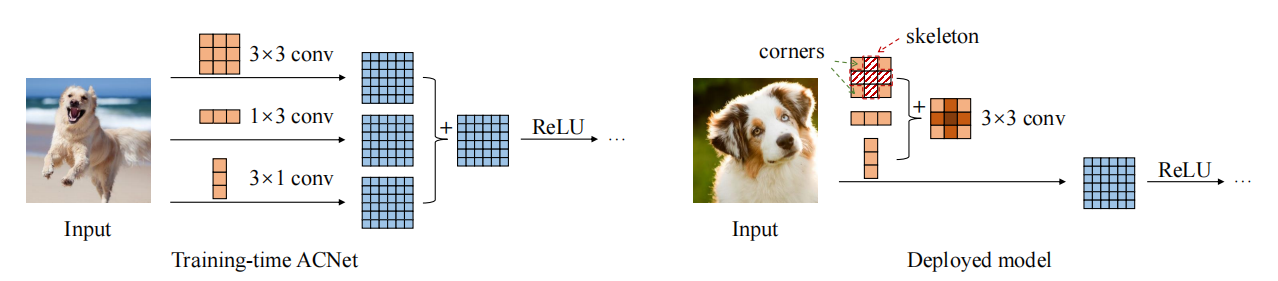
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"كتلة فرع متنوعة: بناء الالتفاف كوحدة شبيهة بالبداية"
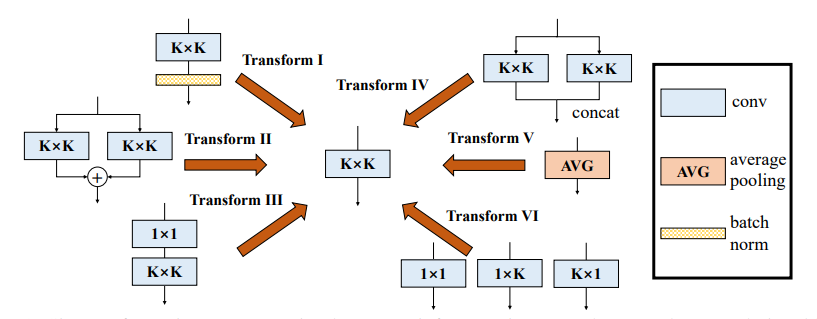
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())تنفيذ Pytorch لـ "mobilenets: شبكات عصبية تلافيفية فعالة لتطبيقات رؤية الأجهزة المحمولة --- CVPR2017"
تنفيذ Pytorch لـ "efficientnet: إعادة التفكير في تحجيم النموذج للشبكات العصبية التلافيفية --- PMLR2019"
تنفيذ Pytorch لـ "الانخراط: قلب وراثة الالتواء للاعتراف البصري ---- CVPR2021"
تنفيذ Pytorch لـ "الالتفاف الديناميكي: الانتباه على نواة الالتواء --- CVPR2020 عن طريق الفم"
تنفيذ Pytorch لـ "CondConv: ملحقات معلمة مشروطة للاستدلال الفعال --- Neups2019"
"Mobilenets: شبكات عصبية تلافيفية فعالة لتطبيقات رؤية الهاتف المحمول"
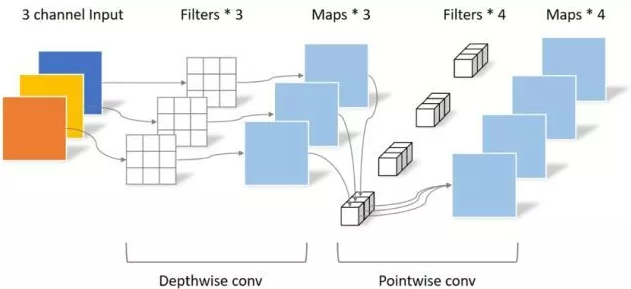
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"كفاءة: إعادة التفكير في تحجيم النموذج للشبكات العصبية التلافيفية"
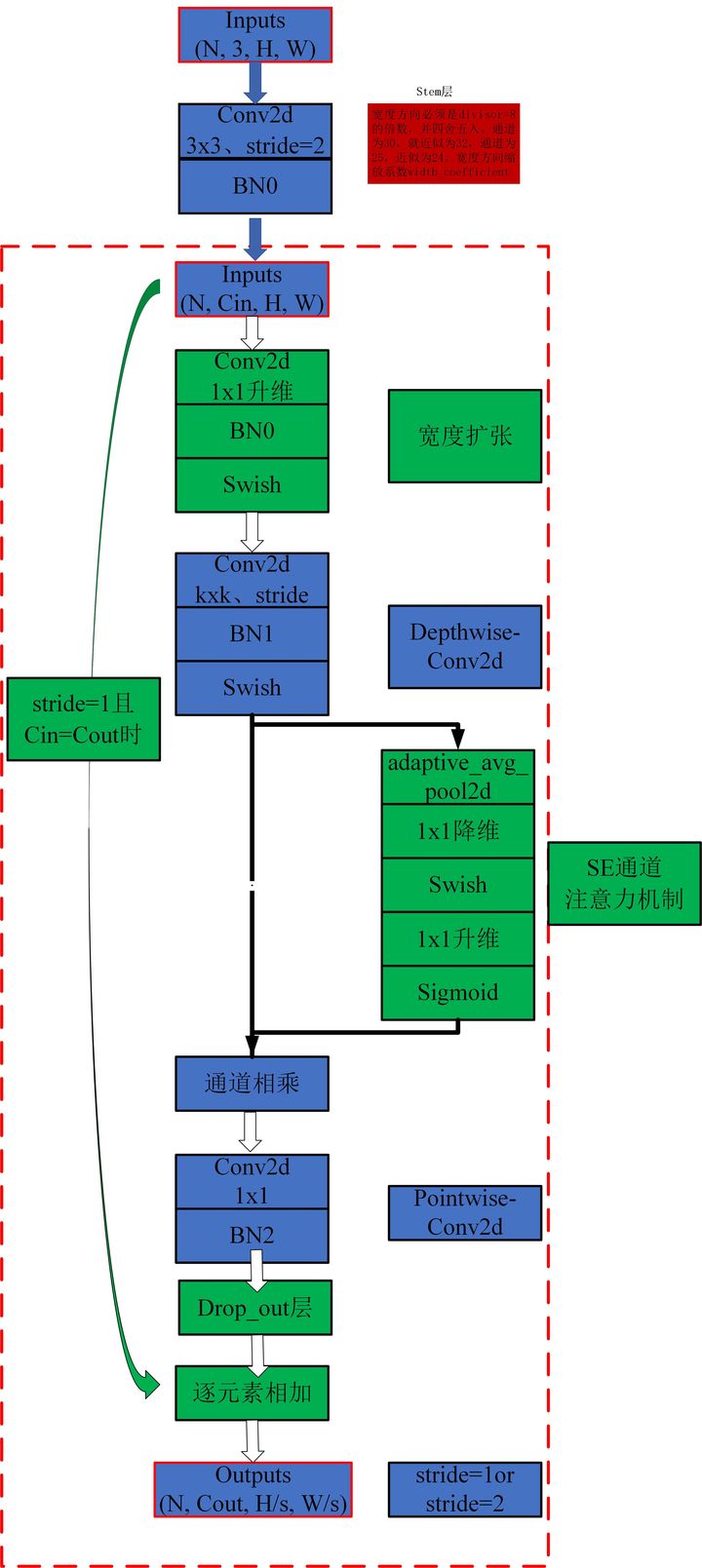
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"الانخراط: قلب ميراث الالتواء للاعتراف البصري"
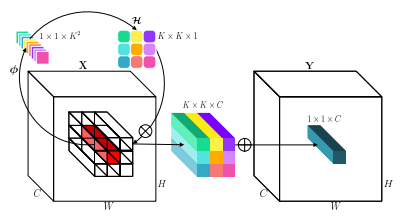
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"الالتفاف الديناميكي: الاهتمام على نواة الالتواء"
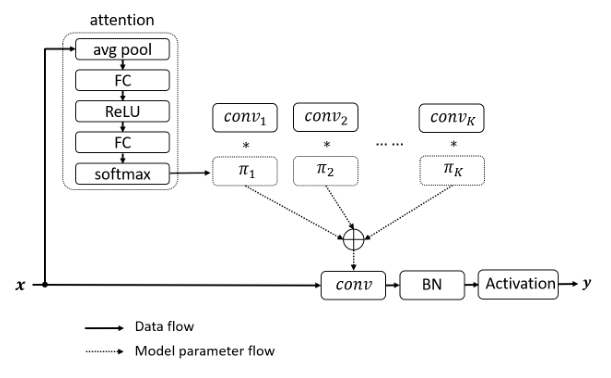
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"CondConv: ملحقات معلمة مشروطة للاستدلال الفعال"
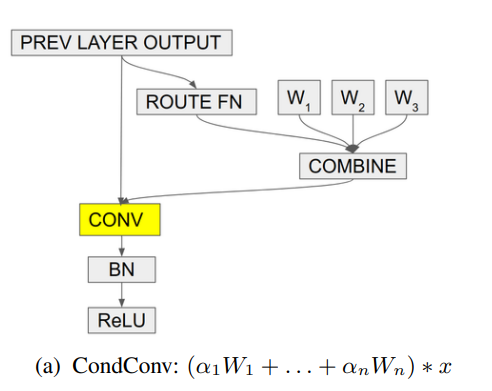
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )أخبار كبيرة! ! ! كملحق للمشروع ، يمكنك الانتباه إلى مشروع PoverpightCV Paper-Paper الذي يقوم حديثًا ، والذي يقوم بجمع وتنظيم التحليل الورقي للمؤتمرات والمجلات الرئيسية.
أخبار كبيرة! ! ! في الآونة الأخيرة ، قمت بتجميع العديد من البرامج التعليمية المرتبطة بـ AI وأوراقًا يجب قراءة على الإنترنت FightSt
أخبار كبيرة! ! ! في الآونة الأخيرة ، تم فتح مكتبة كود كود كائن Yoloair جديدة ، والتي تدمج مجموعة متنوعة من طرز YOLO ، بما في ذلك YOLOV5 و YOLOV7 و YOLOR و YOLOX و YOLOV4 و YOLOV3 ونماذج YOLO الأخرى ، بالإضافة إلى مجموعة متنوعة من آليات الاهتمام الموجودة.
ملخص الورق ECCV2022: ECCV2022-Paper-List


