External Attention pytorch
1.0.0

China yang disederhanakan | Bahasa inggris
Halo, semuanya, saya xiaoma
Untuk Xiaobai (seperti saya): Baru -baru ini, saya akan menemukan masalah ketika saya membaca makalah. Terkadang ide inti dari makalah ini sangat sederhana, dan kode inti mungkin hanya selusin baris. Namun, ketika saya membuka kode sumber rilis penulis, saya menemukan bahwa modul yang diusulkan tertanam dalam kerangka kerja tugas seperti klasifikasi, deteksi, dan segmentasi, yang mengarah pada kode yang relatif berlebihan. Saya tidak terbiasa dengan kerangka kerja tugas tertentu dan sulit bagi saya untuk menemukan kode inti , yang mengarah pada kesulitan tertentu dalam memahami makalah dan ide -ide jaringan.
Untuk Advanced (seperti Anda): Jika Anda menganggap unit -unit dasar seperti CONV, FC, dan RNN sebagai blok bangunan Lego kecil, dan struktur seperti Transformer dan Resnet sebagai Kastil Lego yang telah dibangun. Kemudian modul yang disediakan oleh proyek ini adalah komponen Lego dengan informasi semantik lengkap. Biarkan para peneliti ilmiah menghindari membuat roda berulang kali , pikirkan saja tentang cara menggunakan "komponen Lego" ini untuk membangun karya yang lebih berwarna.
Untuk Master (mungkin seperti Anda): Saya memiliki kemampuan terbatas dan tidak suka menyemprotkan dengan ringan ! Lai Lai
Untuk semua: Proyek ini berkomitmen untuk mengimplementasikan basis kode yang memungkinkan pemula pembelajaran mendalam untuk memahami dan melayani penelitian ilmiah dan komunitas industri .
Pasang langsung melalui PIP
pip install fightingcv-attentionAtau mengkloning repositori
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Seri Perhatian
1. Penggunaan perhatian eksternal
2. Penggunaan Perhatian Diri
3. Penggunaan perhatian diri yang disederhanakan
4. Penggunaan perhatian pemerasan dan eksitasi
5. Penggunaan Perhatian SK
6. Penggunaan perhatian CBAM
7. Penggunaan perhatian BAM
8. Penggunaan perhatian ECA
9. Penggunaan perhatian Danet
10. Penggunaan Piramida Split (PSA)
11. Penggunaan Multi-Head Self-Head Efisien (EMSA)
12. Mengguncang Penggunaan Perhatian
13. Penggunaan Perhatian Muse
14. Penggunaan perhatian SGE
15. A2 Penggunaan perhatian
16. Penggunaan Perhatian Aft
17. Penggunaan perhatian Outlook
18. Penggunaan perhatian VIP
19. Penggunaan Perhatian Coatnet
20. Penggunaan Perhatian Halonet
21. Penggunaan Perhatian Mandiri terpolarisasi
22. Penggunaan Cotattention
23. Penggunaan Perhatian Sisa
24. S2 Penggunaan perhatian
25. Penggunaan perhatian gfnet
26. Penggunaan Perhatian Triplet
27. Mengkoordinasikan Penggunaan Perhatian
28. Penggunaan Perhatian MobileVit
29. Penggunaan perhatian Parnet
30. Penggunaan perhatian UFO
31. Acmix Penggunaan perhatian
32. Penggunaan perhatian mobilevitv2
33. Penggunaan Dat Perhatian
34. Penggunaan perhatian silang
35. Penggunaan perhatian Moatransformer
36. Penggunaan Perhatian CrisscrossteTention
37. Penggunaan perhatian aksial_atensi
Seri Backbone
1. Penggunaan Resnet
2. Penggunaan Resnext
3. Penggunaan MobileVit
4. Penggunaan Konvmixer
5. Penggunaan Shuffletransformer
6. Penggunaan Contnet
7. Penggunaan HATNET
8. Penggunaan mantel
9. Penggunaan Pvt
10. Penggunaan CPVT
11. Penggunaan Pit
12. Penggunaan Crossvit
13. Penggunaan TNT
14. Penggunaan DVIT
15. Penggunaan Ceit
16. Mengumpulkan penggunaan
17. Penggunaan CAIT
18. Penggunaan PatchConvnet
19. Penggunaan Deit
20. Penggunaan Levit
21. Penggunaan VOLO
22. Penggunaan Wadah
23. Penggunaan CMT
24. Penggunaan Efisien
25. Penggunaan ConvNextV2
Seri MLP
1. Penggunaan Repmlp
2. Penggunaan MLP-Mixer
3. Penggunaan Resmlp
4. Penggunaan GMLP
5. Penggunaan SMLP
6. Penggunaan VIP-MLP
Seri ulang parameter (rep)
1. Penggunaan RepVGG
2. Penggunaan Acnet
3. Penggunaan Blok Cabang Beragam (DDB)
Seri Konvolusi
1. Penggunaan konvolusi yang dapat dipisahkan secara mendalam
2. Penggunaan MBCONV
3. Penggunaan involusi
4. Penggunaan DynamicConv
5. Penggunaan CondConv
Implementasi Pytorch dari "Beyond Self-Itention: Perhatian Eksternal Menggunakan Dua Lapisan Linier Untuk Tugas Visual --- Arxiv 2021.05.05"
Implementasi Pytorch dari "Perhatian adalah yang Anda butuhkan --- NIPS2017"
Implementasi Pytorch dari "Jaringan Squeeze-and-Excitation --- CVPR2018"
Implementasi Pytorch dari "Selektif Kernel Networks --- CVPR2019"
Implementasi Pytorch dari "CBAM: Modul Perhatian Blok Konvolusional --- ECCV2018"
Implementasi Pytorch dari "BAM: Modul Perhatian Bottleneck --- BMCV2018"
Implementasi Pytorch dari "ECA-Net: Perhatian Saluran yang Efisien untuk Jaringan Saraf Konvolusional yang Dalam --- CVPR2020"
Pytorch Implementasi "Jaringan Perhatian Ganda untuk Segmentasi Adegan --- CVPR2019"
Implementasi PyTorch dari "Epsanet: Blok Perhatian Pembagi Piramida yang Efisien pada Jaringan Saraf Konvolusi --- ARXIV 2021.05.30"
Implementasi PyTorch dari "Istirahat: Transformator yang efisien untuk pengenalan visual --- ARXIV 2021.05.28"
Implementasi Pytorch dari "SA-NET: Shuffle memperhatikan untuk jaringan saraf konvolusional yang dalam --- ICASSP 2021"
Pytorch Implementasi "Muse: Parallel Multi-Scale Attention untuk urutan ke urutan pembelajaran --- Arxiv 2019.11.17"
Pytorch Implementasi "Peningkatan Grup-Wise Spasial: Meningkatkan Pembelajaran Fitur Semantik Dalam Jaringan Konvolusi --- ARXIV 2019.05.23"
Implementasi PyTorch dari "A2-Nets: Double Attention Networks --- NIPS2018"
Pytorch Implementasi "An Attention Free Transformer --- ICLR2021 (Apple New Work)"
Pytorch Implementasi VOLO: Visi Outlooker untuk Pengenalan Visual --- ArXIV 2021.06.24 "[Analisis Kertas]
Implementasi PyTorch dari Permutator Visi: Arsitektur seperti MLP permutisasi untuk pengenalan visual --- ARXIV 2021.06.23 [Analisis Kertas]
Implementasi Pytorch dari Coatnet: Menikah dengan konvolusi dan perhatian untuk semua ukuran data --- ARXIV 2021.06.09 [Analisis Kertas]
Pytorch Implementasi dari penskalaan perhatian mandiri lokal untuk parameter backbones visual yang efisien --- CVPR2021 oral [analisis kertas]
Implementasi Pytorch dari Polarisasi Sendiri: Menuju Regresi Pixel Berkualitas Tinggi --- ARXIV 2021.07.02 [Analisis Kertas]
Implementasi PyTorch dari jaringan transformator kontekstual untuk pengenalan visual --- ARXIV 2021.07.26 [Analisis kertas]
Pytorch Implementasi Perhatian Residual: Metode yang sederhana namun efektif untuk pengakuan multi-label --- ICCV2021
Implementasi PyTorch dari S²-MLPV2: Peningkatan arsitektur MLP spasial-shift untuk visi --- ARXIV 2021.08.02 [Analisis Kertas]
Pytorch Implementasi Jaringan Filter Global untuk Klasifikasi Gambar --- ARXIV 2021.07.01
Implementasi PyTorch Rotate to Hadir: Modul Perhatian Triplet Konvolusional --- WACV 2021
Implementasi Pytorch dari Koordinat Perhatian untuk Desain Jaringan Seluler yang Efisien --- CVPR 2021
Pytorch Implementasi MobileVit: Light-Weight, General-Purpose, dan Mobile-Friendly Vision Transformer --- ARXIV 2021.10.05
Pytorch Implementasi Jaringan Non-Deep --- ARXIV 2021.10.20
Pytorch Implementasi UFO-VIT: Transformator Visi Linear Kinerja Tinggi Tanpa Softmax --- Arxiv 2021.09.29
Pytorch Implementasi perhatian diri yang dapat dipisahkan untuk transformer visi seluler --- ARXIV 2022.06.06
Pytorch Implementasi tentang integrasi perhatian dan konvolusi diri --- Arxiv 2022.03.14
Pytorch Implementasi Crossformer: Transformator Visi Serbaguna Berengsel pada Perhatian Silang --- ICLR 2022
Pytorch Implementasi agregasi fitur global ke dalam transformator visi lokal
Implementasi Pytorch dari CCNET: Perhatian silang untuk segmentasi semantik
Implementasi Pytorch dari perhatian aksial dalam transformator multidimensi
"Di luar perhatian diri: perhatian eksternal menggunakan dua lapisan linier untuk tugas visual"
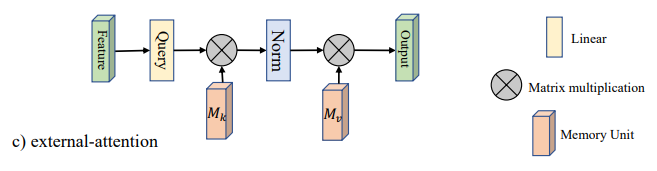
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"Perhatian adalah yang Anda butuhkan"
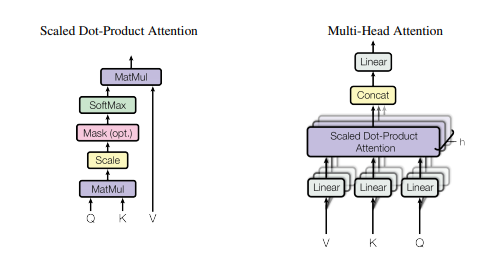
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Tidak ada
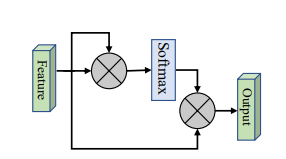
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Jaringan Perasan dan Eksitasi"
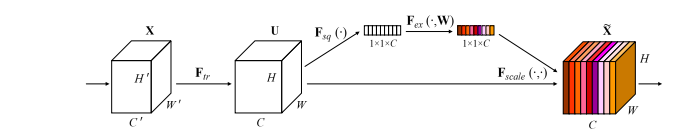
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Jaringan kernel selektif"
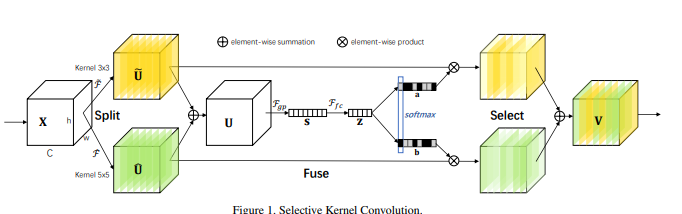
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: Modul Perhatian Blok Konvolusional"
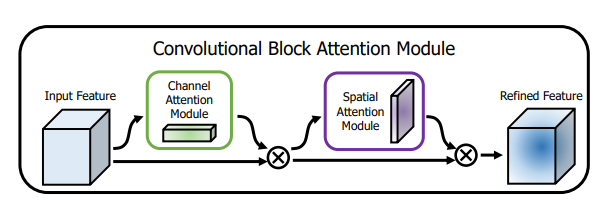
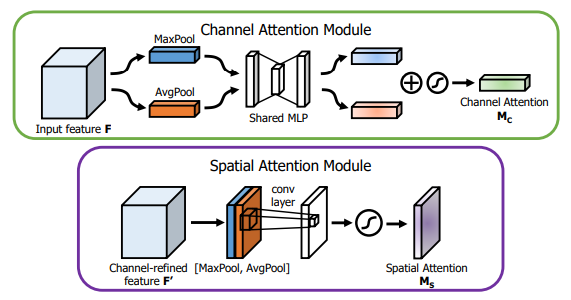
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"BAM: Modul Perhatian Bottleneck"
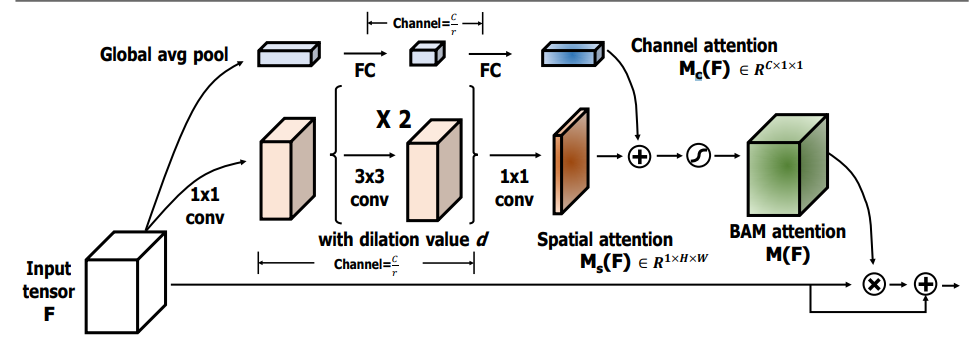
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-Net: Perhatian saluran yang efisien untuk jaringan saraf konvolusional yang dalam"
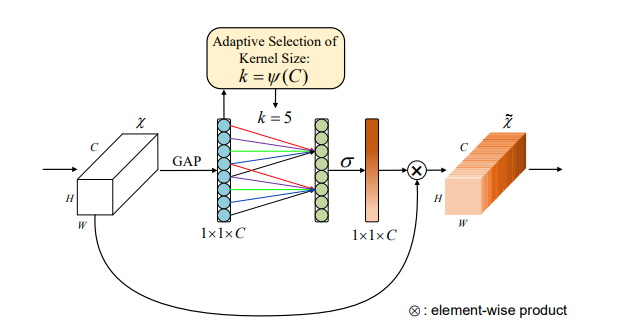
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"Jaringan perhatian ganda untuk segmentasi adegan"
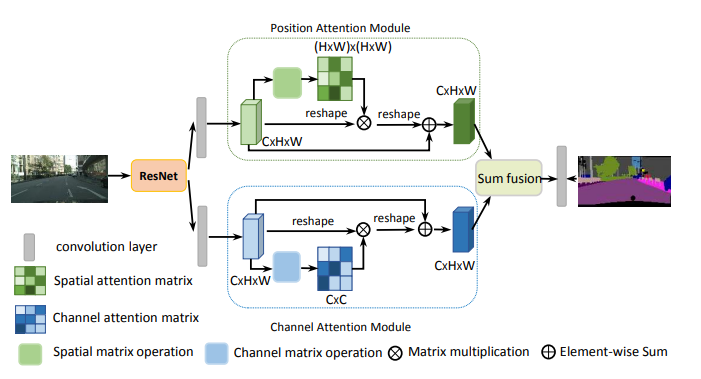
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet: blok perhatian piramida yang efisien pada jaringan saraf konvolusional"
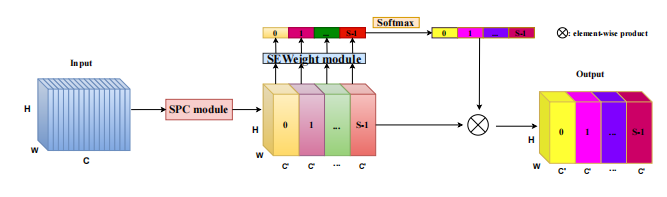
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"Istirahat: Transformator yang efisien untuk pengenalan visual"
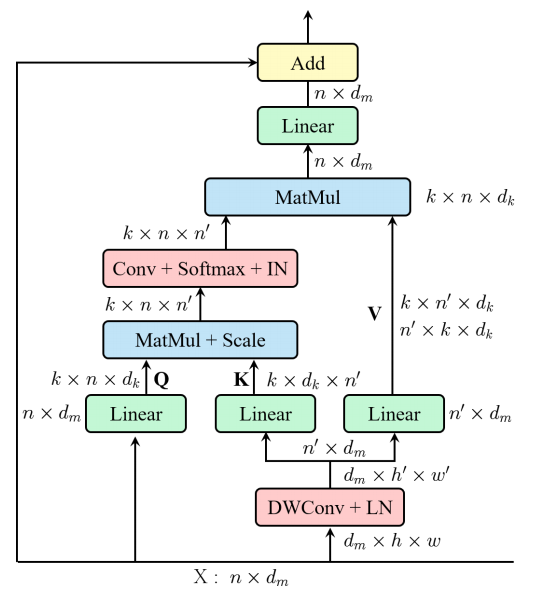
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"Sa-net: pengocok perhatian untuk jaringan saraf konvolusional yang dalam"
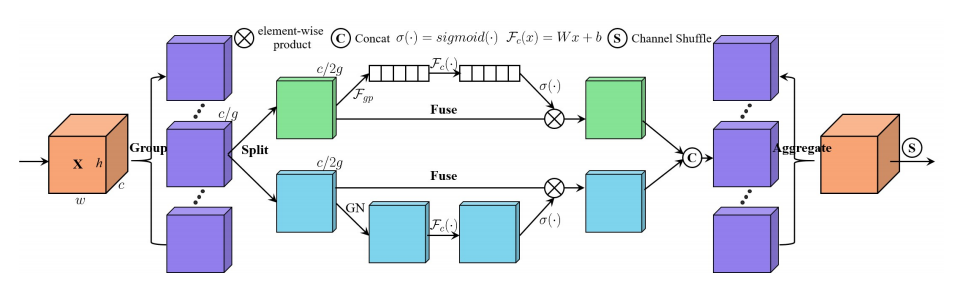
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse: Perhatian Multi-Skala Paralel untuk Pembelajaran Urutan Urutan"
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Peningkatan kelompok-bijaksana spasial: Meningkatkan pembelajaran fitur semantik dalam jaringan konvolusional
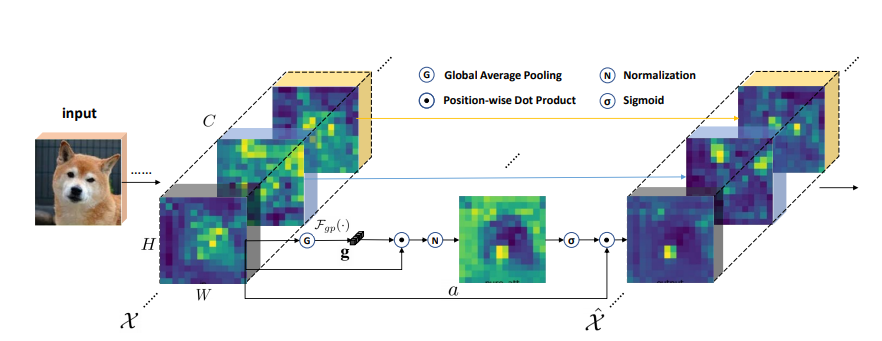
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-nets: Jaringan perhatian ganda
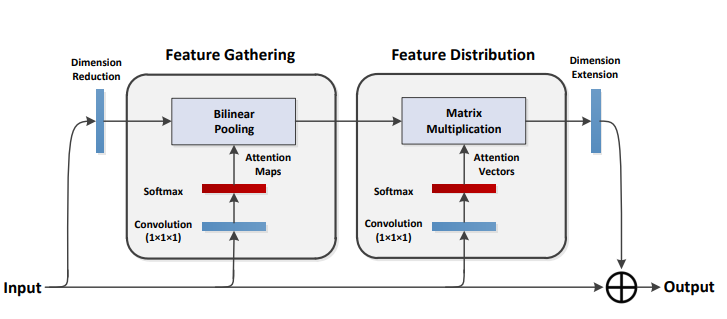
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Transformator bebas perhatian
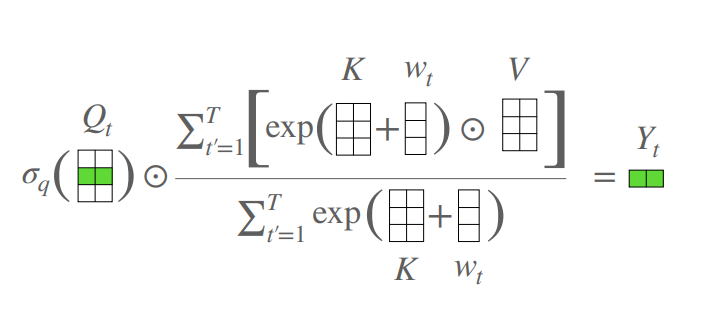
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )VOLO: Penglihatan Visi untuk Pengenalan Visual "
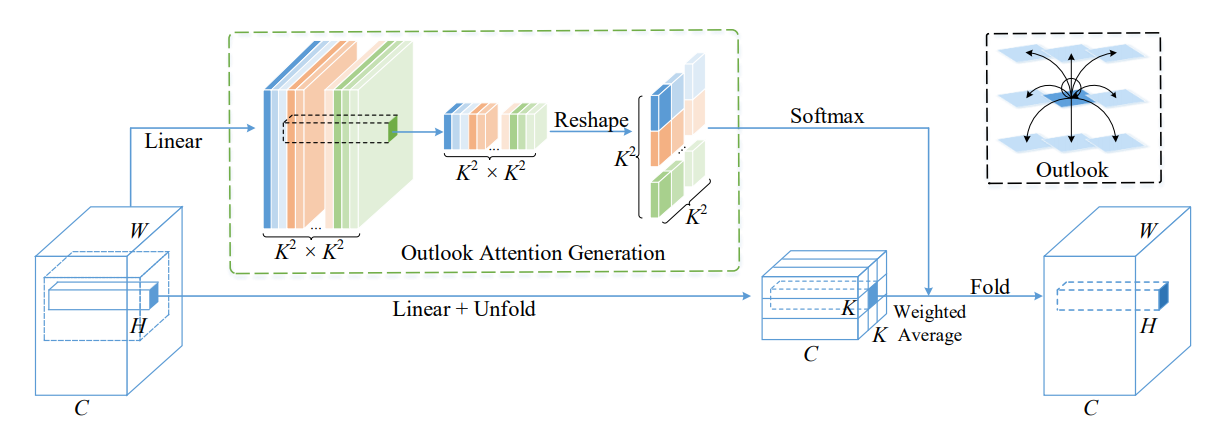
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Permutator Visi: Arsitektur seperti MLP yang dapat diijinkan untuk pengakuan visual "
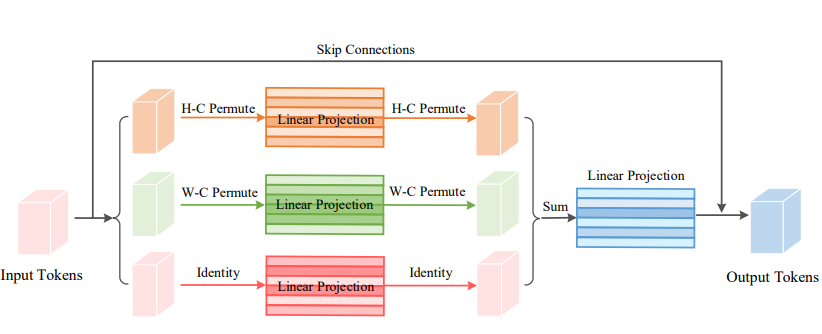
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: Menikah dengan konvolusi dan perhatian untuk semua ukuran data "
Tidak ada
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Menskalakan perhatian diri lokal untuk parameter punggung visual yang efisien "
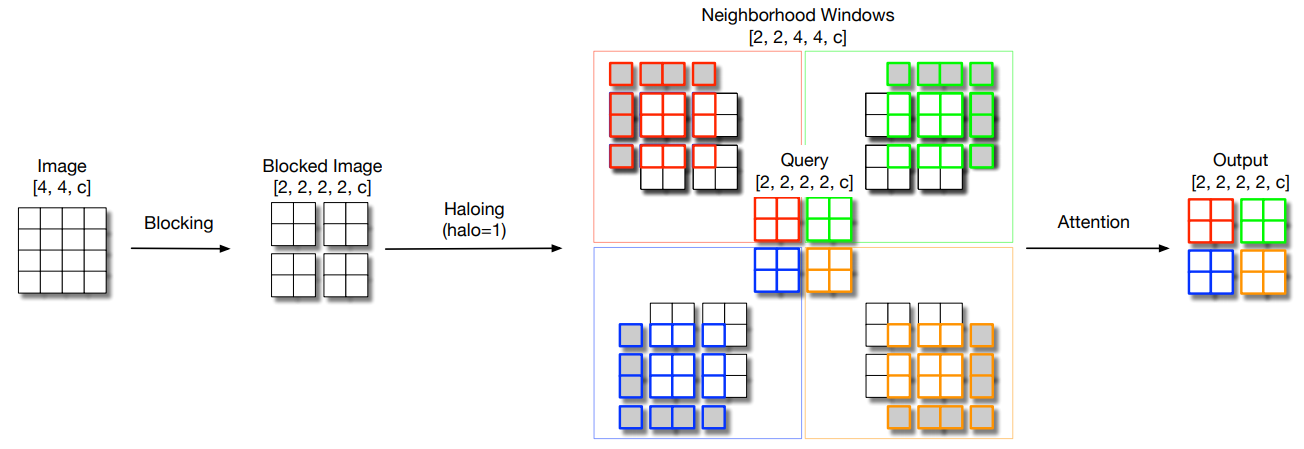
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Perhatian diri terpolarisasi: Menuju regresi piksel berkualitas tinggi "
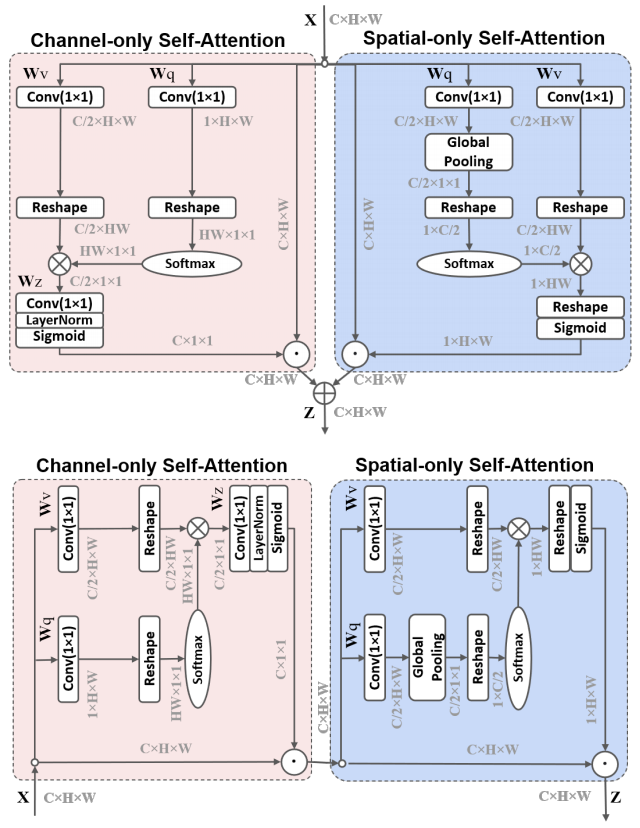
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Jaringan Transformator Kontekstual untuk Pengenalan Visual --- ARXIV 2021.07.26
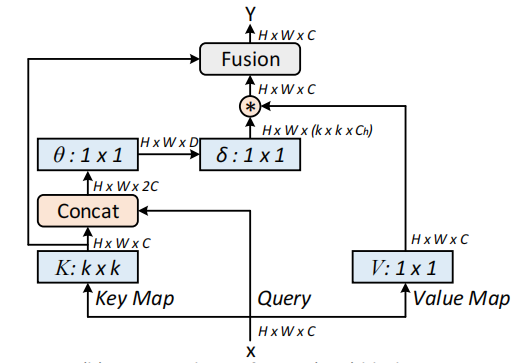
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Perhatian Residual: Metode yang sederhana namun efektif untuk pengakuan multi-label --- ICCV2021
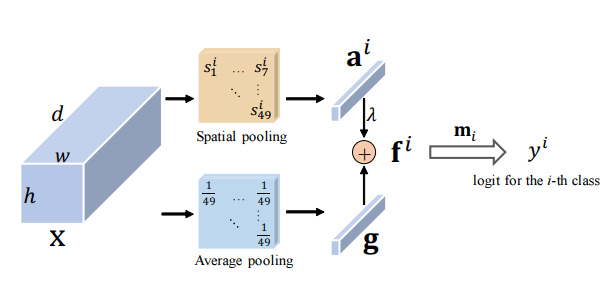
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: Arsitektur MLP shift spasial yang ditingkatkan untuk Visi --- ARXIV 2021.08.02
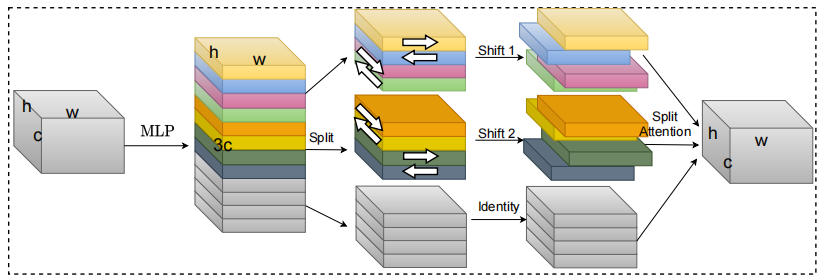
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Jaringan Filter Global untuk Klasifikasi Gambar --- ARXIV 2021.07.01
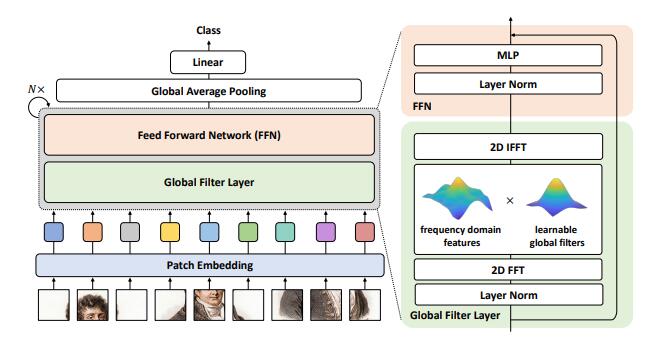
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )ROTATE TO ORGN: Modul Perhatian Triplet Konvolusional --- CVPR 2021
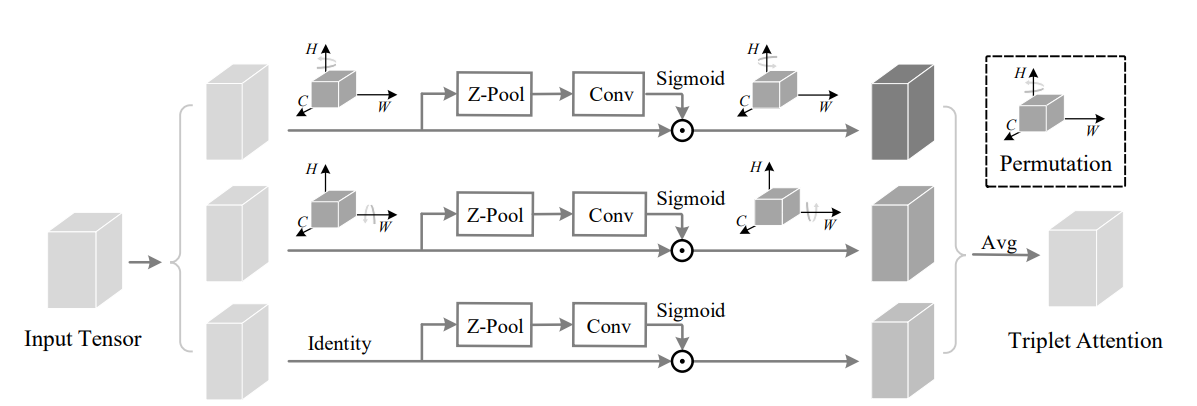
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Koordinat perhatian untuk desain jaringan seluler yang efisien --- CVPR 2021
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit: Transformator penglihatan ringan, serba guna, dan ramah seluler --- Arxiv 2021.10.05
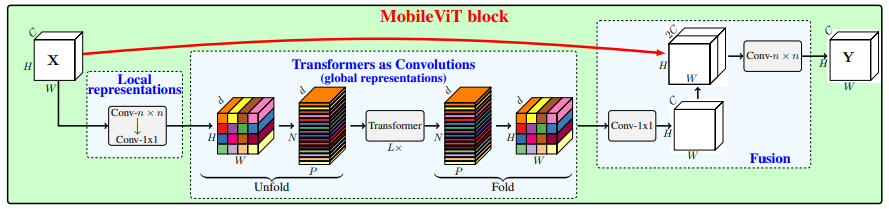
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Jaringan Non-Deep --- ARXIV 2021.10.20
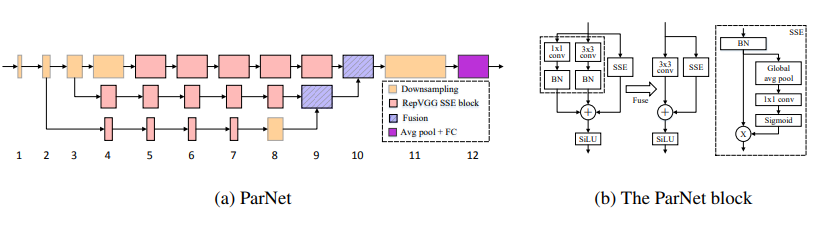
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT: Transformator penglihatan linier berkinerja tinggi tanpa softmax --- arxiv 2021.09.29
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
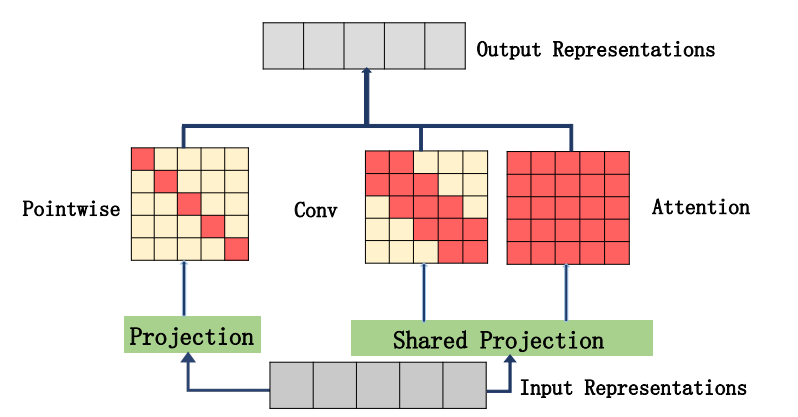
Tentang integrasi perhatian dan konvolusi diri
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
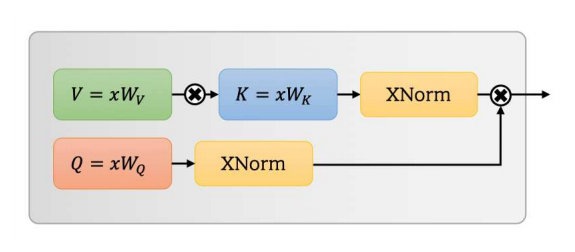
Perhatian diri yang dapat dipisahkan untuk transformator visi seluler --- ARXIV 2022.06.06
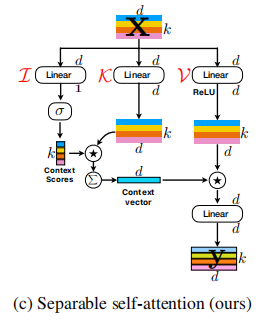
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Transformer penglihatan dengan perhatian yang dapat dideformasi --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer: Transformator visi serbaguna yang berengsel pada perhatian silang --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Mengumpulkan fitur global ke dalam transformator visi lokal
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: Perhatian silang untuk segmentasi semantik
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Perhatian aksial pada transformator multidimensi
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Pytorch Implementasi "Pembelajaran Residual Mendalam Untuk Pengenalan Gambar --- CVPR2016 Kertas Terbaik"
Implementasi Pytorch dari "Transformasi Residual Tergantung untuk Jaringan Saraf Deep --- CVPR2017"
Pytorch Implementasi MobileVit: Light-Weight, General-Purpose, dan Mobile-Friendly Vision Transformer --- ARXIV 2020.10.05
Implementasi tambalan PyTorch adalah semua yang Anda butuhkan? --- ICLR2022 (sedang ditinjau)
Pytorch Implementasi Transformator Shuffle: Memikirkan Kembali Shuffle Spasial Untuk Visi Transformator --- Arxiv 2021.06.07
Implementasi PyTorch dari Contnet: Mengapa tidak menggunakan konvolusi dan transformator pada saat yang sama? --- Arxiv 2021.04.27
Pytorch Implementasi Transformer Visi dengan Perhatian Hirarkis --- Arxiv 2022.06.15
Pytorch Implementasi Transformer Gambar Konvensional CONSAL --- ARXIV 2021.08.26
Pytorch Implementasi Pengkodean Posisi Bersyarat untuk Transformator Visi
Pytorch Implementasi Memikirkan Kembali Dimensi Spasial Transformer Visi --- ICCV 2021
Implementasi PyTorch dari CrossVit: Transformator Visi Multi-Skala Silang untuk Klasifikasi Gambar --- ICCV 2021
Implementasi transformator Pytorch dalam Transformer --- Neurips 2021
Pytorch Implementasi DeepVit: Menuju Transformator Visi yang Lebih Depan
Implementasi Pytorch dari menggabungkan desain konvolusi ke dalam transformator visual
Implementasi PyTorch dari Konvitasi: Meningkatkan Transformer Visi dengan Bias Induktif Konvolusional Soft
Implementasi Pytorch dari Augmenting Networks Convolutional Dengan Agregasi Berbasis Perhatian
Implementasi PyTorch lebih dalam dengan transformator gambar --- ICCV 2021 (oral)
PyTorch Implementasi Transformer Gambar Efisien Data & Distilasi melalui Perhatian --- ICML 2021
Implementasi Levit Pytorch: Transformator Visi dalam Pakaian Convnet untuk Inferensi Lebih Cepat
Pytorch Implementasi VOLO: Visi Outlooker untuk Pengakuan Visual
Implementasi Pytorch dari Container: Konteks Agregasi Jaringan --- Neuips 2021
Pytorch Implementasi CMT: Jaringan Saraf Konvolusional Memenuhi Transformer Visi --- CVPR 2022
Pytorch Implementasi Transformator Visi dengan Perhatian Deformable --- CVPR 2022
Implementasi Pytorch dari Efisiensi: Visi Transformer dengan kecepatan MobileNet
Implementasi PyTorch dari ConvNextV2: Con-desain dan penskalaan convnet dengan autoencoder bertopeng
"Pembelajaran Residual yang Dalam untuk Pengenalan Gambar --- CVPR2016 Paper Terbaik"
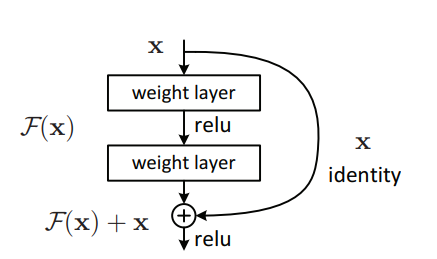
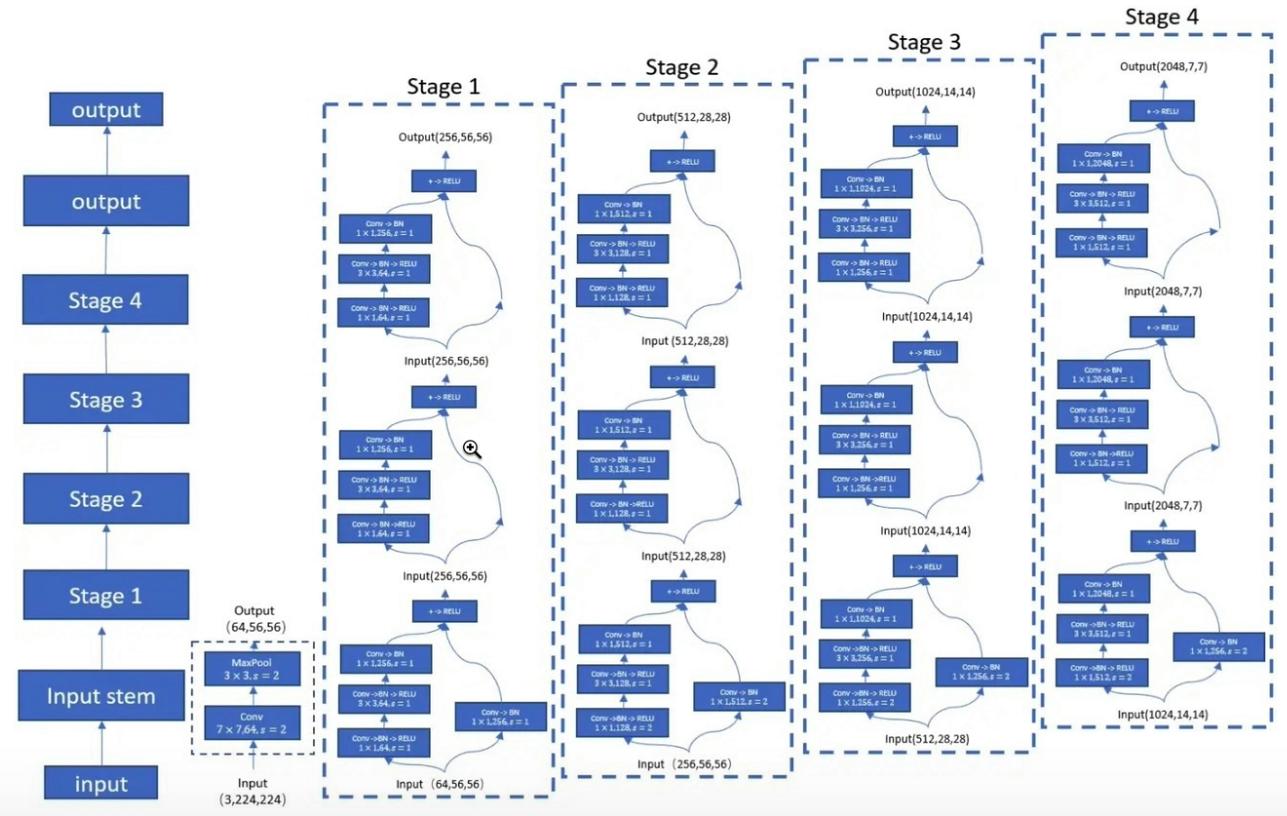
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"Transformasi residual agregat untuk jaringan saraf dalam --- CVPR2017"
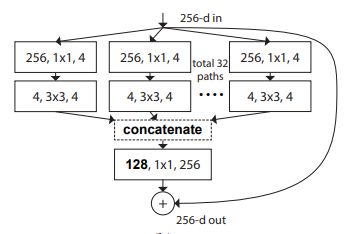
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit: Transformator penglihatan ringan, serba guna, dan ramah seluler --- Arxiv 2020.10.05
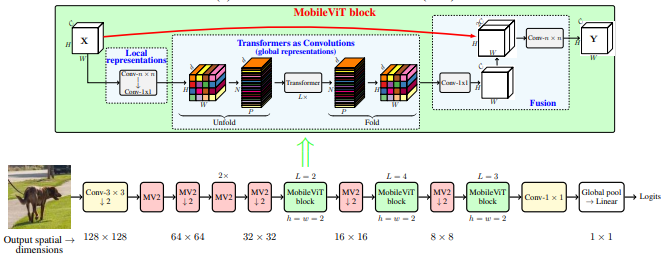
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Patch adalah semua yang Anda butuhkan? --- ICLR2022 (sedang ditinjau)
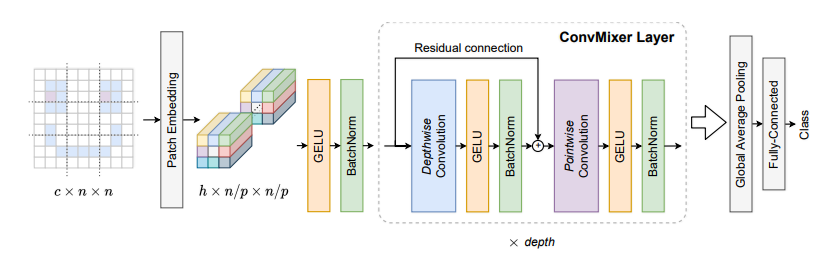
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Shuffle Transformer: Memikirkan Kembali Shuffle Spasial untuk Transformator Visi
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
CONTNET: Mengapa tidak menggunakan konvolusi dan transformator secara bersamaan?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Visi Transformer dengan perhatian hierarkis
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Transformator gambar con-scale con-conentS
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: Baseline yang ditingkatkan dengan transformator penglihatan piramida
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Pengkodean posisi bersyarat untuk transformator penglihatan
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Memikirkan kembali dimensi spasial transformator penglihatan
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit: Transformator visi multi-skala silang untuk klasifikasi gambar
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Transformator dalam transformator
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )DeepVit: Menuju Transformator Visi yang lebih dalam
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Menggabungkan desain konvolusi ke dalam transformator visual
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Konvit: Meningkatkan transformator penglihatan dengan bias induktif konvolusional lunak
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Semakin dalam dengan transformator gambar
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Menambah jaringan konvolusional dengan agregasi berbasis perhatian
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Melatih transformator gambar yang efisien data & distilasi melalui perhatian
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: Transformator penglihatan dalam pakaian Convnet untuk inferensi yang lebih cepat
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )VOLO: Penglihatan Visi untuk Pengenalan Visual
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Container: Jaringan Agregasi Konteks
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: Jaringan saraf konvolusional memenuhi transformator visi
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )EfisienFormer: Visi Transformers dengan kecepatan mobileNet
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )ConvNextV2: co-desain dan penskalaan konvnet dengan autoencoders bertopeng
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Implementasi PyTorch dari "RepMLP: Konvolusi Parameterisasi ulang menjadi lapisan yang sepenuhnya terhubung untuk pengenalan gambar --- ARXIV 2021.05.05"
Implementasi PyTorch dari "MLP-Mixer: All-MLP Architecture for Vision --- Arxiv 2021.05.17"
Implementasi PyTorch dari "ResMLP: FeedForward Networks untuk Klasifikasi Gambar dengan Pelatihan Efisien Data --- ARXIV 2021.05.07"
Pytorch Implementasi "Perhatikan MLP --- ARXIV 2021.05.17"
Pytorch Implementasi "Jarang MLP untuk Pengenalan Gambar: Apakah Perhatian Mandiri Benar-benar Diperlukan? --- Arxiv 2021.09.12"
"RepMLP: RE-Parameterizing Convolutions menjadi lapisan yang sepenuhnya terhubung untuk pengenalan gambar"
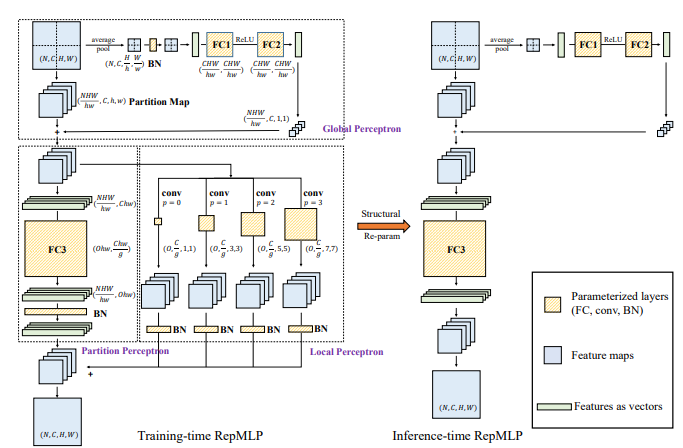
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-Mixer: All-MLP Architecture for Vision"
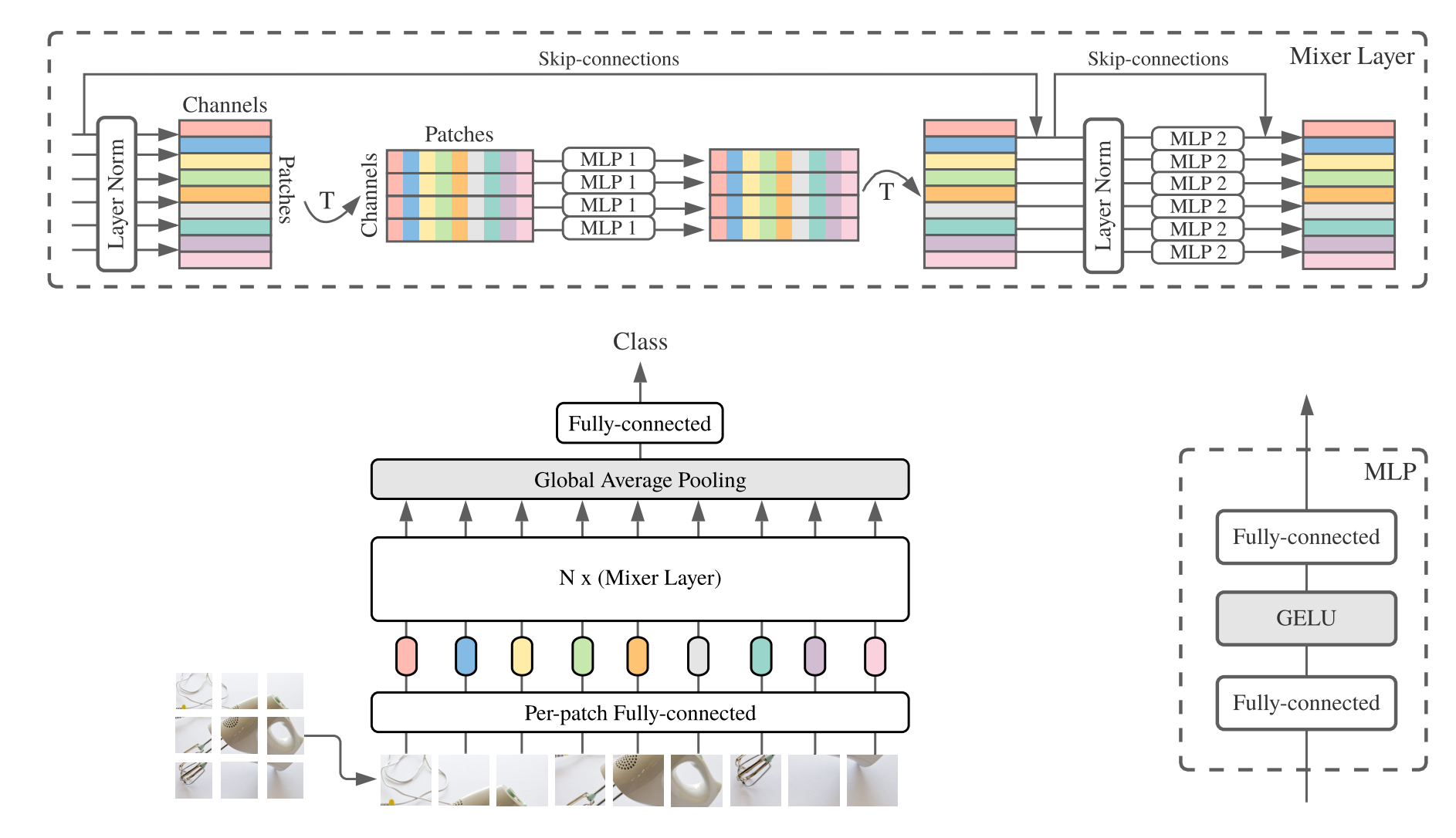
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"Resmlp: FeedForward Networks untuk Klasifikasi Gambar dengan Pelatihan Efisien Data"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Perhatikan MLP"
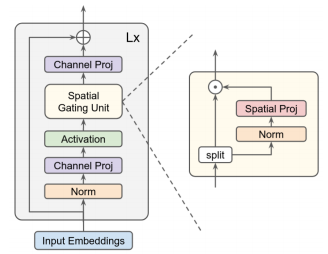
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"MLP jarang untuk pengenalan gambar: Apakah perhatian diri benar-benar diperlukan?"
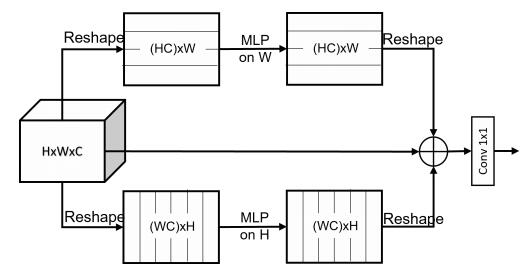
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Permutator Visi: Arsitektur seperti MLP yang permutisasi untuk pengakuan visual"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Pytorch Implementasi "REPVGG: Membuat Convnet VGG-Style Hebat Lagi ---- CVPR2021"
Implementasi Pytorch dari "ACNET: Memperkuat kerangka kernel untuk CNN yang kuat melalui blok konvolusi asimetris --- ICCV2019"
Implementasi Pytorch dari "Beragam Blok Cabang: Membangun Konvolusi sebagai Unit seperti Inception --- CVPR2021"
"Repvgg: Membuat Convnet VGG-Style Hebat Lagi"
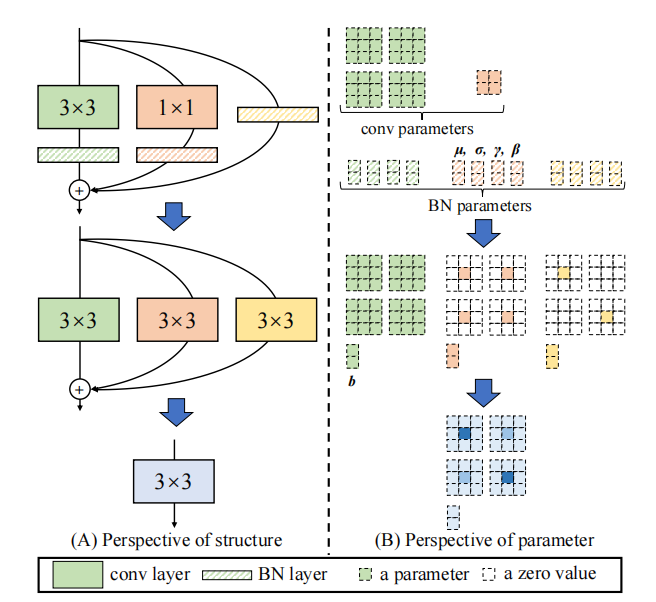
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"Acnet: Memperkuat kerangka kernel untuk CNN yang kuat melalui blok konvolusi asimetris"
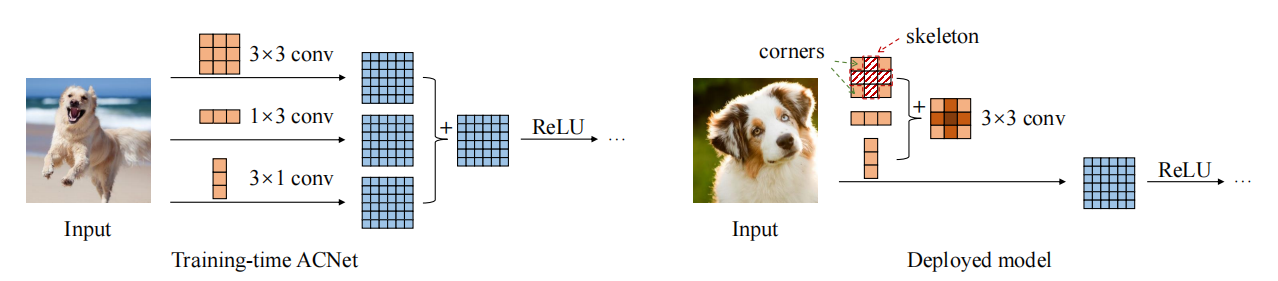
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"Beragam Blok Cabang: Membangun Konvolusi sebagai Unit seperti Inception"
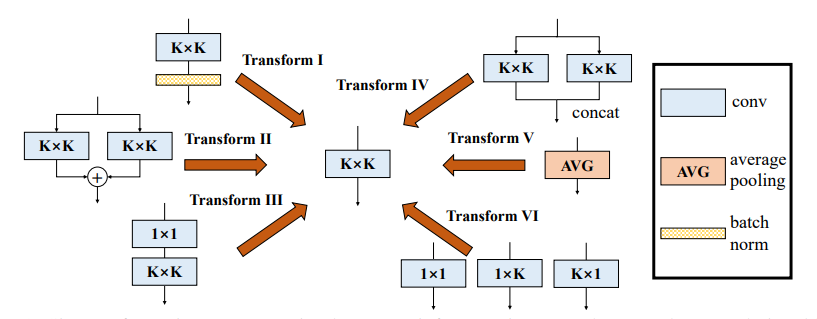
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
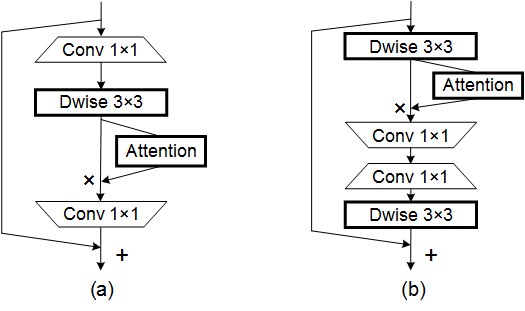
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Implementasi PyTorch dari "MobileNets: Efisien Neural Networks untuk Aplikasi Visi Seluler --- CVPR2017"
Implementasi PyTorch dari "EfficientNet: Rethinking Model Scaling untuk Jaringan Saraf Convolutional --- PMLR2019"
Implementasi Pytorch dari "Involution: Membalikkan Warisan Konvolusi untuk Pengenalan Visual ---- CVPR2021"
Implementasi Pytorch dari "Konvolusi Dinamis: Perhatian atas Kernel Konvolusi --- CVPR2020 Oral"
Implementasi Pytorch dari "CondConV: Konvolusi yang diparameterisasi secara kondisional untuk inferensi yang efisien --- Neurips2019"
"MobileNets: Jaringan saraf konvolusional yang efisien untuk aplikasi penglihatan seluler"
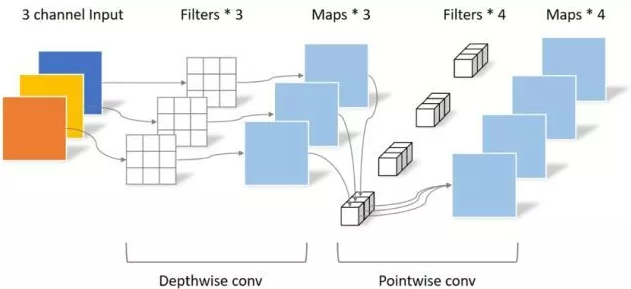
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"EfficientNet: Memikirkan kembali penskalaan model untuk jaringan saraf konvolusional"
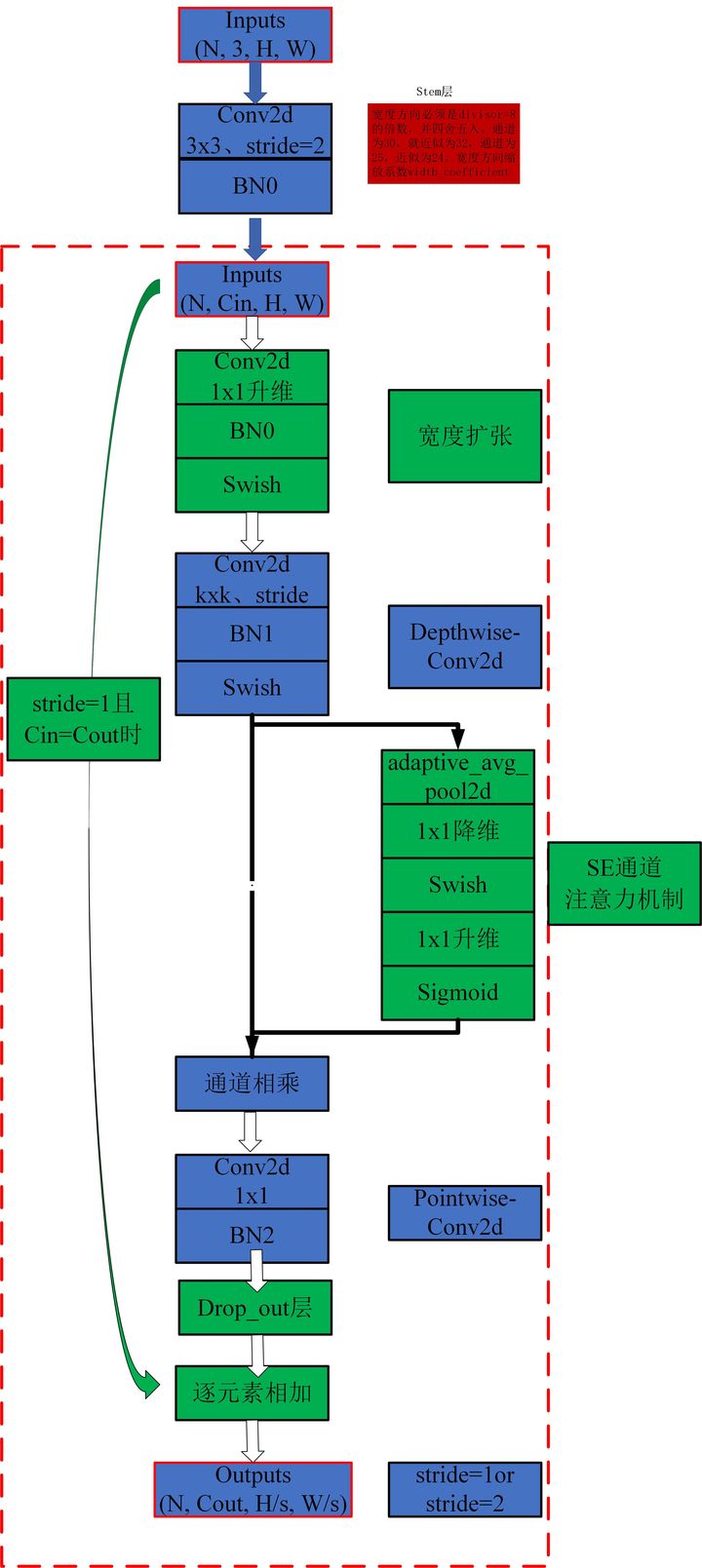
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"Involution: Membalikkan warisan konvolusi untuk pengakuan visual"
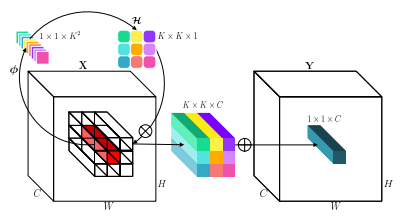
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"Konvolusi Dinamis: Perhatian atas Kernel Konvolusi"
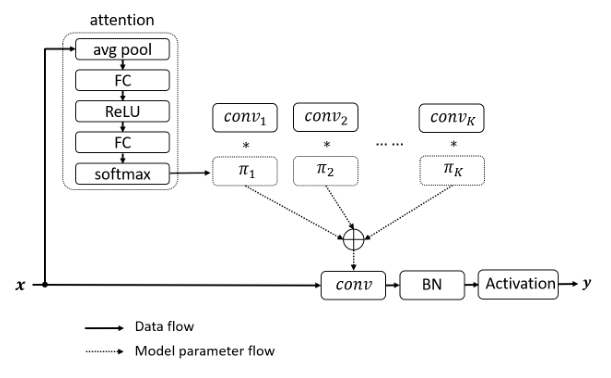
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"Condconv: Konvolusi yang diparameterisasi secara kondisional untuk inferensi yang efisien"
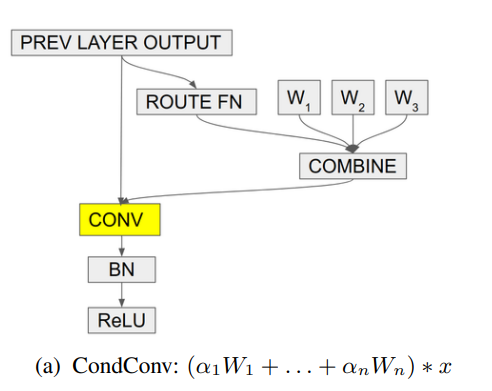
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )Berita besar! Lai Lai Sebagai suplemen untuk proyek ini, Anda dapat memperhatikan proyek open source FightingCV-membaca-bacaan , yang mengumpulkan dan mengatur analisis kertas konferensi dan jurnal utama.
Berita besar! Lai Lai Baru-baru ini, saya telah menyusun berbagai tutorial video terkait AI dan makalah yang harus dibaca di internet FightingCV-Course
Berita besar! Lai Lai Baru -baru ini, perpustakaan kode deteksi objek Yoloir baru telah dibuka, yang mengintegrasikan berbagai model Yolo, termasuk Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 dan model Yolo lainnya, serta berbagai mekanisme perhatian yang ada.
ECCV2022 Ringkasan Kertas: ECCV2022-Paper-List


