External Attention pytorch
1.0.0

Vereinfachtes Chinesisch | Englisch
Hallo allerseits, ich bin Xiaoma
Für Xiaobai (wie ich): Vor kurzem werde ich ein Problem finden, wenn ich ein Papier lese. Manchmal ist die Kernidee des Papiers sehr einfach und der Kerncode kann nur ein Dutzend Zeilen betragen. Als ich jedoch den Quellcode der Veröffentlichung des Autors öffnete, stellte ich fest, dass das vorgeschlagene Modul in Task -Frameworks wie Klassifizierung, Erkennung und Segmentierung eingebettet war, was zu einem relativ redundanten Code führte. Ich bin mit spezifischen Task -Frameworks nicht vertraut und es fällt mir schwer, den Kerncode zu finden , der zu bestimmten Schwierigkeiten beim Verständnis von Arbeiten und Netzwerkideen führt.
Für Fortgeschrittene (wie Sie): Wenn Sie grundlegende Einheiten wie Conv, FC und RNN als kleine LEGO -Bausteine und Strukturen wie Transformer und Resnet als Lego Curles betrachten. Anschließend sind die von diesem Projekt bereitgestellten Module LEGO -Komponenten mit vollständigen semantischen Informationen. Lassen Sie wissenschaftliche Forscher vermeiden, wiederholt Räder zu machen . Überlegen Sie sich einfach, wie Sie diese "LEGO -Komponenten" verwenden, um farbenfrohe Arbeiten zu erstellen.
Für den Meister (mag wie Sie sein): Ich habe begrenzte Fähigkeiten und mag es nicht, leicht zu spritzen ! ! !
Für alle: Dieses Projekt ist verpflichtet, eine Codebasis implementieren zu können, die es Deep Learning -Anfängern ermöglicht, wissenschaftliche Forschung und Industriegemeinschaften zu verstehen und zu dienen .
Direkt über PIP einbauen
pip install fightingcv-attentionOder klonen Sie das Repository
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Achtungsserie
1. Externer Aufmerksamkeitsverbrauch
2. Selfaufsatzverwendung
3.. Vereinfachte Selbstversuche
4. Aufmerksamkeitsverbrauch quetschen und erweitern
5. SK Aufmerksamkeitsverbrauch
6. CBAM -Aufmerksamkeitsverbrauch
7. BAM Aufmerksamkeitsverbrauch
8. ECA -Aufmerksamkeitsverbrauch
9. Danet Aufmerksamkeitsnutzung
10. Pyramid -Aufmerksamkeit (PSA) Verwendung
11. Effiziente Multi-Head-Selbstbekämpfung (EMSA) Nutzung
12. Aufmerksamkeitsverbrauch mischen
13. Muse Aufmerksamkeitsnutzung
14. SGE Aufmerksamkeitsverbrauch
15. A2 Aufmerksamkeitsverbrauch
16. achtern Aufmerksamkeitsverbrauch
17. Outlook Aufmerksamkeitsnutzung
18. VIP Aufmerksamkeitsverbrauch
19. Coatnet Aufmerksamkeitsverbrauch
20. Halonett Aufmerksamkeitsverbrauch
21. Polarisierte Selbstbekämpfungsnutzung
22. Nutzung des Cotattention
23. Rest Aufmerksamkeitsverbrauch
24. S2 Aufmerksamkeitsverbrauch
25. gfnet Aufmerksamkeitsnutzung
26. Triplett Aufmerksamkeitsverbrauch
27. Koordinate der Aufmerksamkeitsverwendung koordinieren
28. Mobilevit Aufmerksamkeitsnutzung
29. PARNET Aufmerksamkeitsnutzung
30. UFO Achtungsnutzung
31. Acmix Aufmerksamkeitsverbrauch
32. Mobilevitv2 Aufmerksamkeitsnutzung
33. DAT Achtungsnutzung
34. Crossformer Aufmerksamkeitsverbrauch
35. Moatransformer Aufmerksamkeitsverbrauch
36. Aufmerksamkeitsverbrauch von Krisscrossattention
37. Axial_Attention Aufmerksamkeitsverbrauch
Backbone -Serie
1. RESNET -Nutzung
2. Nutzung von Resnext
3. Mobilevit Nutzung
4. Konvmixer Nutzung
5. SHUFFLETRANSFORMER -Nutzung
6. Contnet -Verwendung
7. Hatnet Nutzung
8. Mantel Verwendung
9. PVT -Verwendung
10. CPVT -Verwendung
11. Grubenverbrauch
12. Crossvit -Verwendung
13. TNT -Verwendung
14. DVIT -Nutzung
15. CEIT -Nutzung
16. Konvitnutzung
17. Cait -Nutzung
18. PatchConvnet -Verwendung
19. Deit Nutzung
20. Levit Nutzung
21. Volo -Verwendung
22. Behälterverbrauch
23. CMT -Verwendung
24. Effiziente Nutzung
25. Überredenv2 Nutzung
MLP -Serie
1. Repmlp Nutzung
2. Verwendung von MLP-Mixer
3.. RESMLP -Nutzung
4. GMLP -Verwendung
5. SMLP -Verwendung
6. VIP-MLP-Verwendung
Reparameter (Rep) -Serie
1. Repvgg Nutzung
2. ACNET -Verwendung
3. Verbrauch
Faltungsreihe
1. Tiefe trennbare Faltungsverwendung
2. MBCONV -Nutzung
3. Involution Nutzung
4. DynamicConv -Verwendung
5. Kondconv -Nutzung
Pytorch-Implementierung von "Beyond Selbstherd: Externe Aufmerksamkeit unter Verwendung von zwei linearen Schichten für visuelle Aufgaben --- Arxiv 2021.05.05"
Pytorch-Implementierung von "Aufmerksamkeit ist alles, was Sie brauchen --- NIPS2017"
Pytorch-Implementierung von "Squeeze-and-Recitation-Netzwerken --- CVPR2018"
Pytorch-Implementierung von "selektiven Kernel-Netzwerken --- CVPR2019"
Pytorch-Implementierung von "CBAM: Faltungsblock-Aufmerksamkeitsmodul --- ECCV2018"
Pytorch-Implementierung von "BAM: Engpass-Aufmerksamkeitsmodul --- BMCV2018"
Pytorch-Implementierung von "ECA-NET: Effiziente Kanalaufmerksamkeit für tiefe Faltungsnetzwerke --- CVPR2020"
Pytorch-Implementierung von "Doppelaufmerksamkeitsnetzwerk für Szenensegmentierung --- CVPR2019"
Pytorch-Implementierung von "Epsanet: Ein effizienter Pyramid-Aufmerksamkeitsblock für das neuronale Netzwerk von Faltungen --- Arxiv 2021.05.30"
Pytorch-Implementierung von "Rest: Ein effizienter Transformator für die visuelle Erkennung --- Arxiv 2021.05.28"
Pytorch-Implementierung von "SA-NET: Shuffle aufmerksam für tiefe Faltungsnetzwerke --- ICASSP 2021"
Pytorch-Implementierung von "Muse: Parallele Multi-Scale-Aufmerksamkeit für die Sequenz-zur-Sequenz-Lernen --- Arxiv 2019.11.17"
Pytorch-Implementierung von "räumlich gruppenbezogener Verbesserung: Verbesserung des semantischen Lernens in Faltungsnetzwerken --- Arxiv 2019.05.23"
Pytorch-Implementierung von "A2-Nets: Doppelaufmerksamkeitsnetzwerke --- NIPS2018"
Pytorch-Implementierung von "Ein aufmerksamer freier Transformator --- ICLR2021 (Apple New Work)"
Pytorch-Implementierung von Volo: Vision Outlooker für visuelle Erkennung --- Arxiv 2021.06.24 "[Papieranalyse]
Pytorch-Implementierung des Vision-Permutators: Eine durchlässigste MLP-ähnliche Architektur für die visuelle Erkennung --- Arxiv 2021.06.23 [Papieranalyse]
Pytorch-Implementierung von CoatNet: Heirat mit Faltung und Aufmerksamkeit für alle Datengrößen --- ARXIV 2021.06.09 [Papieranalyse]
Pytorch-Implementierung der Skalierung der lokalen Selbstbekämpfung für Parameter Effiziente visuelle Backbones --- CVPR2021 Mund [Papieranalyse]
Pytorch-Implementierung der polarisierten Selbstbekämpfung: Auf dem Weg zu hochwertiger Pixel-Wise-Regression --- Arxiv 2021.07.02 [Papieranalyse]
Pytorch-Implementierung von Kontexttransformator-Netzwerken für die visuelle Erkennung --- Arxiv 2021.07.26 [Papieranalyse]
Pytorch-Implementierung der verbleibenden Aufmerksamkeit: Eine einfache, aber effektive Methode zur Erkennung von Multi-Label --- ICCV2021
Pytorch-Implementierung von S²-MLPV2: Verbesserte räumliche MLP-Architektur für Vision --- Arxiv 2021.08.02 [Papieranalyse]
Pytorch-Implementierung globaler Filternetzwerke für die Bildklassifizierung --- Arxiv 2021.07.01
Pytorch-Implementierung von Drehung, um teilzunehmen: Faltungsmodul Triplett --- WACV 2021
Pytorch-Implementierung der Koordinatenaufmerksamkeit für ein effizientes Design des Mobilfunknetzes --- CVPR 2021
Pytorch-Implementierung von Mobilevit: Leichtes, allgemeines und mobilfreundliches Vision-Transformator --- Arxiv 2021.10.05
Pytorch-Implementierung von nicht-tiefen Netzwerken --- Arxiv 2021.10.20
Pytorch-Implementierung von UFO-vit: Hochleistungs-Linear Vision Transformator ohne Softmax --- Arxiv 2021.09.29
Pytorch-Implementierung trennbarer Selbstbekämpfung für mobile Vision-Transformatoren --- Arxiv 2022.06.06
Pytorch-Implementierung der Integration von Selbstbekämpfung und Faltung --- Arxiv 2022.03.14
Pytorch-Implementierung von Crossformer: Ein vielseitiger Vision-Transformator, der auf dem Cross-Scale-Aufmerksamkeit abhängt --- ICLR 2022
Pytorch -Implementierung von aggregierenden globalen Merkmalen in lokalen Vision -Transformator
Pytorch-Implementierung von CCNET: Aufmerksamkeit für die semantische Segmentierung durchkreuzt
Pytorch -Implementierung der axialen Aufmerksamkeit in mehrdimensionalen Transformatoren
"Jenseits der Selbstbeziehung: Externe Aufmerksamkeit mit zwei linearen Schichten für visuelle Aufgaben"
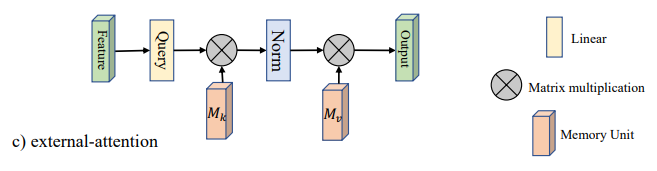
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"Aufmerksamkeit ist alles, was Sie brauchen"
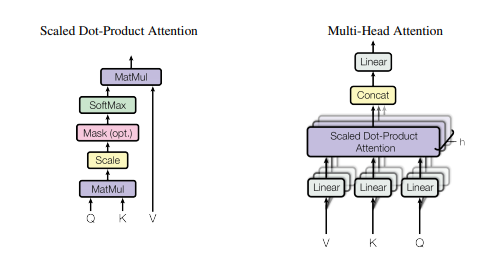
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Keiner
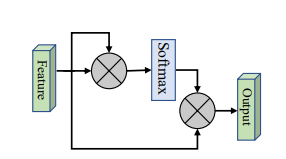
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Squeeze-and-Excitation-Netzwerke"
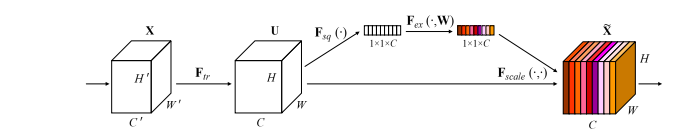
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Selektive Kernel -Netzwerke"
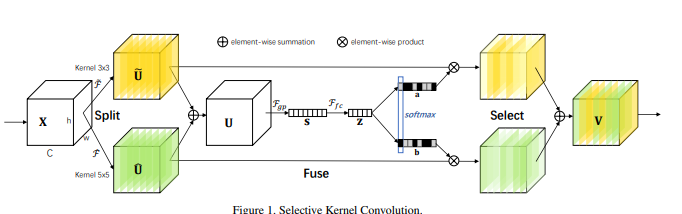
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: Faltungsblock -Aufmerksamkeitsmodul"
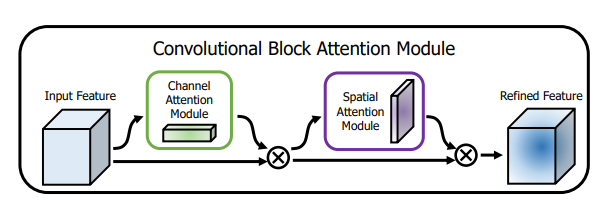
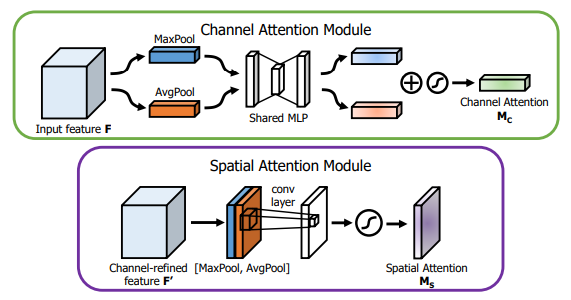
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"BAM: Engpass -Aufmerksamkeitsmodul"
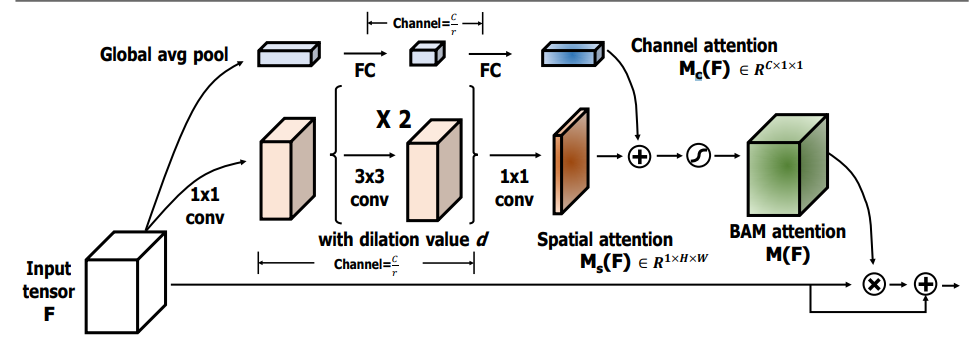
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: Effiziente Kanalaufmerksamkeit für tiefe Faltungsnetzwerke"
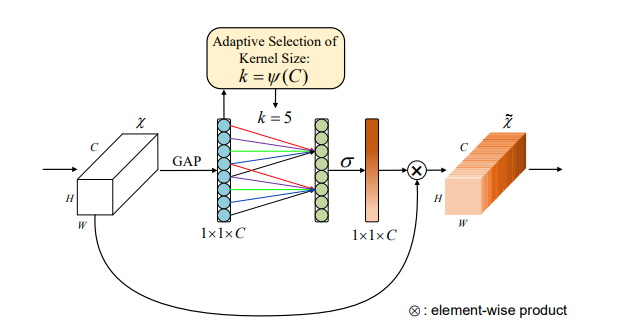
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"Dual Aufmerksamkeitsnetzwerk für Szenensegmentierung"
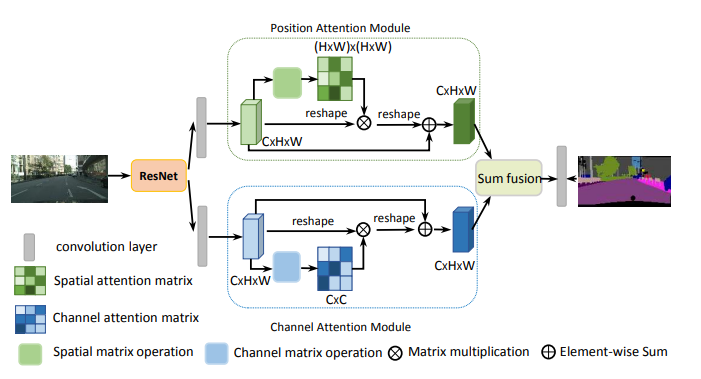
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet: Ein effizienter Pyramid -Aufmerksamkeitsblock auf Faltungsnetzwerk" Aufgeteilte Aufmerksamkeitsblockade "
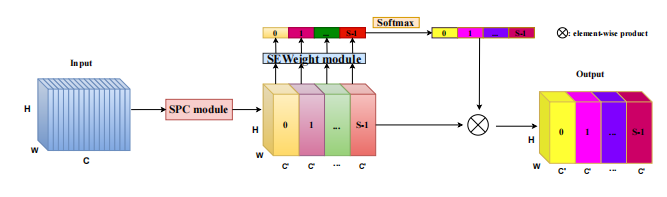
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"Ruhe: Ein effizienter Transformator für die visuelle Erkennung"
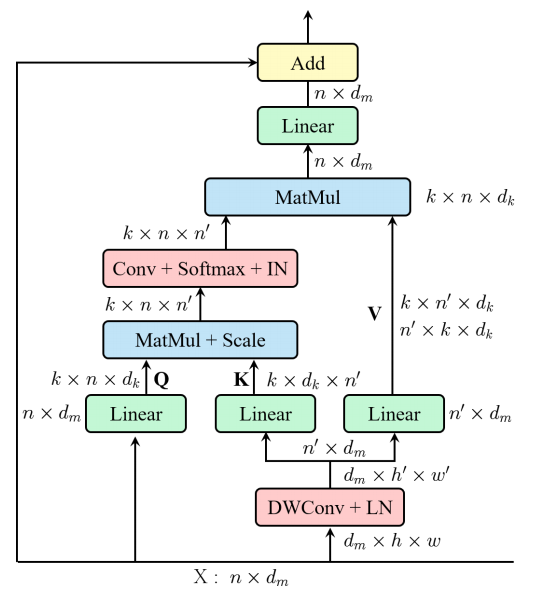
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: Mischen Sie sich auf die tiefe Faltungsnetzwerke", "Faltungsverhältnissen". "
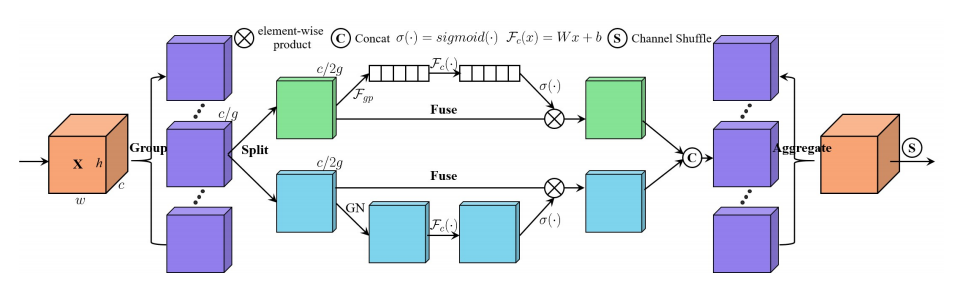
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse: Parallele Multi-Scale-Aufmerksamkeit für die Sequenz zum Sequenzlernen"
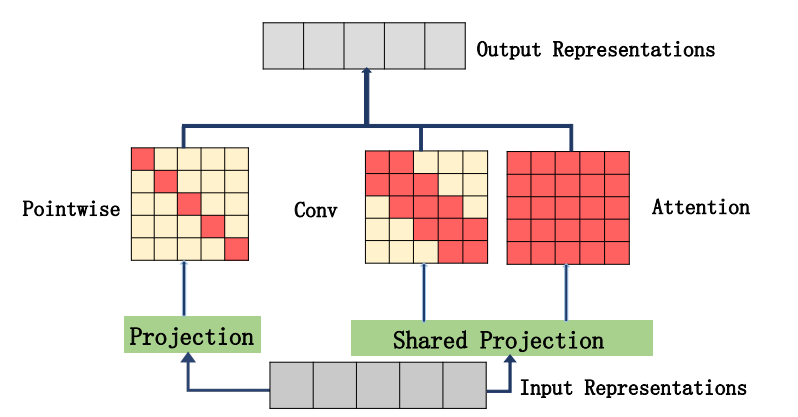
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Räumliche gruppenbezogene Verbesserung: Verbesserung des Lernens des semantischen Merkmals in Faltungsnetzwerken
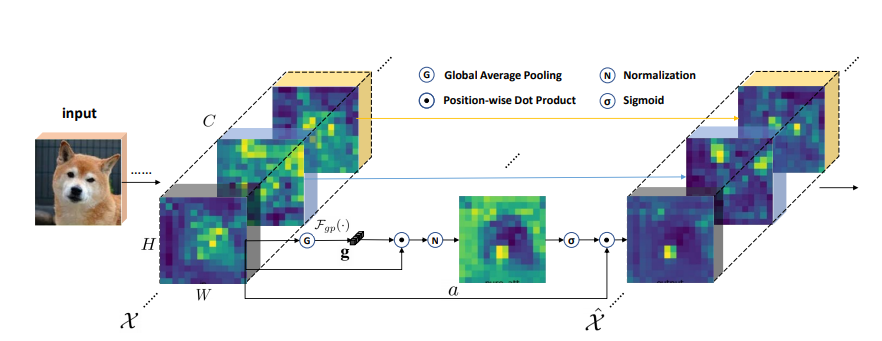
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Netze: Doppelaufmerksamkeitsnetzwerke
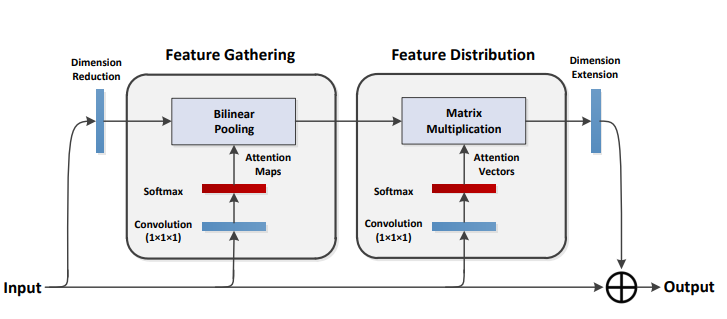
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Ein aufmerksamkeitsfreier Transformator
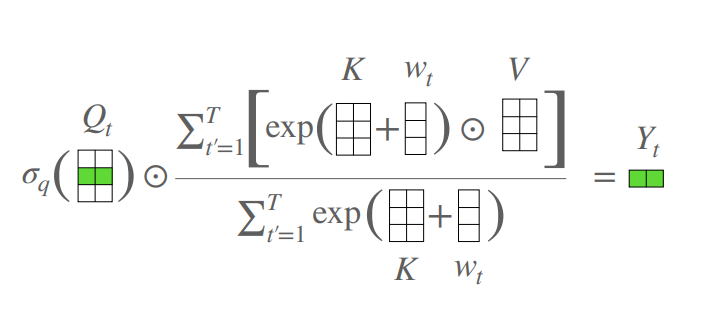
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo: Vision Outlooker für visuelle Erkennung "
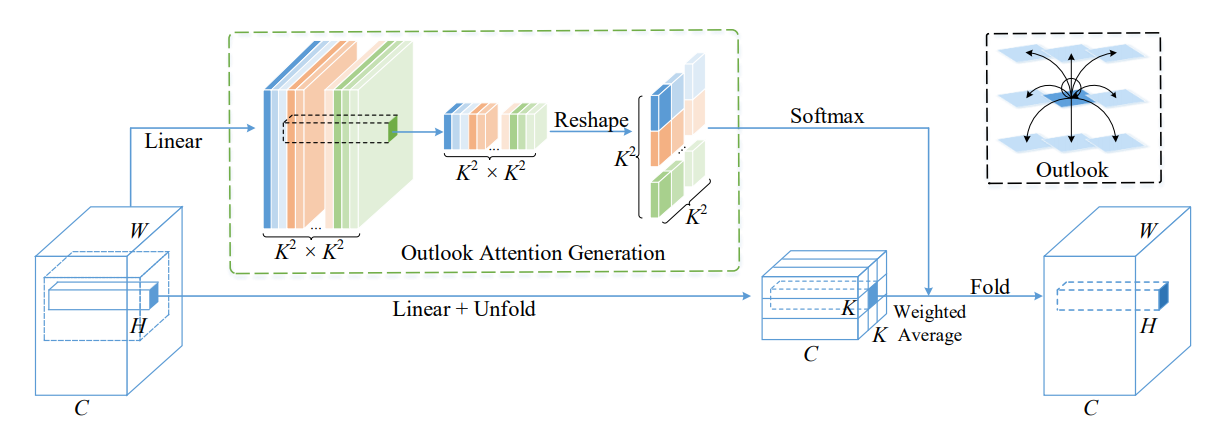
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Vision Permutator: Eine angrenzbare MLP-ähnliche Architektur für die visuelle Erkennung "
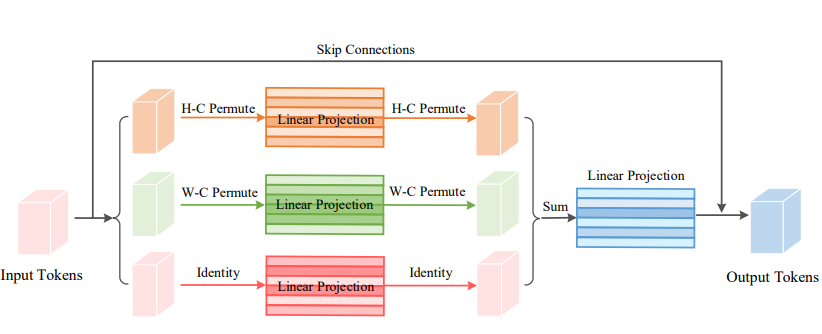
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: Heiraten von Faltung und Aufmerksamkeit für alle Datengrößen "
Keiner
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Skalierung der lokalen Selbstbekämpfung bei Parametern Effiziente visuelle Rückgrate "
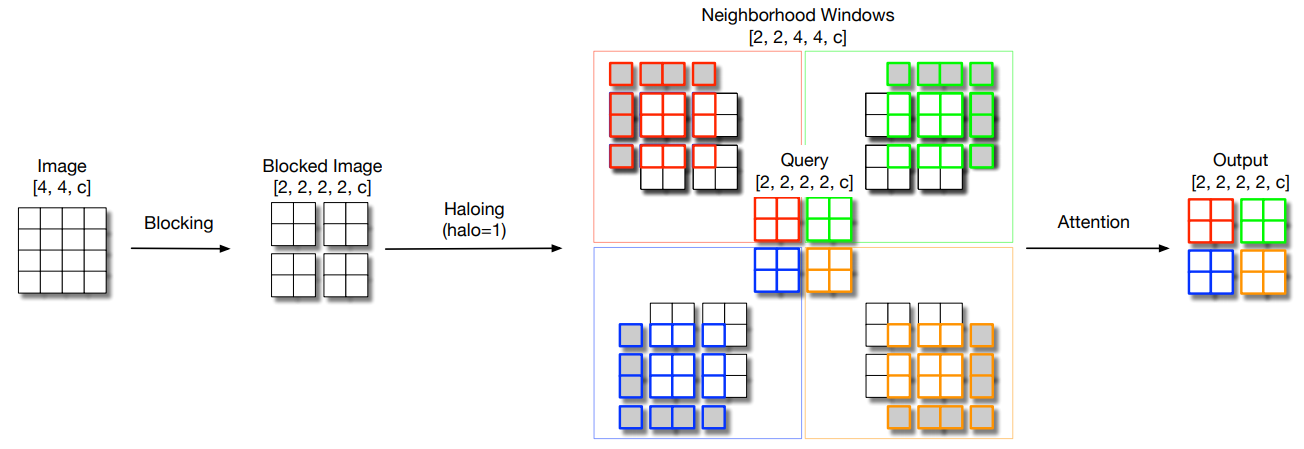
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Polarisierte Selbstbeziehung: Auf der Richtung einer hochwertigen Pixel-Regression "
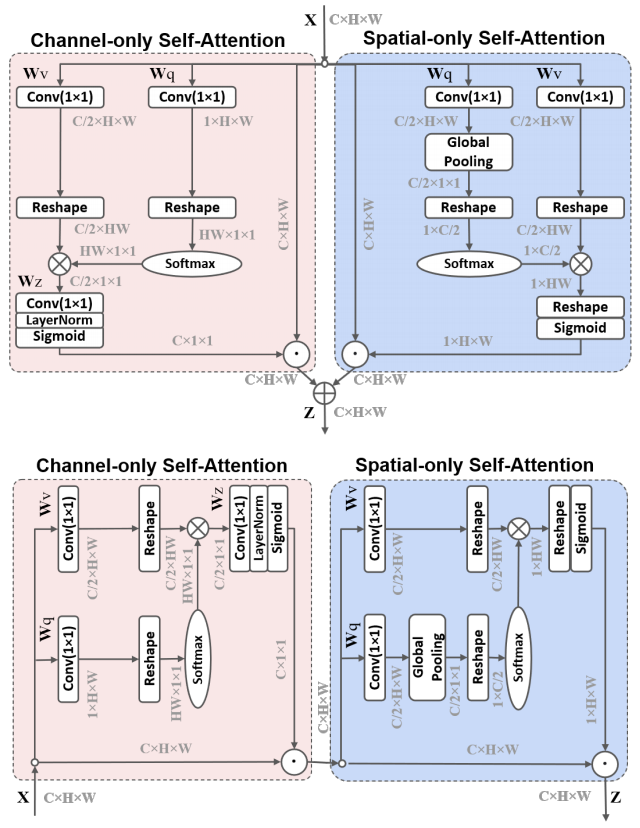
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Kontexttransformator-Netzwerke für die visuelle Erkennung --- Arxiv 2021.07.26
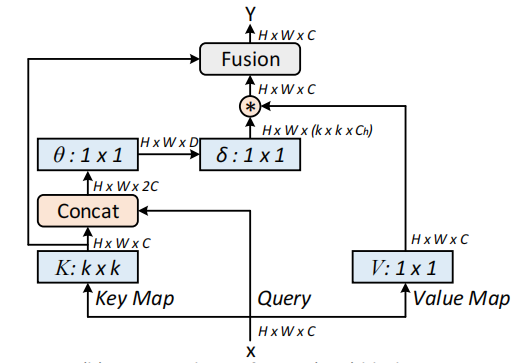
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Restaufmerksamkeit: Eine einfache, aber effektive Methode zur Erkennung von Multi-Label --- ICCV2021
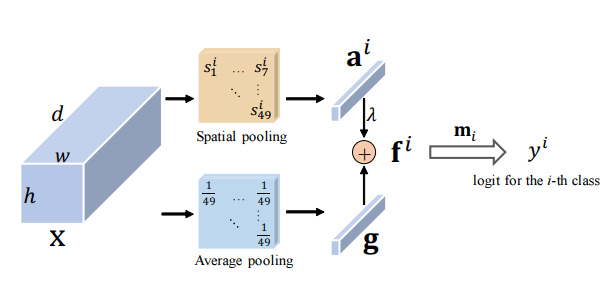
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: Verbesserte räumliche MLP-Architektur für Vision --- Arxiv 2021.08.02
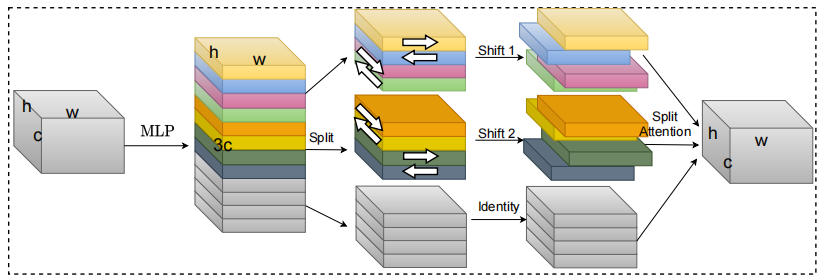
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Globale Filternetzwerke für die Bildklassifizierung --- ARXIV 2021.07.01
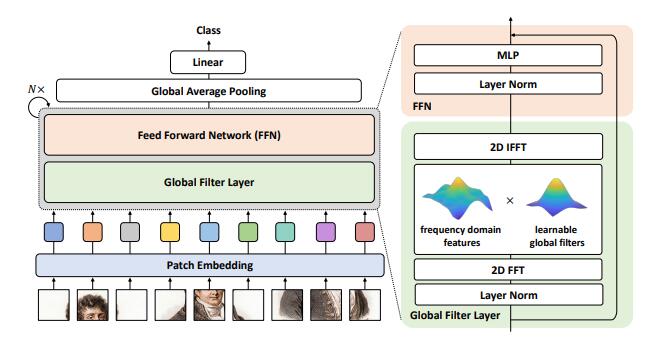
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )Drehen Sie, um teilzunehmen: Aufmerksamkeitsmodul von Faltungskolben --- CVPR 2021
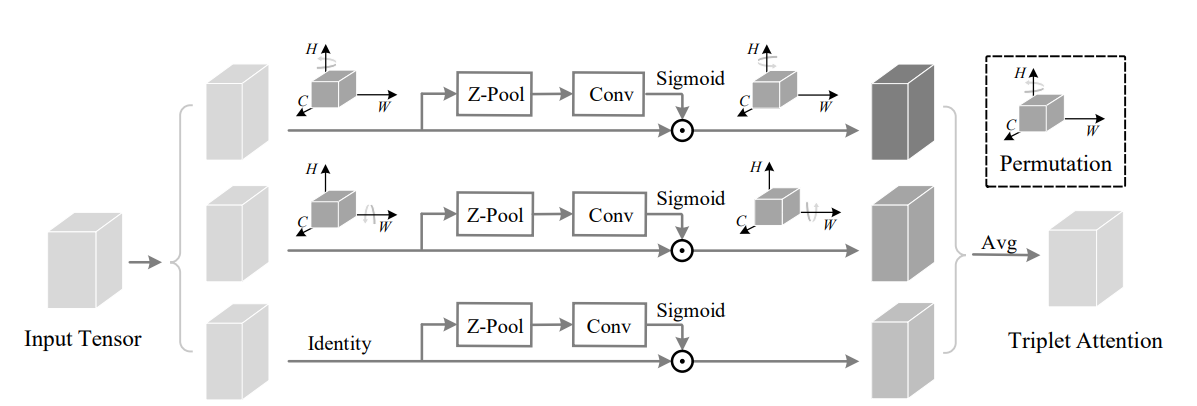
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Koordinieren Sie die Aufmerksamkeit für ein effizientes Design des mobilen Netzwerks --- CVPR 2021
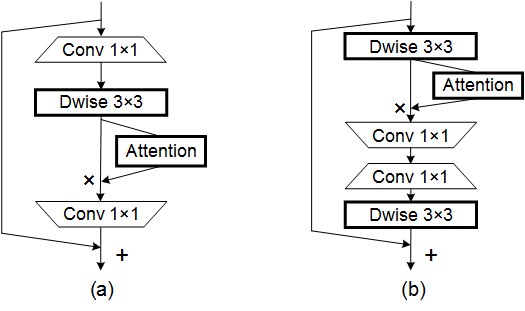
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )Mobilevit: Leichtes, allgemeines und mobilfreundliches Sehtransformator --- Arxiv 2021.10.05
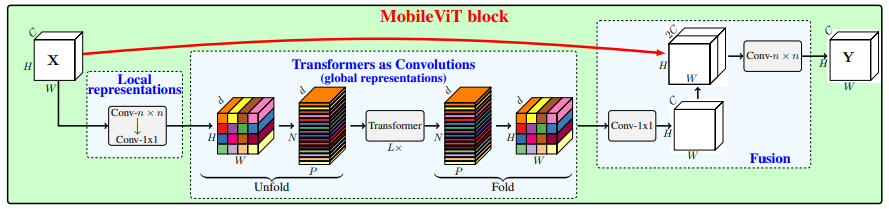
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Nicht-tiefe Netzwerke --- Arxiv 2021.10.20
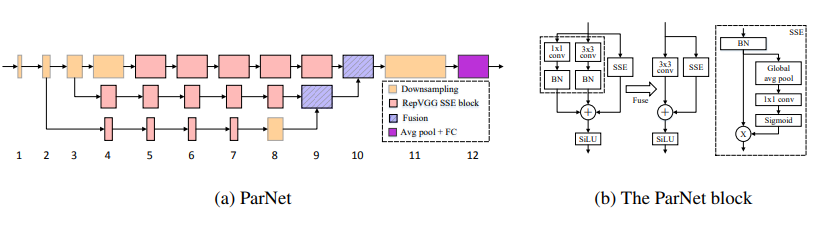
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-vit: Hochleistungslinearer Sehtransformator ohne Softmax --- Arxiv 2021.09.29
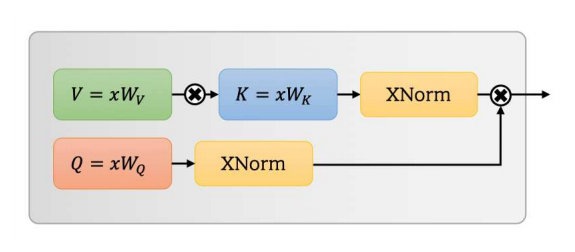
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
Zur Integration von Selbstbekämpfung und Faltung
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
Trennbare Selbstbeziehung für mobile Vision-Transformatoren --- Arxiv 2022.06.06
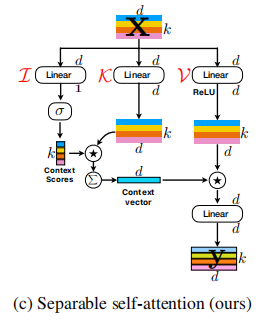
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Vision Transformator mit deformierbarer Aufmerksamkeit --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer: Ein vielseitiger Vision-Transformator, der auf dem skalierenden Aufmerksamkeit hingert --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Globale Merkmale in lokale Vision -Transformator zusammenhängen
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: Aufmerksamkeit der kreuzenden Aufmerksamkeit für die semantische Segmentierung
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Axiale Aufmerksamkeit bei mehrdimensionalen Transformatoren
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Pytorch-Implementierung von "Deep Residual Learning für Bilderkennung --- CVPR2016 Bestes Papier"
Pytorch-Implementierung von "aggregierten Resttransformationen für tiefe neuronale Netze --- CVPR2017"
Pytorch-Implementierung von Mobilevit: Leichtes, allgemeines und mobilfreundliches Sehtransformator --- Arxiv 2020.10.05
Pytorch-Implementierung von Patches sind alles, was Sie brauchen? --- ICLR2022 (unter Rückblick)
Pytorch-Implementierung von Shuffle Transformator: Räume für das Sehtransformator überdenken-ARXIV 2021.06.07
Pytorch-Implementierung von CONTNET: Warum nicht gleichzeitig Faltung und Transformator verwenden? --- Arxiv 2021.04.27
Pytorch-Implementierung von Vision-Transformatoren mit hierarchischer Aufmerksamkeit --- Arxiv 2022.06.15
Pytorch-Implementierung von Co-scale-konv-attentionalen Bildtransformatoren --- Arxiv 2021.08.26
Pytorch -Implementierung von bedingten Positionscodierungen für Vision -Transformatoren
Pytorch-Implementierung von Überdenken räumliche Dimensionen von Vision-Transformatoren --- ICCV 2021
Pytorch-Implementierung von Crossvit: Cross-Tentention Multi-Scale Vision Transformator für die Bildklassifizierung --- ICCV 2021
Pytorch-Implementierung von Transformator in Transformator --- Neurips 2021
Pytorch -Implementierung von Deepvit: Auf dem Weg zu einem tieferen Vision -Transformator
Pytorch -Implementierung der Einbeziehung von Faltungsdesigns in visuelle Transformatoren
Pytorch -Implementierung von Convit: Verbesserung der Sehtransformatoren mit weichen Faltungsverzerrungen
Pytorch-Implementierung von Faltungsnetzwerken mit aufmerksamkeitsbasierter Aggregation
Pytorch-Implementierung von Tiefer mit Bildtransformatoren --- ICCV 2021 (mündlich)
Pytorch-Implementierung dateneffizienter Bildtransformatoren und Destillation durch Aufmerksamkeit --- ICML 2021
Pytorch -Implementierung von Levit: Ein Vision -Transformator in Convnets Kleidung für schnellere Inferenz
Pytorch -Implementierung von Volo: Vision Outlooker für visuelle Erkennung
Pytorch-Implementierung des Containers: Kontextaggregationsnetzwerk --- Neuips 2021
Pytorch-Implementierung von CMT: Faltungsverkäufer neuronale Netze treffen Vision-Transformatoren --- CVPR 2022
Pytorch-Implementierung des Vision-Transformators mit deformierbarer Aufmerksamkeit --- CVPR 2022
Pytorch -Implementierung von Effequentformer: Vision -Transformatoren bei Mobilenet -Geschwindigkeit
Pytorch-Implementierung von Convnextv2: Co-Designing und Skalierung von Überzeugungen mit maskierten Autoencodern
"Tiefes Restlernen für die Bilderkennung --- CVPR2016 Bestes Papier"
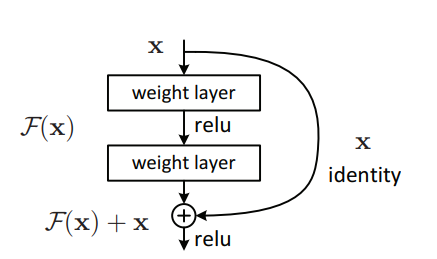
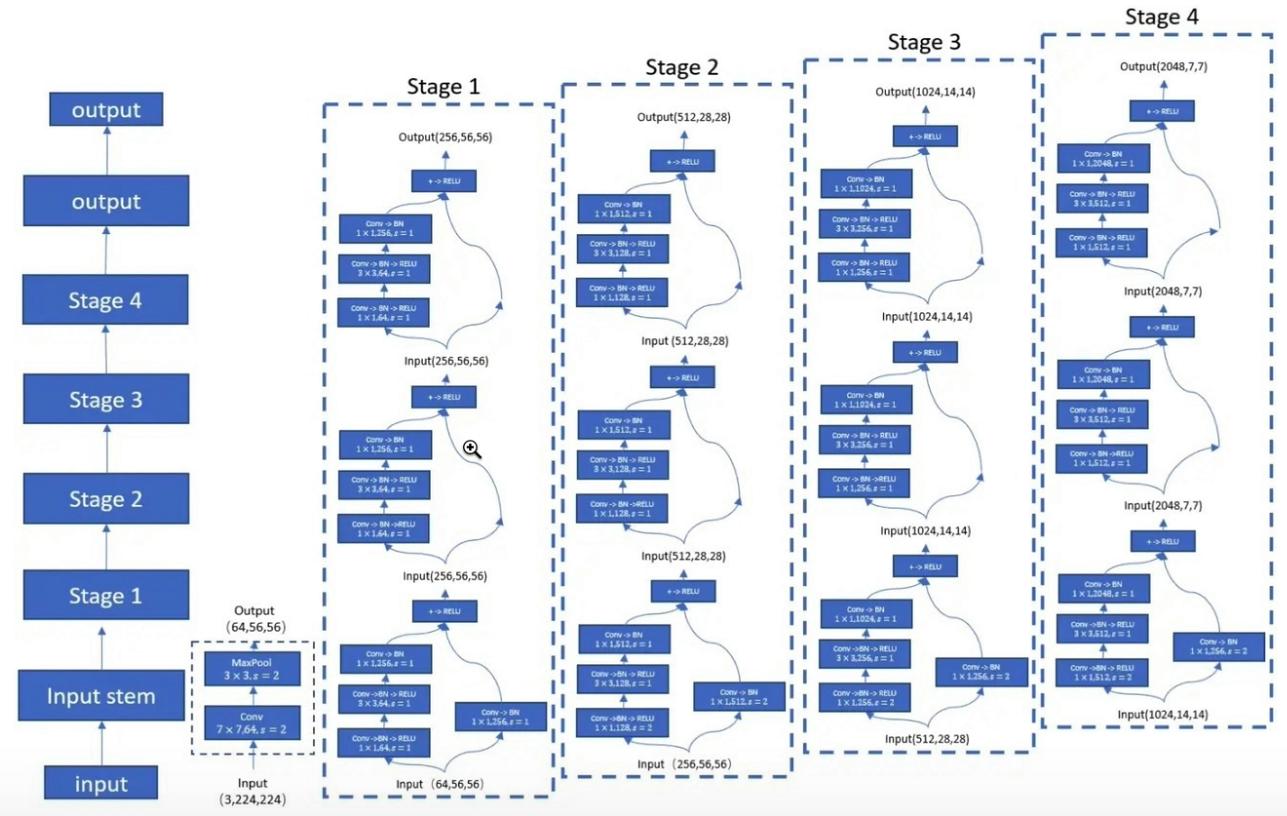
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"Aggregierte Resttransformationen für tiefe neuronale Netze --- CVPR2017"
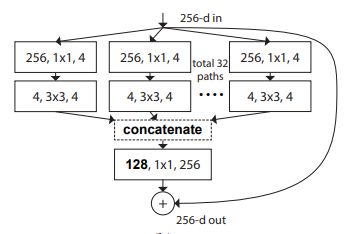
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
Mobilevit: Leichtes, allgemeines und mobilfreundliches Sehtransformator --- Arxiv 2020.10.05
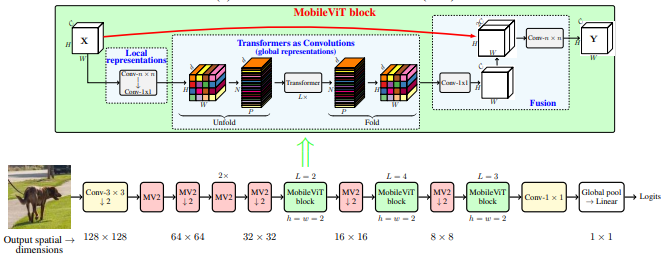
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Patches sind alles, was Sie brauchen? --- ICLR2022 (unter Rückblick)
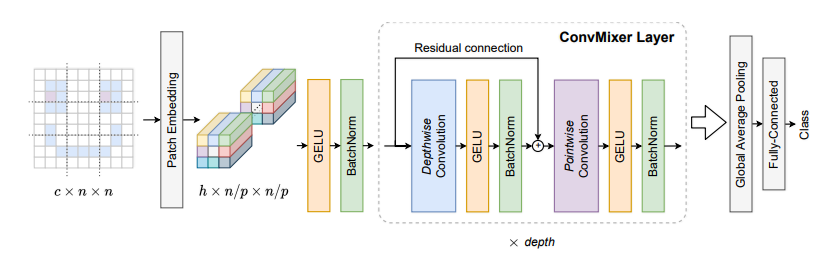
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Shuffle Transformator: Räumliche Shuffle für Sehtransformator überdenken
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
CONTNET: Warum nicht gleichzeitig Faltung und Transformator verwenden?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Vision -Transformatoren mit hierarchischer Aufmerksamkeit
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Co-Scale-Konv-Bereitschaftsbildtransformatoren
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: Verbesserte Baselines mit Pyramiden -Sehtransformator
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Bedingte Positionscodierungen für Sehtransformatoren
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Räumliche Dimensionen von Sehtransformatoren überdenken
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )Crossvit: Cross-Tentention Multi-Scale Vision Transformator für die Bildklassifizierung
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Transformator im Transformator
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )Deepvit: Auf dem Weg zu einem tieferen Vision -Transformator
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Einbeziehung von Faltungsentwürfen in visuelle Transformatoren
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Konvit: Verbesserung von Visionstransformatoren mit weichen, faltenden induktiven Verzerrungen
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Tiefer mit Bildtransformatoren gehen
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Vergrößerungsnetzwerke mit aufmerksamkeitsbasierter Aggregation erhöhen
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Trainingsdateneffiziente Bildtransformatoren und Destillation durch Aufmerksamkeit
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: Ein Vision -Transformator in Convnets Kleidung für eine schnellere Folgerung
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo: Vision Outlooker für visuelle Erkennung
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Container: Kontextaggregationsnetzwerk
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: Faltungsfischnetzwerke treffen Vision Transformers
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )Effizienterformer: Vision -Transformatoren bei Mobilenet -Geschwindigkeit
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )Convnextv2: Co-Designing und Skalierung überzeugen Sie mit maskierten Autoencodern
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Pytorch-Implementierung von "repmlp: Neuparametrisierende Konvolutionen in vollständig vernetzte Ebenen für die Bilderkennung --- Arxiv 2021.05.05"
Pytorch-Implementierung von "MLP-Mixer: Eine All-MLP-Architektur für Vision --- Arxiv 2021.05.17"
Pytorch-Implementierung von "RESMLP: Feedforward-Netzwerke für die Bildklassifizierung mit dateneffizientem Training --- Arxiv 2021.05.07"
Pytorch-Implementierung von "Achten Sie auf MLPs --- Arxiv 2021.05.17"
Pytorch-Implementierung von "spärlichem MLP für die Bilderkennung: Ist die Selbstbekämpfung wirklich notwendig? --- Arxiv 2021.09.12"
"RepMLP: Neuparameterisierung von Konvolutionen in vollständig vernetzte Ebenen zur Bilderkennung"
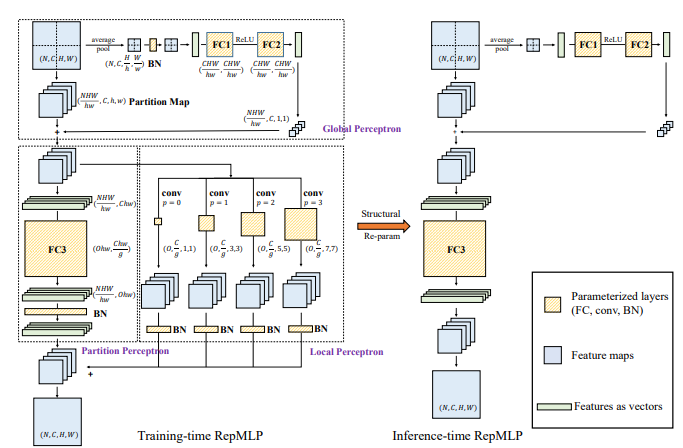
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-Mixer: Eine All-MLP-Architektur für Vision"
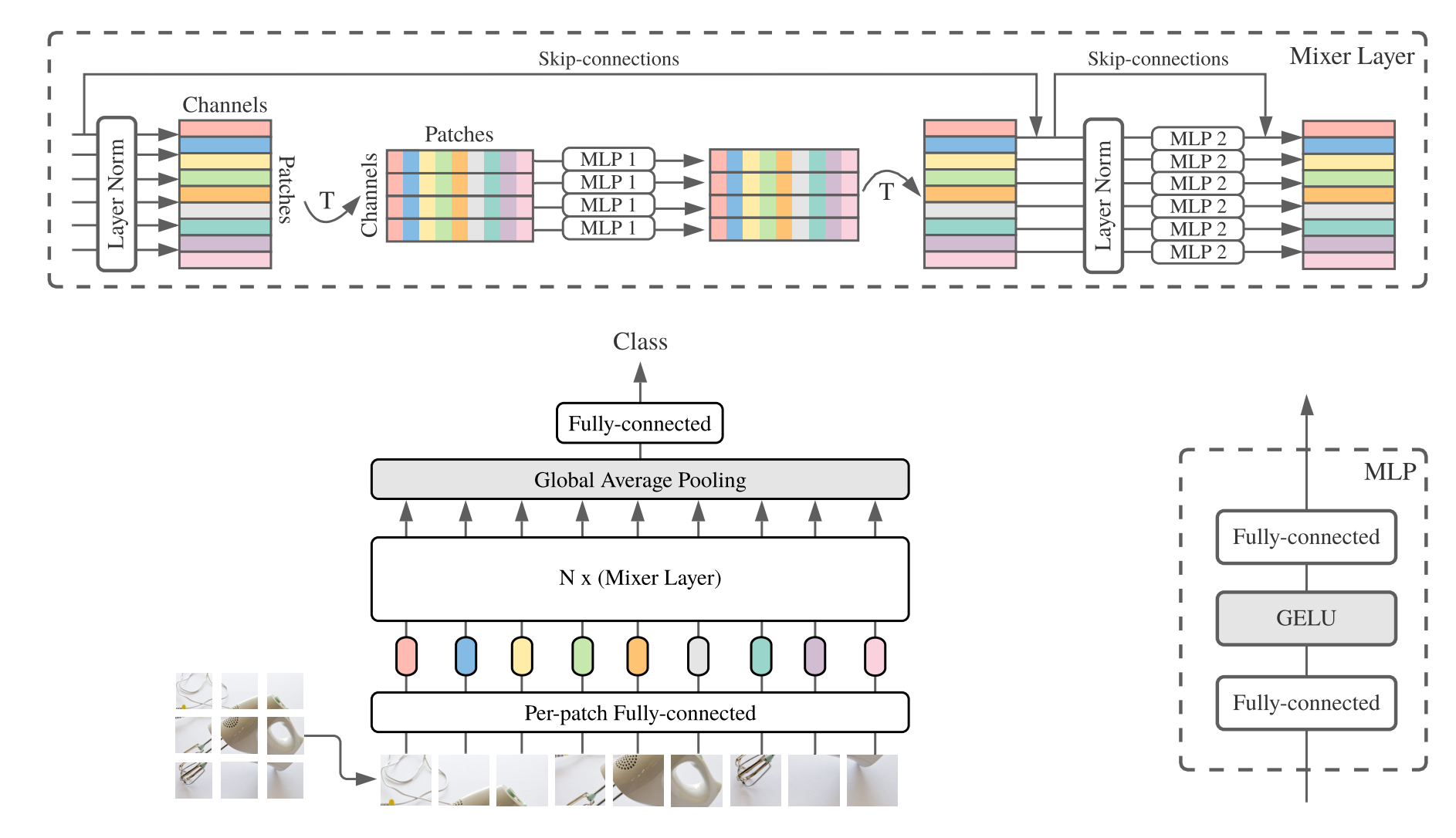
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"RESMLP: Feedforward-Netzwerke für die Bildklassifizierung mit dateneffizientem Training"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Achten Sie auf MLPs"
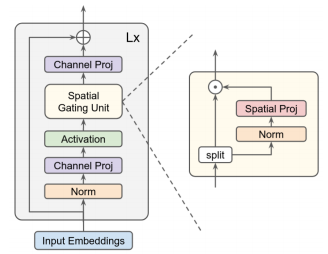
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"Spärliche MLP für die Bilderkennung: Ist die Selbstbekämpfung wirklich notwendig?"
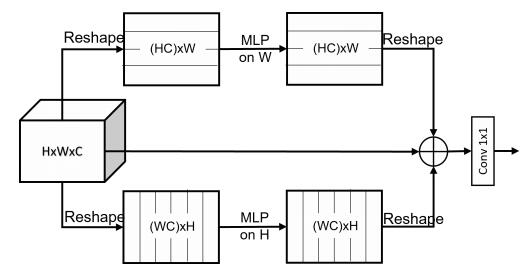
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Vision-Permutator: Eine eindringliche MLP-ähnliche Architektur für die visuelle Erkennung"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Pytorch-Implementierung von "Repvgg: Machen Sie VGG-Stil wieder großartig ---- CVPR2021"
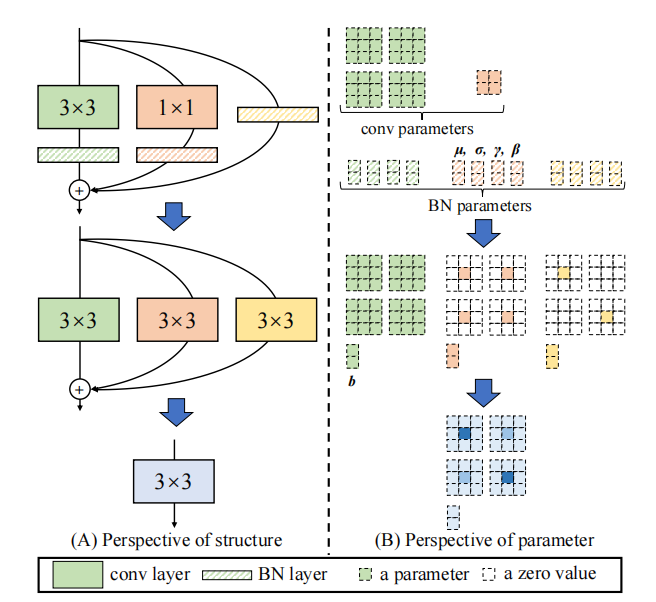
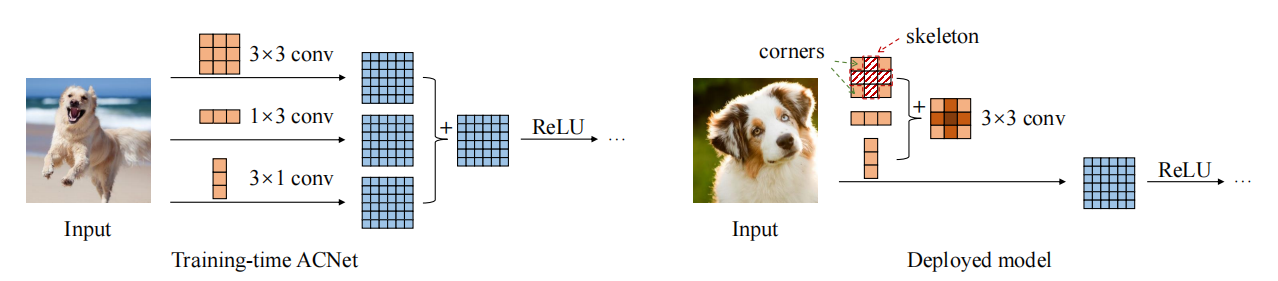
Pytorch-Implementierung von "ACNET: Stärkung der Kernskelette für leistungsstarke CNN über asymmetrische Faltungsblöcke --- ICCV2019"
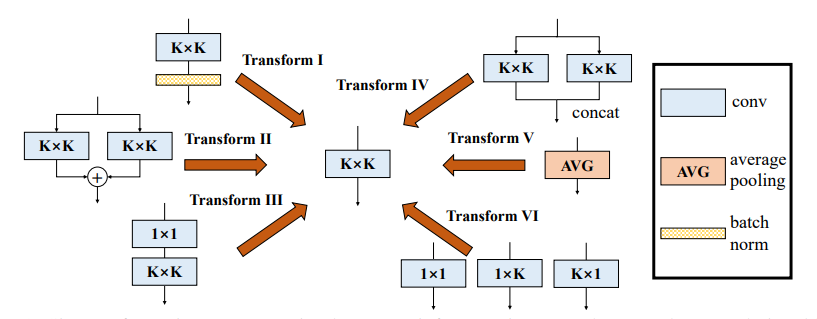
Pytorch-Implementierung von "Diverse Branch Block: Aufbau einer Faltung als auffängliche Einheit --- CVPR2021"
"Repvgg: Lassen Sie VGG-Stil wieder großartig überzeugen"
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"ACNET: Stärkung der Kernskelette für leistungsstarke CNN über asymmetrische Faltungsblöcke"
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"Verschiedener Branchblock: Aufbau einer Faltung als auffängliche Einheit"
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
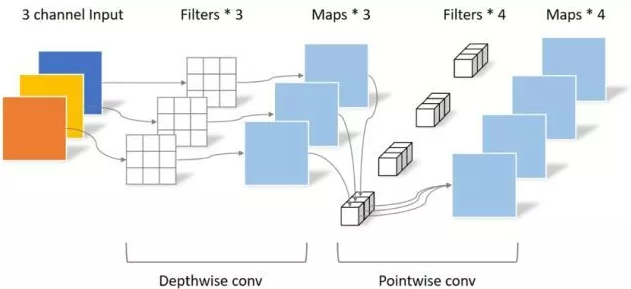
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Pytorch-Implementierung von "Mobilenets: Effiziente Faltungsnetzwerke für mobile Vision Anwendungen --- CVPR2017"
Pytorch-Implementierung von "effizientesNetz: Überdenken der Modellskalierung für Faltungsnetzwerke --- PMLR2019"
Pytorch-Implementierung von "Involution: Umkehrung der Erbschaft der Faltung für die visuelle Erkennung ---- CVPR2021"
Pytorch-Implementierung von "dynamischer Faltung: Aufmerksamkeit über Faltungskerne --- CVPR2020 Oral"
Pytorch-Implementierung von "Condconv: Konditionell parametrisierte Konvolutionen für effiziente Inferenz --- Neurips2019"
"Mobilenets: Effiziente Faltungsnetzwerke für mobile Vision -Anwendungen"
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"EfficientNet: Das Modell Skalierung für Faltungsnetzwerke überdenken"
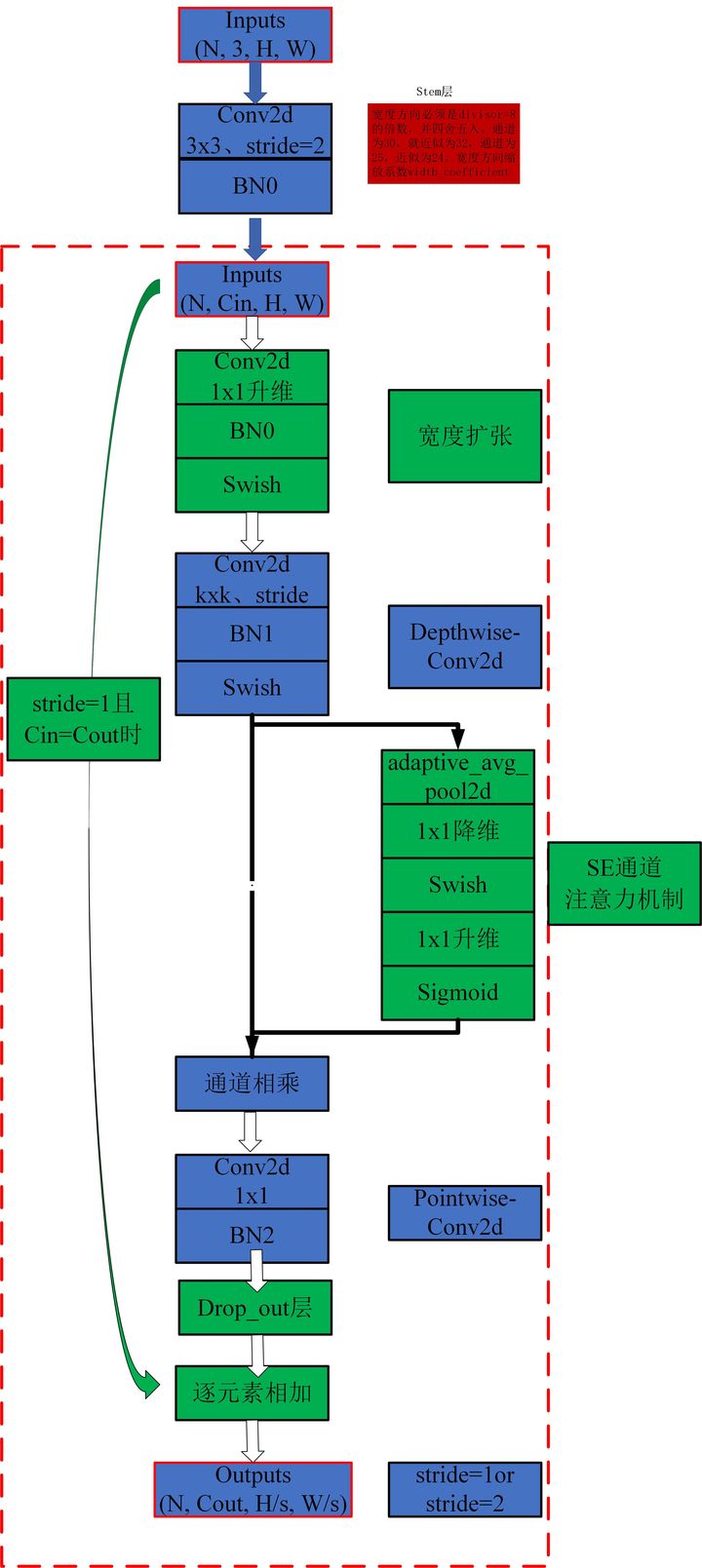
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"Involution: Invertieren der Erben der Faltung für die visuelle Erkennung"
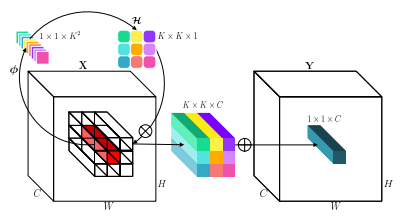
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"Dynamische Faltung: Aufmerksamkeit gegenüber Faltungskerneln"
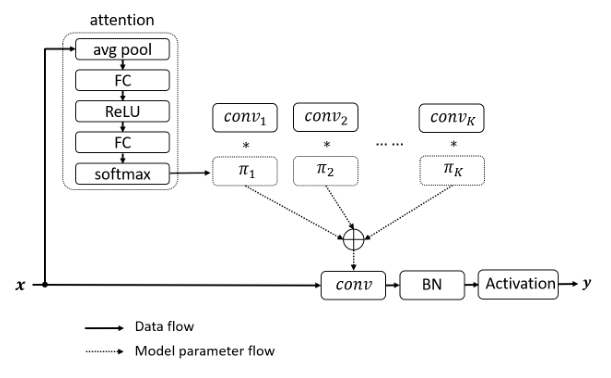
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"Condconv: Konditionell parametrisierte Konvolutionen für effiziente Inferenz"
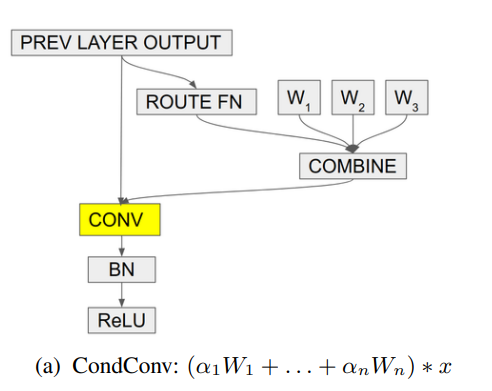
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )Große Neuigkeiten! ! ! Als Ergänzung zum Projekt können Sie auf das neu Open-Source-Projekt Fightcv-Papier-Lesen achten, das die Papieranalyse von wichtigen Konferenzen und Zeitschriften sammelt und organisiert.
Große Neuigkeiten! ! ! Vor kurzem habe ich verschiedene KI-bezogene Video-Tutorials und Must-Read-Papiere im Internet FightingCV-Kurs zusammengestellt
Große Neuigkeiten! ! ! Kürzlich wurde eine neue Yoloair -Objekterkennungscode -Code -Bibliothek geöffnet, die eine Vielzahl von YOLO -Modellen integriert, darunter Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 und andere YOLO -Modelle sowie eine Vielzahl bestehender Aufmerksamkeitsmechanismen.
ECCV2022 Papierzusammenfassung: ECCV2022-Papierliste


