External Attention pytorch
1.0.0

Chinês simplificado | Inglês
Olá a todos, eu sou Xiaoma
Para Xiaobai (como eu): recentemente, encontrarei um problema quando leio um artigo. Às vezes, a idéia principal do artigo é muito simples e o código principal pode ser apenas uma dúzia de linhas. No entanto, quando abri o código -fonte do lançamento do autor, descobri que o módulo proposto estava incorporado em estruturas de tarefas, como classificação, detecção e segmentação, o que levou a um código relativamente redundante. Não estou familiarizado com estruturas de tarefas específicas e é difícil para mim encontrar o código central , o que leva a certas dificuldades em entender documentos e idéias de rede.
Para Advanced (como você): se você considera unidades básicas como Conv, FC e RNN como pequenos blocos de construção de Lego e estruturas como transformador e resnet como castelos de Lego que foram construídos. Em seguida, os módulos fornecidos por este projeto são componentes LEGO com informações semânticas completas. Deixe os pesquisadores científicos evitarem fazer rodas repetidamente , pense em como usar esses "componentes LEGO" para construir obras mais coloridas.
Para Mestre (pode ser como você): tenho habilidade limitada e não gosto de esguichar levemente ! ! !
Para todos: este projeto está comprometido em implementar uma base de código que permite que os iniciantes de aprendizado profundo entendam e sirvam comunidades científicas e industriais .
Instale diretamente através do PIP
pip install fightingcv-attentionOu clonar o repositório
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )Série de atenção
1. Uso de atenção externa
2. Uso de auto -atenção
3. Uso simplificado de auto -atenção
4. Atenção de aperto e excitação Uso
5. SK Atenção Uso
6. Uso de atenção da CBAM
7. Uso de atenção de Bam
8. Uso da atenção do ECA
9. Uso da atenção da danet
10. Uso da Atenção de Pirâmide (PSA)
11. Uso eficiente de auto-distribuição de várias cabeças (EMSA)
12. Atenção de embaralhar o uso de atenção
13. Uso da atenção da musa
14. Uso da atenção da sge
15. A2 Uso de atenção
16. Uso de atenção à popa
17. Uso da atenção da perspectiva
18. Uso da atenção VIP
19. Uso da atenção do casaco
20. Uso de atenção de Halonet
21. Uso polarizado de auto-ataque
22. Uso da cotattion
23. Uso de atenção residual
24. Uso de atenção S2
25. Uso de atenção GFNET
26. Uso de atenção tripleto
27. Coordenar o uso da atenção
28. Uso da atenção do MobileVit
29. Uso da atenção da parnet
30. Uso de atenção OVNI
31. Uso de atenção da Acmix
32. Uso de atenção MobileVitv2
33. Uso de atenção
34. Uso de atenção do formulador cruzado
35. Uso de atenção do Moatransformer
36. Uso da atenção da atenção cruzada
37. ATENÇÃO AXIAL_ATTENÇÃO Uso
Série de backbone
1. Uso de resnet
2. Uso de ressexagem
3. Uso do MobileVit
4. Uso de convmixer
5. Uso do ShuffleTransformer
6. Uso de contagem
7. Uso do hatnet
8. Uso do revestimento
9. Uso de PVT
10. Uso do CPVT
11. Uso do poço
12. Uso cruzado
13. Uso TNT
14. Uso do DVIT
15. Uso de CEIT
16. Uso de convite
17. Uso de cait
18. Uso do patchconvnet
19. Uso deit
20. Uso do levit
21. Uso VOLO
22. Uso do contêiner
23. Uso do CMT
24. Uso eficiente do formador
25. Uso ConvNextv2
Série MLP
1. Uso de repmlp
2. Uso do MLP-Mixer
3. Uso de resmlp
4. Uso do GMLP
5. Uso SMLP
6. Uso VIP-MLP
Série Re-Parâmetro (REP)
1. Uso de repvgg
2. Uso do ACNET
3. Uso diversificado de bloco de ramificação (DDB)
Série de convolução
1. Uso de convolução separável em profundidade
2. Uso do MBConv
3. Uso involutorral
4. Uso dinâmico
5. Uso do Condconv
Implementação de Pytorch de "Beyond Auto-Attention: Atenção externa usando duas camadas lineares para tarefas visuais --- ARXIV 2021.05.05"
Implementação de Pytorch de "Atenção é tudo o que você precisa --- NIPS2017"
Implementação de Pytorch de "redes de aperto e excitação --- CVPR2018"
Implementação de Pytorch de "redes seletivas de kernel --- CVPR2019"
Implementação de Pytorch de "CBAM: Módulo Convolucional Block Atenção --- ECCV2018"
Implementação de Pytorch de "Bam: Módulo de Atenção de Gargneco --- BMCV2018"
Implementação de Pytorch de "ECA-Net: atenção eficiente do canal para redes neurais convolucionais profundas --- CVPR2020"
Implementação de Pytorch de "Dual Atenção Rede de Segmentação de Cenas --- CVPR2019"
Implementação de Pytorch de "EPSAnet: um bloco de atenção eficiente da pirâmide na rede neural convolucional --- ARXIV 2021.05.30"
Implementação de Pytorch de "REST: um transformador eficiente para reconhecimento visual --- ARXIV 2021.05.28"
Implementação de Pytorch de "SA-Net: Shuffle Atentente para redes neurais convolucionais profundas --- ICASSP 2021"
Implementação de Pytorch de "Muse: Parallel Multi-Scale Atenhe para a sequência a seqüência de aprendizado --- ARXIV 2019.11.17"
Implementação de Pytorch de "aprimoramento espacial em grupo: melhorando o aprendizado de recursos semânticos em redes convolucionais --- arxiv 2019.05.23"
Implementação de Pytorch de "A2-Nets: Double Atenção Redes --- NIPS2018"
Implementação de Pytorch de "um transformador livre de atenção --- ICLR2021 (Apple New Work)"
Implementação de Pytorch do VOLO: Vision Outdooker para reconhecimento visual --- ARXIV 2021.06.24 "[Análise de papel]
Implementação de Pytorch do Vision Permutator: Uma arquitetura permitida por MLP para reconhecimento visual --- ARXIV 2021.06.23 [Análise de papel]
Implementação de Pytorch do CoatNet: Casando-se convolução e atenção para todos os tamanhos de dados --- ARXIV 2021.06.09 [Análise de Paper]
Implementação de Pytorch da escala de auto-atimento local para backbones visuais eficientes em parâmetro --- CVPR2021 ORAL [Análise de Papel]
Implementação de Pytorch da auto-atimento polarizado: em direção à regressão de alta qualidade em pixels --- ARXIV 2021.07.02 [Análise de papel]
Implementação de Pytorch de redes de transformadores contextuais para reconhecimento visual --- ARXIV 2021.07.26 [Análise de papel]
Implementação de Pytorch de atenção residual: um método simples, mas eficaz, para o reconhecimento de vários rótulos --- ICCV2021
Implementação de Pytorch de S²-MLPV2: Arquitetura MLP de mudança espacial aprimorada para visão --- ARXIV 2021.08.02 [Análise de papel]
Implementação de Pytorch de redes de filtros globais para classificação de imagem --- ARXIV 2021.07.01
Pytorch Implementação de girar para comparecer: Módulo Convolucional Triplet Atenção --- WACV 2021
Implementação de Pytorch de atenção de coordenadas para design de rede móvel eficiente --- CVPR 2021
Implementação de Pytorch de MobileVit: Transformador de visão leve, de uso geral e amigável para dispositivos móveis --- ARXIV 2021.10.05
Implementação de Pytorch de redes não profundas --- ARXIV 2021.10.20
Implementação de Pytorch de OVNI: transformador de visão linear de alto desempenho sem softmax --- arxiv 2021.09.29
Implementação de Pytorch de auto-atimento separável para transformadores de visão móvel --- ARXIV 2022.06.06
Implementação de Pytorch da integração de auto-distribuição e convolução --- ARXIV 2022.03.14
Implementação de Pytorch do CrossFormer: um versátil Transformador de visão dobra em atenção em escala cruzada --- ICLR 2022
Implementação de Pytorch de agregar recursos globais em transformador de visão local
Implementação de Pytorch do CCNET: atenção cruzada para segmentação semântica
Implementação de Pytorch de atenção axial em transformadores multidimensionais
"Além da auto-atenção: atenção externa usando duas camadas lineares para tarefas visuais"
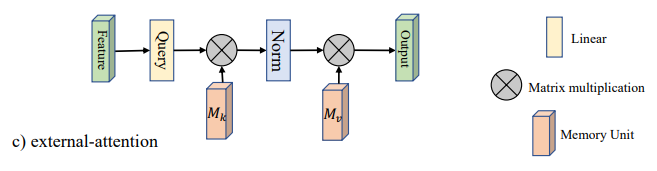
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"Atenção é tudo que você precisa"
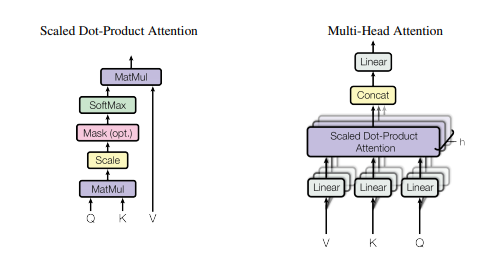
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Nenhum
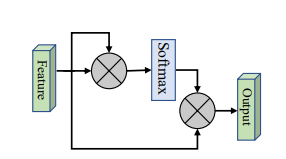
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"Redes de aperto e excitação"
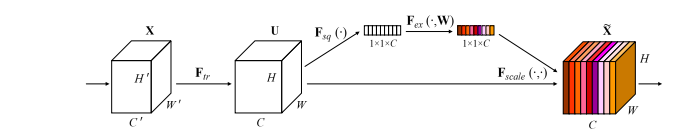
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"Redes seletivas de kernel"
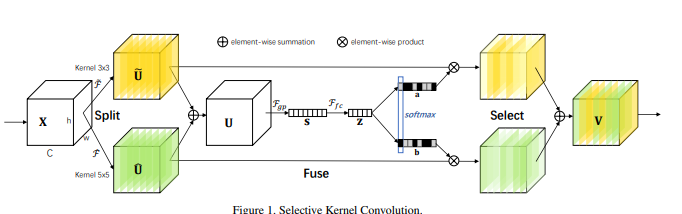
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM: Módulo de Atenção de Bloco Convolucional"
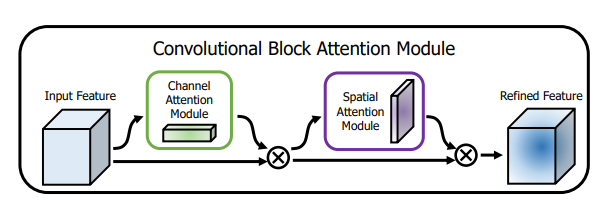
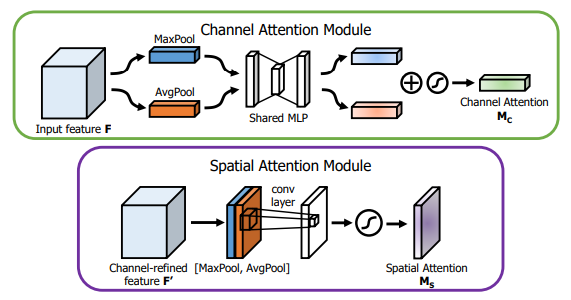
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"Bam: módulo de atenção gargalo"
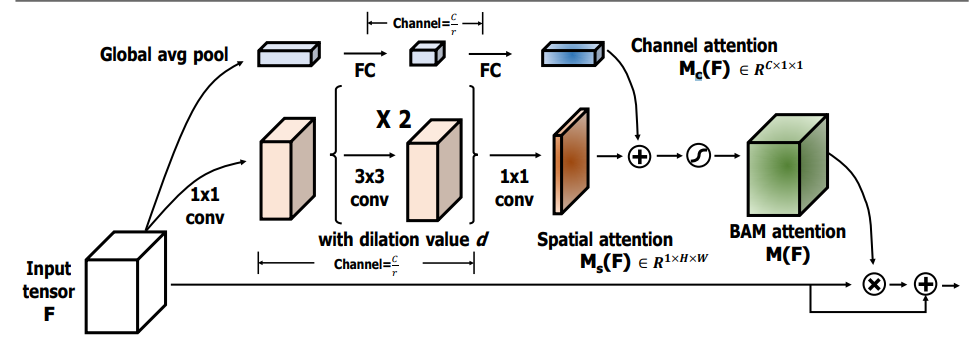
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET: atenção eficiente do canal para profundas redes neurais convolucionais"
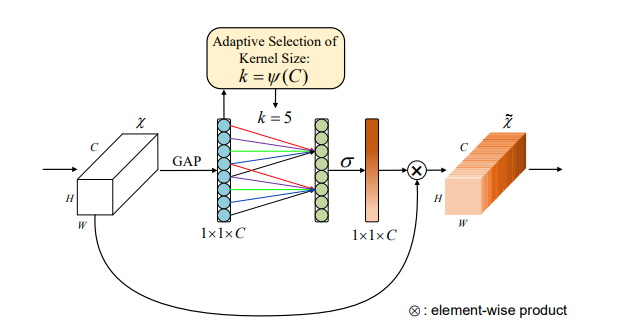
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"Rede de atenção dupla para segmentação de cenas"
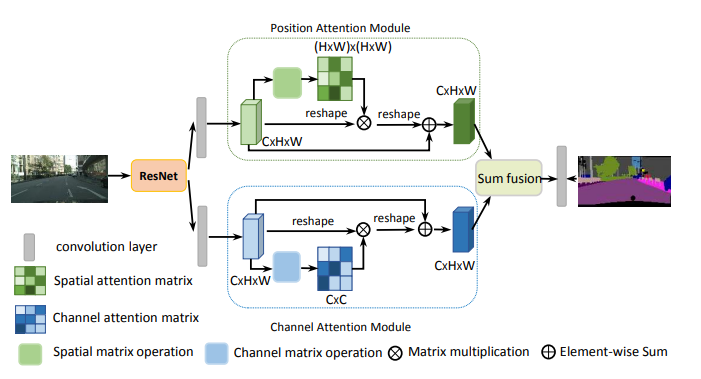
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"EPSANET: um bloco de atenção eficiente da pirâmide na rede neural convolucional"
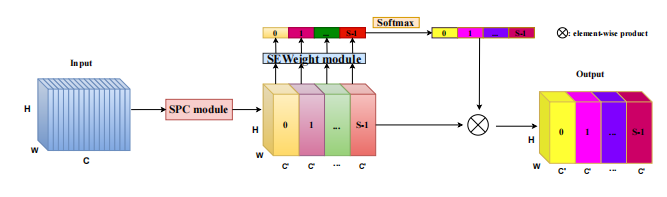
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"Rest: um transformador eficiente para reconhecimento visual"
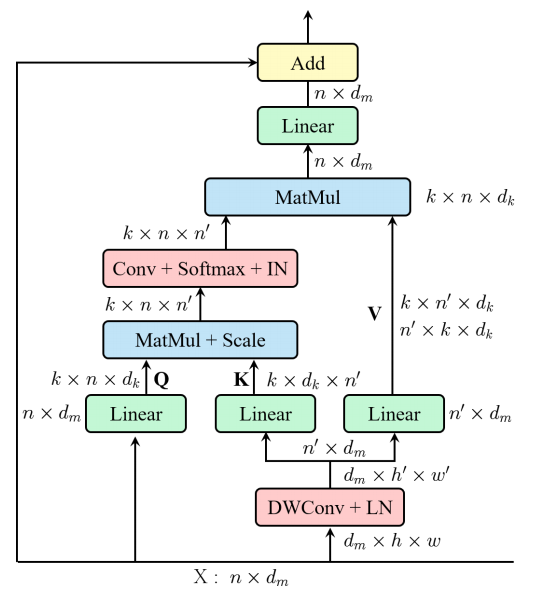
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET: embaralhamento atrevido para profundas redes neurais convolucionais"
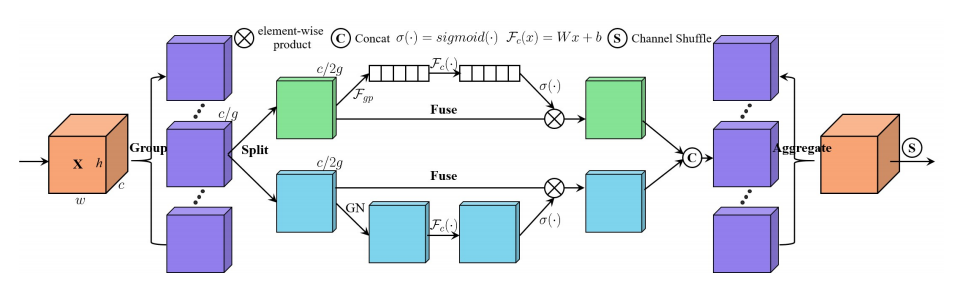
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"MUSE: Atenção paralela em várias escalas para a sequência para seqüência de aprendizado"
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )Melhorar o grupo espacial: melhorando o aprendizado de recursos semânticos em redes convolucionais
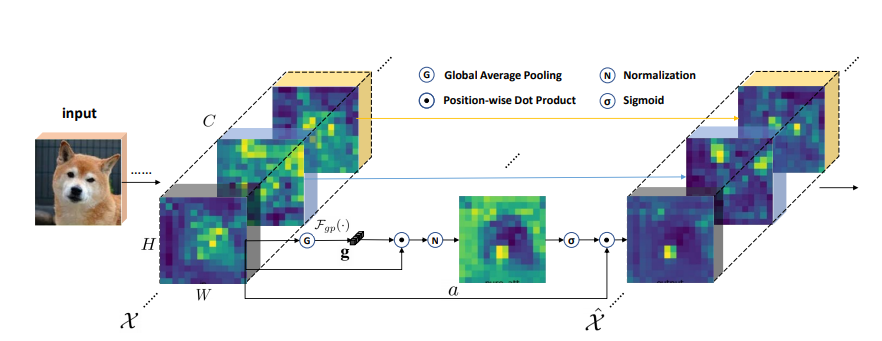
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Nets: redes de atenção dupla
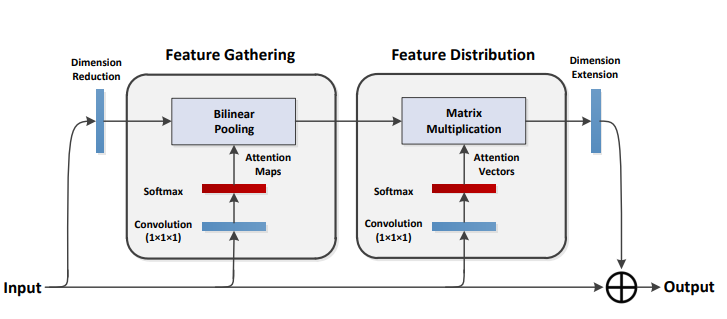
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )Um transformador sem atenção
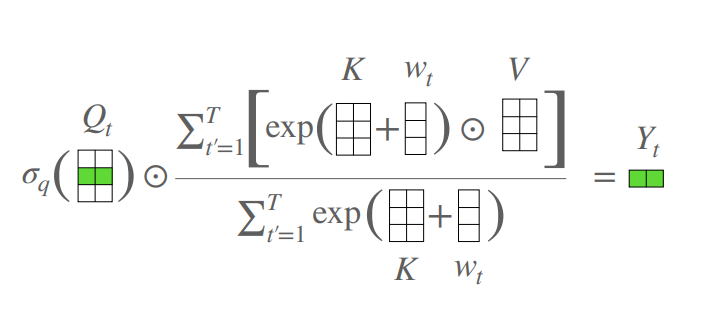
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )VOLO: Vision Outdooker para reconhecimento visual "
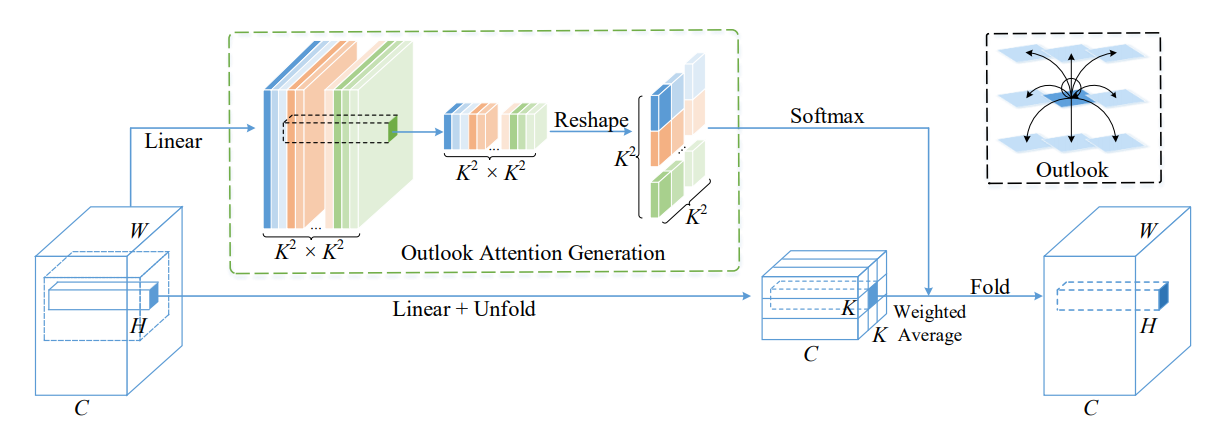
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )Vision Permutator: Uma arquitetura permitida por MLP para reconhecimento visual "
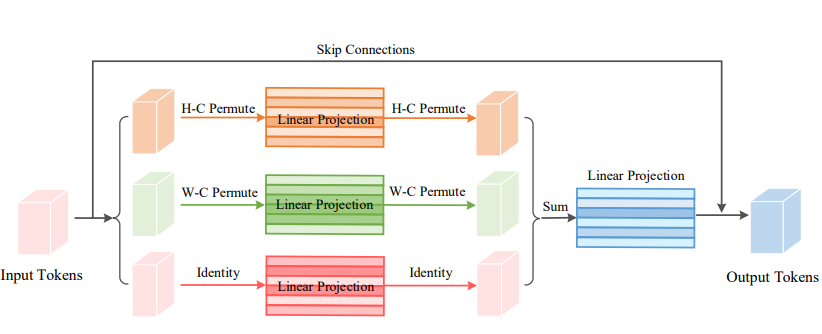
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet: Casar convolução e atenção para todos os tamanhos de dados "
Nenhum
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )Escalando a auto-atendimento local para backbones visuais eficientes em parâmetro "
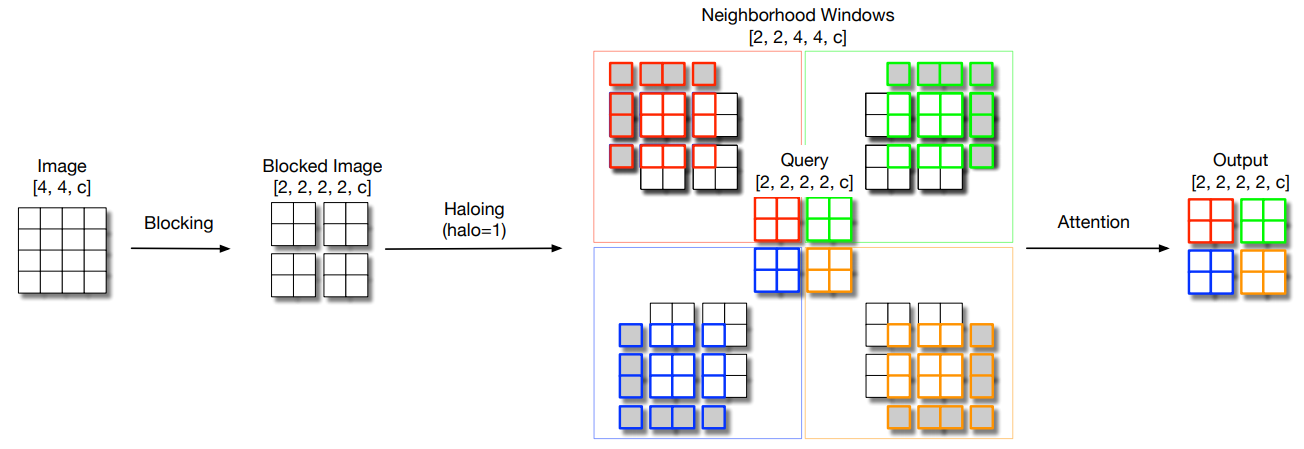
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )Auto-ataque polarizado: em direção à regressão de alta qualidade em pixels "
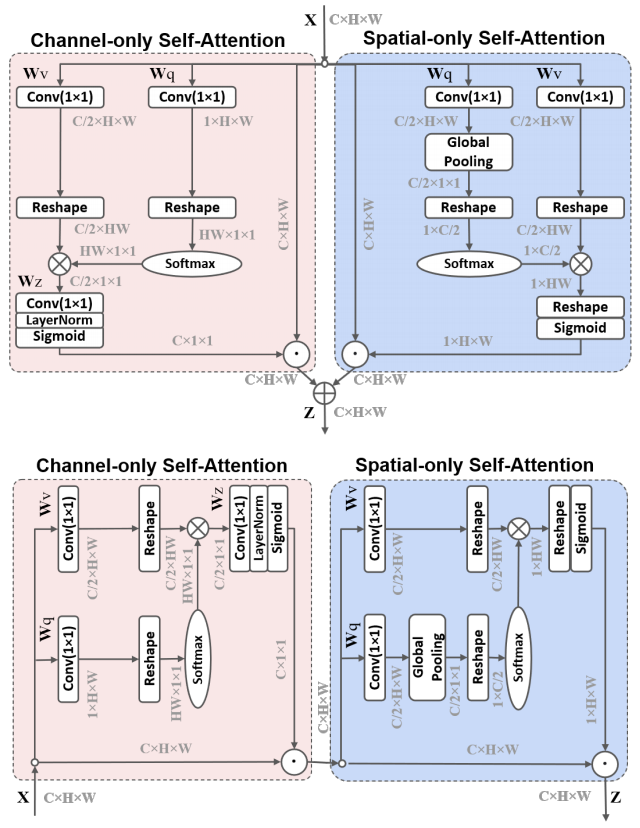
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
Redes de transformadores contextuais para reconhecimento visual --- ARXIV 2021.07.26
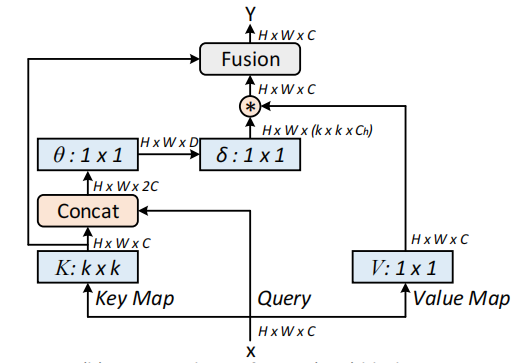
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
Atenção residual: um método simples, mas eficaz para reconhecimento de vários rótulos --- ICCV2021
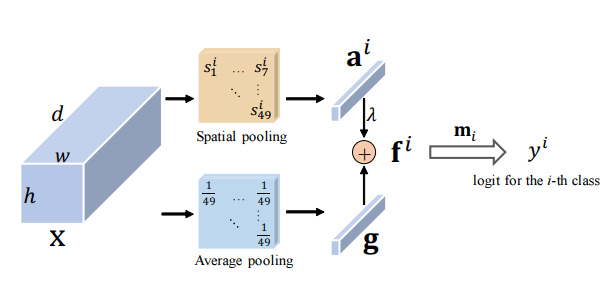
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2: Arquitetura MLP de mudança espacial aprimorada para visão --- ARXIV 2021.08.02
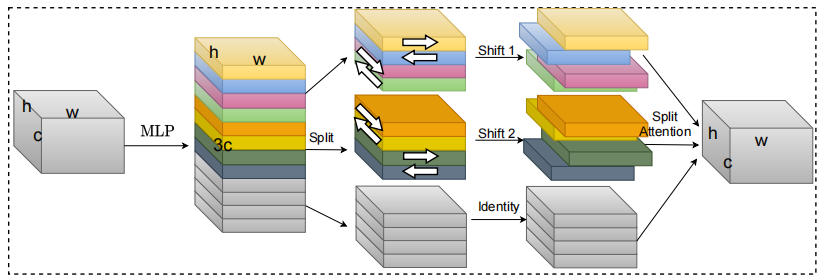
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )Redes de filtros globais para classificação de imagem --- ARXIV 2021.07.01
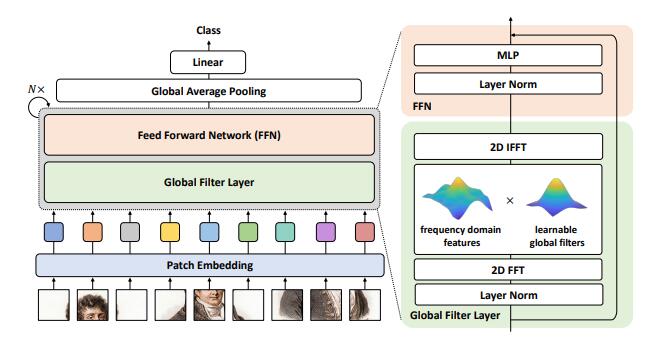
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )Gire para participar: Módulo Convolucional Triplet Atenção --- CVPR 2021
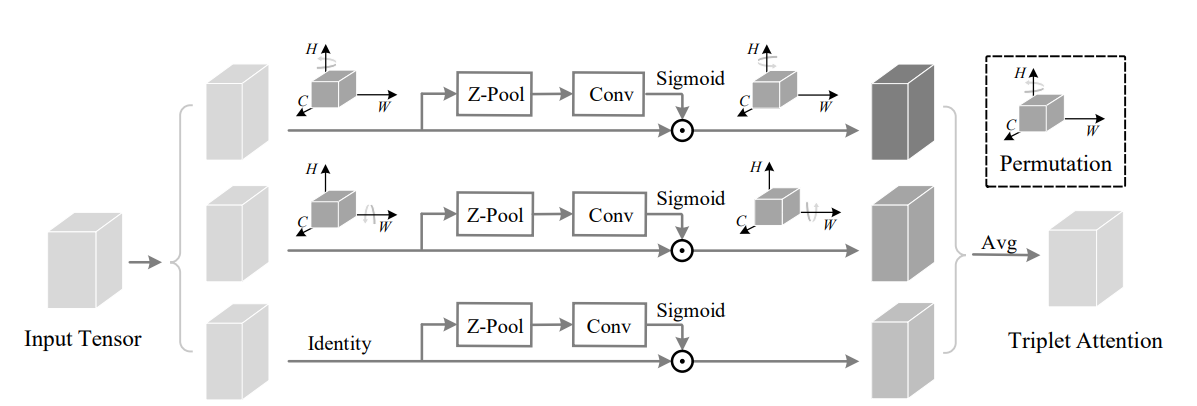
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )Coordenar atenção para design de rede móvel eficiente --- CVPR 2021
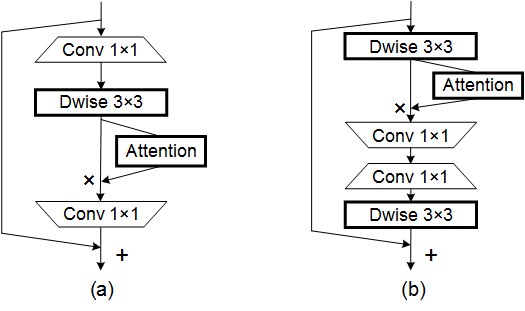
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit: Transformador de visão leve, de uso geral e amigável para dispositivos móveis --- ARXIV 2021.10.05
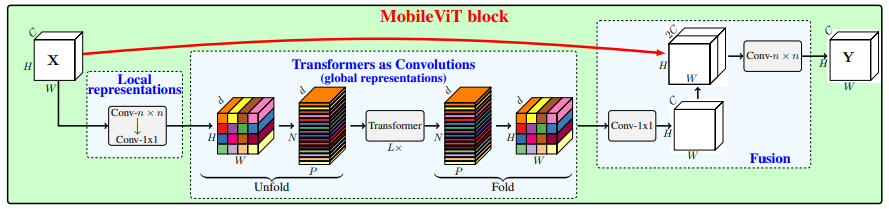
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
Redes não profundas --- ARXIV 2021.10.20
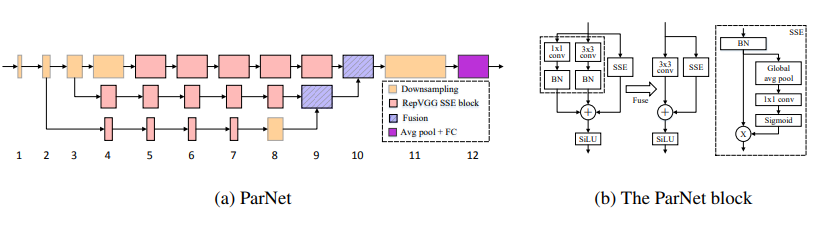
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
OVNI-VIT: Transformador de visão linear de alto desempenho sem softmax --- ARXIV 2021.09.29
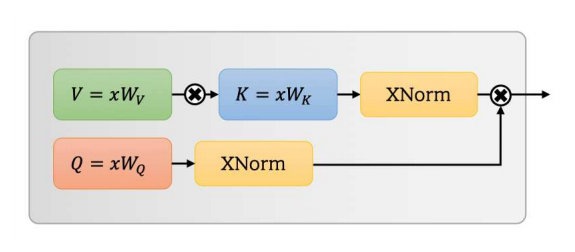
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
Sobre a integração de auto-atimento e convolução
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
ATAÇÃO SEPONCIONAL PARA TRANSFORMADORES DE VISÃO MOVEL --- ARXIV 2022.06.06
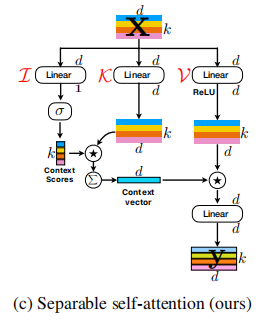
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
Transformador de visão com atenção deformável --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Formulador Cross: Um Transformador de Visão Versátil Torda de Atenção em escala cruzada --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
Agregar recursos globais em transformador de visão local
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET: atenção cruzada para segmentação semântica
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
Atenção axial em transformadores multidimensionais
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Implementação de Pytorch de "Aprendizado residual profundo para reconhecimento de imagem --- CVPR2016 Melhor artigo"
Implementação de Pytorch de "Transformações residuais agregadas para redes neurais profundas --- CVPR2017"
Implementação de Pytorch de MobileVit: Transformador de visão leve, de uso geral e amigável para dispositivos móveis --- ARXIV 2020.10.05
Implementação de patches Pytorch é tudo o que você precisa? --- ICLR2022 (em revisão)
Implementação de Pytorch do transformador de shuffle: repensando o shuffle espacial para o transformador de visão --- arxiv 2021.06.07
Implementação de Pytorch do CONTNET: Por que não usar a convolução e o transformador ao mesmo tempo? --- ARXIV 2021.04.27
Implementação de Pytorch de transformadores de visão com atenção hierárquica --- ARXIV 2022.06.15
Implementação de Pytorch de Transformadores de Imagem Conv-Atrentional Co-escala --- ARXIV 2021.08.26
Implementação de Pytorch de codificações posicionais condicionais para transformadores de visão
Implementação de Pytorch de repensar as dimensões espaciais dos transformadores de visão --- ICCV 2021
Implementação de Pytorch de CrossVit: Transformador de visão em várias escalas para classificação de imagem --- ICCV 2021
Implementação de Pytorch do transformador no transformador --- Neurips 2021
Implementação de Pytorch de DeepVit: em direção a um transformador de visão mais profundo
Implementação de Pytorch de incorporar projetos de convolução em transformadores visuais
Implementação de Pytorch do Convit: Melhorando os transformadores de visão com vieses indutivos convolucionais suaves
Implementação de Pytorch de redes convolucionais aumentadas com agregação baseada em atenção
Implementação de Pytorch de se aprofundar com transformadores de imagem --- ICCV 2021 (oral)
Implementação de Pytorch de Training Transformadores de Imagem e Eficiente de Dados e Destilação através da Atenção --- ICML 2021
Implementação de Pytorch de Levit: um transformador de visão em roupas de convnet para inferência mais rápida
Implementação de Pytorch de Volo: Vision Outdooker para reconhecimento visual
Implementação de Pytorch do contêiner: Rede de agregação de contexto --- Neuips 2021
Implementação de Pytorch de CMT: redes neurais convolucionais Conheça os Transformers da visão --- CVPR 2022
Implementação de Pytorch do Transformer Vision com atenção deformável --- CVPR 2022
Implementação de Pytorch de EfficientFormer: Transformers de visão na velocidade do MobileNet
Implementação de Pytorch de Convnextv2: Co-Design e Scaling Convnets com autoencoders mascarados
"Aprendizado residual profundo para reconhecimento de imagem --- CVPR2016 Melhor artigo"
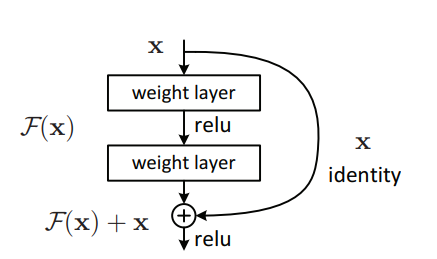
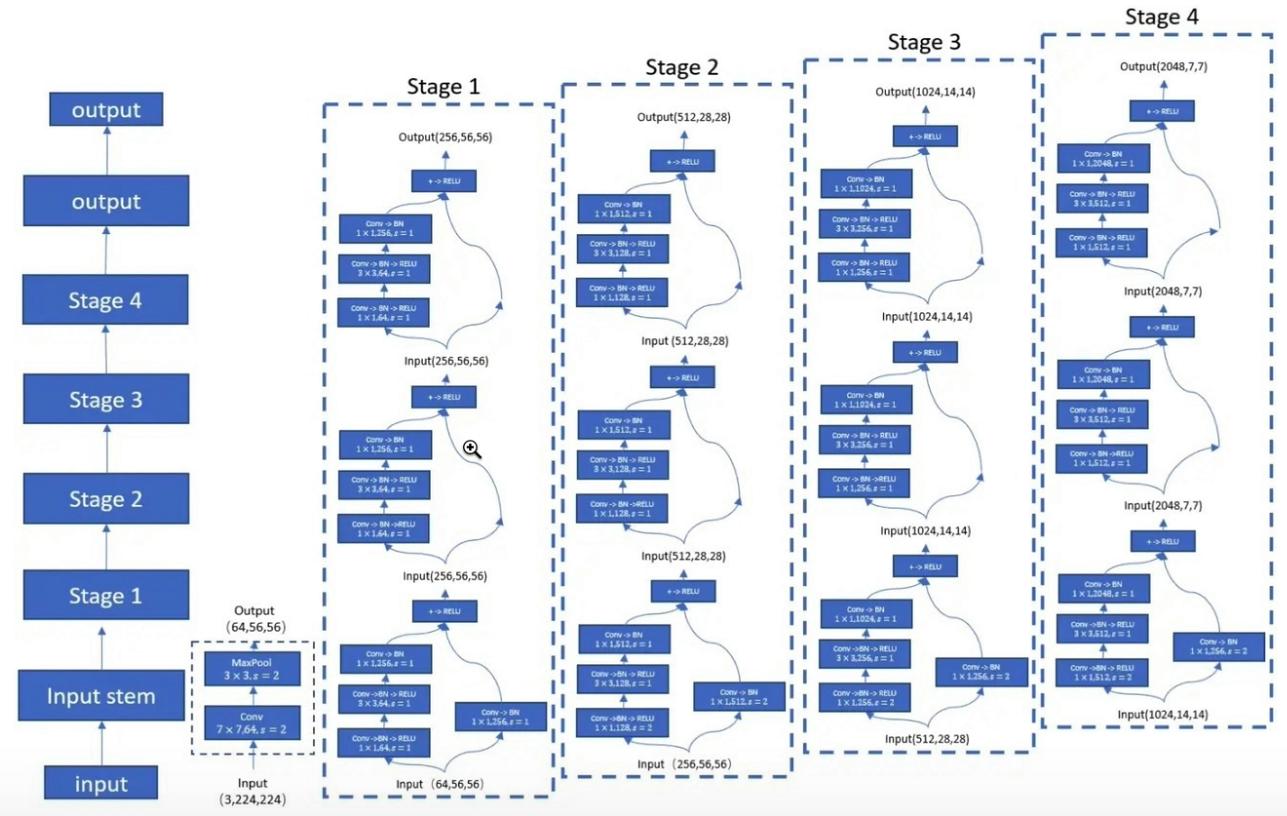
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"Transformações residuais agregadas para redes neurais profundas --- CVPR2017"
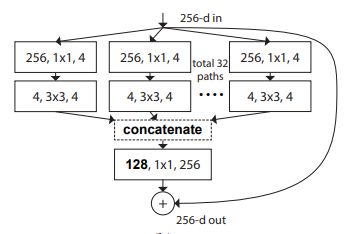
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit: Transformador de visão leve, de uso geral e amigável para dispositivos móveis --- ARXIV 2020.10.05
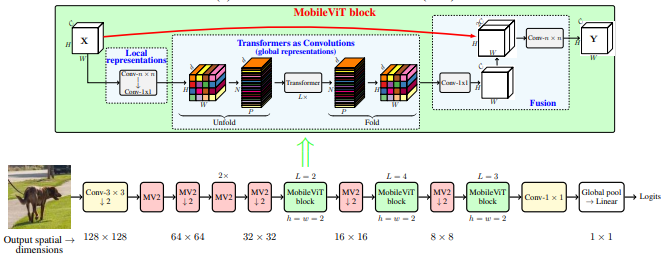
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )Patches são tudo o que você precisa? --- ICLR2022 (em revisão)
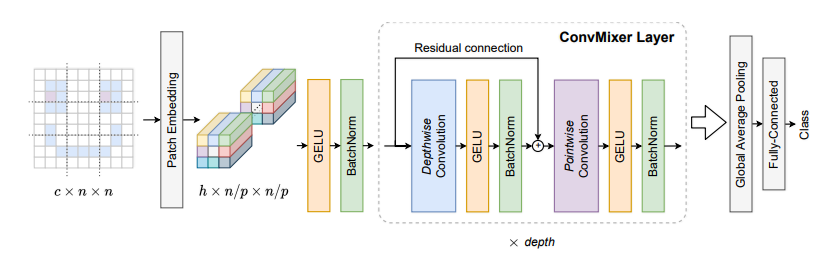
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
Transformador de Shuffle: repensando o shuffle espacial para transformador de visão
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
CONTNET: Por que não usar a convolução e o transformador ao mesmo tempo?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
Transformadores de visão com atenção hierárquica
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
Transformadores de imagem de convicção co-escala
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2: Linhas de base melhoradas com transformador de visão pirâmide
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Codificações posicionais condicionais para transformadores de visão
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )Repensando as dimensões espaciais dos transformadores de visão
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit: Transformador de visão em várias escalas de atendimento cruzado para classificação de imagem
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Transformador no transformador
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )DeepVit: em direção a um transformador de visão mais profundo
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Incorporando projetos de convolução em transformadores visuais
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Convite: Melhorando transformadores de visão com vieses indutivos convolucionais suaves
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )Indo mais fundo com transformadores de imagem
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )Aumentando redes convolucionais com agregação baseada em atenção
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )Treinar transformadores de imagem com eficiência de dados e destilação através da atenção
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit: um transformador de visão em roupas de convnet para inferência mais rápida
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )VOLO: Vision Outdooker para reconhecimento visual
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )Container: Rede de agregação de contexto
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT: as redes neurais convolucionais encontram transformadores de visão
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )EFIFICIFITYFORMER: Transformadores de visão no MobileNet Speed
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )Convnextv2: Co-Design e Scaling Convnets com autoencoders mascarados
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Implementação de Pytorch de "Repmlp: Re-Parametering Convolutions em camadas totalmente conectadas para reconhecimento de imagem --- ARXIV 2021.05.05"
Implementação de Pytorch de "MLP-Mixer: uma arquitetura All-MLP para Vision --- ARXIV 2021.05.17"
Implementação de Pytorch de "RESMLP: Redes Feedforward para classificação de imagem com treinamento com eficiência de dados --- ARXIV 2021.05.07"
Implementação de Pytorch de "Preste atenção aos MLPs --- ARXIV 2021.05.17"
Implementação de Pytorch de "MLP esparso para reconhecimento de imagem: a auto-atimento é realmente necessária? --- ARXIV 2021.09.12"
"Repmlp: re-parametrizando convoluções em camadas totalmente conectadas para reconhecimento de imagem"
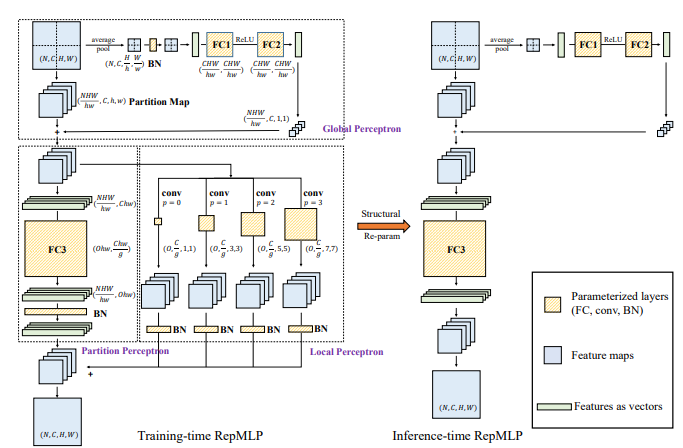
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-Mixer: uma arquitetura All-MLP para visão"
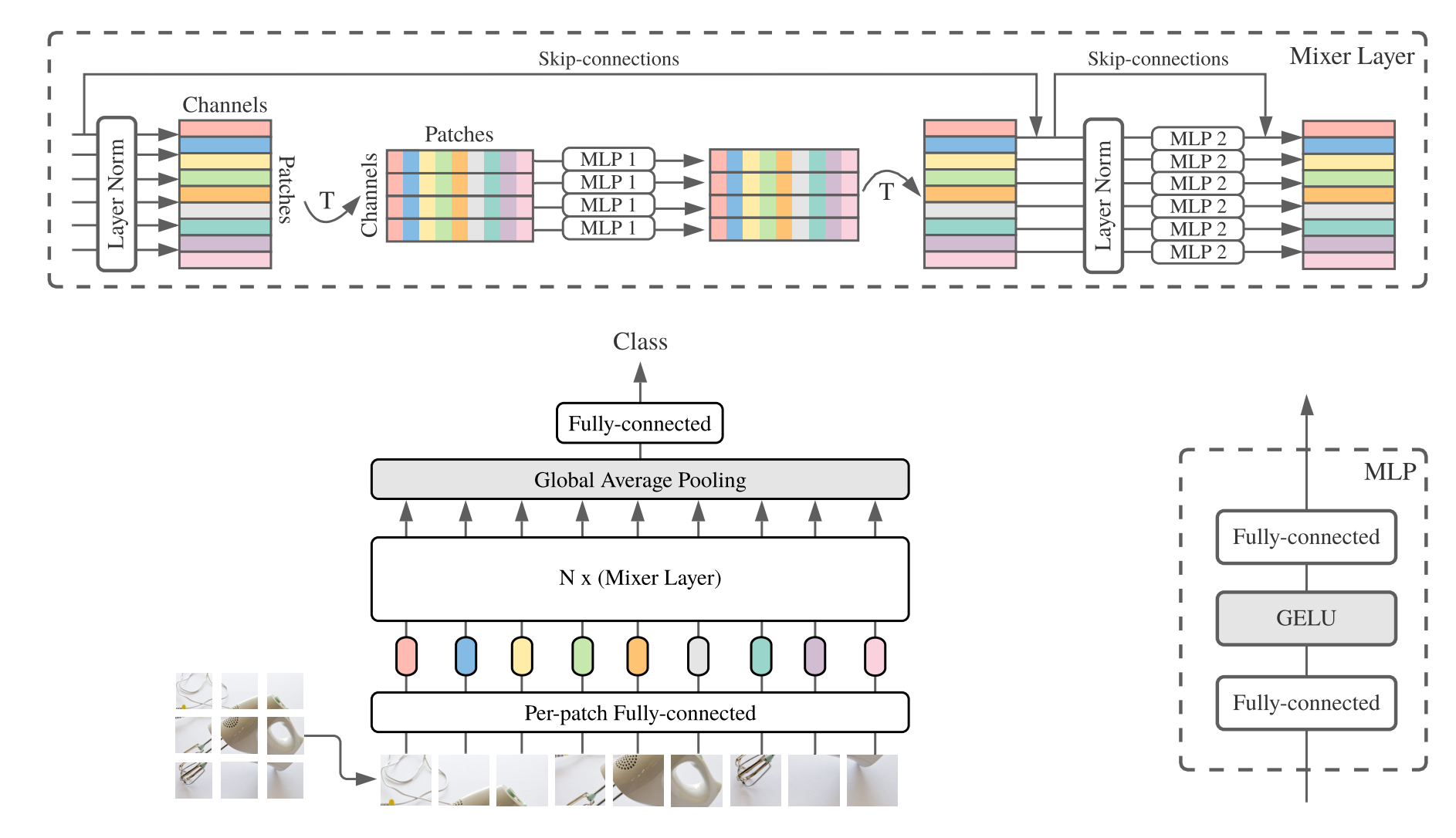
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"Resmlp: Redes Feedforward para classificação de imagem com treinamento com eficiência de dados"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"Preste atenção aos MLPs"
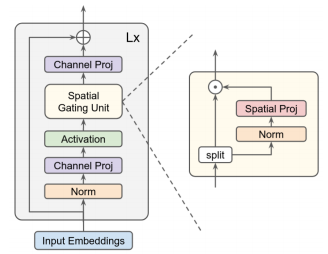
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"MLP esparso para reconhecimento de imagem: a auto-atenção é realmente necessária?"
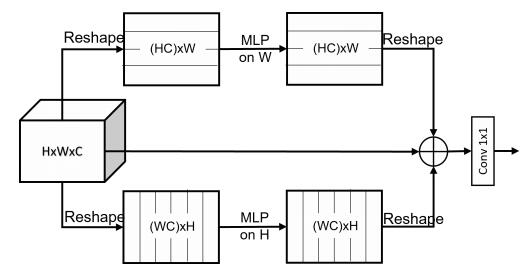
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"Permutador de visão: uma arquitetura permitida por MLP para reconhecimento visual"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )Implementação de Pytorch de "Repvgg: tornando os convênicos de estilo VGG de novo ---- CVPR2021"
Implementação de Pytorch de "ACNET: fortalecendo os esqueletos do kernel para a CNN poderosa via blocos de convolução assimétricos --- ICCV2019"
Implementação de Pytorch de "Diverso Branch Block: Construindo uma convolução como uma unidade semelhante a um início --- CVPR2021"
"REPVGG: Fazendo com que o VGG convnets novamente"
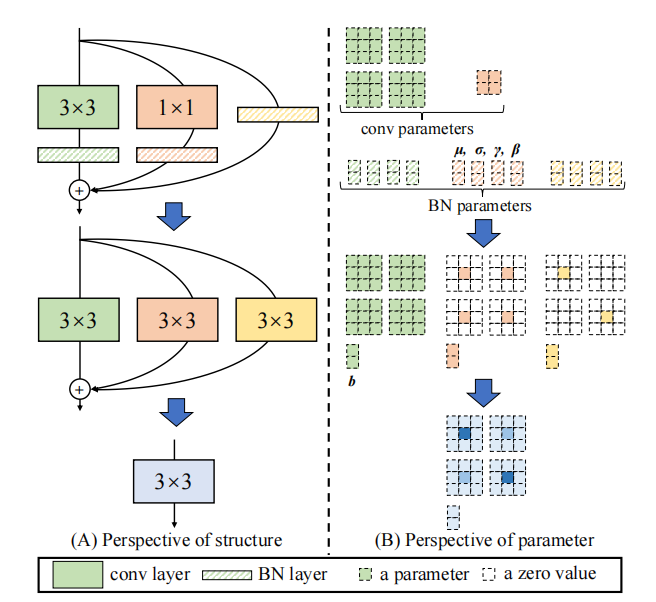
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())"ACNET: fortalecendo os esqueletos do kernel para a CNN poderosa via blocos de convolução assimétricos"
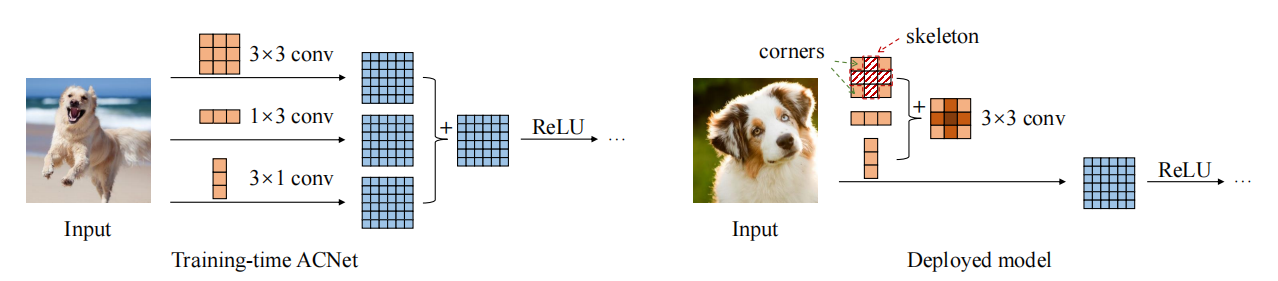
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())"Diverso Branch Block: Construindo uma convolução como uma unidade de início"
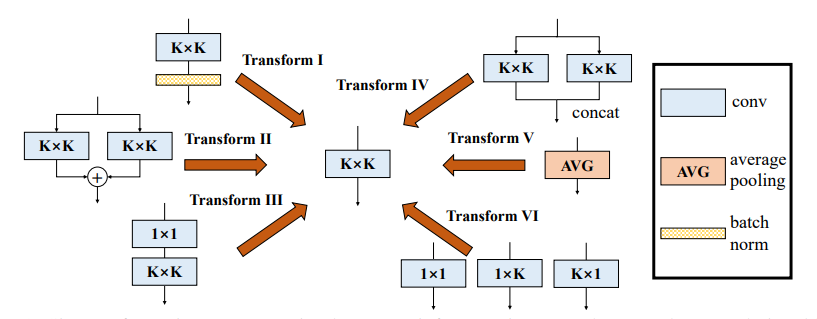
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())Implementação de Pytorch de "Mobilenets: Redes Neurais Convolucionais eficientes para Aplicativos de Visão Móvel --- CVPR2017"
Implementação de Pytorch de "EFABIFITYNET: RETHINANDING MODEL SCALING para redes neurais convolucionais --- PMLR2019"
Implementação de Pytorch de "Involução: invertendo a inereência da convolução pelo reconhecimento visual ---- CVPR2021"
Implementação de Pytorch de "Convolução Dinâmica: Atenção sobre Kernels de Convolução --- CVPR2020 Oral"
Implementação de Pytorch de "CondConv: Convóluis condicionalmente parametrizados para inferência eficiente --- Neurips2019"
"Mobilenets: redes neurais convolucionais eficientes para aplicativos de visão móvel"
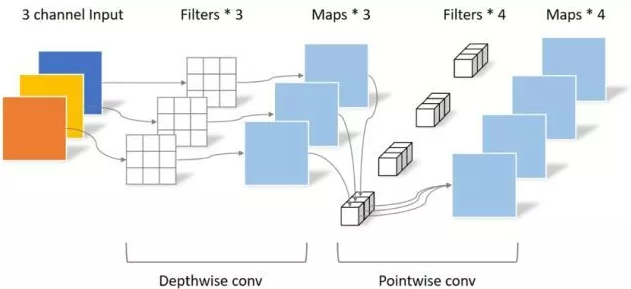
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"EFABIFITYNET: repensando a escala do modelo para redes neurais convolucionais"
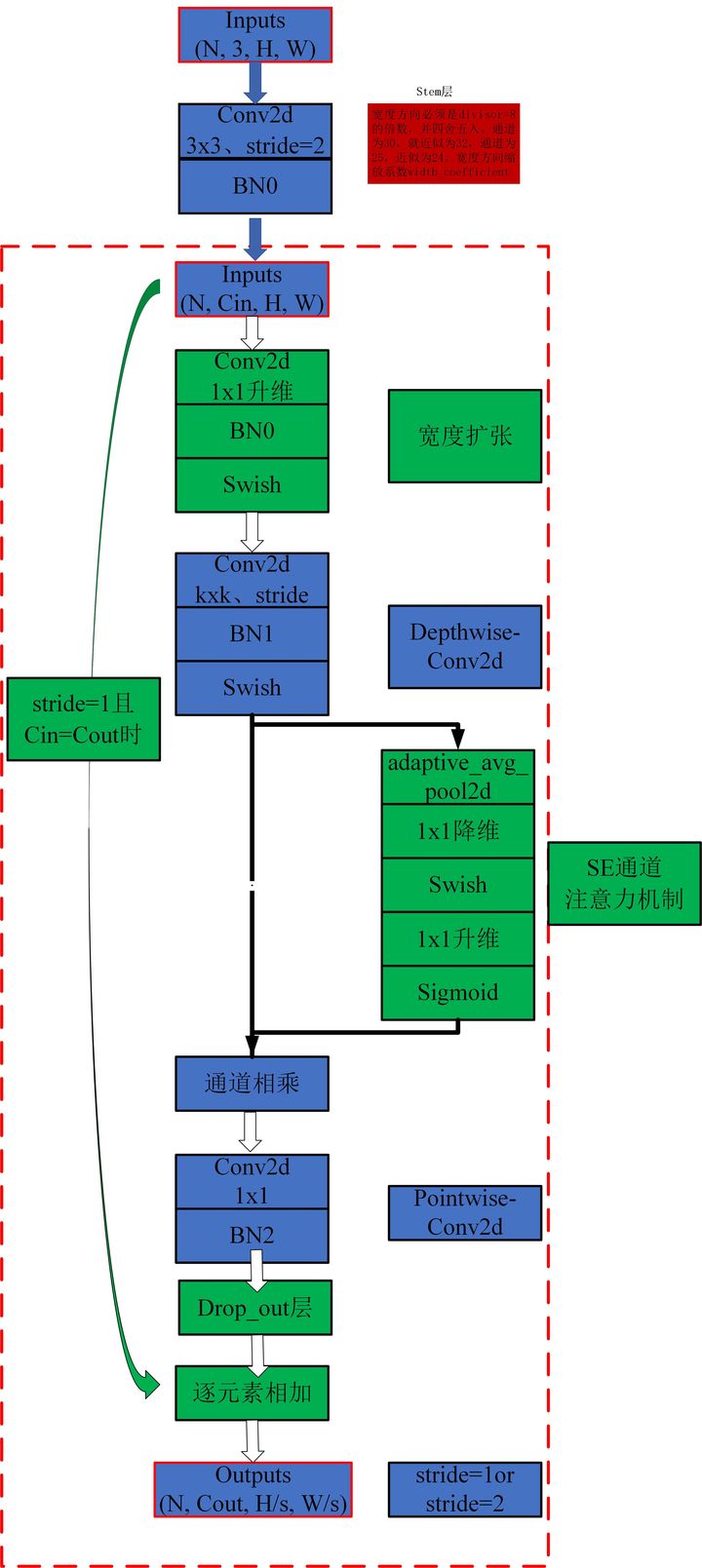
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"Involução: invertendo a inereência da convolução pelo reconhecimento visual"
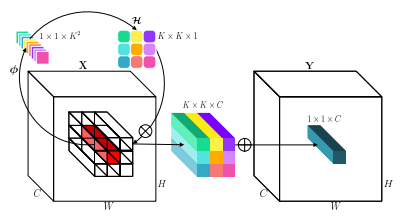
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"Convolução dinâmica: atenção sobre os kernels de convolução"
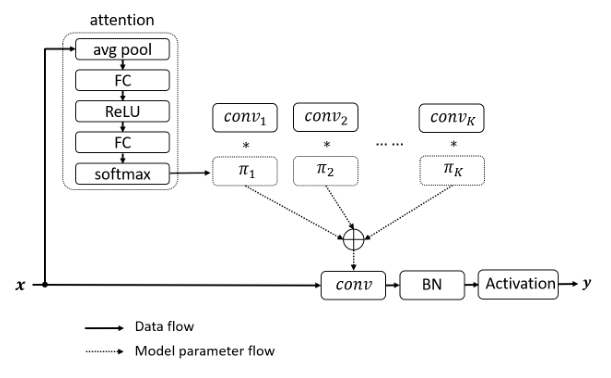
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"Condconv: convoluções condicionalmente parametrizadas para inferência eficiente"
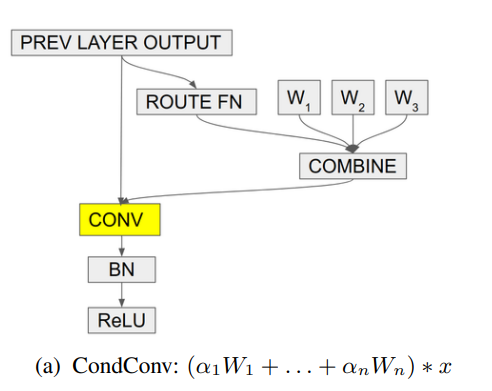
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )Grande notícia! ! ! Como um suplemento ao projeto, você pode prestar atenção ao recém-aberto projeto de projeto FightingCV-paper , que coleta e organiza a análise em papel das principais conferências e periódicos.
Grande notícia! ! ! Recentemente, compilei vários tutoriais em vídeo relacionados à IA e artigos de leitura obrigatória no curso da Internet FightingCV
Grande notícia! ! ! Recentemente, foi aberta uma nova biblioteca de código de detecção de objetos YOLOAIR , que integra uma variedade de modelos YOLO, incluindo Yolov5, Yolov7, Yolor, Yolox, Yolov4, Yolov3 e outros modelos YOLO, além de uma variedade de mecanismos de atenção existentes.
Resumo do artigo ECCV2022: ECCV2022-PAPER-LIST


