External Attention pytorch
1.0.0

単純化された中国人|英語
こんにちは、みなさん、私はXiaomaです
Xiaobai(私のような):最近、論文を読んだときに問題が発見されます。紙のコアアイデアは非常に単純であり、コアコードはわずか1回の行である場合があります。ただし、著者のリリースのソースコードを開くと、提案されたモジュールが分類、検出、セグメンテーションなどのタスクフレームワークに組み込まれているため、比較的冗長コードにつながっていることがわかりました。私は特定のタスクフレームワークに精通しておらず、コアコードを見つけることは困難です。これにより、論文やネットワークのアイデアを理解するのが特定の困難につながります。
Advanced(You)の場合: Conv、FC、RNNなどの基本ユニットを小さなレゴビルディングブロックと見なし、トランスやResnetなどの構造をレゴ城と見なします。次に、このプロジェクトで提供されるモジュールは、完全なセマンティック情報を備えたLEGOコンポーネントです。科学的研究者に車輪の製造を繰り返し避けましょう。これらの「レゴコンポーネント」を使用して、よりカラフルな作品を構築する方法を考えてください。
マスターの場合(あなたのようなものかもしれません):私は能力が限られており、軽く噴出することを好まない! ! !
すべてのために:このプロジェクトは、深い学習初心者が科学研究と産業コミュニティを理解し、サービスを提供できるようにするコードベースの実装に取り組んでいます。
PIPから直接インストールします
pip install fightingcv-attentionまたはリポジトリをクローンします
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )注意シリーズ
1。外部の注意使用量
2。自己注意の使用
3.単純化された自己注意使用量
4.スクイーズアンドエクスケーションの注意の使用
5。SK注意の使用
6。CBAMの注意の使用
7。BAM注意の使用
8。ECA注意の使用
9。Danetの注意の使用
10。Pyramid分割注意(PSA)使用法
11。効率的なマルチヘッドの自己告発(EMSA)使用
12。注意の使用法をシャッフルします
13.注目の使用量をミューズします
14。SGE注意の使用
15。A2注意の使用
16. Aftの注意の使用
17。Outlookの注意の使用法
18。VIP注意の使用
19。Coatnet注意の使用
20。ハロネットの注意の使用
21。偏光自己告発の使用
22。コタットの使用
23。残留注意の使用
24。S2注意の使用
25。GFNET注意の使用
26。トリプレットの注意の使用
27。注意使用量を調整します
28。MobileVit注意の使用
29。Parnetの注意の使用
30。UFO注意の使用
31。ACMIX注意の使用法
32。MobileVitv2注意の使用
33。DAT注意の使用法
34。CrossFormerの注意の使用法
35。Moatransformerの注意の使用法
36。CrissCrossattentionの注意の使用
37。Axial_attention注意の使用
バックボーンシリーズ
1。ResNetの使用
2。snextの使用法
3。MobileVitの使用
4。コンビクサーの使用
5。ShuffleTransformerの使用
6。コンクネットの使用
7。ハットネットの使用
8。コートの使用
9。PVT使用
10。CPVTの使用
11。ピット使用
12。クロスヴィットの使用
13。TNT使用
14。DVIT使用
15。CEITの使用
16。コンビットの使用
17。ケイトの使用
18。PatchConvnetの使用
19。Deitの使用
20。レビットの使用
21. Voloの使用
22。コンテナの使用
23。CMTの使用
24。効率的なフォーマーの使用
25。ConvnextV2の使用
MLPシリーズ
1。REPMLPの使用
2。MLP-Mixerの使用
3。RESMLPの使用
4。GMLP使用
5。SMLPの使用
6。VIP-MLPの使用
Reparameter(rep)シリーズ
1。RepVGGの使用
2。ACNETの使用
3。多様なブランチブロック(DDB)の使用
畳み込みシリーズ
1。深さごとの分離可能な畳み込みの使用
2。MBCONVの使用
3。退縮の使用
4。DynamicConvの使用
5。condconvの使用
Pytorchの実装「自己関節を超えて:視覚タスクに2つの線形層を使用した外部の注意--- ARXIV 2021.05.05」
Pytorchの「注意が必要なすべてです--- NIPS2017」
「スクイーズアンドエクスカテートネットワーク--- CVPR2018」のPytorchの実装
「選択的カーネルネットワーク--- CVPR2019」のPytorchの実装
「CBAM:畳み込みブロック注意モジュール--- ECCV2018」のPytorch実装
「Bam:Bottleneck Attention Module --- BMCV2018」のPytorch実装
「ECA-NET:深い畳み込みニューラルネットワークの効率的なチャネルの注意--- CVPR2020」のPytorch実装」
「シーンセグメンテーションのためのデュアル注意ネットワーク--- CVPR2019」のPytorch実装
「エプサネット:畳み込みニューラルネットワーク上の効率的なピラミッド分割注意ブロック」のPytorch実装--- ARXIV 2021.05.30」
「REST:視覚認識のための効率的な変圧器--- ARXIV 2021.05.28」のPytorchの実装
「sa-net:深い畳み込みニューラルネットワークに気をつけたシャッフル--- ICASSP 2021」のPytorch実装」
「ミューズ:シーケンスのシーケンス学習への並行マルチスケールの注意--- ARXIV 2019.11.17」のPytorchの実装
「空間グループごとの強化:畳み込みネットワークでのセマンティック機能学習の改善--- ARXIV 2019.05.23」のPytorch実装
「A2-Nets:Double Attonest Networks --- NIPS2018」のPytorch実装
Pytorchの「An Tentunes Free Transformer --- ICLR2021(Apple New Work)」の実装
VoloのPytorchの実装:視覚認識のためのVision Outrooker --- Arxiv 2021.06.24 "[論文分析]
視力順列のPytorch実装:視覚認識のための透過性MLP様アーキテクチャ--- ARXIV 2021.06.23 [論文分析]
CoatnetのPytorchの実装:すべてのデータサイズの畳み込みと注意の結婚--- Arxiv 2021.06.09 [論文分析]
パラメーター効率的な視覚バックボーンのためのローカル自己触媒のスケーリングのPytorch実装--- CVPR2021 Oral [Paper Analysis]
Pytorch偏光自己触媒の実装:高品質のピクセルごとの回帰に向けて--- ARXIV 2021.07.02 [論文分析]
Pytorch視覚認識のためのコンテキストトランスネットワークの実装--- ARXIV 2021.07.26 [論文分析]
残留注意のPytorch実装:マルチラベル認識のためのシンプルだが効果的な方法--- ICCV2021
s²-mlpv2のPytorch実装:視力のための空間シフトMLPアーキテクチャの改善--- ARXIV 2021.08.02 [論文分析]
画像分類のためのグローバルフィルターネットワークのPytorch実装--- ARXIV 2021.07.01
Pytorch Rotate to Aestの実装:畳み込みトリプレット注意モジュール--- WACV 2021
効率的なモバイルネットワーク設計のための座標注意のPytorchの実装--- CVPR 2021
Pytorch MobileVitの実装:軽量、汎用、モバイルに優しいビジョントランス
非深いネットワークのPytorch実装--- ARXIV 2021.10.20
UFO-vitのPytorch実装:SoftMaxのない高性能線形視覚変圧器--- ARXIV 2021.09.29
モバイルビジョン変圧器の分離可能な自己触媒のPytorch実装--- Arxiv 2022.06.06
自己触媒と畳み込みの統合に関するPytorchの実装--- ARXIV 2022.03.14
クロスフォーマーのPytorch実装:クロススケールの注意を払う汎用性のある視覚変圧器のヒンジ--- ICLR 2022
グローバルな機能を地元の視覚変圧器に集約するPytorchの実装
CCNETのPytorch実装:セマンティックセグメンテーションのためのCriss-Crossの注意
多次元変圧器における軸方向の注意のPytorch実装
「自己関節を超えて:視覚タスクに2つの線形層を使用した外部の注意」
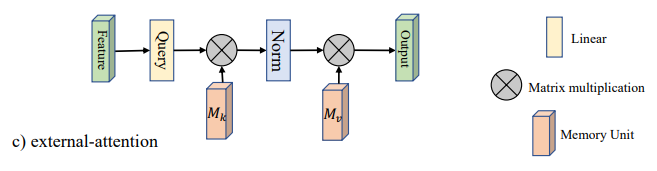
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )「注意が必要です」
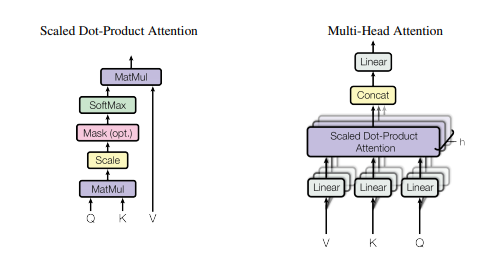
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )なし
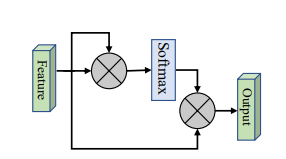
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )「スクイーズアンドエクスケートネットワーク」
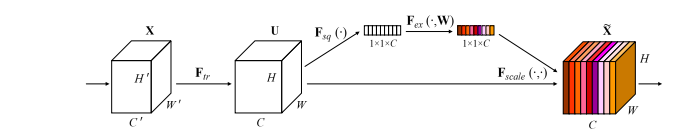
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )「選択的なカーネルネットワーク」
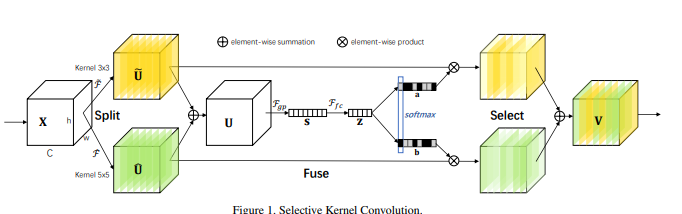
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )「CBAM:畳み込みブロック注意モジュール」
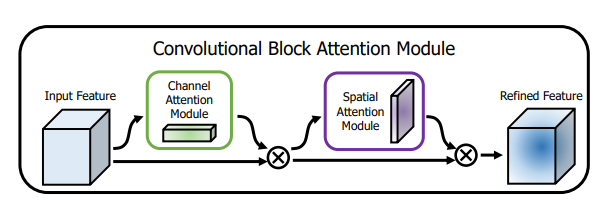
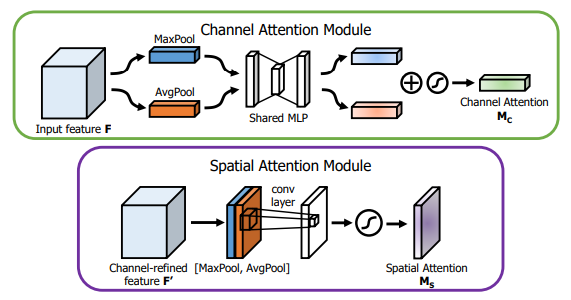
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )「BAM:ボトルネックの注意モジュール」
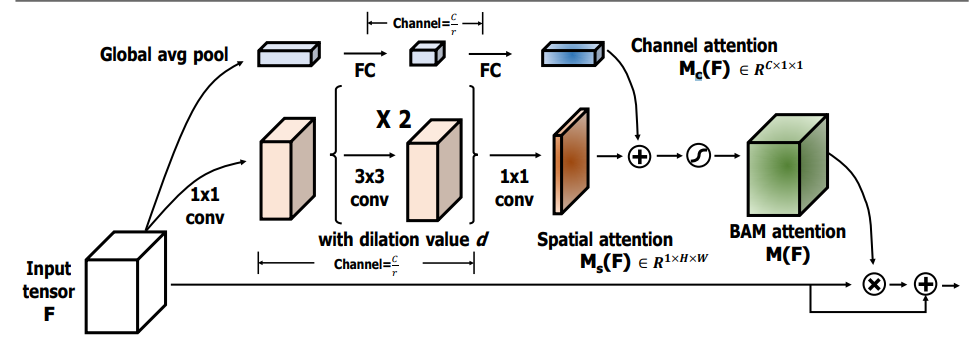
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )「ECA-NET:深い畳み込みニューラルネットワークの効率的なチャネルの注意」
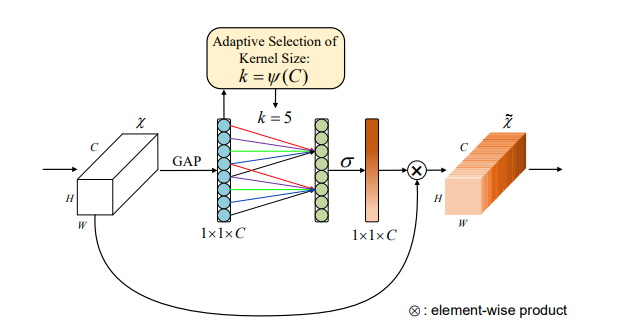
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )「シーンセグメンテーションのためのデュアル注意ネットワーク」
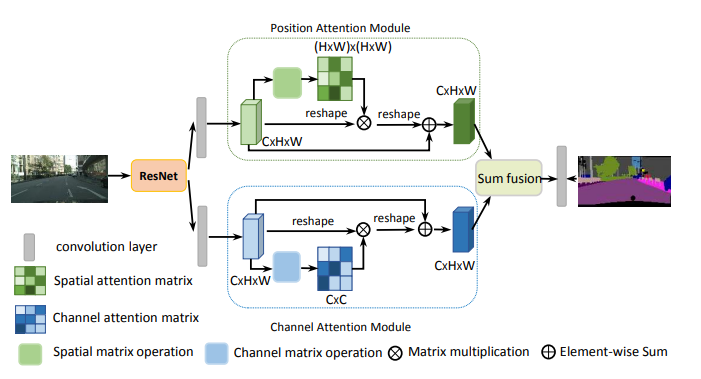
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )「エプサネット:畳み込みニューラルネットワーク上の効率的なピラミッド分割注意ブロック」
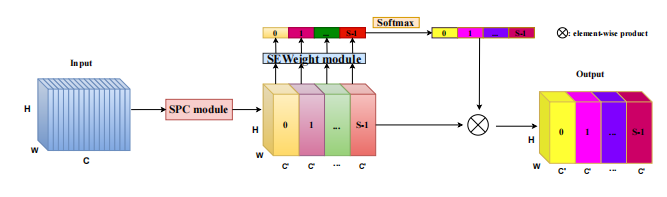
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )「REST:視覚認識のための効率的な変圧器」
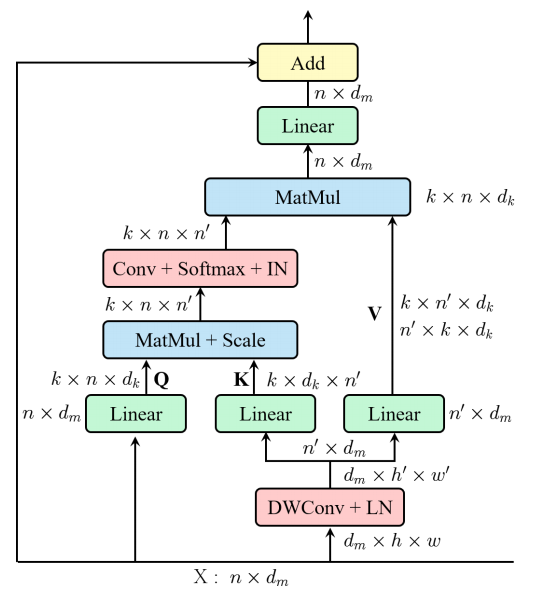
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
「Sa-net:深い畳み込みニューラルネットワークに気を配るシャッフル」
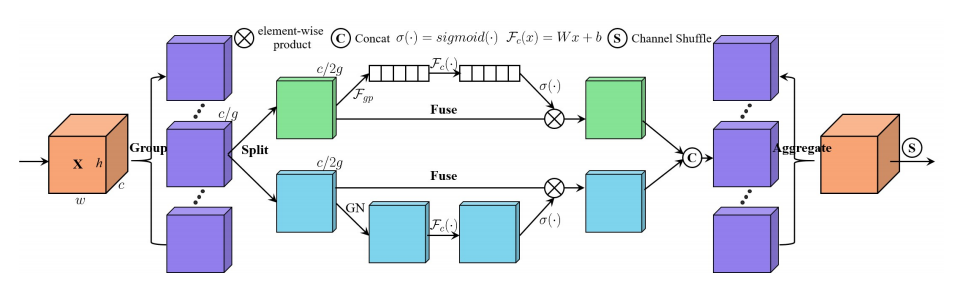
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
「ミューズ:シーケンス学習へのシーケンスのための並行マルチスケールの注意」
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )空間グループごとの強化:畳み込みネットワークでのセマンティック機能学習の改善
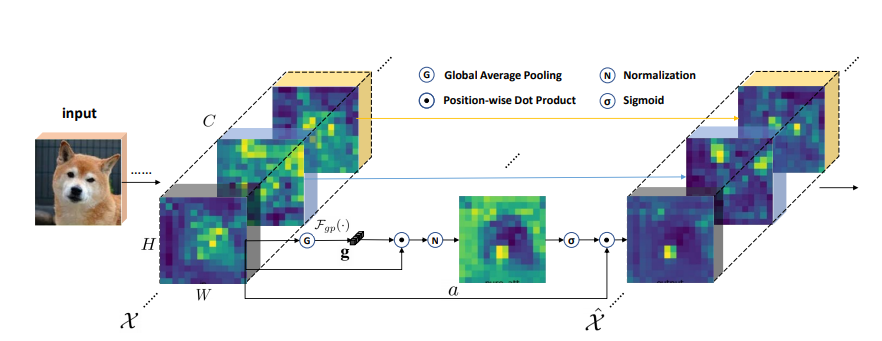
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Nets:ダブル注意ネットワーク
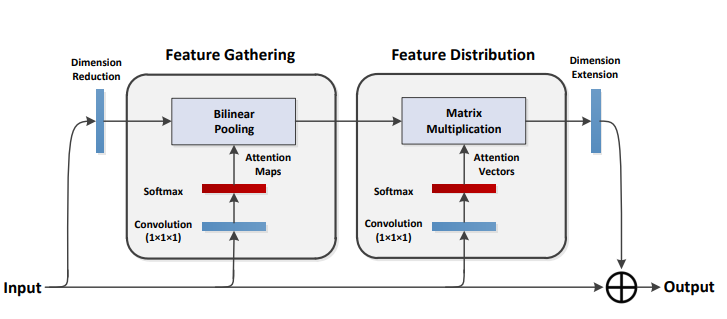
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )注意フリートランス
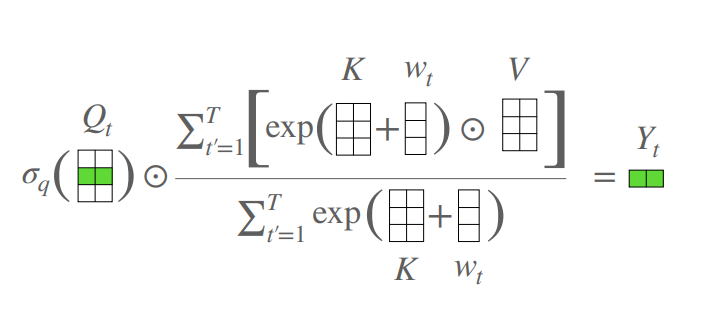
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo:視覚的認識のためのビジョンアウトルーカー」
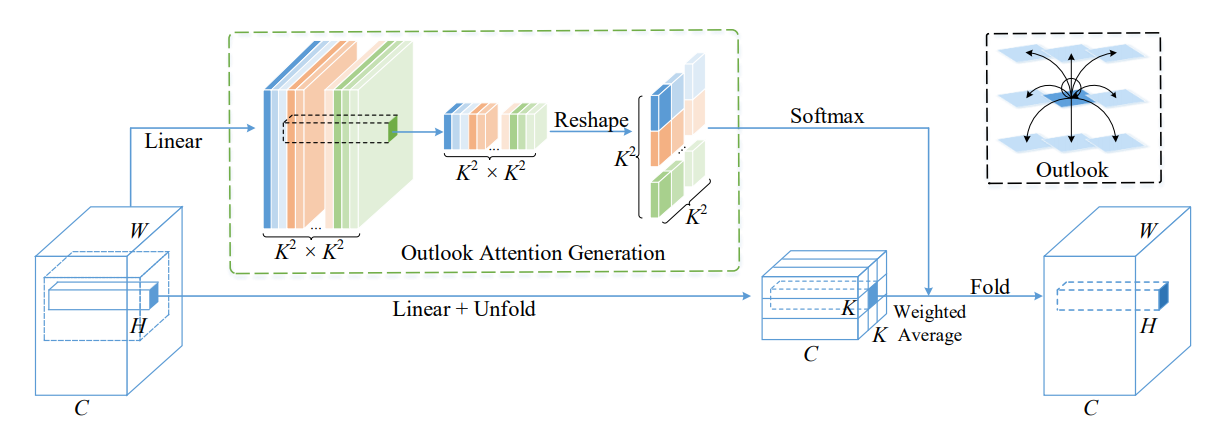
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )ビジョン順列:視覚認識のための順調なMLP様アーキテクチャ」
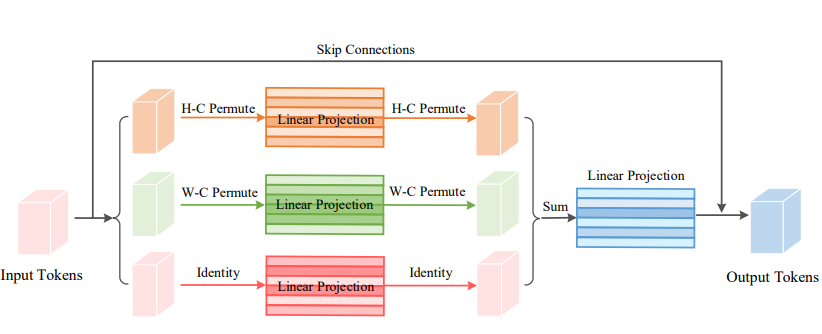
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet:すべてのデータサイズに畳み込みと注意を払う」
なし
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )パラメーターの効率的な視覚的バックボーンのためのローカル自己関節のスケーリング」
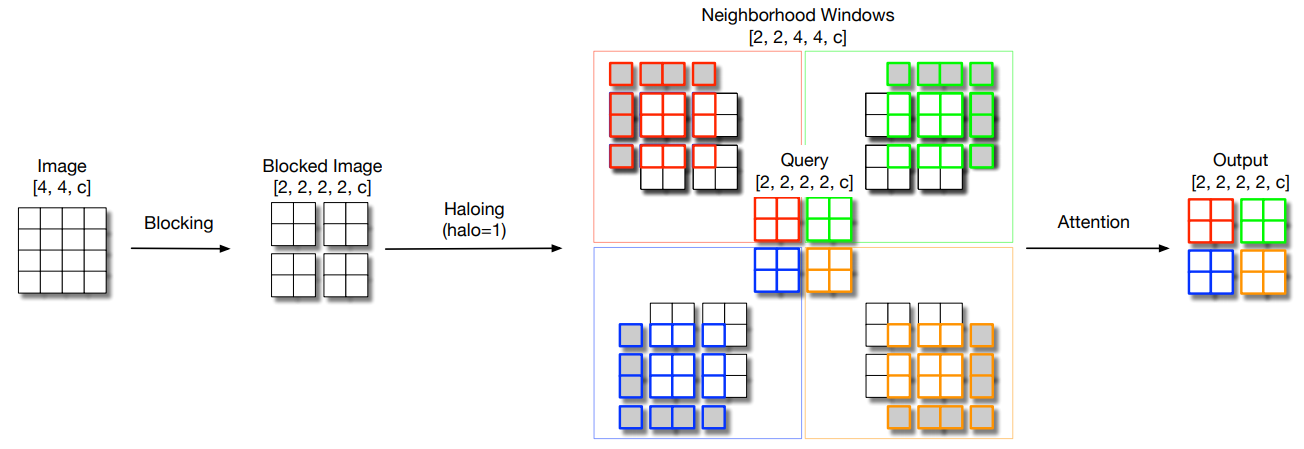
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )偏光自己告発:高品質のピクセルごとの回帰に向けて」
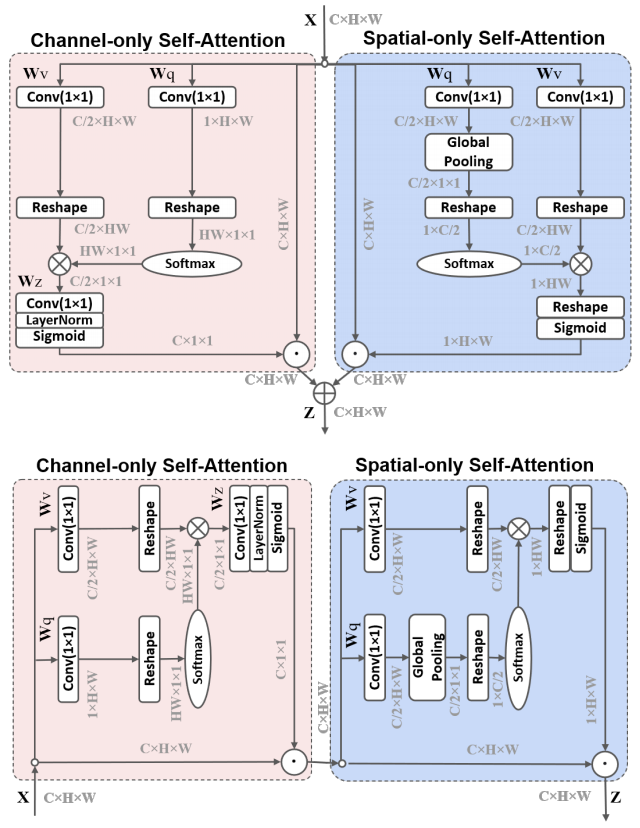
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
視覚認識のためのコンテキストトランスネットワーク--- ARXIV 2021.07.26
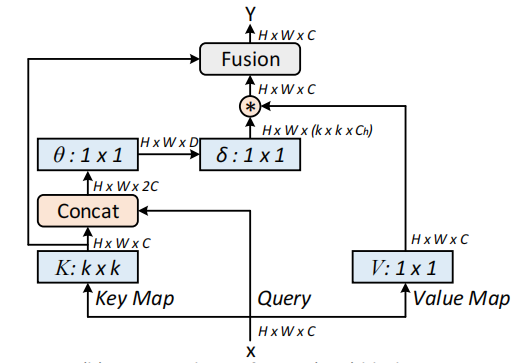
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
残留注意:マルチラベル認識のためのシンプルだが効果的な方法--- ICCV2021
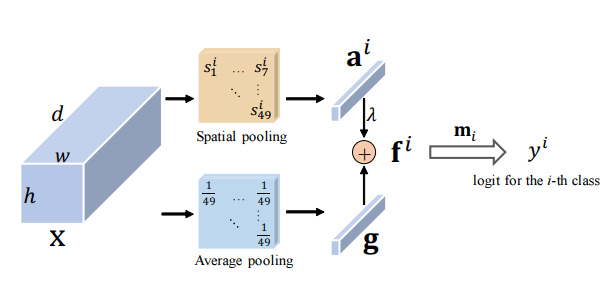
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
s²-mlpv2:視力のための改善された空間シフトMLPアーキテクチャ--- ARXIV 2021.08.02
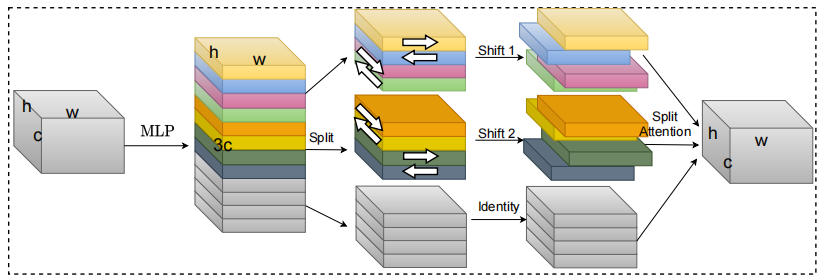
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )画像分類のためのグローバルフィルターネットワーク--- ARXIV 2021.07.01
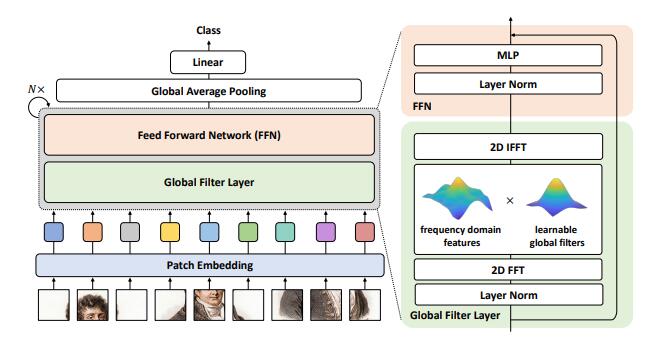
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )参加して回転:畳み込みトリプレット注意モジュール--- CVPR 2021
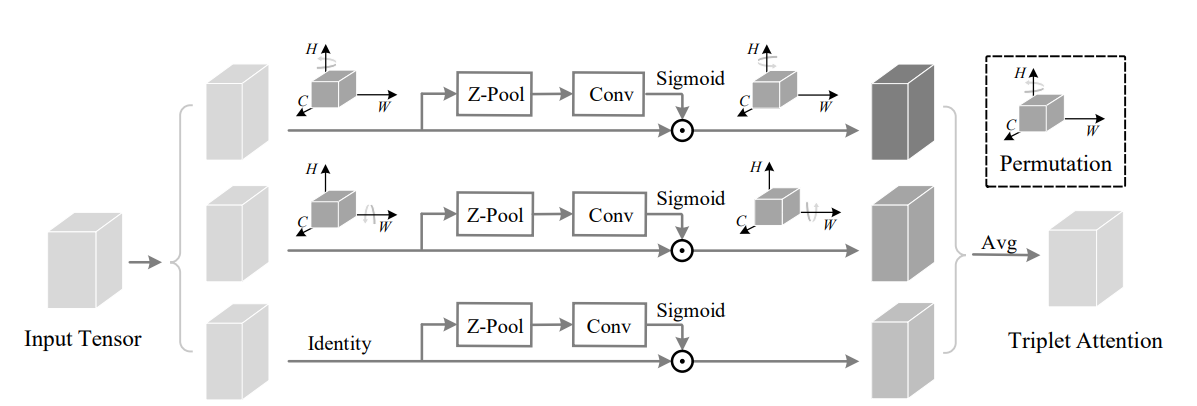
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )効率的なモバイルネットワーク設計のための注意を調整--- CVPR 2021
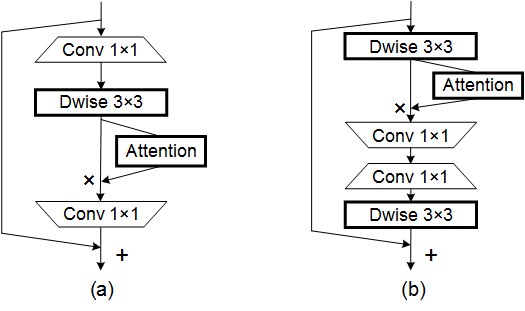
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit:軽量、汎用、モバイルに優しいビジョントランス--- ARXIV 2021.10.05
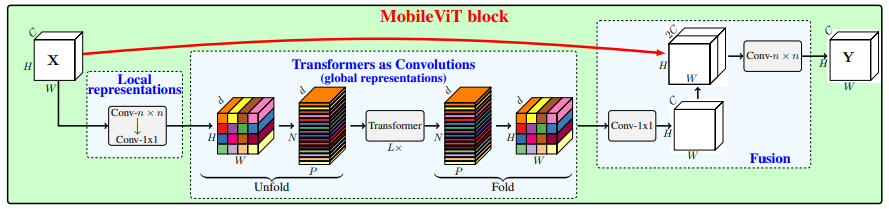
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
非深いネットワーク--- ARXIV 2021.10.20
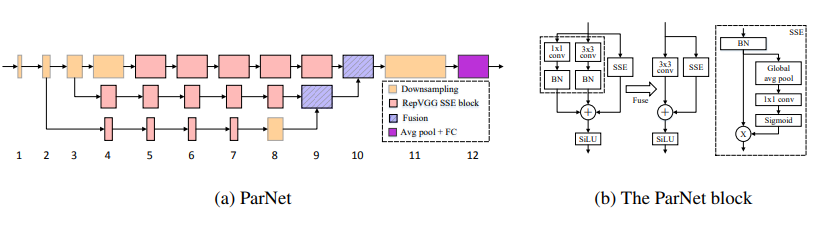
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-vit:SoftMaxのない高性能線形視力変圧器--- ARXIV 2021.09.29
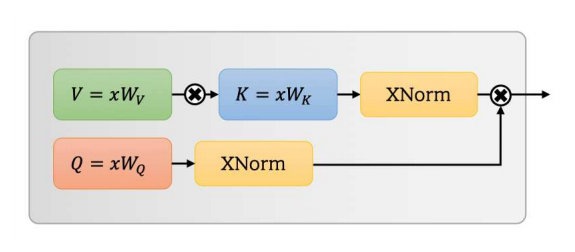
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
自己告発と畳み込みの統合について
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
モバイルビジョン変圧器の分離可能な自己関節--- ARXIV 2022.06.06
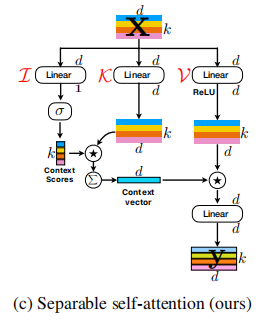
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
変形可能な注意を払う視覚トランス--- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
クロスフォーマー:クロススケールの丁寧な汎用視覚変圧器のヒンジ--- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
グローバルな機能をローカルビジョントランスに集約します
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET:セマンティックセグメンテーションのために注意を喚起します
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
多次元変圧器における軸方向の注意
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
「画像認識のための深い残留学習--- CVPR2016 Best Paper」のPytorchの実装
「深いニューラルネットワークの集約された残差変換--- CVPR2017」のPytorchの実装
Pytorch MobileVitの実装:軽量、汎用、モバイルに優しいビジョントランス
パッチのPytorchの実装はあなたが必要とするすべてですか?--- ICLR2022(レビュー中)
シャッフルトランスのPytorch実装:ビジョントランスのための空間シャッフルの再考--- Arxiv 2021.06.07
ContnetのPytorch実装:同時に畳み込みと変圧器を使用してみませんか?--- Arxiv 2021.04.27
階層的な注意を伴う視覚変圧器のPytorch実装--- Arxiv 2022.06.15
共同スケールの慣習的な画像変圧器のPytorch実装--- ARXIV 2021.08.26
視覚変圧器の条件付き位置エンコーディングのPytorch実装
視覚変圧器の空間寸法の再考のPytorchの実装--- ICCV 2021
Pytorch Crossvitの実装:画像分類のための交差点マルチスケールビジョン変圧器--- ICCV 2021
トランスにおけるトランスのPytorch実装---ニューリップ2021
DeepVitのPytorch実装:より深い視力変圧器に向けて
畳み込みデザインを視覚的な変圧器に組み込むPytorchの実装
パイトーチコンビットの実装:ソフトコンボリューションの誘導バイアスを備えた視覚変圧器の改善
注意ベースの集計を伴う畳み込みネットワークの増強のPytorchの実装
画像変圧器を使用してより深く進むPytorchの実装--- ICCV 2021(Oral)
Pytorchトレーニングの実装データ効率の良い画像変圧器と注意による蒸留--- ICML 2021
レビットのPytorchの実装:より速い推論のためのConvnetの衣服の視覚変圧器
VoloのPytorch実装:Vision Outrookerの視覚的認識のためのルーカー
コンテナのPytorch実装:コンテキスト集約ネットワーク--- Neuips 2021
CMTのPytorchの実装:畳み込みニューラルネットワークは視覚変圧器を満たしています--- CVPR 2022
変形可能な注意を伴う視覚変圧器のPytorch実装--- CVPR 2022
Pytorch EfficientFormerの実装:MobileNet速度での視覚変圧器
convnextv2のpytorch実装:マスクされた自動エンコーダーとの共同設定とスケーリングコンベネット
「画像認識のための深い残留学習--- CVPR2016 Best Paper」
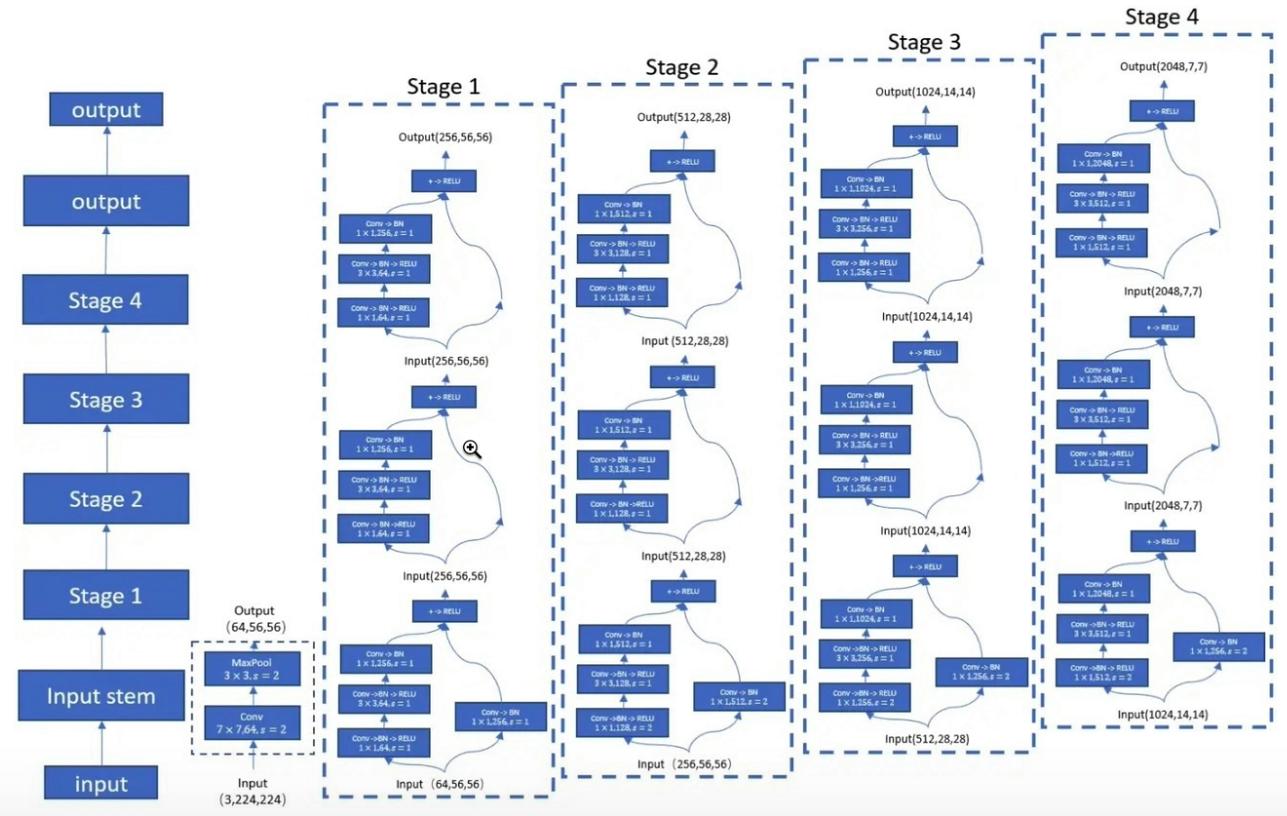
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )「深いニューラルネットワークの集約された残留変換--- CVPR2017」
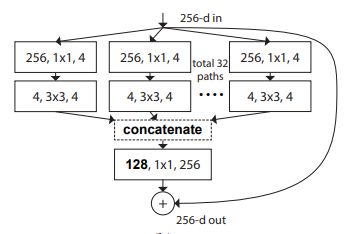
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit:軽量、汎用、モバイルに優しいビジョントランス--- ARXIV 2020.10.05
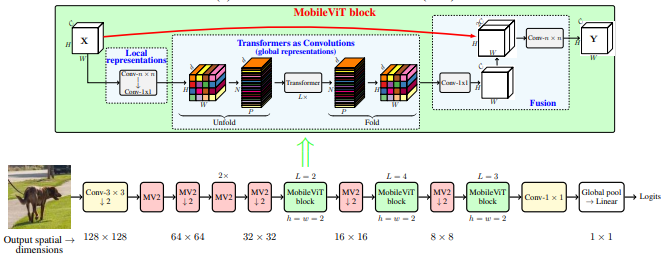
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )パッチはあなたが必要とするすべてですか?--- ICLR2022(レビュー中)
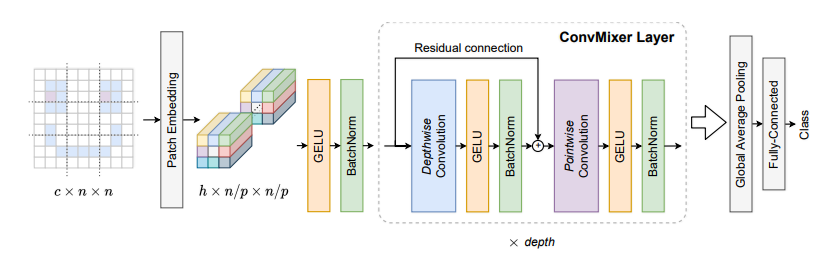
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
シャッフルトランス:ビジョントランスのための空間シャッフルの再考
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
CONTNET:同時に畳み込みと変圧器を使用してみませんか?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
階層的な注意を払ったビジョントランス
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
共同スケールの慣習的な画像変圧器
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2:ピラミッド視力変圧器を使用したベースラインの改善
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )視覚変圧器の条件付き位置エンコーディング
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )視覚変圧器の空間寸法を再考します
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )クロスビット:画像分類のためのクロスアテナントマルチスケールビジョントランス
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )トランスの変圧器
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )DeepVit:より深い視覚変圧器に向けて
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )畳み込みデザインを視覚的な変圧器に組み込む
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )コンビット:ソフトな畳み込み誘導バイアスを備えた視覚変圧器の改善
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )画像変圧器でより深く進みます
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )注意ベースの集計で畳み込みネットワークを増強します
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )データ効率の高い画像変圧器と注意による蒸留をトレーニングします
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )Levit:より速い推論のためのConvnetの衣服の視覚変圧器
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo:視覚認識のためのビジョンアウトルーカー
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )コンテナ:コンテキスト集約ネットワーク
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT:畳み込みニューラルネットワークは、ビジョントランスを満たしています
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )EfficientFormer:MobileNet Speedのビジョン変圧器
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )convnextv2:マスクされた自動エンコーダーとのコンボネットの共同設計とスケーリング
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )「Repmlp:畳み込みを完全に接続されたレイヤーに再パラメーター化するための逆の再パラメーター化のPytorch実装--- ARXIV 2021.05.05」
「MLP-Mixer:Anl-MLP Architecture for Vision --- Arxiv 2021.05.17」のPytorch実装
「resmlp:データ効率の高いトレーニングによる画像分類のためのフィードフォワードネットワークのPytorch実装--- ARXIV 2021.05.07」
「MLPに注意を払ってください--- ARXIV 2021.05.17」のPytorchの実装
「画像認識のためのまばらなMLP:自己attentionは本当に必要ですか? - Arxiv 2021.09.12」のPytorchの実装
「REPMLP:畳み込みを完全に接続されたレイヤーに再パラメータ化するための画像認識」
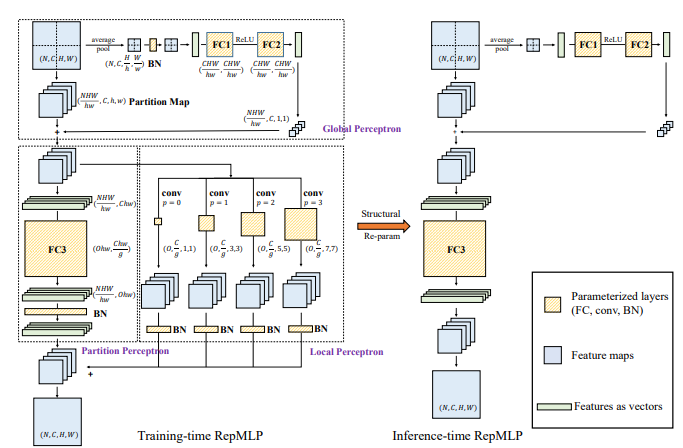
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
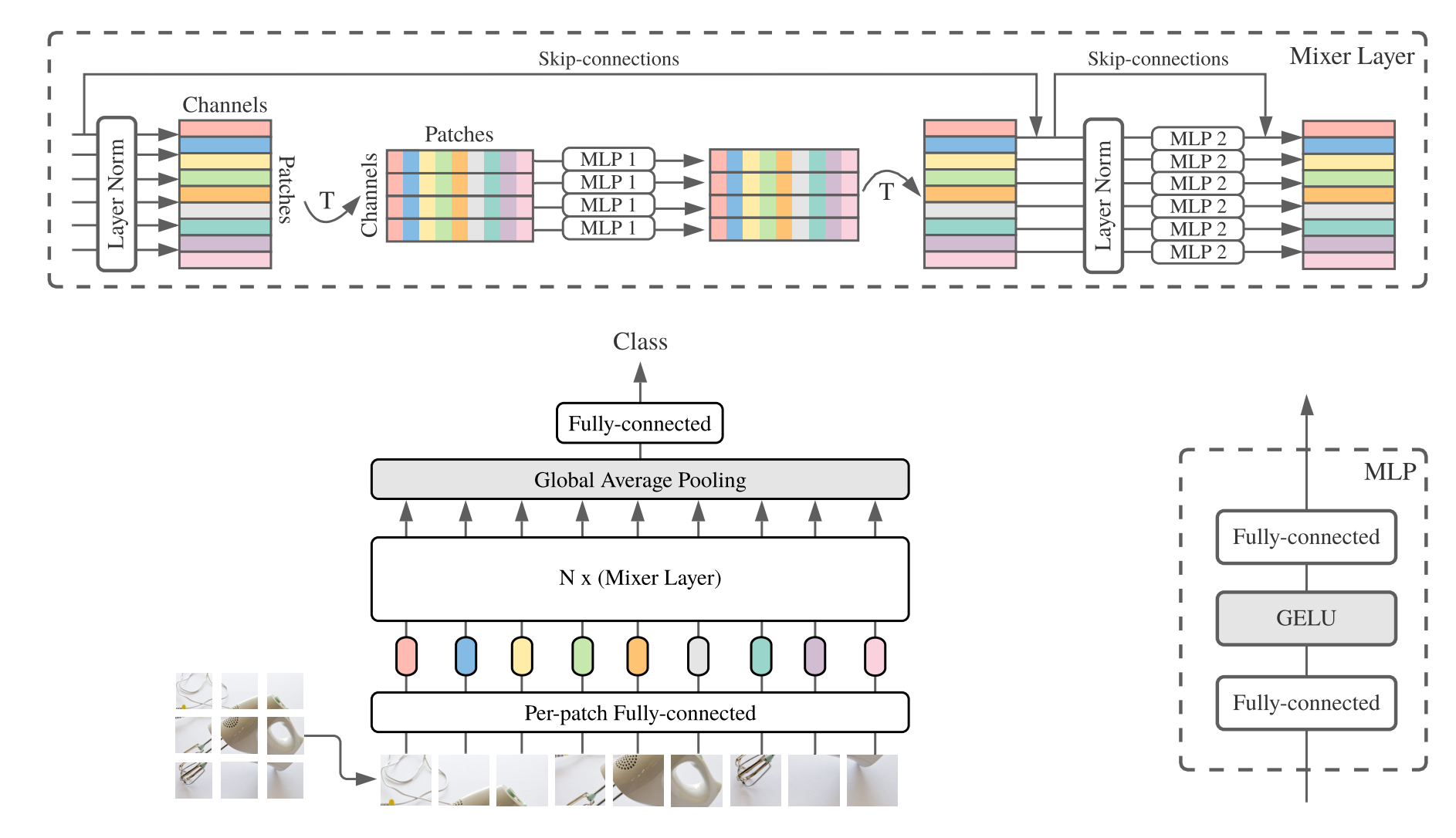
print ((( deployout - out ) ** 2 ). sum ())「MLP-Mixer:ビジョンのためのAll-MLPアーキテクチャ」
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )「RESMLP:データ効率の良いトレーニングを使用した画像分類のためのFeedForwardネットワーク」

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num「MLPに注意を払ってください」
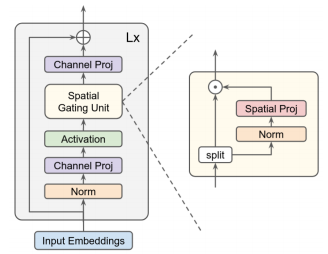
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )「画像認識のためのまばらなMLP:自己attentionは本当に必要ですか?」
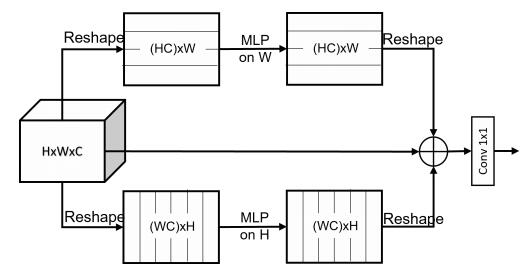
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )「ビジョン順列:視覚的認識のための順調なMLPのようなアーキテクチャ」
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )「repvgg:vggスタイルのコンボネットを再び優れたものにするpytorch実装---- cvpr2021」
「Acnet:非対称畳み込みブロックを介して強力なCNNのカーネルスケルトンの強化」のPytorch実装--- ICCV2019」
「多様なブランチブロックの実装:インセプションのようなユニットとしての畳み込みの構築--- CVPR2021」
「Repvgg:VGGスタイルのコンベネットを再び素晴らしいものにする」
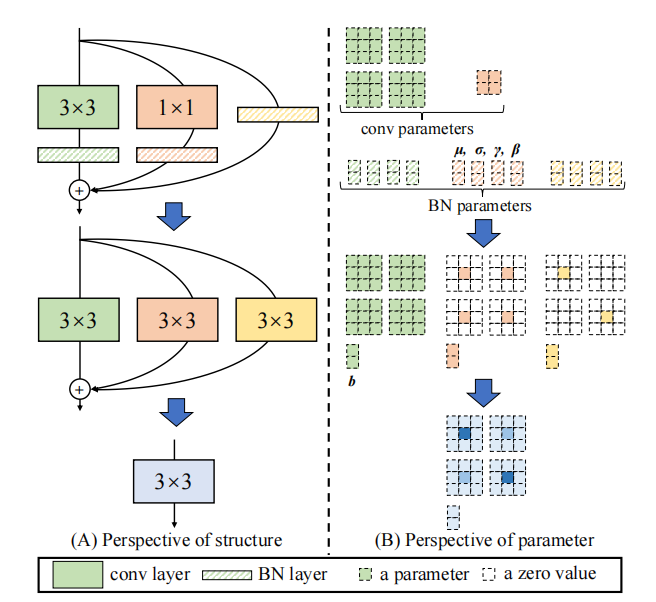
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
print ((( out2 - out ) ** 2 ). sum ())「Acnet:非対称の畳み込みブロックを介して強力なCNNのカーネルスケルトンの強化」
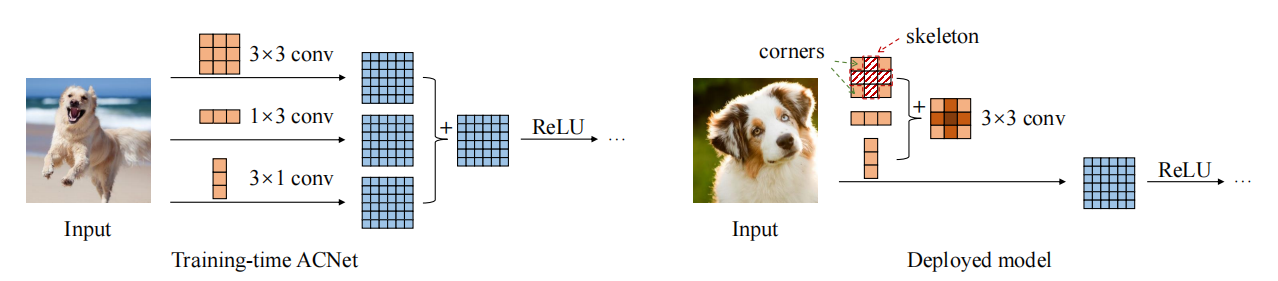
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
print ((( out2 - out ) ** 2 ). sum ())「多様なブランチブロック:インセプションのようなユニットとして畳み込みを構築する」
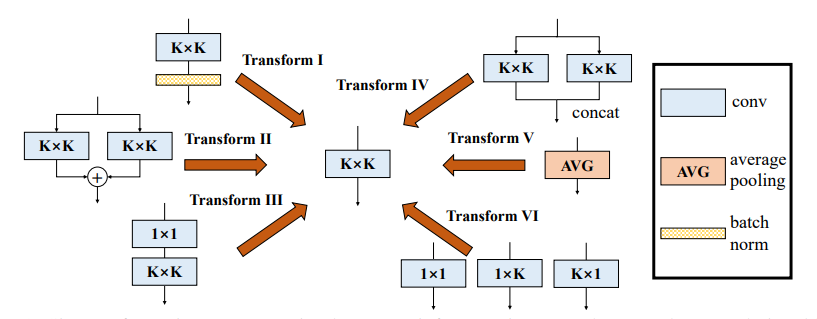
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())「Mobilenets:モバイルビジョンアプリケーション向けの効率的な畳み込みニューラルネットワーク--- CVPR2017」のPytorch実装
「EfficientNet:畳み込みニューラルネットワークの再考モデルスケーリング--- PMLR2019」のPytorch実装
Pytorchの「退縮の実装:視覚認識のための畳み込みの内在を反転させる---- CVPR2021」
「ダイナミック畳み込み:畳み込みカーネルに対する注意」のPytorchの実装--- CVPR2020 Oral」
「condconv:効率的な推論のための条件付きパラメーター化された畳み込み--- Neurips2019」のPytorch実装
「Mobilenets:モバイルビジョンアプリケーション用の効率的な畳み込みニューラルネットワーク」
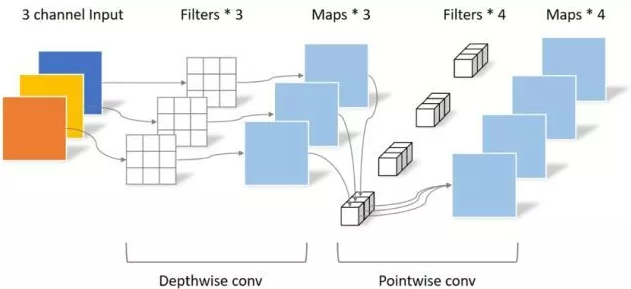
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )「EfficientNet:畳み込みニューラルネットワークのスケーリングの再考モデル」
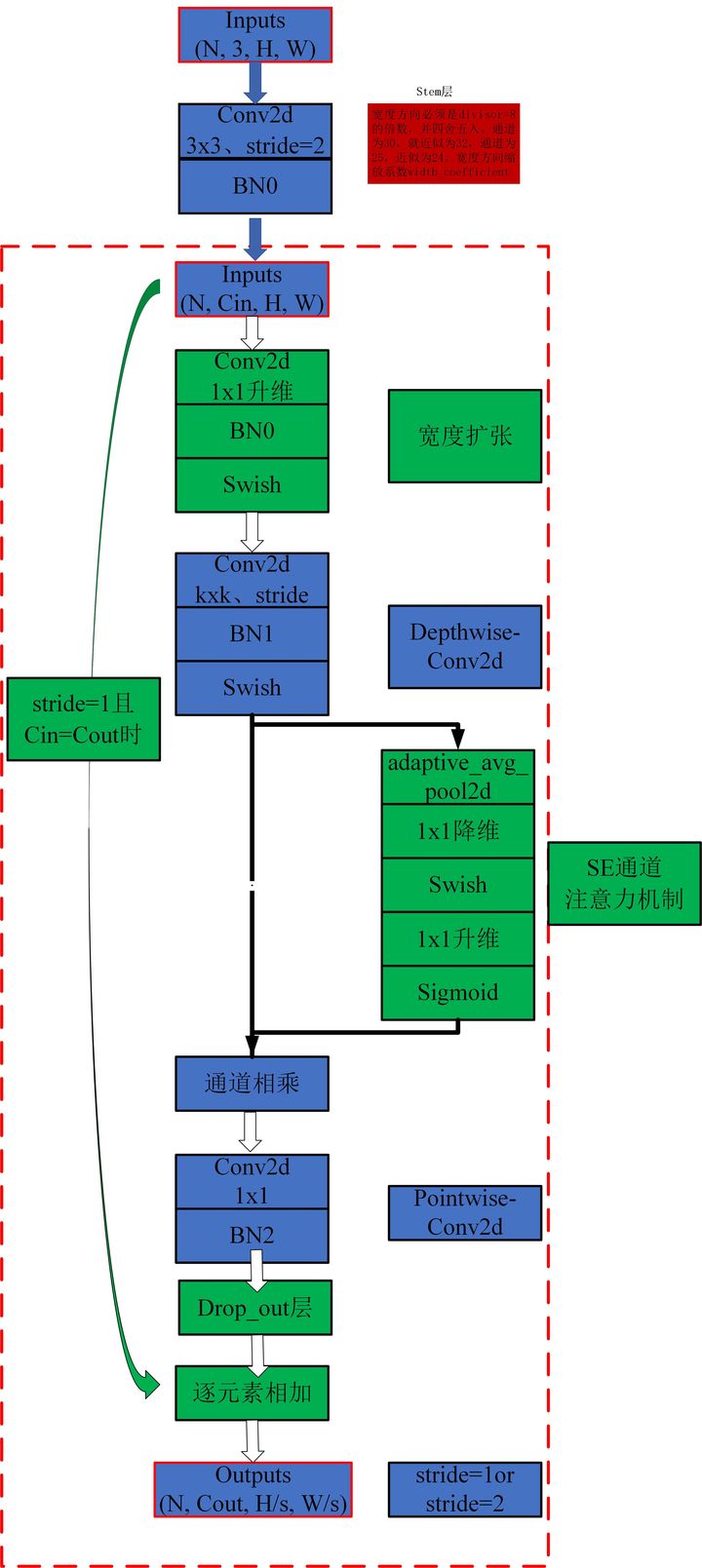
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
「退縮:視覚認識のための畳み込みの内在を反転させる」
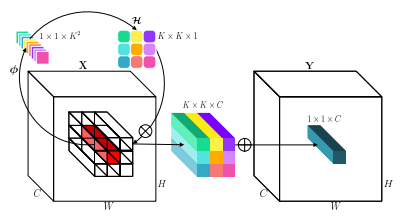
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )「ダイナミック畳み込み:畳み込みカーネルに対する注意」
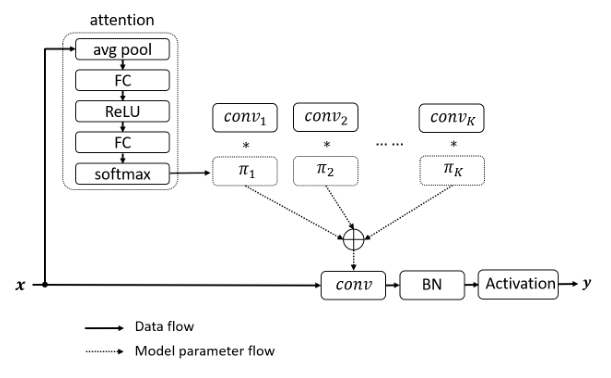
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64「condconv:効率的な推論のための条件付きパラメーター化された畳み込み」
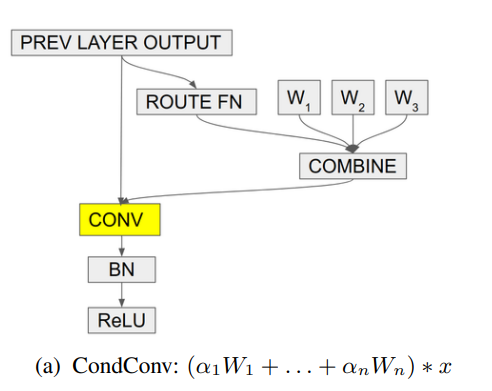
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )ビッグニュース! ! !プロジェクトの補足として、主要な会議や雑誌の論文分析を収集して編成する新しくオープンソースプロジェクトFightCV-Paper-Readingに注意を払うことができます。
ビッグニュース! ! !最近、私はインターネットfightingcv-courseでさまざまなAI関連のビデオチュートリアルと必見の論文を編集しました
ビッグニュース! ! !最近、新しいYoloairオブジェクト検出コードライブラリが開かれました。これは、Yolov5、Yolov7、Yolor、Yolox、Yolov4、Yolov3およびその他のヨロモデル、およびさまざまな既存の注意メカニズムなど、さまざまなヨロモデルを統合しています。
ECCV2022紙の概要:ECCV2022-PAPER-LIST


