External Attention pytorch
1.0.0

단순화 된 중국어 | 영어
안녕하세요, 여러분, 저는 Xiaoma입니다
Xiaobai (나처럼) : 최근에 종이를 읽을 때 문제가 있습니다. 때로는 논문의 핵심 아이디어가 매우 간단하며 핵심 코드는 수십 줄에 불과할 수 있습니다. 그러나 저자 릴리스의 소스 코드를 열었을 때 제안 된 모듈이 분류, 감지 및 세분화와 같은 작업 프레임 워크에 포함되어 비교적 중복 코드로 이어 졌음을 알았습니다. 특정 작업 프레임 워크에 익숙하지 않으며 핵심 코드를 찾기가 어렵 기 때문에 논문과 네트워크 아이디어를 이해하는 데 어려움이 있습니다 .
Advanced (당신과 같은)의 경우 : Conv, FC 및 RNN과 같은 기본 장치를 작은 레고 빌딩 블록으로 간주하고 트랜스포머 및 RESNET과 같은 구조물을 건축 한 레고 성으로 간주합니다. 그런 다음이 프로젝트에서 제공하는 모듈은 완전한 의미 정보가있는 레고 구성 요소입니다. 과학 연구자들이 바퀴를 반복적으로 만드는 것을 피하고 ,이 "레고 구성 요소"를 사용하여 더 화려한 작품을 구축하는 방법에 대해 생각하십시오.
마스터에게 (당신과 같을 수도 있습니다) : 나는 능력이 제한되어 있고 가볍게 분출하는 것을 좋아하지 않습니다 ! ! !
모두 : 이 프로젝트는 딥 러닝 초보자가 과학 연구 및 산업 공동체를 이해하고 서비스 할 수있는 코드 기반을 구현하기 위해 노력하고 있습니다.
PIP를 통해 직접 설치하십시오
pip install fightingcv-attention또는 저장소를 복제하십시오
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch import torch
from torch import nn
from torch . nn import functional as F
# 使用 pip 方式
from fightingcv_attention . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape ) import torch
from torch import nn
from torch . nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model . attention . MobileViTv2Attention import *
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )주의 시리즈
1. 외부주의 사용
2. 자기주의 사용
3. 단순화 된 자기주의 사용
4. 압박 및 발행주의 사용
5. SK주의 사용
6. CBAM주의 사용
7. BAM주의 사용법
8. ECA주의 사용
9. Danet주의 사용
10. 피라미드 분할주의 (PSA) 사용
11. 효율적인 다중 헤드 자체 변환 (EMSA) 사용
12. 셔플 관심 사용
13. 관심 사용을 뮤즈합니다
14. SGE주의 사용법
15. A2주의 사용
16. 후위주의 사용
17. 전망주의 사용
18. VIP주의 사용
19. 코트 넷주의 사용
20. Halonet주의 사용
21. 편광 자체 변환 사용
22. cotattention 사용
23. 잔여주의 사용
24. S2주의 사용
25. GFNET주의 사용
26. 트리플렛주의 사용
27.주의 사용을 조정하십시오
28. MobileVit주의 사용
29. 파넷주의 사용
30. UFO주의 사용
31. ACMIX주의 사용
32. MobileVitv2주의 사용
33. DAT주의 사용
34. 크로스 포어 관심 사용
35. Moatransformer주의 사용
36. 십자형의 관절주의 사용
37. Axial_attention주의 사용
백본 시리즈
1. RESNET 사용
2. Resnext 사용
3. MobileVit 사용
4. ConvMixer 사용
5. Shuffletransformer 사용
6. 콘넷 사용
7. Hatnet 사용
8. 코트 사용
9. PVT 사용
10. CPVT 사용
11. 구덩이 사용
12. CrossVit 사용
13. TNT 사용
14. DVIT 사용
15. CEIT 사용
16. 컨비팅 사용
17. Cait 사용
18. PatchConvNet 사용
19. Deit 사용
20. Levit 사용
21. Volo 사용
22. 컨테이너 사용
23. CMT 사용
24. 효율적인 성능 사용
25. CONDNEXTV2 사용
MLP 시리즈
1. REPMLP 사용
2. MLP 믹서 사용
3. RESMLP 사용
4. GMLP 사용
5. SMLP 사용
6. VIP-MLP 사용
재발계 (REP) 시리즈
1. repvgg 사용
2. ACNET 사용
3. 다양한 분기 블록 (DDB) 사용
컨볼 루션 시리즈
1. 깊이 분리 가능한 컨볼 루션 사용
2. MBCONV 사용량
3. 발병 사용
4. DynamicConv 사용법
5. Condconv 사용
Pytorch의 구현 "Beyond Self-Intention : 시각적 작업을 위해 두 개의 선형 레이어를 사용한 외부주의 --- ARXIV 2021.05.05"
Pytorch는 "주의가 필요합니다 --- NIPS2017"의 Pytorch 구현
"스퀴즈 및 발행 네트워크 --- CVPR2018"의 Pytorch 구현
"선택적 커널 네트워크 --- CVPR2019"의 Pytorch 구현
"CBAM : Convolutional Block주의 모듈 --- ECCV2018"의 Pytorch 구현
"BAM : 병목 현상주의 모듈 --- BMCV2018"의 Pytorch 구현
"ECA-NET : 심층 컨볼 루션 신경 네트워크를위한 효율적인 채널 관심 --- CVPR2020"의 Pytorch 구현
"장면 세분화를위한 이중주의 네트워크 --- CVPR2019"의 Pytorch 구현
"Epsanet : Convolutional Neural Network에서 효율적인 피라미드 분할주의 블록의 Pytorch 구현 --- ARXIV 2021.05.30"
"REST : 시각적 인식을위한 효율적인 변압기 --- ARXIV 2021.05.28"의 Pytorch 구현
"SA-NET : 심층 컨볼 루션 신경 네트워크에 대한 셔플 세상의 Pytorch 구현 --- ICASSP 2021"
"Muse : 시퀀스 학습에 대한 서열에 대한 병렬 다중 규모주의의 Pytorch 구현 --- ARXIV 2019.11.17"
"공간 그룹 별 강화 : 컨볼 루션 네트워크에서 의미 론적 기능 학습 개선 --- ARXIV 2019.05.23"의 Pytorch 구현
"A2-Nets : Double Interection Networks --- NIPS2018"의 Pytorch 구현
Pytorch는 "주의 프리 트랜스포머 --- ICLR2021 (Apple New Work)"의 구현
Volo의 Pytorch 구현 : 시각적 인식을위한 Vision Outlooker --- ARXIV 2021.06.24 "[논문 분석]
Pytorch Vision 순열기의 구현 : 시각적 인식을위한 순열 가능한 MLP 유사 아키텍처 --- ARXIV 2021.06.23 [논문 분석]
Coatnet의 Pytorch 구현 : 모든 데이터 크기에 대한 컨볼 루션 및 관심-ARXIV 2021.06.09 [논문 분석]
파라미터 효율적인 시각적 백본에 대한 로컬 자체 변환 스케일링의 Pytorch 구현 --- CVPR2021 구두 [논문 분석]
편광 자체 변환의 Pytorch 구현 : 고품질 픽셀 주 회귀를 향해 --- ARXIV 2021.07.02 [논문 분석]
시각적 인식을위한 상황에 맞는 변압기 네트워크 구현 --- ARXIV 2021.07.26 [논문 분석]
Pytorch 잔류주의 구현 : 다중 라벨 인식을위한 간단하지만 효과적인 방법 --- ICCV2021
S²-MLPV2의 Pytorch 구현 : 비전을위한 개선 된 공간 시프트 MLP 아키텍처 --- ARXIV 2021.08.02 [용지 분석]
이미지 분류를위한 글로벌 필터 네트워크 구현 --- ARXIV 2021.07.01
Pytorch 회전의 구현 참석 : Convolutional Triplet주의 모듈 --- WACV 2021
효율적인 모바일 네트워크 설계를위한 좌표주의의 Pytorch 구현 --- CVPR 2021
MobileVit의 Pytorch 구현 : 가벼운, 일반적인 목적 및 모바일 친화적 인 Vision Transformer --- ARXIV 2021.10.05
비이 깊은 네트워크의 Pytorch 구현 --- ARXIV 2021.10.20
UFO-VIT의 Pytorch 구현 : SoftMax가없는 고성능 선형 비전 변압기 --- ARXIV 2021.09.29
모바일 비전 변압기를위한 분리 가능한 자체 소송 구현 --- ARXIV 2022.06.06
자체 변환 및 컨센트의 통합에 대한 Pytorch 구현 --- ARXIV 2022.03.14
Crossformer의 Pytorch 구현 : 크로스 규모에 대한 다양한 비전 변압기 --- ICLR 2022
Pytorch는 로컬 비전 변압기로 글로벌 기능을 집계하는 구현
CCNET의 Pytorch 구현 : 시맨틱 세분화를위한 Criss-Cross 관심
다차원 변압기에서 축 방향 관심의 파이토치 구현
"자체 소수를 넘어서 : 시각적 작업을 위해 두 개의 선형 레이어를 사용한 외부주의"
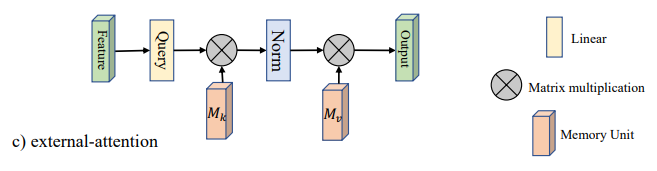
from model . attention . ExternalAttention import ExternalAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ea = ExternalAttention ( d_model = 512 , S = 8 )
output = ea ( input )
print ( output . shape )"주의가 필요한 전부입니다"
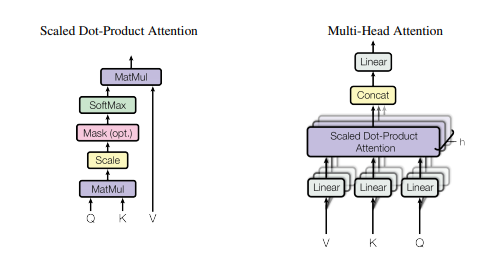
from model . attention . SelfAttention import ScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
sa = ScaledDotProductAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )없음
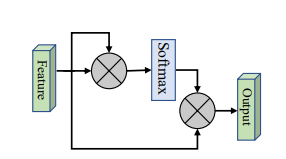
from model . attention . SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input = torch . randn ( 50 , 49 , 512 )
ssa = SimplifiedScaledDotProductAttention ( d_model = 512 , h = 8 )
output = ssa ( input , input , input )
print ( output . shape )"압박 및 발행 네트워크"
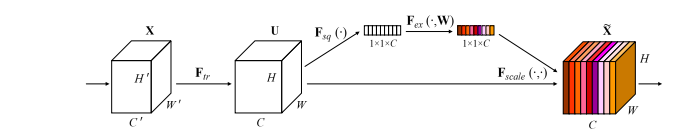
from model . attention . SEAttention import SEAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SEAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"선택적 커널 네트워크"
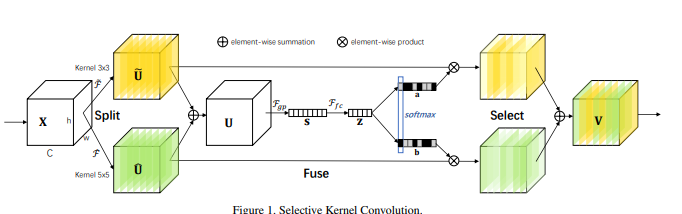
from model . attention . SKAttention import SKAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
se = SKAttention ( channel = 512 , reduction = 8 )
output = se ( input )
print ( output . shape )"CBAM : 컨볼 루션 블록주의 모듈"
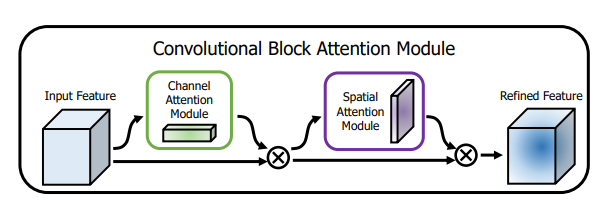
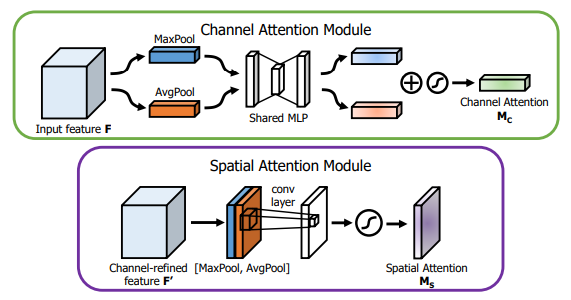
from model . attention . CBAM import CBAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
kernel_size = input . shape [ 2 ]
cbam = CBAMBlock ( channel = 512 , reduction = 16 , kernel_size = kernel_size )
output = cbam ( input )
print ( output . shape )"BAM : 병목 현상주의 모듈"
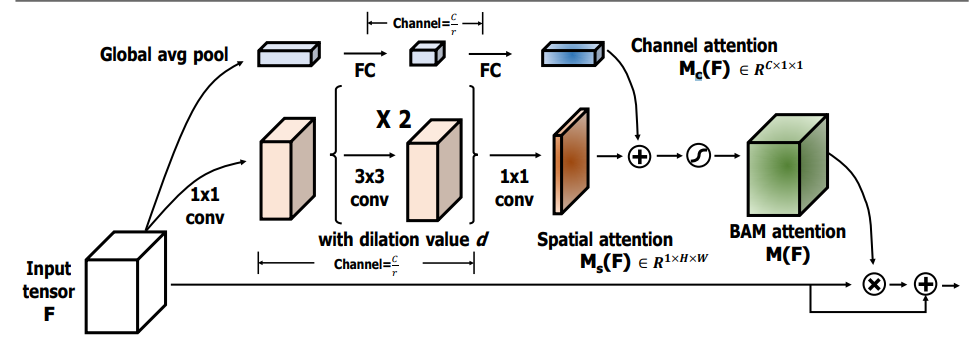
from model . attention . BAM import BAMBlock
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
bam = BAMBlock ( channel = 512 , reduction = 16 , dia_val = 2 )
output = bam ( input )
print ( output . shape )"ECA-NET : 심층 컨볼 루션 신경 네트워크를위한 효율적인 채널주의"
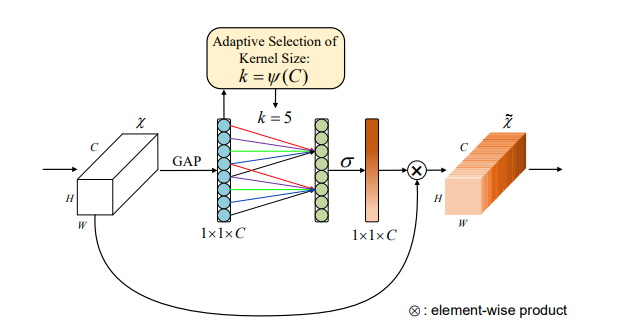
from model . attention . ECAAttention import ECAAttention
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
eca = ECAAttention ( kernel_size = 3 )
output = eca ( input )
print ( output . shape )"장면 세분화를위한 이중주의 네트워크"
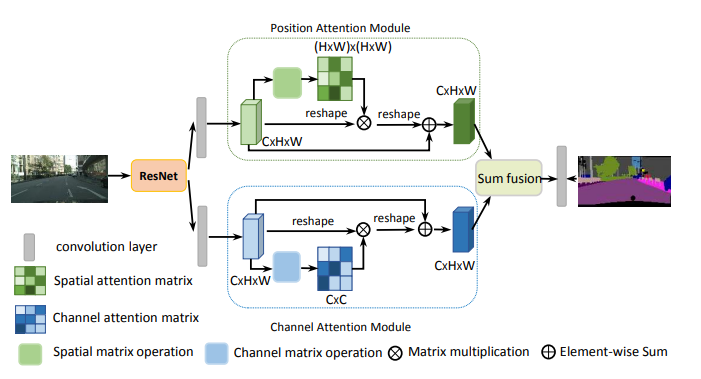
from model . attention . DANet import DAModule
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
danet = DAModule ( d_model = 512 , kernel_size = 3 , H = 7 , W = 7 )
print ( danet ( input ). shape )"Epsanet : Convolutional Neural Network의 효율적인 피라미드 분할주의 블록"
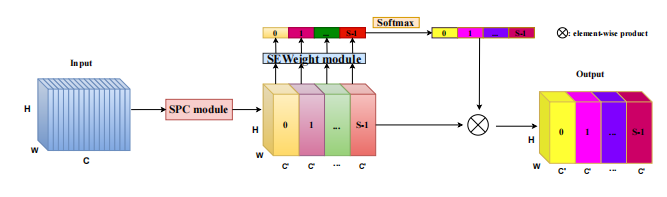
from model . attention . PSA import PSA
import torch
input = torch . randn ( 50 , 512 , 7 , 7 )
psa = PSA ( channel = 512 , reduction = 8 )
output = psa ( input )
print ( output . shape )"REST : 시각적 인식을위한 효율적인 변압기"
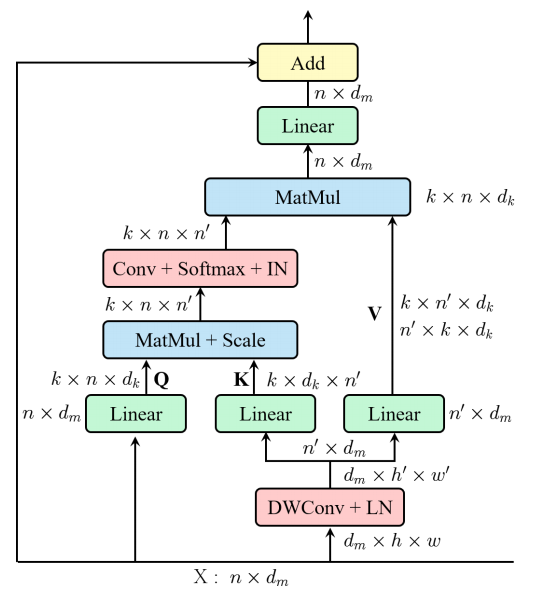
from model . attention . EMSA import EMSA
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 64 , 512 )
emsa = EMSA ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 , H = 8 , W = 8 , ratio = 2 , apply_transform = True )
output = emsa ( input , input , input )
print ( output . shape )
"SA-NET : 깊은 컨볼 루션 신경망에 대한 셔플 주의적 셔플주의"
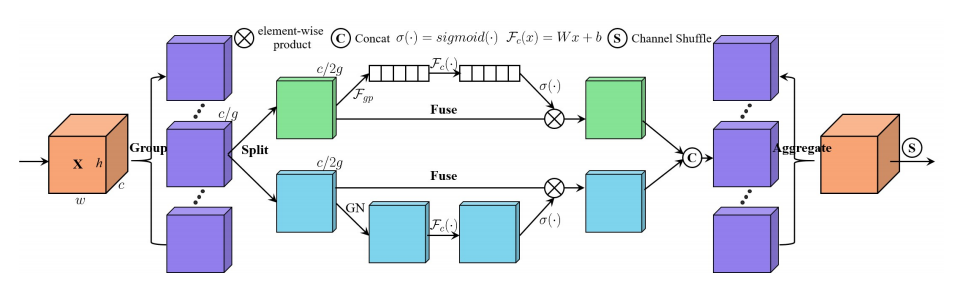
from model . attention . ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
se = ShuffleAttention ( channel = 512 , G = 8 )
output = se ( input )
print ( output . shape )
"Muse : 시퀀스 학습에 대한 서열에 대한 평행 다중 스케일주의"
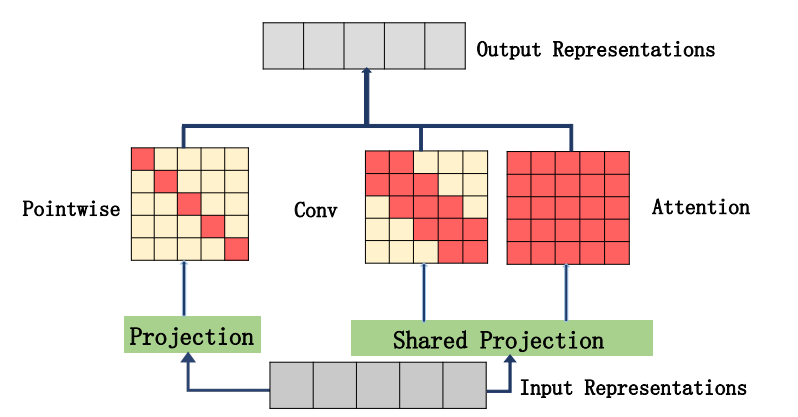
from model . attention . MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
sa = MUSEAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = sa ( input , input , input )
print ( output . shape )공간 그룹 별 강화 : 컨볼 루션 네트워크에서 의미 론적 기능 학습 향상
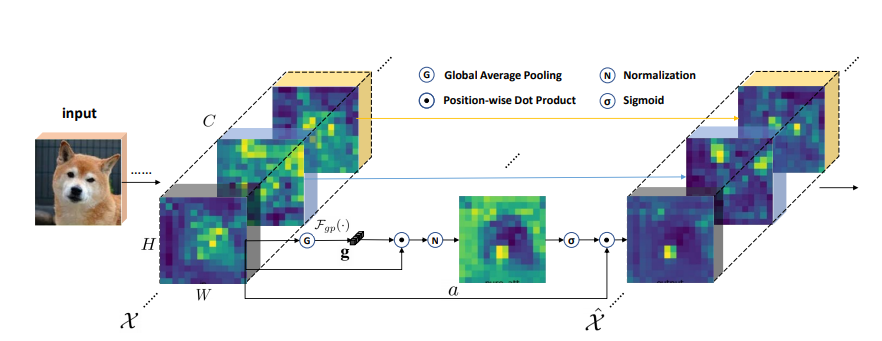
from model . attention . SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
sge = SpatialGroupEnhance ( groups = 8 )
output = sge ( input )
print ( output . shape )A2-Nets : 이중주의 네트워크
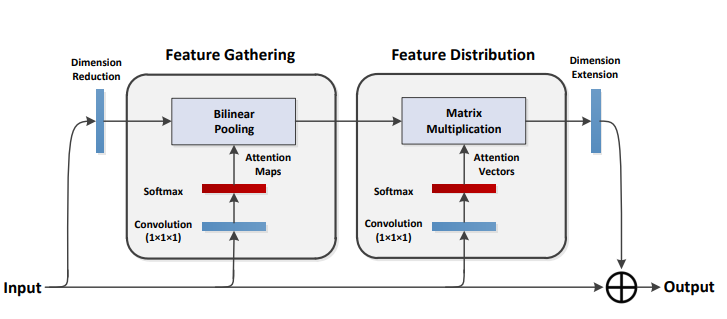
from model . attention . A2Atttention import DoubleAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
a2 = DoubleAttention ( 512 , 128 , 128 , True )
output = a2 ( input )
print ( output . shape )관심없는 트랜스포머
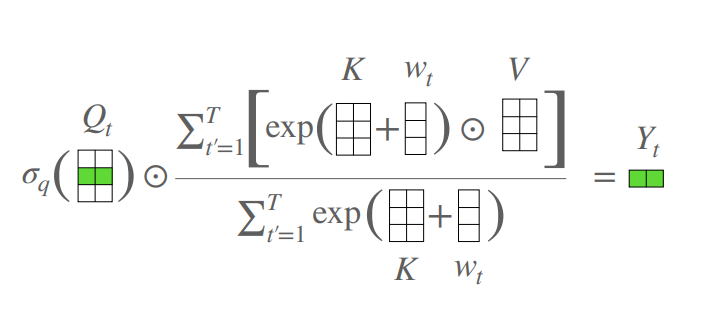
from model . attention . AFT import AFT_FULL
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 49 , 512 )
aft_full = AFT_FULL ( d_model = 512 , n = 49 )
output = aft_full ( input )
print ( output . shape )Volo : 시각적 인식을위한 Vision Outlooker "
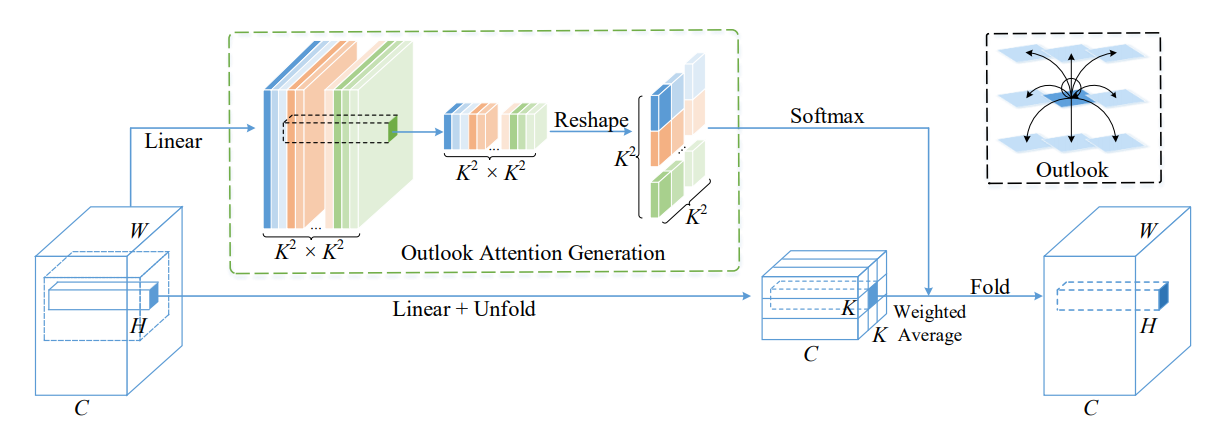
from model . attention . OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 28 , 28 , 512 )
outlook = OutlookAttention ( dim = 512 )
output = outlook ( input )
print ( output . shape )비전 순열기 : 시각적 인식을위한 순열 가능한 MLP와 같은 아키텍처 "
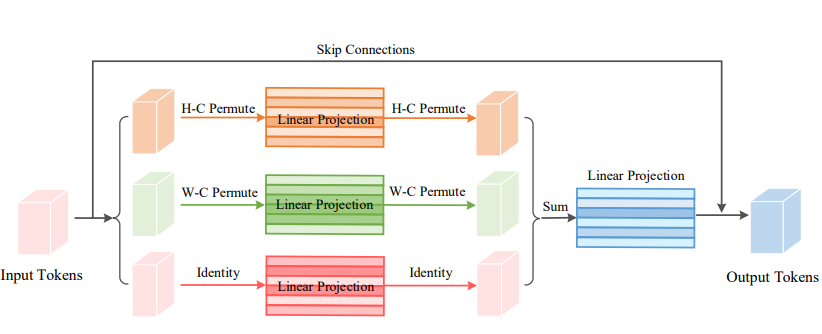
from model . attention . ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 64 , 8 , 8 , 512 )
seg_dim = 8
vip = WeightedPermuteMLP ( 512 , seg_dim )
out = vip ( input )
print ( out . shape )Coatnet : 모든 데이터 크기에 대한 컨볼 루션 및 관심 "
없음
from model . attention . CoAtNet import CoAtNet
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = CoAtNet ( in_ch = 3 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )매개 변수 효율적인 시각적 백본에 대한 로컬 자체 변환 스케일링 ""
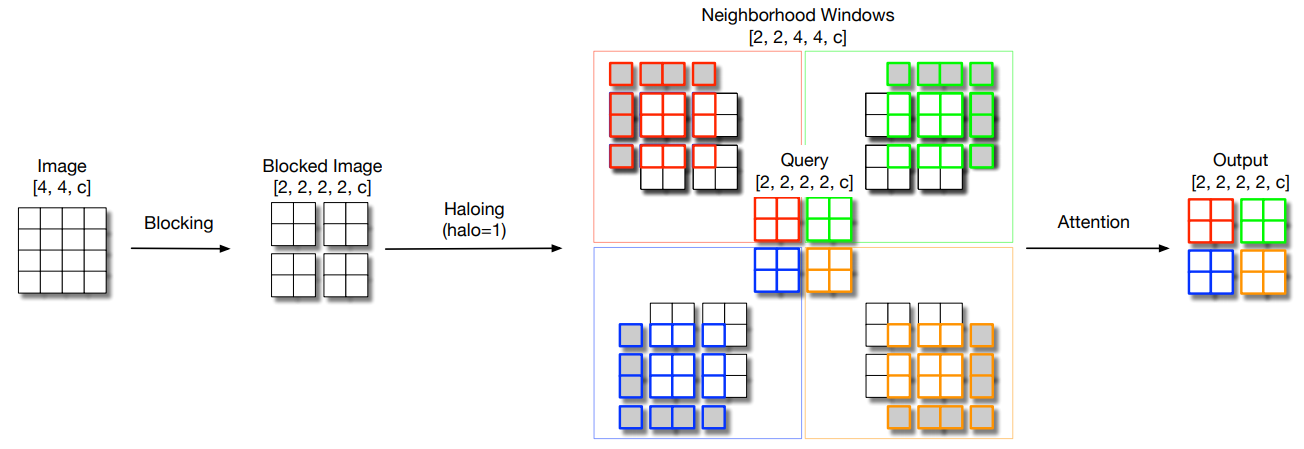
from model . attention . HaloAttention import HaloAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 8 , 8 )
halo = HaloAttention ( dim = 512 ,
block_size = 2 ,
halo_size = 1 ,)
output = halo ( input )
print ( output . shape )편광 자체 변환 : 고품질 픽셀 현명 회귀를 향해 "
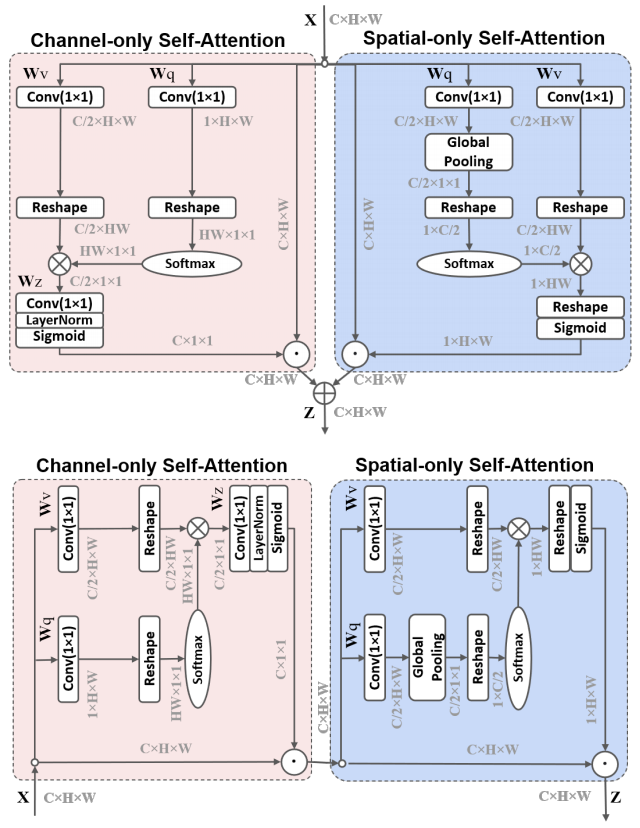
from model . attention . PolarizedSelfAttention import ParallelPolarizedSelfAttention , SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 512 , 7 , 7 )
psa = SequentialPolarizedSelfAttention ( channel = 512 )
output = psa ( input )
print ( output . shape )
시각적 인식을위한 맥락 변압기 네트워크 --- ARXIV 2021.07.26
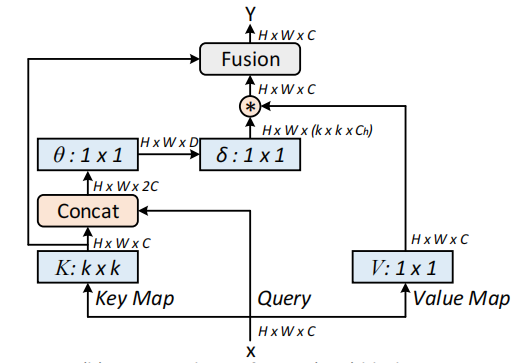
from model . attention . CoTAttention import CoTAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
cot = CoTAttention ( dim = 512 , kernel_size = 3 )
output = cot ( input )
print ( output . shape )
잔여주의 : 다중 표지 인식을위한 간단하지만 효과적인 방법 --- ICCV2021
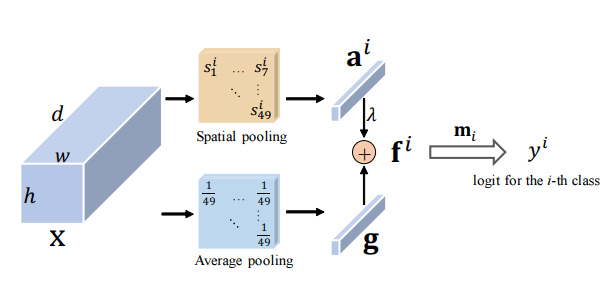
from model . attention . ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
resatt = ResidualAttention ( channel = 512 , num_class = 1000 , la = 0.2 )
output = resatt ( input )
print ( output . shape )
S²-MLPV2 : 비전을위한 개선 된 공간-시프트 MLP 아키텍처 --- ARXIV 2021.08.02
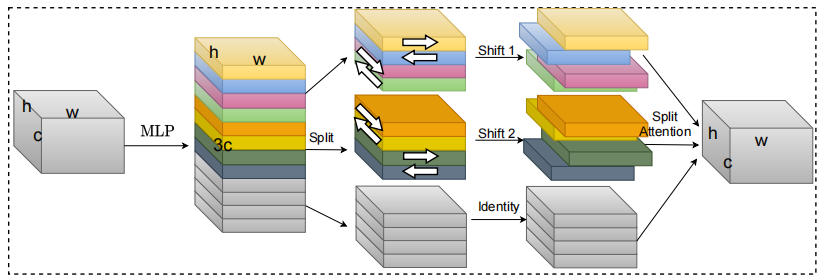
from model . attention . S2Attention import S2Attention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
s2att = S2Attention ( channels = 512 )
output = s2att ( input )
print ( output . shape )이미지 분류를위한 글로벌 필터 네트워크 --- ARXIV 2021.07.01
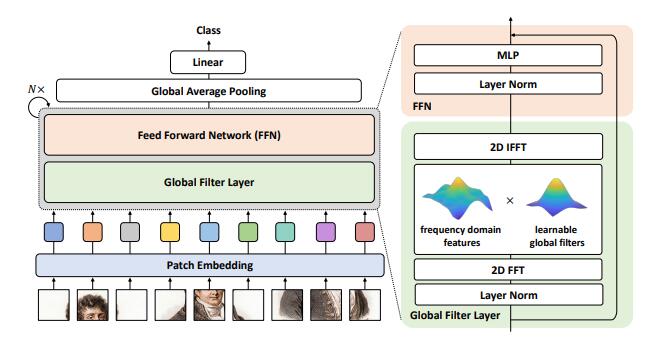
from model . attention . gfnet import GFNet
import torch
from torch import nn
from torch . nn import functional as F
x = torch . randn ( 1 , 3 , 224 , 224 )
gfnet = GFNet ( embed_dim = 384 , img_size = 224 , patch_size = 16 , num_classes = 1000 )
out = gfnet ( x )
print ( out . shape )참석하기 위해 회전 : Convolutional Triplet주의 모듈 --- CVPR 2021
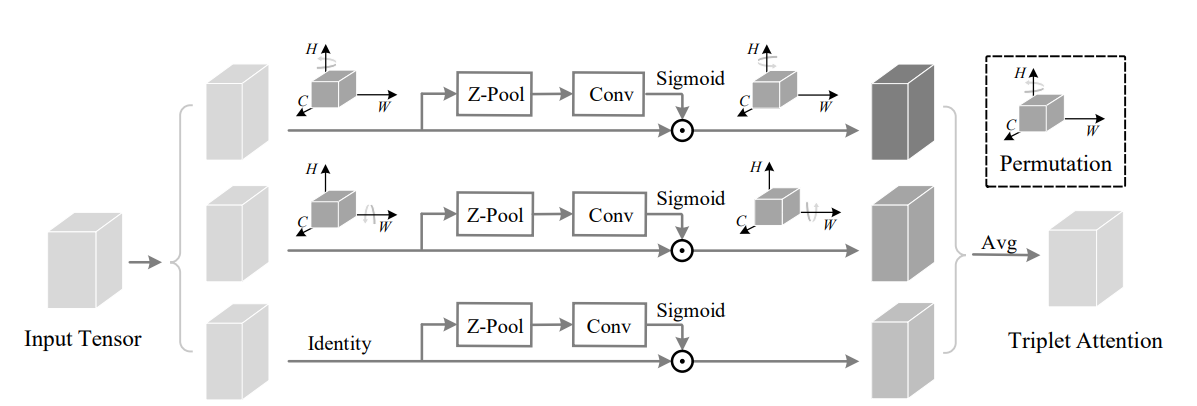
from model . attention . TripletAttention import TripletAttention
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 50 , 512 , 7 , 7 )
triplet = TripletAttention ()
output = triplet ( input )
print ( output . shape )효율적인 모바일 네트워크 설계를위한주의 조정 --- CVPR 2021
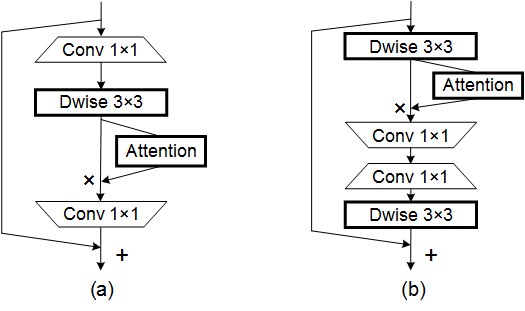
from model . attention . CoordAttention import CoordAtt
import torch
from torch import nn
from torch . nn import functional as F
inp = torch . rand ([ 2 , 96 , 56 , 56 ])
inp_dim , oup_dim = 96 , 96
reduction = 32
coord_attention = CoordAtt ( inp_dim , oup_dim , reduction = reduction )
output = coord_attention ( inp )
print ( output . shape )MobileVit : 가벼운 가중, 일반적인 목적 및 모바일 친화적 인 비전 변압기 --- ARXIV 2021.10.05
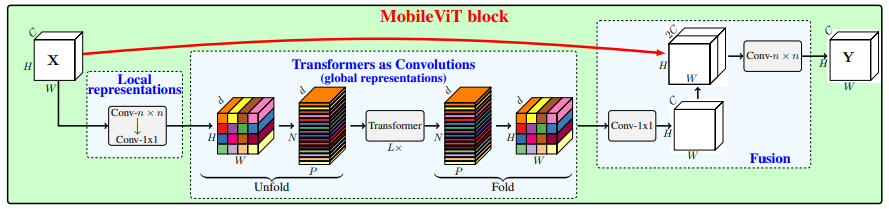
from model . attention . MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
m = MobileViTAttention ()
input = torch . randn ( 1 , 3 , 49 , 49 )
output = m ( input )
print ( output . shape ) #output:(1,3,49,49)
비 깊이 네트워크 --- ARXIV 2021.10.20
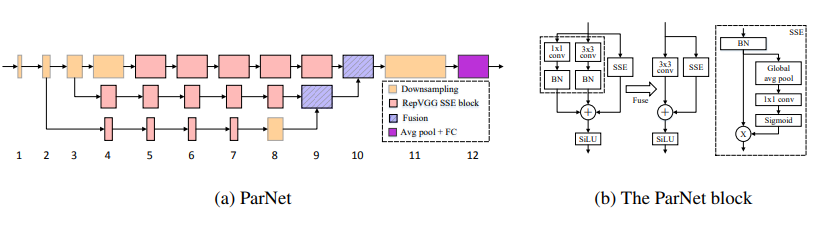
from model . attention . ParNetAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 512 , 7 , 7 )
pna = ParNetAttention ( channel = 512 )
output = pna ( input )
print ( output . shape ) #50,512,7,7
UFO-VIT : SoftMax가없는 고성능 선형 비전 변압기 --- ARXIV 2021.09.29
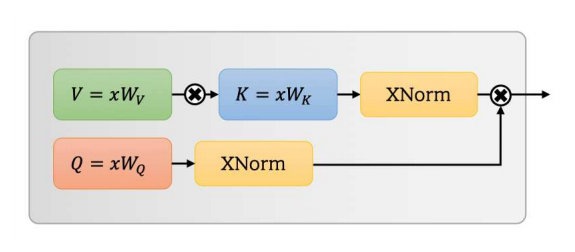
from model . attention . UFOAttention import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
ufo = UFOAttention ( d_model = 512 , d_k = 512 , d_v = 512 , h = 8 )
output = ufo ( input , input , input )
print ( output . shape ) #[50, 49, 512]
자기 변환 및 컨볼 루션의 통합
from model . attention . ACmix import ACmix
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 256 , 7 , 7 )
acmix = ACmix ( in_planes = 256 , out_planes = 256 )
output = acmix ( input )
print ( output . shape )
모바일 비전 변압기에 대한 분리 가능한 자체 변환 --- ARXIV 2022.06.06
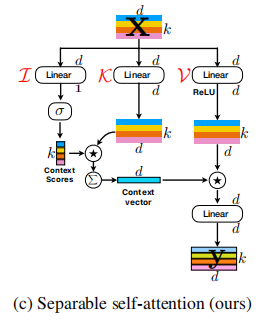
from model . attention . MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 49 , 512 )
sa = MobileViTv2Attention ( d_model = 512 )
output = sa ( input )
print ( output . shape )
변형 가능한 주의력이있는 비전 변압기 --- CVPR2022
from model . attention . DAT import DAT
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DAT (
img_size = 224 ,
patch_size = 4 ,
num_classes = 1000 ,
expansion = 4 ,
dim_stem = 96 ,
dims = [ 96 , 192 , 384 , 768 ],
depths = [ 2 , 2 , 6 , 2 ],
stage_spec = [[ 'L' , 'S' ], [ 'L' , 'S' ], [ 'L' , 'D' , 'L' , 'D' , 'L' , 'D' ], [ 'L' , 'D' ]],
heads = [ 3 , 6 , 12 , 24 ],
window_sizes = [ 7 , 7 , 7 , 7 ] ,
groups = [ - 1 , - 1 , 3 , 6 ],
use_pes = [ False , False , True , True ],
dwc_pes = [ False , False , False , False ],
strides = [ - 1 , - 1 , 1 , 1 ],
sr_ratios = [ - 1 , - 1 , - 1 , - 1 ],
offset_range_factor = [ - 1 , - 1 , 2 , 2 ],
no_offs = [ False , False , False , False ],
fixed_pes = [ False , False , False , False ],
use_dwc_mlps = [ False , False , False , False ],
use_conv_patches = False ,
drop_rate = 0.0 ,
attn_drop_rate = 0.0 ,
drop_path_rate = 0.2 ,
)
output = model ( input )
print ( output [ 0 ]. shape )
Crossformer : 다양한 규모의 주성에 대한 다목적 비전 변압기 --- ICLR 2022
from model . attention . Crossformer import CrossFormer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CrossFormer ( img_size = 224 ,
patch_size = [ 4 , 8 , 16 , 32 ],
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 48 ,
depths = [ 2 , 2 , 6 , 2 ],
num_heads = [ 3 , 6 , 12 , 24 ],
group_size = [ 7 , 7 , 7 , 7 ],
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False ,
merge_size = [[ 2 , 4 ], [ 2 , 4 ], [ 2 , 4 ]]
)
output = model ( input )
print ( output . shape )
글로벌 기능을 로컬 비전 변압기로 집계합니다
from model . attention . MOATransformer import MOATransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = MOATransformer (
img_size = 224 ,
patch_size = 4 ,
in_chans = 3 ,
num_classes = 1000 ,
embed_dim = 96 ,
depths = [ 2 , 2 , 6 ],
num_heads = [ 3 , 6 , 12 ],
window_size = 14 ,
mlp_ratio = 4. ,
qkv_bias = True ,
qk_scale = None ,
drop_rate = 0.0 ,
drop_path_rate = 0.1 ,
ape = False ,
patch_norm = True ,
use_checkpoint = False
)
output = model ( input )
print ( output . shape )
CCNET : 시맨틱 세분화를위한 십자형-교차주의
from model . attention . CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 64 , 7 , 7 )
model = CrissCrossAttention ( 64 )
outputs = model ( input )
print ( outputs . shape )
다차원 변압기에서의 축의 관심
from model . attention . Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__' :
input = torch . randn ( 3 , 128 , 7 , 7 )
model = AxialImageTransformer (
dim = 128 ,
depth = 12 ,
reversible = True
)
outputs = model ( input )
print ( outputs . shape )
Pytorch는 "이미지 인식을위한 깊은 잔류 학습 --- CVPR2016 최고의 종이"의 구현
"심층 신경망을위한 집계 된 잔류 변환 --- CVPR2017"의 Pytorch 구현
MobileVit의 Pytorch 구현 : 가벼운 가중, 일반적인 목적 및 모바일 친화적 인 비전 변압기 --- ARXIV 2020.10.05
Pytorch 패치 구현이 필요합니까? --- ICLR2022 (검토 중)
셔플 변압기의 Pytorch 구현 : Vision Transformer를위한 공간 셔플 재검토 --- ARXIV 2021.06.07
Contnet의 Pytorch 구현 : 동시에 Convolution 및 Transformer를 사용하지 않는 이유는 무엇입니까? --- ARXIV 2021.04.27
계층 적주의를 가진 Vision Transformers의 Pytorch 구현 --- ARXIV 2022.06.15
공동 규모의 공동 설득력있는 이미지 변압기의 Pytorch 구현 --- ARXIV 2021.08.26
시력 변압기를위한 조건부 위치 인코딩의 Pytorch 구현
비전 변압기의 공간 차원 재고를 재고하는 Pytorch 구현 --- ICCV 2021
CrossVit의 Pytorch 구현 : 이미지 분류를위한 교차 해당 멀티 스케일 비전 변압기 --- ICCV 2021
변압기에서 변압기의 Pytorch 구현 --- Neurips 2021
Deepvit의 Pytorch 구현 : Deeper Vision Transformer를 향해
컨 컨 컨볼 루션 설계를 시각적 변압기에 통합하는 Pytorch 구현
Pytorch Convit의 구현 : 소프트 컨볼 루션 유도 바이어스를 갖춘 시력 변압기 향상
주의 기반 집계를 갖춘 컨볼 루션 네트워크를 증강시키는 Pytorch 구현
이미지 변압기와 함께 더 깊어지는 Pytorch 구현 --- ICCV 2021 (Oral)
주의를 통한 교육 데이터 효율적인 이미지 변압기 및 증류의 Pytorch 구현 --- ICML 2021
Levit의 Pytorch 구현 : 더 빠른 추론을위한 Convnet 의류의 비전 변압기
Volo의 Pytorch 구현 : 시각적 인식을위한 Vision Outlooker
컨테이너의 Pytorch 구현 : 컨텍스트 집계 네트워크 --- NEUIPS 2021
CMT의 Pytorch 구현 : Convolutional Neural Networks Meet Vision Transformers --- CVPR 2022
변형 가능한 관심을 가진 비전 변압기의 Pytorch 구현 --- CVPR 2022
Mobilenet 속도에서 효율적인 성분의 Pytorch 구현 : Vision Transformers
CondnextV2의 Pytorch 구현 : 마스크 된 자동 인코더로 공동 디자인 및 스케일링 콩베
"이미지 인식을위한 깊은 잔류 학습 --- CVPR2016 최고의 종이"
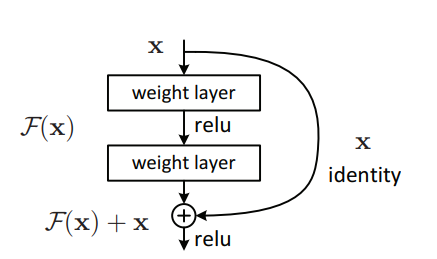
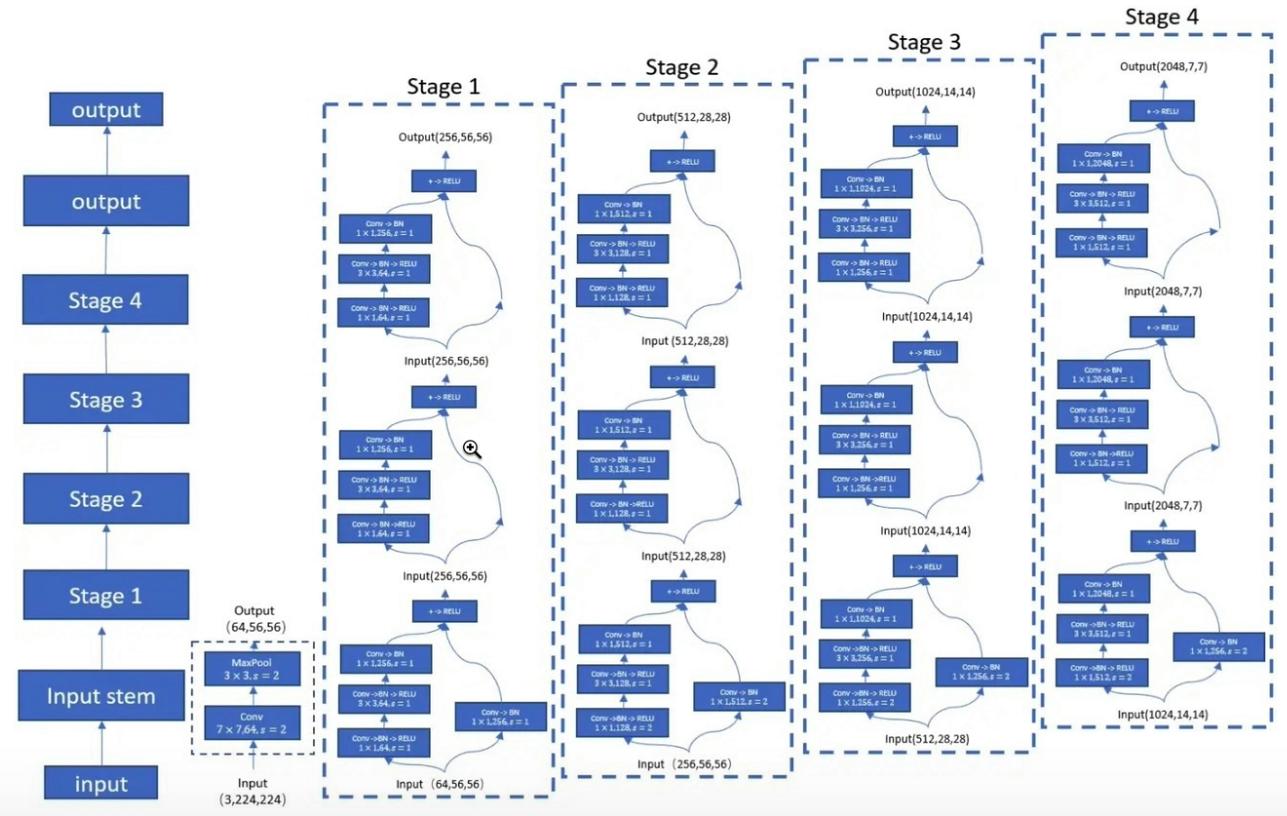
from model . backbone . resnet import ResNet50 , ResNet101 , ResNet152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnet50 = ResNet50 ( 1000 )
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out = resnet50 ( input )
print ( out . shape )"심층 신경망을위한 집계 된 잔류 변형 --- CVPR2017"
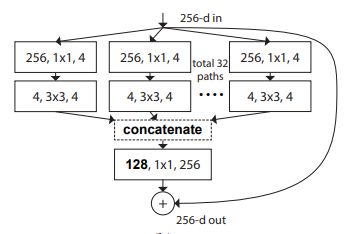
from model . backbone . resnext import ResNeXt50 , ResNeXt101 , ResNeXt152
import torch
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
resnext50 = ResNeXt50 ( 1000 )
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out = resnext50 ( input )
print ( out . shape )
MobileVit : 가벼운 가중, 일반적인 목적 및 모바일 친화적 인 비전 변압기 --- ARXIV 2020.10.05
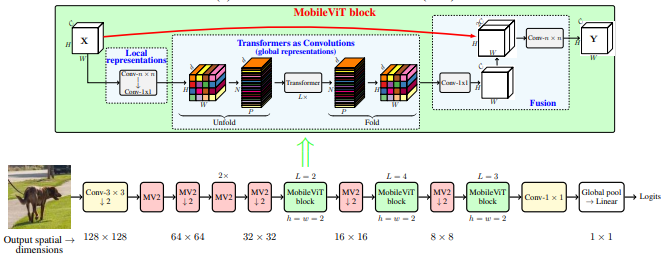
from model . backbone . MobileViT import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
### mobilevit_xxs
mvit_xxs = mobilevit_xxs ()
out = mvit_xxs ( input )
print ( out . shape )
### mobilevit_xs
mvit_xs = mobilevit_xs ()
out = mvit_xs ( input )
print ( out . shape )
### mobilevit_s
mvit_s = mobilevit_s ()
out = mvit_s ( input )
print ( out . shape )패치가 필요합니까? --- ICLR2022 (검토 중)
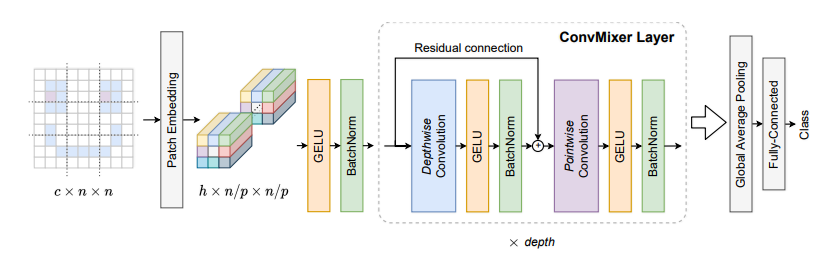
from model . backbone . ConvMixer import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
x = torch . randn ( 1 , 3 , 224 , 224 )
convmixer = ConvMixer ( dim = 512 , depth = 12 )
out = convmixer ( x )
print ( out . shape ) #[1, 1000]
셔플 트랜스포머 : Vision Transformer를위한 공간 셔플을 다시 생각합니다
from model . backbone . ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
sft = ShuffleTransformer ()
output = sft ( input )
print ( output . shape )
Contnet : 왜 Convolution과 Transformer를 동시에 사용하지 않습니까?
from model . backbone . ConTNet import ConTNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == "__main__" :
model = build_model ( use_avgdown = True , relative = True , qkv_bias = True , pre_norm = True )
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )
계층 적 관심을 가진 비전 변압기
from model . backbone . HATNet import HATNet
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
hat = HATNet ( dims = [ 48 , 96 , 240 , 384 ], head_dim = 48 , expansions = [ 8 , 8 , 4 , 4 ],
grid_sizes = [ 8 , 7 , 7 , 1 ], ds_ratios = [ 8 , 4 , 2 , 1 ], depths = [ 2 , 2 , 6 , 3 ])
output = hat ( input )
print ( output . shape )
공동 규모의 설득력있는 이미지 변압기
from model . backbone . CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CoaT ( patch_size = 4 , embed_dims = [ 152 , 152 , 152 , 152 ], serial_depths = [ 2 , 2 , 2 , 2 ], parallel_depth = 6 , num_heads = 8 , mlp_ratios = [ 4 , 4 , 4 , 4 ])
output = model ( input )
print ( output . shape ) # torch.Size([1, 1000])PVT V2 : 피라미드 비전 변압기를 사용한 개선 된 기준
from model . backbone . PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PyramidVisionTransformer (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 2 , 2 , 2 , 2 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )시력 변압기를위한 조건부 위치 인코딩
from model . backbone . CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CPVTV2 (
patch_size = 4 , embed_dims = [ 64 , 128 , 320 , 512 ], num_heads = [ 1 , 2 , 5 , 8 ], mlp_ratios = [ 8 , 8 , 4 , 4 ], qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ), depths = [ 3 , 4 , 6 , 3 ], sr_ratios = [ 8 , 4 , 2 , 1 ])
output = model ( input )
print ( output . shape )비전 변압기의 공간 차원을 다시 생각합니다
from model . backbone . PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PoolingTransformer (
image_size = 224 ,
patch_size = 14 ,
stride = 7 ,
base_dims = [ 64 , 64 , 64 ],
depth = [ 3 , 6 , 4 ],
heads = [ 4 , 8 , 16 ],
mlp_ratio = 4
)
output = model ( input )
print ( output . shape )CrossVit : 이미지 분류를위한 교차 분류 다중 규모 비전 변압기
from model . backbone . CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__" :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 240 , 224 ],
patch_size = [ 12 , 16 ],
embed_dim = [ 192 , 384 ],
depth = [[ 1 , 4 , 0 ], [ 1 , 4 , 0 ], [ 1 , 4 , 0 ]],
num_heads = [ 6 , 6 ],
mlp_ratio = [ 4 , 4 , 1 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )변압기의 변압기
from model . backbone . TnT import TNT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = TNT (
img_size = 224 ,
patch_size = 16 ,
outer_dim = 384 ,
inner_dim = 24 ,
depth = 12 ,
outer_num_heads = 6 ,
inner_num_heads = 4 ,
qkv_bias = False ,
inner_stride = 4 )
output = model ( input )
print ( output . shape )Deepvit : Deeper Vision Transformer쪽으로
from model . backbone . DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DeepVisionTransformer (
patch_size = 16 , embed_dim = 384 ,
depth = [ False ] * 16 ,
apply_transform = [ False ] * 0 + [ True ] * 32 ,
num_heads = 12 ,
mlp_ratio = 3 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
)
output = model ( input )
print ( output . shape )Convolution Designs를 비주얼 변압기에 통합합니다
from model . backbone . CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CeIT (
hybrid_backbone = Image2Tokens (),
patch_size = 4 ,
embed_dim = 192 ,
depth = 12 ,
num_heads = 3 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )컨비팅 : 소프트 컨볼 루션 유도 바이어스로 시력 변압기 향상
from model . backbone . ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
num_heads = 16 ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output . shape )이미지 변압기로 더 깊이 들어갑니다
from model . backbone . CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CaiT (
img_size = 224 ,
patch_size = 16 ,
embed_dim = 192 ,
depth = 24 ,
num_heads = 4 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
init_scale = 1e-5 ,
depth_token_only = 2
)
output = model ( input )
print ( output . shape )주의 기반 집계로 컨볼 루션 네트워크를 보강합니다
from model . backbone . PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = PatchConvnet (
patch_size = 16 ,
embed_dim = 384 ,
depth = 60 ,
num_heads = 1 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ),
Patch_layer = ConvStem ,
Attention_block = Conv_blocks_se ,
depth_token_only = 1 ,
mlp_ratio_clstk = 3.0 ,
)
output = model ( input )
print ( output . shape )주의를 통한 데이터 효율적인 이미지 변압기 및 증류 훈련
from model . backbone . DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = DistilledVisionTransformer (
patch_size = 16 ,
embed_dim = 384 ,
depth = 12 ,
num_heads = 6 ,
mlp_ratio = 4 ,
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 )
)
output = model ( input )
print ( output [ 0 ]. shape )LEVIT : 더 빠른 추론을위한 Convnet 의류의 비전 변압기
from model . backbone . LeViT import *
import torch
from torch import nn
if __name__ == '__main__' :
for name in specification :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = globals ()[ name ]( fuse = True , pretrained = False )
model . eval ()
output = model ( input )
print ( output . shape )Volo : 시각적 인식을위한 Vision Outlooker
from model . backbone . VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VOLO ([ 4 , 4 , 8 , 2 ],
embed_dims = [ 192 , 384 , 384 , 384 ],
num_heads = [ 6 , 12 , 12 , 12 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
downsamples = [ True , False , False , False ],
outlook_attention = [ True , False , False , False ],
post_layers = [ 'ca' , 'ca' ],
)
output = model ( input )
print ( output [ 0 ]. shape )컨테이너 : 컨텍스트 집계 네트워크
from model . backbone . Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionTransformer (
img_size = [ 224 , 56 , 28 , 14 ],
patch_size = [ 4 , 2 , 2 , 2 ],
embed_dim = [ 64 , 128 , 320 , 512 ],
depth = [ 3 , 4 , 8 , 3 ],
num_heads = 16 ,
mlp_ratio = [ 8 , 8 , 4 , 4 ],
qkv_bias = True ,
norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
output = model ( input )
print ( output . shape )CMT : Convolutional Neural Networks는 Vision Transformers를 만납니다
from model . backbone . CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = CMT_Tiny ()
output = model ( input )
print ( output [ 0 ]. shape )효율성 : Mobilenet 속도의 비전 변압기
from model . backbone . EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = EfficientFormer (
layers = EfficientFormer_depth [ 'l1' ],
embed_dims = EfficientFormer_width [ 'l1' ],
downsamples = [ True , True , True , True ],
vit_num = 1 ,
)
output = model ( input )
print ( output [ 0 ]. shape )CONDNEXTV2 : 마스크 된 자동 인코더로 공동 설계 및 스케일링 콩베
from model . backbone . convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__" :
model = convnextv2_atto ()
input = torch . randn ( 1 , 3 , 224 , 224 )
out = model ( input )
print ( out . shape )Pytorch는 "Repmlp : Parameterizing Convolutions를 이미지 인식을 위해 완전히 연결된 레이어로 재현하는 구현 --- ARXIV 2021.05.05"
"MLP-MIXER : Vision for Vision을위한 All-MLP 아키텍처 --- ARXIV 2021.05.17의 Pytorch 구현"
"RESMLP : 데이터 효율적인 교육을 통한 이미지 분류를위한 피드 포워드 네트워크 --- ARXIV 2021.05.07"의 Pytorch 구현 "
Pytorch 구현 "MLPS에주의를 기울여야합니다 --- ARXIV 2021.05.17"
"이미지 인식을위한 스파 스 MLP : 자체 변환이 실제로 필요합니까? --- arxiv 2021.09.12"의 Pytorch 구현
"REPMLP : 이미지 인식을 위해 완전히 연결된 층으로 컨볼 루션을 다시 모색화합니다."
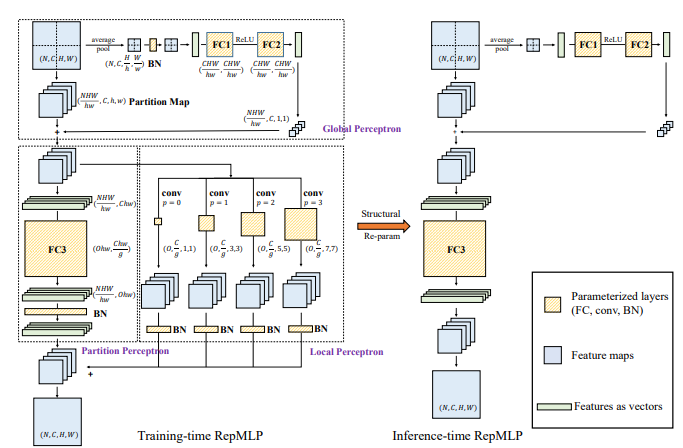
from model . mlp . repmlp import RepMLP
import torch
from torch import nn
N = 4 #batch size
C = 512 #input dim
O = 1024 #output dim
H = 14 #image height
W = 14 #image width
h = 7 #patch height
w = 7 #patch width
fc1_fc2_reduction = 1 #reduction ratio
fc3_groups = 8 # groups
repconv_kernels = [ 1 , 3 , 5 , 7 ] #kernel list
repmlp = RepMLP ( C , O , H , W , h , w , fc1_fc2_reduction , fc3_groups , repconv_kernels = repconv_kernels )
x = torch . randn ( N , C , H , W )
repmlp . eval ()
for module in repmlp . modules ():
if isinstance ( module , nn . BatchNorm2d ) or isinstance ( module , nn . BatchNorm1d ):
nn . init . uniform_ ( module . running_mean , 0 , 0.1 )
nn . init . uniform_ ( module . running_var , 0 , 0.1 )
nn . init . uniform_ ( module . weight , 0 , 0.1 )
nn . init . uniform_ ( module . bias , 0 , 0.1 )
#training result
out = repmlp ( x )
#inference result
repmlp . switch_to_deploy ()
deployout = repmlp ( x )
print ((( deployout - out ) ** 2 ). sum ())"MLP-MIXER : 비전을위한 모든 MLP 아키텍처"
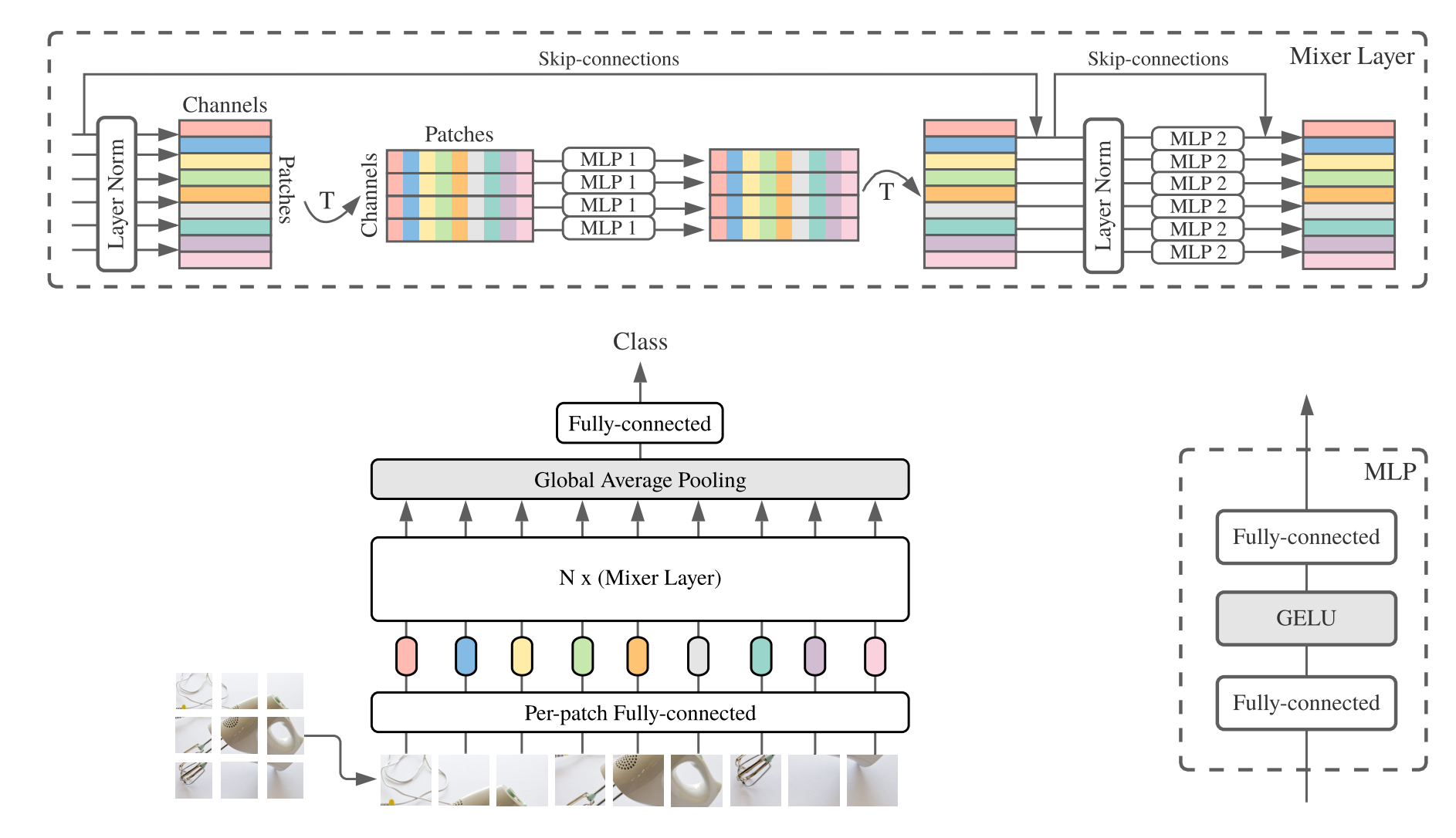
from model . mlp . mlp_mixer import MlpMixer
import torch
mlp_mixer = MlpMixer ( num_classes = 1000 , num_blocks = 10 , patch_size = 10 , tokens_hidden_dim = 32 , channels_hidden_dim = 1024 , tokens_mlp_dim = 16 , channels_mlp_dim = 1024 )
input = torch . randn ( 50 , 3 , 40 , 40 )
output = mlp_mixer ( input )
print ( output . shape )"RESMLP : 데이터 효율적인 교육을 통한 이미지 분류를위한 피드 포워드 네트워크"

from model . mlp . resmlp import ResMLP
import torch
input = torch . randn ( 50 , 3 , 14 , 14 )
resmlp = ResMLP ( dim = 128 , image_size = 14 , patch_size = 7 , class_num = 1000 )
out = resmlp ( input )
print ( out . shape ) #the last dimention is class_num"MLP에주의를 기울이십시오"
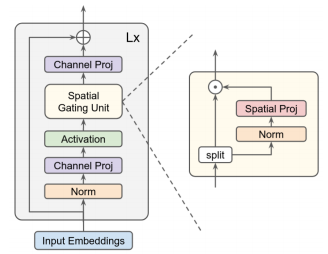
from model . mlp . g_mlp import gMLP
import torch
num_tokens = 10000
bs = 50
len_sen = 49
num_layers = 6
input = torch . randint ( num_tokens ,( bs , len_sen )) #bs,len_sen
gmlp = gMLP ( num_tokens = num_tokens , len_sen = len_sen , dim = 512 , d_ff = 1024 )
output = gmlp ( input )
print ( output . shape )"이미지 인식을위한 스파 스 MLP : 자기 변이가 정말로 필요합니까?"
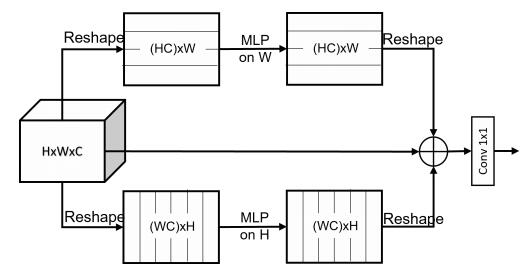
from model . mlp . sMLP_block import sMLPBlock
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 50 , 3 , 224 , 224 )
smlp = sMLPBlock ( h = 224 , w = 224 )
out = smlp ( input )
print ( out . shape )"비전 순열기 : 시각적 인식을위한 순열 가능한 MLP와 같은 아키텍처"
from model . mlp . vip - mlp import VisionPermutator
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 1 , 3 , 224 , 224 )
model = VisionPermutator (
layers = [ 4 , 3 , 8 , 3 ],
embed_dims = [ 384 , 384 , 384 , 384 ],
patch_size = 14 ,
transitions = [ False , False , False , False ],
segment_dim = [ 16 , 16 , 16 , 16 ],
mlp_ratios = [ 3 , 3 , 3 , 3 ],
mlp_fn = WeightedPermuteMLP
)
output = model ( input )
print ( output . shape )"Repvgg : VGG 스타일 컨넷 만들기를 다시 훌륭하게 만들기 ---- CVPR2021"의 Pytorch 구현
"ACNET : 비대칭 컨볼 루션 블록을 통해 강력한 CNN의 커널 골격 강화 --- ICCV2019"의 Pytorch 구현 "
Pytorch "다양한 분기 블록 : 컨퍼런스와 같은 유닛으로서 컨볼 루션 구축 --- CVPR2021"
"REPVGG : VGG 스타일 컨넷을 다시 훌륭하게 만드는 것"
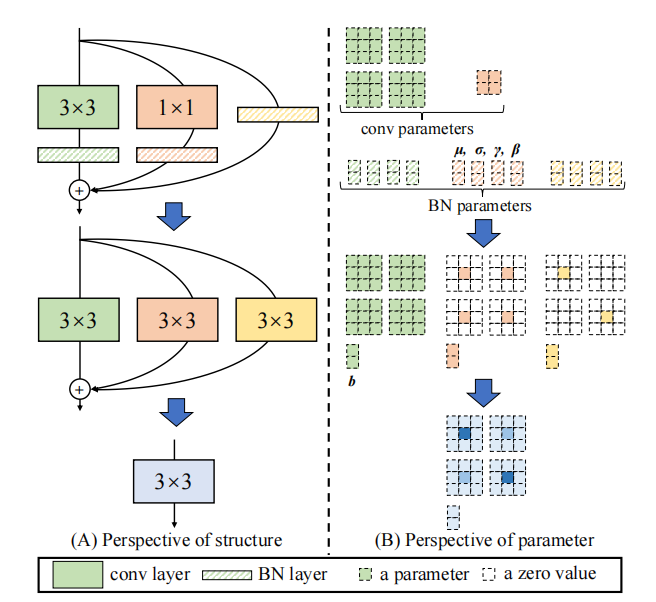
from model . rep . repvgg import RepBlock
import torch
input = torch . randn ( 50 , 512 , 49 , 49 )
repblock = RepBlock ( 512 , 512 )
repblock . eval ()
out = repblock ( input )
repblock . _switch_to_deploy ()
out2 = repblock ( input )
print ( 'difference between vgg and repvgg' )
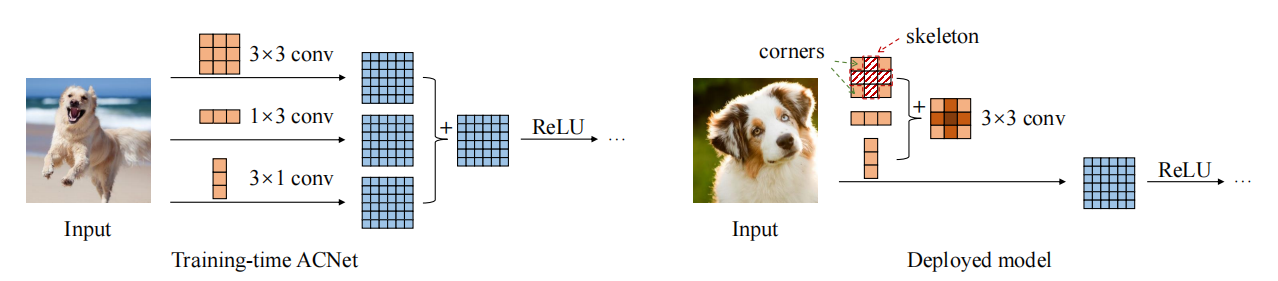
print ((( out2 - out ) ** 2 ). sum ())"ACNET : 비대칭 컨볼 루션 블록을 통해 강력한 CNN을위한 커널 골격 강화"
from model . rep . acnet import ACNet
import torch
from torch import nn
input = torch . randn ( 50 , 512 , 49 , 49 )
acnet = ACNet ( 512 , 512 )
acnet . eval ()
out = acnet ( input )
acnet . _switch_to_deploy ()
out2 = acnet ( input )
print ( 'difference:' )
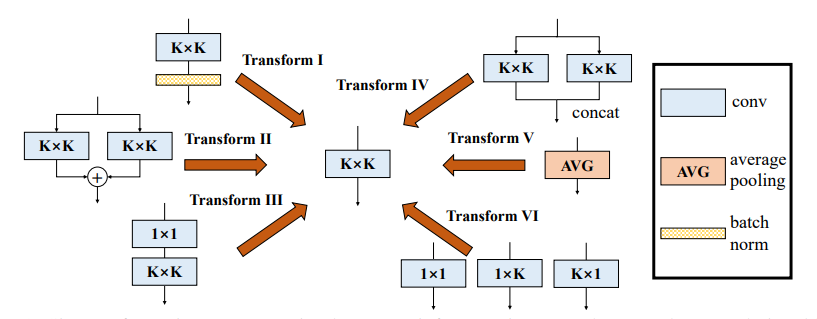
print ((( out2 - out ) ** 2 ). sum ())"다양한 지점 블록 : 내재와 같은 단위로 컨볼 루션 구축"
from model . rep . ddb import transI_conv_bn
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+bn
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
bn1 = nn . BatchNorm2d ( 64 )
bn1 . eval ()
out1 = bn1 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transI_conv_bn ( conv1 , bn1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transII_conv_branch
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
out1 = conv1 ( input ) + conv2 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transII_conv_branch ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIII_conv_sequential
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 64 , 1 , padding = 0 , bias = False )
conv2 = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
out1 = conv2 ( conv1 ( input ))
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 , bias = False )
conv_fuse . weight . data = transIII_conv_sequential ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transIV_conv_concat
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
conv2 = nn . Conv2d ( 64 , 32 , 3 , padding = 1 )
out1 = torch . cat ([ conv1 ( input ), conv2 ( input )], dim = 1 )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transIV_conv_concat ( conv1 , conv2 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transV_avg
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
avg = nn . AvgPool2d ( kernel_size = 3 , stride = 1 )
out1 = avg ( input )
conv = transV_avg ( 64 , 3 )
out2 = conv ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ()) from model . rep . ddb import transVI_conv_scale
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 64 , 7 , 7 )
#conv+conv
conv1x1 = nn . Conv2d ( 64 , 64 , 1 )
conv1x3 = nn . Conv2d ( 64 , 64 ,( 1 , 3 ), padding = ( 0 , 1 ))
conv3x1 = nn . Conv2d ( 64 , 64 ,( 3 , 1 ), padding = ( 1 , 0 ))
out1 = conv1x1 ( input ) + conv1x3 ( input ) + conv3x1 ( input )
#conv_fuse
conv_fuse = nn . Conv2d ( 64 , 64 , 3 , padding = 1 )
conv_fuse . weight . data , conv_fuse . bias . data = transVI_conv_scale ( conv1x1 , conv1x3 , conv3x1 )
out2 = conv_fuse ( input )
print ( "difference:" ,(( out2 - out1 ) ** 2 ). sum (). item ())"Mobilenets : 모바일 비전 애플리케이션을위한 효율적인 컨볼 루션 신경망의 Pytorch 구현 --- CVPR2017"
Pytorch "효율적인 신경 네트워크에 대한 모델 스케일링 재고 링크 --- PMLR2019"의 Pytorch 구현
Pytorch의 "Involution : 시각적 인식을위한 컨볼 루션의 고유를 반전 ---- CVPR2021"
"동적 컨볼 루션 : 컨볼 루션 커널에 대한 관심 --- CVPR2020 구강"의 Pytorch 구현
"Condconv : 효율적인 추론을위한 조건부 파라미터 화 된 컨볼 루션의 Pytorch 구현 --- Neurips2019"
"Mobilenets : 모바일 비전 애플리케이션을위한 효율적인 컨볼 루션 신경 네트워크"
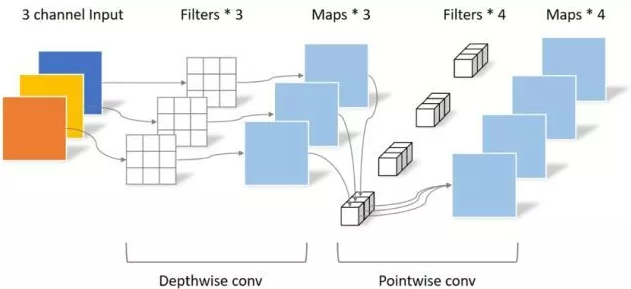
from model . conv . DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
dsconv = DepthwiseSeparableConvolution ( 3 , 64 )
out = dsconv ( input )
print ( out . shape )"효율적인 넷 : Convolutional Neural Networks에 대한 모델 스케일링을 재고합니다."
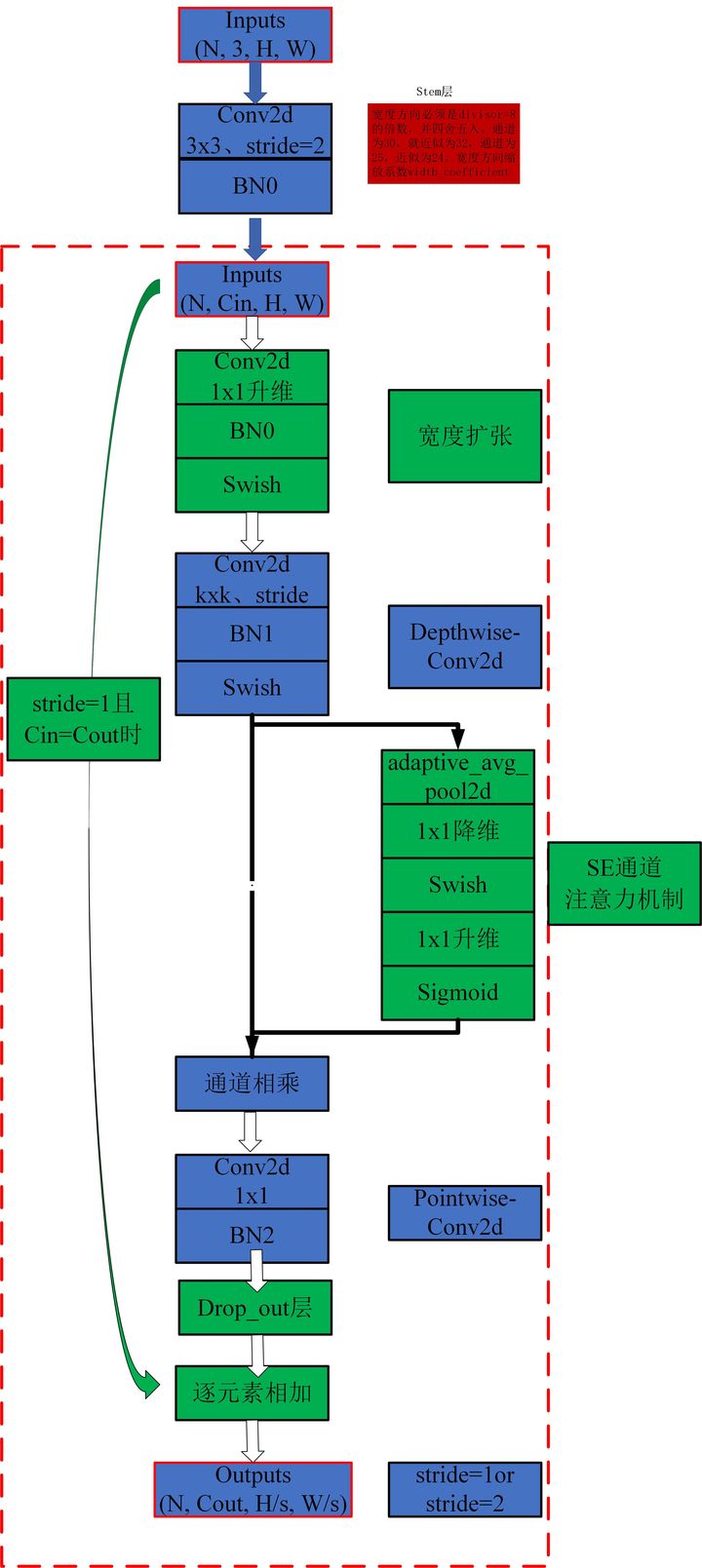
from model . conv . MBConv import MBConvBlock
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 3 , 224 , 224 )
mbconv = MBConvBlock ( ksize = 3 , input_filters = 3 , output_filters = 512 , image_size = 224 )
out = mbconv ( input )
print ( out . shape )
"발병 : 시각적 인식을위한 컨볼 루션의 고유를 반전"
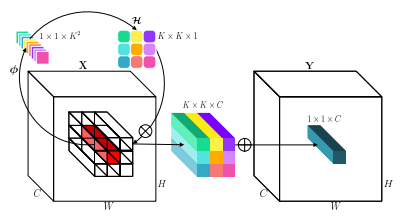
from model . conv . Involution import Involution
import torch
from torch import nn
from torch . nn import functional as F
input = torch . randn ( 1 , 4 , 64 , 64 )
involution = Involution ( kernel_size = 3 , in_channel = 4 , stride = 2 )
out = involution ( input )
print ( out . shape )"동적 컨볼 루션 : 컨볼 루션 커널에 대한주의"
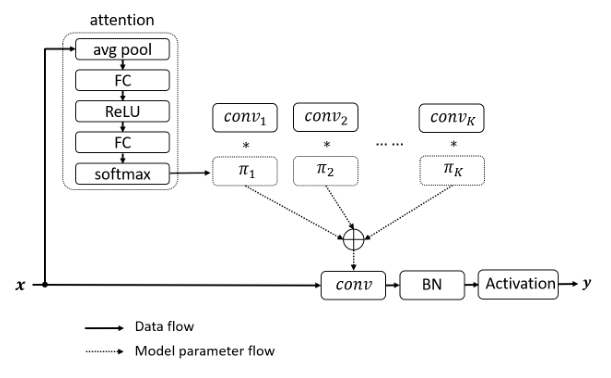
from model . conv . DynamicConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = DynamicConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape ) # 2,32,64,64"Condconv : 효율적인 추론을위한 조건부 매개 변수 컨볼 루션"
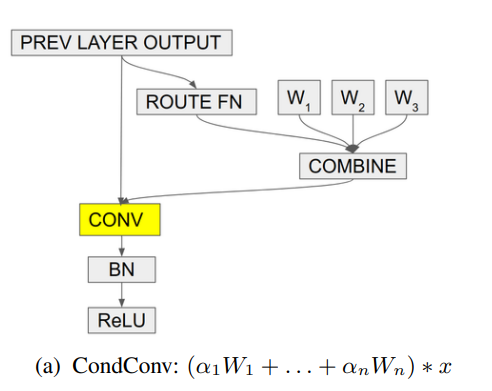
from model . conv . CondConv import *
import torch
from torch import nn
from torch . nn import functional as F
if __name__ == '__main__' :
input = torch . randn ( 2 , 32 , 64 , 64 )
m = CondConv ( in_planes = 32 , out_planes = 64 , kernel_size = 3 , stride = 1 , padding = 1 , bias = False )
out = m ( input )
print ( out . shape )큰 뉴스! ! ! 프로젝트 보충제로서, 주요 회의 및 저널의 논문 분석을 수집하고 구성하는 새로 오픈 소스 프로젝트 FightingCV-Paper-Reading 에주의를 기울일 수 있습니다.
큰 뉴스! ! ! 최근에 나는 인터넷에서 CV-Course 와의 다양한 AI 관련 비디오 자습서와 필수 논문을 편집했습니다.
큰 뉴스! ! ! 최근에, 새로운 Yoloair 객체 감지 코드 라이브러리가 열렸으며, 이는 Yolov5, Yolov7, Yolox, Yolox, Yolov4, Yolov3 및 기타 Yolo 모델을 포함한 다양한 Yolo 모델과 다양한 기존주의 메커니즘을 통합합니다.
ECCV2022 용지 요약 : ECCV2022-PARES-LIST


