Pytorch图像分类
使用Pytorch实施以下论文。
- Resnet(1512.03385)
- 重新连接(1603.05027)
- WRN(1605.07146)
- Densenet(1608.06993,2001.02394)
- 金字塔(1610.02915)
- Resnext(1611.05431)
- Shake Shake(1705.07485)
- 拉尔斯(1708.03888,1801.03137)
- 切口(1708.04552)
- 随机擦除(1708.04896)
- SENET(1709.01507)
- 混音(1710.09412)
- 双切片(1802.07426)
- RICAP(1811.09030)
- Cutmix(1905.04899)
要求
- Ubuntu(仅在Ubuntu上进行测试,因此可能无法在Windows上使用。)
- Python> = 3.7
- pytorch> = 1.4.0
- 火炬
- NVIDIA顶点
pip install -r requirements.txt
用法
python train.py --config configs/cifar/resnet_preact.yaml
CIFAR-10的结果
结果使用几乎与论文相同的设置
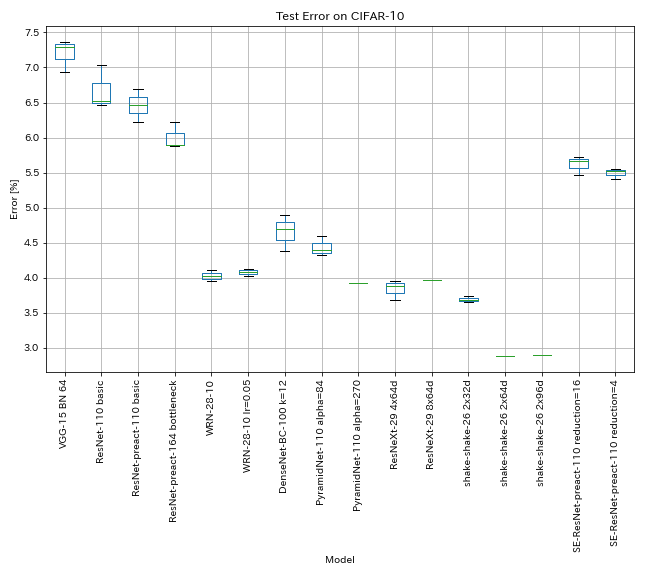
| 模型 | 测试错误(中位数3次) | 测试错误(在纸上) | 训练时间 |
|---|
| VGG样(深度15,w/ bn,频道64) | 7.29 | N/A。 | 1h20m |
| Resnet-11 | 6.52 | 6.43(最佳),6.61 +/- 0.16 | 3H06M |
| 重新连接1010 | 6.47 | 6.37(5跑的中值) | 3H05M |
| 重新连接164瓶颈 | 5.90 | 5.46(中值5次) | 4H01M |
| 重新连接1001瓶颈 | | 4.62(5跑中位数),4.69 +/- 0.20 | |
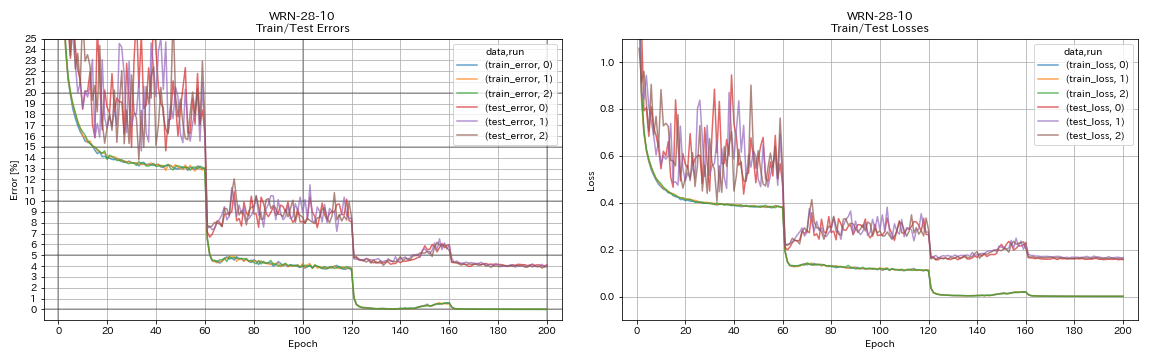
| WRN-28-10 | 4.03 | 4.00(中位数5次) | 16h10m |
| WRN-28-10 W/辍学 | | 3.89(中值5次) | |
| densenet-100(k = 12) | 3.87(1跑) | 4.10(1行) | 24H28M* |
| densenet-100(k = 24) | | 3.74(1跑) | |
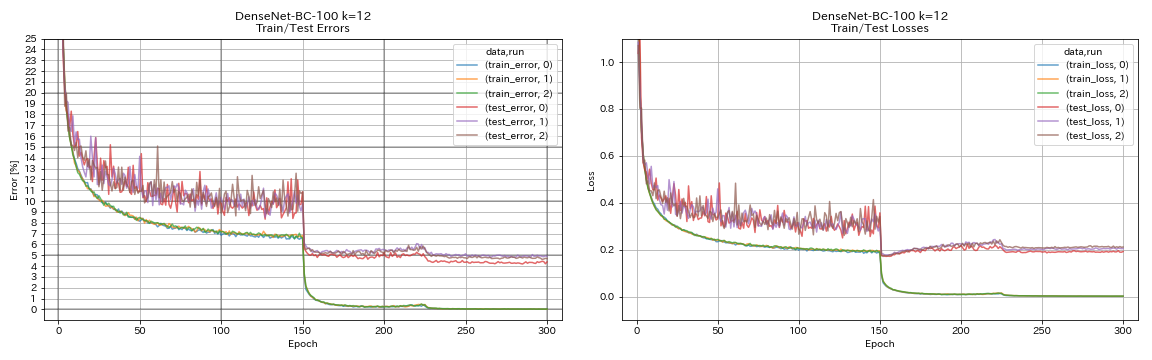
| Densenet-BC-100(k = 12) | 4.69 | 4.51(1跑) | 15h20m |
| Densenet-BC-250(k = 24) | | 3.62(1跑) | |
| Densenet-BC-190(k = 40) | | 3.46(1跑) | |
| 金字塔1110(alpha = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| 金字塔110(alpha = 270) | 3.92(1跑) | 3.73 +/- 0.04 | 24h12m* |
| 金字塔Net-164瓶颈(alpha = 270) | 3.44(1跑) | 3.48 +/- 0.20 | 32H37M* |
| 金字塔272瓶颈(Alpha = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | 〜3.75(图7) | 31h17m |
| Resnext-29 8x64d | 3.97(1跑) | 3.65(平均10次运行) | 42H50M* |
| Resnext-29 16x64d | | 3.58(平均10次运行) | |
| Shake Shake 26 2x32d(SSI) | 3.68 | 3.55(平均3次运行) | 33h49m |
| Shake Shake 26 2x64d(SSI) | 2.88(1跑) | 2.98(平均3次运行) | 78H48M |
| Shake Shake 26 2x96d(SSI) | 2.90(1跑) | 2.86(平均5次运行) | 101H32M* |
笔记
- 培训环境中与论文的差异:
- 经过培训的WRN-28-10,批次尺寸为64(纸128)。
- 经过培训的Densenet-BC-100(K = 12),批次32和初始学习率为0.05(批次尺寸64和初始学习率为0.1)。
- 经过培训的Resnext-29 4x64d,具有单个GPU,批次尺寸32和初始学习率为0.025(8 GPU,批次尺寸128和初始学习率0.1)。
- 训练有素的摇动模型,带有单个GPU(纸上2 GPU)。
- 受过训练的摇震26 2x64d(SSI),批次尺寸为64,初始学习率为0.1。
- 上面报告的测试错误是最后一个时期。
- 与3次运行的实验的计算机不同的计算机上,只有1次运行的实验。
- 这些实验使用了GeForce GTX 980。
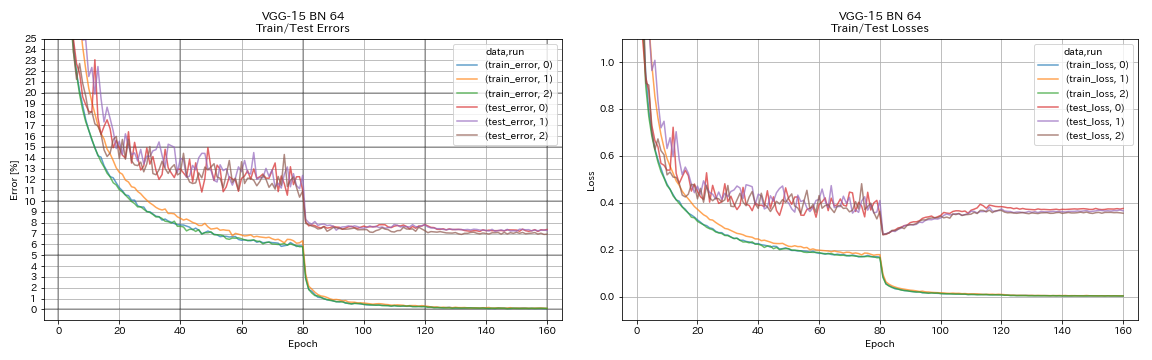
像vgg一样
python train.py --config configs/cifar/vgg.yaml
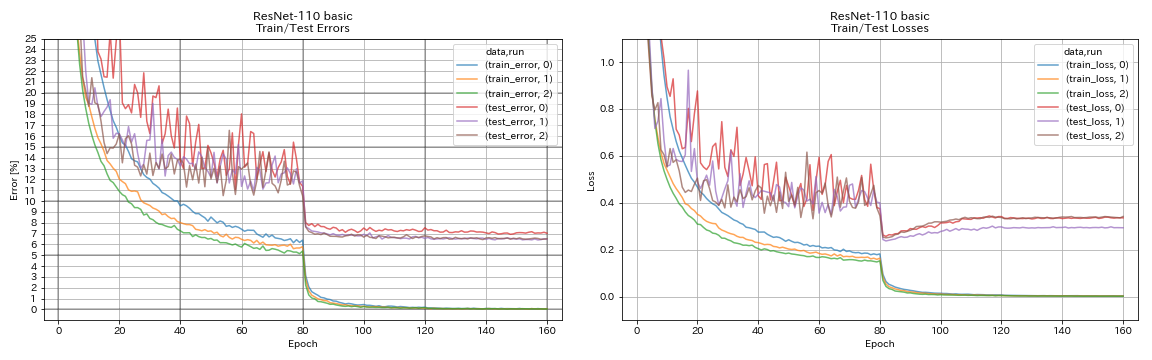
重新连接
python train.py --config configs/cifar/resnet.yaml
重新连接
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00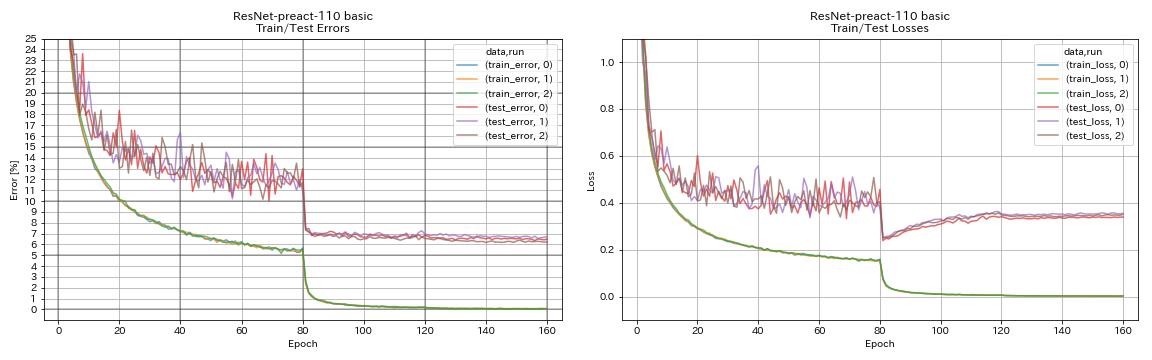
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00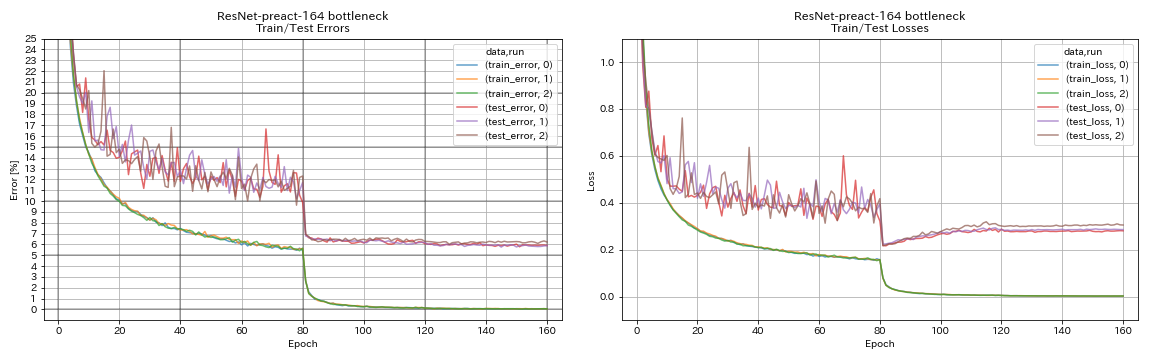
WRN
python train.py --config configs/cifar/wrn.yaml
Densenet
python train.py --config configs/cifar/densenet.yaml
金字塔
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00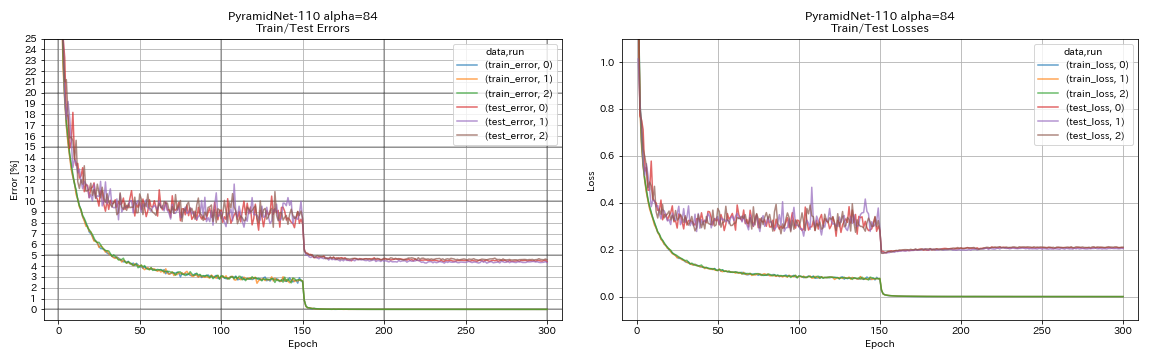
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00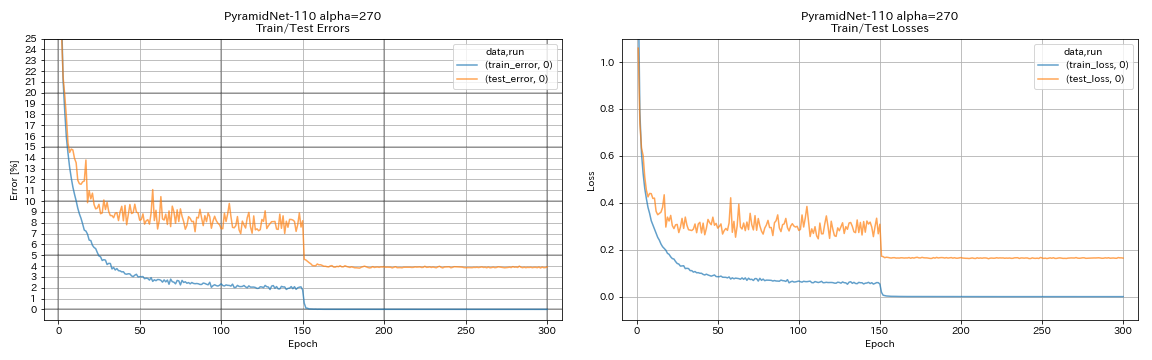
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00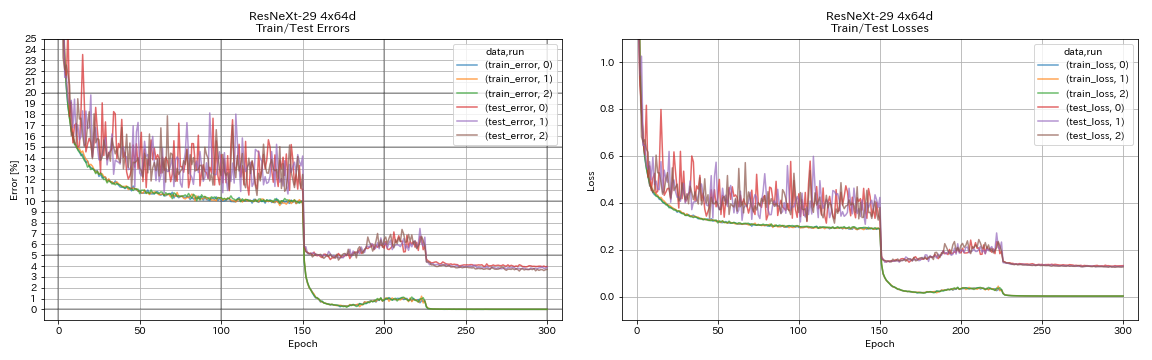
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00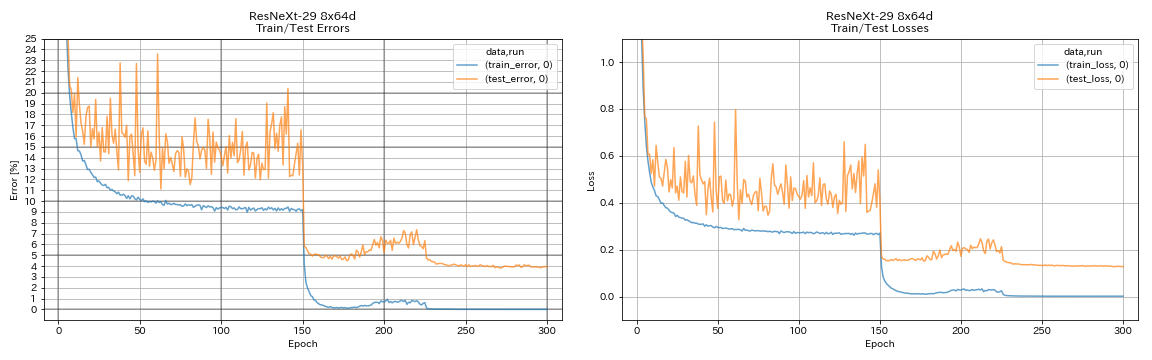
摇晃
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00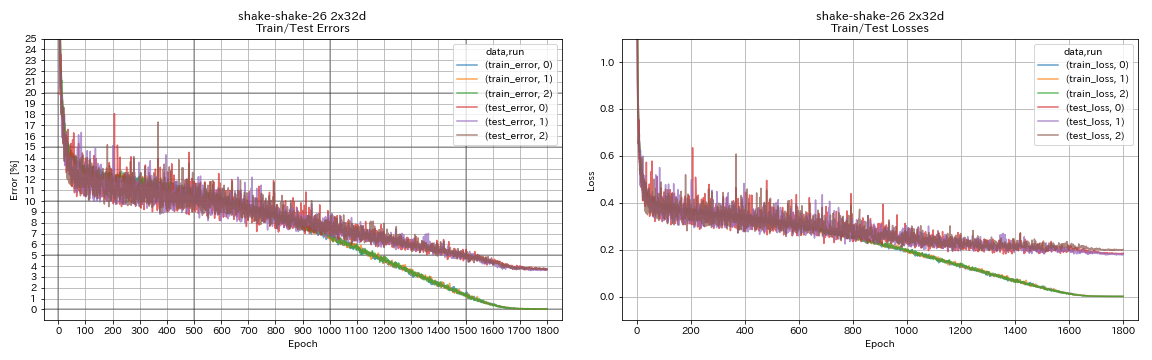
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00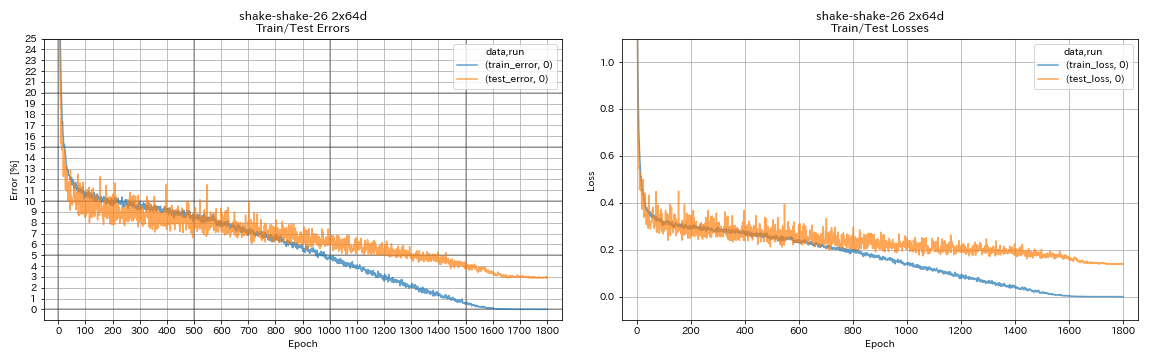
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00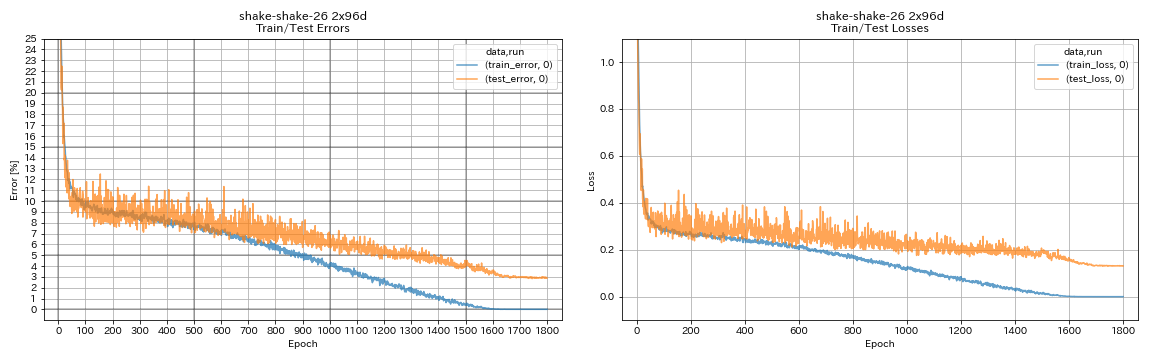
结果
| 模型 | 测试错误(1运行) | #时代 | 训练时间 |
|---|
| 重新连接20,扩大因子4 | 4.91 | 200 | 1h26m |
| 重新连接20,扩大因子4 | 4.01 | 400 | 2h53m |
| 重新连接20,扩大因子4 | 3.99 | 1800 | 12h53m |
| Resnet-Preact-20,扩大因子4,切口16 | 3.71 | 200 | 1h26m |
| Resnet-Preact-20,扩大因子4,切口16 | 3.46 | 400 | 2h53m |
| Resnet-Preact-20,扩大因子4,切口16 | 3.76 | 1800 | 12h53m |
| 重新连接20,延长因子4,RICAP(beta = 0.3) | 3.45 | 200 | 1h26m |
| 重新连接20,延长因子4,RICAP(beta = 0.3) | 3.11 | 400 | 2h53m |
| 重新连接20,延长因子4,RICAP(beta = 0.3) | 3.15 | 1800 | 12h53m |
| 模型 | 测试错误(1运行) | #时代 | 训练时间 |
|---|
| WRN-28-10,切口16 | 3.19 | 200 | 6h35m |
| WRN-28-10,混合(alpha = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10,RICAP(beta = 0.3) | 2.83 | 200 | 6h35m |
| WRN-28-10,双切片(alpha = 0.1) | 2.87 | 200 | 12h42m |
| WRN-28-10,切口16 | 3.07 | 400 | 13h10m |
| WRN-28-10,混合(alpha = 1) | 3.04 | 400 | 13h08m |
| WRN-28-10,RICAP(beta = 0.3) | 2.71 | 400 | 13h08m |
| WRN-28-10,双切片(alpha = 0.1) | 2.76 | 400 | 25h20m |
| Shake Shake 26 2x64d,切口16 | 2.64 | 1800 | 78H55M* |
| Shake Shake 26 2x64d,混合(alpha = 1) | 2.63 | 1800 | 35h56m |
| Shake Shake 26 2x64d,ricap(beta = 0.3) | 2.29 | 1800 | 35h10m |
| Shake Shake-26 2x64d,双切片(alpha = 0.1) | 2.64 | 1800 | 68h34m |
| Shake Shake 26 2x96d,切口16 | 2.50 | 1800 | 60h20m |
| Shake Shake 26 2x96d,混合(alpha = 1) | 2.36 | 1800 | 60h20m |
| Shake Shake 26 2x96d,RICAP(beta = 0.3) | 2.10 | 1800 | 60h20m |
| Shake Shake-26 2x96d,双切片(alpha = 0.1) | 2.41 | 1800 | 113h09m |
| Shake Shake 26 2x128d,切口16 | 2.58 | 1800 | 85H04M |
| Shake Shake 26 2x128d,ricap(beta = 0.3) | 1.97 | 1800 | 85H06M |
笔记
- 表中报告的结果是最后一个时期的测试错误。
- 所有模型均使用余弦退火训练,初始学习率为0.2。
- 这些实验中使用了GeForce GTX 1080 Ti,除了 *使用GEFORCE GTX 980进行的实验。
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True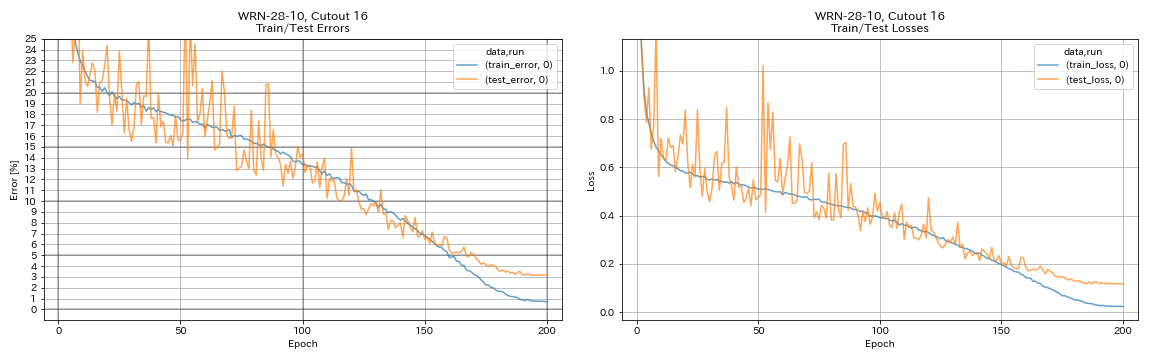
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True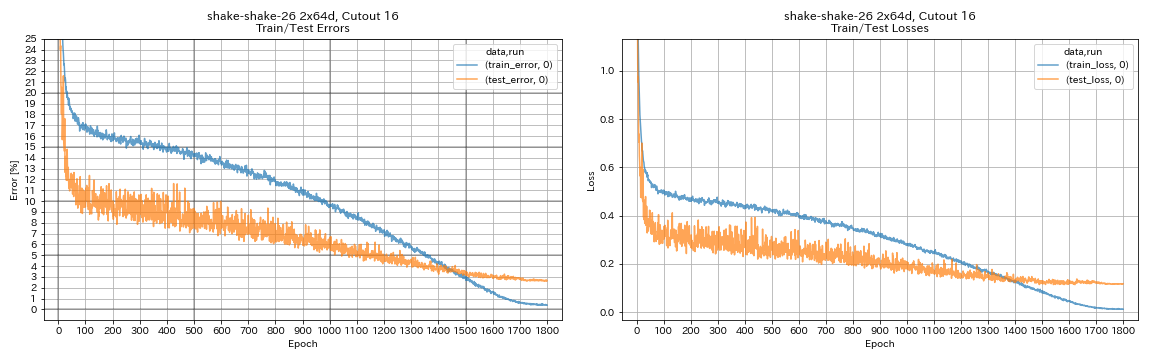
使用多GPU的结果
| 模型 | 批量大小 | #GPU | 测试错误(1运行) | #时代 | 训练时间* |
|---|
| WRN-28-10,RICAP(beta = 0.3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10,RICAP(beta = 0.3) | 256 | 2 | 2.71 | 200 | 2h14m |
| WRN-28-10,RICAP(beta = 0.3) | 128 | 4 | 2.89 | 200 | 1H01M |
| WRN-28-10,RICAP(beta = 0.3) | 64 | 8 | 2.75 | 200 | 34m |
笔记
使用1 GPU
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop False使用2个GPU
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False使用4 GPU
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False使用8 GPU
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False关于时尚人士的结果
| 模型 | 测试错误(1运行) | #时代 | 训练时间 |
|---|
| 重新连接20,延伸因子4,切口12 | 4.17 | 200 | 1h32m |
| 重新连接20,扩大因子4,切口14 | 4.11 | 200 | 1h32m |
| 重新连接50,切口12 | 4.45 | 200 | 57m |
| 重新连接50,切口14 | 4.38 | 200 | 57m |
| 重新连接50,扩大因子4,切口12 | 4.07 | 200 | 3h37m |
| 重新连接50,扩大因子4,切口14 | 4.13 | 200 | 3h39m |
| Shake Shake 26 2x32d(SSI),切口12 | 4.08 | 400 | 3H41M |
| Shake Shake 26 2x32d(SSI),切口14 | 4.05 | 400 | 3h39m |
| Shake Shake 26 2x96d(SSI),切口12 | 3.72 | 400 | 13h46m |
| Shake Shake 26 2x96d(SSI),切口14 | 3.85 | 400 | 13h39m |
| Shake Shake 26 2x96d(SSI),切口12 | 3.65 | 800 | 26h42m |
| Shake Shake 26 2x96d(SSI),切口14 | 3.60 | 800 | 26h42m |
| 模型 | 测试错误(中位数3次) | #时代 | 训练时间 |
|---|
| 重新连接20 | 5.04 | 200 | 26m |
| Resnet-Preact-20,切口6 | 4.84 | 200 | 26m |
| Resnet-Preact-20,切口8 | 4.64 | 200 | 26m |
| Resnet-Preact-20,切口10 | 4.74 | 200 | 26m |
| Resnet-Preact-20,切口12 | 4.68 | 200 | 26m |
| Resnet-Preact-20,切口14 | 4.64 | 200 | 26m |
| Resnet-Preact-20,切口16 | 4.49 | 200 | 26m |
| RESNET-PREACT-20,随机播种 | 4.61 | 200 | 26m |
| Resnet-Preact-20,混合 | 4.92 | 200 | 26m |
| Resnet-Preact-20,混合 | 4.64 | 400 | 52m |
笔记
- 表中报告的结果是最后一个时期的测试错误。
- 所有模型均使用余弦退火训练,初始学习率为0.2。
- 以下数据扩展应用于培训数据:
- 图像在每侧都有4个像素填充,然后从填充图像中随机裁剪28x28个贴片。
- 图像是水平翻转的。
- 这些实验使用了GeForce GTX 1080 Ti。
MNIST的结果
| 模型 | 测试错误(中位数3次) | #时代 | 训练时间 |
|---|
| 重新连接20 | 0.40 | 100 | 12m |
| Resnet-Preact-20,切口6 | 0.32 | 100 | 12m |
| Resnet-Preact-20,切口8 | 0.25 | 100 | 12m |
| Resnet-Preact-20,切口10 | 0.27 | 100 | 12m |
| Resnet-Preact-20,切口12 | 0.26 | 100 | 12m |
| Resnet-Preact-20,切口14 | 0.26 | 100 | 12m |
| Resnet-Preact-20,切口16 | 0.25 | 100 | 12m |
| Resnet-Preact-20,混合(Alpha = 1) | 0.40 | 100 | 12m |
| Resnet-Preact-20,混合(Alpha = 0.5) | 0.38 | 100 | 12m |
| 重新连接20,扩大因子4,切口14 | 0.26 | 100 | 45m |
| 重新连接50,切口14 | 0.29 | 100 | 28m |
| 重新连接50,扩大因子4,切口14 | 0.25 | 100 | 1h50m |
| Shake Shake 26 2x96d(SSI),切口14 | 0.24 | 100 | 3H22M |
笔记
- 表中报告的结果是最后一个时期的测试错误。
- 所有模型均使用余弦退火训练,初始学习率为0.2。
- 这些实验使用了GeForce GTX 1080 Ti。
Kuzushiji-Mnist的结果
| 模型 | 测试错误(中位数3次) | #时代 | 训练时间 |
|---|
| Resnet-Preact-20,切口14 | 0.82(最佳0.67) | 200 | 24m |
| 重新连接20,扩大因子4,切口14 | 0.72(最佳0.67) | 200 | 1h30m |
| 金字塔11-270,切口14 | 0.72(最佳0.70) | 200 | 10h05m |
| Shake Shake 26 2x96d(SSI),切口14 | 0.66(最佳0.63) | 200 | 6h46m |
笔记
- 表中报告的结果是最后一个时期的测试错误。
- 所有模型均使用余弦退火训练,初始学习率为0.2。
- 这些实验使用了GeForce GTX 1080 Ti。
实验
实验剩余单位,学习率调度和数据扩展
在本实验中,研究了以下对分类精度的影响:
- 金字塔样残差单位
- 学习率的余弦退火
- 剪下
- 随机擦除
- 混合
- 缩减采样后的快捷方式
RESNET-PREACCT-56在CIFAR-10上接受培训,在本实验中,初始学习率为0.2。
笔记
- 金字塔纸(1610.02915)表明,在残留单位中,在剩余单位中删除第一个恢复,并在残留单位中添加bn,都提高了分类精度。
- SGDR Paper(1608.03983)显示余弦退火也可以提高分类精度,而无需重新启动。
结果
- 类似金字塔的单元起作用。
- 使用类似金字塔的单位时,最好在下采样后降低捷径,最好不要在捷径下进行捷径。
- 余弦退火稍微提高了准确性。
- 切割,随机播放和混合都很好。
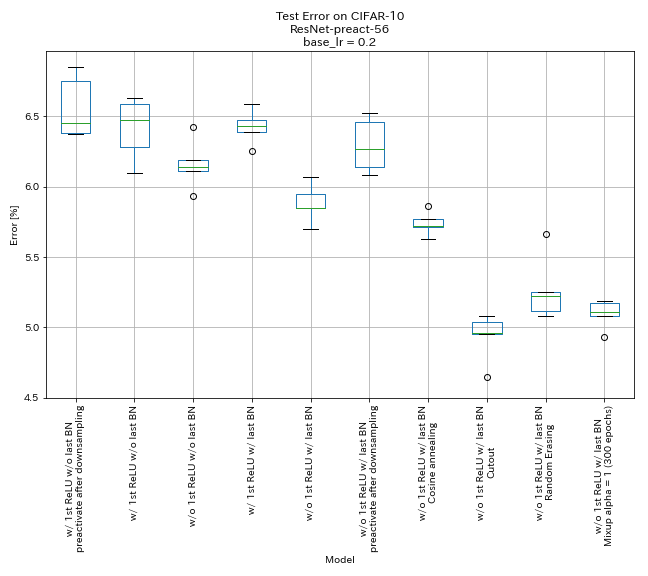
| 模型 | 测试错误(5次运行的中位数) | 训练时间 |
|---|
| w/ ost relu,w/ o上一个bn,降采样后,将捷径倒闭 | 6.45 | 95分钟 |
| W/ 1st Relu,w/ o上一个bn | 6.47 | 95分钟 |
| w/o第一次,w/o上一个bn | 6.14 | 89分钟 |
| W/ 1st Relu,w/ last Bn | 6.43 | 104分钟 |
| w/ o第一恢复,w/ last bn | 5.85 | 98分钟 |
| w/ o第1次,w/ last bn,降采样后,将捷径倒闭 | 6.27 | 98分钟 |
| W/ o第1次,最后BN,余弦退火 | 5.72 | 98分钟 |
| w/ o第1次,最后一个bn,切口 | 4.96 | 98分钟 |
| w/ o 1st relu,w/ last bn,随机播种 | 5.22 | 98分钟 |
| w/ o 1st relu,w/ last bn,混合(300个时代) | 5.11 | 191分钟 |
下采样后,捷径降低了
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
W/ 1st Relu,w/ o上一个bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o第一次,w/o上一个bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
W/ 1st Relu,w/ last Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00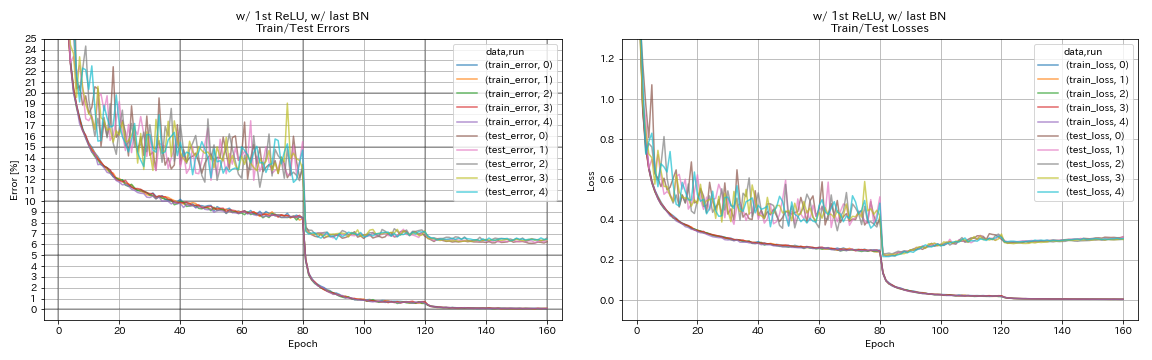
w/ o第一恢复,w/ last bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00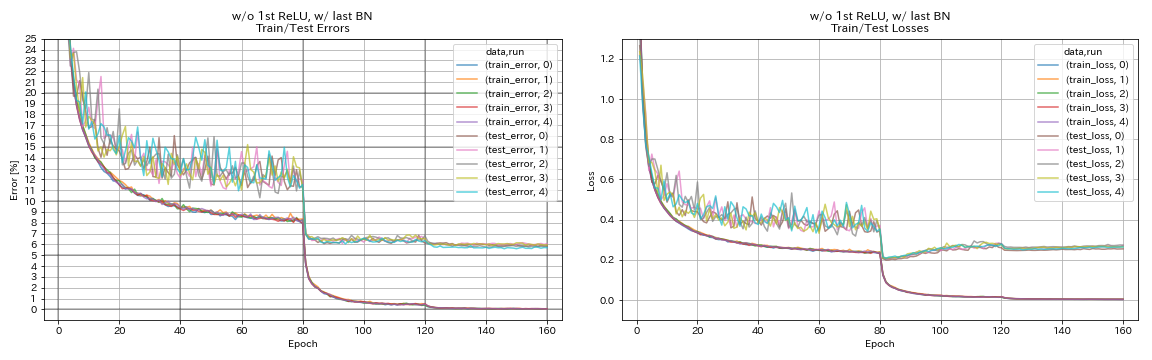
w/ o第1次,w/ last bn,降采样后,将捷径倒闭
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00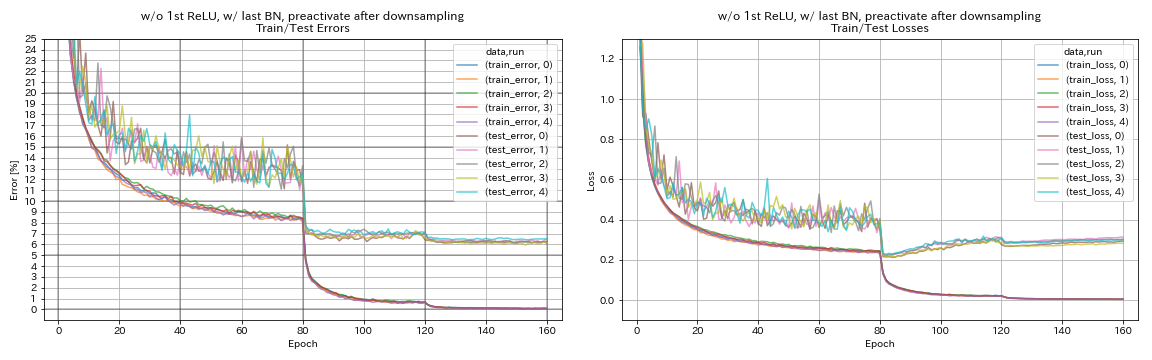
W/ o第1次,最后BN,余弦退火
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00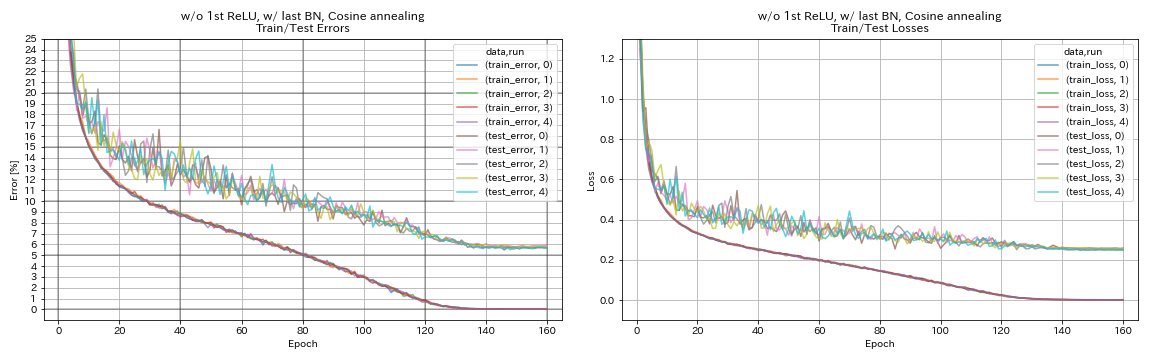
w/ o第1次,最后一个bn,切口
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00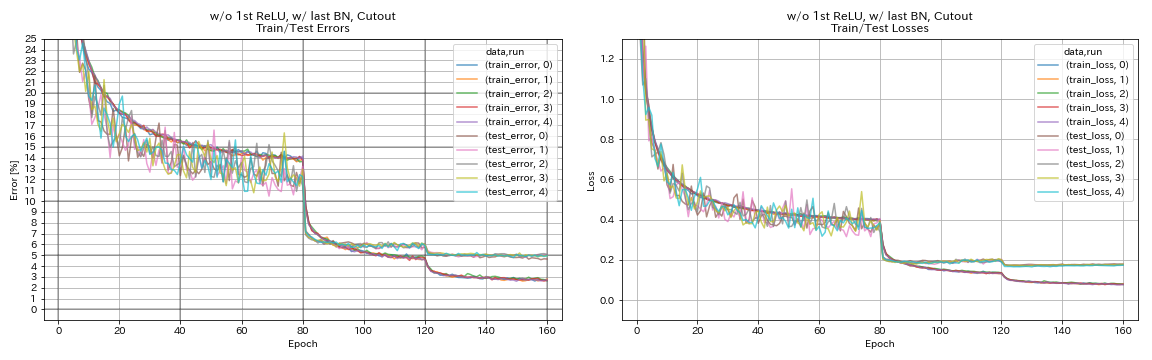
w/ o 1st relu,w/ last bn,随机播种
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00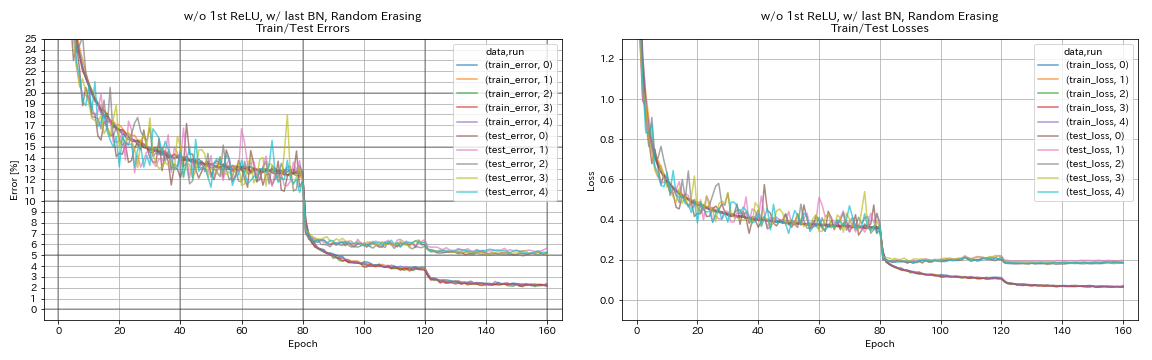
w/ o第一恢复,w/ last bn,混合
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00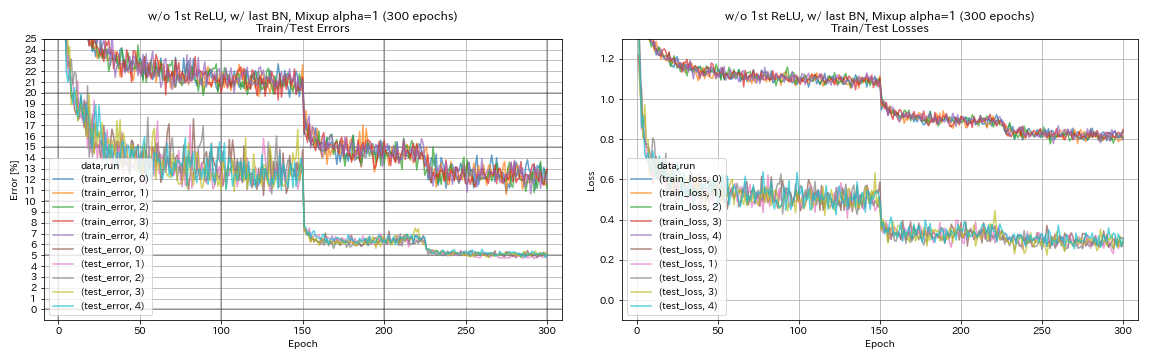
在标签平滑,混合,ricap和双切片上进行实验
CIFAR-10的结果
| 模型 | 测试错误(中位数3次) | #时代 | 训练时间 |
|---|
| 重新连接20 | 7.60 | 200 | 24m |
| Resnet-Preact-20,标签平滑(Epsilon = 0.001) | 7.51 | 200 | 25m |
| 重新连接20,标签平滑(Epsilon = 0.01) | 7.21 | 200 | 25m |
| Resnet-Preact-20,标签平滑(Epsilon = 0.1) | 7.57 | 200 | 25m |
| Resnet-Preact-20,混合(Alpha = 1) | 7.24 | 200 | 26m |
| Resnet-Preact-20,RICAP(beta = 0.3),w/随机作物 | 6.88 | 200 | 28m |
| RESNET-PREACCT-20,RICAP(beta = 0.3) | 6.77 | 200 | 28m |
| Resnet-preact-20,双切片16(alpha = 0.1) | 6.24 | 200 | 45m |
| 重新连接20 | 7.05 | 400 | 49m |
| Resnet-Preact-20,标签平滑(Epsilon = 0.001) | 7.20 | 400 | 49m |
| 重新连接20,标签平滑(Epsilon = 0.01) | 6.97 | 400 | 49m |
| Resnet-Preact-20,标签平滑(Epsilon = 0.1) | 7.16 | 400 | 49m |
| Resnet-Preact-20,混合(Alpha = 1) | 6.66 | 400 | 51m |
| Resnet-Preact-20,RICAP(beta = 0.3),w/随机作物 | 6.30 | 400 | 56m |
| RESNET-PREACCT-20,RICAP(beta = 0.3) | 6.19 | 400 | 56m |
| Resnet-preact-20,双切片16(alpha = 0.1) | 5.55 | 400 | 1h36m |
笔记
- 表中报告的结果是最后一个时期的测试错误。
- 所有模型均使用余弦退火训练,初始学习率为0.2。
- 这些实验使用了GeForce GTX 1080 Ti。
批处理大小和学习率的实验
- 使用GeForce 1080 Ti在CIFAR-10数据集上进行以下实验。
- 表中报告的结果是最后一个时期的测试错误。
学习率的线性缩放规则
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 3.2 | 余弦 | 200 | 10.57 | 22m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 200 | 8.87 | 21m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 200 | 8.40 | 21m |
| 重新连接20 | 512 | 0.4 | 余弦 | 200 | 8.22 | 20m |
| 重新连接20 | 256 | 0.2 | 余弦 | 200 | 8.61 | 22m |
| 重新连接20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| 重新连接20 | 64 | 0.05 | 余弦 | 200 | 8.22 | 28m |
| 重新连接20 | 32 | 0.025 | 余弦 | 200 | 8.00 | 43m |
| 重新连接20 | 16 | 0.0125 | 余弦 | 200 | 7.75 | 1h17m |
| 重新连接20 | 8 | 0.006125 | 余弦 | 200 | 7.70 | 2h32m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 3.2 | 多步 | 200 | 28.97 | 22m |
| 重新连接20 | 2048 | 1.6 | 多步 | 200 | 9.07 | 21m |
| 重新连接20 | 1024 | 0.8 | 多步 | 200 | 8.62 | 21m |
| 重新连接20 | 512 | 0.4 | 多步 | 200 | 8.23 | 20m |
| 重新连接20 | 256 | 0.2 | 多步 | 200 | 8.40 | 21m |
| 重新连接20 | 128 | 0.1 | 多步 | 200 | 8.28 | 24m |
| 重新连接20 | 64 | 0.05 | 多步 | 200 | 8.13 | 28m |
| 重新连接20 | 32 | 0.025 | 多步 | 200 | 7.58 | 43m |
| 重新连接20 | 16 | 0.0125 | 多步 | 200 | 7.93 | 1h18m |
| 重新连接20 | 8 | 0.006125 | 多步 | 200 | 8.31 | 2h34m |
线性缩放 +更长的训练
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 3.2 | 余弦 | 400 | 8.97 | 44m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 400 | 7.85 | 43m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 400 | 7.20 | 42m |
| 重新连接20 | 512 | 0.4 | 余弦 | 400 | 7.83 | 40m |
| 重新连接20 | 256 | 0.2 | 余弦 | 400 | 7.65 | 42m |
| 重新连接20 | 128 | 0.1 | 余弦 | 400 | 7.09 | 47m |
| 重新连接20 | 64 | 0.05 | 余弦 | 400 | 7.17 | 44m |
| 重新连接20 | 32 | 0.025 | 余弦 | 400 | 7.24 | 2h11m |
| 重新连接20 | 16 | 0.0125 | 余弦 | 400 | 7.26 | 4h10m |
| 重新连接20 | 8 | 0.006125 | 余弦 | 400 | 7.02 | 7h53m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 3.2 | 余弦 | 800 | 8.14 | 1h29m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 800 | 7.74 | 1h23m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 800 | 7.15 | 1h31m |
| 重新连接20 | 512 | 0.4 | 余弦 | 800 | 7.27 | 1h25m |
| 重新连接20 | 256 | 0.2 | 余弦 | 800 | 7.22 | 1h26m |
| 重新连接20 | 128 | 0.1 | 余弦 | 800 | 6.68 | 1h35m |
| 重新连接20 | 64 | 0.05 | 余弦 | 800 | 7.18 | 2h20m |
| 重新连接20 | 32 | 0.025 | 余弦 | 800 | 7.03 | 4h16m |
| 重新连接20 | 16 | 0.0125 | 余弦 | 800 | 6.78 | 8h37m |
| 重新连接20 | 8 | 0.006125 | 余弦 | 800 | 6.89 | 16h47m |
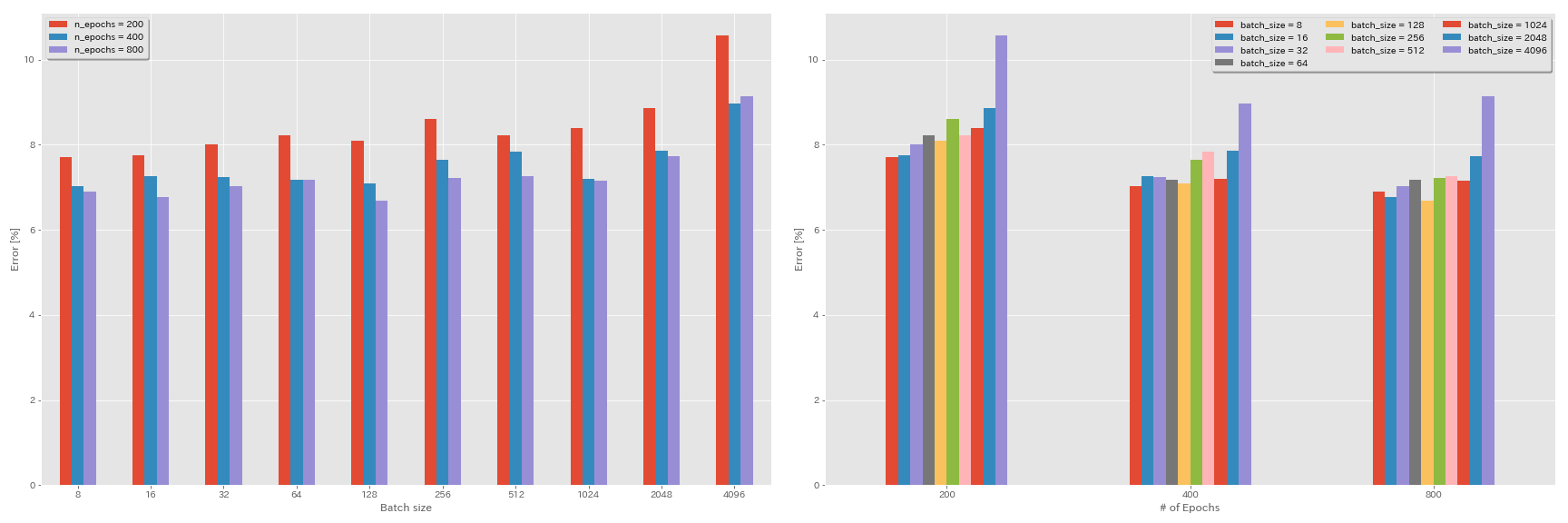
初始学习率的影响
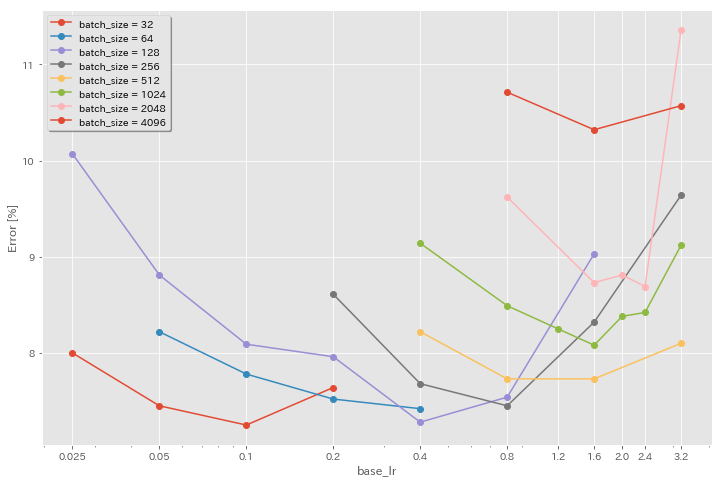
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 3.2 | 余弦 | 200 | 10.57 | 22m |
| 重新连接20 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| 重新连接20 | 4096 | 0.8 | 余弦 | 200 | 10.71 | 22m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 2048 | 3.2 | 余弦 | 200 | 11.34 | 21m |
| 重新连接20 | 2048 | 2.4 | 余弦 | 200 | 8.69 | 21m |
| 重新连接20 | 2048 | 2.0 | 余弦 | 200 | 8.81 | 21m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| 重新连接20 | 2048 | 0.8 | 余弦 | 200 | 9.62 | 21m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 1024 | 3.2 | 余弦 | 200 | 9.12 | 21m |
| 重新连接20 | 1024 | 2.4 | 余弦 | 200 | 8.42 | 22m |
| 重新连接20 | 1024 | 2.0 | 余弦 | 200 | 8.38 | 22m |
| 重新连接20 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| 重新连接20 | 1024 | 1.2 | 余弦 | 200 | 8.25 | 21m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 200 | 8.08 | 22m |
| 重新连接20 | 1024 | 0.4 | 余弦 | 200 | 8.49 | 22m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 512 | 3.2 | 余弦 | 200 | 8.51 | 21m |
| 重新连接20 | 512 | 1.6 | 余弦 | 200 | 7.73 | 20m |
| 重新连接20 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| 重新连接20 | 512 | 0.4 | 余弦 | 200 | 8.22 | 20m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 256 | 3.2 | 余弦 | 200 | 9.64 | 22m |
| 重新连接20 | 256 | 1.6 | 余弦 | 200 | 8.32 | 22m |
| 重新连接20 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| 重新连接20 | 256 | 0.4 | 余弦 | 200 | 7.68 | 22m |
| 重新连接20 | 256 | 0.2 | 余弦 | 200 | 8.61 | 22m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 128 | 1.6 | 余弦 | 200 | 9.03 | 24m |
| 重新连接20 | 128 | 0.8 | 余弦 | 200 | 7.54 | 24m |
| 重新连接20 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| 重新连接20 | 128 | 0.2 | 余弦 | 200 | 7.96 | 24m |
| 重新连接20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| 重新连接20 | 128 | 0.05 | 余弦 | 200 | 8.81 | 24m |
| 重新连接20 | 128 | 0.025 | 余弦 | 200 | 10.07 | 24m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 64 | 0.4 | 余弦 | 200 | 7.42 | 35m |
| 重新连接20 | 64 | 0.2 | 余弦 | 200 | 7.52 | 36m |
| 重新连接20 | 64 | 0.1 | 余弦 | 200 | 7.78 | 37m |
| 重新连接20 | 64 | 0.05 | 余弦 | 200 | 8.22 | 28m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 32 | 0.2 | 余弦 | 200 | 7.64 | 1H05M |
| 重新连接20 | 32 | 0.1 | 余弦 | 200 | 7.25 | 1H08M |
| 重新连接20 | 32 | 0.05 | 余弦 | 200 | 7.45 | 1H07M |
| 重新连接20 | 32 | 0.025 | 余弦 | 200 | 8.00 | 43m |
良好的学习率 +更长的培训
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| 重新连接20 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 200 | 8.08 | 22m |
| 重新连接20 | 512 | 1.6 | 余弦 | 200 | 7.73 | 20m |
| 重新连接20 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| 重新连接20 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| 重新连接20 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| 重新连接20 | 128 | 0.2 | 余弦 | 200 | 7.96 | 24m |
| 重新连接20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 1.6 | 余弦 | 800 | 8.36 | 1h33m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 800 | 7.53 | 1h27m |
| 重新连接20 | 1024 | 1.6 | 余弦 | 800 | 7.30 | 1h30m |
| 重新连接20 | 1024 | 0.8 | 余弦 | 800 | 7.42 | 1h30m |
| 重新连接20 | 512 | 1.6 | 余弦 | 800 | 6.69 | 1h26m |
| 重新连接20 | 512 | 0.8 | 余弦 | 800 | 6.77 | 1h26m |
| 重新连接20 | 256 | 0.8 | 余弦 | 800 | 6.84 | 1h28m |
| 重新连接20 | 128 | 0.4 | 余弦 | 800 | 6.86 | 1h35m |
| 重新连接20 | 128 | 0.2 | 余弦 | 800 | 7.05 | 1h38m |
| 重新连接20 | 128 | 0.1 | 余弦 | 800 | 6.68 | 1h35m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 1.6 | 余弦 | 1600 | 8.25 | 3h10m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 1600 | 7.34 | 2h50m |
| 重新连接20 | 1024 | 1.6 | 余弦 | 1600 | 6.94 | 2h52m |
| 重新连接20 | 512 | 1.6 | 余弦 | 1600 | 6.99 | 2h44m |
| 重新连接20 | 256 | 0.8 | 余弦 | 1600 | 6.95 | 2h50m |
| 重新连接20 | 128 | 0.4 | 余弦 | 1600 | 6.64 | 3H09M |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 4096 | 1.6 | 余弦 | 3200 | 9.52 | 6h15m |
| 重新连接20 | 2048 | 1.6 | 余弦 | 3200 | 6.92 | 5h42m |
| 重新连接20 | 1024 | 1.6 | 余弦 | 3200 | 6.96 | 5h43m |
| 模型 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 2048 | 1.6 | 余弦 | 6400 | 7.45 | 11h44m |
拉斯
- 在原始论文(1708.03888,1801.03137)中,他们使用了多项式衰变学习率调度,但是在这些实验中使用了余弦退火。
- 在此实施中,不使用LARS系数,因此应相应地调整学习率。
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00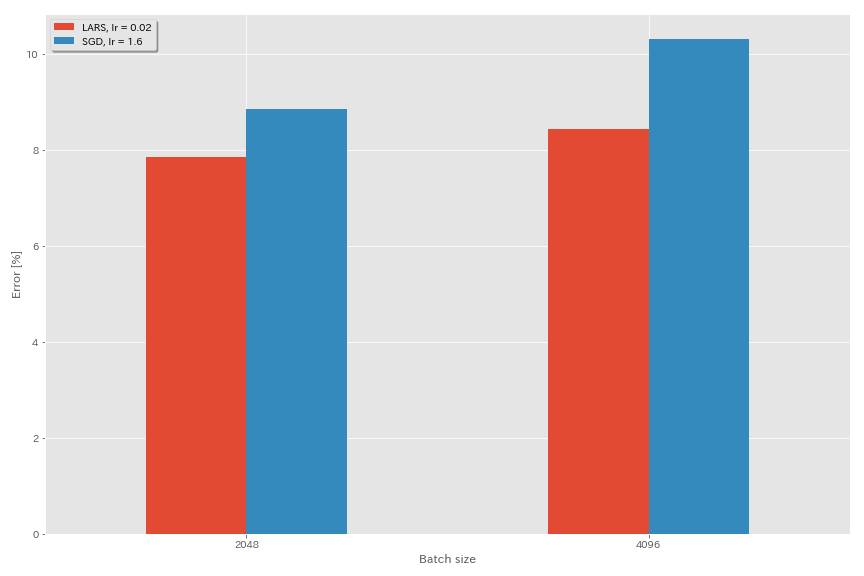
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 4096 | 3.2 | 余弦 | 200 | 10.57(1跑) | 22m |
| 重新连接20 | SGD | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| 重新连接20 | SGD | 4096 | 0.8 | 余弦 | 200 | 10.71(1行) | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.04 | 余弦 | 200 | 9.58 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.03 | 余弦 | 200 | 8.46 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.02 | 余弦 | 200 | 8.21 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.015 | 余弦 | 200 | 8.47 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.01 | 余弦 | 200 | 9.33 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.005 | 余弦 | 200 | 14.31 | 22m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 2048 | 3.2 | 余弦 | 200 | 11.34(1跑) | 21m |
| 重新连接20 | SGD | 2048 | 2.4 | 余弦 | 200 | 8.69(1跑) | 21m |
| 重新连接20 | SGD | 2048 | 2.0 | 余弦 | 200 | 8.81(1跑) | 21m |
| 重新连接20 | SGD | 2048 | 1.6 | 余弦 | 200 | 8.73(1跑) | 22m |
| 重新连接20 | SGD | 2048 | 0.8 | 余弦 | 200 | 9.62(1跑) | 21m |
| 重新连接20 | 拉斯 | 2048 | 0.04 | 余弦 | 200 | 11.58 | 21m |
| 重新连接20 | 拉斯 | 2048 | 0.02 | 余弦 | 200 | 8.05 | 22m |
| 重新连接20 | 拉斯 | 2048 | 0.01 | 余弦 | 200 | 8.07 | 22m |
| 重新连接20 | 拉斯 | 2048 | 0.005 | 余弦 | 200 | 9.65 | 22m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 1024 | 3.2 | 余弦 | 200 | 9.12(1跑) | 21m |
| 重新连接20 | SGD | 1024 | 2.4 | 余弦 | 200 | 8.42(1跑) | 22m |
| 重新连接20 | SGD | 1024 | 2.0 | 余弦 | 200 | 8.38(1跑) | 22m |
| 重新连接20 | SGD | 1024 | 1.6 | 余弦 | 200 | 8.07(1跑) | 22m |
| 重新连接20 | SGD | 1024 | 1.2 | 余弦 | 200 | 8.25(1跑) | 21m |
| 重新连接20 | SGD | 1024 | 0.8 | 余弦 | 200 | 8.08(1跑) | 22m |
| 重新连接20 | SGD | 1024 | 0.4 | 余弦 | 200 | 8.49(1跑) | 22m |
| 重新连接20 | 拉斯 | 1024 | 0.02 | 余弦 | 200 | 9.30 | 22m |
| 重新连接20 | 拉斯 | 1024 | 0.01 | 余弦 | 200 | 7.68 | 22m |
| 重新连接20 | 拉斯 | 1024 | 0.005 | 余弦 | 200 | 8.88 | 23m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 512 | 3.2 | 余弦 | 200 | 8.51(1行) | 21m |
| 重新连接20 | SGD | 512 | 1.6 | 余弦 | 200 | 7.73(1跑) | 20m |
| 重新连接20 | SGD | 512 | 0.8 | 余弦 | 200 | 7.73(1跑) | 21m |
| 重新连接20 | SGD | 512 | 0.4 | 余弦 | 200 | 8.22(1跑) | 20m |
| 重新连接20 | 拉斯 | 512 | 0.015 | 余弦 | 200 | 9.84 | 23m |
| 重新连接20 | 拉斯 | 512 | 0.01 | 余弦 | 200 | 8.05 | 23m |
| 重新连接20 | 拉斯 | 512 | 0.0075 | 余弦 | 200 | 7.58 | 23m |
| 重新连接20 | 拉斯 | 512 | 0.005 | 余弦 | 200 | 7.96 | 23m |
| 重新连接20 | 拉斯 | 512 | 0.0025 | 余弦 | 200 | 8.83 | 23m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 256 | 3.2 | 余弦 | 200 | 9.64(1跑) | 22m |
| 重新连接20 | SGD | 256 | 1.6 | 余弦 | 200 | 8.32(1跑) | 22m |
| 重新连接20 | SGD | 256 | 0.8 | 余弦 | 200 | 7.45(1跑) | 21m |
| 重新连接20 | SGD | 256 | 0.4 | 余弦 | 200 | 7.68(1跑) | 22m |
| 重新连接20 | SGD | 256 | 0.2 | 余弦 | 200 | 8.61(1跑) | 22m |
| 重新连接20 | 拉斯 | 256 | 0.01 | 余弦 | 200 | 8.95 | 27m |
| 重新连接20 | 拉斯 | 256 | 0.005 | 余弦 | 200 | 7.75 | 28m |
| 重新连接20 | 拉斯 | 256 | 0.0025 | 余弦 | 200 | 8.21 | 28m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 128 | 1.6 | 余弦 | 200 | 9.03(1跑) | 24m |
| 重新连接20 | SGD | 128 | 0.8 | 余弦 | 200 | 7.54(1跑) | 24m |
| 重新连接20 | SGD | 128 | 0.4 | 余弦 | 200 | 7.28(1跑) | 24m |
| 重新连接20 | SGD | 128 | 0.2 | 余弦 | 200 | 7.96(1跑) | 24m |
| 重新连接20 | 拉斯 | 128 | 0.005 | 余弦 | 200 | 7.96 | 37m |
| 重新连接20 | 拉斯 | 128 | 0.0025 | 余弦 | 200 | 7.98 | 37m |
| 重新连接20 | 拉斯 | 128 | 0.00125 | 余弦 | 200 | 9.21 | 37m |
| 模型 | 优化器 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | SGD | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| 重新连接20 | SGD | 4096 | 1.6 | 余弦 | 800 | 8.36(1跑) | 1h33m |
| 重新连接20 | SGD | 4096 | 1.6 | 余弦 | 1600 | 8.25(1跑) | 3h10m |
| 重新连接20 | 拉斯 | 4096 | 0.02 | 余弦 | 200 | 8.21 | 22m |
| 重新连接20 | 拉斯 | 4096 | 0.02 | 余弦 | 400 | 7.53 | 44m |
| 重新连接20 | 拉斯 | 4096 | 0.02 | 余弦 | 800 | 7.48 | 1h29m |
| 重新连接20 | 拉斯 | 4096 | 0.02 | 余弦 | 1600 | 7.37(1跑) | 2h58m |
幽灵bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| 模型 | 批量大小 | 幽灵批处理大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 8192 | N/A。 | 1.6 | 余弦 | 200 | 12.35 | 25m* |
| 重新连接20 | 4096 | N/A。 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| 重新连接20 | 2048 | N/A。 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| 重新连接20 | 1024 | N/A。 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| 重新连接20 | 128 | N/A。 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| 模型 | 批量大小 | 幽灵批处理大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 8192 | 128 | 1.6 | 余弦 | 200 | 11.51 | 27m |
| 重新连接20 | 4096 | 128 | 1.6 | 余弦 | 200 | 9.73 | 25m |
| 重新连接20 | 2048 | 128 | 1.6 | 余弦 | 200 | 8.77 | 24m |
| 重新连接20 | 1024 | 128 | 1.6 | 余弦 | 200 | 7.82 | 22m |
| 模型 | 批量大小 | 幽灵批处理大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 8192 | N/A。 | 1.6 | 余弦 | 1600 | | |
| 重新连接20 | 4096 | N/A。 | 1.6 | 余弦 | 1600 | 8.25 | 3h10m |
| 重新连接20 | 2048 | N/A。 | 1.6 | 余弦 | 1600 | 7.34 | 2h50m |
| 重新连接20 | 1024 | N/A。 | 1.6 | 余弦 | 1600 | 6.94 | 2h52m |
| 模型 | 批量大小 | 幽灵批处理大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 8192 | 128 | 1.6 | 余弦 | 1600 | 11.83 | 3h37m |
| 重新连接20 | 4096 | 128 | 1.6 | 余弦 | 1600 | 8.95 | 3H15M |
| 重新连接20 | 2048 | 128 | 1.6 | 余弦 | 1600 | 7.23 | 3H05M |
| 重新连接20 | 1024 | 128 | 1.6 | 余弦 | 1600 | 7.08 | 2h59m |
BN没有重量衰减
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00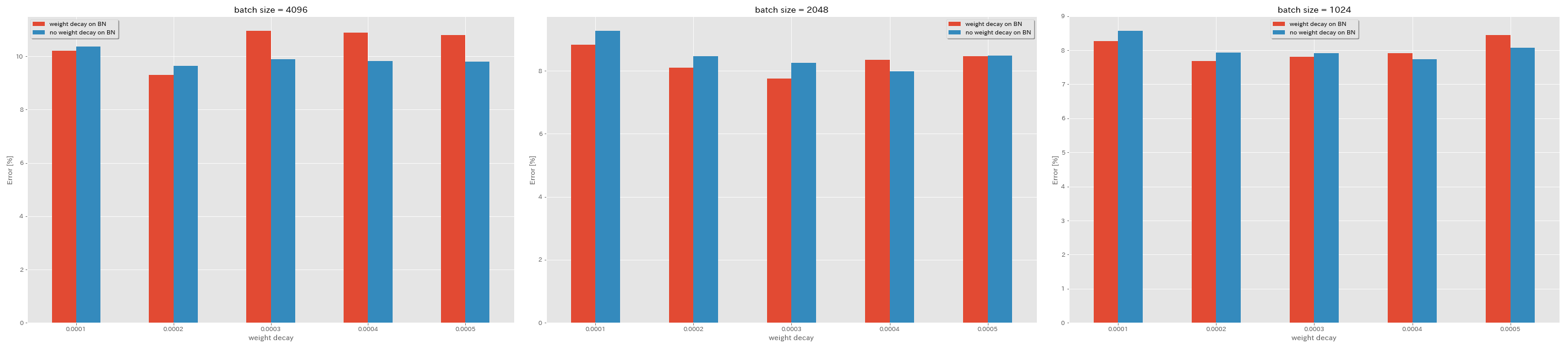
| 模型 | BN的重量衰减 | 重量衰减 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | 是的 | 5E-4 | 4096 | 1.6 | 余弦 | 200 | 10.81 | 22m |
| 重新连接20 | 是的 | 4E-4 | 4096 | 1.6 | 余弦 | 200 | 10.88 | 22m |
| 重新连接20 | 是的 | 3E-4 | 4096 | 1.6 | 余弦 | 200 | 10.96 | 22m |
| 重新连接20 | 是的 | 2E-4 | 4096 | 1.6 | 余弦 | 200 | 9.30 | 22m |
| 重新连接20 | 是的 | 1E-4 | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| 重新连接20 | 不 | 5E-4 | 4096 | 1.6 | 余弦 | 200 | 8.78 | 22m |
| 重新连接20 | 不 | 4E-4 | 4096 | 1.6 | 余弦 | 200 | 9.83 | 22m |
| 重新连接20 | 不 | 3E-4 | 4096 | 1.6 | 余弦 | 200 | 9.90 | 22m |
| 重新连接20 | 不 | 2E-4 | 4096 | 1.6 | 余弦 | 200 | 9.64 | 22m |
| 重新连接20 | 不 | 1E-4 | 4096 | 1.6 | 余弦 | 200 | 10.38 | 22m |
| 模型 | BN的重量衰减 | 重量衰减 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | 是的 | 5E-4 | 2048 | 1.6 | 余弦 | 200 | 8.46 | 20m |
| 重新连接20 | 是的 | 4E-4 | 2048 | 1.6 | 余弦 | 200 | 8.35 | 20m |
| 重新连接20 | 是的 | 3E-4 | 2048 | 1.6 | 余弦 | 200 | 7.76 | 20m |
| 重新连接20 | 是的 | 2E-4 | 2048 | 1.6 | 余弦 | 200 | 8.09 | 20m |
| 重新连接20 | 是的 | 1E-4 | 2048 | 1.6 | 余弦 | 200 | 8.83 | 20m |
| 重新连接20 | 不 | 5E-4 | 2048 | 1.6 | 余弦 | 200 | 8.49 | 20m |
| 重新连接20 | 不 | 4E-4 | 2048 | 1.6 | 余弦 | 200 | 7.98 | 20m |
| 重新连接20 | 不 | 3E-4 | 2048 | 1.6 | 余弦 | 200 | 8.26 | 20m |
| 重新连接20 | 不 | 2E-4 | 2048 | 1.6 | 余弦 | 200 | 8.47 | 20m |
| 重新连接20 | 不 | 1E-4 | 2048 | 1.6 | 余弦 | 200 | 9.27 | 20m |
| 模型 | BN的重量衰减 | 重量衰减 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(中位数3次) | 训练时间 |
|---|
| 重新连接20 | 是的 | 5E-4 | 1024 | 1.6 | 余弦 | 200 | 8.45 | 21m |
| 重新连接20 | 是的 | 4E-4 | 1024 | 1.6 | 余弦 | 200 | 7.91 | 21m |
| 重新连接20 | 是的 | 3E-4 | 1024 | 1.6 | 余弦 | 200 | 7.81 | 21m |
| 重新连接20 | 是的 | 2E-4 | 1024 | 1.6 | 余弦 | 200 | 7.69 | 21m |
| 重新连接20 | 是的 | 1E-4 | 1024 | 1.6 | 余弦 | 200 | 8.26 | 21m |
| 重新连接20 | 不 | 5E-4 | 1024 | 1.6 | 余弦 | 200 | 8.08 | 21m |
| 重新连接20 | 不 | 4E-4 | 1024 | 1.6 | 余弦 | 200 | 7.73 | 21m |
| 重新连接20 | 不 | 3E-4 | 1024 | 1.6 | 余弦 | 200 | 7.92 | 21m |
| 重新连接20 | 不 | 2E-4 | 1024 | 1.6 | 余弦 | 200 | 7.93 | 21m |
| 重新连接20 | 不 | 1E-4 | 1024 | 1.6 | 余弦 | 200 | 8.53 | 21m |
半精度和混合精液的实验
- 以下实验需要NVIDIA顶点。
- 使用GEFORCE 1080 Ti在CIFAR-10数据集上进行以下实验,该数据集没有张量芯。
- 表中报告的结果是最后一个时期的测试错误。
FP16培训
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00混合精液培训
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00结果
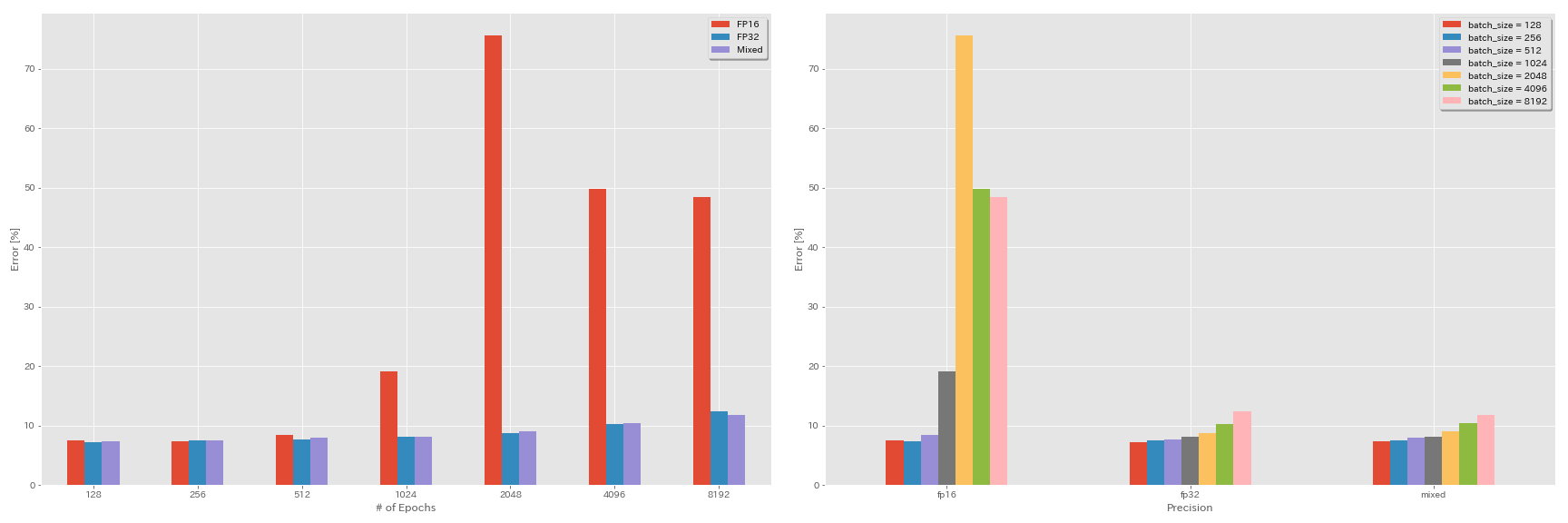
| 模型 | 精确 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | fp32 | 8192 | 1.6 | 余弦 | 200 | | |
| 重新连接20 | fp32 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| 重新连接20 | fp32 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| 重新连接20 | fp32 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| 重新连接20 | fp32 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| 重新连接20 | fp32 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| 重新连接20 | fp32 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| 模型 | 精确 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | FP16 | 8192 | 1.6 | 余弦 | 200 | 48.52 | 33m |
| 重新连接20 | FP16 | 4096 | 1.6 | 余弦 | 200 | 49.84 | 28m |
| 重新连接20 | FP16 | 2048 | 1.6 | 余弦 | 200 | 75.63 | 27m |
| 重新连接20 | FP16 | 1024 | 1.6 | 余弦 | 200 | 19.09 | 27m |
| 重新连接20 | FP16 | 512 | 0.8 | 余弦 | 200 | 7.89 | 26m |
| 重新连接20 | FP16 | 256 | 0.8 | 余弦 | 200 | 7.40 | 28m |
| 重新连接20 | FP16 | 128 | 0.4 | 余弦 | 200 | 7.59 | 32m |
| 模型 | 精确 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | 混合 | 8192 | 1.6 | 余弦 | 200 | 11.78 | 28m |
| 重新连接20 | 混合 | 4096 | 1.6 | 余弦 | 200 | 10.48 | 27m |
| 重新连接20 | 混合 | 2048 | 1.6 | 余弦 | 200 | 8.98 | 26m |
| 重新连接20 | 混合 | 1024 | 1.6 | 余弦 | 200 | 8.05 | 26m |
| 重新连接20 | 混合 | 512 | 0.8 | 余弦 | 200 | 7.81 | 28m |
| 重新连接20 | 混合 | 256 | 0.8 | 余弦 | 200 | 7.58 | 32m |
| 重新连接20 | 混合 | 128 | 0.4 | 余弦 | 200 | 7.37 | 41m |
使用特斯拉V100的结果
| 模型 | 精确 | 批量大小 | 初始LR | LR时间表 | #时代 | 测试错误(1运行) | 训练时间 |
|---|
| 重新连接20 | fp32 | 8192 | 1.6 | 余弦 | 200 | 12.35 | 25m |
| 重新连接20 | fp32 | 4096 | 1.6 | 余弦 | 200 | 9.88 | 19m |
| 重新连接20 | fp32 | 2048 | 1.6 | 余弦 | 200 | 8.87 | 17m |
| 重新连接20 | fp32 | 1024 | 1.6 | 余弦 | 200 | 8.45 | 18m |
| 重新连接20 | 混合 | 8192 | 1.6 | 余弦 | 200 | 11.92 | 25m |
| 重新连接20 | 混合 | 4096 | 1.6 | 余弦 | 200 | 10.16 | 19m |
| 重新连接20 | 混合 | 2048 | 1.6 | 余弦 | 200 | 9.10 | 17m |
| 重新连接20 | 混合 | 1024 | 1.6 | 余弦 | 200 | 7.84 | 16m |
参考
模型架构
- 他,凯明(Kaiming),木安(Xiangyu Zhang),肖奎(Shaoqing Ren)和简·孙(Jian Sun)。 “图像识别的深度残留学习。” IEEE计算机视觉和模式识别会议(CVPR),2016年。Link,Arxiv:1512.03385
- 他,凯明(Kaiming),木安(Xiangyu Zhang),肖奎(Shaoqing Ren)和简·孙(Jian Sun)。 “深层残留网络中的身份映射”。在欧洲计算机视觉会议上(ECCV)。 2016。ARXIV:1603.05027,火炬实施
- Zagoruyko,Sergey和Nikos Komodakis。 “广泛的残留网络”。英国机器视觉会议论文集(BMVC),2016年。ARXIV:1605.07146,火炬实施
- Huang,Gao,Zhuang Liu,Kilian Q Weinberger和Laurens van der Maaten。 “密集连接的卷积网络”。 IEEE计算机视觉和模式识别会议(CVPR),2017年。Link,Arxiv:1608.06993,火炬实施
- Han,Dongyoon,Jiwhan Kim和Junmo Kim。 “深层金字塔残留网络”。 IEEE计算机视觉和模式识别会议(CVPR),2017年。链接,ARXIV:1610.02915,火炬实施,CAFFE实施,Pytorch实施
- Xie,Saining,Ross Girshick,Piotr Dollar,Zhuowen tu和Kaiming He。 “深层神经网络的综合剩余转化。” IEEE计算机视觉和模式识别会议(CVPR),2017年。Link,Arxiv:1611.05431,火炬实施
- 加斯塔尔,Xavier。 “摇动3分的残留网络的正规化。”在2017年国际学习代表会议(ICLR)研讨会上。链接,ARXIV:1705.07485,火炬实施
- Hu,Jie,Li Shen和Gang Sun。 “挤压和激发网络。” IEEE计算机视觉和模式识别会议(CVPR),2018年,第7132-7141页。 Link,Arxiv:1709.01507,Caffe实施
- Huang,Gao,Zhuang Liu,Geoff Pleiss,Laurens van der Maaten和Kilian Q. Weinberger。 “具有密集连接的卷积网络。” IEEE关于模式分析和机器智能的交易(2019)。 ARXIV:2001.02394
正则化,数据增强
- Szegedy,Christian,Vincent Vanhoucke,Sergey Ioffe,Jon Shlens和Zbigniew Wojna。 “重新考虑计算机视觉的启动架构。” IEEE计算机视觉和模式识别会议(CVPR),2016年。Link,Arxiv:1512.00567
- Devries,Terrance和Graham W. Taylor。 “改善了随着切口的卷积神经网络的正则化。” ARXIV预印型ARXIV:1708.04552(2017)。 ARXIV:1708.04552,Pytorch实施
- 阿布·埃尔海哈(Abu-el-Haija),萨米(Sami)。 “与百分比的梯度更新。” ARXIV预印型ARXIV:1708.07227(2017)。 ARXIV:1708.07227
- Zhong,Zhun,Liang Zheng,Guoliang Kang,Shaozi Li和Yi Yang。 “随机删除数据增强。” ARXIV预印型ARXIV:1708.04896(2017)。 Arxiv:1708.04896,Pytorch实施
- Zhang,Hongyi,Moustapha Cisse,Yann N. Dauphin和David Lopez-Paz。 “混合:超出经验风险最小化。”在2017年国际学习代表会议(ICLR)中。
- Kawaguchi,Kenji,Yoshua Bengio,Vikas Verma和Leslie Pack Kaelbling。 “通过分析学习理论理解概括。” ARXIV预印型ARXIV:1802.07426(2018)。 Arxiv:1802.07426,Pytorch实施
- 高桥,Ryo,Takashi Matsubara和Kuniaki Uehara。 “使用随机图像裁剪和对Deep CNN进行补丁的数据增强。”第10届亚洲机器学习会议论文集(ACML),2018年。Link,Arxiv:1811.09030
- Yun,Sangdoo,Dongyoon Han,Seong Joon Oh,Sanghyuk Chun,Junsuk Choe和Youngjoon Yoo。 “ cutmix:正规化策略,以培训具有可本质功能的强分类器。” Arxiv预印型ARXIV:1905.04899(2019)。 Arxiv:1905.04899
大批
- Keskar,Nitish Shirish,Dheevatsa Mudigere,Jorge Nocedal,Mikhail Smelyanskiy和Ping Tak Peter Tang。 “在深度学习的大批量培训中:概括差距和尖锐的最小值。”在2017年国际学习表现会议(ICLR)中。链接,ARXIV:1609.04836
- Hoffer,Elad,Itay Hubara和Daniel Soudry。 “训练更长,更好地概括:在神经网络的大批处理培训中缩小概括差距。”在神经信息处理系统(NIP)的进步中,2017年。Link,Arxiv:1705.08741,Pytorch实施
- Goyal,Priya,Piotr Dollar,Ross Girshick,Pieter Noordhuis,Lukasz Wesolowski,Aapo Kyrola,Andrew Tulloch,Yangqing Jia和Kaiming He。 “准确,大型Minibatch SGD:1小时内训练成像网。” Arxiv预印型ARXIV:1706.02677(2017)。 ARXIV:1706.02677
- 您,杨,伊戈尔·吉特曼和鲍里斯·金斯堡。 “卷积网络的大批量培训。” ARXIV预印型ARXIV:1708.03888(2017)。 Arxiv:1708.03888
- 您,Yang,Zhao Zhang,Cho-Jui Hsieh,James Demmel和Kurt Keutzer。 “成像网训练在几分钟内。” ARXIV预印型ARXIV:1709.05011(2017)。 ARXIV:1709.05011
- 史密斯(Smith),塞缪尔·L(Samuel L. “不要衰减学习率,增加批量的大小。”在2018年国际学习代表会议(ICLR)中。链接,ARXIV:1711.00489
- Gitman,Igor,Deepak Dilipkumar和Ben Parr。 “具有比例更新的梯度下降算法的收敛分析。” ARXIV预印型ARXIV:1801.03137(2018)。 ARXIV:1801.03137 TensorFlow实现
- Jia,Xianyan,Suthao Song,Wei He,Yangzihao Wang,Haidong Rong,Feihu Zhou,Liqiang Xie,Zhenyu Guo,Yuanzhou Yang,Liwei Yu,Tiegang Chen,Tiegang Chen,Guangxiao Hu,Shaohuaiaiaiahuaiaiahuaiaiahiaiahiahi Shi和XiaOwenChu。 “具有混合精确度的高度可扩展的深度学习训练系统:四分钟内训练成像网。” Arxiv预印型ARXIV:1807.11205(2018)。 Arxiv:1807.11205
- Shallue,Christopher J.,Jaehoon Lee,Joseph Antognini,Jascha Sohl-Dickstein,Roy Frostig和George E. Dahl。 “测量数据并行性对神经网络训练的影响。” ARXIV预印型ARXIV:1811.03600(2018)。 Arxiv:1811.03600
- Ying,Chris,Sameer Kumar,Dehao Chen,Tao Wang和Youlong Cheng。 “超级计算机比例尺的图像分类”。在神经信息处理系统(Neurips)研讨会的进步中,2018年。Link,Arxiv:1811.06992
其他的
- Loshchilov,Ilya和Frank Hutter。 “ SGDR:随机梯度下降,温暖重新开始。”在2017年国际学习代表会议(ICLR)中。
- Micikevicius,Paulius,Sharan Narang,Jonah Alben,Gregory Diamos,Erich Elsen,David Garcia,Boris Ginsburg,Michael Houston,Oleksii Kuchaiev,Ganesh Venkatesh和Hao Wu。 “混合精度训练。”在2018年国际学习表现会议(ICLR)中。链接,ARXIV:1710.03740
- Recht,Benjamin,Rebecca Roelofs,Ludwig Schmidt和Vaishaal Shankar。 “ CIFAR-10分类器是否概括为CIFAR-10?” ARXIV预印型ARXIV:1806.00451(2018)。 Arxiv:1806.00451
- 他,Tong,Zhi Zhang,Hang Zhang,Zhongyue Zhang,Junyuan Xie和Mu Li。 “用卷积神经网络进行图像分类的技巧。” ARXIV预印型ARXIV:1812.01187(2018)。 Arxiv:1812.01187


