Classification d'image Pytorch
Les articles suivants sont mis en œuvre à l'aide de Pytorch.
- Resnet (1512.03385)
- Resnet-Preact (1603.05027)
- WRN (1605.07146)
- Denset (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- Découpe (1708.04552)
- Efface aléatoire (1708.04896)
- Senet (1709.01507)
- Mélange (1710.09412)
- Double coutume (1802.07426)
- RICAP (1811.09030)
- Cutmix (1905.04899)
Exigences
- Ubuntu (il n'est testé que sur Ubuntu, donc cela peut ne pas fonctionner sur Windows.)
- Python> = 3,7
- Pytorch> = 1.4.0
- torchion
- Nvidia Apex
pip install -r requirements.txt
Usage
python train.py --config configs/cifar/resnet_preact.yaml
Résultats sur CIFAR-10
Résultats utilisant presque les mêmes paramètres que les articles
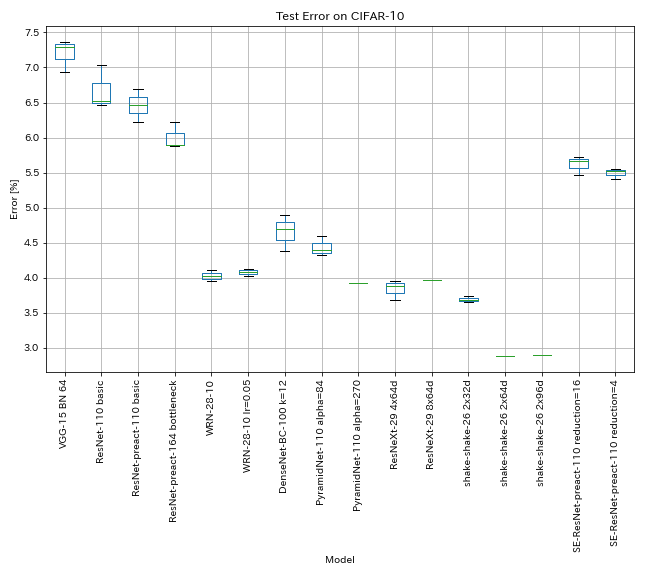
| Modèle | Erreur de test (médiane de 3 courses) | Erreur de test (en papier) | Temps de formation |
|---|
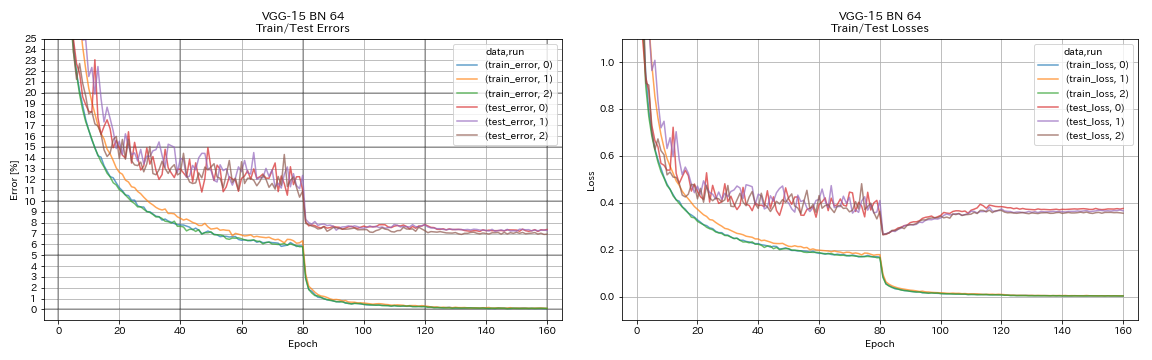
| VGG-like (profondeur 15, w / bn, canal 64) | 7.29 | N / A | 1h20m |
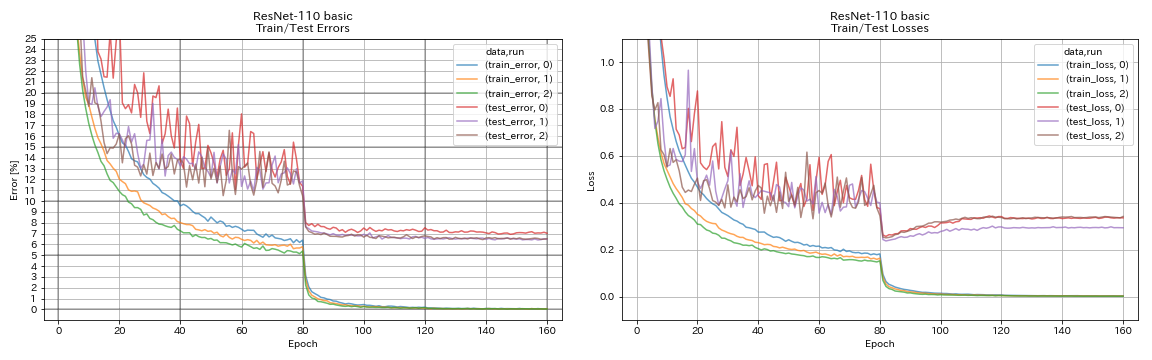
| Resnet-110 | 6.52 | 6,43 (meilleur), 6,61 +/- 0,16 | 3h06m |
| Resnet-préact-110 | 6.47 | 6.37 (médiane de 5 points) | 3h05m |
| Resnet-Preact-164 goulot d'étranglement | 5.90 | 5.46 (médiane de 5 courses) | 4h01m |
| Resnet-Preact-1001 goulot d'étranglement | | 4,62 (médiane de 5 courses), 4,69 +/- 0,20 | |
| WRN-28-10 | 4.03 | 4,00 (médiane de 5 points) | 16h10m |
| WRN-28-10 avec département | | 3,89 (médiane de 5 courses) | |
| Denset-100 (k = 12) | 3,87 (1 course) | 4.10 (1 course) | 24h28m * |
| Denset-100 (k = 24) | | 3,74 (1 course) | |
| Denset-BC-100 (k = 12) | 4.69 | 4.51 (1 course) | 15h20m |
| Denset-BC-250 (k = 24) | | 3,62 (1 course) | |
| Denset-BC-190 (k = 40) | | 3,46 (1 course) | |
| Pyramidnet-110 (alpha = 84) | 4.40 | 4,26 +/- 0,23 | 11h40m |
| Pyramidnet-110 (alpha = 270) | 3,92 (1 course) | 3,73 +/- 0,04 | 24h12m * |
| Goulot d'étranglement pyramidnet-164 (alpha = 270) | 3,44 (1 course) | 3,48 +/- 0,20 | 32h37m * |
| Goulot d'étranglement pyramidnet-272 (alpha = 200) | | 3,31 +/- 0,08 | |
| RESNEXT-29 4X64D | 3.89 | ~ 3,75 (de la figure 7) | 31h17m |
| RESNEXT-29 8X64D | 3,97 (1 course) | 3,65 (moyenne de 10 points) | 42h50m * |
| RESNEXT-29 16X64D | | 3,58 (moyenne de 10 points) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3,55 (moyenne de 3 points) | 33h49m |
| Shake-Shake-26 2x64d (SSI) | 2,88 (1 course) | 2,98 (moyenne de 3 points) | 78h48m |
| Shake-Shake-26 2x96D (SSI) | 2,90 (1 course) | 2,86 (moyenne de 5 points) | 101h32m * |
Notes
- Différences avec les articles dans les milieux de formation:
- WRN-28-10 formé avec une taille de lot 64 (128 en papier).
- Densenet-BC-100 formé (k = 12) avec la taille du lot 32 et le taux d'apprentissage initial 0,05 (taille du lot 64 et taux d'apprentissage initial 0,1 sur papier).
- Resnext-29 formé 4x64d avec un seul GPU, une taille de lot 32 et un taux d'apprentissage initial 0,025 (8 GPU, une taille de lot 128 et un taux d'apprentissage initial 0,1 en papier).
- Modèles de shake-shake formés avec un seul GPU (2 GPU en papier).
- Shake-Shake entraîné 26 2x64d (SSI) avec la taille du lot 64, et le taux d'apprentissage initial 0,1.
- Les erreurs de test signalées ci-dessus sont celles en dernière époque.
- Des expériences avec seulement une seule exécution sont effectuées sur un ordinateur différent de celui utilisé pour les expériences avec 3 cycles.
- GeForce GTX 980 a été utilisé dans ces expériences.
VGG
python train.py --config configs/cifar/vgg.yaml
Resnet
python train.py --config configs/cifar/resnet.yaml
Resnet-préact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00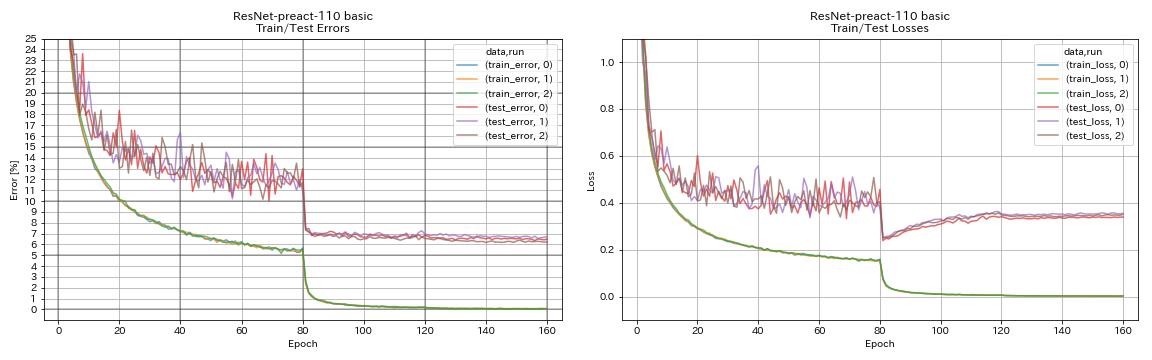
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00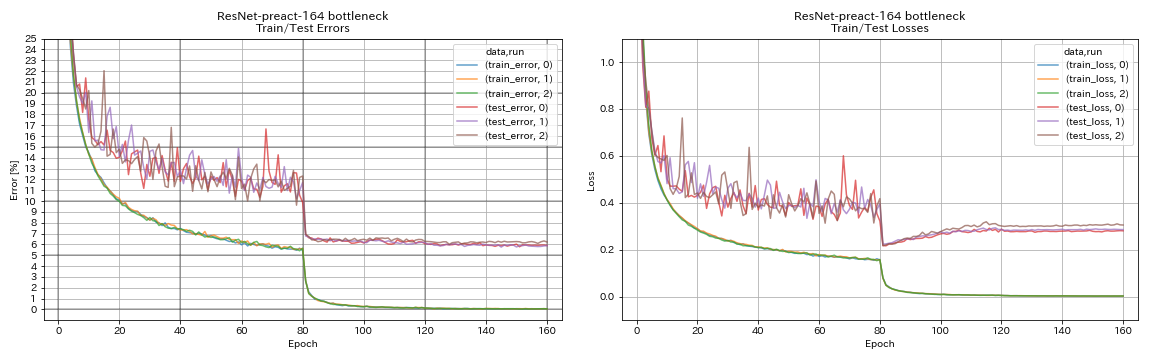
Wrn
python train.py --config configs/cifar/wrn.yaml
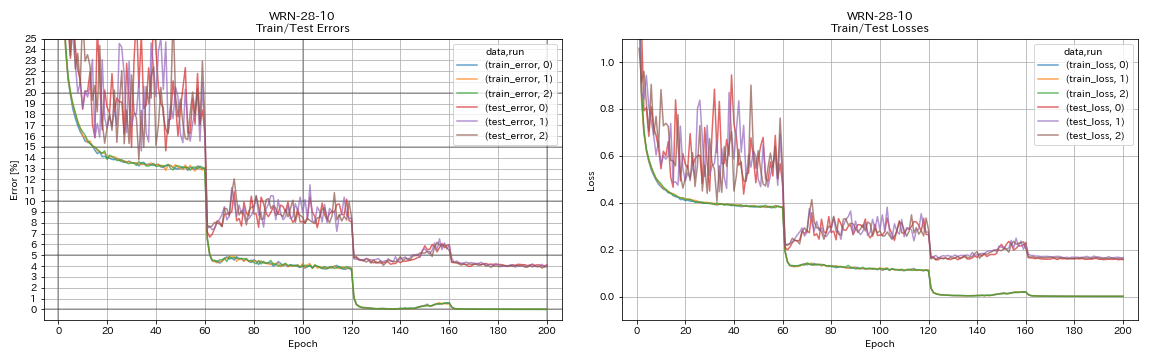
Denset
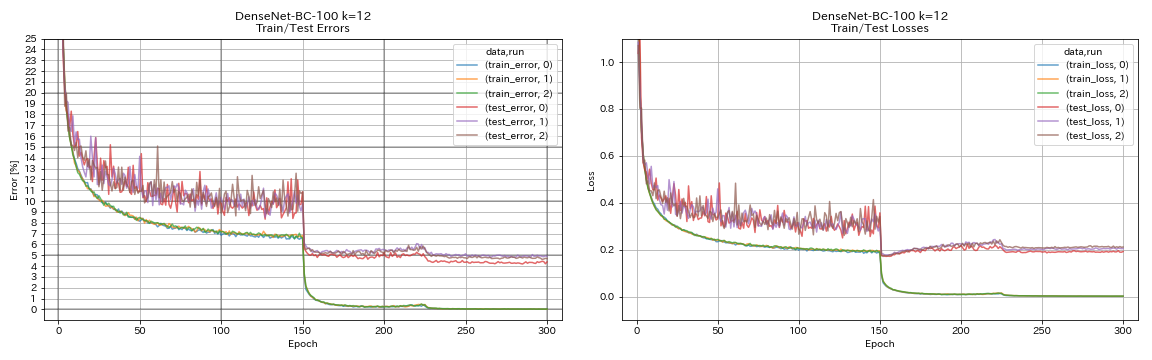
python train.py --config configs/cifar/densenet.yaml
Pyramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00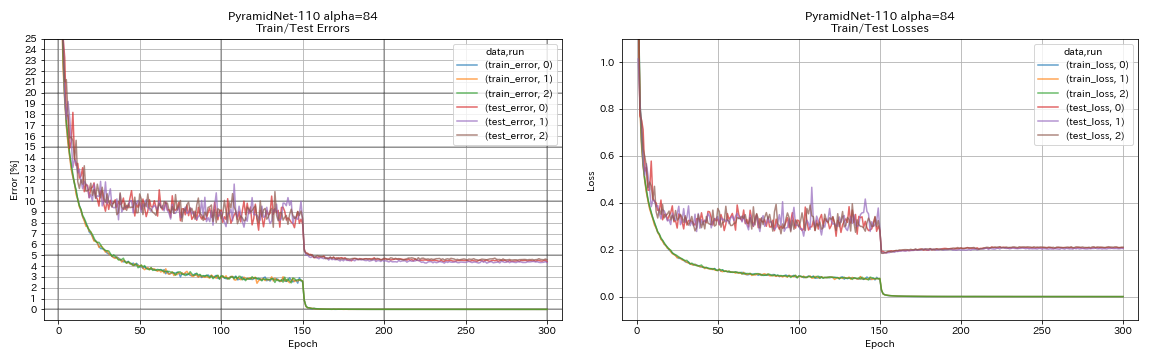
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00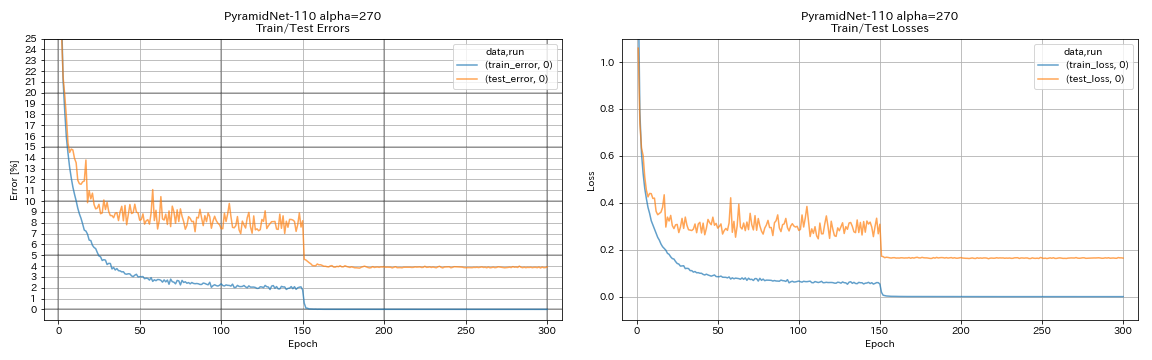
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00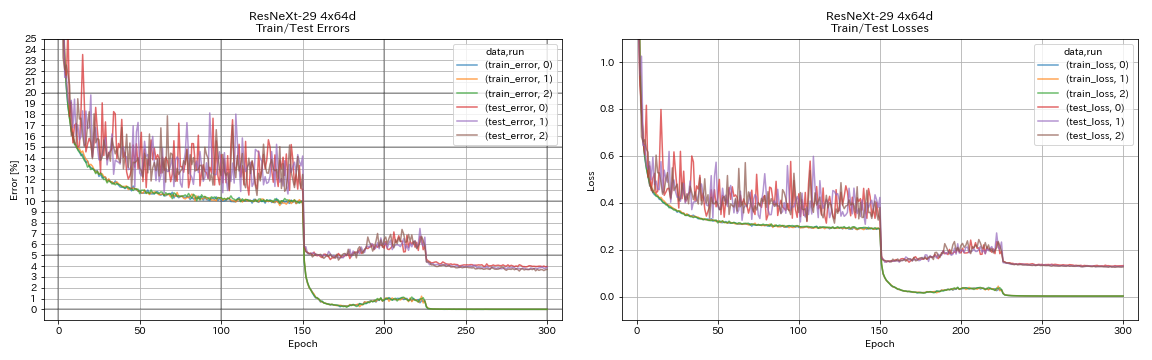
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00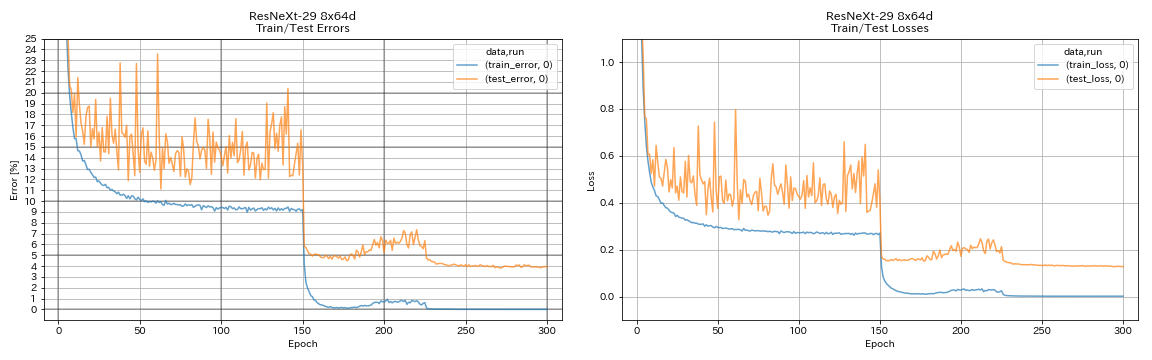
secouer
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00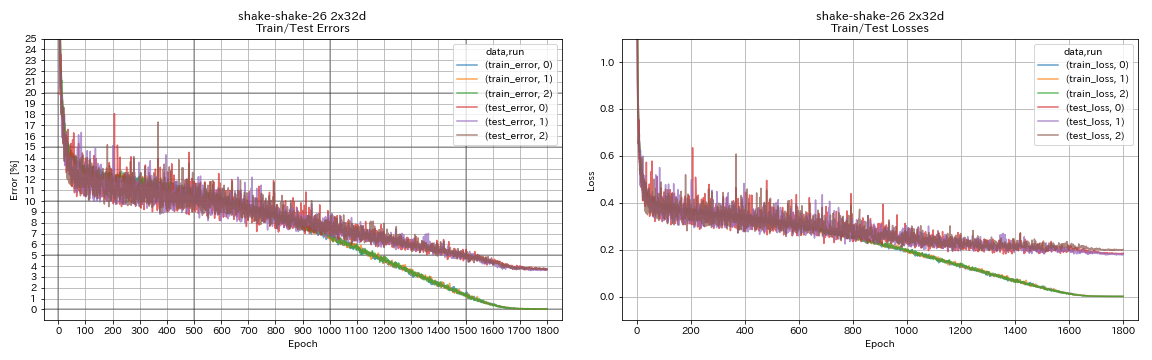
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00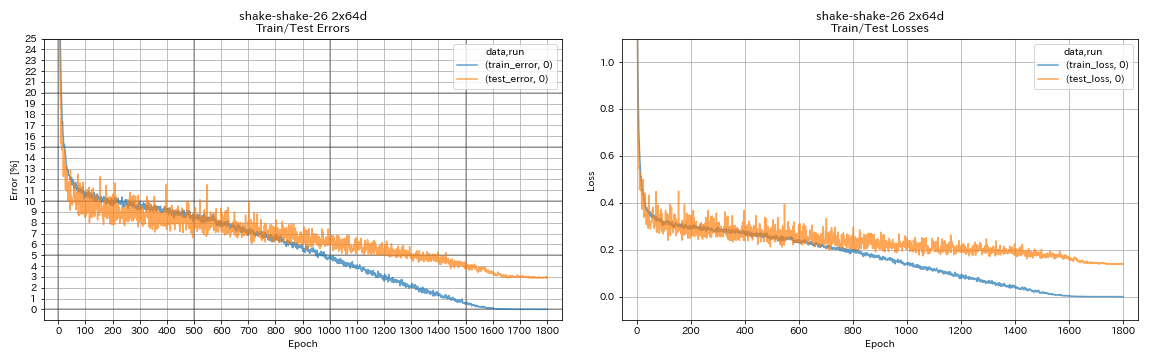
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00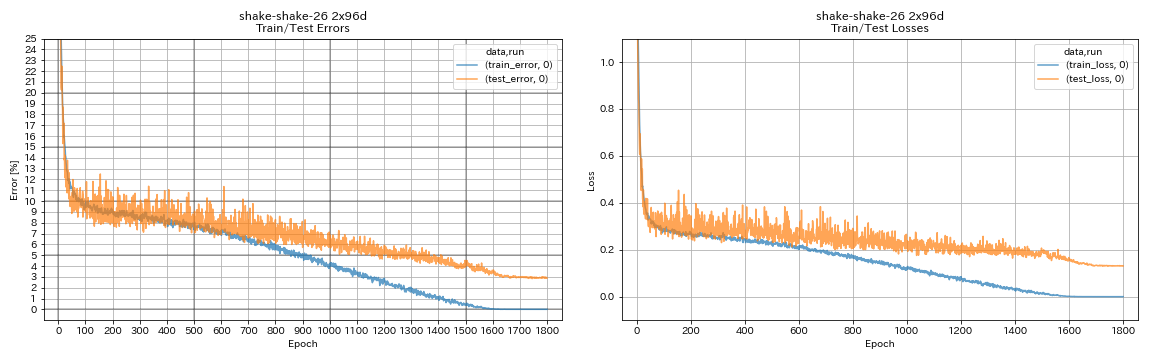
Résultats
| Modèle | Erreur de test (1 Run) | # d'époches | Temps de formation |
|---|
| Resnet-préact-20, élargissement du facteur 4 | 4.91 | 200 | 1h26m |
| Resnet-préact-20, élargissement du facteur 4 | 4.01 | 400 | 2h53m |
| Resnet-préact-20, élargissement du facteur 4 | 3.99 | 1800 | 12h53m |
| Resnet-préact-20, élargissement du facteur 4, découpe 16 | 3.71 | 200 | 1h26m |
| Resnet-préact-20, élargissement du facteur 4, découpe 16 | 3.46 | 400 | 2h53m |
| Resnet-préact-20, élargissement du facteur 4, découpe 16 | 3.76 | 1800 | 12h53m |
| RESNET-PREACT-20, élargissement du facteur 4, RICAP (Beta = 0,3) | 3.45 | 200 | 1h26m |
| RESNET-PREACT-20, élargissement du facteur 4, RICAP (Beta = 0,3) | 3.11 | 400 | 2h53m |
| RESNET-PREACT-20, élargissement du facteur 4, RICAP (Beta = 0,3) | 3.15 | 1800 | 12h53m |
| Modèle | Erreur de test (1 Run) | # d'époches | Temps de formation |
|---|
| WRN-28-10, découpe 16 | 3.19 | 200 | 6h35m |
| WRN-28-10, mélange (alpha = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10, RICAP (bêta = 0,3) | 2.83 | 200 | 6h35m |
| WRN-28-10, double coutume (alpha = 0,1) | 2.87 | 200 | 12h42m |
| WRN-28-10, découpe 16 | 3.07 | 400 | 13h10m |
| WRN-28-10, mélange (alpha = 1) | 3.04 | 400 | 13h08m |
| WRN-28-10, RICAP (bêta = 0,3) | 2.71 | 400 | 13h08m |
| WRN-28-10, double coutume (alpha = 0,1) | 2.76 | 400 | 25h20m |
| Shake-Shake-26 2x64d, découpe 16 | 2.64 | 1800 | 78h55m * |
| Shake-Shake-26 2x64d, mélange (alpha = 1) | 2.63 | 1800 | 35h56m |
| Shake-Shake-26 2x64d, RICAP (bêta = 0,3) | 2.29 | 1800 | 35h10m |
| Shake-Shake-26 2x64d, double coute (alpha = 0,1) | 2.64 | 1800 | 68h34m |
| Shake-Shake-26 2x96d, découpe 16 | 2,50 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, mélange (alpha = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, RICAP (bêta = 0,3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, double coute (alpha = 0,1) | 2.41 | 1800 | 113h09m |
| Shake-Shake-26 2x128d, découpe 16 | 2.58 | 1800 | 85h04m |
| Shake-Shake-26 2x128d, RICAP (bêta = 0,3) | 1.97 | 1800 | 85h06m |
Note
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
- Tous les modèles sont formés en utilisant le recuit des cosinus avec le taux d'apprentissage initial 0,2.
- GeForce GTX 1080 Ti a été utilisé dans ces expériences, à l'exception de ceux avec *, qui sont effectués en utilisant GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True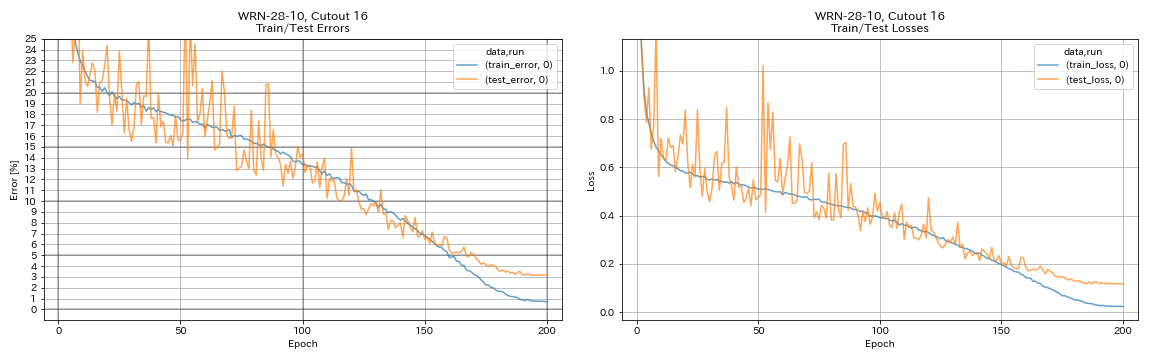
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True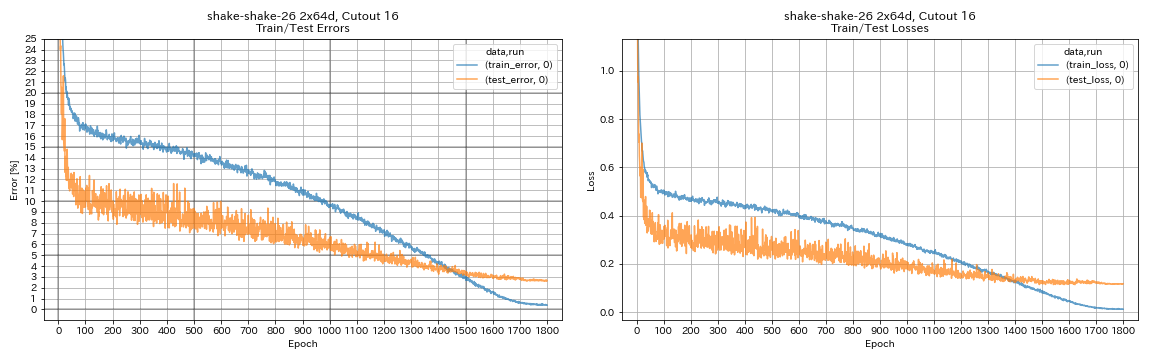
Résultats utilisant le multi-GPU
| Modèle | taille de lot | #Gpus | Erreur de test (1 Run) | # d'époches | Temps de formation * |
|---|
| WRN-28-10, RICAP (bêta = 0,3) | 512 | 1 | 2.63 | 200 | 3h41m |
| WRN-28-10, RICAP (bêta = 0,3) | 256 | 2 | 2.71 | 200 | 2h14m |
| WRN-28-10, RICAP (bêta = 0,3) | 128 | 4 | 2.89 | 200 | 1h01m |
| WRN-28-10, RICAP (bêta = 0,3) | 64 | 8 | 2.75 | 200 | 34m |
Note
- Tesla V100 a été utilisée dans ces expériences.
En utilisant 1 GPU
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUtilisation de 2 GPU
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUtilisation de 4 GPU
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUtilisation de 8 GPU
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseRésultats sur FashionMnist
| Modèle | Erreur de test (1 Run) | # d'époches | Temps de formation |
|---|
| Resnet-préact-20, élargissement du facteur 4, découpe 12 | 4.17 | 200 | 1h32m |
| Resnet-préact-20, élargissement du facteur 4, découpe 14 | 4.11 | 200 | 1h32m |
| Resnet-preact-50, découpe 12 | 4.45 | 200 | 57m |
| Resnet-preact-50, découpe 14 | 4.38 | 200 | 57m |
| Resnet-préact-50, élargissement du facteur 4, découpe 12 | 4.07 | 200 | 3h37m |
| Resnet-préact-50, élargissement du facteur 4, découpe 14 | 4.13 | 200 | 3h39m |
| Shake-Shake-26 2x32d (SSI), découpe 12 | 4.08 | 400 | 3h41m |
| Shake-Shake-26 2x32d (SSI), découpe 14 | 4.05 | 400 | 3h39m |
| Shake-Shake-26 2x96D (SSI), découpe 12 | 3.72 | 400 | 13h46m |
| Shake-Shake-26 2x96D (SSI), découpe 14 | 3.85 | 400 | 13h39m |
| Shake-Shake-26 2x96D (SSI), découpe 12 | 3.65 | 800 | 26h42m |
| Shake-Shake-26 2x96D (SSI), découpe 14 | 3.60 | 800 | 26h42m |
| Modèle | Erreur de test (médiane de 3 courses) | # d'époches | Temps de formation |
|---|
| Resnet-préact-20 | 5.04 | 200 | 26m |
| Resnet-preact-20, découpe 6 | 4.84 | 200 | 26m |
| Resnet-preact-20, découpe 8 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Cutout 10 | 4.74 | 200 | 26m |
| Resnet-Preact-20, découpe 12 | 4.68 | 200 | 26m |
| Resnet-Preact-20, découpe 14 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Cutout 16 | 4.49 | 200 | 26m |
| Resnet-Preact-20, aléatoire | 4.61 | 200 | 26m |
| Resnet-Preact-20, Mixup | 4.92 | 200 | 26m |
| Resnet-Preact-20, Mixup | 4.64 | 400 | 52m |
Note
- Les résultats rapportés dans les tableaux sont les erreurs de test en dernière époques.
- Tous les modèles sont formés en utilisant le recuit des cosinus avec le taux d'apprentissage initial 0,2.
- Les augmentations de données suivantes sont appliquées aux données de formation:
- Les images sont rembourrées avec 4 pixels de chaque côté, et les patchs 28x28 sont recadrés au hasard à partir des images rembourrées.
- Les images sont renversées au hasard horizontalement.
- GeForce GTX 1080 Ti a été utilisé dans ces expériences.
Résultats sur MNIST
| Modèle | Erreur de test (médiane de 3 courses) | # d'époches | Temps de formation |
|---|
| Resnet-préact-20 | 0,40 | 100 | 12m |
| Resnet-preact-20, découpe 6 | 0,32 | 100 | 12m |
| Resnet-preact-20, découpe 8 | 0,25 | 100 | 12m |
| Resnet-Preact-20, Cutout 10 | 0,27 | 100 | 12m |
| Resnet-Preact-20, découpe 12 | 0,26 | 100 | 12m |
| Resnet-Preact-20, découpe 14 | 0,26 | 100 | 12m |
| Resnet-Preact-20, Cutout 16 | 0,25 | 100 | 12m |
| Resnet-préact-20, mélange (alpha = 1) | 0,40 | 100 | 12m |
| Resnet-préact-20, mélange (alpha = 0,5) | 0,38 | 100 | 12m |
| Resnet-préact-20, élargissement du facteur 4, découpe 14 | 0,26 | 100 | 45m |
| Resnet-preact-50, découpe 14 | 0,29 | 100 | 28m |
| Resnet-préact-50, élargissement du facteur 4, découpe 14 | 0,25 | 100 | 1h50m |
| Shake-Shake-26 2x96D (SSI), découpe 14 | 0,24 | 100 | 3h22m |
Note
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
- Tous les modèles sont formés en utilisant le recuit des cosinus avec le taux d'apprentissage initial 0,2.
- GeForce GTX 1080 Ti a été utilisé dans ces expériences.
Résultats sur Kuzushiji-Mnist
| Modèle | Erreur de test (médiane de 3 courses) | # d'époches | Temps de formation |
|---|
| Resnet-Preact-20, découpe 14 | 0,82 (meilleur 0,67) | 200 | 24m |
| Resnet-préact-20, élargissement du facteur 4, découpe 14 | 0,72 (meilleur 0,67) | 200 | 1h30m |
| Pyramidnet-110-270, découpe 14 | 0,72 (meilleur 0,70) | 200 | 10h05m |
| Shake-Shake-26 2x96D (SSI), découpe 14 | 0,66 (meilleur 0,63) | 200 | 6h46m |
Note
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
- Tous les modèles sont formés en utilisant le recuit des cosinus avec le taux d'apprentissage initial 0,2.
- GeForce GTX 1080 Ti a été utilisé dans ces expériences.
Expériences
Expérience sur les unités résiduelles, la planification des taux d'apprentissage et l'augmentation des données
Dans cette expérience, les effets suivants sur la précision de la classification sont étudiés:
- Unités résiduelles de type pyramidnet
- Cosine recuit du taux d'apprentissage
- Découper
- Efface aléatoire
- Mélange
- Préactivation des raccourcis après une réduction des effectifs
Resnet-Preact-56 est formé sur CIFAR-10 avec un taux d'apprentissage initial 0,2 dans cette expérience.
Note
- Le papier pyramidnet (1610.02915) a montré que la suppression du premier RELU dans les unités résiduelles et l'ajout de BN après les dernières convolutions dans les unités résiduelles améliorent la précision de la classification.
- Le papier SGDR (1608.03983) a montré que le recuit des cosinus améliore la précision de la classification même sans redémarrer.
Résultats
- Les unités de type pyramidnet fonctionnent.
- Il pourrait être préférable de ne pas préactiver les raccourcis après avoir échantillonnage lors de l'utilisation d'unités de type pyramidnet.
- Le recuit du cosinus améliore légèrement la précision.
- Découper, alérer et mélangez tous très bien.
- Le mélange nécessite une formation plus longue.
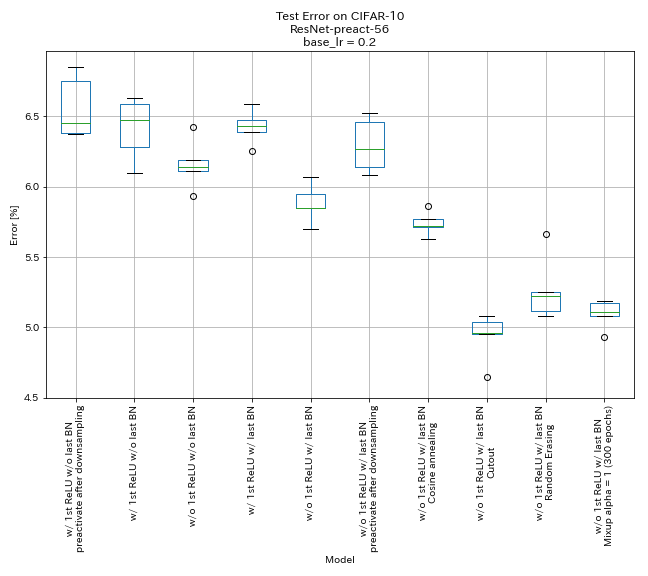
| Modèle | Erreur de test (médiane de 5 courses) | Temps de formation |
|---|
| w / 1st relu, sans dernier BN, préactive le raccourci après les réductions | 6.45 | 95 min |
| w / 1st relu, sans dernier bn | 6.47 | 95 min |
| sans 1ère relu, sans dernier BN | 6.14 | 89 min |
| w / 1st relu, avec dernier BN | 6.43 | 104 min |
| w / o 1st relu, avec dernier BN | 5.85 | 98 min |
| w / o 1st relu, w / dernier BN, préactive le raccourci après la réduction de l'échantillonnage | 6.27 | 98 min |
| w / o 1st relu, w / dernier BN, recuit cosinus | 5.72 | 98 min |
| w / o 1st relu, w / dernier bn, découpe | 4.96 | 98 min |
| w / o 1st relu, w / dernier BN, aléatoire | 5.22 | 98 min |
| w / o 1st relu, w / dernier bn, mélange (300 époques) | 5.11 | 191 min |
Préactiver le raccourci après la réduction de l'échantillonnage
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w / 1st relu, sans dernier bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
sans 1ère relu, sans dernier BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w / 1st relu, avec dernier BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00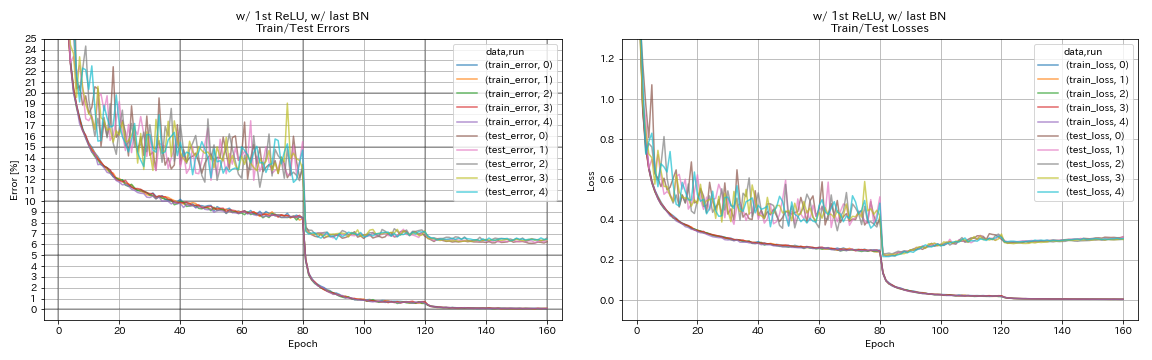
w / o 1st relu, avec dernier BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00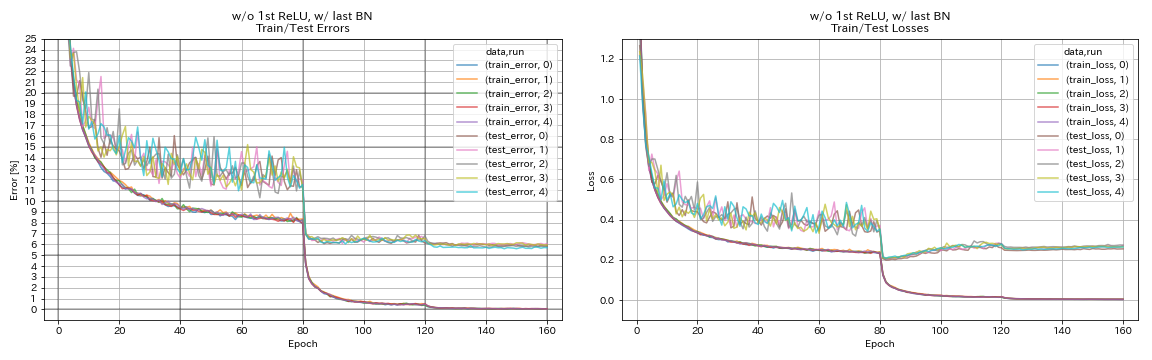
w / o 1st relu, w / dernier BN, préactive le raccourci après la réduction de l'échantillonnage
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00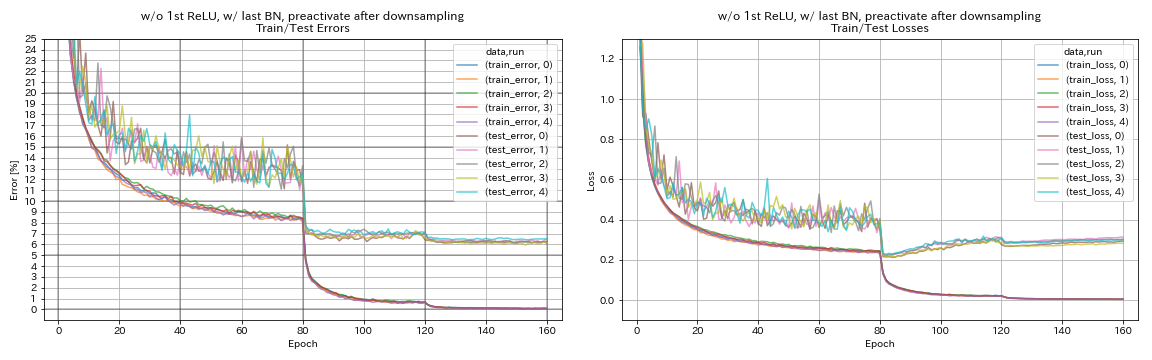
w / o 1st relu, w / dernier BN, recuit cosinus
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00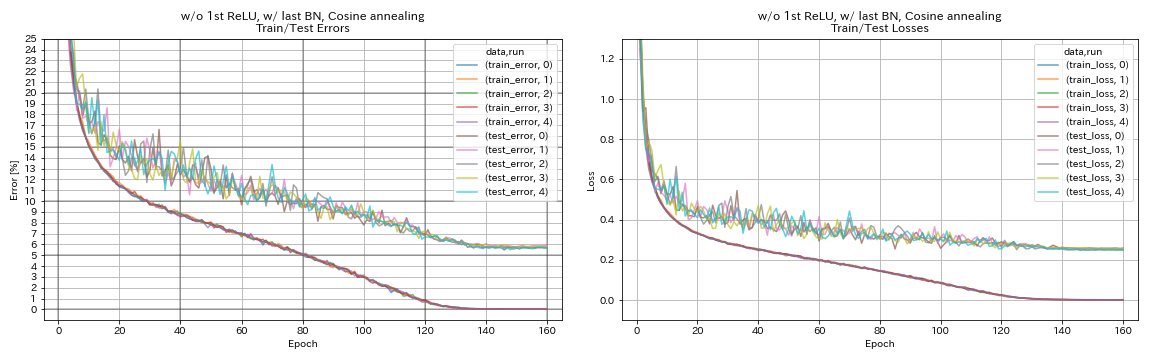
w / o 1st relu, w / dernier bn, découpe
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00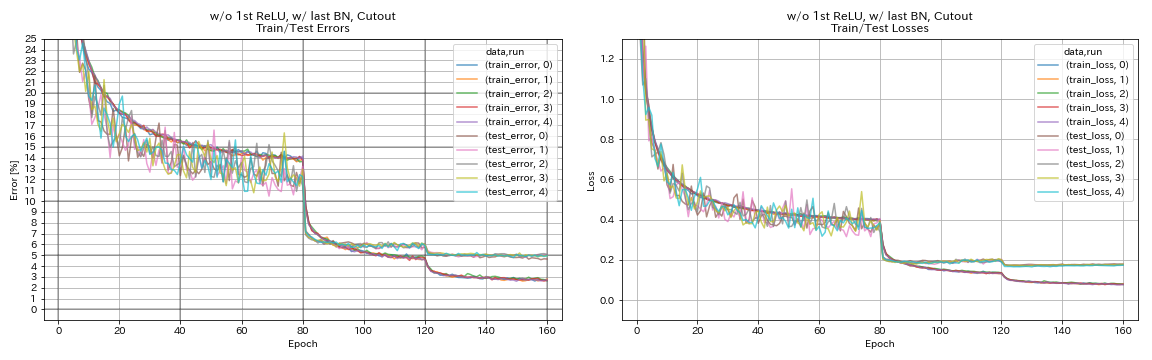
w / o 1st relu, w / dernier BN, aléatoire
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00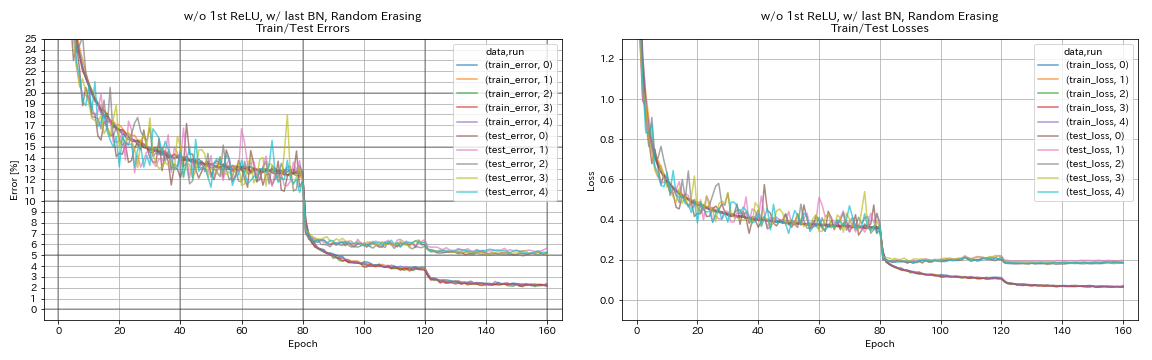
w / o 1st relu, w / dernier bn, mélange
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00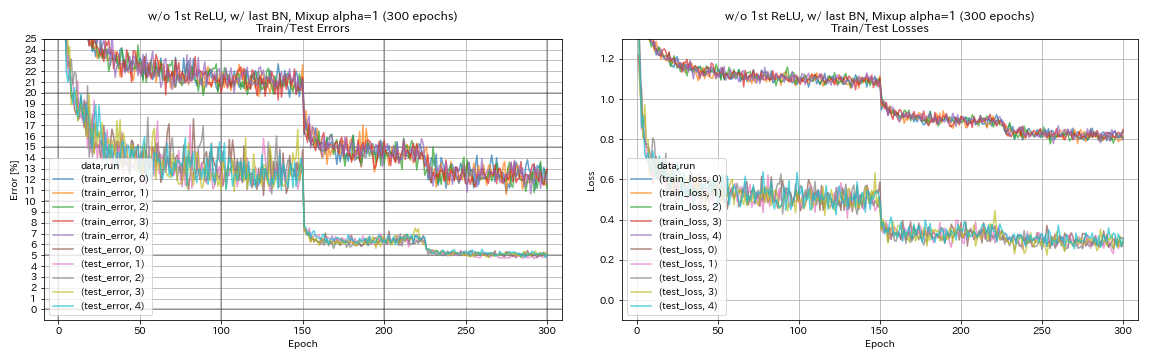
Expériences sur le lissage, le mélange, le RICAP et le double coup
Résultats sur CIFAR-10
| Modèle | Erreur de test (médiane de 3 courses) | # d'époches | Temps de formation |
|---|
| Resnet-préact-20 | 7.60 | 200 | 24m |
| Resnet-préact-20, lissage de l'étiquette (epsilon = 0,001) | 7.51 | 200 | 25m |
| Resnet-préact-20, lissage de l'étiquette (epsilon = 0,01) | 7.21 | 200 | 25m |
| RESNET-PREACT-20, lissage de l'étiquette (Epsilon = 0,1) | 7.57 | 200 | 25m |
| Resnet-préact-20, mélange (alpha = 1) | 7.24 | 200 | 26m |
| Resnet-preact-20, RICAP (bêta = 0,3), avec culture aléatoire | 6.88 | 200 | 28m |
| Resnet-Preact-20, RICAP (Beta = 0,3) | 6.77 | 200 | 28m |
| RESNET-PREACT-20, DUAL-CUTOUT 16 (Alpha = 0,1) | 6.24 | 200 | 45m |
| Resnet-préact-20 | 7.05 | 400 | 49m |
| Resnet-préact-20, lissage de l'étiquette (epsilon = 0,001) | 7.20 | 400 | 49m |
| Resnet-préact-20, lissage de l'étiquette (epsilon = 0,01) | 6.97 | 400 | 49m |
| RESNET-PREACT-20, lissage de l'étiquette (Epsilon = 0,1) | 7.16 | 400 | 49m |
| Resnet-préact-20, mélange (alpha = 1) | 6.66 | 400 | 51m |
| Resnet-preact-20, RICAP (bêta = 0,3), avec culture aléatoire | 6.30 | 400 | 56m |
| Resnet-Preact-20, RICAP (Beta = 0,3) | 6.19 | 400 | 56m |
| RESNET-PREACT-20, DUAL-CUTOUT 16 (Alpha = 0,1) | 5.55 | 400 | 1h36m |
Note
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
- Tous les modèles sont formés en utilisant le recuit des cosinus avec le taux d'apprentissage initial 0,2.
- GeForce GTX 1080 Ti a été utilisé dans ces expériences.
Expériences sur la taille du lot et le taux d'apprentissage
- Les expériences suivantes sont effectuées sur l'ensemble de données CIFAR-10 à l'aide de GEForce 1080 Ti.
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
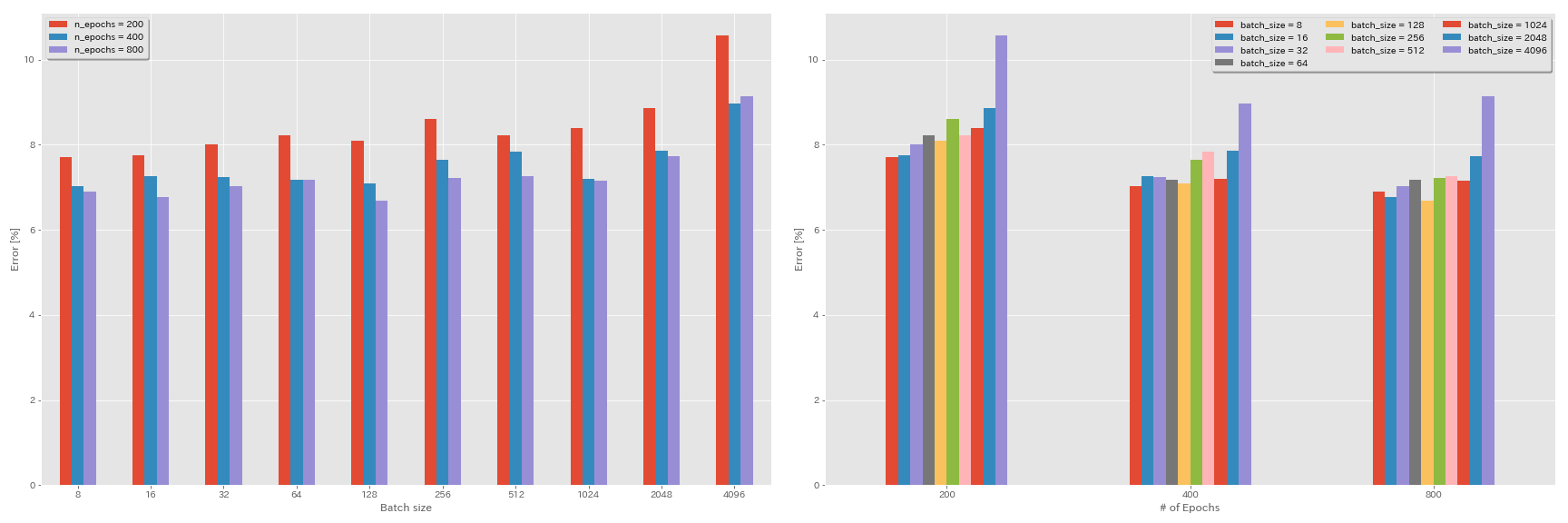
Règle de mise à l'échelle linéaire pour le taux d'apprentissage
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 3.2 | cosinus | 200 | 10.57 | 22m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 200 | 8.87 | 21m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 200 | 8.40 | 21m |
| Resnet-préact-20 | 512 | 0.4 | cosinus | 200 | 8.22 | 20m |
| Resnet-préact-20 | 256 | 0,2 | cosinus | 200 | 8.61 | 22m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 200 | 8.09 | 24m |
| Resnet-préact-20 | 64 | 0,05 | cosinus | 200 | 8.22 | 28m |
| Resnet-préact-20 | 32 | 0,025 | cosinus | 200 | 8.00 | 43m |
| Resnet-préact-20 | 16 | 0,0125 | cosinus | 200 | 7.75 | 1h17m |
| Resnet-préact-20 | 8 | 0,006125 | cosinus | 200 | 7.70 | 2h32m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 3.2 | en plusieurs étapes | 200 | 28.97 | 22m |
| Resnet-préact-20 | 2048 | 1.6 | en plusieurs étapes | 200 | 9.07 | 21m |
| Resnet-préact-20 | 1024 | 0.8 | en plusieurs étapes | 200 | 8.62 | 21m |
| Resnet-préact-20 | 512 | 0.4 | en plusieurs étapes | 200 | 8.23 | 20m |
| Resnet-préact-20 | 256 | 0,2 | en plusieurs étapes | 200 | 8.40 | 21m |
| Resnet-préact-20 | 128 | 0.1 | en plusieurs étapes | 200 | 8.28 | 24m |
| Resnet-préact-20 | 64 | 0,05 | en plusieurs étapes | 200 | 8.13 | 28m |
| Resnet-préact-20 | 32 | 0,025 | en plusieurs étapes | 200 | 7.58 | 43m |
| Resnet-préact-20 | 16 | 0,0125 | en plusieurs étapes | 200 | 7.93 | 1h18m |
| Resnet-préact-20 | 8 | 0,006125 | en plusieurs étapes | 200 | 8.31 | 2h34m |
Échelle linéaire + entraînement plus long
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 3.2 | cosinus | 400 | 8.97 | 44m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 400 | 7.85 | 43m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 400 | 7.20 | 42m |
| Resnet-préact-20 | 512 | 0.4 | cosinus | 400 | 7.83 | 40m |
| Resnet-préact-20 | 256 | 0,2 | cosinus | 400 | 7.65 | 42m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 400 | 7.09 | 47m |
| Resnet-préact-20 | 64 | 0,05 | cosinus | 400 | 7.17 | 44m |
| Resnet-préact-20 | 32 | 0,025 | cosinus | 400 | 7.24 | 2h11m |
| Resnet-préact-20 | 16 | 0,0125 | cosinus | 400 | 7.26 | 4h10m |
| Resnet-préact-20 | 8 | 0,006125 | cosinus | 400 | 7.02 | 7h53m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 3.2 | cosinus | 800 | 8.14 | 1h29m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 800 | 7.74 | 1h23m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 800 | 7.15 | 1h31m |
| Resnet-préact-20 | 512 | 0.4 | cosinus | 800 | 7.27 | 1h25m |
| Resnet-préact-20 | 256 | 0,2 | cosinus | 800 | 7.22 | 1h26m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 800 | 6.68 | 1h35m |
| Resnet-préact-20 | 64 | 0,05 | cosinus | 800 | 7.18 | 2h20m |
| Resnet-préact-20 | 32 | 0,025 | cosinus | 800 | 7.03 | 4h16m |
| Resnet-préact-20 | 16 | 0,0125 | cosinus | 800 | 6.78 | 8h37m |
| Resnet-préact-20 | 8 | 0,006125 | cosinus | 800 | 6.89 | 16h47m |
Effet du taux d'apprentissage initial
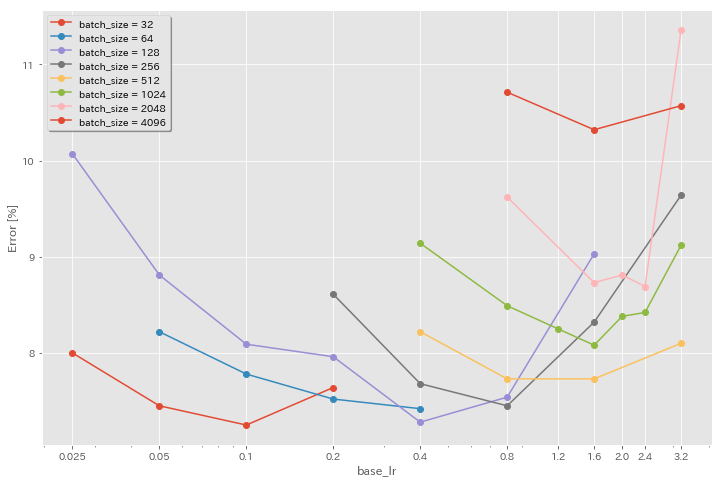
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 3.2 | cosinus | 200 | 10.57 | 22m |
| Resnet-préact-20 | 4096 | 1.6 | cosinus | 200 | 10.32 | 22m |
| Resnet-préact-20 | 4096 | 0.8 | cosinus | 200 | 10.71 | 22m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 2048 | 3.2 | cosinus | 200 | 11.34 | 21m |
| Resnet-préact-20 | 2048 | 2.4 | cosinus | 200 | 8.69 | 21m |
| Resnet-préact-20 | 2048 | 2.0 | cosinus | 200 | 8.81 | 21m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 200 | 8.73 | 22m |
| Resnet-préact-20 | 2048 | 0.8 | cosinus | 200 | 9.62 | 21m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 1024 | 3.2 | cosinus | 200 | 9.12 | 21m |
| Resnet-préact-20 | 1024 | 2.4 | cosinus | 200 | 8.42 | 22m |
| Resnet-préact-20 | 1024 | 2.0 | cosinus | 200 | 8.38 | 22m |
| Resnet-préact-20 | 1024 | 1.6 | cosinus | 200 | 8.07 | 22m |
| Resnet-préact-20 | 1024 | 1.2 | cosinus | 200 | 8.25 | 21m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 200 | 8.08 | 22m |
| Resnet-préact-20 | 1024 | 0.4 | cosinus | 200 | 8.49 | 22m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 512 | 3.2 | cosinus | 200 | 8.51 | 21m |
| Resnet-préact-20 | 512 | 1.6 | cosinus | 200 | 7.73 | 20m |
| Resnet-préact-20 | 512 | 0.8 | cosinus | 200 | 7.73 | 21m |
| Resnet-préact-20 | 512 | 0.4 | cosinus | 200 | 8.22 | 20m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 256 | 3.2 | cosinus | 200 | 9.64 | 22m |
| Resnet-préact-20 | 256 | 1.6 | cosinus | 200 | 8.32 | 22m |
| Resnet-préact-20 | 256 | 0.8 | cosinus | 200 | 7.45 | 21m |
| Resnet-préact-20 | 256 | 0.4 | cosinus | 200 | 7.68 | 22m |
| Resnet-préact-20 | 256 | 0,2 | cosinus | 200 | 8.61 | 22m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 128 | 1.6 | cosinus | 200 | 9.03 | 24m |
| Resnet-préact-20 | 128 | 0.8 | cosinus | 200 | 7.54 | 24m |
| Resnet-préact-20 | 128 | 0.4 | cosinus | 200 | 7.28 | 24m |
| Resnet-préact-20 | 128 | 0,2 | cosinus | 200 | 7.96 | 24m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 200 | 8.09 | 24m |
| Resnet-préact-20 | 128 | 0,05 | cosinus | 200 | 8.81 | 24m |
| Resnet-préact-20 | 128 | 0,025 | cosinus | 200 | 10.07 | 24m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 64 | 0.4 | cosinus | 200 | 7.42 | 35m |
| Resnet-préact-20 | 64 | 0,2 | cosinus | 200 | 7.52 | 36m |
| Resnet-préact-20 | 64 | 0.1 | cosinus | 200 | 7.78 | 37m |
| Resnet-préact-20 | 64 | 0,05 | cosinus | 200 | 8.22 | 28m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 32 | 0,2 | cosinus | 200 | 7.64 | 1h05m |
| Resnet-préact-20 | 32 | 0.1 | cosinus | 200 | 7.25 | 1h08m |
| Resnet-préact-20 | 32 | 0,05 | cosinus | 200 | 7.45 | 1h07m |
| Resnet-préact-20 | 32 | 0,025 | cosinus | 200 | 8.00 | 43m |
Bon taux d'apprentissage + formation plus longue
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 1.6 | cosinus | 200 | 10.32 | 22m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 200 | 8.73 | 22m |
| Resnet-préact-20 | 1024 | 1.6 | cosinus | 200 | 8.07 | 22m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 200 | 8.08 | 22m |
| Resnet-préact-20 | 512 | 1.6 | cosinus | 200 | 7.73 | 20m |
| Resnet-préact-20 | 512 | 0.8 | cosinus | 200 | 7.73 | 21m |
| Resnet-préact-20 | 256 | 0.8 | cosinus | 200 | 7.45 | 21m |
| Resnet-préact-20 | 128 | 0.4 | cosinus | 200 | 7.28 | 24m |
| Resnet-préact-20 | 128 | 0,2 | cosinus | 200 | 7.96 | 24m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 200 | 8.09 | 24m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 1.6 | cosinus | 800 | 8.36 | 1h33m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 800 | 7.53 | 1h27m |
| Resnet-préact-20 | 1024 | 1.6 | cosinus | 800 | 7.30 | 1h30m |
| Resnet-préact-20 | 1024 | 0.8 | cosinus | 800 | 7.42 | 1h30m |
| Resnet-préact-20 | 512 | 1.6 | cosinus | 800 | 6.69 | 1h26m |
| Resnet-préact-20 | 512 | 0.8 | cosinus | 800 | 6.77 | 1h26m |
| Resnet-préact-20 | 256 | 0.8 | cosinus | 800 | 6.84 | 1h28m |
| Resnet-préact-20 | 128 | 0.4 | cosinus | 800 | 6.86 | 1h35m |
| Resnet-préact-20 | 128 | 0,2 | cosinus | 800 | 7.05 | 1h38m |
| Resnet-préact-20 | 128 | 0.1 | cosinus | 800 | 6.68 | 1h35m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 1.6 | cosinus | 1600 | 8.25 | 3h10m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 1600 | 7.34 | 2h50m |
| Resnet-préact-20 | 1024 | 1.6 | cosinus | 1600 | 6.94 | 2h52m |
| Resnet-préact-20 | 512 | 1.6 | cosinus | 1600 | 6.99 | 2h44m |
| Resnet-préact-20 | 256 | 0.8 | cosinus | 1600 | 6.95 | 2h50m |
| Resnet-préact-20 | 128 | 0.4 | cosinus | 1600 | 6.64 | 3h09m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 4096 | 1.6 | cosinus | 3200 | 9.52 | 6h15m |
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 3200 | 6.92 | 5h42m |
| Resnet-préact-20 | 1024 | 1.6 | cosinus | 3200 | 6.96 | 5h43m |
| Modèle | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 2048 | 1.6 | cosinus | 6400 | 7.45 | 11h44m |
Lars
- Dans les articles originaux (1708.03888, 1801.03137), ils ont utilisé la planification du taux d'apprentissage de la désintégration polynomiale, mais le recuit du cosinus est utilisé dans ces expériences.
- Dans cette mise en œuvre, le coefficient LaRS n'est pas utilisé, donc le taux d'apprentissage doit être ajusté en conséquence.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00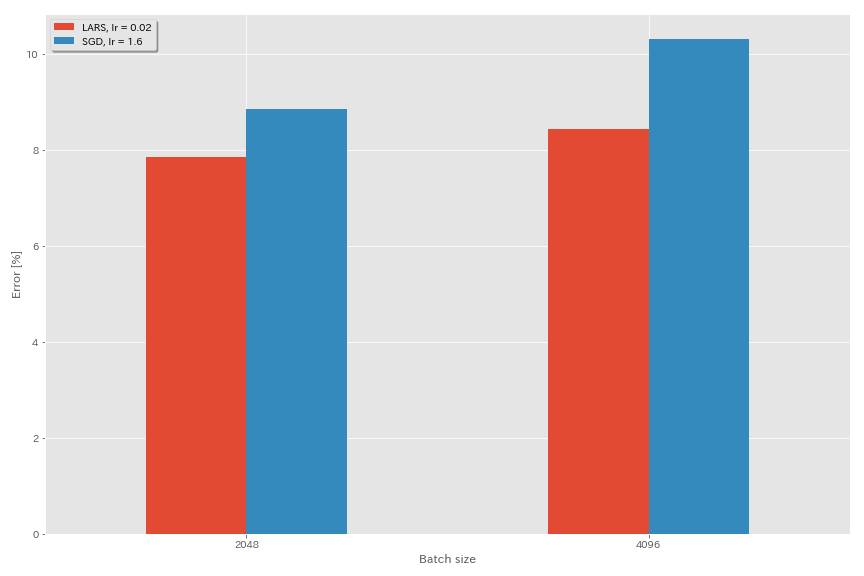
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 4096 | 3.2 | cosinus | 200 | 10,57 (1 course) | 22m |
| Resnet-préact-20 | SGD | 4096 | 1.6 | cosinus | 200 | 10.20 | 22m |
| Resnet-préact-20 | SGD | 4096 | 0.8 | cosinus | 200 | 10,71 (1 course) | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,04 | cosinus | 200 | 9.58 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,03 | cosinus | 200 | 8.46 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,02 | cosinus | 200 | 8.21 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,015 | cosinus | 200 | 8.47 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,01 | cosinus | 200 | 9.33 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,005 | cosinus | 200 | 14.31 | 22m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 2048 | 3.2 | cosinus | 200 | 11.34 (1 course) | 21m |
| Resnet-préact-20 | SGD | 2048 | 2.4 | cosinus | 200 | 8.69 (1 course) | 21m |
| Resnet-préact-20 | SGD | 2048 | 2.0 | cosinus | 200 | 8.81 (1 course) | 21m |
| Resnet-préact-20 | SGD | 2048 | 1.6 | cosinus | 200 | 8,73 (1 course) | 22m |
| Resnet-préact-20 | SGD | 2048 | 0.8 | cosinus | 200 | 9.62 (1 course) | 21m |
| Resnet-préact-20 | Lars | 2048 | 0,04 | cosinus | 200 | 11.58 | 21m |
| Resnet-préact-20 | Lars | 2048 | 0,02 | cosinus | 200 | 8.05 | 22m |
| Resnet-préact-20 | Lars | 2048 | 0,01 | cosinus | 200 | 8.07 | 22m |
| Resnet-préact-20 | Lars | 2048 | 0,005 | cosinus | 200 | 9.65 | 22m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 1024 | 3.2 | cosinus | 200 | 9.12 (1 course) | 21m |
| Resnet-préact-20 | SGD | 1024 | 2.4 | cosinus | 200 | 8.42 (1 course) | 22m |
| Resnet-préact-20 | SGD | 1024 | 2.0 | cosinus | 200 | 8.38 (1 course) | 22m |
| Resnet-préact-20 | SGD | 1024 | 1.6 | cosinus | 200 | 8.07 (1 course) | 22m |
| Resnet-préact-20 | SGD | 1024 | 1.2 | cosinus | 200 | 8.25 (1 course) | 21m |
| Resnet-préact-20 | SGD | 1024 | 0.8 | cosinus | 200 | 8,08 (1 course) | 22m |
| Resnet-préact-20 | SGD | 1024 | 0.4 | cosinus | 200 | 8.49 (1 course) | 22m |
| Resnet-préact-20 | Lars | 1024 | 0,02 | cosinus | 200 | 9h30 | 22m |
| Resnet-préact-20 | Lars | 1024 | 0,01 | cosinus | 200 | 7.68 | 22m |
| Resnet-préact-20 | Lars | 1024 | 0,005 | cosinus | 200 | 8.88 | 23m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 512 | 3.2 | cosinus | 200 | 8,51 (1 course) | 21m |
| Resnet-préact-20 | SGD | 512 | 1.6 | cosinus | 200 | 7.73 (1 course) | 20m |
| Resnet-préact-20 | SGD | 512 | 0.8 | cosinus | 200 | 7.73 (1 course) | 21m |
| Resnet-préact-20 | SGD | 512 | 0.4 | cosinus | 200 | 8.22 (1 course) | 20m |
| Resnet-préact-20 | Lars | 512 | 0,015 | cosinus | 200 | 9.84 | 23m |
| Resnet-préact-20 | Lars | 512 | 0,01 | cosinus | 200 | 8.05 | 23m |
| Resnet-préact-20 | Lars | 512 | 0,0075 | cosinus | 200 | 7.58 | 23m |
| Resnet-préact-20 | Lars | 512 | 0,005 | cosinus | 200 | 7.96 | 23m |
| Resnet-préact-20 | Lars | 512 | 0,0025 | cosinus | 200 | 8.83 | 23m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 256 | 3.2 | cosinus | 200 | 9.64 (1 course) | 22m |
| Resnet-préact-20 | SGD | 256 | 1.6 | cosinus | 200 | 8.32 (1 course) | 22m |
| Resnet-préact-20 | SGD | 256 | 0.8 | cosinus | 200 | 7,45 (1 course) | 21m |
| Resnet-préact-20 | SGD | 256 | 0.4 | cosinus | 200 | 7.68 (1 course) | 22m |
| Resnet-préact-20 | SGD | 256 | 0,2 | cosinus | 200 | 8.61 (1 course) | 22m |
| Resnet-préact-20 | Lars | 256 | 0,01 | cosinus | 200 | 8.95 | 27m |
| Resnet-préact-20 | Lars | 256 | 0,005 | cosinus | 200 | 7.75 | 28m |
| Resnet-préact-20 | Lars | 256 | 0,0025 | cosinus | 200 | 8.21 | 28m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 128 | 1.6 | cosinus | 200 | 9.03 (1 course) | 24m |
| Resnet-préact-20 | SGD | 128 | 0.8 | cosinus | 200 | 7,54 (1 course) | 24m |
| Resnet-préact-20 | SGD | 128 | 0.4 | cosinus | 200 | 7.28 (1 course) | 24m |
| Resnet-préact-20 | SGD | 128 | 0,2 | cosinus | 200 | 7.96 (1 course) | 24m |
| Resnet-préact-20 | Lars | 128 | 0,005 | cosinus | 200 | 7.96 | 37m |
| Resnet-préact-20 | Lars | 128 | 0,0025 | cosinus | 200 | 7.98 | 37m |
| Resnet-préact-20 | Lars | 128 | 0,00125 | cosinus | 200 | 9.21 | 37m |
| Modèle | optimiseur | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | SGD | 4096 | 1.6 | cosinus | 200 | 10.20 | 22m |
| Resnet-préact-20 | SGD | 4096 | 1.6 | cosinus | 800 | 8.36 (1 course) | 1h33m |
| Resnet-préact-20 | SGD | 4096 | 1.6 | cosinus | 1600 | 8.25 (1 course) | 3h10m |
| Resnet-préact-20 | Lars | 4096 | 0,02 | cosinus | 200 | 8.21 | 22m |
| Resnet-préact-20 | Lars | 4096 | 0,02 | cosinus | 400 | 7.53 | 44m |
| Resnet-préact-20 | Lars | 4096 | 0,02 | cosinus | 800 | 7.48 | 1h29m |
| Resnet-préact-20 | Lars | 4096 | 0,02 | cosinus | 1600 | 7.37 (1 course) | 2h58m |
Fantôme BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Modèle | taille de lot | Taille du lot fantôme | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 8192 | N / A | 1.6 | cosinus | 200 | 12.35 | 25m * |
| Resnet-préact-20 | 4096 | N / A | 1.6 | cosinus | 200 | 10.32 | 22m |
| Resnet-préact-20 | 2048 | N / A | 1.6 | cosinus | 200 | 8.73 | 22m |
| Resnet-préact-20 | 1024 | N / A | 1.6 | cosinus | 200 | 8.07 | 22m |
| Resnet-préact-20 | 128 | N / A | 0.4 | cosinus | 200 | 7.28 | 24m |
| Modèle | taille de lot | Taille du lot fantôme | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 8192 | 128 | 1.6 | cosinus | 200 | 11.51 | 27m |
| Resnet-préact-20 | 4096 | 128 | 1.6 | cosinus | 200 | 9.73 | 25m |
| Resnet-préact-20 | 2048 | 128 | 1.6 | cosinus | 200 | 8.77 | 24m |
| Resnet-préact-20 | 1024 | 128 | 1.6 | cosinus | 200 | 7.82 | 22m |
| Modèle | taille de lot | Taille du lot fantôme | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 8192 | N / A | 1.6 | cosinus | 1600 | | |
| Resnet-préact-20 | 4096 | N / A | 1.6 | cosinus | 1600 | 8.25 | 3h10m |
| Resnet-préact-20 | 2048 | N / A | 1.6 | cosinus | 1600 | 7.34 | 2h50m |
| Resnet-préact-20 | 1024 | N / A | 1.6 | cosinus | 1600 | 6.94 | 2h52m |
| Modèle | taille de lot | Taille du lot fantôme | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | 8192 | 128 | 1.6 | cosinus | 1600 | 11.83 | 3h37m |
| Resnet-préact-20 | 4096 | 128 | 1.6 | cosinus | 1600 | 8.95 | 3h15m |
| Resnet-préact-20 | 2048 | 128 | 1.6 | cosinus | 1600 | 7.23 | 3h05m |
| Resnet-préact-20 | 1024 | 128 | 1.6 | cosinus | 1600 | 7.08 | 2h59m |
Pas de désintégration de poids sur BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00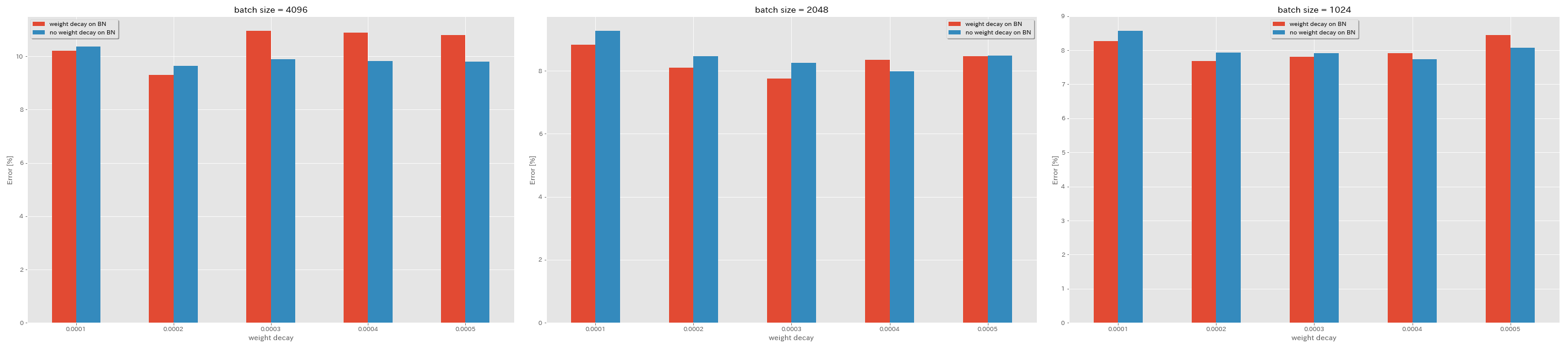
| Modèle | Débrassement du poids sur BN | décomposition du poids | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | Oui | 5E-4 | 4096 | 1.6 | cosinus | 200 | 10.81 | 22m |
| Resnet-préact-20 | Oui | 4E-4 | 4096 | 1.6 | cosinus | 200 | 10.88 | 22m |
| Resnet-préact-20 | Oui | 3E-4 | 4096 | 1.6 | cosinus | 200 | 10.96 | 22m |
| Resnet-préact-20 | Oui | 2E-4 | 4096 | 1.6 | cosinus | 200 | 9h30 | 22m |
| Resnet-préact-20 | Oui | 1E-4 | 4096 | 1.6 | cosinus | 200 | 10.20 | 22m |
| Resnet-préact-20 | Non | 5E-4 | 4096 | 1.6 | cosinus | 200 | 8.78 | 22m |
| Resnet-préact-20 | Non | 4E-4 | 4096 | 1.6 | cosinus | 200 | 9.83 | 22m |
| Resnet-préact-20 | Non | 3E-4 | 4096 | 1.6 | cosinus | 200 | 9.90 | 22m |
| Resnet-préact-20 | Non | 2E-4 | 4096 | 1.6 | cosinus | 200 | 9.64 | 22m |
| Resnet-préact-20 | Non | 1E-4 | 4096 | 1.6 | cosinus | 200 | 10.38 | 22m |
| Modèle | Débrassement du poids sur BN | décomposition du poids | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | Oui | 5E-4 | 2048 | 1.6 | cosinus | 200 | 8.46 | 20m |
| Resnet-préact-20 | Oui | 4E-4 | 2048 | 1.6 | cosinus | 200 | 8.35 | 20m |
| Resnet-préact-20 | Oui | 3E-4 | 2048 | 1.6 | cosinus | 200 | 7.76 | 20m |
| Resnet-préact-20 | Oui | 2E-4 | 2048 | 1.6 | cosinus | 200 | 8.09 | 20m |
| Resnet-préact-20 | Oui | 1E-4 | 2048 | 1.6 | cosinus | 200 | 8.83 | 20m |
| Resnet-préact-20 | Non | 5E-4 | 2048 | 1.6 | cosinus | 200 | 8.49 | 20m |
| Resnet-préact-20 | Non | 4E-4 | 2048 | 1.6 | cosinus | 200 | 7.98 | 20m |
| Resnet-préact-20 | Non | 3E-4 | 2048 | 1.6 | cosinus | 200 | 8.26 | 20m |
| Resnet-préact-20 | Non | 2E-4 | 2048 | 1.6 | cosinus | 200 | 8.47 | 20m |
| Resnet-préact-20 | Non | 1E-4 | 2048 | 1.6 | cosinus | 200 | 9.27 | 20m |
| Modèle | Débrassement du poids sur BN | décomposition du poids | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (médiane de 3 courses) | Temps de formation |
|---|
| Resnet-préact-20 | Oui | 5E-4 | 1024 | 1.6 | cosinus | 200 | 8.45 | 21m |
| Resnet-préact-20 | Oui | 4E-4 | 1024 | 1.6 | cosinus | 200 | 7.91 | 21m |
| Resnet-préact-20 | Oui | 3E-4 | 1024 | 1.6 | cosinus | 200 | 7.81 | 21m |
| Resnet-préact-20 | Oui | 2E-4 | 1024 | 1.6 | cosinus | 200 | 7.69 | 21m |
| Resnet-préact-20 | Oui | 1E-4 | 1024 | 1.6 | cosinus | 200 | 8.26 | 21m |
| Resnet-préact-20 | Non | 5E-4 | 1024 | 1.6 | cosinus | 200 | 8.08 | 21m |
| Resnet-préact-20 | Non | 4E-4 | 1024 | 1.6 | cosinus | 200 | 7.73 | 21m |
| Resnet-préact-20 | Non | 3E-4 | 1024 | 1.6 | cosinus | 200 | 7.92 | 21m |
| Resnet-préact-20 | Non | 2E-4 | 1024 | 1.6 | cosinus | 200 | 7.93 | 21m |
| Resnet-préact-20 | Non | 1E-4 | 1024 | 1.6 | cosinus | 200 | 8.53 | 21m |
Expériences sur la demi-précision et la précision mixte
- Les expériences suivantes ont besoin de nvidia apex.
- Les expériences suivantes sont effectuées sur un ensemble de données CIFAR-10 à l'aide de GEForce 1080 Ti, qui n'a pas de noyaux de tenseur.
- Les résultats rapportés dans le tableau sont les erreurs de test en dernière époques.
Formation FP16
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Formation de précision mixte
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Résultats
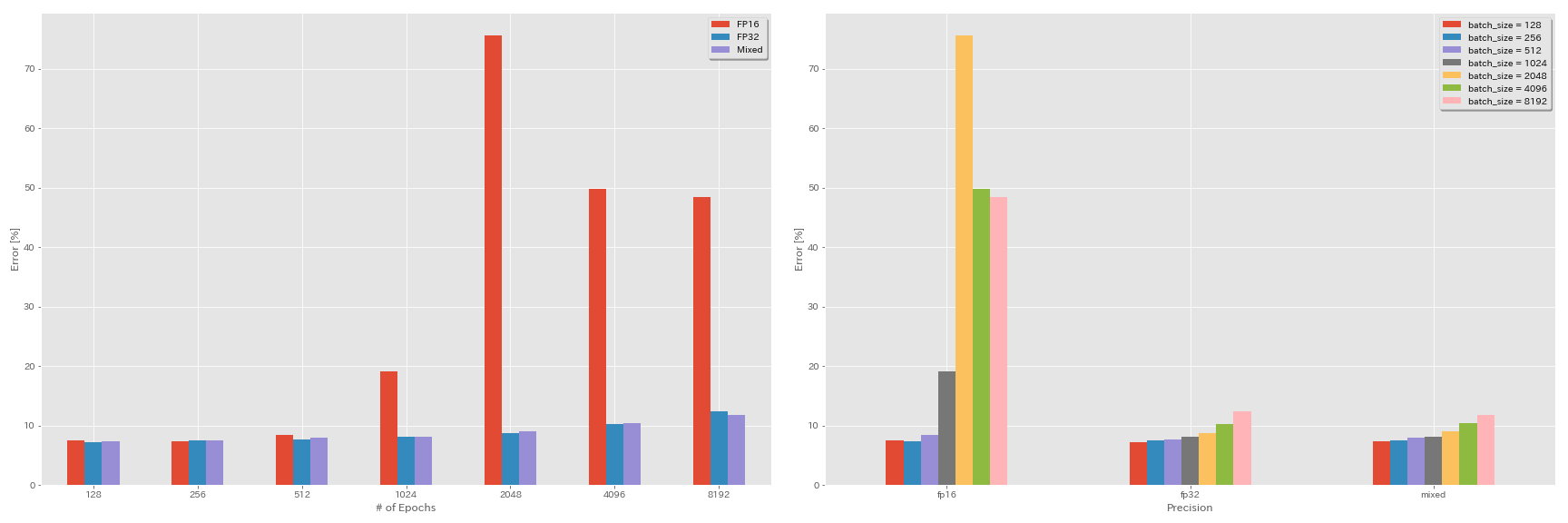
| Modèle | précision | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | Fp32 | 8192 | 1.6 | cosinus | 200 | | |
| Resnet-préact-20 | Fp32 | 4096 | 1.6 | cosinus | 200 | 10.32 | 22m |
| Resnet-préact-20 | Fp32 | 2048 | 1.6 | cosinus | 200 | 8.73 | 22m |
| Resnet-préact-20 | Fp32 | 1024 | 1.6 | cosinus | 200 | 8.07 | 22m |
| Resnet-préact-20 | Fp32 | 512 | 0.8 | cosinus | 200 | 7.73 | 21m |
| Resnet-préact-20 | Fp32 | 256 | 0.8 | cosinus | 200 | 7.45 | 21m |
| Resnet-préact-20 | Fp32 | 128 | 0.4 | cosinus | 200 | 7.28 | 24m |
| Modèle | précision | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | FP16 | 8192 | 1.6 | cosinus | 200 | 48,52 | 33m |
| Resnet-préact-20 | FP16 | 4096 | 1.6 | cosinus | 200 | 49.84 | 28m |
| Resnet-préact-20 | FP16 | 2048 | 1.6 | cosinus | 200 | 75.63 | 27m |
| Resnet-préact-20 | FP16 | 1024 | 1.6 | cosinus | 200 | 19.09 | 27m |
| Resnet-préact-20 | FP16 | 512 | 0.8 | cosinus | 200 | 7.89 | 26m |
| Resnet-préact-20 | FP16 | 256 | 0.8 | cosinus | 200 | 7.40 | 28m |
| Resnet-préact-20 | FP16 | 128 | 0.4 | cosinus | 200 | 7.59 | 32m |
| Modèle | précision | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | mixte | 8192 | 1.6 | cosinus | 200 | 11.78 | 28m |
| Resnet-préact-20 | mixte | 4096 | 1.6 | cosinus | 200 | 10.48 | 27m |
| Resnet-préact-20 | mixte | 2048 | 1.6 | cosinus | 200 | 8.98 | 26m |
| Resnet-préact-20 | mixte | 1024 | 1.6 | cosinus | 200 | 8.05 | 26m |
| Resnet-préact-20 | mixte | 512 | 0.8 | cosinus | 200 | 7.81 | 28m |
| Resnet-préact-20 | mixte | 256 | 0.8 | cosinus | 200 | 7.58 | 32m |
| Resnet-préact-20 | mixte | 128 | 0.4 | cosinus | 200 | 7.37 | 41m |
Résultats utilisant Tesla V100
| Modèle | précision | taille de lot | LR initial | calendrier LR | # d'époches | Erreur de test (1 Run) | Temps de formation |
|---|
| Resnet-préact-20 | Fp32 | 8192 | 1.6 | cosinus | 200 | 12.35 | 25m |
| Resnet-préact-20 | Fp32 | 4096 | 1.6 | cosinus | 200 | 9.88 | 19m |
| Resnet-préact-20 | Fp32 | 2048 | 1.6 | cosinus | 200 | 8.87 | 17m |
| Resnet-préact-20 | Fp32 | 1024 | 1.6 | cosinus | 200 | 8.45 | 18m |
| Resnet-préact-20 | mixte | 8192 | 1.6 | cosinus | 200 | 11.92 | 25m |
| Resnet-préact-20 | mixte | 4096 | 1.6 | cosinus | 200 | 10.16 | 19m |
| Resnet-préact-20 | mixte | 2048 | 1.6 | cosinus | 200 | 9.10 | 17m |
| Resnet-préact-20 | mixte | 1024 | 1.6 | cosinus | 200 | 7.84 | 16m |
Références
Architecture modèle
- Lui, Kaiming, Xiangyu Zhang, Shaoqing Ren et Jian Sun. "Apprentissage résiduel profond pour la reconnaissance d'image." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2016. Link, Arxiv: 1512.03385
- Lui, Kaiming, Xiangyu Zhang, Shaoqing Ren et Jian Sun. "Mappages d'identité dans des réseaux résiduels profonds." Dans la conférence européenne sur la vision par ordinateur (ECCV). 2016. Arxiv: 1603.05027, mise en œuvre de la torche
- Zagoruyko, Sergey et Nikos Komodakis. "Réseaux résiduels larges." Proceedings of the British Mined Vision Conference (BMVC), 2016. Arxiv: 1605.07146, mise en œuvre de la torche
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger et Laurens van der Maaten. "Réseaux convolutionnels densément connectés." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2017. Link, Arxiv: 1608.06993, mise en œuvre de la torche
- Han, Dongyoon, Jiwhan Kim et Junmo Kim. "Réseaux résiduels pyramidaux profonds." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2017. Link, Arxiv: 1610.02915, implémentation de la torche, implémentation de la CAFE, implémentation de Pytorch
- Xie, Saint, Ross Girshick, Piotr Dollar, Zhuowen Tu et Kaiming He. "Transformations résiduelles agrégées pour les réseaux de neurones profonds." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2017. Link, Arxiv: 1611.05431, mise en œuvre de la torche
- Gastaldi, Xavier. "Regardalisation de secouer des réseaux résiduels à 3 branches." Dans International Conference on Learning Representations (ICLR) Workshop, 2017. Link, Arxiv: 1705.07485, mise en œuvre du torch
- Hu, Jie, Li Shen et Gang Sun. "Réseaux de compression et d'excitation." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2018, pp. 7132-7141. Link, Arxiv: 1709.01507, implémentation de la CAFFE
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten et Kilian Q. Weinberger. "Réseaux convolutionnels avec une connectivité dense." Transactions IEEE sur l'analyse des modèles et l'intelligence machine (2019). Arxiv: 2001.02394
Régularisation, augmentation des données
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens et Zbigniew Wojna. "Repenser l'architecture de création pour la vision par ordinateur." La conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2016. Link, Arxiv: 1512.00567
- Devries, Terrance et Graham W. Taylor. "Amélioration de la régularisation des réseaux de neurones convolutionnels avec découpe." ARXIV Préprint Arxiv: 1708.04552 (2017). Arxiv: 1708.04552, mise en œuvre de Pytorch
- Abu-el-Haija, Sami. "Mises à jour du gradient proportionnel avec pour pourlta." Arxiv Preprint Arxiv: 1708.07227 (2017). Arxiv: 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li et Yi Yang. "Augmentation aléatoire des données d'effacement." ARXIV Préprint Arxiv: 1708.04896 (2017). Arxiv: 1708.04896, mise en œuvre de Pytorch
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin et David Lopez-Paz. "Mélange: au-delà de la minimisation empirique des risques." Dans International Conference on Learning Representations (ICLR), 2017. Link, Arxiv: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma et Leslie Pack Kaeling. "Vers la compréhension de la généralisation via la théorie de l'apprentissage analytique." ARXIV Préprint Arxiv: 1802.07426 (2018). Arxiv: 1802.07426, mise en œuvre de Pytorch
- Takahashi, Ryo, Takashi Matsubara et Kuniaki Uehara. "Augmentation des données à l'aide de recadrage d'images aléatoires et de correctifs pour les CNN profonds." Actes de la 10e Conférence asiatique sur l'apprentissage automatique (ACML), 2018. Link, Arxiv: 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe et Youngjoon Yoo. "Cutmix: stratégie de régularisation pour former des classificateurs solides avec des fonctionnalités localisables." ARXIV Préprint Arxiv: 1905.04899 (2019). Arxiv: 1905.04899
Grand lot
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy et Ping Tak Peter Tang. "Sur une formation en grande partie pour l'apprentissage en profondeur: l'écart de généralisation et les minima nets." Dans International Conference on Learning Representations (ICLR), 2017. Link, Arxiv: 1609.04836
- Hoffer, Elad, Itay Hubara et Daniel Soudry. "Formez plus longtemps, généralisez mieux: combler l'écart de généralisation dans la formation en grande partie des réseaux de neurones." Dans Advances in Neural Information Processing Systems (NIPS), 2017. Link, Arxiv: 1705.08741, Implémentation de Pytorch
- Goyal, Priya, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia et Kaiming He. "SGD à minibatch précis et grand: formation d'imaget en 1 heure." ARXIV Préprint Arxiv: 1706.02677 (2017). Arxiv: 1706.02677
- Vous, Yang, Igor Gitman et Boris Ginsburg. "Grande formation par lots des réseaux convolutionnels." ARXIV Préprint Arxiv: 1708.03888 (2017). Arxiv: 1708.03888
- Vous, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel et Kurt Keutzer. "Imagenet s'entraînant en quelques minutes." ARXIV Préprint Arxiv: 1709.05011 (2017). Arxiv: 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying et Quoc V. Le. "Ne décomposez pas le taux d'apprentissage, augmentez la taille du lot." Dans International Conference on Learning Representations (ICLR), 2018. Link, Arxiv: 1711.00489
- Gitman, Igor, Deepak Dilipkumar et Ben Parr. "Analyse de convergence des algorithmes de descente de gradient avec des mises à jour proportionnelles." ARXIV Préprint Arxiv: 1801.03137 (2018). Arxiv: 1801.03137 Implémentation de TensorFlow
- Jia, Xianyan, Shutao Song, Wei He, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi et Xiaowen Chu. "Système d'entraînement d'apprentissage en profondeur hautement évolutif avec une précision mixte: formation ImageNet en quatre minutes." ARXIV Préprint Arxiv: 1807.11205 (2018). Arxiv: 1807.11205
- MALLE, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig et George E. Dahl. "Mesurer les effets du parallélisme des données sur la formation du réseau neuronal." ARXIV Préprint Arxiv: 1811.03600 (2018). Arxiv: 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang et Youlong Cheng. "Classification d'image à l'échelle du supercalculateur." Dans Advances in Neural Information Processing Systems (NEIPS) Workshop, 2018. Link, Arxiv: 1811.06992
Autres
- Loshchilov, Ilya et Frank Hutter. "SGDR: Descente de gradient stochastique avec des redémarrages chauds." Dans International Conference on Learning Representations (ICLR), 2017. Link, Arxiv: 1608.03983, mise en œuvre des lasagnes
- Mikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh et Hao Wu. "Formation de précision mixte." Dans International Conference on Learning Representations (ICLR), 2018. Link, Arxiv: 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt et Vaishaal Shankar. "Les classificateurs CIFAR-10 se généralisent-ils à CIFAR-10?" ARXIV Préprint Arxiv: 1806.00451 (2018). Arxiv: 1806.00451
- Lui, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie et Mu Li. "Sac de trucs pour la classification d'images avec des réseaux de neurones convolutionnels." ARXIV Préprint Arxiv: 1812.01187 (2018). Arxiv: 1812.01187


