Pytorch画像分類
Pytorchを使用して、次の論文が実装されます。
- resnet(1512.03385)
- resnet preact(1603.05027)
- WRN(1605.07146)
- Densenet(1608.06993、2001.02394)
- Pyramidnet(1610.02915)
- resnext(1611.05431)
- シェイクシェイク(1705.07485)
- Lars(1708.03888、1801.03137)
- カットアウト(1708.04552)
- ランダム消去(1708.04896)
- セネット(1709.01507)
- ミックスアップ(1710.09412)
- デュアルカットアウト(1802.07426)
- リカップ(1811.09030)
- CutMix(1905.04899)
要件
- Ubuntu(Ubuntuでのみテストされているため、Windowsで動作しない可能性があります。)
- Python> = 3.7
- pytorch> = 1.4.0
- Torchvision
- nvidia apex
pip install -r requirements.txt
使用法
python train.py --config configs/cifar/resnet_preact.yaml
CIFAR-10の結果
結果は、論文とほぼ同じ設定を使用しています
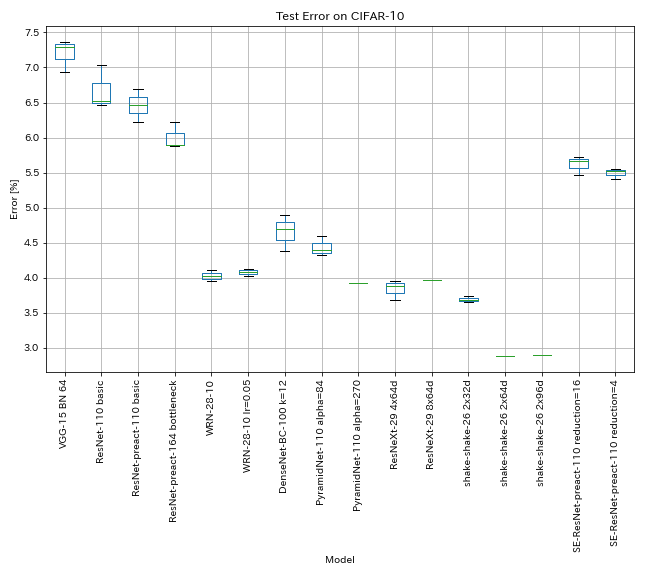
| モデル | テストエラー(3回のランの中央値) | テストエラー(論文内) | トレーニング時間 |
|---|
| vgg-like(深さ15、w/ bn、チャネル64) | 7.29 | n/a | 1H20m |
| ResNet-1010 | 6.52 | 6.43(最高)、6.61 +/- 0.16 | 3H06M |
| ResNet-PreAct -10 | 6.47 | 6.37(5回のランの中央値) | 3H05M |
| Resnet-Preat-164ボトルネック | 5.90 | 5.46(5回のランの中央値) | 4H01M |
| Resnet-Preat-1001ボトルネック | | 4.62(5回のランの中央値)、4.69 +/- 0.20 | |
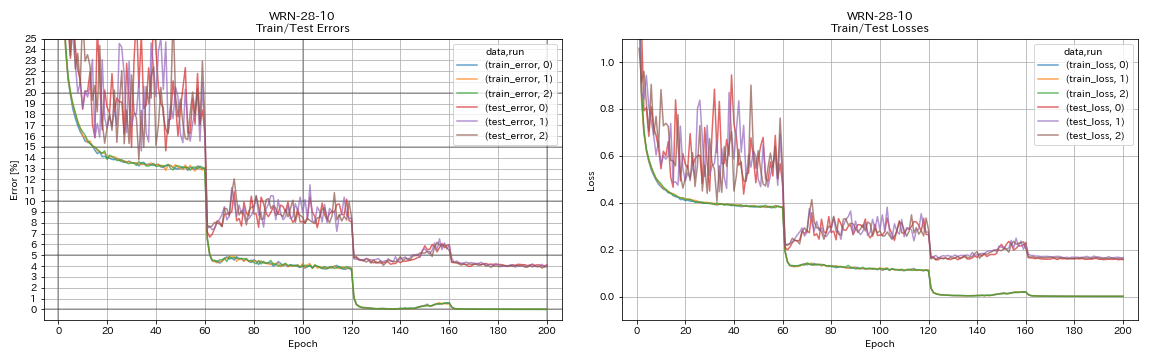
| WRN-28-10 | 4.03 | 4.00(5回のランの中央値) | 16H10M |
| WRN-28-10 W/ドロップアウト | | 3.89(5回のランの中央値) | |
| densenet-100(k = 12) | 3.87(1ラン) | 4.10(1ラン) | 24h28m* |
| densenet-100(k = 24) | | 3.74(1ラン) | |
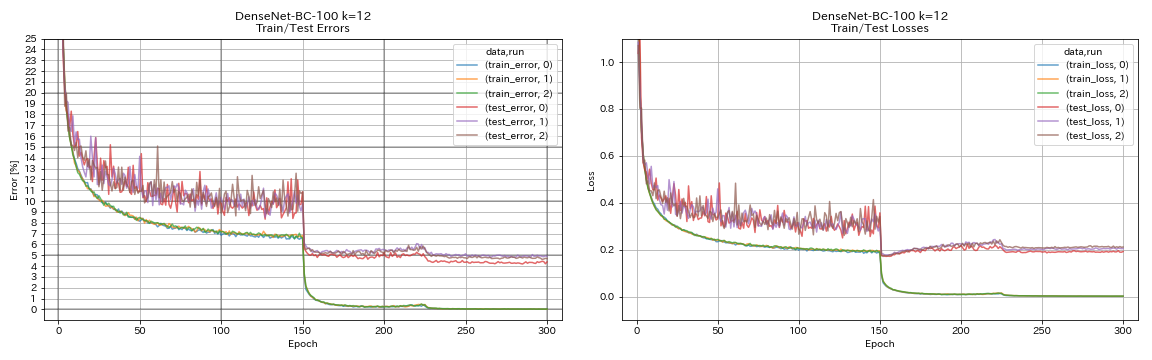
| Densenet-BC-100(k = 12) | 4.69 | 4.51(1ラン) | 15H20m |
| Densenet-BC-250(k = 24) | | 3.62(1ラン) | |
| Densenet-BC-190(k = 40) | | 3.46(1ラン) | |
| pyramidnet-1010(alpha = 84) | 4.40 | 4.26 +/- 0.23 | 11H40M |
| pyramidnet-1010(alpha = 270) | 3.92(1ラン) | 3.73 +/- 0.04 | 24h12m* |
| pyramidnet-164ボトルネック(alpha = 270) | 3.44(1ラン) | 3.48 +/- 0.20 | 32h37m* |
| pyramidnet-272ボトルネック(alpha = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | 〜3.75(図7から) | 31h17m |
| ResNext-29 8x64d | 3.97(1ラン) | 3.65(平均10回のラン) | 42h50m* |
| ResNext-29 16x64d | | 3.58(平均10回のラン) | |
| Shake-Shake-26 2x32d(SSI) | 3.68 | 3.55(平均3回のラン) | 33H49m |
| Shake-Shake-26 2x64d(SSI) | 2.88(1ラン) | 2.98(平均3回のラン) | 78H48M |
| Shake-Shake-26 2x96d(SSI) | 2.90(1ラン) | 2.86(平均5回のラン) | 101h32m* |
メモ
- トレーニング設定の論文との違い:
- バッチサイズ64(紙で128)で訓練されたWRN-28-10。
- バッチサイズ32および初期学習率0.05(バッチサイズ64および初期学習率0.1)の訓練されたデンセンBC-100(k = 12)。
- 単一のGPU、バッチサイズ32、および初期学習率0.025(8 GPU、バッチサイズ128、初期学習率0.1)を備えた訓練されたResNext-29 4x64D。
- 単一のGPU(紙に2 GPU)で訓練されたシェイクシェイクモデル。
- バッチサイズ64で訓練されたシェイクシェイク26 2x64d(SSI)、および初期学習率0.1。
- 上記のテストエラーは、最後のエポックのものです。
- 1回の実行のみの実験は、3回の実行での実験に使用されたコンピューターとは異なるコンピューターで行われます。
- GeForce GTX 980がこれらの実験で使用されました。
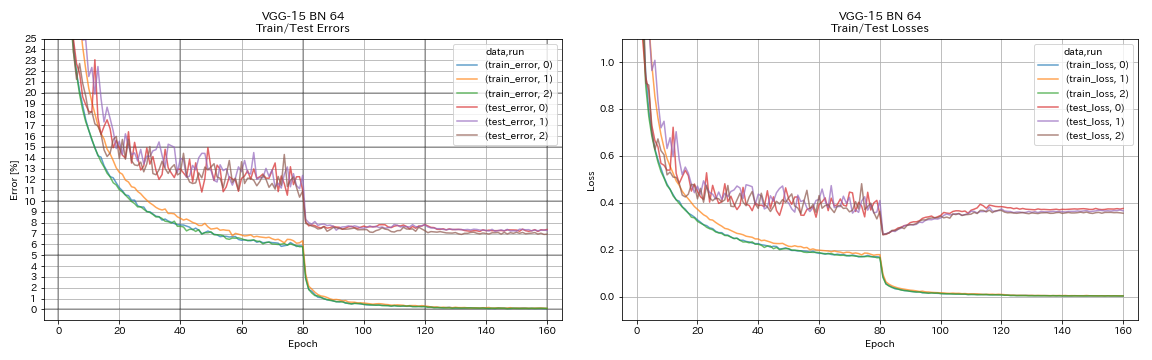
vgg-like
python train.py --config configs/cifar/vgg.yaml
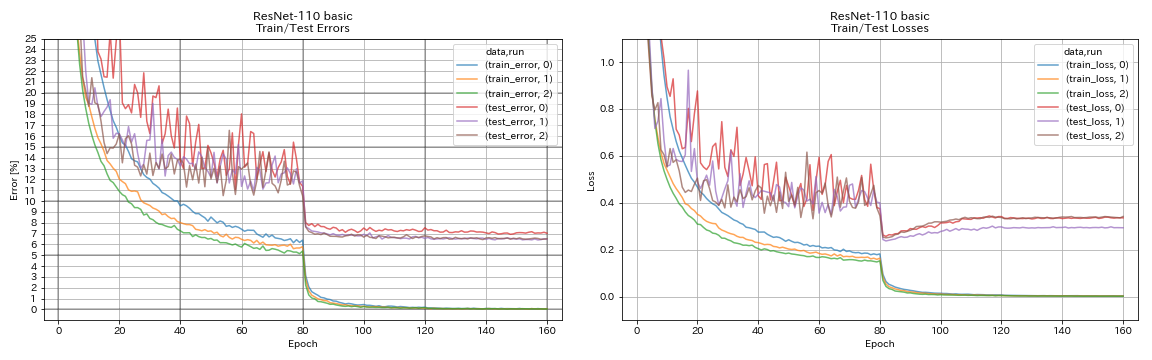
resnet
python train.py --config configs/cifar/resnet.yaml
resnet preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00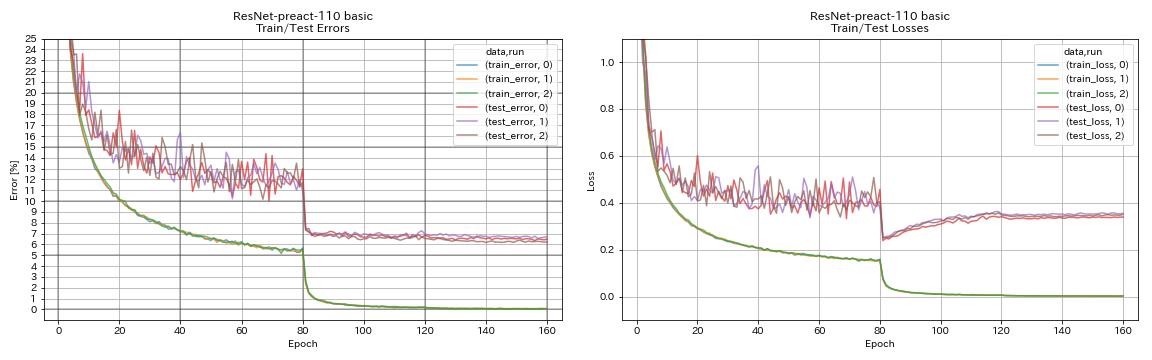
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00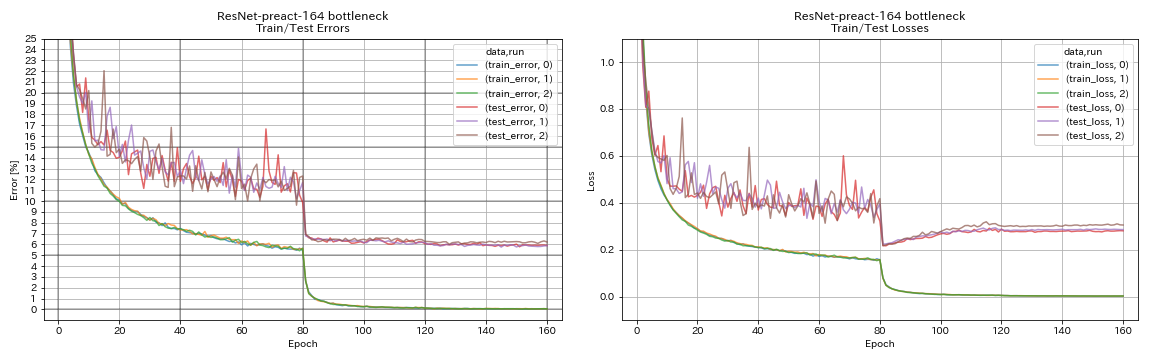
wrn
python train.py --config configs/cifar/wrn.yaml
デンセン
python train.py --config configs/cifar/densenet.yaml
Pyramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00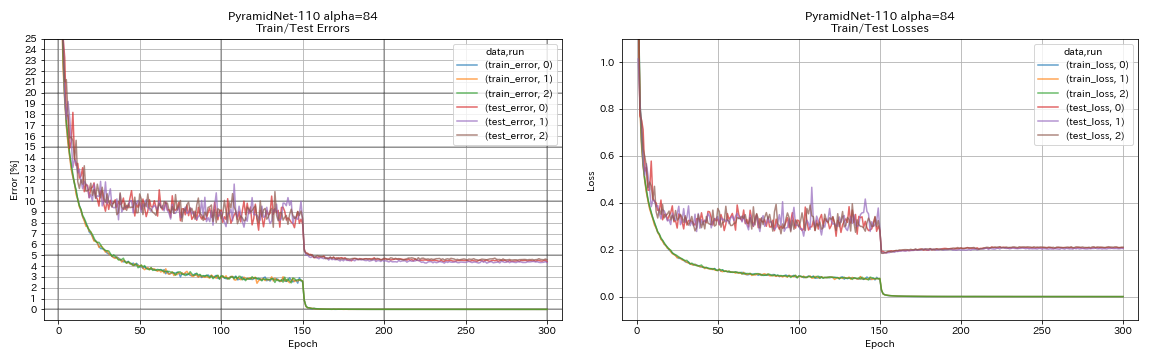
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00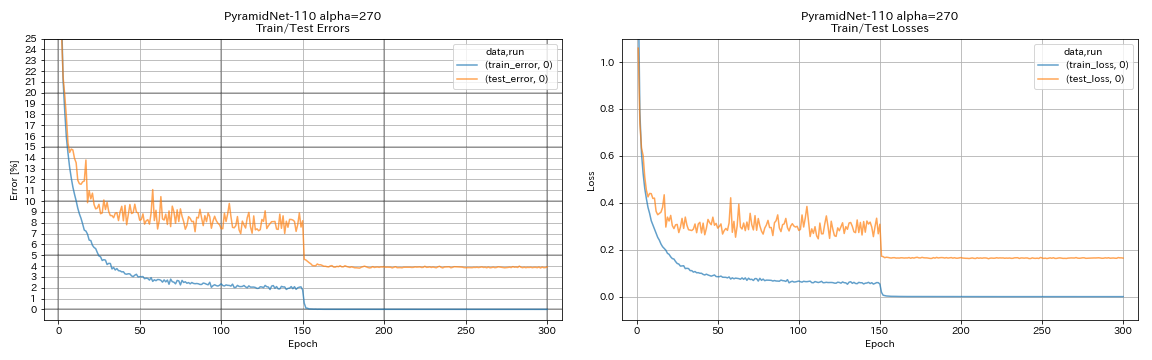
snnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00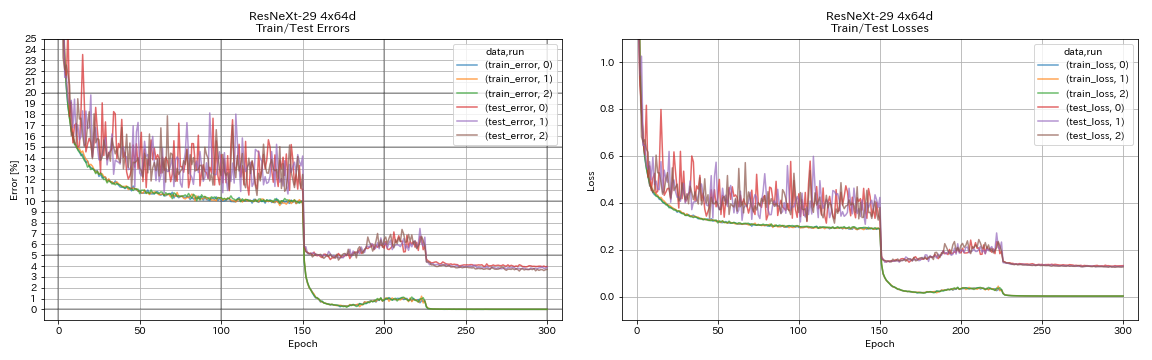
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00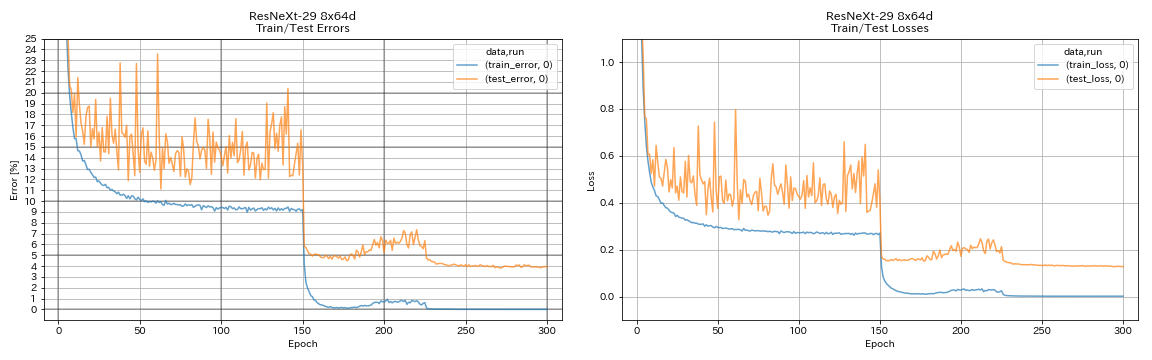
シェイクシェイク
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00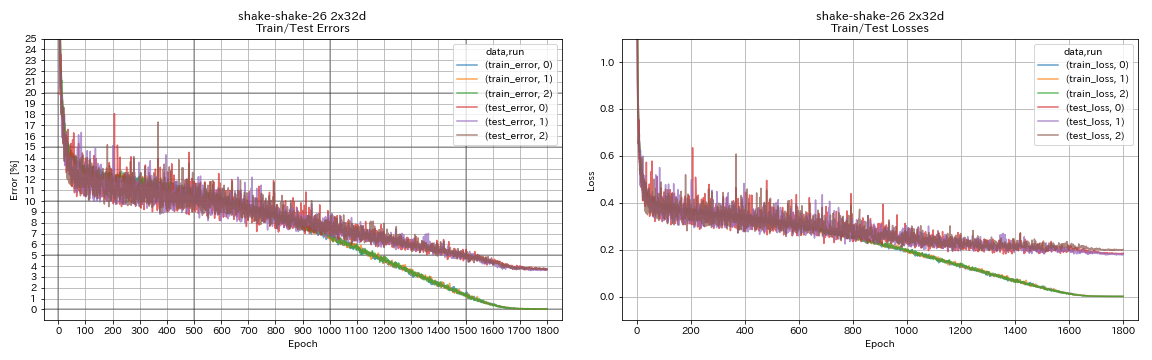
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00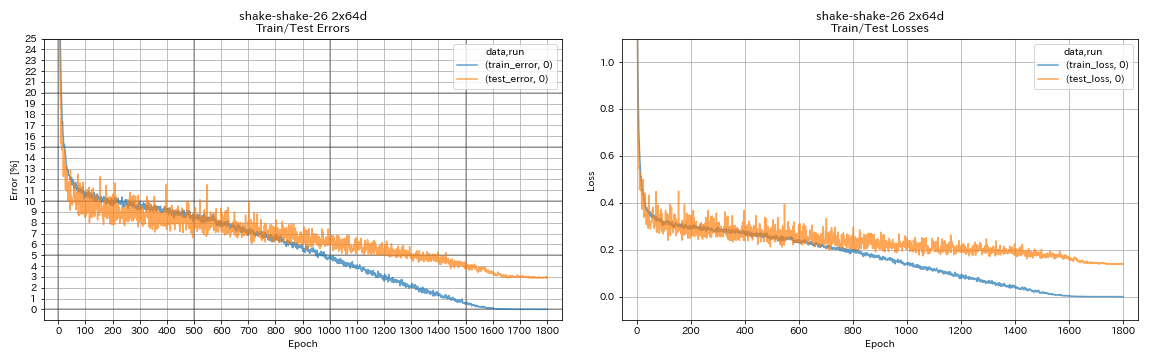
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00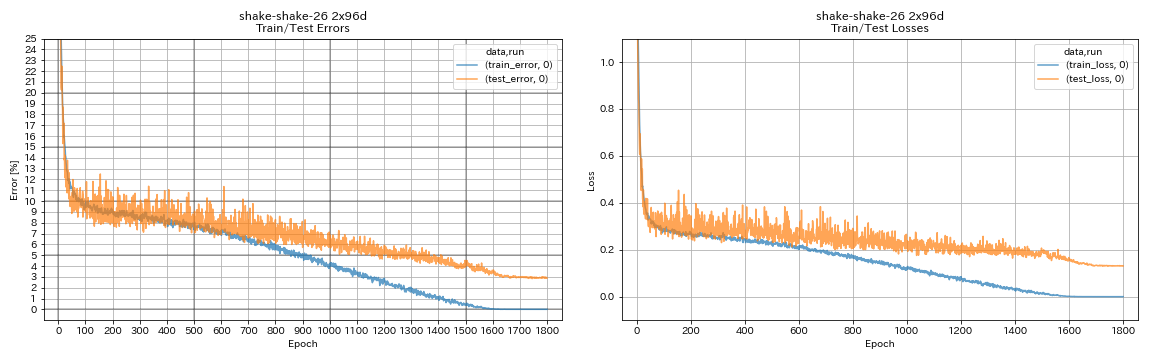
結果
| モデル | テストエラー(1回の実行) | エポックの# | トレーニング時間 |
|---|
| Resnet-Preat-20、拡大因子4 | 4.91 | 200 | 1H26M |
| Resnet-Preat-20、拡大因子4 | 4.01 | 400 | 2H53M |
| Resnet-Preat-20、拡大因子4 | 3.99 | 1800 | 12H53M |
| Resnet-Preat-20、拡大因子4、切り抜き16 | 3.71 | 200 | 1H26M |
| Resnet-Preat-20、拡大因子4、切り抜き16 | 3.46 | 400 | 2H53M |
| Resnet-Preat-20、拡大因子4、切り抜き16 | 3.76 | 1800 | 12H53M |
| Resnet-Preat-20、拡大因子4、RICAP(ベータ= 0.3) | 3.45 | 200 | 1H26M |
| Resnet-Preat-20、拡大因子4、RICAP(ベータ= 0.3) | 3.11 | 400 | 2H53M |
| Resnet-Preat-20、拡大因子4、RICAP(ベータ= 0.3) | 3.15 | 1800 | 12H53M |
| モデル | テストエラー(1回の実行) | エポックの# | トレーニング時間 |
|---|
| WRN-28-10、カットアウト16 | 3.19 | 200 | 6h35m |
| WRN-28-10、ミックスアップ(alpha = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10、RICAP(ベータ= 0.3) | 2.83 | 200 | 6h35m |
| WRN-28-10、デュアルカットアウト(アルファ= 0.1) | 2.87 | 200 | 12H42M |
| WRN-28-10、カットアウト16 | 3.07 | 400 | 13H10M |
| WRN-28-10、ミックスアップ(alpha = 1) | 3.04 | 400 | 13H08M |
| WRN-28-10、RICAP(ベータ= 0.3) | 2.71 | 400 | 13H08M |
| WRN-28-10、デュアルカットアウト(アルファ= 0.1) | 2.76 | 400 | 25H20M |
| Shake-Shake-26 2x64d、カットアウト16 | 2.64 | 1800 | 78h55m* |
| Shake-Shake-26 2x64d、Mixup(alpha = 1) | 2.63 | 1800 | 35H56M |
| Shake-Shake-26 2x64d、ricap(beta = 0.3) | 2.29 | 1800 | 35H10M |
| Shake-Shake-26 2x64d、デュアルカットアウト(alpha = 0.1) | 2.64 | 1800 | 68H34M |
| Shake-Shake-26 2x96d、カットアウト16 | 2.50 | 1800 | 60H20M |
| Shake-Shake-26 2x96d、Mixup(alpha = 1) | 2.36 | 1800 | 60H20M |
| Shake-Shake-26 2x96d、ricap(beta = 0.3) | 2.10 | 1800 | 60H20M |
| Shake-Shake-26 2x96d、デュアルカットアウト(alpha = 0.1) | 2.41 | 1800 | 113H09M |
| Shake-Shake-26 2x128d、カットアウト16 | 2.58 | 1800 | 85H04M |
| Shake-Shake-26 2x128d、ricap(beta = 0.3) | 1.97 | 1800 | 85H06M |
注記
- 表で報告されている結果は、最後のエポックのテストエラーです。
- すべてのモデルは、初期学習率0.2でコサインアニーリングを使用してトレーニングされています。
- GeForce GTX 1080 TIは、GeForce GTX 980を使用して行われる *を除くこれらの実験で使用されました。
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True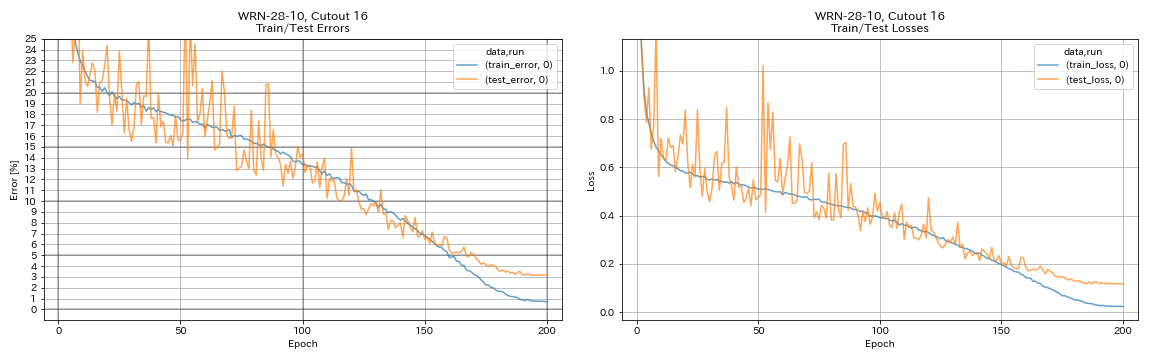
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True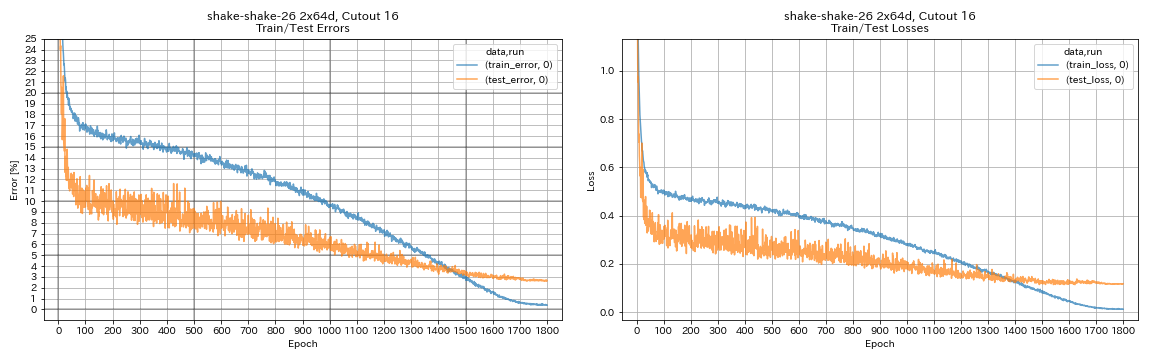
マルチGPUを使用した結果
| モデル | バッチサイズ | #gpus | テストエラー(1回の実行) | エポックの# | トレーニング時間* |
|---|
| WRN-28-10、RICAP(ベータ= 0.3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10、RICAP(ベータ= 0.3) | 256 | 2 | 2.71 | 200 | 2H14M |
| WRN-28-10、RICAP(ベータ= 0.3) | 128 | 4 | 2.89 | 200 | 1H01M |
| WRN-28-10、RICAP(ベータ= 0.3) | 64 | 8 | 2.75 | 200 | 34m |
注記
- Tesla V100は、これらの実験で使用されました。
1 GPUを使用します
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop False2 GPUを使用します
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False4つのGPUを使用します
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False8 GPUを使用します
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseFashionMnistの結果
| モデル | テストエラー(1回の実行) | エポックの# | トレーニング時間 |
|---|
| ResNet-Preat-20、拡大因子4、カットアウト12 | 4.17 | 200 | 1H32M |
| Resnet-Preat-20、拡大因子4、カットアウト14 | 4.11 | 200 | 1H32M |
| ResNet-PreAct-50、カットアウト12 | 4.45 | 200 | 57m |
| ResNet-PreAct-50、カットアウト14 | 4.38 | 200 | 57m |
| Resnet-Preat-50、拡大因子4、カットアウト12 | 4.07 | 200 | 3H37M |
| Resnet-Preat-50、拡大因子4、切り抜き14 | 4.13 | 200 | 3H39m |
| Shake-Shake-26 2x32d(SSI)、カットアウト12 | 4.08 | 400 | 3H41M |
| Shake-Shake-26 2x32d(SSI)、カットアウト14 | 4.05 | 400 | 3H39m |
| Shake-Shake-26 2x96d(SSI)、カットアウト12 | 3.72 | 400 | 13H46m |
| Shake-Shake-26 2x96d(SSI)、カットアウト14 | 3.85 | 400 | 13H39m |
| Shake-Shake-26 2x96d(SSI)、カットアウト12 | 3.65 | 800 | 26H42m |
| Shake-Shake-26 2x96d(SSI)、カットアウト14 | 3.60 | 800 | 26H42m |
| モデル | テストエラー(3回のランの中央値) | エポックの# | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 5.04 | 200 | 26m |
| Resnet-Preat-20、Sutout 6 | 4.84 | 200 | 26m |
| Resnet-Preat-20、カットアウト8 | 4.64 | 200 | 26m |
| Resnet-Preat-20、Sutout10 | 4.74 | 200 | 26m |
| Resnet-Preat-20、カットアウト12 | 4.68 | 200 | 26m |
| ResNet-Preat-20、カットアウト14 | 4.64 | 200 | 26m |
| ResNet-Preat-20、カットアウト16 | 4.49 | 200 | 26m |
| ResNet-PreAct-20、ランダムラッシング | 4.61 | 200 | 26m |
| Resnet-Preat-20、ミックスアップ | 4.92 | 200 | 26m |
| Resnet-Preat-20、ミックスアップ | 4.64 | 400 | 52m |
注記
- テーブルで報告されている結果は、最後のエポックのテストエラーです。
- すべてのモデルは、初期学習率0.2でコサインアニーリングを使用してトレーニングされています。
- 次のデータ増強がトレーニングデータに適用されます。
- 画像は両側に4ピクセルでパッド入り、28x28パッチはパッド入りの画像からランダムにトリミングされています。
- 画像は水平にランダムに反転します。
- GeForce GTX 1080 TIがこれらの実験で使用されました。
Mnistの結果
| モデル | テストエラー(3回のランの中央値) | エポックの# | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 0.40 | 100 | 12m |
| Resnet-Preat-20、Sutout 6 | 0.32 | 100 | 12m |
| Resnet-Preat-20、カットアウト8 | 0.25 | 100 | 12m |
| Resnet-Preat-20、Sutout10 | 0.27 | 100 | 12m |
| Resnet-Preat-20、カットアウト12 | 0.26 | 100 | 12m |
| ResNet-Preat-20、カットアウト14 | 0.26 | 100 | 12m |
| ResNet-Preat-20、カットアウト16 | 0.25 | 100 | 12m |
| resnet-preacct-20、mixup(alpha = 1) | 0.40 | 100 | 12m |
| Resnet-Preat-20、Mixup(alpha = 0.5) | 0.38 | 100 | 12m |
| Resnet-Preat-20、拡大因子4、カットアウト14 | 0.26 | 100 | 45m |
| ResNet-PreAct-50、カットアウト14 | 0.29 | 100 | 28m |
| Resnet-Preat-50、拡大因子4、切り抜き14 | 0.25 | 100 | 1h50m |
| Shake-Shake-26 2x96d(SSI)、カットアウト14 | 0.24 | 100 | 3H22M |
注記
- 表で報告されている結果は、最後のエポックのテストエラーです。
- すべてのモデルは、初期学習率0.2でコサインアニーリングを使用してトレーニングされています。
- GeForce GTX 1080 TIがこれらの実験で使用されました。
Kuzushiji-Mnistの結果
| モデル | テストエラー(3回のランの中央値) | エポックの# | トレーニング時間 |
|---|
| ResNet-Preat-20、カットアウト14 | 0.82(ベスト0.67) | 200 | 24m |
| Resnet-Preat-20、拡大因子4、カットアウト14 | 0.72(ベスト0.67) | 200 | 1h30m |
| Pyramidnet-10-270、カットアウト14 | 0.72(ベスト0.70) | 200 | 10H05M |
| Shake-Shake-26 2x96d(SSI)、カットアウト14 | 0.66(ベスト0.63) | 200 | 6H46M |
注記
- 表で報告されている結果は、最後のエポックのテストエラーです。
- すべてのモデルは、初期学習率0.2でコサインアニーリングを使用してトレーニングされています。
- GeForce GTX 1080 TIがこれらの実験で使用されました。
実験
残留ユニット、学習率のスケジューリング、およびデータ増強の実験
この実験では、分類精度に対する以下の影響を調査します。
- ピラミッドネットのような残差ユニット
- 学習率のコサインアニーリング
- 切り取る
- ランダム消去
- 混合
- ダウンサンプリング後のショートカットの事前活性化
ResNet-Preat-56は、この実験で初期学習率0.2でCIFAR-10でトレーニングされています。
注記
- Pyramidnet Paper(1610.02915)は、残差ユニットで最初のreluを除去し、残差ユニットでの最後の畳み込みの後にBNを追加することが両方とも分類精度を向上させることを示しました。
- SGDRペーパー(1608.03983)は、コサインアニーリングが再起動せずに分類の精度を改善することを示しました。
結果
- Pyramidnetのようなユニットは機能します。
- PyramidNetのようなユニットを使用した場合、ダウンサンプリング後にショートカットを事前にアクティブ化しない方が良いかもしれません。
- コサインアニーリングは、精度をわずかに改善します。
- カットアウト、ランダムラッシング、およびミックスアップはすべてうまく機能します。
- ミックスアップには、より長いトレーニングが必要です。
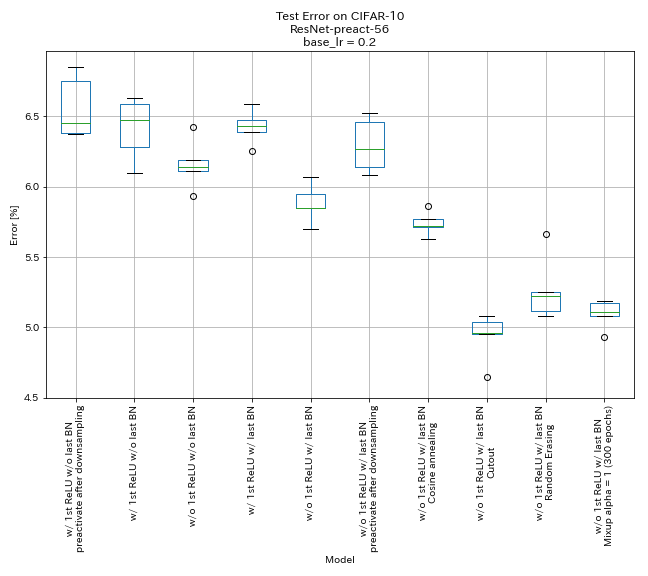
| モデル | テストエラー(5回のランの中央値) | トレーニング時間 |
|---|
| 最初のrelu、最後のbnを使用して、ダウンサンプリング後のショートカットを事前にアクティブ化する | 6.45 | 95分 |
| w/ strt relu、w/ o最後のbn | 6.47 | 95分 |
| 最初のrelu w/o、最後のbn w/o | 6.14 | 89分 |
| w/ strt relu、w/ last bn | 6.43 | 104分 |
| 最初のrelu、最後のbn w/ w/ o | 5.85 | 98分 |
| w/ o 1st Relu、最後のbn、ダウンサンプリング後のショートカットを事前にアクティブ化する | 6.27 | 98分 |
| 最初のrelu、最後のbn、コサインアニーリングw/ w/ o | 5.72 | 98分 |
| w/ o 1st Relu、w/ last bn、cutout | 4.96 | 98分 |
| 最初のrelu、最後のbn、ランダム化 | 5.22 | 98分 |
| w/ o 1st relu、w/ last bn、mixup(300エポック) | 5.11 | 191分 |
ダウンサンプリング後のショートカットを事前にアクティブ化します
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ strt relu、w/ o最後のbn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
最初のrelu w/o、最後のbn w/o
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ strt relu、w/ last bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00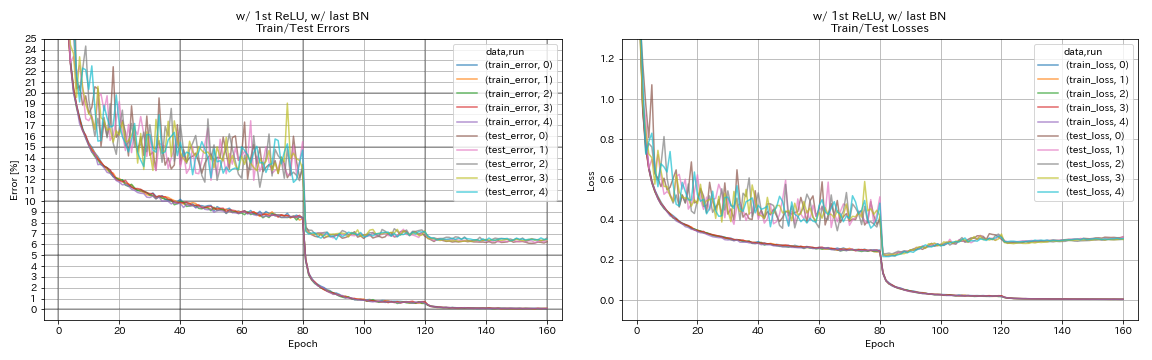
最初のrelu、最後のbn w/ w/ o
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00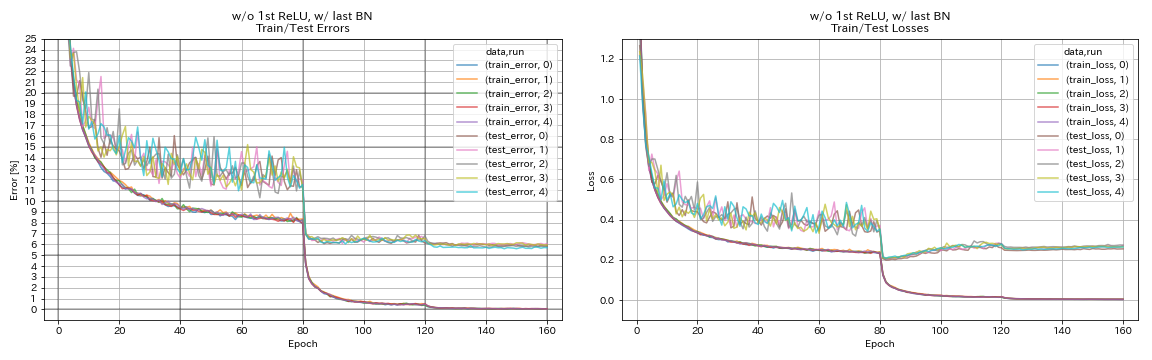
w/ o 1st Relu、最後のbn、ダウンサンプリング後のショートカットを事前にアクティブ化する
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00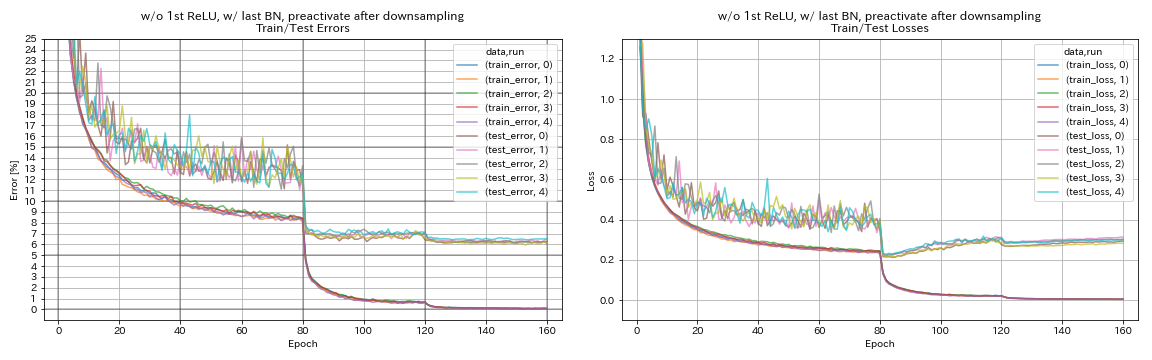
最初のrelu、最後のbn、コサインアニーリングw/ w/ o
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00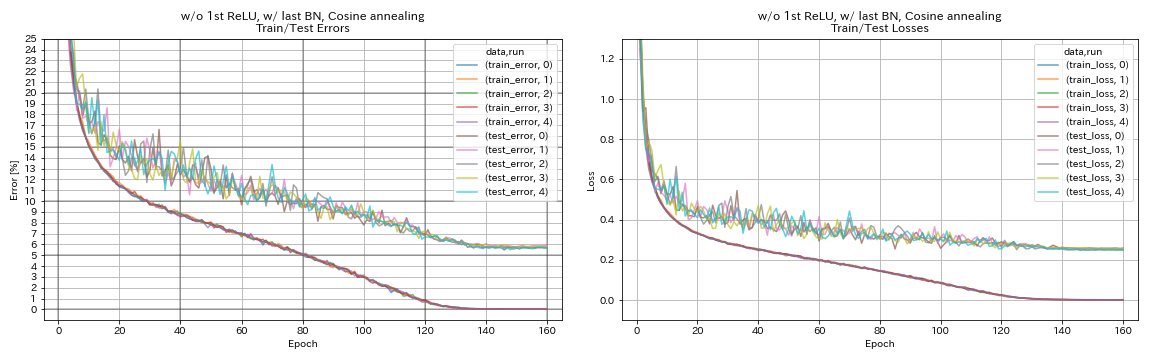
w/ o 1st Relu、w/ last bn、cutout
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00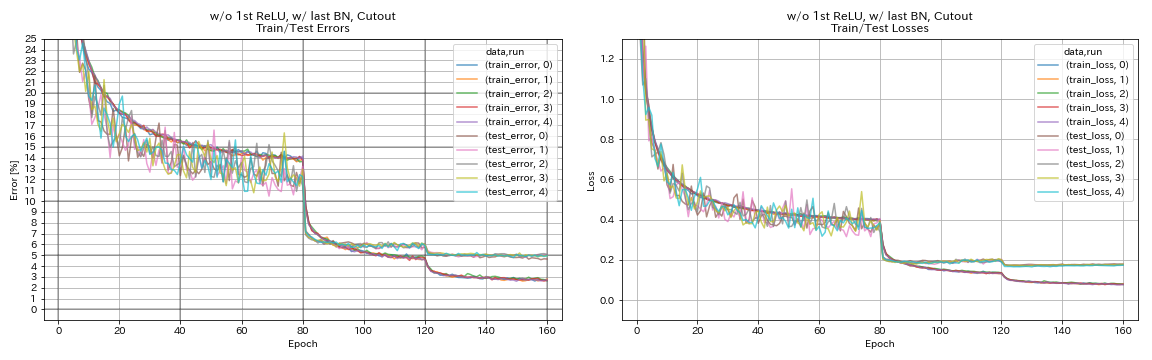
最初のrelu、最後のbn、ランダム化
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00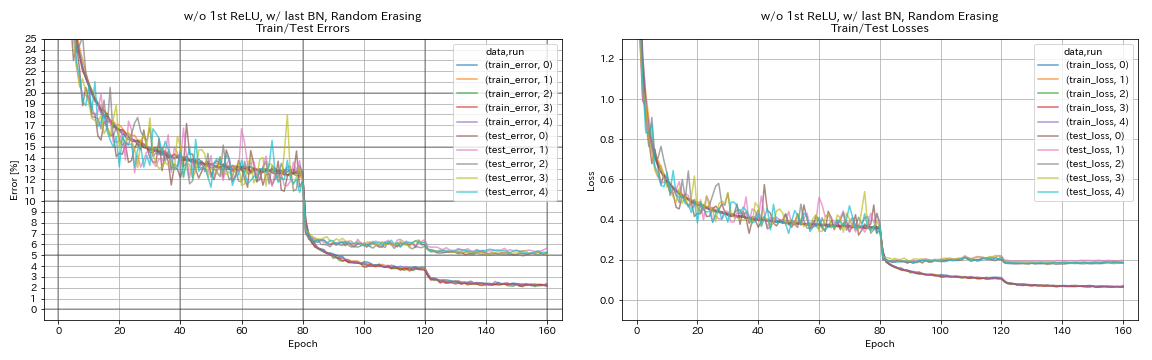
w/ o 1st Relu、w/ last bn、mixup
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00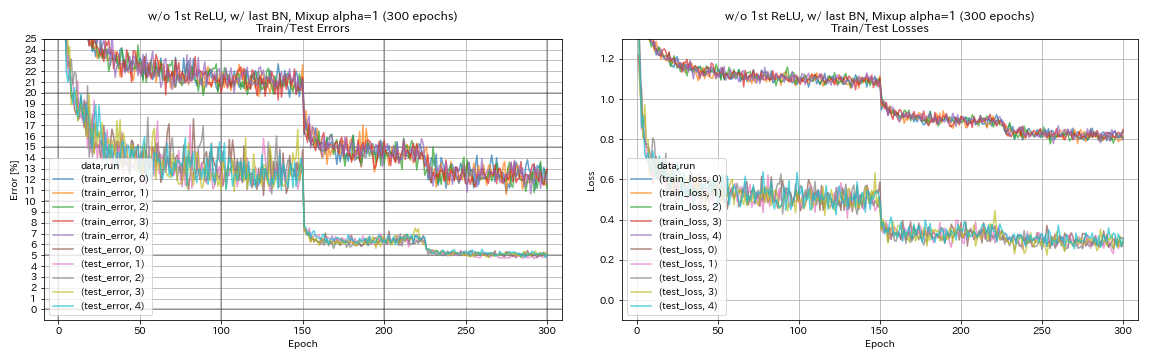
ラベルのスムージング、ミックス、リカップ、デュアルカットアウトの実験
CIFAR-10の結果
| モデル | テストエラー(3回のランの中央値) | エポックの# | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 7.60 | 200 | 24m |
| ResNet-PreAct-20、ラベルスムージング(Epsilon = 0.001) | 7.51 | 200 | 25m |
| ResNet-PreAct-20、ラベルスムージング(Epsilon = 0.01) | 7.21 | 200 | 25m |
| Resnet-Preat-20、ラベルスムージング(Epsilon = 0.1) | 7.57 | 200 | 25m |
| resnet-preacct-20、mixup(alpha = 1) | 7.24 | 200 | 26m |
| ResNet-Preat-20、RICAP(ベータ= 0.3)、ランダム作物 | 6.88 | 200 | 28m |
| resnet-preacct-20、ricap(beta = 0.3) | 6.77 | 200 | 28m |
| resnet-preacct-20、dual-cutout 16(alpha = 0.1) | 6.24 | 200 | 45m |
| ResNet-PreAct-20 | 7.05 | 400 | 49m |
| ResNet-PreAct-20、ラベルスムージング(Epsilon = 0.001) | 7.20 | 400 | 49m |
| ResNet-PreAct-20、ラベルスムージング(Epsilon = 0.01) | 6.97 | 400 | 49m |
| Resnet-Preat-20、ラベルスムージング(Epsilon = 0.1) | 7.16 | 400 | 49m |
| resnet-preacct-20、mixup(alpha = 1) | 6.66 | 400 | 51m |
| ResNet-Preat-20、RICAP(ベータ= 0.3)、ランダム作物 | 6.30 | 400 | 56m |
| resnet-preacct-20、ricap(beta = 0.3) | 6.19 | 400 | 56m |
| resnet-preacct-20、dual-cutout 16(alpha = 0.1) | 5.55 | 400 | 1H36M |
注記
- 表で報告されている結果は、最後のエポックのテストエラーです。
- すべてのモデルは、初期学習率0.2でコサインアニーリングを使用してトレーニングされています。
- GeForce GTX 1080 TIがこれらの実験で使用されました。
バッチサイズと学習率の実験
- GEFORCE 1080 TIを使用して、CIFAR-10データセットで以下の実験が行われます。
- 表で報告されている結果は、最後のエポックのテストエラーです。
学習率の線形スケーリングルール
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 3.2 | 余弦 | 200 | 10.57 | 22m |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 200 | 8.87 | 21m |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 200 | 8.40 | 21m |
| ResNet-PreAct-20 | 512 | 0.4 | 余弦 | 200 | 8.22 | 20m |
| ResNet-PreAct-20 | 256 | 0.2 | 余弦 | 200 | 8.61 | 22m |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| ResNet-PreAct-20 | 64 | 0.05 | 余弦 | 200 | 8.22 | 28m |
| ResNet-PreAct-20 | 32 | 0.025 | 余弦 | 200 | 8.00 | 43m |
| ResNet-PreAct-20 | 16 | 0.0125 | 余弦 | 200 | 7.75 | 1H17M |
| ResNet-PreAct-20 | 8 | 0.006125 | 余弦 | 200 | 7.70 | 2H32M |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 3.2 | マルチステップ | 200 | 28.97 | 22m |
| ResNet-PreAct-20 | 2048 | 1.6 | マルチステップ | 200 | 9.07 | 21m |
| ResNet-PreAct-20 | 1024 | 0.8 | マルチステップ | 200 | 8.62 | 21m |
| ResNet-PreAct-20 | 512 | 0.4 | マルチステップ | 200 | 8.23 | 20m |
| ResNet-PreAct-20 | 256 | 0.2 | マルチステップ | 200 | 8.40 | 21m |
| ResNet-PreAct-20 | 128 | 0.1 | マルチステップ | 200 | 8.28 | 24m |
| ResNet-PreAct-20 | 64 | 0.05 | マルチステップ | 200 | 8.13 | 28m |
| ResNet-PreAct-20 | 32 | 0.025 | マルチステップ | 200 | 7.58 | 43m |
| ResNet-PreAct-20 | 16 | 0.0125 | マルチステップ | 200 | 7.93 | 1h18m |
| ResNet-PreAct-20 | 8 | 0.006125 | マルチステップ | 200 | 8.31 | 2H34M |
線形スケーリング +長いトレーニング
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 3.2 | 余弦 | 400 | 8.97 | 44m |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 400 | 7.85 | 43m |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 400 | 7.20 | 42m |
| ResNet-PreAct-20 | 512 | 0.4 | 余弦 | 400 | 7.83 | 40m |
| ResNet-PreAct-20 | 256 | 0.2 | 余弦 | 400 | 7.65 | 42m |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 400 | 7.09 | 47m |
| ResNet-PreAct-20 | 64 | 0.05 | 余弦 | 400 | 7.17 | 44m |
| ResNet-PreAct-20 | 32 | 0.025 | 余弦 | 400 | 7.24 | 2H11M |
| ResNet-PreAct-20 | 16 | 0.0125 | 余弦 | 400 | 7.26 | 4H10M |
| ResNet-PreAct-20 | 8 | 0.006125 | 余弦 | 400 | 7.02 | 7H53M |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 3.2 | 余弦 | 800 | 8.14 | 1H29M |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 800 | 7.74 | 1H23M |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 800 | 7.15 | 1H31M |
| ResNet-PreAct-20 | 512 | 0.4 | 余弦 | 800 | 7.27 | 1H25M |
| ResNet-PreAct-20 | 256 | 0.2 | 余弦 | 800 | 7.22 | 1H26M |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 800 | 6.68 | 1h35m |
| ResNet-PreAct-20 | 64 | 0.05 | 余弦 | 800 | 7.18 | 2H20M |
| ResNet-PreAct-20 | 32 | 0.025 | 余弦 | 800 | 7.03 | 4H16M |
| ResNet-PreAct-20 | 16 | 0.0125 | 余弦 | 800 | 6.78 | 8H37M |
| ResNet-PreAct-20 | 8 | 0.006125 | 余弦 | 800 | 6.89 | 16H47M |
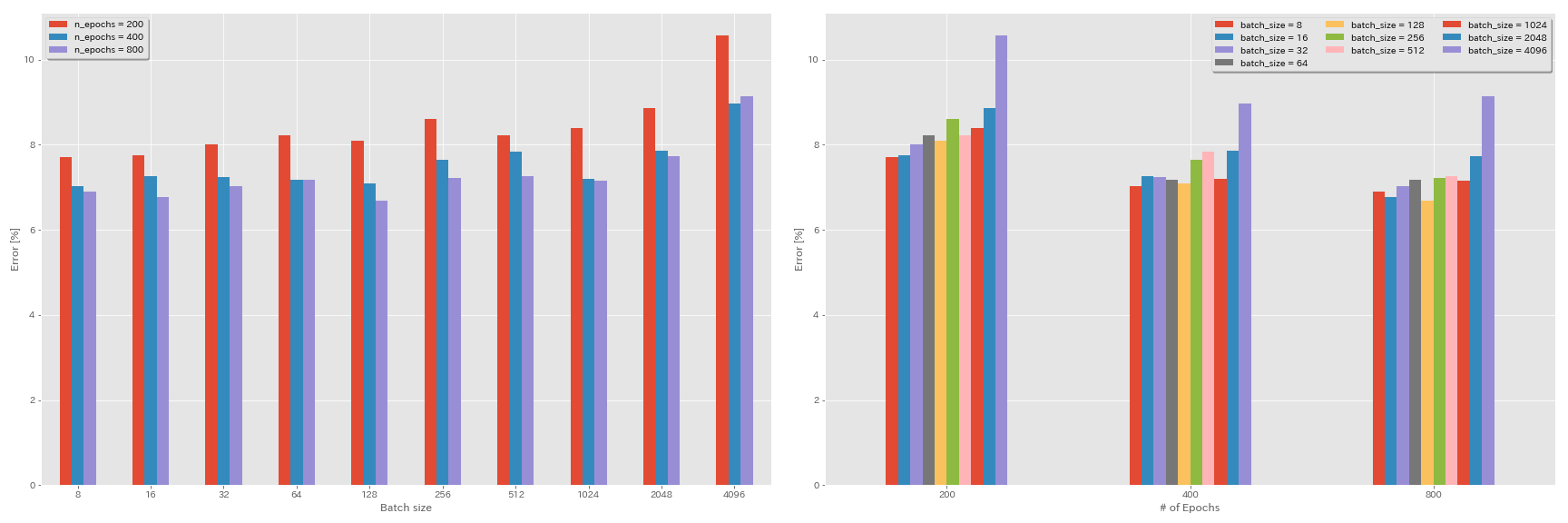
初期学習率の影響
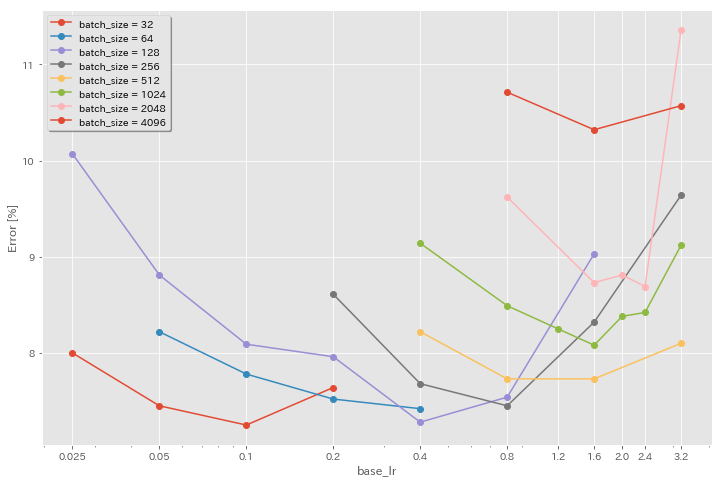
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 3.2 | 余弦 | 200 | 10.57 | 22m |
| ResNet-PreAct-20 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| ResNet-PreAct-20 | 4096 | 0.8 | 余弦 | 200 | 10.71 | 22m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 2048 | 3.2 | 余弦 | 200 | 11.34 | 21m |
| ResNet-PreAct-20 | 2048 | 2.4 | 余弦 | 200 | 8.69 | 21m |
| ResNet-PreAct-20 | 2048 | 2.0 | 余弦 | 200 | 8.81 | 21m |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| ResNet-PreAct-20 | 2048 | 0.8 | 余弦 | 200 | 9.62 | 21m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 1024 | 3.2 | 余弦 | 200 | 9.12 | 21m |
| ResNet-PreAct-20 | 1024 | 2.4 | 余弦 | 200 | 8.42 | 22m |
| ResNet-PreAct-20 | 1024 | 2.0 | 余弦 | 200 | 8.38 | 22m |
| ResNet-PreAct-20 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| ResNet-PreAct-20 | 1024 | 1.2 | 余弦 | 200 | 8.25 | 21m |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 200 | 8.08 | 22m |
| ResNet-PreAct-20 | 1024 | 0.4 | 余弦 | 200 | 8.49 | 22m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 512 | 3.2 | 余弦 | 200 | 8.51 | 21m |
| ResNet-PreAct-20 | 512 | 1.6 | 余弦 | 200 | 7.73 | 20m |
| ResNet-PreAct-20 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| ResNet-PreAct-20 | 512 | 0.4 | 余弦 | 200 | 8.22 | 20m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 256 | 3.2 | 余弦 | 200 | 9.64 | 22m |
| ResNet-PreAct-20 | 256 | 1.6 | 余弦 | 200 | 8.32 | 22m |
| ResNet-PreAct-20 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| ResNet-PreAct-20 | 256 | 0.4 | 余弦 | 200 | 7.68 | 22m |
| ResNet-PreAct-20 | 256 | 0.2 | 余弦 | 200 | 8.61 | 22m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 128 | 1.6 | 余弦 | 200 | 9.03 | 24m |
| ResNet-PreAct-20 | 128 | 0.8 | 余弦 | 200 | 7.54 | 24m |
| ResNet-PreAct-20 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| ResNet-PreAct-20 | 128 | 0.2 | 余弦 | 200 | 7.96 | 24m |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| ResNet-PreAct-20 | 128 | 0.05 | 余弦 | 200 | 8.81 | 24m |
| ResNet-PreAct-20 | 128 | 0.025 | 余弦 | 200 | 10.07 | 24m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 64 | 0.4 | 余弦 | 200 | 7.42 | 35m |
| ResNet-PreAct-20 | 64 | 0.2 | 余弦 | 200 | 7.52 | 36m |
| ResNet-PreAct-20 | 64 | 0.1 | 余弦 | 200 | 7.78 | 37m |
| ResNet-PreAct-20 | 64 | 0.05 | 余弦 | 200 | 8.22 | 28m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 32 | 0.2 | 余弦 | 200 | 7.64 | 1H05M |
| ResNet-PreAct-20 | 32 | 0.1 | 余弦 | 200 | 7.25 | 1h08m |
| ResNet-PreAct-20 | 32 | 0.05 | 余弦 | 200 | 7.45 | 1H07M |
| ResNet-PreAct-20 | 32 | 0.025 | 余弦 | 200 | 8.00 | 43m |
優れた学習率 +より長いトレーニング
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| ResNet-PreAct-20 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 200 | 8.08 | 22m |
| ResNet-PreAct-20 | 512 | 1.6 | 余弦 | 200 | 7.73 | 20m |
| ResNet-PreAct-20 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| ResNet-PreAct-20 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| ResNet-PreAct-20 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| ResNet-PreAct-20 | 128 | 0.2 | 余弦 | 200 | 7.96 | 24m |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 200 | 8.09 | 24m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 1.6 | 余弦 | 800 | 8.36 | 1H33M |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 800 | 7.53 | 1H27M |
| ResNet-PreAct-20 | 1024 | 1.6 | 余弦 | 800 | 7.30 | 1h30m |
| ResNet-PreAct-20 | 1024 | 0.8 | 余弦 | 800 | 7.42 | 1h30m |
| ResNet-PreAct-20 | 512 | 1.6 | 余弦 | 800 | 6.69 | 1H26M |
| ResNet-PreAct-20 | 512 | 0.8 | 余弦 | 800 | 6.77 | 1H26M |
| ResNet-PreAct-20 | 256 | 0.8 | 余弦 | 800 | 6.84 | 1h28m |
| ResNet-PreAct-20 | 128 | 0.4 | 余弦 | 800 | 6.86 | 1h35m |
| ResNet-PreAct-20 | 128 | 0.2 | 余弦 | 800 | 7.05 | 1h38m |
| ResNet-PreAct-20 | 128 | 0.1 | 余弦 | 800 | 6.68 | 1h35m |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 1.6 | 余弦 | 1600 | 8.25 | 3H10M |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 1600 | 7.34 | 2h50m |
| ResNet-PreAct-20 | 1024 | 1.6 | 余弦 | 1600 | 6.94 | 2H52M |
| ResNet-PreAct-20 | 512 | 1.6 | 余弦 | 1600 | 6.99 | 2H44M |
| ResNet-PreAct-20 | 256 | 0.8 | 余弦 | 1600 | 6.95 | 2h50m |
| ResNet-PreAct-20 | 128 | 0.4 | 余弦 | 1600 | 6.64 | 3H09M |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 4096 | 1.6 | 余弦 | 3200 | 9.52 | 6H15M |
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 3200 | 6.92 | 5H42M |
| ResNet-PreAct-20 | 1024 | 1.6 | 余弦 | 3200 | 6.96 | 5H43M |
| モデル | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 2048 | 1.6 | 余弦 | 6400 | 7.45 | 11h44m |
ラース
- 元の論文(1708.03888、1801.03137)では、多項式減衰学習率のスケジューリングを使用しましたが、これらの実験ではコサインアニーリングが使用されています。
- この実装では、Lars係数は使用されていないため、それに応じて学習率を調整する必要があります。
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00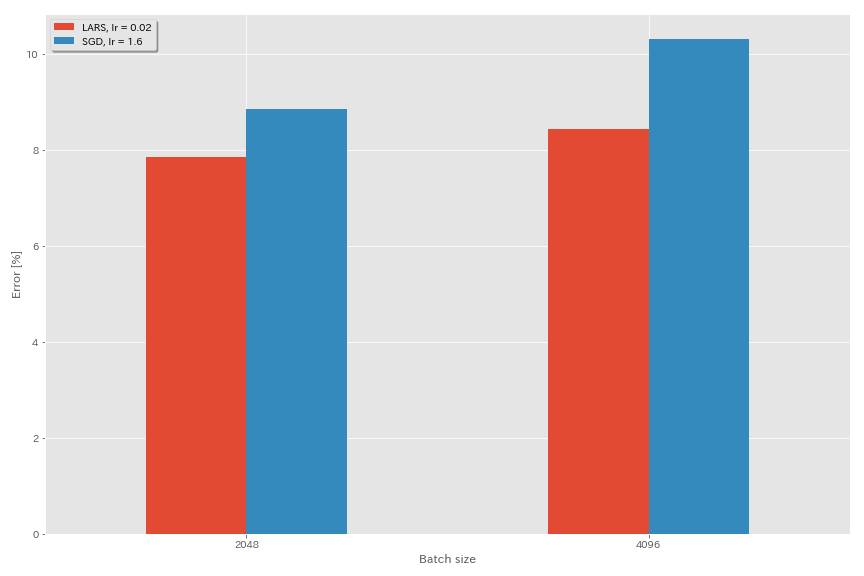
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 4096 | 3.2 | 余弦 | 200 | 10.57(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| ResNet-PreAct-20 | SGD | 4096 | 0.8 | 余弦 | 200 | 10.71(1ラン) | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.04 | 余弦 | 200 | 9.58 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.03 | 余弦 | 200 | 8.46 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.02 | 余弦 | 200 | 8.21 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.015 | 余弦 | 200 | 8.47 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.01 | 余弦 | 200 | 9.33 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.005 | 余弦 | 200 | 14.31 | 22m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 2048 | 3.2 | 余弦 | 200 | 11.34(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 2048 | 2.4 | 余弦 | 200 | 8.69(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 2048 | 2.0 | 余弦 | 200 | 8.81(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 2048 | 1.6 | 余弦 | 200 | 8.73(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 2048 | 0.8 | 余弦 | 200 | 9.62(1ラン) | 21m |
| ResNet-PreAct-20 | ラース | 2048 | 0.04 | 余弦 | 200 | 11.58 | 21m |
| ResNet-PreAct-20 | ラース | 2048 | 0.02 | 余弦 | 200 | 8.05 | 22m |
| ResNet-PreAct-20 | ラース | 2048 | 0.01 | 余弦 | 200 | 8.07 | 22m |
| ResNet-PreAct-20 | ラース | 2048 | 0.005 | 余弦 | 200 | 9.65 | 22m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 1024 | 3.2 | 余弦 | 200 | 9.12(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 1024 | 2.4 | 余弦 | 200 | 8.42(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 1024 | 2.0 | 余弦 | 200 | 8.38(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 1024 | 1.6 | 余弦 | 200 | 8.07(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 1024 | 1.2 | 余弦 | 200 | 8.25(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 1024 | 0.8 | 余弦 | 200 | 8.08(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 1024 | 0.4 | 余弦 | 200 | 8.49(1ラン) | 22m |
| ResNet-PreAct-20 | ラース | 1024 | 0.02 | 余弦 | 200 | 9.30 | 22m |
| ResNet-PreAct-20 | ラース | 1024 | 0.01 | 余弦 | 200 | 7.68 | 22m |
| ResNet-PreAct-20 | ラース | 1024 | 0.005 | 余弦 | 200 | 8.88 | 23m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 512 | 3.2 | 余弦 | 200 | 8.51(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 512 | 1.6 | 余弦 | 200 | 7.73(1ラン) | 20m |
| ResNet-PreAct-20 | SGD | 512 | 0.8 | 余弦 | 200 | 7.73(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 512 | 0.4 | 余弦 | 200 | 8.22(1ラン) | 20m |
| ResNet-PreAct-20 | ラース | 512 | 0.015 | 余弦 | 200 | 9.84 | 23m |
| ResNet-PreAct-20 | ラース | 512 | 0.01 | 余弦 | 200 | 8.05 | 23m |
| ResNet-PreAct-20 | ラース | 512 | 0.0075 | 余弦 | 200 | 7.58 | 23m |
| ResNet-PreAct-20 | ラース | 512 | 0.005 | 余弦 | 200 | 7.96 | 23m |
| ResNet-PreAct-20 | ラース | 512 | 0.0025 | 余弦 | 200 | 8.83 | 23m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 256 | 3.2 | 余弦 | 200 | 9.64(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 256 | 1.6 | 余弦 | 200 | 8.32(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 256 | 0.8 | 余弦 | 200 | 7.45(1ラン) | 21m |
| ResNet-PreAct-20 | SGD | 256 | 0.4 | 余弦 | 200 | 7.68(1ラン) | 22m |
| ResNet-PreAct-20 | SGD | 256 | 0.2 | 余弦 | 200 | 8.61(1ラン) | 22m |
| ResNet-PreAct-20 | ラース | 256 | 0.01 | 余弦 | 200 | 8.95 | 27m |
| ResNet-PreAct-20 | ラース | 256 | 0.005 | 余弦 | 200 | 7.75 | 28m |
| ResNet-PreAct-20 | ラース | 256 | 0.0025 | 余弦 | 200 | 8.21 | 28m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 128 | 1.6 | 余弦 | 200 | 9.03(1ラン) | 24m |
| ResNet-PreAct-20 | SGD | 128 | 0.8 | 余弦 | 200 | 7.54(1ラン) | 24m |
| ResNet-PreAct-20 | SGD | 128 | 0.4 | 余弦 | 200 | 7.28(1ラン) | 24m |
| ResNet-PreAct-20 | SGD | 128 | 0.2 | 余弦 | 200 | 7.96(1ラン) | 24m |
| ResNet-PreAct-20 | ラース | 128 | 0.005 | 余弦 | 200 | 7.96 | 37m |
| ResNet-PreAct-20 | ラース | 128 | 0.0025 | 余弦 | 200 | 7.98 | 37m |
| ResNet-PreAct-20 | ラース | 128 | 0.00125 | 余弦 | 200 | 9.21 | 37m |
| モデル | オプティマイザ | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | SGD | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| ResNet-PreAct-20 | SGD | 4096 | 1.6 | 余弦 | 800 | 8.36(1ラン) | 1H33M |
| ResNet-PreAct-20 | SGD | 4096 | 1.6 | 余弦 | 1600 | 8.25(1ラン) | 3H10M |
| ResNet-PreAct-20 | ラース | 4096 | 0.02 | 余弦 | 200 | 8.21 | 22m |
| ResNet-PreAct-20 | ラース | 4096 | 0.02 | 余弦 | 400 | 7.53 | 44m |
| ResNet-PreAct-20 | ラース | 4096 | 0.02 | 余弦 | 800 | 7.48 | 1H29M |
| ResNet-PreAct-20 | ラース | 4096 | 0.02 | 余弦 | 1600 | 7.37(1ラン) | 2H58M |
ゴーストBn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| モデル | バッチサイズ | ゴーストバッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 8192 | n/a | 1.6 | 余弦 | 200 | 12.35 | 25m* |
| ResNet-PreAct-20 | 4096 | n/a | 1.6 | 余弦 | 200 | 10.32 | 22m |
| ResNet-PreAct-20 | 2048 | n/a | 1.6 | 余弦 | 200 | 8.73 | 22m |
| ResNet-PreAct-20 | 1024 | n/a | 1.6 | 余弦 | 200 | 8.07 | 22m |
| ResNet-PreAct-20 | 128 | n/a | 0.4 | 余弦 | 200 | 7.28 | 24m |
| モデル | バッチサイズ | ゴーストバッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 8192 | 128 | 1.6 | 余弦 | 200 | 11.51 | 27m |
| ResNet-PreAct-20 | 4096 | 128 | 1.6 | 余弦 | 200 | 9.73 | 25m |
| ResNet-PreAct-20 | 2048 | 128 | 1.6 | 余弦 | 200 | 8.77 | 24m |
| ResNet-PreAct-20 | 1024 | 128 | 1.6 | 余弦 | 200 | 7.82 | 22m |
| モデル | バッチサイズ | ゴーストバッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 8192 | n/a | 1.6 | 余弦 | 1600 | | |
| ResNet-PreAct-20 | 4096 | n/a | 1.6 | 余弦 | 1600 | 8.25 | 3H10M |
| ResNet-PreAct-20 | 2048 | n/a | 1.6 | 余弦 | 1600 | 7.34 | 2h50m |
| ResNet-PreAct-20 | 1024 | n/a | 1.6 | 余弦 | 1600 | 6.94 | 2H52M |
| モデル | バッチサイズ | ゴーストバッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 8192 | 128 | 1.6 | 余弦 | 1600 | 11.83 | 3H37M |
| ResNet-PreAct-20 | 4096 | 128 | 1.6 | 余弦 | 1600 | 8.95 | 3H15M |
| ResNet-PreAct-20 | 2048 | 128 | 1.6 | 余弦 | 1600 | 7.23 | 3H05M |
| ResNet-PreAct-20 | 1024 | 128 | 1.6 | 余弦 | 1600 | 7.08 | 2H59M |
BNに重量減衰はありません
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00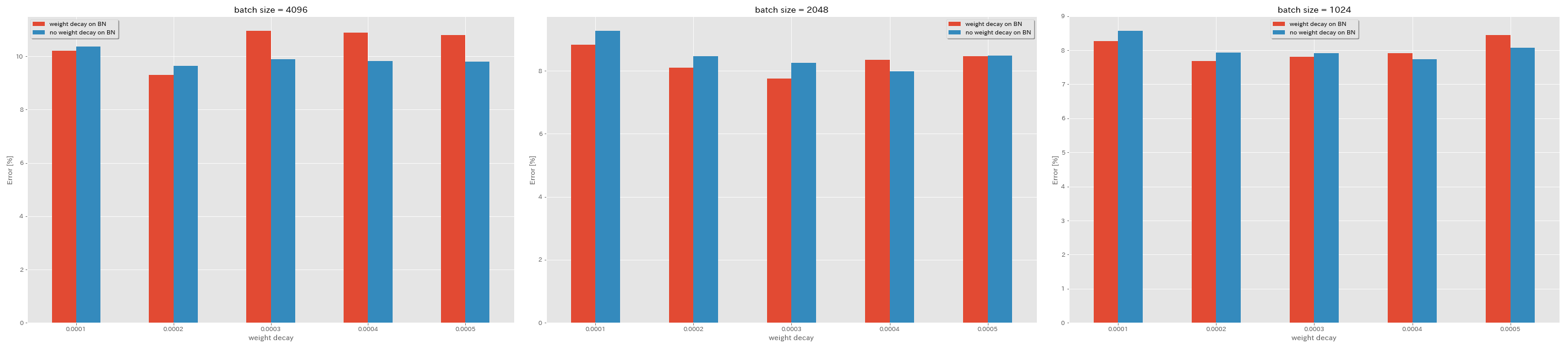
| モデル | BNの重量減衰 | 重量減衰 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | はい | 5E-4 | 4096 | 1.6 | 余弦 | 200 | 10.81 | 22m |
| ResNet-PreAct-20 | はい | 4E-4 | 4096 | 1.6 | 余弦 | 200 | 10.88 | 22m |
| ResNet-PreAct-20 | はい | 3E-4 | 4096 | 1.6 | 余弦 | 200 | 10.96 | 22m |
| ResNet-PreAct-20 | はい | 2E-4 | 4096 | 1.6 | 余弦 | 200 | 9.30 | 22m |
| ResNet-PreAct-20 | はい | 1E-4 | 4096 | 1.6 | 余弦 | 200 | 10.20 | 22m |
| ResNet-PreAct-20 | いいえ | 5E-4 | 4096 | 1.6 | 余弦 | 200 | 8.78 | 22m |
| ResNet-PreAct-20 | いいえ | 4E-4 | 4096 | 1.6 | 余弦 | 200 | 9.83 | 22m |
| ResNet-PreAct-20 | いいえ | 3E-4 | 4096 | 1.6 | 余弦 | 200 | 9.90 | 22m |
| ResNet-PreAct-20 | いいえ | 2E-4 | 4096 | 1.6 | 余弦 | 200 | 9.64 | 22m |
| ResNet-PreAct-20 | いいえ | 1E-4 | 4096 | 1.6 | 余弦 | 200 | 10.38 | 22m |
| モデル | BNの重量減衰 | 重量減衰 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | はい | 5E-4 | 2048 | 1.6 | 余弦 | 200 | 8.46 | 20m |
| ResNet-PreAct-20 | はい | 4E-4 | 2048 | 1.6 | 余弦 | 200 | 8.35 | 20m |
| ResNet-PreAct-20 | はい | 3E-4 | 2048 | 1.6 | 余弦 | 200 | 7.76 | 20m |
| ResNet-PreAct-20 | はい | 2E-4 | 2048 | 1.6 | 余弦 | 200 | 8.09 | 20m |
| ResNet-PreAct-20 | はい | 1E-4 | 2048 | 1.6 | 余弦 | 200 | 8.83 | 20m |
| ResNet-PreAct-20 | いいえ | 5E-4 | 2048 | 1.6 | 余弦 | 200 | 8.49 | 20m |
| ResNet-PreAct-20 | いいえ | 4E-4 | 2048 | 1.6 | 余弦 | 200 | 7.98 | 20m |
| ResNet-PreAct-20 | いいえ | 3E-4 | 2048 | 1.6 | 余弦 | 200 | 8.26 | 20m |
| ResNet-PreAct-20 | いいえ | 2E-4 | 2048 | 1.6 | 余弦 | 200 | 8.47 | 20m |
| ResNet-PreAct-20 | いいえ | 1E-4 | 2048 | 1.6 | 余弦 | 200 | 9.27 | 20m |
| モデル | BNの重量減衰 | 重量減衰 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(3回のランの中央値) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | はい | 5E-4 | 1024 | 1.6 | 余弦 | 200 | 8.45 | 21m |
| ResNet-PreAct-20 | はい | 4E-4 | 1024 | 1.6 | 余弦 | 200 | 7.91 | 21m |
| ResNet-PreAct-20 | はい | 3E-4 | 1024 | 1.6 | 余弦 | 200 | 7.81 | 21m |
| ResNet-PreAct-20 | はい | 2E-4 | 1024 | 1.6 | 余弦 | 200 | 7.69 | 21m |
| ResNet-PreAct-20 | はい | 1E-4 | 1024 | 1.6 | 余弦 | 200 | 8.26 | 21m |
| ResNet-PreAct-20 | いいえ | 5E-4 | 1024 | 1.6 | 余弦 | 200 | 8.08 | 21m |
| ResNet-PreAct-20 | いいえ | 4E-4 | 1024 | 1.6 | 余弦 | 200 | 7.73 | 21m |
| ResNet-PreAct-20 | いいえ | 3E-4 | 1024 | 1.6 | 余弦 | 200 | 7.92 | 21m |
| ResNet-PreAct-20 | いいえ | 2E-4 | 1024 | 1.6 | 余弦 | 200 | 7.93 | 21m |
| ResNet-PreAct-20 | いいえ | 1E-4 | 1024 | 1.6 | 余弦 | 200 | 8.53 | 21m |
ハーフメリジョンの実験、および混合精度
- 以下の実験にはnvidia apexが必要です。
- テンソルコアがないGeForce 1080 Tiを使用して、CIFAR-10データセットで以下の実験が行われます。
- 表で報告されている結果は、最後のエポックのテストエラーです。
FP16トレーニング
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00混合精液トレーニング
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00結果
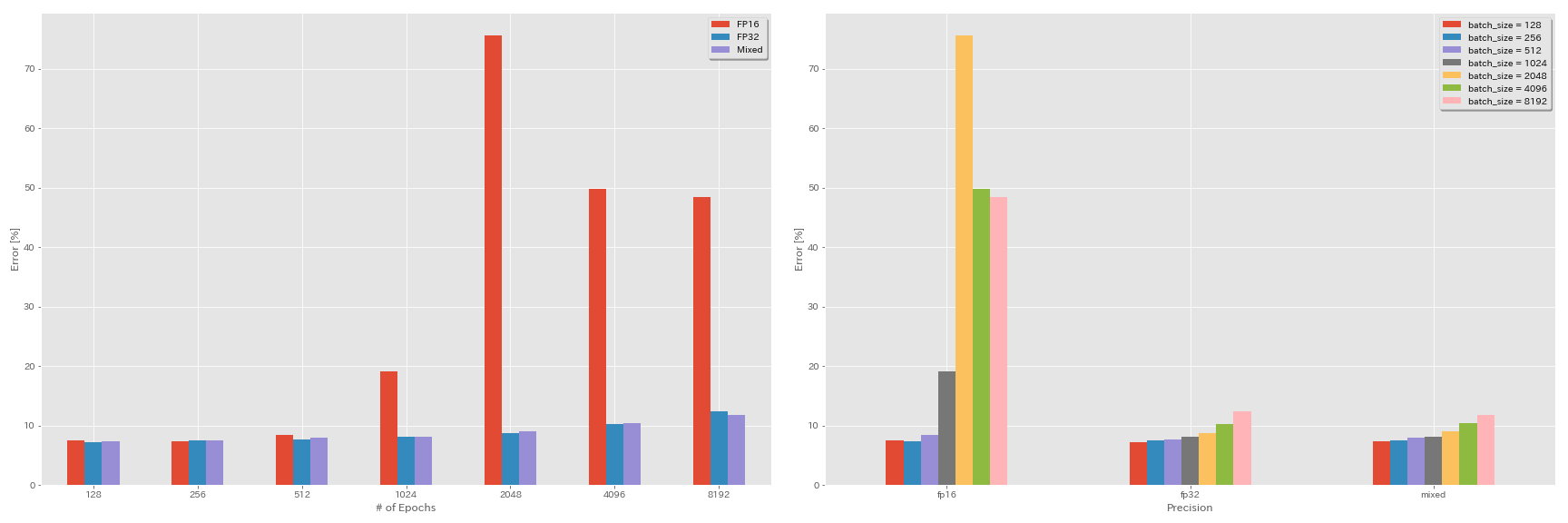
| モデル | 精度 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | FP32 | 8192 | 1.6 | 余弦 | 200 | | |
| ResNet-PreAct-20 | FP32 | 4096 | 1.6 | 余弦 | 200 | 10.32 | 22m |
| ResNet-PreAct-20 | FP32 | 2048 | 1.6 | 余弦 | 200 | 8.73 | 22m |
| ResNet-PreAct-20 | FP32 | 1024 | 1.6 | 余弦 | 200 | 8.07 | 22m |
| ResNet-PreAct-20 | FP32 | 512 | 0.8 | 余弦 | 200 | 7.73 | 21m |
| ResNet-PreAct-20 | FP32 | 256 | 0.8 | 余弦 | 200 | 7.45 | 21m |
| ResNet-PreAct-20 | FP32 | 128 | 0.4 | 余弦 | 200 | 7.28 | 24m |
| モデル | 精度 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | FP16 | 8192 | 1.6 | 余弦 | 200 | 48.52 | 33m |
| ResNet-PreAct-20 | FP16 | 4096 | 1.6 | 余弦 | 200 | 49.84 | 28m |
| ResNet-PreAct-20 | FP16 | 2048 | 1.6 | 余弦 | 200 | 75.63 | 27m |
| ResNet-PreAct-20 | FP16 | 1024 | 1.6 | 余弦 | 200 | 19.09 | 27m |
| ResNet-PreAct-20 | FP16 | 512 | 0.8 | 余弦 | 200 | 7.89 | 26m |
| ResNet-PreAct-20 | FP16 | 256 | 0.8 | 余弦 | 200 | 7.40 | 28m |
| ResNet-PreAct-20 | FP16 | 128 | 0.4 | 余弦 | 200 | 7.59 | 32m |
| モデル | 精度 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | 混合 | 8192 | 1.6 | 余弦 | 200 | 11.78 | 28m |
| ResNet-PreAct-20 | 混合 | 4096 | 1.6 | 余弦 | 200 | 10.48 | 27m |
| ResNet-PreAct-20 | 混合 | 2048 | 1.6 | 余弦 | 200 | 8.98 | 26m |
| ResNet-PreAct-20 | 混合 | 1024 | 1.6 | 余弦 | 200 | 8.05 | 26m |
| ResNet-PreAct-20 | 混合 | 512 | 0.8 | 余弦 | 200 | 7.81 | 28m |
| ResNet-PreAct-20 | 混合 | 256 | 0.8 | 余弦 | 200 | 7.58 | 32m |
| ResNet-PreAct-20 | 混合 | 128 | 0.4 | 余弦 | 200 | 7.37 | 41m |
Tesla V100を使用した結果
| モデル | 精度 | バッチサイズ | 初期LR | LRスケジュール | エポックの# | テストエラー(1回の実行) | トレーニング時間 |
|---|
| ResNet-PreAct-20 | FP32 | 8192 | 1.6 | 余弦 | 200 | 12.35 | 25m |
| ResNet-PreAct-20 | FP32 | 4096 | 1.6 | 余弦 | 200 | 9.88 | 19m |
| ResNet-PreAct-20 | FP32 | 2048 | 1.6 | 余弦 | 200 | 8.87 | 17m |
| ResNet-PreAct-20 | FP32 | 1024 | 1.6 | 余弦 | 200 | 8.45 | 18m |
| ResNet-PreAct-20 | 混合 | 8192 | 1.6 | 余弦 | 200 | 11.92 | 25m |
| ResNet-PreAct-20 | 混合 | 4096 | 1.6 | 余弦 | 200 | 10.16 | 19m |
| ResNet-PreAct-20 | 混合 | 2048 | 1.6 | 余弦 | 200 | 9.10 | 17m |
| ResNet-PreAct-20 | 混合 | 1024 | 1.6 | 余弦 | 200 | 7.84 | 16m |
参照
モデルアーキテクチャ
- 彼、Kaiming、Xiangyu Zhang、Shaoqing Ren、Jian Sun。 「画像認識のための深い残留学習。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2016年リンク、ARXIV:1512.03385
- 彼、Kaiming、Xiangyu Zhang、Shaoqing Ren、Jian Sun。 「深い残留ネットワークのIDマッピング。」コンピュータービジョンに関する欧州会議(ECCV)。 2016。Arxiv:1603.05027、Torchの実装
- Zagoruyko、Sergey、Nikos Komodakis。 「広い残留ネットワーク。」 British Machine Vision Conference(BMVC)の議事録、2016年。Arxiv:1605.07146、Torch実装
- Huang、Gao、Zhuang Liu、Kilian Q Weinberger、Laurens van der Maaten。 「密に接続された畳み込みネットワーク。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2017。Link、ARXIV:1608.06993、Torchの実装
- ハン、ドンヨーン、jiwhanキム、およびジュンモ・キム。 「深いピラミッド型残留ネットワーク。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2017年リンク、Arxiv:1610.02915、トーチの実装、カフェ実装、Pytorch実装
- Xie、Saings、Ross Girshick、Piotr Dollar、Zhuowen Tu、Kaiming He。 「深いニューラルネットワークの集約された残留変換。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2017年。リンク、ARXIV:1611.05431、Torchの実装
- ガスタルディ、ザビエル。 「3ブランチの残差ネットワークのシェイクシェイク正規化。」学習表現に関する国際会議(ICLR)ワークショップ、2017年。リンク、ARXIV:1705.07485、Torchの実装
- Hu、Jie、Li Shen、Gang Sun。 「スクイーズアンドエクスケートネットワーク。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2018、pp。7132-7141。 Link、Arxiv:1709.01507、Caffe実装
- Huang、Gao、Zhuang Liu、Geoff Pleiss、Laurens van der Maaten、Kilian Q. Weinberger。 「密な接続を備えた畳み込みネットワーク。」パターン分析とマシンインテリジェンスに関するIEEEトランザクション(2019)。 Arxiv:2001.02394
正則化、データ増強
- Szegedy、Christian、Vincent Vanhoucke、Sergey Ioffe、Jon Shlens、Zbigniew Wojna。 「コンピュータービジョンの開始アーキテクチャを再考します。」コンピュータービジョンとパターン認識に関するIEEE会議(CVPR)、2016年リンク、ARXIV:1512.00567
- Devries、Terrance、Graham W. Taylor。 「切り抜きによる畳み込みニューラルネットワークの正則化の改善。」 Arxiv Preprint Arxiv:1708.04552(2017)。 Arxiv:1708.04552、Pytorchの実装
- アブ・エル・ハイジャ、サミ。 「パーセントデルタを使用した比例勾配の更新。」 Arxiv Preprint arxiv:1708.07227(2017)。 Arxiv:1708.07227
- Zhong、Zhun、Liang Zheng、Guoliang Kang、Shaozi Li、Yi Yang。 「データ増強をランダムに消去します。」 Arxiv Preprint arxiv:1708.04896(2017)。 ARXIV:1708.04896、Pytorchの実装
- Zhang、Hongyi、Moustapha Cisse、Yann N. Dauphin、David Lopez-Paz。 「混合:経験的リスクの最小化を超えて。」学習表現に関する国際会議(ICLR)、2017年。リンク、ARXIV:1710.09412
- 川口、ケンジ、ヨシュア・ベンギオ、ヴィカス・ヴァーマ、レスリー・パック・ケールブリング。 「分析学習理論を介した一般化の理解に向けて」 Arxiv Preprint Arxiv:1802.07426(2018)。 Arxiv:1802.07426、Pytorchの実装
- 高橋、リョー、松本高橋、ueharaki。 「深いCNNのためのランダムな画像のトリミングとパッチングを使用したデータ増強。」第10回アジアの機械学習会議(ACML)、2018年の議事録。リンク、Arxiv:1811.09030
- ユン、サングドゥー、ドンヨーン・ハン、ソング・ジュン・オー、サンギョク・チュン、ジュンスク・チョー、ヤングジョン・ユ。 「CutMix:ローカライズ可能な機能を備えた強力な分類器をトレーニングするための正規化戦略。」 Arxiv Preprint Arxiv:1905.04899(2019)。 Arxiv:1905.04899
大きなバッチ
- ケスカル、ニティッシュ・シリッシュ、ディーヴァッサ・ムディゲール、ホルヘ・ノセダル、ミハイル・スマリアンスキー、ピン・タク・ピーター・タン。 「深い学習のための大打撃トレーニングについて:一般化ギャップとシャープミニマ。」学習表現に関する国際会議(ICLR)、2017年。リンク、ARXIV:1609.04836
- Hoffer、Elad、Itay Hubara、Daniel Soudry。 「より長く訓練し、より良く一般化:ニューラルネットワークの大規模なバッチトレーニングの一般化ギャップを埋めます。」神経情報処理システム(NIP)の進歩、2017年リンク、ARXIV:1705.08741、Pytorch実装
- Goyal、Priya、Piotr Dollar、Ross Girshick、Pieter Noordhuis、Lukasz Wesolowski、Aapo Kyrola、Andrew Tulloch、Yangqing Jia、Kaiming He。 「正確で大きなミニバッチSGD:1時間でイメージネットをトレーニングします。」 Arxiv Preprint arxiv:1706.02677(2017)。 Arxiv:1706.02677
- あなた、ヤン、イゴール・ギットマン、ボリス・ギンズバーグ。 「畳み込みネットワークの大規模なバッチトレーニング。」 Arxiv Preprint arxiv:1708.03888(2017)。 Arxiv:1708.03888
- あなた、ヤン、Zhao Zhang、Cho-Jui Hsieh、James Demmel、Kurt Keutzer。 「数分でのイメージネットトレーニング。」 Arxiv Preprint arxiv:1709.05011(2017)。 Arxiv:1709.05011
- スミス、サミュエル・L・、ピーター・ジャン・キンダーマンズ、クリス・イン、Quoc V. Le。 「学習率を減少させないでください。バッチサイズを増やします。」学習表現に関する国際会議(ICLR)、2018年。リンク、ARXIV:1711.00489
- Gitman、Igor、Deepak Dilipkumar、およびBen Parr。 「比例更新を伴う勾配降下アルゴリズムの収束分析。」 Arxiv Preprint arxiv:1801.03137(2018)。 Arxiv:1801.03137 Tensorflowの実装
- Jia、Xianyan、Shutao Song、Wei He、Yangzihao Wang、Haidong Rong、Feihu Zhou、Liqiang Xie、Zhenyu Guo、Yuanzhou Yang、Liwei Yu、Tiegang Chen、Guangxiao Hu、Shaohuai shi、Xiaowen Chu。 「混合精通による高度にスケーラブルなディープラーニングトレーニングシステム:4分でイメージネットをトレーニングします。」 Arxiv Preprint Arxiv:1807.11205(2018)。 Arxiv:1807.11205
- 子、クリストファーJ.、ジェフーンリー、ジョセフアントニーニ、ジャスカソールディックスタイン、ロイフロスティグ、ジョージE.ダール。 「ニューラルネットワークトレーニングに対するデータ並列性の影響の測定。」 Arxiv Preprint arxiv:1811.03600(2018)。 Arxiv:1811.03600
- Ying、Chris、Sameer Kumar、Dehao Chen、Tao Wang、およびYoulong Cheng。 「スーパーコンピュータースケールでの画像分類。」神経情報処理システム(ニューリップ)ワークショップの進歩、2018年リンク、arxiv:1811.06992
その他
- ロシュチロフ、イリヤ、フランク・ハター。 「SGDR:温かい再起動を伴う確率的勾配降下」学習表現に関する国際会議(ICLR)、2017年リンク、ARXIV:1608.03983、Lasagne実装
- Micikevicius、Paulius、Sharan Narang、Jonah Alben、Gregory Diamos、Erich Elsen、David Garcia、Boris Ginsburg、Michael Houston、Oleksii Kuchaiev、Ganesh Venkatesh、Hao Wu。 「混合精密トレーニング。」学習表現に関する国際会議(ICLR)、2018年リンク、ARXIV:1710.03740
- Recht、Benjamin、Rebecca Roelofs、Ludwig Schmidt、およびVaishaal Shankar。 「CIFAR-10分類器はCIFAR-10に一般化しますか?」 arxiv preprint arxiv:1806.00451(2018)。 Arxiv:1806.00451
- 彼、トン、Zhi Zhang、Hang Zhang、Zhongyue Zhang、Junyuan Xie、およびMu Li。 「畳み込みニューラルネットワークを備えた画像分類のためのトリックのバッグ。」 Arxiv Preprint arxiv:1812.01187(2018)。 Arxiv:1812.01187


