Классификация изображений Pytorch
Следующие документы реализованы с использованием Pytorch.
- Resnet (1512.03385)
- Resnet-Preact (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- встряхнуть (1705.07485)
- Ларс (1708.03888, 1801.03137)
- Вырез (1708.04552)
- Случайное стирание (1708.04896)
- Senet (1709.01507)
- Миксуп (1710.09412)
- Двойной нарезка (1802,07426)
- RICAP (1811.09030)
- Cutmix (1905.04899)
Требования
- Ubuntu (он тестируется только на Ubuntu, поэтому он может не работать на Windows.)
- Python> = 3,7
- Pytorch> = 1.4.0
- TOCHVISION
- Nvidia Apex
pip install -r requirements.txt
Использование
python train.py --config configs/cifar/resnet_preact.yaml
Результаты на CIFAR-10
Результаты с использованием почти тех же настроек, что и бумаги
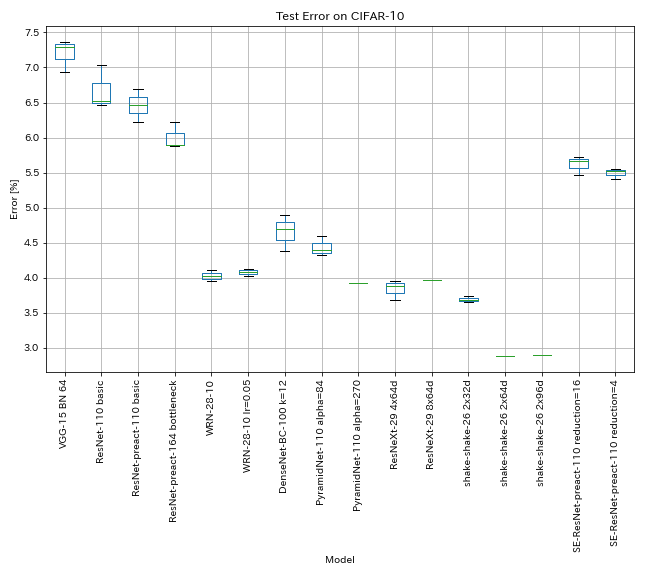
| Модель | Ошибка теста (медиана 3 прогона) | Ошибка теста (в бумаге) | Время обучения |
|---|
| Vgg-like (глубина 15, w/ bn, канал 64) | 7.29 | N/a | 1h20M |
| Resnet-110 | 6.52 | 6,43 (лучшее), 6,61 +/- 0,16 | 3H06M |
| RESNET-PREACT-110 | 6.47 | 6.37 (медиана 5 пробежек) | 3H05M |
| RESNET-PREACT-164 Узкое место | 5.90 | 5,46 (медиана 5 пробежек) | 4H01M |
| RESNET-PREACT-1001 Узкое место | | 4,62 (медиана 5 пробежек), 4,69 +/- 0,20 | |
| WRN-28-10 | 4.03 | 4.00 (медиана 5 пробежек) | 16h10m |
| WRN-28-10 с отсеванием | | 3.89 (медиана из 5 пробежек) | |
| Densenet-100 (k = 12) | 3.87 (1 пробег) | 4.10 (1 пробег) | 24h28m* |
| Densenet-100 (k = 24) | | 3.74 (1 пробег) | |
| Densenet-BC-100 (K = 12) | 4.69 | 4.51 (1 пробег) | 15h20M |
| Densenet-BC-250 (k = 24) | | 3.62 (1 пробег) | |
| Densenet-BC-190 (K = 40) | | 3.46 (1 пробег) | |
| Pyramidnet-110 (альфа = 84) | 4.40 | 4,26 +/- 0,23 | 11h40m |
| Pyramidnet-110 (альфа = 270) | 3.92 (1 пробег) | 3,73 +/- 0,04 | 24h12m* |
| Pyramidnet-164 узкое место (альфа = 270) | 3.44 (1 пробег) | 3,48 +/- 0,20 | 32H37M* |
| Pyramidnet-272 узкое место (альфа = 200) | | 3.31 +/- 0,08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (из рисунка 7) | 31h17m |
| Resnext-29 8x64d | 3.97 (1 пробег) | 3,65 (в среднем 10 пробежек) | 42H50M* |
| Resnext-29 16x64d | | 3,58 (в среднем 10 пробежек) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3,55 (в среднем 3 пробега) | 33H49M |
| Shake-Shake-26 2x64d (SSI) | 2.88 (1 пробег) | 2,98 (в среднем 3 пробега) | 78h48m |
| Shake-Shake-26 2x96d (SSI) | 2.90 (1 пробег) | 2,86 (в среднем 5 пробежек) | 101h32m* |
Примечания
- Различия с документами в условиях обучения:
- Обучен WRN-28-10 с размером партии 64 (128 в бумаге).
- Обученные Densenet-BC-100 (K = 12) с размером пакета 32 и начальной скоростью обучения 0,05 (размер партии 64 и начальная скорость обучения 0,1 в бумаге).
- Обученные resnext-29 4x64d с одним графическим процессором, размером партии 32 и начальной скоростью обучения 0,025 (8 графических процессоров, размер партии 128 и начальная скорость обучения 0,1 в бумаге).
- Обученные модели встряхивания с одним графическим процессором (2 графические процессоры в бумаге).
- Обученные встряхивающие встряхивание 26 2x64D (SSI) с размером партии 64 и начальной скоростью обучения 0,1.
- Тестовые ошибки, о которых сообщалось выше, являются последними эпохи.
- Эксперименты с 1 пробежкой проводятся на разных компьютерах, а не к экспериментам с 3 прогонами.
- GeForce GTX 980 использовался в этих экспериментах.
VGG-подобный
python train.py --config configs/cifar/vgg.yaml
Resnet
python train.py --config configs/cifar/resnet.yaml
Resnet-Preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00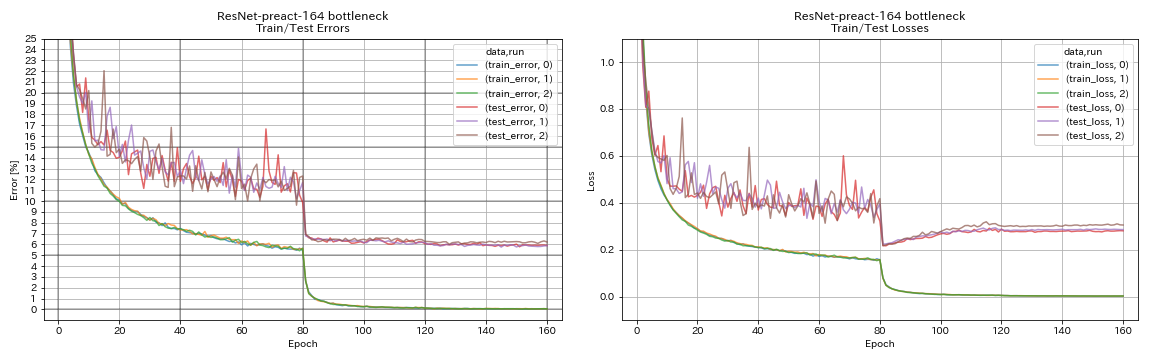
WRN
python train.py --config configs/cifar/wrn.yaml
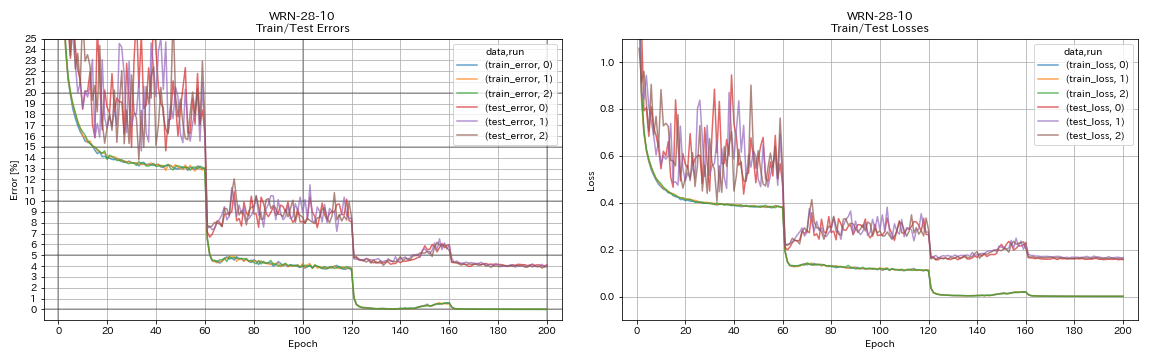
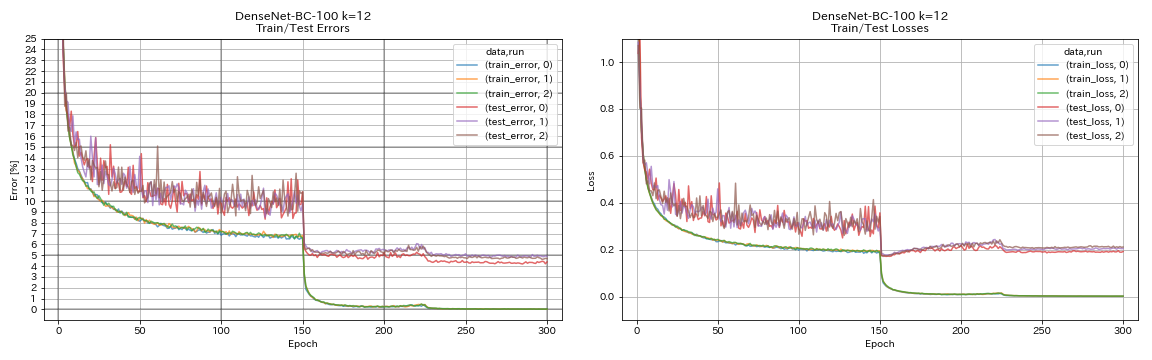
Денсенет
python train.py --config configs/cifar/densenet.yaml
Pyramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00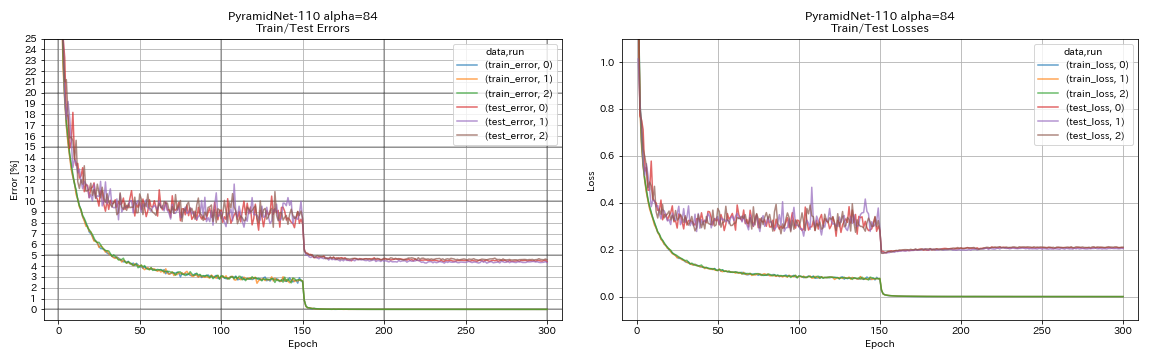
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00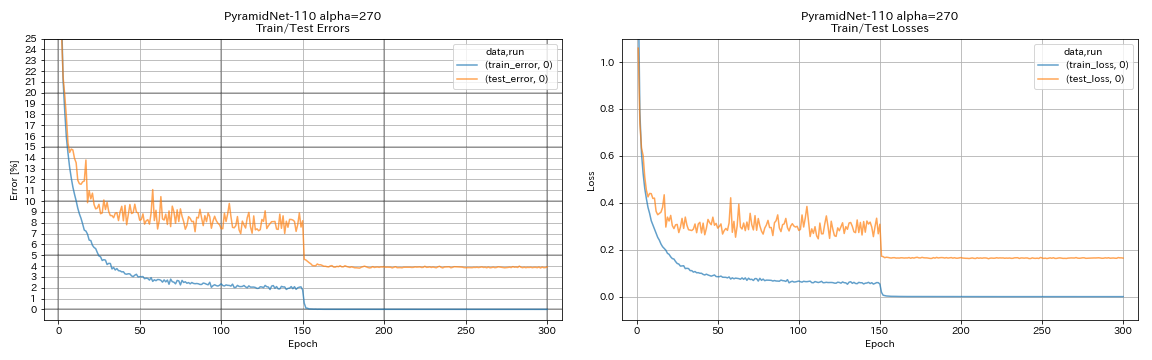
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00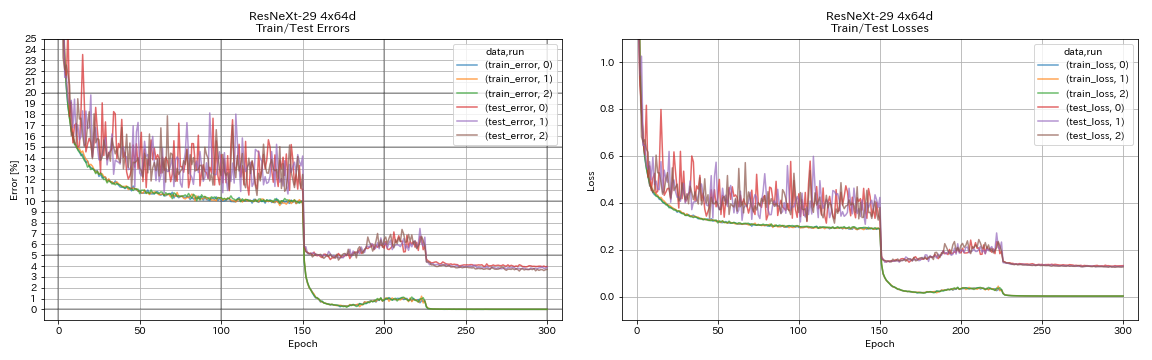
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00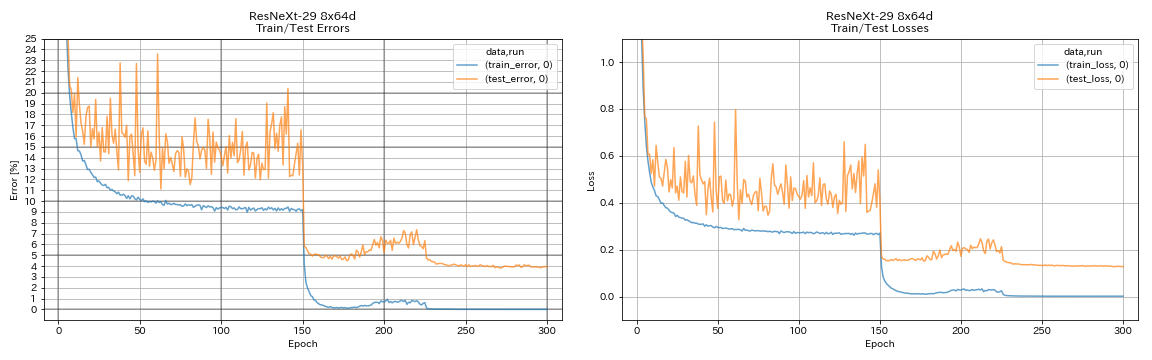
встряхнуть
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00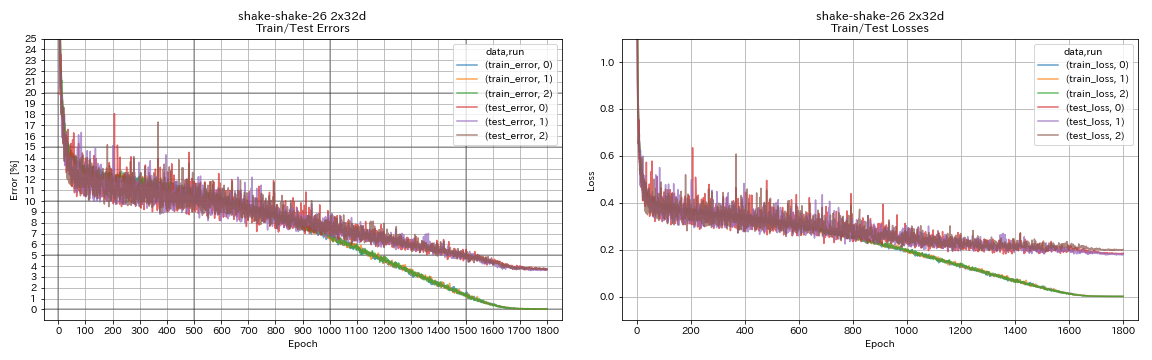
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00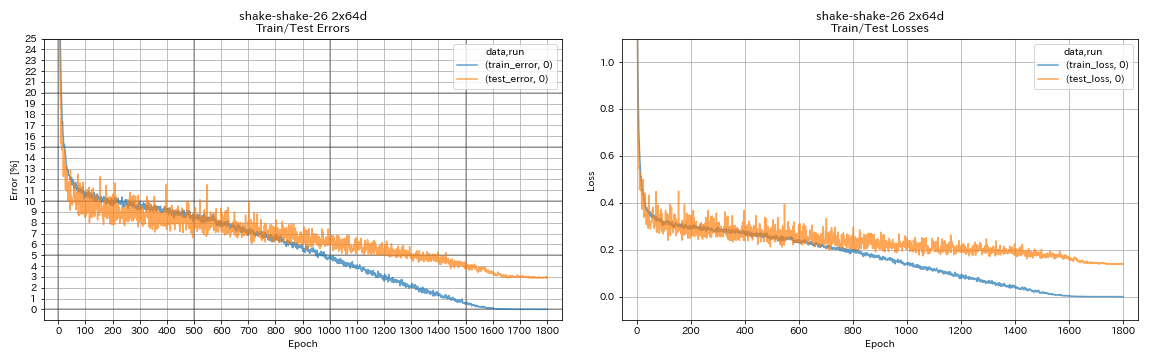
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00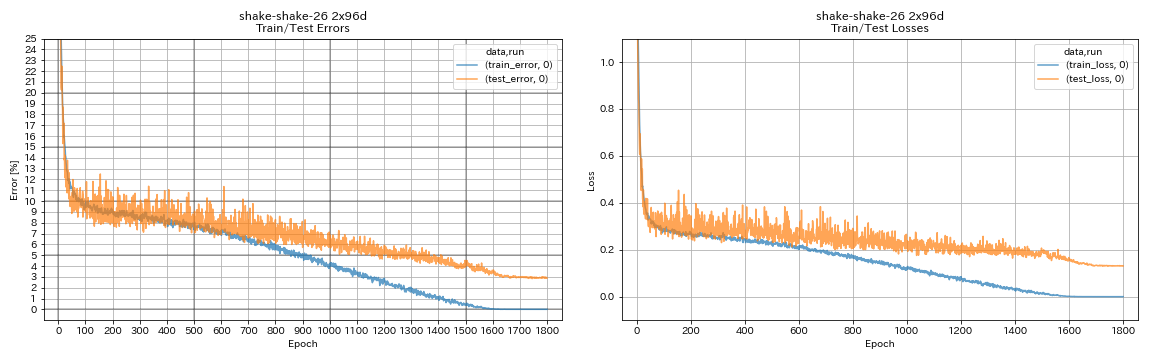
Результаты
| Модель | Ошибка теста (1 запуск) | # эпох | Время обучения |
|---|
| Resnet-Preact-20, Factor 4 расширяющегося фактора 4 | 4.91 | 200 | 1H26M |
| Resnet-Preact-20, Factor 4 расширяющегося фактора 4 | 4.01 | 400 | 2H53M |
| Resnet-Preact-20, Factor 4 расширяющегося фактора 4 | 3.99 | 1800 | 12H53M |
| Resnet-Preact-20, Factor 4, вырез 16, вырез 16 | 3.71 | 200 | 1H26M |
| Resnet-Preact-20, Factor 4, вырез 16, вырез 16 | 3.46 | 400 | 2H53M |
| Resnet-Preact-20, Factor 4, вырез 16, вырез 16 | 3.76 | 1800 | 12H53M |
| Resnet-Preact-20, Factor 4, RICAP (бета = 0,3) | 3.45 | 200 | 1H26M |
| Resnet-Preact-20, Factor 4, RICAP (бета = 0,3) | 3.11 | 400 | 2H53M |
| Resnet-Preact-20, Factor 4, RICAP (бета = 0,3) | 3.15 | 1800 | 12H53M |
| Модель | Ошибка теста (1 запуск) | # эпох | Время обучения |
|---|
| WRN-28-10, вырез 16 | 3.19 | 200 | 6H35M |
| WRN-28-10, Mixup (альфа = 1) | 3.32 | 200 | 6H35M |
| WRN-28-10, RICAP (бета = 0,3) | 2.83 | 200 | 6H35M |
| WRN-28-10, двойная вырезанная (альфа = 0,1) | 2.87 | 200 | 12H42M |
| WRN-28-10, вырез 16 | 3.07 | 400 | 13h10m |
| WRN-28-10, Mixup (альфа = 1) | 3.04 | 400 | 13h08m |
| WRN-28-10, RICAP (бета = 0,3) | 2.71 | 400 | 13h08m |
| WRN-28-10, двойная вырезанная (альфа = 0,1) | 2.76 | 400 | 25h20M |
| Shake-Shake-26 2x64d, вырез 16 | 2.64 | 1800 | 78h55m* |
| Shake-Shake-26 2x64d, Mixup (альфа = 1) | 2.63 | 1800 | 35H56M |
| Shake-Shake-26 2x64d, RICAP (бета = 0,3) | 2.29 | 1800 | 35H10M |
| Shake-Shake-26 2x64d, двойная вырезанная (альфа = 0,1) | 2.64 | 1800 | 68H34M |
| Shake-Shake-26 2x96d, вырез 16 | 2.50 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Mixup (альфа = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, RICAP (бета = 0,3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, двойная вырезанная (альфа = 0,1) | 2.41 | 1800 | 113H09M |
| Shake-Shake-26 2x128d, вырез 16 | 2.58 | 1800 | 85H04M |
| Shake-Shake-26 2x128d, RICAP (бета = 0,3) | 1.97 | 1800 | 85H06M |
Примечание
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
- Все модели обучаются с использованием косинусного отжига с начальной скоростью обучения 0,2.
- GEFORCE GTX 1080 TI использовали в этих экспериментах, за исключением тех, которые с *, которые выполняются с использованием GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True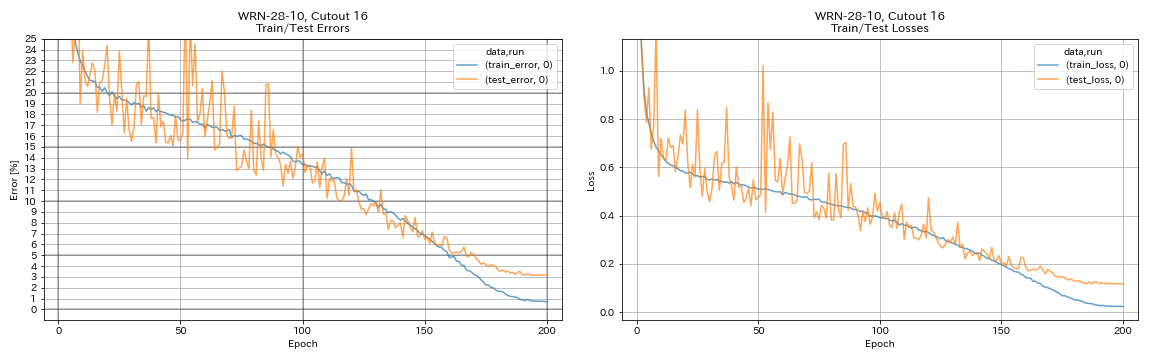
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True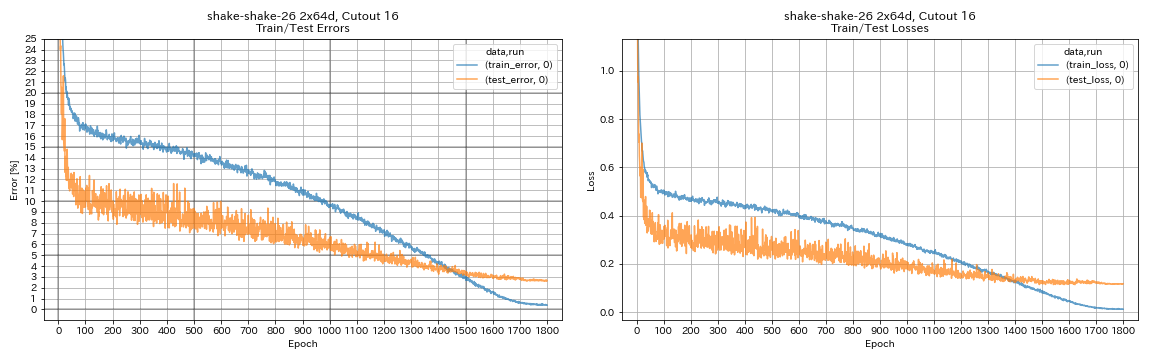
Результаты с использованием мульти-GPU
| Модель | Размер партии | #Gpus | Ошибка теста (1 запуск) | # эпох | Время обучения* |
|---|
| WRN-28-10, RICAP (бета = 0,3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10, RICAP (бета = 0,3) | 256 | 2 | 2.71 | 200 | 2H14M |
| WRN-28-10, RICAP (бета = 0,3) | 128 | 4 | 2.89 | 200 | 1h01m |
| WRN-28-10, RICAP (бета = 0,3) | 64 | 8 | 2.75 | 200 | 34 м |
Примечание
- Tesla V100 использовалась в этих экспериментах.
Используя 1 графин
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseИспользуя 2 графические процессоры
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseИспользуя 4 графические процессоры
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseИспользуя 8 графических процессоров
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseРезультаты по модекнистам
| Модель | Ошибка теста (1 запуск) | # эпох | Время обучения |
|---|
| Resnet-Preact-20, Factor 4, Cutout 12 | 4.17 | 200 | 1h32m |
| Resnet-Preact-20, Factor 4, вырез 14, вырез 14 | 4.11 | 200 | 1h32m |
| Resnet-Preact-50, вырез 12 | 4.45 | 200 | 57м |
| Resnet-Preact-50, вырез 14 | 4.38 | 200 | 57м |
| Resnet-Preact-50, Factor 4, вырез 12, вырез 12 | 4.07 | 200 | 3H37M |
| Resnet-Preact-50, Factor 4, вырез 14, вырез 14 | 4.13 | 200 | 3H39M |
| Shake-Shake-26 2x32d (SSI), вырез 12 | 4.08 | 400 | 3H41M |
| Shake-Shake-26 2x32d (SSI), вырез 14 | 4.05 | 400 | 3H39M |
| Shake-Shake-26 2x96d (SSI), вырез 12 | 3.72 | 400 | 13h46m |
| Shake-Shake-26 2x96d (SSI), вырез 14 | 3.85 | 400 | 13h39m |
| Shake-Shake-26 2x96d (SSI), вырез 12 | 3.65 | 800 | 26H42M |
| Shake-Shake-26 2x96d (SSI), вырез 14 | 3.60 | 800 | 26H42M |
| Модель | Ошибка теста (медиана 3 прогона) | # эпох | Время обучения |
|---|
| RESNET-PREACT-20 | 5.04 | 200 | 26 м |
| Resnet-Preact-20, вырез 6 | 4.84 | 200 | 26 м |
| Resnet-Preact-20, вырез 8 | 4.64 | 200 | 26 м |
| RESNET-PREACT-20, CUPTOUT 10 | 4.74 | 200 | 26 м |
| Resnet-Preact-20, вырез 12 | 4.68 | 200 | 26 м |
| Resnet-Preact-20, вырез 14 | 4.64 | 200 | 26 м |
| Resnet-Preact-20, вырез 16 | 4.49 | 200 | 26 м |
| RESNET-PREACT-20, Рэндерозирование | 4.61 | 200 | 26 м |
| Resnet-Preact-20, Mixup | 4.92 | 200 | 26 м |
| Resnet-Preact-20, Mixup | 4.64 | 400 | 52 м |
Примечание
- Результаты, представленные в таблицах, являются тестовыми ошибками в последние эпохи.
- Все модели обучаются с использованием косинусного отжига с начальной скоростью обучения 0,2.
- Следующие дополнения данных применяются к данным обучения:
- Изображения наполнены 4 пикселями с каждой стороны, а пятна 28x28 случайно обрезаны из мягких изображений.
- Изображения случайно перевернуты горизонтально.
- GeForce GTX 1080 Ti использовался в этих экспериментах.
Результаты на MNIST
| Модель | Ошибка теста (медиана 3 прогона) | # эпох | Время обучения |
|---|
| RESNET-PREACT-20 | 0,40 | 100 | 12 м |
| Resnet-Preact-20, вырез 6 | 0,32 | 100 | 12 м |
| Resnet-Preact-20, вырез 8 | 0,25 | 100 | 12 м |
| RESNET-PREACT-20, CUPTOUT 10 | 0,27 | 100 | 12 м |
| Resnet-Preact-20, вырез 12 | 0,26 | 100 | 12 м |
| Resnet-Preact-20, вырез 14 | 0,26 | 100 | 12 м |
| Resnet-Preact-20, вырез 16 | 0,25 | 100 | 12 м |
| Resnet-praact-20, mixup (alpha = 1) | 0,40 | 100 | 12 м |
| Resnet-Praact-20, Mixup (альфа = 0,5) | 0,38 | 100 | 12 м |
| Resnet-Preact-20, Factor 4, вырез 14, вырез 14 | 0,26 | 100 | 45м |
| Resnet-Preact-50, вырез 14 | 0,29 | 100 | 28 м |
| Resnet-Preact-50, Factor 4, вырез 14, вырез 14 | 0,25 | 100 | 1h50M |
| Shake-Shake-26 2x96d (SSI), вырез 14 | 0,24 | 100 | 3H22M |
Примечание
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
- Все модели обучаются с использованием косинусного отжига с начальной скоростью обучения 0,2.
- GeForce GTX 1080 Ti использовался в этих экспериментах.
Результаты на Кузушиджи-Мнист
| Модель | Ошибка теста (медиана 3 прогона) | # эпох | Время обучения |
|---|
| Resnet-Preact-20, вырез 14 | 0,82 (лучшее 0,67) | 200 | 24 м |
| Resnet-Preact-20, Factor 4, вырез 14, вырез 14 | 0,72 (лучшее 0,67) | 200 | 1H30м |
| Pyramidnet-110-270, вырез 14 | 0,72 (лучшее 0,70) | 200 | 10h05m |
| Shake-Shake-26 2x96d (SSI), вырез 14 | 0,66 (лучший 0,63) | 200 | 6H46M |
Примечание
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
- Все модели обучаются с использованием косинусного отжига с начальной скоростью обучения 0,2.
- GeForce GTX 1080 Ti использовался в этих экспериментах.
Эксперименты
Экспериментируйте на остаточных единицах, планировании скорости обучения и увеличении данных
В этом эксперименте исследуются влияние следующего на точность классификации:
- Пирамидневые остаточные единицы
- Косинус отжиг уровня обучения
- Вырезать
- Случайное стирание
- Смешивание
- Предварительная активация ярлыков после снижения дискретиза
Resnet-Preact-56 обучается на CIFAR-10 с начальной скоростью обучения 0,2 в этом эксперименте.
Примечание
- Pyramidnet Paper (1610.02915) показала, что удаление первого RELU в остаточных единицах и добавление BN после последних свертков в остаточных единицах оба улучшают точность классификации.
- Paper SGDR (1608.03983) показал, что отжиг косинуса повышает точность классификации даже без перезапуска.
Результаты
- Пиропиоподобные подразделения работают.
- Возможно, лучше не предварительно преодолевать ярлыки после снижения при использовании пирамидневых единиц.
- Косинутный отжиг слегка повышает точность.
- Вырез, случайная сеть и смешивание все работают отлично.
- Миксуп нуждается в более длительной тренировке.
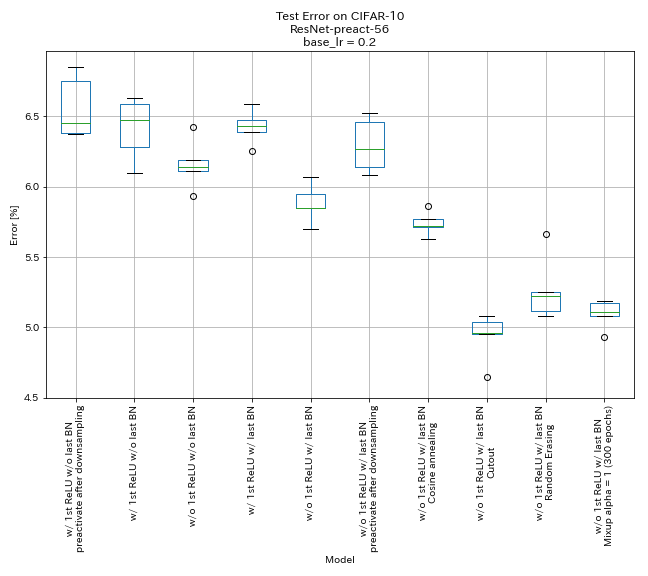
| Модель | Ошибка теста (медиана 5 прогонов) | Время обучения |
|---|
| w/ 1 -й Relu, без последнего bn, предварительный ярлык после снижения дискретизации | 6.45 | 95 мин |
| w/ 1 -й Relu, без последнего bn | 6.47 | 95 мин |
| без 1 -й Relu, без последнего bn | 6.14 | 89 мин |
| w/ 1 -й Relu, w/ последний bn | 6.43 | 104 мин |
| без 1 -й Relu, w/ последний bn | 5.85 | 98 мин |
| без 1 -й Relu, с последним BN, предварительно протекает ярлык после снижения дискретизации | 6.27 | 98 мин |
| без 1 -й Relu, с последним Bn, косинусным отжигом | 5.72 | 98 мин |
| без 1 -й Relu, с последним bn, вырез | 4.96 | 98 мин |
| без 1 -й Relu, w/ last bn, случайное | 5.22 | 98 мин |
| без 1 -й Relu, с последним Bn, Mixup (300 эпох) | 5.11 | 191 мин |
предварительно протекает ярлык после снижения
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ 1 -й Relu, без последнего bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
без 1 -й Relu, без последнего bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ 1 -й Relu, w/ последний bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00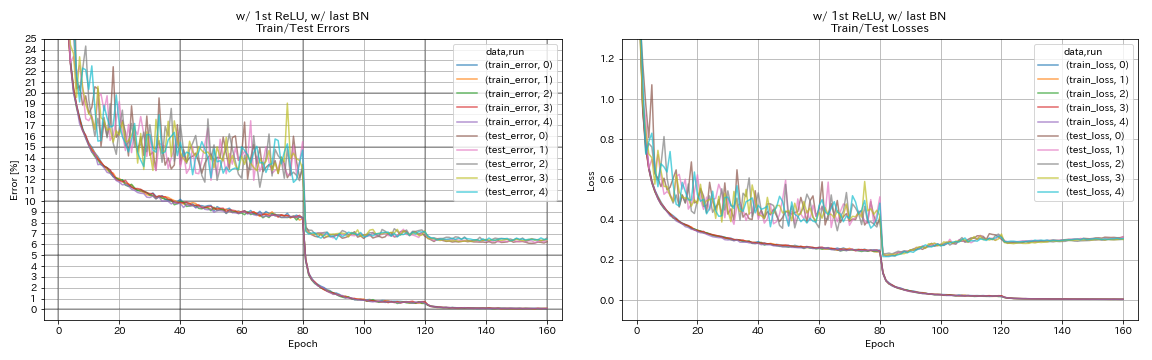
без 1 -й Relu, w/ последний bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00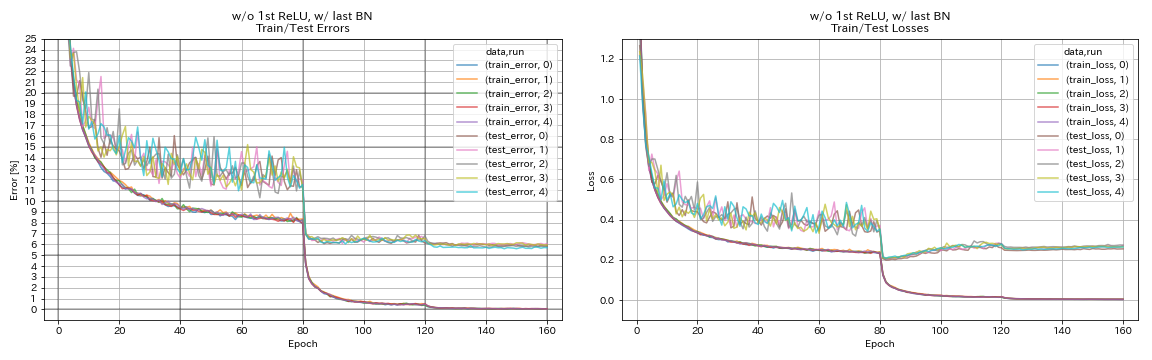
без 1 -й Relu, с последним BN, предварительно протекает ярлык после снижения дискретизации
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00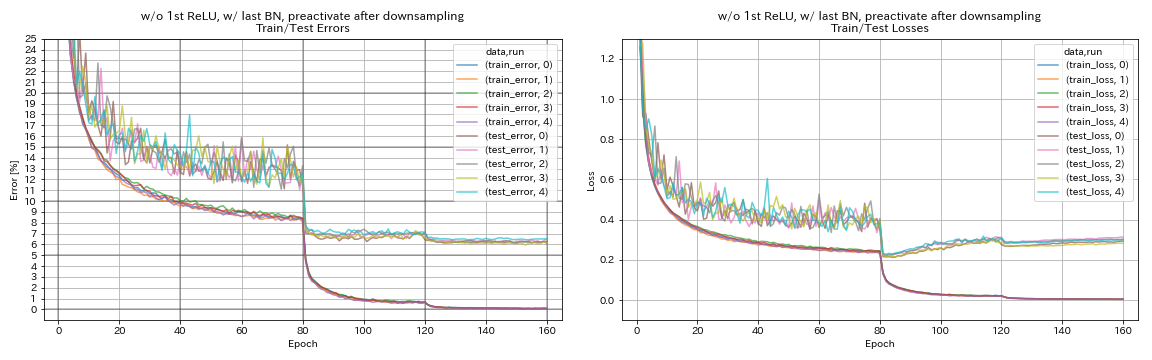
без 1 -й Relu, с последним Bn, косинусным отжигом
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00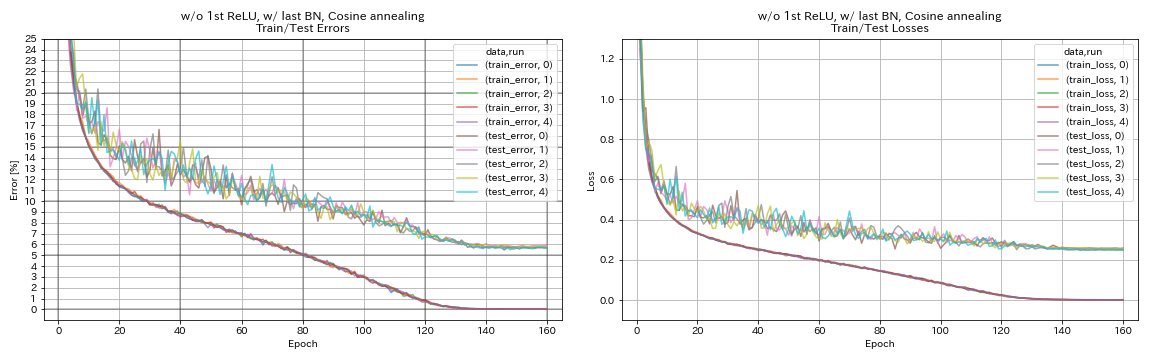
без 1 -й Relu, с последним bn, вырез
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00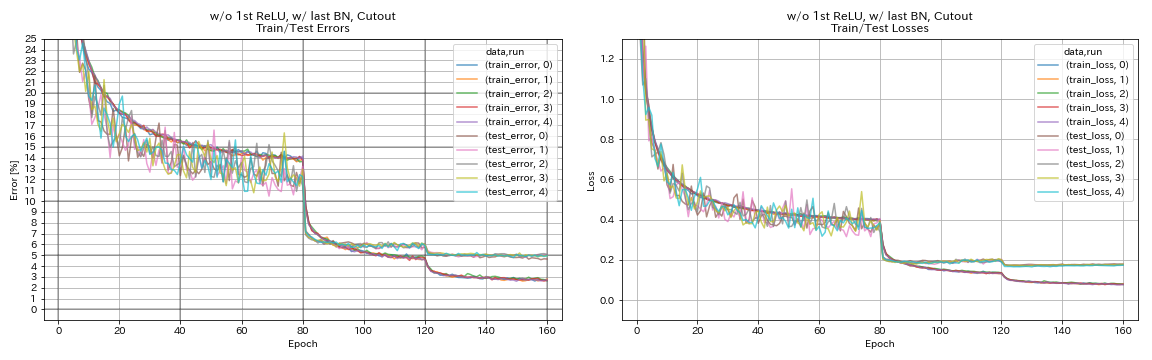
без 1 -й Relu, w/ last bn, случайное
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00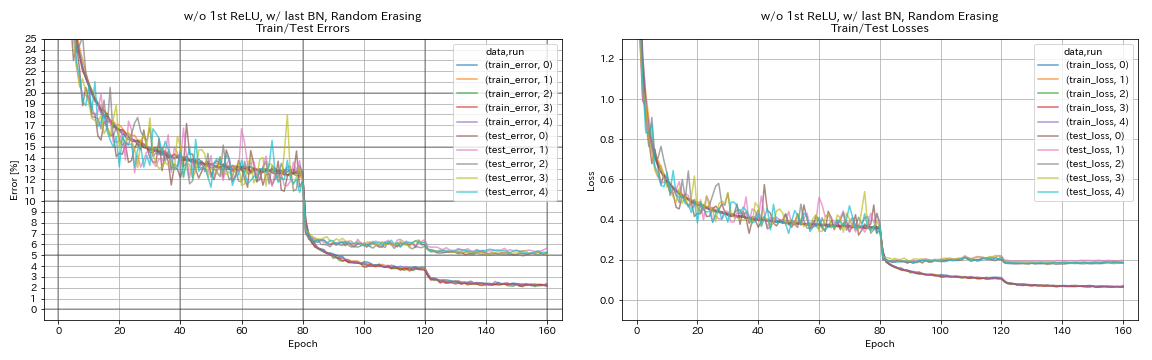
без 1 -й Relu, с последним Bn, Mixup
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00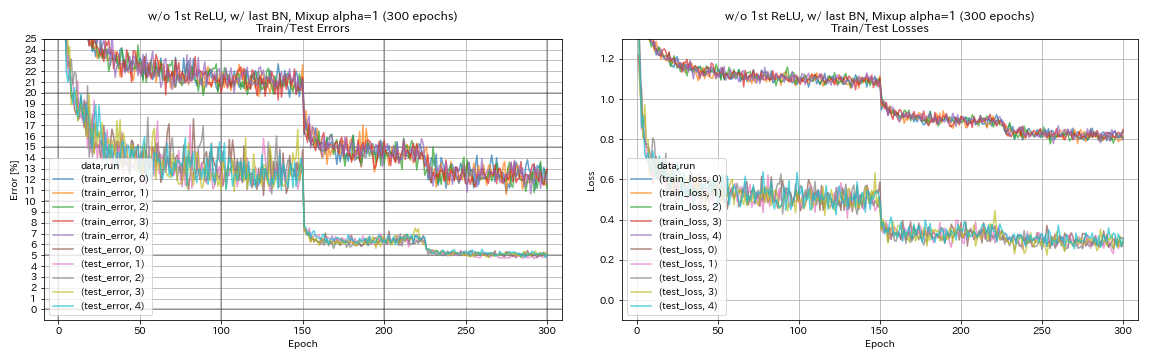
Эксперименты по сглаживанию метки, смешиванию, RICAP и двойным вырезанию
Результаты на CIFAR-10
| Модель | Ошибка теста (медиана 3 прогона) | # эпох | Время обучения |
|---|
| RESNET-PREACT-20 | 7.60 | 200 | 24 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,001) | 7,51 | 200 | 25 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,01) | 7.21 | 200 | 25 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,1) | 7.57 | 200 | 25 м |
| Resnet-praact-20, mixup (alpha = 1) | 7.24 | 200 | 26 м |
| Resnet-Preact-20, RICAP (бета = 0,3), с случайной культурой | 6,88 | 200 | 28 м |
| Resnet-Praact-20, RICAP (бета = 0,3) | 6.77 | 200 | 28 м |
| Resnet-Preact-20, двойной нарезание 16 (альфа = 0,1) | 6.24 | 200 | 45м |
| RESNET-PREACT-20 | 7.05 | 400 | 49 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,001) | 7.20 | 400 | 49 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,01) | 6.97 | 400 | 49 м |
| Resnet-Preact-20, сглаживание метки (epsilon = 0,1) | 7.16 | 400 | 49 м |
| Resnet-praact-20, mixup (alpha = 1) | 6.66 | 400 | 51 м |
| Resnet-Preact-20, RICAP (бета = 0,3), с случайной культурой | 6.30 | 400 | 56 м |
| Resnet-Praact-20, RICAP (бета = 0,3) | 6.19 | 400 | 56 м |
| Resnet-Preact-20, двойной нарезание 16 (альфа = 0,1) | 5,55 | 400 | 1h36m |
Примечание
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
- Все модели обучаются с использованием косинусного отжига с начальной скоростью обучения 0,2.
- GeForce GTX 1080 Ti использовался в этих экспериментах.
Эксперименты по размеру партии и скорости обучения
- Следующие эксперименты проводятся на наборе данных CIFAR-10 с использованием GEFORCE 1080 TI.
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
Линейное правило масштабирования для обучения
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | косинус | 200 | 10.57 | 22M |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 200 | 8.87 | 21 м |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 200 | 8.40 | 21 м |
| RESNET-PREACT-20 | 512 | 0,4 | косинус | 200 | 8.22 | 20 м |
| RESNET-PREACT-20 | 256 | 0,2 | косинус | 200 | 8.61 | 22M |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 200 | 8.09 | 24 м |
| RESNET-PREACT-20 | 64 | 0,05 | косинус | 200 | 8.22 | 28 м |
| RESNET-PREACT-20 | 32 | 0,025 | косинус | 200 | 8.00 | 43 м |
| RESNET-PREACT-20 | 16 | 0,0125 | косинус | 200 | 7,75 | 1h17m |
| RESNET-PREACT-20 | 8 | 0,006125 | косинус | 200 | 7.70 | 2H32M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | Multistep | 200 | 28.97 | 22M |
| RESNET-PREACT-20 | 2048 | 1.6 | Multistep | 200 | 9.07 | 21 м |
| RESNET-PREACT-20 | 1024 | 0,8 | Multistep | 200 | 8.62 | 21 м |
| RESNET-PREACT-20 | 512 | 0,4 | Multistep | 200 | 8.23 | 20 м |
| RESNET-PREACT-20 | 256 | 0,2 | Multistep | 200 | 8.40 | 21 м |
| RESNET-PREACT-20 | 128 | 0,1 | Multistep | 200 | 8.28 | 24 м |
| RESNET-PREACT-20 | 64 | 0,05 | Multistep | 200 | 8.13 | 28 м |
| RESNET-PREACT-20 | 32 | 0,025 | Multistep | 200 | 7.58 | 43 м |
| RESNET-PREACT-20 | 16 | 0,0125 | Multistep | 200 | 7.93 | 1h18m |
| RESNET-PREACT-20 | 8 | 0,006125 | Multistep | 200 | 8.31 | 2H34M |
Линейное масштабирование + более длительное обучение
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | косинус | 400 | 8.97 | 44 м |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 400 | 7,85 | 43 м |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 400 | 7.20 | 42 м |
| RESNET-PREACT-20 | 512 | 0,4 | косинус | 400 | 7.83 | 40 м |
| RESNET-PREACT-20 | 256 | 0,2 | косинус | 400 | 7,65 | 42 м |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 400 | 7.09 | 47м |
| RESNET-PREACT-20 | 64 | 0,05 | косинус | 400 | 7.17 | 44 м |
| RESNET-PREACT-20 | 32 | 0,025 | косинус | 400 | 7.24 | 2H11M |
| RESNET-PREACT-20 | 16 | 0,0125 | косинус | 400 | 7.26 | 4 ч .10м |
| RESNET-PREACT-20 | 8 | 0,006125 | косинус | 400 | 7.02 | 7H53M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | косинус | 800 | 8.14 | 1h29m |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 800 | 7.74 | 1H23M |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 800 | 7.15 | 1h31m |
| RESNET-PREACT-20 | 512 | 0,4 | косинус | 800 | 7.27 | 1h25m |
| RESNET-PREACT-20 | 256 | 0,2 | косинус | 800 | 7.22 | 1H26M |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 800 | 6.68 | 1h35m |
| RESNET-PREACT-20 | 64 | 0,05 | косинус | 800 | 7.18 | 2H20м |
| RESNET-PREACT-20 | 32 | 0,025 | косинус | 800 | 7.03 | 4H16M |
| RESNET-PREACT-20 | 16 | 0,0125 | косинус | 800 | 6.78 | 8H37M |
| RESNET-PREACT-20 | 8 | 0,006125 | косинус | 800 | 6,89 | 16h47m |
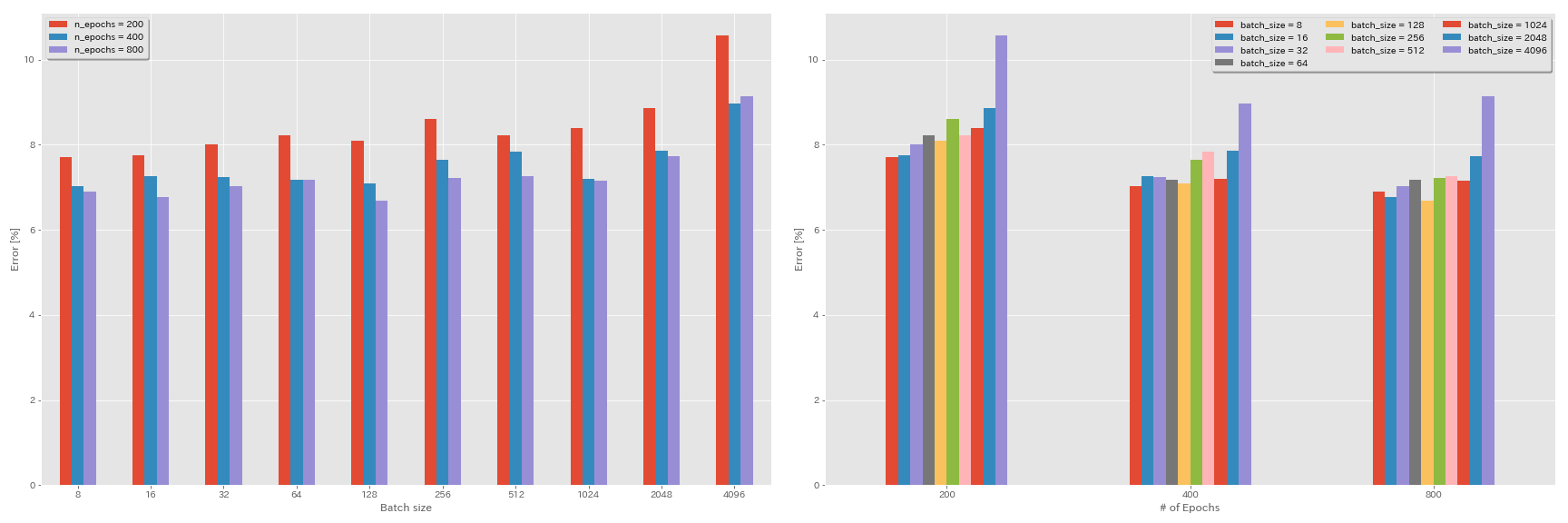
Влияние начального уровня обучения
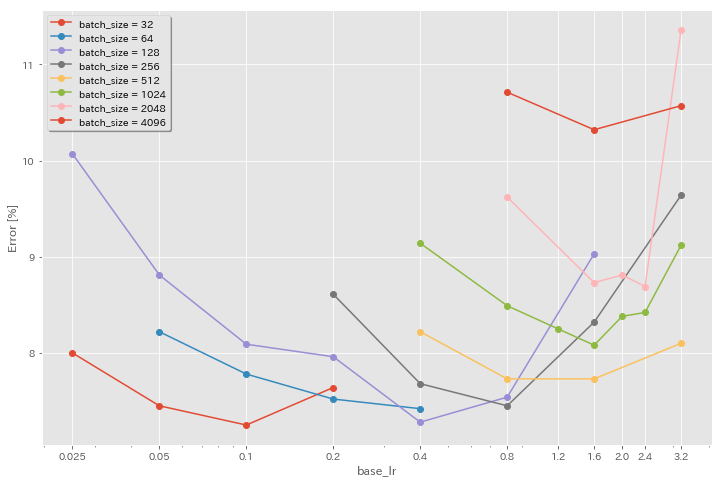
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | косинус | 200 | 10.57 | 22M |
| RESNET-PREACT-20 | 4096 | 1.6 | косинус | 200 | 10.32 | 22M |
| RESNET-PREACT-20 | 4096 | 0,8 | косинус | 200 | 10.71 | 22M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 2048 | 3.2 | косинус | 200 | 11.34 | 21 м |
| RESNET-PREACT-20 | 2048 | 2.4 | косинус | 200 | 8.69 | 21 м |
| RESNET-PREACT-20 | 2048 | 2.0 | косинус | 200 | 8.81 | 21 м |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 200 | 8.73 | 22M |
| RESNET-PREACT-20 | 2048 | 0,8 | косинус | 200 | 9.62 | 21 м |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 1024 | 3.2 | косинус | 200 | 9.12 | 21 м |
| RESNET-PREACT-20 | 1024 | 2.4 | косинус | 200 | 8.42 | 22M |
| RESNET-PREACT-20 | 1024 | 2.0 | косинус | 200 | 8.38 | 22M |
| RESNET-PREACT-20 | 1024 | 1.6 | косинус | 200 | 8.07 | 22M |
| RESNET-PREACT-20 | 1024 | 1.2 | косинус | 200 | 8.25 | 21 м |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 200 | 8.08 | 22M |
| RESNET-PREACT-20 | 1024 | 0,4 | косинус | 200 | 8.49 | 22M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 512 | 3.2 | косинус | 200 | 8.51 | 21 м |
| RESNET-PREACT-20 | 512 | 1.6 | косинус | 200 | 7.73 | 20 м |
| RESNET-PREACT-20 | 512 | 0,8 | косинус | 200 | 7.73 | 21 м |
| RESNET-PREACT-20 | 512 | 0,4 | косинус | 200 | 8.22 | 20 м |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 256 | 3.2 | косинус | 200 | 9.64 | 22M |
| RESNET-PREACT-20 | 256 | 1.6 | косинус | 200 | 8.32 | 22M |
| RESNET-PREACT-20 | 256 | 0,8 | косинус | 200 | 7.45 | 21 м |
| RESNET-PREACT-20 | 256 | 0,4 | косинус | 200 | 7.68 | 22M |
| RESNET-PREACT-20 | 256 | 0,2 | косинус | 200 | 8.61 | 22M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 128 | 1.6 | косинус | 200 | 9.03 | 24 м |
| RESNET-PREACT-20 | 128 | 0,8 | косинус | 200 | 7.54 | 24 м |
| RESNET-PREACT-20 | 128 | 0,4 | косинус | 200 | 7.28 | 24 м |
| RESNET-PREACT-20 | 128 | 0,2 | косинус | 200 | 7,96 | 24 м |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 200 | 8.09 | 24 м |
| RESNET-PREACT-20 | 128 | 0,05 | косинус | 200 | 8.81 | 24 м |
| RESNET-PREACT-20 | 128 | 0,025 | косинус | 200 | 10.07 | 24 м |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 64 | 0,4 | косинус | 200 | 7.42 | 35м |
| RESNET-PREACT-20 | 64 | 0,2 | косинус | 200 | 7.52 | 36M |
| RESNET-PREACT-20 | 64 | 0,1 | косинус | 200 | 7.78 | 37м |
| RESNET-PREACT-20 | 64 | 0,05 | косинус | 200 | 8.22 | 28 м |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 32 | 0,2 | косинус | 200 | 7.64 | 1h05m |
| RESNET-PREACT-20 | 32 | 0,1 | косинус | 200 | 7.25 | 1h08m |
| RESNET-PREACT-20 | 32 | 0,05 | косинус | 200 | 7.45 | 1h07m |
| RESNET-PREACT-20 | 32 | 0,025 | косинус | 200 | 8.00 | 43 м |
Хорошая скорость обучения + более длительное обучение
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | косинус | 200 | 10.32 | 22M |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 200 | 8.73 | 22M |
| RESNET-PREACT-20 | 1024 | 1.6 | косинус | 200 | 8.07 | 22M |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 200 | 8.08 | 22M |
| RESNET-PREACT-20 | 512 | 1.6 | косинус | 200 | 7.73 | 20 м |
| RESNET-PREACT-20 | 512 | 0,8 | косинус | 200 | 7.73 | 21 м |
| RESNET-PREACT-20 | 256 | 0,8 | косинус | 200 | 7.45 | 21 м |
| RESNET-PREACT-20 | 128 | 0,4 | косинус | 200 | 7.28 | 24 м |
| RESNET-PREACT-20 | 128 | 0,2 | косинус | 200 | 7,96 | 24 м |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 200 | 8.09 | 24 м |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | косинус | 800 | 8.36 | 1h33m |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 800 | 7.53 | 1H27M |
| RESNET-PREACT-20 | 1024 | 1.6 | косинус | 800 | 7.30 | 1H30м |
| RESNET-PREACT-20 | 1024 | 0,8 | косинус | 800 | 7.42 | 1H30м |
| RESNET-PREACT-20 | 512 | 1.6 | косинус | 800 | 6.69 | 1H26M |
| RESNET-PREACT-20 | 512 | 0,8 | косинус | 800 | 6.77 | 1H26M |
| RESNET-PREACT-20 | 256 | 0,8 | косинус | 800 | 6.84 | 1H28M |
| RESNET-PREACT-20 | 128 | 0,4 | косинус | 800 | 6.86 | 1h35m |
| RESNET-PREACT-20 | 128 | 0,2 | косинус | 800 | 7.05 | 1h38m |
| RESNET-PREACT-20 | 128 | 0,1 | косинус | 800 | 6.68 | 1h35m |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | косинус | 1600 | 8.25 | 3H10м |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 1600 | 7.34 | 2H50м |
| RESNET-PREACT-20 | 1024 | 1.6 | косинус | 1600 | 6.94 | 2H52M |
| RESNET-PREACT-20 | 512 | 1.6 | косинус | 1600 | 6.99 | 2H44M |
| RESNET-PREACT-20 | 256 | 0,8 | косинус | 1600 | 6,95 | 2H50м |
| RESNET-PREACT-20 | 128 | 0,4 | косинус | 1600 | 6.64 | 3H09M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | косинус | 3200 | 9.52 | 6h15m |
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 3200 | 6.92 | 5H42M |
| RESNET-PREACT-20 | 1024 | 1.6 | косинус | 3200 | 6.96 | 5H43M |
| Модель | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 2048 | 1.6 | косинус | 6400 | 7.45 | 11h44m |
Ларс
- В первоначальных документах (1708.03888, 1801.03137) они использовали планирование скорости обучения полиномиального распада, но в этих экспериментах используется отжиг косинуса.
- В этой реализации коэффициент LARS не используется, поэтому скорость обучения следует скорректировать соответствующим образом.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00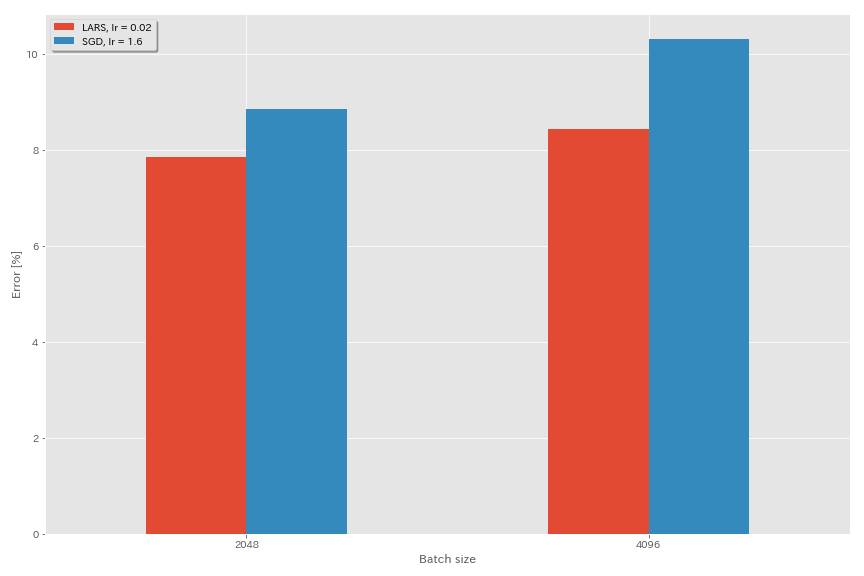
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 4096 | 3.2 | косинус | 200 | 10.57 (1 бег) | 22M |
| RESNET-PREACT-20 | SGD | 4096 | 1.6 | косинус | 200 | 10.20 | 22M |
| RESNET-PREACT-20 | SGD | 4096 | 0,8 | косинус | 200 | 10.71 (1 пробег) | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,04 | косинус | 200 | 9.58 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,03 | косинус | 200 | 8.46 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,02 | косинус | 200 | 8.21 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,015 | косинус | 200 | 8.47 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,01 | косинус | 200 | 9.33 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,005 | косинус | 200 | 14.31 | 22M |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 2048 | 3.2 | косинус | 200 | 11.34 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 2048 | 2.4 | косинус | 200 | 8,69 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 2048 | 2.0 | косинус | 200 | 8,81 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 2048 | 1.6 | косинус | 200 | 8.73 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 2048 | 0,8 | косинус | 200 | 9.62 (1 пробег) | 21 м |
| RESNET-PREACT-20 | Ларс | 2048 | 0,04 | косинус | 200 | 11.58 | 21 м |
| RESNET-PREACT-20 | Ларс | 2048 | 0,02 | косинус | 200 | 8.05 | 22M |
| RESNET-PREACT-20 | Ларс | 2048 | 0,01 | косинус | 200 | 8.07 | 22M |
| RESNET-PREACT-20 | Ларс | 2048 | 0,005 | косинус | 200 | 9.65 | 22M |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 1024 | 3.2 | косинус | 200 | 9.12 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 1024 | 2.4 | косинус | 200 | 8.42 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 1024 | 2.0 | косинус | 200 | 8.38 (1 бег) | 22M |
| RESNET-PREACT-20 | SGD | 1024 | 1.6 | косинус | 200 | 8,07 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 1024 | 1.2 | косинус | 200 | 8.25 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 1024 | 0,8 | косинус | 200 | 8.08 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 1024 | 0,4 | косинус | 200 | 8.49 (1 бег) | 22M |
| RESNET-PREACT-20 | Ларс | 1024 | 0,02 | косинус | 200 | 9.30 | 22M |
| RESNET-PREACT-20 | Ларс | 1024 | 0,01 | косинус | 200 | 7.68 | 22M |
| RESNET-PREACT-20 | Ларс | 1024 | 0,005 | косинус | 200 | 8.88 | 23 м |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 512 | 3.2 | косинус | 200 | 8.51 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 512 | 1.6 | косинус | 200 | 7.73 (1 пробег) | 20 м |
| RESNET-PREACT-20 | SGD | 512 | 0,8 | косинус | 200 | 7.73 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 512 | 0,4 | косинус | 200 | 8.22 (1 пробег) | 20 м |
| RESNET-PREACT-20 | Ларс | 512 | 0,015 | косинус | 200 | 9.84 | 23 м |
| RESNET-PREACT-20 | Ларс | 512 | 0,01 | косинус | 200 | 8.05 | 23 м |
| RESNET-PREACT-20 | Ларс | 512 | 0,0075 | косинус | 200 | 7.58 | 23 м |
| RESNET-PREACT-20 | Ларс | 512 | 0,005 | косинус | 200 | 7,96 | 23 м |
| RESNET-PREACT-20 | Ларс | 512 | 0,0025 | косинус | 200 | 8.83 | 23 м |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 256 | 3.2 | косинус | 200 | 9.64 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 256 | 1.6 | косинус | 200 | 8.32 (1 бег) | 22M |
| RESNET-PREACT-20 | SGD | 256 | 0,8 | косинус | 200 | 7.45 (1 пробег) | 21 м |
| RESNET-PREACT-20 | SGD | 256 | 0,4 | косинус | 200 | 7.68 (1 пробег) | 22M |
| RESNET-PREACT-20 | SGD | 256 | 0,2 | косинус | 200 | 8.61 (1 пробег) | 22M |
| RESNET-PREACT-20 | Ларс | 256 | 0,01 | косинус | 200 | 8.95 | 27м |
| RESNET-PREACT-20 | Ларс | 256 | 0,005 | косинус | 200 | 7,75 | 28 м |
| RESNET-PREACT-20 | Ларс | 256 | 0,0025 | косинус | 200 | 8.21 | 28 м |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 128 | 1.6 | косинус | 200 | 9.03 (1 пробег) | 24 м |
| RESNET-PREACT-20 | SGD | 128 | 0,8 | косинус | 200 | 7,54 (1 пробег) | 24 м |
| RESNET-PREACT-20 | SGD | 128 | 0,4 | косинус | 200 | 7.28 (1 пробег) | 24 м |
| RESNET-PREACT-20 | SGD | 128 | 0,2 | косинус | 200 | 7.96 (1 пробег) | 24 м |
| RESNET-PREACT-20 | Ларс | 128 | 0,005 | косинус | 200 | 7,96 | 37м |
| RESNET-PREACT-20 | Ларс | 128 | 0,0025 | косинус | 200 | 7,98 | 37м |
| RESNET-PREACT-20 | Ларс | 128 | 0,00125 | косинус | 200 | 9.21 | 37м |
| Модель | оптимизатор | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | SGD | 4096 | 1.6 | косинус | 200 | 10.20 | 22M |
| RESNET-PREACT-20 | SGD | 4096 | 1.6 | косинус | 800 | 8.36 (1 пробег) | 1h33m |
| RESNET-PREACT-20 | SGD | 4096 | 1.6 | косинус | 1600 | 8.25 (1 пробег) | 3H10м |
| RESNET-PREACT-20 | Ларс | 4096 | 0,02 | косинус | 200 | 8.21 | 22M |
| RESNET-PREACT-20 | Ларс | 4096 | 0,02 | косинус | 400 | 7.53 | 44 м |
| RESNET-PREACT-20 | Ларс | 4096 | 0,02 | косинус | 800 | 7.48 | 1h29m |
| RESNET-PREACT-20 | Ларс | 4096 | 0,02 | косинус | 1600 | 7.37 (1 пробег) | 2H58M |
Призрак Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Модель | Размер партии | Призрачный размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 8192 | N/a | 1.6 | косинус | 200 | 12.35 | 25 м* |
| RESNET-PREACT-20 | 4096 | N/a | 1.6 | косинус | 200 | 10.32 | 22M |
| RESNET-PREACT-20 | 2048 | N/a | 1.6 | косинус | 200 | 8.73 | 22M |
| RESNET-PREACT-20 | 1024 | N/a | 1.6 | косинус | 200 | 8.07 | 22M |
| RESNET-PREACT-20 | 128 | N/a | 0,4 | косинус | 200 | 7.28 | 24 м |
| Модель | Размер партии | Призрачный размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 8192 | 128 | 1.6 | косинус | 200 | 11.51 | 27м |
| RESNET-PREACT-20 | 4096 | 128 | 1.6 | косинус | 200 | 9.73 | 25 м |
| RESNET-PREACT-20 | 2048 | 128 | 1.6 | косинус | 200 | 8.77 | 24 м |
| RESNET-PREACT-20 | 1024 | 128 | 1.6 | косинус | 200 | 7.82 | 22M |
| Модель | Размер партии | Призрачный размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 8192 | N/a | 1.6 | косинус | 1600 | | |
| RESNET-PREACT-20 | 4096 | N/a | 1.6 | косинус | 1600 | 8.25 | 3H10м |
| RESNET-PREACT-20 | 2048 | N/a | 1.6 | косинус | 1600 | 7.34 | 2H50м |
| RESNET-PREACT-20 | 1024 | N/a | 1.6 | косинус | 1600 | 6.94 | 2H52M |
| Модель | Размер партии | Призрачный размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | 8192 | 128 | 1.6 | косинус | 1600 | 11.83 | 3H37M |
| RESNET-PREACT-20 | 4096 | 128 | 1.6 | косинус | 1600 | 8.95 | 3H15M |
| RESNET-PREACT-20 | 2048 | 128 | 1.6 | косинус | 1600 | 7.23 | 3H05M |
| RESNET-PREACT-20 | 1024 | 128 | 1.6 | косинус | 1600 | 7.08 | 2H59M |
Нет распада веса на BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00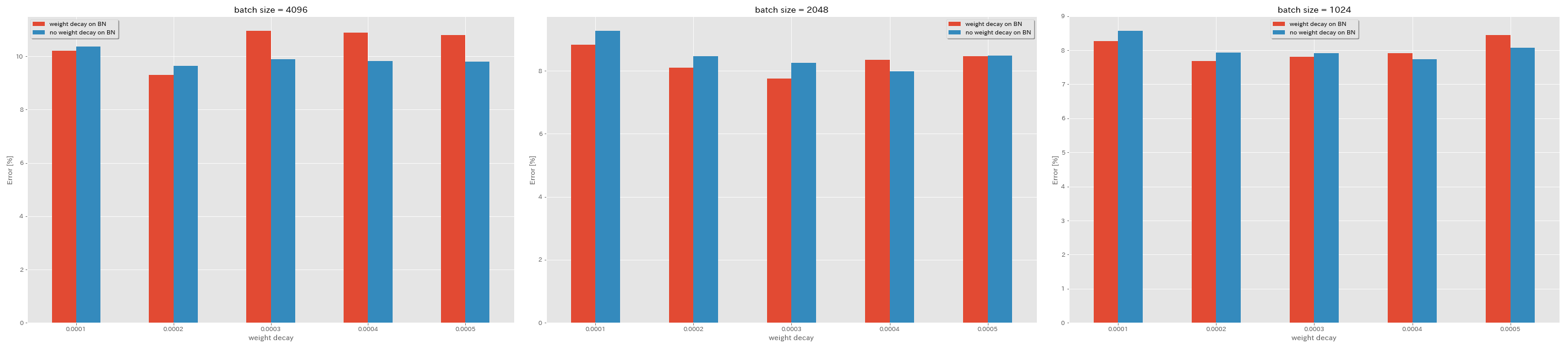
| Модель | распад веса на BN | распад веса | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | да | 5e-4 | 4096 | 1.6 | косинус | 200 | 10.81 | 22M |
| RESNET-PREACT-20 | да | 4e-4 | 4096 | 1.6 | косинус | 200 | 10.88 | 22M |
| RESNET-PREACT-20 | да | 3E-4 | 4096 | 1.6 | косинус | 200 | 10.96 | 22M |
| RESNET-PREACT-20 | да | 2E-4 | 4096 | 1.6 | косинус | 200 | 9.30 | 22M |
| RESNET-PREACT-20 | да | 1E-4 | 4096 | 1.6 | косинус | 200 | 10.20 | 22M |
| RESNET-PREACT-20 | нет | 5e-4 | 4096 | 1.6 | косинус | 200 | 8.78 | 22M |
| RESNET-PREACT-20 | нет | 4e-4 | 4096 | 1.6 | косинус | 200 | 9.83 | 22M |
| RESNET-PREACT-20 | нет | 3E-4 | 4096 | 1.6 | косинус | 200 | 9.90 | 22M |
| RESNET-PREACT-20 | нет | 2E-4 | 4096 | 1.6 | косинус | 200 | 9.64 | 22M |
| RESNET-PREACT-20 | нет | 1E-4 | 4096 | 1.6 | косинус | 200 | 10.38 | 22M |
| Модель | распад веса на BN | распад веса | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | да | 5e-4 | 2048 | 1.6 | косинус | 200 | 8.46 | 20 м |
| RESNET-PREACT-20 | да | 4e-4 | 2048 | 1.6 | косинус | 200 | 8.35 | 20 м |
| RESNET-PREACT-20 | да | 3E-4 | 2048 | 1.6 | косинус | 200 | 7.76 | 20 м |
| RESNET-PREACT-20 | да | 2E-4 | 2048 | 1.6 | косинус | 200 | 8.09 | 20 м |
| RESNET-PREACT-20 | да | 1E-4 | 2048 | 1.6 | косинус | 200 | 8.83 | 20 м |
| RESNET-PREACT-20 | нет | 5e-4 | 2048 | 1.6 | косинус | 200 | 8.49 | 20 м |
| RESNET-PREACT-20 | нет | 4e-4 | 2048 | 1.6 | косинус | 200 | 7,98 | 20 м |
| RESNET-PREACT-20 | нет | 3E-4 | 2048 | 1.6 | косинус | 200 | 8.26 | 20 м |
| RESNET-PREACT-20 | нет | 2E-4 | 2048 | 1.6 | косинус | 200 | 8.47 | 20 м |
| RESNET-PREACT-20 | нет | 1E-4 | 2048 | 1.6 | косинус | 200 | 9.27 | 20 м |
| Модель | распад веса на BN | распад веса | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (медиана 3 прогона) | Время обучения |
|---|
| RESNET-PREACT-20 | да | 5e-4 | 1024 | 1.6 | косинус | 200 | 8.45 | 21 м |
| RESNET-PREACT-20 | да | 4e-4 | 1024 | 1.6 | косинус | 200 | 7.91 | 21 м |
| RESNET-PREACT-20 | да | 3E-4 | 1024 | 1.6 | косинус | 200 | 7,81 | 21 м |
| RESNET-PREACT-20 | да | 2E-4 | 1024 | 1.6 | косинус | 200 | 7.69 | 21 м |
| RESNET-PREACT-20 | да | 1E-4 | 1024 | 1.6 | косинус | 200 | 8.26 | 21 м |
| RESNET-PREACT-20 | нет | 5e-4 | 1024 | 1.6 | косинус | 200 | 8.08 | 21 м |
| RESNET-PREACT-20 | нет | 4e-4 | 1024 | 1.6 | косинус | 200 | 7.73 | 21 м |
| RESNET-PREACT-20 | нет | 3E-4 | 1024 | 1.6 | косинус | 200 | 7.92 | 21 м |
| RESNET-PREACT-20 | нет | 2E-4 | 1024 | 1.6 | косинус | 200 | 7.93 | 21 м |
| RESNET-PREACT-20 | нет | 1E-4 | 1024 | 1.6 | косинус | 200 | 8.53 | 21 м |
Эксперименты по полуоперации и смешанному назначению
- После экспериментов нужна apex nvidia.
- Следующие эксперименты проводятся в наборе данных CIFAR-10 с использованием GEFORCE 1080 TI, который не имеет тензоров.
- Результаты, представленные в таблице, являются тестовыми ошибками в последние эпохи.
FP16 Обучение
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Обучение смешанного назначения
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Результаты
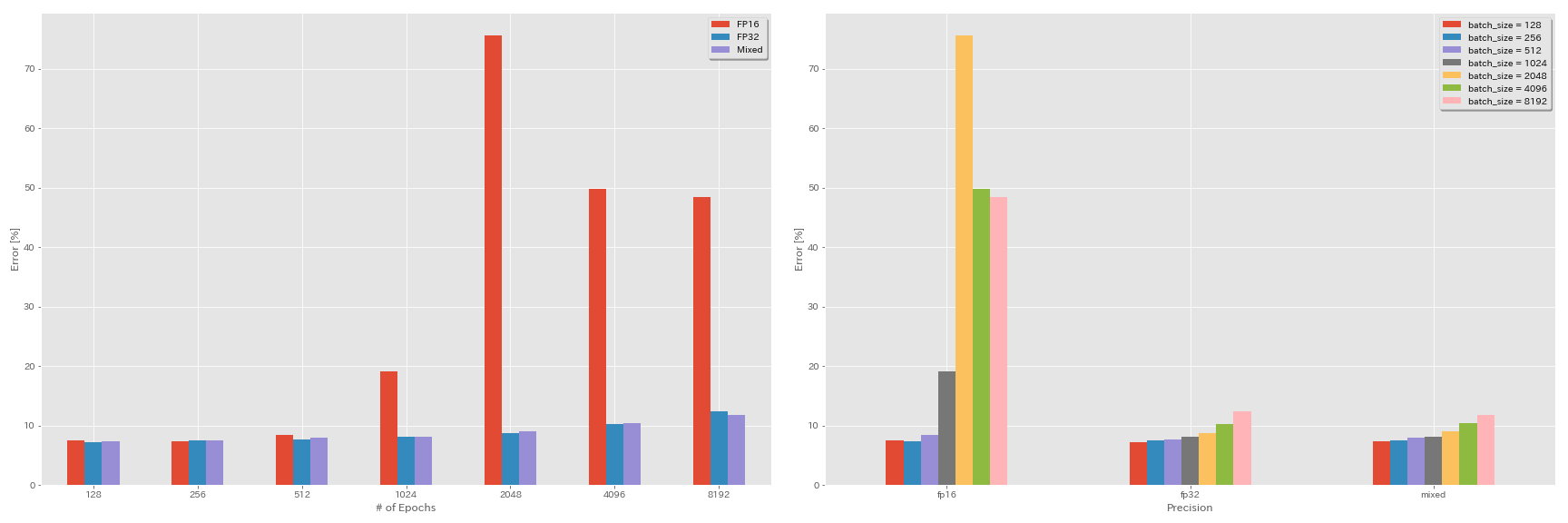
| Модель | точность | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | FP32 | 8192 | 1.6 | косинус | 200 | | |
| RESNET-PREACT-20 | FP32 | 4096 | 1.6 | косинус | 200 | 10.32 | 22M |
| RESNET-PREACT-20 | FP32 | 2048 | 1.6 | косинус | 200 | 8.73 | 22M |
| RESNET-PREACT-20 | FP32 | 1024 | 1.6 | косинус | 200 | 8.07 | 22M |
| RESNET-PREACT-20 | FP32 | 512 | 0,8 | косинус | 200 | 7.73 | 21 м |
| RESNET-PREACT-20 | FP32 | 256 | 0,8 | косинус | 200 | 7.45 | 21 м |
| RESNET-PREACT-20 | FP32 | 128 | 0,4 | косинус | 200 | 7.28 | 24 м |
| Модель | точность | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | FP16 | 8192 | 1.6 | косинус | 200 | 48.52 | 33 м |
| RESNET-PREACT-20 | FP16 | 4096 | 1.6 | косинус | 200 | 49,84 | 28 м |
| RESNET-PREACT-20 | FP16 | 2048 | 1.6 | косинус | 200 | 75,63 | 27м |
| RESNET-PREACT-20 | FP16 | 1024 | 1.6 | косинус | 200 | 19.09 | 27м |
| RESNET-PREACT-20 | FP16 | 512 | 0,8 | косинус | 200 | 7.89 | 26 м |
| RESNET-PREACT-20 | FP16 | 256 | 0,8 | косинус | 200 | 7.40 | 28 м |
| RESNET-PREACT-20 | FP16 | 128 | 0,4 | косинус | 200 | 7.59 | 32 м |
| Модель | точность | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | смешанный | 8192 | 1.6 | косинус | 200 | 11.78 | 28 м |
| RESNET-PREACT-20 | смешанный | 4096 | 1.6 | косинус | 200 | 10.48 | 27м |
| RESNET-PREACT-20 | смешанный | 2048 | 1.6 | косинус | 200 | 8.98 | 26 м |
| RESNET-PREACT-20 | смешанный | 1024 | 1.6 | косинус | 200 | 8.05 | 26 м |
| RESNET-PREACT-20 | смешанный | 512 | 0,8 | косинус | 200 | 7,81 | 28 м |
| RESNET-PREACT-20 | смешанный | 256 | 0,8 | косинус | 200 | 7.58 | 32 м |
| RESNET-PREACT-20 | смешанный | 128 | 0,4 | косинус | 200 | 7.37 | 41 м |
Результаты с использованием Tesla v100
| Модель | точность | Размер партии | начальный LR | LR график | # эпох | Ошибка теста (1 запуск) | Время обучения |
|---|
| RESNET-PREACT-20 | FP32 | 8192 | 1.6 | косинус | 200 | 12.35 | 25 м |
| RESNET-PREACT-20 | FP32 | 4096 | 1.6 | косинус | 200 | 9.88 | 19м |
| RESNET-PREACT-20 | FP32 | 2048 | 1.6 | косинус | 200 | 8.87 | 17 м |
| RESNET-PREACT-20 | FP32 | 1024 | 1.6 | косинус | 200 | 8.45 | 18 м |
| RESNET-PREACT-20 | смешанный | 8192 | 1.6 | косинус | 200 | 11.92 | 25 м |
| RESNET-PREACT-20 | смешанный | 4096 | 1.6 | косинус | 200 | 10.16 | 19м |
| RESNET-PREACT-20 | смешанный | 2048 | 1.6 | косинус | 200 | 9.10 | 17 м |
| RESNET-PREACT-20 | смешанный | 1024 | 1.6 | косинус | 200 | 7.84 | 16M |
Ссылки
Модель архитектура
- Он, Каминг, Сянгю Чжан, Шаоцинг Рен и Цзянь Сан. «Глубокое остаточное обучение для распознавания изображений». Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2016. Ссылка, Arxiv: 1512.03385
- Он, Каминг, Сянгю Чжан, Шаоцинг Рен и Цзянь Сан. «Сопоставления личных данных в глубоких остаточных сетях». В Европейской конференции по компьютерному видению (ECCV). 2016. Arxiv: 1603.05027, реализация факела
- Загоруйко, Сергей и Никос Комодакис. «Широкие остаточные сети». Материалы Британской конференции по машинному видению (BMVC), 2016. Arxiv: 1605.07146, реализация факела
- Хуан, Гао, Чжуан Лю, Килиан Quinberger и Лоренс ван дер Маатен. «Гудлевые сверточные сети». Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2017. Ссылка, Arxiv: 1608.06993, Реализация Torch
- Хан, Дунгун, Джихан Ким и Джунмо Ким. «Глубокие пирамидальные остаточные сети». Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2017. Ссылка, Arxiv: 1610.02915, реализация Torch, реализация Caffe, реализация Pytorch
- Се, Санинг, Росс Гиршик, Пиот -Доллар, Чжуоуэн Ту и Каминг Хе. «Агрегированные остаточные преобразования для глубоких нейронных сетей». Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2017. Ссылка, Arxiv: 1611.05431, Реализация Torch
- Гастальди, Ксавье. «Регуляризация остаточных сетей с 3-вешенками». В Международной конференции по обучению представлений (ICLR) Семинар, 2017. Ссылка, Arxiv: 1705.07485, реализация Torch
- Ху, Цзе, Ли Шен и Банг Сан. "Стинка и сети." Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2018, с. 7132-7141. Ссылка, Arxiv: 1709.01507, реализация Caffe
- Хуан, Гао, Чжуан Лю, Джефф Плейсс, Лоренс ван дер Маатен и Килиан В. Вайнбергер. «Связанные сети с плотным подключением». IEEE транзакции по анализу шаблонов и интеллекта машин (2019). ARXIV: 2001.02394
Регуляризация, увеличение данных
- Сегедди, Кристиан, Винсент Ванхук, Сергей Иоффе, Джон Шленс и Збигнев Война. «Переосмысление основополагающей архитектуры для компьютерного зрения». Конференция IEEE по компьютерному видению и распознаванию шаблонов (CVPR), 2016. Ссылка, Arxiv: 1512.00567
- Деври, Терранс и Грэм В. Тейлор. «Улучшенная регуляризация сверточных нейронных сетей с вырезом». Arxiv Preprint arxiv: 1708.04552 (2017). Arxiv: 1708.04552, реализация Pytorch
- Абу-Эль-Хайджа, Сами. «Пропорциональные обновления градиента с процентной роликой». Arxiv Preprint arxiv: 1708.07227 (2017). Arxiv: 1708.07227
- Жонг, Чжун, Лян Чжэн, Гуолиан Кан, Шаози Ли и И Ян. «Случайное увеличение данных». Arxiv Preprint arxiv: 1708.04896 (2017). Arxiv: 1708.04896, реализация Pytorch
- Чжан, Хонги, Мустафа Сиссе, Янн Н. Дофин и Дэвид Лопес-Паз. «Смешивание: за пределами эмпирической минимизации риска». В Международной конференции по обучению представлений (ICLR), 2017. Ссылка, Arxiv: 1710.09412
- Кавагучи, Кенджи, Йошуа Бенгио, Викас Верма и Лесли Пак Кэльбблинг. «На пути к пониманию обобщения посредством аналитической теории обучения». Arxiv Preprint arxiv: 1802.07426 (2018). Arxiv: 1802.07426, реализация Pytorch
- Такахаши, Рио, Такаши Мацубара и Куниаки Уэхара. «Увеличение данных с использованием случайного обрезки изображения и исправления для глубоких CNN». Материалы 10 -й Азиатской конференции по машинному обучению (ACML), 2018. Ссылка, Arxiv: 1811.09030
- Юн, Сангду, Дунгун Хан, Сон Джун О, Сангюк Чун, Джунсук Чо и Янгджун Ю. «Cutmix: стратегия регуляризации для обучения сильных классификаторов с локализацией». Arxiv Preprint arxiv: 1905.04899 (2019). Arxiv: 1905.04899
Большая партия
- Кескар, Нитиш Шириш, Дхиватса Мудигер, Хорхе Ноцедал, Михаил Смьяльский и Пинг Так Питер Тан. «Об обучении с большим партией для глубокого обучения: разрыв в обобщении и резкие минимумы». В Международной конференции по обучению представлений (ICLR), 2017. Ссылка, Arxiv: 1609.04836
- Хоффер, Элад, Итай Хубара и Даниэль Судри. «Тренируйтесь дольше, обобщите лучше: закрытие разрыва в обобщении в больших партийных тренировках нейронных сетей». В «Авансах в системах обработки нейронной информации» (NIPS), 2017. Link, Arxiv: 1705.08741, реализация Pytorch
- Гоял, Прия, Петр Доллар, Росс Гиршик, Питер Нордхуис, Лукаш Весоловски, Аапо Кирола, Эндрю Таллох, Янцени Цзя и Каминг. «Точный, большой Minibatch SGD: Training ImageNet за 1 час». Arxiv Preprint arxiv: 1706.02677 (2017). Arxiv: 1706.02677
- Вы, Ян, Игорь Гитман и Борис Гинзбург. «Большой партийный обучение сверточных сетей». Arxiv Preprint arxiv: 1708.03888 (2017). Arxiv: 1708.03888
- Вы, Ян, Чжао Чжан, Чо-Юи Сьи, Джеймс Деммель и Курт Кейцер. "ImageNet Training за считанные минуты". Arxiv Preprint arxiv: 1709.05011 (2017). Arxiv: 1709.05011
- Смит, Сэмюэль Л., Питер-Ян Киндеманс, Крис Йин и Кук В. Ле. «Не распадайте скорость обучения, увеличивайте размер партии». На Международной конференции по обучению представлений (ICLR), 2018. Ссылка, Arxiv: 1711.00489
- Гитман, Игорь, Дипак Дилипкумар и Бен Парр. «Анализ конвергенции алгоритмов градиентного происхождения с пропорциональными обновлениями». Arxiv Preprint arxiv: 1801.03137 (2018). ARXIV: 1801.03137 Реализация TensorFlow
- Цзя, Сяанян, Сонг Шетао, Вэй Хе, Янзихао Ванг, Хайдонг Ронг, Фейху Чжоу, Лицян Се, Чжениу Го, Юаньху Ян, Ливей Ю, Тиганг Чен, Гуансиао Ху, Шауай Ши и Сяоуэн Чу. «Система тренировок с глубоким обучением с помощью смешанного назначения: обучение ImageNet за четыре минуты». Arxiv Preprint arxiv: 1807.11205 (2018). Arxiv: 1807.11205
- Whalue, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Fortig и George E. Dahl. «Измерение влияния параллелизма данных на обучение нейронной сети». Arxiv Preprint Arxiv: 1811.03600 (2018). Arxiv: 1811.03600
- Инг, Крис, Самир Кумар, Дехао Чен, Тао Ван и Юлонг Ченг. «Классификация изображений в SuperComputer Scale». В «Достижениях в области нейронных систем обработки информации» (Neurips), 2018. Ссылка, Arxiv: 1811.06992
Другие
- Лошчилов, Илья и Фрэнк Хаттер. «SGDR: Стохастический градиент спуск с теплыми перезапусками». В Международной конференции по обучению представлений (ICLR), 2017. Ссылка, Arxiv: 1608.03983, внедрение лазаньи
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Эрих Эльсен, Дэвид Гарсия, Борис Гинзбург, Майкл Хьюстон, Олексии Кучайев, Ганеш Венкатеш и Хао Ву. «Смешанная точная тренировка». На Международной конференции по обучению представлений (ICLR), 2018. Ссылка, Arxiv: 1710.03740
- Рехт, Бенджамин, Ребекка Роелофс, Людвиг Шмидт и Вайшаал Шанкар. "Обобщают ли классификаторы CIFAR-10 до CIFAR-10?" Arxiv Preprint arxiv: 1806.00451 (2018). Arxiv: 1806.00451
- Он, Тонг, Чжи Чжан, Ханг Чжан, Чжунгью Чжан, Джуниюан Се и Му Ли. «Сумка уловок для классификации изображений с сверточными нейронными сетями». Arxiv Preprint arxiv: 1812.01187 (2018). Arxiv: 1812.01187


