Pytorch -Bildklassifizierung
Die folgenden Papiere werden mit Pytorch implementiert.
- Resnet (1512.03385)
- Resnet-preect (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- Ausschnitt (1708.04552)
- Zufällige Lösche (1708.04896)
- Senet (1709.01507)
- Mischung (1710.09412)
- Dual-Cutout (1802.07426)
- Ricap (1811.09030)
- Cutmix (1905.04899)
Anforderungen
- Ubuntu (es wird nur auf Ubuntu getestet, daher funktioniert es möglicherweise nicht unter Windows.)
- Python> = 3,7
- Pytorch> = 1.4.0
- Torchvision
- Nvidia Apex
pip install -r requirements.txt
Verwendung
python train.py --config configs/cifar/resnet_preact.yaml
Ergebnisse zu CIFAR-10
Ergebnisse mit fast den gleichen Einstellungen wie Papiere
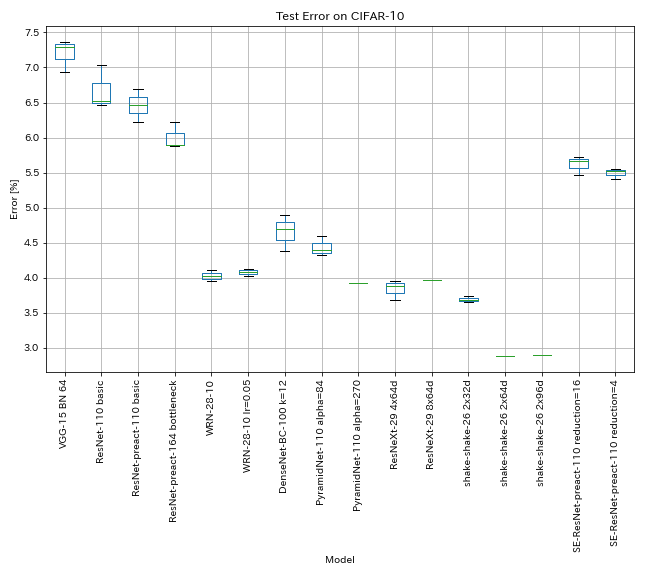
| Modell | Testfehler (Median von 3 Läufen) | Testfehler (in Papier) | Trainingszeit |
|---|
| VGG-ähnlich (Tiefe 15, W/ Bn, Kanal 64) | 7.29 | N / A | 1H20M |
| Resnet-110 | 6.52 | 6,43 (am besten), 6,61 +/- 0,16 | 3H06m |
| Resnet-Preact-110 | 6.47 | 6.37 (Median von 5 Läufen) | 3H05m |
| Resnet-Preact-164 Engpass | 5.90 | 5.46 (Median von 5 Läufen) | 4H01m |
| Resnet-preect-1001 Engpass | | 4,62 (Median von 5 Läufen), 4,69 +/- 0,20 | |
| WRN-28-10 | 4.03 | 4.00 (Median von 5 Läufen) | 16H10m |
| WRN-28-10 W/ Dropout | | 3.89 (Median von 5 Läufen) | |
| Densenet-100 (K = 12) | 3,87 (1 Lauf) | 4.10 (1 Lauf) | 24H28m* |
| Densenet-100 (k = 24) | | 3.74 (1 Lauf) | |
| Densenet-BC-100 (K = 12) | 4.69 | 4,51 (1 Lauf) | 15H20m |
| Densenet-BC-250 (K = 24) | | 3.62 (1 Lauf) | |
| Densenet-BC-190 (K = 40) | | 3.46 (1 Lauf) | |
| Pyramidnet-110 (Alpha = 84) | 4.40 | 4,26 +/- 0,23 | 11H40m |
| Pyramidnet-110 (Alpha = 270) | 3,92 (1 Lauf) | 3,73 +/- 0,04 | 24H12m* |
| Pyramidnet-164-Engpass (Alpha = 270) | 3.44 (1 Lauf) | 3,48 +/- 0,20 | 32H37M* |
| Pyramidnet-272-Engpass (Alpha = 200) | | 3,31 +/- 0,08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (aus Abbildung 7) | 31H17m |
| Resnext-29 8x64d | 3,97 (1 Lauf) | 3,65 (durchschnittlich 10 Läufe) | 42H50M* |
| Resnext-29 16x64d | | 3,58 (durchschnittlich 10 Läufe) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3,55 (durchschnittlich 3 Läufe) | 33H49m |
| Shake-Shake-26 2x64d (SSI) | 2,88 (1 Lauf) | 2,98 (durchschnittlich 3 Läufe) | 78H48M |
| Shake-Shake-26 2x96d (SSI) | 2,90 (1 Lauf) | 2,86 (durchschnittlich 5 Läufe) | 101H32m* |
Notizen
- Unterschiede mit Papieren in den Trainingseinstellungen:
- Trainierte WRN-28-10 mit Chargengröße 64 (128 in Papier).
- Trainierte Densenet-BC-100 (K = 12) mit Stapelgröße 32 und anfängliche Lernrate 0,05 (Stapelgröße 64 und anfängliche Lernrate 0,1 in Papier).
- Trainierte Resnext-29 4x64d mit einer einzelnen GPU, einer Stapelgröße 32 und der anfänglichen Lernrate 0,025 (8 GPUs, Stapelgröße 128 und anfängliche Lernrate 0,1 in Papier).
- Ausgebildete Shake-Shake-Modelle mit einer einzelnen GPU (2 GPUs in Papier).
- Ausgebildeter Shake-Shake 26 2x64d (SSI) mit Chargengröße 64 und anfängliche Lernrate 0,1.
- Die oben angegebenen Testfehler sind diejenigen in der letzten Epoche.
- Experimente mit nur 1 Lauf werden auf einem anderen Computer durchgeführt als für Experimente mit 3 Läufen.
- Geforce GTX 980 wurde in diesen Experimenten verwendet.
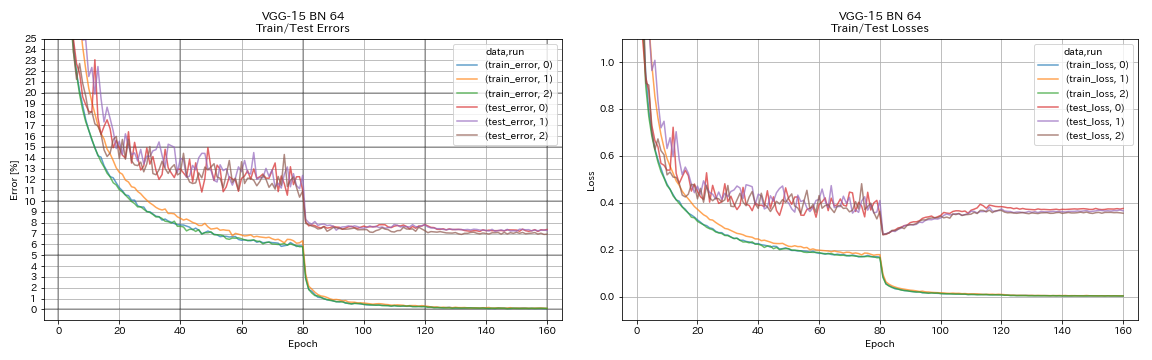
VGG-ähnlich
python train.py --config configs/cifar/vgg.yaml
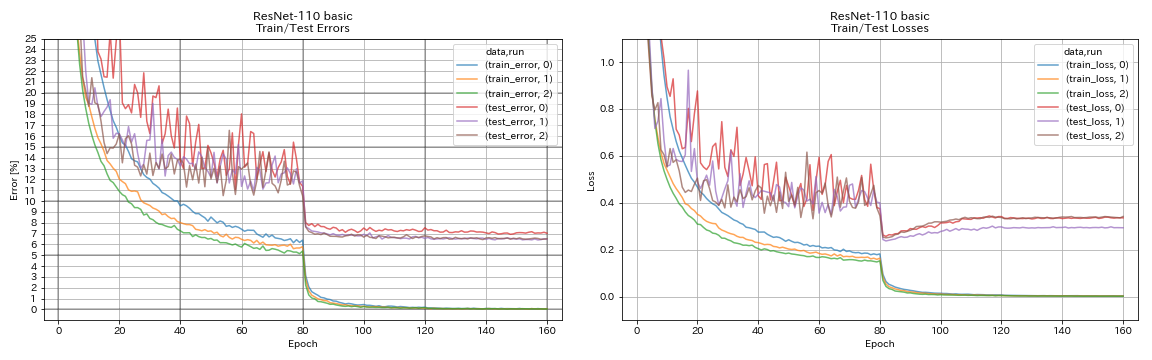
Resnet
python train.py --config configs/cifar/resnet.yaml
Resnet-preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00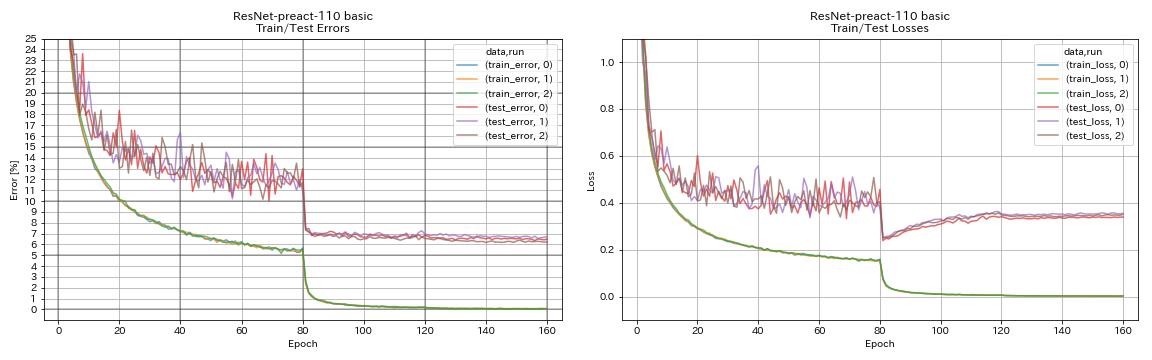
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00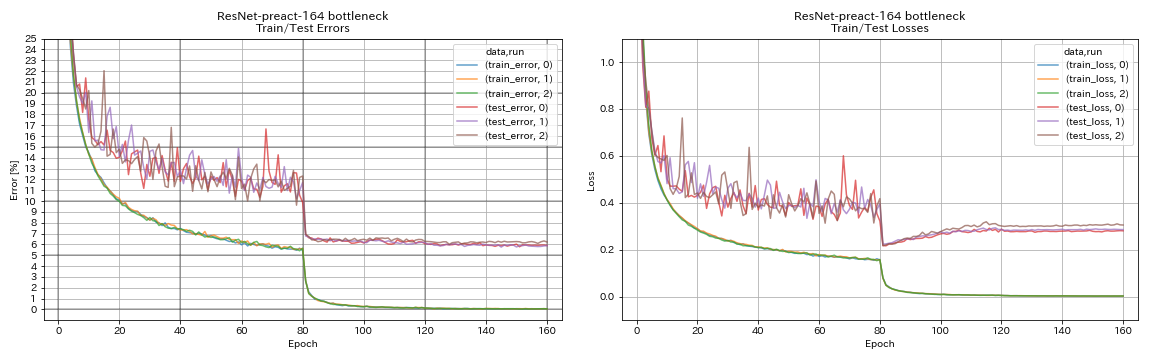
Wrn
python train.py --config configs/cifar/wrn.yaml
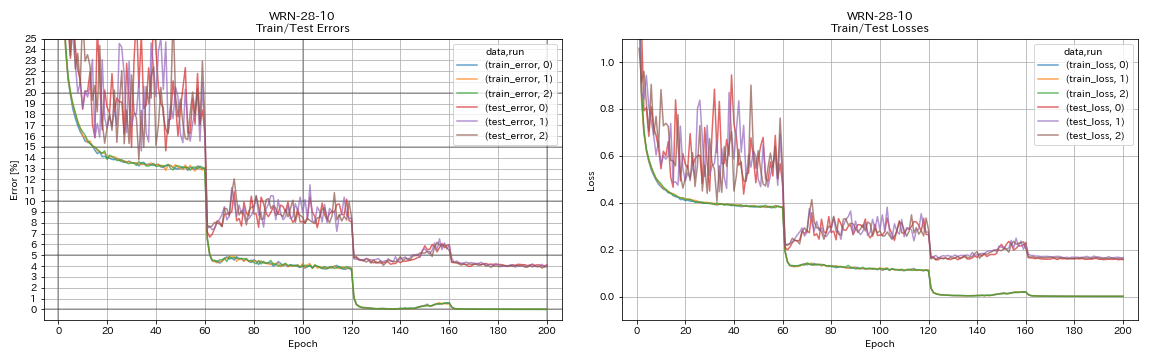
Densenet
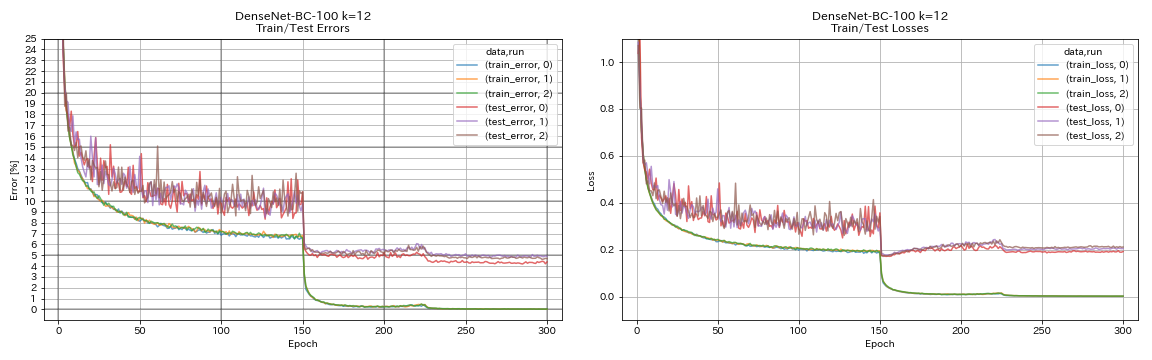
python train.py --config configs/cifar/densenet.yaml
Pyramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00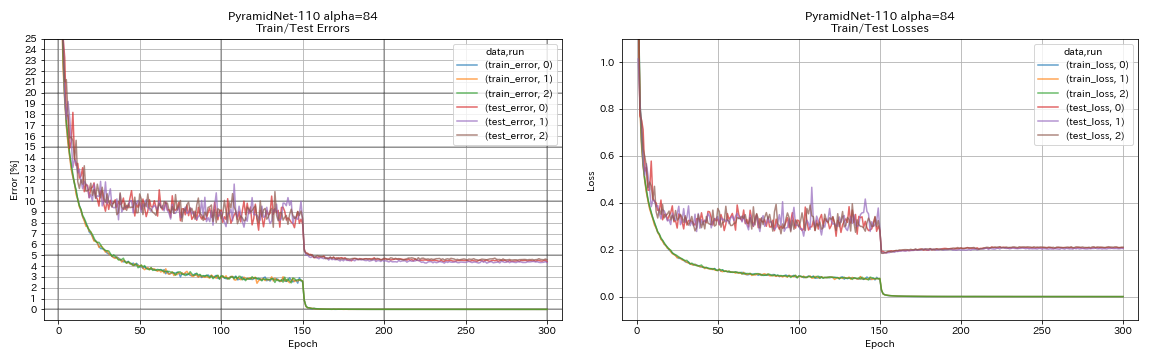
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00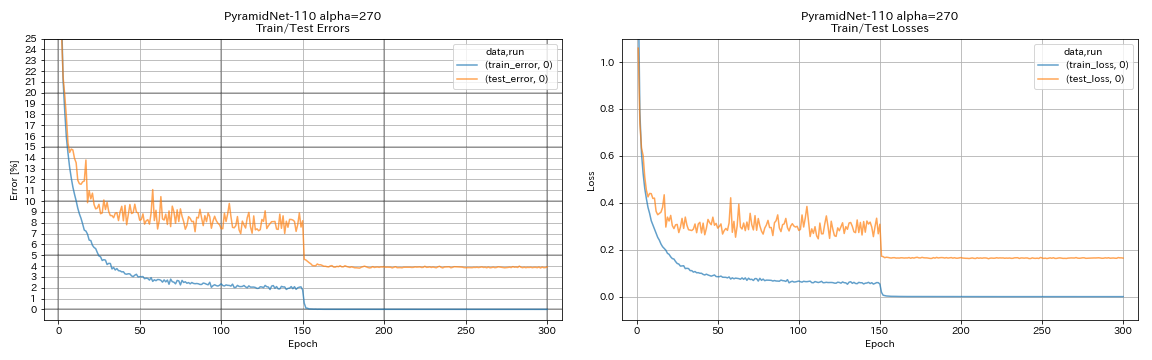
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00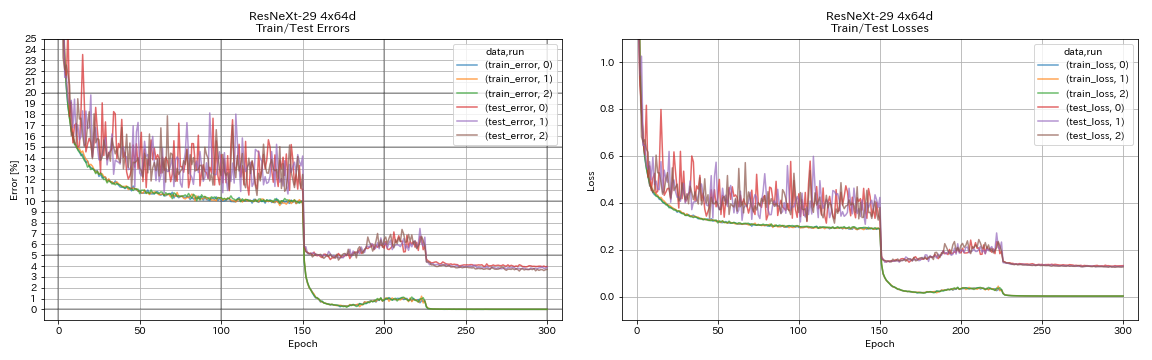
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00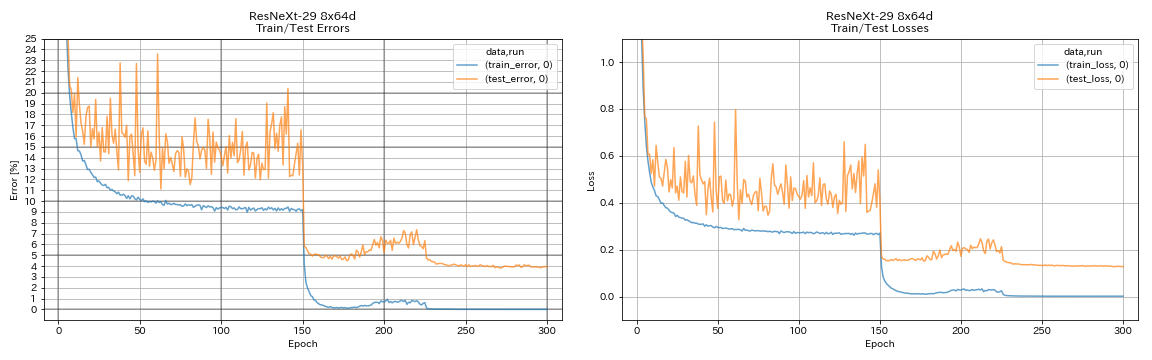
Shake-Shake
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00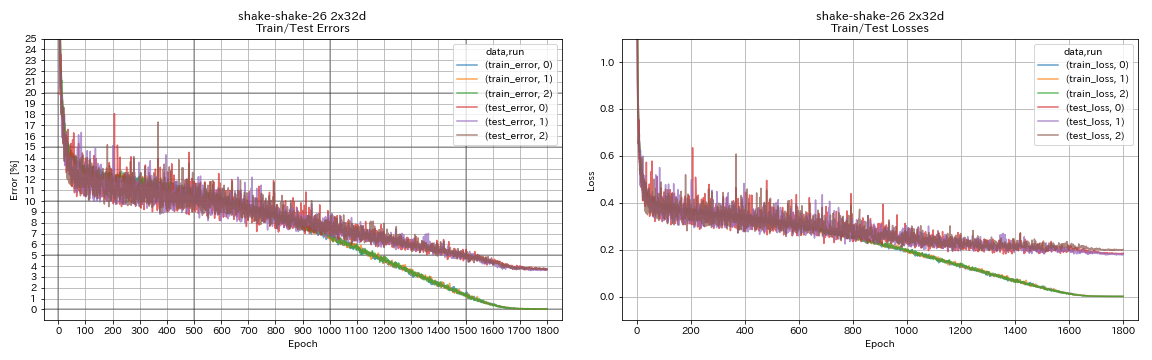
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00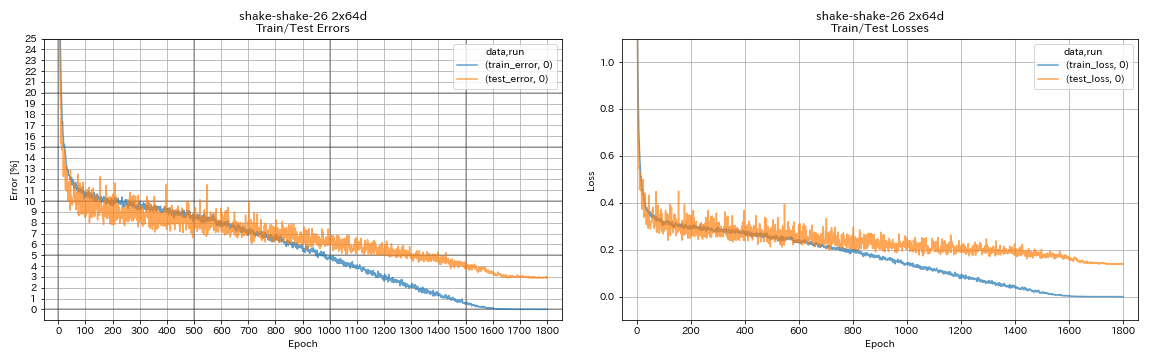
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00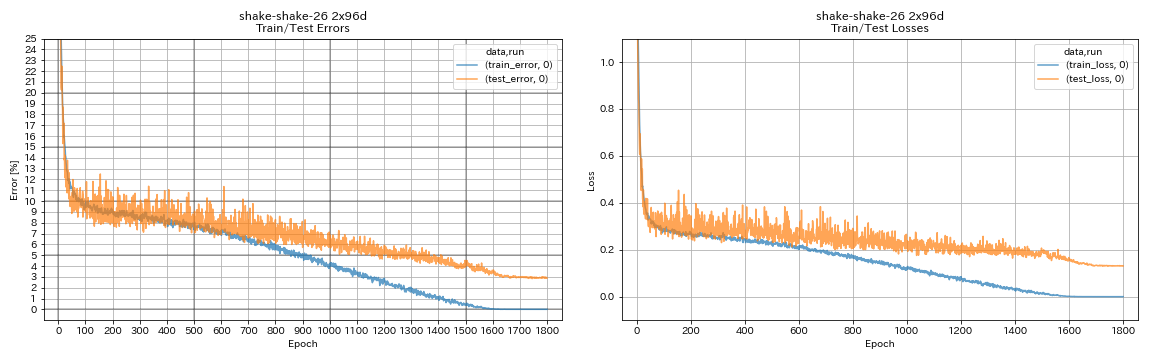
Ergebnisse
| Modell | Testfehler (1 Lauf) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20, Verbreiter Faktor 4 | 4.91 | 200 | 1H26m |
| Resnet-Preact-20, Verbreiter Faktor 4 | 4.01 | 400 | 2H53m |
| Resnet-Preact-20, Verbreiter Faktor 4 | 3.99 | 1800 | 12H53m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 16 | 3.71 | 200 | 1H26m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 16 | 3.46 | 400 | 2H53m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 16 | 3.76 | 1800 | 12H53m |
| Resnet-Preact-20, Verbreiter Faktor 4, RICAP (Beta = 0,3) | 3.45 | 200 | 1H26m |
| Resnet-Preact-20, Verbreiter Faktor 4, RICAP (Beta = 0,3) | 3.11 | 400 | 2H53m |
| Resnet-Preact-20, Verbreiter Faktor 4, RICAP (Beta = 0,3) | 3.15 | 1800 | 12H53m |
| Modell | Testfehler (1 Lauf) | Anzahl der Epochen | Trainingszeit |
|---|
| WRN-28-10, Ausschnitt 16 | 3.19 | 200 | 6H35m |
| WRN-28-10, Mixup (Alpha = 1) | 3.32 | 200 | 6H35m |
| WRN-28-10, RICAP (Beta = 0,3) | 2.83 | 200 | 6H35m |
| WRN-28-10, Dual-Cutout (Alpha = 0,1) | 2.87 | 200 | 12H42m |
| WRN-28-10, Ausschnitt 16 | 3.07 | 400 | 13H10m |
| WRN-28-10, Mixup (Alpha = 1) | 3.04 | 400 | 13H08m |
| WRN-28-10, RICAP (Beta = 0,3) | 2.71 | 400 | 13H08m |
| WRN-28-10, Dual-Cutout (Alpha = 0,1) | 2.76 | 400 | 25H20m |
| Shake-Shake-26 2x64d, Ausschnitt 16 | 2.64 | 1800 | 78H55m* |
| Shake-Shake-26 2x64d, Mixup (Alpha = 1) | 2.63 | 1800 | 35H56m |
| Shake-Shake-26 2x64d, Ricap (Beta = 0,3) | 2.29 | 1800 | 35H10m |
| Shake-Shake-26 2x64d, Dual-Cutout (Alpha = 0,1) | 2.64 | 1800 | 68H34m |
| Shake-Shake-26 2x96d, Ausschnitt 16 | 2.50 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Mischung (Alpha = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Ricap (Beta = 0,3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Dual-Cutout (Alpha = 0,1) | 2.41 | 1800 | 113H09m |
| Shake-Shake-26 2x128d, Ausschnitt 16 | 2.58 | 1800 | 85H04m |
| Shake-Shake-26 2x128d, Ricap (Beta = 0,3) | 1.97 | 1800 | 85H06m |
Notiz
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
- Alle Modelle werden unter Verwendung von Cosinus -Glühen mit anfänglicher Lernrate 0,2 trainiert.
- Geforce GTX 1080 TI wurde in diesen Experimenten verwendet, mit Ausnahme von *, die unter Verwendung von GeForce GTX 980 durchgeführt werden.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True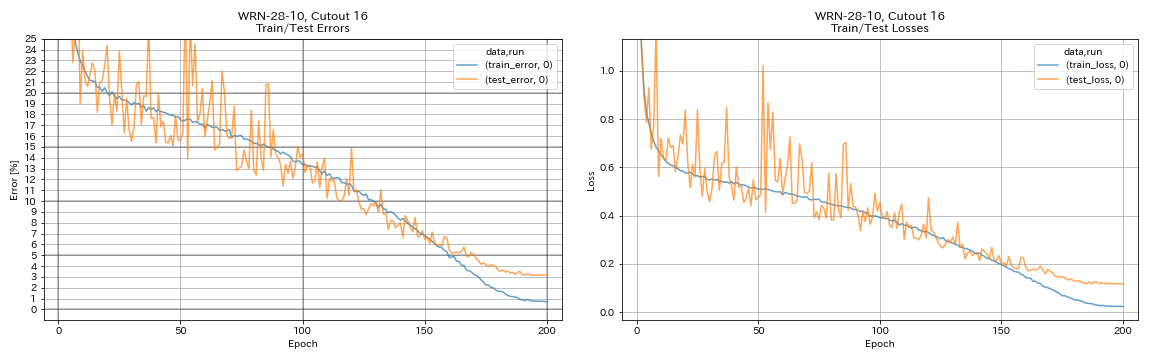
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True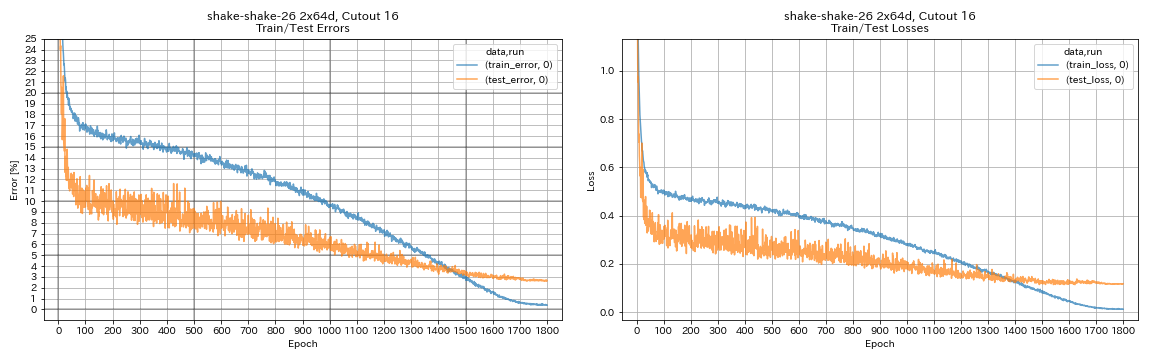
Ergebnisse mit Multi-GPU
| Modell | Chargengröße | #Gpus | Testfehler (1 Lauf) | Anzahl der Epochen | Trainingszeit* |
|---|
| WRN-28-10, RICAP (Beta = 0,3) | 512 | 1 | 2.63 | 200 | 3H41m |
| WRN-28-10, RICAP (Beta = 0,3) | 256 | 2 | 2.71 | 200 | 2H14m |
| WRN-28-10, RICAP (Beta = 0,3) | 128 | 4 | 2.89 | 200 | 1H01m |
| WRN-28-10, RICAP (Beta = 0,3) | 64 | 8 | 2.75 | 200 | 34 m |
Notiz
- Tesla v100 wurde in diesen Experimenten verwendet.
Mit 1 gpu
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMit 2 gpus
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMit 4 gpus
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMit 8 gpus
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseErgebnisse auf FashionMnist
| Modell | Testfehler (1 Lauf) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 12 | 4.17 | 200 | 1H32m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 14 | 4.11 | 200 | 1H32m |
| Resnet-Preact-50, Ausschnitt 12 | 4.45 | 200 | 57m |
| Resnet-Preact-50, Ausschnitt 14 | 4.38 | 200 | 57m |
| Resnet-Preact-50, Verbreiter Faktor 4, Ausschnitt 12 | 4.07 | 200 | 3H37m |
| Resnet-Preact-50, Verbreiter Faktor 4, Ausschnitt 14 | 4.13 | 200 | 3H39m |
| Shake-Shake-26 2x32d (SSI), Ausschnitt 12 | 4.08 | 400 | 3H41m |
| Shake-Shake-26 2x32d (SSI), Ausschnitt 14 | 4.05 | 400 | 3H39m |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 12 | 3.72 | 400 | 13H46m |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 14 | 3.85 | 400 | 13H39m |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 12 | 3.65 | 800 | 26H42m |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 14 | 3.60 | 800 | 26H42m |
| Modell | Testfehler (Median von 3 Läufen) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20 | 5.04 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 6 | 4.84 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 8 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 10 | 4.74 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 12 | 4.68 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 14 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Ausschnitt 16 | 4.49 | 200 | 26m |
| Resnet-Preact-20, Randomerasing | 4.61 | 200 | 26m |
| Resnet-Preact-20, Mischung | 4.92 | 200 | 26m |
| Resnet-Preact-20, Mischung | 4.64 | 400 | 52 m |
Notiz
- Die in den Tabellen angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
- Alle Modelle werden unter Verwendung von Cosinus -Glühen mit anfänglicher Lernrate 0,2 trainiert.
- Die folgenden Datenvergrößerungen werden auf die Schulungsdaten angewendet:
- Die Bilder sind auf jeder Seite mit 4 Pixel gepolstert und 28x28 -Patches werden zufällig aus den gepolsterten Bildern geschnitten.
- Bilder werden zufällig horizontal umgedreht.
- Geforce GTX 1080 TI wurde in diesen Experimenten verwendet.
Ergebnisse auf MNIST
| Modell | Testfehler (Median von 3 Läufen) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20 | 0,40 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 6 | 0,32 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 8 | 0,25 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 10 | 0,27 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 12 | 0,26 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 14 | 0,26 | 100 | 12 m |
| Resnet-Preact-20, Ausschnitt 16 | 0,25 | 100 | 12 m |
| Resnet-preact-20, Mixup (Alpha = 1) | 0,40 | 100 | 12 m |
| Resnet-preact-20, Mischung (Alpha = 0,5) | 0,38 | 100 | 12 m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 14 | 0,26 | 100 | 45 m |
| Resnet-Preact-50, Ausschnitt 14 | 0,29 | 100 | 28m |
| Resnet-Preact-50, Verbreiter Faktor 4, Ausschnitt 14 | 0,25 | 100 | 1H50M |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 14 | 0,24 | 100 | 3H22m |
Notiz
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
- Alle Modelle werden unter Verwendung von Cosinus -Glühen mit anfänglicher Lernrate 0,2 trainiert.
- Geforce GTX 1080 TI wurde in diesen Experimenten verwendet.
Ergebnisse zu Kuzushiji-Mnist
| Modell | Testfehler (Median von 3 Läufen) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20, Ausschnitt 14 | 0,82 (Beste 0,67) | 200 | 24m |
| Resnet-Preact-20, Verbreiter Faktor 4, Ausschnitt 14 | 0,72 (Beste 0,67) | 200 | 1H30M |
| Pyramidnet-110-270, Ausschnitt 14 | 0,72 (Beste 0,70) | 200 | 10H05m |
| Shake-Shake-26 2x96d (SSI), Ausschnitt 14 | 0,66 (Beste 0,63) | 200 | 6H46m |
Notiz
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
- Alle Modelle werden unter Verwendung von Cosinus -Glühen mit anfänglicher Lernrate 0,2 trainiert.
- Geforce GTX 1080 TI wurde in diesen Experimenten verwendet.
Experimente
Experimentieren Sie zu Resteinheiten, Lernrateplanung und Datenerweiterung
In diesem Experiment werden die Auswirkungen der folgenden Klassifizierungsgenauigkeit untersucht:
- Pyramidnet-ähnliche Resteinheiten
- Cosinus Glühen der Lernrate
- Ausgeschnitten
- Zufällige Löschung
- Verwechslung
- Vorwirkung von Verknüpfungen nach dem Abtastung
Resnet-Preact-56 wird in diesem Experiment auf CIFAR-10 mit anfänglicher Lernrate 0,2 trainiert.
Notiz
- Pyramidnet -Papier (1610.02915) zeigte, dass das Entfernen der ersten Relu in Resteinheiten und Hinzufügen von BN nach letzten Konvolutionen in Resteinheiten die Klassifizierungsgenauigkeit verbessern.
- SGDR -Papier (1608.03983) zeigte, dass Cosinus -Glühen auch ohne Neustart die Klassifizierungsgenauigkeit verbessert.
Ergebnisse
- Pyramidnet-ähnliche Einheiten funktioniert.
- Es könnte besser sein, keine Abkürzungen nach dem Down-Sampling bei der Verwendung von Pyramidnet-ähnlichen Einheiten nicht vorzuwirken.
- Cosinus -Tempern verbessert leicht die Genauigkeit.
- Ausschnitt, Randomerasing und Verwechseln funktionieren alle hervorragend.
- Mischung braucht ein längeres Training.
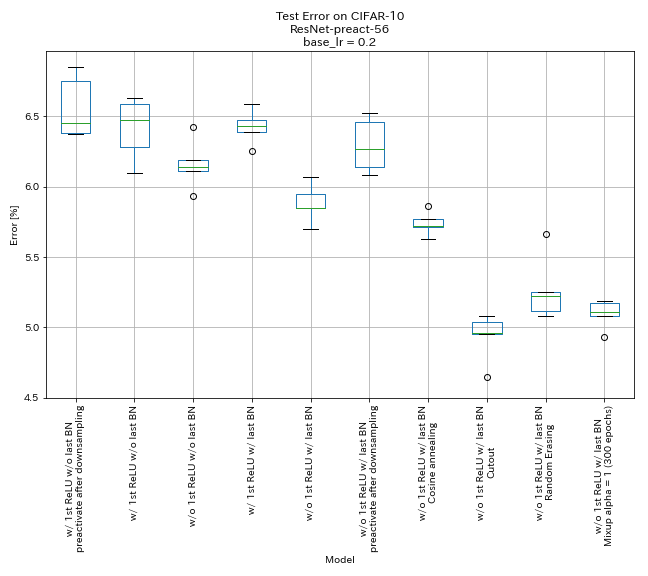
| Modell | Testfehler (Median von 5 Läufen) | Trainingszeit |
|---|
| w/ 1. Relu, ohne letzte BN, vorwirkung Verknüpfung nach dem Down -Sampling | 6.45 | 95 min |
| w/ 1. relu, ohne letztes Bn | 6.47 | 95 min |
| w/o 1. relu, ohne letztes Bn | 6.14 | 89 min |
| w/ 1. relu, mit letztem Bn | 6.43 | 104 min |
| w/ o 1. relu, mit letztem Bn | 5.85 | 98 min |
| w/ o 1. Relu, mit letzter BN, vorwirkende Verknüpfung nach dem Abtastung | 6.27 | 98 min |
| w/ o 1. Relu, mit letztem Bn, Cosinus Tempern | 5.72 | 98 min |
| w/ o 1. Relu, mit letzter Bn, Ausschnitt | 4.96 | 98 min |
| w/ o 1. Relu, mit letzter BN, Randomerasing | 5.22 | 98 min |
| w/ o 1. Relu, mit letzter Bn, Mischung (300 Epochen) | 5.11 | 191 min |
Vorwirkungsabkürzung nach dem Down -Sampling
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ 1. relu, ohne letztes Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o 1. relu, ohne letztes Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ 1. relu, mit letztem Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00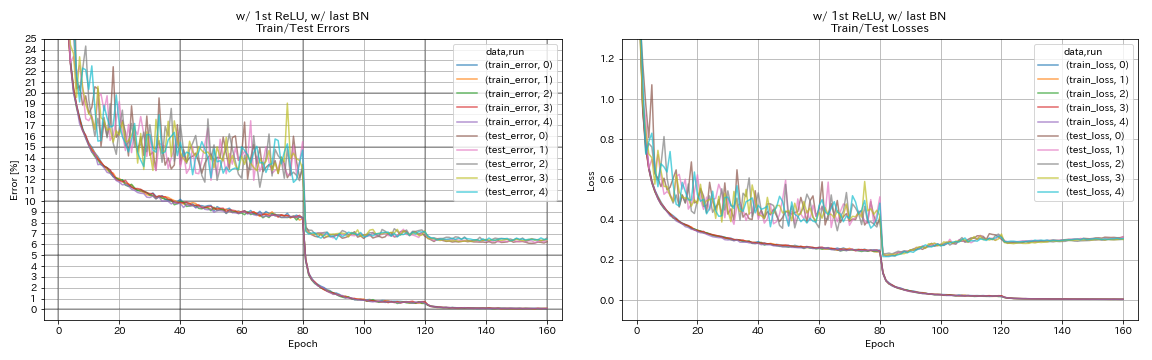
w/ o 1. relu, mit letztem Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00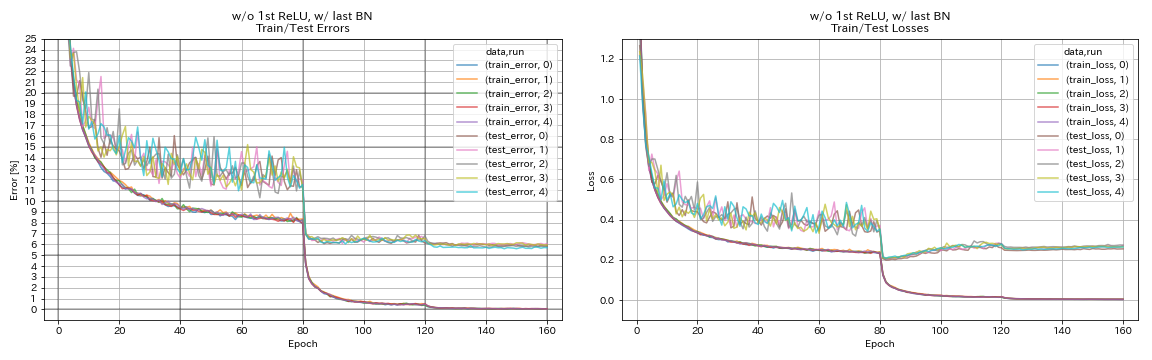
w/ o 1. Relu, mit letzter BN, vorwirkende Verknüpfung nach dem Abtastung
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00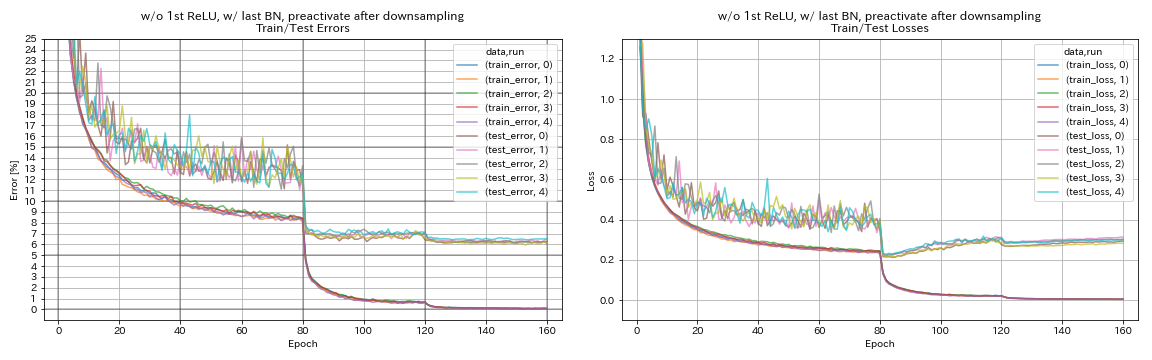
w/ o 1. Relu, mit letztem Bn, Cosinus Tempern
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00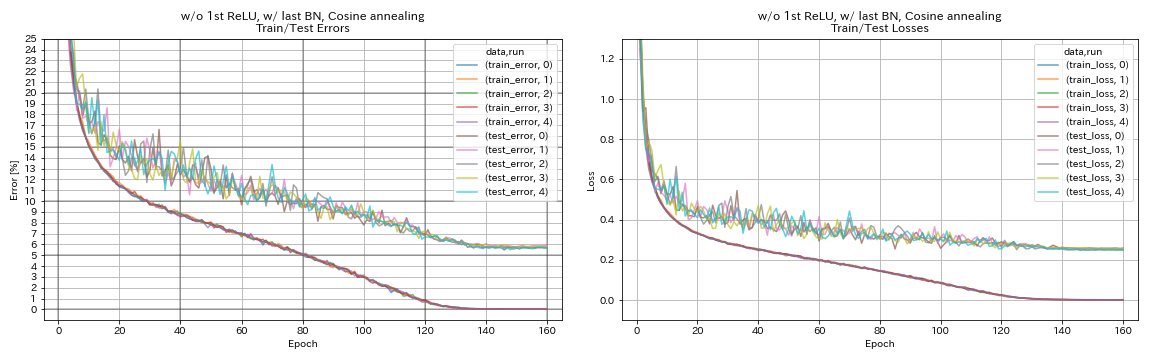
w/ o 1. Relu, mit letzter Bn, Ausschnitt
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00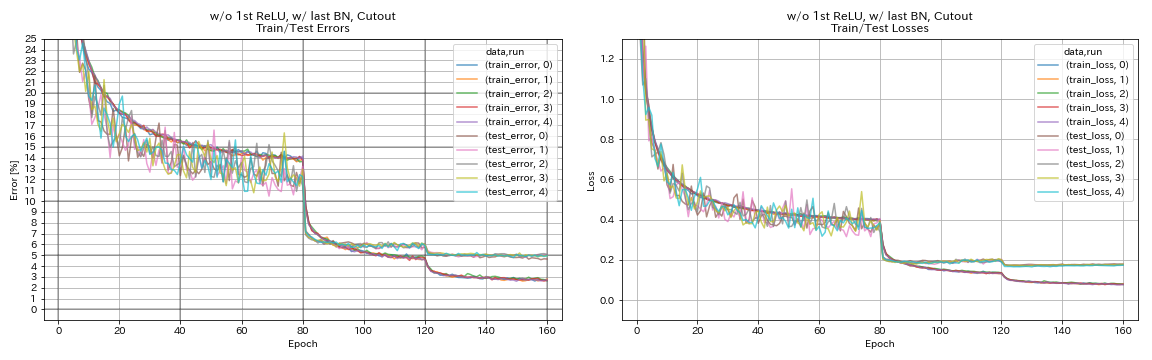
w/ o 1. Relu, mit letzter BN, Randomerasing
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00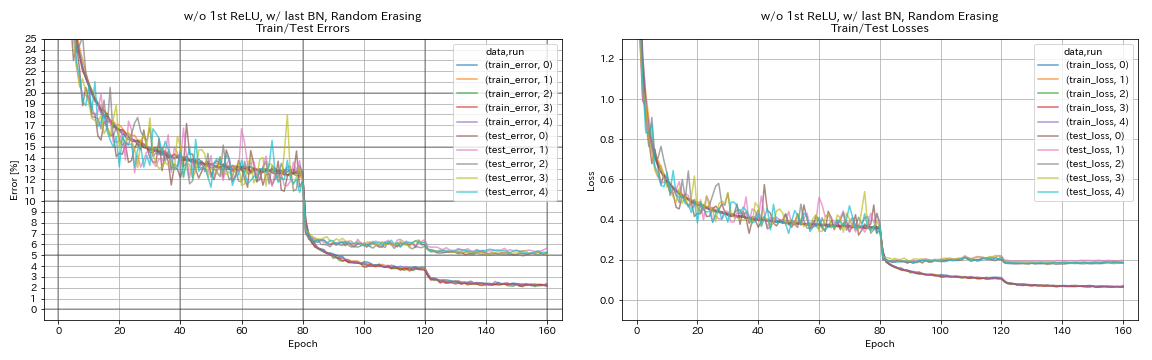
w/ o 1. relu, mit letztem Bn, Verwechslung
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00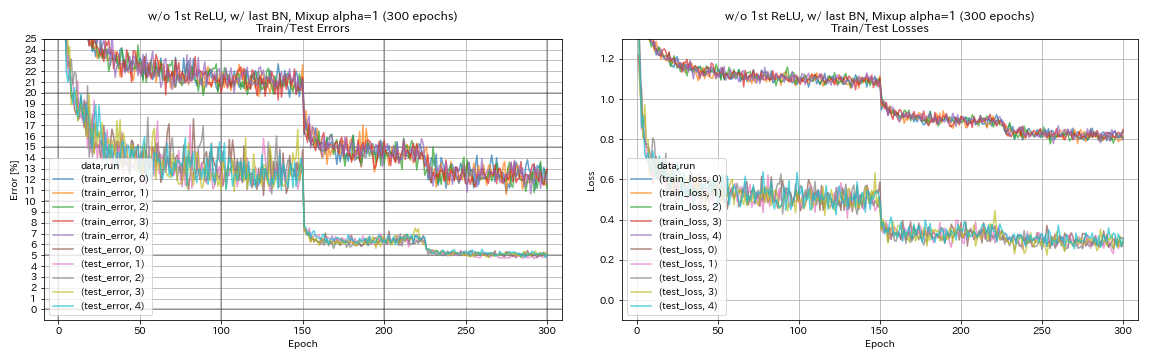
Experimente zur Glättung, Verwechslung, Ricap und Dual-Cutout
Ergebnisse zu CIFAR-10
| Modell | Testfehler (Median von 3 Läufen) | Anzahl der Epochen | Trainingszeit |
|---|
| Resnet-Preact-20 | 7.60 | 200 | 24m |
| Resnet-preact-20, Etikettenglättung (Epsilon = 0,001) | 7.51 | 200 | 25m |
| Resnet-preact-20, Etikett-Glättung (Epsilon = 0,01) | 7.21 | 200 | 25m |
| Resnet-preact-20, Etikett-Glättung (Epsilon = 0,1) | 7.57 | 200 | 25m |
| Resnet-preact-20, Mixup (Alpha = 1) | 7.24 | 200 | 26m |
| Resnet-preact-20, ricap (Beta = 0,3), mit zufälliger Ernte | 6.88 | 200 | 28m |
| Resnet-Preact-20, RICAP (Beta = 0,3) | 6.77 | 200 | 28m |
| Resnet-Preact-20, Dual-Cutout 16 (Alpha = 0,1) | 6.24 | 200 | 45 m |
| Resnet-Preact-20 | 7.05 | 400 | 49m |
| Resnet-preact-20, Etikettenglättung (Epsilon = 0,001) | 7.20 | 400 | 49m |
| Resnet-preact-20, Etikett-Glättung (Epsilon = 0,01) | 6.97 | 400 | 49m |
| Resnet-preact-20, Etikett-Glättung (Epsilon = 0,1) | 7.16 | 400 | 49m |
| Resnet-preact-20, Mixup (Alpha = 1) | 6.66 | 400 | 51 m |
| Resnet-preact-20, ricap (Beta = 0,3), mit zufälliger Ernte | 6.30 | 400 | 56 m |
| Resnet-Preact-20, RICAP (Beta = 0,3) | 6.19 | 400 | 56 m |
| Resnet-Preact-20, Dual-Cutout 16 (Alpha = 0,1) | 5.55 | 400 | 1H36m |
Notiz
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
- Alle Modelle werden unter Verwendung von Cosinus -Glühen mit anfänglicher Lernrate 0,2 trainiert.
- Geforce GTX 1080 TI wurde in diesen Experimenten verwendet.
Experimente zur Chargengröße und der Lernrate
- Die folgenden Experimente erfolgen mit CIFAR-10-Datensatz mit GeForce 1080 Ti.
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
Lineare Skalierungsregel für die Lernrate
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | Kosinus | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 200 | 8.87 | 21m |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 512 | 0,4 | Kosinus | 200 | 8.22 | 20m |
| Resnet-Preact-20 | 256 | 0,2 | Kosinus | 200 | 8.61 | 22m |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 200 | 8.09 | 24m |
| Resnet-Preact-20 | 64 | 0,05 | Kosinus | 200 | 8.22 | 28m |
| Resnet-Preact-20 | 32 | 0,025 | Kosinus | 200 | 8.00 | 43 m |
| Resnet-Preact-20 | 16 | 0,0125 | Kosinus | 200 | 7.75 | 1H17m |
| Resnet-Preact-20 | 8 | 0,006125 | Kosinus | 200 | 7.70 | 2H32m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | Multisep | 200 | 28.97 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | Multisep | 200 | 9.07 | 21m |
| Resnet-Preact-20 | 1024 | 0,8 | Multisep | 200 | 8.62 | 21m |
| Resnet-Preact-20 | 512 | 0,4 | Multisep | 200 | 8.23 | 20m |
| Resnet-Preact-20 | 256 | 0,2 | Multisep | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 128 | 0,1 | Multisep | 200 | 8.28 | 24m |
| Resnet-Preact-20 | 64 | 0,05 | Multisep | 200 | 8.13 | 28m |
| Resnet-Preact-20 | 32 | 0,025 | Multisep | 200 | 7.58 | 43 m |
| Resnet-Preact-20 | 16 | 0,0125 | Multisep | 200 | 7.93 | 1H18m |
| Resnet-Preact-20 | 8 | 0,006125 | Multisep | 200 | 8.31 | 2H34m |
Lineare Skalierung + längeres Training
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | Kosinus | 400 | 8.97 | 44 m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 400 | 7.85 | 43 m |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 400 | 7.20 | 42 m |
| Resnet-Preact-20 | 512 | 0,4 | Kosinus | 400 | 7.83 | 40 m |
| Resnet-Preact-20 | 256 | 0,2 | Kosinus | 400 | 7.65 | 42 m |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 400 | 7.09 | 47m |
| Resnet-Preact-20 | 64 | 0,05 | Kosinus | 400 | 7.17 | 44 m |
| Resnet-Preact-20 | 32 | 0,025 | Kosinus | 400 | 7.24 | 2H11m |
| Resnet-Preact-20 | 16 | 0,0125 | Kosinus | 400 | 7.26 | 4H10m |
| Resnet-Preact-20 | 8 | 0,006125 | Kosinus | 400 | 7.02 | 7H53m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | Kosinus | 800 | 8.14 | 1H29m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 800 | 7.74 | 1H23M |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 800 | 7.15 | 1H31m |
| Resnet-Preact-20 | 512 | 0,4 | Kosinus | 800 | 7.27 | 1H25m |
| Resnet-Preact-20 | 256 | 0,2 | Kosinus | 800 | 7.22 | 1H26m |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 800 | 6.68 | 1H35m |
| Resnet-Preact-20 | 64 | 0,05 | Kosinus | 800 | 7.18 | 2H20M |
| Resnet-Preact-20 | 32 | 0,025 | Kosinus | 800 | 7.03 | 4H16m |
| Resnet-Preact-20 | 16 | 0,0125 | Kosinus | 800 | 6.78 | 8H37M |
| Resnet-Preact-20 | 8 | 0,006125 | Kosinus | 800 | 6.89 | 16H47m |
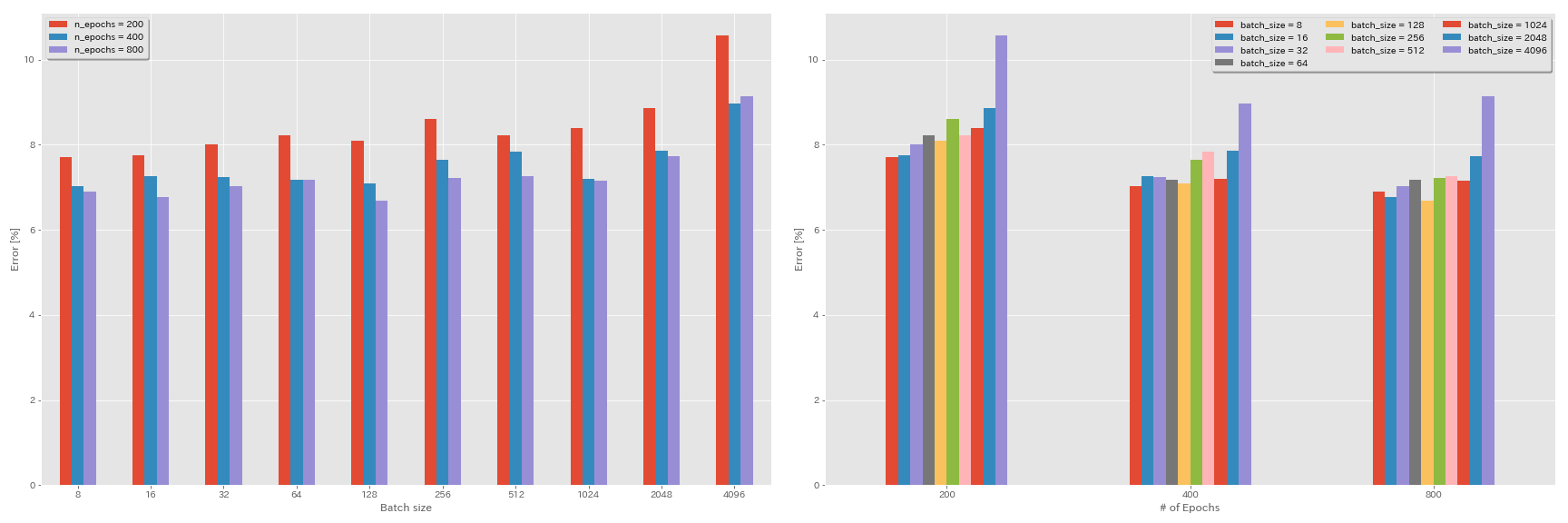
Auswirkung der anfänglichen Lernrate
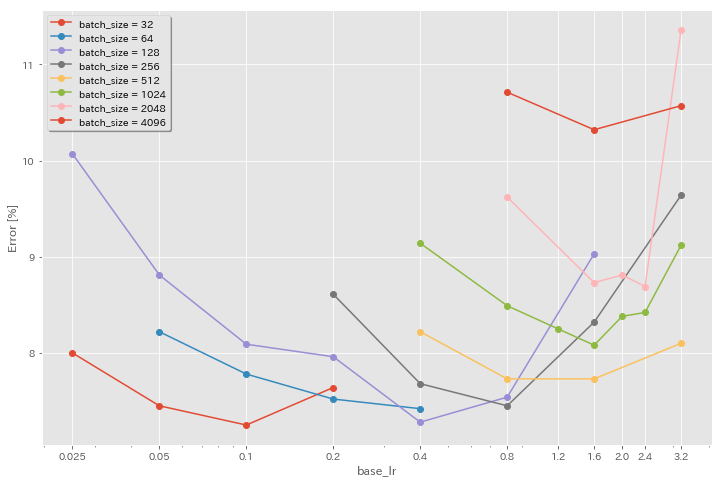
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | Kosinus | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 4096 | 1.6 | Kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 4096 | 0,8 | Kosinus | 200 | 10.71 | 22m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 2048 | 3.2 | Kosinus | 200 | 11.34 | 21m |
| Resnet-Preact-20 | 2048 | 2.4 | Kosinus | 200 | 8.69 | 21m |
| Resnet-Preact-20 | 2048 | 2.0 | Kosinus | 200 | 8.81 | 21m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 2048 | 0,8 | Kosinus | 200 | 9.62 | 21m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 1024 | 3.2 | Kosinus | 200 | 9.12 | 21m |
| Resnet-Preact-20 | 1024 | 2.4 | Kosinus | 200 | 8.42 | 22m |
| Resnet-Preact-20 | 1024 | 2.0 | Kosinus | 200 | 8.38 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | Kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 1.2 | Kosinus | 200 | 8.25 | 21m |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 1024 | 0,4 | Kosinus | 200 | 8.49 | 22m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 512 | 3.2 | Kosinus | 200 | 8.51 | 21m |
| Resnet-Preact-20 | 512 | 1.6 | Kosinus | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0,8 | Kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 512 | 0,4 | Kosinus | 200 | 8.22 | 20m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 256 | 3.2 | Kosinus | 200 | 9.64 | 22m |
| Resnet-Preact-20 | 256 | 1.6 | Kosinus | 200 | 8.32 | 22m |
| Resnet-Preact-20 | 256 | 0,8 | Kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 256 | 0,4 | Kosinus | 200 | 7.68 | 22m |
| Resnet-Preact-20 | 256 | 0,2 | Kosinus | 200 | 8.61 | 22m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 128 | 1.6 | Kosinus | 200 | 9.03 | 24m |
| Resnet-Preact-20 | 128 | 0,8 | Kosinus | 200 | 7.54 | 24m |
| Resnet-Preact-20 | 128 | 0,4 | Kosinus | 200 | 7.28 | 24m |
| Resnet-Preact-20 | 128 | 0,2 | Kosinus | 200 | 7.96 | 24m |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 200 | 8.09 | 24m |
| Resnet-Preact-20 | 128 | 0,05 | Kosinus | 200 | 8.81 | 24m |
| Resnet-Preact-20 | 128 | 0,025 | Kosinus | 200 | 10.07 | 24m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 64 | 0,4 | Kosinus | 200 | 7.42 | 35 m |
| Resnet-Preact-20 | 64 | 0,2 | Kosinus | 200 | 7.52 | 36 m |
| Resnet-Preact-20 | 64 | 0,1 | Kosinus | 200 | 7.78 | 37m |
| Resnet-Preact-20 | 64 | 0,05 | Kosinus | 200 | 8.22 | 28m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 32 | 0,2 | Kosinus | 200 | 7.64 | 1H05m |
| Resnet-Preact-20 | 32 | 0,1 | Kosinus | 200 | 7.25 | 1H08m |
| Resnet-Preact-20 | 32 | 0,05 | Kosinus | 200 | 7.45 | 1H07M |
| Resnet-Preact-20 | 32 | 0,025 | Kosinus | 200 | 8.00 | 43 m |
Gute Lernrate + längeres Training
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | Kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | Kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 512 | 1.6 | Kosinus | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0,8 | Kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 256 | 0,8 | Kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 128 | 0,4 | Kosinus | 200 | 7.28 | 24m |
| Resnet-Preact-20 | 128 | 0,2 | Kosinus | 200 | 7.96 | 24m |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 200 | 8.09 | 24m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | Kosinus | 800 | 8.36 | 1H33M |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 800 | 7.53 | 1H27M |
| Resnet-Preact-20 | 1024 | 1.6 | Kosinus | 800 | 7.30 | 1H30M |
| Resnet-Preact-20 | 1024 | 0,8 | Kosinus | 800 | 7.42 | 1H30M |
| Resnet-Preact-20 | 512 | 1.6 | Kosinus | 800 | 6.69 | 1H26m |
| Resnet-Preact-20 | 512 | 0,8 | Kosinus | 800 | 6.77 | 1H26m |
| Resnet-Preact-20 | 256 | 0,8 | Kosinus | 800 | 6.84 | 1H28m |
| Resnet-Preact-20 | 128 | 0,4 | Kosinus | 800 | 6.86 | 1H35m |
| Resnet-Preact-20 | 128 | 0,2 | Kosinus | 800 | 7.05 | 1H38M |
| Resnet-Preact-20 | 128 | 0,1 | Kosinus | 800 | 6.68 | 1H35m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | Kosinus | 1600 | 8.25 | 3H10m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 1600 | 7.34 | 2H50m |
| Resnet-Preact-20 | 1024 | 1.6 | Kosinus | 1600 | 6.94 | 2H52m |
| Resnet-Preact-20 | 512 | 1.6 | Kosinus | 1600 | 6.99 | 2H44m |
| Resnet-Preact-20 | 256 | 0,8 | Kosinus | 1600 | 6.95 | 2H50m |
| Resnet-Preact-20 | 128 | 0,4 | Kosinus | 1600 | 6.64 | 3H09m |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | Kosinus | 3200 | 9.52 | 6H15m |
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 3200 | 6.92 | 5H42m |
| Resnet-Preact-20 | 1024 | 1.6 | Kosinus | 3200 | 6.96 | 5H43M |
| Modell | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 2048 | 1.6 | Kosinus | 6400 | 7.45 | 11H44m |
Lars
- In den Originalpapieren (1708.03888, 1801.03137) verwendeten sie die polynomiale Abklinger -Lernrate -Planung, aber in diesen Experimenten wird Cosinus -Tempern verwendet.
- In dieser Implementierung wird der LARS -Koeffizient nicht verwendet, sodass die Lernrate entsprechend angepasst werden sollte.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00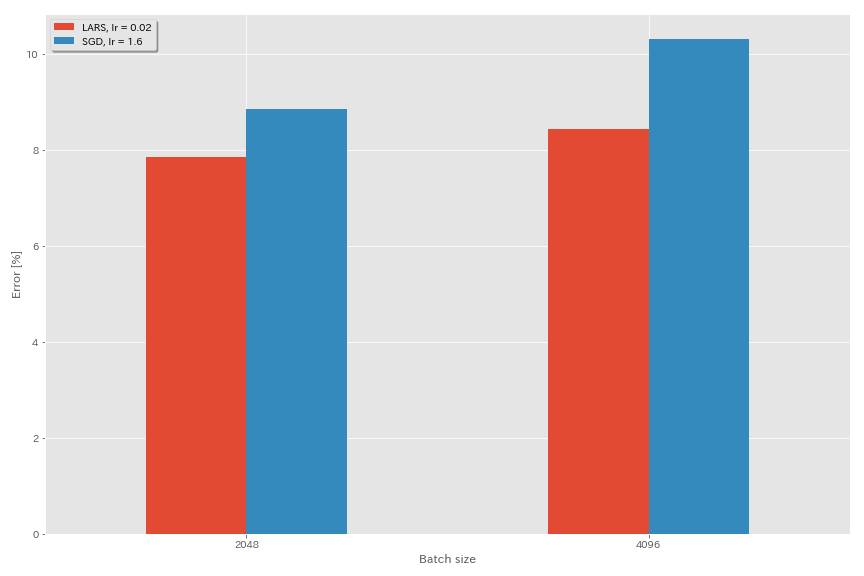
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 4096 | 3.2 | Kosinus | 200 | 10.57 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | Kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 0,8 | Kosinus | 200 | 10.71 (1 Lauf) | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,04 | Kosinus | 200 | 9.58 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,03 | Kosinus | 200 | 8.46 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | Kosinus | 200 | 8.21 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,015 | Kosinus | 200 | 8.47 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,01 | Kosinus | 200 | 9.33 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,005 | Kosinus | 200 | 14.31 | 22m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 2048 | 3.2 | Kosinus | 200 | 11.34 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.4 | Kosinus | 200 | 8.69 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.0 | Kosinus | 200 | 8,81 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 1.6 | Kosinus | 200 | 8.73 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 2048 | 0,8 | Kosinus | 200 | 9.62 (1 Lauf) | 21m |
| Resnet-Preact-20 | Lars | 2048 | 0,04 | Kosinus | 200 | 11.58 | 21m |
| Resnet-Preact-20 | Lars | 2048 | 0,02 | Kosinus | 200 | 8.05 | 22m |
| Resnet-Preact-20 | Lars | 2048 | 0,01 | Kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | Lars | 2048 | 0,005 | Kosinus | 200 | 9.65 | 22m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 1024 | 3.2 | Kosinus | 200 | 9.12 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 2.4 | Kosinus | 200 | 8.42 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 2.0 | Kosinus | 200 | 8.38 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.6 | Kosinus | 200 | 8.07 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.2 | Kosinus | 200 | 8.25 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 0,8 | Kosinus | 200 | 8.08 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 0,4 | Kosinus | 200 | 8.49 (1 Lauf) | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,02 | Kosinus | 200 | 9.30 | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,01 | Kosinus | 200 | 7.68 | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,005 | Kosinus | 200 | 8.88 | 23 m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 512 | 3.2 | Kosinus | 200 | 8.51 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 512 | 1.6 | Kosinus | 200 | 7.73 (1 Lauf) | 20m |
| Resnet-Preact-20 | SGD | 512 | 0,8 | Kosinus | 200 | 7.73 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 512 | 0,4 | Kosinus | 200 | 8.22 (1 Lauf) | 20m |
| Resnet-Preact-20 | Lars | 512 | 0,015 | Kosinus | 200 | 9.84 | 23 m |
| Resnet-Preact-20 | Lars | 512 | 0,01 | Kosinus | 200 | 8.05 | 23 m |
| Resnet-Preact-20 | Lars | 512 | 0,0075 | Kosinus | 200 | 7.58 | 23 m |
| Resnet-Preact-20 | Lars | 512 | 0,005 | Kosinus | 200 | 7.96 | 23 m |
| Resnet-Preact-20 | Lars | 512 | 0,0025 | Kosinus | 200 | 8.83 | 23 m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 256 | 3.2 | Kosinus | 200 | 9.64 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 256 | 1.6 | Kosinus | 200 | 8.32 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0,8 | Kosinus | 200 | 7.45 (1 Lauf) | 21m |
| Resnet-Preact-20 | SGD | 256 | 0,4 | Kosinus | 200 | 7.68 (1 Lauf) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0,2 | Kosinus | 200 | 8.61 (1 Lauf) | 22m |
| Resnet-Preact-20 | Lars | 256 | 0,01 | Kosinus | 200 | 8.95 | 27m |
| Resnet-Preact-20 | Lars | 256 | 0,005 | Kosinus | 200 | 7.75 | 28m |
| Resnet-Preact-20 | Lars | 256 | 0,0025 | Kosinus | 200 | 8.21 | 28m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 128 | 1.6 | Kosinus | 200 | 9.03 (1 Lauf) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0,8 | Kosinus | 200 | 7,54 (1 Lauf) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0,4 | Kosinus | 200 | 7.28 (1 Lauf) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0,2 | Kosinus | 200 | 7,96 (1 Lauf) | 24m |
| Resnet-Preact-20 | Lars | 128 | 0,005 | Kosinus | 200 | 7.96 | 37m |
| Resnet-Preact-20 | Lars | 128 | 0,0025 | Kosinus | 200 | 7.98 | 37m |
| Resnet-Preact-20 | Lars | 128 | 0,00125 | Kosinus | 200 | 9.21 | 37m |
| Modell | Optimierer | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | SGD | 4096 | 1.6 | Kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | Kosinus | 800 | 8.36 (1 Lauf) | 1H33M |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | Kosinus | 1600 | 8.25 (1 Lauf) | 3H10m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | Kosinus | 200 | 8.21 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | Kosinus | 400 | 7.53 | 44 m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | Kosinus | 800 | 7.48 | 1H29m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | Kosinus | 1600 | 7.37 (1 Lauf) | 2H58m |
Ghost Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Modell | Chargengröße | Ghost Batchgröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 8192 | N / A | 1.6 | Kosinus | 200 | 12.35 | 25m* |
| Resnet-Preact-20 | 4096 | N / A | 1.6 | Kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | N / A | 1.6 | Kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | N / A | 1.6 | Kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 128 | N / A | 0,4 | Kosinus | 200 | 7.28 | 24m |
| Modell | Chargengröße | Ghost Batchgröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | Kosinus | 200 | 11.51 | 27m |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | Kosinus | 200 | 9.73 | 25m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | Kosinus | 200 | 8.77 | 24m |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | Kosinus | 200 | 7.82 | 22m |
| Modell | Chargengröße | Ghost Batchgröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 8192 | N / A | 1.6 | Kosinus | 1600 | | |
| Resnet-Preact-20 | 4096 | N / A | 1.6 | Kosinus | 1600 | 8.25 | 3H10m |
| Resnet-Preact-20 | 2048 | N / A | 1.6 | Kosinus | 1600 | 7.34 | 2H50m |
| Resnet-Preact-20 | 1024 | N / A | 1.6 | Kosinus | 1600 | 6.94 | 2H52m |
| Modell | Chargengröße | Ghost Batchgröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | Kosinus | 1600 | 11.83 | 3H37m |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | Kosinus | 1600 | 8.95 | 3H15m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | Kosinus | 1600 | 7.23 | 3H05m |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | Kosinus | 1600 | 7.08 | 2H59m |
Kein Gewichtsverfall bei BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00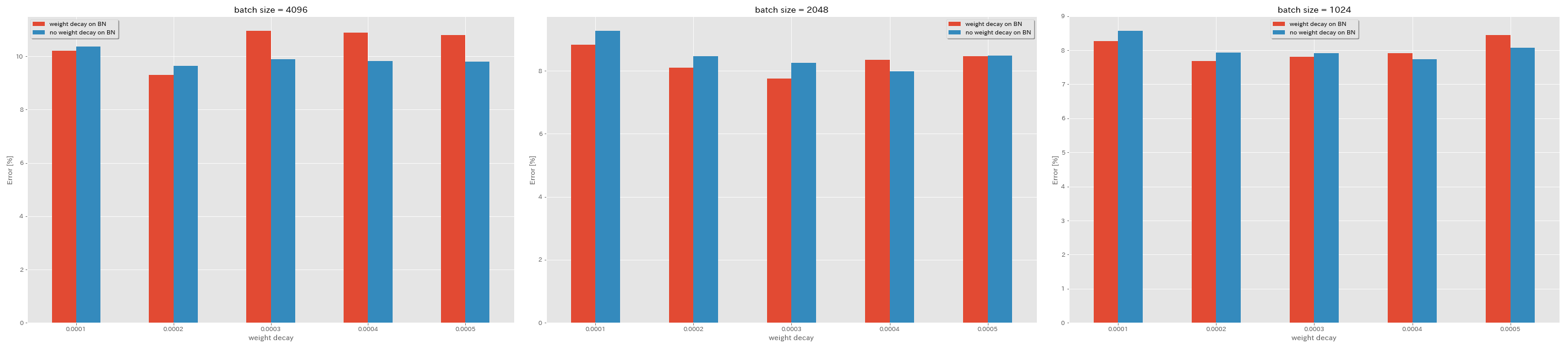
| Modell | Gewichtsverfall bei BN | Gewichtsverfall | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | Ja | 5e-4 | 4096 | 1.6 | Kosinus | 200 | 10.81 | 22m |
| Resnet-Preact-20 | Ja | 4e-4 | 4096 | 1.6 | Kosinus | 200 | 10.88 | 22m |
| Resnet-Preact-20 | Ja | 3e-4 | 4096 | 1.6 | Kosinus | 200 | 10.96 | 22m |
| Resnet-Preact-20 | Ja | 2E-4 | 4096 | 1.6 | Kosinus | 200 | 9.30 | 22m |
| Resnet-Preact-20 | Ja | 1e-4 | 4096 | 1.6 | Kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | NEIN | 5e-4 | 4096 | 1.6 | Kosinus | 200 | 8.78 | 22m |
| Resnet-Preact-20 | NEIN | 4e-4 | 4096 | 1.6 | Kosinus | 200 | 9.83 | 22m |
| Resnet-Preact-20 | NEIN | 3e-4 | 4096 | 1.6 | Kosinus | 200 | 9.90 | 22m |
| Resnet-Preact-20 | NEIN | 2E-4 | 4096 | 1.6 | Kosinus | 200 | 9.64 | 22m |
| Resnet-Preact-20 | NEIN | 1e-4 | 4096 | 1.6 | Kosinus | 200 | 10.38 | 22m |
| Modell | Gewichtsverfall bei BN | Gewichtsverfall | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | Ja | 5e-4 | 2048 | 1.6 | Kosinus | 200 | 8.46 | 20m |
| Resnet-Preact-20 | Ja | 4e-4 | 2048 | 1.6 | Kosinus | 200 | 8.35 | 20m |
| Resnet-Preact-20 | Ja | 3e-4 | 2048 | 1.6 | Kosinus | 200 | 7.76 | 20m |
| Resnet-Preact-20 | Ja | 2E-4 | 2048 | 1.6 | Kosinus | 200 | 8.09 | 20m |
| Resnet-Preact-20 | Ja | 1e-4 | 2048 | 1.6 | Kosinus | 200 | 8.83 | 20m |
| Resnet-Preact-20 | NEIN | 5e-4 | 2048 | 1.6 | Kosinus | 200 | 8.49 | 20m |
| Resnet-Preact-20 | NEIN | 4e-4 | 2048 | 1.6 | Kosinus | 200 | 7.98 | 20m |
| Resnet-Preact-20 | NEIN | 3e-4 | 2048 | 1.6 | Kosinus | 200 | 8.26 | 20m |
| Resnet-Preact-20 | NEIN | 2E-4 | 2048 | 1.6 | Kosinus | 200 | 8.47 | 20m |
| Resnet-Preact-20 | NEIN | 1e-4 | 2048 | 1.6 | Kosinus | 200 | 9.27 | 20m |
| Modell | Gewichtsverfall bei BN | Gewichtsverfall | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (Median von 3 Läufen) | Trainingszeit |
|---|
| Resnet-Preact-20 | Ja | 5e-4 | 1024 | 1.6 | Kosinus | 200 | 8.45 | 21m |
| Resnet-Preact-20 | Ja | 4e-4 | 1024 | 1.6 | Kosinus | 200 | 7.91 | 21m |
| Resnet-Preact-20 | Ja | 3e-4 | 1024 | 1.6 | Kosinus | 200 | 7.81 | 21m |
| Resnet-Preact-20 | Ja | 2E-4 | 1024 | 1.6 | Kosinus | 200 | 7.69 | 21m |
| Resnet-Preact-20 | Ja | 1e-4 | 1024 | 1.6 | Kosinus | 200 | 8.26 | 21m |
| Resnet-Preact-20 | NEIN | 5e-4 | 1024 | 1.6 | Kosinus | 200 | 8.08 | 21m |
| Resnet-Preact-20 | NEIN | 4e-4 | 1024 | 1.6 | Kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | NEIN | 3e-4 | 1024 | 1.6 | Kosinus | 200 | 7.92 | 21m |
| Resnet-Preact-20 | NEIN | 2E-4 | 1024 | 1.6 | Kosinus | 200 | 7.93 | 21m |
| Resnet-Preact-20 | NEIN | 1e-4 | 1024 | 1.6 | Kosinus | 200 | 8.53 | 21m |
Experimente zur halben Präzision und zur Mischprezision
- Folgende Experimente benötigen Nvidia Apex.
- Die folgenden Experimente erfolgen mit CIFAR-10-Datensatz mit GeForce 1080 Ti, das keine Tensorkerne aufweist.
- Die in der Tabelle angegebenen Ergebnisse sind die Testfehler bei den letzten Epochen.
FP16 Training
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Training mit gemischter Präzision
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Ergebnisse
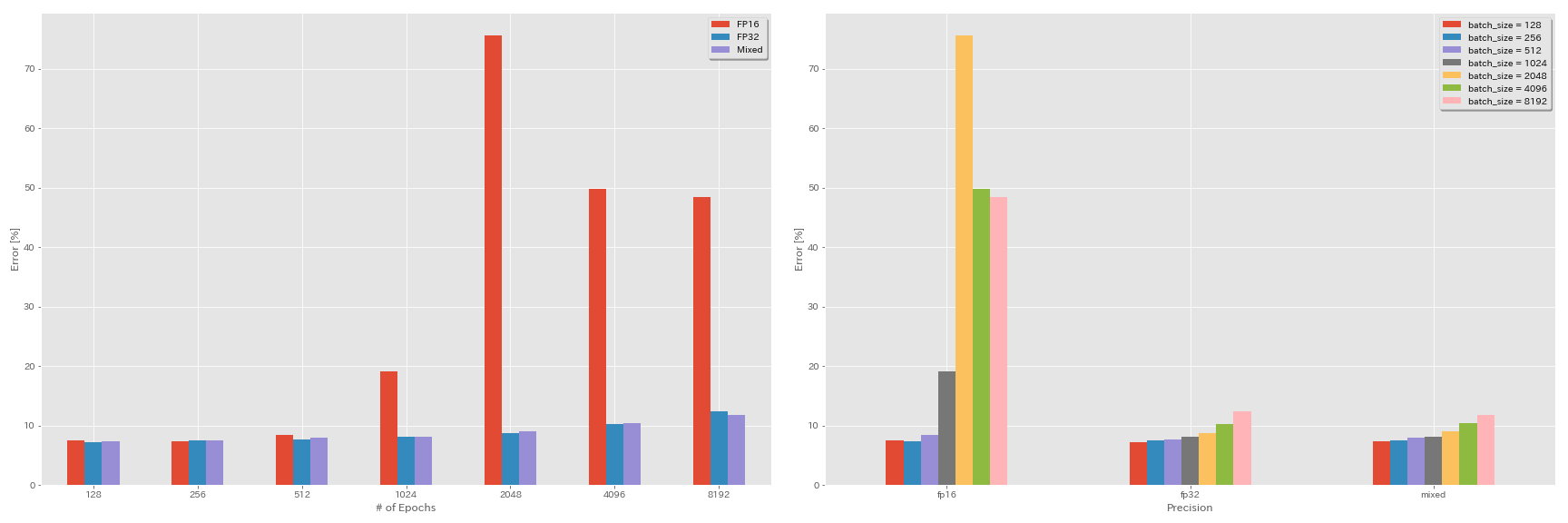
| Modell | Präzision | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | FP32 | 8192 | 1.6 | Kosinus | 200 | | |
| Resnet-Preact-20 | FP32 | 4096 | 1.6 | Kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | FP32 | 2048 | 1.6 | Kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | FP32 | 1024 | 1.6 | Kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | FP32 | 512 | 0,8 | Kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | FP32 | 256 | 0,8 | Kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | FP32 | 128 | 0,4 | Kosinus | 200 | 7.28 | 24m |
| Modell | Präzision | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | FP16 | 8192 | 1.6 | Kosinus | 200 | 48,52 | 33 m |
| Resnet-Preact-20 | FP16 | 4096 | 1.6 | Kosinus | 200 | 49,84 | 28m |
| Resnet-Preact-20 | FP16 | 2048 | 1.6 | Kosinus | 200 | 75,63 | 27m |
| Resnet-Preact-20 | FP16 | 1024 | 1.6 | Kosinus | 200 | 19.09 | 27m |
| Resnet-Preact-20 | FP16 | 512 | 0,8 | Kosinus | 200 | 7.89 | 26m |
| Resnet-Preact-20 | FP16 | 256 | 0,8 | Kosinus | 200 | 7.40 | 28m |
| Resnet-Preact-20 | FP16 | 128 | 0,4 | Kosinus | 200 | 7.59 | 32 m |
| Modell | Präzision | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | gemischt | 8192 | 1.6 | Kosinus | 200 | 11.78 | 28m |
| Resnet-Preact-20 | gemischt | 4096 | 1.6 | Kosinus | 200 | 10.48 | 27m |
| Resnet-Preact-20 | gemischt | 2048 | 1.6 | Kosinus | 200 | 8.98 | 26m |
| Resnet-Preact-20 | gemischt | 1024 | 1.6 | Kosinus | 200 | 8.05 | 26m |
| Resnet-Preact-20 | gemischt | 512 | 0,8 | Kosinus | 200 | 7.81 | 28m |
| Resnet-Preact-20 | gemischt | 256 | 0,8 | Kosinus | 200 | 7.58 | 32 m |
| Resnet-Preact-20 | gemischt | 128 | 0,4 | Kosinus | 200 | 7.37 | 41 m |
Ergebnisse mit Tesla v100
| Modell | Präzision | Chargengröße | Anfang LR | LR -Zeitplan | Anzahl der Epochen | Testfehler (1 Lauf) | Trainingszeit |
|---|
| Resnet-Preact-20 | FP32 | 8192 | 1.6 | Kosinus | 200 | 12.35 | 25m |
| Resnet-Preact-20 | FP32 | 4096 | 1.6 | Kosinus | 200 | 9.88 | 19m |
| Resnet-Preact-20 | FP32 | 2048 | 1.6 | Kosinus | 200 | 8.87 | 17m |
| Resnet-Preact-20 | FP32 | 1024 | 1.6 | Kosinus | 200 | 8.45 | 18m |
| Resnet-Preact-20 | gemischt | 8192 | 1.6 | Kosinus | 200 | 11.92 | 25m |
| Resnet-Preact-20 | gemischt | 4096 | 1.6 | Kosinus | 200 | 10.16 | 19m |
| Resnet-Preact-20 | gemischt | 2048 | 1.6 | Kosinus | 200 | 9.10 | 17m |
| Resnet-Preact-20 | gemischt | 1024 | 1.6 | Kosinus | 200 | 7.84 | 16m |
Referenzen
Modellarchitektur
- Er, Kaiming, Xiangyu Zhang, Shaoqing Ren und Jian Sun. "Tiefes Restlernen für die Bilderkennung." Die IEEE -Konferenz über Computer Vision und Mustererkennung (CVPR), 2016. Link, Arxiv: 1512.03385
- Er, Kaiming, Xiangyu Zhang, Shaoqing Ren und Jian Sun. "Identitätszuordnungen in tiefen Restnetzwerken." In der Europäischen Konferenz über Computer Vision (ECCV). 2016. ARXIV: 1603.05027, Taschenlampe -Implementierung
- Zagoruyko, Sergey und Nikos Komodakis. "Breite Restnetzwerke." Proceedings of the British Machine Vision Conference (BMVC), 2016. ARXIV: 1605.07146, Fackelimplementierung
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger und Laurens van der Maaten. "Dicht verbundene Faltungsnetzwerke." Die IEEE -Konferenz über Computer Vision und Mustererkennung (CVPR), 2017. Link, Arxiv: 1608.06993, Torchimplementierung
- Han, Dongyoon, Jiwhan Kim und Junmo Kim. "Deep Pyramidal Rest Networks." Die IEEE -Konferenz über Computer Vision und Mustererkennung (CVPR), 2017.
- Xie, Saint, Ross Girshick, Piotr -Dollar, Zhuowen Tu und Kaiming He. "Aggregierte Resttransformationen für tiefe neuronale Netze." Die IEEE -Konferenz über Computer Vision und Mustererkennung (CVPR), 2017. Link, Arxiv: 1611.05431, Torchimplementierung
- Gastaldi, Xavier. "Shake-Shake-Regularisierung von 3-Branch-Restnetzwerken." In International Conference on Learning Repräsentations (ICLR) Workshop, 2017.
- Hu, Jie, Li Shen und Gang Sun. "Squeeze-and-Excitation-Netzwerke." Die IEEE-Konferenz über Computer Vision und Mustererkennung (CVPR), 2018, S. 7132-7141. Link, Arxiv: 1709.01507, Kaffe -Implementierung
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten und Kilian Q. Weinberger. "Faltungsnetzwerke mit einer dichten Konnektivität." IEEE -Transaktionen zur Musteranalyse und Maschine Intelligence (2019). ARXIV: 2001.02394
Regularisierung, Datenvergrößerung
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shrens und Zbigniew Wojna. "Die Inception -Architektur für Computer Vision überdenken." Die IEEE -Konferenz über Computer Vision und Mustererkennung (CVPR), 2016. Link, Arxiv: 1512.00567
- Devries, Terrance und Graham W. Taylor. "Verbesserte Regularisierung von Faltungsnetzwerken mit Ausschnitten." Arxiv Preprint Arxiv: 1708.04552 (2017). ARXIV: 1708.04552, Pytorch -Implementierung
- Abu-El-Haija, Sami. "Proportionierte Gradientenaktualisierungen mit Prozentdelta." Arxiv Preprint Arxiv: 1708.07227 (2017). ARXIV: 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li und Yi Yang. "Zufällige Löschdatenvergrößerung." Arxiv Preprint Arxiv: 1708.04896 (2017). ARXIV: 1708.04896, Pytorch -Implementierung
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin und David Lopez-Paz. "Mischung: Über empirische Risikominimierung hinaus." In der Internationalen Konferenz über Lernrepräsentationen (ICLR), 2017. Link, Arxiv: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma und Leslie Pack Kaelbling. "Zum Verständnis der Verallgemeinerung über die analytische Lerntheorie." Arxiv Preprint Arxiv: 1802.07426 (2018). ARXIV: 1802.07426, Pytorch -Implementierung
- Takahashi, Ryo, Takashi Matsubara und Kuniaki Uehara. "Datenvergrößerung mit zufälligen Bildfassungen und Patchen für tiefe ZNNs." Proceedings der 10. Asienkonferenz über maschinelles Lernen (ACML), 2018. Link, Arxiv: 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe und Youngjoon Yoo. "Cutmix: Regularisierungsstrategie, um starke Klassifizierer mit lokalisierbaren Merkmalen zu schulen." Arxiv Preprint Arxiv: 1905.04899 (2019). Arxiv: 1905.04899
Große Charge
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy und Ping Tak Peter Tang. "Bei großem Batch-Training für Deep Learning: Generalisierungslücke und scharfe Minima." In der Internationalen Konferenz über Lernrepräsentationen (ICLR), 2017. Link, Arxiv: 1609.04836
- Hoffer, Elad, Itay Hubrara und Daniel Soudry. "Länger trainieren, besser verallgemeinern: Die Verallgemeinerungslücke im großen Batch -Training neuronaler Netzwerke schließen." In Fortschritten in neuronalen Informationsverarbeitungssystemen (NIPS), 2017. Link, Arxiv: 1705.08741, Pytorch -Implementierung
- Goyal, Priya, Piotr -Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia und Kaiming He. "Genau, große Minibatch -SGD: Trainingsbild in 1 Stunde." Arxiv Preprint Arxiv: 1706.02677 (2017). Arxiv: 1706.02677
- Sie, Yang, Igor Gitman und Boris Ginsburg. "Großes Batch -Training von Faltungsnetzwerken." Arxiv Preprint Arxiv: 1708.03888 (2017). ARXIV: 1708.03888
- Sie, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel und Kurt Keutzer. "ImageNet Training in Minuten." Arxiv Preprint Arxiv: 1709.05011 (2017). ARXIV: 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying und Quoc V. Le. "Verfallen Sie die Lernrate nicht, erhöhen Sie die Chargengröße." In der Internationalen Konferenz über Lernrepräsentationen (ICLR), 2018. Link, Arxiv: 1711.00489
- Gitman, Igor, Deepak Dilipkumar und Ben Parr. "Konvergenzanalyse von Algorithmen für Gradientenabfälle mit proportionalen Aktualisierungen." Arxiv Preprint Arxiv: 1801.03137 (2018). ARXIV: 1801.03137 TensorFlow -Implementierung
- Jia, Xianyan, Shutao Song, Wei, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou yang, liwei yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi und Xiaowen Chu. "Hoch skalierbares, tiefes Lerntrainingssystem mit gemischtem Prezision: Trainingsbild in vier Minuten." Arxiv Preprint Arxiv: 1807.11205 (2018). ARXIV: 1807.11205
- Shaleue, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig und George E. Dahl. "Messung der Auswirkungen von Datenparallelität auf das neuronale Netzwerktraining." Arxiv Preprint Arxiv: 1811.03600 (2018). Arxiv: 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang und Youlong Cheng. "Bildklassifizierung in Supercomputerskala." In Advances in Neural Information Processing Systems (Neurips) Workshop, 2018. Link, Arxiv: 1811.06992
Andere
- Loshchilov, Ilya und Frank Hutter. "SGDR: Stochastischer Gradientenabstieg mit warmen Neustarts." In der Internationalen Konferenz über Lernrepräsentationen (ICLR), 2017. Link, Arxiv: 1608.03983, Lasagne -Implementierung
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh und Hao Wu. "Gemischtes Präzisionstraining." In der Internationalen Konferenz über Lernrepräsentationen (ICLR), 2018. Link, Arxiv: 1710.03740
- RELHT, Benjamin, Rebecca Roelofs, Ludwig Schmidt und Vaishaal Shankar. "Verallgemeinern CIFAR-10-Klassifikatoren auf CIFAR-10?" Arxiv Preprint Arxiv: 1806.00451 (2018). Arxiv: 1806.00451
- Er, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie und Mu Li. "Tasche von Tricks für die Bildklassifizierung mit Faltungsnetzwerken." Arxiv Preprint Arxiv: 1812.01187 (2018). Arxiv: 1812.01187


