Classificação de imagem Pytorch
Os documentos a seguir são implementados usando Pytorch.
- Resnet (1512.03385)
- Resnet-PreAct (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- Cutout (1708.04552)
- Apagamento aleatório (1708.04896)
- Senet (1709.01507)
- Mixup (1710.09412)
- Duplo corte (1802.07426)
- Ricap (1811.09030)
- Cutmix (1905.04899)
Requisitos
- Ubuntu (é testado apenas no Ubuntu, para não funcionar no Windows.)
- Python> = 3.7
- Pytorch> = 1.4.0
- Torchvision
- Nvidia Apex
pip install -r requirements.txt
Uso
python train.py --config configs/cifar/resnet_preact.yaml
Resultados no CIFAR-10
Resultados usando quase as mesmas configurações dos papéis
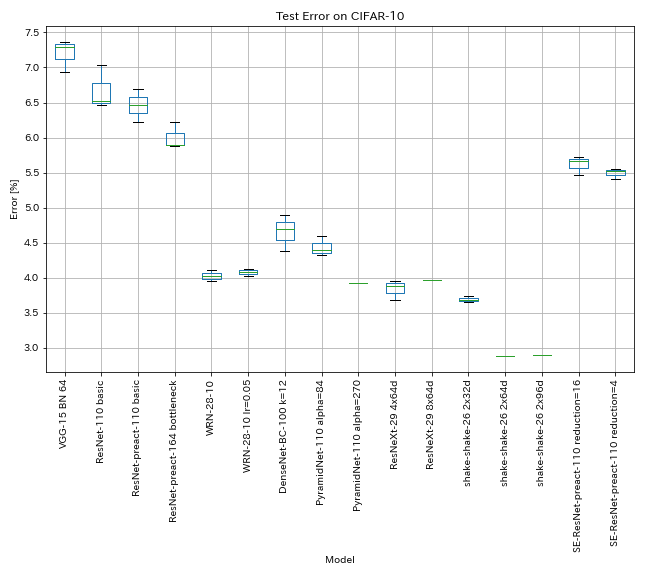
| Modelo | Erro de teste (mediana de 3 execuções) | Erro de teste (em papel) | Tempo de treinamento |
|---|
| VGG (profundidade 15, w/ bn, canal 64) | 7.29 | N / D | 1H20M |
| Resnet-110 | 6.52 | 6.43 (melhor), 6,61 +/- 0,16 | 3H06M |
| Resnet-PreAct-110 | 6.47 | 6.37 (mediana de 5 corridas) | 3H05m |
| Gardeco de Resnet-PreAct-164 | 5.90 | 5.46 (mediana de 5 corridas) | 4H01M |
| Gargetlek de Resnet-PreAct-1001 | | 4,62 (mediana de 5 corridas), 4,69 +/- 0,20 | |
| WRN-28-10 | 4.03 | 4,00 (mediana de 5 corridas) | 16H10M |
| WRN-28-10 com abandono | | 3,89 (mediana de 5 corridas) | |
| Densenet-100 (k = 12) | 3,87 (1 corrida) | 4.10 (1 corrida) | 24h28m* |
| Densenet-100 (k = 24) | | 3,74 (1 corrida) | |
| Densenet-BC-100 (k = 12) | 4.69 | 4.51 (1 corrida) | 15h20m |
| Densenet-BC-250 (k = 24) | | 3.62 (1 corrida) | |
| Densenet-BC-190 (k = 40) | | 3.46 (1 corrida) | |
| Pyramidnet-110 (alfa = 84) | 4.40 | 4,26 +/- 0,23 | 11h40m |
| Pyramidnet-110 (alfa = 270) | 3,92 (1 corrida) | 3,73 +/- 0,04 | 24H12M* |
| Gargalos pyramidnet-164 (alfa = 270) | 3.44 (1 corrida) | 3,48 +/- 0,20 | 32H37M* |
| PyramidNet-272 Gargnekeck (Alpha = 200) | | 3,31 +/- 0,08 | |
| Resnext-29 4x64d | 3.89 | ~ 3,75 (da Figura 7) | 31H17M |
| Resnext-29 8x64d | 3,97 (1 corrida) | 3,65 (média de 10 corridas) | 42H50M* |
| Resnext-29 16x64d | | 3,58 (média de 10 corridas) | |
| Shake-shake-26 2x32d (SSI) | 3.68 | 3,55 (média de 3 corridas) | 33H49m |
| Shake-shake-26 2x64D (SSI) | 2.88 (1 corrida) | 2,98 (média de 3 corridas) | 78H48M |
| Shake-shake-26 2x96D (SSI) | 2,90 (1 corrida) | 2,86 (média de 5 execuções) | 101H32M* |
Notas
- Diferenças com documentos em ambientes de treinamento:
- WRN-28-10 treinado com tamanho de lote 64 (128 em papel).
- DendeNet-BC-100 treinado (k = 12) com tamanho de lote 32 e taxa de aprendizado inicial 0,05 (tamanho do lote 64 e taxa de aprendizado inicial 0,1 em papel).
- Resnext-29 treinado 4x64D com uma única GPU, tamanho do lote 32 e taxa de aprendizado inicial 0,025 (8 GPUs, tamanho do lote 128 e taxa de aprendizado inicial 0,1 em papel).
- Modelos de shake treinados com uma única GPU (2 GPUs em papel).
- Shake treinado Shake 26 2x64D (SSI) com tamanho de lote 64 e taxa de aprendizado inicial 0,1.
- Os erros de teste relatados acima são os que, finalmente, a época.
- Experimentos com apenas 1 corrida são feitos em computador diferente da usada para experimentos com 3 corridas.
- O GeForce GTX 980 foi usado nessas experiências.
VGG como como VGG
python train.py --config configs/cifar/vgg.yaml
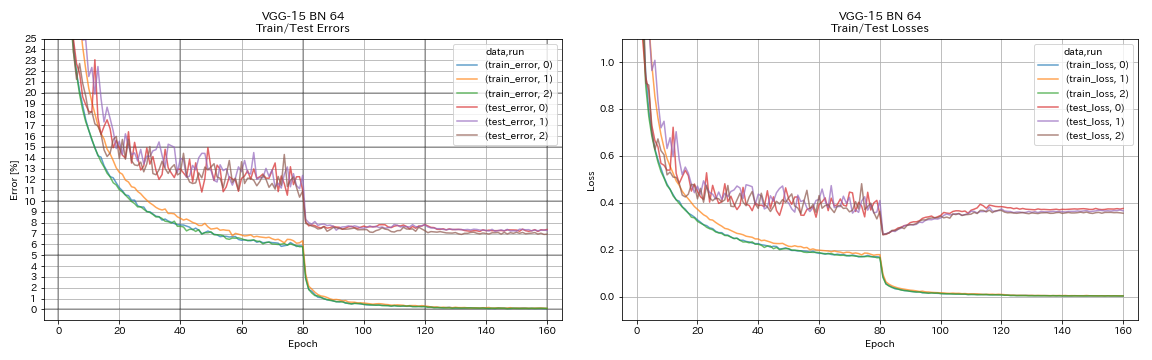
Resnet
python train.py --config configs/cifar/resnet.yaml
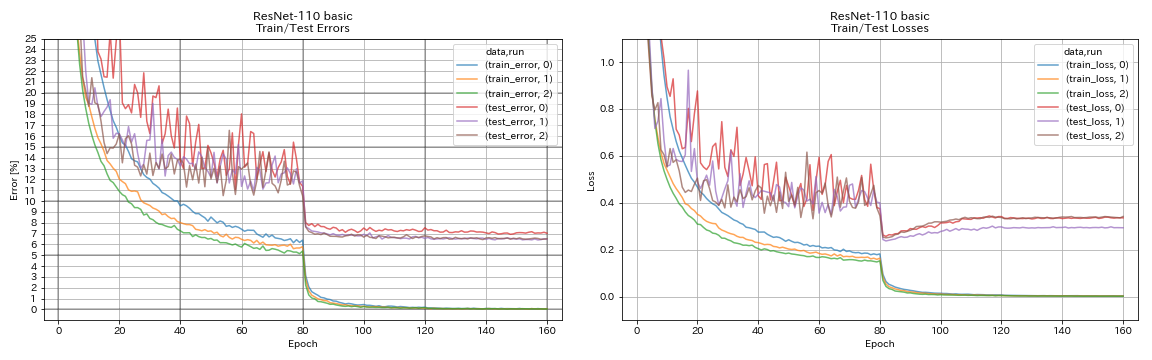
Resnet-PreAct
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00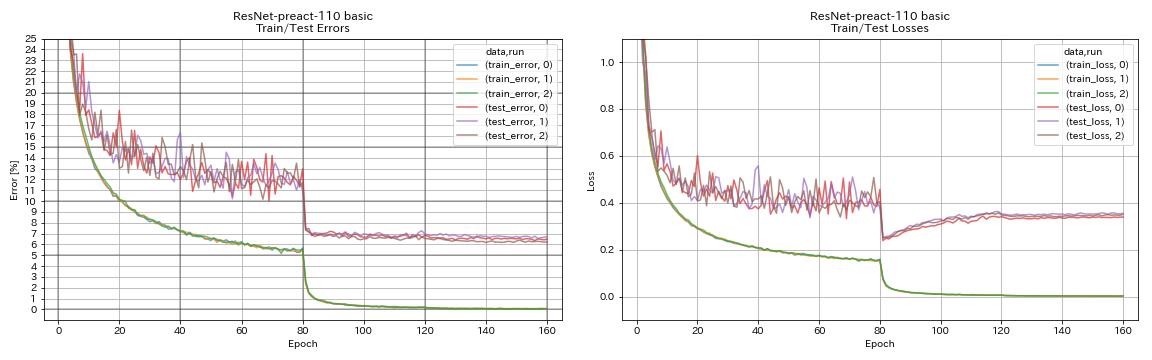
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00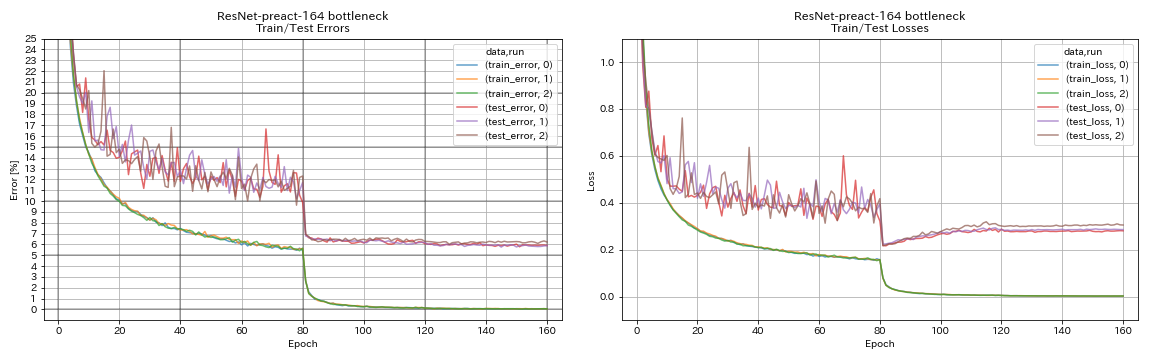
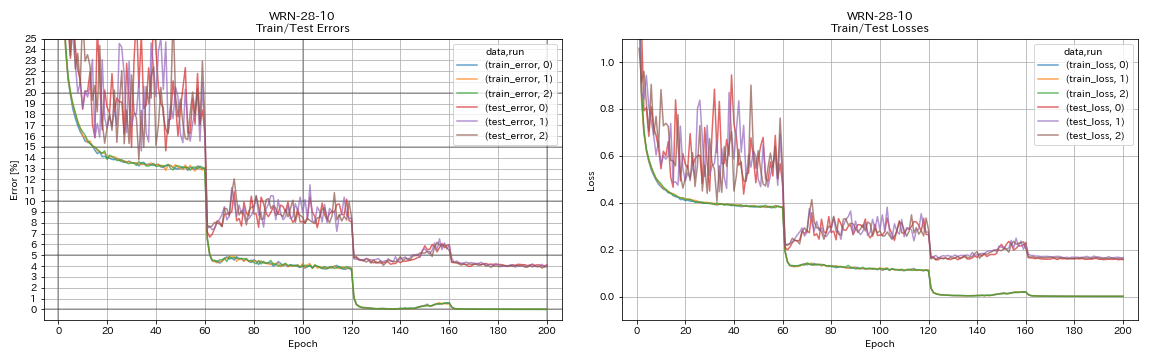
Wrn
python train.py --config configs/cifar/wrn.yaml
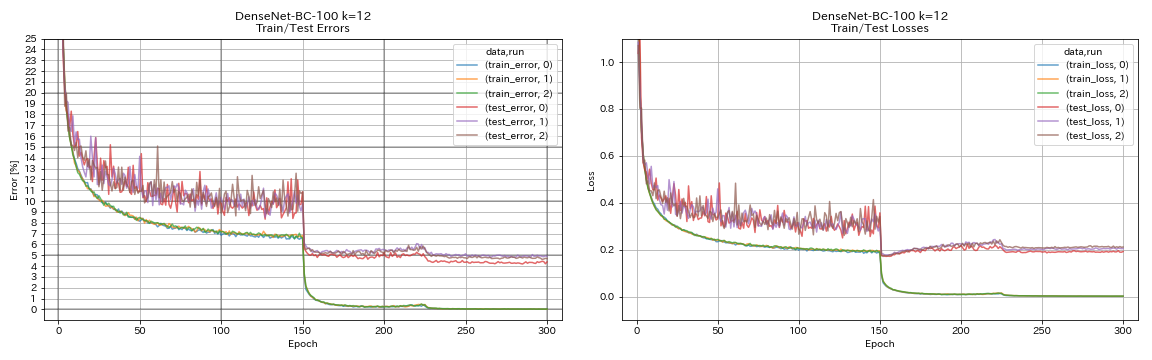
Densenet
python train.py --config configs/cifar/densenet.yaml
Piramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00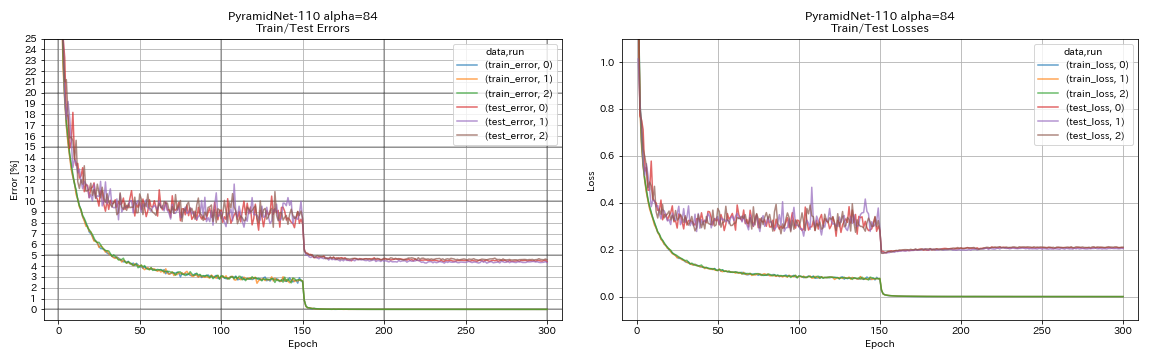
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00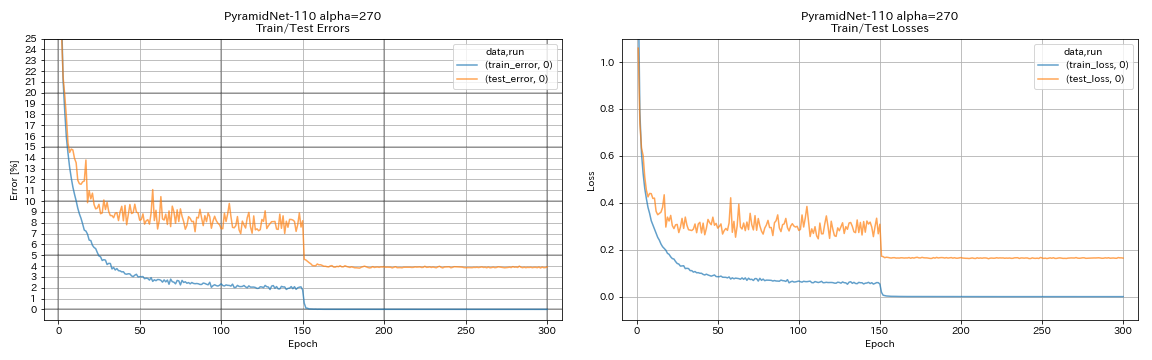
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00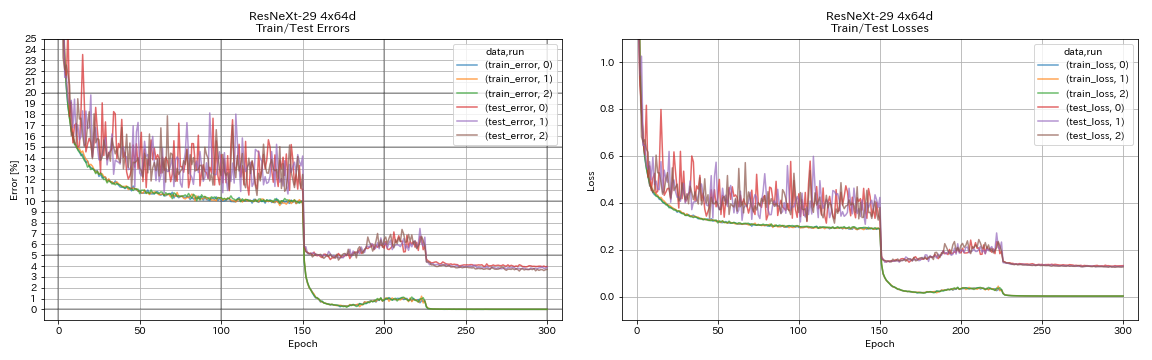
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00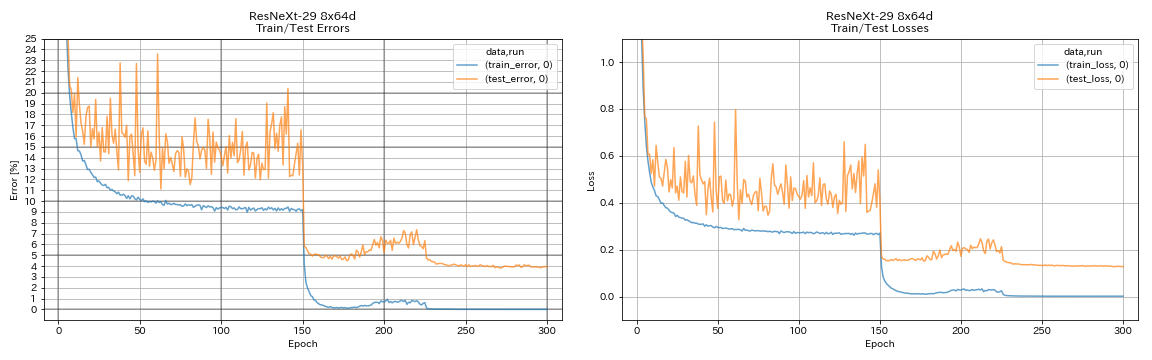
Shake-shake
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00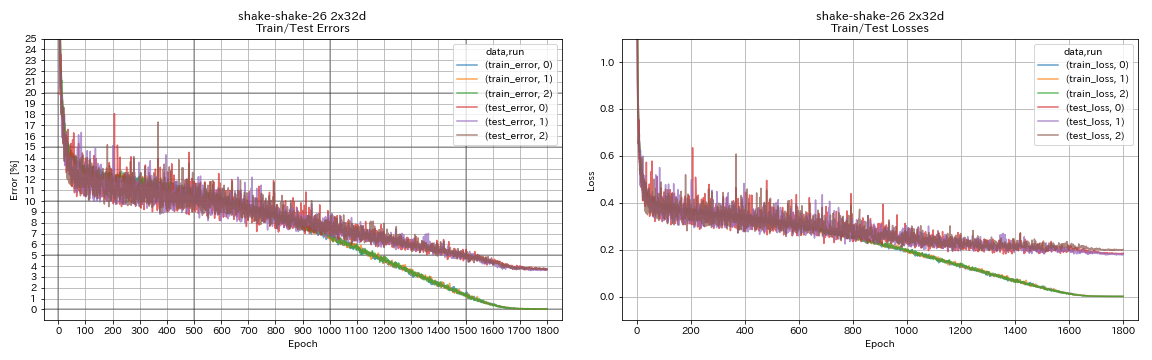
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00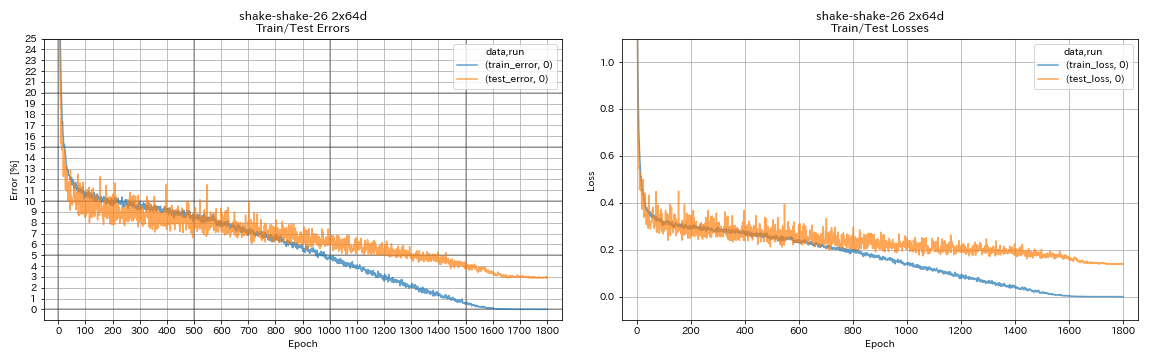
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00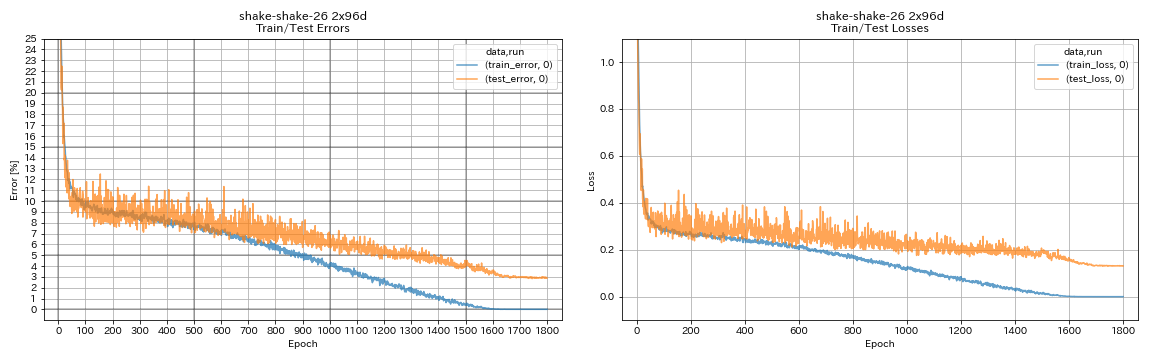
Resultados
| Modelo | Erro de teste (1 execução) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20, fator ampliado 4 | 4.91 | 200 | 1H26M |
| Resnet-PreAct-20, fator ampliado 4 | 4.01 | 400 | 2H53M |
| Resnet-PreAct-20, fator ampliado 4 | 3.99 | 1800 | 12H53m |
| Resnet-PreAct-20, Fator 4, Cutout 16 | 3.71 | 200 | 1H26M |
| Resnet-PreAct-20, Fator 4, Cutout 16 | 3.46 | 400 | 2H53M |
| Resnet-PreAct-20, Fator 4, Cutout 16 | 3.76 | 1800 | 12H53m |
| Resnet-PreAct-20, fator 4, RiCap (beta = 0,3) | 3.45 | 200 | 1H26M |
| Resnet-PreAct-20, fator 4, RiCap (beta = 0,3) | 3.11 | 400 | 2H53M |
| Resnet-PreAct-20, fator 4, RiCap (beta = 0,3) | 3.15 | 1800 | 12H53m |
| Modelo | Erro de teste (1 execução) | # de épocas | Tempo de treinamento |
|---|
| WRN-28-10, recorte 16 | 3.19 | 200 | 6H35m |
| WRN-28-10, Mixup (alfa = 1) | 3.32 | 200 | 6H35m |
| WRN-28-10, RICAP (Beta = 0,3) | 2.83 | 200 | 6H35m |
| WRN-28-10, corte duplo (alfa = 0,1) | 2.87 | 200 | 12h42m |
| WRN-28-10, recorte 16 | 3.07 | 400 | 13H10M |
| WRN-28-10, Mixup (alfa = 1) | 3.04 | 400 | 13H08M |
| WRN-28-10, RICAP (Beta = 0,3) | 2.71 | 400 | 13H08M |
| WRN-28-10, corte duplo (alfa = 0,1) | 2.76 | 400 | 25h20m |
| shake-shake-26 2x64d, recorte 16 | 2.64 | 1800 | 78H55M* |
| shake-shake-26 2x64d, mistura (alfa = 1) | 2.63 | 1800 | 35H56m |
| shake-shake-26 2x64d, ricap (beta = 0,3) | 2.29 | 1800 | 35H10M |
| shake-shake-26 2x64d, corte duplo (alfa = 0,1) | 2.64 | 1800 | 68H34M |
| shake-shake-26 2x96d, recorte 16 | 2,50 | 1800 | 60H20M |
| shake-shake-26 2x96d, mistura (alfa = 1) | 2.36 | 1800 | 60H20M |
| shake-shake-26 2x96D, ricap (beta = 0,3) | 2.10 | 1800 | 60H20M |
| Shake-shake-26 2x96D, corte duplo (alfa = 0,1) | 2.41 | 1800 | 113H09M |
| shake-shake-26 2x128d, recorte 16 | 2.58 | 1800 | 85H04M |
| shake-shake-26 2x128d, ricap (beta = 0,3) | 1.97 | 1800 | 85H06M |
Observação
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
- Todos os modelos são treinados usando o recozimento cosseno com a taxa de aprendizado inicial 0,2.
- O GeForce GTX 1080 Ti foi usado nessas experiências, exceto as *, que são feitas usando o GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True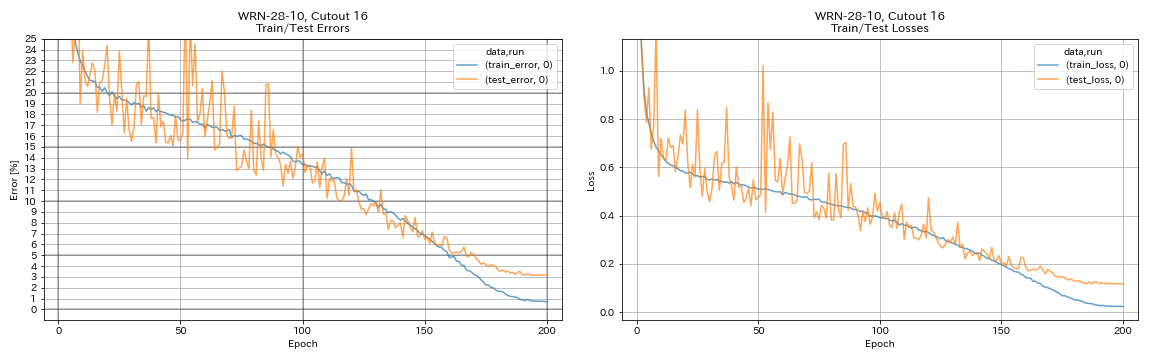
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True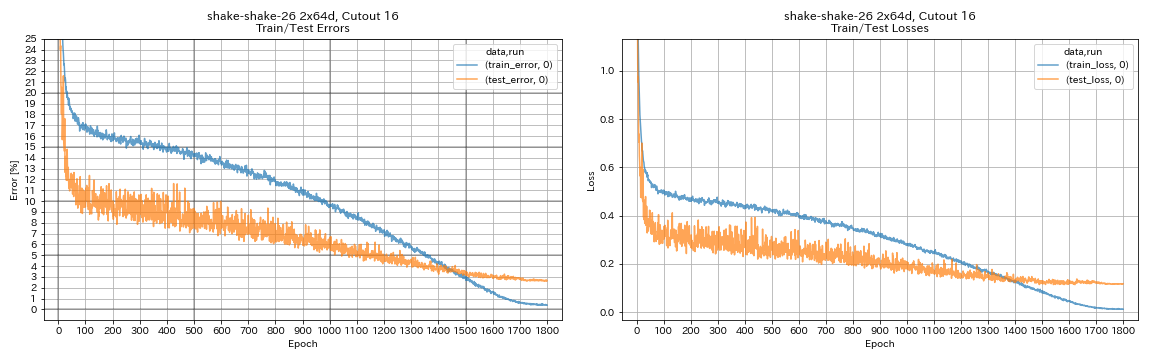
Resultados usando multi-GPU
| Modelo | Tamanho do lote | #GPUS | Erro de teste (1 execução) | # de épocas | Tempo de treinamento* |
|---|
| WRN-28-10, RICAP (Beta = 0,3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10, RICAP (Beta = 0,3) | 256 | 2 | 2.71 | 200 | 2H14M |
| WRN-28-10, RICAP (Beta = 0,3) | 128 | 4 | 2.89 | 200 | 1H01M |
| WRN-28-10, RICAP (Beta = 0,3) | 64 | 8 | 2.75 | 200 | 34m |
Observação
- O Tesla V100 foi usado nessas experiências.
Usando 1 GPU
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 2 GPUs
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 4 GPUs
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 8 GPUs
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseResultados no FashionMnist
| Modelo | Erro de teste (1 execução) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20, Fator 4, Cutout 12 | 4.17 | 200 | 1H32M |
| Resnet-PreAct-20, Fator 4, Cutout 14 | 4.11 | 200 | 1H32M |
| Resnet-PreAct-50, recorte 12 | 4.45 | 200 | 57m |
| Resnet-PreAct-50, recorte 14 | 4.38 | 200 | 57m |
| Resnet-PreAct-50, Fator 4, Cutout 12 | 4.07 | 200 | 3H37M |
| Resnet-PreAct-50, Fator 4, Cutout 14 | 4.13 | 200 | 3H39M |
| shake-shake-26 2x32d (ssi), recorte 12 | 4.08 | 400 | 3H41M |
| shake-shake-26 2x32d (ssi), recorte 14 | 4.05 | 400 | 3H39M |
| shake-shake-26 2x96d (ssi), recorte 12 | 3.72 | 400 | 13H46m |
| Shake-shake-26 2x96D (SSI), Cutout 14 | 3.85 | 400 | 13H39M |
| shake-shake-26 2x96d (ssi), recorte 12 | 3.65 | 800 | 26H42m |
| Shake-shake-26 2x96D (SSI), Cutout 14 | 3.60 | 800 | 26H42m |
| Modelo | Erro de teste (mediana de 3 execuções) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 5.04 | 200 | 26m |
| Resnet-PreAct-20, Cutout 6 | 4.84 | 200 | 26m |
| Resnet-PreAct-20, Cutout 8 | 4.64 | 200 | 26m |
| Resnet-PreAct-20, Cutout 10 | 4.74 | 200 | 26m |
| Resnet-PreAct-20, Cutout 12 | 4.68 | 200 | 26m |
| Resnet-PreAct-20, Cutout 14 | 4.64 | 200 | 26m |
| Resnet-PreAct-20, Cutout 16 | 4.49 | 200 | 26m |
| Resnet-preact-20, Randomerasing | 4.61 | 200 | 26m |
| Resnet-PreAct-20, mistura | 4.92 | 200 | 26m |
| Resnet-PreAct-20, mistura | 4.64 | 400 | 52m |
Observação
- Os resultados relatados nas tabelas são os erros de teste nas últimas épocas.
- Todos os modelos são treinados usando o recozimento cosseno com a taxa de aprendizado inicial 0,2.
- Aumentos de dados a seguir são aplicados aos dados de treinamento:
- As imagens são acolchoadas com 4 pixels de cada lado e os patches de 28x28 são cortados aleatoriamente das imagens acolchoadas.
- As imagens são invertidas aleatoriamente horizontalmente.
- O GeForce GTX 1080 Ti foi usado nessas experiências.
Resultados no mnist
| Modelo | Erro de teste (mediana de 3 execuções) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 0,40 | 100 | 12m |
| Resnet-PreAct-20, Cutout 6 | 0,32 | 100 | 12m |
| Resnet-PreAct-20, Cutout 8 | 0,25 | 100 | 12m |
| Resnet-PreAct-20, Cutout 10 | 0,27 | 100 | 12m |
| Resnet-PreAct-20, Cutout 12 | 0,26 | 100 | 12m |
| Resnet-PreAct-20, Cutout 14 | 0,26 | 100 | 12m |
| Resnet-PreAct-20, Cutout 16 | 0,25 | 100 | 12m |
| Resnet-preact-20, mixup (alfa = 1) | 0,40 | 100 | 12m |
| Resnet-PreAct-20, Mixup (alfa = 0,5) | 0,38 | 100 | 12m |
| Resnet-PreAct-20, Fator 4, Cutout 14 | 0,26 | 100 | 45m |
| Resnet-PreAct-50, recorte 14 | 0,29 | 100 | 28m |
| Resnet-PreAct-50, Fator 4, Cutout 14 | 0,25 | 100 | 1h50m |
| Shake-shake-26 2x96D (SSI), Cutout 14 | 0,24 | 100 | 3H22m |
Observação
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
- Todos os modelos são treinados usando o recozimento cosseno com a taxa de aprendizado inicial 0,2.
- O GeForce GTX 1080 Ti foi usado nessas experiências.
Resultados em Kuzushiji-mnist
| Modelo | Erro de teste (mediana de 3 execuções) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20, Cutout 14 | 0,82 (melhor 0,67) | 200 | 24m |
| Resnet-PreAct-20, Fator 4, Cutout 14 | 0,72 (melhor 0,67) | 200 | 1H30M |
| Pyramidnet-110-270, recorte 14 | 0,72 (melhor 0,70) | 200 | 10H05m |
| Shake-shake-26 2x96D (SSI), Cutout 14 | 0,66 (melhor 0,63) | 200 | 6H46m |
Observação
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
- Todos os modelos são treinados usando o recozimento cosseno com a taxa de aprendizado inicial 0,2.
- O GeForce GTX 1080 Ti foi usado nessas experiências.
Experimentos
Experimento em unidades residuais, agendamento de taxas de aprendizado e aumento de dados
Neste experimento, os efeitos do seguinte na precisão da classificação são investigados:
- Unidades residuais semelhantes a piramidnet
- Reconeração de Cosseno da Taxa de Aprendizagem
- Recortar
- Apagamento aleatório
- Confusão
- Preativação de atalhos após a redução de amostragem
Resnet-PreAct-56 é treinado no CIFAR-10 com taxa de aprendizado inicial 0,2 neste experimento.
Observação
- O papel da piramidnet (1610.02915) mostrou que a remoção do primeiro relu em unidades residuais e a adição de BN após as últimas convoluções em unidades residuais melhoram a precisão da classificação.
- O papel SGDR (1608.03983) mostrou que o recozimento cosseno melhora a precisão da classificação, mesmo sem reiniciar.
Resultados
- As unidades semelhantes a piramidnet funcionam.
- Pode ser melhor não preativar os atalhos após a redução do amostramento ao usar unidades do tipo pyramidnet.
- O recozimento de cosseno melhora levemente a precisão.
- Cutout, Randomerasing e Mixup funcionam muito bem.
- A mistura precisa de treinamento mais longo.
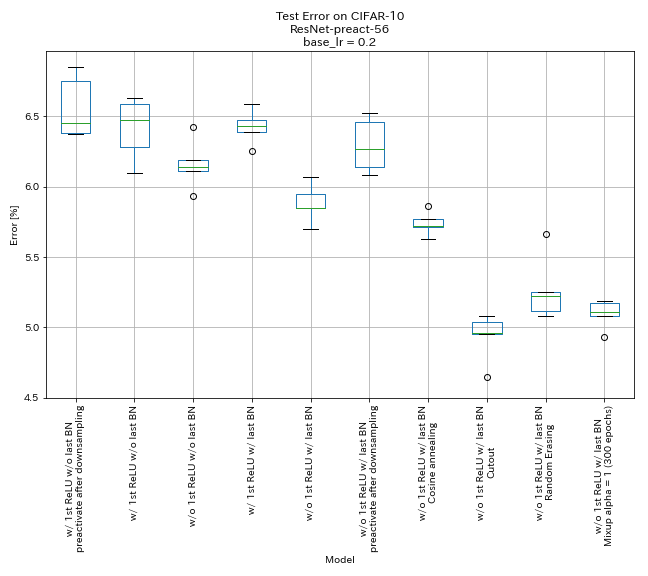
| Modelo | Erro de teste (mediana de 5 execuções) | Tempo de treinamento |
|---|
| w/ 1º Relu, sem o último bn, pré -ativo após a redução de downsampling | 6.45 | 95 min |
| w/ 1º Relu, sem o último BN | 6.47 | 95 min |
| w/o 1º Relu, sem último BN | 6.14 | 89 min |
| com 1º relu, com último BN | 6.43 | 104 min |
| w/ o 1º relu, com último BN | 5.85 | 98 min |
| w/ o 1º Relu, com último BN, pré -ativo de atalho após a denominação | 6.27 | 98 min |
| w/ o 1º Relu, com último BN, CoLOVELING | 5.72 | 98 min |
| w/ o 1º Relu, com último bn, recorte | 4.96 | 98 min |
| w/ o 1º Relu, com último Bn, Randomerasing | 5.22 | 98 min |
| w/ o 1º relu, com último bn, mistura (300 épocas) | 5.11 | 191 min |
atalho pré -reativo após a redução de amostragem
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ 1º Relu, sem o último BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o 1º Relu, sem último BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
com 1º relu, com último BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00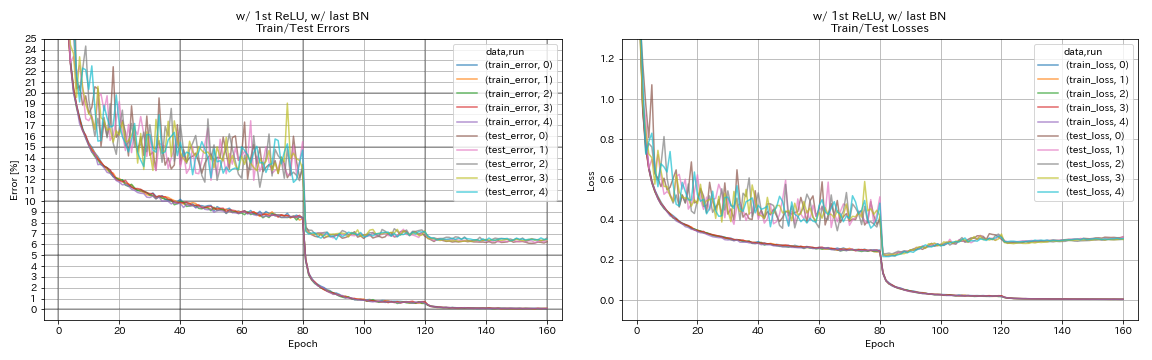
w/ o 1º relu, com último BN
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00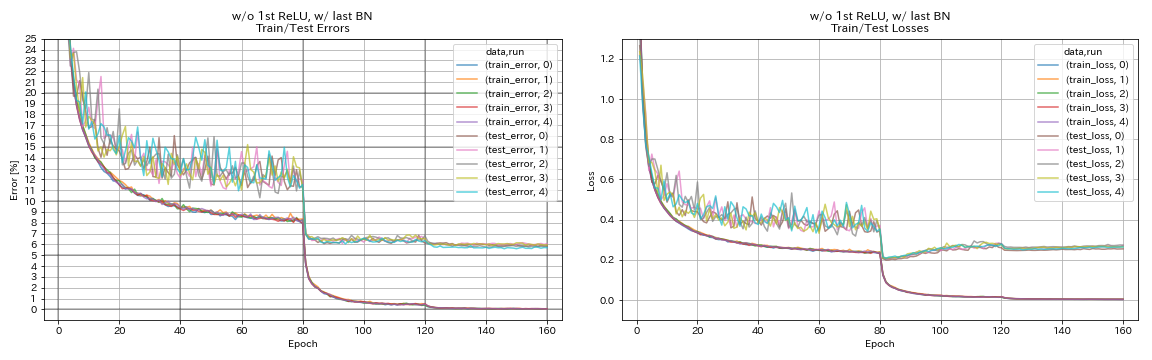
w/ o 1º Relu, com último BN, pré -ativo de atalho após a denominação
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00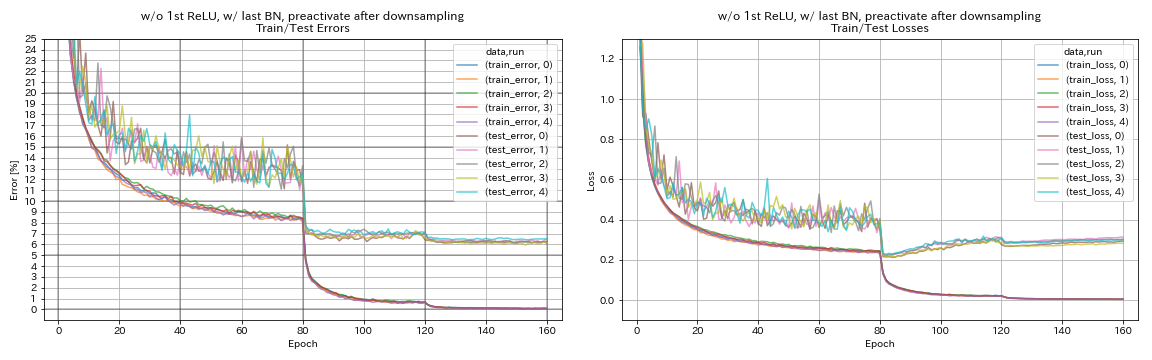
w/ o 1º Relu, com último BN, CoLOVELING
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00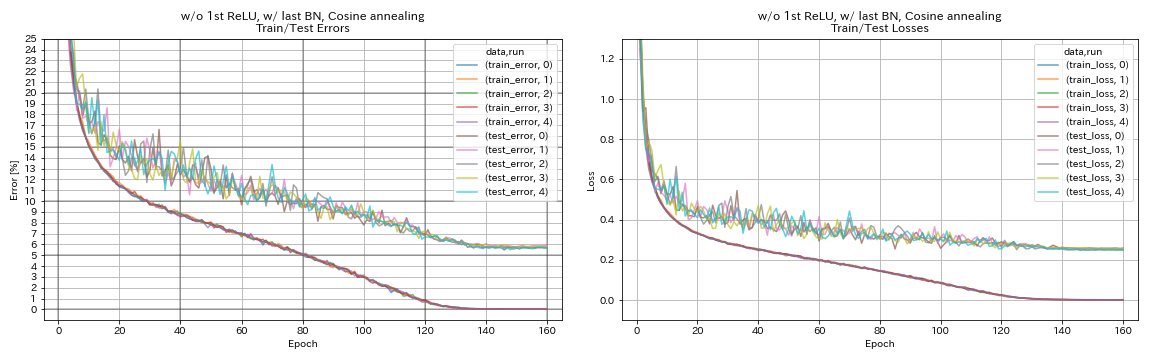
w/ o 1º Relu, com último bn, recorte
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00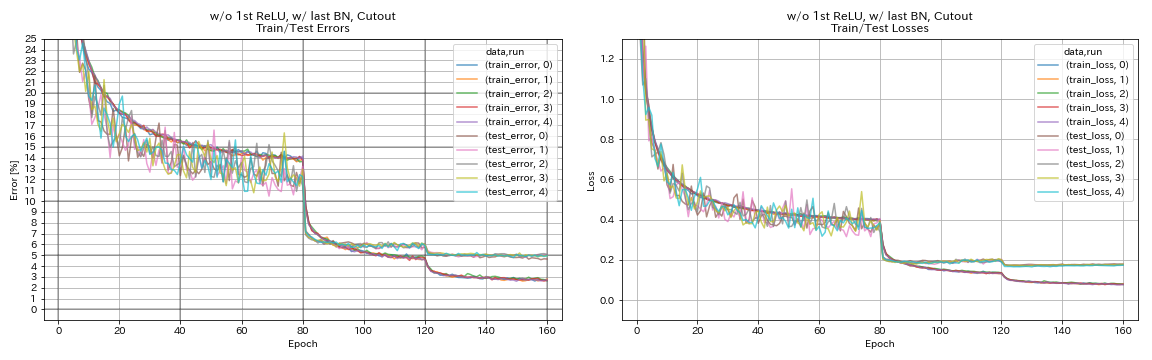
w/ o 1º Relu, com último Bn, Randomerasing
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00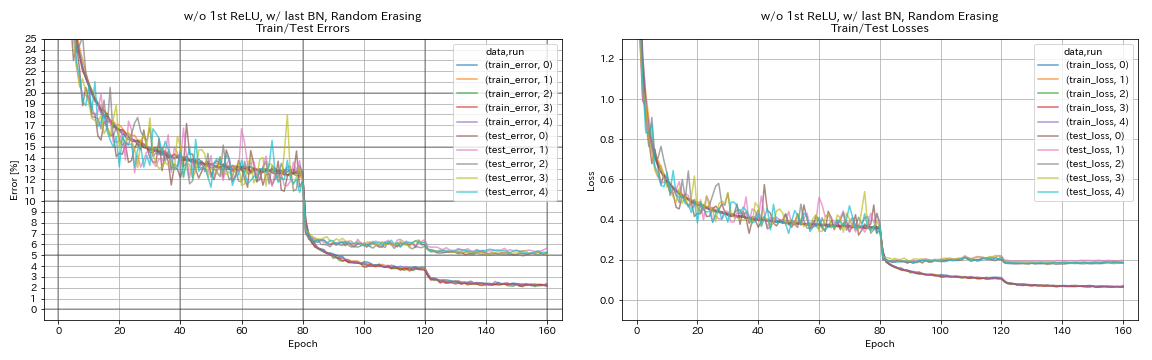
w/ o 1º Relu, com último bn, mistura
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00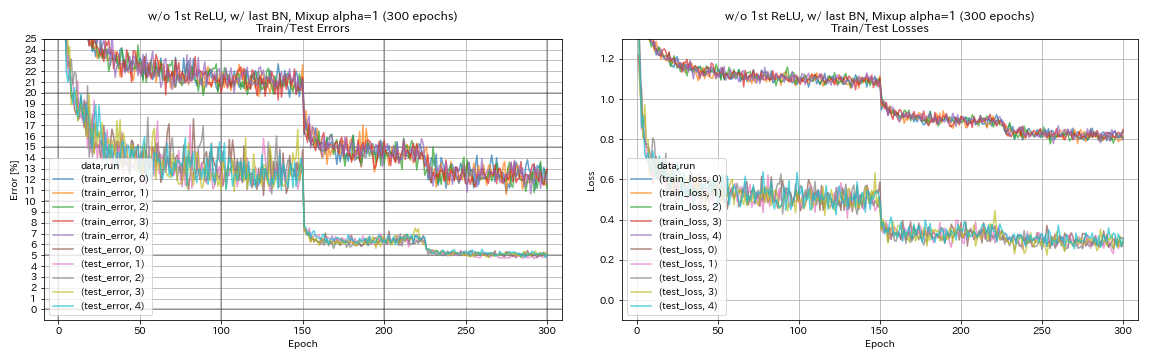
Experimentos sobre suavização de etiquetas, mistura, ricap e duplo corte
Resultados no CIFAR-10
| Modelo | Erro de teste (mediana de 3 execuções) | # de épocas | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 7.60 | 200 | 24m |
| Resnet-PreAct-20, suavização de etiquetas (epsilon = 0,001) | 7.51 | 200 | 25m |
| Resnet-preact-20, suavização de etiquetas (epsilon = 0,01) | 7.21 | 200 | 25m |
| Resnet-PreAct-20, suavização de etiquetas (epsilon = 0,1) | 7.57 | 200 | 25m |
| Resnet-preact-20, mixup (alfa = 1) | 7.24 | 200 | 26m |
| Resnet-preact-20, ricap (beta = 0,3), com colheita aleatória | 6.88 | 200 | 28m |
| Resnet-PreAct-20, Ricap (beta = 0,3) | 6.77 | 200 | 28m |
| Resnet-preact-20, corte duplo 16 (alfa = 0,1) | 6.24 | 200 | 45m |
| Resnet-PreAct-20 | 7.05 | 400 | 49m |
| Resnet-PreAct-20, suavização de etiquetas (epsilon = 0,001) | 7.20 | 400 | 49m |
| Resnet-preact-20, suavização de etiquetas (epsilon = 0,01) | 6.97 | 400 | 49m |
| Resnet-PreAct-20, suavização de etiquetas (epsilon = 0,1) | 7.16 | 400 | 49m |
| Resnet-preact-20, mixup (alfa = 1) | 6.66 | 400 | 51m |
| Resnet-preact-20, ricap (beta = 0,3), com colheita aleatória | 6.30 | 400 | 56m |
| Resnet-PreAct-20, Ricap (beta = 0,3) | 6.19 | 400 | 56m |
| Resnet-preact-20, corte duplo 16 (alfa = 0,1) | 5.55 | 400 | 1H36M |
Observação
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
- Todos os modelos são treinados usando o recozimento cosseno com a taxa de aprendizado inicial 0,2.
- O GeForce GTX 1080 Ti foi usado nessas experiências.
Experimentos sobre o tamanho do lote e a taxa de aprendizado
- A seguir, as experiências são feitas no conjunto de dados CIFAR-10 usando o GeForce 1080 Ti.
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
Regra de escala linear para taxa de aprendizagem
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 3.2 | cosseno | 200 | 10.57 | 22m |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 200 | 8.87 | 21m |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 200 | 8.40 | 21m |
| Resnet-PreAct-20 | 512 | 0,4 | cosseno | 200 | 8.22 | 20m |
| Resnet-PreAct-20 | 256 | 0,2 | cosseno | 200 | 8.61 | 22m |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 200 | 8.09 | 24m |
| Resnet-PreAct-20 | 64 | 0,05 | cosseno | 200 | 8.22 | 28m |
| Resnet-PreAct-20 | 32 | 0,025 | cosseno | 200 | 8.00 | 43m |
| Resnet-PreAct-20 | 16 | 0,0125 | cosseno | 200 | 7.75 | 1H17M |
| Resnet-PreAct-20 | 8 | 0,006125 | cosseno | 200 | 7.70 | 2H32M |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 3.2 | MultireSp | 200 | 28.97 | 22m |
| Resnet-PreAct-20 | 2048 | 1.6 | MultireSp | 200 | 9.07 | 21m |
| Resnet-PreAct-20 | 1024 | 0,8 | MultireSp | 200 | 8.62 | 21m |
| Resnet-PreAct-20 | 512 | 0,4 | MultireSp | 200 | 8.23 | 20m |
| Resnet-PreAct-20 | 256 | 0,2 | MultireSp | 200 | 8.40 | 21m |
| Resnet-PreAct-20 | 128 | 0.1 | MultireSp | 200 | 8.28 | 24m |
| Resnet-PreAct-20 | 64 | 0,05 | MultireSp | 200 | 8.13 | 28m |
| Resnet-PreAct-20 | 32 | 0,025 | MultireSp | 200 | 7.58 | 43m |
| Resnet-PreAct-20 | 16 | 0,0125 | MultireSp | 200 | 7.93 | 1H18M |
| Resnet-PreAct-20 | 8 | 0,006125 | MultireSp | 200 | 8.31 | 2H34M |
Escala linear + treinamento mais longo
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 3.2 | cosseno | 400 | 8.97 | 44m |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 400 | 7.85 | 43m |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 400 | 7.20 | 42m |
| Resnet-PreAct-20 | 512 | 0,4 | cosseno | 400 | 7.83 | 40m |
| Resnet-PreAct-20 | 256 | 0,2 | cosseno | 400 | 7.65 | 42m |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 400 | 7.09 | 47m |
| Resnet-PreAct-20 | 64 | 0,05 | cosseno | 400 | 7.17 | 44m |
| Resnet-PreAct-20 | 32 | 0,025 | cosseno | 400 | 7.24 | 2H11m |
| Resnet-PreAct-20 | 16 | 0,0125 | cosseno | 400 | 7.26 | 4H10M |
| Resnet-PreAct-20 | 8 | 0,006125 | cosseno | 400 | 7.02 | 7H53m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 3.2 | cosseno | 800 | 8.14 | 1H29M |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 800 | 7.74 | 1H23M |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 800 | 7.15 | 1H31M |
| Resnet-PreAct-20 | 512 | 0,4 | cosseno | 800 | 7.27 | 1H25M |
| Resnet-PreAct-20 | 256 | 0,2 | cosseno | 800 | 7.22 | 1H26M |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 800 | 6.68 | 1H35M |
| Resnet-PreAct-20 | 64 | 0,05 | cosseno | 800 | 7.18 | 2H20M |
| Resnet-PreAct-20 | 32 | 0,025 | cosseno | 800 | 7.03 | 4H16M |
| Resnet-PreAct-20 | 16 | 0,0125 | cosseno | 800 | 6.78 | 8H37M |
| Resnet-PreAct-20 | 8 | 0,006125 | cosseno | 800 | 6.89 | 16H47M |
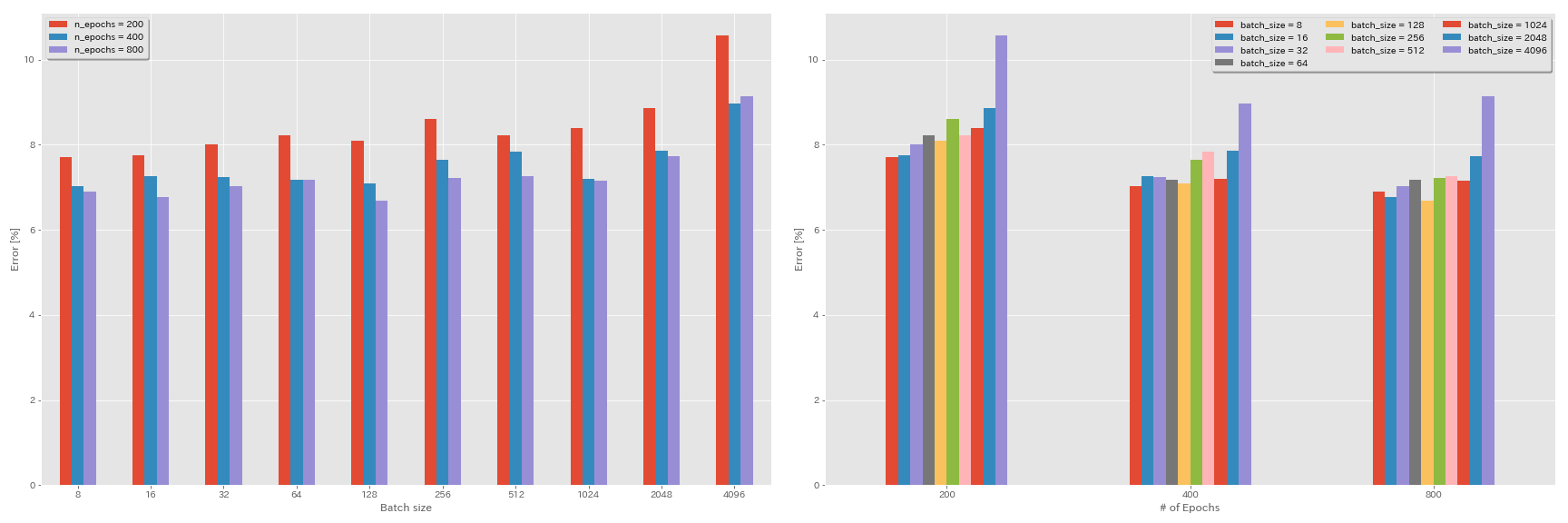
Efeito da taxa de aprendizagem inicial
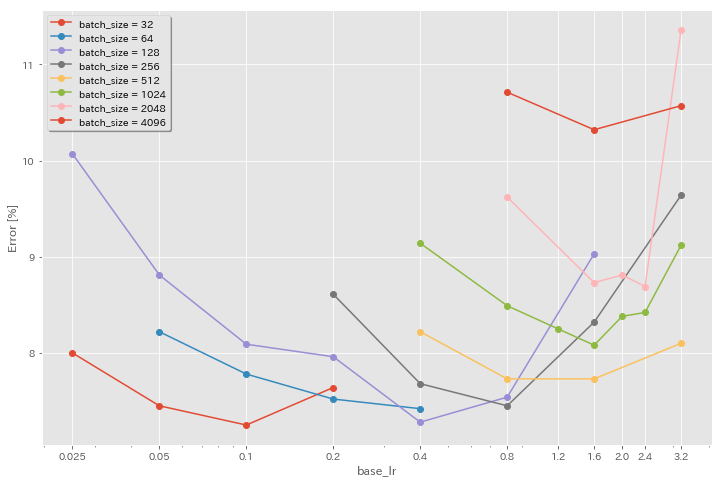
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 3.2 | cosseno | 200 | 10.57 | 22m |
| Resnet-PreAct-20 | 4096 | 1.6 | cosseno | 200 | 10.32 | 22m |
| Resnet-PreAct-20 | 4096 | 0,8 | cosseno | 200 | 10.71 | 22m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 2048 | 3.2 | cosseno | 200 | 11.34 | 21m |
| Resnet-PreAct-20 | 2048 | 2.4 | cosseno | 200 | 8.69 | 21m |
| Resnet-PreAct-20 | 2048 | 2.0 | cosseno | 200 | 8.81 | 21m |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 200 | 8.73 | 22m |
| Resnet-PreAct-20 | 2048 | 0,8 | cosseno | 200 | 9.62 | 21m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 1024 | 3.2 | cosseno | 200 | 9.12 | 21m |
| Resnet-PreAct-20 | 1024 | 2.4 | cosseno | 200 | 8.42 | 22m |
| Resnet-PreAct-20 | 1024 | 2.0 | cosseno | 200 | 8.38 | 22m |
| Resnet-PreAct-20 | 1024 | 1.6 | cosseno | 200 | 8.07 | 22m |
| Resnet-PreAct-20 | 1024 | 1.2 | cosseno | 200 | 8.25 | 21m |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 200 | 8.08 | 22m |
| Resnet-PreAct-20 | 1024 | 0,4 | cosseno | 200 | 8.49 | 22m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 512 | 3.2 | cosseno | 200 | 8.51 | 21m |
| Resnet-PreAct-20 | 512 | 1.6 | cosseno | 200 | 7.73 | 20m |
| Resnet-PreAct-20 | 512 | 0,8 | cosseno | 200 | 7.73 | 21m |
| Resnet-PreAct-20 | 512 | 0,4 | cosseno | 200 | 8.22 | 20m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 256 | 3.2 | cosseno | 200 | 9.64 | 22m |
| Resnet-PreAct-20 | 256 | 1.6 | cosseno | 200 | 8.32 | 22m |
| Resnet-PreAct-20 | 256 | 0,8 | cosseno | 200 | 7.45 | 21m |
| Resnet-PreAct-20 | 256 | 0,4 | cosseno | 200 | 7.68 | 22m |
| Resnet-PreAct-20 | 256 | 0,2 | cosseno | 200 | 8.61 | 22m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 128 | 1.6 | cosseno | 200 | 9.03 | 24m |
| Resnet-PreAct-20 | 128 | 0,8 | cosseno | 200 | 7.54 | 24m |
| Resnet-PreAct-20 | 128 | 0,4 | cosseno | 200 | 7.28 | 24m |
| Resnet-PreAct-20 | 128 | 0,2 | cosseno | 200 | 7.96 | 24m |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 200 | 8.09 | 24m |
| Resnet-PreAct-20 | 128 | 0,05 | cosseno | 200 | 8.81 | 24m |
| Resnet-PreAct-20 | 128 | 0,025 | cosseno | 200 | 10.07 | 24m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 64 | 0,4 | cosseno | 200 | 7.42 | 35m |
| Resnet-PreAct-20 | 64 | 0,2 | cosseno | 200 | 7.52 | 36m |
| Resnet-PreAct-20 | 64 | 0.1 | cosseno | 200 | 7.78 | 37m |
| Resnet-PreAct-20 | 64 | 0,05 | cosseno | 200 | 8.22 | 28m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 32 | 0,2 | cosseno | 200 | 7.64 | 1H05M |
| Resnet-PreAct-20 | 32 | 0.1 | cosseno | 200 | 7.25 | 1H08M |
| Resnet-PreAct-20 | 32 | 0,05 | cosseno | 200 | 7.45 | 1H07M |
| Resnet-PreAct-20 | 32 | 0,025 | cosseno | 200 | 8.00 | 43m |
Boa taxa de aprendizado + treinamento mais longo
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 1.6 | cosseno | 200 | 10.32 | 22m |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 200 | 8.73 | 22m |
| Resnet-PreAct-20 | 1024 | 1.6 | cosseno | 200 | 8.07 | 22m |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 200 | 8.08 | 22m |
| Resnet-PreAct-20 | 512 | 1.6 | cosseno | 200 | 7.73 | 20m |
| Resnet-PreAct-20 | 512 | 0,8 | cosseno | 200 | 7.73 | 21m |
| Resnet-PreAct-20 | 256 | 0,8 | cosseno | 200 | 7.45 | 21m |
| Resnet-PreAct-20 | 128 | 0,4 | cosseno | 200 | 7.28 | 24m |
| Resnet-PreAct-20 | 128 | 0,2 | cosseno | 200 | 7.96 | 24m |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 200 | 8.09 | 24m |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 1.6 | cosseno | 800 | 8.36 | 1H33M |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 800 | 7.53 | 1H27M |
| Resnet-PreAct-20 | 1024 | 1.6 | cosseno | 800 | 7h30 | 1H30M |
| Resnet-PreAct-20 | 1024 | 0,8 | cosseno | 800 | 7.42 | 1H30M |
| Resnet-PreAct-20 | 512 | 1.6 | cosseno | 800 | 6.69 | 1H26M |
| Resnet-PreAct-20 | 512 | 0,8 | cosseno | 800 | 6.77 | 1H26M |
| Resnet-PreAct-20 | 256 | 0,8 | cosseno | 800 | 6.84 | 1H28M |
| Resnet-PreAct-20 | 128 | 0,4 | cosseno | 800 | 6.86 | 1H35M |
| Resnet-PreAct-20 | 128 | 0,2 | cosseno | 800 | 7.05 | 1H38M |
| Resnet-PreAct-20 | 128 | 0.1 | cosseno | 800 | 6.68 | 1H35M |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 1.6 | cosseno | 1600 | 8.25 | 3H10M |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 1600 | 7.34 | 2h50m |
| Resnet-PreAct-20 | 1024 | 1.6 | cosseno | 1600 | 6.94 | 2H52m |
| Resnet-PreAct-20 | 512 | 1.6 | cosseno | 1600 | 6.99 | 2H44M |
| Resnet-PreAct-20 | 256 | 0,8 | cosseno | 1600 | 6.95 | 2h50m |
| Resnet-PreAct-20 | 128 | 0,4 | cosseno | 1600 | 6.64 | 3H09M |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 4096 | 1.6 | cosseno | 3200 | 9.52 | 6H15m |
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 3200 | 6.92 | 5H42m |
| Resnet-PreAct-20 | 1024 | 1.6 | cosseno | 3200 | 6.96 | 5H43M |
| Modelo | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 2048 | 1.6 | cosseno | 6400 | 7.45 | 11h44m |
Lars
- Nos artigos originais (1708.03888, 1801.03137), eles usaram o agendamento da taxa de aprendizado de decaimento polinomial, mas o recozimento cosseno é usado nesses experimentos.
- Nesta implementação, o coeficiente LARS não é usado, portanto, a taxa de aprendizado deve ser ajustada de acordo.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00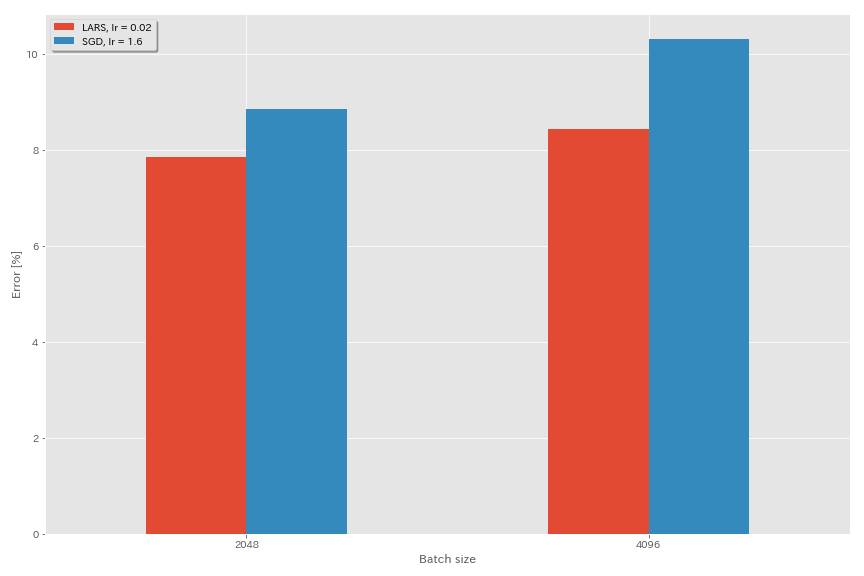
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 4096 | 3.2 | cosseno | 200 | 10.57 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 4096 | 1.6 | cosseno | 200 | 10.20 | 22m |
| Resnet-PreAct-20 | Sgd | 4096 | 0,8 | cosseno | 200 | 10.71 (1 corrida) | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,04 | cosseno | 200 | 9.58 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,03 | cosseno | 200 | 8.46 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,02 | cosseno | 200 | 8.21 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,015 | cosseno | 200 | 8.47 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,01 | cosseno | 200 | 9.33 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,005 | cosseno | 200 | 14.31 | 22m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 2048 | 3.2 | cosseno | 200 | 11.34 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 2048 | 2.4 | cosseno | 200 | 8.69 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 2048 | 2.0 | cosseno | 200 | 8.81 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 2048 | 1.6 | cosseno | 200 | 8.73 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 2048 | 0,8 | cosseno | 200 | 9.62 (1 corrida) | 21m |
| Resnet-PreAct-20 | Lars | 2048 | 0,04 | cosseno | 200 | 11.58 | 21m |
| Resnet-PreAct-20 | Lars | 2048 | 0,02 | cosseno | 200 | 8.05 | 22m |
| Resnet-PreAct-20 | Lars | 2048 | 0,01 | cosseno | 200 | 8.07 | 22m |
| Resnet-PreAct-20 | Lars | 2048 | 0,005 | cosseno | 200 | 9.65 | 22m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 1024 | 3.2 | cosseno | 200 | 9.12 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 1024 | 2.4 | cosseno | 200 | 8.42 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 1024 | 2.0 | cosseno | 200 | 8.38 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 1024 | 1.6 | cosseno | 200 | 8.07 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 1024 | 1.2 | cosseno | 200 | 8.25 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 1024 | 0,8 | cosseno | 200 | 8.08 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 1024 | 0,4 | cosseno | 200 | 8.49 (1 corrida) | 22m |
| Resnet-PreAct-20 | Lars | 1024 | 0,02 | cosseno | 200 | 9.30 | 22m |
| Resnet-PreAct-20 | Lars | 1024 | 0,01 | cosseno | 200 | 7.68 | 22m |
| Resnet-PreAct-20 | Lars | 1024 | 0,005 | cosseno | 200 | 8.88 | 23m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 512 | 3.2 | cosseno | 200 | 8.51 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 512 | 1.6 | cosseno | 200 | 7.73 (1 corrida) | 20m |
| Resnet-PreAct-20 | Sgd | 512 | 0,8 | cosseno | 200 | 7.73 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 512 | 0,4 | cosseno | 200 | 8.22 (1 corrida) | 20m |
| Resnet-PreAct-20 | Lars | 512 | 0,015 | cosseno | 200 | 9.84 | 23m |
| Resnet-PreAct-20 | Lars | 512 | 0,01 | cosseno | 200 | 8.05 | 23m |
| Resnet-PreAct-20 | Lars | 512 | 0,0075 | cosseno | 200 | 7.58 | 23m |
| Resnet-PreAct-20 | Lars | 512 | 0,005 | cosseno | 200 | 7.96 | 23m |
| Resnet-PreAct-20 | Lars | 512 | 0,0025 | cosseno | 200 | 8.83 | 23m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 256 | 3.2 | cosseno | 200 | 9.64 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 256 | 1.6 | cosseno | 200 | 8.32 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 256 | 0,8 | cosseno | 200 | 7.45 (1 corrida) | 21m |
| Resnet-PreAct-20 | Sgd | 256 | 0,4 | cosseno | 200 | 7.68 (1 corrida) | 22m |
| Resnet-PreAct-20 | Sgd | 256 | 0,2 | cosseno | 200 | 8.61 (1 corrida) | 22m |
| Resnet-PreAct-20 | Lars | 256 | 0,01 | cosseno | 200 | 8.95 | 27m |
| Resnet-PreAct-20 | Lars | 256 | 0,005 | cosseno | 200 | 7.75 | 28m |
| Resnet-PreAct-20 | Lars | 256 | 0,0025 | cosseno | 200 | 8.21 | 28m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 128 | 1.6 | cosseno | 200 | 9.03 (1 corrida) | 24m |
| Resnet-PreAct-20 | Sgd | 128 | 0,8 | cosseno | 200 | 7.54 (1 corrida) | 24m |
| Resnet-PreAct-20 | Sgd | 128 | 0,4 | cosseno | 200 | 7.28 (1 corrida) | 24m |
| Resnet-PreAct-20 | Sgd | 128 | 0,2 | cosseno | 200 | 7.96 (1 corrida) | 24m |
| Resnet-PreAct-20 | Lars | 128 | 0,005 | cosseno | 200 | 7.96 | 37m |
| Resnet-PreAct-20 | Lars | 128 | 0,0025 | cosseno | 200 | 7.98 | 37m |
| Resnet-PreAct-20 | Lars | 128 | 0,00125 | cosseno | 200 | 9.21 | 37m |
| Modelo | otimizador | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Sgd | 4096 | 1.6 | cosseno | 200 | 10.20 | 22m |
| Resnet-PreAct-20 | Sgd | 4096 | 1.6 | cosseno | 800 | 8.36 (1 corrida) | 1H33M |
| Resnet-PreAct-20 | Sgd | 4096 | 1.6 | cosseno | 1600 | 8.25 (1 corrida) | 3H10M |
| Resnet-PreAct-20 | Lars | 4096 | 0,02 | cosseno | 200 | 8.21 | 22m |
| Resnet-PreAct-20 | Lars | 4096 | 0,02 | cosseno | 400 | 7.53 | 44m |
| Resnet-PreAct-20 | Lars | 4096 | 0,02 | cosseno | 800 | 7.48 | 1H29M |
| Resnet-PreAct-20 | Lars | 4096 | 0,02 | cosseno | 1600 | 7.37 (1 corrida) | 2H58m |
Fantasma Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Modelo | Tamanho do lote | Tamanho do lote fantasma | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 8192 | N / D | 1.6 | cosseno | 200 | 12.35 | 25m* |
| Resnet-PreAct-20 | 4096 | N / D | 1.6 | cosseno | 200 | 10.32 | 22m |
| Resnet-PreAct-20 | 2048 | N / D | 1.6 | cosseno | 200 | 8.73 | 22m |
| Resnet-PreAct-20 | 1024 | N / D | 1.6 | cosseno | 200 | 8.07 | 22m |
| Resnet-PreAct-20 | 128 | N / D | 0,4 | cosseno | 200 | 7.28 | 24m |
| Modelo | Tamanho do lote | Tamanho do lote fantasma | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 8192 | 128 | 1.6 | cosseno | 200 | 11.51 | 27m |
| Resnet-PreAct-20 | 4096 | 128 | 1.6 | cosseno | 200 | 9.73 | 25m |
| Resnet-PreAct-20 | 2048 | 128 | 1.6 | cosseno | 200 | 8.77 | 24m |
| Resnet-PreAct-20 | 1024 | 128 | 1.6 | cosseno | 200 | 7.82 | 22m |
| Modelo | Tamanho do lote | Tamanho do lote fantasma | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 8192 | N / D | 1.6 | cosseno | 1600 | | |
| Resnet-PreAct-20 | 4096 | N / D | 1.6 | cosseno | 1600 | 8.25 | 3H10M |
| Resnet-PreAct-20 | 2048 | N / D | 1.6 | cosseno | 1600 | 7.34 | 2h50m |
| Resnet-PreAct-20 | 1024 | N / D | 1.6 | cosseno | 1600 | 6.94 | 2H52m |
| Modelo | Tamanho do lote | Tamanho do lote fantasma | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | 8192 | 128 | 1.6 | cosseno | 1600 | 11.83 | 3H37M |
| Resnet-PreAct-20 | 4096 | 128 | 1.6 | cosseno | 1600 | 8.95 | 3H15m |
| Resnet-PreAct-20 | 2048 | 128 | 1.6 | cosseno | 1600 | 7.23 | 3H05m |
| Resnet-PreAct-20 | 1024 | 128 | 1.6 | cosseno | 1600 | 7.08 | 2H59M |
Sem decaimento de peso no BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00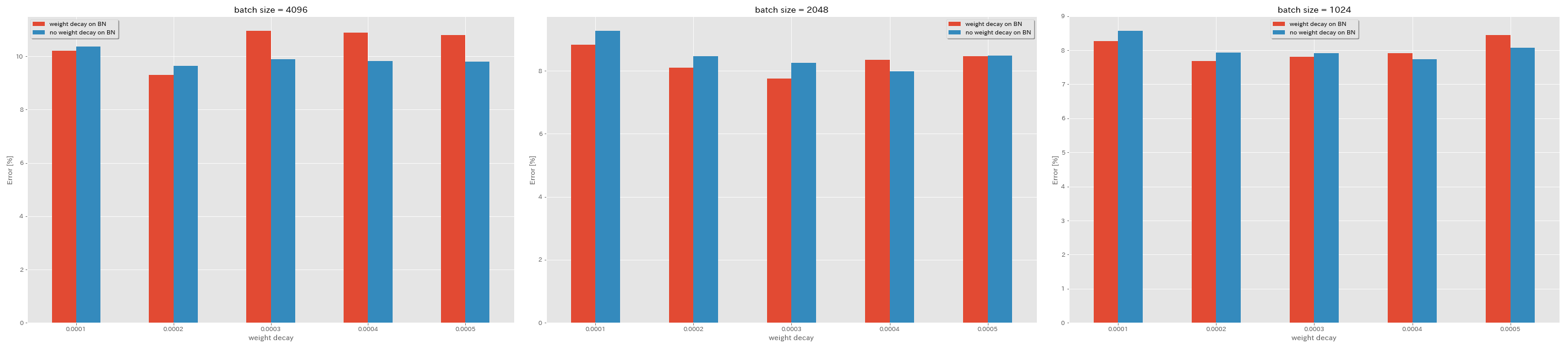
| Modelo | decaimento de peso no BN | decaimento de peso | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | sim | 5E-4 | 4096 | 1.6 | cosseno | 200 | 10.81 | 22m |
| Resnet-PreAct-20 | sim | 4E-4 | 4096 | 1.6 | cosseno | 200 | 10.88 | 22m |
| Resnet-PreAct-20 | sim | 3E-4 | 4096 | 1.6 | cosseno | 200 | 10.96 | 22m |
| Resnet-PreAct-20 | sim | 2E-4 | 4096 | 1.6 | cosseno | 200 | 9.30 | 22m |
| Resnet-PreAct-20 | sim | 1e-4 | 4096 | 1.6 | cosseno | 200 | 10.20 | 22m |
| Resnet-PreAct-20 | não | 5E-4 | 4096 | 1.6 | cosseno | 200 | 8.78 | 22m |
| Resnet-PreAct-20 | não | 4E-4 | 4096 | 1.6 | cosseno | 200 | 9.83 | 22m |
| Resnet-PreAct-20 | não | 3E-4 | 4096 | 1.6 | cosseno | 200 | 9.90 | 22m |
| Resnet-PreAct-20 | não | 2E-4 | 4096 | 1.6 | cosseno | 200 | 9.64 | 22m |
| Resnet-PreAct-20 | não | 1e-4 | 4096 | 1.6 | cosseno | 200 | 10.38 | 22m |
| Modelo | decaimento de peso no BN | decaimento de peso | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | sim | 5E-4 | 2048 | 1.6 | cosseno | 200 | 8.46 | 20m |
| Resnet-PreAct-20 | sim | 4E-4 | 2048 | 1.6 | cosseno | 200 | 8.35 | 20m |
| Resnet-PreAct-20 | sim | 3E-4 | 2048 | 1.6 | cosseno | 200 | 7.76 | 20m |
| Resnet-PreAct-20 | sim | 2E-4 | 2048 | 1.6 | cosseno | 200 | 8.09 | 20m |
| Resnet-PreAct-20 | sim | 1e-4 | 2048 | 1.6 | cosseno | 200 | 8.83 | 20m |
| Resnet-PreAct-20 | não | 5E-4 | 2048 | 1.6 | cosseno | 200 | 8.49 | 20m |
| Resnet-PreAct-20 | não | 4E-4 | 2048 | 1.6 | cosseno | 200 | 7.98 | 20m |
| Resnet-PreAct-20 | não | 3E-4 | 2048 | 1.6 | cosseno | 200 | 8.26 | 20m |
| Resnet-PreAct-20 | não | 2E-4 | 2048 | 1.6 | cosseno | 200 | 8.47 | 20m |
| Resnet-PreAct-20 | não | 1e-4 | 2048 | 1.6 | cosseno | 200 | 9.27 | 20m |
| Modelo | decaimento de peso no BN | decaimento de peso | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (mediana de 3 execuções) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | sim | 5E-4 | 1024 | 1.6 | cosseno | 200 | 8.45 | 21m |
| Resnet-PreAct-20 | sim | 4E-4 | 1024 | 1.6 | cosseno | 200 | 7.91 | 21m |
| Resnet-PreAct-20 | sim | 3E-4 | 1024 | 1.6 | cosseno | 200 | 7.81 | 21m |
| Resnet-PreAct-20 | sim | 2E-4 | 1024 | 1.6 | cosseno | 200 | 7.69 | 21m |
| Resnet-PreAct-20 | sim | 1e-4 | 1024 | 1.6 | cosseno | 200 | 8.26 | 21m |
| Resnet-PreAct-20 | não | 5E-4 | 1024 | 1.6 | cosseno | 200 | 8.08 | 21m |
| Resnet-PreAct-20 | não | 4E-4 | 1024 | 1.6 | cosseno | 200 | 7.73 | 21m |
| Resnet-PreAct-20 | não | 3E-4 | 1024 | 1.6 | cosseno | 200 | 7.92 | 21m |
| Resnet-PreAct-20 | não | 2E-4 | 1024 | 1.6 | cosseno | 200 | 7.93 | 21m |
| Resnet-PreAct-20 | não | 1e-4 | 1024 | 1.6 | cosseno | 200 | 8.53 | 21m |
Experiências em meia precisão e precisão mista
- A seguir, as experiências precisam de nvidia ápice.
- A seguir, as experiências são feitas no conjunto de dados CIFAR-10 usando o GeForce 1080 Ti, que não possui núcleos tensores.
- Os resultados relatados na tabela são os erros de teste nas últimas épocas.
Treinamento FP16
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Treinamento de precisão mista
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Resultados
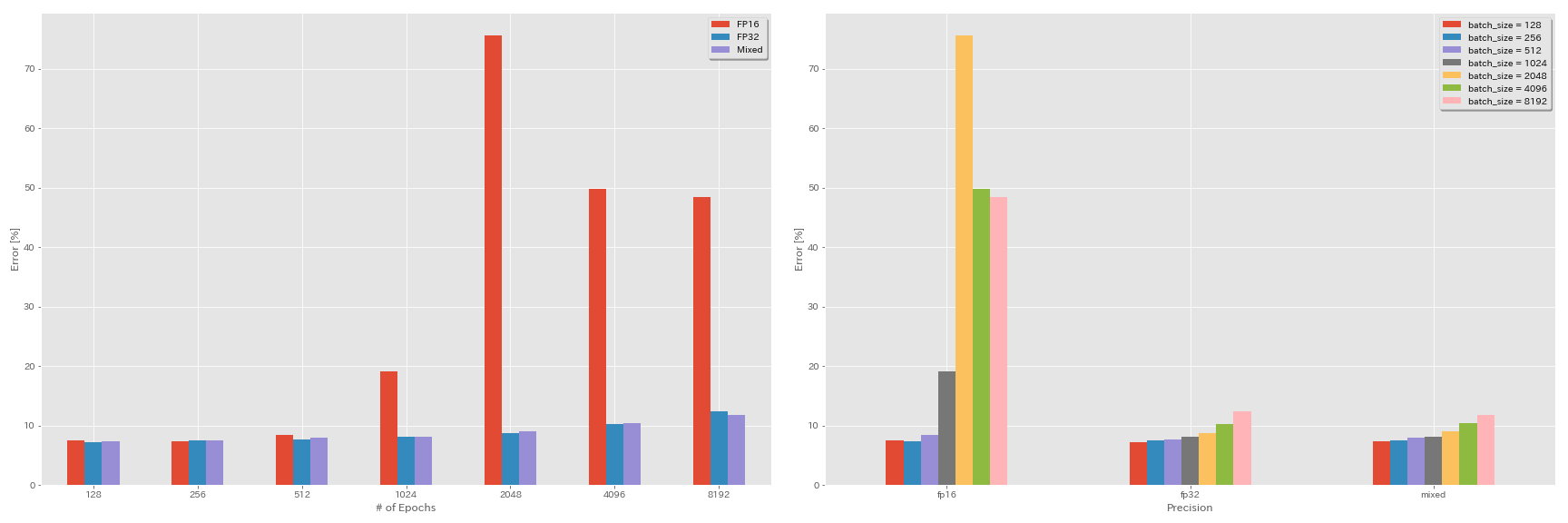
| Modelo | precisão | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Fp32 | 8192 | 1.6 | cosseno | 200 | | |
| Resnet-PreAct-20 | Fp32 | 4096 | 1.6 | cosseno | 200 | 10.32 | 22m |
| Resnet-PreAct-20 | Fp32 | 2048 | 1.6 | cosseno | 200 | 8.73 | 22m |
| Resnet-PreAct-20 | Fp32 | 1024 | 1.6 | cosseno | 200 | 8.07 | 22m |
| Resnet-PreAct-20 | Fp32 | 512 | 0,8 | cosseno | 200 | 7.73 | 21m |
| Resnet-PreAct-20 | Fp32 | 256 | 0,8 | cosseno | 200 | 7.45 | 21m |
| Resnet-PreAct-20 | Fp32 | 128 | 0,4 | cosseno | 200 | 7.28 | 24m |
| Modelo | precisão | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | FP16 | 8192 | 1.6 | cosseno | 200 | 48.52 | 33m |
| Resnet-PreAct-20 | FP16 | 4096 | 1.6 | cosseno | 200 | 49.84 | 28m |
| Resnet-PreAct-20 | FP16 | 2048 | 1.6 | cosseno | 200 | 75.63 | 27m |
| Resnet-PreAct-20 | FP16 | 1024 | 1.6 | cosseno | 200 | 19.09 | 27m |
| Resnet-PreAct-20 | FP16 | 512 | 0,8 | cosseno | 200 | 7.89 | 26m |
| Resnet-PreAct-20 | FP16 | 256 | 0,8 | cosseno | 200 | 7.40 | 28m |
| Resnet-PreAct-20 | FP16 | 128 | 0,4 | cosseno | 200 | 7.59 | 32m |
| Modelo | precisão | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | misturado | 8192 | 1.6 | cosseno | 200 | 11.78 | 28m |
| Resnet-PreAct-20 | misturado | 4096 | 1.6 | cosseno | 200 | 10.48 | 27m |
| Resnet-PreAct-20 | misturado | 2048 | 1.6 | cosseno | 200 | 8.98 | 26m |
| Resnet-PreAct-20 | misturado | 1024 | 1.6 | cosseno | 200 | 8.05 | 26m |
| Resnet-PreAct-20 | misturado | 512 | 0,8 | cosseno | 200 | 7.81 | 28m |
| Resnet-PreAct-20 | misturado | 256 | 0,8 | cosseno | 200 | 7.58 | 32m |
| Resnet-PreAct-20 | misturado | 128 | 0,4 | cosseno | 200 | 7.37 | 41m |
Resultados usando Tesla V100
| Modelo | precisão | Tamanho do lote | LR inicial | Cronograma de LR | # de épocas | Erro de teste (1 execução) | Tempo de treinamento |
|---|
| Resnet-PreAct-20 | Fp32 | 8192 | 1.6 | cosseno | 200 | 12.35 | 25m |
| Resnet-PreAct-20 | Fp32 | 4096 | 1.6 | cosseno | 200 | 9.88 | 19m |
| Resnet-PreAct-20 | Fp32 | 2048 | 1.6 | cosseno | 200 | 8.87 | 17m |
| Resnet-PreAct-20 | Fp32 | 1024 | 1.6 | cosseno | 200 | 8.45 | 18m |
| Resnet-PreAct-20 | misturado | 8192 | 1.6 | cosseno | 200 | 11.92 | 25m |
| Resnet-PreAct-20 | misturado | 4096 | 1.6 | cosseno | 200 | 10.16 | 19m |
| Resnet-PreAct-20 | misturado | 2048 | 1.6 | cosseno | 200 | 9.10 | 17m |
| Resnet-PreAct-20 | misturado | 1024 | 1.6 | cosseno | 200 | 7.84 | 16m |
Referências
Arquitetura de modelo
- Ele, Kaiming, Xiangyu Zhang, Shaoqing Ren e Jian Sun. "Aprendizagem residual profunda para reconhecimento de imagem". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2016. Link, Arxiv: 1512.03385
- Ele, Kaiming, Xiangyu Zhang, Shaoqing Ren e Jian Sun. "Mapeamentos de identidade em redes residuais profundas". Na Conferência Europeia sobre Visão Computal (ECCV). 2016. Arxiv: 1603.05027, implementação da tocha
- Zagoruyko, Sergey e Nikos Komodakis. "Redes residuais amplas". Anais da British Machine Vision Conference (BMVC), 2016. Arxiv: 1605.07146, implementação da tocha
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger e Laurens van der Maaten. "Redes convolucionais densamente conectadas". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2017. Link, Arxiv: 1608.06993, implementação da tocha
- Han, Dongyoon, Jiwhan Kim e Junmo Kim. "Redes residuais piramidais profundas". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2017. Link, ARXIV: 1610.02915, implementação da tocha, implementação de cafe, implementação de pytorch
- Xie, Singing, Ross Girshick, Piotr Dollar, Zhuowen Tu e Kaiming He. "Transformações residuais agregadas para redes neurais profundas". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2017. Link, arxiv: 1611.05431, implementação da tocha
- Gastaldi, Xavier. "A regularização de shake-shake de redes residuais de 3 ramos". Em Conferência Internacional sobre Representações de Aprendizagem (ICLR) Workshop, 2017. Link, Arxiv: 1705.07485, Torch Implementation
- Hu, Jie, Li Shen e Gang Sun. "Redes de aperto e excitação". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2018, pp. 7132-7141. Link, Arxiv: 1709.01507, implementação de Caffe
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten e Kilian Q. Weinberger. "Redes convolucionais com conectividade densa". IEEE Transações sobre análise de padrões e inteligência de máquina (2019). ARXIV: 2001.02394
Regularização, aumento de dados
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens e Zbigniew Wojna. "Repensando a arquitetura inicial para a visão computacional". A conferência do IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2016. Link, Arxiv: 1512.00567
- Devries, Terrance e Graham W. Taylor. "A regularização aprimorada de redes neurais convolucionais com recorte". Arxiv pré -impressão Arxiv: 1708.04552 (2017). ARXIV: 1708.04552, implementação de Pytorch
- Abu-El-Haija, Sami. "Atualizações proporcionais de gradiente com porcentagem". Arxiv pré -impressão Arxiv: 1708.07227 (2017). ARXIV: 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li e Yi Yang. "Apagamento aleatório de dados". Arxiv pré -impressão Arxiv: 1708.04896 (2017). ARXIV: 1708.04896, implementação de Pytorch
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin e David Lopez-Paz. "Mixup: além da minimização empírica de riscos". Em Conferência Internacional sobre Representações de Aprendizagem (ICLR), 2017. Link, Arxiv: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma e Leslie Pack Keelbling. "Para entender a generalização por meio da teoria da aprendizagem analítica". Arxiv pré -impressão Arxiv: 1802.07426 (2018). ARXIV: 1802.07426, implementação de Pytorch
- Takahashi, Ryo, Takashi Matsubara e Kuniaki Uehara. "O aumento de dados usando o corte e a remendos de imagens aleatórias para CNNs profundas". Anais da 10ª Conferência Asiática sobre Machine Learning (ACML), 2018. Link, Arxiv: 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe e Youngjoon Yoo. "Cutmix: estratégia de regularização para treinar classificadores fortes com recursos localizáveis". Arxiv pré -impressão Arxiv: 1905.04899 (2019). ARXIV: 1905.04899
Lote grande
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy e Ping Tak Peter Tang. "No treinamento de grande lotes para aprendizado profundo: lacuna de generalização e mínimos nítidos". Em Conferência Internacional sobre Representações de Aprendizagem (ICLR), 2017. Link, Arxiv: 1609.04836
- Hoffer, Elad, Itay Hubara e Daniel Soudry. "Treine mais tempo, generalize melhor: fechar a lacuna de generalização em grandes treinamentos em lote de redes neurais". Em Advances in Neural Information Processing Systems (NIPS), 2017. Link, ARXIV: 1705.08741, implementação de Pytorch
- Goyal, Priya, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia e Kaiming He. "SGD preciso e grande de minibatch: treinamento de imagenet em 1 hora". Arxiv pré -impressão Arxiv: 1706.02677 (2017). ARXIV: 1706.02677
- Você, Yang, Igor Gitman e Boris Ginsburg. "Grande treinamento em lote de redes convolucionais". Arxiv pré -impressão Arxiv: 1708.03888 (2017). ARXIV: 1708.03888
- Você, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel e Kurt Keutzer. "Treinamento do ImageNet em minutos." Arxiv pré -impressão Arxiv: 1709.05011 (2017). ARXIV: 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying e Quoc V. Le. "Não decair a taxa de aprendizado, aumente o tamanho do lote". Em Conferência Internacional sobre Representações de Aprendizagem (ICLR), 2018. Link, Arxiv: 1711.00489
- Gitman, Igor, Deepak Dilipkumar e Ben Parr. "Análise de convergência de algoritmos de descida de gradiente com atualizações proporcionais". Arxiv pré -impressão Arxiv: 1801.03137 (2018). ARXIV: 1801.03137 Implementação de tensorflow
- Jia, Xianyan, Shutao Song, Wei He, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi, and Xiaowen Chu. "Sistema de treinamento de aprendizado profundo altamente escalável com precisão mista: treinamento de imagenet em quatro minutos". Arxiv pré -impressão Arxiv: 1807.11205 (2018). ARXIV: 1807.11205
- Shallue, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig e George E. Dahl. "Medir os efeitos do paralelismo de dados no treinamento da rede neural". Arxiv pré -impressão Arxiv: 1811.03600 (2018). ARXIV: 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang e Youlong Cheng. "Classificação da imagem na escala do supercomputador." Em Advances in Neural Information Processing Systems (Neurips) Workshop, 2018. Link, Arxiv: 1811.06992
Outros
- Loshchilov, Ilya e Frank Hutter. "SGDR: descida de gradiente estocástico com reinicializações quentes." Em Conferência Internacional sobre Representações de Aprendizagem (ICLR), 2017. Link, Arxiv: 1608.03983, implementação da lasanha
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh e Hao Wu. "Treinamento de precisão mista". Em Conferência Internacional sobre Representações de Aprendizagem (ICLR), 2018. Link, Arxiv: 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt e Vaishaal Shankar. "Os classificadores CIFAR-10 generalizam para o CIFAR-10?" Arxiv pré -impressão Arxiv: 1806.00451 (2018). ARXIV: 1806.00451
- Ele, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie e Mu Li. "Bolsa de truques para classificação de imagens com redes neurais convolucionais". Arxiv pré -impressão Arxiv: 1812.01187 (2018). ARXIV: 1812.01187


