Clasificación de imagen de Pytorch
Los siguientes documentos se implementan utilizando Pytorch.
- Resnet (1512.03385)
- Resnet-PREACC (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- Recorte (1708.04552)
- Borrando aleatorio (1708.04896)
- Seneto (1709.01507)
- Mezcla (1710.09412)
- Corte dual (1802.07426)
- RICAP (1811.09030)
- Cutmix (1905.04899)
Requisitos
- Ubuntu (solo se prueba en Ubuntu, por lo que puede no funcionar en Windows).
- Python> = 3.7
- Pytorch> = 1.4.0
- vía antorcha
- Ápice nvidia
pip install -r requirements.txt
Uso
python train.py --config configs/cifar/resnet_preact.yaml
Resultados en CIFAR-10
Resultados que usan la misma configuración que los documentos
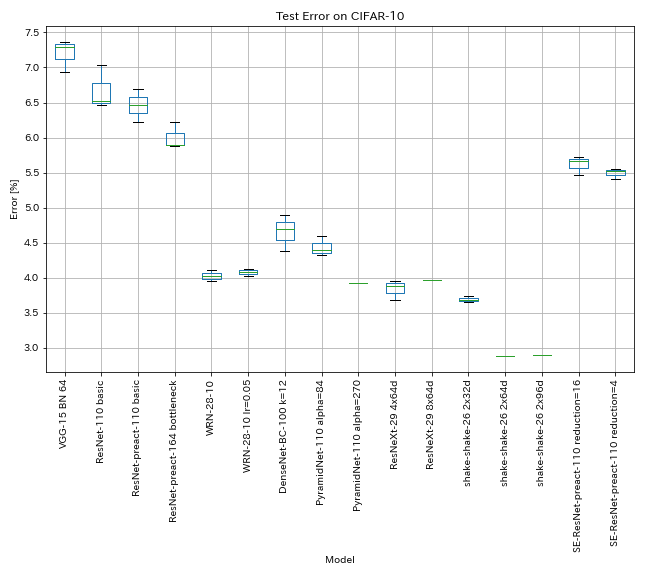
| Modelo | Error de prueba (mediana de 3 carreras) | Error de prueba (en papel) | Tiempo de entrenamiento |
|---|
| VGG-Like (profundidad 15, w/ bn, canal 64) | 7.29 | N / A | 1h20m |
| Resnet-110 | 6.52 | 6.43 (mejor), 6.61 +/- 0.16 | 3h06m |
| Resnet-PREACC-110 | 6.47 | 6.37 (mediana de 5 carreras) | 3h05m |
| RETNET-PREACT-164 Cuello de botella | 5.90 | 5.46 (mediana de 5 carreras) | 4h01m |
| Resnet-PREACT-1001 Coloque de botella | | 4.62 (mediana de 5 carreras), 4.69 +/- 0.20 | |
| WRN-28-10 | 4.03 | 4.00 (mediana de 5 carreras) | 16h10m |
| WRN-28-10 con abandono | | 3.89 (mediana de 5 carreras) | |
| Densenet-100 (k = 12) | 3.87 (1 ejecución) | 4.10 (1 ejecución) | 24h28m* |
| Densenet-100 (k = 24) | | 3.74 (1 ejecución) | |
| Densenet-BC-100 (k = 12) | 4.69 | 4.51 (1 ejecución) | 15h20m |
| Densenet-BC-250 (k = 24) | | 3.62 (1 ejecución) | |
| Densenet-BC-190 (k = 40) | | 3.46 (1 ejecución) | |
| Pyramidnet-110 (alfa = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| Pyramidnet-10 (alfa = 270) | 3.92 (1 ejecución) | 3.73 +/- 0.04 | 24h12m* |
| Pyramidnet-164 cuello de botella (alfa = 270) | 3.44 (1 ejecución) | 3.48 +/- 0.20 | 32h37m* |
| Pyramidnet-272 cuello de botella (alfa = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (de la Figura 7) | 31h17m |
| Resnext-29 8x64d | 3.97 (1 carrera) | 3.65 (promedio de 10 carreras) | 42h50m* |
| Resnext-29 16x64d | | 3.58 (promedio de 10 carreras) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3.55 (promedio de 3 carreras) | 33h49m |
| Shake-Shake-26 2x64d (SSI) | 2.88 (1 ejecución) | 2.98 (promedio de 3 carreras) | 78h48m |
| Shake-Shake-26 2x96d (SSI) | 2.90 (1 ejecución) | 2.86 (promedio de 5 carreras) | 101h32m* |
Notas
- Diferencias con los documentos en entornos de capacitación:
- WRN-28-10 entrenado con tamaño por lotes 64 (128 en papel).
- Densenet-BC-100 entrenado (k = 12) con tamaño de lote 32 y tasa de aprendizaje inicial 0.05 (tamaño de lote 64 y tasa de aprendizaje inicial 0.1 en papel).
- Resnext-29 entrenado 4x64d con una sola GPU, tamaño por lotes 32 y tasa de aprendizaje inicial 0.025 (8 GPU, tamaño de lote 128 y tasa de aprendizaje inicial 0.1 en papel).
- Modelos entrenados de sacudidas con una sola GPU (2 GPU en papel).
- Shake-Shake entrenado 26 2x64d (SSI) con tamaño de lote 64 y tasa de aprendizaje inicial 0.1.
- Los errores de prueba informados anteriormente son los de la última época.
- Los experimentos con solo 1 ejecución se realizan en una computadora diferente de la utilizada para experimentos con 3 ejecuciones.
- GeForce GTX 980 se usó en estos experimentos.
VGG como VGG
python train.py --config configs/cifar/vgg.yaml
Resnet
python train.py --config configs/cifar/resnet.yaml
Resnet-PRAACT
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00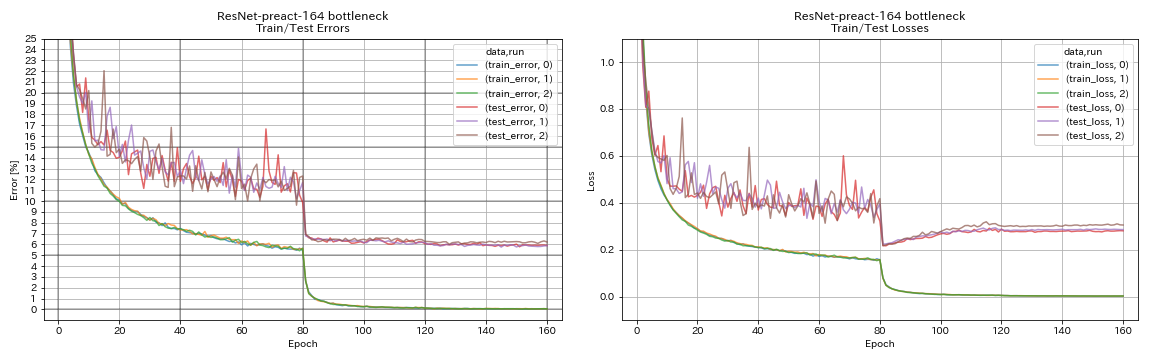
WRN
python train.py --config configs/cifar/wrn.yaml
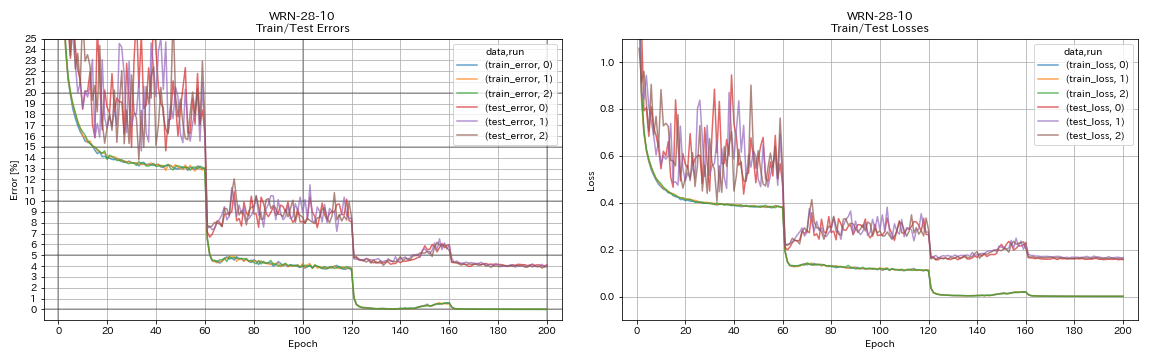
Densenet
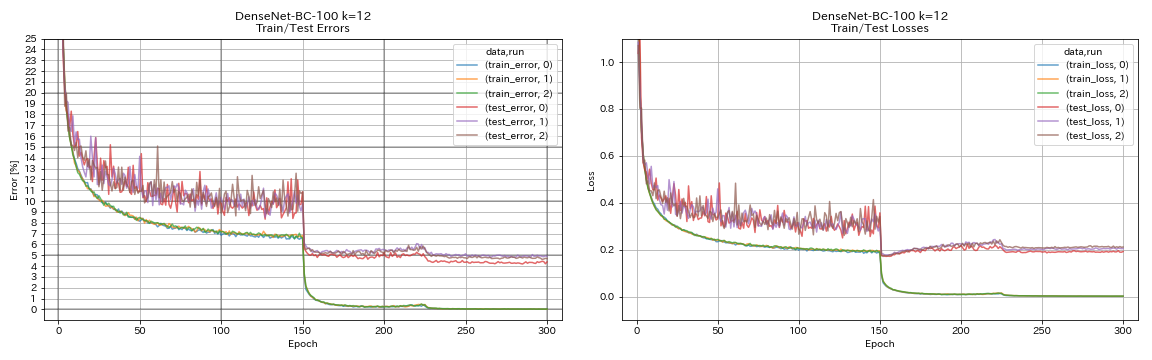
python train.py --config configs/cifar/densenet.yaml
Pirámide
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00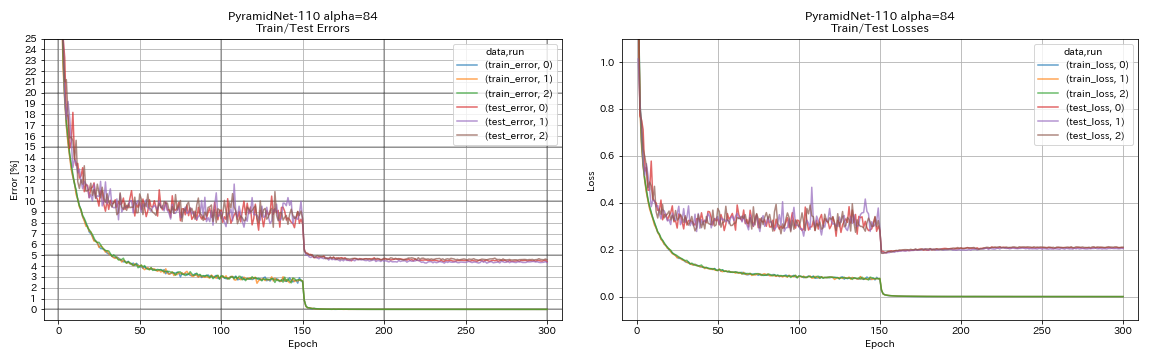
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00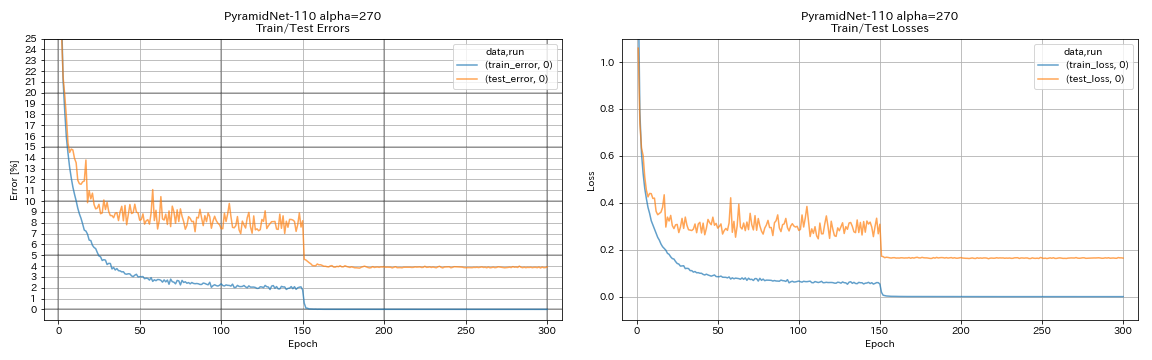
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00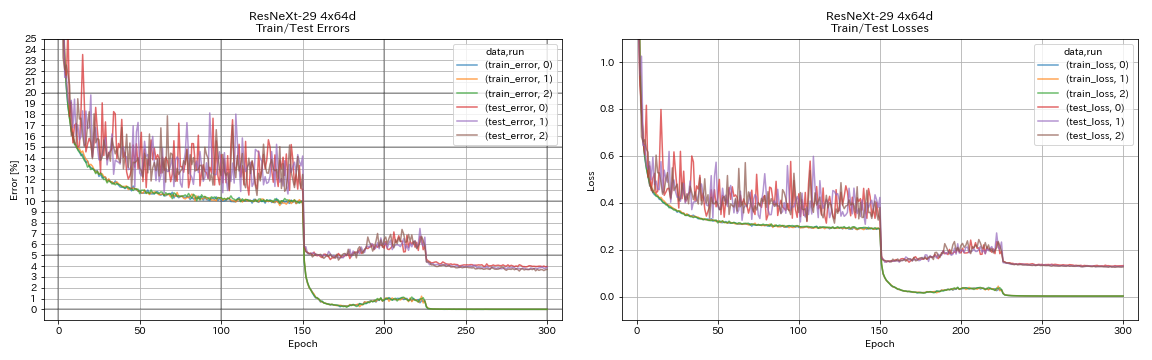
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00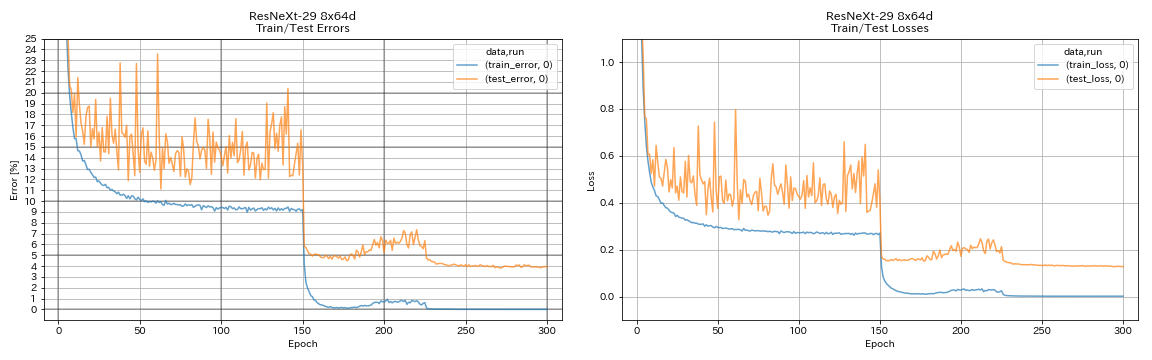
batido
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00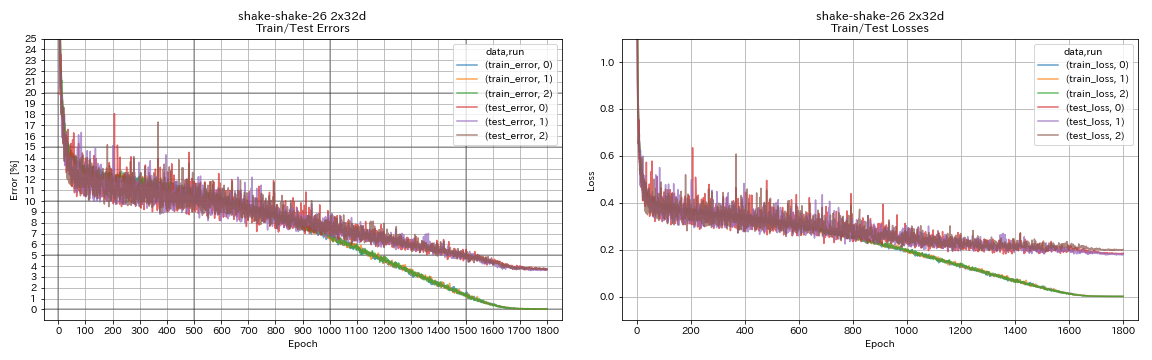
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00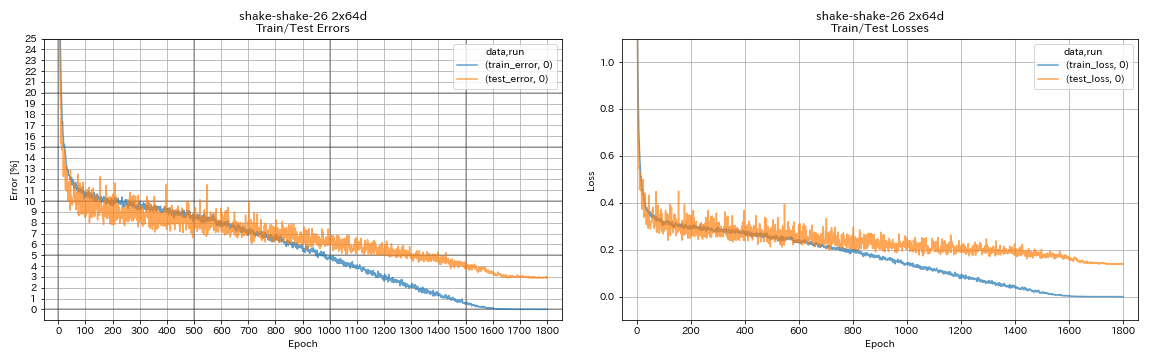
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00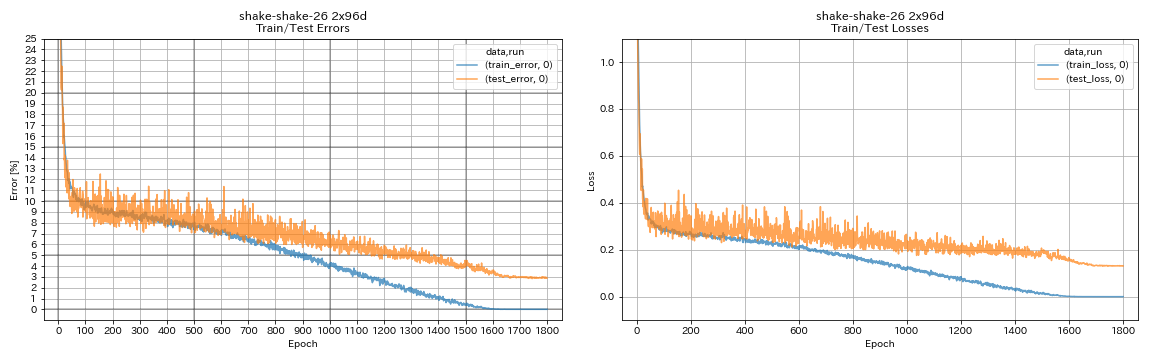
Resultados
| Modelo | Error de prueba (1 ejecución) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-PREACT-20, Factor amplio 4 | 4.91 | 200 | 1H26M |
| Resnet-PREACT-20, Factor amplio 4 | 4.01 | 400 | 2h53m |
| Resnet-PREACT-20, Factor amplio 4 | 3.99 | 1800 | 12h53m |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 16 | 3.71 | 200 | 1H26M |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 16 | 3.46 | 400 | 2h53m |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 16 | 3.76 | 1800 | 12h53m |
| Resnet-PREACT-20, Factor de ampliación 4, RICAP (beta = 0.3) | 3.45 | 200 | 1H26M |
| Resnet-PREACT-20, Factor de ampliación 4, RICAP (beta = 0.3) | 3.11 | 400 | 2h53m |
| Resnet-PREACT-20, Factor de ampliación 4, RICAP (beta = 0.3) | 3.15 | 1800 | 12h53m |
| Modelo | Error de prueba (1 ejecución) | # de épocas | Tiempo de entrenamiento |
|---|
| WRN-28-10, recorte 16 | 3.19 | 200 | 6h35m |
| WRN-28-10, mezcla (alfa = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10, RICAP (beta = 0.3) | 2.83 | 200 | 6h35m |
| WRN-28-10, doble corte (alfa = 0.1) | 2.87 | 200 | 12h42m |
| WRN-28-10, recorte 16 | 3.07 | 400 | 13h10m |
| WRN-28-10, mezcla (alfa = 1) | 3.04 | 400 | 13h08m |
| WRN-28-10, RICAP (beta = 0.3) | 2.71 | 400 | 13h08m |
| WRN-28-10, doble corte (alfa = 0.1) | 2.76 | 400 | 25h20m |
| Shake-shake-26 2x64d, recorte 16 | 2.64 | 1800 | 78h55m* |
| Shake-shake-26 2x64d, mezcla (alfa = 1) | 2.63 | 1800 | 35h56m |
| Shake-Shake-26 2x64d, RICAP (beta = 0.3) | 2.29 | 1800 | 35h10m |
| Shake-Shake-26 2x64d, doble corte (alfa = 0.1) | 2.64 | 1800 | 68h34m |
| Shake-shake-26 2x96d, recorte 16 | 2.50 | 1800 | 60h20m |
| Shake-shake-26 2x96d, mezcla (alfa = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, RICAP (beta = 0.3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, doble corte (alfa = 0.1) | 2.41 | 1800 | 113h09m |
| Shake-shake-26 2x128d, recorte 16 | 2.58 | 1800 | 85h04m |
| Shake-Shake-26 2x128d, RICAP (beta = 0.3) | 1.97 | 1800 | 85h06m |
Nota
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
- Todos los modelos están entrenados con recocido de coseno con la tasa de aprendizaje inicial 0.2.
- GeForce GTX 1080 Ti se usó en estos experimentos, excepto los que *, que se realizan usando GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True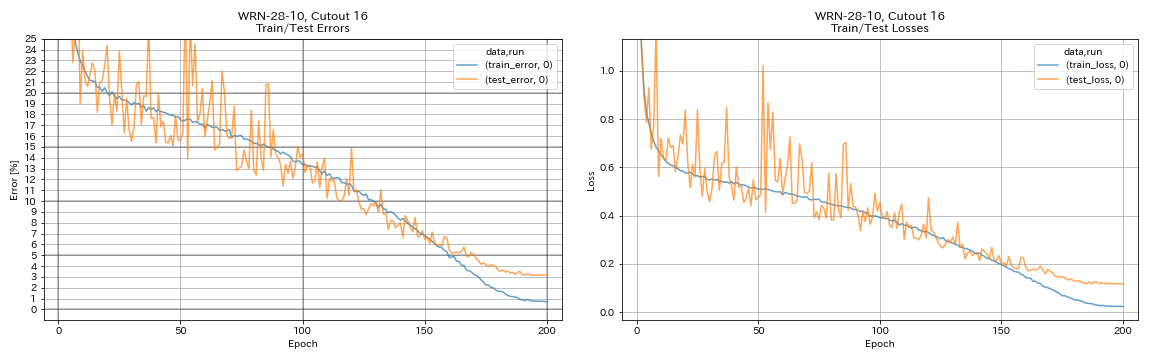
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True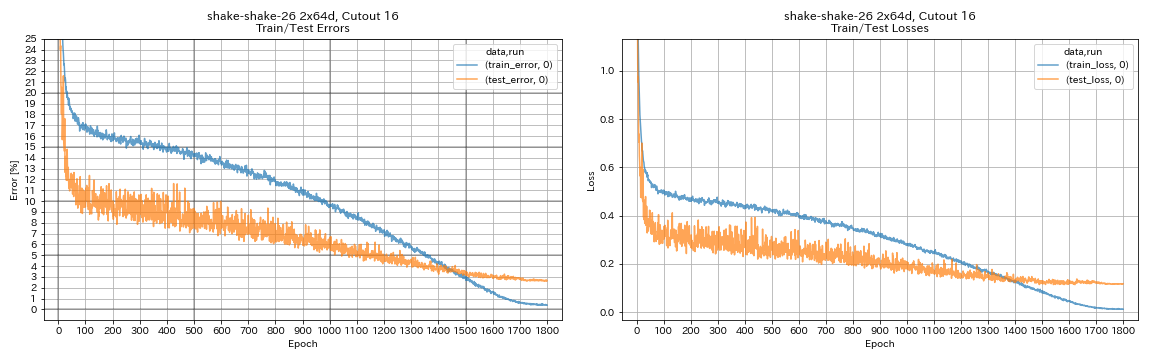
Resultados utilizando multi-GPU
| Modelo | tamaño por lotes | #GPUS | Error de prueba (1 ejecución) | # de épocas | Tiempo de entrenamiento* |
|---|
| WRN-28-10, RICAP (beta = 0.3) | 512 | 1 | 2.63 | 200 | 3h41m |
| WRN-28-10, RICAP (beta = 0.3) | 256 | 2 | 2.71 | 200 | 2h14m |
| WRN-28-10, RICAP (beta = 0.3) | 128 | 4 | 2.89 | 200 | 1h01m |
| WRN-28-10, RICAP (beta = 0.3) | 64 | 8 | 2.75 | 200 | 34m |
Nota
- Tesla V100 se usó en estos experimentos.
Usando 1 GPU
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 2 GPU
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 4 GPU
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseUsando 8 GPU
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseResultados en FashionMnist
| Modelo | Error de prueba (1 ejecución) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-PREACT-20, Factor de ampliación 4, recorte 12 | 4.17 | 200 | 1h32m |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 14 | 4.11 | 200 | 1h32m |
| Resnet-PREACT-50, CUTOUT 12 | 4.45 | 200 | 57m |
| Resnet-PREACT-50, CUTOUT 14 | 4.38 | 200 | 57m |
| Resnet-PREACT-50, Factor de ampliación 4, recorte 12 | 4.07 | 200 | 3h37m |
| Resnet-PREACT-50, Factor de ampliación 4, recorte 14 | 4.13 | 200 | 3H39m |
| Shake-shake-26 2x32d (SSI), recorte 12 | 4.08 | 400 | 3h41m |
| Shake-Shake-26 2x32d (SSI), recorte 14 | 4.05 | 400 | 3H39m |
| Shake-shake-26 2x96d (SSI), recorte 12 | 3.72 | 400 | 13h46m |
| Shake-Shake-26 2x96d (SSI), recorte 14 | 3.85 | 400 | 13h39m |
| Shake-shake-26 2x96d (SSI), recorte 12 | 3.65 | 800 | 26h42m |
| Shake-Shake-26 2x96d (SSI), recorte 14 | 3.60 | 800 | 26h42m |
| Modelo | Error de prueba (mediana de 3 carreras) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 5.04 | 200 | 26m |
| Resnet-PREACT-20, CUTOUT 6 | 4.84 | 200 | 26m |
| Resnet-PREACT-20, CUTOUT 8 | 4.64 | 200 | 26m |
| Resnet-PREACT-20, CUTOUT 10 | 4.74 | 200 | 26m |
| Resnet-PREACT-20, CUTOUT 12 | 4.68 | 200 | 26m |
| Resnet-PREACC-20, CUTOUT 14 | 4.64 | 200 | 26m |
| Resnet-PREACC-20, CUTOUT 16 | 4.49 | 200 | 26m |
| Resnet-PREACT-20, Romenera | 4.61 | 200 | 26m |
| Resnet-PREACC-20, MECHUP | 4.92 | 200 | 26m |
| Resnet-PREACC-20, MECHUP | 4.64 | 400 | 52m |
Nota
- Los resultados informados en las tablas son los errores de prueba en las últimas épocas.
- Todos los modelos están entrenados con recocido de coseno con la tasa de aprendizaje inicial 0.2.
- Los siguientes aumentos de datos se aplican a los datos de capacitación:
- Las imágenes están acolchadas con 4 píxeles en cada lado, y los parches 28x28 se recortan al azar de las imágenes acolchadas.
- Las imágenes se voltean al azar horizontalmente.
- GeForce GTX 1080 Ti se usó en estos experimentos.
Resultados en Mnist
| Modelo | Error de prueba (mediana de 3 carreras) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 0.40 | 100 | 12m |
| Resnet-PREACT-20, CUTOUT 6 | 0.32 | 100 | 12m |
| Resnet-PREACT-20, CUTOUT 8 | 0.25 | 100 | 12m |
| Resnet-PREACT-20, CUTOUT 10 | 0.27 | 100 | 12m |
| Resnet-PREACT-20, CUTOUT 12 | 0.26 | 100 | 12m |
| Resnet-PREACC-20, CUTOUT 14 | 0.26 | 100 | 12m |
| Resnet-PREACC-20, CUTOUT 16 | 0.25 | 100 | 12m |
| Resnet-PREACT-20, MIXP (alfa = 1) | 0.40 | 100 | 12m |
| Resnet-PREACT-20, MIXP (alfa = 0.5) | 0.38 | 100 | 12m |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 14 | 0.26 | 100 | 45m |
| Resnet-PREACT-50, CUTOUT 14 | 0.29 | 100 | 28m |
| Resnet-PREACT-50, Factor de ampliación 4, recorte 14 | 0.25 | 100 | 1h50m |
| Shake-Shake-26 2x96d (SSI), recorte 14 | 0.24 | 100 | 3H22M |
Nota
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
- Todos los modelos están entrenados con recocido de coseno con la tasa de aprendizaje inicial 0.2.
- GeForce GTX 1080 Ti se usó en estos experimentos.
Resultados en kuzushiji-mnist
| Modelo | Error de prueba (mediana de 3 carreras) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-PREACC-20, CUTOUT 14 | 0.82 (mejor 0.67) | 200 | 24m |
| Resnet-PREACC-20, Factor de ampliación 4, recorte 14 | 0.72 (mejor 0.67) | 200 | 1h30m |
| Pyramidnet-110-270, recorte 14 | 0.72 (mejor 0.70) | 200 | 10h05m |
| Shake-Shake-26 2x96d (SSI), recorte 14 | 0.66 (mejor 0.63) | 200 | 6h46m |
Nota
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
- Todos los modelos están entrenados con recocido de coseno con la tasa de aprendizaje inicial 0.2.
- GeForce GTX 1080 Ti se usó en estos experimentos.
Experimentos
Experimentar en unidades residuales, programación de tarifas de aprendizaje y aumento de datos
En este experimento, se investigan los efectos de lo siguiente sobre la precisión de la clasificación:
- Unidades residuales de PyramidNet similares a
- Recocido coseno de la tasa de aprendizaje
- Separar
- Borrado aleatorio
- Confusión
- Preactivación de atajos después de la redacción
Resnet-PREACT-56 está entrenado en CIFAR-10 con la tasa de aprendizaje inicial 0.2 en este experimento.
Nota
- Pyramidnet Paper (1610.02915) mostró que eliminar el primer relu en las unidades residuales y agregar BN después de las últimas convoluciones en unidades residuales mejoran la precisión de la clasificación.
- El documento SGDR (1608.03983) mostró que el recocido de coseno mejora la precisión de la clasificación incluso sin reiniciar.
Resultados
- Las unidades similares a Pyramidnet funciona.
- Puede ser mejor no preactivar atajos después de la reducción de muestras cuando se usa unidades similares a Pyramidnet.
- El recocido de coseno mejora ligeramente la precisión.
- Recorte, al azar y mezclar todo funcionan muy bien.
- La confusión necesita un entrenamiento más largo.
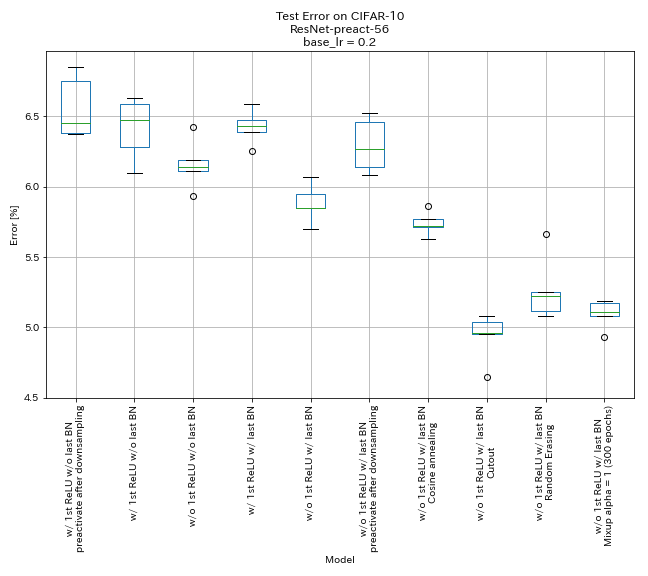
| Modelo | Error de prueba (mediana de 5 carreras) | Tiempo de entrenamiento |
|---|
| w/ 1er relu, sin último bn, atajo preactivado después del muestreo descendente | 6.45 | 95 min |
| w/ 1st relu, sin último bn | 6.47 | 95 min |
| sin el primer relu, sin último bn | 6.14 | 89 min |
| w/ 1st Relu, w/ último bn | 6.43 | 104 min |
| sin primer relu, w/ último bn | 5.85 | 98 min |
| sin primer relu, w/ último bn, atajo preactivado después del muestreo descendente | 6.27 | 98 min |
| sin primer relu, w/ último bn, recocido de coseno | 5.72 | 98 min |
| sin 1er relu, w/ último bn, recorte | 4.96 | 98 min |
| sin 1er relu, w/ último bn, aleatorres. | 5.22 | 98 min |
| sin 1er relu, w/ último bn, mezcla (300 épocas) | 5.11 | 191 min |
Acactive el acceso directo después de la reducción de muestras
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ 1st relu, sin último bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
sin el primer relu, sin último bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ 1st Relu, w/ último bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00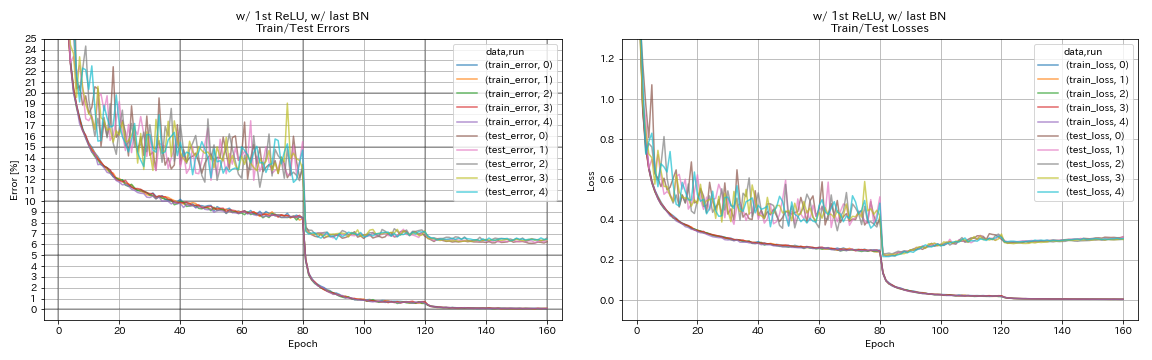
sin primer relu, w/ último bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00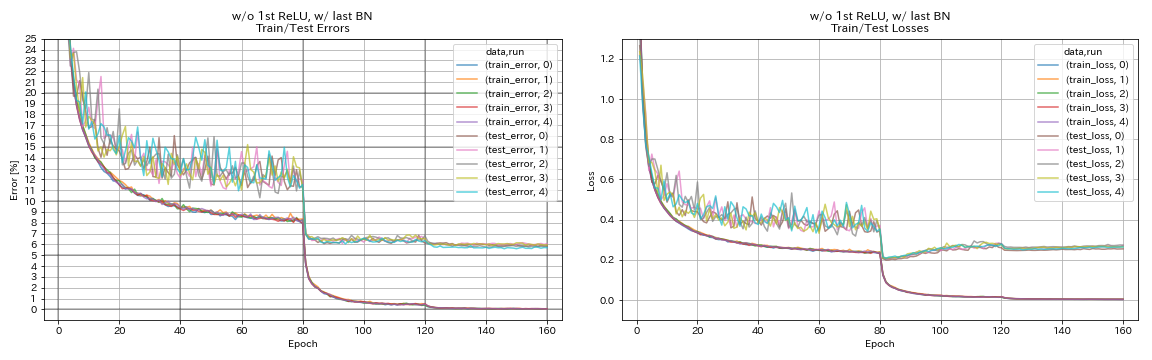
sin primer relu, w/ último bn, atajo preactivado después del muestreo descendente
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00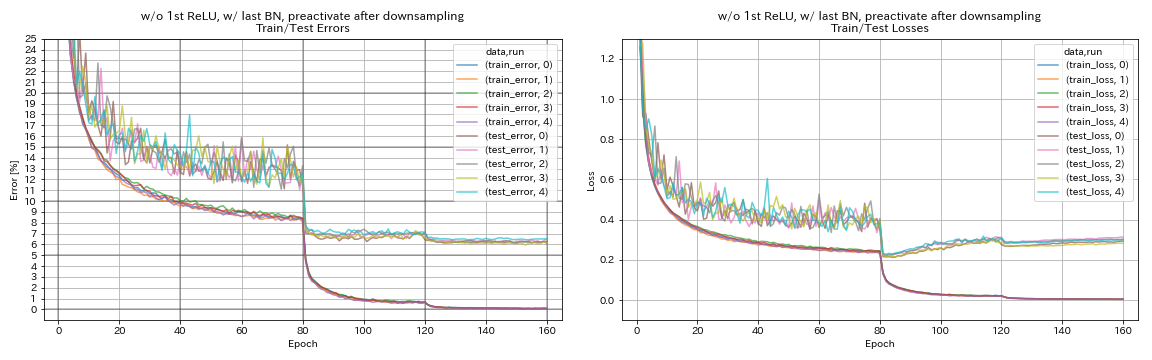
sin primer relu, w/ último bn, recocido de coseno
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00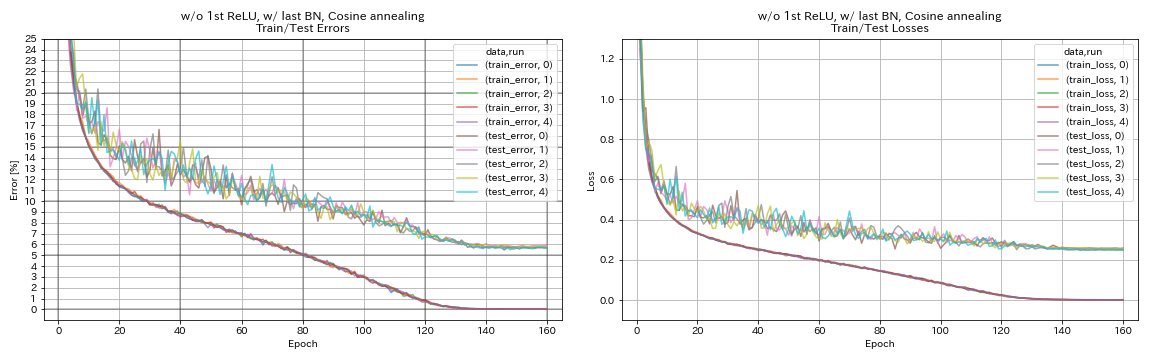
sin 1er relu, w/ último bn, recorte
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00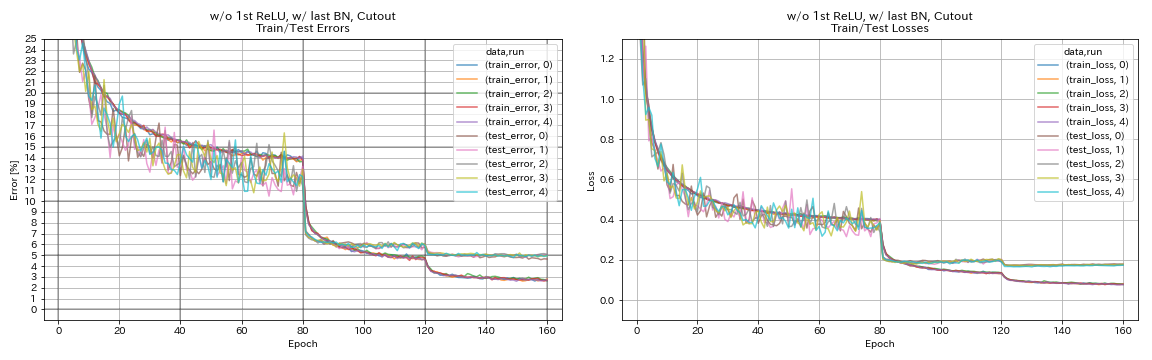
sin 1er relu, w/ último bn, aleatorres.
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00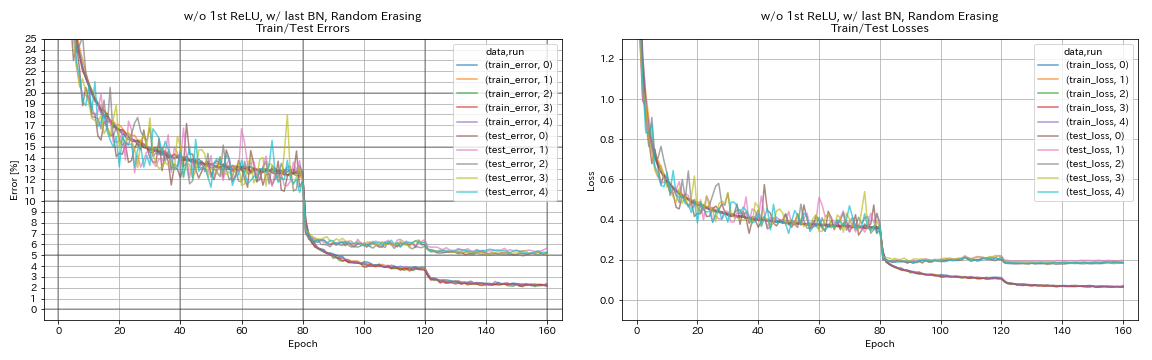
sin 1er relu, w/ último bn, confusión
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00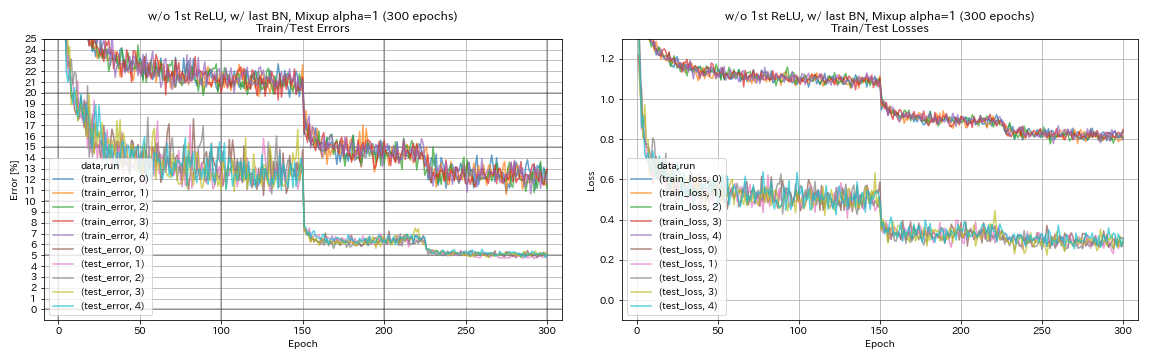
Experimentos sobre suavizado de etiquetas, mezcla, RICAP y doble corte
Resultados en CIFAR-10
| Modelo | Error de prueba (mediana de 3 carreras) | # de épocas | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 7.60 | 200 | 24m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.001) | 7.51 | 200 | 25m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.01) | 7.21 | 200 | 25m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.1) | 7.57 | 200 | 25m |
| Resnet-PREACT-20, MIXP (alfa = 1) | 7.24 | 200 | 26m |
| Resnet-PREACT-20, RICAP (beta = 0.3), con cultivo aleatorio | 6.88 | 200 | 28m |
| Resnet-PREACT-20, RICAP (beta = 0.3) | 6.77 | 200 | 28m |
| Resnet-PREACT-20, DUAL-CUTOUT 16 (alfa = 0.1) | 6.24 | 200 | 45m |
| Resnet-presaact-20 | 7.05 | 400 | 49m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.001) | 7.20 | 400 | 49m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.01) | 6.97 | 400 | 49m |
| Resnet-PREACT-20, Etiquetado de etiquetas (Epsilon = 0.1) | 7.16 | 400 | 49m |
| Resnet-PREACT-20, MIXP (alfa = 1) | 6.66 | 400 | 51m |
| Resnet-PREACT-20, RICAP (beta = 0.3), con cultivo aleatorio | 6.30 | 400 | 56m |
| Resnet-PREACT-20, RICAP (beta = 0.3) | 6.19 | 400 | 56m |
| Resnet-PREACT-20, DUAL-CUTOUT 16 (alfa = 0.1) | 5.55 | 400 | 1h36m |
Nota
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
- Todos los modelos están entrenados con recocido de coseno con la tasa de aprendizaje inicial 0.2.
- GeForce GTX 1080 Ti se usó en estos experimentos.
Experimentos sobre el tamaño del lote y la tasa de aprendizaje
- Los siguientes experimentos se realizan en el conjunto de datos CIFAR-10 utilizando GeForce 1080 Ti.
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
Regla de escala lineal para la tasa de aprendizaje
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 3.2 | coseno | 200 | 10.57 | 22m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 200 | 8.87 | 21m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 200 | 8.40 | 21m |
| Resnet-presaact-20 | 512 | 0.4 | coseno | 200 | 8.22 | 20m |
| Resnet-presaact-20 | 256 | 0.2 | coseno | 200 | 8.61 | 22m |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 200 | 8.09 | 24m |
| Resnet-presaact-20 | 64 | 0.05 | coseno | 200 | 8.22 | 28m |
| Resnet-presaact-20 | 32 | 0.025 | coseno | 200 | 8.00 | 43m |
| Resnet-presaact-20 | 16 | 0.0125 | coseno | 200 | 7.75 | 1h17m |
| Resnet-presaact-20 | 8 | 0.006125 | coseno | 200 | 7.70 | 2h32m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 3.2 | múltiples | 200 | 28.97 | 22m |
| Resnet-presaact-20 | 2048 | 1.6 | múltiples | 200 | 9.07 | 21m |
| Resnet-presaact-20 | 1024 | 0.8 | múltiples | 200 | 8.62 | 21m |
| Resnet-presaact-20 | 512 | 0.4 | múltiples | 200 | 8.23 | 20m |
| Resnet-presaact-20 | 256 | 0.2 | múltiples | 200 | 8.40 | 21m |
| Resnet-presaact-20 | 128 | 0.1 | múltiples | 200 | 8.28 | 24m |
| Resnet-presaact-20 | 64 | 0.05 | múltiples | 200 | 8.13 | 28m |
| Resnet-presaact-20 | 32 | 0.025 | múltiples | 200 | 7.58 | 43m |
| Resnet-presaact-20 | 16 | 0.0125 | múltiples | 200 | 7.93 | 1h18m |
| Resnet-presaact-20 | 8 | 0.006125 | múltiples | 200 | 8.31 | 2h34m |
Escalado lineal + entrenamiento más largo
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 3.2 | coseno | 400 | 8.97 | 44m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 400 | 7.85 | 43m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 400 | 7.20 | 42m |
| Resnet-presaact-20 | 512 | 0.4 | coseno | 400 | 7.83 | 40m |
| Resnet-presaact-20 | 256 | 0.2 | coseno | 400 | 7.65 | 42m |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 400 | 7.09 | 47m |
| Resnet-presaact-20 | 64 | 0.05 | coseno | 400 | 7.17 | 44m |
| Resnet-presaact-20 | 32 | 0.025 | coseno | 400 | 7.24 | 2h11m |
| Resnet-presaact-20 | 16 | 0.0125 | coseno | 400 | 7.26 | 4h10m |
| Resnet-presaact-20 | 8 | 0.006125 | coseno | 400 | 7.02 | 7h53m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 3.2 | coseno | 800 | 8.14 | 1H29m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 800 | 7.74 | 1H23m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 800 | 7.15 | 1h31m |
| Resnet-presaact-20 | 512 | 0.4 | coseno | 800 | 7.27 | 1H25m |
| Resnet-presaact-20 | 256 | 0.2 | coseno | 800 | 7.22 | 1H26M |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 800 | 6.68 | 1h35m |
| Resnet-presaact-20 | 64 | 0.05 | coseno | 800 | 7.18 | 2h20m |
| Resnet-presaact-20 | 32 | 0.025 | coseno | 800 | 7.03 | 4h16m |
| Resnet-presaact-20 | 16 | 0.0125 | coseno | 800 | 6.78 | 8h37m |
| Resnet-presaact-20 | 8 | 0.006125 | coseno | 800 | 6.89 | 16h47m |
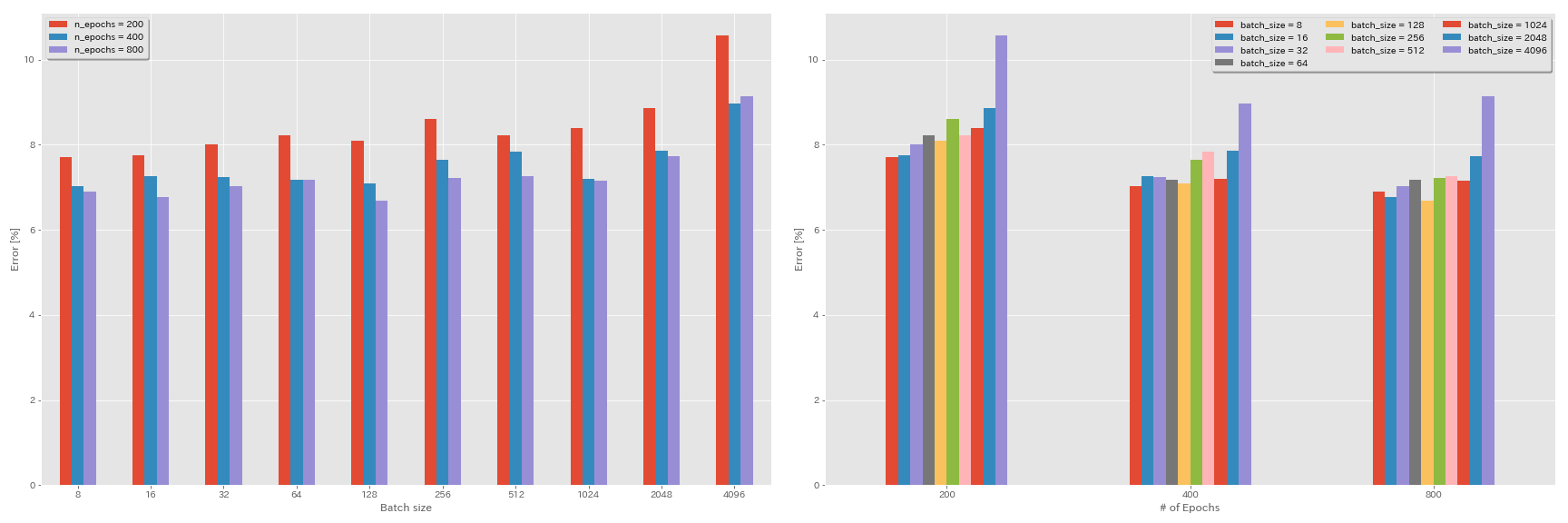
Efecto de la tasa de aprendizaje inicial
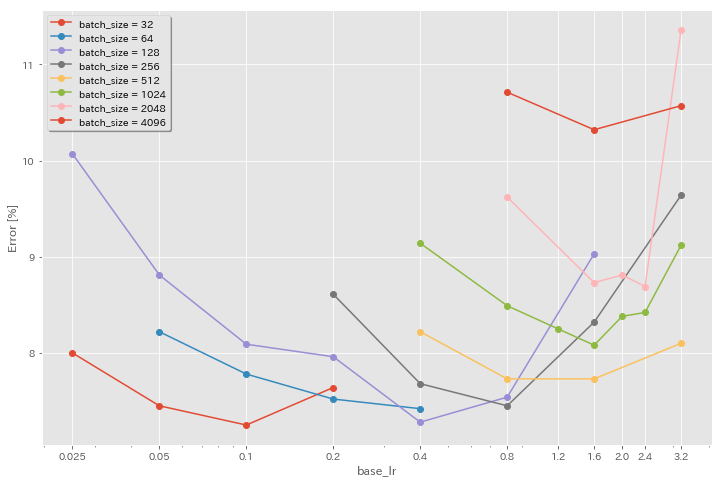
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 3.2 | coseno | 200 | 10.57 | 22m |
| Resnet-presaact-20 | 4096 | 1.6 | coseno | 200 | 10.32 | 22m |
| Resnet-presaact-20 | 4096 | 0.8 | coseno | 200 | 10.71 | 22m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 2048 | 3.2 | coseno | 200 | 11.34 | 21m |
| Resnet-presaact-20 | 2048 | 2.4 | coseno | 200 | 8.69 | 21m |
| Resnet-presaact-20 | 2048 | 2.0 | coseno | 200 | 8.81 | 21m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 200 | 8.73 | 22m |
| Resnet-presaact-20 | 2048 | 0.8 | coseno | 200 | 9.62 | 21m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 1024 | 3.2 | coseno | 200 | 9.12 | 21m |
| Resnet-presaact-20 | 1024 | 2.4 | coseno | 200 | 8.42 | 22m |
| Resnet-presaact-20 | 1024 | 2.0 | coseno | 200 | 8.38 | 22m |
| Resnet-presaact-20 | 1024 | 1.6 | coseno | 200 | 8.07 | 22m |
| Resnet-presaact-20 | 1024 | 1.2 | coseno | 200 | 8.25 | 21m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 200 | 8.08 | 22m |
| Resnet-presaact-20 | 1024 | 0.4 | coseno | 200 | 8.49 | 22m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 512 | 3.2 | coseno | 200 | 8.51 | 21m |
| Resnet-presaact-20 | 512 | 1.6 | coseno | 200 | 7.73 | 20m |
| Resnet-presaact-20 | 512 | 0.8 | coseno | 200 | 7.73 | 21m |
| Resnet-presaact-20 | 512 | 0.4 | coseno | 200 | 8.22 | 20m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 256 | 3.2 | coseno | 200 | 9.64 | 22m |
| Resnet-presaact-20 | 256 | 1.6 | coseno | 200 | 8.32 | 22m |
| Resnet-presaact-20 | 256 | 0.8 | coseno | 200 | 7.45 | 21m |
| Resnet-presaact-20 | 256 | 0.4 | coseno | 200 | 7.68 | 22m |
| Resnet-presaact-20 | 256 | 0.2 | coseno | 200 | 8.61 | 22m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 128 | 1.6 | coseno | 200 | 9.03 | 24m |
| Resnet-presaact-20 | 128 | 0.8 | coseno | 200 | 7.54 | 24m |
| Resnet-presaact-20 | 128 | 0.4 | coseno | 200 | 7.28 | 24m |
| Resnet-presaact-20 | 128 | 0.2 | coseno | 200 | 7.96 | 24m |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 200 | 8.09 | 24m |
| Resnet-presaact-20 | 128 | 0.05 | coseno | 200 | 8.81 | 24m |
| Resnet-presaact-20 | 128 | 0.025 | coseno | 200 | 10.07 | 24m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 64 | 0.4 | coseno | 200 | 7.42 | 35m |
| Resnet-presaact-20 | 64 | 0.2 | coseno | 200 | 7.52 | 36m |
| Resnet-presaact-20 | 64 | 0.1 | coseno | 200 | 7.78 | 37m |
| Resnet-presaact-20 | 64 | 0.05 | coseno | 200 | 8.22 | 28m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 32 | 0.2 | coseno | 200 | 7.64 | 1h05m |
| Resnet-presaact-20 | 32 | 0.1 | coseno | 200 | 7.25 | 1h08m |
| Resnet-presaact-20 | 32 | 0.05 | coseno | 200 | 7.45 | 1h07m |
| Resnet-presaact-20 | 32 | 0.025 | coseno | 200 | 8.00 | 43m |
Buena tasa de aprendizaje + capacitación más larga
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 1.6 | coseno | 200 | 10.32 | 22m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 200 | 8.73 | 22m |
| Resnet-presaact-20 | 1024 | 1.6 | coseno | 200 | 8.07 | 22m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 200 | 8.08 | 22m |
| Resnet-presaact-20 | 512 | 1.6 | coseno | 200 | 7.73 | 20m |
| Resnet-presaact-20 | 512 | 0.8 | coseno | 200 | 7.73 | 21m |
| Resnet-presaact-20 | 256 | 0.8 | coseno | 200 | 7.45 | 21m |
| Resnet-presaact-20 | 128 | 0.4 | coseno | 200 | 7.28 | 24m |
| Resnet-presaact-20 | 128 | 0.2 | coseno | 200 | 7.96 | 24m |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 200 | 8.09 | 24m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 1.6 | coseno | 800 | 8.36 | 1h33m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 800 | 7.53 | 1H27m |
| Resnet-presaact-20 | 1024 | 1.6 | coseno | 800 | 7.30 | 1h30m |
| Resnet-presaact-20 | 1024 | 0.8 | coseno | 800 | 7.42 | 1h30m |
| Resnet-presaact-20 | 512 | 1.6 | coseno | 800 | 6.69 | 1H26M |
| Resnet-presaact-20 | 512 | 0.8 | coseno | 800 | 6.77 | 1H26M |
| Resnet-presaact-20 | 256 | 0.8 | coseno | 800 | 6.84 | 1H28m |
| Resnet-presaact-20 | 128 | 0.4 | coseno | 800 | 6.86 | 1h35m |
| Resnet-presaact-20 | 128 | 0.2 | coseno | 800 | 7.05 | 1h38m |
| Resnet-presaact-20 | 128 | 0.1 | coseno | 800 | 6.68 | 1h35m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 1.6 | coseno | 1600 | 8.25 | 3h10m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 1600 | 7.34 | 2h50m |
| Resnet-presaact-20 | 1024 | 1.6 | coseno | 1600 | 6.94 | 2h52m |
| Resnet-presaact-20 | 512 | 1.6 | coseno | 1600 | 6.99 | 2h44m |
| Resnet-presaact-20 | 256 | 0.8 | coseno | 1600 | 6.95 | 2h50m |
| Resnet-presaact-20 | 128 | 0.4 | coseno | 1600 | 6.64 | 3h09m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 4096 | 1.6 | coseno | 3200 | 9.52 | 6h15m |
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 3200 | 6.92 | 5h42m |
| Resnet-presaact-20 | 1024 | 1.6 | coseno | 3200 | 6.96 | 5h43m |
| Modelo | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 2048 | 1.6 | coseno | 6400 | 7.45 | 11h44m |
Prolongada
- En los documentos originales (1708.03888, 1801.03137), utilizaron la programación de tasas de aprendizaje de desintegración polinómica, pero el recocido de coseno se usa en estos experimentos.
- En esta implementación, no se utiliza el coeficiente de LARS, por lo que la tasa de aprendizaje debe ajustarse en consecuencia.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00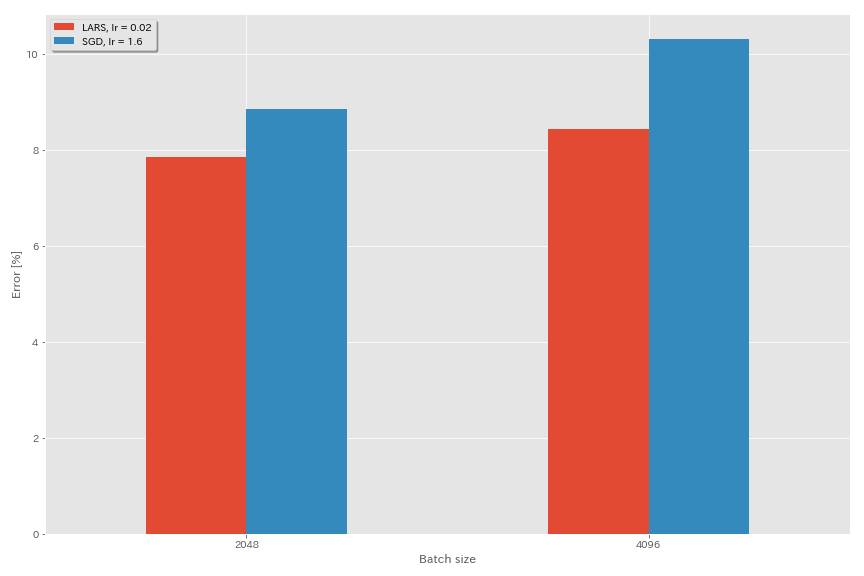
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 4096 | 3.2 | coseno | 200 | 10.57 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 4096 | 1.6 | coseno | 200 | 10.20 | 22m |
| Resnet-presaact-20 | Sgd | 4096 | 0.8 | coseno | 200 | 10.71 (1 ejecución) | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.04 | coseno | 200 | 9.58 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.03 | coseno | 200 | 8.46 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.02 | coseno | 200 | 8.21 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.015 | coseno | 200 | 8.47 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.01 | coseno | 200 | 9.33 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.005 | coseno | 200 | 14.31 | 22m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 2048 | 3.2 | coseno | 200 | 11.34 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 2048 | 2.4 | coseno | 200 | 8.69 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 2048 | 2.0 | coseno | 200 | 8.81 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 2048 | 1.6 | coseno | 200 | 8.73 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 2048 | 0.8 | coseno | 200 | 9.62 (1 carrera) | 21m |
| Resnet-presaact-20 | Prolongada | 2048 | 0.04 | coseno | 200 | 11.58 | 21m |
| Resnet-presaact-20 | Prolongada | 2048 | 0.02 | coseno | 200 | 8.05 | 22m |
| Resnet-presaact-20 | Prolongada | 2048 | 0.01 | coseno | 200 | 8.07 | 22m |
| Resnet-presaact-20 | Prolongada | 2048 | 0.005 | coseno | 200 | 9.65 | 22m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 1024 | 3.2 | coseno | 200 | 9.12 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 1024 | 2.4 | coseno | 200 | 8.42 (1 ejecución) | 22m |
| Resnet-presaact-20 | Sgd | 1024 | 2.0 | coseno | 200 | 8.38 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 1024 | 1.6 | coseno | 200 | 8.07 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 1024 | 1.2 | coseno | 200 | 8.25 (1 ejecución) | 21m |
| Resnet-presaact-20 | Sgd | 1024 | 0.8 | coseno | 200 | 8.08 (1 ejecución) | 22m |
| Resnet-presaact-20 | Sgd | 1024 | 0.4 | coseno | 200 | 8.49 (1 carrera) | 22m |
| Resnet-presaact-20 | Prolongada | 1024 | 0.02 | coseno | 200 | 9.30 | 22m |
| Resnet-presaact-20 | Prolongada | 1024 | 0.01 | coseno | 200 | 7.68 | 22m |
| Resnet-presaact-20 | Prolongada | 1024 | 0.005 | coseno | 200 | 8.88 | 23m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 512 | 3.2 | coseno | 200 | 8.51 (1 ejecución) | 21m |
| Resnet-presaact-20 | Sgd | 512 | 1.6 | coseno | 200 | 7.73 (1 carrera) | 20m |
| Resnet-presaact-20 | Sgd | 512 | 0.8 | coseno | 200 | 7.73 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 512 | 0.4 | coseno | 200 | 8.22 (1 ejecución) | 20m |
| Resnet-presaact-20 | Prolongada | 512 | 0.015 | coseno | 200 | 9.84 | 23m |
| Resnet-presaact-20 | Prolongada | 512 | 0.01 | coseno | 200 | 8.05 | 23m |
| Resnet-presaact-20 | Prolongada | 512 | 0.0075 | coseno | 200 | 7.58 | 23m |
| Resnet-presaact-20 | Prolongada | 512 | 0.005 | coseno | 200 | 7.96 | 23m |
| Resnet-presaact-20 | Prolongada | 512 | 0.0025 | coseno | 200 | 8.83 | 23m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 256 | 3.2 | coseno | 200 | 9.64 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 256 | 1.6 | coseno | 200 | 8.32 (1 ejecución) | 22m |
| Resnet-presaact-20 | Sgd | 256 | 0.8 | coseno | 200 | 7.45 (1 carrera) | 21m |
| Resnet-presaact-20 | Sgd | 256 | 0.4 | coseno | 200 | 7.68 (1 carrera) | 22m |
| Resnet-presaact-20 | Sgd | 256 | 0.2 | coseno | 200 | 8.61 (1 carrera) | 22m |
| Resnet-presaact-20 | Prolongada | 256 | 0.01 | coseno | 200 | 8.95 | 27m |
| Resnet-presaact-20 | Prolongada | 256 | 0.005 | coseno | 200 | 7.75 | 28m |
| Resnet-presaact-20 | Prolongada | 256 | 0.0025 | coseno | 200 | 8.21 | 28m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 128 | 1.6 | coseno | 200 | 9.03 (1 carrera) | 24m |
| Resnet-presaact-20 | Sgd | 128 | 0.8 | coseno | 200 | 7.54 (1 carrera) | 24m |
| Resnet-presaact-20 | Sgd | 128 | 0.4 | coseno | 200 | 7.28 (1 carrera) | 24m |
| Resnet-presaact-20 | Sgd | 128 | 0.2 | coseno | 200 | 7.96 (1 carrera) | 24m |
| Resnet-presaact-20 | Prolongada | 128 | 0.005 | coseno | 200 | 7.96 | 37m |
| Resnet-presaact-20 | Prolongada | 128 | 0.0025 | coseno | 200 | 7.98 | 37m |
| Resnet-presaact-20 | Prolongada | 128 | 0.00125 | coseno | 200 | 9.21 | 37m |
| Modelo | optimizador | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sgd | 4096 | 1.6 | coseno | 200 | 10.20 | 22m |
| Resnet-presaact-20 | Sgd | 4096 | 1.6 | coseno | 800 | 8.36 (1 carrera) | 1h33m |
| Resnet-presaact-20 | Sgd | 4096 | 1.6 | coseno | 1600 | 8.25 (1 ejecución) | 3h10m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.02 | coseno | 200 | 8.21 | 22m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.02 | coseno | 400 | 7.53 | 44m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.02 | coseno | 800 | 7.48 | 1H29m |
| Resnet-presaact-20 | Prolongada | 4096 | 0.02 | coseno | 1600 | 7.37 (1 carrera) | 2h58m |
Ghost Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Modelo | tamaño por lotes | Tamaño de lote fantasma | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 8192 | N / A | 1.6 | coseno | 200 | 12.35 | 25m* |
| Resnet-presaact-20 | 4096 | N / A | 1.6 | coseno | 200 | 10.32 | 22m |
| Resnet-presaact-20 | 2048 | N / A | 1.6 | coseno | 200 | 8.73 | 22m |
| Resnet-presaact-20 | 1024 | N / A | 1.6 | coseno | 200 | 8.07 | 22m |
| Resnet-presaact-20 | 128 | N / A | 0.4 | coseno | 200 | 7.28 | 24m |
| Modelo | tamaño por lotes | Tamaño de lote fantasma | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 8192 | 128 | 1.6 | coseno | 200 | 11.51 | 27m |
| Resnet-presaact-20 | 4096 | 128 | 1.6 | coseno | 200 | 9.73 | 25m |
| Resnet-presaact-20 | 2048 | 128 | 1.6 | coseno | 200 | 8.77 | 24m |
| Resnet-presaact-20 | 1024 | 128 | 1.6 | coseno | 200 | 7.82 | 22m |
| Modelo | tamaño por lotes | Tamaño de lote fantasma | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 8192 | N / A | 1.6 | coseno | 1600 | | |
| Resnet-presaact-20 | 4096 | N / A | 1.6 | coseno | 1600 | 8.25 | 3h10m |
| Resnet-presaact-20 | 2048 | N / A | 1.6 | coseno | 1600 | 7.34 | 2h50m |
| Resnet-presaact-20 | 1024 | N / A | 1.6 | coseno | 1600 | 6.94 | 2h52m |
| Modelo | tamaño por lotes | Tamaño de lote fantasma | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | 8192 | 128 | 1.6 | coseno | 1600 | 11.83 | 3h37m |
| Resnet-presaact-20 | 4096 | 128 | 1.6 | coseno | 1600 | 8.95 | 3h15m |
| Resnet-presaact-20 | 2048 | 128 | 1.6 | coseno | 1600 | 7.23 | 3h05m |
| Resnet-presaact-20 | 1024 | 128 | 1.6 | coseno | 1600 | 7.08 | 2h59m |
Sin descomposición de peso en BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00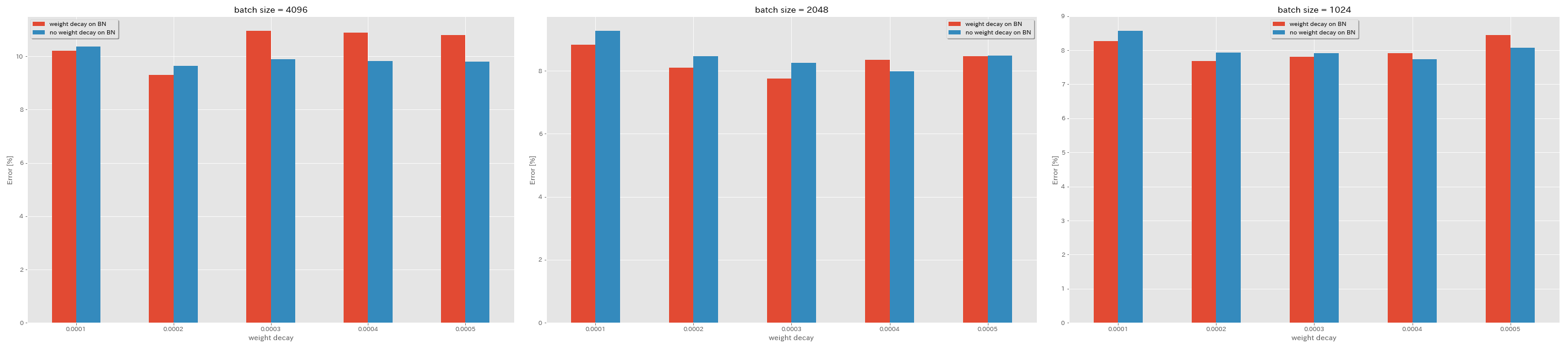
| Modelo | Decadencia de peso en BN | descomposición de peso | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sí | 5E-4 | 4096 | 1.6 | coseno | 200 | 10.81 | 22m |
| Resnet-presaact-20 | Sí | 4E-4 | 4096 | 1.6 | coseno | 200 | 10.88 | 22m |
| Resnet-presaact-20 | Sí | 3E-4 | 4096 | 1.6 | coseno | 200 | 10.96 | 22m |
| Resnet-presaact-20 | Sí | 2E-4 | 4096 | 1.6 | coseno | 200 | 9.30 | 22m |
| Resnet-presaact-20 | Sí | 1e-4 | 4096 | 1.6 | coseno | 200 | 10.20 | 22m |
| Resnet-presaact-20 | No | 5E-4 | 4096 | 1.6 | coseno | 200 | 8.78 | 22m |
| Resnet-presaact-20 | No | 4E-4 | 4096 | 1.6 | coseno | 200 | 9.83 | 22m |
| Resnet-presaact-20 | No | 3E-4 | 4096 | 1.6 | coseno | 200 | 9.90 | 22m |
| Resnet-presaact-20 | No | 2E-4 | 4096 | 1.6 | coseno | 200 | 9.64 | 22m |
| Resnet-presaact-20 | No | 1e-4 | 4096 | 1.6 | coseno | 200 | 10.38 | 22m |
| Modelo | Decadencia de peso en BN | descomposición de peso | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sí | 5E-4 | 2048 | 1.6 | coseno | 200 | 8.46 | 20m |
| Resnet-presaact-20 | Sí | 4E-4 | 2048 | 1.6 | coseno | 200 | 8.35 | 20m |
| Resnet-presaact-20 | Sí | 3E-4 | 2048 | 1.6 | coseno | 200 | 7.76 | 20m |
| Resnet-presaact-20 | Sí | 2E-4 | 2048 | 1.6 | coseno | 200 | 8.09 | 20m |
| Resnet-presaact-20 | Sí | 1e-4 | 2048 | 1.6 | coseno | 200 | 8.83 | 20m |
| Resnet-presaact-20 | No | 5E-4 | 2048 | 1.6 | coseno | 200 | 8.49 | 20m |
| Resnet-presaact-20 | No | 4E-4 | 2048 | 1.6 | coseno | 200 | 7.98 | 20m |
| Resnet-presaact-20 | No | 3E-4 | 2048 | 1.6 | coseno | 200 | 8.26 | 20m |
| Resnet-presaact-20 | No | 2E-4 | 2048 | 1.6 | coseno | 200 | 8.47 | 20m |
| Resnet-presaact-20 | No | 1e-4 | 2048 | 1.6 | coseno | 200 | 9.27 | 20m |
| Modelo | Decadencia de peso en BN | descomposición de peso | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (mediana de 3 carreras) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | Sí | 5E-4 | 1024 | 1.6 | coseno | 200 | 8.45 | 21m |
| Resnet-presaact-20 | Sí | 4E-4 | 1024 | 1.6 | coseno | 200 | 7.91 | 21m |
| Resnet-presaact-20 | Sí | 3E-4 | 1024 | 1.6 | coseno | 200 | 7.81 | 21m |
| Resnet-presaact-20 | Sí | 2E-4 | 1024 | 1.6 | coseno | 200 | 7.69 | 21m |
| Resnet-presaact-20 | Sí | 1e-4 | 1024 | 1.6 | coseno | 200 | 8.26 | 21m |
| Resnet-presaact-20 | No | 5E-4 | 1024 | 1.6 | coseno | 200 | 8.08 | 21m |
| Resnet-presaact-20 | No | 4E-4 | 1024 | 1.6 | coseno | 200 | 7.73 | 21m |
| Resnet-presaact-20 | No | 3E-4 | 1024 | 1.6 | coseno | 200 | 7.92 | 21m |
| Resnet-presaact-20 | No | 2E-4 | 1024 | 1.6 | coseno | 200 | 7.93 | 21m |
| Resnet-presaact-20 | No | 1e-4 | 1024 | 1.6 | coseno | 200 | 8.53 | 21m |
Experimentos sobre medios precisiones y precisión mixta
- Los siguientes experimentos necesitan NVIDIA APEX.
- Los siguientes experimentos se realizan en el conjunto de datos CIFAR-10 utilizando GeForce 1080 Ti, que no tiene núcleos de tensor.
- Los resultados informados en la tabla son los errores de prueba en las últimas épocas.
FP16 Entrenamiento
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Entrenamiento de precisión mixta
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Resultados
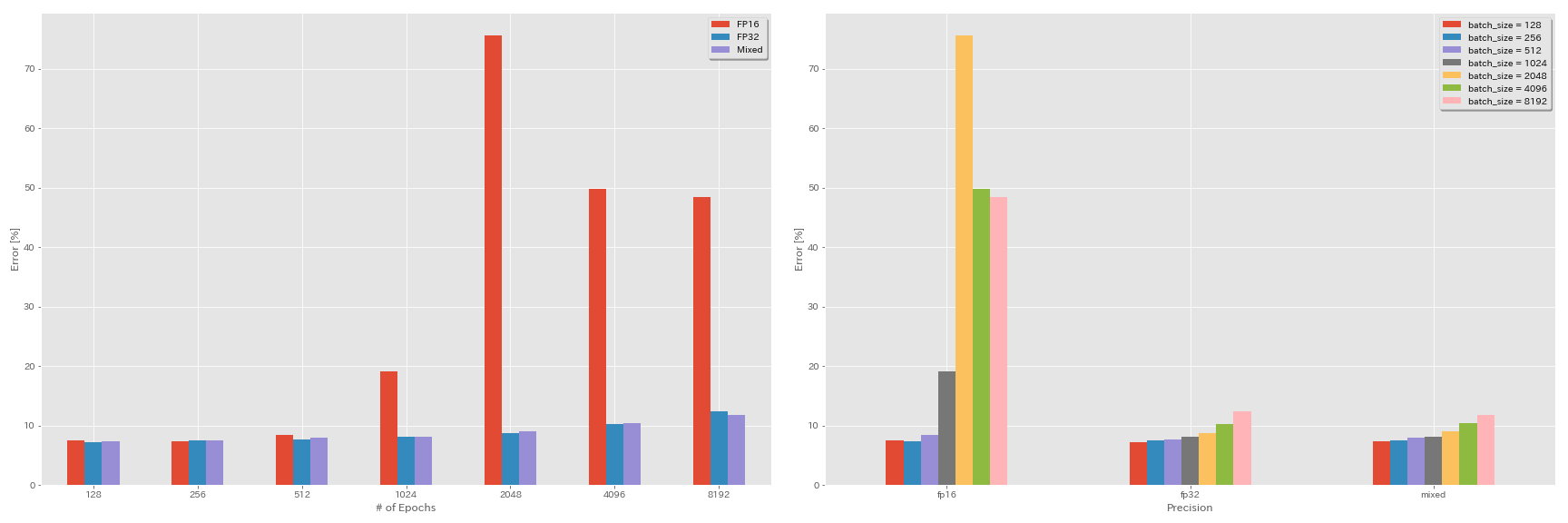
| Modelo | precisión | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | FP32 | 8192 | 1.6 | coseno | 200 | | |
| Resnet-presaact-20 | FP32 | 4096 | 1.6 | coseno | 200 | 10.32 | 22m |
| Resnet-presaact-20 | FP32 | 2048 | 1.6 | coseno | 200 | 8.73 | 22m |
| Resnet-presaact-20 | FP32 | 1024 | 1.6 | coseno | 200 | 8.07 | 22m |
| Resnet-presaact-20 | FP32 | 512 | 0.8 | coseno | 200 | 7.73 | 21m |
| Resnet-presaact-20 | FP32 | 256 | 0.8 | coseno | 200 | 7.45 | 21m |
| Resnet-presaact-20 | FP32 | 128 | 0.4 | coseno | 200 | 7.28 | 24m |
| Modelo | precisión | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | FP16 | 8192 | 1.6 | coseno | 200 | 48.52 | 33m |
| Resnet-presaact-20 | FP16 | 4096 | 1.6 | coseno | 200 | 49.84 | 28m |
| Resnet-presaact-20 | FP16 | 2048 | 1.6 | coseno | 200 | 75.63 | 27m |
| Resnet-presaact-20 | FP16 | 1024 | 1.6 | coseno | 200 | 19.09 | 27m |
| Resnet-presaact-20 | FP16 | 512 | 0.8 | coseno | 200 | 7.89 | 26m |
| Resnet-presaact-20 | FP16 | 256 | 0.8 | coseno | 200 | 7.40 | 28m |
| Resnet-presaact-20 | FP16 | 128 | 0.4 | coseno | 200 | 7.59 | 32m |
| Modelo | precisión | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | mezclado | 8192 | 1.6 | coseno | 200 | 11.78 | 28m |
| Resnet-presaact-20 | mezclado | 4096 | 1.6 | coseno | 200 | 10.48 | 27m |
| Resnet-presaact-20 | mezclado | 2048 | 1.6 | coseno | 200 | 8.98 | 26m |
| Resnet-presaact-20 | mezclado | 1024 | 1.6 | coseno | 200 | 8.05 | 26m |
| Resnet-presaact-20 | mezclado | 512 | 0.8 | coseno | 200 | 7.81 | 28m |
| Resnet-presaact-20 | mezclado | 256 | 0.8 | coseno | 200 | 7.58 | 32m |
| Resnet-presaact-20 | mezclado | 128 | 0.4 | coseno | 200 | 7.37 | 41m |
Resultados utilizando Tesla V100
| Modelo | precisión | tamaño por lotes | LR inicial | horario LR | # de épocas | Error de prueba (1 ejecución) | Tiempo de entrenamiento |
|---|
| Resnet-presaact-20 | FP32 | 8192 | 1.6 | coseno | 200 | 12.35 | 25m |
| Resnet-presaact-20 | FP32 | 4096 | 1.6 | coseno | 200 | 9.88 | 19m |
| Resnet-presaact-20 | FP32 | 2048 | 1.6 | coseno | 200 | 8.87 | 17m |
| Resnet-presaact-20 | FP32 | 1024 | 1.6 | coseno | 200 | 8.45 | 18m |
| Resnet-presaact-20 | mezclado | 8192 | 1.6 | coseno | 200 | 11.92 | 25m |
| Resnet-presaact-20 | mezclado | 4096 | 1.6 | coseno | 200 | 10.16 | 19m |
| Resnet-presaact-20 | mezclado | 2048 | 1.6 | coseno | 200 | 9.10 | 17m |
| Resnet-presaact-20 | mezclado | 1024 | 1.6 | coseno | 200 | 7.84 | 16m |
Referencias
Arquitectura modelo
- Él, Kaiming, Xiangyu Zhang, Shaoqing Ren y Jian Sun. "Aprendizaje residual profundo para el reconocimiento de imágenes". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2016. Link, ARXIV: 1512.03385
- Él, Kaiming, Xiangyu Zhang, Shaoqing Ren y Jian Sun. "Mapeaciones de identidad en redes residuales profundas". En la Conferencia Europea sobre Visión Computadora (ECCV). 2016. ARXIV: 1603.05027, implementación de la antorcha
- Zagoruyko, Sergey y Nikos Komodakis. "Amplias redes residuales". Actas de la British Machine Vision Conference (BMVC), 2016. ARXIV: 1605.07146, Implementación de antorcha
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger y Laurens van der Maaten. "Redes convolucionales densamente conectadas". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2017. Link, ARXIV: 1608.06993, Implementación de la antorcha
- Han, Dongyoon, Jiwhan Kim y Junmo Kim. "Redes residuales piramidales profundas". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2017. Link, ARXIV: 1610.02915, implementación de la antorcha, implementación de Caffe, implementación de Pytorch
- Xie, Saining, Ross Girshick, Piotr Dollar, Zhuowen Tu y Kaiming He. "Transformaciones residuales agregadas para redes neuronales profundas". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2017. Link, ARXIV: 1611.05431, Implementación de la antorcha
- Gastaldi, Xavier. "Shake-shake regularización de redes residuales de 3 ramas". Taller de la Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2017. Link, ARXIV: 1705.07485, Implementación de la antorcha
- Hu, Jie, Li Shen y Gang Sun. "Redes de compresión y excitación". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2018, pp. 7132-7141. Link, ARXIV: 1709.01507, implementación de Caffe
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten y Kilian Q. Weinberger. "Redes convolucionales con conectividad densa". Transacciones IEEE sobre análisis de patrones e inteligencia de máquinas (2019). ARXIV: 2001.02394
Regularización, aumento de datos
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens y Zbigniew Wojna. "Repensar la arquitectura de inicio para la visión por computadora". La conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2016. Link, ARXIV: 1512.00567
- Devries, Terrance y Graham W. Taylor. "Mejora regularización de redes neuronales convolucionales con recorte". ARXIV Preprint ARXIV: 1708.04552 (2017). ARXIV: 1708.04552, implementación de Pytorch
- Abu-El-Haija, Sami. "Actualizaciones proporcionales de gradiente con porcentaje de Delta". ARXIV Preprint ARXIV: 1708.07227 (2017). ARXIV: 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li y Yi Yang. "Aumento de datos de borrado aleatorio". ARXIV Preprint ARXIV: 1708.04896 (2017). ARXIV: 1708.04896, implementación de Pytorch
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin y David López-Paz. "Mezcla: más allá de la minimización del riesgo empírico". En Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2017. Link, ARXIV: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma y Leslie Pack Kaelbling. "Para comprender la generalización a través de la teoría del aprendizaje analítico". ARXIV Preprint ARXIV: 1802.07426 (2018). ARXIV: 1802.07426, implementación de Pytorch
- Takahashi, Ryo, Takashi Matsubara y Kuniaki Uehara. "Aumento de datos utilizando recorte de imágenes aleatorios y parches para CNN profundos". Actas de la décima Conferencia Asiática sobre aprendizaje automático (ACML), 2018. Link, ARXIV: 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon oh, Sanghyuk Chun, Junsuk Choe y Yooon Yoo. "Cutmix: estrategia de regularización para entrenar clasificadores fuertes con características localizables". Arxiv Preprint ARXIV: 1905.04899 (2019). ARXIV: 1905.04899
Lote grande
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy y Ping Tak Peter Tang. "En el entrenamiento de lotes grandes para el aprendizaje profundo: brecha de generalización y mínimos agudos". En Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2017. Link, ARXIV: 1609.04836
- Hoffer, Elad, Itay Hubara y Daniel Soudry. "Entrene más tiempo, generalice mejor: cerrar la brecha de generalización en el entrenamiento por lotes grandes de las redes neuronales". En Advances in Neural Information Processing Systems (NIPS), 2017. Link, ARXIV: 1705.08741, implementación de Pytorch
- Goyal, Priya, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia y Kaiming He. "SGD de minibatch grande y preciso: entrenamiento de Imagenet en 1 hora". ARXIV Preprint ARXIV: 1706.02677 (2017). ARXIV: 1706.02677
- Usted, Yang, Igor Gitman y Boris Ginsburg. "Gran entrenamiento por lotes de redes convolucionales". ARXIV Preprint ARXIV: 1708.03888 (2017). ARXIV: 1708.03888
- Usted, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel y Kurt Keutzer. "Entrenamiento de Imagenet en minutos". Arxiv Preprint ARXIV: 1709.05011 (2017). ARXIV: 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying y Quoc V. Le. "No decaves la tasa de aprendizaje, aumente el tamaño del lote". En Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2018. Link, ARXIV: 1711.00489
- Gitman, Igor, Deepak Dilipkumar y Ben Parr. "Análisis de convergencia de algoritmos de descenso de gradiente con actualizaciones proporcionales". ARXIV Preprint ARXIV: 1801.03137 (2018). ARXIV: 1801.03137 TensorFlow Implementación
- Jia, Xianyan, Stavao Song, Wei He, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi y Xiaowen Chu. "Sistema de entrenamiento de aprendizaje profundo altamente escalable con precisión mixta: entrenamiento Imagenet en cuatro minutos". Arxiv Preprint ARXIV: 1807.11205 (2018). ARXIV: 1807.11205
- Willue, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig y George E. Dahl. "Medir los efectos del paralelismo de los datos en la capacitación en redes neuronales". ARXIV Preprint ARXIV: 1811.03600 (2018). ARXIV: 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang y YouLong Cheng. "Clasificación de imágenes a escala de supercomputador". En Avances en Taller de Sistemas de Procesamiento de Información de Información Neural (Neurips), 2018. Link, ARXIV: 1811.06992
Otros
- Loshchilov, Ilya y Frank Hutter. "SGDR: descenso de gradiente estocástico con reinicios cálidos". En Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2017. Link, ARXIV: 1608.03983, Implementación de Lasaña
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David García, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh y Hao Wu. "Entrenamiento de precisión mixto". En Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR), 2018. Link, ARXIV: 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt y Vaishaal Shankar. "¿Se generalizan los clasificadores CIFAR-10 a CIFAR-10?" ARXIV Preprint ARXIV: 1806.00451 (2018). ARXIV: 1806.00451
- Él, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie y Mu Li. "Bolsa de trucos para la clasificación de imágenes con redes neuronales convolucionales". ARXIV Preprint ARXIV: 1812.01187 (2018). ARXIV: 1812.01187


