تصنيف صورة Pytorch
يتم تنفيذ الأوراق التالية باستخدام Pytorch.
- Resnet (1512.03385)
- Resnet-preact (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993 ، 2001.02394)
- Pyramidnet (1610.02915)
- RESNEXT (1611.05431)
- Shake-Shake (1705.07485)
- لارس (1708.03888 ، 1801.03137)
- قطع (1708.04552)
- محو عشوائي (1708.04896)
- سينيت (1709.01507)
- mixup (1710.09412)
- Cutout مزدوج (1802.07426)
- ريكاب (1811.09030)
- Cutmix (1905.04899)
متطلبات
- Ubuntu (يتم اختباره فقط على Ubuntu ، لذلك قد لا يعمل على Windows.)
- بيثون> = 3.7
- Pytorch> = 1.4.0
- Torchvision
- Nvidia Apex
pip install -r requirements.txt
الاستخدام
python train.py --config configs/cifar/resnet_preact.yaml
النتائج على CIFAR-10
النتائج باستخدام نفس الإعدادات تقريبًا مثل الأوراق
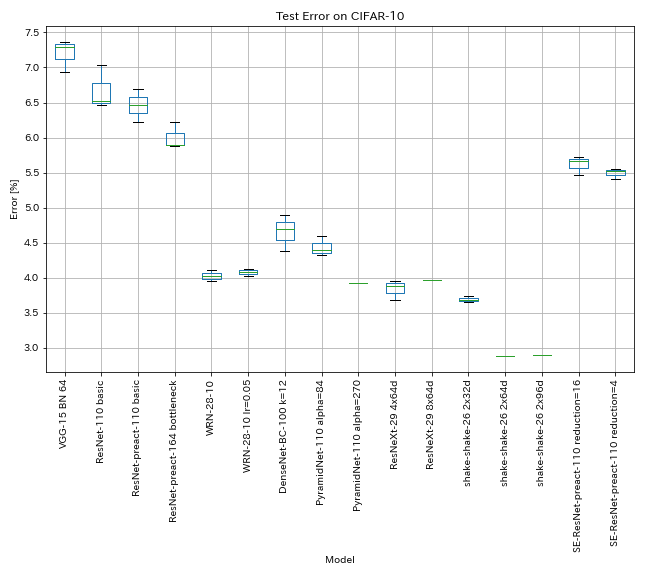
| نموذج | خطأ اختبار (متوسط 3 أشواط) | اختبار خطأ (في الورق) | وقت التدريب |
|---|
| يشبه VGG (العمق 15 ، ث/ مليار ، القناة 64) | 7.29 | ن/أ | 1H20M |
| RESNET-110 | 6.52 | 6.43 (أفضل) ، 6.61 +/- 0.16 | 3H06M |
| RESNET-PREACT-110 | 6.47 | 6.37 (متوسط 5 أشواط) | 3H05M |
| RESNET-PEACT-164 عنق الزجاجة | 5.90 | 5.46 (متوسط 5 أشواط) | 4H01M |
| RESNET-PEACT-1001 عنق الزجاجة | | 4.62 (متوسط 5 أشواط) ، 4.69 +/- 0.20 | |
| WRN-28-10 | 4.03 | 4.00 (متوسط 5 أشواط) | 16H10M |
| WRN-28-10 ث/ التسرب | | 3.89 (متوسط 5 أشواط) | |
| Densenet-100 (K = 12) | 3.87 (1 تشغيل) | 4.10 (1 تشغيل) | 24H28M* |
| Densenet-100 (K = 24) | | 3.74 (1 تشغيل) | |
| Densenet-BC-100 (K = 12) | 4.69 | 4.51 (1 تشغيل) | 15H20M |
| Densenet-BC-250 (K = 24) | | 3.62 (1 تشغيل) | |
| Densenet-BC-190 (K = 40) | | 3.46 (1 تشغيل) | |
| Pyramidnet-110 (ألفا = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| Pyramidnet-110 (ألفا = 270) | 3.92 (1 تشغيل) | 3.73 +/- 0.04 | 24H12M* |
| Pyramidnet-164 عنق الزجاجة (ألفا = 270) | 3.44 (1 تشغيل) | 3.48 +/- 0.20 | 32H37M* |
| Pyramidnet-272 عنق الزجاجة (ألفا = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (من الشكل 7) | 31h17m |
| Resnext-29 8x64d | 3.97 (1 تشغيل) | 3.65 (متوسط 10 أشواط) | 42H50M* |
| Resnext-29 16x64d | | 3.58 (متوسط 10 أشواط) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3.55 (متوسط 3 أشواط) | 33h49m |
| Shake-Shake-26 2x64D (SSI) | 2.88 (1 تشغيل) | 2.98 (متوسط 3 أشواط) | 78H48M |
| Shake-Shake-26 2x96D (SSI) | 2.90 (1 تشغيل) | 2.86 (متوسط 5 أشواط) | 101H32M* |
ملحوظات
- الاختلافات مع الأوراق في إعدادات التدريب:
- مدرب WRN-28-10 مع حجم الدُفعة 64 (128 في الورق).
- Densenet-BC-100 (K = 12) مع حجم الدُفعة 32 ومعدل التعلم الأولي 0.05 (حجم الدفعة 64 ومعدل التعلم الأولي 0.1 في الورق).
- RESNEXT-29 4x64D مع وحدة معالجة الرسومات واحدة وحجم الدُفعة 32 ومعدل التعلم الأولي 0.025 (8 وحدات معالجة الرسومات وحجم الدُفعة 128 ومعدل التعلم الأولي 0.1 في الورق).
- نماذج Shake Shake المدربة مع وحدة معالجة الرسومات واحدة (وحدات معالجة الرسومات 2 في الورق).
- Shake Shake Shake 26 2x64D (SSI) مع حجم الدُفعة 64 ، ومعدل التعلم الأولي 0.1.
- أخطاء الاختبار المذكورة أعلاه هي تلك الموجودة في العصر الأخير.
- يتم إجراء تجارب مع تشغيل واحد فقط على جهاز كمبيوتر مختلف من تلك المستخدمة في التجارب التي تحتوي على 3 أشواط.
- تم استخدام Geforce GTX 980 في هذه التجارب.
تشبه VGG
python train.py --config configs/cifar/vgg.yaml
Resnet
python train.py --config configs/cifar/resnet.yaml
Resnet-preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00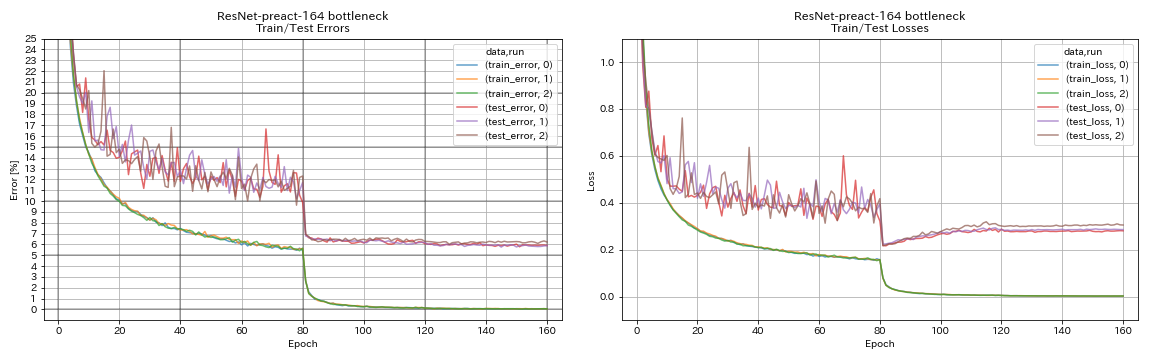
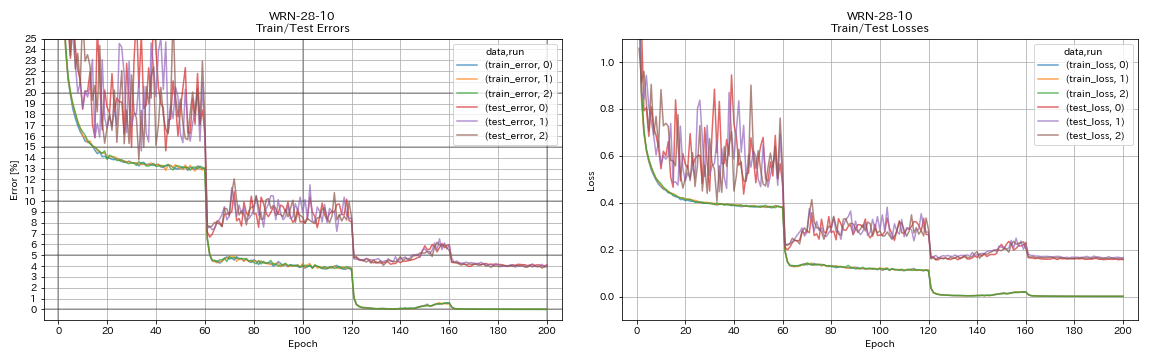
WRN
python train.py --config configs/cifar/wrn.yaml
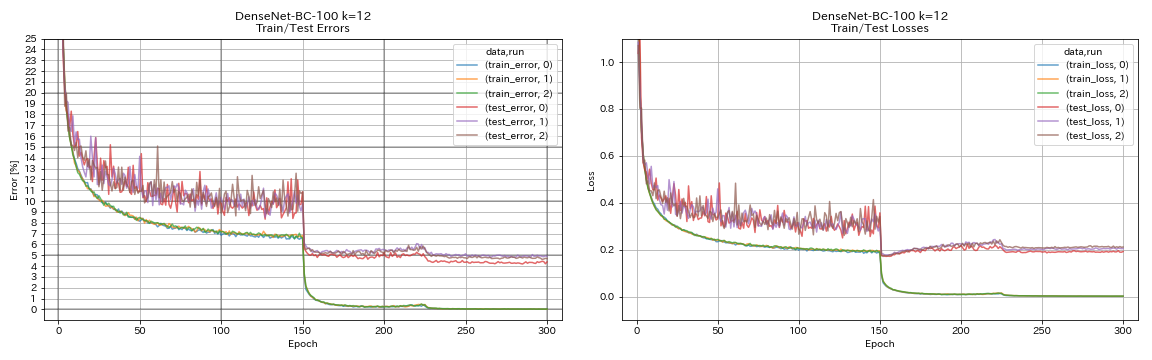
Densenet
python train.py --config configs/cifar/densenet.yaml
الهرم
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00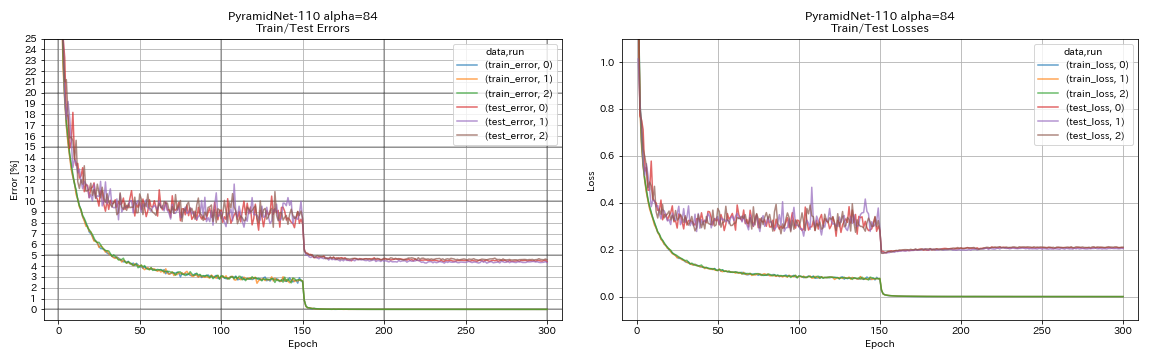
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00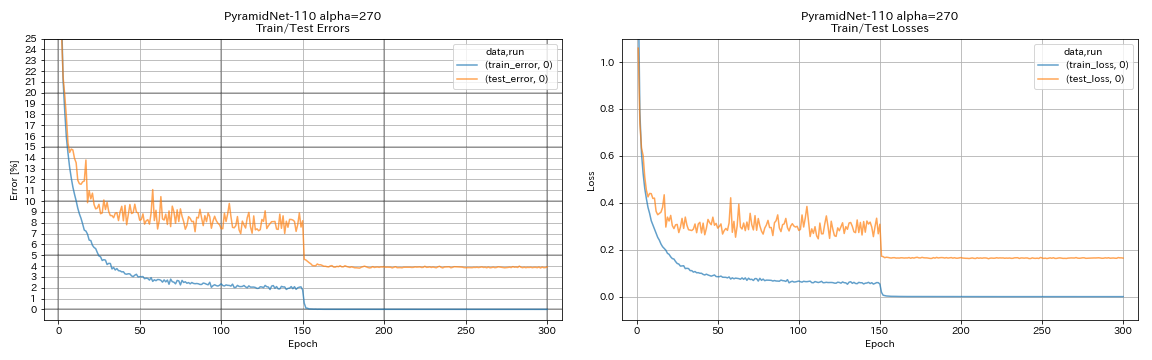
RESNEXT
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00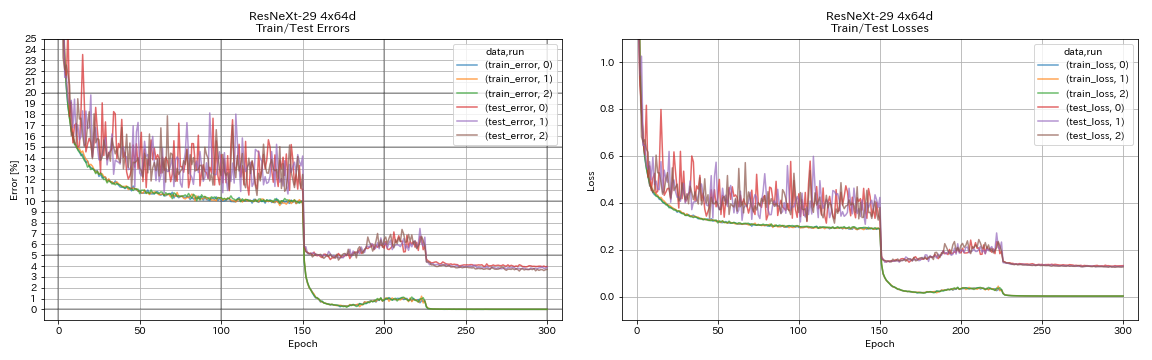
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00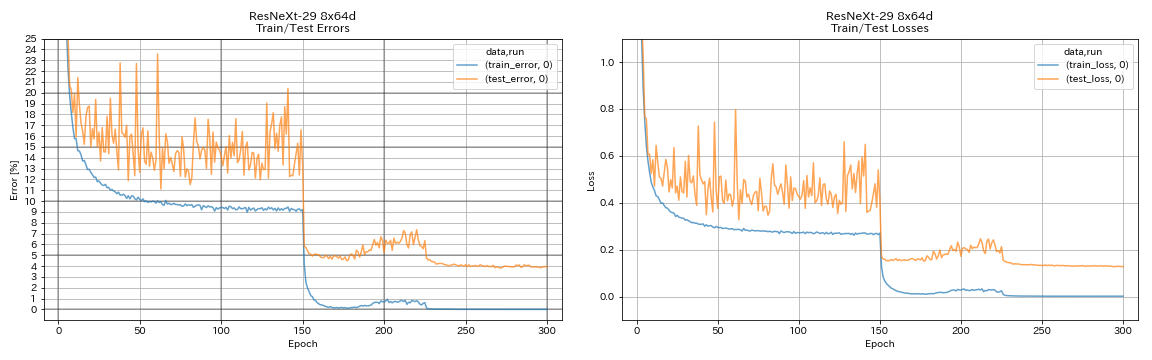
هز
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00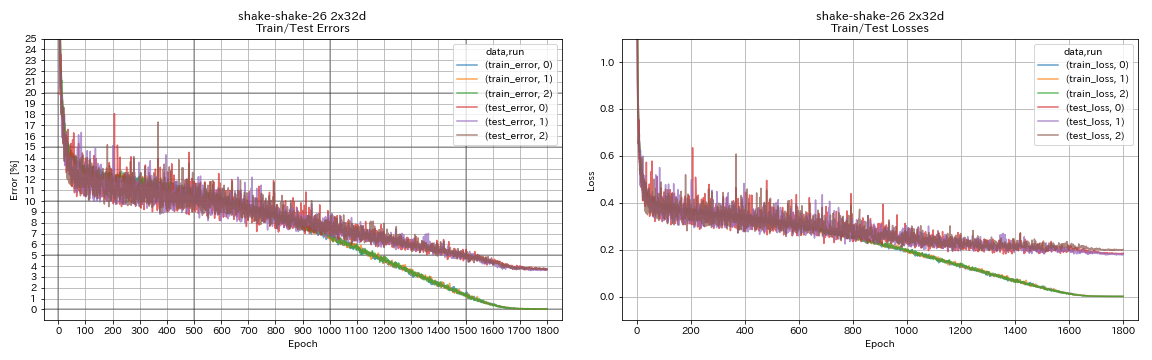
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00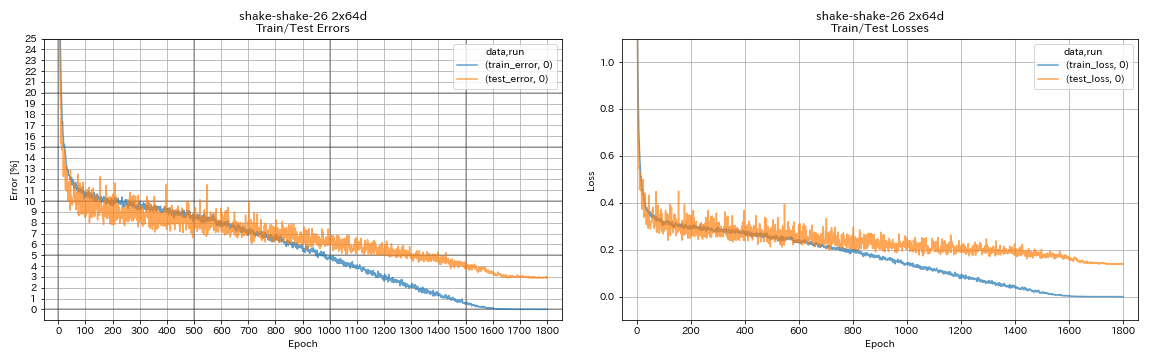
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00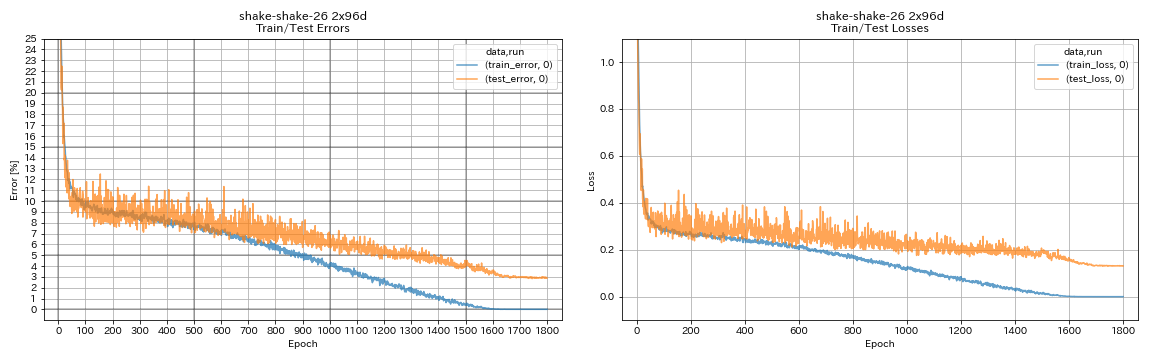
نتائج
| نموذج | اختبار خطأ (1 تشغيل) | # من الحقبة | وقت التدريب |
|---|
| Resnet-Preact-20 ، عامل الاتساع 4 | 4.91 | 200 | 1H26M |
| Resnet-Preact-20 ، عامل الاتساع 4 | 4.01 | 400 | 2H53M |
| Resnet-Preact-20 ، عامل الاتساع 4 | 3.99 | 1800 | 12H53M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 16 | 3.71 | 200 | 1H26M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 16 | 3.46 | 400 | 2H53M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 16 | 3.76 | 1800 | 12H53M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، RICAP (بيتا = 0.3) | 3.45 | 200 | 1H26M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، RICAP (بيتا = 0.3) | 3.11 | 400 | 2H53M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، RICAP (بيتا = 0.3) | 3.15 | 1800 | 12H53M |
| نموذج | اختبار خطأ (1 تشغيل) | # من الحقبة | وقت التدريب |
|---|
| WRN-28-10 ، قطع 16 | 3.19 | 200 | 6H35M |
| WRN-28-10 ، mixup (ألفا = 1) | 3.32 | 200 | 6H35M |
| WRN-28-10 ، RICAP (بيتا = 0.3) | 2.83 | 200 | 6H35M |
| WRN-28-10 ، Dual Cutout (ألفا = 0.1) | 2.87 | 200 | 12H42M |
| WRN-28-10 ، قطع 16 | 3.07 | 400 | 13H10M |
| WRN-28-10 ، mixup (ألفا = 1) | 3.04 | 400 | 13H08M |
| WRN-28-10 ، RICAP (بيتا = 0.3) | 2.71 | 400 | 13H08M |
| WRN-28-10 ، Dual Cutout (ألفا = 0.1) | 2.76 | 400 | 25H20M |
| Shake-Shake-26 2x64D ، Cutout 16 | 2.64 | 1800 | 78H55M* |
| Shake-shake-26 2x64d ، mixup (ألفا = 1) | 2.63 | 1800 | 35H56M |
| Shake-Shake-26 2x64D ، Ricap (بيتا = 0.3) | 2.29 | 1800 | 35H10M |
| Shake-Shake-26 2x64D ، Dual Cutout (ألفا = 0.1) | 2.64 | 1800 | 68H34M |
| Shake-Shake-26 2x96D ، Cutout 16 | 2.50 | 1800 | 60H20M |
| Shake-shake-26 2x96d ، mixup (ألفا = 1) | 2.36 | 1800 | 60H20M |
| Shake-Shake-26 2x96D ، Ricap (بيتا = 0.3) | 2.10 | 1800 | 60H20M |
| Shake-shake-26 2x96d ، dual cutout (ألفا = 0.1) | 2.41 | 1800 | 113H09M |
| Shake-shake-26 2x128d ، cutout 16 | 2.58 | 1800 | 85h04m |
| Shake-Shake-26 2x128d ، Ricap (بيتا = 0.3) | 1.97 | 1800 | 85H06M |
ملحوظة
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
- يتم تدريب جميع النماذج باستخدام جيب التمام الصلب مع معدل التعلم الأولي 0.2.
- تم استخدام GeForce GTX 1080 Ti في هذه التجارب ، باستثناء تلك التي تحتوي على *، والتي يتم القيام بها باستخدام GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True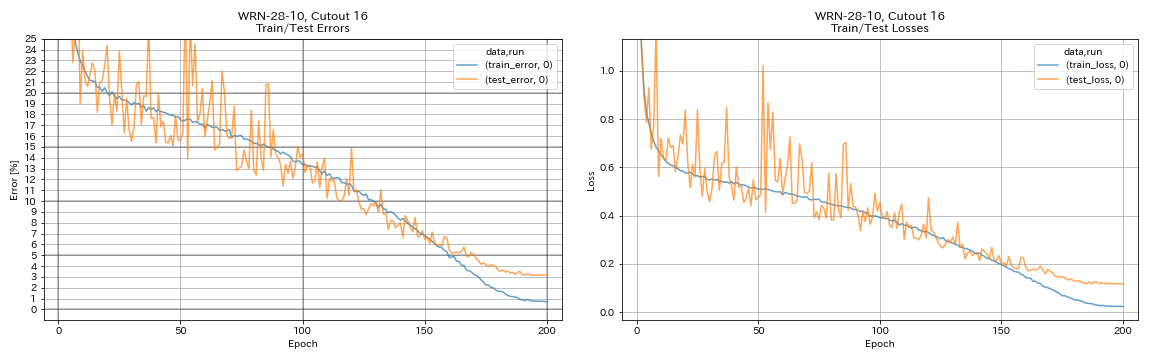
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True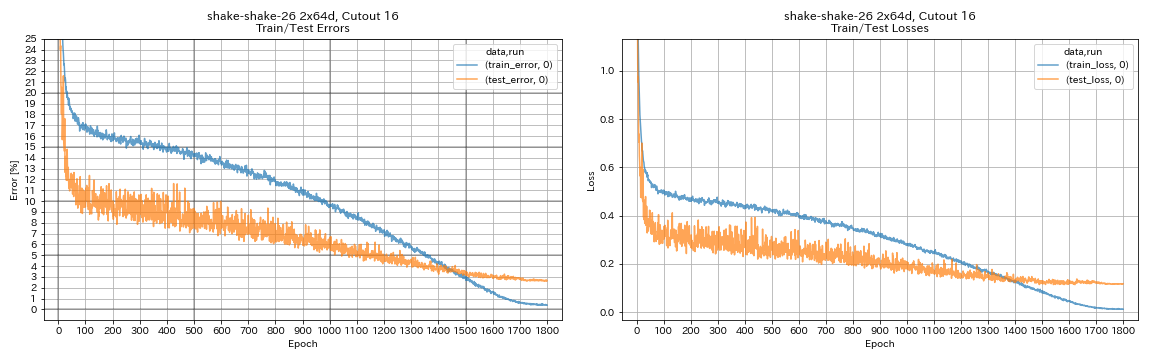
النتائج باستخدام متعددة GPU
| نموذج | حجم الدُفعة | #gpus | اختبار خطأ (1 تشغيل) | # من الحقبة | وقت التدريب* |
|---|
| WRN-28-10 ، RICAP (بيتا = 0.3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10 ، RICAP (بيتا = 0.3) | 256 | 2 | 2.71 | 200 | 2H14M |
| WRN-28-10 ، RICAP (بيتا = 0.3) | 128 | 4 | 2.89 | 200 | 1H01M |
| WRN-28-10 ، RICAP (بيتا = 0.3) | 64 | 8 | 2.75 | 200 | 34m |
ملحوظة
- تم استخدام Tesla V100 في هذه التجارب.
باستخدام 1 وحدة معالجة الرسومات
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseباستخدام 2 وحدات معالجة الرسومات
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseباستخدام 4 وحدات معالجة الرسومات
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseباستخدام 8 وحدات معالجة الرسومات
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseنتائج على الموضة
| نموذج | اختبار خطأ (1 تشغيل) | # من الحقبة | وقت التدريب |
|---|
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 12 | 4.17 | 200 | 1H32M |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 14 | 4.11 | 200 | 1H32M |
| RESNET-PEACT-50 ، Cutout 12 | 4.45 | 200 | 57 م |
| RESNET-PEACT-50 ، Cutout 14 | 4.38 | 200 | 57 م |
| RESNET-PEACT-50 ، عامل الاتساع 4 ، قطع 12 | 4.07 | 200 | 3H37M |
| RESNET-PEACT-50 ، عامل الاتساع 4 ، قطع 14 | 4.13 | 200 | 3H39M |
| Shake-Shake-26 2x32d (SSI) ، قطع 12 | 4.08 | 400 | 3H41M |
| Shake-Shake-26 2x32d (SSI) ، قطع 14 | 4.05 | 400 | 3H39M |
| Shake-Shake-26 2x96D (SSI) ، Cutout 12 | 3.72 | 400 | 13H46M |
| Shake-Shake-26 2x96D (SSI) ، قطع 14 | 3.85 | 400 | 13h39m |
| Shake-Shake-26 2x96D (SSI) ، Cutout 12 | 3.65 | 800 | 26H42M |
| Shake-Shake-26 2x96D (SSI) ، قطع 14 | 3.60 | 800 | 26H42M |
| نموذج | خطأ اختبار (متوسط 3 أشواط) | # من الحقبة | وقت التدريب |
|---|
| RESNET-PEACT-20 | 5.04 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 6 | 4.84 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 8 | 4.64 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 10 | 4.74 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 12 | 4.68 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 14 | 4.64 | 200 | 26 م |
| RESNET-PEACT-20 ، Cutout 16 | 4.49 | 200 | 26 م |
| RESNET-PEACT-20 ، عشوائي | 4.61 | 200 | 26 م |
| RESNET-PEACT-20 ، MIXUP | 4.92 | 200 | 26 م |
| RESNET-PEACT-20 ، MIXUP | 4.64 | 400 | 52 م |
ملحوظة
- النتائج التي تم الإبلاغ عنها في الجداول هي أخطاء الاختبار في الحقبة الأخيرة.
- يتم تدريب جميع النماذج باستخدام جيب التمام الصلب مع معدل التعلم الأولي 0.2.
- يتم تطبيق زيادة البيانات التالية على بيانات التدريب:
- الصور مبطنة مع 4 بكسل على كل جانب ، ويتم اقتصاص بقع 28 × 28 بشكل عشوائي من الصور المبطنة.
- يتم قلب الصور بشكل عشوائي أفقيا.
- تم استخدام Geforce GTX 1080 Ti في هذه التجارب.
نتائج على Mnist
| نموذج | خطأ اختبار (متوسط 3 أشواط) | # من الحقبة | وقت التدريب |
|---|
| RESNET-PEACT-20 | 0.40 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 6 | 0.32 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 8 | 0.25 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 10 | 0.27 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 12 | 0.26 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 14 | 0.26 | 100 | 12 م |
| RESNET-PEACT-20 ، Cutout 16 | 0.25 | 100 | 12 م |
| RESNET-PEACT-20 ، mixup (ألفا = 1) | 0.40 | 100 | 12 م |
| RESNET-PEACT-20 ، mixup (ألفا = 0.5) | 0.38 | 100 | 12 م |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 14 | 0.26 | 100 | 45 م |
| RESNET-PEACT-50 ، Cutout 14 | 0.29 | 100 | 28 م |
| RESNET-PEACT-50 ، عامل الاتساع 4 ، قطع 14 | 0.25 | 100 | 1H50M |
| Shake-Shake-26 2x96D (SSI) ، قطع 14 | 0.24 | 100 | 3H22M |
ملحوظة
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
- يتم تدريب جميع النماذج باستخدام جيب التمام الصلب مع معدل التعلم الأولي 0.2.
- تم استخدام Geforce GTX 1080 Ti في هذه التجارب.
نتائج على Kuzushiji-Mnist
| نموذج | خطأ اختبار (متوسط 3 أشواط) | # من الحقبة | وقت التدريب |
|---|
| RESNET-PEACT-20 ، Cutout 14 | 0.82 (أفضل 0.67) | 200 | 24m |
| RESNET-PEACT-20 ، عامل الاتساع 4 ، قطع 14 | 0.72 (أفضل 0.67) | 200 | 1H30M |
| Pyramidnet-110-270 ، Cutout 14 | 0.72 (أفضل 0.70) | 200 | 10H05M |
| Shake-Shake-26 2x96D (SSI) ، قطع 14 | 0.66 (أفضل 0.63) | 200 | 6H46M |
ملحوظة
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
- يتم تدريب جميع النماذج باستخدام جيب التمام الصلب مع معدل التعلم الأولي 0.2.
- تم استخدام Geforce GTX 1080 Ti في هذه التجارب.
التجارب
تجربة على الوحدات المتبقية وجدولة معدل التعلم وزيادة البيانات
في هذه التجربة ، يتم التحقيق في تأثيرات ما يلي على دقة التصنيف:
- وحدات متبقية تشبه الهرم
- جيب التمام الصلب معدل التعلم
- انقطاع
- محو عشوائي
- خلط
- تنشيط الاختصارات بعد الانخفاض
يتم تدريب RESNET-PEACT-56 على CIFAR-10 مع معدل التعلم الأولي 0.2 في هذه التجربة.
ملحوظة
- أظهرت Pyramidnet Paper (1610.02915) أن إزالة RELU الأولى في الوحدات المتبقية وإضافة BN بعد آخر تلوينات في الوحدات المتبقية على حد سواء على تحسين دقة التصنيف.
- أظهرت ورقة SGDR (1608.03983) أن تلبيد جيب التمام يحسن دقة التصنيف حتى دون إعادة التشغيل.
نتائج
- الوحدات التي تشبه الهرم.
- قد يكون من الأفضل عدم تنشيط اختصارات بعد التخفيضات عند استخدام وحدات تشبه الهرم.
- جيب التمام الصلب يحسن قليلاً من الدقة.
- القطع ، عشوائية ، ومزيج كل شيء يعمل بشكل رائع.
- يحتاج الخلط إلى تدريب أطول.
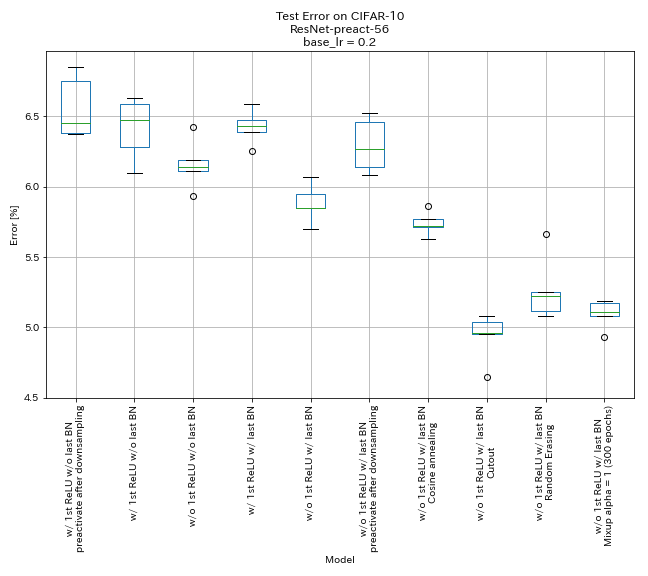
| نموذج | خطأ اختبار (متوسط 5 أشواط) | وقت التدريب |
|---|
| w/ 1st releu ، w/ o Last Bn ، preactivate اختصار بعد الانخفاض | 6.45 | 95 دقيقة |
| W/ 1st relu ، w/ o Last Bn | 6.47 | 95 دقيقة |
| w/o 1st relu ، w/o last bn | 6.14 | 89 دقيقة |
| W/ 1st relu ، ث/ آخر مليار | 6.43 | 104 دقيقة |
| w/ o 1st relu ، w/ last bn | 5.85 | 98 دقيقة |
| w/ o 1st relu ، w/ last bn ، preactivate اختصار بعد الانخفاض | 6.27 | 98 دقيقة |
| w/ o 1st relu ، w/ last bn ، جيب التمام الصلب | 5.72 | 98 دقيقة |
| w/ o 1st relu ، w/ last bn ، cutout | 4.96 | 98 دقيقة |
| w/ o 1st relu ، w/ last bn ، عشوائي | 5.22 | 98 دقيقة |
| w/ o 1st relu ، w/ last bn ، mixup (300 epochs) | 5.11 | 191 دقيقة |
اختصار preactivate بعد الانخفاض
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
W/ 1st relu ، w/ o Last Bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o 1st relu ، w/o last bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
W/ 1st relu ، ث/ آخر مليار
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00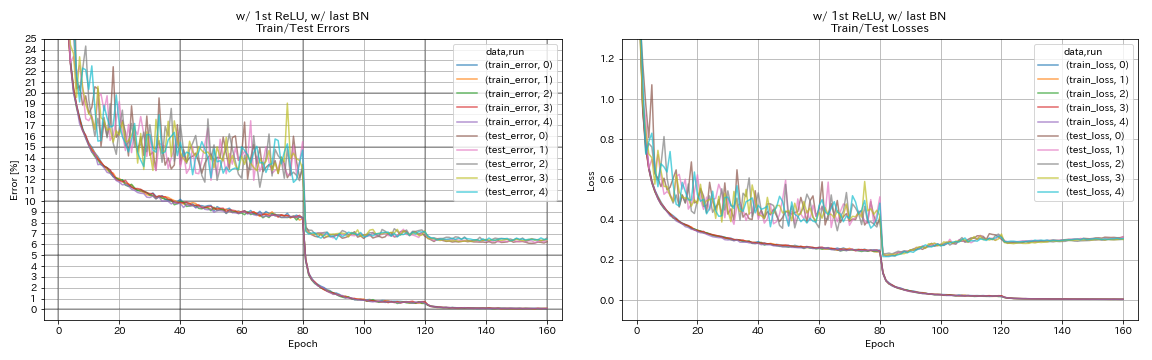
w/ o 1st relu ، w/ last bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00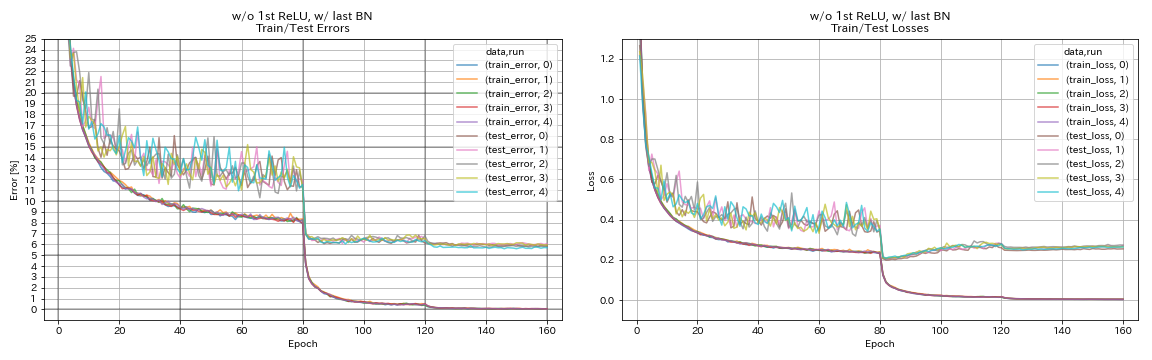
w/ o 1st relu ، w/ last bn ، preactivate اختصار بعد الانخفاض
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00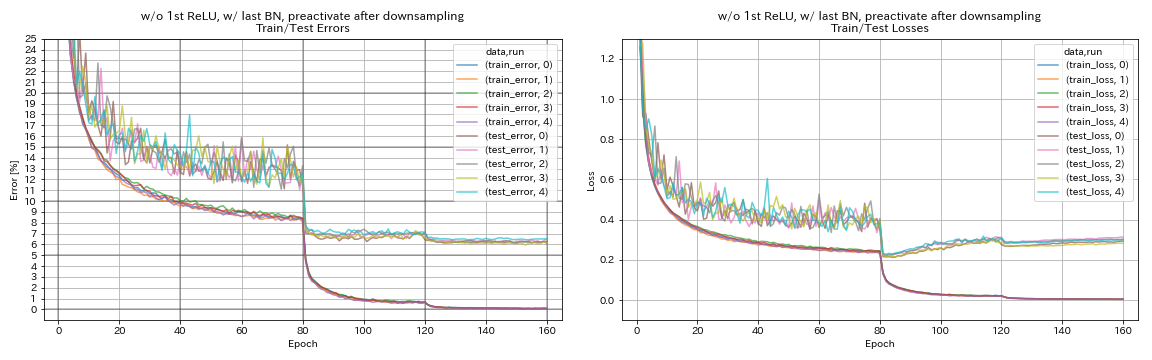
w/ o 1st relu ، w/ last bn ، جيب التمام الصلب
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00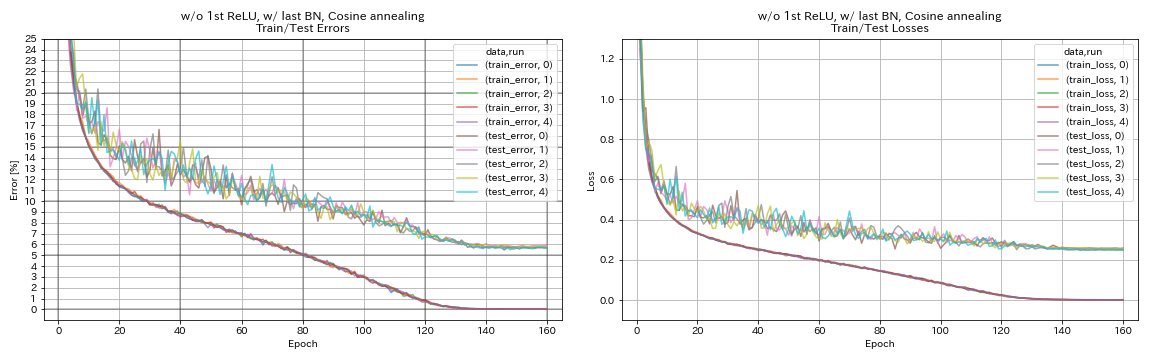
w/ o 1st relu ، w/ last bn ، cutout
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00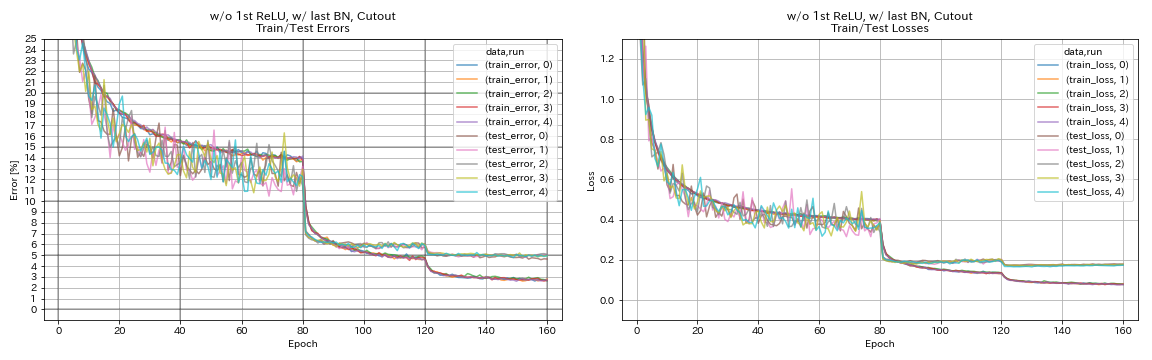
w/ o 1st relu ، w/ last bn ، عشوائي
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00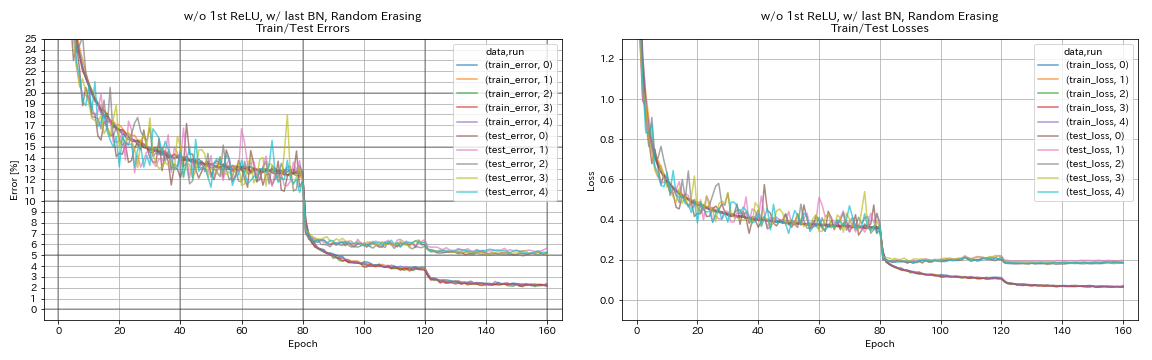
w/ o 1st relu ، w/ last bn ، mixup
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00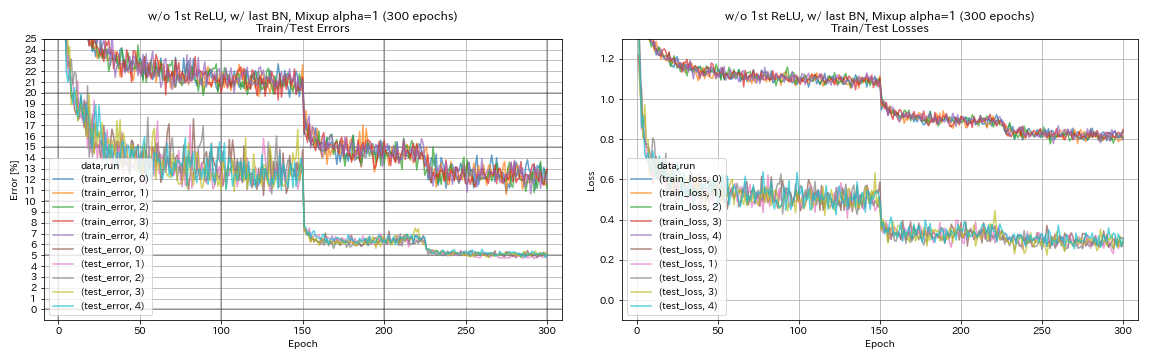
تجارب على تجانس الملصقات ، والخلط ، والريكاب ، والضغط المزدوج
النتائج على CIFAR-10
| نموذج | خطأ اختبار (متوسط 3 أشواط) | # من الحقبة | وقت التدريب |
|---|
| RESNET-PEACT-20 | 7.60 | 200 | 24m |
| RESNET-PEACT-20 ، تجانس الملصقات (Epsilon = 0.001) | 7.51 | 200 | 25m |
| RESNET-PEACT-20 ، تجانس الملصقات (Epsilon = 0.01) | 7.21 | 200 | 25m |
| RESNET-PEACT-20 ، تجانس التسمية (Epsilon = 0.1) | 7.57 | 200 | 25m |
| RESNET-PEACT-20 ، mixup (ألفا = 1) | 7.24 | 200 | 26 م |
| RESNET-PEACT-20 ، RICAP (بيتا = 0.3) ، ث/ محصول عشوائي | 6.88 | 200 | 28 م |
| RESNET-PEACT-20 ، RICAP (بيتا = 0.3) | 6.77 | 200 | 28 م |
| RESNET-PEACT-20 ، Dual Cutout 16 (ألفا = 0.1) | 6.24 | 200 | 45 م |
| RESNET-PEACT-20 | 7.05 | 400 | 49 م |
| RESNET-PEACT-20 ، تجانس الملصقات (Epsilon = 0.001) | 7.20 | 400 | 49 م |
| RESNET-PEACT-20 ، تجانس الملصقات (Epsilon = 0.01) | 6.97 | 400 | 49 م |
| RESNET-PEACT-20 ، تجانس التسمية (Epsilon = 0.1) | 7.16 | 400 | 49 م |
| RESNET-PEACT-20 ، mixup (ألفا = 1) | 6.66 | 400 | 51 م |
| RESNET-PEACT-20 ، RICAP (بيتا = 0.3) ، ث/ محصول عشوائي | 6.30 | 400 | 56 م |
| RESNET-PEACT-20 ، RICAP (بيتا = 0.3) | 6.19 | 400 | 56 م |
| RESNET-PEACT-20 ، Dual Cutout 16 (ألفا = 0.1) | 5.55 | 400 | 1H36M |
ملحوظة
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
- يتم تدريب جميع النماذج باستخدام جيب التمام الصلب مع معدل التعلم الأولي 0.2.
- تم استخدام Geforce GTX 1080 Ti في هذه التجارب.
تجارب على حجم الدُفعة ومعدل التعلم
- تتم التجارب التالية على مجموعة بيانات CIFAR-10 باستخدام GeForce 1080 Ti.
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
قاعدة التحجيم الخطي لمعدل التعلم
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 3.2 | جيب التمام | 200 | 10.57 | 22 م |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 200 | 8.87 | 21m |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 200 | 8.40 | 21m |
| RESNET-PEACT-20 | 512 | 0.4 | جيب التمام | 200 | 8.22 | 20m |
| RESNET-PEACT-20 | 256 | 0.2 | جيب التمام | 200 | 8.61 | 22 م |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 200 | 8.09 | 24m |
| RESNET-PEACT-20 | 64 | 0.05 | جيب التمام | 200 | 8.22 | 28 م |
| RESNET-PEACT-20 | 32 | 0.025 | جيب التمام | 200 | 8.00 | 43 م |
| RESNET-PEACT-20 | 16 | 0.0125 | جيب التمام | 200 | 7.75 | 1H17M |
| RESNET-PEACT-20 | 8 | 0.006125 | جيب التمام | 200 | 7.70 | 2H32M |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 3.2 | متعددة | 200 | 28.97 | 22 م |
| RESNET-PEACT-20 | 2048 | 1.6 | متعددة | 200 | 9.07 | 21m |
| RESNET-PEACT-20 | 1024 | 0.8 | متعددة | 200 | 8.62 | 21m |
| RESNET-PEACT-20 | 512 | 0.4 | متعددة | 200 | 8.23 | 20m |
| RESNET-PEACT-20 | 256 | 0.2 | متعددة | 200 | 8.40 | 21m |
| RESNET-PEACT-20 | 128 | 0.1 | متعددة | 200 | 8.28 | 24m |
| RESNET-PEACT-20 | 64 | 0.05 | متعددة | 200 | 8.13 | 28 م |
| RESNET-PEACT-20 | 32 | 0.025 | متعددة | 200 | 7.58 | 43 م |
| RESNET-PEACT-20 | 16 | 0.0125 | متعددة | 200 | 7.93 | 1H18M |
| RESNET-PEACT-20 | 8 | 0.006125 | متعددة | 200 | 8.31 | 2H34M |
التحجيم الخطي + التدريب لفترة أطول
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 3.2 | جيب التمام | 400 | 8.97 | 44 م |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 400 | 7.85 | 43 م |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 400 | 7.20 | 42 م |
| RESNET-PEACT-20 | 512 | 0.4 | جيب التمام | 400 | 7.83 | 40 م |
| RESNET-PEACT-20 | 256 | 0.2 | جيب التمام | 400 | 7.65 | 42 م |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 400 | 7.09 | 47 م |
| RESNET-PEACT-20 | 64 | 0.05 | جيب التمام | 400 | 7.17 | 44 م |
| RESNET-PEACT-20 | 32 | 0.025 | جيب التمام | 400 | 7.24 | 2H11M |
| RESNET-PEACT-20 | 16 | 0.0125 | جيب التمام | 400 | 7.26 | 4H10M |
| RESNET-PEACT-20 | 8 | 0.006125 | جيب التمام | 400 | 7.02 | 7H53M |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 3.2 | جيب التمام | 800 | 8.14 | 1H29M |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 800 | 7.74 | 1H23M |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 800 | 7.15 | 1H31M |
| RESNET-PEACT-20 | 512 | 0.4 | جيب التمام | 800 | 7.27 | 1H25M |
| RESNET-PEACT-20 | 256 | 0.2 | جيب التمام | 800 | 7.22 | 1H26M |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 800 | 6.68 | 1H35M |
| RESNET-PEACT-20 | 64 | 0.05 | جيب التمام | 800 | 7.18 | 2H20M |
| RESNET-PEACT-20 | 32 | 0.025 | جيب التمام | 800 | 7.03 | 4H16M |
| RESNET-PEACT-20 | 16 | 0.0125 | جيب التمام | 800 | 6.78 | 8H37M |
| RESNET-PEACT-20 | 8 | 0.006125 | جيب التمام | 800 | 6.89 | 16H47M |
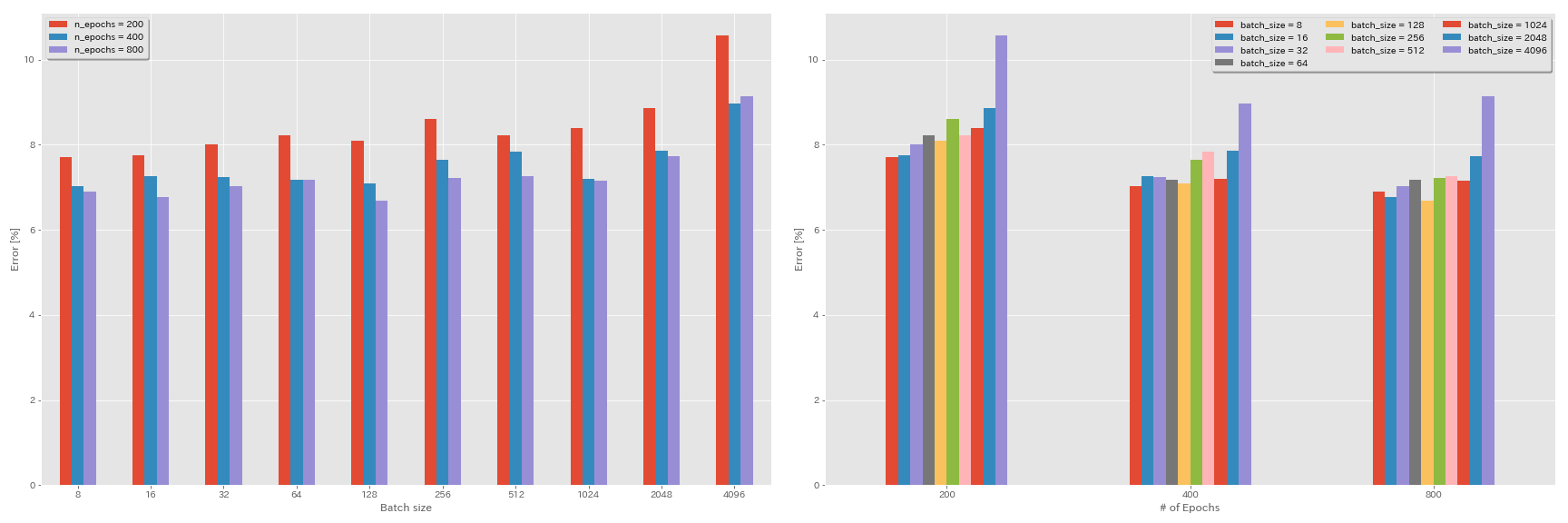
تأثير معدل التعلم الأولي
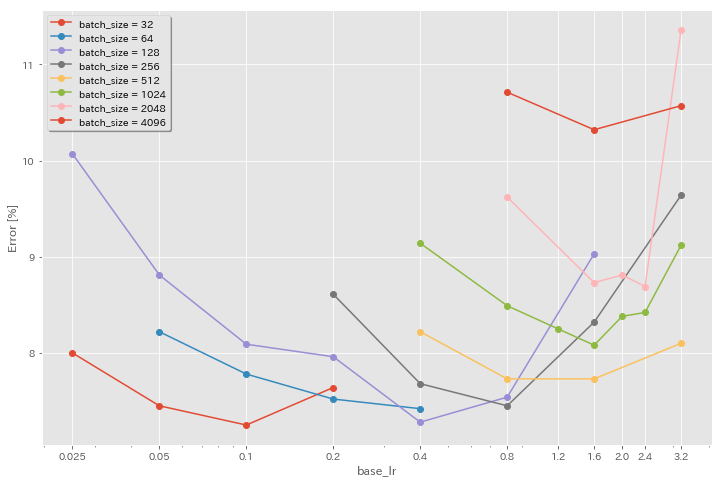
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 3.2 | جيب التمام | 200 | 10.57 | 22 م |
| RESNET-PEACT-20 | 4096 | 1.6 | جيب التمام | 200 | 10.32 | 22 م |
| RESNET-PEACT-20 | 4096 | 0.8 | جيب التمام | 200 | 10.71 | 22 م |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 2048 | 3.2 | جيب التمام | 200 | 11.34 | 21m |
| RESNET-PEACT-20 | 2048 | 2.4 | جيب التمام | 200 | 8.69 | 21m |
| RESNET-PEACT-20 | 2048 | 2.0 | جيب التمام | 200 | 8.81 | 21m |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 200 | 8.73 | 22 م |
| RESNET-PEACT-20 | 2048 | 0.8 | جيب التمام | 200 | 9.62 | 21m |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 1024 | 3.2 | جيب التمام | 200 | 9.12 | 21m |
| RESNET-PEACT-20 | 1024 | 2.4 | جيب التمام | 200 | 8.42 | 22 م |
| RESNET-PEACT-20 | 1024 | 2.0 | جيب التمام | 200 | 8.38 | 22 م |
| RESNET-PEACT-20 | 1024 | 1.6 | جيب التمام | 200 | 8.07 | 22 م |
| RESNET-PEACT-20 | 1024 | 1.2 | جيب التمام | 200 | 8.25 | 21m |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 200 | 8.08 | 22 م |
| RESNET-PEACT-20 | 1024 | 0.4 | جيب التمام | 200 | 8.49 | 22 م |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 512 | 3.2 | جيب التمام | 200 | 8.51 | 21m |
| RESNET-PEACT-20 | 512 | 1.6 | جيب التمام | 200 | 7.73 | 20m |
| RESNET-PEACT-20 | 512 | 0.8 | جيب التمام | 200 | 7.73 | 21m |
| RESNET-PEACT-20 | 512 | 0.4 | جيب التمام | 200 | 8.22 | 20m |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 256 | 3.2 | جيب التمام | 200 | 9.64 | 22 م |
| RESNET-PEACT-20 | 256 | 1.6 | جيب التمام | 200 | 8.32 | 22 م |
| RESNET-PEACT-20 | 256 | 0.8 | جيب التمام | 200 | 7.45 | 21m |
| RESNET-PEACT-20 | 256 | 0.4 | جيب التمام | 200 | 7.68 | 22 م |
| RESNET-PEACT-20 | 256 | 0.2 | جيب التمام | 200 | 8.61 | 22 م |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 128 | 1.6 | جيب التمام | 200 | 9.03 | 24m |
| RESNET-PEACT-20 | 128 | 0.8 | جيب التمام | 200 | 7.54 | 24m |
| RESNET-PEACT-20 | 128 | 0.4 | جيب التمام | 200 | 7.28 | 24m |
| RESNET-PEACT-20 | 128 | 0.2 | جيب التمام | 200 | 7.96 | 24m |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 200 | 8.09 | 24m |
| RESNET-PEACT-20 | 128 | 0.05 | جيب التمام | 200 | 8.81 | 24m |
| RESNET-PEACT-20 | 128 | 0.025 | جيب التمام | 200 | 10.07 | 24m |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 64 | 0.4 | جيب التمام | 200 | 7.42 | 35m |
| RESNET-PEACT-20 | 64 | 0.2 | جيب التمام | 200 | 7.52 | 36 م |
| RESNET-PEACT-20 | 64 | 0.1 | جيب التمام | 200 | 7.78 | 37 م |
| RESNET-PEACT-20 | 64 | 0.05 | جيب التمام | 200 | 8.22 | 28 م |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 32 | 0.2 | جيب التمام | 200 | 7.64 | 1H05M |
| RESNET-PEACT-20 | 32 | 0.1 | جيب التمام | 200 | 7.25 | 1H08M |
| RESNET-PEACT-20 | 32 | 0.05 | جيب التمام | 200 | 7.45 | 1H07M |
| RESNET-PEACT-20 | 32 | 0.025 | جيب التمام | 200 | 8.00 | 43 م |
معدل تعلم جيد + تدريب أطول
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 1.6 | جيب التمام | 200 | 10.32 | 22 م |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 200 | 8.73 | 22 م |
| RESNET-PEACT-20 | 1024 | 1.6 | جيب التمام | 200 | 8.07 | 22 م |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 200 | 8.08 | 22 م |
| RESNET-PEACT-20 | 512 | 1.6 | جيب التمام | 200 | 7.73 | 20m |
| RESNET-PEACT-20 | 512 | 0.8 | جيب التمام | 200 | 7.73 | 21m |
| RESNET-PEACT-20 | 256 | 0.8 | جيب التمام | 200 | 7.45 | 21m |
| RESNET-PEACT-20 | 128 | 0.4 | جيب التمام | 200 | 7.28 | 24m |
| RESNET-PEACT-20 | 128 | 0.2 | جيب التمام | 200 | 7.96 | 24m |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 200 | 8.09 | 24m |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 1.6 | جيب التمام | 800 | 8.36 | 1H33M |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 800 | 7.53 | 1H27M |
| RESNET-PEACT-20 | 1024 | 1.6 | جيب التمام | 800 | 7.30 | 1H30M |
| RESNET-PEACT-20 | 1024 | 0.8 | جيب التمام | 800 | 7.42 | 1H30M |
| RESNET-PEACT-20 | 512 | 1.6 | جيب التمام | 800 | 6.69 | 1H26M |
| RESNET-PEACT-20 | 512 | 0.8 | جيب التمام | 800 | 6.77 | 1H26M |
| RESNET-PEACT-20 | 256 | 0.8 | جيب التمام | 800 | 6.84 | 1H28M |
| RESNET-PEACT-20 | 128 | 0.4 | جيب التمام | 800 | 6.86 | 1H35M |
| RESNET-PEACT-20 | 128 | 0.2 | جيب التمام | 800 | 7.05 | 1H38M |
| RESNET-PEACT-20 | 128 | 0.1 | جيب التمام | 800 | 6.68 | 1H35M |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 1.6 | جيب التمام | 1600 | 8.25 | 3H10M |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 1600 | 7.34 | 2H50M |
| RESNET-PEACT-20 | 1024 | 1.6 | جيب التمام | 1600 | 6.94 | 2H52M |
| RESNET-PEACT-20 | 512 | 1.6 | جيب التمام | 1600 | 6.99 | 2H44M |
| RESNET-PEACT-20 | 256 | 0.8 | جيب التمام | 1600 | 6.95 | 2H50M |
| RESNET-PEACT-20 | 128 | 0.4 | جيب التمام | 1600 | 6.64 | 3H09M |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 4096 | 1.6 | جيب التمام | 3200 | 9.52 | 6H15M |
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 3200 | 6.92 | 5H42M |
| RESNET-PEACT-20 | 1024 | 1.6 | جيب التمام | 3200 | 6.96 | 5H43M |
| نموذج | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 2048 | 1.6 | جيب التمام | 6400 | 7.45 | 11h44m |
لارس
- في الأوراق الأصلية (1708.03888 ، 1801.03137) ، استخدموا جدولة معدل تعلم التحلل متعدد الحدود ، ولكن يتم استخدام جيب التمام في هذه التجارب.
- في هذا التنفيذ ، لا يتم استخدام معامل LARS ، لذلك يجب تعديل معدل التعلم وفقًا لذلك.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00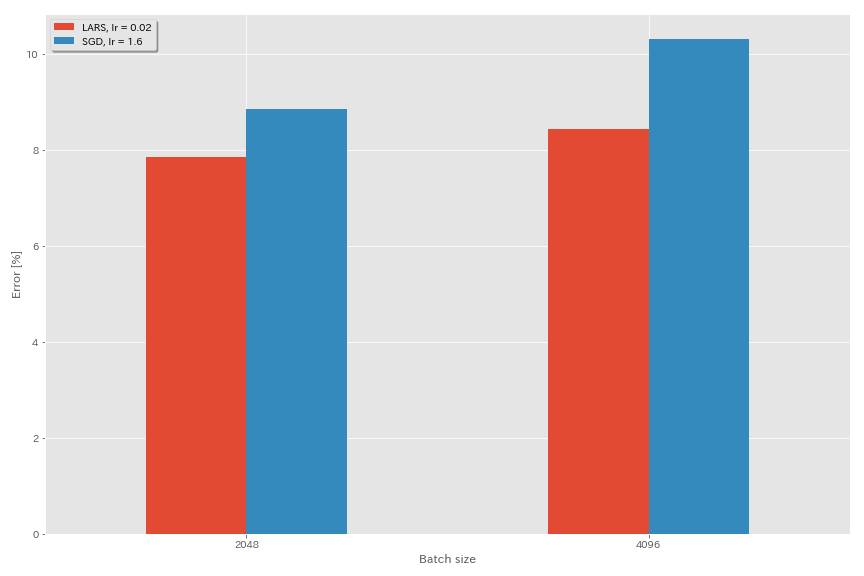
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 4096 | 3.2 | جيب التمام | 200 | 10.57 (تشغيل واحد) | 22 م |
| RESNET-PEACT-20 | SGD | 4096 | 1.6 | جيب التمام | 200 | 10.20 | 22 م |
| RESNET-PEACT-20 | SGD | 4096 | 0.8 | جيب التمام | 200 | 10.71 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.04 | جيب التمام | 200 | 9.58 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.03 | جيب التمام | 200 | 8.46 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.02 | جيب التمام | 200 | 8.21 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.015 | جيب التمام | 200 | 8.47 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.01 | جيب التمام | 200 | 9.33 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.005 | جيب التمام | 200 | 14.31 | 22 م |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 2048 | 3.2 | جيب التمام | 200 | 11.34 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 2048 | 2.4 | جيب التمام | 200 | 8.69 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 2048 | 2.0 | جيب التمام | 200 | 8.81 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 2048 | 1.6 | جيب التمام | 200 | 8.73 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 2048 | 0.8 | جيب التمام | 200 | 9.62 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | لارس | 2048 | 0.04 | جيب التمام | 200 | 11.58 | 21m |
| RESNET-PEACT-20 | لارس | 2048 | 0.02 | جيب التمام | 200 | 8.05 | 22 م |
| RESNET-PEACT-20 | لارس | 2048 | 0.01 | جيب التمام | 200 | 8.07 | 22 م |
| RESNET-PEACT-20 | لارس | 2048 | 0.005 | جيب التمام | 200 | 9.65 | 22 م |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 1024 | 3.2 | جيب التمام | 200 | 9.12 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 1024 | 2.4 | جيب التمام | 200 | 8.42 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 1024 | 2.0 | جيب التمام | 200 | 8.38 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 1024 | 1.6 | جيب التمام | 200 | 8.07 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 1024 | 1.2 | جيب التمام | 200 | 8.25 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 1024 | 0.8 | جيب التمام | 200 | 8.08 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 1024 | 0.4 | جيب التمام | 200 | 8.49 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | لارس | 1024 | 0.02 | جيب التمام | 200 | 9.30 | 22 م |
| RESNET-PEACT-20 | لارس | 1024 | 0.01 | جيب التمام | 200 | 7.68 | 22 م |
| RESNET-PEACT-20 | لارس | 1024 | 0.005 | جيب التمام | 200 | 8.88 | 23m |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 512 | 3.2 | جيب التمام | 200 | 8.51 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 512 | 1.6 | جيب التمام | 200 | 7.73 (1 تشغيل) | 20m |
| RESNET-PEACT-20 | SGD | 512 | 0.8 | جيب التمام | 200 | 7.73 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 512 | 0.4 | جيب التمام | 200 | 8.22 (1 تشغيل) | 20m |
| RESNET-PEACT-20 | لارس | 512 | 0.015 | جيب التمام | 200 | 9.84 | 23m |
| RESNET-PEACT-20 | لارس | 512 | 0.01 | جيب التمام | 200 | 8.05 | 23m |
| RESNET-PEACT-20 | لارس | 512 | 0.0075 | جيب التمام | 200 | 7.58 | 23m |
| RESNET-PEACT-20 | لارس | 512 | 0.005 | جيب التمام | 200 | 7.96 | 23m |
| RESNET-PEACT-20 | لارس | 512 | 0.0025 | جيب التمام | 200 | 8.83 | 23m |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 256 | 3.2 | جيب التمام | 200 | 9.64 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 256 | 1.6 | جيب التمام | 200 | 8.32 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 256 | 0.8 | جيب التمام | 200 | 7.45 (1 تشغيل) | 21m |
| RESNET-PEACT-20 | SGD | 256 | 0.4 | جيب التمام | 200 | 7.68 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | SGD | 256 | 0.2 | جيب التمام | 200 | 8.61 (1 تشغيل) | 22 م |
| RESNET-PEACT-20 | لارس | 256 | 0.01 | جيب التمام | 200 | 8.95 | 27 م |
| RESNET-PEACT-20 | لارس | 256 | 0.005 | جيب التمام | 200 | 7.75 | 28 م |
| RESNET-PEACT-20 | لارس | 256 | 0.0025 | جيب التمام | 200 | 8.21 | 28 م |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 128 | 1.6 | جيب التمام | 200 | 9.03 (1 تشغيل) | 24m |
| RESNET-PEACT-20 | SGD | 128 | 0.8 | جيب التمام | 200 | 7.54 (تشغيل واحد) | 24m |
| RESNET-PEACT-20 | SGD | 128 | 0.4 | جيب التمام | 200 | 7.28 (1 تشغيل) | 24m |
| RESNET-PEACT-20 | SGD | 128 | 0.2 | جيب التمام | 200 | 7.96 (1 تشغيل) | 24m |
| RESNET-PEACT-20 | لارس | 128 | 0.005 | جيب التمام | 200 | 7.96 | 37 م |
| RESNET-PEACT-20 | لارس | 128 | 0.0025 | جيب التمام | 200 | 7.98 | 37 م |
| RESNET-PEACT-20 | لارس | 128 | 0.00125 | جيب التمام | 200 | 9.21 | 37 م |
| نموذج | مُحسّن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | SGD | 4096 | 1.6 | جيب التمام | 200 | 10.20 | 22 م |
| RESNET-PEACT-20 | SGD | 4096 | 1.6 | جيب التمام | 800 | 8.36 (1 تشغيل) | 1H33M |
| RESNET-PEACT-20 | SGD | 4096 | 1.6 | جيب التمام | 1600 | 8.25 (1 تشغيل) | 3H10M |
| RESNET-PEACT-20 | لارس | 4096 | 0.02 | جيب التمام | 200 | 8.21 | 22 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.02 | جيب التمام | 400 | 7.53 | 44 م |
| RESNET-PEACT-20 | لارس | 4096 | 0.02 | جيب التمام | 800 | 7.48 | 1H29M |
| RESNET-PEACT-20 | لارس | 4096 | 0.02 | جيب التمام | 1600 | 7.37 (1 تشغيل) | 2H58M |
شبح bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| نموذج | حجم الدُفعة | حجم دفعة الأشباح | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 8192 | ن/أ | 1.6 | جيب التمام | 200 | 12.35 | 25 م* |
| RESNET-PEACT-20 | 4096 | ن/أ | 1.6 | جيب التمام | 200 | 10.32 | 22 م |
| RESNET-PEACT-20 | 2048 | ن/أ | 1.6 | جيب التمام | 200 | 8.73 | 22 م |
| RESNET-PEACT-20 | 1024 | ن/أ | 1.6 | جيب التمام | 200 | 8.07 | 22 م |
| RESNET-PEACT-20 | 128 | ن/أ | 0.4 | جيب التمام | 200 | 7.28 | 24m |
| نموذج | حجم الدُفعة | حجم دفعة الأشباح | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 8192 | 128 | 1.6 | جيب التمام | 200 | 11.51 | 27 م |
| RESNET-PEACT-20 | 4096 | 128 | 1.6 | جيب التمام | 200 | 9.73 | 25m |
| RESNET-PEACT-20 | 2048 | 128 | 1.6 | جيب التمام | 200 | 8.77 | 24m |
| RESNET-PEACT-20 | 1024 | 128 | 1.6 | جيب التمام | 200 | 7.82 | 22 م |
| نموذج | حجم الدُفعة | حجم دفعة الأشباح | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 8192 | ن/أ | 1.6 | جيب التمام | 1600 | | |
| RESNET-PEACT-20 | 4096 | ن/أ | 1.6 | جيب التمام | 1600 | 8.25 | 3H10M |
| RESNET-PEACT-20 | 2048 | ن/أ | 1.6 | جيب التمام | 1600 | 7.34 | 2H50M |
| RESNET-PEACT-20 | 1024 | ن/أ | 1.6 | جيب التمام | 1600 | 6.94 | 2H52M |
| نموذج | حجم الدُفعة | حجم دفعة الأشباح | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | 8192 | 128 | 1.6 | جيب التمام | 1600 | 11.83 | 3H37M |
| RESNET-PEACT-20 | 4096 | 128 | 1.6 | جيب التمام | 1600 | 8.95 | 3H15M |
| RESNET-PEACT-20 | 2048 | 128 | 1.6 | جيب التمام | 1600 | 7.23 | 3H05M |
| RESNET-PEACT-20 | 1024 | 128 | 1.6 | جيب التمام | 1600 | 7.08 | 2H59M |
لا تسوس الوزن على BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00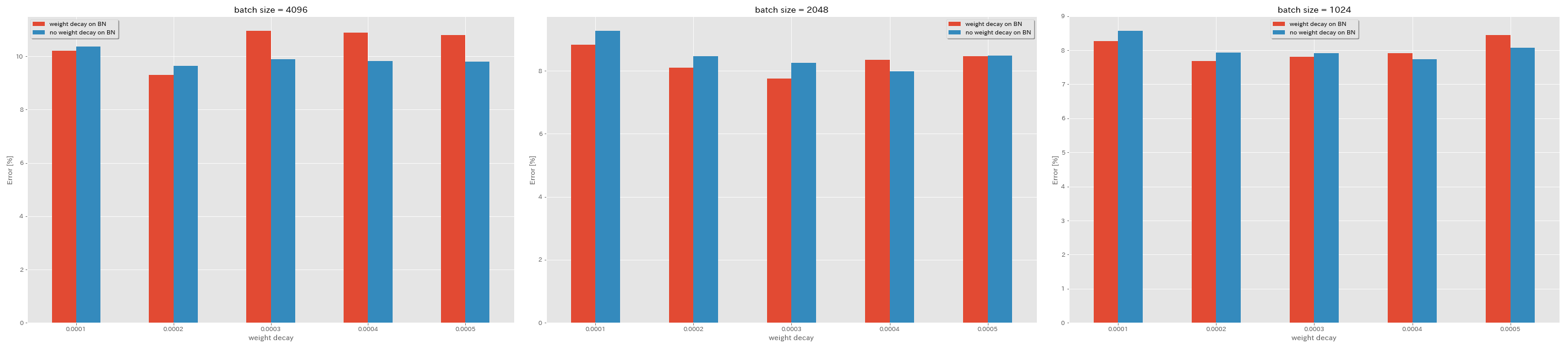
| نموذج | تسوس الوزن على BN | انحلال الوزن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | نعم | 5e-4 | 4096 | 1.6 | جيب التمام | 200 | 10.81 | 22 م |
| RESNET-PEACT-20 | نعم | 4E-4 | 4096 | 1.6 | جيب التمام | 200 | 10.88 | 22 م |
| RESNET-PEACT-20 | نعم | 3e-4 | 4096 | 1.6 | جيب التمام | 200 | 10.96 | 22 م |
| RESNET-PEACT-20 | نعم | 2E-4 | 4096 | 1.6 | جيب التمام | 200 | 9.30 | 22 م |
| RESNET-PEACT-20 | نعم | 1E-4 | 4096 | 1.6 | جيب التمام | 200 | 10.20 | 22 م |
| RESNET-PEACT-20 | لا | 5e-4 | 4096 | 1.6 | جيب التمام | 200 | 8.78 | 22 م |
| RESNET-PEACT-20 | لا | 4E-4 | 4096 | 1.6 | جيب التمام | 200 | 9.83 | 22 م |
| RESNET-PEACT-20 | لا | 3e-4 | 4096 | 1.6 | جيب التمام | 200 | 9.90 | 22 م |
| RESNET-PEACT-20 | لا | 2E-4 | 4096 | 1.6 | جيب التمام | 200 | 9.64 | 22 م |
| RESNET-PEACT-20 | لا | 1E-4 | 4096 | 1.6 | جيب التمام | 200 | 10.38 | 22 م |
| نموذج | تسوس الوزن على BN | انحلال الوزن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | نعم | 5e-4 | 2048 | 1.6 | جيب التمام | 200 | 8.46 | 20m |
| RESNET-PEACT-20 | نعم | 4E-4 | 2048 | 1.6 | جيب التمام | 200 | 8.35 | 20m |
| RESNET-PEACT-20 | نعم | 3e-4 | 2048 | 1.6 | جيب التمام | 200 | 7.76 | 20m |
| RESNET-PEACT-20 | نعم | 2E-4 | 2048 | 1.6 | جيب التمام | 200 | 8.09 | 20m |
| RESNET-PEACT-20 | نعم | 1E-4 | 2048 | 1.6 | جيب التمام | 200 | 8.83 | 20m |
| RESNET-PEACT-20 | لا | 5e-4 | 2048 | 1.6 | جيب التمام | 200 | 8.49 | 20m |
| RESNET-PEACT-20 | لا | 4E-4 | 2048 | 1.6 | جيب التمام | 200 | 7.98 | 20m |
| RESNET-PEACT-20 | لا | 3e-4 | 2048 | 1.6 | جيب التمام | 200 | 8.26 | 20m |
| RESNET-PEACT-20 | لا | 2E-4 | 2048 | 1.6 | جيب التمام | 200 | 8.47 | 20m |
| RESNET-PEACT-20 | لا | 1E-4 | 2048 | 1.6 | جيب التمام | 200 | 9.27 | 20m |
| نموذج | تسوس الوزن على BN | انحلال الوزن | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | خطأ اختبار (متوسط 3 أشواط) | وقت التدريب |
|---|
| RESNET-PEACT-20 | نعم | 5e-4 | 1024 | 1.6 | جيب التمام | 200 | 8.45 | 21m |
| RESNET-PEACT-20 | نعم | 4E-4 | 1024 | 1.6 | جيب التمام | 200 | 7.91 | 21m |
| RESNET-PEACT-20 | نعم | 3e-4 | 1024 | 1.6 | جيب التمام | 200 | 7.81 | 21m |
| RESNET-PEACT-20 | نعم | 2E-4 | 1024 | 1.6 | جيب التمام | 200 | 7.69 | 21m |
| RESNET-PEACT-20 | نعم | 1E-4 | 1024 | 1.6 | جيب التمام | 200 | 8.26 | 21m |
| RESNET-PEACT-20 | لا | 5e-4 | 1024 | 1.6 | جيب التمام | 200 | 8.08 | 21m |
| RESNET-PEACT-20 | لا | 4E-4 | 1024 | 1.6 | جيب التمام | 200 | 7.73 | 21m |
| RESNET-PEACT-20 | لا | 3e-4 | 1024 | 1.6 | جيب التمام | 200 | 7.92 | 21m |
| RESNET-PEACT-20 | لا | 2E-4 | 1024 | 1.6 | جيب التمام | 200 | 7.93 | 21m |
| RESNET-PEACT-20 | لا | 1E-4 | 1024 | 1.6 | جيب التمام | 200 | 8.53 | 21m |
تجارب على نصف الدقة ، ودقة مختلطة
- فيما يلي التجارب تحتاج إلى Nvidia Apex.
- تتم التجارب التالية على مجموعة بيانات CIFAR-10 باستخدام GeForce 1080 Ti ، والتي لا تحتوي على نوى توتر.
- النتائج التي تم الإبلاغ عنها في الجدول هي أخطاء الاختبار في الفحوصات الأخيرة.
FP16 التدريب
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00تدريب مختلط الدقة
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00نتائج
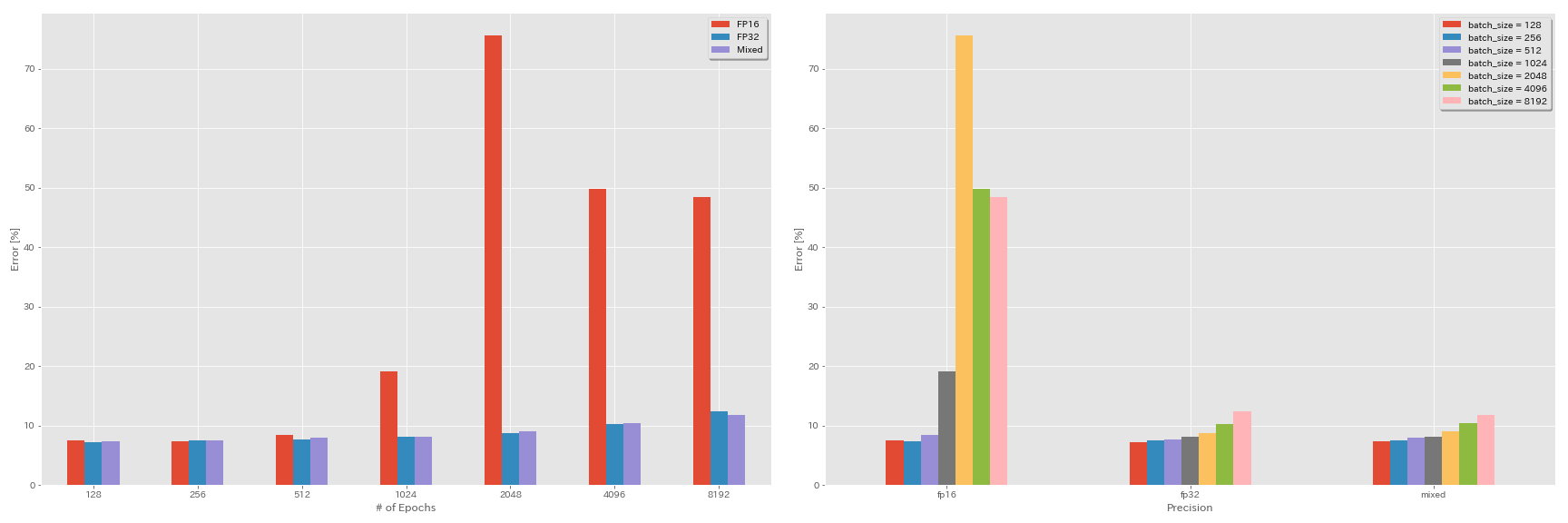
| نموذج | دقة | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | FP32 | 8192 | 1.6 | جيب التمام | 200 | | |
| RESNET-PEACT-20 | FP32 | 4096 | 1.6 | جيب التمام | 200 | 10.32 | 22 م |
| RESNET-PEACT-20 | FP32 | 2048 | 1.6 | جيب التمام | 200 | 8.73 | 22 م |
| RESNET-PEACT-20 | FP32 | 1024 | 1.6 | جيب التمام | 200 | 8.07 | 22 م |
| RESNET-PEACT-20 | FP32 | 512 | 0.8 | جيب التمام | 200 | 7.73 | 21m |
| RESNET-PEACT-20 | FP32 | 256 | 0.8 | جيب التمام | 200 | 7.45 | 21m |
| RESNET-PEACT-20 | FP32 | 128 | 0.4 | جيب التمام | 200 | 7.28 | 24m |
| نموذج | دقة | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | FP16 | 8192 | 1.6 | جيب التمام | 200 | 48.52 | 33 م |
| RESNET-PEACT-20 | FP16 | 4096 | 1.6 | جيب التمام | 200 | 49.84 | 28 م |
| RESNET-PEACT-20 | FP16 | 2048 | 1.6 | جيب التمام | 200 | 75.63 | 27 م |
| RESNET-PEACT-20 | FP16 | 1024 | 1.6 | جيب التمام | 200 | 19.09 | 27 م |
| RESNET-PEACT-20 | FP16 | 512 | 0.8 | جيب التمام | 200 | 7.89 | 26 م |
| RESNET-PEACT-20 | FP16 | 256 | 0.8 | جيب التمام | 200 | 7.40 | 28 م |
| RESNET-PEACT-20 | FP16 | 128 | 0.4 | جيب التمام | 200 | 7.59 | 32 متر |
| نموذج | دقة | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | مختلط | 8192 | 1.6 | جيب التمام | 200 | 11.78 | 28 م |
| RESNET-PEACT-20 | مختلط | 4096 | 1.6 | جيب التمام | 200 | 10.48 | 27 م |
| RESNET-PEACT-20 | مختلط | 2048 | 1.6 | جيب التمام | 200 | 8.98 | 26 م |
| RESNET-PEACT-20 | مختلط | 1024 | 1.6 | جيب التمام | 200 | 8.05 | 26 م |
| RESNET-PEACT-20 | مختلط | 512 | 0.8 | جيب التمام | 200 | 7.81 | 28 م |
| RESNET-PEACT-20 | مختلط | 256 | 0.8 | جيب التمام | 200 | 7.58 | 32 متر |
| RESNET-PEACT-20 | مختلط | 128 | 0.4 | جيب التمام | 200 | 7.37 | 41 م |
النتائج باستخدام Tesla V100
| نموذج | دقة | حجم الدُفعة | LR الأولي | جدول LR | # من الحقبة | اختبار خطأ (1 تشغيل) | وقت التدريب |
|---|
| RESNET-PEACT-20 | FP32 | 8192 | 1.6 | جيب التمام | 200 | 12.35 | 25m |
| RESNET-PEACT-20 | FP32 | 4096 | 1.6 | جيب التمام | 200 | 9.88 | 19M |
| RESNET-PEACT-20 | FP32 | 2048 | 1.6 | جيب التمام | 200 | 8.87 | 17m |
| RESNET-PEACT-20 | FP32 | 1024 | 1.6 | جيب التمام | 200 | 8.45 | 18 م |
| RESNET-PEACT-20 | مختلط | 8192 | 1.6 | جيب التمام | 200 | 11.92 | 25m |
| RESNET-PEACT-20 | مختلط | 4096 | 1.6 | جيب التمام | 200 | 10.16 | 19M |
| RESNET-PEACT-20 | مختلط | 2048 | 1.6 | جيب التمام | 200 | 9.10 | 17m |
| RESNET-PEACT-20 | مختلط | 1024 | 1.6 | جيب التمام | 200 | 7.84 | 16m |
مراجع
النموذج العمارة
- هو ، Kaiming ، Xiangyu Zhang ، Shaoqing Ren ، وجيان صن. "التعلم المتبقي العميق للتعرف على الصور." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2016. الرابط ، Arxiv: 1512.03385
- هو ، Kaiming ، Xiangyu Zhang ، Shaoqing Ren ، وجيان صن. "تعيينات الهوية في الشبكات المتبقية العميقة." في المؤتمر الأوروبي حول رؤية الكمبيوتر (ECCV). 2016. Arxiv: 1603.05027 ، تنفيذ الشعلة
- Zagoruyko و Sergey و Nikos Komodakis. "شبكات متبقية واسعة." وقائع المؤتمر البريطاني للآلة الرؤية (BMVC) ، 2016. Arxiv: 1605.07146 ، تنفيذ الشعلة
- هوانغ ، قاو ، تشوانغ ليو ، كيليان س وينبرجر ، ولورينز فان دير ماتن. "شبكات تلافيفية متصلة بكثافة." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2017. Link ، Arxiv: 1608.06993 ، تنفيذ الشعلة
- هان ، دونجيون ، جيوان كيم ، وجونمو كيم. "الشبكات المتبقية الهرمية العميقة." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2017. Link ، Arxiv: 1610.02915 ، تنفيذ الشعلة ، تنفيذ الكافيين ، تنفيذ Pytorch
- Xie ، Sinting ، Ross Girshick ، Piotr Dollar ، Zhuowen Tu ، و Kaiming He. "التحولات المتبقية المجمعة للشبكات العصبية العميقة." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2017. Link ، Arxiv: 1611.05431 ، تنفيذ الشعلة
- غاستالدي ، كزافييه. "التنظيم Shake من 3 شبكات متبقية الفرع." في ورشة عمل المؤتمر الدولي لتمثيل التعلم (ICLR) ، 2017. Link ، Arxiv: 1705.07485 ، تنفيذ الشعلة
- Hu و Jie و Li Shen و Gang Sun. "شبكات الضغط والإثبات." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2018 ، الصفحات 7132-7141. Link ، Arxiv: 1709.01507 ، تنفيذ الكافيين
- هوانغ ، قاو ، تشوانغ ليو ، جيف بليس ، لورينز فان دير ماتن ، وكيليان ك. وينبرجر. "الشبكات التلافيفية مع اتصال كثيف." معاملات IEEE على تحليل الأنماط وذكاء الآلة (2019). Arxiv: 2001.02394
التنظيم ، زيادة البيانات
- Szegedy و Christian و Vincent Vanhoucke و Sergey Ioffe و Jon Shlens و Zbigniew Wojna. "إعادة التفكير في الهندسة المعمارية لرؤية الكمبيوتر." مؤتمر IEEE حول رؤية الكمبيوتر والتعرف على الأنماط (CVPR) ، 2016. الرابط ، Arxiv: 1512.00567
- Devries و Terrance و Graham W. Taylor. "تحسين تنظيم الشبكات العصبية التلافيفية مع قطع." Arxiv preprint Arxiv: 1708.04552 (2017). Arxiv: 1708.04552 ، تطبيق Pytorch
- أبو إيل هايجا ، سامي. "تحديثات التدرج المتناسب مع النسبة المئوية." Arxiv preprint Arxiv: 1708.07227 (2017). Arxiv: 1708.07227
- تشونغ ، تشون ، ليانغ تشنغ ، غوليانغ كانغ ، شاوزي لي ، ويي يانغ. "محو البيانات العشوائية تكبير البيانات." Arxiv preprint Arxiv: 1708.04896 (2017). Arxiv: 1708.04896 ، تطبيق Pytorch
- تشانغ ، هونغي ، موستافا سيس ، يان ن. دوفين ، وديفيد لوبيز باز. "مزيج: ما وراء التقليل من المخاطر التجريبية." في المؤتمر الدولي حول تمثيلات التعلم (ICLR) ، 2017. Link ، Arxiv: 1710.09412
- Kawaguchi ، Kenji ، Yoshua Bengio ، Vikas Verma ، و Leslie Pack Kaelbling. "نحو فهم التعميم من خلال نظرية التعلم التحليلي." Arxiv preprint Arxiv: 1802.07426 (2018). Arxiv: 1802.07426 ، تطبيق Pytorch
- تاكاهاشي ، ريو ، تاكاشي ماتسوبارا ، وكونياكي أوهارا. "زيادة البيانات باستخدام زراعة الصور العشوائية والترقيع ل CNNs العميقة." وقائع المؤتمر الآسيوي العاشر حول التعلم الآلي (ACML) ، 2018. Link ، Arxiv: 1811.09030
- يون ، سانجدو ، دونجيون هان ، سيونغ جون أوه ، سانغيوك تشون ، جونسوك تشوي ، ويونغجون يو. "Cutmix: استراتيجية التنظيم لتدريب المصنفات القوية بميزات قابلة للتوضع." Arxiv preprint Arxiv: 1905.04899 (2019). Arxiv: 1905.04899
دفعة كبيرة
- Keskar ، Nitish Shirish ، Dheevatsa Mudigere ، Jorge Nocedal ، Mikhail Smelyanskiy ، و Ping Tak Peter Tang. "على التدريب على الدفعة الكبيرة للتعلم العميق: فجوة التعميم والحد الأدنى الحاد." في المؤتمر الدولي حول تمثيلات التعلم (ICLR) ، 2017. Link ، Arxiv: 1609.04836
- هوففر ، عداد ، إيتاي هوبارا ، ودانييل سودري. "تدرب لفترة أطول ، وتعميم أفضل: إغلاق فجوة التعميم في تدريب كبير على الدفعة الشبكات العصبية." في التقدم في أنظمة معالجة المعلومات العصبية (NIPS) ، 2017. Link ، Arxiv: 1705.08741 ، Pytorch.
- Goyal ، Priya ، Piotr Dollar ، Ross Girshick ، Pieter Noordhuis ، Lukasz Wesolowski ، Aapo Kyrola ، Andrew Tulloch ، Yangqing Jia ، and Kaiming He. "دقيقة ، MiniBatch SGD: تدريب ImageNet في ساعة واحدة." Arxiv preprint Arxiv: 1706.02677 (2017). Arxiv: 1706.02677
- أنت ، يانغ ، إيغور جيتمان ، وبوريس جينسبورغ. "تدريب دفعة كبيرة للشبكات التلافيفية." Arxiv preprint Arxiv: 1708.03888 (2017). Arxiv: 1708.03888
- أنت ، يانغ ، تشاو تشانغ ، تشو جوي هسيه ، جيمس ديميل ، وكورت كوتزر. "تدريب ImageNet في دقائق." Arxiv preprint Arxiv: 1709.05011 (2017). Arxiv: 1709.05011
- سميث ، صموئيل ل. "لا تتحلل معدل التعلم ، وزيادة حجم الدفعة." في المؤتمر الدولي حول تمثيلات التعلم (ICLR) ، 2018. Link ، Arxiv: 1711.00489
- جيتمان ، إيغور ، ديباك ديليبكومار ، وبن بار. "تحليل التقارب من خوارزميات النسب التدرج مع تحديثات نسبية." Arxiv preprint Arxiv: 1801.03137 (2018). Arxiv: 1801.03137 تنفيذ TensorFlow
- جيا ، شيانيان ، سونغو ستاو ، وي ، يانغزياو وانغ ، هايدونغ رونغ ، فايهو تشو ، ليكيانغ شي ، تشينيو قوه ، يوانتشو يانغ ، ليوي يو ، تايغانغ تشن ، قوانغشيو هوو ، شاوهو شيو ، xiaowen chu. "نظام التدريب على التعلم العميق القابل للتطوير مع الدقة المختلطة: تدريب ImageNet في أربع دقائق." Arxiv preprint Arxiv: 1807.11205 (2018). Arxiv: 1807.11205
- شارو ، كريستوفر ج. ، جايهون لي ، جوزيف أنتونيني ، جاسشا سول ديكشتاين ، روي فروستج ، وجورج دال. "قياس آثار التوازي البيانات على التدريب على الشبكة العصبية." Arxiv preprint Arxiv: 1811.03600 (2018). Arxiv: 1811.03600
- يينغ ، كريس ، سمير كومار ، ديهاو تشن ، تاو وانغ ، و youlong cheng. "تصنيف الصور على مقياس الحاسوب الخارق." في السلف في ورشة عمل أنظمة معالجة المعلومات العصبية (Neups) ، 2018. Link ، Arxiv: 1811.06992
آحرون
- لوششيلوف ، إيليا ، وفرانك هوتر. "SGDR: النسب المتدرج العشوائي مع إعادة تشغيل دافئة." في المؤتمر الدولي حول تمثيلات التعلم (ICLR) ، 2017. Link ، Arxiv: 1608.03983 ، تنفيذ لازانيا
- Micikevicius ، Pailius ، Sharan Narang ، Jonah Alben ، Gregory Diamos ، Erich Elsen ، David Garcia ، Boris Ginsburg ، Michael Houston ، Oleksii Kuchaiev ، Ganesh Venkatesh ، and Hao Wu. "التدريب الدقيق المختلط." في المؤتمر الدولي حول تمثيلات التعلم (ICLR) ، 2018. Link ، Arxiv: 1710.03740
- Recht ، Benjamin ، Rebecca Roelofs ، Ludwig Schmidt ، و Vaishaal Shankar. "هل يعتمد مصنفات CIFAR-10 على CIFAR-10؟" Arxiv preprint Arxiv: 1806.00451 (2018). Arxiv: 1806.00451
- هو ، تونغ ، زهي تشانغ ، هانج تشانغ ، تشونغويو تشانغ ، جونيوان شي ، ومو لي. "حقيبة الحيل لتصنيف الصور مع الشبكات العصبية التلافيفية." Arxiv preprint Arxiv: 1812.01187 (2018). Arxiv: 1812.01187


