Klasifikasi Gambar Pytorch
Makalah berikut diimplementasikan menggunakan Pytorch.
- Resnet (1512.03385)
- Resnet-Preact (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- Cutout (1708.04552)
- Penghapusan acak (1708.04896)
- Senet (1709.01507)
- Mixup (1710.09412)
- Dual-Cutout (1802.07426)
- RICAP (1811.09030)
- Cutmix (1905.04899)
Persyaratan
- Ubuntu (hanya diuji di Ubuntu, jadi mungkin tidak berfungsi pada windows.)
- Python> = 3.7
- Pytorch> = 1.4.0
- Torchvision
- NVIDIA APEX
pip install -r requirements.txt
Penggunaan
python train.py --config configs/cifar/resnet_preact.yaml
Hasil pada CIFAR-10
Hasil menggunakan pengaturan yang hampir sama dengan makalah
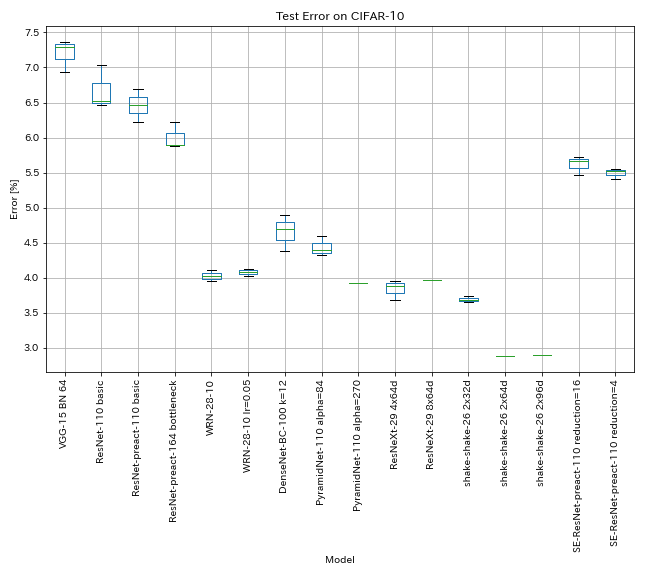
| Model | Kesalahan uji (median 3 run) | Kesalahan uji (di dalam kertas) | Waktu pelatihan |
|---|
| VGG-Like (kedalaman 15, w/ bn, saluran 64) | 7.29 | N/a | 1h20m |
| ResNet-110 | 6.52 | 6.43 (terbaik), 6.61 +/- 0.16 | 3H06M |
| Resnet-Preact-110 | 6.47 | 6.37 (median 5 run) | 3H05m |
| Resnet-Preact-164 Bottleneck | 5.90 | 5.46 (median 5 run) | 4H01M |
| Resnet-Preact-1001 Bottleneck | | 4.62 (median 5 run), 4.69 +/- 0.20 | |
| WRN-28-10 | 4.03 | 4,00 (median 5 run) | 16h10m |
| WRN-28-10 w/ dropout | | 3.89 (median 5 run) | |
| Densenet-100 (k = 12) | 3.87 (1 lari) | 4.10 (1 lari) | 24h28m* |
| Densenet-100 (k = 24) | | 3.74 (1 lari) | |
| Densenet-BC-100 (k = 12) | 4.69 | 4.51 (1 lari) | 15h20m |
| Densenet-BC-250 (k = 24) | | 3.62 (1 lari) | |
| Densenet-BC-190 (k = 40) | | 3.46 (1 lari) | |
| Pyramidnet-110 (alpha = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| Pyramidnet-110 (alpha = 270) | 3.92 (1 lari) | 3.73 +/- 0,04 | 24h12m* |
| PyramidNet-164 Bottleneck (Alpha = 270) | 3.44 (1 lari) | 3.48 +/- 0.20 | 32H37M* |
| PyramidNet-272 Bottleneck (Alpha = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (dari Gambar 7) | 31h17m |
| Resnext-29 8x64d | 3.97 (1 lari) | 3,65 (rata -rata 10 run) | 42h50m* |
| Resnext-29 16x64d | | 3.58 (rata -rata 10 run) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3.55 (rata -rata 3 run) | 33H49M |
| Shake-Shake-26 2x64d (SSI) | 2.88 (1 lari) | 2.98 (rata -rata 3 run) | 78h48m |
| Shake-Shake-26 2x96d (SSI) | 2.90 (1 lari) | 2.86 (rata -rata 5 run) | 101h32m* |
Catatan
- Perbedaan dengan makalah dalam pengaturan pelatihan:
- Latih WRN-28-10 dengan ukuran batch 64 (128 di kertas).
- Densenet-BC-100 terlatih (k = 12) dengan ukuran batch 32 dan tingkat pembelajaran awal 0,05 (ukuran batch 64 dan tingkat pembelajaran awal 0,1 dalam kertas).
- RESNEXT-29 Latih 4x64D dengan GPU tunggal, ukuran batch 32 dan tingkat pembelajaran awal 0,025 (8 GPU, ukuran batch 128 dan tingkat pembelajaran awal 0,1 dalam kertas).
- Model shake-shake terlatih dengan satu GPU (2 GPU di dalam kertas).
- Shake-shake terlatih 26 2x64d (SSI) dengan ukuran batch 64, dan tingkat pembelajaran awal 0,1.
- Kesalahan uji yang dilaporkan di atas adalah yang pada zaman terakhir.
- Eksperimen dengan hanya 1 run dilakukan pada komputer yang berbeda dari yang digunakan untuk percobaan dengan 3 run.
- GeForce GTX 980 digunakan dalam percobaan ini.
Seperti VGG
python train.py --config configs/cifar/vgg.yaml
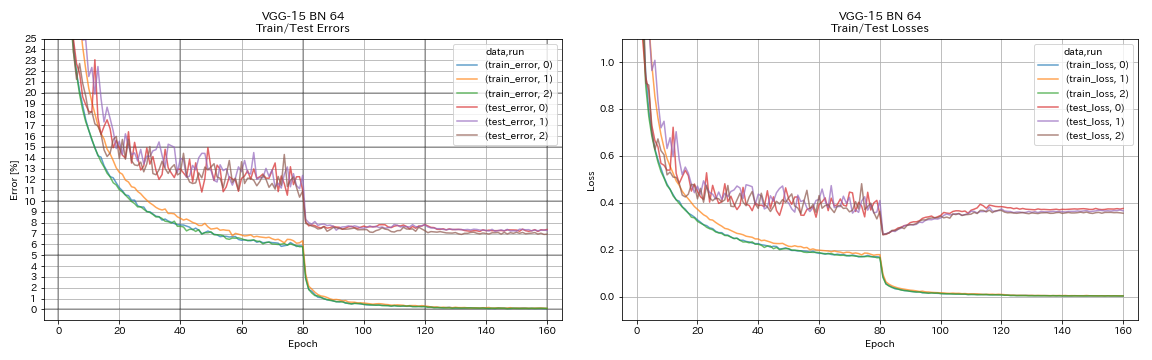
Resnet
python train.py --config configs/cifar/resnet.yaml
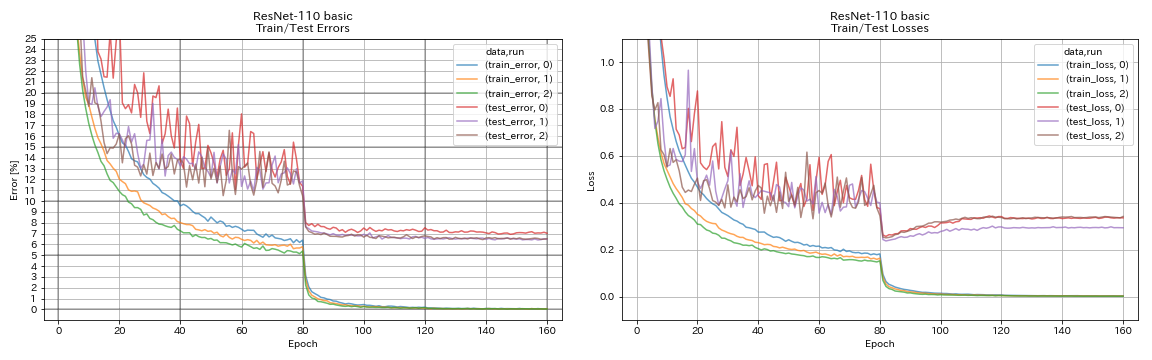
Resnet-Preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00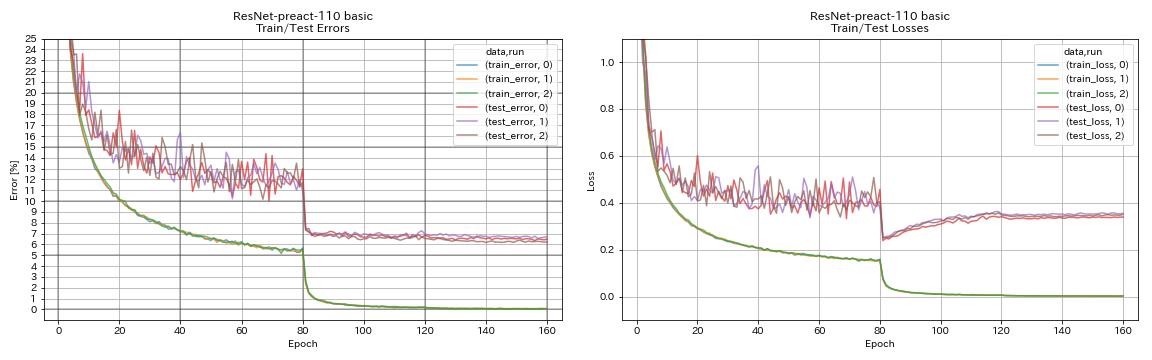
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00
Wrn
python train.py --config configs/cifar/wrn.yaml
Densenet
python train.py --config configs/cifar/densenet.yaml
Piramidnet
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00
Shake-shake
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00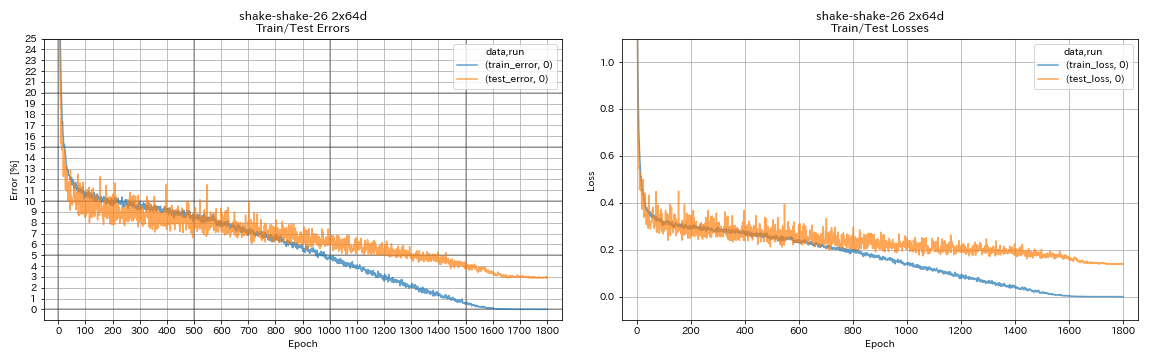
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00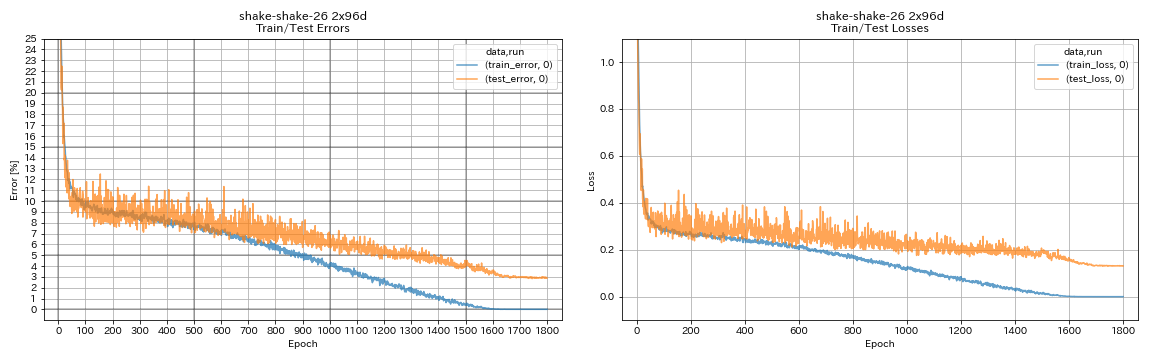
Hasil
| Model | Kesalahan tes (1 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-preact-20, faktor pelebaran 4 | 4.91 | 200 | 1H26M |
| Resnet-preact-20, faktor pelebaran 4 | 4.01 | 400 | 2h53m |
| Resnet-preact-20, faktor pelebaran 4 | 3.99 | 1800 | 12h53m |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 16 | 3.71 | 200 | 1H26M |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 16 | 3.46 | 400 | 2h53m |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 16 | 3.76 | 1800 | 12h53m |
| Resnet-Preact-20, Faktor Pelebaran 4, RICAP (beta = 0,3) | 3.45 | 200 | 1H26M |
| Resnet-Preact-20, Faktor Pelebaran 4, RICAP (beta = 0,3) | 3.11 | 400 | 2h53m |
| Resnet-Preact-20, Faktor Pelebaran 4, RICAP (beta = 0,3) | 3.15 | 1800 | 12h53m |
| Model | Kesalahan tes (1 run) | # zaman | Waktu pelatihan |
|---|
| WRN-28-10, Cutout 16 | 3.19 | 200 | 6h35m |
| WRN-28-10, mixup (alpha = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10, RICAP (beta = 0,3) | 2.83 | 200 | 6h35m |
| WRN-28-10, dual-cutout (alpha = 0,1) | 2.87 | 200 | 12h42m |
| WRN-28-10, Cutout 16 | 3.07 | 400 | 13H10M |
| WRN-28-10, mixup (alpha = 1) | 3.04 | 400 | 13H08M |
| WRN-28-10, RICAP (beta = 0,3) | 2.71 | 400 | 13H08M |
| WRN-28-10, dual-cutout (alpha = 0,1) | 2.76 | 400 | 25h20m |
| Shake-Shake-26 2x64d, Cutout 16 | 2.64 | 1800 | 78h55m* |
| Shake-Shake-26 2x64d, mixup (alpha = 1) | 2.63 | 1800 | 35H56M |
| Shake-Shake-26 2x64d, RICAP (beta = 0,3) | 2.29 | 1800 | 35h10m |
| Shake-Shake-26 2x64d, Dual-Cutout (Alpha = 0,1) | 2.64 | 1800 | 68H34M |
| Shake-Shake-26 2x96d, Cutout 16 | 2.50 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, MixUp (Alpha = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, RICAP (beta = 0,3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96D, Dual-Cutout (Alpha = 0,1) | 2.41 | 1800 | 113H09M |
| Shake-Shake-26 2x128d, Cutout 16 | 2.58 | 1800 | 85H04M |
| Shake-Shake-26 2x128d, RICAP (beta = 0,3) | 1.97 | 1800 | 85H06M |
Catatan
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
- Semua model dilatih menggunakan anil cosinus dengan tingkat pembelajaran awal 0,2.
- GeForce GTX 1080 Ti digunakan dalam percobaan ini, kecuali yang dengan *, yang dilakukan dengan menggunakan GeForce GTX 980.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True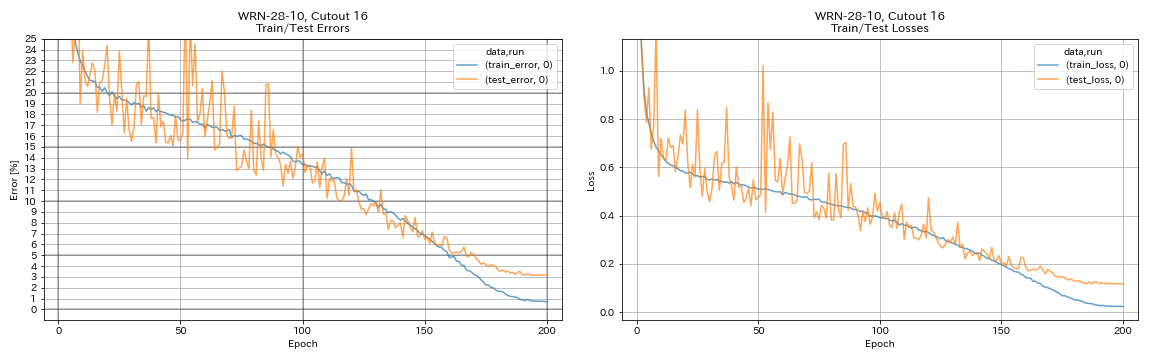
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True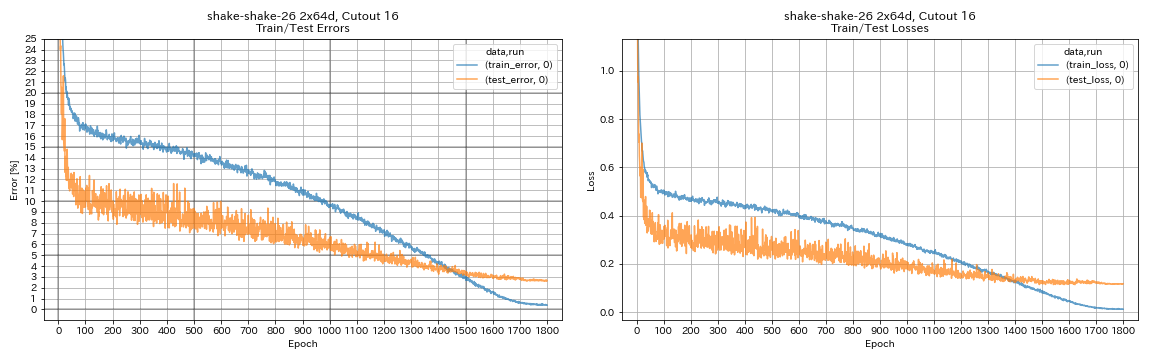
Hasil Menggunakan Multi-GPU
| Model | Ukuran batch | #Gpus | Kesalahan tes (1 run) | # zaman | Waktu Pelatihan* |
|---|
| WRN-28-10, RICAP (beta = 0,3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10, RICAP (beta = 0,3) | 256 | 2 | 2.71 | 200 | 2h14m |
| WRN-28-10, RICAP (beta = 0,3) | 128 | 4 | 2.89 | 200 | 1H01M |
| WRN-28-10, RICAP (beta = 0,3) | 64 | 8 | 2.75 | 200 | 34m |
Catatan
- Tesla V100 digunakan dalam percobaan ini.
Menggunakan 1 GPU
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMenggunakan 2 GPU
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMenggunakan 4 GPU
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseMenggunakan 8 GPU
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseHasil di FashionMnist
| Model | Kesalahan tes (1 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-preact-20, faktor pelebaran 4, cutout 12 | 4.17 | 200 | 1H32M |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 14 | 4.11 | 200 | 1H32M |
| Resnet-Preact-50, Cutout 12 | 4.45 | 200 | 57m |
| Resnet-Preact-50, Cutout 14 | 4.38 | 200 | 57m |
| Resnet-Preact-50, Faktor Pelebaran 4, Cutout 12 | 4.07 | 200 | 3H37M |
| Resnet-Preact-50, Faktor Pelebaran 4, Cutout 14 | 4.13 | 200 | 3H39M |
| Shake-Shake-26 2x32d (SSI), Cutout 12 | 4.08 | 400 | 3H41M |
| Shake-Shake-26 2x32d (SSI), Cutout 14 | 4.05 | 400 | 3H39M |
| Shake-Shake-26 2x96d (SSI), Cutout 12 | 3.72 | 400 | 13H46M |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 3.85 | 400 | 13h39m |
| Shake-Shake-26 2x96d (SSI), Cutout 12 | 3.65 | 800 | 26h42m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 3.60 | 800 | 26h42m |
| Model | Kesalahan uji (median 3 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 5.04 | 200 | 26m |
| Resnet-Preact-20, Cutout 6 | 4.84 | 200 | 26m |
| Resnet-Preact-20, Cutout 8 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Cutout 10 | 4.74 | 200 | 26m |
| Resnet-Preact-20, Cutout 12 | 4.68 | 200 | 26m |
| Resnet-Preact-20, Cutout 14 | 4.64 | 200 | 26m |
| Resnet-Preact-20, Cutout 16 | 4.49 | 200 | 26m |
| Resnet-Preact-20, Acomererasing | 4.61 | 200 | 26m |
| Resnet-Preact-20, mixup | 4.92 | 200 | 26m |
| Resnet-Preact-20, mixup | 4.64 | 400 | 52m |
Catatan
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
- Semua model dilatih menggunakan anil cosinus dengan tingkat pembelajaran awal 0,2.
- Augmentasi data berikut diterapkan pada data pelatihan:
- Gambar empuk dengan 4 piksel di setiap sisi, dan tambalan 28x28 dipotong secara acak dari gambar empuk.
- Gambar dibalik secara horizontal secara acak.
- GeForce GTX 1080 Ti digunakan dalam percobaan ini.
Hasil pada MNIST
| Model | Kesalahan uji (median 3 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 0.40 | 100 | 12m |
| Resnet-Preact-20, Cutout 6 | 0.32 | 100 | 12m |
| Resnet-Preact-20, Cutout 8 | 0.25 | 100 | 12m |
| Resnet-Preact-20, Cutout 10 | 0.27 | 100 | 12m |
| Resnet-Preact-20, Cutout 12 | 0.26 | 100 | 12m |
| Resnet-Preact-20, Cutout 14 | 0.26 | 100 | 12m |
| Resnet-Preact-20, Cutout 16 | 0.25 | 100 | 12m |
| Resnet-preact-20, mixup (alpha = 1) | 0.40 | 100 | 12m |
| Resnet-preact-20, mixup (alpha = 0,5) | 0.38 | 100 | 12m |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 14 | 0.26 | 100 | 45m |
| Resnet-Preact-50, Cutout 14 | 0.29 | 100 | 28m |
| Resnet-Preact-50, Faktor Pelebaran 4, Cutout 14 | 0.25 | 100 | 1H50m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 0.24 | 100 | 3H22M |
Catatan
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
- Semua model dilatih menggunakan anil cosinus dengan tingkat pembelajaran awal 0,2.
- GeForce GTX 1080 Ti digunakan dalam percobaan ini.
Hasil pada Kuzushiji-Mnist
| Model | Kesalahan uji (median 3 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-Preact-20, Cutout 14 | 0,82 (terbaik 0,67) | 200 | 24m |
| Resnet-Preact-20, Faktor Pelebaran 4, Cutout 14 | 0,72 (terbaik 0,67) | 200 | 1h30m |
| PyramidNet-110-270, Cutout 14 | 0,72 (terbaik 0,70) | 200 | 10h05m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 0,66 (terbaik 0,63) | 200 | 6h46m |
Catatan
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
- Semua model dilatih menggunakan anil cosinus dengan tingkat pembelajaran awal 0,2.
- GeForce GTX 1080 Ti digunakan dalam percobaan ini.
Eksperimen
Eksperimen pada unit residual, penjadwalan tingkat pembelajaran, dan augmentasi data
Dalam percobaan ini, efek dari yang berikut ini pada akurasi klasifikasi diselidiki:
- Unit residu seperti piramidnet
- Cosine Annealing of Learning Rate
- Cutout
- Penghapusan acak
- Mixup
- Preactivation shortcuts setelah downsampling
ResNet-Preact-56 dilatih pada CIFAR-10 dengan tingkat pembelajaran awal 0,2 dalam percobaan ini.
Catatan
- Kertas Pyramidnet (1610.02915) menunjukkan bahwa menghilangkan relu pertama dalam unit residu dan menambahkan BN setelah konvolusi terakhir dalam unit residual keduanya meningkatkan akurasi klasifikasi.
- SGDR Paper (1608.03983) menunjukkan anil kosinus meningkatkan akurasi klasifikasi bahkan tanpa restart.
Hasil
- Unit seperti piramidnet berfungsi.
- Mungkin lebih baik untuk tidak melakukan pra-preactivate shortcuts setelah downsampling saat menggunakan unit seperti piramidnet.
- Cosinine Annealing sedikit meningkatkan akurasi.
- Cutout, Randomerasing, dan Mixup semuanya bekerja dengan baik.
- Mixup membutuhkan pelatihan yang lebih lama.
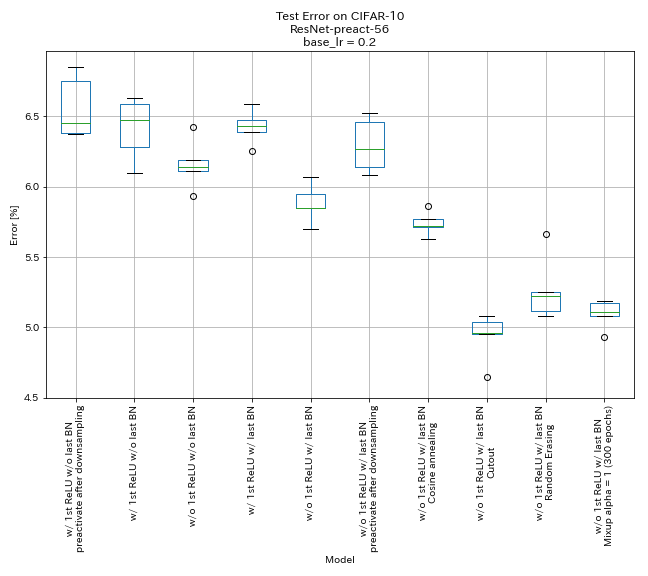
| Model | Kesalahan uji (median 5 run) | Waktu pelatihan |
|---|
| W/ 1st relu, tanpa bn terakhir, pra -reactivate shortcut setelah downsampling | 6.45 | 95 menit |
| W/ 1st relu, tanpa bn terakhir | 6.47 | 95 menit |
| w/o 1st relu, tanpa bn terakhir | 6.14 | 89 menit |
| w/ 1st relu, w/ bn terakhir | 6.43 | 104 mnt |
| w/ o 1st relu, w/ terakhir bn | 5.85 | 98 menit |
| w/ o 1st relu, w/ bn terakhir, practivate shortcut setelah downsampling | 6.27 | 98 menit |
| w/ o 1st relu, w/ bn terakhir, anil cosinus | 5.72 | 98 menit |
| w/ o 1st relu, w/ terakhir bn, cutout | 4.96 | 98 menit |
| W/ O 1st Relu, W/ Last Bn, Randomerasing | 5.22 | 98 menit |
| W/ O 1st Relu, W/ Last Bn, MixUp (300 Epochs) | 5.11 | 191 mnt |
Preactivate shortcut setelah downsampling
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
W/ 1st relu, tanpa bn terakhir
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o 1st relu, tanpa bn terakhir
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ 1st relu, w/ bn terakhir
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00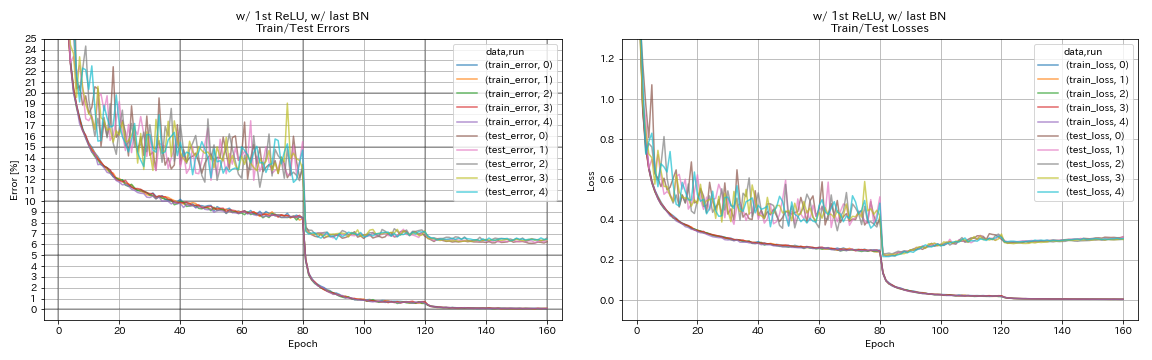
w/ o 1st relu, w/ terakhir bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00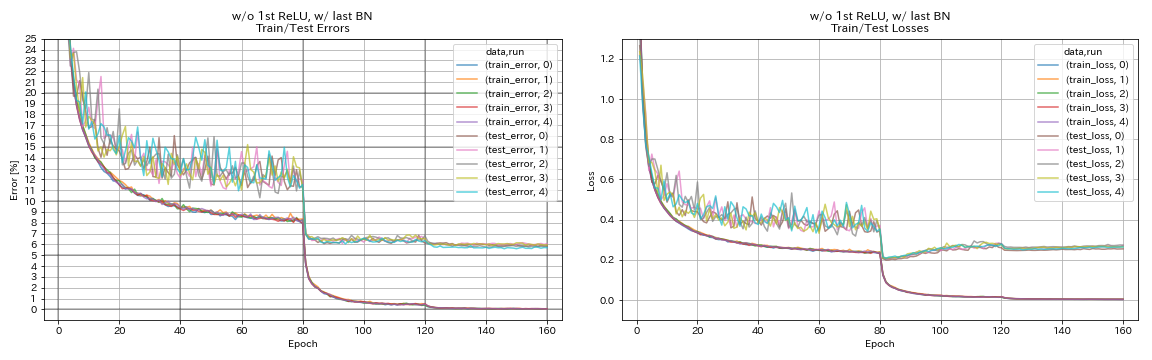
w/ o 1st relu, w/ bn terakhir, practivate shortcut setelah downsampling
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00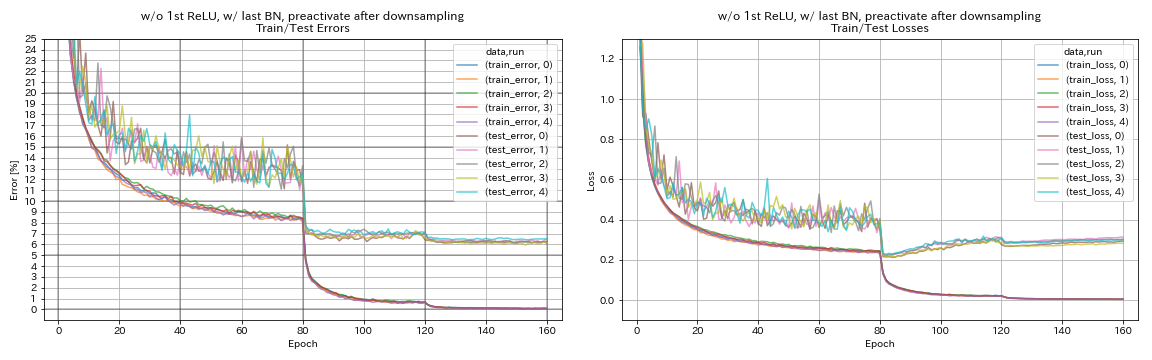
w/ o 1st relu, w/ bn terakhir, anil cosinus
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00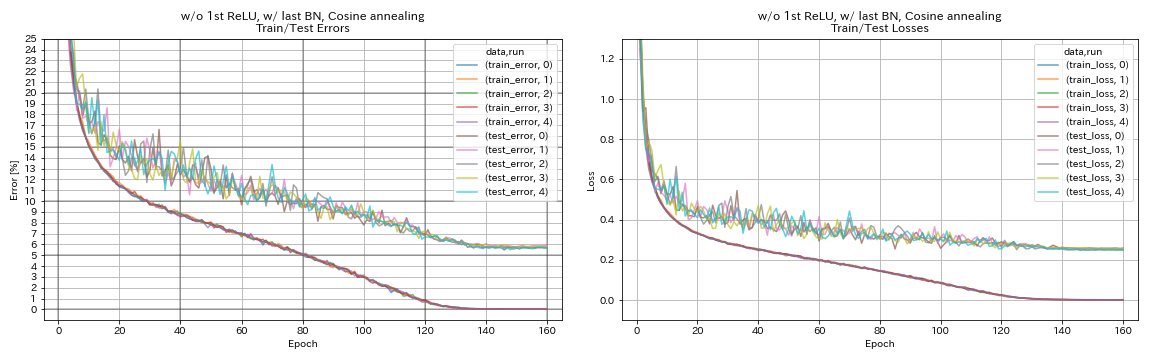
w/ o 1st relu, w/ terakhir bn, cutout
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00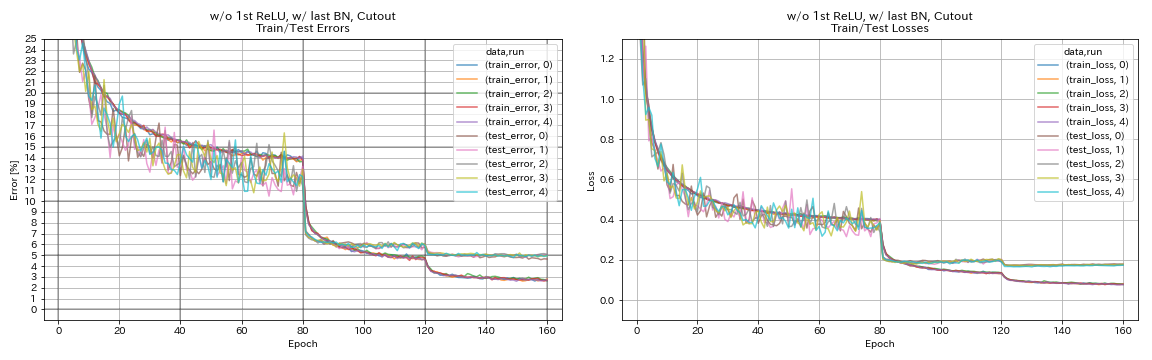
W/ O 1st Relu, W/ Last Bn, Randomerasing
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00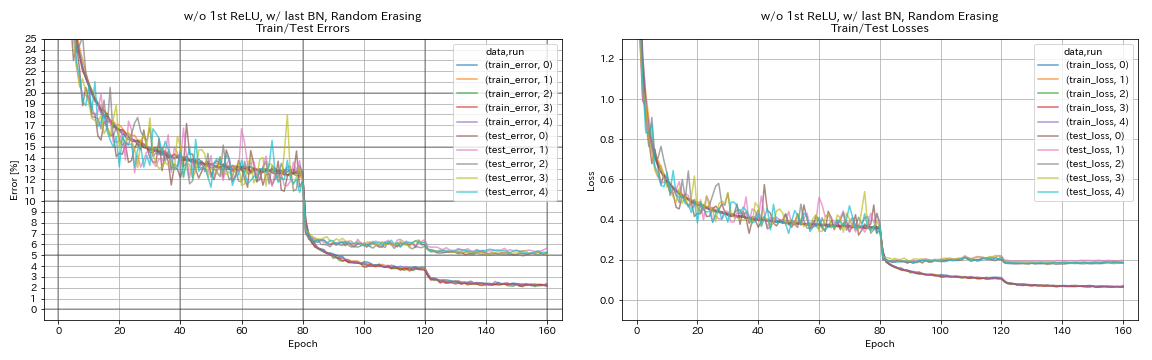
w/ o 1st relu, w/ bn terakhir, mixup
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00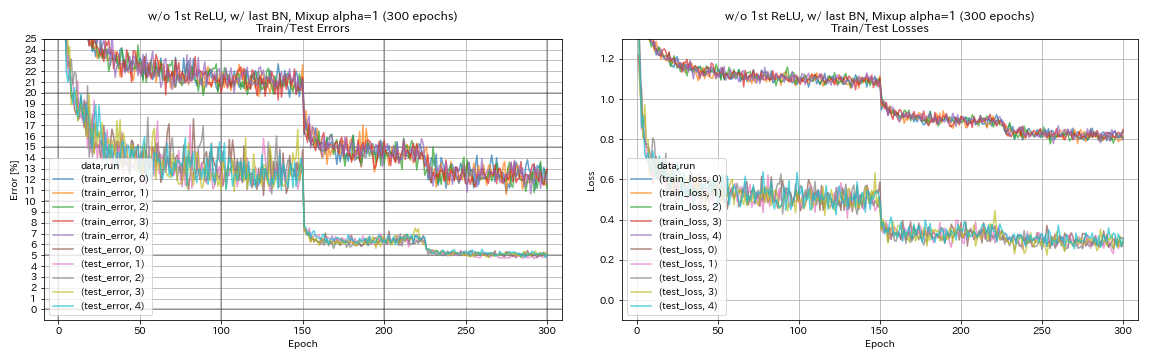
Eksperimen pada label smoothing, mixup, ricap, dan dual-cutout
Hasil pada CIFAR-10
| Model | Kesalahan uji (median 3 run) | # zaman | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 7.60 | 200 | 24m |
| Resnet-Preact-20, label smoothing (epsilon = 0,001) | 7.51 | 200 | 25m |
| Resnet-Preact-20, label smoothing (epsilon = 0,01) | 7.21 | 200 | 25m |
| Resnet-Preact-20, label smoothing (epsilon = 0,1) | 7.57 | 200 | 25m |
| Resnet-preact-20, mixup (alpha = 1) | 7.24 | 200 | 26m |
| Resnet-preact-20, ricap (beta = 0,3), w/ tanaman acak | 6.88 | 200 | 28m |
| ResNet-Preact-20, RICAP (beta = 0,3) | 6.77 | 200 | 28m |
| ResNet-Preact-20, ganda-potong 16 (alpha = 0,1) | 6.24 | 200 | 45m |
| Resnet-Preact-20 | 7.05 | 400 | 49m |
| Resnet-Preact-20, label smoothing (epsilon = 0,001) | 7.20 | 400 | 49m |
| Resnet-Preact-20, label smoothing (epsilon = 0,01) | 6.97 | 400 | 49m |
| Resnet-Preact-20, label smoothing (epsilon = 0,1) | 7.16 | 400 | 49m |
| Resnet-preact-20, mixup (alpha = 1) | 6.66 | 400 | 51m |
| Resnet-preact-20, ricap (beta = 0,3), w/ tanaman acak | 6.30 | 400 | 56m |
| ResNet-Preact-20, RICAP (beta = 0,3) | 6.19 | 400 | 56m |
| ResNet-Preact-20, ganda-potong 16 (alpha = 0,1) | 5.55 | 400 | 1H36M |
Catatan
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
- Semua model dilatih menggunakan anil cosinus dengan tingkat pembelajaran awal 0,2.
- GeForce GTX 1080 Ti digunakan dalam percobaan ini.
Eksperimen pada ukuran batch dan tingkat pembelajaran
- Eksperimen berikut dilakukan pada dataset CIFAR-10 menggunakan GeForce 1080 Ti.
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
Aturan penskalaan linier untuk tingkat pembelajaran
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | kosinus | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 200 | 8.87 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | kosinus | 200 | 8.22 | 20m |
| Resnet-Preact-20 | 256 | 0.2 | kosinus | 200 | 8.61 | 22m |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 200 | 8.09 | 24m |
| Resnet-Preact-20 | 64 | 0,05 | kosinus | 200 | 8.22 | 28m |
| Resnet-Preact-20 | 32 | 0,025 | kosinus | 200 | 8.00 | 43m |
| Resnet-Preact-20 | 16 | 0,0125 | kosinus | 200 | 7.75 | 1H17M |
| Resnet-Preact-20 | 8 | 0.006125 | kosinus | 200 | 7.70 | 2h32m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | multistep | 200 | 28.97 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | multistep | 200 | 9.07 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | multistep | 200 | 8.62 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | multistep | 200 | 8.23 | 20m |
| Resnet-Preact-20 | 256 | 0.2 | multistep | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 128 | 0.1 | multistep | 200 | 8.28 | 24m |
| Resnet-Preact-20 | 64 | 0,05 | multistep | 200 | 8.13 | 28m |
| Resnet-Preact-20 | 32 | 0,025 | multistep | 200 | 7.58 | 43m |
| Resnet-Preact-20 | 16 | 0,0125 | multistep | 200 | 7.93 | 1H18M |
| Resnet-Preact-20 | 8 | 0.006125 | multistep | 200 | 8.31 | 2h34m |
Penskalaan linier + pelatihan yang lebih lama
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | kosinus | 400 | 8.97 | 44m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 400 | 7.85 | 43m |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 400 | 7.20 | 42m |
| Resnet-Preact-20 | 512 | 0.4 | kosinus | 400 | 7.83 | 40m |
| Resnet-Preact-20 | 256 | 0.2 | kosinus | 400 | 7.65 | 42m |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 400 | 7.09 | 47m |
| Resnet-Preact-20 | 64 | 0,05 | kosinus | 400 | 7.17 | 44m |
| Resnet-Preact-20 | 32 | 0,025 | kosinus | 400 | 7.24 | 2h11m |
| Resnet-Preact-20 | 16 | 0,0125 | kosinus | 400 | 7.26 | 4h10m |
| Resnet-Preact-20 | 8 | 0.006125 | kosinus | 400 | 7.02 | 7h53m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | kosinus | 800 | 8.14 | 1H29m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 800 | 7.74 | 1H23M |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 800 | 7.15 | 1H31m |
| Resnet-Preact-20 | 512 | 0.4 | kosinus | 800 | 7.27 | 1H25m |
| Resnet-Preact-20 | 256 | 0.2 | kosinus | 800 | 7.22 | 1H26M |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 800 | 6.68 | 1H35m |
| Resnet-Preact-20 | 64 | 0,05 | kosinus | 800 | 7.18 | 2h20m |
| Resnet-Preact-20 | 32 | 0,025 | kosinus | 800 | 7.03 | 4h16m |
| Resnet-Preact-20 | 16 | 0,0125 | kosinus | 800 | 6.78 | 8h37m |
| Resnet-Preact-20 | 8 | 0.006125 | kosinus | 800 | 6.89 | 16h47m |
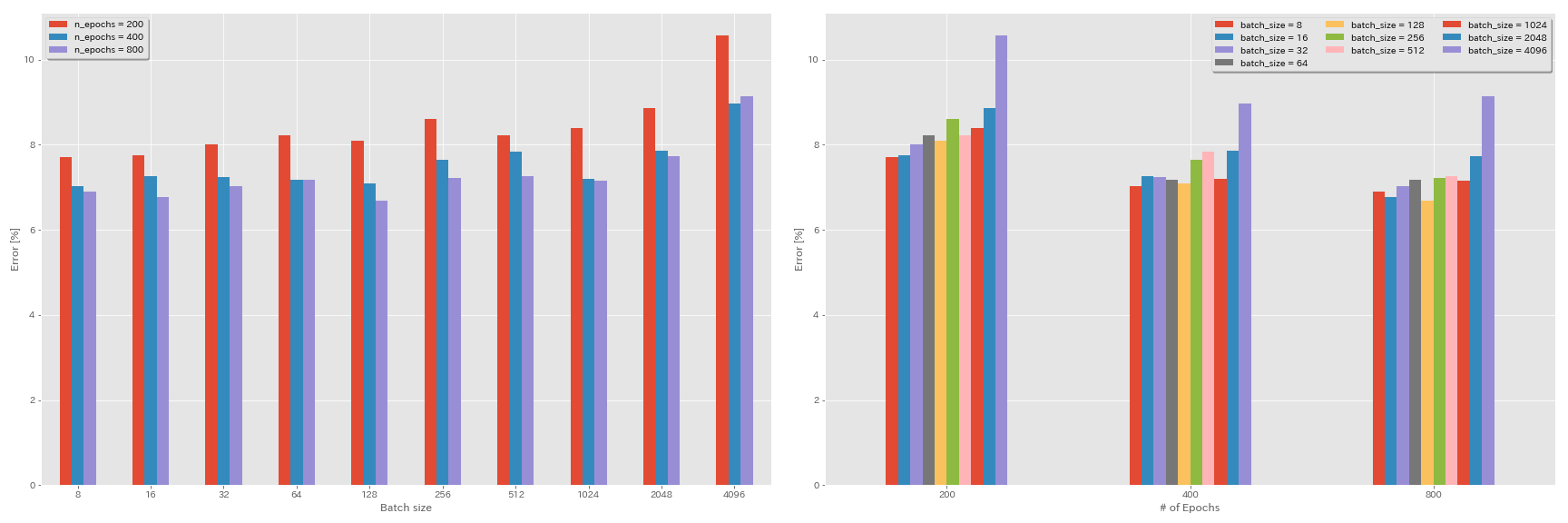
Pengaruh Tingkat Pembelajaran Awal
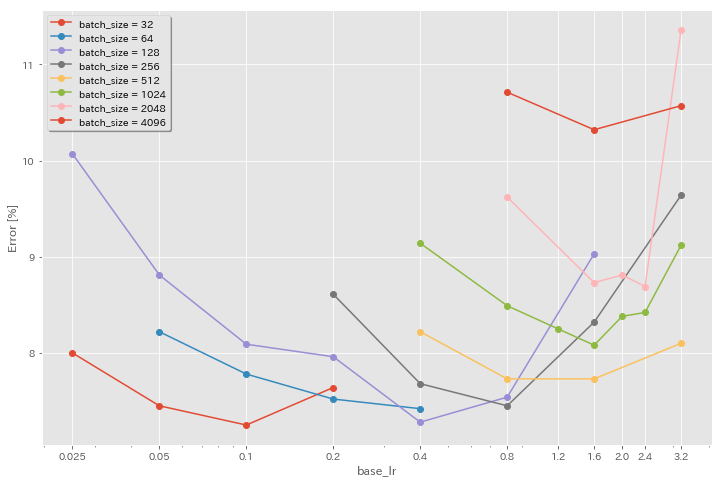
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | kosinus | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 4096 | 1.6 | kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 4096 | 0.8 | kosinus | 200 | 10.71 | 22m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 2048 | 3.2 | kosinus | 200 | 11.34 | 21m |
| Resnet-Preact-20 | 2048 | 2.4 | kosinus | 200 | 8.69 | 21m |
| Resnet-Preact-20 | 2048 | 2.0 | kosinus | 200 | 8.81 | 21m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 2048 | 0.8 | kosinus | 200 | 9.62 | 21m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 1024 | 3.2 | kosinus | 200 | 9.12 | 21m |
| Resnet-Preact-20 | 1024 | 2.4 | kosinus | 200 | 8.42 | 22m |
| Resnet-Preact-20 | 1024 | 2.0 | kosinus | 200 | 8.38 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 1.2 | kosinus | 200 | 8.25 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 1024 | 0.4 | kosinus | 200 | 8.49 | 22m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 512 | 3.2 | kosinus | 200 | 8.51 | 21m |
| Resnet-Preact-20 | 512 | 1.6 | kosinus | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0.8 | kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | kosinus | 200 | 8.22 | 20m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 256 | 3.2 | kosinus | 200 | 9.64 | 22m |
| Resnet-Preact-20 | 256 | 1.6 | kosinus | 200 | 8.32 | 22m |
| Resnet-Preact-20 | 256 | 0.8 | kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 256 | 0.4 | kosinus | 200 | 7.68 | 22m |
| Resnet-Preact-20 | 256 | 0.2 | kosinus | 200 | 8.61 | 22m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 128 | 1.6 | kosinus | 200 | 9.03 | 24m |
| Resnet-Preact-20 | 128 | 0.8 | kosinus | 200 | 7.54 | 24m |
| Resnet-Preact-20 | 128 | 0.4 | kosinus | 200 | 7.28 | 24m |
| Resnet-Preact-20 | 128 | 0.2 | kosinus | 200 | 7.96 | 24m |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 200 | 8.09 | 24m |
| Resnet-Preact-20 | 128 | 0,05 | kosinus | 200 | 8.81 | 24m |
| Resnet-Preact-20 | 128 | 0,025 | kosinus | 200 | 10.07 | 24m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 64 | 0.4 | kosinus | 200 | 7.42 | 35m |
| Resnet-Preact-20 | 64 | 0.2 | kosinus | 200 | 7.52 | 36m |
| Resnet-Preact-20 | 64 | 0.1 | kosinus | 200 | 7.78 | 37m |
| Resnet-Preact-20 | 64 | 0,05 | kosinus | 200 | 8.22 | 28m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 32 | 0.2 | kosinus | 200 | 7.64 | 1H05m |
| Resnet-Preact-20 | 32 | 0.1 | kosinus | 200 | 7.25 | 1H08M |
| Resnet-Preact-20 | 32 | 0,05 | kosinus | 200 | 7.45 | 1H07M |
| Resnet-Preact-20 | 32 | 0,025 | kosinus | 200 | 8.00 | 43m |
Tingkat belajar yang baik + pelatihan yang lebih lama
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 512 | 1.6 | kosinus | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0.8 | kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 256 | 0.8 | kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 128 | 0.4 | kosinus | 200 | 7.28 | 24m |
| Resnet-Preact-20 | 128 | 0.2 | kosinus | 200 | 7.96 | 24m |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 200 | 8.09 | 24m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | kosinus | 800 | 8.36 | 1H33M |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 800 | 7.53 | 1H27M |
| Resnet-Preact-20 | 1024 | 1.6 | kosinus | 800 | 7.30 | 1h30m |
| Resnet-Preact-20 | 1024 | 0.8 | kosinus | 800 | 7.42 | 1h30m |
| Resnet-Preact-20 | 512 | 1.6 | kosinus | 800 | 6.69 | 1H26M |
| Resnet-Preact-20 | 512 | 0.8 | kosinus | 800 | 6.77 | 1H26M |
| Resnet-Preact-20 | 256 | 0.8 | kosinus | 800 | 6.84 | 1H28M |
| Resnet-Preact-20 | 128 | 0.4 | kosinus | 800 | 6.86 | 1H35m |
| Resnet-Preact-20 | 128 | 0.2 | kosinus | 800 | 7.05 | 1H38M |
| Resnet-Preact-20 | 128 | 0.1 | kosinus | 800 | 6.68 | 1H35m |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | kosinus | 1600 | 8.25 | 3h10m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 1600 | 7.34 | 2h50m |
| Resnet-Preact-20 | 1024 | 1.6 | kosinus | 1600 | 6.94 | 2h52m |
| Resnet-Preact-20 | 512 | 1.6 | kosinus | 1600 | 6.99 | 2h44m |
| Resnet-Preact-20 | 256 | 0.8 | kosinus | 1600 | 6.95 | 2h50m |
| Resnet-Preact-20 | 128 | 0.4 | kosinus | 1600 | 6.64 | 3H09M |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | kosinus | 3200 | 9.52 | 6h15m |
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 3200 | 6.92 | 5h42m |
| Resnet-Preact-20 | 1024 | 1.6 | kosinus | 3200 | 6.96 | 5H43M |
| Model | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 2048 | 1.6 | kosinus | 6400 | 7.45 | 11h44m |
Lars
- Dalam makalah asli (1708.03888, 1801.03137), mereka menggunakan penjadwalan tingkat pembelajaran peluruhan polinomial, tetapi anil cosinus digunakan dalam percobaan ini.
- Dalam implementasi ini, koefisien LARS tidak digunakan, sehingga tingkat pembelajaran harus disesuaikan sesuai.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00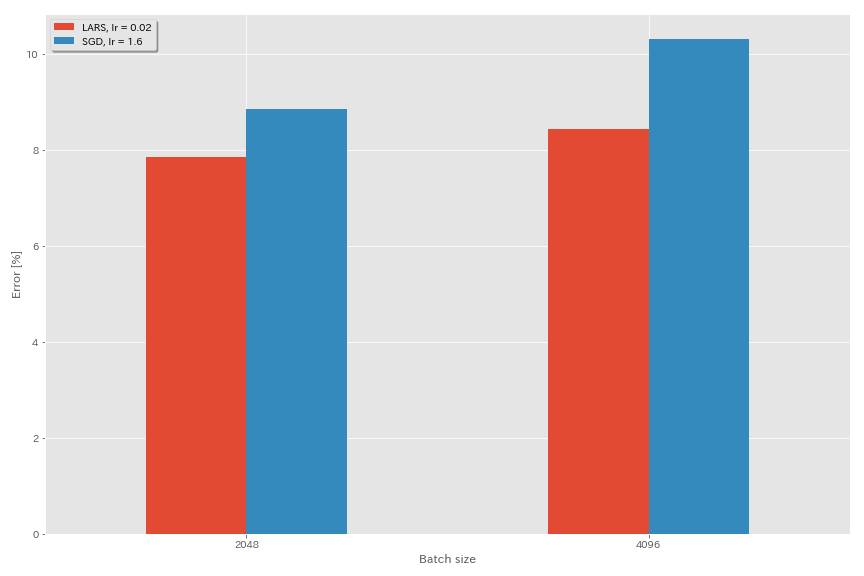
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 4096 | 3.2 | kosinus | 200 | 10.57 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 0.8 | kosinus | 200 | 10.71 (1 lari) | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,04 | kosinus | 200 | 9.58 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,03 | kosinus | 200 | 8.46 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | kosinus | 200 | 8.21 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,015 | kosinus | 200 | 8.47 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,01 | kosinus | 200 | 9.33 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,005 | kosinus | 200 | 14.31 | 22m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 2048 | 3.2 | kosinus | 200 | 11.34 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.4 | kosinus | 200 | 8.69 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.0 | kosinus | 200 | 8.81 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 1.6 | kosinus | 200 | 8.73 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 2048 | 0.8 | kosinus | 200 | 9.62 (1 lari) | 21m |
| Resnet-Preact-20 | Lars | 2048 | 0,04 | kosinus | 200 | 11.58 | 21m |
| Resnet-Preact-20 | Lars | 2048 | 0,02 | kosinus | 200 | 8.05 | 22m |
| Resnet-Preact-20 | Lars | 2048 | 0,01 | kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | Lars | 2048 | 0,005 | kosinus | 200 | 9.65 | 22m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 1024 | 3.2 | kosinus | 200 | 9.12 (1 run) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 2.4 | kosinus | 200 | 8.42 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 2.0 | kosinus | 200 | 8.38 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.6 | kosinus | 200 | 8.07 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.2 | kosinus | 200 | 8.25 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 0.8 | kosinus | 200 | 8.08 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 0.4 | kosinus | 200 | 8.49 (1 lari) | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,02 | kosinus | 200 | 9.30 | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,01 | kosinus | 200 | 7.68 | 22m |
| Resnet-Preact-20 | Lars | 1024 | 0,005 | kosinus | 200 | 8.88 | 23m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 512 | 3.2 | kosinus | 200 | 8.51 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 512 | 1.6 | kosinus | 200 | 7.73 (1 lari) | 20m |
| Resnet-Preact-20 | SGD | 512 | 0.8 | kosinus | 200 | 7.73 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 512 | 0.4 | kosinus | 200 | 8.22 (1 lari) | 20m |
| Resnet-Preact-20 | Lars | 512 | 0,015 | kosinus | 200 | 9.84 | 23m |
| Resnet-Preact-20 | Lars | 512 | 0,01 | kosinus | 200 | 8.05 | 23m |
| Resnet-Preact-20 | Lars | 512 | 0,0075 | kosinus | 200 | 7.58 | 23m |
| Resnet-Preact-20 | Lars | 512 | 0,005 | kosinus | 200 | 7.96 | 23m |
| Resnet-Preact-20 | Lars | 512 | 0,0025 | kosinus | 200 | 8.83 | 23m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 256 | 3.2 | kosinus | 200 | 9.64 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 256 | 1.6 | kosinus | 200 | 8.32 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0.8 | kosinus | 200 | 7.45 (1 lari) | 21m |
| Resnet-Preact-20 | SGD | 256 | 0.4 | kosinus | 200 | 7.68 (1 lari) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0.2 | kosinus | 200 | 8.61 (1 lari) | 22m |
| Resnet-Preact-20 | Lars | 256 | 0,01 | kosinus | 200 | 8.95 | 27m |
| Resnet-Preact-20 | Lars | 256 | 0,005 | kosinus | 200 | 7.75 | 28m |
| Resnet-Preact-20 | Lars | 256 | 0,0025 | kosinus | 200 | 8.21 | 28m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 128 | 1.6 | kosinus | 200 | 9.03 (1 lari) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0.8 | kosinus | 200 | 7.54 (1 lari) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0.4 | kosinus | 200 | 7.28 (1 lari) | 24m |
| Resnet-Preact-20 | SGD | 128 | 0.2 | kosinus | 200 | 7.96 (1 lari) | 24m |
| Resnet-Preact-20 | Lars | 128 | 0,005 | kosinus | 200 | 7.96 | 37m |
| Resnet-Preact-20 | Lars | 128 | 0,0025 | kosinus | 200 | 7.98 | 37m |
| Resnet-Preact-20 | Lars | 128 | 0.00125 | kosinus | 200 | 9.21 | 37m |
| Model | pengoptimal | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | SGD | 4096 | 1.6 | kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | kosinus | 800 | 8.36 (1 lari) | 1H33M |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | kosinus | 1600 | 8.25 (1 lari) | 3h10m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | kosinus | 200 | 8.21 | 22m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | kosinus | 400 | 7.53 | 44m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | kosinus | 800 | 7.48 | 1H29m |
| Resnet-Preact-20 | Lars | 4096 | 0,02 | kosinus | 1600 | 7.37 (1 lari) | 2h58m |
Ghost Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| Model | Ukuran batch | Ukuran batch hantu | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 8192 | N/a | 1.6 | kosinus | 200 | 12.35 | 25m* |
| Resnet-Preact-20 | 4096 | N/a | 1.6 | kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | N/a | 1.6 | kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | N/a | 1.6 | kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 128 | N/a | 0.4 | kosinus | 200 | 7.28 | 24m |
| Model | Ukuran batch | Ukuran batch hantu | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | kosinus | 200 | 11.51 | 27m |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | kosinus | 200 | 9.73 | 25m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | kosinus | 200 | 8.77 | 24m |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | kosinus | 200 | 7.82 | 22m |
| Model | Ukuran batch | Ukuran batch hantu | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 8192 | N/a | 1.6 | kosinus | 1600 | | |
| Resnet-Preact-20 | 4096 | N/a | 1.6 | kosinus | 1600 | 8.25 | 3h10m |
| Resnet-Preact-20 | 2048 | N/a | 1.6 | kosinus | 1600 | 7.34 | 2h50m |
| Resnet-Preact-20 | 1024 | N/a | 1.6 | kosinus | 1600 | 6.94 | 2h52m |
| Model | Ukuran batch | Ukuran batch hantu | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | kosinus | 1600 | 11.83 | 3H37M |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | kosinus | 1600 | 8.95 | 3h15m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | kosinus | 1600 | 7.23 | 3H05m |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | kosinus | 1600 | 7.08 | 2h59m |
Tidak ada pembusukan berat pada BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00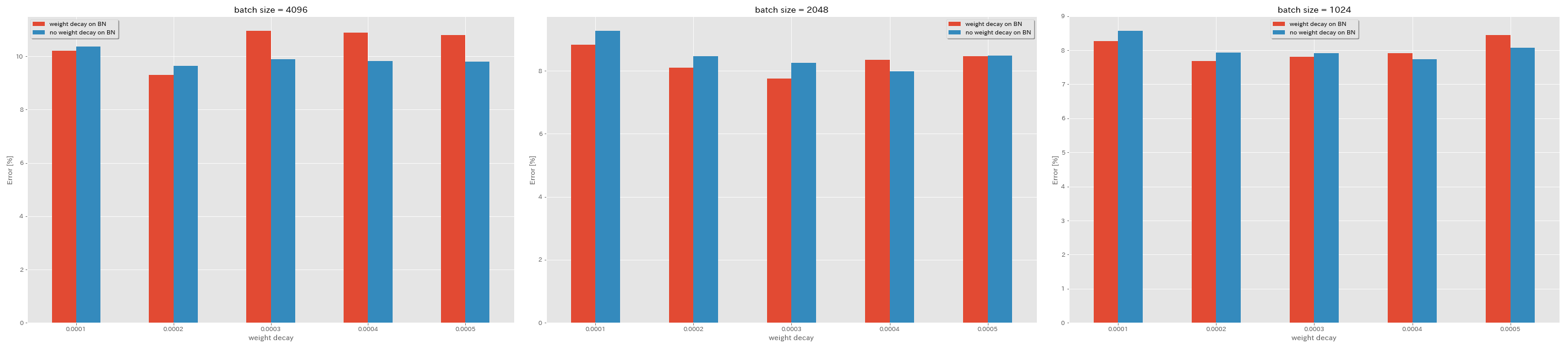
| Model | Kerusakan berat pada BN | Kerusakan berat badan | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | Ya | 5e-4 | 4096 | 1.6 | kosinus | 200 | 10.81 | 22m |
| Resnet-Preact-20 | Ya | 4e-4 | 4096 | 1.6 | kosinus | 200 | 10.88 | 22m |
| Resnet-Preact-20 | Ya | 3e-4 | 4096 | 1.6 | kosinus | 200 | 10.96 | 22m |
| Resnet-Preact-20 | Ya | 2e-4 | 4096 | 1.6 | kosinus | 200 | 9.30 | 22m |
| Resnet-Preact-20 | Ya | 1E-4 | 4096 | 1.6 | kosinus | 200 | 10.20 | 22m |
| Resnet-Preact-20 | TIDAK | 5e-4 | 4096 | 1.6 | kosinus | 200 | 8.78 | 22m |
| Resnet-Preact-20 | TIDAK | 4e-4 | 4096 | 1.6 | kosinus | 200 | 9.83 | 22m |
| Resnet-Preact-20 | TIDAK | 3e-4 | 4096 | 1.6 | kosinus | 200 | 9.90 | 22m |
| Resnet-Preact-20 | TIDAK | 2e-4 | 4096 | 1.6 | kosinus | 200 | 9.64 | 22m |
| Resnet-Preact-20 | TIDAK | 1E-4 | 4096 | 1.6 | kosinus | 200 | 10.38 | 22m |
| Model | Kerusakan berat pada BN | Kerusakan berat badan | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | Ya | 5e-4 | 2048 | 1.6 | kosinus | 200 | 8.46 | 20m |
| Resnet-Preact-20 | Ya | 4e-4 | 2048 | 1.6 | kosinus | 200 | 8.35 | 20m |
| Resnet-Preact-20 | Ya | 3e-4 | 2048 | 1.6 | kosinus | 200 | 7.76 | 20m |
| Resnet-Preact-20 | Ya | 2e-4 | 2048 | 1.6 | kosinus | 200 | 8.09 | 20m |
| Resnet-Preact-20 | Ya | 1E-4 | 2048 | 1.6 | kosinus | 200 | 8.83 | 20m |
| Resnet-Preact-20 | TIDAK | 5e-4 | 2048 | 1.6 | kosinus | 200 | 8.49 | 20m |
| Resnet-Preact-20 | TIDAK | 4e-4 | 2048 | 1.6 | kosinus | 200 | 7.98 | 20m |
| Resnet-Preact-20 | TIDAK | 3e-4 | 2048 | 1.6 | kosinus | 200 | 8.26 | 20m |
| Resnet-Preact-20 | TIDAK | 2e-4 | 2048 | 1.6 | kosinus | 200 | 8.47 | 20m |
| Resnet-Preact-20 | TIDAK | 1E-4 | 2048 | 1.6 | kosinus | 200 | 9.27 | 20m |
| Model | Kerusakan berat pada BN | Kerusakan berat badan | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan uji (median 3 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | Ya | 5e-4 | 1024 | 1.6 | kosinus | 200 | 8.45 | 21m |
| Resnet-Preact-20 | Ya | 4e-4 | 1024 | 1.6 | kosinus | 200 | 7.91 | 21m |
| Resnet-Preact-20 | Ya | 3e-4 | 1024 | 1.6 | kosinus | 200 | 7.81 | 21m |
| Resnet-Preact-20 | Ya | 2e-4 | 1024 | 1.6 | kosinus | 200 | 7.69 | 21m |
| Resnet-Preact-20 | Ya | 1E-4 | 1024 | 1.6 | kosinus | 200 | 8.26 | 21m |
| Resnet-Preact-20 | TIDAK | 5e-4 | 1024 | 1.6 | kosinus | 200 | 8.08 | 21m |
| Resnet-Preact-20 | TIDAK | 4e-4 | 1024 | 1.6 | kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | TIDAK | 3e-4 | 1024 | 1.6 | kosinus | 200 | 7.92 | 21m |
| Resnet-Preact-20 | TIDAK | 2e-4 | 1024 | 1.6 | kosinus | 200 | 7.93 | 21m |
| Resnet-Preact-20 | TIDAK | 1E-4 | 1024 | 1.6 | kosinus | 200 | 8.53 | 21m |
Eksperimen pada setengah presisi, dan presisi campuran
- Eksperimen berikut membutuhkan NVIDIA APEX.
- Eksperimen berikut dilakukan pada dataset CIFAR-10 menggunakan GeForce 1080 Ti, yang tidak memiliki inti tensor.
- Hasil yang dilaporkan dalam tabel adalah kesalahan uji pada zaman terakhir.
Pelatihan FP16
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00Pelatihan presisi campuran
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00Hasil
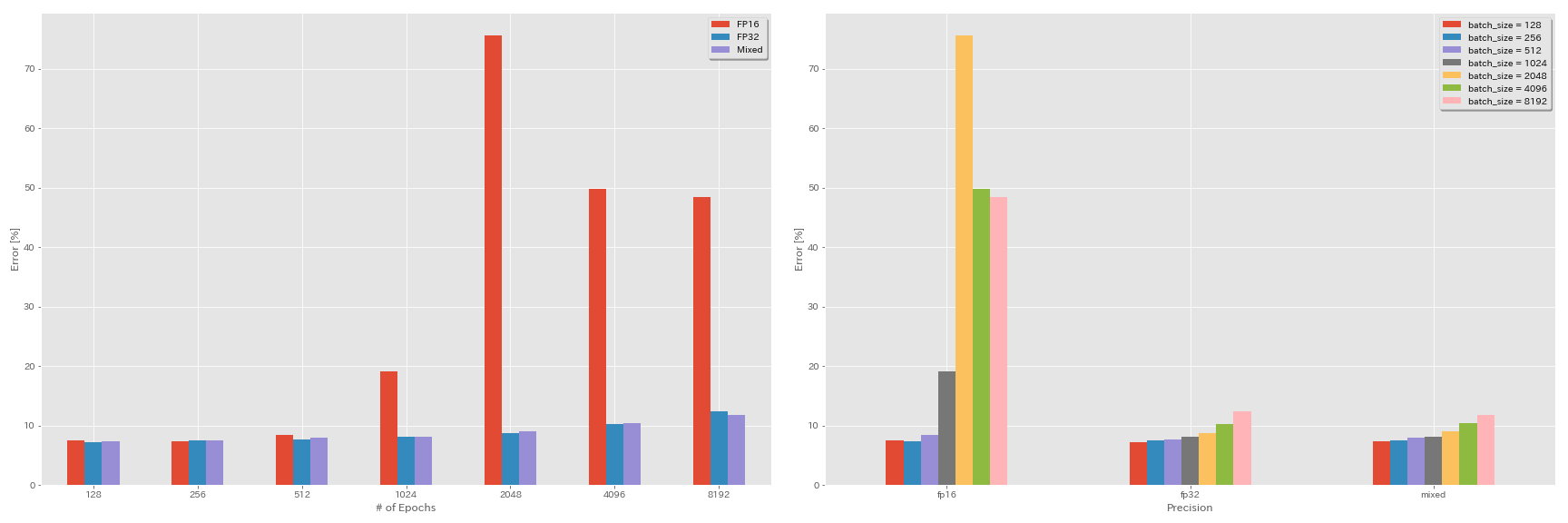
| Model | presisi | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | FP32 | 8192 | 1.6 | kosinus | 200 | | |
| Resnet-Preact-20 | FP32 | 4096 | 1.6 | kosinus | 200 | 10.32 | 22m |
| Resnet-Preact-20 | FP32 | 2048 | 1.6 | kosinus | 200 | 8.73 | 22m |
| Resnet-Preact-20 | FP32 | 1024 | 1.6 | kosinus | 200 | 8.07 | 22m |
| Resnet-Preact-20 | FP32 | 512 | 0.8 | kosinus | 200 | 7.73 | 21m |
| Resnet-Preact-20 | FP32 | 256 | 0.8 | kosinus | 200 | 7.45 | 21m |
| Resnet-Preact-20 | FP32 | 128 | 0.4 | kosinus | 200 | 7.28 | 24m |
| Model | presisi | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | FP16 | 8192 | 1.6 | kosinus | 200 | 48.52 | 33m |
| Resnet-Preact-20 | FP16 | 4096 | 1.6 | kosinus | 200 | 49.84 | 28m |
| Resnet-Preact-20 | FP16 | 2048 | 1.6 | kosinus | 200 | 75.63 | 27m |
| Resnet-Preact-20 | FP16 | 1024 | 1.6 | kosinus | 200 | 19.09 | 27m |
| Resnet-Preact-20 | FP16 | 512 | 0.8 | kosinus | 200 | 7.89 | 26m |
| Resnet-Preact-20 | FP16 | 256 | 0.8 | kosinus | 200 | 7.40 | 28m |
| Resnet-Preact-20 | FP16 | 128 | 0.4 | kosinus | 200 | 7.59 | 32m |
| Model | presisi | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | campur aduk | 8192 | 1.6 | kosinus | 200 | 11.78 | 28m |
| Resnet-Preact-20 | campur aduk | 4096 | 1.6 | kosinus | 200 | 10.48 | 27m |
| Resnet-Preact-20 | campur aduk | 2048 | 1.6 | kosinus | 200 | 8.98 | 26m |
| Resnet-Preact-20 | campur aduk | 1024 | 1.6 | kosinus | 200 | 8.05 | 26m |
| Resnet-Preact-20 | campur aduk | 512 | 0.8 | kosinus | 200 | 7.81 | 28m |
| Resnet-Preact-20 | campur aduk | 256 | 0.8 | kosinus | 200 | 7.58 | 32m |
| Resnet-Preact-20 | campur aduk | 128 | 0.4 | kosinus | 200 | 7.37 | 41m |
Hasil Menggunakan Tesla V100
| Model | presisi | Ukuran batch | LR awal | Jadwal LR | # zaman | Kesalahan tes (1 run) | Waktu pelatihan |
|---|
| Resnet-Preact-20 | FP32 | 8192 | 1.6 | kosinus | 200 | 12.35 | 25m |
| Resnet-Preact-20 | FP32 | 4096 | 1.6 | kosinus | 200 | 9.88 | 19m |
| Resnet-Preact-20 | FP32 | 2048 | 1.6 | kosinus | 200 | 8.87 | 17m |
| Resnet-Preact-20 | FP32 | 1024 | 1.6 | kosinus | 200 | 8.45 | 18m |
| Resnet-Preact-20 | campur aduk | 8192 | 1.6 | kosinus | 200 | 11.92 | 25m |
| Resnet-Preact-20 | campur aduk | 4096 | 1.6 | kosinus | 200 | 10.16 | 19m |
| Resnet-Preact-20 | campur aduk | 2048 | 1.6 | kosinus | 200 | 9.10 | 17m |
| Resnet-Preact-20 | campur aduk | 1024 | 1.6 | kosinus | 200 | 7.84 | 16m |
Referensi
Arsitektur Model
- Dia, Kaiming, Xiangyu Zhang, Shaoqing Ren, dan Jian Sun. "Pembelajaran residu yang mendalam untuk pengenalan gambar." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2016. Tautan, ARXIV: 1512.03385
- Dia, Kaiming, Xiangyu Zhang, Shaoqing Ren, dan Jian Sun. "Pemetaan identitas dalam jaringan residu yang dalam." Dalam Konferensi Eropa tentang Visi Komputer (ECCV). 2016. ARXIV: 1603.05027, implementasi obor
- Zagoruyko, Sergey, dan Nikos Komodakis. "Jaringan residual yang luas." Prosiding Konferensi Visi Mesin Inggris (BMVC), 2016. Arxiv: 1605.07146, Implementasi Obor
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger, dan Laurens van der Maaten. "Jaringan konvolusional yang terhubung padat." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2017. Tautan, Arxiv: 1608.06993, Implementasi Obor
- Han, Dongyoon, Jiwhan Kim, dan Junmo Kim. "Jaringan residu piramidal yang dalam." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2017. Tautan, Arxiv: 1610.02915, Implementasi Obor, Implementasi Caffe, Implementasi Pytorch
- Xie, Saining, Ross Girshick, Piotr Dollar, Zhuowen Tu, dan Kaiming He. "Transformasi residual agregat untuk jaringan saraf yang dalam." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2017. Tautan, Arxiv: 1611.05431, Implementasi Obor
- Gastaldi, Xavier. "Shake-Shake regularisasi jaringan residu 3-cabang." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR) Lokakarya, 2017. Tautan, Arxiv: 1705.07485, Implementasi Obor
- Hu, Jie, Li Shen, dan Gang Sun. "Jaringan pemerasan-dan-eksitasi." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2018, hlm. 7132-7141. Link, Arxiv: 1709.01507, Implementasi Caffe
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten, dan Kilian Q. Weinberger. "Jaringan konvolusional dengan konektivitas padat." Transaksi IEEE tentang Analisis Pola dan Kecerdasan Mesin (2019). ARXIV: 2001.02394
Regularisasi, augmentasi data
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, dan Zbigniew Wojna. "Memikirkan kembali arsitektur awal untuk visi komputer." Konferensi IEEE tentang Visi Komputer dan Pengenalan Pola (CVPR), 2016. Tautan, Arxiv: 1512.00567
- Devries, Terrance, dan Graham W. Taylor. "Peningkatan regularisasi jaringan saraf konvolusional dengan potongan." ARXIV Preprint ARXIV: 1708.04552 (2017). ARXIV: 1708.04552, Implementasi Pytorch
- Abu-El-Haija, Sami. "Pembaruan Gradien Proporsional dengan Persentdelta." ARXIV Preprint ARXIV: 1708.07227 (2017). Arxiv: 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li, dan Yi Yang. "Augmentasi Data Menghapus Acak." ARXIV Preprint ARXIV: 1708.04896 (2017). ARXIV: 1708.04896, Implementasi Pytorch
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin, dan David Lopez-Paz. "Mixup: Di luar minimalisasi risiko empiris." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR), 2017. Tautan, Arxiv: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma, dan Leslie Pack Kaelbling. "Menuju Pemahaman Generalisasi Melalui Teori Pembelajaran Analitik." ARXIV Preprint ARXIV: 1802.07426 (2018). ARXIV: 1802.07426, Implementasi Pytorch
- Takahashi, Ryo, Takashi Matsubara, dan Kuniaki Uehara. "Augmentasi data menggunakan penanaman dan penambalan gambar acak untuk CNN dalam." Prosiding Konferensi Asia ke -10 tentang Pembelajaran Mesin (ACML), 2018. Link, Arxiv: 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, dan Youngjoon Yoo. "Cutmix: Strategorisasi strategi untuk melatih pengklasifikasi yang kuat dengan fitur -fitur yang dapat dilokalkan." ARXIV Preprint ARXIV: 1905.04899 (2019). Arxiv: 1905.04899
Batch besar
- Keskar, Shirish Nitish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, dan Ping Tak Peter Tang. "Pada pelatihan batch besar untuk pembelajaran yang mendalam: kesenjangan generalisasi dan minimum yang tajam." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR), 2017. Link, ARXIV: 1609.04836
- Hoffer, Elad, Itay Hubara, dan Daniel Soudry. "Berlatih lebih lama, Generalisasi lebih baik: Menutup kesenjangan generalisasi dalam pelatihan batch besar jaringan saraf." Dalam Kemajuan Sistem Pemrosesan Informasi Saraf (NIPS), 2017. Tautan, ARXIV: 1705.08741, Implementasi Pytorch
- Goyal, Priya, Dolar Piotr, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, dan Kaiming He. "SGD minibatch yang akurat, pelatihan Imagenet dalam 1 jam." ARXIV Preprint ARXIV: 1706.02677 (2017). Arxiv: 1706.02677
- Anda, Yang, Igor Gitman, dan Boris Ginsburg. "Pelatihan Batch Besar Jaringan Konvolusional." ARXIV Preprint ARXIV: 1708.03888 (2017). Arxiv: 1708.03888
- Anda, Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel, dan Kurt Keutzer. "Latihan Imagenet dalam hitungan menit." ARXIV Preprint ARXIV: 1709.05011 (2017). Arxiv: 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying, dan Quoc V. Le. "Jangan membusuk tingkat pembelajaran, tingkatkan ukuran batch." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR), 2018. Link, Arxiv: 1711.00489
- Gitman, Igor, Deepak Dilipkumar, dan Ben Parr. "Analisis konvergensi algoritma keturunan gradien dengan pembaruan proporsional." ARXIV Preprint ARXIV: 1801.03137 (2018). ARXIV: 1801.03137 Implementasi TensorFlow
- Jia, Xianyan, Lagu Shutao, Wei He, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi, dan Xiaow. "Sistem pelatihan pembelajaran mendalam yang sangat terukur dengan presisi campuran: pelatihan Imagenet dalam empat menit." ARXIV Preprint ARXIV: 1807.11205 (2018). Arxiv: 1807.11205
- Shallue, Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig, dan George E. Dahl. "Mengukur efek paralelisme data pada pelatihan jaringan saraf." ARXIV Preprint ARXIV: 1811.03600 (2018). Arxiv: 1811.03600
- Ying, Chris, Sameer Kumar, DeHao Chen, Tao Wang, dan YouLong Cheng. "Klasifikasi Gambar pada Skala Superkomputer." Dalam Kemajuan dalam Sistem Pemrosesan Informasi Saraf (Neurips) Workshop, 2018. Link, Arxiv: 1811.06992
Yang lain
- Loshchilov, Ilya, dan Frank Hutter. "SGDR: Penurunan gradien stokastik dengan restart hangat." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR), 2017. Tautan, Arxiv: 1608.03983, Implementasi Lasagna
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, dan Hao Wu. "Pelatihan Presisi Campuran." Dalam Konferensi Internasional tentang Representasi Pembelajaran (ICLR), 2018. Link, Arxiv: 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt, dan Vaishaal Shankar. "Apakah CIFAR-10 Classifiers menggeneralisasi ke CIFAR-10?" ARXIV Preprint ARXIV: 1806.00451 (2018). Arxiv: 1806.00451
- Dia, Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, dan Mu Li. "Kantung trik untuk klasifikasi gambar dengan jaringan saraf konvolusional." ARXIV Preprint ARXIV: 1812.01187 (2018). Arxiv: 1812.01187


