การจำแนกรูปภาพ Pytorch
เอกสารต่อไปนี้ถูกนำไปใช้โดยใช้ pytorch
- Resnet (1512.03385)
- Resnet-Preact (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- Pyramidnet (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- Lars (1708.03888, 1801.03137)
- คัตเอาท์ (1708.04552)
- การลบแบบสุ่ม (1708.04896)
- Senet (1709.01507)
- MIXUP (1710.09412)
- Dual-Cutout (1802.07426)
- Ricap (1811.09030)
- Cutmix (1905.04899)
ความต้องการ
- Ubuntu (มีการทดสอบเฉพาะใน Ubuntu เท่านั้นดังนั้นจึงอาจไม่ทำงานบน Windows)
- Python> = 3.7
- pytorch> = 1.4.0
- คบเพลิง
- Nvidia Apex
pip install -r requirements.txt
การใช้งาน
python train.py --config configs/cifar/resnet_preact.yaml
ผลลัพธ์ใน CIFAR-10
ผลลัพธ์โดยใช้การตั้งค่าเกือบเท่ากันกับเอกสาร
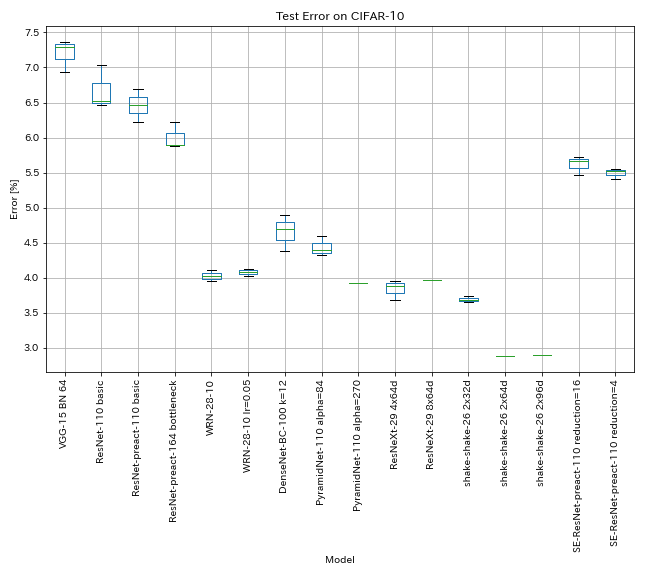
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | ข้อผิดพลาดในการทดสอบ (ในกระดาษ) | เวลาฝึกอบรม |
|---|
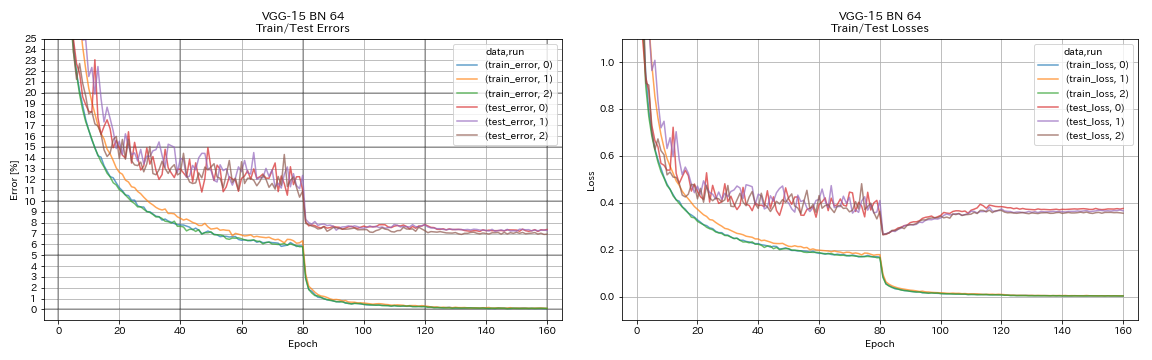
| VGG-like (ความลึก 15, w/ bn, ช่อง 64) | 7.29 | N/A | 1h20m |
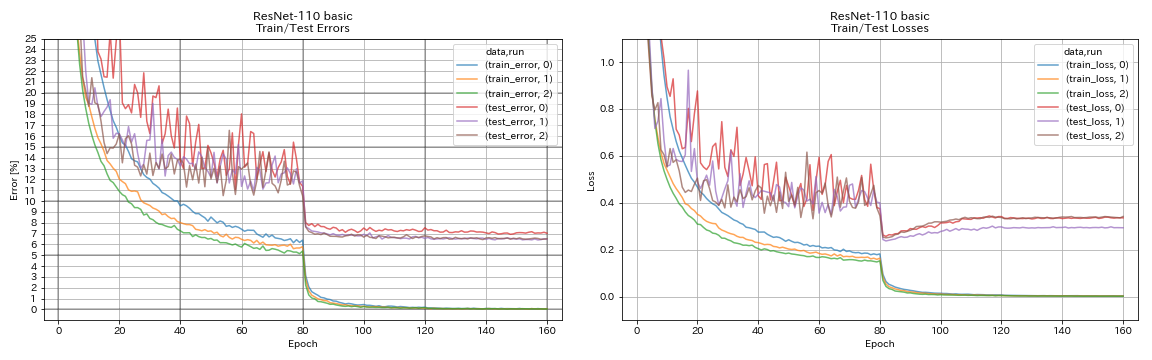
| resnet-110 | 6.52 | 6.43 (ดีที่สุด), 6.61 +/- 0.16 | 3H06M |
| Resnet-Preact-110 | 6.47 | 6.37 (ค่ามัธยฐาน 5 วิ่ง) | 3H05M |
| คอขวด Resnet-Preact-164 | 5.90 | 5.46 (ค่ามัธยฐาน 5 วิ่ง) | 4H01M |
| คอขวด Resnet-Preact-1001 | | 4.62 (ค่ามัธยฐาน 5 วิ่ง), 4.69 +/- 0.20 | |
| WRN-28-10 | 4.03 | 4.00 (ค่ามัธยฐาน 5 วิ่ง) | 16h10m |
| WRN-28-10 w/ ออกกลางคัน | | 3.89 (ค่ามัธยฐาน 5 วิ่ง) | |
| densenet-100 (k = 12) | 3.87 (1 วิ่ง) | 4.10 (1 วิ่ง) | 24H28M* |
| densenet-100 (k = 24) | | 3.74 (1 วิ่ง) | |
| Densenet-BC-100 (k = 12) | 4.69 | 4.51 (1 วิ่ง) | 15h20m |
| Densenet-BC-2550 (k = 24) | | 3.62 (1 วิ่ง) | |
| Densenet-BC-190 (k = 40) | | 3.46 (1 วิ่ง) | |
| PyramidNet-110 (Alpha = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| PyramidNet-110 (Alpha = 270) | 3.92 (1 วิ่ง) | 3.73 +/- 0.04 | 24H12M* |
| Pyramidnet-164 คอขวด (Alpha = 270) | 3.44 (1 วิ่ง) | 3.48 +/- 0.20 | 32H37M* |
| PyramidNet-272 คอขวด (Alpha = 200) | | 3.31 +/- 0.08 | |
| resnext-29 4x64d | 3.89 | ~ 3.75 (จากรูปที่ 7) | 31H17M |
| resnext-29 8x64d | 3.97 (1 วิ่ง) | 3.65 (เฉลี่ย 10 วิ่ง) | 42h50m* |
| resnext-29 16x64d | | 3.58 (เฉลี่ย 10 วิ่ง) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3.55 (เฉลี่ย 3 วิ่ง) | 33h49m |
| Shake-Shake-26 2x64d (SSI) | 2.88 (1 วิ่ง) | 2.98 (เฉลี่ย 3 วิ่ง) | 78h48m |
| Shake-Shake-26 2x96d (SSI) | 2.90 (1 วิ่ง) | 2.86 (เฉลี่ย 5 วิ่ง) | 101H32M* |
หมายเหตุ
- ความแตกต่างกับเอกสารในการตั้งค่าการฝึกอบรม:
- WRN-28-10 ที่ผ่านการฝึกอบรมด้วยชุดขนาด 64 (128 ในกระดาษ)
- Densenet-BC-100 (k = 12) ที่ผ่านการฝึกอบรมด้วยขนาดแบทช์ 32 และอัตราการเรียนรู้เริ่มต้น 0.05 (ขนาดแบทช์ 64 และอัตราการเรียนรู้เริ่มต้น 0.1 ในกระดาษ)
- Resnext-29 4x64d ที่ผ่านการฝึกอบรมด้วย GPU เดียวขนาดแบทช์ 32 และอัตราการเรียนรู้เริ่มต้น 0.025 (8 GPUs ขนาดแบทช์ 128 และอัตราการเรียนรู้เริ่มต้น 0.1 ในกระดาษ)
- รุ่น Shake-Shake ที่ผ่านการฝึกอบรมด้วย GPU เดียว (2 GPU ในกระดาษ)
- ได้รับการฝึกฝน Shake-Shake 26 2x64d (SSI) ที่มีขนาดแบทช์ 64 และอัตราการเรียนรู้เริ่มต้น 0.1
- ข้อผิดพลาดในการทดสอบที่รายงานข้างต้นเป็นสิ่งที่เกิดขึ้นในยุคสุดท้าย
- การทดลองที่มีการรันเพียง 1 ครั้งจะทำบนคอมพิวเตอร์ที่แตกต่างจากที่ใช้สำหรับการทดลองที่มีการวิ่ง 3 ครั้ง
- GeForce GTX 980 ถูกนำมาใช้ในการทดลองเหล่านี้
เหมือน VGG
python train.py --config configs/cifar/vgg.yaml
resnet
python train.py --config configs/cifar/resnet.yaml
resnet-preact
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00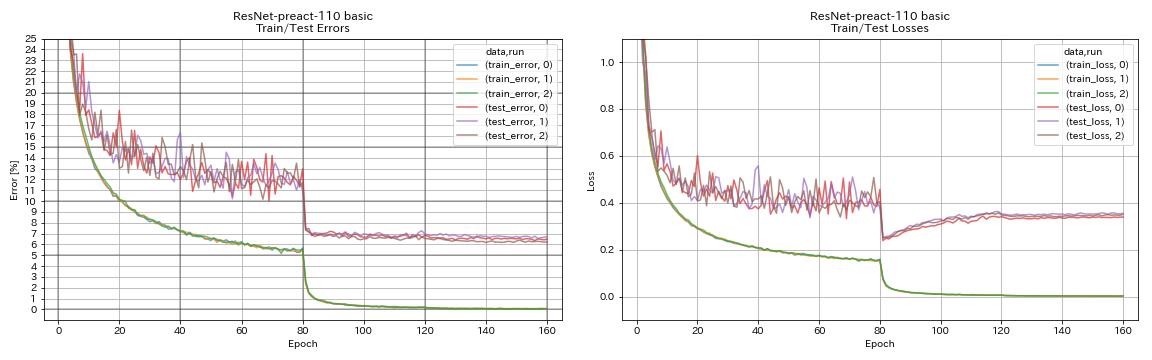
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00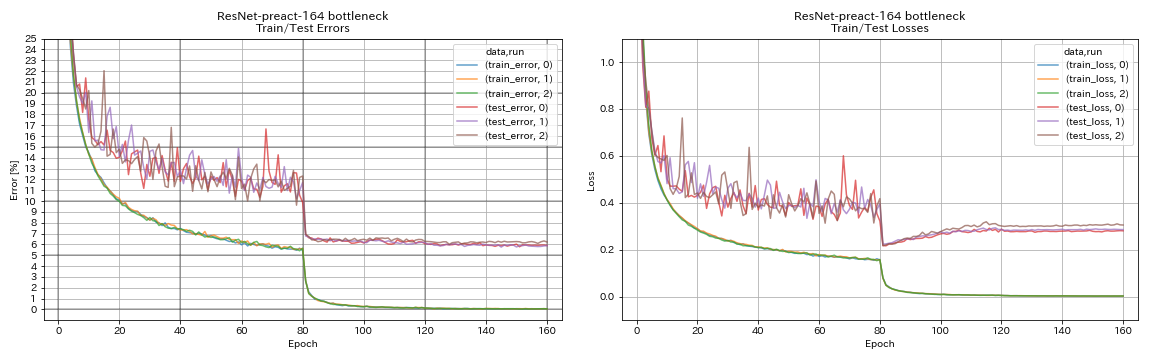
wrn
python train.py --config configs/cifar/wrn.yaml
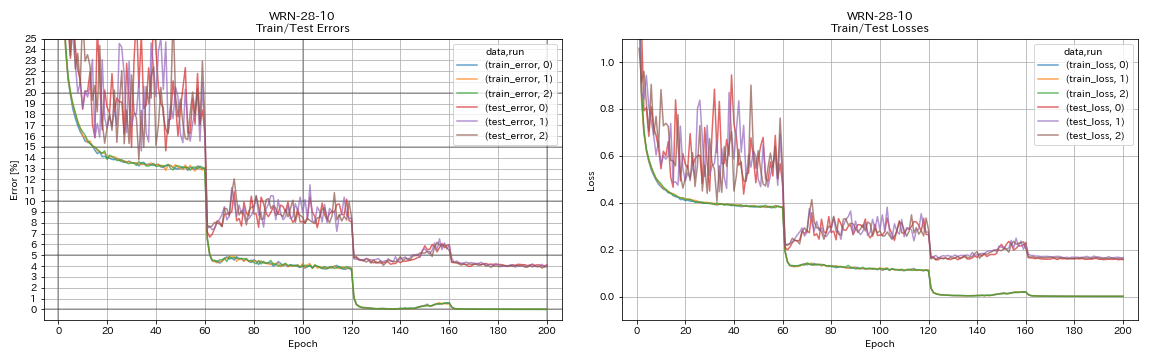
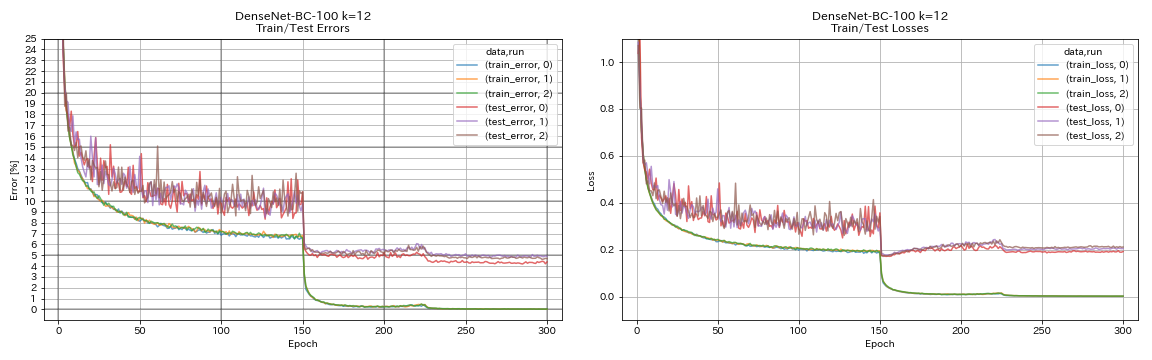
เดนเซเนต
python train.py --config configs/cifar/densenet.yaml
ปิรามิดเน็ต
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00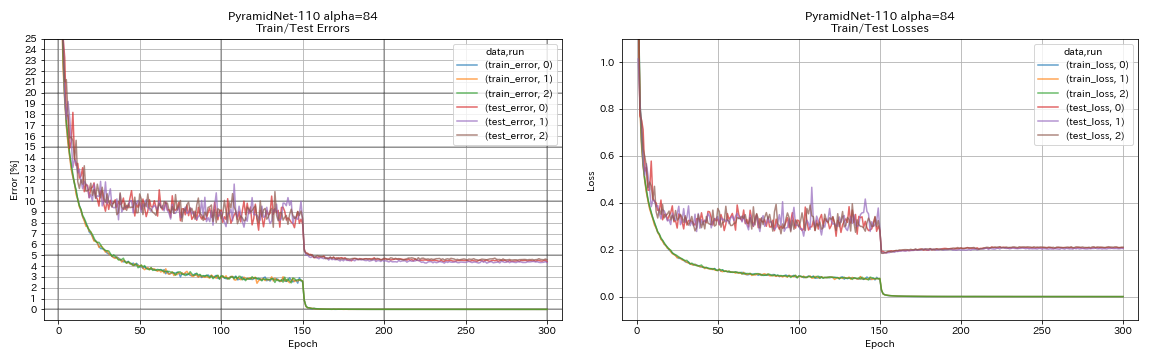
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00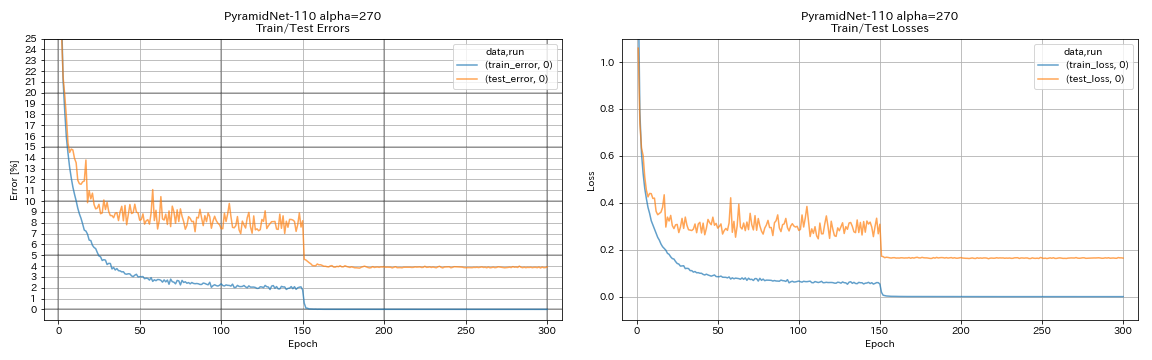
resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00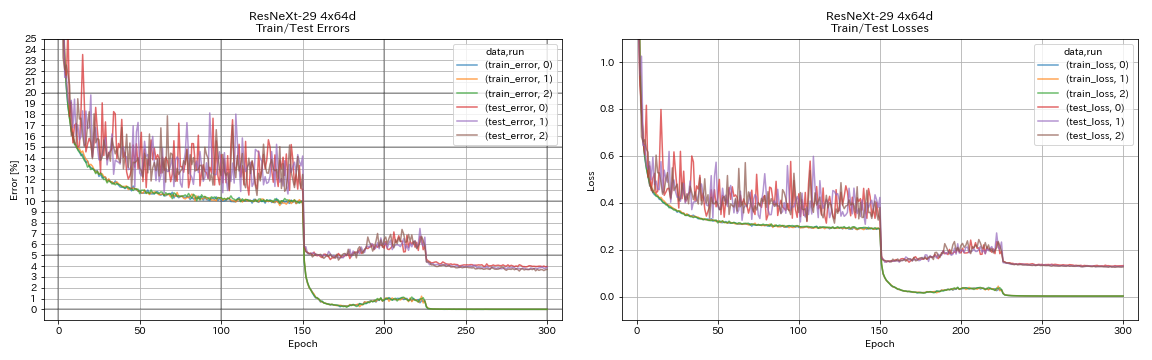
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00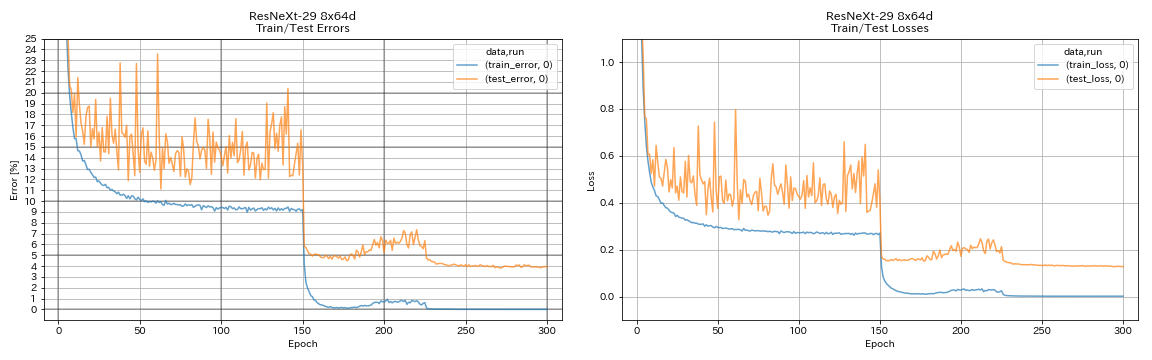
เขย่า
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00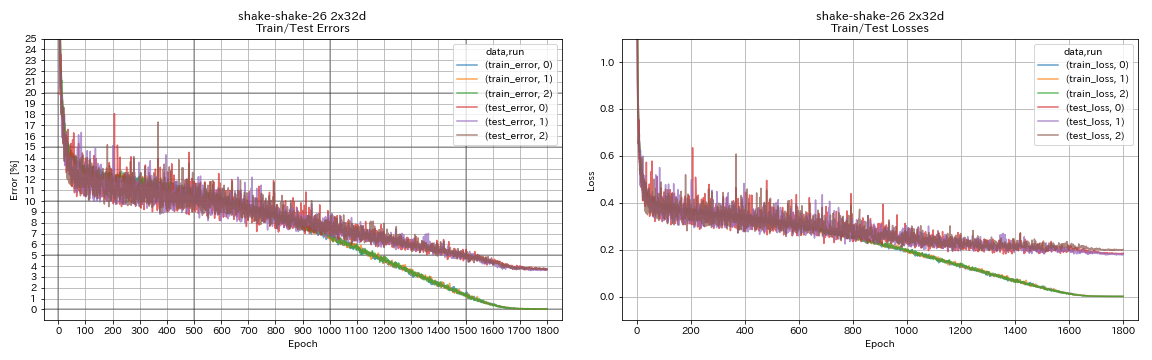
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00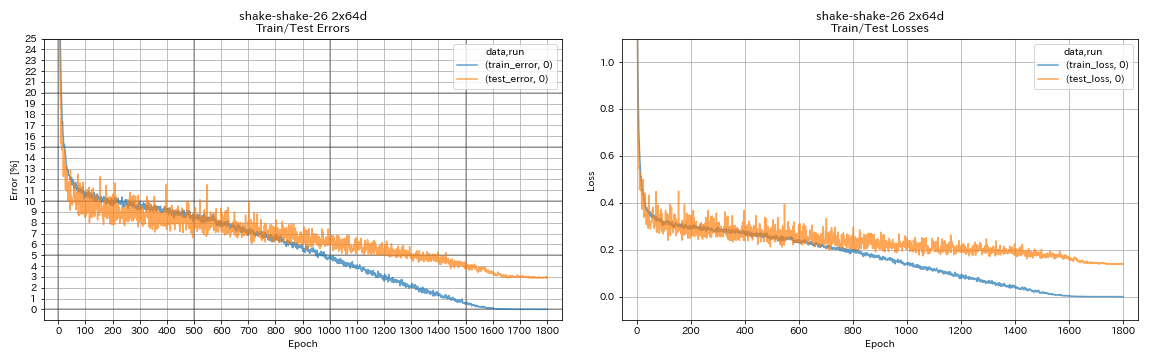
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00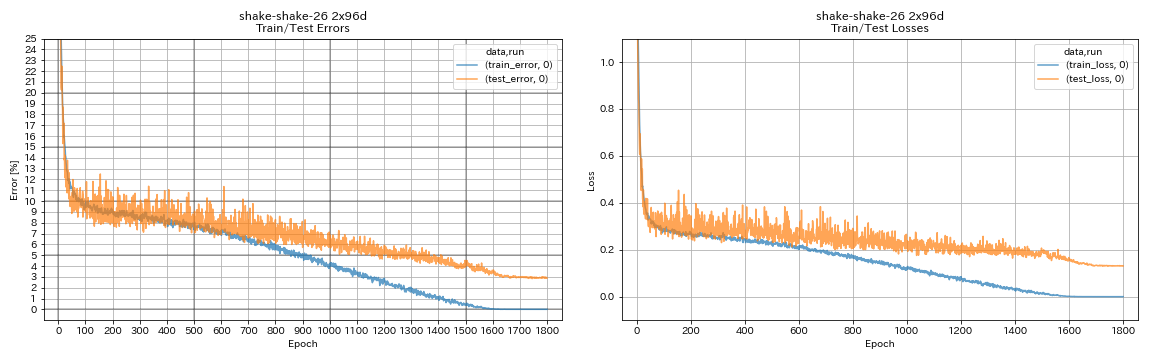
ผลลัพธ์
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (1 รัน) | # ของยุค | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20, Widening Factor 4 | 4.91 | 200 | 1h26m |
| Resnet-Preact-20, Widening Factor 4 | 4.01 | 400 | 2h53m |
| Resnet-Preact-20, Widening Factor 4 | 3.99 | 1800 | 12h53m |
| Resnet-Preact-20, Widening Factor 4, Cutout 16 | 3.71 | 200 | 1h26m |
| Resnet-Preact-20, Widening Factor 4, Cutout 16 | 3.46 | 400 | 2h53m |
| Resnet-Preact-20, Widening Factor 4, Cutout 16 | 3.76 | 1800 | 12h53m |
| Resnet-Preact-20, ปัจจัยกว้าง 4, RICAP (beta = 0.3) | 3.45 | 200 | 1h26m |
| Resnet-Preact-20, ปัจจัยกว้าง 4, RICAP (beta = 0.3) | 3.11 | 400 | 2h53m |
| Resnet-Preact-20, ปัจจัยกว้าง 4, RICAP (beta = 0.3) | 3.15 | 1800 | 12h53m |
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (1 รัน) | # ของยุค | เวลาฝึกอบรม |
|---|
| WRN-28-10, cutout 16 | 3.19 | 200 | 6h35m |
| WRN-28-10, MIXUP (alpha = 1) | 3.32 | 200 | 6h35m |
| WRN-28-10, RICAP (เบต้า = 0.3) | 2.83 | 200 | 6h35m |
| WRN-28-10, dual-cutout (alpha = 0.1) | 2.87 | 200 | 12h42m |
| WRN-28-10, cutout 16 | 3.07 | 400 | 13h10m |
| WRN-28-10, MIXUP (alpha = 1) | 3.04 | 400 | 13h08m |
| WRN-28-10, RICAP (เบต้า = 0.3) | 2.71 | 400 | 13h08m |
| WRN-28-10, dual-cutout (alpha = 0.1) | 2.76 | 400 | 25h20m |
| Shake-Shake-26 2x64d, Cutout 16 | 2.64 | 1800 | 78h55m* |
| Shake-Shake-26 2x64d, Mixup (Alpha = 1) | 2.63 | 1800 | 35h56m |
| Shake-Shake-26 2x64d, Ricap (beta = 0.3) | 2.29 | 1800 | 35h10m |
| Shake-Shake-26 2x64d, Dual-Cutout (Alpha = 0.1) | 2.64 | 1800 | 68h34m |
| Shake-Shake-26 2x96d, Cutout 16 | 2.50 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Mixup (Alpha = 1) | 2.36 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Ricap (beta = 0.3) | 2.10 | 1800 | 60h20m |
| Shake-Shake-26 2x96d, Dual-Cutout (Alpha = 0.1) | 2.41 | 1800 | 113h09m |
| Shake-Shake-26 2x128d, Cutout 16 | 2.58 | 1800 | 85h04m |
| Shake-Shake-26 2x128d, Ricap (beta = 0.3) | 1.97 | 1800 | 85h06m |
บันทึก
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
- ทุกรุ่นได้รับการฝึกฝนโดยใช้การหลอมโคไซน์ด้วยอัตราการเรียนรู้เริ่มต้น 0.2
- GeForce GTX 1080 TI ถูกนำมาใช้ในการทดลองเหล่านี้ยกเว้นที่มี *ซึ่งทำโดยใช้ GeForce GTX 980
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True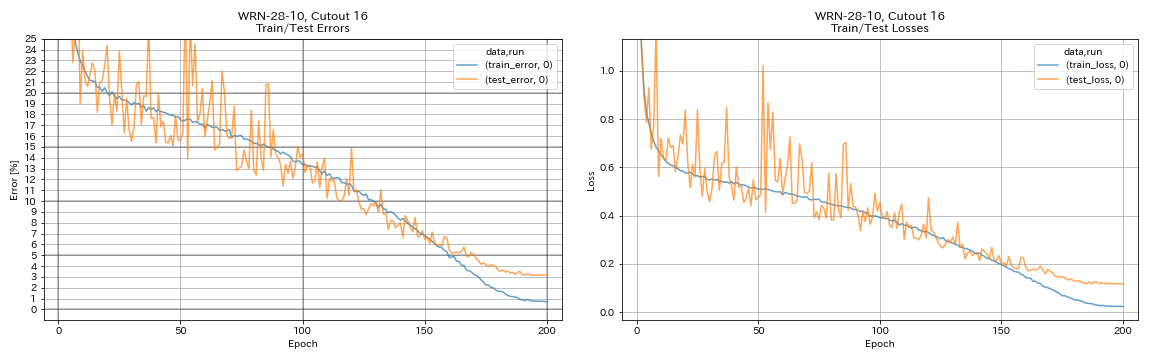
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True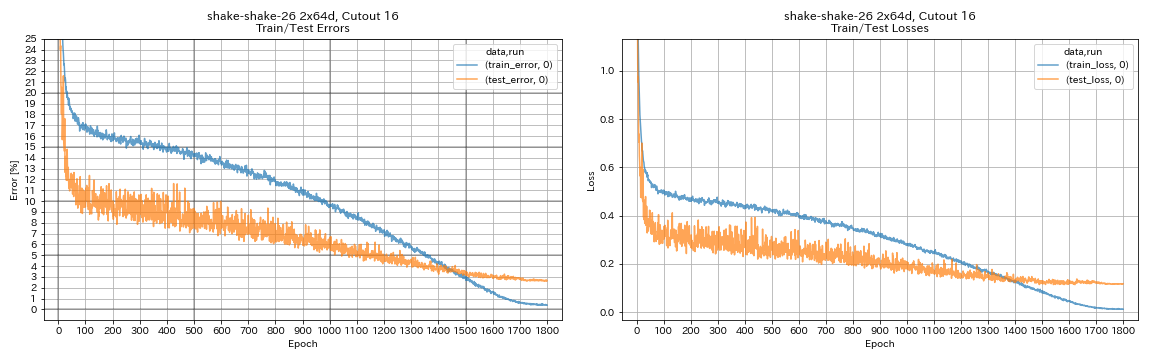
ผลลัพธ์โดยใช้ multi-gpu
| แบบอย่าง | ขนาดแบทช์ | #GPUS | ข้อผิดพลาดในการทดสอบ (1 รัน) | # ของยุค | เวลาฝึกอบรม* |
|---|
| WRN-28-10, RICAP (เบต้า = 0.3) | 512 | 1 | 2.63 | 200 | 3H41M |
| WRN-28-10, RICAP (เบต้า = 0.3) | 256 | 2 | 2.71 | 200 | 2h14m |
| WRN-28-10, RICAP (เบต้า = 0.3) | 128 | 4 | 2.89 | 200 | 1h01m |
| WRN-28-10, RICAP (เบต้า = 0.3) | 64 | 8 | 2.75 | 200 | 34m |
บันทึก
- Tesla V100 ถูกนำมาใช้ในการทดลองเหล่านี้
ใช้ 1 gpu
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseใช้ 2 GPU
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseใช้ 4 GPU
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseใช้ 8 GPU
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop Falseผลลัพธ์เกี่ยวกับ FashionMnist
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (1 รัน) | # ของยุค | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20, Widening Factor 4, Cutout 12 | 4.17 | 200 | 1h32m |
| Resnet-Preact-20, Widening Factor 4, Cutout 14 | 4.11 | 200 | 1h32m |
| resnet-preact-50, cutout 12 | 4.45 | 200 | 57m |
| resnet-preact-50, cutout 14 | 4.38 | 200 | 57m |
| Resnet-Preact-50, Widening Factor 4, Cutout 12 | 4.07 | 200 | 3H37M |
| Resnet-Preact-50, Widening Factor 4, Cutout 14 | 4.13 | 200 | 3H39M |
| Shake-Shake-26 2x32d (SSI), cutout 12 | 4.08 | 400 | 3H41M |
| Shake-Shake-26 2x32d (SSI), cutout 14 | 4.05 | 400 | 3H39M |
| Shake-Shake-26 2x96d (SSI), cutout 12 | 3.72 | 400 | 13h46m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 3.85 | 400 | 13H39M |
| Shake-Shake-26 2x96d (SSI), cutout 12 | 3.65 | 800 | 26h42m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 3.60 | 800 | 26h42m |
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | # ของยุค | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 5.04 | 200 | 26m |
| resnet-preact-20, cutout 6 | 4.84 | 200 | 26m |
| resnet-preact-20, cutout 8 | 4.64 | 200 | 26m |
| resnet-preact-20, cutout 10 | 4.74 | 200 | 26m |
| resnet-preact-20, cutout 12 | 4.68 | 200 | 26m |
| resnet-preact-20, cutout 14 | 4.64 | 200 | 26m |
| resnet-preact-20, cutout 16 | 4.49 | 200 | 26m |
| resnet-preact-20, การสุ่ม | 4.61 | 200 | 26m |
| resnet-preact-20, mixup | 4.92 | 200 | 26m |
| resnet-preact-20, mixup | 4.64 | 400 | 52m |
บันทึก
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
- ทุกรุ่นได้รับการฝึกฝนโดยใช้การหลอมโคไซน์ด้วยอัตราการเรียนรู้เริ่มต้น 0.2
- การเพิ่มข้อมูลต่อไปนี้จะถูกนำไปใช้กับข้อมูลการฝึกอบรม:
- รูปภาพมีเบาะด้วย 4 พิกเซลในแต่ละด้านและ 28x28 แพทช์ถูกครอบตัดแบบสุ่มจากภาพเบาะ
- ภาพจะพลิกแบบสุ่มในแนวนอน
- GeForce GTX 1080 TI ใช้ในการทดลองเหล่านี้
ผลลัพธ์ของ MNIST
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | # ของยุค | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 0.40 | 100 | 12m |
| resnet-preact-20, cutout 6 | 0.32 | 100 | 12m |
| resnet-preact-20, cutout 8 | 0.25 | 100 | 12m |
| resnet-preact-20, cutout 10 | 0.27 | 100 | 12m |
| resnet-preact-20, cutout 12 | 0.26 | 100 | 12m |
| resnet-preact-20, cutout 14 | 0.26 | 100 | 12m |
| resnet-preact-20, cutout 16 | 0.25 | 100 | 12m |
| resnet-preact-20, mixup (alpha = 1) | 0.40 | 100 | 12m |
| Resnet-Preact-20, Mixup (alpha = 0.5) | 0.38 | 100 | 12m |
| Resnet-Preact-20, Widening Factor 4, Cutout 14 | 0.26 | 100 | 45m |
| resnet-preact-50, cutout 14 | 0.29 | 100 | 28m |
| Resnet-Preact-50, Widening Factor 4, Cutout 14 | 0.25 | 100 | 1h50m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 0.24 | 100 | 3H22M |
บันทึก
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
- ทุกรุ่นได้รับการฝึกฝนโดยใช้การหลอมโคไซน์ด้วยอัตราการเรียนรู้เริ่มต้น 0.2
- GeForce GTX 1080 TI ใช้ในการทดลองเหล่านี้
ผลลัพธ์เกี่ยวกับ kuzushiji-mnist
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | # ของยุค | เวลาฝึกอบรม |
|---|
| resnet-preact-20, cutout 14 | 0.82 (ดีที่สุด 0.67) | 200 | 24 เมตร |
| Resnet-Preact-20, Widening Factor 4, Cutout 14 | 0.72 (ดีที่สุด 0.67) | 200 | 1h30m |
| Pyramidnet-110-270, Cutout 14 | 0.72 (ดีที่สุด 0.70) | 200 | 10h05m |
| Shake-Shake-26 2x96d (SSI), Cutout 14 | 0.66 (ดีที่สุด 0.63) | 200 | 6h46m |
บันทึก
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
- ทุกรุ่นได้รับการฝึกฝนโดยใช้การหลอมโคไซน์ด้วยอัตราการเรียนรู้เริ่มต้น 0.2
- GeForce GTX 1080 TI ใช้ในการทดลองเหล่านี้
การทดลอง
ทดลองหน่วยที่เหลือการกำหนดตารางอัตราการเรียนรู้และการเพิ่มข้อมูล
ในการทดลองนี้จะมีการตรวจสอบผลกระทบของความแม่นยำในการจำแนกประเภทต่อไปนี้:
- หน่วยตกค้างเหมือนพีระมิดเน็ต
- การหลอม cosine ของอัตราการเรียนรู้
- การตัดทอน
- การลบแบบสุ่ม
- การผสมผสาน
- preactivation ทางลัดหลังการลดลง
Resnet-Preact-56 ได้รับการฝึกฝนเกี่ยวกับ CIFAR-10 ด้วยอัตราการเรียนรู้เริ่มต้น 0.2 ในการทดลองนี้
บันทึก
- PyramidNet Paper (1610.02915) แสดงให้เห็นว่าการลบ RELU ครั้งแรกในหน่วยที่เหลือและเพิ่ม BN หลังจากการประชุมครั้งสุดท้ายในหน่วยที่เหลือทั้งสองปรับปรุงความแม่นยำในการจำแนกประเภท
- กระดาษ SGDR (1608.03983) แสดงให้เห็นว่าการหลอมแบบโคไซน์ช่วยเพิ่มความแม่นยำในการจำแนกประเภทแม้จะไม่มีการรีสตาร์ท
ผลลัพธ์
- หน่วยที่มีลักษณะคล้าย Pyramidnet ใช้งานได้
- มันอาจจะดีกว่าที่จะไม่ทำปฏิกิริยาทางลัดก่อนการสุ่มตัวอย่างเมื่อใช้หน่วยคล้ายพีระมิดเน็ต
- การหลอมโคไซน์ช่วยเพิ่มความแม่นยำเล็กน้อย
- คัตเอาท์สุ่มและการผสมทั้งหมดทำงานได้ดี
- การผสมผสานต้องการการฝึกอบรมที่ยาวนานขึ้น
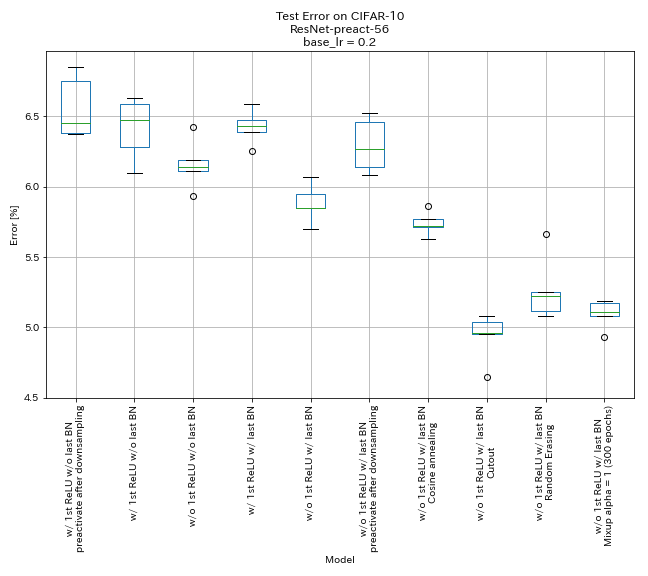
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐาน 5 วิ่ง) | เวลาฝึกอบรม |
|---|
| w/ 1st relu, w/ o ล่าสุด bn, preactivate ทางลัดหลังจาก downsampling | 6.45 | 95 นาที |
| w/ 1st relu, w/ o ล่าสุด bn | 6.47 | 95 นาที |
| w/o 1st relu, w/o ล่าสุด bn | 6.14 | 89 นาที |
| w/ 1st relu, w/ สุดท้าย bn | 6.43 | 104 นาที |
| w/ o 1st relu, w/ สุดท้าย bn | 5.85 | 98 นาที |
| w/ o 1st relu, w/ last bn, preactivate ทางลัดหลังการลดลง | 6.27 | 98 นาที |
| w/ o 1st relu, w/ last bn, การหลอมโคไซน์ | 5.72 | 98 นาที |
| w/ o 1st relu, w/ สุดท้าย bn, cutout | 4.96 | 98 นาที |
| w/ o 1st relu, w/ สุดท้าย bn, randomerasing | 5.22 | 98 นาที |
| w/ o 1st relu, w/ last bn, mixup (300 epochs) | 5.11 | 191 นาที |
preactivate ทางลัดหลังการสุ่มตัวอย่าง
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00
w/ 1st relu, w/ o ล่าสุด bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00
w/o 1st relu, w/o ล่าสุด bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00
w/ 1st relu, w/ สุดท้าย bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00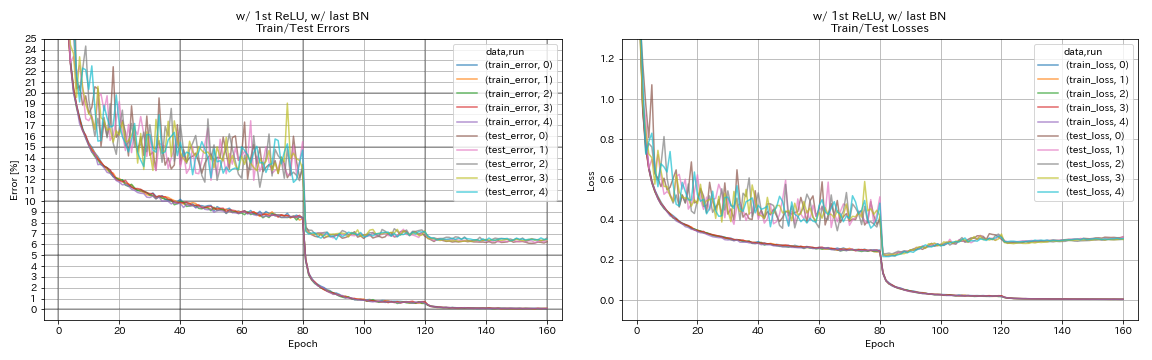
w/ o 1st relu, w/ สุดท้าย bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00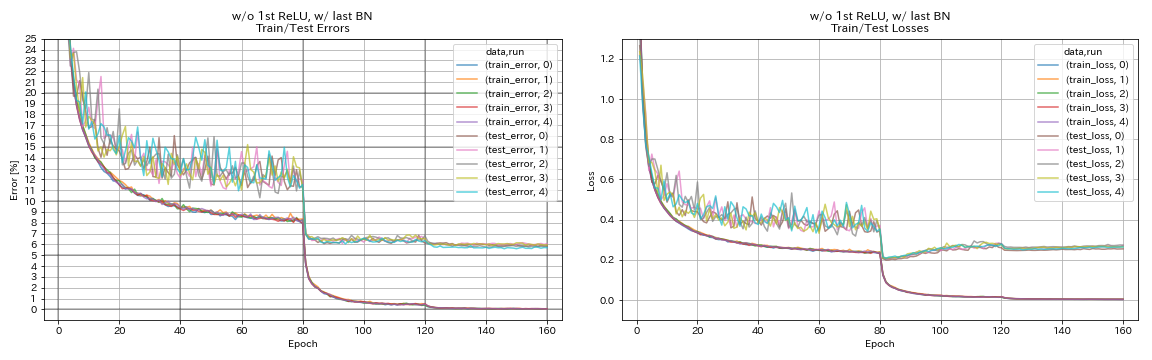
w/ o 1st relu, w/ last bn, preactivate ทางลัดหลังการลดลง
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00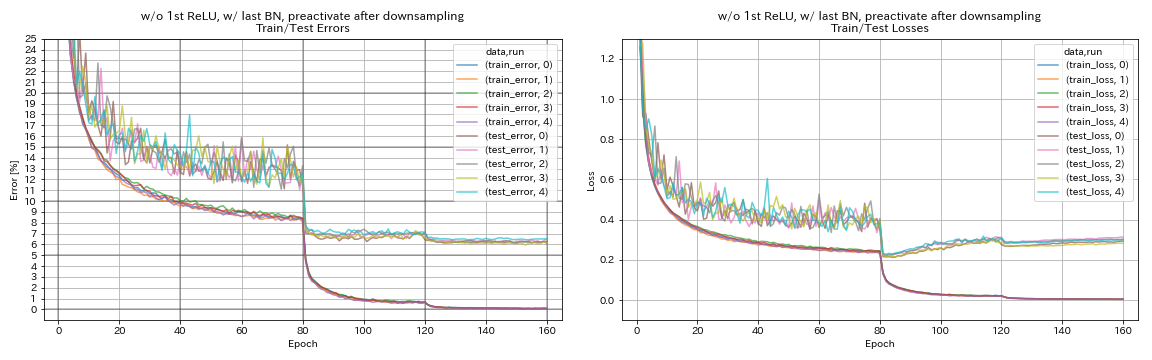
w/ o 1st relu, w/ last bn, การหลอมโคไซน์
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00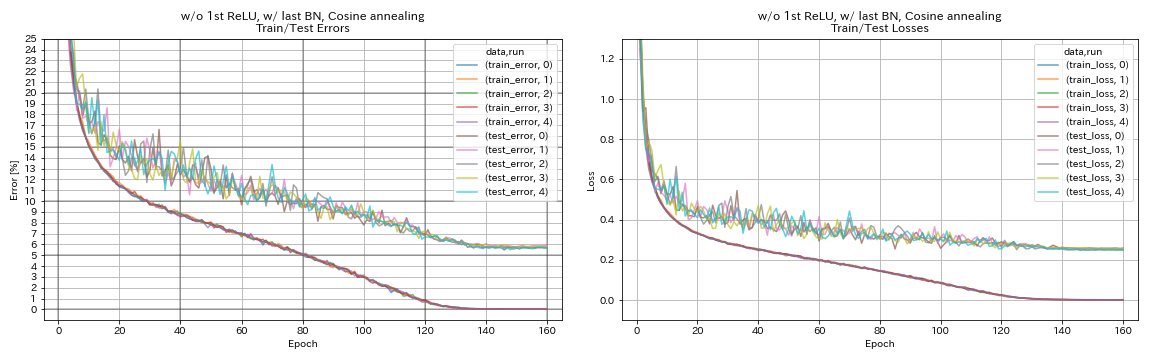
w/ o 1st relu, w/ สุดท้าย bn, cutout
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00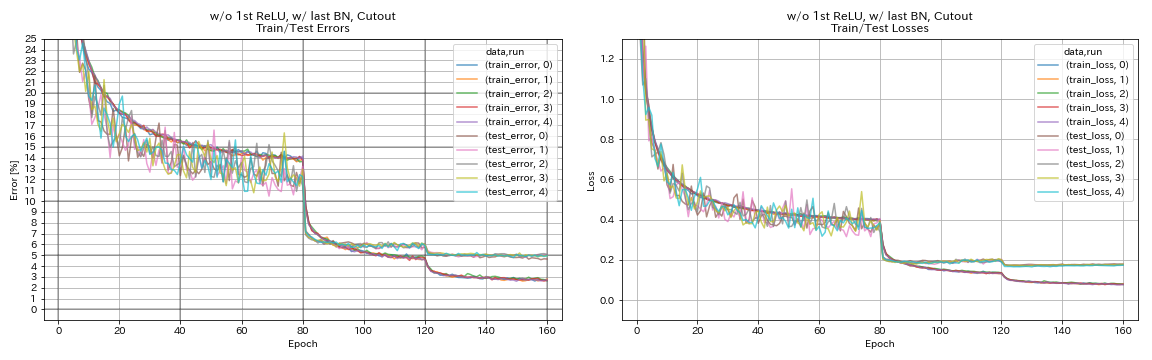
w/ o 1st relu, w/ สุดท้าย bn, randomerasing
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00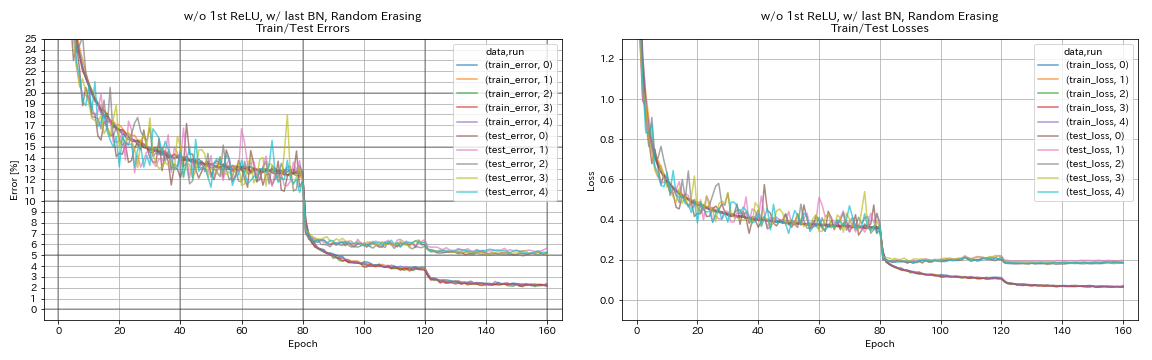
w/ o 1st relu, w/ last bn, mixup
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00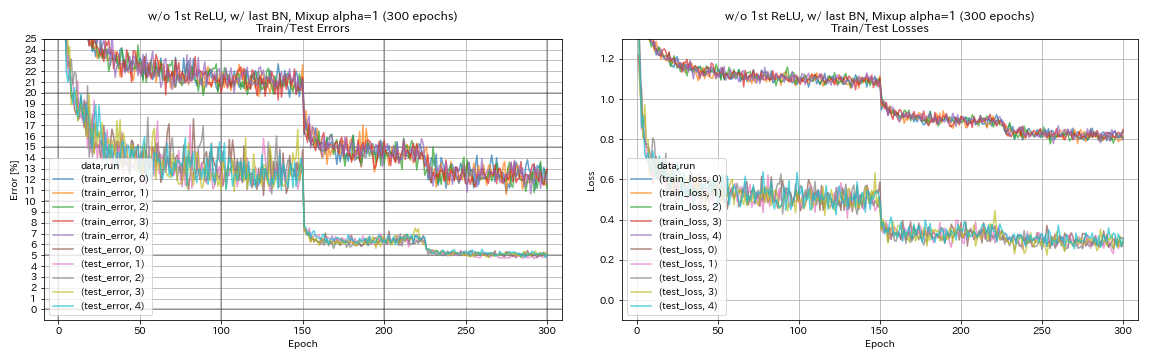
การทดลองเกี่ยวกับการปรับฉลากให้เรียบมิกซ์, ริคัพและสองคาสเอาท์
ผลลัพธ์ใน CIFAR-10
| แบบอย่าง | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | # ของยุค | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 7.60 | 200 | 24 เมตร |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.001) | 7.51 | 200 | 25m |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.01) | 7.21 | 200 | 25m |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.1) | 7.57 | 200 | 25m |
| resnet-preact-20, mixup (alpha = 1) | 7.24 | 200 | 26m |
| resnet-preact-20, ricap (beta = 0.3), w/ crop แบบสุ่ม | 6.88 | 200 | 28m |
| Resnet-Preact-20, RICAP (เบต้า = 0.3) | 6.77 | 200 | 28m |
| Resnet-Preact-20, Dual-Cutout 16 (Alpha = 0.1) | 6.24 | 200 | 45m |
| Resnet-Preact-20 | 7.05 | 400 | 49m |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.001) | 7.20 | 400 | 49m |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.01) | 6.97 | 400 | 49m |
| Resnet-Preact-20, Label Smoothing (Epsilon = 0.1) | 7.16 | 400 | 49m |
| resnet-preact-20, mixup (alpha = 1) | 6.66 | 400 | 51m |
| resnet-preact-20, ricap (beta = 0.3), w/ crop แบบสุ่ม | 6.30 | 400 | 56m |
| Resnet-Preact-20, RICAP (เบต้า = 0.3) | 6.19 | 400 | 56m |
| Resnet-Preact-20, Dual-Cutout 16 (Alpha = 0.1) | 5.55 | 400 | 1h36m |
บันทึก
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
- ทุกรุ่นได้รับการฝึกฝนโดยใช้การหลอมโคไซน์ด้วยอัตราการเรียนรู้เริ่มต้น 0.2
- GeForce GTX 1080 TI ใช้ในการทดลองเหล่านี้
การทดลองขนาดแบทช์และอัตราการเรียนรู้
- การทดลองต่อไปนี้จะทำในชุดข้อมูล CIFAR-10 โดยใช้ GeForce 1080 TI
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
กฎการปรับขนาดเชิงเส้นสำหรับอัตราการเรียนรู้
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | โคไซน์ | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 200 | 8.87 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | โคไซน์ | 200 | 8.22 | 20m |
| Resnet-Preact-20 | 256 | 0.2 | โคไซน์ | 200 | 8.61 | 22m |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 200 | 8.09 | 24 เมตร |
| Resnet-Preact-20 | 64 | 0.05 | โคไซน์ | 200 | 8.22 | 28m |
| Resnet-Preact-20 | 32 | 0.025 | โคไซน์ | 200 | 8.00 | 43m |
| Resnet-Preact-20 | 16 | 0.0125 | โคไซน์ | 200 | 7.75 | 1H17M |
| Resnet-Preact-20 | 8 | 0.006125 | โคไซน์ | 200 | 7.70 | 2h32m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | หลายขั้นตอน | 200 | 28.97 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | หลายขั้นตอน | 200 | 9.07 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | หลายขั้นตอน | 200 | 8.62 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | หลายขั้นตอน | 200 | 8.23 | 20m |
| Resnet-Preact-20 | 256 | 0.2 | หลายขั้นตอน | 200 | 8.40 | 21m |
| Resnet-Preact-20 | 128 | 0.1 | หลายขั้นตอน | 200 | 8.28 | 24 เมตร |
| Resnet-Preact-20 | 64 | 0.05 | หลายขั้นตอน | 200 | 8.13 | 28m |
| Resnet-Preact-20 | 32 | 0.025 | หลายขั้นตอน | 200 | 7.58 | 43m |
| Resnet-Preact-20 | 16 | 0.0125 | หลายขั้นตอน | 200 | 7.93 | 1h18m |
| Resnet-Preact-20 | 8 | 0.006125 | หลายขั้นตอน | 200 | 8.31 | 2h34m |
การปรับขนาดเชิงเส้น + การฝึกอบรมอีกต่อไป
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | โคไซน์ | 400 | 8.97 | 44m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 400 | 7.85 | 43m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 400 | 7.20 | 42m |
| Resnet-Preact-20 | 512 | 0.4 | โคไซน์ | 400 | 7.83 | 40m |
| Resnet-Preact-20 | 256 | 0.2 | โคไซน์ | 400 | 7.65 | 42m |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 400 | 7.09 | 47m |
| Resnet-Preact-20 | 64 | 0.05 | โคไซน์ | 400 | 7.17 | 44m |
| Resnet-Preact-20 | 32 | 0.025 | โคไซน์ | 400 | 7.24 | 2h11m |
| Resnet-Preact-20 | 16 | 0.0125 | โคไซน์ | 400 | 7.26 | 4H10M |
| Resnet-Preact-20 | 8 | 0.006125 | โคไซน์ | 400 | 7.02 | 7h53m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | โคไซน์ | 800 | 8.14 | 1h29m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 800 | 7.74 | 1h23m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 800 | 7.15 | 1h31m |
| Resnet-Preact-20 | 512 | 0.4 | โคไซน์ | 800 | 7.27 | 1h25m |
| Resnet-Preact-20 | 256 | 0.2 | โคไซน์ | 800 | 7.22 | 1h26m |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 800 | 6.68 | 1h35m |
| Resnet-Preact-20 | 64 | 0.05 | โคไซน์ | 800 | 7.18 | 2h20m |
| Resnet-Preact-20 | 32 | 0.025 | โคไซน์ | 800 | 7.03 | 4H16M |
| Resnet-Preact-20 | 16 | 0.0125 | โคไซน์ | 800 | 6.78 | 8H37M |
| Resnet-Preact-20 | 8 | 0.006125 | โคไซน์ | 800 | 6.89 | 16h47m |
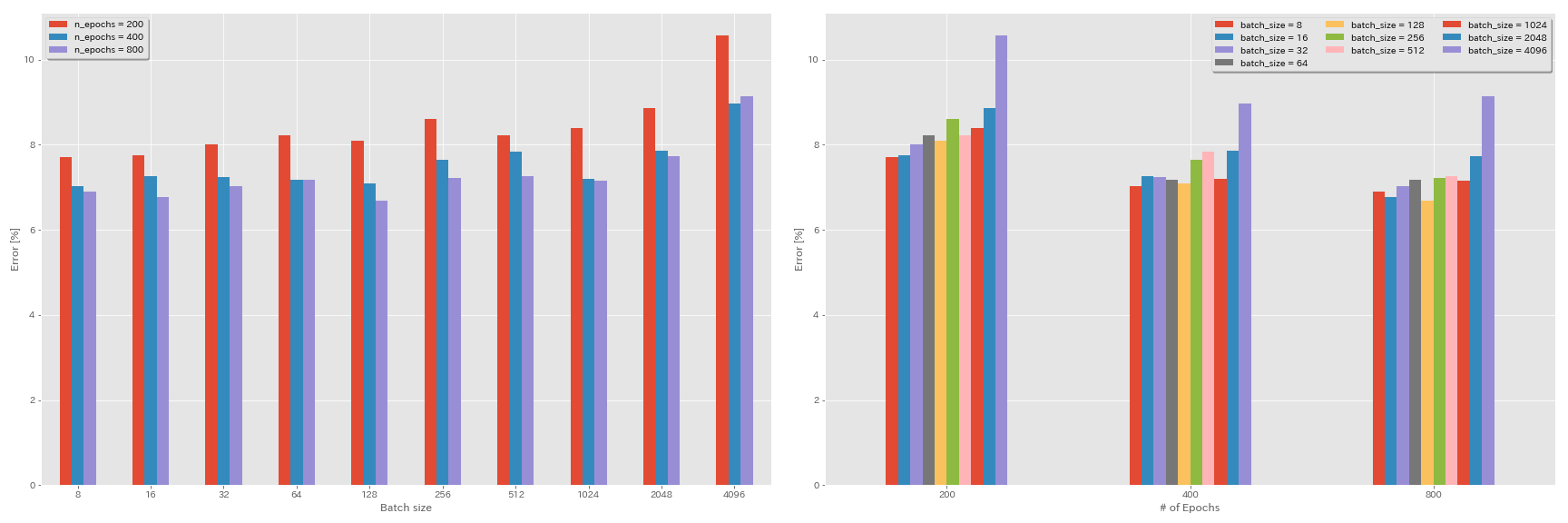
ผลของอัตราการเรียนรู้เริ่มต้น
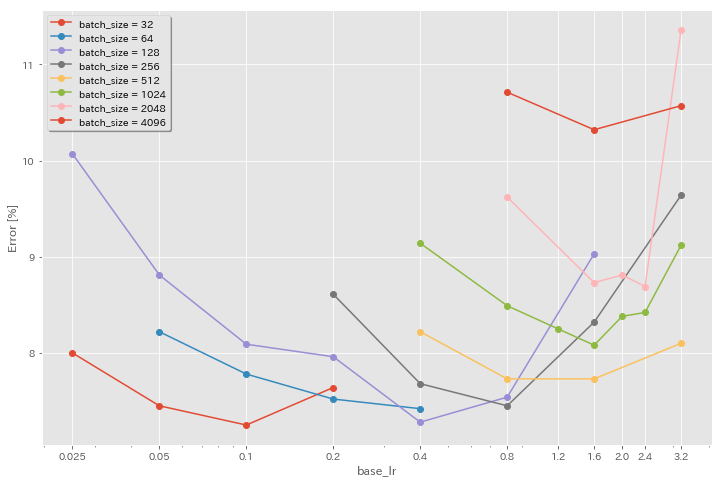
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 3.2 | โคไซน์ | 200 | 10.57 | 22m |
| Resnet-Preact-20 | 4096 | 1.6 | โคไซน์ | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 4096 | 0.8 | โคไซน์ | 200 | 10.71 | 22m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 2048 | 3.2 | โคไซน์ | 200 | 11.34 | 21m |
| Resnet-Preact-20 | 2048 | 2.4 | โคไซน์ | 200 | 8.69 | 21m |
| Resnet-Preact-20 | 2048 | 2.0 | โคไซน์ | 200 | 8.81 | 21m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 2048 | 0.8 | โคไซน์ | 200 | 9.62 | 21m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 1024 | 3.2 | โคไซน์ | 200 | 9.12 | 21m |
| Resnet-Preact-20 | 1024 | 2.4 | โคไซน์ | 200 | 8.42 | 22m |
| Resnet-Preact-20 | 1024 | 2.0 | โคไซน์ | 200 | 8.38 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | โคไซน์ | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 1.2 | โคไซน์ | 200 | 8.25 | 21m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 1024 | 0.4 | โคไซน์ | 200 | 8.49 | 22m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 512 | 3.2 | โคไซน์ | 200 | 8.51 | 21m |
| Resnet-Preact-20 | 512 | 1.6 | โคไซน์ | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0.8 | โคไซน์ | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 512 | 0.4 | โคไซน์ | 200 | 8.22 | 20m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 256 | 3.2 | โคไซน์ | 200 | 9.64 | 22m |
| Resnet-Preact-20 | 256 | 1.6 | โคไซน์ | 200 | 8.32 | 22m |
| Resnet-Preact-20 | 256 | 0.8 | โคไซน์ | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 256 | 0.4 | โคไซน์ | 200 | 7.68 | 22m |
| Resnet-Preact-20 | 256 | 0.2 | โคไซน์ | 200 | 8.61 | 22m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 128 | 1.6 | โคไซน์ | 200 | 9.03 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.8 | โคไซน์ | 200 | 7.54 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.4 | โคไซน์ | 200 | 7.28 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.2 | โคไซน์ | 200 | 7.96 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 200 | 8.09 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.05 | โคไซน์ | 200 | 8.81 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.025 | โคไซน์ | 200 | 10.07 | 24 เมตร |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 64 | 0.4 | โคไซน์ | 200 | 7.42 | 35m |
| Resnet-Preact-20 | 64 | 0.2 | โคไซน์ | 200 | 7.52 | 36 เมตร |
| Resnet-Preact-20 | 64 | 0.1 | โคไซน์ | 200 | 7.78 | 37m |
| Resnet-Preact-20 | 64 | 0.05 | โคไซน์ | 200 | 8.22 | 28m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 32 | 0.2 | โคไซน์ | 200 | 7.64 | 1h05m |
| Resnet-Preact-20 | 32 | 0.1 | โคไซน์ | 200 | 7.25 | 1h08m |
| Resnet-Preact-20 | 32 | 0.05 | โคไซน์ | 200 | 7.45 | 1H07M |
| Resnet-Preact-20 | 32 | 0.025 | โคไซน์ | 200 | 8.00 | 43m |
อัตราการเรียนรู้ที่ดี + การฝึกอบรมอีกต่อไป
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | โคไซน์ | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | 1.6 | โคไซน์ | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 200 | 8.08 | 22m |
| Resnet-Preact-20 | 512 | 1.6 | โคไซน์ | 200 | 7.73 | 20m |
| Resnet-Preact-20 | 512 | 0.8 | โคไซน์ | 200 | 7.73 | 21m |
| Resnet-Preact-20 | 256 | 0.8 | โคไซน์ | 200 | 7.45 | 21m |
| Resnet-Preact-20 | 128 | 0.4 | โคไซน์ | 200 | 7.28 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.2 | โคไซน์ | 200 | 7.96 | 24 เมตร |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 200 | 8.09 | 24 เมตร |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | โคไซน์ | 800 | 8.36 | 1h33m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 800 | 7.53 | 1h27m |
| Resnet-Preact-20 | 1024 | 1.6 | โคไซน์ | 800 | 7.30 | 1h30m |
| Resnet-Preact-20 | 1024 | 0.8 | โคไซน์ | 800 | 7.42 | 1h30m |
| Resnet-Preact-20 | 512 | 1.6 | โคไซน์ | 800 | 6.69 | 1h26m |
| Resnet-Preact-20 | 512 | 0.8 | โคไซน์ | 800 | 6.77 | 1h26m |
| Resnet-Preact-20 | 256 | 0.8 | โคไซน์ | 800 | 6.84 | 1h28m |
| Resnet-Preact-20 | 128 | 0.4 | โคไซน์ | 800 | 6.86 | 1h35m |
| Resnet-Preact-20 | 128 | 0.2 | โคไซน์ | 800 | 7.05 | 1h38m |
| Resnet-Preact-20 | 128 | 0.1 | โคไซน์ | 800 | 6.68 | 1h35m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | โคไซน์ | 1600 | 8.25 | 3H10M |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 1600 | 7.34 | 2h50m |
| Resnet-Preact-20 | 1024 | 1.6 | โคไซน์ | 1600 | 6.94 | 2h52m |
| Resnet-Preact-20 | 512 | 1.6 | โคไซน์ | 1600 | 6.99 | 2h44m |
| Resnet-Preact-20 | 256 | 0.8 | โคไซน์ | 1600 | 6.95 | 2h50m |
| Resnet-Preact-20 | 128 | 0.4 | โคไซน์ | 1600 | 6.64 | 3H09M |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 4096 | 1.6 | โคไซน์ | 3200 | 9.52 | 6h15m |
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 3200 | 6.92 | 5h42m |
| Resnet-Preact-20 | 1024 | 1.6 | โคไซน์ | 3200 | 6.96 | 5h43m |
| แบบอย่าง | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 2048 | 1.6 | โคไซน์ | 6400 | 7.45 | 11h44m |
ลาร์ส
- ในเอกสารต้นฉบับ (1708.03888, 1801.03137) พวกเขาใช้การกำหนดตารางการเรียนรู้การสลายตัวของพหุนาม
- ในการดำเนินการนี้ไม่ได้ใช้สัมประสิทธิ์ LARS ดังนั้นควรปรับอัตราการเรียนรู้ตามนั้น
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00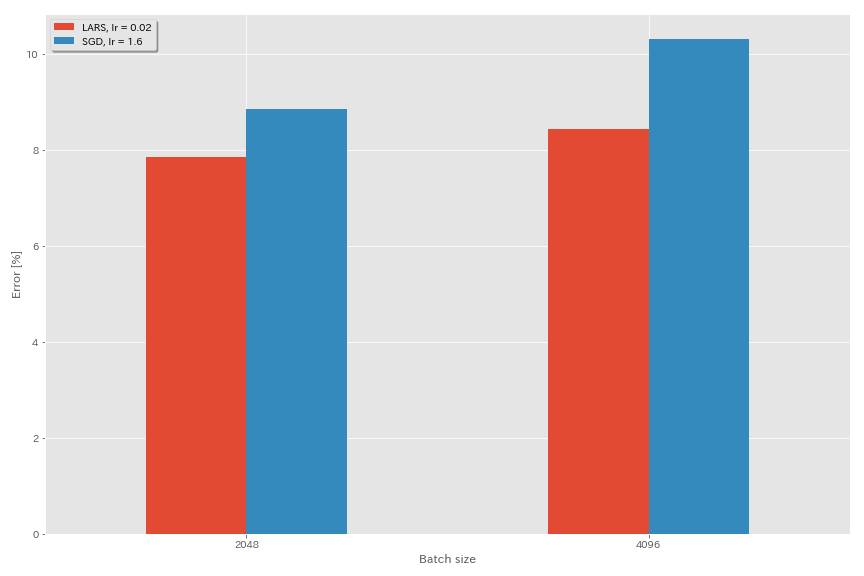
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 4096 | 3.2 | โคไซน์ | 200 | 10.57 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | โคไซน์ | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 0.8 | โคไซน์ | 200 | 10.71 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.04 | โคไซน์ | 200 | 9.58 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.03 | โคไซน์ | 200 | 8.46 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.02 | โคไซน์ | 200 | 8.21 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.015 | โคไซน์ | 200 | 8.47 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.01 | โคไซน์ | 200 | 9.33 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.005 | โคไซน์ | 200 | 14.31 | 22m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 2048 | 3.2 | โคไซน์ | 200 | 11.34 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.4 | โคไซน์ | 200 | 8.69 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 2.0 | โคไซน์ | 200 | 8.81 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 2048 | 1.6 | โคไซน์ | 200 | 8.73 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 2048 | 0.8 | โคไซน์ | 200 | 9.62 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | ลาร์ส | 2048 | 0.04 | โคไซน์ | 200 | 11.58 | 21m |
| Resnet-Preact-20 | ลาร์ส | 2048 | 0.02 | โคไซน์ | 200 | 8.05 | 22m |
| Resnet-Preact-20 | ลาร์ส | 2048 | 0.01 | โคไซน์ | 200 | 8.07 | 22m |
| Resnet-Preact-20 | ลาร์ส | 2048 | 0.005 | โคไซน์ | 200 | 9.65 | 22m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 1024 | 3.2 | โคไซน์ | 200 | 9.12 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 2.4 | โคไซน์ | 200 | 8.42 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 2.0 | โคไซน์ | 200 | 8.38 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.6 | โคไซน์ | 200 | 8.07 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 1.2 | โคไซน์ | 200 | 8.25 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 1024 | 0.8 | โคไซน์ | 200 | 8.08 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 1024 | 0.4 | โคไซน์ | 200 | 8.49 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | ลาร์ส | 1024 | 0.02 | โคไซน์ | 200 | 9.30 | 22m |
| Resnet-Preact-20 | ลาร์ส | 1024 | 0.01 | โคไซน์ | 200 | 7.68 | 22m |
| Resnet-Preact-20 | ลาร์ส | 1024 | 0.005 | โคไซน์ | 200 | 8.88 | 23m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 512 | 3.2 | โคไซน์ | 200 | 8.51 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 512 | 1.6 | โคไซน์ | 200 | 7.73 (1 วิ่ง) | 20m |
| Resnet-Preact-20 | SGD | 512 | 0.8 | โคไซน์ | 200 | 7.73 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 512 | 0.4 | โคไซน์ | 200 | 8.22 (1 วิ่ง) | 20m |
| Resnet-Preact-20 | ลาร์ส | 512 | 0.015 | โคไซน์ | 200 | 9.84 | 23m |
| Resnet-Preact-20 | ลาร์ส | 512 | 0.01 | โคไซน์ | 200 | 8.05 | 23m |
| Resnet-Preact-20 | ลาร์ส | 512 | 0.0075 | โคไซน์ | 200 | 7.58 | 23m |
| Resnet-Preact-20 | ลาร์ส | 512 | 0.005 | โคไซน์ | 200 | 7.96 | 23m |
| Resnet-Preact-20 | ลาร์ส | 512 | 0.0025 | โคไซน์ | 200 | 8.83 | 23m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 256 | 3.2 | โคไซน์ | 200 | 9.64 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 256 | 1.6 | โคไซน์ | 200 | 8.32 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0.8 | โคไซน์ | 200 | 7.45 (1 วิ่ง) | 21m |
| Resnet-Preact-20 | SGD | 256 | 0.4 | โคไซน์ | 200 | 7.68 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | SGD | 256 | 0.2 | โคไซน์ | 200 | 8.61 (1 วิ่ง) | 22m |
| Resnet-Preact-20 | ลาร์ส | 256 | 0.01 | โคไซน์ | 200 | 8.95 | 27m |
| Resnet-Preact-20 | ลาร์ส | 256 | 0.005 | โคไซน์ | 200 | 7.75 | 28m |
| Resnet-Preact-20 | ลาร์ส | 256 | 0.0025 | โคไซน์ | 200 | 8.21 | 28m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 128 | 1.6 | โคไซน์ | 200 | 9.03 (1 วิ่ง) | 24 เมตร |
| Resnet-Preact-20 | SGD | 128 | 0.8 | โคไซน์ | 200 | 7.54 (1 วิ่ง) | 24 เมตร |
| Resnet-Preact-20 | SGD | 128 | 0.4 | โคไซน์ | 200 | 7.28 (1 วิ่ง) | 24 เมตร |
| Resnet-Preact-20 | SGD | 128 | 0.2 | โคไซน์ | 200 | 7.96 (1 วิ่ง) | 24 เมตร |
| Resnet-Preact-20 | ลาร์ส | 128 | 0.005 | โคไซน์ | 200 | 7.96 | 37m |
| Resnet-Preact-20 | ลาร์ส | 128 | 0.0025 | โคไซน์ | 200 | 7.98 | 37m |
| Resnet-Preact-20 | ลาร์ส | 128 | 0.00125 | โคไซน์ | 200 | 9.21 | 37m |
| แบบอย่าง | การเพิ่มประสิทธิภาพ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | SGD | 4096 | 1.6 | โคไซน์ | 200 | 10.20 | 22m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | โคไซน์ | 800 | 8.36 (1 วิ่ง) | 1h33m |
| Resnet-Preact-20 | SGD | 4096 | 1.6 | โคไซน์ | 1600 | 8.25 (1 วิ่ง) | 3H10M |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.02 | โคไซน์ | 200 | 8.21 | 22m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.02 | โคไซน์ | 400 | 7.53 | 44m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.02 | โคไซน์ | 800 | 7.48 | 1h29m |
| Resnet-Preact-20 | ลาร์ส | 4096 | 0.02 | โคไซน์ | 1600 | 7.37 (1 วิ่ง) | 2h58m |
ผี BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| แบบอย่าง | ขนาดแบทช์ | ขนาดชุดผี | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 8192 | N/A | 1.6 | โคไซน์ | 200 | 12.35 | 25m* |
| Resnet-Preact-20 | 4096 | N/A | 1.6 | โคไซน์ | 200 | 10.32 | 22m |
| Resnet-Preact-20 | 2048 | N/A | 1.6 | โคไซน์ | 200 | 8.73 | 22m |
| Resnet-Preact-20 | 1024 | N/A | 1.6 | โคไซน์ | 200 | 8.07 | 22m |
| Resnet-Preact-20 | 128 | N/A | 0.4 | โคไซน์ | 200 | 7.28 | 24 เมตร |
| แบบอย่าง | ขนาดแบทช์ | ขนาดชุดผี | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | โคไซน์ | 200 | 11.51 | 27m |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | โคไซน์ | 200 | 9.73 | 25m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | โคไซน์ | 200 | 8.77 | 24 เมตร |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | โคไซน์ | 200 | 7.82 | 22m |
| แบบอย่าง | ขนาดแบทช์ | ขนาดชุดผี | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 8192 | N/A | 1.6 | โคไซน์ | 1600 | | |
| Resnet-Preact-20 | 4096 | N/A | 1.6 | โคไซน์ | 1600 | 8.25 | 3H10M |
| Resnet-Preact-20 | 2048 | N/A | 1.6 | โคไซน์ | 1600 | 7.34 | 2h50m |
| Resnet-Preact-20 | 1024 | N/A | 1.6 | โคไซน์ | 1600 | 6.94 | 2h52m |
| แบบอย่าง | ขนาดแบทช์ | ขนาดชุดผี | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | 8192 | 128 | 1.6 | โคไซน์ | 1600 | 11.83 | 3H37M |
| Resnet-Preact-20 | 4096 | 128 | 1.6 | โคไซน์ | 1600 | 8.95 | 3h15m |
| Resnet-Preact-20 | 2048 | 128 | 1.6 | โคไซน์ | 1600 | 7.23 | 3H05M |
| Resnet-Preact-20 | 1024 | 128 | 1.6 | โคไซน์ | 1600 | 7.08 | 2h59m |
ไม่มีการสลายตัวของน้ำหนักใน BN
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00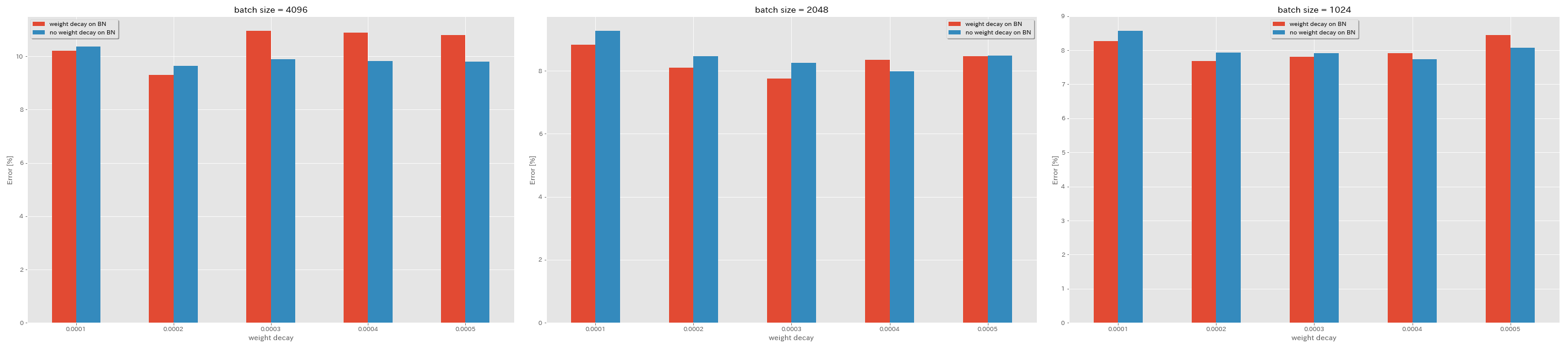
| แบบอย่าง | การสลายตัวของน้ำหนักใน BN | การสลายตัวของน้ำหนัก | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | ใช่ | 5E-4 | 4096 | 1.6 | โคไซน์ | 200 | 10.81 | 22m |
| Resnet-Preact-20 | ใช่ | 4e-4 | 4096 | 1.6 | โคไซน์ | 200 | 10.88 | 22m |
| Resnet-Preact-20 | ใช่ | 3e-4 | 4096 | 1.6 | โคไซน์ | 200 | 10.96 | 22m |
| Resnet-Preact-20 | ใช่ | 2e-4 | 4096 | 1.6 | โคไซน์ | 200 | 9.30 | 22m |
| Resnet-Preact-20 | ใช่ | 1E-4 | 4096 | 1.6 | โคไซน์ | 200 | 10.20 | 22m |
| Resnet-Preact-20 | เลขที่ | 5E-4 | 4096 | 1.6 | โคไซน์ | 200 | 8.78 | 22m |
| Resnet-Preact-20 | เลขที่ | 4e-4 | 4096 | 1.6 | โคไซน์ | 200 | 9.83 | 22m |
| Resnet-Preact-20 | เลขที่ | 3e-4 | 4096 | 1.6 | โคไซน์ | 200 | 9.90 | 22m |
| Resnet-Preact-20 | เลขที่ | 2e-4 | 4096 | 1.6 | โคไซน์ | 200 | 9.64 | 22m |
| Resnet-Preact-20 | เลขที่ | 1E-4 | 4096 | 1.6 | โคไซน์ | 200 | 10.38 | 22m |
| แบบอย่าง | การสลายตัวของน้ำหนักใน BN | การสลายตัวของน้ำหนัก | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | ใช่ | 5E-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.46 | 20m |
| Resnet-Preact-20 | ใช่ | 4e-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.35 | 20m |
| Resnet-Preact-20 | ใช่ | 3e-4 | 2048 | 1.6 | โคไซน์ | 200 | 7.76 | 20m |
| Resnet-Preact-20 | ใช่ | 2e-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.09 | 20m |
| Resnet-Preact-20 | ใช่ | 1E-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.83 | 20m |
| Resnet-Preact-20 | เลขที่ | 5E-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.49 | 20m |
| Resnet-Preact-20 | เลขที่ | 4e-4 | 2048 | 1.6 | โคไซน์ | 200 | 7.98 | 20m |
| Resnet-Preact-20 | เลขที่ | 3e-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.26 | 20m |
| Resnet-Preact-20 | เลขที่ | 2e-4 | 2048 | 1.6 | โคไซน์ | 200 | 8.47 | 20m |
| Resnet-Preact-20 | เลขที่ | 1E-4 | 2048 | 1.6 | โคไซน์ | 200 | 9.27 | 20m |
| แบบอย่าง | การสลายตัวของน้ำหนักใน BN | การสลายตัวของน้ำหนัก | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (ค่ามัธยฐานของ 3 วิ่ง) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | ใช่ | 5E-4 | 1024 | 1.6 | โคไซน์ | 200 | 8.45 | 21m |
| Resnet-Preact-20 | ใช่ | 4e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.91 | 21m |
| Resnet-Preact-20 | ใช่ | 3e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.81 | 21m |
| Resnet-Preact-20 | ใช่ | 2e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.69 | 21m |
| Resnet-Preact-20 | ใช่ | 1E-4 | 1024 | 1.6 | โคไซน์ | 200 | 8.26 | 21m |
| Resnet-Preact-20 | เลขที่ | 5E-4 | 1024 | 1.6 | โคไซน์ | 200 | 8.08 | 21m |
| Resnet-Preact-20 | เลขที่ | 4e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.73 | 21m |
| Resnet-Preact-20 | เลขที่ | 3e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.92 | 21m |
| Resnet-Preact-20 | เลขที่ | 2e-4 | 1024 | 1.6 | โคไซน์ | 200 | 7.93 | 21m |
| Resnet-Preact-20 | เลขที่ | 1E-4 | 1024 | 1.6 | โคไซน์ | 200 | 8.53 | 21m |
การทดลองเกี่ยวกับความแม่นยำครึ่งและความแม่นยำผสม
- การทดลองต่อไปนี้จำเป็นต้องมี Nvidia Apex
- การทดลองต่อไปนี้จะทำในชุดข้อมูล CIFAR-10 โดยใช้ GeForce 1080 TI ซึ่งไม่มีแกนเทนเซอร์
- ผลลัพธ์ที่รายงานในตารางคือข้อผิดพลาดในการทดสอบในยุคสุดท้าย
การฝึกอบรม FP16
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00การฝึกอบรมแบบผสมผสาน
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00ผลลัพธ์
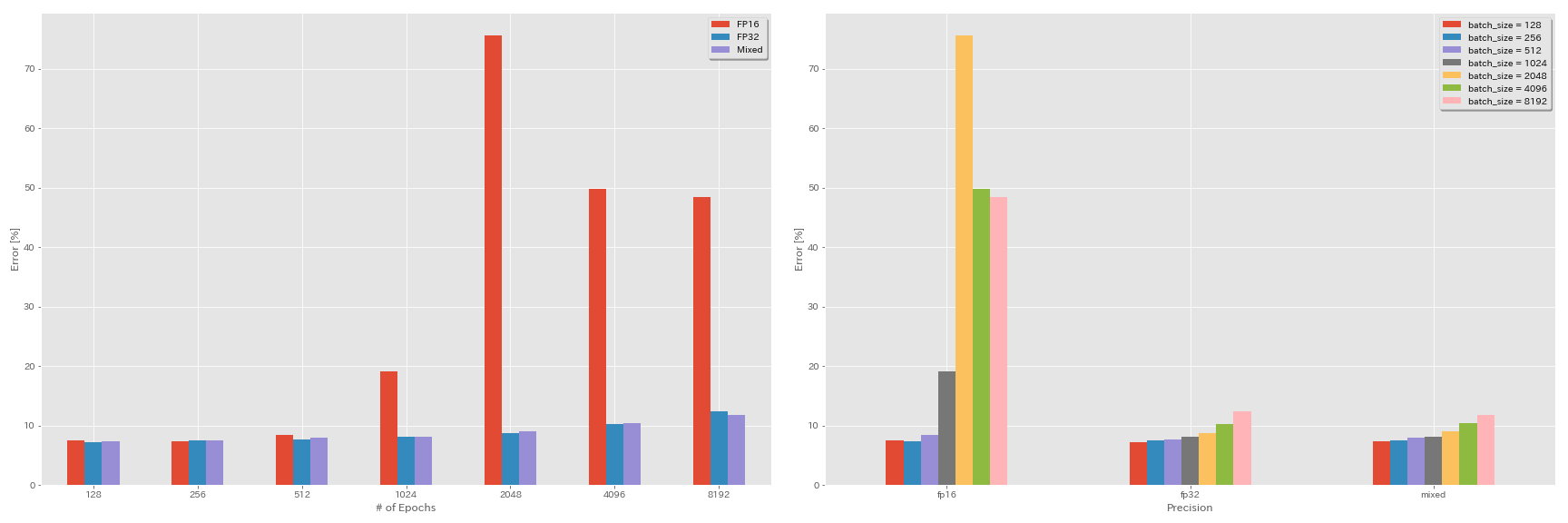
| แบบอย่าง | ความแม่นยำ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | fp32 | 8192 | 1.6 | โคไซน์ | 200 | | |
| Resnet-Preact-20 | fp32 | 4096 | 1.6 | โคไซน์ | 200 | 10.32 | 22m |
| Resnet-Preact-20 | fp32 | 2048 | 1.6 | โคไซน์ | 200 | 8.73 | 22m |
| Resnet-Preact-20 | fp32 | 1024 | 1.6 | โคไซน์ | 200 | 8.07 | 22m |
| Resnet-Preact-20 | fp32 | 512 | 0.8 | โคไซน์ | 200 | 7.73 | 21m |
| Resnet-Preact-20 | fp32 | 256 | 0.8 | โคไซน์ | 200 | 7.45 | 21m |
| Resnet-Preact-20 | fp32 | 128 | 0.4 | โคไซน์ | 200 | 7.28 | 24 เมตร |
| แบบอย่าง | ความแม่นยำ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | FP16 | 8192 | 1.6 | โคไซน์ | 200 | 48.52 | 33m |
| Resnet-Preact-20 | FP16 | 4096 | 1.6 | โคไซน์ | 200 | 49.84 | 28m |
| Resnet-Preact-20 | FP16 | 2048 | 1.6 | โคไซน์ | 200 | 75.63 | 27m |
| Resnet-Preact-20 | FP16 | 1024 | 1.6 | โคไซน์ | 200 | 19.09 | 27m |
| Resnet-Preact-20 | FP16 | 512 | 0.8 | โคไซน์ | 200 | 7.89 | 26m |
| Resnet-Preact-20 | FP16 | 256 | 0.8 | โคไซน์ | 200 | 7.40 | 28m |
| Resnet-Preact-20 | FP16 | 128 | 0.4 | โคไซน์ | 200 | 7.59 | 32m |
| แบบอย่าง | ความแม่นยำ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | ผสมกัน | 8192 | 1.6 | โคไซน์ | 200 | 11.78 | 28m |
| Resnet-Preact-20 | ผสมกัน | 4096 | 1.6 | โคไซน์ | 200 | 10.48 | 27m |
| Resnet-Preact-20 | ผสมกัน | 2048 | 1.6 | โคไซน์ | 200 | 8.98 | 26m |
| Resnet-Preact-20 | ผสมกัน | 1024 | 1.6 | โคไซน์ | 200 | 8.05 | 26m |
| Resnet-Preact-20 | ผสมกัน | 512 | 0.8 | โคไซน์ | 200 | 7.81 | 28m |
| Resnet-Preact-20 | ผสมกัน | 256 | 0.8 | โคไซน์ | 200 | 7.58 | 32m |
| Resnet-Preact-20 | ผสมกัน | 128 | 0.4 | โคไซน์ | 200 | 7.37 | 41m |
ผลลัพธ์โดยใช้ Tesla v100
| แบบอย่าง | ความแม่นยำ | ขนาดแบทช์ | LR เริ่มต้น | ตาราง LR | # ของยุค | ข้อผิดพลาดในการทดสอบ (1 รัน) | เวลาฝึกอบรม |
|---|
| Resnet-Preact-20 | fp32 | 8192 | 1.6 | โคไซน์ | 200 | 12.35 | 25m |
| Resnet-Preact-20 | fp32 | 4096 | 1.6 | โคไซน์ | 200 | 9.88 | 19m |
| Resnet-Preact-20 | fp32 | 2048 | 1.6 | โคไซน์ | 200 | 8.87 | 17m |
| Resnet-Preact-20 | fp32 | 1024 | 1.6 | โคไซน์ | 200 | 8.45 | 18m |
| Resnet-Preact-20 | ผสมกัน | 8192 | 1.6 | โคไซน์ | 200 | 11.92 | 25m |
| Resnet-Preact-20 | ผสมกัน | 4096 | 1.6 | โคไซน์ | 200 | 10.16 | 19m |
| Resnet-Preact-20 | ผสมกัน | 2048 | 1.6 | โคไซน์ | 200 | 9.10 | 17m |
| Resnet-Preact-20 | ผสมกัน | 1024 | 1.6 | โคไซน์ | 200 | 7.84 | 16m |
การอ้างอิง
สถาปัตยกรรมแบบจำลอง
- เขา, Kaiming, Xiangyu Zhang, Shaoqing Ren และ Jian Sun "การเรียนรู้ที่เหลืออยู่ลึกสำหรับการจดจำภาพ" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2016. ลิงก์, arxiv: 1512.03385
- เขา, Kaiming, Xiangyu Zhang, Shaoqing Ren และ Jian Sun "การแมปข้อมูลประจำตัวในเครือข่ายที่เหลืออยู่ลึก" ในการประชุมยุโรปเกี่ยวกับวิสัยทัศน์คอมพิวเตอร์ (ECCV) 2016. Arxiv: 1603.05027, การใช้งานคบเพลิง
- Zagoruyko, Sergey และ Nikos Komodakis "เครือข่ายที่เหลืออยู่กว้าง" การประชุมวิสัยทัศน์ของ British Machine Vision Conference (BMVC), 2016. Arxiv: 1605.07146, การใช้งาน Torch
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger และ Laurens van der Maaten "เครือข่าย Convolutional ที่เชื่อมต่อหนาแน่น" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2017. ลิงก์, arxiv: 1608.06993, การใช้งานคบเพลิง
- ฮัน, ดองปี, Jiwhan Kim และ Junmo Kim "เครือข่ายที่เหลือจากเสี้ยม" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2017. ลิงก์, arxiv: 1610.02915, การติดตั้งคบเพลิง, การใช้งานคาเฟอีน, การใช้งาน Pytorch
- Xie, Sained, Ross Girshick, Piotr Dollar, Zhuowen Tu และ Kaiming เขา "การเปลี่ยนแปลงที่เหลือรวมสำหรับเครือข่ายประสาทลึก" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2017. ลิงก์, arxiv: 1611.05431, การใช้งานคบเพลิง
- Gastaldi, Xavier "Shake Shake การทำให้เป็นมาตรฐานของเครือข่ายที่เหลือ 3 สาขา" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR) การประชุมเชิงปฏิบัติการ, 2017. ลิงก์, arxiv: 1705.07485, การใช้งานคบเพลิง
- Hu, Jie, Li Shen และ Gang Sun "เครือข่ายการบีบและการกระตุ้น" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2018, pp. 7132-7141 Link, arxiv: 1709.01507, การใช้งานคาเฟอีน
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten และ Kilian Q. Weinberger "เครือข่าย convolutional ที่มีการเชื่อมต่อหนาแน่น" ธุรกรรม IEEE เกี่ยวกับการวิเคราะห์รูปแบบและความฉลาดของเครื่องจักร (2019) arxiv: 2001.02394
การทำให้เป็นมาตรฐานการเพิ่มข้อมูล
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens และ Zbigniew Wojna "ทบทวนสถาปัตยกรรมเริ่มต้นสำหรับการมองเห็นคอมพิวเตอร์" การประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2016. ลิงก์, arxiv: 1512.00567
- Devries, Terrance และ Graham W. Taylor "ปรับปรุงการทำให้เป็นมาตรฐานของเครือข่ายประสาทแบบ convolutional ด้วย cutout" arxiv preprint arxiv: 1708.04552 (2017) arxiv: 1708.04552, การใช้งาน Pytorch
- Abu-El-Haija, Sami "การอัปเดตการไล่ระดับสีตามสัดส่วนด้วย PercentDelta" arxiv preprint arxiv: 1708.07227 (2017) arxiv: 1708.07227
- Zhong, Zhun, เหลียงเจิ้ง, Guoliang Kang, Shaozi Li และ Yi Yang "การลบข้อมูลการลบแบบสุ่ม" arxiv preprint arxiv: 1708.04896 (2017) arxiv: 1708.04896, การใช้งาน Pytorch
- จาง, ฮงยี่, Moustapha Cisse, Yann N. Dauphin และ David Lopez-Paz "Mixup: นอกเหนือจากการลดความเสี่ยงเชิงประจักษ์" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR), 2017. ลิงก์, arxiv: 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma และ Leslie Pack Kaelbling "สู่การทำความเข้าใจทั่วไปผ่านทฤษฎีการเรียนรู้เชิงวิเคราะห์" arxiv preprint arxiv: 1802.07426 (2018) arxiv: 1802.07426, การใช้งาน Pytorch
- Takahashi, Ryo, Takashi Matsubara และ Kuniaki Uehara "การเพิ่มข้อมูลโดยใช้การครอบตัดภาพแบบสุ่มและการปะทุสำหรับ CNNs ลึก" การดำเนินการของการประชุมเอเชียที่ 10 เกี่ยวกับการเรียนรู้ของเครื่อง (ACML), 2018. ลิงก์, arxiv: 1811.09030
- หยุน, ซางดู, ดองยูฮัน, ซองจุนโอน, Sanghyuk Chun, Junsuk Choe และ Youngjoon Yoo "Cutmix: กลยุทธ์การทำให้เป็นมาตรฐานในการฝึกอบรมนักแยกประเภทที่แข็งแกร่งด้วยคุณสมบัติที่สามารถปรับได้" arxiv preprint arxiv: 1905.04899 (2019) arxiv: 1905.04899
ชุดใหญ่
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy และ Ping Tak Peter Tang "ในการฝึกอบรมขนาดใหญ่สำหรับการเรียนรู้อย่างลึกซึ้ง: ช่องว่างการวางนัยทั่วไปและ minima ที่คมชัด" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR), 2017. ลิงก์, อาร์กซ์: 1609.04836
- Hoffer, Elad, Itay Hubara และ Daniel Soudry "ฝึกฝนอีกต่อไป, ทั่วไปดีขึ้น: การปิดช่องว่างทั่วไปในการฝึกอบรมแบทช์ขนาดใหญ่ของเครือข่ายประสาท" ในความก้าวหน้าในระบบการประมวลผลข้อมูลประสาท (NIPS), 2017. ลิงก์, arxiv: 1705.08741, การใช้งาน Pytorch
- Goyal, Priya, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia และ Kaiming เขา "Minibatch ขนาดใหญ่ที่แม่นยำ SGD: การฝึกอบรม Imagenet ใน 1 ชั่วโมง" arxiv preprint arxiv: 1706.02677 (2017) arxiv: 1706.02677
- คุณ, Yang, Igor Gitman และ Boris Ginsburg "การฝึกอบรมชุดใหญ่ของเครือข่าย Convolutional" arxiv preprint arxiv: 1708.03888 (2017) arxiv: 1708.03888
- คุณ, หยาง, Zhao Zhang, Cho-Jui Hsieh, James Demmel และ Kurt Keutzer "การฝึกอบรม Imagenet ในไม่กี่นาที" arxiv preprint arxiv: 1709.05011 (2017) arxiv: 1709.05011
- Smith, Samuel L. , Pieter-Jan Kindermans, Chris Ying และ Quoc V. Le "อย่าสลายอัตราการเรียนรู้เพิ่มขนาดแบทช์" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR), 2018. ลิงก์, arxiv: 1711.00489
- Gitman, Igor, Deepak Dilipkumar และ Ben Parr "การวิเคราะห์การบรรจบกันของอัลกอริทึมการไล่ระดับสีไล่ระดับสีด้วยการอัปเดตตามสัดส่วน" arxiv preprint arxiv: 1801.03137 (2018) arxiv: 1801.03137 การใช้งาน Tensorflow
- Jia, Xianyan, Shutao Song, Wei เขา, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai "ระบบการฝึกอบรมการเรียนรู้เชิงลึกที่ปรับขนาดได้สูงพร้อมความแม่นยำผสม: การฝึกอบรม Imagenet ในสี่นาที" arxiv preprint arxiv: 1807.11205 (2018) arxiv: 1807.11205
- Christopher J. , Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig และ George E. Dahl "การวัดผลกระทบของข้อมูลแบบขนานของข้อมูลต่อการฝึกอบรมเครือข่ายประสาท" arxiv preprint arxiv: 1811.03600 (2018) arxiv: 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang และ Youlong Cheng "การจำแนกภาพในระดับซูเปอร์คอมพิวเตอร์" ในความก้าวหน้าในระบบการประมวลผลข้อมูลระบบประสาท (Neurips) Workshop, 2018. ลิงก์, arxiv: 1811.06992
คนอื่น
- Loshchilov, Ilya และ Frank Hutter "SGDR: การไล่ระดับสีแบบสโตแคสติกด้วยการรีสตาร์ทที่อบอุ่น" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR), 2017. ลิงก์, อาร์กซ์: 1608.03983, การใช้งานลาซาน
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh และ Hao Wu "ผสมความแม่นยำผสม" ในการประชุมนานาชาติเกี่ยวกับการเป็นตัวแทนการเรียนรู้ (ICLR), 2018. ลิงก์, arxiv: 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt และ Vaishaal Shankar "ตัวแยกประเภท CIFAR-10 ทำให้ CIFAR-10 หรือไม่" arxiv preprint arxiv: 1806.00451 (2018) arxiv: 1806.00451
- เขาตองจีจางแขวนจางจงจงจางจุนหยวน Xie และมูลี่ "กระเป๋าของเทคนิคสำหรับการจำแนกรูปภาพด้วยเครือข่ายประสาทแบบ convolutional" arxiv preprint arxiv: 1812.01187 (2018) arxiv: 1812.01187


