Pytorch 이미지 분류
다음 논문은 Pytorch를 사용하여 구현됩니다.
- RESNET (1512.03385)
- RESNET-PREACT (1603.05027)
- WRN (1605.07146)
- Densenet (1608.06993, 2001.02394)
- 피라미드 넷 (1610.02915)
- Resnext (1611.05431)
- Shake-Shake (1705.07485)
- LARS (1708.03888, 1801.03137)
- 컷 아웃 (1708.04552)
- 무작위 지우기 (1708.04896)
- Senet (1709.01507)
- 믹스 업 (1710.09412)
- 듀얼 컷 아웃 (1802.07426)
- RICAP (1811.09030)
- Cutmix (1905.04899)
요구 사항
- Ubuntu (우분투에서만 테스트되었으므로 Windows에서는 작동하지 않을 수 있습니다.)
- 파이썬> = 3.7
- Pytorch> = 1.4.0
- 횃불
- nvidia apex
pip install -r requirements.txt
용법
python train.py --config configs/cifar/resnet_preact.yaml
CIFAR-10에 대한 결과
종이와 거의 동일한 설정을 사용한 결과
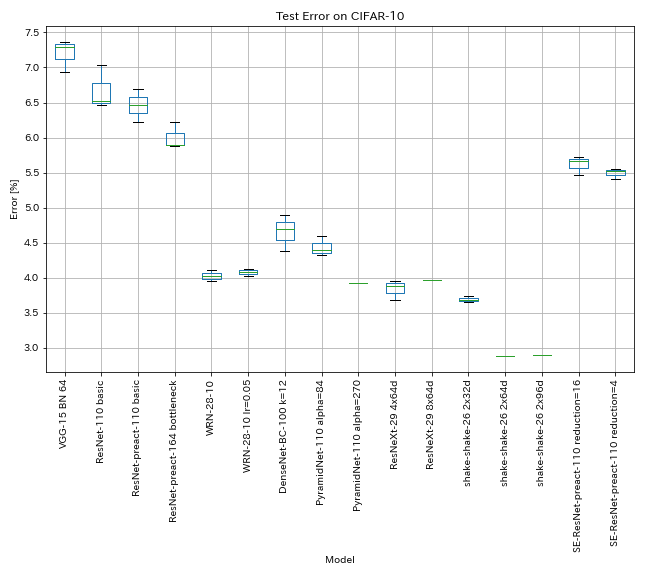
| 모델 | 테스트 오류 (중앙값 3 실행) | 테스트 오류 (종이) | 훈련 시간 |
|---|
| VGG- 유사 (깊이 15, bn, 채널 64) | 7.29 | N/A | 1H20M |
| RESNET-110 | 6.52 | 6.43 (최고), 6.61 +/- 0.16 | 3H06m |
| RESNET-PREACT-110 | 6.47 | 6.37 (중앙값 5 런) | 3H05m |
| RESNET-PREACT-164 병목 현상 | 5.90 | 5.46 (중앙값 5 런) | 4H01m |
| RESNET-PREACT-10001 병목 현상 | | 4.62 (중앙값 5 런), 4.69 +/- 0.20 | |
| WRN-28-10 | 4.03 | 4.00 (중앙값 5 런) | 16H10m |
| WRN-28-10 W/ 드롭 아웃 | | 3.89 (중앙값 5 런) | |
| Densenet-100 (k = 12) | 3.87 (1 런) | 4.10 (1 런) | 24h28m* |
| Densenet-100 (k = 24) | | 3.74 (1 런) | |
| Densenet-BC-100 (k = 12) | 4.69 | 4.51 (1 런) | 15h20m |
| Densenet-BC-250 (k = 24) | | 3.62 (1 런) | |
| Densenet-BC-190 (k = 40) | | 3.46 (1 런) | |
| 피라미드 넷 -110 (alpha = 84) | 4.40 | 4.26 +/- 0.23 | 11h40m |
| 피라미드 넷 -110 (alpha = 270) | 3.92 (1 런) | 3.73 +/- 0.04 | 24h12m* |
| Pyramidnet-164 병목 현상 (alpha = 270) | 3.44 (1 런) | 3.48 +/- 0.20 | 32h37m* |
| Pyramidnet-272 병목 현상 (alpha = 200) | | 3.31 +/- 0.08 | |
| Resnext-29 4x64d | 3.89 | ~ 3.75 (그림 7에서) | 31h17m |
| Resnext-29 8x64d | 3.97 (1 런) | 3.65 (평균 10 런) | 42h50m* |
| Resnext-29 16x64d | | 3.58 (평균 10 런) | |
| Shake-Shake-26 2x32d (SSI) | 3.68 | 3.55 (평균 3 런) | 33h49m |
| Shake-Shake-26 2x64d (SSI) | 2.88 (1 런) | 2.98 (평균 3 런) | 78h48m |
| Shake-Shake-26 2x96d (SSI) | 2.90 (1 런) | 2.86 (평균 5 런) | 101h32m* |
메모
- 교육 환경에서 논문의 차이점 :
- 배치 크기 64 (종이 128)로 훈련 된 WRN-28-10.
- 배치 크기 32 및 초기 학습 속도 0.05 (배치 크기 64 및 초기 학습 속도 0.1 종이)를 갖는 훈련 된 Densenet-BC-100 (k = 12).
- 단일 GPU, 배치 크기 32 및 초기 학습 속도 0.025 (8 개의 GPU, 배치 크기 128 및 초기 학습 속도 0.1 종이)를 갖춘 Resnext-29 4x64D.
- 단일 GPU (종이에 2 GPU)가있는 훈련 된 쉐이크 셰이크 모델.
- 배치 크기 64, 초기 학습 속도 0.1 인 훈련 된 쉐이크 셰이크 26 2x64d (SSI).
- 위에서보고 된 테스트 오류는 마침내 에포크입니다.
- 단 1 번의 실행에 대한 실험은 3 번의 실험에 사용되는 컴퓨터와 다른 컴퓨터에서 수행됩니다.
- Geforce GTX 980 이이 실험에서 사용되었습니다.
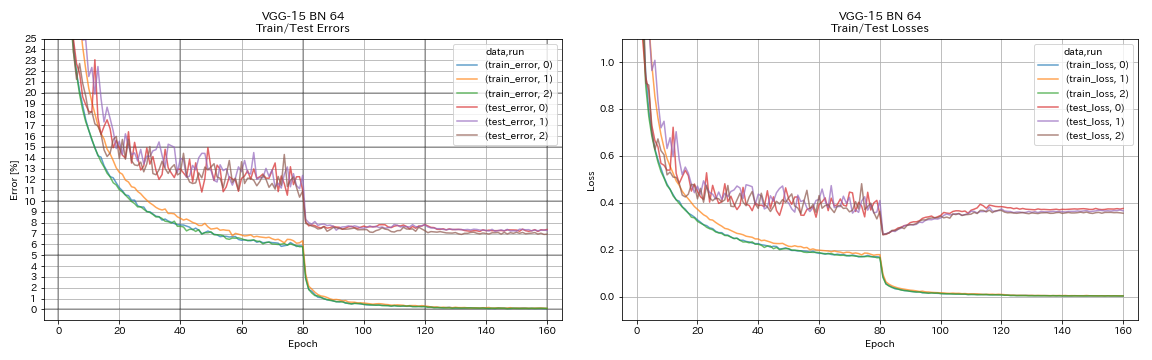
VGG와 같은
python train.py --config configs/cifar/vgg.yaml
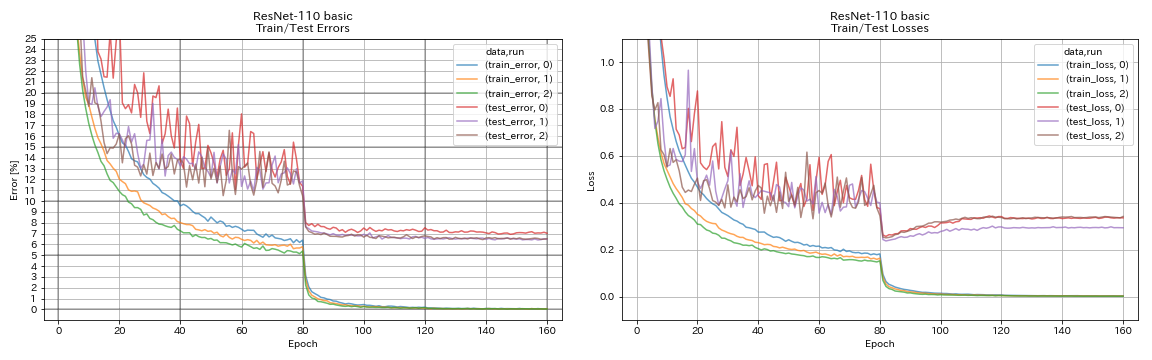
RESNET
python train.py --config configs/cifar/resnet.yaml
RESNET-PREACT
python train.py --config configs/cifar/resnet_preact.yaml
train.output_dir experiments/resnet_preact_basic_110/exp00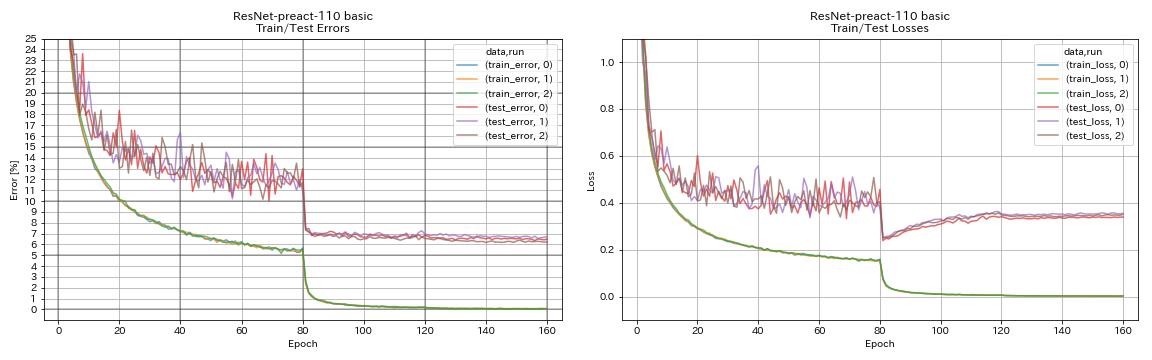
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 164
model.resnet_preact.block_type bottleneck
train.output_dir experiments/resnet_preact_bottleneck_164/exp00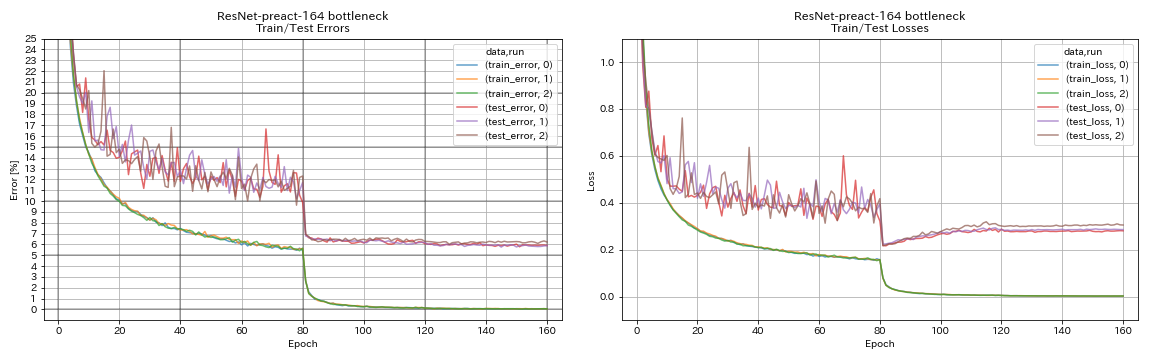
wrn
python train.py --config configs/cifar/wrn.yaml
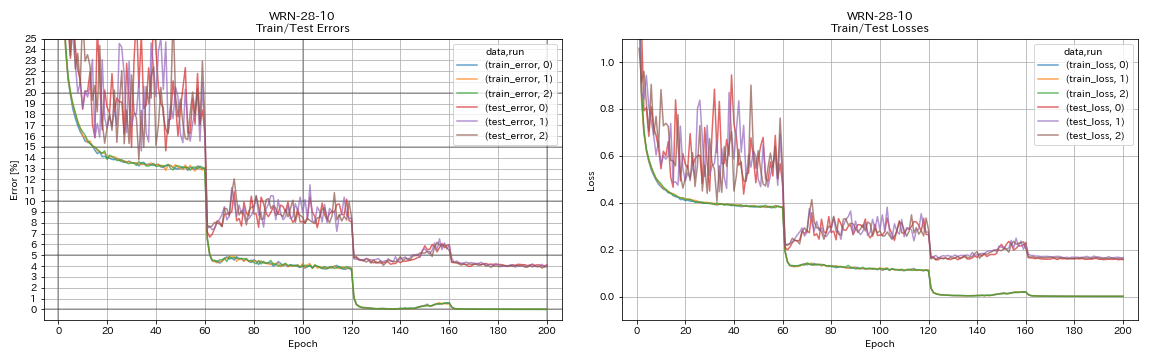
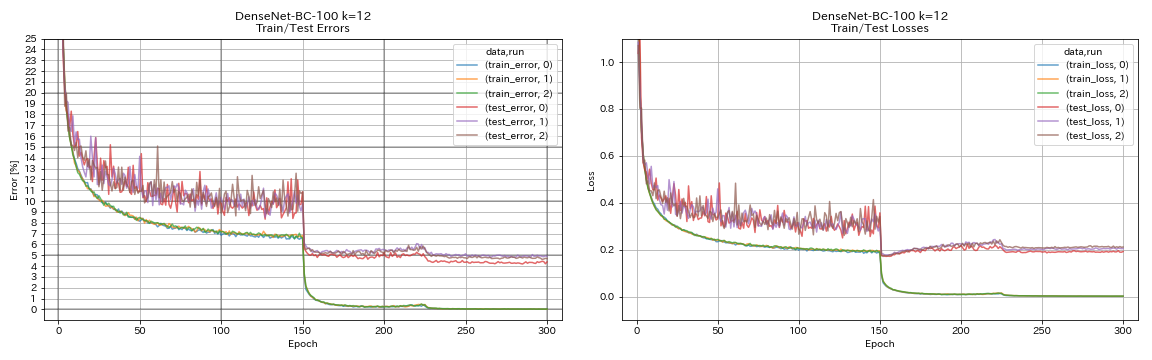
Densenet
python train.py --config configs/cifar/densenet.yaml
피라미드 넷
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 84
train.output_dir experiments/pyramidnet_basic_110_84/exp00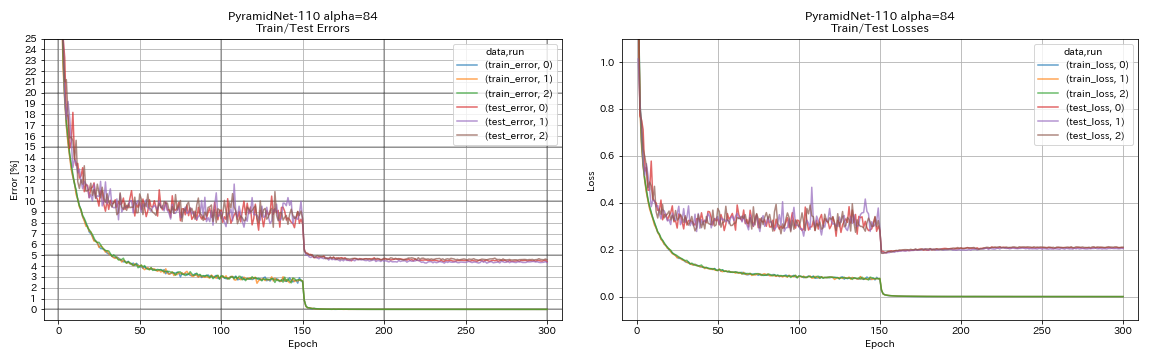
python train.py --config configs/cifar/pyramidnet.yaml
model.pyramidnet.depth 110
model.pyramidnet.block_type basic
model.pyramidnet.alpha 270
train.output_dir experiments/pyramidnet_basic_110_270/exp00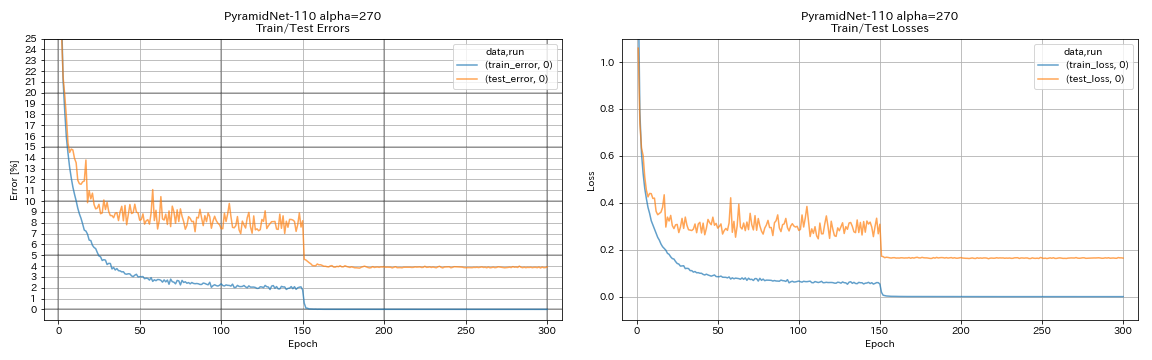
Resnext
python train.py --config configs/cifar/resnext.yaml
model.resnext.cardinality 4
train.batch_size 32
train.base_lr 0.025
train.output_dir experiments/resnext_29_4x64d/exp00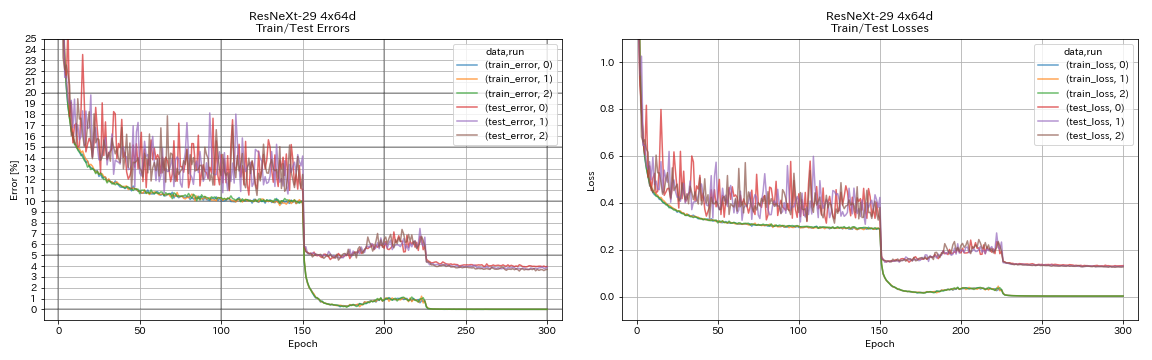
python train.py --config configs/cifar/resnext.yaml
train.batch_size 64
train.base_lr 0.05
train.output_dir experiments/resnext_29_8x64d/exp00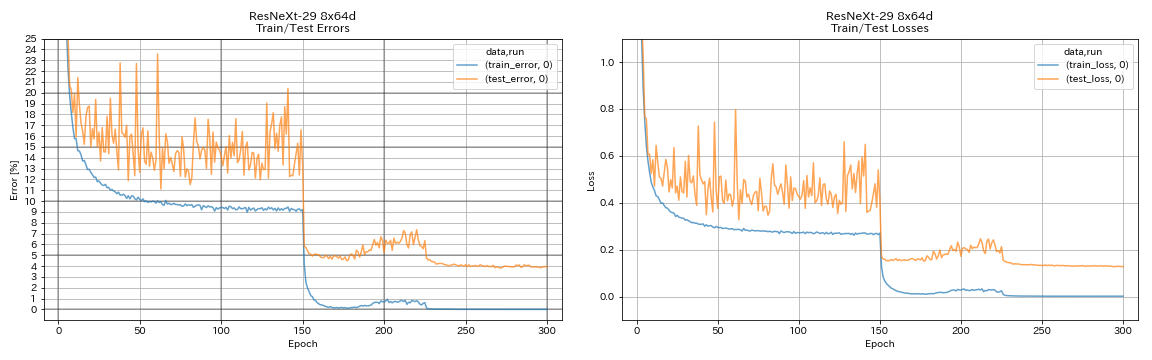
쉐이크 쉐이크
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 32
train.output_dir experiments/shake_shake_26_2x32d_SSI/exp00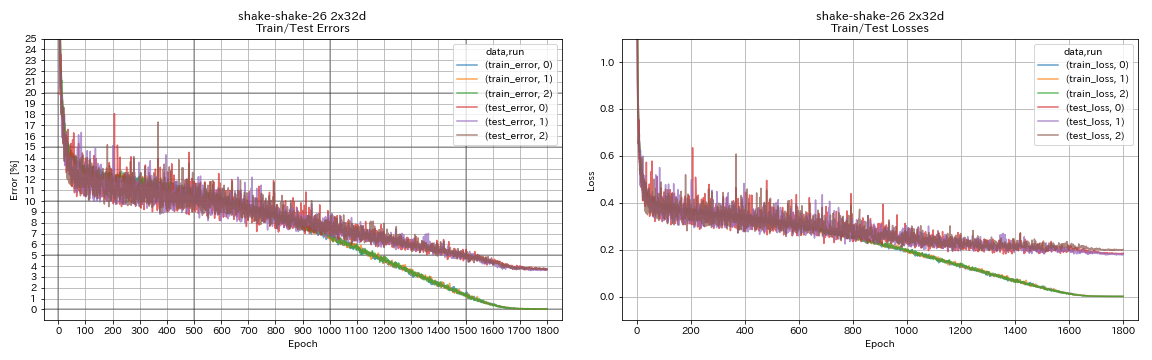
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x64d_SSI/exp00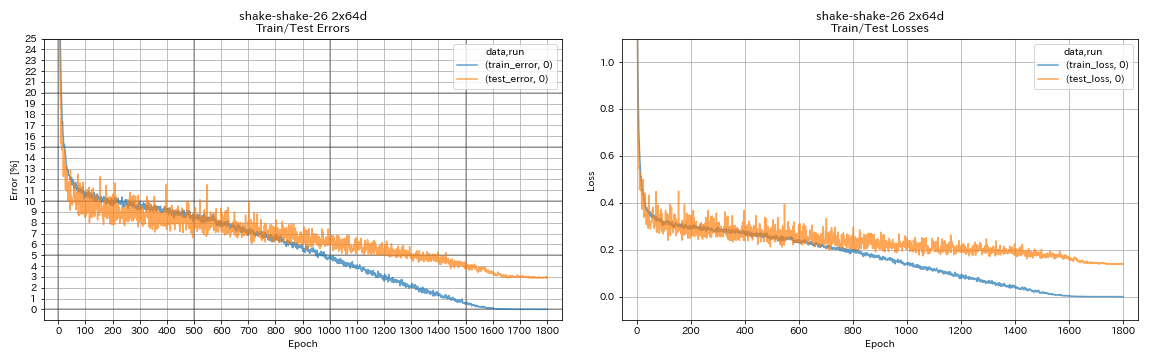
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 96
train.batch_size 64
train.base_lr 0.1
train.output_dir experiments/shake_shake_26_2x96d_SSI/exp00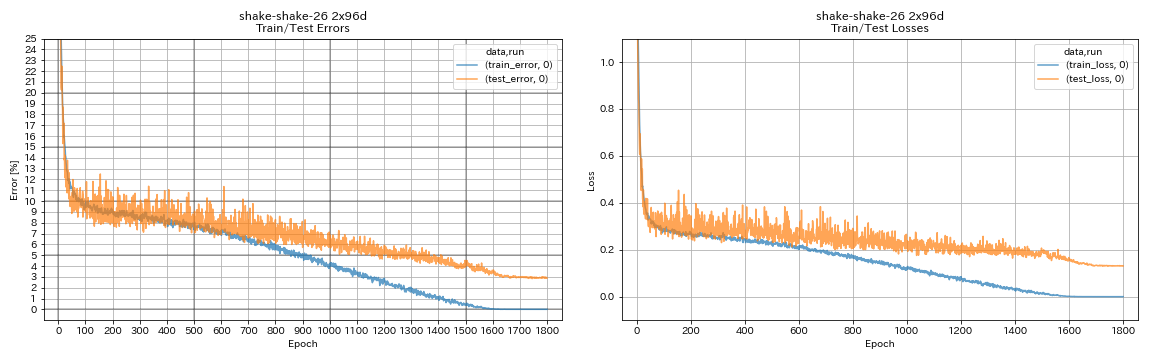
결과
| 모델 | 테스트 오류 (1 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20, 확대 계수 4 | 4.91 | 200 | 1H26m |
| RESNET-PREACT-20, 확대 계수 4 | 4.01 | 400 | 2H53m |
| RESNET-PREACT-20, 확대 계수 4 | 3.99 | 1800 | 12H53m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 16 | 3.71 | 200 | 1H26m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 16 | 3.46 | 400 | 2H53m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 16 | 3.76 | 1800 | 12H53m |
| RESNET-PREACT-20, 확대 계수 4, RICAP (베타 = 0.3) | 3.45 | 200 | 1H26m |
| RESNET-PREACT-20, 확대 계수 4, RICAP (베타 = 0.3) | 3.11 | 400 | 2H53m |
| RESNET-PREACT-20, 확대 계수 4, RICAP (베타 = 0.3) | 3.15 | 1800 | 12H53m |
| 모델 | 테스트 오류 (1 실행) | 에포크의 # | 훈련 시간 |
|---|
| WRN-28-10, 컷 아웃 16 | 3.19 | 200 | 6H35m |
| WRN-28-10, 믹스 업 (alpha = 1) | 3.32 | 200 | 6H35m |
| WRN-28-10, RICAP (베타 = 0.3) | 2.83 | 200 | 6H35m |
| WRN-28-10, 듀얼 커넥트 (alpha = 0.1) | 2.87 | 200 | 12H42m |
| WRN-28-10, 컷 아웃 16 | 3.07 | 400 | 13H10m |
| WRN-28-10, 믹스 업 (alpha = 1) | 3.04 | 400 | 13H08m |
| WRN-28-10, RICAP (베타 = 0.3) | 2.71 | 400 | 13H08m |
| WRN-28-10, 듀얼 커넥트 (alpha = 0.1) | 2.76 | 400 | 25h20m |
| Shake-Shake-26 2x64d, 컷 아웃 16 | 2.64 | 1800 | 78h55m* |
| Shake-Shake-26 2x64d, Mixup (alpha = 1) | 2.63 | 1800 | 35H56m |
| Shake-Shake-26 2x64d, Ricap (베타 = 0.3) | 2.29 | 1800 | 35H10m |
| Shake-Shake-26 2x64d, 듀얼 커넥트 (alpha = 0.1) | 2.64 | 1800 | 68h34m |
| Shake-Shake-26 2x96d, 컷 아웃 16 | 2.50 | 1800 | 60H20m |
| Shake-Shake-26 2x96d, Mixup (alpha = 1) | 2.36 | 1800 | 60H20m |
| Shake-Shake-26 2x96d, Ricap (베타 = 0.3) | 2.10 | 1800 | 60H20m |
| Shake-Shake-26 2x96d, 듀얼 커넥트 (alpha = 0.1) | 2.41 | 1800 | 113h09m |
| Shake-Shake-26 2x128d, 컷 아웃 16 | 2.58 | 1800 | 85h04m |
| Shake-Shake-26 2x128d, Ricap (베타 = 0.3) | 1.97 | 1800 | 85h06m |
메모
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
- 모든 모델은 초기 학습 속도 0.2로 코사인 어닐링을 사용하여 훈련됩니다.
- Geforce GTX 1080 Ti는 Geforce GTX 980을 사용하여 수행되는 *이있는 실험을 제외한이 실험에서 사용되었습니다.
python train.py --config configs/cifar/wrn.yaml
train.batch_size 64
train.output_dir experiments/wrn_28_10_cutout16
scheduler.type cosine
augmentation.use_cutout True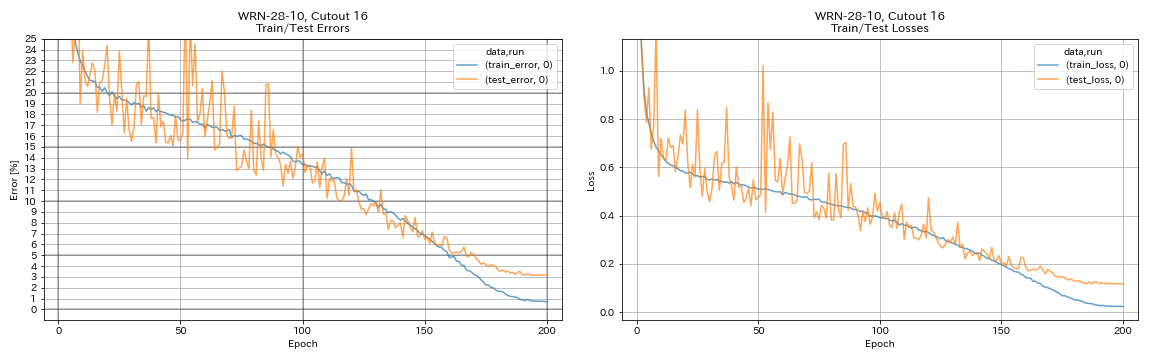
python train.py --config configs/cifar/shake_shake.yaml
model.shake_shake.initial_channels 64
train.batch_size 64
train.base_lr 0.1
scheduler.epochs 300
train.output_dir experiments/shake_shake_26_2x64d_SSI_cutout16/exp00
augmentation.use_cutout True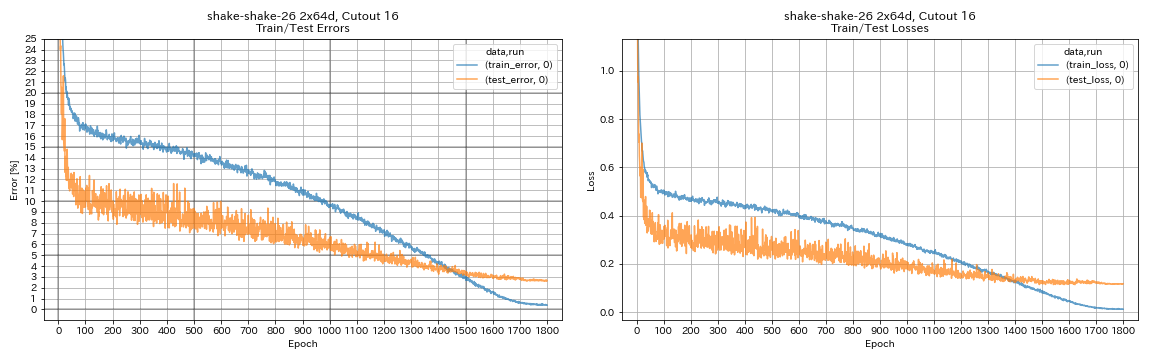
멀티 GPU를 사용한 결과
| 모델 | 배치 크기 | #gpus | 테스트 오류 (1 실행) | 에포크의 # | 훈련 시간* |
|---|
| WRN-28-10, RICAP (베타 = 0.3) | 512 | 1 | 2.63 | 200 | 3H41m |
| WRN-28-10, RICAP (베타 = 0.3) | 256 | 2 | 2.71 | 200 | 2H14m |
| WRN-28-10, RICAP (베타 = 0.3) | 128 | 4 | 2.89 | 200 | 1H01m |
| WRN-28-10, RICAP (베타 = 0.3) | 64 | 8 | 2.75 | 200 | 34m |
메모
- Tesla V100 이이 실험에서 사용되었습니다.
1 GPU 사용
python train.py --config configs/cifar/wrn.yaml
train.base_lr 0.2
train.batch_size 512
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_1gpu/exp00
augmentation.use_ricap True
augmentation.use_random_crop False2 GPU 사용
python -m torch.distributed.launch --nproc_per_node 2
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 256
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_2gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False4 GPU 사용
python -m torch.distributed.launch --nproc_per_node 4
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 128
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_4gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop False8 gpus 사용
python -m torch.distributed.launch --nproc_per_node 8
train.py --config configs/cifar/wrn.yaml
train.distributed True
train.base_lr 0.2
train.batch_size 64
scheduler.epochs 200
scheduler.type cosine
train.output_dir experiments/wrn_28_10_ricap_8gpus/exp00
augmentation.use_ricap True
augmentation.use_random_crop FalseFashionMnist에 대한 결과
| 모델 | 테스트 오류 (1 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 12 | 4.17 | 200 | 1H32m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 14 | 4.11 | 200 | 1H32m |
| RESNET-PREACT-50, 컷 아웃 12 | 4.45 | 200 | 57m |
| RESNET-PREACT-50, 컷 아웃 14 | 4.38 | 200 | 57m |
| RESNET-PREACT-50, 확대 계수 4, 컷 아웃 12 | 4.07 | 200 | 3H37m |
| RESNET-PREACT-50, 확대 계수 4, 컷 아웃 14 | 4.13 | 200 | 3H39m |
| Shake-Shake-26 2x32d (SSI), 컷 아웃 12 | 4.08 | 400 | 3H41m |
| Shake-Shake-26 2x32d (SSI), 컷 아웃 14 | 4.05 | 400 | 3H39m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 12 | 3.72 | 400 | 13H46m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 14 | 3.85 | 400 | 13H39m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 12 | 3.65 | 800 | 26H42m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 14 | 3.60 | 800 | 26H42m |
| 모델 | 테스트 오류 (중앙값 3 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 5.04 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 6 | 4.84 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 8 | 4.64 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 10 | 4.74 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 12 | 4.68 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 14 | 4.64 | 200 | 26m |
| RESNET-PREACT-20, 컷 아웃 16 | 4.49 | 200 | 26m |
| RESNET-PREACT-20, Randomerasing | 4.61 | 200 | 26m |
| RESNET-PREACT-20, 믹스 업 | 4.92 | 200 | 26m |
| RESNET-PREACT-20, 믹스 업 | 4.64 | 400 | 52m |
메모
- 테이블 에보 고 된 결과는 마침내 시대의 테스트 오류입니다.
- 모든 모델은 초기 학습 속도 0.2로 코사인 어닐링을 사용하여 훈련됩니다.
- 다음 데이터 확대는 교육 데이터에 적용됩니다.
- 이미지는 양쪽에 4 픽셀로 패딩되며 28x28 패치는 패딩 된 이미지에서 무작위로 자릅니다.
- 이미지는 수평으로 무작위로 뒤집 힙니다.
- Geforce GTX 1080 Ti 가이 실험에서 사용되었습니다.
mnist에 대한 결과
| 모델 | 테스트 오류 (중앙값 3 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 0.40 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 6 | 0.32 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 8 | 0.25 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 10 | 0.27 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 12 | 0.26 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 14 | 0.26 | 100 | 12m |
| RESNET-PREACT-20, 컷 아웃 16 | 0.25 | 100 | 12m |
| Resnet-Preact-20, Mixup (alpha = 1) | 0.40 | 100 | 12m |
| Resnet-Preact-20, Mixup (alpha = 0.5) | 0.38 | 100 | 12m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 14 | 0.26 | 100 | 45m |
| RESNET-PREACT-50, 컷 아웃 14 | 0.29 | 100 | 28m |
| RESNET-PREACT-50, 확대 계수 4, 컷 아웃 14 | 0.25 | 100 | 1H50m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 14 | 0.24 | 100 | 3H22m |
메모
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
- 모든 모델은 초기 학습 속도 0.2로 코사인 어닐링을 사용하여 훈련됩니다.
- Geforce GTX 1080 Ti 가이 실험에서 사용되었습니다.
Kuzushiji-Mnist에 대한 결과
| 모델 | 테스트 오류 (중앙값 3 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20, 컷 아웃 14 | 0.82 (최고 0.67) | 200 | 24m |
| RESNET-PREACT-20, 확대 계수 4, 컷 아웃 14 | 0.72 (최고 0.67) | 200 | 1H30m |
| 피라미드 넷 -110-270, 컷 아웃 14 | 0.72 (최고 0.70) | 200 | 10H05m |
| Shake-Shake-26 2x96d (SSI), 컷 아웃 14 | 0.66 (최고 0.63) | 200 | 6H46m |
메모
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
- 모든 모델은 초기 학습 속도 0.2로 코사인 어닐링을 사용하여 훈련됩니다.
- Geforce GTX 1080 Ti 가이 실험에서 사용되었습니다.
실험
잔여 단위, 학습 속도 예약 및 데이터 확대 실험
이 실험에서 분류 정확도에 대한 다음의 영향을 조사합니다.
- 피라미드 넷 같은 잔류 유닛
- 학습 속도의 코사인 어닐링
- 차단
- 임의의 지우기
- 믹스 업
- 다운 샘플링 후 바로 가기의 사전화
RESNET-PREACT-56 은이 실험에서 초기 학습 속도 0.2로 CIFAR-10에서 교육을받습니다.
메모
- Pyramidnet Pap
- SGDR PAPER (1608.03983)는 코사인 어닐링이 다시 시작하지 않고도 분류 정확도를 향상시키는 것으로 나타났습니다.
결과
- 피라미드 넷 같은 장치가 작동합니다.
- 피라미드 넷과 같은 장치를 사용할 때 다운 샘플링 후 바로 가기를 사전에 사전에 사전에 사전하지 않는 것이 좋습니다.
- 코사인 어닐링은 정확도를 약간 향상시킵니다.
- 컷 아웃, 무작위 적용 및 Mixup은 모두 훌륭하게 작동합니다.
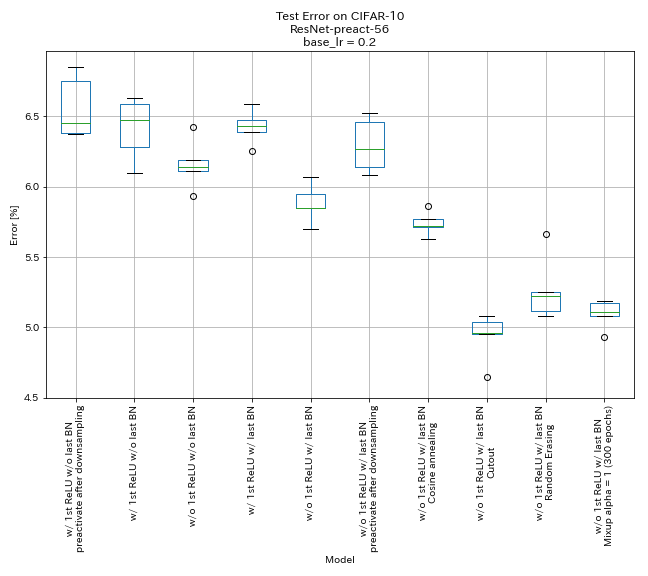
| 모델 | 테스트 오류 (중앙값 5 실행) | 훈련 시간 |
|---|
| w/ 1st Relu, 마지막 bn, 다운 샘플링 후 바로 가기를 사전 활성화 | 6.45 | 95 분 |
| 1st Relu, 마지막 bn w/ o w/ o | 6.47 | 95 분 |
| w/o 1st Relu, 마지막 bn w/o | 6.14 | 89 분 |
| 1st Relu, 마지막 bn | 6.43 | 104 분 |
| w/ o 1st Relu, 마지막 bn | 5.85 | 98 분 |
| w/ o 1st Relu, 마지막 bn, 다운 샘플링 후 바로 가기를 사전 활성화 | 6.27 | 98 분 |
| w/ o 1st Relu, 마지막 bn, 코사인 어닐링 | 5.72 | 98 분 |
| w/ o 1st Relu, 마지막 bn, 컷 아웃 | 4.96 | 98 분 |
| w/ o 1st Relu, 마지막 bn, 무작위 | 5.22 | 98 분 |
| w/ o 1st Relu, 마지막 Bn, Mixup (300 Epochs) | 5.11 | 191 분 |
다운 샘플링 후 바로 가기를 사전 확인하십시오
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_after_downsampling/exp00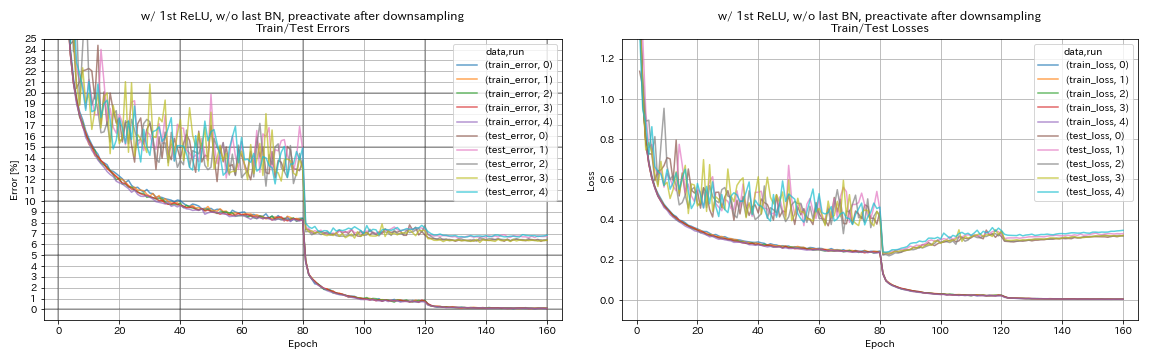
1st Relu, 마지막 bn w/ o w/ o
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_w_relu_wo_bn/exp00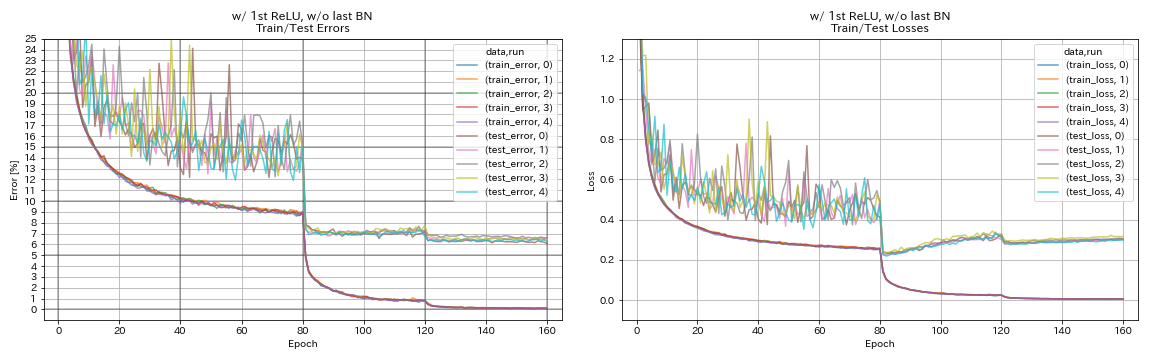
w/o 1st Relu, 마지막 bn w/o
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn False
train.output_dir experiments/resnet_preact_wo_relu_wo_bn/exp00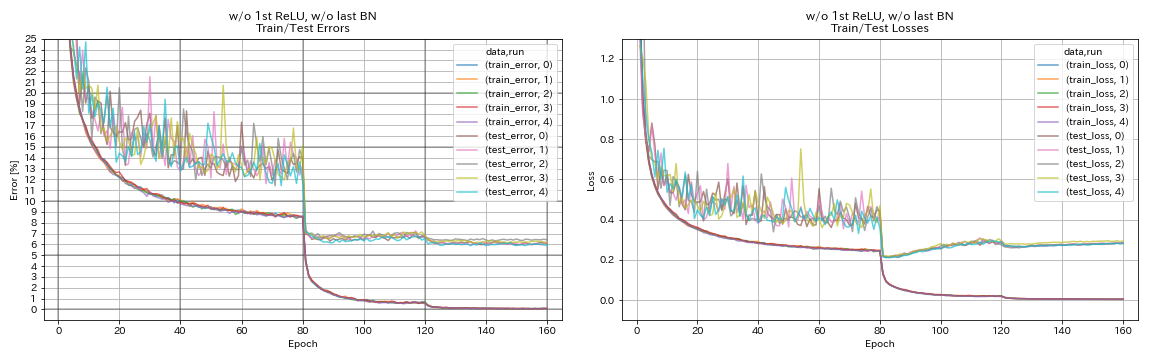
1st Relu, 마지막 bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu False
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_w_relu_w_bn/exp00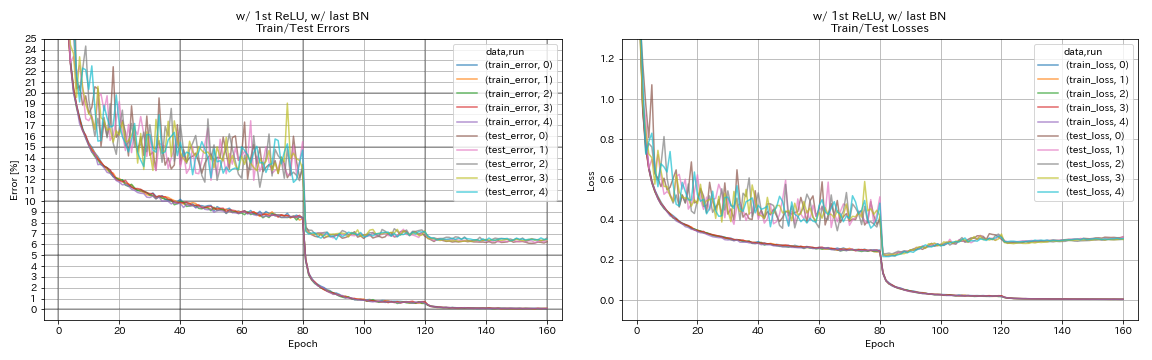
w/ o 1st Relu, 마지막 bn
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_wo_relu_w_bn/exp00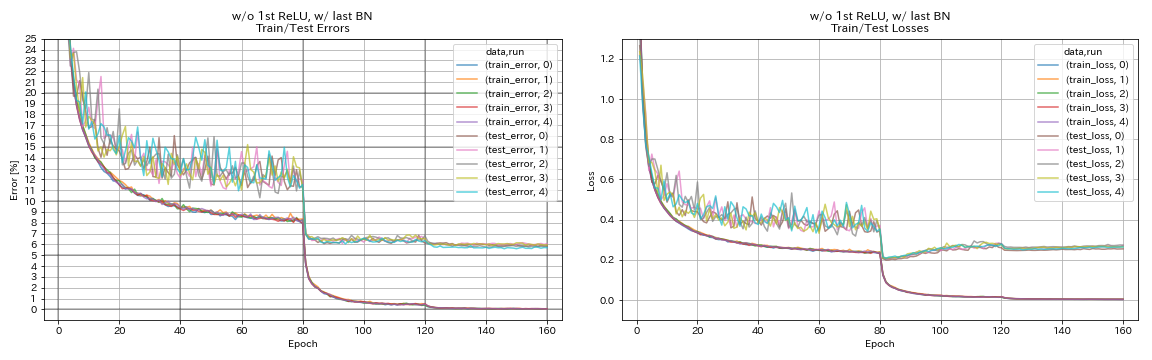
w/ o 1st Relu, 마지막 bn, 다운 샘플링 후 바로 가기를 사전 활성화
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, True, True] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
train.output_dir experiments/resnet_preact_after_downsampling_wo_relu_w_bn/exp00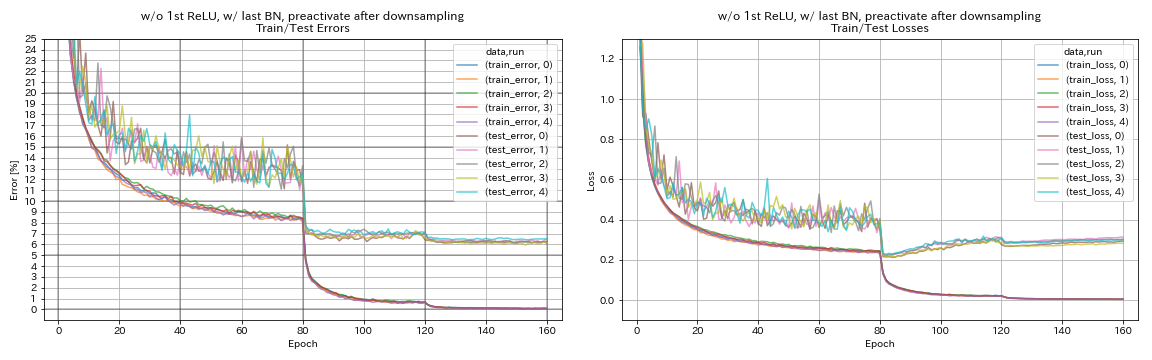
w/ o 1st Relu, 마지막 bn, 코사인 어닐링
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
scheduler.type cosine
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cosine/exp00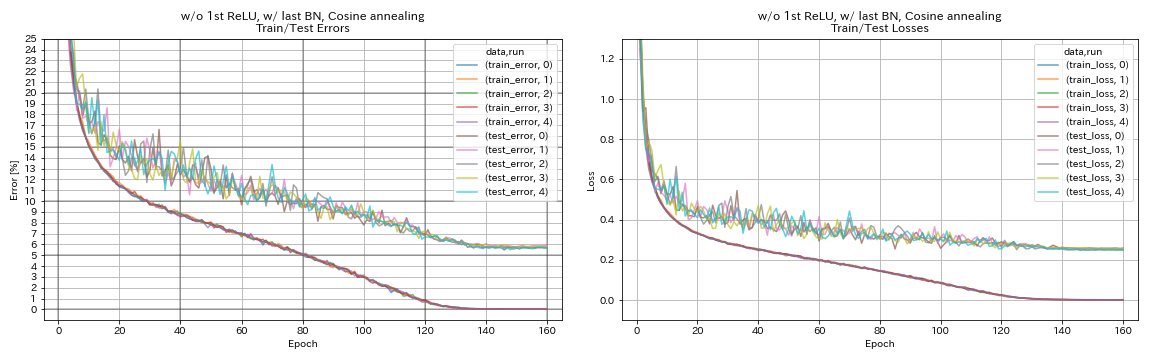
w/ o 1st Relu, 마지막 bn, 컷 아웃
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_cutout True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_cutout/exp00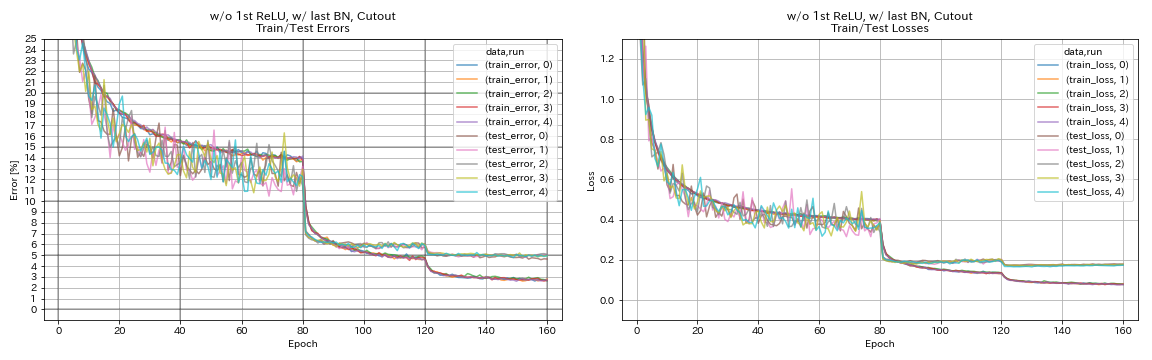
w/ o 1st Relu, 마지막 bn, 무작위
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_random_erasing True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_random_erasing/exp00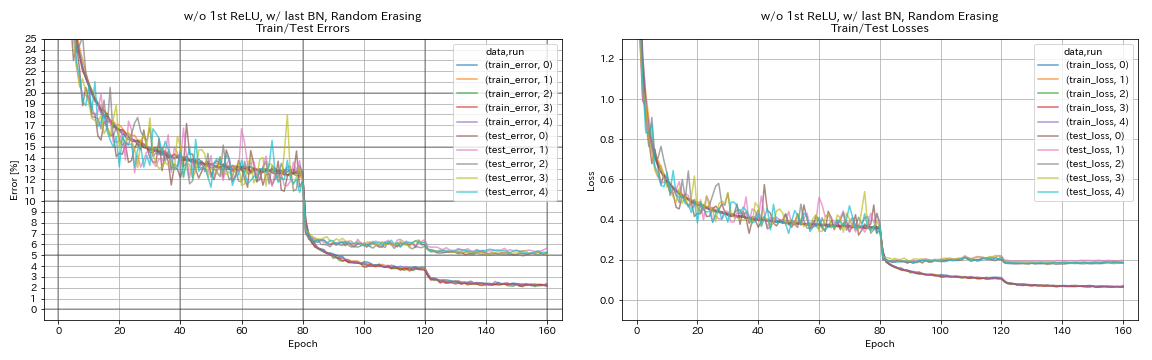
w/ o 1st Relu, 마지막 bn, 믹스 업
python train.py --config configs/cifar/resnet_preact.yaml
train.base_lr 0.2
model.resnet_preact.depth 56
model.resnet_preact.preact_stage ' [True, False, False] '
model.resnet_preact.remove_first_relu True
model.resnet_preact.add_last_bn True
augmentation.use_mixup True
train.output_dir experiments/resnet_preact_wo_relu_w_bn_mixup/exp00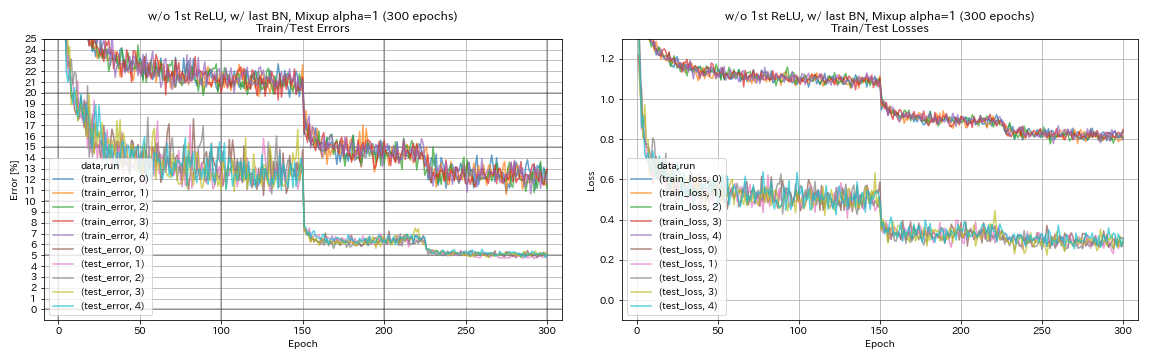
라벨 스무딩, 믹스 업, RICAP 및 듀얼 커넥트에 대한 실험
CIFAR-10에 대한 결과
| 모델 | 테스트 오류 (중앙값 3 실행) | 에포크의 # | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 7.60 | 200 | 24m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.001) | 7.51 | 200 | 25m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.01) | 7.21 | 200 | 25m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.1) | 7.57 | 200 | 25m |
| Resnet-Preact-20, Mixup (alpha = 1) | 7.24 | 200 | 26m |
| RESNET-PREACT-20, RICAP (베타 = 0.3), 임의의 작물이 있습니다 | 6.88 | 200 | 28m |
| RESNET-PREACT-20, RICAP (베타 = 0.3) | 6.77 | 200 | 28m |
| RESNET-PREACT-20, DUAL-CUTOUT 16 (alpha = 0.1) | 6.24 | 200 | 45m |
| RESNET-PREACT-20 | 7.05 | 400 | 49m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.001) | 7.20 | 400 | 49m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.01) | 6.97 | 400 | 49m |
| RESNET-PREACT-20, 레이블 스무딩 (Epsilon = 0.1) | 7.16 | 400 | 49m |
| Resnet-Preact-20, Mixup (alpha = 1) | 6.66 | 400 | 51m |
| RESNET-PREACT-20, RICAP (베타 = 0.3), 임의의 작물이 있습니다 | 6.30 | 400 | 56m |
| RESNET-PREACT-20, RICAP (베타 = 0.3) | 6.19 | 400 | 56m |
| RESNET-PREACT-20, DUAL-CUTOUT 16 (alpha = 0.1) | 5.55 | 400 | 1H36m |
메모
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
- 모든 모델은 초기 학습 속도 0.2로 코사인 어닐링을 사용하여 훈련됩니다.
- Geforce GTX 1080 Ti 가이 실험에서 사용되었습니다.
배치 크기 및 학습 속도 실험
- 다음 실험은 Geforce 1080 Ti를 사용하여 CIFAR-10 데이터 세트에서 수행됩니다.
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
학습 속도에 대한 선형 스케일링 규칙
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | 코사인 | 200 | 10.57 | 22m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 200 | 8.87 | 21m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 200 | 8.40 | 21m |
| RESNET-PREACT-20 | 512 | 0.4 | 코사인 | 200 | 8.22 | 20m |
| RESNET-PREACT-20 | 256 | 0.2 | 코사인 | 200 | 8.61 | 22m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 200 | 8.09 | 24m |
| RESNET-PREACT-20 | 64 | 0.05 | 코사인 | 200 | 8.22 | 28m |
| RESNET-PREACT-20 | 32 | 0.025 | 코사인 | 200 | 8.00 | 43m |
| RESNET-PREACT-20 | 16 | 0.0125 | 코사인 | 200 | 7.75 | 1H17m |
| RESNET-PREACT-20 | 8 | 0.006125 | 코사인 | 200 | 7.70 | 2H32m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | 다단계 | 200 | 28.97 | 22m |
| RESNET-PREACT-20 | 2048 | 1.6 | 다단계 | 200 | 9.07 | 21m |
| RESNET-PREACT-20 | 1024 | 0.8 | 다단계 | 200 | 8.62 | 21m |
| RESNET-PREACT-20 | 512 | 0.4 | 다단계 | 200 | 8.23 | 20m |
| RESNET-PREACT-20 | 256 | 0.2 | 다단계 | 200 | 8.40 | 21m |
| RESNET-PREACT-20 | 128 | 0.1 | 다단계 | 200 | 8.28 | 24m |
| RESNET-PREACT-20 | 64 | 0.05 | 다단계 | 200 | 8.13 | 28m |
| RESNET-PREACT-20 | 32 | 0.025 | 다단계 | 200 | 7.58 | 43m |
| RESNET-PREACT-20 | 16 | 0.0125 | 다단계 | 200 | 7.93 | 1H18m |
| RESNET-PREACT-20 | 8 | 0.006125 | 다단계 | 200 | 8.31 | 2H34m |
선형 스케일링 + 더 긴 훈련
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | 코사인 | 400 | 8.97 | 44m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 400 | 7.85 | 43m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 400 | 7.20 | 42m |
| RESNET-PREACT-20 | 512 | 0.4 | 코사인 | 400 | 7.83 | 40m |
| RESNET-PREACT-20 | 256 | 0.2 | 코사인 | 400 | 7.65 | 42m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 400 | 7.09 | 47m |
| RESNET-PREACT-20 | 64 | 0.05 | 코사인 | 400 | 7.17 | 44m |
| RESNET-PREACT-20 | 32 | 0.025 | 코사인 | 400 | 7.24 | 2H11m |
| RESNET-PREACT-20 | 16 | 0.0125 | 코사인 | 400 | 7.26 | 4H10m |
| RESNET-PREACT-20 | 8 | 0.006125 | 코사인 | 400 | 7.02 | 7H53m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | 코사인 | 800 | 8.14 | 1H29m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 800 | 7.74 | 1H23m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 800 | 7.15 | 1H31m |
| RESNET-PREACT-20 | 512 | 0.4 | 코사인 | 800 | 7.27 | 1H25m |
| RESNET-PREACT-20 | 256 | 0.2 | 코사인 | 800 | 7.22 | 1H26m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 800 | 6.68 | 1H35m |
| RESNET-PREACT-20 | 64 | 0.05 | 코사인 | 800 | 7.18 | 2h20m |
| RESNET-PREACT-20 | 32 | 0.025 | 코사인 | 800 | 7.03 | 4H16m |
| RESNET-PREACT-20 | 16 | 0.0125 | 코사인 | 800 | 6.78 | 8H37m |
| RESNET-PREACT-20 | 8 | 0.006125 | 코사인 | 800 | 6.89 | 16H47m |
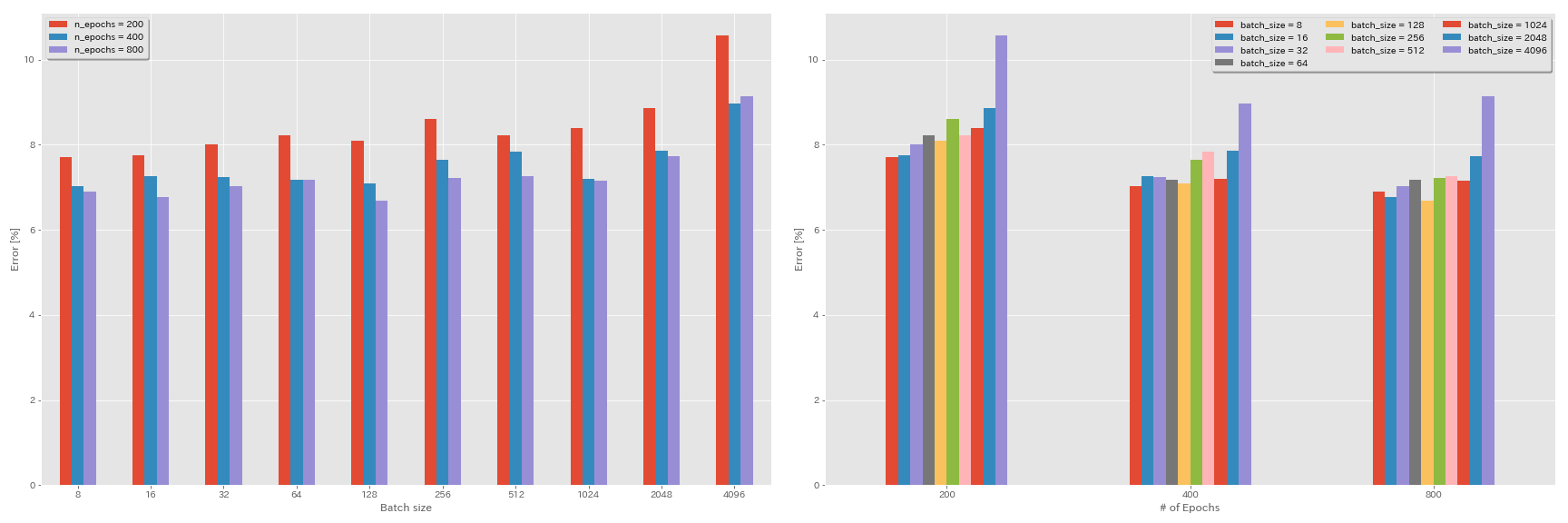
초기 학습 속도의 영향
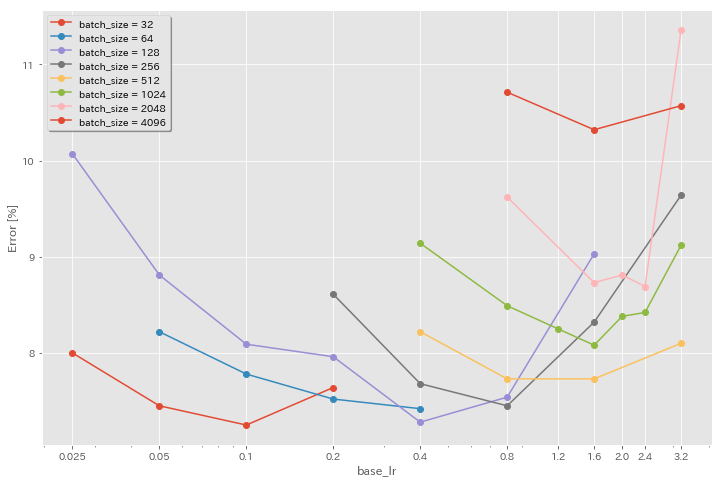
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 3.2 | 코사인 | 200 | 10.57 | 22m |
| RESNET-PREACT-20 | 4096 | 1.6 | 코사인 | 200 | 10.32 | 22m |
| RESNET-PREACT-20 | 4096 | 0.8 | 코사인 | 200 | 10.71 | 22m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 2048 | 3.2 | 코사인 | 200 | 11.34 | 21m |
| RESNET-PREACT-20 | 2048 | 2.4 | 코사인 | 200 | 8.69 | 21m |
| RESNET-PREACT-20 | 2048 | 2.0 | 코사인 | 200 | 8.81 | 21m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 200 | 8.73 | 22m |
| RESNET-PREACT-20 | 2048 | 0.8 | 코사인 | 200 | 9.62 | 21m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 1024 | 3.2 | 코사인 | 200 | 9.12 | 21m |
| RESNET-PREACT-20 | 1024 | 2.4 | 코사인 | 200 | 8.42 | 22m |
| RESNET-PREACT-20 | 1024 | 2.0 | 코사인 | 200 | 8.38 | 22m |
| RESNET-PREACT-20 | 1024 | 1.6 | 코사인 | 200 | 8.07 | 22m |
| RESNET-PREACT-20 | 1024 | 1.2 | 코사인 | 200 | 8.25 | 21m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 200 | 8.08 | 22m |
| RESNET-PREACT-20 | 1024 | 0.4 | 코사인 | 200 | 8.49 | 22m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 512 | 3.2 | 코사인 | 200 | 8.51 | 21m |
| RESNET-PREACT-20 | 512 | 1.6 | 코사인 | 200 | 7.73 | 20m |
| RESNET-PREACT-20 | 512 | 0.8 | 코사인 | 200 | 7.73 | 21m |
| RESNET-PREACT-20 | 512 | 0.4 | 코사인 | 200 | 8.22 | 20m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 256 | 3.2 | 코사인 | 200 | 9.64 | 22m |
| RESNET-PREACT-20 | 256 | 1.6 | 코사인 | 200 | 8.32 | 22m |
| RESNET-PREACT-20 | 256 | 0.8 | 코사인 | 200 | 7.45 | 21m |
| RESNET-PREACT-20 | 256 | 0.4 | 코사인 | 200 | 7.68 | 22m |
| RESNET-PREACT-20 | 256 | 0.2 | 코사인 | 200 | 8.61 | 22m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 128 | 1.6 | 코사인 | 200 | 9.03 | 24m |
| RESNET-PREACT-20 | 128 | 0.8 | 코사인 | 200 | 7.54 | 24m |
| RESNET-PREACT-20 | 128 | 0.4 | 코사인 | 200 | 7.28 | 24m |
| RESNET-PREACT-20 | 128 | 0.2 | 코사인 | 200 | 7.96 | 24m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 200 | 8.09 | 24m |
| RESNET-PREACT-20 | 128 | 0.05 | 코사인 | 200 | 8.81 | 24m |
| RESNET-PREACT-20 | 128 | 0.025 | 코사인 | 200 | 10.07 | 24m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 64 | 0.4 | 코사인 | 200 | 7.42 | 35m |
| RESNET-PREACT-20 | 64 | 0.2 | 코사인 | 200 | 7.52 | 36m |
| RESNET-PREACT-20 | 64 | 0.1 | 코사인 | 200 | 7.78 | 37m |
| RESNET-PREACT-20 | 64 | 0.05 | 코사인 | 200 | 8.22 | 28m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 32 | 0.2 | 코사인 | 200 | 7.64 | 1H05m |
| RESNET-PREACT-20 | 32 | 0.1 | 코사인 | 200 | 7.25 | 1H08m |
| RESNET-PREACT-20 | 32 | 0.05 | 코사인 | 200 | 7.45 | 1H07m |
| RESNET-PREACT-20 | 32 | 0.025 | 코사인 | 200 | 8.00 | 43m |
좋은 학습 속도 + 더 긴 교육
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | 코사인 | 200 | 10.32 | 22m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 200 | 8.73 | 22m |
| RESNET-PREACT-20 | 1024 | 1.6 | 코사인 | 200 | 8.07 | 22m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 200 | 8.08 | 22m |
| RESNET-PREACT-20 | 512 | 1.6 | 코사인 | 200 | 7.73 | 20m |
| RESNET-PREACT-20 | 512 | 0.8 | 코사인 | 200 | 7.73 | 21m |
| RESNET-PREACT-20 | 256 | 0.8 | 코사인 | 200 | 7.45 | 21m |
| RESNET-PREACT-20 | 128 | 0.4 | 코사인 | 200 | 7.28 | 24m |
| RESNET-PREACT-20 | 128 | 0.2 | 코사인 | 200 | 7.96 | 24m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 200 | 8.09 | 24m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | 코사인 | 800 | 8.36 | 1H33m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 800 | 7.53 | 1H27m |
| RESNET-PREACT-20 | 1024 | 1.6 | 코사인 | 800 | 7.30 | 1H30m |
| RESNET-PREACT-20 | 1024 | 0.8 | 코사인 | 800 | 7.42 | 1H30m |
| RESNET-PREACT-20 | 512 | 1.6 | 코사인 | 800 | 6.69 | 1H26m |
| RESNET-PREACT-20 | 512 | 0.8 | 코사인 | 800 | 6.77 | 1H26m |
| RESNET-PREACT-20 | 256 | 0.8 | 코사인 | 800 | 6.84 | 1H28m |
| RESNET-PREACT-20 | 128 | 0.4 | 코사인 | 800 | 6.86 | 1H35m |
| RESNET-PREACT-20 | 128 | 0.2 | 코사인 | 800 | 7.05 | 1H38m |
| RESNET-PREACT-20 | 128 | 0.1 | 코사인 | 800 | 6.68 | 1H35m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | 코사인 | 1600 | 8.25 | 3H10m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 1600 | 7.34 | 2H50m |
| RESNET-PREACT-20 | 1024 | 1.6 | 코사인 | 1600 | 6.94 | 2H52m |
| RESNET-PREACT-20 | 512 | 1.6 | 코사인 | 1600 | 6.99 | 2H44m |
| RESNET-PREACT-20 | 256 | 0.8 | 코사인 | 1600 | 6.95 | 2H50m |
| RESNET-PREACT-20 | 128 | 0.4 | 코사인 | 1600 | 6.64 | 3H09m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 4096 | 1.6 | 코사인 | 3200 | 9.52 | 6H15m |
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 3200 | 6.92 | 5H42m |
| RESNET-PREACT-20 | 1024 | 1.6 | 코사인 | 3200 | 6.96 | 5H43m |
| 모델 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 2048 | 1.6 | 코사인 | 6400 | 7.45 | 11h44m |
라스
- 원래 논문 (1708.03888, 1801.03137)에서는 다항식 붕괴 학습 속도 일정을 사용했지만이 실험에는 코사인 어닐링이 사용됩니다.
- 이 구현에서는 LARS 계수가 사용되지 않으므로 학습 속도를 적절하게 조정해야합니다.
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.optimizer lars
train.base_lr 0.02
train.batch_size 4096
scheduler.type cosine
train.output_dir experiments/resnet_preact_lars/exp00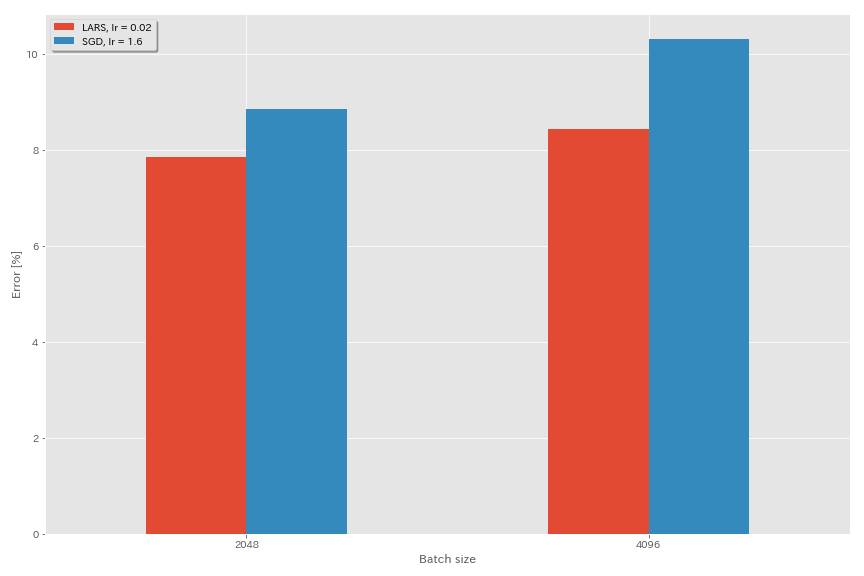
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 4096 | 3.2 | 코사인 | 200 | 10.57 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 4096 | 1.6 | 코사인 | 200 | 10.20 | 22m |
| RESNET-PREACT-20 | sgd | 4096 | 0.8 | 코사인 | 200 | 10.71 (1 런) | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.04 | 코사인 | 200 | 9.58 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.03 | 코사인 | 200 | 8.46 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.02 | 코사인 | 200 | 8.21 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.015 | 코사인 | 200 | 8.47 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.01 | 코사인 | 200 | 9.33 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.005 | 코사인 | 200 | 14.31 | 22m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 2048 | 3.2 | 코사인 | 200 | 11.34 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 2048 | 2.4 | 코사인 | 200 | 8.69 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 2048 | 2.0 | 코사인 | 200 | 8.81 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 2048 | 1.6 | 코사인 | 200 | 8.73 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 2048 | 0.8 | 코사인 | 200 | 9.62 (1 런) | 21m |
| RESNET-PREACT-20 | 라스 | 2048 | 0.04 | 코사인 | 200 | 11.58 | 21m |
| RESNET-PREACT-20 | 라스 | 2048 | 0.02 | 코사인 | 200 | 8.05 | 22m |
| RESNET-PREACT-20 | 라스 | 2048 | 0.01 | 코사인 | 200 | 8.07 | 22m |
| RESNET-PREACT-20 | 라스 | 2048 | 0.005 | 코사인 | 200 | 9.65 | 22m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 1024 | 3.2 | 코사인 | 200 | 9.12 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 1024 | 2.4 | 코사인 | 200 | 8.42 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 1024 | 2.0 | 코사인 | 200 | 8.38 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 1024 | 1.6 | 코사인 | 200 | 8.07 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 1024 | 1.2 | 코사인 | 200 | 8.25 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 1024 | 0.8 | 코사인 | 200 | 8.08 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 1024 | 0.4 | 코사인 | 200 | 8.49 (1 런) | 22m |
| RESNET-PREACT-20 | 라스 | 1024 | 0.02 | 코사인 | 200 | 9.30 | 22m |
| RESNET-PREACT-20 | 라스 | 1024 | 0.01 | 코사인 | 200 | 7.68 | 22m |
| RESNET-PREACT-20 | 라스 | 1024 | 0.005 | 코사인 | 200 | 8.88 | 23m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 512 | 3.2 | 코사인 | 200 | 8.51 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 512 | 1.6 | 코사인 | 200 | 7.73 (1 런) | 20m |
| RESNET-PREACT-20 | sgd | 512 | 0.8 | 코사인 | 200 | 7.73 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 512 | 0.4 | 코사인 | 200 | 8.22 (1 런) | 20m |
| RESNET-PREACT-20 | 라스 | 512 | 0.015 | 코사인 | 200 | 9.84 | 23m |
| RESNET-PREACT-20 | 라스 | 512 | 0.01 | 코사인 | 200 | 8.05 | 23m |
| RESNET-PREACT-20 | 라스 | 512 | 0.0075 | 코사인 | 200 | 7.58 | 23m |
| RESNET-PREACT-20 | 라스 | 512 | 0.005 | 코사인 | 200 | 7.96 | 23m |
| RESNET-PREACT-20 | 라스 | 512 | 0.0025 | 코사인 | 200 | 8.83 | 23m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 256 | 3.2 | 코사인 | 200 | 9.64 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 256 | 1.6 | 코사인 | 200 | 8.32 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 256 | 0.8 | 코사인 | 200 | 7.45 (1 런) | 21m |
| RESNET-PREACT-20 | sgd | 256 | 0.4 | 코사인 | 200 | 7.68 (1 런) | 22m |
| RESNET-PREACT-20 | sgd | 256 | 0.2 | 코사인 | 200 | 8.61 (1 런) | 22m |
| RESNET-PREACT-20 | 라스 | 256 | 0.01 | 코사인 | 200 | 8.95 | 27m |
| RESNET-PREACT-20 | 라스 | 256 | 0.005 | 코사인 | 200 | 7.75 | 28m |
| RESNET-PREACT-20 | 라스 | 256 | 0.0025 | 코사인 | 200 | 8.21 | 28m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 128 | 1.6 | 코사인 | 200 | 9.03 (1 런) | 24m |
| RESNET-PREACT-20 | sgd | 128 | 0.8 | 코사인 | 200 | 7.54 (1 런) | 24m |
| RESNET-PREACT-20 | sgd | 128 | 0.4 | 코사인 | 200 | 7.28 (1 런) | 24m |
| RESNET-PREACT-20 | sgd | 128 | 0.2 | 코사인 | 200 | 7.96 (1 런) | 24m |
| RESNET-PREACT-20 | 라스 | 128 | 0.005 | 코사인 | 200 | 7.96 | 37m |
| RESNET-PREACT-20 | 라스 | 128 | 0.0025 | 코사인 | 200 | 7.98 | 37m |
| RESNET-PREACT-20 | 라스 | 128 | 0.00125 | 코사인 | 200 | 9.21 | 37m |
| 모델 | 최적화 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | sgd | 4096 | 1.6 | 코사인 | 200 | 10.20 | 22m |
| RESNET-PREACT-20 | sgd | 4096 | 1.6 | 코사인 | 800 | 8.36 (1 런) | 1H33m |
| RESNET-PREACT-20 | sgd | 4096 | 1.6 | 코사인 | 1600 | 8.25 (1 런) | 3H10m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.02 | 코사인 | 200 | 8.21 | 22m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.02 | 코사인 | 400 | 7.53 | 44m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.02 | 코사인 | 800 | 7.48 | 1H29m |
| RESNET-PREACT-20 | 라스 | 4096 | 0.02 | 코사인 | 1600 | 7.37 (1 런) | 2H58m |
유령 Bn
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.5
train.batch_size 4096
train.subdivision 32
scheduler.type cosine
train.output_dir experiments/resnet_preact_ghost_batch/exp00| 모델 | 배치 크기 | 유령 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 8192 | N/A | 1.6 | 코사인 | 200 | 12.35 | 25m* |
| RESNET-PREACT-20 | 4096 | N/A | 1.6 | 코사인 | 200 | 10.32 | 22m |
| RESNET-PREACT-20 | 2048 | N/A | 1.6 | 코사인 | 200 | 8.73 | 22m |
| RESNET-PREACT-20 | 1024 | N/A | 1.6 | 코사인 | 200 | 8.07 | 22m |
| RESNET-PREACT-20 | 128 | N/A | 0.4 | 코사인 | 200 | 7.28 | 24m |
| 모델 | 배치 크기 | 유령 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 8192 | 128 | 1.6 | 코사인 | 200 | 11.51 | 27m |
| RESNET-PREACT-20 | 4096 | 128 | 1.6 | 코사인 | 200 | 9.73 | 25m |
| RESNET-PREACT-20 | 2048 | 128 | 1.6 | 코사인 | 200 | 8.77 | 24m |
| RESNET-PREACT-20 | 1024 | 128 | 1.6 | 코사인 | 200 | 7.82 | 22m |
| 모델 | 배치 크기 | 유령 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 8192 | N/A | 1.6 | 코사인 | 1600 | | |
| RESNET-PREACT-20 | 4096 | N/A | 1.6 | 코사인 | 1600 | 8.25 | 3H10m |
| RESNET-PREACT-20 | 2048 | N/A | 1.6 | 코사인 | 1600 | 7.34 | 2H50m |
| RESNET-PREACT-20 | 1024 | N/A | 1.6 | 코사인 | 1600 | 6.94 | 2H52m |
| 모델 | 배치 크기 | 유령 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 8192 | 128 | 1.6 | 코사인 | 1600 | 11.83 | 3H37m |
| RESNET-PREACT-20 | 4096 | 128 | 1.6 | 코사인 | 1600 | 8.95 | 3H15m |
| RESNET-PREACT-20 | 2048 | 128 | 1.6 | 코사인 | 1600 | 7.23 | 3H05m |
| RESNET-PREACT-20 | 1024 | 128 | 1.6 | 코사인 | 1600 | 7.08 | 2H59m |
Bn에서 체중 부패가 없습니다
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.no_weight_decay_on_bn True
train.weight_decay 5e-4
scheduler.type cosine
train.output_dir experiments/resnet_preact_no_weight_decay_on_bn/exp00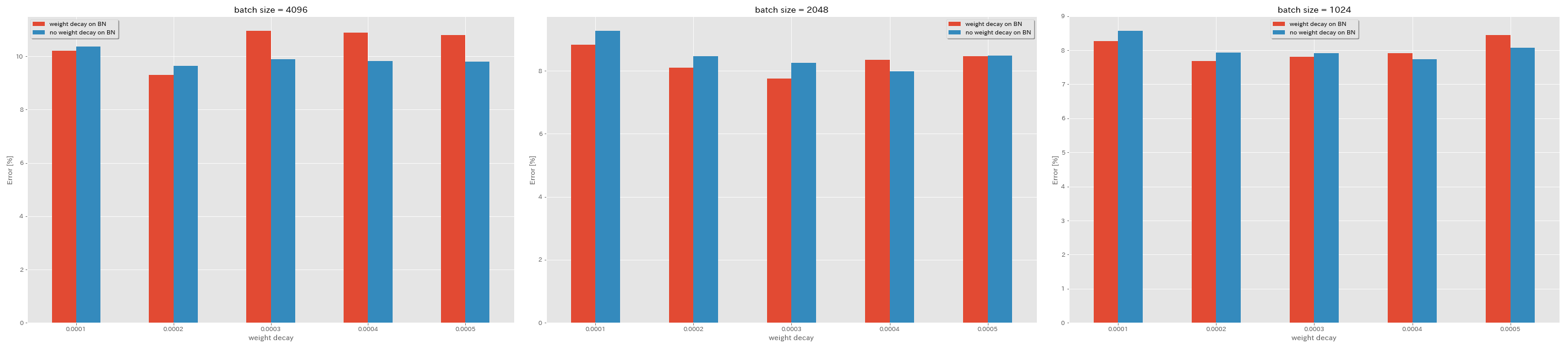
| 모델 | Bn의 체중 감소 | 체중 부패 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 예 | 5E-4 | 4096 | 1.6 | 코사인 | 200 | 10.81 | 22m |
| RESNET-PREACT-20 | 예 | 4E-4 | 4096 | 1.6 | 코사인 | 200 | 10.88 | 22m |
| RESNET-PREACT-20 | 예 | 3E-4 | 4096 | 1.6 | 코사인 | 200 | 10.96 | 22m |
| RESNET-PREACT-20 | 예 | 2E-4 | 4096 | 1.6 | 코사인 | 200 | 9.30 | 22m |
| RESNET-PREACT-20 | 예 | 1E-4 | 4096 | 1.6 | 코사인 | 200 | 10.20 | 22m |
| RESNET-PREACT-20 | 아니요 | 5E-4 | 4096 | 1.6 | 코사인 | 200 | 8.78 | 22m |
| RESNET-PREACT-20 | 아니요 | 4E-4 | 4096 | 1.6 | 코사인 | 200 | 9.83 | 22m |
| RESNET-PREACT-20 | 아니요 | 3E-4 | 4096 | 1.6 | 코사인 | 200 | 9.90 | 22m |
| RESNET-PREACT-20 | 아니요 | 2E-4 | 4096 | 1.6 | 코사인 | 200 | 9.64 | 22m |
| RESNET-PREACT-20 | 아니요 | 1E-4 | 4096 | 1.6 | 코사인 | 200 | 10.38 | 22m |
| 모델 | Bn의 체중 감소 | 체중 부패 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 예 | 5E-4 | 2048 | 1.6 | 코사인 | 200 | 8.46 | 20m |
| RESNET-PREACT-20 | 예 | 4E-4 | 2048 | 1.6 | 코사인 | 200 | 8.35 | 20m |
| RESNET-PREACT-20 | 예 | 3E-4 | 2048 | 1.6 | 코사인 | 200 | 7.76 | 20m |
| RESNET-PREACT-20 | 예 | 2E-4 | 2048 | 1.6 | 코사인 | 200 | 8.09 | 20m |
| RESNET-PREACT-20 | 예 | 1E-4 | 2048 | 1.6 | 코사인 | 200 | 8.83 | 20m |
| RESNET-PREACT-20 | 아니요 | 5E-4 | 2048 | 1.6 | 코사인 | 200 | 8.49 | 20m |
| RESNET-PREACT-20 | 아니요 | 4E-4 | 2048 | 1.6 | 코사인 | 200 | 7.98 | 20m |
| RESNET-PREACT-20 | 아니요 | 3E-4 | 2048 | 1.6 | 코사인 | 200 | 8.26 | 20m |
| RESNET-PREACT-20 | 아니요 | 2E-4 | 2048 | 1.6 | 코사인 | 200 | 8.47 | 20m |
| RESNET-PREACT-20 | 아니요 | 1E-4 | 2048 | 1.6 | 코사인 | 200 | 9.27 | 20m |
| 모델 | Bn의 체중 감소 | 체중 부패 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (중앙값 3 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 예 | 5E-4 | 1024 | 1.6 | 코사인 | 200 | 8.45 | 21m |
| RESNET-PREACT-20 | 예 | 4E-4 | 1024 | 1.6 | 코사인 | 200 | 7.91 | 21m |
| RESNET-PREACT-20 | 예 | 3E-4 | 1024 | 1.6 | 코사인 | 200 | 7.81 | 21m |
| RESNET-PREACT-20 | 예 | 2E-4 | 1024 | 1.6 | 코사인 | 200 | 7.69 | 21m |
| RESNET-PREACT-20 | 예 | 1E-4 | 1024 | 1.6 | 코사인 | 200 | 8.26 | 21m |
| RESNET-PREACT-20 | 아니요 | 5E-4 | 1024 | 1.6 | 코사인 | 200 | 8.08 | 21m |
| RESNET-PREACT-20 | 아니요 | 4E-4 | 1024 | 1.6 | 코사인 | 200 | 7.73 | 21m |
| RESNET-PREACT-20 | 아니요 | 3E-4 | 1024 | 1.6 | 코사인 | 200 | 7.92 | 21m |
| RESNET-PREACT-20 | 아니요 | 2E-4 | 1024 | 1.6 | 코사인 | 200 | 7.93 | 21m |
| RESNET-PREACT-20 | 아니요 | 1E-4 | 1024 | 1.6 | 코사인 | 200 | 8.53 | 21m |
하프 프리 보안 및 혼합-프레임에 대한 실험
- 실험에 이어 Nvidia apex가 필요합니다.
- 다음 실험은 텐서 코어가없는 Geforce 1080 Ti를 사용하여 CIFAR-10 데이터 세트에서 수행됩니다.
- 표에보고 된 결과는 마지막 시대의 테스트 오류입니다.
FP16 훈련
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O3
scheduler.type cosine
train.output_dir experiments/resnet_preact_fp16/exp00혼합-정밀 훈련
python train.py --config configs/cifar/resnet_preact.yaml
model.resnet_preact.depth 20
train.base_lr 1.6
train.batch_size 4096
train.precision O1
scheduler.type cosine
train.output_dir experiments/resnet_preact_mixed_precision/exp00결과
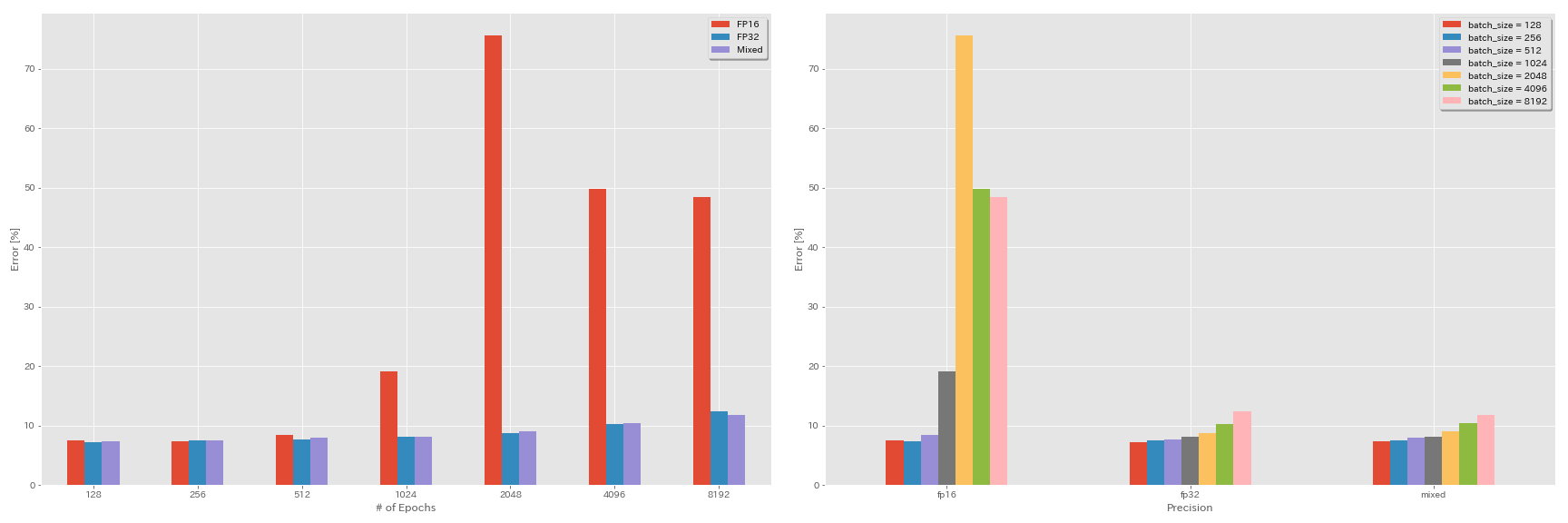
| 모델 | 정도 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | FP32 | 8192 | 1.6 | 코사인 | 200 | | |
| RESNET-PREACT-20 | FP32 | 4096 | 1.6 | 코사인 | 200 | 10.32 | 22m |
| RESNET-PREACT-20 | FP32 | 2048 | 1.6 | 코사인 | 200 | 8.73 | 22m |
| RESNET-PREACT-20 | FP32 | 1024 | 1.6 | 코사인 | 200 | 8.07 | 22m |
| RESNET-PREACT-20 | FP32 | 512 | 0.8 | 코사인 | 200 | 7.73 | 21m |
| RESNET-PREACT-20 | FP32 | 256 | 0.8 | 코사인 | 200 | 7.45 | 21m |
| RESNET-PREACT-20 | FP32 | 128 | 0.4 | 코사인 | 200 | 7.28 | 24m |
| 모델 | 정도 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | FP16 | 8192 | 1.6 | 코사인 | 200 | 48.52 | 33m |
| RESNET-PREACT-20 | FP16 | 4096 | 1.6 | 코사인 | 200 | 49.84 | 28m |
| RESNET-PREACT-20 | FP16 | 2048 | 1.6 | 코사인 | 200 | 75.63 | 27m |
| RESNET-PREACT-20 | FP16 | 1024 | 1.6 | 코사인 | 200 | 19.09 | 27m |
| RESNET-PREACT-20 | FP16 | 512 | 0.8 | 코사인 | 200 | 7.89 | 26m |
| RESNET-PREACT-20 | FP16 | 256 | 0.8 | 코사인 | 200 | 7.40 | 28m |
| RESNET-PREACT-20 | FP16 | 128 | 0.4 | 코사인 | 200 | 7.59 | 32m |
| 모델 | 정도 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | 혼합 | 8192 | 1.6 | 코사인 | 200 | 11.78 | 28m |
| RESNET-PREACT-20 | 혼합 | 4096 | 1.6 | 코사인 | 200 | 10.48 | 27m |
| RESNET-PREACT-20 | 혼합 | 2048 | 1.6 | 코사인 | 200 | 8.98 | 26m |
| RESNET-PREACT-20 | 혼합 | 1024 | 1.6 | 코사인 | 200 | 8.05 | 26m |
| RESNET-PREACT-20 | 혼합 | 512 | 0.8 | 코사인 | 200 | 7.81 | 28m |
| RESNET-PREACT-20 | 혼합 | 256 | 0.8 | 코사인 | 200 | 7.58 | 32m |
| RESNET-PREACT-20 | 혼합 | 128 | 0.4 | 코사인 | 200 | 7.37 | 41m |
Tesla V100을 사용한 결과
| 모델 | 정도 | 배치 크기 | 초기 LR | LR 일정 | 에포크의 # | 테스트 오류 (1 실행) | 훈련 시간 |
|---|
| RESNET-PREACT-20 | FP32 | 8192 | 1.6 | 코사인 | 200 | 12.35 | 25m |
| RESNET-PREACT-20 | FP32 | 4096 | 1.6 | 코사인 | 200 | 9.88 | 19m |
| RESNET-PREACT-20 | FP32 | 2048 | 1.6 | 코사인 | 200 | 8.87 | 17m |
| RESNET-PREACT-20 | FP32 | 1024 | 1.6 | 코사인 | 200 | 8.45 | 18m |
| RESNET-PREACT-20 | 혼합 | 8192 | 1.6 | 코사인 | 200 | 11.92 | 25m |
| RESNET-PREACT-20 | 혼합 | 4096 | 1.6 | 코사인 | 200 | 10.16 | 19m |
| RESNET-PREACT-20 | 혼합 | 2048 | 1.6 | 코사인 | 200 | 9.10 | 17m |
| RESNET-PREACT-20 | 혼합 | 1024 | 1.6 | 코사인 | 200 | 7.84 | 16m |
참조
모델 아키텍처
- 그는 Kaiming, Xiangyu Zhang, Shaoqing Ren 및 Jian Sun. "이미지 인식을위한 깊은 잔류 학습." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 회의 (CVPR), 2016. Link, Arxiv : 1512.03385
- 그는 Kaiming, Xiangyu Zhang, Shaoqing Ren 및 Jian Sun. "심층 잔류 네트워크에서의 정체성 매핑." 컴퓨터 비전에 관한 유럽 회의 (ECCV). 2016. ARXIV : 1603.05027, 토치 구현
- Zagoruyko, Sergey 및 Nikos Komodakis. "넓은 잔류 네트워크." Britring Machine Vision Conference (BMVC), 2016. ARXIV : 1605.07146, Torch 구현
- Huang, Gao, Zhuang Liu, Kilian Q Weinberger 및 Laurens van der Maaten. "조밀하게 연결된 컨볼 루션 네트워크." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 컨퍼런스 (CVPR), 2017. Link, ARXIV : 1608.06993, Torch 구현
- 한, Dongyoon, Jiwhan Kim 및 Junmo Kim. "깊은 피라미드 잔류 네트워크." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 회의 (CVPR), 2017. Link, Arxiv : 1610.02915, Torch 구현, 카페 구현, Pytorch 구현
- Xie, Saining, Ross Girshick, Piotr Dollar, Zhuowen Tu 및 Kaiming HE. "깊은 신경 네트워크를위한 집계 된 잔류 변형." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 컨퍼런스 (CVPR), 2017. Link, ARXIV : 1611.05431, Torch 구현
- Gastaldi, Xavier. "3 브랜치 잔류 네트워크의 쉐이크 쉐이크 정규화." ICLR (International Conference on Learning Representations) 워크숍, 2017. Link, ARXIV : 1705.07485, Torch 구현
- Hu, Jie, Li Shen 및 Gang Sun. "압박 및 발행 네트워크." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 회의 (CVPR), 2018, pp. 7132-7141. Link, Arxiv : 1709.01507, 카페 구현
- Huang, Gao, Zhuang Liu, Geoff Pleiss, Laurens van der Maaten 및 Kilian Q. Weinberger. "밀도가 높은 연결을 가진 컨볼 루션 네트워크." 패턴 분석 및 기계 지능에 대한 IEEE 거래 (2019). ARXIV : 2001.02394
정규화, 데이터 확대
- Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens 및 Zbigniew Wojna. "컴퓨터 비전을위한 시작 아키텍처를 다시 생각합니다." 컴퓨터 비전 및 패턴 인식에 관한 IEEE 회의 (CVPR), 2016. Link, Arxiv : 1512.00567
- Devries, Terrance 및 Graham W. Taylor. "컷 아웃으로 컨볼 루션 신경 네트워크의 정규화 개선." Arxiv preprint arxiv : 1708.04552 (2017). ARXIV : 1708.04552, Pytorch 구현
- 아부 엘 하이 자, 사미. "퍼센트 델타를 사용한 비례 그라디언트 업데이트." Arxiv preprint arxiv : 1708.07227 (2017). ARXIV : 1708.07227
- Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li 및 Yi Yang. "임의의 데이터 확대를 지우는 것." Arxiv preprint arxiv : 1708.04896 (2017). ARXIV : 1708.04896, Pytorch 구현
- Zhang, Hongyi, Moustapha Cisse, Yann N. Dauphin 및 David Lopez-Paz. "믹스 업 : 경험적 위험 최소화를 넘어서." ICLR (International Conference on Learning Representations), 2017. Link, ARXIV : 1710.09412
- Kawaguchi, Kenji, Yoshua Bengio, Vikas Verma 및 Leslie Pack Kaelbling. "분석 학습 이론을 통한 일반화를 이해하기 위해." Arxiv preprint arxiv : 1802.07426 (2018). ARXIV : 1802.07426, Pytorch 구현
- Takahashi, Ryo, Takashi Matsubara 및 Kuniaki Uehara. "랜덤 이미지 자르기 및 심층 CNN의 패치를 사용한 데이터 확대." Machine Learning에 관한 제 10 차 아시아 회의 (ACML)의 절차, 2018. Link, ARXIV : 1811.09030
- Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe 및 Youngjoon Yoo. "Cutmix : 현지화 가능한 기능으로 강력한 분류기를 훈련시키는 정규화 전략." Arxiv preprint arxiv : 1905.04899 (2019). ARXIV : 1905.04899
큰 배치
- Keskar, Nitish Shirish, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy 및 Ping Tak Peter Tang. "딥 러닝을위한 대규모 배치 훈련 : 일반화 격차와 선명한 최소값." ICLR (International Conference on Learning Representations), 2017. Link, ARXIV : 1609.04836
- Hoffer, Elad, Itay Hubara 및 Daniel Soudry. "더 오래 훈련하고, 더 나은 일반화 : 신경망의 대규모 배치 훈련에서 일반화 격차를 닫습니다." NIPS (Neural Information Processing Systems), 2017. Link, ARXIV : 1705.08741, Pytorch 구현
- Goyal, Priya, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia 및 Kaiming He. "정확하고 큰 미니 배트 SGD : 1 시간 안에 Imagenet을 훈련시킵니다." Arxiv preprint arxiv : 1706.02677 (2017). ARXIV : 1706.02677
- Yang, Igor Gitman 및 Boris Ginsburg. "컨볼 루션 네트워크의 대규모 배치 교육." Arxiv preprint arxiv : 1708.03888 (2017). ARXIV : 1708.03888
- Yang, Zhao Zhang, Cho-Jui Hsieh, James Demmel 및 Kurt Keutzer. "몇 분 안에 이미지 훈련." Arxiv preprint arxiv : 1709.05011 (2017). ARXIV : 1709.05011
- Smith, Samuel L., Pieter-Jan Kindermans, Chris Ying 및 Quoc V. Le. "학습 속도를 부패시키지 말고 배치 크기를 늘리십시오." ICLR (International Conference on Learning Presentations), 2018. Link, ARXIV : 1711.00489
- Gitman, Igor, Deepak Dilipkumar 및 Ben Parr. "비례 업데이트가있는 그라디언트 하강 알고리즘의 수렴 분석." Arxiv preprint arxiv : 1801.03137 (2018). ARXIV : 1801.03137 텐서 플로 구현
- Jia, Xianyan, Shutao Song, Wei HE, Yangzihao Wang, Haidong Rong, Feihu Zhou, Liqiang Xie, Zhenyu Guo, Yuanzhou Yang, Liwei Yu, Tiegang Chen, Guangxiao Hu, Shaohuai Shi 및 Xiaowen Chu. "혼합 정밀도를 갖춘 고도로 확장 가능한 딥 러닝 교육 시스템 : 4 분 안에 Imagenet을 훈련시킵니다." Arxiv preprint arxiv : 1807.11205 (2018). ARXIV : 1807.11205
- Christopher J., Jaehoon Lee, Joseph Antognini, Jascha Sohl-Dickstein, Roy Frostig 및 George E. Dahl. "신경 네트워크 훈련에 대한 데이터 병렬 처리의 영향 측정." Arxiv preprint arxiv : 1811.03600 (2018). ARXIV : 1811.03600
- Ying, Chris, Sameer Kumar, Dehao Chen, Tao Wang 및 Youlong Cheng. "슈퍼 컴퓨터 척도의 이미지 분류." Neural Information Processing Systems (Neurips) 워크숍, 2018. Link, Arxiv : 1811.06992의 발전.
기타
- Loshchilov, Ilya 및 Frank Hutter. "SGDR : 따뜻한 재시작으로 확률 론적 구배 출신." ICLR (International Conference on Learning Representations), 2017. Link, ARXIV : 1608.03983, Lasagne 구현
- Micikevicius, Paulius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh 및 Hao Wu. "혼합 정밀 훈련." ICLR (International Conference on Learning Presentations), 2018. Link, ARXIV : 1710.03740
- Recht, Benjamin, Rebecca Roelofs, Ludwig Schmidt 및 Vaishaal Shankar. "CIFAR-10 분류기는 CIFAR-10에 일반화합니까?" Arxiv preprint arxiv : 1806.00451 (2018). ARXIV : 1806.00451
- 그는 Tong, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie 및 Mu Li. "Convolutional Neural Networks를 사용한 이미지 분류를위한 트릭 백." Arxiv preprint arxiv : 1812.01187 (2018). ARXIV : 1812.01187


