pytorch original transformer
1.0.0
该回购包含原始变压器纸的Pytorch实现(:link:Vaswani等人)。
它的目的是使开始和学习变压器变得容易。
变压器最初是由Vaswani等人提出的。在一份名为“注意”的开创性论文中。
您可能以一种或另一种方式听说过变形金刚。 GPT-3和BERT列举了一些知名的?主要的想法是,他们表明您不必使用经常性或卷积层,而简单的体系结构和注意力相结合是超级强大的。它给予了更好的长距离依赖建模的好处,并且体系结构本身高度可行(:Computer :: Computer :: Computer :: Computer :: :)可以提高更好的计算效率!
这是他们美丽简单的建筑的样子:

该存储库应该是理解变形金刚作为原始变压器本身的学习资源,而不再是SOTA。
为此,代码(希望)评论得很好,我已经包括了playground.py 。所以我们走了!
您可以在眼睛的眼睛中解析这个吗?

playground.py也visualize_positional_encodings() 。

根据源/目标令牌的位置,您“选择此图像的一行”,然后将其添加到嵌入矢量中,仅此而已。他们也可以学习,但是这样做是更奇怪的! ?
同样,您可以在O(1)中解析这一点吗?

noup?所以我想,这里被可视化:

现在非常容易理解。现在,这部分对于变压器的成功至关重要吗?我怀疑。但这很酷,使事情变得更加复杂。 ? ( .set_sarcasm(True) )
注意:模型维度基本上是嵌入矢量的大小,使用的基线变压器使用512,大一个1024
第一次听到标签平滑的声音听起来很艰难,但事实并非如此。通常,您将目标词汇分布设置为one-hot 。含义为30k中的1个位置(或您的词汇大小的任何内容)设置为1。概率和其他所有内容。

在标签平滑而不是放置1。
注意:PAD令牌的分布设置为所有零,因为我们不希望模型预测这些模型!
除了这个仓库(好吧),我强烈建议您继续阅读Jay Alammar的这个令人惊叹的博客!
Transformer最初是在WMT-14数据集上针对NMT(神经机器翻译)任务进行培训的:
我所做的(目前)是我在IWSLT数据集上训练了我的模型,该数据集较小,因为我会说这些语言,因此,我会更容易调试和播放。
我还将很快在WMT-14上训练我的模型,看看Todos部分。
无论如何!让我们看看这个回购实际上可以为您做什么!好吧,它可以翻译!
从我的德语到英文IWSLT模型的一些简短翻译:
输入: Ich bin ein guter Mensch, denke ich. (“黄金”:我是一个好人)
输出: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
或以人为可读的格式: I think I'm a good person.
这实际上还不错!也许比Google翻译的“金”翻译更好。
当然有这样的失败情况:
输入: Hey Alter, wie geht es dir? (伙计怎么样?)
输出: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
或以人类可读的格式: Hey, age, how are you?
实际上,这也不是完全糟糕的!因为:
同样,对于英语到德国模型。
因此,我们讨论了什么是变形金刚,以及它们可以为您做什么(除其他事项)。
让我们来运行这个东西吧!按照下一步:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create (这将创建一个全新的Conda环境)。activate pytorch-transformer (用于从控制台运行脚本或在IDE中设置解释器)就是这样!它应该在开箱即用的执行环境中进行处理,以处理依赖关系。
可能需要一段时间,因为我会自动下载Spacy的英语和德语统计模型。
Pytorch Pip软件包将与某些版本的Cuda/cudnn捆绑在一起,但强烈建议您事先安装系统范围的CUDA,这主要是因为GPU驱动程序。我还建议使用Minconda安装程序作为在系统上获得Conda的一种方式。遵循此设置的点1和第2点,并为您的系统使用最新版本的minconda和cuda/cudnn。
只需从您的Anaconda控制台运行jupyter notebook ,它将在您的默认浏览器中打开会话。
打开The Annotated Transformer ++.ipynb ,您可以玩!
注意:如果DLL load failed while importing win32api: The specified module could not be found
只需pip uninstall pywin32 ,然后pip install pywin32或conda install pywin32就可以修复它!
您只需要链接您在设置部分中创建的Python环境即可。
要运行培训启动training_script.py ,您将要指定一些设置:
--batch_size这很重要的是将设置为最大值,而最大值不会使您无法存储--dataset_name IWSLT和WMT14之间的选择(在添加多GPU支持之前,不建议WMT14)--language_direction E2G和G2E之间的选择因此(从控制台)运行的示例将看起来像这样:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
该代码对您的评论进行了很好的评论,因此您可以(希望)了解培训本身的工作原理。
脚本将:
models/checkpoints/models/binaries/data/ )runs/ ,只需运行tensorboard --logdir=runs注意:TORCH文本中的数据加载速度很慢,因此我已经实施了一个自定义包装器,该包装器添加了缓存机制,并使事情更快地〜30倍! (第一次运行东西时会很慢)
第二部分是要与模型一起玩,并了解它们的翻译方式!
要获得一些翻译启动translation_script.py ,您需要设置一些设置:
--source_sentence取决于您指定的模型,应该是英语/德语句子--model_name预处理的型号之一: iwslt_e2g , iwslt_g2e或您的型号(*)--dataset_name与模型同步,如果在IWSLT上训练了该模型,则IWSLT--language_direction保持同步, E2G如果训练模型从英语翻译为德语(*)注意:训练模型后,它将被倾倒到models/binaries中,查看其名称是什么,并通过--model_name参数指定它,如果您想使用它以用于翻译目的。如果您指定了一些验证的型号,他们将在您第一次运行翻译脚本时自动下载。
我也将在此处链接IWSLT预计的模型链接:英语和德语和英语。
就是这样,您还可以可视化注意力查看本节。有关更多信息。
我在训练时跟踪了3条曲线:
BLEU是一种基于N克的度量,用于定量评估机器翻译模型的质量。
我使用了Awesome NLTK Python模块提供的BLEU-4度量。
当前的结果,模型接受了20个时代的培训(De Deutch代表德语的德语?):):
| 模型 | BLEU得分 | 数据集 |
|---|---|---|
| 基线变压器(EN-DE) | 27.8 | IWSLT VAL |
| 基线变压器(DE-EN) | 33.2 | IWSLT VAL |
| 基线变压器(EN-DE) | x | WMT-14 Val |
| 基线变压器(DE-EN) | x | WMT-14 Val |
我使用贪婪的解码来获得这些,因此这是一个悲观的估计,我会尽快添加横梁解码。
重要说明:初始化对变压器很重要!我最初认为,使用Xavier初始化的其他实现再次是这些任意启发式方法之一,而Pytorch默认Init将会做 - 我是错误的:
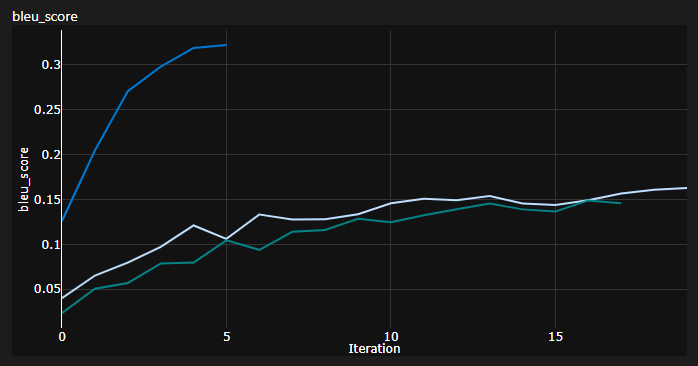
您可以在这里看到3次运行,2个下部使用的pytorch默认初始化(一种用于KL散射损失的mean ,而使用的较好的batchmean ),而上部使用的Xavier统一初始化!
想法:您也可以定期将翻译转换为源句子的参考批次。
尽管我没有这样做,但这将为您提供一些定性的见解,尽管我没有这样做。
当您很难定量地评估模型(例如在gan和nst领域)时,也会做类似的事情。
上面的图是我的Azure ML运行中的片段,但是当我在本地运行的东西时,我会使用张量。
只需运行tensorboard --logdir=runs ,您就可以在培训期间跟踪指标。
您可以使用translation_script.py并将--visualize_attention设置为真实,以便在源和目标句子中“注意”模型“注意”。
这是我对输入句子的注意力Ich bin ein guter Mensch, denke ich.
这些属于编码器的第6层。您可以看到所有8个多头注意力头。

这属于自我注意解码器MHA(多头注意)模块的解码器第6层。
您会注意到一个有趣的三角形模式,该模式来自目标令牌无法展望的事实!

第三种类型的MHA模块是参与其中的源,它看起来与您看到的编码图相似。
随意按照自己的节奏进行比赛!
注意:这个模型显然存在一些偏见问题,但我不会在这里进行分析
如果您想在WMT-14数据集中训练变压器,则确实需要一个体面的硬件。
作者接受:
如果我的计算正确,则相当于约19个时期(100k步,每个步骤的基线都有〜25000令牌,WMT-14的SRC/TRG令牌为〜130m src/trg令牌),对于大个子(300k步骤)而言,它的基线为3x。
另一方面,在IWSLT数据集上训练该模型更为可行。我花了我:
我本来可以将K80推到3500多个令牌/批次,但有一些CUDA出现在内存问题上。
最后,还有几个Todos,我希望很快就会添加:
存储库已经拥有所需的一切,这些只是奖励点。我已经测试了从环境设置到自动模型下载等所有内容。
如果您很难理解代码,我在本视频中对本文进行了深入的概述:
我还有更多视频,可以进一步帮助您了解变形金刚:
我发现这些资源有用(在开发此资源时):
我在带注释的变压器中找到了模型设计的一些灵感,但我发现很难理解,并且有一些错误。它主要是考虑到研究人员。希望这种回购也能使对变压器的理解也向普通人开放! ?
如果您发现此代码有用,请引用以下内容:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
如果您想在生活中拥有更多与AI相关的内容?请考虑:


