pytorch original transformer
1.0.0
이 repo에는 원래 변압기 용지의 Pytorch 구현이 포함되어 있습니다 (: Link : Vaswani et al.).
트랜스포머에 대해 쉽게 연주하고 배울 수 있도록하는 것이 목표입니다.
변압기는 원래 Vaswani et al. 주의를 기울이라는 주요 논문에서는 필요한 전부입니다.
당신은 아마도 변압기에 대해 어떤 식 으로든 들었을 것입니다. 잘 알려진 몇 가지를 지명하려면 GPT-3과 Bert ?. 주요 아이디어는 그들이 당신이 반복적이거나 컨볼 루션 층을 사용할 필요가 없으며주의와 함께 간단한 건축이 매우 강력하다는 것을 보여 주었다. 그것은 훨씬 더 나은 장거리 의존성 모델링 의 이점을 제공했으며 아키텍처 자체는 매우 병렬화 가능 합니다 (: Computer :: Computer :: Computer :) 더 나은 컴퓨팅 효율성으로 이어집니다!
아름답고 단순한 건축물이 어떻게 보이는지는 다음과 같습니다.

이 repo는 원래 변압기 자체가 더 이상 SOTA가 아니기 때문에 변압기를 이해하기위한 학습 자원이어야합니다.
이 목적을 위해 코드는 (희망적으로) 잘 댓글을 달았으며 playground.py 를 포함 시켰습니다. 여기서 단어를 사용하기 어렵지만 한 번도 시각화 된 몇 가지 개념을 시각화했습니다. 그래서 우리는 간다!
눈을 엿볼 때 이것을 구문 분석 할 수 있습니까?

NOTE NONE I. playground.py 에서 visualize_positional_encodings() 함수를 실행합니다.

소스/대상 토큰의 위치에 따라 "이 이미지의 한 줄을 선택"하면 벡터가 포함 된 벡터에 추가합니다. 그들은 또한 배울 수 있었지만 분명히 이런 식으로하는 것이 더 멋지다! ?
마찬가지로 이것을 O(1) 로 구문 분석 할 수 있습니까?

Noup? 그래서 여기에 시각화되어 있다고 생각했습니다.

지금 이해하기 쉽습니다. 이제이 부분이 변압기의 성공에 결정적인 지 여부? 나는 그것을 의심한다. 그러나 그것은 시원하고 물건을 더 복잡하게 만듭니다. ? ( .set_sarcasm(True) )
참고 : 모델 차원은 기본적으로 임베딩 벡터의 크기, 기준선 변압기 512, Big One 1024입니다.
라벨 스무딩에 대해 처음 들으면 힘들지만 그렇지 않습니다. 일반적으로 대상 어휘 분포를 one-hot 로 설정합니다. 30K 중 1 위치 (또는 어휘 크기가 무엇이든)를 의미합니다. 확률 및 기타 모든 것은 0으로 설정됩니다.

1을 배치하는 대신 라벨 스무딩에서. 특정 위치에 0.9라고 말하면 다른 위치에 나머지 "확률 질량"을 고르게 분포합니다 (위의 이미지에서 다른 자주색 음영으로 시각화되어 크기 4의 가상의 어휘 - 4 열).
참고 : PAD Token의 분포는 모델을 예측하는 것을 원하지 않기 때문에 모든 0으로 설정됩니다!
이 저장소 (Well Duh) 외에도 Jay Alammar 의이 놀라운 블로그를 읽어보십시오!
Transformer는 원래 WMT-14 데이터 세트에서 NMT (Neural Machine Translation) 작업을 위해 교육을 받았습니다.
내가 한 일은 (지금) 영어-독일어 쌍을 위해 훨씬 작은 IWSLT 데이터 세트에서 모델을 훈련시키는 것입니다. 해당 언어를 사용하여 디버깅하고 놀기 쉽습니다.
또한 곧 WMT-14에서 모델을 훈련시키고 Todos 섹션을 살펴 보겠습니다.
어쨌든! 이 repo가 실제로 당신을 위해 무엇을 할 수 있는지 봅시다! 글쎄, 그것은 번역 할 수 있습니다!
내 독일어에서 영어 IWSLT 모델까지의 짧은 번역 :
입력 : Ich bin ein guter Mensch, denke ich. ( "금": 나는 좋은 사람입니다.
출력 : ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
또는 사람이 읽을 수있는 형식 : I think I'm a good person.
실제로 꽤 좋습니다! Google Translate의 "Gold"번역보다 IMO가 더 나을 수도 있습니다.
물론 다음과 같은 실패 사례가 있습니다.
입력 : Hey Alter, wie geht es dir? (어때요?)
출력 : ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
아니면 인간이 읽을 수있는 형식으로 : Hey, age, how are you?
실제로 완전히 나쁘지는 않습니다! 왜냐하면:
영어에서 독일 모델과 마찬가지로.
그래서 우리는 트랜스포머가 무엇인지, 그리고 그들이 당신을 위해 무엇을 할 수 있는지에 대해 이야기했습니다.
이 일을 실행합시다! 다음 단계를 따르십시오.
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repo 로 탐색하십시오.conda env create 실행하십시오 (이는 새로운 콘다 환경을 생성 할 것입니다).activate pytorch-transformer (콘솔에서 스크립트를 실행하거나 IDE에서 통역사를 설정) 그게 다야! 의존성을 다루는 환경에서 실행되는 환경에서 작동해야합니다.
영어와 독일어에 대한 Spacy의 통계 모델을 자동으로 다운로드하므로 시간이 걸릴 수 있습니다.
Pytorch Pip 패키지에는 Cuda/Cudnn의 일부 버전이 번들로 제공되지만 대부분 GPU 드라이버로 인해 시스템 전체 Cuda를 미리 설치하는 것이 좋습니다. 또한 Miniconda Installer를 시스템에서 Conda를 얻는 방법으로 사용하는 것이 좋습니다. 이 설정의 1과 2 포인트를 따르고 시스템에 가장 최신 버전의 Miniconda 및 Cuda/Cudnn을 사용하십시오.
jupyter notebook 에서 Anaconda Console에서 실행하면 기본 브라우저에서 세션을 열게됩니다.
The Annotated Transformer ++.ipynb 는 재생할 준비가되었다!
참고 : DLL load failed while importing win32api: The specified module could not be found
pip uninstall pywin32 다음 pip install pywin32 또는 conda install pywin32 수정해야합니다!
설정 섹션에서 만든 파이썬 환경을 연결하면됩니다.
교육을 실행하려면 training_script.py 시작하려면 지정할 몇 가지 설정이 있습니다.
--batch_size 메모리에서 cuda를 줄 수없는 최대 값으로 설정하는 것이 중요합니다.--dataset_name IWSLT 와 WMT14 사이의 선택 (멀티 GPU 지원을 추가하기 전까지는 WMT14가 권장되지 않습니다)--language_direction E2G 와 G2E 사이를 선택하십시오 따라서 (콘솔에서) 실행 예제는 다음과 같습니다.
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
코드는 잘 댓글을 달 수 있으므로 교육 자체가 어떻게 작동하는지 (희망적으로) 이해할 수 있습니다.
스크립트는 다음과 같습니다.
models/checkpoints/models/binaries/data/ )runs/ , run tensorboard --logdir=runs참고 : Torch 텍스트에서는 데이터로드가 느리기 때문에 캐싱 메커니즘을 추가하고 ~ 30 배 더 빠르게 만드는 사용자 정의 래퍼를 구현했습니다! (처음으로 물건을 실행할 때 느리게됩니다)
두 번째 부분은 모델을 가지고 노는 것과 그들이 어떻게 번역하는지 보는 것입니다!
번역을 시작하려면 translation_script.py 를 시작하려면 다음을 설정하려는 몇 가지 설정이 있습니다.
--source_sentence 모델에 따라 지정된 모델에 따라 영어/독일어 문장이어야합니다.--model_name 사전에 사전 된 모델 이름 중 하나 : iwslt_e2g , iwslt_g2e 또는 모델 (*)--dataset_name 모델과 IWSLT에서 교육을받은 경우 IWSLT 모델과 동기화하십시오.--language_direction 모델이 영어에서 독일어로 번역하도록 훈련 된 경우 동기화, E2G (*) 참고 : 모델 --model_name 훈련시킨 후에는 models/binaries 에 버려지게됩니다. 사기가 발생한 일부 모델을 지정하면 번역 스크립트를 처음 실행할 때 자동으로 다운로드됩니다 .
여기서는 IWSLT 사전 제기 된 모델 링크를 여기에 연결합니다.
그것이 당신 이이 섹션을 확인할 수도 있습니다. 자세한 정보.
훈련하는 동안 3 개의 곡선을 추적했습니다.
Bleu는 기계 번역 모델의 품질을 정량적으로 평가하기위한 N-Gram 기반 메트릭입니다.
Awesome NLTK Python 모듈이 제공 한 BLEU-4 메트릭을 사용했습니다.
현재 결과, 모델은 20 개의 에포크에 대해 훈련을 받았습니다 (De Chord in Deutch in German?) : :
| 모델 | 블루 스코어 | 데이터 세트 |
|---|---|---|
| 기준 변압기 (en-de) | 27.8 | Iwslt val |
| 기준 변압기 (de-en) | 33.2 | Iwslt val |
| 기준 변압기 (en-de) | 엑스 | WMT-14 발 |
| 기준 변압기 (de-en) | 엑스 | WMT-14 발 |
나는 욕심 많은 디코딩을 사용하여 이것들을 얻었으므로 비관적 인 추정치입니다. 곧 빔 디코딩을 추가 할 것입니다.
중요 참고 사항 : 트랜스포머의 초기화가 중요합니다! 처음에는 Xavier 초기화를 사용한 다른 구현이 다시 임의의 휴리스틱 중 하나이며 Pytorch Default Init가 할 것이라고 생각했습니다.
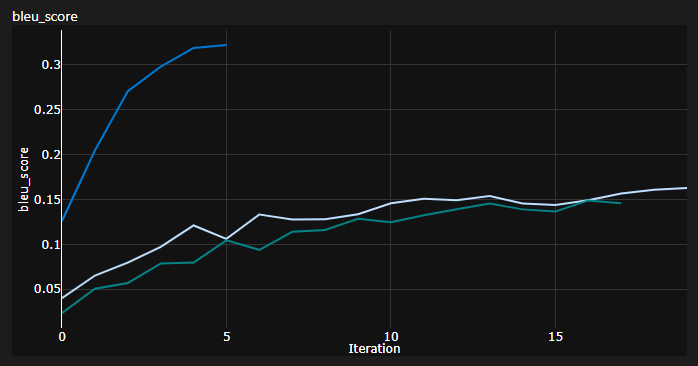
여기에서 3 번의 런을 볼 수 있습니다. 2 개의 낮은 런은 Pytorch Default 초기화를 사용했으며 (하나는 KL 발산 손실에 사용 된 mean 및 더 나은 하나는 batchmean 나은 사용)를 사용하는 반면, 상단은 Xavier 균일 초기화를 사용했습니다!
아이디어 : 잠재적으로 소스 문장의 참조 배치에 대한 번역을 주기적으로 볼 수 있습니다.
그것은 내가 그렇게하지 않았지만 변압기가 어떻게 진행되고 있는지에 대한 질적 통찰력을 줄 것입니다.
GAN 및 NST 필드에서와 같이 모델을 정량적으로 평가할 때 비슷한 일이 이루어집니다.
위의 줄거리는 Azure ML 실행의 스 니펫이지만 로컬로 물건을 실행할 때 Tensorboard를 사용합니다.
tensorboard --logdir=runs 교육 중에 메트릭을 추적 할 수 있습니다.
translation_script.py 를 사용하고 --visualize_attention TRUE로 설정하여 소스 및 대상 문장에서 모델이 "주의를 기울이는"내용을 추가로 이해할 수 있습니다.
다음은 입력 문장 Ich bin ein guter Mensch, denke ich.
이들은 인코더의 계층 6에 속합니다. 8 개의 멀티 헤드주의 헤드를 모두 볼 수 있습니다.

그리고 이것은 자체 변환 디코더 MHA (다중 헤드주의) 모듈의 디코더 계층 6에 속합니다.
대상 토큰이 앞서 볼 수 없다는 사실에서 비롯된 흥미로운 삼각 패턴을 알 수 있습니다!

MHA 모듈의 세 번째 유형은 참석 한 소스이며 인코더에 대해 보았던 플롯과 유사하게 보입니다.
자신의 속도로 자유롭게 플레이하십시오!
참고 :이 모델에는 분명히 편견 문제가 있지만 여기서는 해당 분석에 들어 가지 않을 것입니다.
WMT-14 데이터 세트에서 변압기를 훈련 시키려면 괜찮은 하드웨어가 필요합니다.
저자는 다음을 취했습니다.
내 계산이 ~ 19 개의 에포크 (100k 단계, 각 단계에는 ~ 25000 토큰이 있었고 WMT-14에는 기준선에 대해 ~ 130m SRC/TRG 토큰이 있고 3 배의 빅 1에 대한 3 배)에 해당합니다.
반면에 IWSLT 데이터 세트에서 모델을 훈련시키는 것이 훨씬 더 실현 가능합니다. 나를 데려 갔다 :
K80을 3500 개 이상의 토큰/배치로 밀었을 수도 있지만 메모리 문제에서 약간의 CUDA가있었습니다.
마지막으로 곧 추가 할 수있는 몇 개의 토도가 더 있습니다.
리포에는 이미 필요한 모든 것이 있습니다. 보너스 포인트 일뿐입니다. 환경 설정에서 자동 모델 다운로드 등 모든 것을 테스트했습니다.
코드를 이해하는 데 어려움이있는 경우이 비디오에서 논문에 대한 심층적 인 개요를 수행했습니다.
트랜스포머를 이해하는 데 도움이되는 더 많은 비디오가 있습니다.
이 리소스가 유용하다는 것을 알았습니다 (이것을 개발하는 동안).
주석이 달린 변압기에서 모델 디자인에 대한 영감을 얻었지만 이해하기 어렵고 버그가있었습니다. 주로 연구원을 염두에두고 쓰여졌습니다. 바라건대이 repo는 일반적인 사람들에게 트랜스포머에 대한 이해를 열어주기를 바랍니다! ?
이 코드가 유용하다고 생각되면 다음을 인용하십시오.
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
인생에서 AI 관련 콘텐츠를 더 많이 원한다면 다음을 고려하십시오.


