pytorch original transformer
1.0.0
Dieses Repo enthält die Pytorch -Implementierung des ursprünglichen Transformatorpapiers (: Link: Vaswani et al.).
Es zielt darauf ab, das Spielen und Lernen von Transformatoren leicht zu machen.
Transformatoren wurden ursprünglich von Vaswani et al. In einem wegweisenden Papier namens Aufmerksamkeit ist alles, was Sie brauchen.
Sie haben wahrscheinlich auf die eine oder andere Weise von Transformatoren gehört. GPT-3 und Bert, um ein paar bekannte zu nennen? Die Hauptidee ist, dass sie gezeigt haben, dass Sie keine rezidivierenden oder Faltungsschichten verwenden müssen und dass eine einfache Architektur, die mit Aufmerksamkeit gekoppelt ist, sehr mächtig ist. Es gab den Vorteil einer viel besseren Abhängigkeitsmodellierung von langfristigen Abhängigkeiten und die Architektur selbst ist sehr parallelisierbar (: Computer :: Computer :: Computer :) Dies führt zu einer besseren Berechnung der Effizienz!
So sieht ihre wunderschön einfache Architektur aus:

Dieses Repo soll eine Lernressource für das Verständnis von Transformatoren sein, da der ursprüngliche Transformator für sich selbst kein Sota mehr ist.
Zu diesem Zweck ist der Code (hoffentlich) gut kommentiert, und ich habe den playground.py aufgenommen. Also hier gehen wir!
Können Sie diesen in einen Blick auf das Auge analysieren?

Ich kann auch nicht die Funktion visualize_positional_encodings() von playground.py ausführen. Py Wir erhalten Folgendes:

Abhängig von der Position Ihres Quell-/Ziel -Tokens "wählen Sie eine Zeile dieses Bildes" und fügen sie dem Einbettungsvektor hinzu, das ist es. Sie könnten auch gelernt werden, aber es ist offensichtlich einfach mehr, es so zu machen! ?
Kannst du diesen in O(1) analysieren?

NOUP? Also dachte ich, hier wird es sich visualisiert:

Es ist jetzt super leicht zu verstehen. Nun, ob dieser Teil entscheidend für den Erfolg des Transformators? Ich bezweifle es. Aber es ist cool und macht die Dinge komplizierter. ? ( .set_sarcasm(True) )
HINWEIS: Die Modelldimension ist im Grunde die Größe des Einbettungsvektors, der Basistransformator verwendet 512, der große 1024
Zum ersten Mal hörst du von dem Etikett glättend, es klingt hart, aber es ist nicht so. Normalerweise setzen Sie Ihre Zielvokabularverteilung auf einen one-hot . Das heißt 1 Position von 30k (oder was auch immer Ihre Vokabellengröße ist) ist auf 1. Wahrscheinlichkeit und alles andere auf 0 eingestellt.

Bei der Glättung von Etiketten, anstatt 1 zu platzieren, platzieren Sie in dieser bestimmten Position sagen Sie sagen 0,9 und Sie verteilen gleichmäßig den Rest der "Wahrscheinlichkeitsmasse" über die anderen Positionen (dies wird als ein anderer Lila -Schatten auf dem Bild oben in einem fiktiven Vokab der Größe 4 - daher 4 Säulen visualisiert).
Hinweis: Die Verteilung von Pad Token ist auf alle Nullen eingestellt, da wir nicht möchten, dass unser Modell diese vorhersagt!
Abgesehen von diesem Repo (na duh) kann ich Ihnen nur empfehlen, diesen erstaunlichen Blog von Jay Alammar zu lesen!
Der Transformator wurde ursprünglich für die NMT-Aufgabe (Neural Machine Translation) im WMT-14-Datensatz für:
Was ich (vorerst) getan habe, ist, dass ich meine Modelle auf dem IWSLT-Datensatz trainiert habe, was für das englisch-deutsche Sprachpaar viel kleiner ist, da ich diese Sprachen spreche, damit es einfacher ist, zu debuggen und herumzuspielen.
Ich werde meine Models auch bald auf WMT-14 trainieren und einen Blick auf den Todos-Abschnitt werfen.
Wie auch immer! Mal sehen, was dieses Repo praktisch für Sie tun kann! Nun, es kann übersetzen!
Einige kurze Übersetzungen von meinem Deutsch zum englischen IWSLT -Modell:
Eingabe: Ich bin ein guter Mensch, denke ich. ("Gold": Ich bin ein guter Mensch, den ich denke)
Ausgabe: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
Oder in der menschlichen lesbaren Form: I think I'm a good person.
Was eigentlich ziemlich gut ist! Vielleicht sogar besser imo als Google Translate "Gold" -Translation.
Es gibt natürlich solche Fehlerfälle:
Eingabe: Hey Alter, wie geht es dir? (Wie läuft es, Alter?)
Ausgabe: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
Oder in der menschlichen lesbaren Form: Hey, age, how are you?
Was eigentlich auch nicht ganz schlecht ist! Weil:
Ähnlich für die Engländer des deutschen Modells.
Also haben wir darüber gesprochen, was Transformatoren sind und was sie für Sie tun können (unter anderem).
Lassen Sie uns dieses Ding zum Laufen bringen! Befolgen Sie die nächsten Schritte:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create aus dem Projektverzeichnis aus (dadurch werden eine brandneue Conda -Umgebung geschaffen).activate pytorch-transformer (zum Ausführen von Skripten aus Ihrer Konsole oder festlegen oder den Interpreter in Ihrer IDE festlegen). Das war's! Es sollte eine optimale Ausführungsdatei von Environment.yml funktionieren, die sich mit Abhängigkeiten befasst.
Es kann eine Weile dauern, da ich automatisch die statistischen Modelle von Spact für Englisch und Deutsch herunterlade.
Das Pytorch-PIP-Paket wird mit einer Version von CUDA/CUDNN mit ihm gebündelt. Es wird jedoch dringend empfohlen, dass Sie vorher ein systemweites CUDA installieren, hauptsächlich wegen der GPU-Treiber. Ich empfehle auch, das Miniconda -Installationsprogramm zu verwenden, um Conda auf Ihr System zu bringen. Folgen Sie durch die Punkte 1 und 2 dieses Setups und verwenden Sie die aktuellsten Versionen von Miniconda und CUDA/CUDNN für Ihr System.
Führen Sie einfach jupyter notebook von Ihnen Anaconda -Konsole aus und es wird die Sitzung in Ihrem Standardbrowser geöffnet.
Öffnen Sie The Annotated Transformer ++.ipynb und Sie können spielen!
HINWEIS: Wenn Sie DLL load failed while importing win32api: The specified module could not be found
pip uninstall pywin32 einfach und pip install pywin32 oder conda install pywin32 sollte es reparieren!
Sie müssen nur die Python -Umgebung verknüpfen, die Sie im Setup -Abschnitt erstellt haben.
Um das Training auszuführen, starten Sie das training_script.py , es gibt einige Einstellungen, die Sie angeben möchten:
--batch_size -Dies ist wichtig, um einen Höchstwert zu setzen, der Ihnen keine CUDA aus dem Speicher verleiht--dataset_name -Wählen Sie zwischen IWSLT und WMT14 (WMT14 ist nicht ratsam, wenn ich Multi-GPU-Unterstützung hinzufüge)--language_direction -Wählen Sie zwischen E2G und G2E Ein Beispiel -Lauf (aus der Konsole) würde also so aussehen:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
Der Code ist gut kommentiert, sodass Sie (hoffentlich) verstehen können, wie das Training selbst funktioniert.
Das Skript wird:
models/checkpoints/models/binaries/data/ )runs/ , einfach tensorboard --logdir=runs von Ihrer Anaconda aus.Hinweis: Das Laden von Daten ist im Torchtext langsam, und daher habe ich einen benutzerdefinierten Wrapper implementiert, der die Caching -Mechanismen hinzufügt und die Dinge ~ 30x schneller macht! (Es wird langsam sein, wenn Sie zum ersten Mal Sachen laufen)
Im zweiten Teil geht es darum, mit den Modellen zu spielen und zu sehen, wie sie übersetzen!
Um einige Übersetzungen zu erhalten, starten Sie die translation_script.py , es gibt einige Einstellungen, die Sie festlegen möchten:
--source_sentence -Abhängig vom Modell geben Sie an, dass dies entweder ein englischer/deutscher Satz sein sollte--model_name -Einer der vorbereiteten Modellnamen: iwslt_e2g , iwslt_g2e oder Ihr Modell (*)--dataset_name -Halten Sie dies synchron mit dem Modell, IWSLT wenn das Modell auf IWSLT trainiert wurde--language_direction -Halten Sie synchron, E2G wenn das Modell geschult wurde, um von Englisch auf Deutsch zu übersetzen (*) Hinweis: Nachdem Sie Ihr Modell trainiert haben, wird es in models/binaries abgelassen. Sehen Sie, wie es heißt, und geben Sie es über den Parameter --model_name an, wenn Sie mit ihm für Übersetzungszwecke spielen möchten. Wenn Sie einige der vorbereiteten Modelle angeben, werden sie automatisch heruntergeladen, wenn Sie das Übersetzungsskript zum ersten Mal ausführen.
Ich werde auch hier IWSLT -Modelllinks verknüpfen: Englisch mit Deutsch und Deutsch mit Englisch.
Das ist es, dass Sie auch die Aufmerksamkeit visualisieren können. Überprüfen Sie diesen Abschnitt. Für weitere Informationen.
Ich habe 3 Kurven während des Trainings verfolgt:
BLEU ist eine N-Gram-basierte Metrik zur quantitativen Bewertung der Qualität von maschinellen Übersetzungsmodellen.
Ich habe die BLEU-4-Metrik verwendet, die vom fantastischen NLTK- Python-Modul bereitgestellt wurde.
Aktuelle Ergebnisse wurden Modelle für 20 Epochen ausgebildet (DE steht für Deutch IE Deutsch in Deutsch?):
| Modell | Bleu -Score | Datensatz |
|---|---|---|
| Baseline-Transformator (EN-de) | 27.8 | Iwslt val |
| Baseline-Transformator (DE-EN) | 33.2 | Iwslt val |
| Baseline-Transformator (EN-de) | X | WMT-14 Val |
| Baseline-Transformator (DE-EN) | X | WMT-14 Val |
Ich habe diese mit gierigem Dekodieren bekommen, also ist es eine pessimistische Schätzung. Ich werde bald eine Strahldekodierung hinzufügen.
Wichtiger Hinweis: Die Initialisierung ist für den Transformator sehr wichtig! Ich dachte zunächst, dass andere Implementierungen mit Xavier -Initialisierung wieder eine dieser willkürlichen Heuristiken sind und dass Pytorch -Standard -Init es tun wird - ich habe mich geirrt:
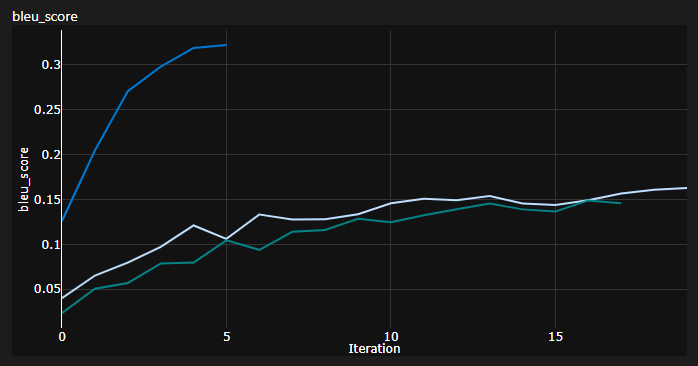
Sie können hier 3 Läufe sehen, die 2 unteren verwendeten Pytorch -Standardinitialisierung (ein verwendeter mean für den KL -Divergenzverlust und das bessere Gebrauchs batchmean ), während die obere Xavier -Uniform -Initialisierung verwendet wurde!
Idee: Sie können möglicherweise auch regelmäßig Übersetzungen für eine Referenzstapel von Quellsätzen ablegen.
Das würde Ihnen einen qualitativen Einblick geben, wie es dem Transformator geht, obwohl ich das nicht getan habe.
Ähnliches erfolgt, wenn Sie Ihr Modell quantitativ wie in Gans- und NST -Feldern quantitativ bewerten.
Die obige Handlung ist ein Ausschnitt aus meinem Azure ML -Lauf, aber wenn ich Sachen lokal ausführe, benutze ich Tensorboard.
Führen Sie einfach tensorboard --logdir=runs von Ihrer Anaconda -Konsole aus und Sie können Ihre Metriken während des Trainings verfolgen.
Sie können die translation_script.py verwenden und die --visualize_attention auf True festlegen, um zusätzlich zu verstehen, was Ihr Modell in den Quell- und Zielsätzen "Aufmerksamkeit schenken".
Hier sind die Aufmerksamkeit, die ich für den Eingangssatz erhalte Ich bin ein guter Mensch, denke ich.
Diese gehören zur Schicht 6 des Encoders. Sie können alle 8 Multi-Head-Aufmerksamkeitsköpfe sehen.

Und dieser gehört zur Decoder-Schicht 6 des Selbstbekämpfungsdecoder-MHA-Moduls (Mehrköpfe).
Sie können ein interessantes dreieckiges Muster bemerken, das sich aus der Tatsache ergibt, dass Target -Token nicht nach vorne schauen können!

Die dritte Art des MHA -Moduls ist die Quelle, die an einem teilnimmt und ähnelt der Handlung, die Sie für den Encoder gesehen haben.
Fühlen Sie sich frei, in Ihrem eigenen Tempo damit zu spielen!
Hinweis: Es gibt offensichtlich einige Verzerrungsprobleme mit diesem Modell, aber ich werde hier nicht in diese Analyse eingehen
Sie brauchen wirklich eine anständige Hardware, wenn Sie den Transformator im WMT-14- Datensatz trainieren möchten.
Die Autoren nahmen:
Wenn meine Berechnungen stimmen, sind ~ 19 Epochen (100K-Schritte, jeder Schritt hatte ~ 25.000 Token und WMT-14 ~ 130 m SRC/TRG-Token) für die Basislinie und 3x das für die großen (300k-Schritte).
Andererseits ist es viel praktikabler, das Modell im IWSLT -Datensatz zu trainieren. Es brauchte mich:
Ich hätte K80s bis 3500+ Token/Charge schieben können, hatte aber einige Cuda aus Gedächtnisproblemen.
Schließlich gibt es noch ein paar Todos, die ich hoffentlich bald hinzufügen werde:
Das Repo hat bereits alles, was es braucht, dies sind nur die Bonuspunkte. Ich habe alles vom Umgebungs -Setup über automatische Modell -Download usw. getestet.
Wenn Sie Schwierigkeiten haben, den Code zu verstehen, habe ich in diesem Video einen detaillierten Überblick über das Papier gemacht:
Ich habe noch einige Videos, die Ihnen weiter helfen könnten, Transformers zu verstehen:
Ich fand diese Ressourcen nützlich (während ich diese entwickelte):
Ich fand etwas Inspiration für das Modelldesign im dem kommentierten Transformator, aber ich fand es schwer zu verstehen, und es hatte einige Fehler. Es wurde hauptsächlich mit Forschern geschrieben. Hoffentlich öffnet dieses Repo auch das Verständnis von Transformatoren für die gemeinsamen Leute! ?
Wenn Sie diesen Code nützlich finden, geben Sie Folgendes an:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
Wenn Sie gerne mehr KI-bezogene Inhalte in Ihrem Leben haben würden? Überlegen Sie sich:


