pytorch original transformer
1.0.0
يحتوي هذا الريبو على تنفيذ Pytorch لورقة المحولات الأصلية (: الرابط: Vaswani et al.).
إنه يهدف إلى تسهيل البدء في اللعب والتعلم عن المحولات.
تم اقتراح المحولات في الأصل بواسطة فاسواني وآخرون. في ورقة صامتة تدعى الانتباه هو كل ما تحتاجه.
ربما سمعت عن المحولات بطريقة أو بأخرى. GPT-3 و Bert على سبيل المثال لا الحصر تلك المعروفة؟ الفكرة الرئيسية هي أنهم أظهروا أنك لست مضطرًا إلى استخدام طبقات متكررة أو تلافيفية وأن الهندسة المعمارية البسيطة إلى جانب الاهتمام قوية للغاية. لقد أعطى فائدة نمذجة التبعية بعيدة المدى أفضل بكثير والهندسة المعمارية نفسها قابلة للتوازي للغاية (: الكمبيوتر :: الكمبيوتر :: :) الذي يؤدي إلى حساب أفضل لحساب!
إليكم كيف تبدو الهندسة المعمارية البسيطة بشكل جميل:

من المفترض أن يكون هذا الريبو مورد تعليمي لفهم المحولات لأن المحول الأصلي في حد ذاته لم يعد سوتا.
لهذا الغرض ، يتم التعليق بشكل جيد (نأمل) ، وقد قمت بتضمين playground.py حيث قمت بتصور بعض المفاهيم التي يصعب شرحها باستخدام الكلمات ولكن بسيطة للغاية بمجرد تصورها. لذلك هنا نذهب!
هل يمكنك تحليل هذا واحد في لمحة عن العين؟

لا يمكن أن تقوم بتشغيل وظيفة visualize_positional_encodings() من playground.py نحصل على هذا:

اعتمادًا على موضع المصدر/الرمز المميز الخاص بك "اختر صفًا واحدًا من هذه الصورة" وتضيفه إلى ناقل التضمين ، هذا كل شيء. يمكن أن يتعلموا أيضًا ، لكن من الرائع أن تفعل ذلك مثل هذا ، من الواضح! ؟
وبالمثل ، يمكنك تحليل هذا واحد في O(1) ؟

نوب؟ لذلك اعتقدت ، هنا هو تصور:

من السهل الفهم الآن. الآن ما إذا كان هذا الجزء حاسمًا لنجاح المحول؟ أنا أشك في ذلك. لكنه رائع ويجعل الأمور أكثر تعقيدًا. ؟ ( .set_sarcasm(True) )
ملاحظة: الأبعاد النموذجية هو في الأساس حجم متجه التضمين ، المحول الأساسي المستخدم 512 ، واحد 1024
لأول مرة تسمع عن تجانس التسمية يبدو صعبًا ولكنه ليس كذلك. عادةً ما تقوم بتعيين توزيع المفردات المستهدف على one-hot . بمعنى 1 موقف من 30 ألف (أو أيا كان حجم المفردات الخاص بك) تم تعيينه على 1. الاحتمال وكل شيء آخر إلى 0.

في تنعيم الملصقات بدلاً من وضع 1. في هذا الموضع المعين ، تقول 0.9 وتوزع بالتساوي بقية "كتلة الاحتمالات" على المواضع الأخرى (التي يتم تصورها كظلال مختلفة من اللون الأرجواني على الصورة أعلاه في مفردات خيالية بحجم 4 - وبالتالي 4 أعمدة)
ملاحظة: يتم تعيين توزيع Pad Token على جميع الأصفار لأننا لا نريد أن يتنبأ نموذجنا بها!
بصرف النظر عن هذا الريبو (حسنا duh) ، أوصي بشدة بالمضي قدمًا وقراءة هذه المدونة المذهلة من تأليف جاي ألام!
تم تدريب المحول في الأصل لمهمة NMT (ترجمة الآلة العصبية) على مجموعة بيانات WMT-14 لـ:
ما فعلته (في الوقت الحالي) هو أنني قمت بتدريب نماذجي على مجموعة بيانات IWSLT ، والتي هي أصغر بكثير ، لزوج اللغة الإنجليزية الألمانية ، وأنا أتحدث هذه اللغات ، لذلك من الأسهل تصحيحها واللعب حولها.
سأقوم أيضًا بتدريب النماذج الخاصة بي على WMT-14 قريبًا ، ألقِ نظرة على قسم Todos.
على أي حال! دعونا نرى ما يمكن أن يفعله هذا الريبو عمليا من أجلك! حسنا يمكن أن تترجم!
بعض الترجمات القصيرة من نموذج IWSLT الألماني إلى اللغة الإنجليزية:
المدخلات: Ich bin ein guter Mensch, denke ich. ("الذهب": أنا شخص جيد على ما أعتقد)
الإخراج: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
أو بتنسيق قابل للقراءة الإنسان: I think I'm a good person.
وهو في الواقع جيد جدا! ربما أفضل من IMO من ترجمة جوجل ترجمة "الذهب".
هناك بالطبع حالات فشل مثل هذا:
المدخلات: Hey Alter, wie geht es dir? (كيف تسير الأمور؟)
الإخراج: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
أو بتنسيق قابل للقراءة الإنسان: Hey, age, how are you?
وهو في الواقع ليس سيئا تماما! لأن:
وبالمثل للنموذج الإنجليزي إلى الألماني.
لذلك تحدثنا عن ماهية المحولات ، وما يمكنهم فعله من أجلك (من بين أشياء أخرى).
دعونا نجعل هذا الشيء يعمل! اتبع الخطوات التالية:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create من Project Directory (سيؤدي ذلك إلى إنشاء بيئة جديدة تمامًا).activate pytorch-transformer (لتشغيل البرامج النصية من وحدة التحكم الخاصة بك أو اضبط المترجم المترجم في IDE) هذا كل شيء! يجب أن تعمل خارج البيئة المنفذة.
قد يستغرق الأمر بعض الوقت حيث أقوم بتنزيل النماذج الإحصائية لـ Spacy تلقائيًا للغة الإنجليزية والألمانية.
ستأتي حزمة Pytorch Pip مع بعض إصدار Cuda/Cudnn معها ، ولكن يوصى بشدة بتثبيت CUDA على مستوى النظام مسبقًا ، معظمها بسبب برامج تشغيل GPU. أوصي أيضًا باستخدام Miniconda Installer كوسيلة للحصول على كوندا على نظامك. تابع النقطتين 1 و 2 من هذا الإعداد واستخدم أحدث إصدارات Miniconda و CUDA/CUDNN لنظامك.
ما عليك سوى تشغيل jupyter notebook منك Anaconda Console وسوف يفتح الجلسة في متصفحك الافتراضي.
افتح The Annotated Transformer ++.ipynb وأنت مستعد للعب!
ملاحظة: إذا DLL load failed while importing win32api: The specified module could not be found
ما عليك سوى القيام pip uninstall pywin32 ، ثم إما pip install pywin32 أو conda install pywin32 يجب إصلاحه!
تحتاج فقط إلى ربط بيئة بيثون التي أنشأتها في قسم الإعداد.
لتشغيل التدريب ، ابدأ training_script.py ، هناك بعض الإعدادات التي ستحددها:
--batch_size -من المهم ضبط القيمة القصوى التي لن تمنحك CUDA خارج الذاكرة--dataset_name اختيار بين IWSLT و WMT14 (لا يُنصح بـ WMT14 حتى أضيف دعم متعدد GPU)--language_direction -اختيار بين E2G و G2E لذا فإن مثالًا على ذلك (من وحدة التحكم) سيبدو هكذا:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
تم التعليق بشكل جيد حتى تتمكن (نأمل) من فهم كيفية عمل التدريب نفسه.
سوف السيناريو:
models/checkpoints/models/binaries/data/ )runs/ ، ما عليك سوى تشغيل tensorboard --logdir=runs من Anaconda الخاص بكملاحظة: تحميل البيانات بطيء في نص الشعلة ، ولذا قمت بتطبيق غلاف مخصص يضيف آليات التخزين المؤقت ويجعل الأمور أسرع 30x! (ستكون بطيئة في المرة الأولى التي تقوم فيها بتشغيل الأشياء)
الجزء الثاني هو كل شيء عن اللعب مع النماذج ورؤية كيف تترجم!
للحصول على بعض الترجمات ، ابدأ translation_script.py ، هناك بعض الإعدادات التي تريد تعيينها:
--source_sentence -اعتمادًا على النموذج الذي تحدده ، يجب أن يكون إما جملة باللغة الإنجليزية/الألمانية--model_name -أحد أسماء النماذج المسبق: iwslt_e2g أو iwslt_g2e أو نموذجك (*)--dataset_name -حافظ على هذا المزامنة مع النموذج ، IWSLT إذا تم تدريب النموذج على iwslt--language_direction -الحفاظ على المزامنة ، E2G إذا تم تدريب النموذج على الترجمة من اللغة الإنجليزية إلى الألمانية (*) ملاحظة: بعد تدريب النموذج الخاص بك ، سيتم إلقاؤه في models/binaries انظر إلى ما هو اسمه وحدده عبر المعلمة --model_name إذا كنت تريد اللعب به لغرض الترجمة. إذا قمت بتحديد بعض النماذج المسبقة ، فسيتم تنزيلها تلقائيًا في المرة الأولى التي تقوم فيها بتشغيل البرنامج النصي للترجمة.
سأربط روابط نموذج IWSLT المسبق هنا أيضًا: اللغة الإنجليزية إلى الألمانية والألمانية إلى الإنجليزية.
هذا كل شيء يمكنك أيضًا تصور الانتباه إلى هذا القسم. لمزيد من المعلومات.
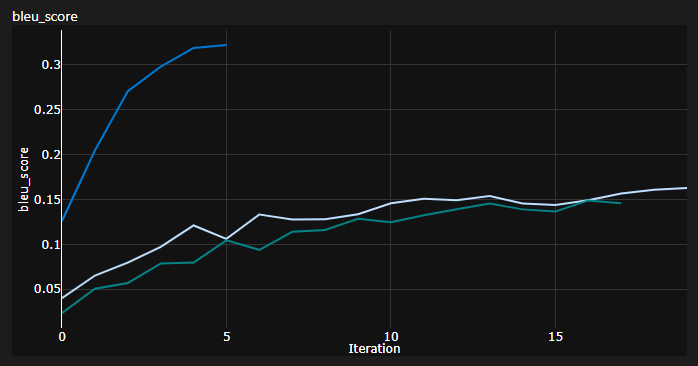
لقد تتبعت 3 منحنيات أثناء التدريب:
Bleu هو مقياس قائم على N-Gram لتقييم جودة نماذج الترجمة الآلية.
لقد استخدمت مقياس Bleu-4 المقدم من وحدة NLTK Python الرائعة.
النتائج الحالية ، تم تدريب النماذج على 20 عصرًا (De Stands for Deutch IE German باللغة الألمانية؟):
| نموذج | درجة بليو | مجموعة البيانات |
|---|---|---|
| محول خط الأساس (en-de) | 27.8 | iwslt val |
| محول خط الأساس (De-en) | 33.2 | iwslt val |
| محول خط الأساس (en-de) | x | WMT-14 Val |
| محول خط الأساس (De-en) | x | WMT-14 Val |
لقد حصلت على هذه باستخدام فك التشفير الجشع ، لذا فهو تقدير متشائم ، سأضيف فك تشفير الشعاع قريبًا.
ملاحظة مهمة: التهيئة مهمة للغاية للمحول! لقد اعتقدت في البداية أن التطبيقات الأخرى التي تستخدم تهيئة كزافييه هي مرة أخرى واحدة من تلك الاستدلال التعسفي وأن الافتراضي الافتراضي سيفعل - كنت مخطئًا:
يمكنك أن ترى هنا 3 أشواط ، و 2 أقل من التهيئة الافتراضية Pytorch (واحد مستخدم mean لفقدان التباعد KL وأفضل واحد المستخدمة batchmean ) ، في حين أن التهيئة الموحدة Xavier المستخدمة!
الفكرة: من المحتمل أن تتخلص من الترجمات بشكل دوري للحصول على مجموعة مرجعية من جمل المصدر.
هذا من شأنه أن يمنحك بعض الرؤية النوعية حول كيفية قيام المحول ، على الرغم من أنني لم أفعل ذلك.
يتم القيام بشيء مماثل عندما يكون لديك وقت صعب تقييم النموذج الخاص بك كما هو الحال في الحقول Gans و NST.
المؤامرة أعلاه هي مقتطف من تشغيل Azure ML ، لكن عندما أقوم بتشغيل الأشياء محليًا ، أستخدم Tensorboard.
فقط قم بتشغيل tensorboard --logdir=runs من وحدة التحكم في Anaconda ويمكنك تتبع المقاييس الخاصة بك أثناء التدريب.
يمكنك استخدام translation_script.py وتعيين --visualize_attention إلى صواب لفهم ما هو نموذجك "الاهتمام به" في الجمل المصدر والهدف.
فيما يلي الاهتمام الذي أحصل عليه في جملة الإدخال Ich bin ein guter Mensch, denke ich.
هذه تنتمي إلى الطبقة 6 من التشفير. يمكنك رؤية جميع رؤوس الاهتمام 8 متعددة الرأس.

وهذا واحد ينتمي إلى وحدة فك الترميز 6 من وحدة فك ترميز الاهتمام الذاتي MHA (اهتمام متعدد الرأس).
يمكنك أن تلاحظ نمطًا ثلاثيًا مثيرًا للاهتمام يأتي من حقيقة أن الرموز المستهدفة لا يمكن أن تتطلع إلى الأمام!

النوع الثالث من وحدة MHA هو المصدر الذي يحضر واحد ويبدو مشابهًا للمؤامرة التي رأيتها للمشفر.
لا تتردد في اللعب معها في وتيرتك!
ملاحظة: من الواضح أن هناك بعض المشكلات التحيز في هذا النموذج ، لكنني لن أذهب إلى هذا التحليل هنا
تحتاج حقًا إلى جهاز لائق إذا كنت ترغب في تدريب المحول على مجموعة بيانات WMT-14 .
استغرق المؤلفون:
إذا كانت الحسابات الخاصة بي صحيحة والتي تصل إلى حوالي 19 حصرًا (100 ألف خطوة ، كان لكل خطوة ~ 25000 رمز و WMT-14 لديها ~ 130m SRC/TRG الرموز) لخط الأساس و 3x بالنسبة إلى واحدة كبيرة (300 ألف خطوة).
من ناحية أخرى ، من الممكن تدريب النموذج على مجموعة بيانات IWSLT . استغرق الأمر مني:
كان بإمكاني دفع K80s إلى 3500+ رموز/دفعة ولكن كان لدي بعض مشاكل الذاكرة.
أخيرًا ، هناك زوجان آخران نأمل أن أضيفه قريبًا:
إن الريبو لديه بالفعل كل ما يحتاجه ، فهذه مجرد نقاط مكافأة. لقد اختبرت كل شيء من إعداد البيئة ، إلى تنزيل النموذج التلقائي ، إلخ.
إذا كنت تواجه صعوبات في فهم الكود ، فقد قمت بإلقاء نظرة عامة متعمقة على الورقة في هذا الفيديو:
لدي المزيد من مقاطع الفيديو التي يمكن أن تساعدك على فهم المحولات:
لقد وجدت هذه الموارد مفيدة (أثناء تطوير هذا الموارد):
لقد وجدت بعض الإلهام لتصميم النموذج في المحول المشروح ، لكنني وجدت صعوبة في فهمه ، وكان لديه بعض الأخطاء. لقد كتب بشكل رئيسي مع الباحثين في الاعتبار. نأمل أن يفتح هذا الريبو فهم المحولات للقوم المشترك أيضًا! ؟
إذا وجدت هذا الرمز مفيدًا ، فيرجى الاستشهاد بما يلي:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
إذا كنت ترغب في الحصول على المزيد من المحتوى المتعلق بالنيابة في حياتك؟ ، فكر في:


