pytorch original transformer
1.0.0
このレポは、元のトランスペーパーのPytorch実装が含まれています(:link:vaswani et al。)。
変圧器について演奏して学習しやすくすることを目的としています。
トランスはもともとVaswaniらによって提案されました。注意と呼ばれる独創的な論文では、あなたが必要とするすべてです。
あなたはおそらく何らかの形で変圧器のことを聞いたでしょう。 GPT-3とBertは、いくつかの有名なものを挙げていますか?主なアイデアは、彼らがあなたが再発層または畳み込み層を使用する必要がないことを示し、注意と組み合わされた単純なアーキテクチャが非常に強力であることを示したことです。それははるかに優れた長距離依存モデリングの利点を与え、アーキテクチャ自体は非常に並列化可能です(:Computer :: Computer :: Computer :)は、より良い計算効率につながります!
これらの美しくシンプルなアーキテクチャがどのように見えるかは次のとおりです。

このレポは、元の変圧器自体がもはやソタではないため、変圧器を理解するための学習リソースであると想定されています。
そのために、コードは(できれば)よくコメントされており、私はplayground.pyを含めました。そこには、言葉を使って説明するのが難しいが、視覚化されると非常にシンプルないくつかの概念を視覚化しました。だからここに行きます!
目を垣間見ることができますか?

どちらもできません。visualize_positional_encodings visualize_positional_encodings() function from playground.pyこれを取得します。

ソース/ターゲットトークンの位置に応じて、「この画像の1つの行を選択する」と、ベクトルの埋め込みに追加します。彼らも学ぶこともできますが、明らかにこのようにそれをする方が派手です! ?
同様に、これをO(1)で解析できますか?

noup?だから、ここで視覚化されていると思った:

今はとても簡単です。今、この部分が変圧器の成功に不可欠であったかどうか?私はそれを疑う。しかし、それはクールで、物事をより複雑にします。 ? ( .set_sarcasm(True) )
注:モデル寸法は基本的に埋め込みベクトルのサイズ、ベースライントランス512、ビッグワン、1024
初めてラベルのスムージングを聞いたとき、それは大変に聞こえますが、そうではありません。通常、ターゲットの語彙分布をone-hotに設定します。 30kのうち1ポジション(または音声サイズが何であれ)を意味することは、1。確率と他のすべてが0に設定されています。

1を配置する代わりにラベルのスムージングでは、その特定の位置に0.9と言い、他の位置に残りの「確率質量」を均等に配布します(これは、サイズ4の架空の音声で上記の画像の異なる紫色として視覚化されています - したがって4列)
注:パッドトークンの分布は、モデルにそれらを予測したくないため、すべてのゼロに設定されています!
このリポジトリ(よく)を除いて、Jay Alammarのこの素晴らしいブログを読むことを強くお勧めします!
トランスはもともと、WMT-14データセットのNMT(ニューラルマシン翻訳)タスクのために訓練されました。
私が(今のところ)私がしたことは、私がそれらの言語を話すので、デバッグとプレイが簡単になるので、英語 - ドイツ語のペアのためにはるかに小さいIWSLTデータセットで自分のモデルをトレーニングしたことです。
また、WMT-14でモデルをすぐにトレーニングして、Todosセクションをご覧ください。
とにかく!このリポジトリが実際にあなたのために何ができるか見てみましょう!さて、それは翻訳できます!
私のドイツ語から英語のIWSLTモデルからの短い翻訳:
入力: Ich bin ein guter Mensch, denke ich. (「ゴールド」:私はいい人だと思います)
出力: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
または人間の読み取り可能な形式で: I think I'm a good person.
これは実際にはかなり良いです! Google Translateの「ゴールド」翻訳よりも優れたIMOかもしれません。
もちろん、このような失敗の場合があります:
入力: Hey Alter, wie geht es dir? (どうですか?)
出力: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
または人間の読み取り可能な形式: Hey, age, how are you?
これは実際には完全に悪いわけではありません!なぜなら:
同様に、英語からドイツのモデルについて。
そこで、私たちは変圧器とは何か、そして彼らがあなたのために何ができるか(とりわけ)について話しました。
このことを実行しましょう!次のステップに従ってください:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoに移動しますconda env create実行します(これにより、新しいConda環境が作成されます)。activate pytorch-transformerます(コンソールからスクリプトを実行するか、IDEでインタープリターを設定します)それでおしまい!依存関係を扱うboxの実行環境を実行する環境を実行する必要があります。
英語とドイツ語のSpacyの統計モデルを自動的にダウンロードしているため、しばらく時間がかかる場合があります。
Pytorch Pipパッケージには、Cuda/Cudnnのバージョンがバンドルされますが、主にGPUドライバーのおかげで、システム全体のCUDAを事前にインストールすることを強くお勧めします。また、Minicondaインストーラーをシステムに搭載する方法として使用することをお勧めします。このセットアップのポイント1と2をフォローし、システムに最新のバージョンとCUDA/CUDNNを使用します。
Anacondaコンソールからjupyter notebookを実行するだけで、デフォルトのブラウザでセッションを開きます。
The Annotated Transformer ++.ipynbを開くと、プレイする準備ができています!
注: DLL load failed while importing win32api: The specified module could not be found
pip uninstall pywin32実行するだけで、 pip install pywin32またはconda install pywin32修正するだけです!
セットアップセクションで作成したPython環境をリンクするだけです。
トレーニングを実行するには、 training_script.pyを開始するには、指定したい設定がいくつかあります。
--batch_sizeこれは、メモリからcudaを与えない最大値に設定することが重要です--dataset_name - IWSLTとWMT14を選択します(WMT14はマルチGPUサポートを追加するまでお勧めしません)--language_direction - E2GとG2Eを選択しますしたがって、(コンソールから)実行の例は次のようになります。
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
コードはよくコメントされているため、トレーニング自体がどのように機能するかを(できれば)理解できます。
スクリプトは次のとおりです。
models/checkpoints/models/binaries/data/の下に配置したとき)runs/ 、 tensorboard --logdir=runs注:トーチテキストではデータの読み込みが遅いため、キャッシュメカニズムを追加し、物事を30倍高速にするカスタムラッパーを実装しました。 (最初に物を実行するのは遅くなるでしょう)
2番目の部分は、モデルで遊んで、それらがどのように翻訳されるかを見ることです!
いくつかの翻訳を取得するには、 translation_script.pyを開始するには、設定したい設定がいくつかあります。
--source_sentenceモデルに応じて、これを指定することで、英語/ドイツ文のいずれかである必要があります--model_name事前に処理されたモデル名の1つ: iwslt_e2g 、 iwslt_g2eまたはモデル(*)--dataset_nameモデルがiwsltでトレーニングされている場合は、モデルと同期してくださいIWSLT--language_direction同期を続け、 E2Gモデルが英語からドイツ語に翻訳するように訓練されている場合はE2G (*)注:モデルをトレーニングすると、 models/binariesにダンプされます。名前が何であるかを確認し、翻訳目的で再生したい場合は、 --model_nameパラメーターを介して指定します。翻訳スクリプトを初めて実行するときに、事前に守られたモデルの一部を指定すると、最初に実行されたときに自動的にダウンロードされます。
IWSLTの前提条件のモデルリンクもここにリンクします:英語からドイツ語、ドイツ語に英語に。
それだけです。また、このセクションをチェックしてください。詳細については。
トレーニング中に3つの曲線を追跡しました。
BLEUは、機械翻訳モデルの品質を定量的に評価するためのN-GRAMベースのメトリックです。
Awesome NLTK Pythonモジュールが提供するBLEU-4メトリックを使用しました。
現在の結果、モデルは20エポックのために訓練されました(Deはドイツ語でドイツ語のDeutchの略ですか?):
| モデル | ブルースコア | データセット |
|---|---|---|
| ベースライントランス(EN-DE) | 27.8 | IWSLT VAL |
| ベースライン変圧器(de-en) | 33.2 | IWSLT VAL |
| ベースライントランス(EN-DE) | x | WMT-14 VAL |
| ベースライン変圧器(de-en) | x | WMT-14 VAL |
貪欲なデコードを使用してこれらを手に入れたので、それは悲観的な推定です。すぐにビームデコードを追加します。
重要な注意:変圧器にとって初期化は重要です! Xavierの初期化を使用した他の実装は、これらの任意のヒューリスティックの1つであり、PytorchのデフォルトINITが行うと考えていました。
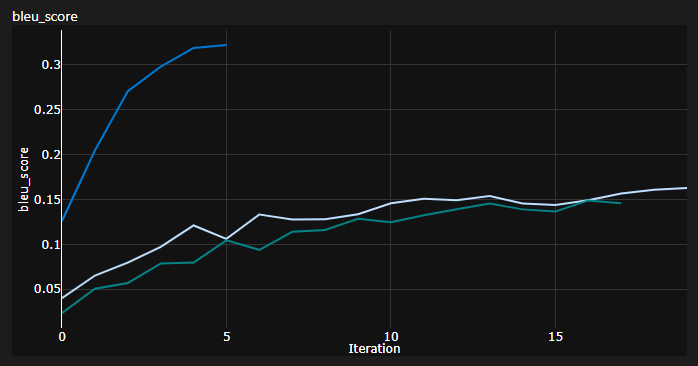
ここでは、3回のランを見ることができます。2つの下部はPytorchデフォルトの初期化(1つはKL Divergence Lossにmean使用し、1つは使用済みbatchmean )を使用しますが、上部はXavier均一初期化を使用しました。
アイデア:ソース文の参照バッチの翻訳を定期的にダンプする可能性もあります。
それは、私はそれをしませんでしたが、変圧器の様子についての定性的な洞察を与えます。
GANSやNSTフィールドのようにモデルを定量的に評価するのに苦労している場合、同様のことが行われます。
上記のプロットは、Azure MLの実行からのスニペットですが、地元で荷物を実行すると、テンソルボードを使用しています。
tensorboard --logdir=runsと、トレーニング中にメトリックを追跡できます。
translation_script.py使用して、 --visualize_attention Trueに設定して、ソースとターゲットの文でモデルが「注意を払っている」ことをさらに理解することができます。
ここに私が入力文Ich bin ein guter Mensch, denke ich.
これらはエンコーダーのレイヤー6に属します。 8つのマルチヘッド注意ヘッドのすべてを見ることができます。

そして、これは、自己関節デコーダーMHA(マルチヘッドの注意)モジュールのデコーダーレイヤー6に属します。
ターゲットトークンが先を見ることができないという事実に由来する興味深い三角形のパターンに気付くことができます!

MHAモジュールの3番目のタイプは、出席したソースであり、エンコーダーで見たプロットに似ています。
あなた自身のペースでそれで遊んでください!
注:このモデルには明らかにバイアスの問題がありますが、ここでその分析には入りません
WMT-14データセットでトランスをトレーニングしたい場合は、まともなハードウェアが必要です。
著者は次のようにしました:
私の計算が正しい場合、それが約19エポック(100kステップ、各ステップには〜25000トークン、WMT-14にはベースラインの場合は130mのSRC/TRGトークンがあります)、3倍(300Kステップ)があります。
一方、 IWSLTデータセットでモデルをトレーニングする方がはるかに実行可能です。それは私を取りました:
K80を3500以上のトークン/バッチにプッシュすることもできましたが、メモリの問題からいくつかのCUDAがありました。
最後に、さらにいくつかのTODOがあります。
リポジトリにはすでに必要なものがすべて揃っていますが、これらは単なるボーナスポイントです。環境セットアップから自動モデルのダウンロードなど、すべてをテストしました。
コードを理解するのが難しい場合は、このビデオで論文の詳細な概要を概念しました。
私はあなたがトランスフォーマーをさらに理解するのに役立つかもしれないビデオをいくつか持っています:
これらのリソースが役立つことがわかりました(これを開発している間):
注釈付き変圧器でモデル設計のインスピレーションを見つけましたが、理解するのが難しく、バグがありました。それは主に研究者を念頭に置いて書かれていました。うまくいけば、このリポジトリは、トランスフォーマーの理解を共通の人々にも広げます! ?
このコードが便利だと思う場合は、以下を引用してください。
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
あなたの人生でさらにAI関連のコンテンツを持っていることを望んでいますか?


