pytorch original transformer
1.0.0
Este repositorio contiene la implementación de Pytorch del papel transformador original (: Link: Vaswani et al.).
Tiene como objetivo hacer que sea fácil comenzar a jugar y aprender sobre Transformers.
Los transformadores fueron propuestos originalmente por Vaswani et al. En un artículo seminal llamado atención es todo lo que necesitas.
Probablemente escuchaste de Transformers de una forma u otra. GPT-3 y Bert, por nombrar algunos bien conocidos? La idea principal es que demostraron que no tiene que usar capas recurrentes o convolucionales y que la arquitectura simple junto con la atención es súper poderosa. Dio el beneficio de un modelado de dependencia de largo alcance mucho mejor y la arquitectura en sí misma es altamente paralelizable (: Computer :: Computer :: Computer :) ¡Lo que conduce a una mejor eficiencia de cálculo!
Así es como se ve su arquitectura bellamente simple:

Se supone que este repositorio es un recurso de aprendizaje para comprender los transformadores, ya que el transformador original en sí mismo ya no es un SOTA.
Para ese propósito, el código está (con suerte) bien comentado e he incluido el playground.py donde he visualizado un par de conceptos que son difíciles de explicar usando palabras pero súper simples una vez visualizados. ¡Así que aquí vamos!
¿Puedes analizar este en un vistazo al ojo?

Tampoco puede. Ejecutando la función visualize_positional_encodings() desde playground.py obtenemos esto:

Dependiendo de la posición de su token de origen/objetivo, "elija una fila de esta imagen" y la agregue a su vector de incrustación, eso es todo. También se podrían aprender, pero es más elegante hacerlo así, ¡obviamente! ?
Del mismo modo, ¿puedes analizar este en O(1) ?

Noup? Entonces pensé, aquí está visualizado:

Es muy fácil de entender ahora. ¿Ahora si esta parte fue crucial para el éxito de Transformer? Dudo. Pero es genial y hace que las cosas sean más complicadas. ? ( .set_sarcasm(True) )
Nota: La dimensión del modelo es básicamente el tamaño del vector de incrustación, transformador de línea de base utilizado 512, el Big One 1024
La primera vez que escuchas sobre el suavizado de la etiqueta, suena difícil, pero no lo es. Por lo general, establece su distribución de vocabulario objetivo en un one-hot . Que significa 1 posición de 30k (o cualquiera que sea su tamaño de vocabulario) se establece en 1. probabilidad y todo lo demás a 0.

En el suavizado de etiquetas en lugar de colocar 1. En esa posición en particular que coloca, digamos 0.9 y distribuye uniformemente el resto de la "masa de probabilidad" sobre las otras posiciones (que se visualiza como un tono diferente de púrpura en la imagen de arriba en una vocabulario ficticia de tamaño 4 - por lo tanto 4 columnas)
Nota: ¡La distribución de Token de la almohadilla se establece en todos los ceros, ya que no queremos que nuestro modelo predice esos!
¡Además de este repositorio (bueno duh), le recomiendo que sigas adelante y lea este increíble blog de Jay Alammar!
Transformer fue entrenado originalmente para la tarea NMT (traducción automática neural) en el conjunto de datos WMT-14 para:
Lo que hice (por ahora) es que entrené mis modelos en el conjunto de datos IWSLT, que es mucho más pequeño, para el par de idiomas inglés-alemán, ya que hablo esos idiomas, por lo que es más fácil depurar y jugar.
También entrenaré mis modelos en WMT-14 pronto, eche un vistazo a la sección TODOS.
¡De todos modos! ¡Veamos qué puede hacer este repositorio prácticamente por usted! Bueno, puede traducir!
Algunas traducciones cortas de mi modelo de alemán a inglés iwslt:
Entrada: Ich bin ein guter Mensch, denke ich. ("Oro": Creo que soy una buena persona)
Salida: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
O en formato legible por humanos: I think I'm a good person.
¡Lo cual es bastante bueno! Tal vez incluso mejor IMO que la traducción "dorada" de Google Translate.
Por supuesto, hay casos de falla como este:
Entrada: Hey Alter, wie geht es dir? (¿Cómo te va, amigo?)
Salida: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
O en formato legible por humanos: Hey, age, how are you?
¡Lo cual en realidad tampoco es completamente malo! Porque:
Del mismo modo para el modelo inglés a alemán.
Así que hablamos sobre qué son los transformadores y lo que pueden hacer por usted (entre otras cosas).
¡Hagamos que esto funcione! Sigue los siguientes pasos:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create desde el directorio de proyectos (esto creará un entorno de condena nuevo).activate pytorch-transformer (para ejecutar scripts desde su consola o establecer el intérprete en su IDE) ¡Eso es todo! Debe funcionar archivo de ejecución.YML de uso de casa fuera de la caja que se ocupa de las dependencias.
Puede llevar un tiempo ya que estoy descargando automáticamente los modelos estadísticos de Spacy para inglés y alemán.
El paquete Pytorch Pip vendrá con alguna versión de CUDA/CUDNN, pero se recomienda encarecidamente que instale un CUDA de todo el sistema de antemano, principalmente debido a los controladores de GPU. También recomiendo usar el instalador de Miniconda como una forma de obtener conda en su sistema. Siga los puntos 1 y 2 de esta configuración y use las versiones más actualizadas de Miniconda y Cuda/Cudnn para su sistema.
Simplemente ejecute jupyter notebook desde su consola Anaconda y abrirá la sesión en su navegador predeterminado.
Abra The Annotated Transformer ++.ipynb y estará listo para jugar!
NOTA: Si obtiene DLL load failed while importing win32api: The specified module could not be found
¡Simplemente pip uninstall pywin32 y luego pip install pywin32 o conda install pywin32 debería arreglarlo!
Solo necesita vincular el entorno Python que creó en la sección Configuración.
Para ejecutar la capacitación, comience el training_script.py , hay un par de configuraciones que querrá especificar:
--batch_size -Esto es importante para establecer un valor máximo que no le dará CUDA fuera de memoria--dataset_name -Elija entre IWSLT y WMT14 (WMT14 no es aconsejable hasta que agrego soporte de múltiples GPU)--language_direction -Elija entre E2G y G2E Entonces, una ejecución de ejemplo (desde la consola) se vería así:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
El código está bien comentado para que pueda (con suerte) comprender cómo funciona la capacitación en sí.
El guión:
models/checkpoints/models/binaries/data/ )runs/ , simplemente ejecute tensorboard --logdir=runs desde su anacondaNota: La carga de datos es lenta en el texto de la antorcha, por lo que he implementado un envoltorio personalizado que agrega los mecanismos de almacenamiento en caché y hace que las cosas sean ~ 30x más rápido. (será lento la primera vez que ejecute cosas)
¡La segunda parte se trata de jugar con las modelos y ver cómo se traducen!
Para obtener algunas traducciones, comience la translation_script.py , hay un par de configuraciones que querrá establecer:
--source_sentence -Dependiendo del modelo que especifique que esto debería ser oración inglesa/alemana--model_name -Uno de los nombres de modelos previos a la aparición: iwslt_e2g , iwslt_g2e o su modelo (*)--dataset_name -Mantenga esto en sincronización con el modelo, IWSLT si el modelo fue entrenado en iwslt--language_direction -manténgase sincronizado, E2G si el modelo fue entrenado para traducir del inglés al alemán (*) Nota: Después de entrenar a su modelo, se verá en models/binaries , vea cómo se llama y lo especifique a través del parámetro --model_name si desea jugar con él para el propósito de traducción. Si especifica algunos de los modelos previos a la aparición, se descargarán automáticamente la primera vez que ejecuta el script de traducción.
Vincularé los enlaces de modelos previos a la aparición aquí también: inglés a alemán y alemán a inglés.
Eso es todo, también puede visualizar la atención, consulte esta sección. Para más información.
Rastreé 3 curvas mientras entrenaba:
Bleu es una métrica basada en N-Gram para evaluar cuantitativamente la calidad de los modelos de traducción automática.
Utilicé la métrica Bleu-4 proporcionada por el impresionante módulo NLTK Python.
Resultados actuales, los modelos fueron entrenados para 20 épocas (DE significa Deutch, es decir, alemán en alemán?):
| Modelo | Puntuación de Bleu | Conjunto de datos |
|---|---|---|
| Transformador de línea de base (en-de) | 27.8 | Iwslt val |
| Transformador de línea de base (De-en) | 33.2 | Iwslt val |
| Transformador de línea de base (en-de) | incógnita | WMT-14 Val |
| Transformador de línea de base (De-en) | incógnita | WMT-14 Val |
Los conseguí usando una decodificación codiciosa, así que es una estimación pesimista, agregaré la decodificación del haz pronto.
Nota importante: ¡La inicialización es importante para el transformador! Inicialmente pensé que otras implementaciones que utilizan la inicialización de Xavier son nuevamente una de esas heurísticas arbitrarias y que Pytorch predeterminó el init. Estaba equivocado:
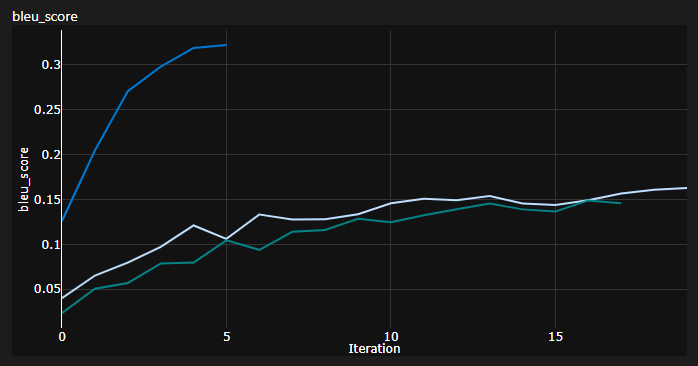
Puede ver aquí 3 corridas, los 2 inferiores usaron la inicialización predeterminada de Pytorch (una mean utilizada para la pérdida de divergencia KL y el mejor usado batchmean ), mientras que el superior usó la inicialización de uniforme Xavier .
Idea: potencialmente también podría volcar traducciones periódicamente para un lote de referencia de oraciones fuente.
Eso le daría una visión cualitativa de cómo está el transformador, aunque no hice eso.
Algo similar se hace cuando tiene dificultades para evaluar cuantitativamente su modelo, como en los campos Gans y NST.
La trama anterior es un fragmento de mi Azure ML Run, pero cuando ejecuto cosas localmente uso TensorBoard.
Simplemente ejecute tensorboard --logdir=runs desde su consola Anaconda y puede rastrear sus métricas durante el entrenamiento.
Puede usar la translation_script.py y establecer el --visualize_attention en verdad para comprender además a qué estaba "prestando atención" en las oraciones de origen y objetivo.
Aquí están las atenciones que obtengo para la oración de entrada Ich bin ein guter Mensch, denke ich.
Estos pertenecen a la capa 6 del codificador. Puedes ver todos los 8 cabezas de atención de múltiples cabezas.

Y este pertenece a la capa 6 del decodificador del módulo del decodificador de autoatención MHA (atención múltiple).
¡Puede notar un patrón triangular interesante que proviene del hecho de que Target Tokens no puede mirar hacia el futuro!

El tercer tipo de módulo MHA es la fuente que atiende una y se ve similar a la trama que vio para el codificador.
¡Siéntase libre de jugar con él a su propio ritmo!
Nota: Obviamente, hay algunos problemas de sesgo con este modelo, pero no entraré en ese análisis aquí
Realmente necesita un hardware decente si desea entrenar el transformador en el conjunto de datos WMT-14 .
Los autores tomaron:
Si mis cálculos son correctos, asciende a ~ 19 épocas (100k pasos, cada paso tenía ~ 25000 tokens y WMT-14 tiene ~ 130 m tokens SRC/TRG) para la línea de base y 3x que para la grande (300k pasos).
Por otro lado, es mucho más factible entrenar el modelo en el conjunto de datos IWSLT . Me tomó:
Podría haber llevado a K80 a 3500+ tokens/lotes, pero tuve algunos problemas de CUDA fuera de la memoria.
Finalmente, hay un par de Todos más que espero agregar muy pronto:
El repositorio ya tiene todo lo que necesita, estos son solo los puntos de bonificación. He probado todo, desde la configuración del entorno hasta la descarga automática del modelo, etc.
Si tiene dificultades para comprender el código, hice una visión general en profundidad del documento en este video:
Tengo algunos videos más que podrían ayudarlo a comprender los transformadores:
Encontré estos recursos útiles (mientras desarrollaba este):
Encontré algo de inspiración para el diseño del modelo en el transformador anotado, pero me resultó difícil de entender, y tenía algunos errores. Fue escrito principalmente con investigadores en mente. ¡Esperemos que este repositorio abre la comprensión de los transformadores a la gente común también! ?
Si encuentra útil este código, cite lo siguiente:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
¿Si te encantaría tener un contenido más relacionado con la IA en tu vida?, Considere:


