pytorch original transformer
1.0.0
repo นี้มีการใช้งาน pytorch ของกระดาษหม้อแปลงต้นฉบับ (: ลิงก์: Vaswani et al.)
มันมุ่งเป้าไปที่การทำให้ ง่ายต่อการเริ่มเล่นและเรียนรู้ เกี่ยวกับหม้อแปลง
หม้อแปลงถูกเสนอโดย Vaswani และคณะ ในกระดาษน้ำเชื้อที่เรียกว่าความสนใจคือสิ่งที่คุณต้องการ
คุณอาจเคยได้ยินเรื่อง Transformers ไม่ทางใดก็ทางหนึ่ง GPT-3 และ Bert เพื่อตั้งชื่อคนที่รู้จักกันดี? แนวคิดหลักคือพวกเขาแสดงให้เห็นว่าคุณไม่จำเป็นต้องใช้เลเยอร์ที่เกิดขึ้นซ้ำหรือเลเยอร์และสถาปัตยกรรมที่เรียบง่ายควบคู่ไปกับความสนใจนั้นทรงพลังมาก มันให้ประโยชน์ของ การสร้างแบบจำลองการพึ่งพาระยะยาวที่ดีขึ้นมาก และสถาปัตยกรรมเองนั้น สามารถขนานกันได้ สูง (: คอมพิวเตอร์ :: คอมพิวเตอร์ :: คอมพิวเตอร์ :) ซึ่งนำไปสู่ประสิทธิภาพการคำนวณที่ดีขึ้น!
นี่คือลักษณะสถาปัตยกรรมที่เรียบง่ายของพวกเขาที่มีลักษณะ:

repo นี้ควรจะเป็นทรัพยากรการเรียนรู้สำหรับการทำความเข้าใจหม้อแปลงเนื่องจากหม้อแปลงดั้งเดิมด้วยตัวเองไม่ใช่ SOTA อีกต่อไป
เพื่อจุดประสงค์นั้นรหัสนั้นมีความคิดเห็นที่ดี (หวังว่า) และฉันได้รวม playground.py ที่ฉันได้เห็นภาพแนวคิดสองอย่างที่ยากที่จะอธิบายโดยใช้คำ แต่ง่ายมากเมื่อมองเห็นได้ แล้วไปกันเถอะ!
คุณสามารถแยกวิเคราะห์อันนี้ได้หรือไม่?

I. ไม่สามารถเรียกใช้ฟังก์ชั่น visualize_positional_encodings() จาก playground.py เราได้รับสิ่งนี้:

ขึ้นอยู่กับตำแหน่งของโทเค็นต้นทาง/เป้าหมายของคุณ "เลือกหนึ่งแถวของภาพนี้" และคุณเพิ่มลงในเวกเตอร์ฝังตัวนั่นคือ พวกเขายังสามารถเรียนรู้ได้ แต่มันก็เป็นเรื่องแปลกที่จะทำเช่นนี้อย่างเห็นได้ชัด! -
ในทำนองเดียวกันคุณสามารถแยกวิเคราะห์อันนี้ใน O(1) ได้หรือไม่?

Noup? ดังนั้นฉันคิดว่าที่นี่มันถูกมองเห็น:

ตอนนี้เข้าใจง่ายสุด ๆ ตอนนี้ส่วนนี้มีความสำคัญต่อความสำเร็จของ Transformer หรือไม่? ฉันสงสัยมัน แต่มันเจ๋งและทำให้สิ่งต่าง ๆ ซับซ้อนขึ้น - ( .set_sarcasm(True) )
หมายเหตุ: มิติของโมเดลนั้นเป็นขนาดของเวกเตอร์ฝังตัวหม้อแปลงพื้นฐานที่ใช้ 512 ขนาดใหญ่ 1024
ครั้งแรกที่คุณได้ยินว่าฉลากทำให้การปรับให้เรียบมันฟังดูยาก แต่ก็ไม่ใช่ คุณมักจะตั้งค่าการกระจายคำศัพท์เป้าหมายของคุณเป็น one-hot ความหมาย 1 ตำแหน่งออกจาก 30k (หรือขนาดคำศัพท์ของคุณคืออะไร) ถูกตั้งค่าเป็น 1 ความน่าจะเป็นและทุกอย่างอื่นเป็น 0

ในฉลากเรียบเนียนแทนที่จะวาง 1 ในตำแหน่งนั้น ๆ ที่คุณวางไว้ 0.9 และคุณแจกจ่ายส่วนที่เหลือของ "มวลความน่าจะเป็น" อย่างเท่าเทียมกันเหนือตำแหน่งอื่น ๆ
หมายเหตุ: การกระจายของ Pad Token ถูกตั้งค่าเป็นศูนย์ทั้งหมดเนื่องจากเราไม่ต้องการให้โมเดลของเราทำนายสิ่งเหล่านั้น!
นอกเหนือจาก repo นี้ (ดี duh) ฉันขอแนะนำให้คุณไปข้างหน้าและอ่านบล็อกที่น่าทึ่งนี้โดย Jay Alammar!
Transformer ได้รับการฝึกฝนสำหรับงาน NMT (Neural Machine) ในชุดข้อมูล WMT-14 สำหรับ:
สิ่งที่ฉันทำ (ตอนนี้) คือฉันได้รับการฝึกฝนแบบจำลองของฉันในชุดข้อมูล IWSLT ซึ่งมีขนาดเล็กกว่ามากสำหรับคู่ภาษาอังกฤษ-เยอรมันในขณะที่ฉันพูดภาษาเหล่านั้นดังนั้นจึงง่ายต่อการดีบักและเล่นรอบ ๆ
ฉันจะฝึกอบรมแบบจำลองของฉันใน WMT-14 เร็ว ๆ นี้ลองดูที่ส่วน Todos
อย่างไรก็ตาม มาดูกันว่า repo นี้สามารถทำอะไรให้คุณได้บ้าง! มันสามารถแปลได้!
การแปลสั้น ๆ จากรุ่นภาษาเยอรมันเป็นภาษาอังกฤษ IWSLT:
อินพุต: Ich bin ein guter Mensch, denke ich. ("ทอง": ฉันเป็นคนดีที่ฉันคิด)
เอาท์พุท: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
หรือในรูปแบบที่มนุษย์อ่านได้: I think I'm a good person.
ซึ่งจริงๆแล้วค่อนข้างดี! อาจจะดีกว่า IMO มากกว่าการแปล "ทองคำ" ของ Google Translate
มีกรณีความล้มเหลวแน่นอนเช่นนี้:
อินพุต: Hey Alter, wie geht es dir? (เป็นยังไงบ้าง?)
เอาท์พุท: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
หรือในรูปแบบที่มนุษย์อ่านได้: Hey, age, how are you?
ซึ่งจริง ๆ แล้วยังไม่เลวเลย! เพราะ:
ในทำนองเดียวกันสำหรับโมเดลภาษาอังกฤษเป็นภาษาเยอรมัน
ดังนั้นเราจึงพูดคุยเกี่ยวกับสิ่งที่ Transformers และสิ่งที่พวกเขาสามารถทำเพื่อคุณ (เหนือสิ่งอื่นใด)
มาทำสิ่งนี้กันเถอะ! ทำตามขั้นตอนถัดไป:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create จาก Project Directory (จะสร้างสภาพแวดล้อม conda ใหม่ล่าสุด)activate pytorch-transformer (สำหรับการรันสคริปต์จากคอนโซลของคุณหรือตั้งค่าล่ามใน IDE ของคุณ) แค่ไหน! มันควรทำงานนอกกรอบการดำเนินการ environment.yml ไฟล์ที่เกี่ยวข้องกับการพึ่งพา
อาจใช้เวลาสักครู่เพราะฉันกำลังดาวน์โหลดโมเดลสถิติของ Spacy สำหรับภาษาอังกฤษและภาษาเยอรมันโดยอัตโนมัติ
แพ็คเกจ Pytorch Pip จะมาพร้อมกับ Cuda/Cudnn บางรุ่นกับมัน แต่ขอแนะนำให้คุณติดตั้ง Cuda ทั่วทั้งระบบล่วงหน้าส่วนใหญ่เป็นเพราะไดรเวอร์ GPU ฉันขอแนะนำให้ใช้ Miniconda Installer เป็นวิธีรับ conda ในระบบของคุณ ติดตามคะแนน 1 และ 2 ของการตั้งค่านี้และใช้ Miniconda และ Cuda/Cudnn รุ่นที่ทันสมัยที่สุดสำหรับระบบของคุณ
เพียงเรียกใช้ jupyter notebook จากคุณ Anaconda Console และจะเปิดเซสชันในเบราว์เซอร์เริ่มต้นของคุณ
เปิด The Annotated Transformer ++.ipynb และคุณพร้อมที่จะเล่น!
หมายเหตุ: หากคุณได้รับ DLL load failed while importing win32api: The specified module could not be found
เพียงแค่ทำการ pip uninstall pywin32 จากนั้น pip install pywin32 หรือ conda install pywin32 ควรแก้ไข!
คุณเพียงแค่ต้องเชื่อมโยงสภาพแวดล้อม Python ที่คุณสร้างขึ้นในส่วนการตั้งค่า
ในการเรียกใช้การฝึกอบรมเริ่ม training_script.py มีการตั้งค่าสองสามรายการที่คุณต้องการระบุ:
--batch_size -นี่เป็นสิ่งสำคัญในการตั้งค่าเป็นค่าสูงสุดที่จะไม่ให้ cuda จากหน่วยความจำ--dataset_name เลือกระหว่าง IWSLT และ WMT14 (WMT14 ไม่แนะนำจนกว่าฉันจะเพิ่มการสนับสนุนหลาย GPU)--language_direction -เลือกระหว่าง E2G และ G2E ดังนั้นตัวอย่างการรัน (จากคอนโซล) จะมีลักษณะเช่นนี้:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
รหัสได้รับการแสดงความคิดเห็นอย่างดีเพื่อให้คุณสามารถเข้าใจได้ว่าการฝึกอบรมนั้นทำงานอย่างไร
สคริปต์จะ:
models/checkpoints/models/binaries/data/ )runs/ , เพียงเรียกใช้ tensorboard --logdir=runs จาก Anaconda ของคุณหมายเหตุ: การโหลดข้อมูลช้าในข้อความคบเพลิงดังนั้นฉันจึงใช้ wrapper แบบกำหนดเองซึ่งเพิ่มกลไกการแคชและทำให้สิ่งต่าง ๆ ~ 30x เร็วขึ้น! (มันจะช้าในครั้งแรกที่คุณเรียกใช้สิ่งของ)
ส่วนที่สองคือทั้งหมดที่เกี่ยวกับการเล่นกับนางแบบและดูว่าพวกเขาแปลได้อย่างไร!
เพื่อให้ได้การแปลบางอย่างเริ่มต้น translation_script.py มีการตั้งค่าสองสามรายการที่คุณต้องการตั้งค่า:
--source_sentence -ขึ้นอยู่กับรูปแบบที่คุณระบุว่าสิ่งนี้ควรเป็นประโยคภาษาอังกฤษ/เยอรมัน--model_name -หนึ่งในชื่อรุ่นที่ผ่านการฝึกอบรม: iwslt_e2g , iwslt_g2e หรือโมเดลของคุณ (*)--dataset_name -เก็บสิ่งนี้ไว้ในการซิงค์กับโมเดล IWSLT ถ้าโมเดลได้รับการฝึกฝนบน iwslt--language_direction -โปรดซิงค์กัน E2G หากโมเดลได้รับการฝึกฝนให้แปลจากภาษาอังกฤษเป็นภาษาเยอรมัน (*) หมายเหตุ: หลังจากที่คุณฝึกอบรมโมเดลของคุณมันจะถูกทิ้งลงใน models/binaries ให้ดูว่าชื่อของมันคืออะไรและระบุผ่านพารามิเตอร์ --model_name หากคุณต้องการเล่นเพื่อจุดประสงค์ในการแปล หากคุณระบุรุ่นที่ผ่านการฝึกอบรมบางอย่างพวกเขาจะ ได้รับการดาวน์โหลดโดยอัตโนมัติ ในครั้งแรกที่คุณเรียกใช้สคริปต์การแปล
ฉันจะเชื่อมโยงลิงค์รูปแบบของ IWSLT ที่ได้รับการฝึกฝนที่นี่เช่นกัน: ภาษาอังกฤษกับภาษาเยอรมันและเยอรมันเป็นภาษาอังกฤษ
นั่นคือคุณสามารถเห็นภาพความสนใจตรวจสอบส่วนนี้ สำหรับข้อมูลเพิ่มเติม
ฉันติดตาม 3 เส้นโค้งขณะฝึก:
Bleu เป็นตัวชี้วัดที่ใช้ N-GRAM สำหรับการประเมินปริมาณคุณภาพของแบบจำลองการแปลของเครื่อง
ฉันใช้ตัวชี้วัด Bleu-4 ที่จัดทำโดยโมดูล NLTK Python ที่ยอดเยี่ยม
ผลลัพธ์ในปัจจุบันแบบจำลองได้รับการฝึกฝนมา 20 ยุค (เดอย่อสำหรับ Deutch เช่นภาษาเยอรมันในภาษาเยอรมัน?):
| แบบอย่าง | คะแนน Bleu | ชุดข้อมูล |
|---|---|---|
| หม้อแปลงพื้นฐาน (en-de) | 27.8 | iwslt val |
| หม้อแปลงพื้นฐาน (de-en) | 33.2 | iwslt val |
| หม้อแปลงพื้นฐาน (en-de) | x | WMT-14 val |
| หม้อแปลงพื้นฐาน (de-en) | x | WMT-14 val |
ฉันได้รับสิ่งเหล่านี้โดยใช้การถอดรหัสโลภดังนั้นจึงเป็นการประเมินในแง่ร้ายฉันจะเพิ่มการถอดรหัสลำแสงในไม่ช้า
หมายเหตุสำคัญ: การเริ่มต้นมีความสำคัญมากสำหรับหม้อแปลง! ตอนแรกฉันคิดว่าการใช้งานอื่น ๆ ที่ใช้การเริ่มต้นของซาเวียร์เป็นหนึ่งในฮิวริสติกโดยพลการและการเริ่มต้นของ Pytorch จะทำ - ฉันผิด:
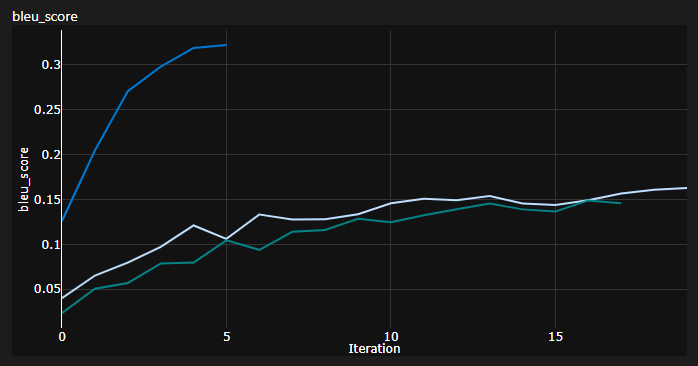
คุณสามารถเห็นการวิ่ง 3 ครั้งที่นี่ 2 คนที่ต่ำกว่าใช้การเริ่มต้นเริ่มต้น Pytorch (หนึ่งที่ใช้ mean สำหรับการสูญเสียความแตกต่างของ KL และสิ่งที่ดีกว่าใช้ batchmean ) ในขณะที่อันบนที่ใช้การเริ่มต้น ชุด Xavier !
แนวคิด: คุณสามารถถ่ายโอนการแปลเป็นระยะสำหรับชุดอ้างอิงของประโยคต้นฉบับ
นั่นจะให้ข้อมูลเชิงลึกเชิงคุณภาพเกี่ยวกับวิธีการที่หม้อแปลงกำลังทำแม้ว่าฉันจะไม่ได้ทำเช่นนั้น
สิ่งที่คล้ายกันเกิดขึ้นเมื่อคุณมีช่วงเวลาที่ยากลำบากในการประเมินแบบจำลองของคุณเช่นในเขตข้อมูล Gans และ NST
พล็อตด้านบนเป็นตัวอย่างจาก Azure ML Run ของฉัน แต่เมื่อฉันเรียกใช้สิ่งของในพื้นที่ฉันใช้ Tensorboard
เพียงเรียกใช้ tensorboard --logdir=runs จากคอนโซล Anaconda ของคุณและคุณสามารถติดตามตัวชี้วัดของคุณในระหว่างการฝึกอบรม
คุณสามารถใช้ translation_script.py และตั้งค่า --visualize_attention เป็นจริงเพื่อทำความเข้าใจเพิ่มเติมว่าโมเดลของคุณคือ "การให้ความสนใจ" ในประโยคต้นฉบับและประโยคเป้าหมาย
นี่คือความสนใจที่ฉันได้รับสำหรับประโยคอินพุต Ich bin ein guter Mensch, denke ich.
สิ่งเหล่านี้เป็นของเลเยอร์ 6 ของตัวเข้ารหัส คุณสามารถเห็นหัวความสนใจหลายหัว 8 หัวทั้งหมด

และอันนี้เป็นของชั้นถอดรหัส 6 ของโมดูลตัวถอดรหัสด้วยตนเอง MHA (ความสนใจหลายหัว)
คุณสามารถสังเกตเห็น รูปแบบสามเหลี่ยม ที่น่าสนใจซึ่งมาจากความจริงที่ว่าโทเค็นเป้าหมายไม่สามารถมองไปข้างหน้าได้!

โมดูล MHA ประเภทที่ 3 เป็นแหล่งที่มาที่เข้าร่วมและดูคล้ายกับพล็อตที่คุณเห็นสำหรับตัวเข้ารหัส
อย่าลังเลที่จะเล่นกับมันด้วยความเร็วของคุณเอง!
หมายเหตุ: เห็นได้ชัดว่ามีปัญหาอคติบางอย่างกับโมเดลนี้ แต่ฉันจะไม่เข้าไปวิเคราะห์ที่นี่
คุณต้องการฮาร์ดแวร์ที่ดีจริงๆหากคุณต้องการฝึกอบรมหม้อแปลงในชุดข้อมูล WMT-14
ผู้เขียนใช้:
หากการคำนวณของฉันถูกต้องว่ามีจำนวน ~ 19 ขั้นตอน (ขั้นตอน 100K แต่ละขั้นตอนมีโทเค็น ~ 25000 และ WMT-14 มีโทเค็น ~ 130m SRC/TRG) สำหรับพื้นฐานและ 3x ที่สำหรับขั้นตอนใหญ่ (300K ขั้นตอน)
ในทางกลับกันมันเป็นไปได้มากขึ้นในการฝึกอบรมโมเดลในชุดข้อมูล IWSLT ฉันต้องใช้เวลา:
ฉันสามารถผลัก K80s ถึง 3,500+ โทเค็น/แบทช์ แต่มีปัญหาบางอย่างจากหน่วยความจำ
ในที่สุดก็มี Todos อีกสองสามตัวซึ่งฉันหวังว่าจะเพิ่มเร็ว ๆ นี้:
repo มีทุกสิ่งที่ต้องการแล้วนี่เป็นเพียงคะแนนโบนัส ฉันได้ทดสอบทุกอย่างตั้งแต่การตั้งค่าสภาพแวดล้อมการดาวน์โหลดโมเดลอัตโนมัติ ฯลฯ
หากคุณมีปัญหาในการทำความเข้าใจกับรหัสฉันทำภาพรวมเชิงลึกของกระดาษในวิดีโอนี้:
ฉันมีวิดีโอเพิ่มเติมที่อาจช่วยให้คุณเข้าใจหม้อแปลง:
ฉันพบว่าทรัพยากรเหล่านี้มีประโยชน์ (ในขณะที่พัฒนาสิ่งนี้):
ฉันพบแรงบันดาลใจบางอย่างสำหรับการออกแบบแบบจำลองในหม้อแปลงหมายเหตุประกอบ แต่ฉันพบว่ามันยากที่จะเข้าใจและมีข้อบกพร่องบางอย่าง ส่วนใหญ่เขียนขึ้นโดยคำนึงถึงนักวิจัย หวังว่า repo นี้จะเปิดความเข้าใจของ Transformers ให้กับคนทั่วไปเช่นกัน! -
หากคุณพบว่ารหัสนี้มีประโยชน์โปรดอ้างอิงสิ่งต่อไปนี้:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
หากคุณชอบที่จะมีเนื้อหาที่เกี่ยวข้องกับ AI มากขึ้นในชีวิตของคุณลองพิจารณา:


