pytorch original transformer
1.0.0
Este repo contém a implementação de Pytorch do artigo de transformador original (: Link: Vaswani et al.).
O objetivo é facilitar o início de jogar e aprender sobre transformadores.
Os transformadores foram originalmente propostos por Vaswani et al. Em um artigo seminal chamado atenção, é tudo o que você precisa.
Você provavelmente ouviu falar de transformadores de uma maneira ou de outra. GPT-3 e Bert para citar alguns conhecidos? A idéia principal é que eles mostraram que você não precisa usar camadas recorrentes ou convolucionais e que a arquitetura simples, juntamente com a atenção, é super poderosa. Ele deu o benefício de uma modelagem de dependência de longo alcance muito melhor e a arquitetura em si é altamente paralelagável (: Computer :: Computer :: Computer :) que leva a uma melhor eficiência de computação!
Aqui está como sua arquitetura lindamente simples se parece:

Este repositório deve ser um recurso de aprendizado para entender os transformadores como o transformador original por si só não é mais um SOTA.
Para esse fim, o código é (espero) bem comentado e incluí o playground.py , onde visualizei alguns conceitos difíceis de explicar usando palavras, mas super simples depois de visualizados. Então aqui vamos nós!
Você pode analisar este em um vislumbre do olho?

visualize_positional_encodings() playground.py .

Dependendo da posição do seu token de origem/destino, você "escolha uma linha desta imagem" e você a adiciona ao seu vetor de incorporação, é isso. Eles também poderiam ser aprendidos, mas é mais chique fazer assim, obviamente! ?
Da mesma forma, você pode analisar este em O(1) ?

Noup? Então eu pensei, aqui está visualizado:

É super fácil de entender agora. Agora, se essa parte foi crucial para o sucesso do transformador? Eu duvido. Mas é legal e torna as coisas mais complicadas. ? ( .set_sarcasm(True) )
Nota: A dimensão do modelo é basicamente do tamanho do vetor de incorporação, o transformador de linha de base usado 512, o grande 1024
Primeira vez que você ouve falar de suavização de etiquetas, parece difícil, mas não é. Você geralmente define sua distribuição de vocabulário de destino como um one-hot . Significado 1 Posição de 30k (ou qualquer que seja o tamanho do seu vocabulário) está definido como 1. Probabilidade e tudo mais para 0.

Na rótulo suavizando em vez de colocar 1. Nessa posição específica, você coloca, digamos 0.9 e você distribui uniformemente o restante da "massa de probabilidade" sobre as outras posições (que é visualizada como um tom diferente de roxo na imagem acima em um vocabulário fictício de tamanho 4 - portanto 4 colunas)
Nota: a distribuição do token do pad é definida como todos os zeros, pois não queremos que nosso modelo o preveja!
Além deste repositório (bem duh), eu recomendo que você vá em frente e leia este blog incrível de Jay Alammar!
O transformador foi originalmente treinado para a tarefa NMT (Tradução da Máquina Neural) no conjunto de dados WMT-14 para:
O que eu fiz (por enquanto) é treinei meus modelos no conjunto de dados IWSLT, que é muito menor, para o par de idiomas inglês-alemão, enquanto falo esses idiomas, por isso é mais fácil depurar e brincar.
Também treinarei meus modelos no WMT-14 em breve, dê uma olhada na seção Todos.
De qualquer forma! Vamos ver o que esse repo pode praticamente fazer por você! Bem, ele pode traduzir!
Algumas traduções curtas do meu modelo alemão para inglês IWSLT:
Entrada: Ich bin ein guter Mensch, denke ich. ("Gold": eu sou uma boa pessoa, eu acho)
Saída: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
Ou em formato legível por humanos: I think I'm a good person.
O que é realmente muito bom! Talvez ainda melhor IMO do que a tradução "Gold" do Google Translate.
É claro que existem casos de falha como este:
Entrada: Hey Alter, wie geht es dir? (Como vai cara?)
Saída: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
Ou em formato legível pelo homem: Hey, age, how are you?
O que na verdade também não é completamente ruim! Porque:
Da mesma forma, para o modelo inglês para alemão.
Por isso, conversamos sobre o que são transformadores e o que eles podem fazer por você (entre outras coisas).
Vamos fazer isso funcionando! Siga os próximos passos:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create From Project Directory (isso criará um novo ambiente do CONDA).activate pytorch-transformer (para executar scripts do seu console ou definir o intérprete no seu IDE) É isso! Ele deve funcionar fora do arquivo de execução do ambiente.YML, que lida com dependências.
Pode demorar um pouco, pois estou baixando automaticamente os modelos estatísticos de Spacy para inglês e alemão.
O pacote Pytorch Pip será incluído com alguma versão do CUDA/CUDNN com ele, mas é altamente recomendável que você instale um CUDA em todo o sistema, com antecedência, principalmente por causa dos drivers de GPU. Eu também recomendo o uso do Miniconda Installer como uma maneira de obter o CONDA no seu sistema. Siga os pontos 1 e 2 desta configuração e use as versões mais atualizadas do Miniconda e Cuda/Cudnn para o seu sistema.
Basta executar jupyter notebook seu console Anaconda e ele abrirá a sessão no seu navegador padrão.
Abra The Annotated Transformer ++.ipynb e você estará pronto para jogar!
NOTA: Se você receber DLL load failed while importing win32api: The specified module could not be found
Basta pip uninstall pywin32 e, em seguida, pip install pywin32 ou conda install pywin32 deve corrigi -lo!
Você só precisa vincular o ambiente Python que você criou na seção de configuração.
Para executar o treinamento, inicie o training_script.py , há algumas configurações que você deseja especificar:
--batch_size -é importante definir para um valor máximo que não lhe dará CUDA fora da memória--dataset_name -Escolha entre IWSLT e WMT14 (WMT14 não é aconselhável até que eu adicione suporte multi-GPU)--language_direction -Escolha entre E2G e G2E Portanto, um exemplo de execução (do console) ficaria assim:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
O código é bem comentado para que você possa (espero) entender como o treinamento em si funciona.
O script irá:
models/checkpoints/models/binaries/data/ )runs/ , basta executar tensorboard --logdir=runs do seu anacondaNota: O carregamento de dados é lento no texto da tocha e, portanto, implementei um invólucro personalizado que adiciona os mecanismos de cache e torna as coisas ~ 30x mais rápido! (Vai ficar lento na primeira vez que você executa coisas)
A segunda parte é brincar com os modelos e ver como eles traduzem!
Para obter algumas traduções inicia a translation_script.py , há algumas configurações que você deseja definir:
--source_sentence -Dependendo do modelo que você especificará isso deve ser uma frase em inglês/alemão--model_name -Um dos nomes de modelos pré -tenhados: iwslt_e2g , iwslt_g2e ou seu modelo (*)--dataset_name -Mantenha isso em sincronia com o modelo, IWSLT se o modelo foi treinado no iWSLT--language_direction -Keep in Sync, E2G se o modelo foi treinado para traduzir do inglês para o alemão (*) NOTA: Depois de treinar seu modelo, ele será despejado em models/binaries veja o que é o nome e especificará -lo através do parâmetro --model_name se você deseja brincar com ele para fins de tradução. Se você especificar alguns dos modelos pré -treinados, eles serão baixados automaticamente na primeira vez que você executará o script de tradução.
Vou vincular links de modelo iWSLT aqui também: inglês ao alemão e alemão ao inglês.
É isso que você também pode visualizar a atenção, verifique esta seção. Para mais informações.
Eu rastreei 3 curvas durante o treinamento:
Bleu é uma métrica baseada em n-gramas para avaliar quantitativamente a qualidade dos modelos de tradução de máquinas.
Eu usei a métrica bleu-4 fornecida pelo incrível módulo NLTK Python.
Resultados atuais, os modelos foram treinados para 20 épocas (deutes, ou seja, alemão em alemão?):
| Modelo | Pontuação bleu | Conjunto de dados |
|---|---|---|
| Transformador de linha de base (EN-DE) | 27.8 | IWSLT VAL |
| Transformador de linha de base (De-en) | 33.2 | IWSLT VAL |
| Transformador de linha de base (EN-DE) | x | WMT-14 VAL |
| Transformador de linha de base (De-en) | x | WMT-14 VAL |
Eu os tenho usando decodificação gananciosa, por isso é uma estimativa pessimista, adicionarei a decodificação do feixe em breve.
Nota importante: a inicialização é muito importante para o transformador! Inicialmente, pensei que outras implementações usando a inicialização do Xavier é novamente uma daquelas heurísticas arbitrárias e que o ingresso padrão de Pytorch fará - eu estava errado:
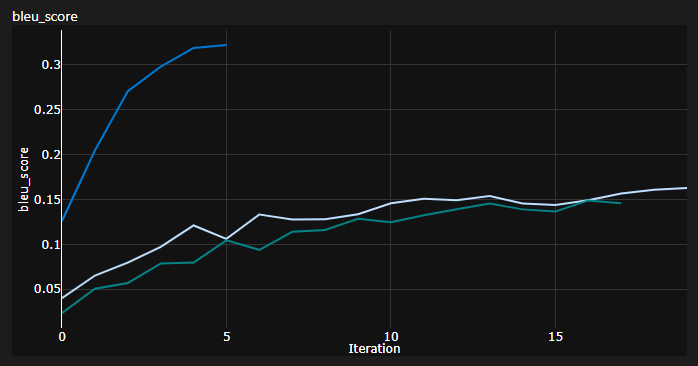
Você pode ver aqui 3 execuções, os dois mais baixos usavam a inicialização padrão do pytorch (uma mean usada para a perda de divergência de KL e a melhor usava batchmean ), enquanto o superior usou a inicialização uniforme Xavier !
Ideia: você também poderia despejar traduções periodicamente para um lote de referência de frases de origem.
Isso lhe daria algumas dicas qualitativas sobre como o transformador está, embora eu não tenha feito isso.
Uma coisa semelhante é feita quando você tem dificuldade em avaliar quantitativamente seu modelo, como nos campos Gans e NST.
O gráfico acima é um trecho do meu Azure ML Run, mas quando eu corro coisas localmente, uso o Tensorboard.
Basta executar tensorboard --logdir=runs do seu console da Anaconda e você pode rastrear suas métricas durante o treinamento.
Você pode usar o translation_script.py e definir o --visualize_attention como verdadeiro para entender também o que seu modelo estava "prestando atenção" nas frases de origem e destino.
Aqui estão as atenções que recebo para a sentença de entrada Ich bin ein guter Mensch, denke ich.
Eles pertencem à camada 6 do codificador. Você pode ver todas as 8 cabeças de atenção de várias cabeças.

E este pertence à camada de decodificador 6 do módulo MHA de decodificador de auto-distribuição (atenção multi-cabeça).
Você pode notar um padrão triangular interessante que vem do fato de que os tokens de destino não podem olhar para o futuro!

O terceiro tipo de módulo MHA é a fonte que compareceu e se parece com o gráfico que você viu para o codificador.
Sinta -se à vontade para brincar com ele no seu próprio ritmo!
Nota: Obviamente, existem alguns problemas de viés com este modelo, mas não vou entrar nessa análise aqui
Você realmente precisa de um hardware decente se desejar treinar o transformador no conjunto de dados WMT-14 .
Os autores tomaram:
Se meus cálculos estiverem corretos, que equivale a ~ 19 épocas (100 mil degraus, cada etapa teve ~ 25000 tokens e WMT-14 possui ~ 130m src/trg tokens) para a linha de base e 3x que para o grande (300 mil degraus).
Por outro lado, é muito mais viável treinar o modelo no conjunto de dados IWSLT . Isso me levou:
Eu poderia ter empurrado os K80s a 3500 mais de tokens/lote, mas tive alguns problemas de CUDA.
Finalmente, há mais alguns Todos, que espero acrescentar em breve:
O repo já tem tudo o que precisa, esses são apenas os pontos de bônus. Eu testei tudo, desde configuração do ambiente até download automático de modelos, etc.
Se você está tendo dificuldades para entender o código, fiz uma visão geral aprofundada do artigo neste vídeo:
Tenho mais alguns vídeos que podem ajudá -lo a entender os transformadores:
Achei esses recursos úteis (enquanto desenvolveu este):
Encontrei alguma inspiração para o design do modelo no transformador anotado, mas achei difícil de entender, e ele tinha alguns bugs. Foi escrito principalmente com pesquisadores em mente. Espero que este repo abre o entendimento dos transformadores para o povo comum também! ?
Se você achar esse código útil, cite o seguinte:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
Se você adoraria ter mais conteúdo relacionado à IA em sua vida?, Considere:


