pytorch original transformer
1.0.0
Этот репо содержит реализацию Pytorch оригинальной бумаги трансформатора (: ссылка: Vaswani et al.).
Он направлен на то, чтобы легко начать играть и узнать о трансформаторах.
Трансформеры были первоначально предложены Vaswani et al. В оригинальной статье, называемое внимание, - это все, что вам нужно.
Вы, вероятно, слышали о трансформерах так или иначе. GPT-3 и Bert, чтобы назвать несколько хорошо известных? Основная идея заключается в том, что они показали, что вам не нужно использовать повторяющиеся или сверточные слои, и эта простая архитектура в сочетании с вниманием очень мощная. Это дало преимущество гораздо лучшего моделирования зависимостей дальнего действия , а сама архитектура очень параллелизируется (: Computer :: Computer :: Computer :), что приводит к лучшему вычислению эффективности!
Вот как выглядит их красиво простая архитектура:

Предполагается, что это репо является учебным ресурсом для понимания трансформаторов, поскольку само по себе первоначальный трансформатор больше не является SOTA.
Для этой цели код (надеюсь) хорошо прокомментирован, и я включил playground.py , где я визуализировал пару концепций, которые трудно объяснить, используя слова, но супер простой после визуализации. Итак, вот и мы!
Можете ли вы проанализировать это в взгляде на глаза?

Также I. Запуск функции visualize_positional_encodings() от playground.py Мы получаем это:

В зависимости от положения вашего источника/токена цели, вы «выбираете одну ряд этого изображения», и вы добавляете его в его встраивание вектора, вот и все. Их также можно было изучить, но это просто более модно делать это, очевидно,! ?
Точно так же вы можете проанализировать это в O(1) ?

Noup? Итак, я подумал, что это визуализировано:

Сейчас это очень легко понять. Теперь была ли эта часть решающей для успеха трансформатора? Я сомневаюсь в этом. Но это круто и делает вещи более сложными. ? ( .set_sarcasm(True) )
Примечание: измерение модели - это в основном размер вектора встраивания, базовый трансформатор использовал 512, Большой 1024
Впервые вы слышите об сглаживании лейбла, это звучит жестко, но это не так. Вы обычно устанавливаете свой целевой словарный распределение на one-hot . Значение 1 позиция из 30 тыс. (Или какой бы ни был размер слока), установлена на 1. Вероятность и все остальное до 0.

В сглаживании метки вместо размещения 1. В этой конкретной позиции вы размещаете 0,9, и вы равномерно распределяете остальную часть «вероятности массы» по другим положениям (который визуализируется как другой оттенок фиолетового изображения на изображении выше в вымышленном словаре размера 4 - отсюда 4 колонн)
Примечание. Распределение Pad Token установлено на все нулы, так как мы не хотим, чтобы наша модель предсказывала их!
Помимо этого репо (ну, да), я настоятельно рекомендую вам прочитать этот удивительный блог Джея Аламара!
Трансформатор был первоначально обучен задаче NMT (перевод нейронной машины) в наборе данных WMT-14 для:
Что я сделал (пока), так это то, что я обучил свои модели на наборе данных IWSLT, который намного меньше, для английского языкового языка, так как я говорю на этих языках, так что его легче отлаживать и играть.
Я также скоро обучу свои модели на WMT-14, посмотрите на раздел Todos.
В любом случае! Посмотрим, что этот репо может практически для вас! Ну, это может перевести!
Несколько коротких переводов от моей модели немецкого на английский IWSLT:
Ввод: Ich bin ein guter Mensch, denke ich. («Золото»: я думаю, я хороший человек)
Вывод: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
Или в формате, читаемом человеком: I think I'm a good person.
Что на самом деле довольно хорошо! Может быть, даже лучше, чем перевод «золота» Google Translate.
Есть, конечно, такие случаи неудачи, как это:
Ввод: Hey Alter, wie geht es dir? (Как дела, чувак?)
Вывод: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
Или в формате, читаемом человеком: Hey, age, how are you?
Что на самом деле также не совсем плохо! Потому что:
Точно так же для английского до немецкой модели.
Итак, мы говорили о том, что такое трансформаторы, и что они могут сделать для вас (среди прочего).
Давайте запустим эту вещь! Следуйте следующим шагам:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create из Project Directory (это создаст совершенно новую среду Conda).activate pytorch-transformer (для выполнения сценариев из вашей консоли или установить интерпретатор в вашем IDE) Вот и все! Он должен работать вне коробки для выполнения среды.
Это может занять некоторое время, так как я автоматически загружаю статистические модели Spacy для английского и немецкого языка.
Пакет Pytorch Pip будет поставляться с некоторой версией Cuda/Cudnn с ним, но настоятельно рекомендуется заранее установить общеобразовательную CUDA, в основном из-за драйверов GPU. Я также рекомендую использовать установщик Miniconda в качестве способа получить Conda в вашей системе. Следите за точками 1 и 2 этой установки и используйте самые современные версии Miniconda и Cuda/Cudnn для вашей системы.
Просто запустите jupyter notebook от вас консоли Anaconda, и она откроет сеанс в вашем браузере по умолчанию.
Откройте The Annotated Transformer ++.ipynb , и вы готовы к игре!
ПРИМЕЧАНИЕ. Если вы получите DLL load failed while importing win32api: The specified module could not be found
Просто сделайте pip uninstall pywin32 , а затем pip install pywin32 или conda install pywin32 должен его исправить!
Вам просто нужно связать среду Python, которую вы создали в разделе «Настройка».
Чтобы запустить обучение, запустите training_script.py , есть пара настроек, которые вы захотите указать:
--batch_size -важно установить максимальное значение, которое не даст вам Cuda из памяти--dataset_name -выберите между IWSLT и WMT14 (WMT14 не рекомендуется, пока я не добавлю поддержку с несколькими GPU)--language_direction -выбор между E2G и G2E Таким образом, пример прогона (из консоли) будет выглядеть так:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
Код хорошо прокомментирован, поэтому вы можете (надеюсь) понять, как работает сама обучение.
Сценарий будет:
models/checkpoints/models/binaries/data/ )runs/ , просто запустите tensorboard --logdir=runs из вашей AnacondaПРИМЕЧАНИЕ. Нагрузка данных медленно в тексте Torch, и поэтому я реализовал пользовательскую обертку, которая добавляет механизмы кэширования и делает вещи ~ 30 раз быстрее! (Это будет медленно, когда вы запустите вещи)
Вторая часть - это игра с моделями и увидеть, как они переводят!
Чтобы получить некоторые переводы, запустите translation_script.py , есть пара настроек, которые вы захотите установить:
--source_sentence -в зависимости от модели, которую вы указываете--model_name -одно из предварительно предварительно проведенных имен модели: iwslt_e2g , iwslt_g2e или ваша модель (*)--dataset_name -сохранить это синхронизировать с моделью, IWSLT если модель была обучена на IWSLT--language_direction -сохранить синхронизацию, E2G если модель была обучена переводу с английского на немецкий (*) Примечание. После обучения своей модели она будет сброшена в models/binaries Посмотрите, что его имя, и укажите ее через параметр --model_name если вы хотите играть с ним с целью перевода. Если вы указали некоторые из предварительно предварительно проведенных моделей, они автоматически загружатся в первый раз, когда вы запустите сценарий перевода.
Я также свяжу ссылки на предварительную модель IWSLT здесь: английский на немецкий и немецкий на английский.
Вот и все, вы также можете визуализировать внимание, чтобы проверить этот раздел. Для получения дополнительной информации.
Я отслеживал 3 кривых во время обучения:
Bleu-это метрика на основе N-грамма для количественной оценки качества моделей машинного перевода.
Я использовал метрику Bleu-4, предоставленную удивительным модулем NLTK Python.
Текущие результаты, модели были обучены для 20 эпох (DE обозначает Deatch IE German на немецком языке?):
| Модель | Bleu Score | Набор данных |
|---|---|---|
| Базовый трансформатор (en-de) | 27.8 | Iwslt val |
| Базовый трансформатор (de-en) | 33,2 | Iwslt val |
| Базовый трансформатор (en-de) | х | WMT-14 Val |
| Базовый трансформатор (de-en) | х | WMT-14 Val |
Я получил их с помощью жадного декодирования, так что это пессимистическая оценка, я скоро добавлю декодирование луча.
Важное примечание: инициализация имеет большое значение для трансформатора! Первоначально я думал, что другие реализации, использующие инициализацию Ксавье, снова являются одной из тех произвольных эвристических данных, и что подойдет Pytorch Default Init - я ошибался: я ошибался:
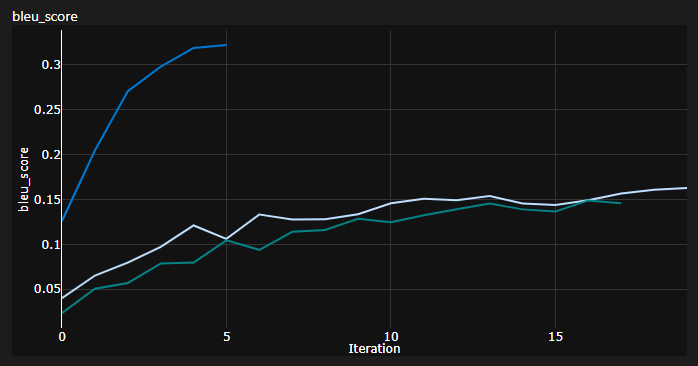
Здесь вы можете увидеть 3 прогона, 2 нижних используемых инициализации по умолчанию Pytorch (одна используемая mean для потери дивергенции KL, а также лучше используется batchmean ), в то время как верхняя - инициализация Ксавьера !
Идея: вы можете также периодически сбрасывать переводы для эталонной партии исходных предложений.
Это дало бы вам качественное представление о том, как дела у трансформатора, хотя я этого не делал.
Аналогичная вещь сделана, когда вам трудно количественно оценивать вашу модель, как в Gans и NST Fields.
Приведенный выше сюжет - это фрагмент из моего запуска Azure ML, но когда я запускаю вещи локально, я использую Tensorboard.
Просто запустите tensorboard --logdir=runs из вашей консоли Anaconda, и вы можете отслеживать свои метрики во время обучения.
Вы можете использовать translation_script.py и установить --visualize_attention , чтобы дополнительно понять, на что ваша модель «обращает внимание» в исходных и целевых предложениях.
Вот внимание, которое я получаю за входное предложение Ich bin ein guter Mensch, denke ich.
Они принадлежат слою 6 энкодера. Вы можете увидеть все 8 голов внимания.

И этот принадлежит к слою декодера 6 модуля декодера самого атмосфера MHA (мульти-головного внимания).
Вы можете заметить интересный треугольный рисунок , который исходит от того факта, что токены Target не могут смотреть в будущее!

3 -й тип модуля MHA - это источник, посещающий один, и он выглядит похоже на сюжет, который вы видели для энкодера.
Не стесняйтесь играть с этим в своем собственном темпе!
ПРИМЕЧАНИЕ: очевидно, есть некоторые проблемы с предвзятостью с этой моделью, но я не буду вдаваться в этот анализ здесь
Вам действительно нужно приличное оборудование, если вы хотите обучить трансформатор на наборе данных WMT-14 .
Авторы взяли:
Если мои расчеты правы, которые составляют ~ 19 эпох (100 тыс. Шагов, на каждом этапе имеется ~ 25000 токенов, а WMT-14 имеет ~ 130 млн. Переходы SRC/TRG) для базового уровня и в 3 раза, что для большого (300 тыс. Шагов).
С другой стороны, гораздо более целесообразно обучать модель на наборе данных IWSLT . Мне потребовалось:
Я мог бы вытолкнуть токены/партию K80s до 3500+, но у меня было несколько проблем с памятью.
Наконец, есть еще пара Todos, которые, надеюсь, скоро добавлю:
У репо уже есть все, что ему нужно, это всего лишь бонусные баллы. Я протестировал все: от настройки среды до автоматической загрузки модели и т. Д.
Если у вас возникли трудности с пониманием кода, я сделал подробный обзор статьи в этом видео:
У меня есть еще несколько видео, которые могли бы помочь вам понять трансформаторы:
Я нашел эти ресурсы полезными (при разработке этого):
Я нашел некоторое вдохновение для дизайна модели в аннотированном трансформаторе, но мне было трудно понять, и у него были некоторые ошибки. Это было в основном написано с учетом исследователей. Надеемся, что этот репо открывает понимание трансформеров для обычных людей! ?
Если вы найдете этот код полезным, пожалуйста, укажите следующее:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
Если вы хотели бы иметь еще немного контента, связанного с AI в вашей жизни?, Подумайте:


