pytorch original transformer
1.0.0
Ce dépôt contient une implémentation Pytorch du papier transformateur d'origine (: lien: Vaswani et al.).
Il vise à faciliter le début de la lecture et de l'apprentissage des transformateurs.
Les transformateurs ont été initialement proposés par Vaswani et al. Dans un papier séminal appelé l'attention est tout ce dont vous avez besoin.
Vous avez probablement entendu parler des transformateurs d'une manière ou d'une autre. GPT-3 et Bert pour n'en nommer quelques-uns bien connus ?. L'idée principale est qu'ils ont montré que vous n'avez pas à utiliser des couches récurrentes ou convolutionnelles et cette simple architecture associée à l'attention est super puissante. Il a donné l'avantage d' une bien meilleure modélisation de dépendances à longue portée et l'architecture elle-même est très parallélisable (: Computer :: Computer :: :) Ce qui conduit à mieux calculer l'efficacité!
Voici à quoi ressemble leur architecture magnifiquement simple:

Ce dépôt est censé être une ressource d'apprentissage pour comprendre les transformateurs, car le transformateur d'origine n'est plus une SOTA.
À cette fin, le code est (espérons-le) bien commenté et j'ai inclus le playground.py où j'ai visualisé quelques concepts qui sont difficiles à expliquer en utilisant des mots mais super simple une fois visualisé. Alors c'est parti!
Pouvez-vous analyser celui-ci dans un aperçu de l'œil?

Je ne peux pas non plus. Exécution de la fonction visualize_positional_encodings() de playground.py Nous obtenons ceci:

Selon la position de votre jeton source / cible, vous "choisissez une ligne de cette image" et vous l'ajoutez à son vecteur d'intégration, c'est tout. Ils pourraient également être appris, mais c'est juste plus fantaisiste de le faire comme ça, évidemment! ?
De même, pouvez-vous analyser celui-ci en O(1) ?

Noup? Alors j'ai pensé, ici, il est visualisé:

C'est super facile à comprendre maintenant. Maintenant, si cette partie était cruciale pour le succès de Transformer? J'en doute. Mais c'est cool et rend les choses plus compliquées. ? ( .set_sarcasm(True) )
Remarque: La dimension du modèle est essentiellement la taille du vecteur d'incorporation, le transformateur de base utilisé 512, le Big 1024
La première fois que vous entendez parler de lissage de l'étiquette, cela semble difficile, mais ce n'est pas le cas. Vous définissez généralement votre distribution de vocabulaire cible à one-hot . Cela signifie que 1 position sur 30K (ou quelle que soit votre taille de vocabulaire) est définie sur 1. Probabilité et tout le reste à 0.

En lissage de l'étiquette au lieu de placer 1. Sur cette position particulière, vous placez 0.9 et vous distribuez uniformément le reste de la "masse de probabilité" sur les autres positions (qui est visualisée comme une autre nuance de violet sur l'image ci-dessus dans un vocabulaire fictif de taille 4 - d'où 4 colonnes))
Remarque: La distribution de Pad Token est définie sur tous les zéros car nous ne voulons pas que notre modèle les prédise!
Mis à part ce dépôt (enfin duh), je vous recommande fortement de continuer et de lire ce blog incroyable de Jay Alamm!
Le transformateur a été initialement formé pour la tâche NMT (traduction de la machine neurale) sur l'ensemble de données WMT-14 pour:
Ce que j'ai fait (pour l'instant), c'est que j'ai formé mes modèles sur l'ensemble de données IWSLT, qui est beaucoup plus petit, pour la paire de langue anglaise-allemande, car je parle ces langues, il est donc plus facile de déboguer et de jouer.
Je vais également bientôt entraîner mes modèles sur WMT-14, jetez un œil à la section Todos.
De toute façon! Voyons ce que ce repo peut pratiquement faire pour vous! Eh bien, cela peut traduire!
Quelques courtes traductions de mon modèle allemand à l'anglais IWSLT:
Entrée: Ich bin ein guter Mensch, denke ich. ("Gold": je suis une bonne personne je pense)
Sortie: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
Ou en format lisible par l'homme: I think I'm a good person.
Ce qui est en fait assez bon! Peut-être encore mieux IMO que la traduction "or" de Google.
Il y a bien sûr des cas d'échec comme ceci:
Entrée: Hey Alter, wie geht es dir? (Comment ça va mec?)
Sortie: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
Ou dans un format lisible par l'homme: Hey, age, how are you?
Ce qui n'est pas non plus complètement mauvais! Parce que:
De même pour le modèle anglais à allemand.
Nous avons donc parlé de ce que sont les transformateurs et de ce qu'ils peuvent faire pour vous (entre autres).
Faisons courir cette chose! Suivez les étapes suivantes:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create à partir du répertoire de projet (cela créera un tout nouvel environnement conda).activate pytorch-transformer (pour exécuter des scripts à partir de votre console ou définir l'interprète dans votre IDE) C'est ça! Il devrait fonctionner à l'exécution du fichier Environment.yml à l'exécution de la boîte qui traite des dépendances.
Cela peut prendre un certain temps car je télécharge automatiquement les modèles statistiques de Spacy pour l'anglais et l'allemand.
Le package Pytorch PIP sera livré avec une version de CUDA / CUDNN avec, mais il est fortement recommandé d'installer un CUDA à l'échelle du système, principalement en raison des pilotes GPU. Je recommande également d'utiliser le programme d'installation de MiniConda comme moyen d'obtenir Conda sur votre système. Suivez les points 1 et 2 de cette configuration et utilisez les versions les plus à jour de MiniConda et Cuda / Cudnn pour votre système.
Exécutez simplement jupyter notebook de votre console Anaconda et cela ouvrira la session dans votre navigateur par défaut.
Ouvrez The Annotated Transformer ++.ipynb et vous êtes prêt à jouer!
Remarque: Si vous obtenez DLL load failed while importing win32api: The specified module could not be found
Faites simplement pip uninstall pywin32 , puis pip install pywin32 ou conda install pywin32 devrait le réparer!
Vous avez juste besoin de lier l'environnement Python que vous avez créé dans la section Configuration.
Pour exécuter la formation, démarrez le training_script.py , il y a quelques paramètres que vous voudrez spécifier:
--batch_size - Il est important de régler une valeur maximale qui ne vous donnera pas Cuda hors de mémoire--dataset_name - Choisissez entre IWSLT et WMT14 (WMT14 n'est pas conseillé avant d'ajouter une prise en charge multi-GPU)--language_direction - Choisissez entre E2G et G2E Ainsi, un exemple de course (à partir de la console) ressemblerait à ceci:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
Le code est bien commenté afin que vous puissiez (espérons) comprendre comment la formation elle-même fonctionne.
Le script sera:
models/checkpoints/models/binaries/data/ )runs/ , il suffit d'exécuter tensorboard --logdir=runs à partir de votre anacondaRemarque: le chargement des données est lent dans le texte de la torche, et j'ai donc implémenté un wrapper personnalisé qui ajoute les mécanismes de mise en cache et rend les choses ~ 30x plus rapidement! (ce sera lent la première fois que vous exécutez des trucs)
La deuxième partie consiste à jouer avec les modèles et à voir comment ils se traduisent!
Pour obtenir des traductions, démarrez la translation_script.py , il y a quelques paramètres que vous voudrez définir:
--source_sentence - Selon le modèle, vous spécifiez que cela devrait être une phrase anglaise / allemande--model_name - l'un des noms de modèle pré-entraînés: iwslt_e2g , iwslt_g2e ou votre modèle (*)--dataset_name - Gardez ceci en synchronisation avec le modèle, IWSLT Si le modèle a été formé sur IWSLT--language_direction - Restez en synchronisation, E2G si le modèle a été formé pour se traduire de l'anglais en allemand (*) Remarque: Après avoir formé votre modèle, il sera jeté dans models/binaries voir quel est son nom et le spécifier via le paramètre --model_name si vous souhaitez jouer avec lui à des fins de traduction. Si vous spécifiez certains des modèles pré-entraînés, ils seront automatiquement téléchargés la première fois que vous exécutez le script de traduction.
Je vais également lier les liens du modèle pré-entraîné IWSLT ici: l'anglais vers l'allemand et l'allemand vers l'anglais.
C'est tout ce que vous pouvez également visualiser l'attention, consultez cette section. Pour plus d'informations.
J'ai suivi 3 courbes pendant l'entraînement:
BLEU est une métrique basée sur N-gram pour évaluer quantitativement la qualité des modèles de traduction automatique.
J'ai utilisé la métrique Bleu-4 fournie par le génial module NLTK Python.
Résultats actuels, les modèles ont été formés pour 20 époques (DE signifie Deutch IE allemand en allemand?):
| Modèle | Score de Bleu | Ensemble de données |
|---|---|---|
| Transformateur de base (EN-DE) | 27.8 | Iwslt val |
| Transformateur de base (DE-EN) | 33.2 | Iwslt val |
| Transformateur de base (EN-DE) | x | WMT-14 Val |
| Transformateur de base (DE-EN) | x | WMT-14 Val |
Je les ai à l'aide d'un décodage gourmand donc c'est une estimation pessimiste, j'ajouterai bientôt le décodage du faisceau.
Remarque importante: L'initialisation compte beaucoup pour le transformateur! J'ai d'abord pensé que d'autres implémentations utilisant l'initialisation de Xavier sont à nouveau l'une de ces heuristiques arbitraires et que l'initiale par défaut de Pytorch fera - j'avais tort:
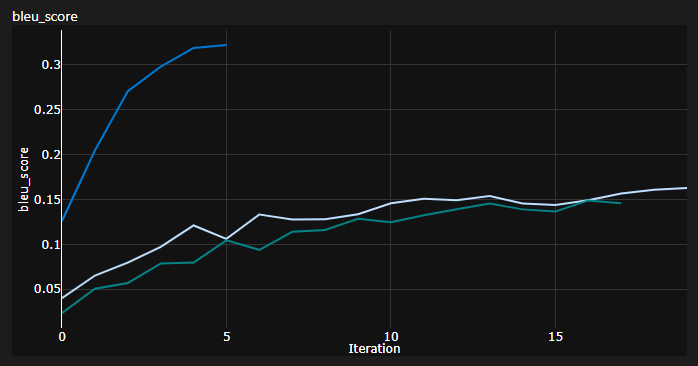
Vous pouvez voir ici 3 exécutions, les 2 inférieurs inférieurs ont utilisé l'initialisation par défaut de Pytorch (une mean utilisée pour la perte de divergence de KL et le meilleur de batchmean utilisé), tandis que l'initialisation uniforme Xavier supérieure a utilisé!
Idée: vous pouvez potentiellement vider périodiquement les traductions pour un lot de référence de phrases source.
Cela vous donnerait un aperçu qualitatif de la façon dont le transformateur va, même si je n'ai pas fait cela.
Une chose similaire est faite lorsque vous avez du mal à évaluer quantitativement votre modèle comme dans les champs Gans et NST.
Le tracé ci-dessus est un extrait de ma course Azure ML, mais lorsque j'exécute des trucs localement, j'utilise Tensorboard.
Il suffit d'exécuter tensorboard --logdir=runs à partir de votre console Anaconda et vous pouvez suivre vos mesures pendant la formation.
Vous pouvez utiliser le translation_script.py et définir le --visualize_attention pour comprendre en outre à quoi votre modèle "faisait attention" dans les phrases source et cible.
Voici les attentions que j'obtiens pour la phrase d'entrée Ich bin ein guter Mensch, denke ich.
Ceux-ci appartiennent à la couche 6 de l'encodeur. Vous pouvez voir toutes les 8 têtes d'attention multiples.

Et celui-ci appartient à la couche de décodeur 6 du module MHA du décodeur d'auto-agencement (attention multi-tête).
Vous pouvez remarquer un modèle triangulaire intéressant qui vient du fait que les jetons cibles ne peuvent pas regarder vers l'avenir!

Le 3ème type de module MHA est la source qui présente une et elle ressemble à l'intrigue que vous avez vue pour l'encodeur.
N'hésitez pas à jouer avec à votre rythme!
Remarque: il y a évidemment quelques problèmes de biais avec ce modèle, mais je n'entrerai pas dans cette analyse ici
Vous avez vraiment besoin d'un matériel décent si vous souhaitez former le transformateur sur l'ensemble de données WMT-14 .
Les auteurs ont pris:
Si mes calculs sont corrects, cela s'élève à ~ 19 époques (100 000 étapes, chaque étape avait ~ 25 000 jetons et WMT-14 a ~ 130 m de jetons SRC / TRG) pour la ligne de base et 3x pour le grand (300k étapes).
D'un autre côté, il est beaucoup plus possible de former le modèle sur l'ensemble de données IWSLT . Il m'a fallu:
J'aurais pu pousser K80 à 3500+ jetons / lot, mais il avait des problèmes de mémoire CUDA.
Enfin, il y a quelques todos de plus que j'ajouterai très bientôt:
Le repo a déjà tout ce dont il a besoin, ce ne sont que les points bonus. J'ai tout testé, de la configuration de l'environnement, au téléchargement automatique du modèle, etc.
Si vous avez des difficultés à comprendre le code, j'ai fait un aperçu approfondi du document dans cette vidéo:
J'ai d'autres vidéos qui pourraient vous aider à comprendre les transformateurs:
J'ai trouvé ces ressources utiles (tout en développant celui-ci):
J'ai trouvé une certaine inspiration pour la conception du modèle dans le transformateur annoté, mais j'ai eu du mal à comprendre, et il avait quelques bugs. Il a été principalement écrit en pensant aux chercheurs. Espérons que ce repo ouvre également la compréhension des transformateurs aux gens du commun! ?
Si vous trouvez ce code utile, veuillez citer ce qui suit:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
Si vous aimeriez avoir plus de contenu lié à l'IA dans votre vie ?, Considérez:


