pytorch original transformer
1.0.0
Repo ini berisi implementasi Pytorch dari kertas transformator asli (: tautan: Vaswani et al.).
Ini bertujuan membuatnya mudah untuk mulai bermain dan belajar tentang Transformers.
Transformer awalnya diusulkan oleh Vaswani et al. Dalam makalah seminal yang disebut perhatian adalah semua yang Anda butuhkan.
Anda mungkin mendengar tentang Transformers dengan satu atau lain cara. GPT-3 dan Bert untuk beberapa nama yang terkenal? Gagasan utamanya adalah bahwa mereka menunjukkan bahwa Anda tidak perlu menggunakan lapisan berulang atau konvolusional dan arsitektur sederhana yang ditambah dengan perhatian sangat kuat. Ini memberi manfaat dari pemodelan ketergantungan jangka panjang yang jauh lebih baik dan arsitektur itu sendiri sangat paraleliz dapat paralel (: Computer :: Computer :: Computer :) Yang mengarah pada efisiensi komputasi yang lebih baik!
Inilah rupa arsitekturnya yang sangat sederhana:

Repo ini seharusnya menjadi sumber belajar untuk memahami transformator sebagai transformator asli dengan sendirinya bukan sota lagi.
Untuk tujuan itu kode (semoga) berkomentar dengan baik dan saya telah memasukkan playground.py di mana saya telah memvisualisasikan beberapa konsep yang sulit dijelaskan menggunakan kata -kata tetapi super sederhana setelah divisualisasikan. Jadi begini!
Bisakah Anda mengurai yang satu ini dalam sekilas mata?

Juga tidak bisa saya menjalankan fungsi visualize_positional_encodings() dari playground.py kita mendapatkan ini:

Bergantung pada posisi token sumber/target Anda, Anda "pilih satu baris gambar ini" dan Anda menambahkannya ke vektor yang menanamkan, itu saja. Mereka juga bisa dipelajari, tetapi lebih suka melakukannya seperti ini, jelas! ?
Demikian pula dapatkah Anda menguraikan yang satu ini di O(1) ?

Noup? Jadi saya pikir, ini dia divisualisasikan:

Sangat mudah dimengerti sekarang. Sekarang apakah bagian ini sangat penting untuk keberhasilan transformator? Saya meragukannya. Tapi itu keren dan membuat segalanya lebih rumit. ? ( .set_sarcasm(True) )
Catatan: Dimensi model pada dasarnya adalah ukuran vektor embedding, transformator awal yang digunakan 512, yang besar 1024
Pertama kali Anda mendengar label smoothing kedengarannya sulit tapi tidak. Anda biasanya mengatur distribusi kosa kata target Anda ke one-hot . Artinya 1 posisi dari 30k (atau berapa pun ukuran vocab Anda) diatur ke 1. Probabilitas dan yang lainnya ke 0.

Dalam label smoothing alih -alih menempatkan 1. Pada posisi tertentu yang Anda tempatkan mengatakan 0,9 dan Anda secara merata mendistribusikan sisa "massa probabilitas" di atas posisi lain (yang divisualisasikan sebagai warna ungu yang berbeda pada gambar di atas dalam kosakata fiksi ukuran 4 - karenanya 4 kolom)
Catatan: Distribusi Pad Token diatur ke semua nol karena kami tidak ingin model kami memprediksi itu!
Selain repo ini (well duh) saya akan sangat merekomendasikan Anda untuk melanjutkan dan membaca blog yang luar biasa ini oleh Jay Alammar!
Transformer awalnya dilatih untuk tugas NMT (Neural Machine Translation) pada dataset WMT-14 untuk:
Apa yang saya lakukan (untuk saat ini) adalah saya melatih model saya pada dataset IWSLT, yang jauh lebih kecil, untuk pasangan bahasa Inggris-Jerman, karena saya berbicara bahasa-bahasa itu sehingga lebih mudah untuk men-debug dan bermain-main.
Saya juga akan melatih model saya di WMT-14 segera, lihat bagian Todos.
Omong-omong! Mari kita lihat apa yang dapat dilakukan repo ini untuk Anda! Baik itu bisa diterjemahkan!
Beberapa terjemahan singkat dari model IWSLT bahasa Jerman ke bahasa Inggris saya:
Input: Ich bin ein guter Mensch, denke ich. ("Emas": Saya adalah orang yang baik saya pikir)
Output: ['<s>', 'I', 'think', 'I', "'m", 'a', 'good', 'person', '.', '</s>']
Atau dalam format yang dapat dibaca manusia: I think I'm a good person.
Yang sebenarnya cukup bagus! Mungkin IMO yang bahkan lebih baik daripada terjemahan "emas" Google Translate.
Tentu saja ada kasus kegagalan seperti ini:
Input: Hey Alter, wie geht es dir? (Bagaimana kabarmu bung?)
Output: ['<s>', 'Hey', ',', 'age', 'how', 'are', 'you', '?', '</s>']
Atau dalam format yang dapat dibaca manusia: Hey, age, how are you?
Yang sebenarnya juga tidak sepenuhnya buruk! Karena:
Demikian pula untuk model bahasa Inggris ke Jerman.
Jadi kami berbicara tentang apa Transformers, dan apa yang dapat mereka lakukan untuk Anda (antara lain).
Mari kita mulai berjalan! Ikuti langkah selanjutnya:
git clone https://github.com/gordicaleksa/pytorch-original-transformercd path_to_repoconda env create dari Project Directory (ini akan menciptakan lingkungan Conda baru).activate pytorch-transformer (untuk menjalankan skrip dari konsol Anda atau atur interpreter di IDE Anda) Itu saja! Ini harus bekerja di luar kotak pelaksanaan lingkungan.yml file yang berurusan dengan dependensi.
Mungkin perlu beberapa saat karena saya secara otomatis mengunduh model statistik Spacy untuk bahasa Inggris dan Jerman.
Paket Pytorch Pip akan dibundel dengan beberapa versi CUDA/CUDNN dengan itu, tetapi sangat disarankan agar Anda memasang CUDA di seluruh sistem sebelumnya, sebagian besar karena driver GPU. Saya juga merekomendasikan menggunakan Installer Miniconda sebagai cara untuk mendapatkan Conda di sistem Anda. Ikuti poin 1 dan 2 dari pengaturan ini dan gunakan versi miniconda dan cudnn yang paling mutakhir untuk sistem Anda.
Cukup jalankan jupyter notebook dari Anda Anaconda Console dan itu akan membuka sesi di browser default Anda.
Buka The Annotated Transformer ++.ipynb dan Anda siap untuk bermain!
Catatan: Jika Anda mendapatkan DLL load failed while importing win32api: The specified module could not be found
Lakukan saja pip uninstall pywin32 dan kemudian pip install pywin32 atau conda install pywin32 harus memperbaikinya!
Anda hanya perlu menautkan lingkungan Python yang Anda buat di bagian pengaturan.
Untuk menjalankan pelatihan, mulailah training_script.py , ada beberapa pengaturan yang ingin Anda tentukan:
--batch_size -Ini penting untuk menetapkan nilai maksimum yang tidak akan memberi Anda Cuda keluar dari memori--dataset_name -Pilih antara IWSLT dan WMT14 (WMT14 tidak disarankan sampai saya menambahkan dukungan multi-GPU)--language_direction -Pilih antara E2G dan G2E Jadi contoh jalankan (dari konsol) akan terlihat seperti ini:
python training_script.py --batch_size 1500 --dataset_name IWSLT --language_direction G2E
Kode ini dikomentari dengan baik sehingga Anda dapat (semoga) memahami bagaimana pelatihan itu sendiri bekerja.
Skrip akan:
models/checkpoints/models/binaries/data/ )runs/ , cukup jalankan tensorboard --logdir=runs dari anaconda AndaCatatan: Pemuatan data lambat dalam teks obor, dan jadi saya telah menerapkan pembungkus khusus yang menambahkan mekanisme caching dan membuat segalanya ~ 30x lebih cepat! (Ini akan lambat saat Anda menjalankan barang)
Bagian kedua adalah semua tentang bermain dengan model dan melihat bagaimana mereka menerjemahkan!
Untuk mendapatkan beberapa terjemahan, mulailah translation_script.py , ada beberapa pengaturan yang ingin Anda atur:
--source_sentence -tergantung pada model yang Anda tentukan ini harus menjadi kalimat Inggris/Jerman--model_name -Salah satu nama model pretrained: iwslt_e2g , iwslt_g2e atau model Anda (*)--dataset_name -tetap sinkron dengan model, IWSLT jika model dilatih di IWSLT--language_direction -tetap sinkron, E2G jika model dilatih untuk diterjemahkan dari bahasa Inggris ke Jerman (*) Catatan: Setelah Anda melatih model Anda, itu akan dibuang ke models/binaries lihat apa namanya dan tentukan melalui parameter --model_name jika Anda ingin bermain dengannya untuk tujuan terjemahan. Jika Anda menentukan beberapa model pretrained, mereka akan secara otomatis diunduh saat pertama kali Anda menjalankan skrip terjemahan.
Saya akan menautkan tautan model pretrained di sini juga: bahasa Inggris ke Jerman dan Jerman ke Inggris.
Itu saja Anda juga dapat memvisualisasikan perhatian memeriksa bagian ini. untuk info lebih lanjut.
Saya melacak 3 kurva saat pelatihan:
Bleu adalah metrik berbasis N-gram untuk secara kuantitatif mengevaluasi kualitas model terjemahan mesin.
Saya menggunakan metrik bleu-4 yang disediakan oleh modul python nltk yang mengagumkan.
Hasil saat ini, model dilatih untuk 20 zaman (de singkatan dari Deutch yaitu Jerman dalam bahasa Jerman?):
| Model | Skor Bleu | Dataset |
|---|---|---|
| Transformator Baseline (END) | 27.8 | IWSLT Val |
| Transformator Baseline (De-en) | 33.2 | IWSLT Val |
| Transformator Baseline (END) | X | WMT-14 Val |
| Transformator Baseline (De-en) | X | WMT-14 Val |
Saya mendapatkan ini menggunakan decoding serakah jadi ini adalah perkiraan pesimistis, saya akan segera menambahkan decoding balok.
Catatan penting: Inisialisasi sangat penting bagi transformator! Awalnya saya berpikir bahwa implementasi lain menggunakan inisialisasi Xavier sekali lagi adalah salah satu heuristik sewenang -wenang dan bahwa init default Pytorch akan melakukannya - saya salah:
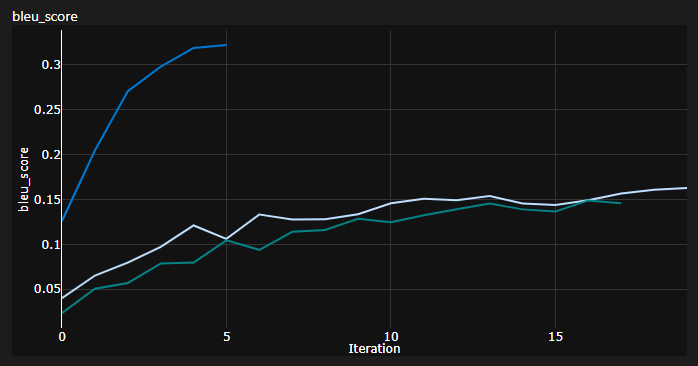
Anda dapat melihat di sini 3 berjalan, 2 yang lebih rendah menggunakan inisialisasi default Pytorch (satu digunakan mean untuk kehilangan divergensi KL dan yang lebih baik menggunakan batchmean ), sedangkan yang atas menggunakan inisialisasi seragam Xavier !
Ide: Anda berpotensi juga secara berkala membuang terjemahan untuk batch referensi kalimat sumber.
Itu akan memberi Anda beberapa wawasan kualitatif tentang bagaimana transformatornya lakukan, meskipun saya tidak melakukan itu.
Hal yang serupa dilakukan ketika Anda mengalami kesulitan mengevaluasi secara kuantitatif model Anda seperti di bidang GANS dan NST.
Plot di atas adalah cuplikan dari Azure ML Run saya tetapi ketika saya menjalankan barang secara lokal saya menggunakan Tensorboard.
Cukup jalankan tensorboard --logdir=runs dari konsol Anaconda Anda dan Anda dapat melacak metrik Anda selama pelatihan.
Anda dapat menggunakan translation_script.py dan mengatur --visualize_attention untuk benar untuk juga memahami apa yang model Anda "memperhatikan" dalam kalimat sumber dan target.
Berikut adalah perhatian yang saya dapatkan untuk kalimat input Ich bin ein guter Mensch, denke ich.
Ini milik lapisan 6 dari encoder. Anda dapat melihat semua 8 kepala perhatian multi-head.

Dan yang ini milik Decoder Layer 6 dari modul Decoder MHA (Multi-Head Attention).
Anda dapat melihat pola segitiga yang menarik yang berasal dari fakta bahwa token target tidak dapat melihat ke depan!

Jenis modul MHA ke -3 adalah sumber yang menghadiri satu dan terlihat mirip dengan plot yang Anda lihat untuk encoder.
Jangan ragu untuk bermain dengannya dengan kecepatan Anda sendiri!
Catatan: Jelas ada beberapa masalah bias dengan model ini tetapi saya tidak akan masuk ke analisis itu di sini
Anda benar-benar membutuhkan perangkat keras yang layak jika Anda ingin melatih transformator pada dataset WMT-14 .
Penulis mengambil:
Jika perhitungan saya benar yang berjumlah ~ 19 zaman (100 ribu langkah, setiap langkah memiliki ~ 25000 token dan WMT-14 memiliki token ~ 130m SRC/TRG) untuk baseline dan 3x yang untuk yang besar (langkah 300k).
Di sisi lain, jauh lebih layak untuk melatih model pada dataset IWSLT . Butuh:
Saya bisa mendorong K80 ke 3500+ token/batch tetapi memiliki beberapa CUDA keluar dari masalah memori.
Akhirnya ada beberapa lagi Todos yang mudah -mudahan akan segera saya tambahkan:
Repo sudah memiliki semua yang dibutuhkan, ini hanya poin bonus. Saya telah menguji semuanya dari pengaturan lingkungan, hingga unduhan model otomatis, dll.
Jika Anda mengalami kesulitan memahami kode, saya melakukan gambaran mendalam tentang makalah ini dalam video ini:
Saya memiliki beberapa video lagi yang selanjutnya dapat membantu Anda memahami Transformers:
Saya menemukan sumber daya ini bermanfaat (saat mengembangkan yang ini):
Saya menemukan beberapa inspirasi untuk desain model dalam transformator beranotasi tetapi saya merasa sulit untuk dipahami, dan ada beberapa bug. Itu terutama ditulis dengan mempertimbangkan peneliti. Semoga repo ini membuka pemahaman Transformers kepada rakyat biasa juga! ?
Jika Anda menemukan kode ini bermanfaat, silakan kutip yang berikut:
@misc{Gordić2020PyTorchOriginalTransformer,
author = {Gordić, Aleksa},
title = {pytorch-original-transformer},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/gordicaleksa/pytorch-original-transformer}},
}
Jika Anda ingin memiliki lagi konten terkait AI dalam hidup Anda ?, Pertimbangkan:


