doctr
v0.10.0
通过TensorFlow 2&Pytorch提供的任何人都可以无缝且可访问光学角色识别
您可以从这个存储库中期望的是:

端到端的OCR是在Doctr中使用两阶段方法实现的:文本检测(本地化单词),然后使用文本识别(识别单词中的所有字符)。因此,您可以从可用实现列表中选择用于文本检测的体系结构,也可以选择用于文本识别的架构。
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )可以从PDF或图像解释文档:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])让我们使用默认预定的模型进行示例:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )如果您在包含旋转页面或具有多个盒子方向的页面的文档上使用Doctr,则有多种选择来处理:
如果您仅使用带直词的直档页面(水平,相同的读取方向),请考虑将assume_straight_boxes=True传递给ocr_predictor。它将直接适合您的页面上的直箱,然后返回直箱,这使其成为最快的选项。
如果您希望预测器输出直框(无论您的页面的方向如何,最终的本地化都将转换为直框),则需要在预测器中传递export_as_straight_boxes=True 。否则,如果assume_straight_pages=False ,它将返回旋转的边界框(可能为0°角)。
如果两个选项都设置为false,则预测器将始终适合并返回旋转的框。
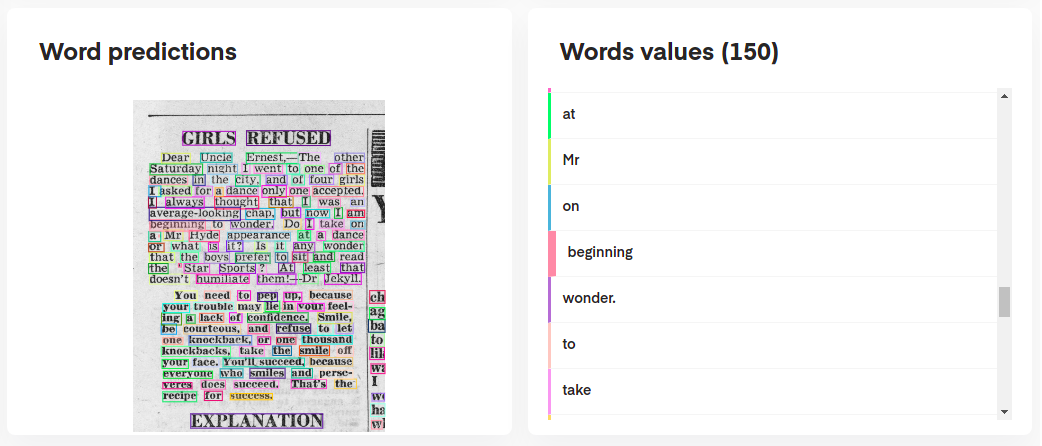
为了解释模型的预测,您可以按以下方式进行交互可视化它们:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
甚至从其预测中重建原始文档:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
ocr_predictor返回带有嵌套结构的Document对象(带有Page , Block , Line , Word , Artefact )。要更好地了解我们的文档模型,请检查我们的文档:
您还可以将它们导出为嵌套的dict,更适合JSON格式:
json_output = result . export ()与OCR相比,KIE预测变量是一个更灵活的预测指标,因为您的检测模型可以检测文档中的多个类。例如,您可以拥有一个检测模型来检测文档中的日期和地址。
KIE预测指标使使用识别模型多个类的检测器可以使用探测器,并可以为您设置整个管道。
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )每个页面的Kie预测结果以字典格式为单词格式,每个键代表一个类名称,其值是该类的预测。

需要安装Python 3.10(或更高)和PIP。
然后,您可以使用PYPI安装包装的最新版本,如下所示:
pip install python-doctr
配x 请注意,基本安装不是独立的,因为它没有提供深度学习框架,这是包装运行所必需的。
我们试图将特定于框架的依赖项保持在最低限度。您可以按以下方式安装特定于框架的构建:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "对于带有M1芯片的MacBook,您将需要一些其他软件包或特定版本:
另外,您可以从源安装它,这将需要您安装git。首先克隆项目存储库:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.同样,如果您希望避免丢失依赖关系的风险,则可以安装TensorFlow或Pytorch构建:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]学分应得的:该存储库正在实施发表的研究论文中的架构。
完整的软件包文档可在此处提供详细规格。
为您提供最小的演示应用程序,以便您使用我们的端到端OCR模型!

礼貌?拥抱脸?一探究竟
如果您希望在本地使用它,则需要额外的依赖性(简化)。
pip install -r demo/tf-requirements.txt然后在默认浏览器中运行您的应用程序:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txt然后在默认浏览器中运行您的应用程序:
USE_TORCH=1 streamlit run demo/app.py您不想让您的演示实际运行Python,而是希望在Web浏览器中运行所有内容吗?查看我们的TensorFlow.js演示以开始!
我们提供Docker容器支持,以易于测试和部署。这是可用的码头标签。
Doctr docker图像已经准备就绪,并且基于CUDA 12.2 。确保您的主机至少为12.2 ,否则火炬或Tensorflow将无法初始化GPU。请确保将Docker配置为使用GPU。
要验证和配置Docker的GPU支持,请遵循NVIDIA容器工具包安装指南中提供的说明。
一旦将Docker配置为使用GPU,您就可以以GPU支持运行Doctr Docker容器:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bashDoctr的Docker映像遵循特定的标签命名: <deps>-py<python_version>-<doctr_version|YYYY-MM> 。这是标签结构的分解:
<deps> : tf , torch , tf-viz-html-contrib或torch-viz-html-contrib 。<python_version> : 3.9.18或3.11.8 3.10.13<doctr_version> :标签> = v0.11.0<YYYY-MM> :例如2014-10以下是不同图像标签的示例:
| 标签 | 描述 |
|---|---|
tf-py3.10.13-v0.11.0 | TensorFlow版本3.10.13带有Doctr v0.11.0 。 |
torch-viz-html-contrib-py3.11.8-2024-10 | 具有额外依赖性的火炬版本3.11.8来自2024-10 main上的最新提交。 |
torch-py3.11.8-2024-10 | Pytorch版本3.11.8来自2024-10 main的最新提交。 |
您还可以在计算机上本地构建Doctr Docker图像。
docker build -t doctr .您可以使用构建参数指定自定义Python版本和Doctr版本。例如,要构建使用TensorFlow,Python版本3.9.10和Doctr版本v0.7.0构建Doctr映像,请运行以下命令:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .提供了一个示例脚本,用于简单的文档分析PDF或图像文件:
python scripts/analyze.py path/to/your/doc.pdf所有脚本参数均可使用python scripts/analyze.py --help
希望将学说集成到您的API中?这是一个模板,可让您使用出色的FastAPI框架开始使用完全工作的API。
运行API模板需要特定依赖项,您可以按以下方式安装:
cd api/
pip install poetry
make lock
pip install -r requirements.txt您现在可以在本地运行API:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:app另外,如果您愿意使用:
PORT=8002 docker-compose up -d --build您的API现在应该在端口8002上本地运行。访问您的自动构建文档,请访问http:// localhost:8002/redoc,并享受您的三个功能路线(“/dintection”,“/nesutition”,“/nesutition”,“/ofcr”,“/ocr”,“,”,“/kie”)。这是Python的一个示例,可以将请求发送到OCR路线:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())在寻找更多关于Doctr功能的插图吗?您可能需要查看旨在为您提供更广泛概述的Jupyter笔记本电脑。
如果您想引用此项目,请随时使用此Bibtex参考:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}如果您向下滚动到本节,您很可能会感谢开源。您是否想扩展我们支持角色的范围?还是提交论文实施?还是以其他任何方式做出贡献?
您很幸运,我们编写了一个简短的指南(参见CONTRIBUTING )供您轻松完成!
根据Apache 2.0许可分发。有关更多信息,请参见LICENSE 。


