doctr
v0.10.0
Pengenalan karakter optik dibuat mulus & dapat diakses oleh siapa pun, ditenagai oleh TensorFlow 2 & Pytorch
Apa yang dapat Anda harapkan dari repositori ini:

OCR end-to-end dicapai dalam doktrs menggunakan pendekatan dua tahap: deteksi teks (melokalisasi kata), lalu pengenalan teks (identifikasi semua karakter dalam kata). Dengan demikian, Anda dapat memilih arsitektur yang digunakan untuk deteksi teks, dan yang untuk pengenalan teks dari daftar implementasi yang tersedia.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Dokumen dapat ditafsirkan dari PDF atau gambar:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Mari kita gunakan model pretrained default sebagai contoh:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Jika Anda menggunakan Doctr pada dokumen yang menyertakan halaman yang diputar, atau halaman dengan beberapa orientasi kotak, Anda memiliki beberapa opsi untuk menanganinya:
Jika Anda hanya menggunakan halaman dokumen lurus dengan kata -kata lurus (horizontal, arah bacaan yang sama), pertimbangkan lewat assume_straight_boxes=True untuk OCR_Predictor. Ini akan langsung sesuai dengan kotak lurus di halaman Anda dan mengembalikan kotak lurus, yang menjadikannya opsi tercepat.
Jika Anda ingin prediktor mengeluarkan kotak lurus (tidak peduli orientasi halaman Anda, lokalisasi akhir akan dikonversi ke kotak lurus), Anda perlu lulus export_as_straight_boxes=True dalam prediktor. Kalau tidak, jika assume_straight_pages=False , itu akan mengembalikan kotak pembatas yang diputar (berpotensi dengan sudut 0 °).
Jika kedua opsi diatur ke false, prediktor akan selalu sesuai dan mengembalikan kotak yang diputar.
Untuk menafsirkan prediksi model Anda, Anda dapat memvisualisasikannya secara interaktif sebagai berikut:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
Atau bahkan membangun kembali dokumen asli dari prediksi:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
ocr_predictor mengembalikan objek Document dengan struktur bersarang (dengan Page , Block , Line , Word , Artefact ). Untuk mendapatkan pemahaman yang lebih baik tentang model dokumen kami, periksa dokumentasi kami:
Anda juga dapat mengekspornya sebagai dikte bersarang, lebih sesuai untuk format JSON:
json_output = result . export ()Prediktor KIE adalah prediktor yang lebih fleksibel dibandingkan dengan OCR karena model deteksi Anda dapat mendeteksi beberapa kelas dalam dokumen. Misalnya, Anda dapat memiliki model deteksi untuk mendeteksi hanya tanggal dan alamat dalam dokumen.
Prediktor KIE memungkinkan untuk menggunakan detektor dengan beberapa kelas dengan model pengakuan dan untuk memiliki seluruh pipa yang sudah diatur untuk Anda.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Hasil prediktor KIE per halaman berada dalam format kamus dengan masing -masing kunci yang mewakili nama kelas dan nilainya adalah prediksi untuk kelas itu.

Python 3.10 (atau lebih tinggi) dan PIP diharuskan menginstal Doctr.
Anda kemudian dapat menginstal rilis terbaru paket menggunakan PYPI sebagai berikut:
pip install python-doctr
️ Harap dicatat bahwa instalasi dasar tidak mandiri, karena tidak memberikan kerangka kerja pembelajaran yang mendalam, yang diperlukan agar paket dijalankan.
Kami mencoba menjaga ketergantungan spesifik kerangka kerja seminimal mungkin. Anda dapat menginstal build khusus kerangka kerja sebagai berikut:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Untuk MacBooks dengan M1 Chip, Anda akan memerlukan beberapa paket tambahan atau versi tertentu:
Atau, Anda dapat menginstalnya dari sumber, yang mengharuskan Anda menginstal git. Klon pertama Repositori Proyek:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Sekali lagi, jika Anda lebih suka menghindari risiko kehilangan dependensi, Anda dapat memasang TensorFlow atau Pytorch Build:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Kredit di mana itu jatuh tempo: Repositori ini menerapkan, antara lain, arsitektur dari makalah penelitian yang diterbitkan.
Dokumentasi paket lengkap tersedia di sini untuk spesifikasi terperinci.
Aplikasi demo minimal disediakan bagi Anda untuk bermain dengan model OCR ujung ke ujung kami!

Milik? Face memeluk ?, Doctr sekarang memiliki versi yang sepenuhnya digunakan yang tersedia di spasi! Lihatlah
Jika Anda lebih suka menggunakannya secara lokal, ada ketergantungan tambahan (streamLit) yang diperlukan.
pip install -r demo/tf-requirements.txtKemudian jalankan aplikasi Anda di browser default Anda dengan:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtKemudian jalankan aplikasi Anda di browser default Anda dengan:
USE_TORCH=1 streamlit run demo/app.pyDaripada meminta demo Anda benar -benar menjalankan Python, Anda lebih suka menjalankan semuanya di browser web Anda? Lihat demo TensorFlow.js kami untuk memulai!
Kami menawarkan dukungan wadah Docker untuk pengujian dan penyebaran yang mudah. Berikut adalah tag Docker yang tersedia ..
Gambar Doctrer Docker siap GPU dan berdasarkan CUDA 12.2 . Pastikan host Anda setidaknya 12.2 , jika tidak, TENCH atau TENSORTFLOW tidak akan dapat menginisialisasi GPU. Harap pastikan bahwa Docker dikonfigurasi untuk menggunakan GPU Anda.
Untuk memverifikasi dan mengonfigurasi dukungan GPU untuk Docker, silakan ikuti instruksi yang disediakan dalam Panduan Instalasi Toolkit Kontainer NVIDIA.
Setelah Docker dikonfigurasi untuk menggunakan GPU, Anda dapat menjalankan wadah Doctrer Docker dengan dukungan GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash Gambar Docker untuk doktr ikuti nomenklatur tag tertentu: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Berikut ini rincian struktur tag:
<deps> : tf , torch , tf-viz-html-contrib atau torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 atau 3.11.8 .<doctr_version> : tag> = v0.11.0<YYYY-MM> : misalnya 2014-10Berikut adalah contoh dari berbagai tag gambar:
| Menandai | Keterangan |
|---|---|
tf-py3.10.13-v0.11.0 | TensorFlow Versi 3.10.13 dengan Doctr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Obor dengan ketergantungan tambahan versi 3.11.8 dari komit terbaru di main pada 2024-10 . |
torch-py3.11.8-2024-10 | PyTorch Versi 3.11.8 dari komit terbaru di main di 2024-10 . |
Anda juga dapat membangun gambar Doctrer Docker secara lokal di komputer Anda.
docker build -t doctr . Anda dapat menentukan versi Python dan versi doktrik khusus menggunakan argumen build. Misalnya, untuk membangun gambar doktr dengan TensorFlow, Python Versi 3.9.10 , dan Versi Doctr v0.7.0 , jalankan perintah berikut:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Contoh skrip disediakan untuk analisis dokumentasi sederhana dari PDF atau file gambar:
python scripts/analyze.py path/to/your/doc.pdf Semua argumen skrip dapat diperiksa menggunakan python scripts/analyze.py --help
Ingin mengintegrasikan doktr ke dalam API Anda? Berikut ini adalah templat untuk memulai dengan API yang bekerja sepenuhnya menggunakan kerangka FASTAPI yang indah.
Dependensi spesifik diperlukan untuk menjalankan templat API, yang dapat Anda instal sebagai berikut:
cd api/
pip install poetry
make lock
pip install -r requirements.txtAnda sekarang dapat menjalankan API Anda secara lokal:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appAtau, Anda dapat menjalankan server yang sama pada wadah Docker jika Anda lebih suka menggunakan:
PORT=8002 docker-compose up -d --buildAPI Anda sekarang harus berjalan secara lokal di port 8002 Anda. Mengakses dokumentasi yang dibuat secara otomatis di http: // localhost: 8002/redoc dan nikmati tiga rute fungsional Anda ("/deteksi", "/pengakuan", "/occ", "/kie"). Berikut adalah contoh dengan Python untuk mengirim permintaan ke rute OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
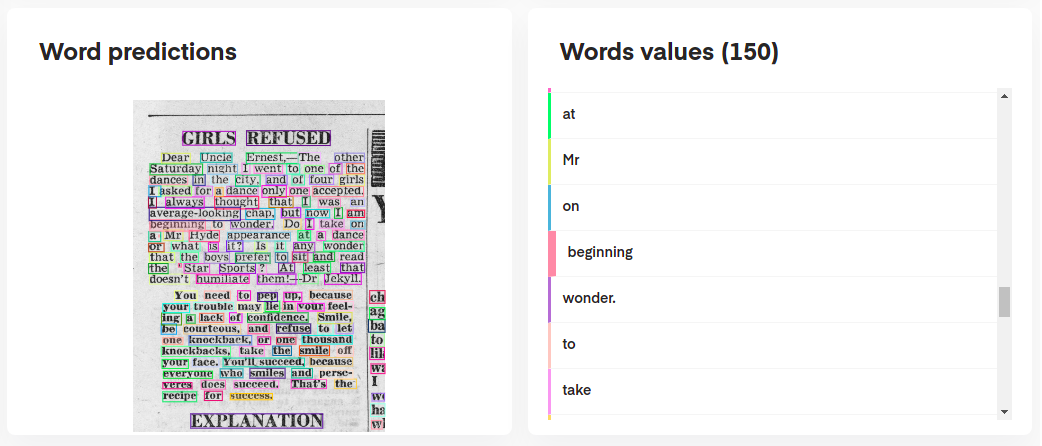
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())Mencari lebih banyak ilustrasi fitur doktr? Anda mungkin ingin memeriksa buku catatan Jupyter yang dirancang untuk memberi Anda gambaran yang lebih luas.
Jika Anda ingin mengutip proyek ini, jangan ragu untuk menggunakan referensi Bibtex ini:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Jika Anda menggulir ke bagian ini, kemungkinan besar Anda menghargai open source. Apakah Anda merasa ingin memperluas jangkauan karakter yang didukung kami? Atau mungkin mengirimkan implementasi kertas? Atau berkontribusi dengan cara lain?
Anda beruntung, kami menyusun panduan pendek (lih. CONTRIBUTING ) untuk Anda lakukan dengan mudah!
Didistribusikan di bawah lisensi Apache 2.0. Lihat LICENSE untuk informasi lebih lanjut.


