doctr
v0.10.0
Reconhecimento óptico de caracteres tornado sem costura e acessível a qualquer pessoa, alimentada por Tensorflow 2 & pytorch
O que você pode esperar deste repositório:

O OCR de ponta a ponta é alcançado em Doutr, usando uma abordagem de dois estágios: detecção de texto (localização de palavras) e, em seguida, o reconhecimento de texto (identifique todos os caracteres da palavra). Como tal, você pode selecionar a arquitetura usada para detecção de texto e o reconhecimento de texto da lista de implementações disponíveis.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Os documentos podem ser interpretados a partir de PDF ou imagens:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Vamos usar o modelo pré -terenciado padrão para um exemplo:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Se você usar o Doutring em documentos que incluem páginas giradas ou páginas com várias orientações de caixa, você tem várias opções para lidar com isso:
Se você usar apenas páginas diretas de documentos com palavras retas (horizontal, mesma direção de leitura), considere passar assume_straight_boxes=True ao OCR_Predictor. Ele caberá diretamente caixas retas na sua página e retornará caixas retas, o que a torna a opção mais rápida.
Se você deseja que o preditor de saída de caixas retas (independentemente da orientação de suas páginas, as localizações finais serão convertidas em caixas retas), você precisa passar por export_as_straight_boxes=True no preditor. Caso contrário, se assume_straight_pages=False , ele retornará caixas delimitadoras giradas (potencialmente com um ângulo de 0 °).
Se ambas as opções estiverem definidas como falsas, o preditor sempre se encaixará e retornará caixas giradas.
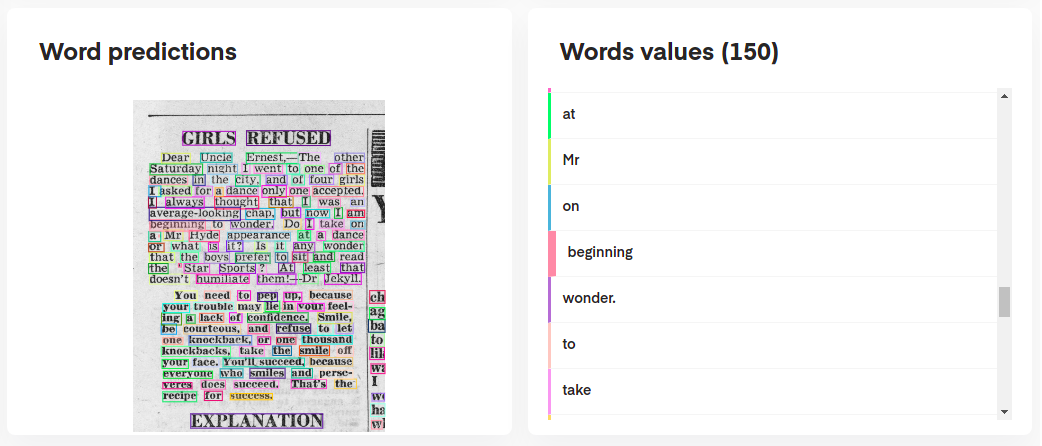
Para interpretar as previsões do seu modelo, você pode visualizá -las interativamente da seguinte maneira:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
Ou até reconstruir o documento original de suas previsões:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
O ocr_predictor retorna um objeto Document com uma estrutura aninhada (com Page , Block , Line , Word , Artefact ). Para entender melhor nosso modelo de documentos, verifique nossa documentação:
Você também pode exportá -los como um ditado aninhado, mais apropriado para o formato JSON:
json_output = result . export ()O KIE Predictor é um preditor mais flexível em comparação com o OCR, pois seu modelo de detecção pode detectar várias classes em um documento. Por exemplo, você pode ter um modelo de detecção para detectar apenas datas e endereços em um documento.
O KIE Predictor possibilita o uso do detector com várias classes com um modelo de reconhecimento e ter todo o pipeline já configurado para você.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Os resultados do Kie Predictor por página estão em um formato de dicionário com cada tecla representando um nome de classe e seu valor são as previsões para essa classe.

Python 3.10 (ou superior) e PIP são necessários para instalar o doutr.
Você pode instalar a versão mais recente do pacote usando o Pypi da seguinte maneira:
pip install python-doctr
️ Observe que a instalação básica não é independente, pois não fornece uma estrutura de aprendizado profundo, necessária para que o pacote seja executado.
Tentamos manter as dependências específicas da estrutura ao mínimo. Você pode instalar construções específicas da estrutura da estrutura:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Para MacBooks com chip M1, você precisará de alguns pacotes adicionais ou versões específicas:
Como alternativa, você pode instalá -lo da fonte, que exigirá que você instale o Git. Primeiro clone o repositório do projeto:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Novamente, se você preferir evitar o risco de falta de dependências, pode instalar o Tensorflow ou a compilação Pytorch:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Créditos onde é devido: este repositório está implementando, entre outros, arquiteturas de trabalhos de pesquisa publicados.
A documentação completa do pacote está disponível aqui para especificações detalhadas.
Um aplicativo de demonstração mínimo é fornecido para você brincar com nossos modelos de OCR de ponta a ponta!

Cortesia de? Abraçando o rosto?, Doctr agora tem uma versão totalmente implantada disponível em espaços! Confira
Se você preferir usá -lo localmente, existe uma dependência extra (simplit) necessária.
pip install -r demo/tf-requirements.txtEm seguida, execute seu aplicativo no seu navegador padrão com:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtEm seguida, execute seu aplicativo no seu navegador padrão com:
USE_TORCH=1 streamlit run demo/app.pyEm vez de ter sua demonstração realmente executando o Python, você prefere executar tudo no seu navegador da web? Confira nossa demonstração do tensorflow.js para começar!
Oferecemos suporte ao contêiner do Docker para facilitar testes e implantação. Aqui estão as tags de docker disponíveis ..
As imagens do Doctr Docker estão prontas para GPU e baseadas no CUDA 12.2 . Verifique se o seu host tem pelo menos 12.2 , caso contrário, a tocha ou o TensorFlow não poderá inicializar a GPU. Certifique -se de que o Docker esteja configurado para usar sua GPU.
Para verificar e configurar o suporte à GPU para o Docker, siga as instruções fornecidas no guia de instalação do kit de ferramentas de contêiner NVIDIA.
Depois que o Docker estiver configurado para usar as GPUs, você pode executar contêineres Doctr Docker com suporte à GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash As imagens do Docker para Doutr seguem uma nomenclatura de tag específica: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Aqui está um detalhamento da estrutura de tags:
<deps> : tf , torch , tf-viz-html-contrib ou torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 ou 3.11.8 .<doctr_version> : uma tag> = v0.11.0<YYYY-MM> : por exemplo 2014-10Aqui estão exemplos de diferentes tags de imagem:
| Marcação | Descrição |
|---|---|
tf-py3.10.13-v0.11.0 | Tensorflow versão 3.10.13 com Doutr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Torda com dependências extras versão 3.11.8 da última confirmação no main em 2024-10 . |
torch-py3.11.8-2024-10 | Pytorch versão 3.11.8 da última confirmação em main em 2024-10 . |
Você também pode criar imagens do Doctr Docker localmente no seu computador.
docker build -t doctr . Você pode especificar versões Python personalizadas e versões de doutração usando argumentos de construção. Por exemplo, para construir uma imagem de doutral com tensorflow, python versão 3.9.10 e doutring versão v0.7.0 , execute o seguinte comando:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Um script de exemplo é fornecido para uma análise simples de documentação de um arquivo de PDF ou imagem:
python scripts/analyze.py path/to/your/doc.pdf Todos os argumentos de script podem ser verificados usando python scripts/analyze.py --help
Procurando integrar a doutrina à sua API? Aqui está um modelo para você começar com uma API totalmente funcionando usando a maravilhosa estrutura FASTAPI.
Dependências específicas são necessárias para executar o modelo da API, que você pode instalar da seguinte maneira:
cd api/
pip install poetry
make lock
pip install -r requirements.txtAgora você pode executar sua API localmente:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appComo alternativa, você pode executar o mesmo servidor em um contêiner do Docker, se preferir usar:
PORT=8002 docker-compose up -d --buildSua API agora deve estar em execução localmente na sua porta 8002. Acesse sua documentação automaticamente construída em http: // localhost: 8002/redoc e aproveite suas três rotas funcionais ("/detecção", "/reconhecimento", "/ocr", "/kie"). Aqui está um exemplo com Python para enviar uma solicitação para a rota OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())Procurando mais ilustrações de recursos de Doutr? Você pode verificar os notebooks Jupyter projetados para fornecer uma visão geral mais ampla.
Se você deseja citar este projeto, sinta -se à vontade para usar esta referência BibTex:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Se você rolou para esta seção, provavelmente apreciará o código aberto. Você sente vontade de estender o alcance de nossos personagens apoiados? Ou talvez enviar uma implementação em papel? Ou contribuindo de alguma outra maneira?
Você está com sorte, compilamos um guia curto (cf. CONTRIBUTING ) para você fazê -lo facilmente!
Distribuído sob a licença Apache 2.0. Consulte LICENSE para obter mais informações.


