doctr
v0.10.0
การจดจำตัวละครแบบออพติคอลทำให้ทุกคนสามารถเข้าถึงได้และสามารถเข้าถึงได้โดย TensorFlow 2 & Pytorch
สิ่งที่คุณคาดหวังจากที่เก็บนี้:

OCR แบบ end-to-end ทำได้ใน DOCTR โดยใช้วิธีการสองขั้นตอน: การตรวจจับข้อความ (คำภาษาท้องถิ่น) จากนั้นการจดจำข้อความ (ระบุอักขระทั้งหมดในคำ) ดังนั้นคุณสามารถเลือกสถาปัตยกรรมที่ใช้สำหรับการตรวจจับข้อความและหนึ่งสำหรับการจดจำข้อความจากรายการการใช้งานที่มีอยู่
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )เอกสารสามารถตีความได้จาก PDF หรือรูปภาพ:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])ลองใช้โมเดลที่ได้รับการฝึกฝนเริ่มต้นสำหรับตัวอย่าง:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )หากคุณใช้ DOCTR บนเอกสารที่มีหน้าหมุนหรือหน้าเว็บที่มีการวางแนวหลายกล่องคุณมีตัวเลือกหลายตัวเลือกในการจัดการ:
หากคุณใช้หน้าเอกสารตรงที่มีคำตรง (แนวนอนการอ่านทิศทางเดียวกัน) ให้พิจารณาผ่าน assume_straight_boxes=True กับ OCR_PREDICTOR มันจะพอดีกับกล่องตรงบนหน้าของคุณโดยตรงและส่งคืนกล่องตรงซึ่งทำให้เป็นตัวเลือกที่เร็วที่สุด
หากคุณต้องการให้ตัวทำนายสามารถส่งออกกล่องตรง (ไม่ว่าการปฐมนิเทศของหน้าเว็บของคุณจะมีการเปลี่ยนตำแหน่งสุดท้ายเป็นกล่องตรง) คุณจะต้องส่ง export_as_straight_boxes=True ในตัวทำนาย มิฉะนั้นหากสมมติว่า assume_straight_pages=False มันจะส่งคืนกล่องขอบเขตหมุน (อาจมีมุม 0 °)
หากตัวเลือกทั้งสองถูกตั้งค่าเป็นเท็จตัวทำนายจะพอดีและส่งคืนกล่องหมุน
ในการตีความการคาดการณ์ของแบบจำลองของคุณคุณสามารถเห็นภาพพวกเขาแบบโต้ตอบได้ดังนี้:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
หรือแม้แต่สร้างเอกสารต้นฉบับใหม่จากการคาดการณ์:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
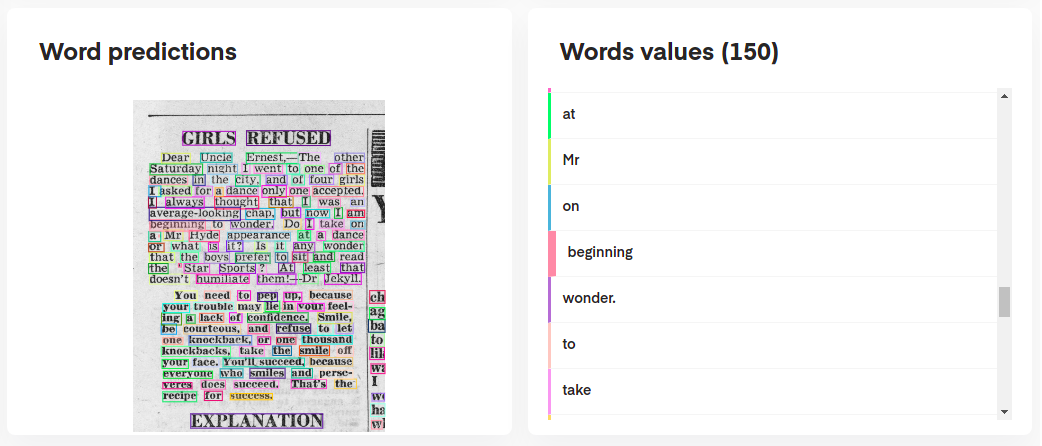
ocr_predictor ส่งคืนวัตถุ Document ด้วยโครงสร้างที่ซ้อนกัน (พร้อม Page , Block , Line , Word , Artefact ) เพื่อให้เข้าใจโมเดลเอกสารของเราได้ดีขึ้นให้ตรวจสอบเอกสารของเรา:
นอกจากนี้คุณยังสามารถส่งออกเป็น dict ที่ซ้อนกันเหมาะสมกว่าสำหรับรูปแบบ JSON:
json_output = result . export ()ตัวทำนาย KIE เป็นตัวทำนายที่ยืดหยุ่นมากขึ้นเมื่อเทียบกับ OCR เนื่องจากแบบจำลองการตรวจจับของคุณสามารถตรวจจับหลายคลาสในเอกสาร ตัวอย่างเช่นคุณสามารถมีรูปแบบการตรวจจับเพื่อตรวจจับเพียงวันที่และที่อยู่ในเอกสาร
ตัวทำนาย KIE ทำให้สามารถใช้เครื่องตรวจจับกับหลายคลาสที่มีรูปแบบการรับรู้และมีการตั้งค่าไปป์ไลน์ทั้งหมดสำหรับคุณแล้ว
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )ผลการทำนาย KIE ต่อหน้าอยู่ในรูปแบบพจนานุกรมโดยแต่ละคีย์แสดงชื่อคลาสและค่าของมันคือการคาดการณ์สำหรับคลาสนั้น

Python 3.10 (หรือสูงกว่า) และ PIP จำเป็นต้องติดตั้ง DOCTR
จากนั้นคุณสามารถติดตั้งแพ็คเกจล่าสุดโดยใช้ PYPI ดังนี้:
pip install python-doctr
โปรดทราบว่าการติดตั้งขั้นพื้นฐานไม่ใช่แบบสแตนด์อโลนเนื่องจากไม่ได้ให้กรอบการเรียนรู้อย่างลึกซึ้งซึ่งจำเป็นสำหรับแพ็คเกจที่จะเรียกใช้
เราพยายามที่จะรักษาเฟรมเวิร์กเฉพาะการพึ่งพาให้น้อยที่สุด คุณสามารถติดตั้งการสร้างเฉพาะเฟรมเวิร์กดังต่อไปนี้:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "สำหรับ MacBooks ที่มีชิป M1 คุณจะต้องมีแพ็คเกจเพิ่มเติมหรือเวอร์ชันเฉพาะ:
หรือคุณสามารถติดตั้งได้จากแหล่งที่มาซึ่งจะทำให้คุณต้องติดตั้ง Git โคลนครั้งแรกที่เก็บโครงการ:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.อีกครั้งหากคุณต้องการหลีกเลี่ยงความเสี่ยงของการพึ่งพาที่หายไปคุณสามารถติดตั้ง tensorflow หรือ pytorch build:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]เครดิตที่ครบกำหนด: พื้นที่เก็บข้อมูลนี้กำลังดำเนินการในหมู่คนอื่น ๆ สถาปัตยกรรมจากงานวิจัยที่ตีพิมพ์
เอกสารประกอบแพ็คเกจเต็มรูปแบบมีอยู่ที่นี่สำหรับข้อมูลจำเพาะโดยละเอียด
มีแอพสาธิตขั้นต่ำให้คุณเล่นกับรุ่น OCR แบบ end-to-end ของเรา!

ได้รับความอนุเคราะห์? Hugging Face? DOCTR ตอนนี้มีเวอร์ชันที่มีการปรับใช้อย่างสมบูรณ์ในพื้นที่! ตรวจสอบ
หากคุณต้องการใช้ในเครื่องมีการพึ่งพาพิเศษ (streamlit) ที่จำเป็น
pip install -r demo/tf-requirements.txtจากนั้นเรียกใช้แอปของคุณในเบราว์เซอร์เริ่มต้นด้วย:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtจากนั้นเรียกใช้แอปของคุณในเบราว์เซอร์เริ่มต้นด้วย:
USE_TORCH=1 streamlit run demo/app.pyแทนที่จะมีการสาธิตของคุณที่ใช้ Python จริง ๆ แล้วคุณต้องการเรียกใช้ทุกอย่างในเว็บเบราว์เซอร์ของคุณหรือไม่? ตรวจสอบการสาธิต tensorflow.js ของเราเพื่อเริ่มต้น!
เราให้การสนับสนุนคอนเทนเนอร์ Docker สำหรับการทดสอบและการปรับใช้อย่างง่ายดาย นี่คือแท็ก Docker ที่มีอยู่ ..
ภาพ DOCTR DOCKER พร้อม GPU และขึ้นอยู่กับ CUDA 12.2 ตรวจสอบให้แน่ใจว่าโฮสต์ของคุณ อย่างน้อย 12.2 มิฉะนั้นไฟฉายหรือเทนเซอร์โฟลจะไม่สามารถเริ่มต้น GPU ได้ โปรดตรวจสอบให้แน่ใจว่า Docker ได้รับการกำหนดค่าให้ใช้ GPU ของคุณ
ในการตรวจสอบและกำหนดค่าการสนับสนุน GPU สำหรับ Docker โปรดทำตามคำแนะนำที่ให้ไว้ในคู่มือการติดตั้งชุดเครื่องมือคอนเทนเนอร์ NVIDIA
เมื่อ Docker ได้รับการกำหนดค่าให้ใช้ GPU แล้วคุณสามารถเรียกใช้คอนเทนเนอร์ DOCTR Docker ด้วยการสนับสนุน GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash ภาพนักเทียบท่าสำหรับ DOCTR ติดตามการตั้งชื่อแท็กเฉพาะ: <deps>-py<python_version>-<doctr_version|YYYY-MM> นี่คือรายละเอียดของโครงสร้างแท็ก:
<deps> : tf , torch , tf-viz-html-contrib หรือ torch-viz-html-contrib<python_version> : 3.9.18 , 3.10.13 หรือ 3.11.8<doctr_version> : แท็ก> = v0.11.0<YYYY-MM> : เช่น 2014-10นี่คือตัวอย่างของแท็กภาพที่แตกต่างกัน:
| ติดแท็ก | คำอธิบาย |
|---|---|
tf-py3.10.13-v0.11.0 | TensorFlow เวอร์ชัน 3.10.13 พร้อม DOCTR v0.11.0 |
torch-viz-html-contrib-py3.11.8-2024-10 | คบเพลิงที่มีการพึ่งพาพิเศษเวอร์ชัน 3.11.8 จากการกระทำล่าสุดเกี่ยวกับ main ใน 2024-10 |
torch-py3.11.8-2024-10 | Pytorch เวอร์ชัน 3.11.8 จากการกระทำล่าสุดเกี่ยวกับ main ใน 2024-10 |
นอกจากนี้คุณยังสามารถสร้างรูปภาพ Doctr Docker ในคอมพิวเตอร์ของคุณ
docker build -t doctr . คุณสามารถระบุรุ่น Python ที่กำหนดเองและ DOCTR เวอร์ชันโดยใช้อาร์กิวเมนต์บิลด์ ตัวอย่างเช่นในการสร้างภาพ DOCTR ด้วย tensorflow, Python เวอร์ชัน 3.9.10 และ DOCTR เวอร์ชัน v0.7.0 ให้เรียกใช้คำสั่งต่อไปนี้:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .ตัวอย่างสคริปต์มีไว้สำหรับการวิเคราะห์เอกสารอย่างง่าย ๆ ของไฟล์ PDF หรือรูปภาพ:
python scripts/analyze.py path/to/your/doc.pdf สามารถตรวจสอบอาร์กิวเมนต์สคริปต์ทั้งหมดได้โดยใช้ python scripts/analyze.py --help
กำลังมองหาการรวม DOCTR เข้ากับ API ของคุณหรือไม่? นี่คือเทมเพลตเพื่อให้คุณเริ่มต้นด้วย API ที่ทำงานได้อย่างเต็มที่โดยใช้เฟรมเวิร์ก Fastapi ที่ยอดเยี่ยม
การพึ่งพาเฉพาะจะต้องเรียกใช้เทมเพลต API ซึ่งคุณสามารถติดตั้งได้ดังนี้:
cd api/
pip install poetry
make lock
pip install -r requirements.txtตอนนี้คุณสามารถเรียกใช้ API ของคุณในพื้นที่:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appหรือคุณสามารถเรียกใช้เซิร์ฟเวอร์เดียวกันบนคอนเทนเนอร์ Docker ได้หากคุณต้องการใช้:
PORT=8002 docker-compose up -d --buildตอนนี้ API ของคุณควรทำงานในเครื่องในพอร์ต 8002 ของคุณเข้าถึงเอกสารที่สร้างขึ้นโดยอัตโนมัติที่ http: // localhost: 8002/redoc และเพลิดเพลินกับเส้นทางการทำงานทั้งสามของคุณ ("/การตรวจจับ", "/การจดจำ", "/ocr", "/kie") นี่คือตัวอย่างของ Python เพื่อส่งคำขอไปยังเส้นทาง OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())กำลังมองหาภาพประกอบเพิ่มเติมของคุณสมบัติ DOCTR หรือไม่? คุณอาจต้องการตรวจสอบสมุดบันทึก Jupyter ที่ออกแบบมาเพื่อให้ภาพรวมที่กว้างขึ้น
หากคุณต้องการอ้างถึงโครงการนี้อย่าลังเลที่จะใช้การอ้างอิง bibtex นี้:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}หากคุณเลื่อนลงไปที่ส่วนนี้คุณน่าจะชื่นชมโอเพ่นซอร์ส คุณรู้สึกอยากขยายช่วงของตัวละครที่เราสนับสนุนหรือไม่? หรืออาจส่งการใช้งานกระดาษ? หรือมีส่วนร่วมในทางอื่น?
คุณโชคดีเรารวบรวมคู่มือสั้น ๆ (เช่น CONTRIBUTING ) เพื่อให้คุณทำเช่นนั้นได้อย่างง่ายดาย!
แจกจ่ายภายใต้ใบอนุญาต Apache 2.0 ดู LICENSE สำหรับข้อมูลเพิ่มเติม


