doctr
v0.10.0
Оптическое распознавание персонажа сделано бесшовным и доступным для всех, приводящих в действие Tensorflow 2 & Pytorch
Что вы можете ожидать от этого репозитория:

Сводительный OCR достигается в доктроме с использованием двухэтапного подхода: обнаружение текста (локализация слов), затем распознавание текста (идентифицируйте все символы в слове). Таким образом, вы можете выбрать архитектуру, используемую для обнаружения текста, и предназначенную для распознавания текста из списка доступных реализаций.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Документы можно интерпретировать из PDF или изображений:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Давайте используем предварительную модель по умолчанию для примера:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Если вы используете Dectr на документах, которые включают повернутые страницы или страницы с несколькими ориентациями на коробку, у вас есть несколько вариантов для обработки:
Если вы используете прямые страницы документов только с прямыми словами (горизонтальное, одно и то же направление считывания), рассмотрите возможность передачи assume_straight_boxes=True to ocr_predictor. Он будет непосредственно поместить прямые коробки на вашей странице и вернет прямые коробки, что делает его самым быстрым вариантом.
Если вы хотите, чтобы предиктор выводил прямые коробки (независимо от ориентации ваших страниц, окончательные локализации будут преобразованы в прямые коробки), вам необходимо передавать export_as_straight_boxes=True в предикторе. В противном случае, если assume_straight_pages=False , он вернет повернутые ограничивающие ящики (потенциально с углом 0 °).
Если оба параметра установлены на False, предиктор всегда будет подходить и возвращать повернутые коробки.
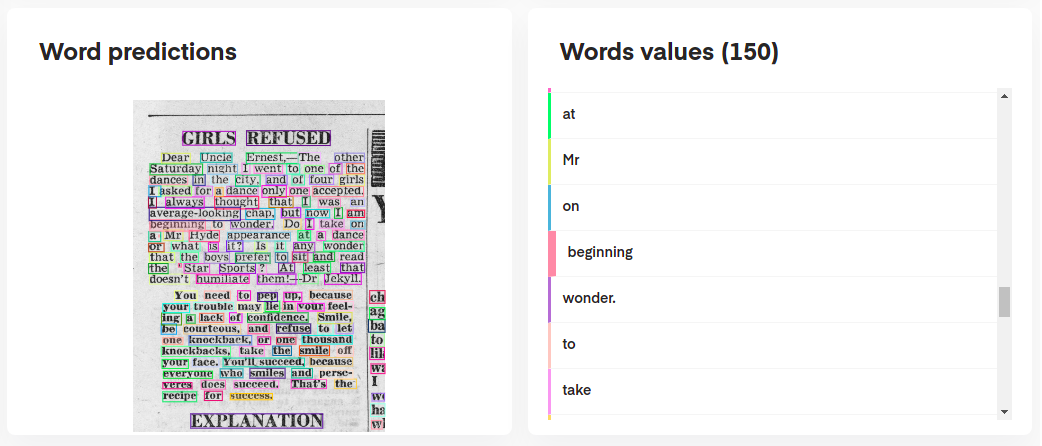
Чтобы интерпретировать прогнозы вашей модели, вы можете визуализировать их интерактивно следующим образом:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
Или даже восстановить первоначальный документ из его прогнозов:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
ocr_predictor возвращает объект Document с вложенной структурой (с Page , Block , Line , Word , Artefact ). Чтобы лучше понять нашу модель документа, проверьте нашу документацию:
Вы также можете экспортировать их в качестве вложенного дикта, более подходящего для формата JSON:
json_output = result . export ()Kie Predictor является более гибким предиктором по сравнению с OCR, поскольку ваша модель обнаружения может обнаружить несколько классов в документе. Например, вы можете иметь модель обнаружения для обнаружения только дат и адресов в документе.
Kie Predictor позволяет использовать детектор с несколькими классами с моделью распознавания и для вас уже настроить весь трубопровод.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Результаты предиктора KIE на страницу находятся в формате словаря, причем каждый ключ представляет имя класса, и его значение являются прогнозами для этого класса.

Python 3.10 (или выше) и PIP необходимы для установки Doctr.
Затем вы можете установить последний выпуск пакета, используя PYPI следующим образом:
pip install python-doctr
️ Обратите внимание, что базовая установка не является автономной, поскольку она не обеспечивает глубокую структуру обучения, которая требуется для запуска пакета.
Мы стараемся свести к минимуму зависимости, специфичные для фреймворта. Вы можете установить сборы, специфичные для фреймворика следующим образом:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Для MacBooks с чипом M1 вам понадобятся дополнительные пакеты или конкретные версии:
В качестве альтернативы, вы можете установить его из Source, который потребует от вас установки GIT. Сначала клонировать репозиторий проекта:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Опять же, если вы предпочитаете избегать риска отсутствия зависимостей, вы можете установить Tensorflow или сборку Pytorch:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Кредиты, где это связано: этот репозиторий внедряет, среди прочего, архитектуры из опубликованных исследовательских работ.
Полная документация по пакетам доступна здесь для подробных спецификаций.
Минимальное демонстрационное приложение предоставляется для игры с нашими сквозными моделями OCR!

Предоставлено? Обнимаю лицо?, Доктр теперь имеет полностью развернутую версию, доступную на пространствах! Проверьте это
Если вы предпочитаете использовать его локально, требуется дополнительная зависимость (стрижка).
pip install -r demo/tf-requirements.txtЗатем запустите приложение в браузере по умолчанию с:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtЗатем запустите приложение в браузере по умолчанию с:
USE_TORCH=1 streamlit run demo/app.pyВместо того, чтобы ваш демонстрация фактически запускает Python, вы бы предпочли запустить все в своем веб -браузере? Проверьте нашу демонстрацию Tensorflow.js, чтобы начать!
Мы предлагаем поддержку контейнеров Docker для легкого тестирования и развертывания. Вот доступные теги Docker ..
Изображения Doctr Docker готовы к графическим процессорам и основаны на CUDA 12.2 . Убедитесь, что ваш хост составляет не менее 12.2 , в противном случае Torch или Tensorflow не сможет инициализировать GPU. Пожалуйста, убедитесь, что Docker настроен на использование вашего GPU.
Чтобы проверить и настроить поддержку GPU для Docker, следуйте инструкциям, представленным в Руководстве по установке контейнера NVIDIA.
Как только Docker настроен на использование графических процессоров, вы можете запустить контейнеры Doctr Docker с поддержкой GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash Изображения Docker для Dectr Следуйте определенной номенклатуре тега: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Вот разбивка структуры тега:
<deps> : tf , torch , tf-viz-html-contrib или torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 или 3.11.8 .<doctr_version> : A Tag> = v0.11.0<YYYY-MM> : например 2014-10Вот примеры различных тегов изображения:
| Ярлык | Описание |
|---|---|
tf-py3.10.13-v0.11.0 | Tensorflow версия 3.10.13 с Doctr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Факел с дополнительными зависимостями Версия 3.11.8 из последнего Commit on main в 2024-10 . |
torch-py3.11.8-2024-10 | Pytorch версия 3.11.8 из последнего Commit on main в 2024-10 . |
Вы также можете создавать изображения Doctr Docker локально на вашем компьютере.
docker build -t doctr . Вы можете указать пользовательские версии Python и версии доктр, используя сборки сборки. Например, чтобы создать изображение доктри с Tensorflow, версию Python 3.9.10 и Doctr Version v0.7.0 , запустите следующую команду:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Пример сценария представлен для простого анализа документации PDF или файла изображения:
python scripts/analyze.py path/to/your/doc.pdf Все аргументы сценария можно проверить с помощью python scripts/analyze.py --help
Хотите интегрировать доктр в свой API? Вот шаблон, который вы можете начать с полностью работающего API с использованием замечательной структуры Fastapi.
Конкретные зависимости необходимы для запуска шаблона API, который вы можете установить следующим образом:
cd api/
pip install poetry
make lock
pip install -r requirements.txtТеперь вы можете запустить свой API на местном уровне:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appВ качестве альтернативы, вы можете запустить тот же сервер на контейнере Docker, если предпочитаете использовать:
PORT=8002 docker-compose up -d --buildВаш API теперь должен работать локально на вашем порту 8002. Доступ к вашей автоматически построенной документации по адресу http: // localhost: 8002/redoc и наслаждайтесь тремя функциональными маршрутами («/обнаружение», «/распознавание», «/ocr», «/kie»). Вот пример с Python для отправки запроса на маршрут OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())Ищете больше иллюстраций функций доктрита? Возможно, вы захотите проверить ноутбуки Jupyter, разработанные, чтобы дать вам более широкий обзор.
Если вы хотите привести этот проект, не стесняйтесь использовать эту ссылку на Bibtex:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Если вы прокрутите в этом разделе, вы, скорее всего, оцените открытый исходный код. Вы хотите расширить диапазон наших поддерживаемых персонажей? Или, может быть, отправка бумаги реализации? Или внести свой вклад в любое другое дело?
Вам повезло, мы собрали короткое руководство (ср. CONTRIBUTING ) для вас, чтобы легко это сделать!
Распределено по лицензии Apache 2.0. Смотрите LICENSE для получения дополнительной информации.


