doctr
v0.10.0
أصبح التعرف على الأحرف البصرية سلسًا ويمكن الوصول إليه لأي شخص ، مدعوم من TensorFlow 2 & Pytorch
ما يمكن أن تتوقعه من هذا المستودع:

يتم تحقيق OCR من طرف إلى طرف في DOCTR باستخدام نهج مرحلتين: الكشف عن النص (توطين الكلمات) ، ثم التعرف على النص (حدد جميع الأحرف في الكلمة). على هذا النحو ، يمكنك تحديد البنية المستخدمة للكشف عن النص ، والتعرف على النص من قائمة التطبيقات المتاحة.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )يمكن تفسير المستندات من PDF أو الصور:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])دعونا نستخدم النموذج الافتراضي المسبق للمثال:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )إذا كنت تستخدم Doctr على المستندات التي تتضمن صفحات متناورة ، أو صفحات ذات اتجاهات مربع متعددة ، فلديك خيارات متعددة للتعامل معها:
إذا كنت تستخدم صفحات المستندات المستقيمة فقط بكلمات مستقيمة (أفقي ، نفس اتجاه القراءة) ، ففكر في تمرير assume_straight_boxes=True إلى OCR_PREDICTOR. سوف يناسب مربعات مستقيمة مباشرة على صفحتك وإرجاع مربعات مستقيمة ، مما يجعلها أسرع الخيار.
إذا كنت تريد أن يخرج المتنبئ صناديق مستقيمة (بغض النظر عن اتجاه صفحاتك ، فسيتم تحويل التوترات النهائية إلى صناديق مستقيمة) ، فأنت بحاجة إلى تمرير export_as_straight_boxes=True في المتنبئ. خلاف ذلك ، إذا assume_straight_pages=False ، فسيعود مربعات محيطة تدوير (يحتمل أن تكون بزاوية 0 درجة).
إذا تم تعيين كلا الخيارين على خطأ ، فإن المتنبئ سوف يلائم دائمًا الصناديق المدورة وإرجاعها.
لتفسير تنبؤات النموذج الخاص بك ، يمكنك تصورها بشكل تفاعلي على النحو التالي:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
أو حتى إعادة بناء الوثيقة الأصلية من تنبؤاتها:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
يقوم ocr_predictor بإرجاع كائن Document بهيكل متداخل (مع Page ، Block ، Line ، Word ، Artefact ). للحصول على فهم أفضل لنموذج المستندات لدينا ، تحقق من وثائقنا:
يمكنك أيضًا تصديرها على أنها قفلة متداخلة ، أكثر ملاءمة لتنسيق JSON:
json_output = result . export ()يعد تنبؤ KIE مؤشرًا أكثر مرونة مقارنةً بـ OCR حيث أن نموذج الكشف الخاص بك يمكنه اكتشاف فئات متعددة في وثيقة. على سبيل المثال ، يمكنك الحصول على نموذج اكتشاف للكشف عن التواريخ والعناوين في وثيقة فقط.
يتيح تنبؤ KIE استخدام الكاشف مع فئات متعددة مع نموذج التعرف وأن يكون لديك خط الأنابيب بالكامل بالفعل.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )تكون نتائج تنبؤ KIE لكل صفحة في تنسيق قاموس مع كل مفتاح يمثل اسم الفصل وقيمته هي تنبؤات لتلك الفئة.

Python 3.10 (أو أعلى) و PIP مطلوبة لتثبيت Doctr.
يمكنك بعد ذلك تثبيت أحدث إصدار من الحزمة باستخدام PYPI على النحو التالي:
pip install python-doctr
️ يرجى ملاحظة أن التثبيت الأساسي ليس مستقلًا ، لأنه لا يوفر إطارًا تعليميًا عميقًا ، وهو أمر مطلوب لتشغيل الحزمة.
نحاول الحفاظ على التبعيات الخاصة بالإطار إلى الحد الأدنى. يمكنك تثبيت بنيات إطار خاصة على النحو التالي:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "بالنسبة إلى MacBooks باستخدام M1 Chip ، ستحتاج إلى بعض الحزم الإضافية أو الإصدارات المحددة:
بدلاً من ذلك ، يمكنك تثبيته من المصدر ، والذي سيتطلب منك تثبيت GIT. أول استنساخ مستودع المشروع:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.مرة أخرى ، إذا كنت تفضل تجنب خطر فقدان التبعيات ، فيمكنك تثبيت TensorFlow أو Bytorch Build:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]الاعتمادات التي يتم استحقاقها: يقوم هذا المستودع بتنفيذ ، من بين أمور أخرى ، من أوراق البحث المنشورة.
تتوفر وثائق الحزمة الكاملة هنا للمواصفات التفصيلية.
يتم توفير تطبيق تجريبي بسيط لك للعب مع نماذج OCR من طرف إلى طرف!

من باب المجاملة؟ Hugging Face؟ ، Dorts لديها الآن نسخة منتشرة بالكامل متوفرة على المساحات! تحقق من ذلك
إذا كنت تفضل استخدامه محليًا ، فهناك تبعية إضافية (STIPELIT) مطلوبة.
pip install -r demo/tf-requirements.txtثم قم بتشغيل تطبيقك في متصفحك الافتراضي مع:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtثم قم بتشغيل تطبيقك في متصفحك الافتراضي مع:
USE_TORCH=1 streamlit run demo/app.pyبدلاً من أن يكون العرض التجريبي الخاص بك يعمل فعليًا على Python ، تفضل تشغيل كل شيء في متصفح الويب الخاص بك؟ تحقق من العرض التوضيحي tensorflow.js للبدء!
نحن نقدم دعم حاوية Docker لسهولة الاختبار والنشر. فيما يلي علامات Docker المتاحة ..
صور Doctr Docker جاهزة GPU ويستند إلى CUDA 12.2 . تأكد من أن مضيفك هو 12.2 على الأقل ، وإلا لن يتمكن Torch أو TensorFlow من تهيئة وحدة معالجة الرسومات. يرجى التأكد من تكوين Docker لاستخدام GPU الخاص بك.
للتحقق من دعم GPU وتكوينه لـ Docker ، يرجى اتباع الإرشادات الواردة في دليل تثبيت مجموعة أدوات NVIDIA Container.
بمجرد تكوين Docker لاستخدام وحدات معالجة الرسومات ، يمكنك تشغيل حاويات DoctR Docker مع دعم GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash تتبع صور Docker لـ DOCTR تسميات علامة محددة: <deps>-py<python_version>-<doctr_version|YYYY-MM> . إليك انهيار بنية العلامة:
<deps> : tf ، torch ، tf-viz-html-contrib أو torch-viz-html-contrib .<python_version> : 3.9.18 ، 3.10.13 أو 3.11.8 .<doctr_version> : علامة> = v0.11.0<YYYY-MM> : على سبيل المثال 2014-10فيما يلي أمثلة لعلامات الصور المختلفة:
| علامة | وصف |
|---|---|
tf-py3.10.13-v0.11.0 | الإصدار TensorFlow 3.10.13 مع Doctr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | الشعلة مع تبعيات إضافية الإصدار 3.11.8 من أحدث الالتزام على main في 2024-10 . |
torch-py3.11.8-2024-10 | إصدار Pytorch 3.11.8 من أحدث الالتزام على main في 2024-10 . |
يمكنك أيضًا إنشاء صور Doctr Docker محليًا على جهاز الكمبيوتر الخاص بك.
docker build -t doctr . يمكنك تحديد إصدارات Python المخصصة وإصدارات Doctr باستخدام وسيطات بناء. على سبيل المثال ، لإنشاء صورة Doctr مع TensorFlow و Python الإصدار 3.9.10 و Doctr Version v0.7.0 ، قم بتشغيل الأمر التالي:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .يتم توفير برنامج نصي مثال لتحليل وثائق بسيط لملف PDF أو ملف الصورة:
python scripts/analyze.py path/to/your/doc.pdf يمكن فحص جميع وسيطات البرنامج النصي باستخدام python scripts/analyze.py --help
هل تبحث عن دمج واجهة برمجة التطبيقات الخاصة بك؟ فيما يلي قالبًا لتبدأ به واجهة برمجة تطبيقات تعمل بالكامل باستخدام إطار عمل Fastapi الرائع.
هناك حاجة إلى تبعيات محددة لتشغيل قالب API ، والذي يمكنك تثبيته على النحو التالي:
cd api/
pip install poetry
make lock
pip install -r requirements.txtيمكنك الآن تشغيل API محليًا:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appبدلاً من ذلك ، يمكنك تشغيل الخادم نفسه على حاوية Docker إذا كنت تفضل استخدام:
PORT=8002 docker-compose up -d --buildيجب أن تعمل واجهة برمجة التطبيقات الخاصة بك الآن محليًا على المنفذ 8002. الوصول إلى وثائقك التي تم إنشاؤها تلقائيًا في http: // localhost: 8002/redoc واستمتع بطرقك الوظيفية الثلاثة ("/detection" ، "/التعرف" ، "/OCR" ، "/Kie"). فيما يلي مثال مع Python لإرسال طلب إلى مسار OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
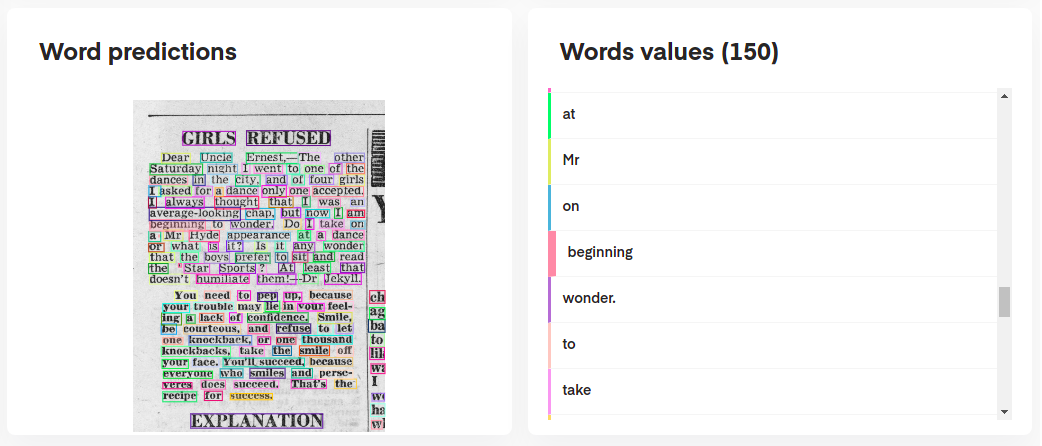
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())هل تبحث عن مزيد من الرسوم التوضيحية لميزات DORTR؟ قد ترغب في التحقق من أجهزة الكمبيوتر المحمولة Jupyter المصممة لتمنحك نظرة عامة أوسع.
إذا كنت ترغب في الاستشهاد بهذا المشروع ، فلا تتردد في استخدام مرجع Bibtex هذا:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}إذا قمت بالتمرير إلى هذا القسم ، فمن المرجح أن تقدر المصدر المفتوح. هل تشعر برغبة في توسيع نطاق شخصياتنا المدعومة؟ أو ربما تقديم تنفيذ الورق؟ أو المساهمة بأي طريقة أخرى؟
أنت محظوظ ، قمنا بتجميع دليل قصير ( CONTRIBUTING ) لكي تفعل ذلك بسهولة!
موزعة تحت رخصة Apache 2.0. انظر LICENSE لمزيد من المعلومات.


