doctr
v0.10.0
光学キャラクター認識は、Tensorflow 2&Pytorchを搭載した、誰でもシームレスでアクセスしやすくなりました
このリポジトリに期待できること:

エンドツーエンドのOCRは、2段階のアプローチを使用して教義で達成されます:テキスト検出(単語のローカライズ)、次にテキスト認識(単語のすべての文字を識別)。そのため、テキスト検出に使用されるアーキテクチャ、および利用可能な実装のリストからテキスト認識のアーキテクチャを選択できます。
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )ドキュメントは、PDFまたは画像から解釈できます。
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])例として、デフォルトの前提型モデルを使用しましょう。
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )回転したページ、または複数のボックスの向きを持つページを含むドキュメントにDoctrを使用する場合は、それを処理するための複数のオプションがあります。
ストレートワード(水平、同じ読み取り方向)でストレートドキュメントページのみを使用する場合は、 assume_straight_boxes=True渡すことを検討してください。それはあなたのページに直接ストレートボックスをフィットし、ストレートボックスを返します。これにより、最速のオプションになります。
予測子にストレートボックスを出力したい場合(ページの方向に関係なく、最終的なローカリゼーションはストレートボックスに変換されます)、 export_as_straight_boxes=True予測子に渡す必要があります。それ以外の場合、 assume_straight_pages=Falseの場合、回転した境界ボックス(潜在的に0°の角度で)を返します。
両方のオプションがfalseに設定されている場合、予測子は常に適合し、回転したボックスを返します。
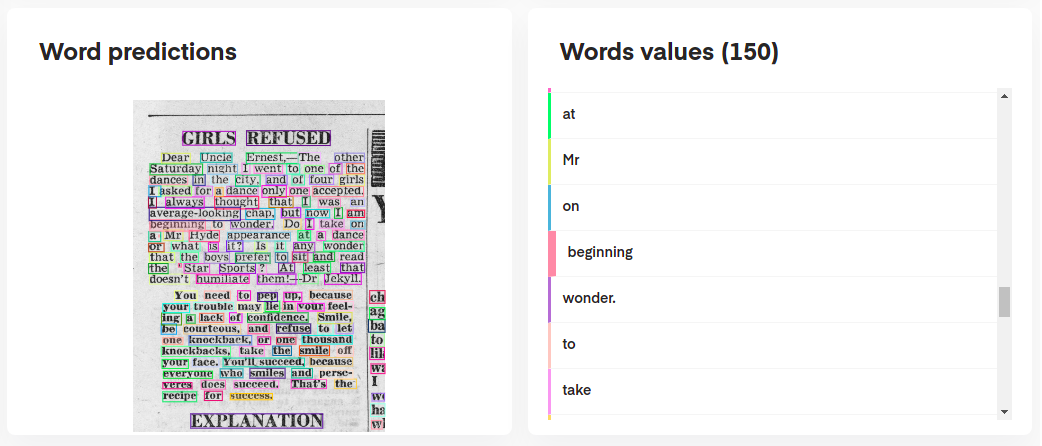
モデルの予測を解釈するには、次のようにモデルをインタラクティブに視覚化できます。
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
または、その予測から元のドキュメントを再構築することもできます。
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
ocr_predictor 、ネストされた構造( Page 、 Block 、 Line 、 Word 、 Artefact )を備えたDocumentオブジェクトを返します。ドキュメントモデルをよりよく理解するには、ドキュメントを確認してください。
また、JSON形式により適したネストされたDICTとしてエクスポートすることもできます。
json_output = result . export ()KIE予測子は、検出モデルがドキュメント内の複数のクラスを検出できるため、OCRと比較してより柔軟な予測因子です。たとえば、ドキュメント内の日付とアドレスを検出するための検出モデルを持つことができます。
KIE予測子は、認識モデルを備えた複数のクラスで検出器を使用し、パイプライン全体をすでにセットアップすることを可能にします。
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )ページごとのKIE予測子の結果は辞書形式で、各キーはクラス名を表しており、そのクラスの予測です。

Python 3.10(またはそれ以上)とPIPは、Doctrを設置するために必要です。
次に、次のようにPYPIを使用してパッケージの最新リリースをインストールできます。
pip install python-doctr
ショ和 基本的なインストールは、パッケージを実行するために必要な深い学習フレームワークを提供しないため、スタンドアロンではありません。
フレームワーク固有の依存関係を最小限に抑えようとします。次のように、フレームワーク固有のビルドをインストールできます。
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "M1チップを備えたMacBookの場合、追加のパッケージまたは特定のバージョンが必要です。
または、ソースからインストールすることもできます。これにより、Gitをインストールする必要があります。最初にプロジェクトリポジトリをクローンします:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.繰り返しますが、依存関係の欠落のリスクを回避したい場合は、TensorflowまたはPytorchビルドをインストールできます。
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]その期限があるクレジット:このリポジトリは、とりわけ公開されている研究論文のアーキテクチャを実装しています。
完全な仕様については、完全なパッケージドキュメントをご覧ください。
エンドツーエンドのOCRモデルで再生できる最小限のデモアプリが提供されています!

礼儀?顔を抱き締める?、Doctrには、スペースで利用可能な完全に展開されたバージョンがあります!それをチェックしてください
ローカルで使用したい場合は、必要な追加の依存関係(retrienlit)があります。
pip install -r demo/tf-requirements.txt次に、デフォルトのブラウザでアプリを実行します。
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txt次に、デフォルトのブラウザでアプリを実行します。
USE_TORCH=1 streamlit run demo/app.pyデモを実際にPythonを実行する代わりに、Webブラウザですべてを実行することをお勧めします。 Tensorflow.jsデモをチェックして始めましょう!
簡単なテストと展開のためのDockerコンテナサポートを提供しています。これが利用可能なDockerタグです。
Doctr Docker画像はGPU対応であり、CUDA 12.2に基づいています。ホストが少なくとも12.2であることを確認してください。そうしないと、TorchまたはTensorflowがGPUを初期化できなくなります。 DockerがGPUを使用するように構成されていることを確認してください。
DockerのGPUサポートを確認および構成するには、NVIDIA Container Toolkitインストールガイドで提供されている指示に従ってください。
DockerがGPUを使用するように構成されたら、GPUサポートを使用してDoctr Dockerコンテナを実行できます。
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bashDockerの画像は<deps>-py<python_version>-<doctr_version|YYYY-MM>特定のタグの命名法に従います。これがタグ構造の内訳です:
<deps> : tf 、 torch 、 tf-viz-html-contribまたはtorch-viz-html-contrib 。<python_version> : 3.9.18または3.11.8 3.10.13<doctr_version> :ag> = v0.11.0<YYYY-MM> :EG 2014-10さまざまな画像タグの例があります。
| タグ | 説明 |
|---|---|
tf-py3.10.13-v0.11.0 | Tensorflowバージョン3.10.13 with doctr v0.11.0 。 |
torch-viz-html-contrib-py3.11.8-2024-10 | 2024-10のmainでの最新のコミットからの追加依存関係を持つトーチバージョン3.11.8 。 |
torch-py3.11.8-2024-10 | Pytorchバージョン3.11.8 、 2024-10にmainの最新のコミットメントから。 |
また、コンピューターにDoctr Docker画像をローカルに作成することもできます。
docker build -t doctr .ビルド引数を使用して、カスタムPythonバージョンとDoctrバージョンを指定できます。たとえば、Tensorflow、Pythonバージョン3.9.10 、およびDoctrバージョンv0.7.0を使用して教義画像を構築するには、次のコマンドを実行します。
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .PDFまたは画像ファイルの簡単なドキュメント分析には、例のスクリプトが提供されています。
python scripts/analyze.py path/to/your/doc.pdfすべてのスクリプト引数はpython scripts/analyze.py --help
DoctrをAPIに統合したいですか? Wonderful Fastapiフレームワークを使用して、完全に機能するAPIを開始するためのテンプレートを次に示します。
APIテンプレートを実行するには、特定の依存関係が必要です。これを次のようにインストールできます。
cd api/
pip install poetry
make lock
pip install -r requirements.txtこれでAPIをローカルに実行できます。
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appまたは、次のことを好む場合は、Dockerコンテナで同じサーバーを実行できます。
PORT=8002 docker-compose up -d --buildAPIはポート8002でローカルに実行されるようになりました。http:// localhost:8002/redocで自動的に構築されたドキュメントにアクセスし、3つの機能ルート(「/検出」、「/認識」、「/ocr」、「/kie」)をお楽しみください。 OCRルートにリクエストを送信するPythonの例を次に示します。
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())教義の特徴のより多くのイラストをお探しですか?より広い概要を提供するように設計されたJupyterノートブックを確認することをお勧めします。
このプロジェクトを引用したい場合は、このbibtexリファレンスをお気軽に使用してください。
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}このセクションにスクロールした場合、オープンソースに感謝します。サポートされているキャラクターの範囲を拡張したいと思いますか?それとも、紙の実装を提出しますか?または他の方法で貢献しますか?
あなたは運が良ければ、私たちはあなたが簡単にそうするために短いガイド( CONTRIBUTING参照)をまとめました!
Apache 2.0ライセンスの下で配布。詳細については、 LICENSE参照してください。


