doctr
v0.10.0
Reconocimiento de caracteres ópticos hecho perfecto y accesible para cualquier persona, alimentado por Tensorflow 2 y Pytorch
Lo que puede esperar de este repositorio:

El OCR de extremo a extremo se logra en Doctr utilizando un enfoque de dos etapas: detección de texto (palabras de localización), luego reconocimiento de texto (identificar todos los caracteres en la palabra). Como tal, puede seleccionar la arquitectura utilizada para la detección de texto, y la para el reconocimiento de texto de la lista de implementaciones disponibles.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Los documentos se pueden interpretar a partir de PDF o imágenes:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Usemos el modelo de petróleo predeterminado para un ejemplo:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Si utiliza doctr en documentos que incluyen páginas rotadas o páginas con múltiples orientaciones de caja, tiene múltiples opciones para manejarlo:
Si solo usa páginas de documentos directos con palabras rectas (horizontal, la misma dirección de lectura), considere pasar assume_straight_boxes=True al OCR_Predictor. Se ajustará directamente las cajas rectas en su página y devolverá las cajas rectas, lo que lo convierte en la opción más rápida.
Si desea que el predictor salga de cuadros rectos (sin importar la orientación de sus páginas, las localizaciones finales se convertirán en cajas rectas), debe pasar export_as_straight_boxes=True en el predictor. De lo contrario, si assume_straight_pages=False , devolverá cuadros delimitadores rotados (potencialmente con un ángulo de 0 °).
Si ambas opciones se establecen en False, el predictor siempre se ajustará y devolverá las cajas rotadas.
Para interpretar las predicciones de su modelo, puede visualizarlas interactivamente de la siguiente manera:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
O incluso reconstruir el documento original de sus predicciones:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
El ocr_predictor devuelve un objeto Document con una estructura anidada (con Page , Block , Line , Word , Artefact ). Para obtener una mejor comprensión de nuestro modelo de documento, consulte nuestra documentación:
También puede exportarlos como un dict anidado, más apropiado para el formato JSON:
json_output = result . export ()El predictor KIE es un predictor más flexible en comparación con el OCR, ya que su modelo de detección puede detectar múltiples clases en un documento. Por ejemplo, puede tener un modelo de detección para detectar solo fechas y direcciones en un documento.
El Predictor de KIE permite usar el detector con múltiples clases con un modelo de reconocimiento y tener toda la tubería ya configurada para usted.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Los resultados del predictor de KIE por página están en un formato de diccionario con cada clave que representa un nombre de clase y su valor son las predicciones para esa clase.

Python 3.10 (o superior) y PIP deben instalar Doctr.
Luego puede instalar la última versión del paquete usando Pypi de la siguiente manera:
pip install python-doctr
️ Tenga en cuenta que la instalación básica no es independiente, ya que no proporciona un marco de aprendizaje profundo, que se requiere para que el paquete se ejecute.
Tratamos de mantener al mínimo dependencias específicas del marco. Puede instalar compilaciones específicas de marco de la siguiente manera:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Para MacBooks con chip M1, necesitará algunos paquetes adicionales o versiones específicas:
Alternativamente, puede instalarlo desde la fuente, lo que requerirá que instale GIT. Primer clon El repositorio del proyecto:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Nuevamente, si prefiere evitar el riesgo de faltar dependencias, puede instalar TensorFlow o Pytorch Build:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Créditos donde se debe: este repositorio está implementando, entre otros, arquitecturas de trabajos de investigación publicados.
La documentación del paquete completo está disponible aquí para especificaciones detalladas.
¡Se proporciona una aplicación de demostración mínima para que juegue con nuestros modelos OCR de extremo a extremo!

Cortesía de? ¡Abrazando la cara?, Doctr ahora tiene una versión completamente implementada disponible en espacios! Échale un vistazo
Si prefiere usarlo localmente, hay una dependencia adicional (optimista) que se requiere.
pip install -r demo/tf-requirements.txtLuego ejecute su aplicación en su navegador predeterminado con:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtLuego ejecute su aplicación en su navegador predeterminado con:
USE_TORCH=1 streamlit run demo/app.pyEn lugar de que su demostración realmente ejecute Python, ¿preferiría ejecutar todo en su navegador web? ¡Mira nuestra demostración de tensorflow.js para comenzar!
Ofrecemos soporte de contenedores Docker para fáciles de prueba e implementación. Aquí están las etiquetas Docker disponibles.
Las imágenes Doctr Docker están listas para GPU y se basan en CUDA 12.2 . Asegúrese de que su anfitrión tenga al menos 12.2 , de lo contrario, la antorcha o la tensorflow no podrán inicializar la GPU. Asegúrese de que Docker esté configurado para usar su GPU.
Para verificar y configurar el soporte de GPU para Docker, siga las instrucciones proporcionadas en la Guía de instalación del kit de herramientas de contenedores NVIDIA.
Una vez que Docker está configurado para usar GPU, puede ejecutar Doctr Docker contenedores con soporte de GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash Las imágenes de Docker para Doctr siguen una nomenclatura de etiqueta específica: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Aquí hay un desglose de la estructura de la etiqueta:
<deps> : tf , torch , tf-viz-html-contrib o torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 o 3.11.8 .<doctr_version> : una etiqueta> = v0.11.0<YYYY-MM> : EG 2014-10Aquí hay ejemplos de diferentes etiquetas de imagen:
| Etiqueta | Descripción |
|---|---|
tf-py3.10.13-v0.11.0 | TensorFlow Versión 3.10.13 con Doctr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Antorcha con dependencias adicionales Versión 3.11.8 de la última confirmación en main en 2024-10 . |
torch-py3.11.8-2024-10 | PYTORCH Versión 3.11.8 de la última confirmación en main en 2024-10 . |
También puede construir imágenes Doctr Docker localmente en su computadora.
docker build -t doctr . Puede especificar versiones personalizadas de Python y versiones de Doctr utilizando argumentos de compilación. Por ejemplo, para construir una imagen de doctr con TensorFlow, Python versión 3.9.10 y Doctr versión v0.7.0 , ejecute el siguiente comando:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Se proporciona un script de ejemplo para un análisis de documentación simple de un PDF o archivo de imagen:
python scripts/analyze.py path/to/your/doc.pdf Todos los argumentos de script se pueden verificar utilizando python scripts/analyze.py --help
¿Buscas integrar doctr en tu API? Aquí hay una plantilla para comenzar con una API completamente en funcionamiento utilizando el maravilloso marco de Fastapi.
Se requieren dependencias específicas para ejecutar la plantilla API, que puede instalar de la siguiente manera:
cd api/
pip install poetry
make lock
pip install -r requirements.txtAhora puede ejecutar su API localmente:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appAlternativamente, puede ejecutar el mismo servidor en un contenedor Docker si prefiere usar:
PORT=8002 docker-compose up -d --buildSu API ahora debería estar ejecutándose localmente en su puerto 8002. Acceda a su documentación construida automáticamente en http: // localhost: 8002/redoc y disfruta de sus tres rutas funcionales ("/detección", "/reconocimiento", "/ocr", "/kie"). Aquí hay un ejemplo con Python para enviar una solicitud a la ruta OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
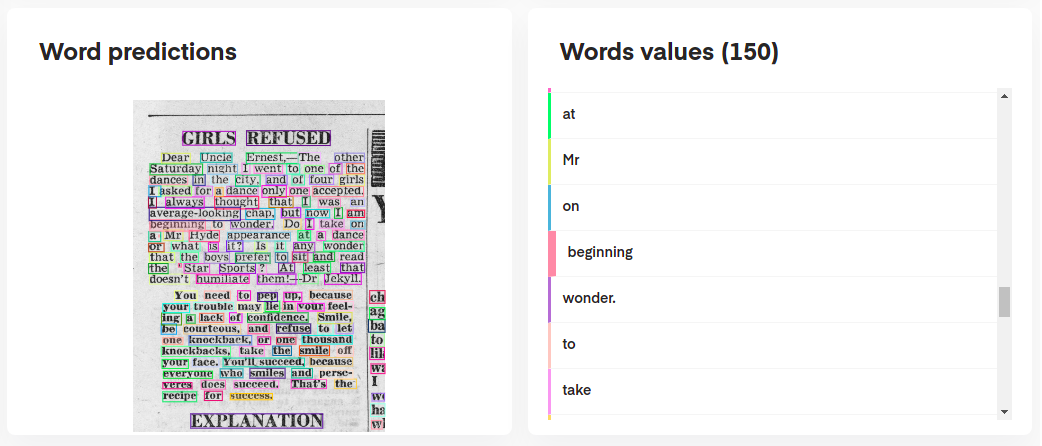
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())¿Busca más ilustraciones de las características de doctr? Es posible que desee consultar los cuadernos Jupyter diseñados para brindarle una descripción más amplia.
Si desea citar este proyecto, no dude en usar esta referencia de Bibtex:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Si se desplaza a esta sección, lo más probable es que aprecie el código abierto. ¿Sientes que extender el rango de nuestros personajes compatibles? ¿O tal vez enviar una implementación en papel? O contribuir de alguna otra manera?
¡Estás de suerte, compilamos una guía corta (cf. CONTRIBUTING ) para que lo hagas fácilmente!
Distribuido bajo la licencia Apache 2.0. Vea LICENSE para más información.


