doctr
v0.10.0
OPTISCHE Charaktererkennung nahtlos und für jeden zugänglich gemacht, angetrieben von TensorFlow 2 & Pytorch
Was Sie von diesem Repository erwarten können:

Die End-to-End-OCR wird in der Doktrin unter Verwendung eines zweistufigen Ansatzes erreicht: Texterkennung (Lokalisierung von Wörtern) und dann Texterkennung (identifizieren Sie alle Zeichen im Wort). Aus diesem Grund können Sie die Architektur auswählen, die zur Erkennung von Textnutzungen verwendet wird, und die für die Texterkennung aus der Liste der verfügbaren Implementierungen.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Dokumente können aus PDF oder Bildern interpretiert werden:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Verwenden wir das Standardmodell für ein Beispiel:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Sollten Sie Doctr für Dokumente verwenden, die gedrehte Seiten oder Seiten mit mehreren Kastenorientierungen enthalten, haben Sie mehrere Optionen, um es zu verarbeiten:
Wenn Sie nur gerade Dokumentseiten mit geraden Wörtern (horizontal, gleiche Lesrichtung) verwenden, sollten Sie das Übergeben assume_straight_boxes=True zum OCR_PREDICTOR verwenden. Es passt direkt gerade Kästchen auf Ihre Seite und kehrt gerade Boxen zurück, was es zur schnellsten Option macht.
Wenn Sie möchten, dass der Prädiktor gerade Boxen ausgibt (unabhängig von der Ausrichtung Ihrer Seiten, werden die endgültigen Lokalisierungen in geraden Kästchen konvertiert), müssen Sie im Prädiktor export_as_straight_boxes=True übergeben. Andernfalls gibt es bei assume_straight_pages=False rotierte Begrenzungsboxen zurück (möglicherweise mit einem Winkel von 0 °).
Wenn beide Optionen auf False eingestellt sind, passt der Prädiktor immer und kehrt gedrehte Kartons zurück.
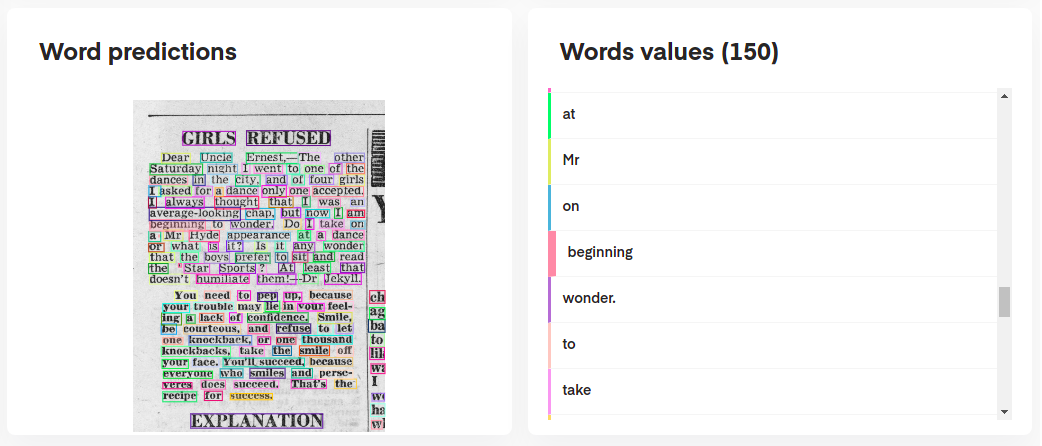
Um die Vorhersagen Ihres Modells zu interpretieren, können Sie sie interaktiv wie folgt visualisieren:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
Oder sogar das Originaldokument aus seinen Vorhersagen wieder aufbauen:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
Der ocr_predictor gibt ein Document mit einer verschachtelten Struktur zurück (mit Page , Block , Line , Word , Artefact ). Um unser Dokumentmodell besser zu verstehen, überprüfen Sie unsere Dokumentation:
Sie können sie auch als verschachteltes Diktat exportieren, das eher für das JSON -Format geeignet ist:
json_output = result . export ()Der KIE -Prädiktor ist ein flexiblerer Prädiktor im Vergleich zu OCR, da Ihr Erkennungsmodell mehrere Klassen in einem Dokument erkennen kann. Beispielsweise können Sie ein Erkennungsmodell haben, um nur Daten und Adressen in einem Dokument zu erkennen.
Der KIE -Prädiktor ermöglicht es, den Detektor mit mehreren Klassen mit einem Erkennungsmodell zu verwenden und die gesamte Pipeline bereits für Sie eingerichtet zu haben.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Die KIE -Prädiktorergebnisse pro Seite befinden sich in einem Wörterbuchformat, wobei jeder Schlüssel einen Klassennamen darstellt, und der Wert sind die Vorhersagen für diese Klasse.

Python 3.10 (oder höher) und PIP sind erforderlich, um Doctr zu installieren.
Sie können dann die neueste Version des Pakets mit PYPI wie folgt installieren:
pip install python-doctr
Euen Bitte beachten Sie, dass die grundlegende Installation nicht eigenständig ist, da sie keinen Deep -Learning -Framework bietet, der für das Paket erforderlich ist.
Wir versuchen, rahmenspezifische Abhängigkeiten auf ein Minimum zu führen. Sie können rahmenspezifische Builds wie folgt installieren:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Für MacBooks mit M1 -Chip benötigen Sie einige zusätzliche Pakete oder bestimmte Versionen:
Alternativ können Sie es aus der Quelle installieren, sodass Sie Git installieren müssen. Erst klonen Sie das Projektrepository:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Wenn Sie es vorziehen, das Risiko fehlender Abhängigkeiten zu vermeiden, können Sie den Tensorflow oder den Pytorch -Build installieren:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Credits, wo es fällig ist: Dieses Repository implementiert unter anderem Architekturen aus veröffentlichten Forschungsarbeiten.
Die vollständige Paketdokumentation finden Sie hier für detaillierte Spezifikationen.
Eine minimale Demo-App wird für Sie bereitgestellt, um mit unseren End-to-End-OCR-Modellen zu spielen!

Mit freundlicher Genehmigung von? Umarmendes Gesicht?, Doctr hat jetzt eine vollständig bereitgestellte Version auf Räumen verfügbar! Hör zu
Wenn Sie es vorziehen, es lokal zu verwenden, ist eine zusätzliche Abhängigkeit (stromlit) erforderlich.
pip install -r demo/tf-requirements.txtFühren Sie dann Ihre App in Ihrem Standardbrowser mit: Aus:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtFühren Sie dann Ihre App in Ihrem Standardbrowser mit: Aus:
USE_TORCH=1 streamlit run demo/app.pyAnstatt Ihre Demo tatsächlich Python auszuführen, würden Sie es vorziehen, alles in Ihrem Webbrowser auszuführen? Schauen Sie sich unsere Demo von TensorFlow.js an, um loszulegen!
Wir bieten Docker -Container -Unterstützung für einfache Tests und Bereitstellung an. Hier sind die verfügbaren Docker -Tags ..
Die Doctr-Docker-Bilder sind GPU-fähig und basieren auf CUDA 12.2 . Stellen Sie sicher, dass Ihr Host mindestens 12.2 ist, andernfalls kann Fackel oder Tensorflow die GPU nicht initialisieren. Bitte stellen Sie sicher, dass Docker für die Verwendung Ihrer GPU konfiguriert ist.
Um die GPU -Unterstützung für Docker zu überprüfen und zu konfigurieren, befolgen Sie die Anweisungen im Installationshandbuch für NVIDIA Container Toolkit.
Sobald Docker für die Verwendung von GPUs konfiguriert ist, können Sie Doctr Docker -Container mit GPU -Unterstützung ausführen:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash Die Docker-Bilder für Doctr folgen einer spezifischen Tag-Nomenklatur: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Hier ist eine Aufschlüsselung der Tag -Struktur:
<deps> : tf , torch , tf-viz-html-contrib oder torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 oder 3.11.8 .<doctr_version> : ein Tag> = v0.11.0<YYYY-MM> : z. B. 2014-10Hier sind Beispiele für verschiedene Bild -Tags:
| Etikett | Beschreibung |
|---|---|
tf-py3.10.13-v0.11.0 | TensorFlow Version 3.10.13 mit Doktr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Torch mit zusätzlichen Abhängigkeiten Version 3.11.8 aus dem neuesten Commit on main in 2024-10 . |
torch-py3.11.8-2024-10 | Pytorch Version 3.11.8 aus dem neuesten Commit on main in 2024-10 . |
Sie können auch Doctr Docker -Bilder lokal auf Ihrem Computer erstellen.
docker build -t doctr . Sie können benutzerdefinierte Python -Versionen und Doktr -Versionen mithilfe von Build -Argumenten angeben. Um beispielsweise ein Doktrimbild mit TensorFlow, Python Version 3.9.10 und Doctr -Version v0.7.0 zu erstellen, führen Sie den folgenden Befehl aus:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Für eine einfache Dokumentationsanalyse einer PDF- oder Bilddatei wird ein Beispiel -Skript vorgesehen:
python scripts/analyze.py path/to/your/doc.pdf Alle Skriptargumente können mit python scripts/analyze.py --help überprüft werden
Möchten Sie Doctr in Ihre API integrieren? Hier ist eine Vorlage, mit der Sie mit einer vollständig funktionierenden API mit dem wunderbaren Fastapi -Framework beginnen können.
Für die Ausführung der API -Vorlage sind spezifische Abhängigkeiten erforderlich, die Sie wie folgt installieren können:
cd api/
pip install poetry
make lock
pip install -r requirements.txtSie können jetzt Ihre API lokal ausführen:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appAlternativ können Sie denselben Server auf einem Docker -Container ausführen, wenn Sie es vorziehen:
PORT=8002 docker-compose up -d --buildIhre API sollte jetzt lokal auf Ihrem Port 8002 ausgeführt werden. Greifen Sie auf Ihre automatisch gebaute Dokumentation unter http: // localhost: 8002/Redoc zu und genießen Sie Ihre drei funktionalen Routen ("/Erkennung", "/Erkennung", "/ocr",/kie "). Hier ist ein Beispiel mit Python, um eine Anfrage an die OCR -Route zu senden:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())Suchen Sie nach weiteren Abbildungen von Dokternfunktionen? Möglicherweise möchten Sie die Jupyter -Notizbücher überprüfen, die Ihnen einen breiteren Überblick geben sollen.
Wenn Sie dieses Projekt zitieren möchten, können Sie diese Bibtex -Referenz verwenden:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Wenn Sie in diesen Abschnitt gescrollt sind, schätzen Sie Open Source höchstwahrscheinlich. Haben Sie Lust, den Bereich unserer unterstützten Charaktere zu erweitern? Oder vielleicht eine Papier -Implementierung einreichen? Oder auf andere Weise beitragen?
Sie haben Glück, wir haben einen kurzen Leitfaden (vgl. CONTRIBUTING ) zusammengestellt, damit Sie dies leicht tun können!
Unter der Apache 2.0 -Lizenz verteilt. Weitere Informationen finden Sie LICENSE .


