doctr
v0.10.0
광학 문자 인식은 Tensorflow 2 & Pytorch로 구동되는 모든 사람이 원활하고 액세스 할 수 있습니다.
이 저장소에서 기대할 수있는 것 :

엔드 투 엔드 OCR은 교리에서 2 단계 접근법 (텍스트 감지) (로컬 화), 텍스트 인식 (단어의 모든 문자 식별)을 사용하여 달성됩니다. 따라서 텍스트 감지에 사용되는 아키텍처와 사용 가능한 구현 목록에서 텍스트 인식을위한 아키텍처를 선택할 수 있습니다.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )문서는 PDF 또는 이미지에서 해석 할 수 있습니다.
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])예를 들어, 기본 사전 처리 된 모델을 사용해 봅시다.
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )회전 페이지가 포함 된 문서 또는 여러 상자 방향이있는 페이지에 교리를 사용하는 경우 다음을 처리 할 수있는 여러 가지 옵션이 있습니다.
직선 단어 (수평, 동일한 읽기 방향)가있는 직선 문서 페이지 만 사용하는 경우 OCR_PREDICTOR에 assume_straight_boxes=True 전달하는 것을 고려하십시오. 페이지의 직선 상자에 직접 맞고 직선 상자를 반환하므로 가장 빠른 옵션이됩니다.
예측 변수가 직선 상자를 출력하려면 (페이지의 방향에 관계없이 최종 로컬라이즈가 직선 상자로 변환됩니다) 예측기에서 export_as_straight_boxes=True 전달해야합니다. 그렇지 않으면 assume_straight_pages=False 인 경우 회전 된 경계 상자를 반환합니다 (잠재적으로 0 °의 각도).
두 옵션이 모두 False로 설정되면 예측 변수는 항상 맞고 회전 된 상자를 반환합니다.
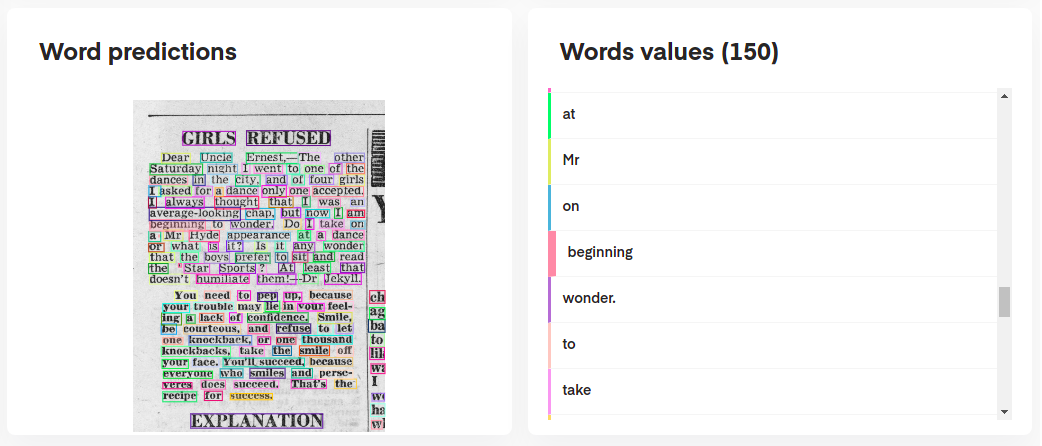
모델의 예측을 해석하려면 다음과 같이 대화식으로 시각화 할 수 있습니다.
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
또는 예측에서 원본 문서를 재구성 할 수도 있습니다.
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
ocr_predictor 중첩 된 구조 ( Page , Block , Line , Word , Artefact 포함)를 가진 Document 개체를 반환합니다. 문서 모델을 더 잘 이해하려면 문서를 확인하십시오.
JSON 형식에 더 적합한 중첩 DITT로 내보낼 수도 있습니다.
json_output = result . export ()KIE 예측 변수는 Detection 모델이 문서에서 여러 클래스를 감지 할 수 있기 때문에 OCR에 비해보다 유연한 예측 변수입니다. 예를 들어, 문서의 날짜와 주소 만 감지하는 감지 모델을 가질 수 있습니다.
KIE Predictor는 인식 모델이있는 여러 클래스와 함께 탐지기를 사용하고 전체 파이프 라인을 이미 설정할 수있게합니다.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )페이지 당 KIE 예측 변수 결과는 각 키가 클래스 이름을 나타내는 사전 형식이며 해당 클래스의 예측입니다.

Python 3.10 (이상) 및 PIP는 교리를 설치해야합니다.
그런 다음 다음과 같이 PYPI를 사용하여 패키지의 최신 릴리스를 설치할 수 있습니다.
pip install python-doctr
켈 기본 설치는 독립형이 아니며, 패키지가 실행되는 데 필요한 딥 러닝 프레임 워크를 제공하지 않기 때문에 독립형이 아닙니다.
우리는 프레임 워크 별 종속성을 최소로 유지하려고 노력합니다. 다음과 같이 프레임 워크 별 빌드를 설치할 수 있습니다.
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "M1 칩이있는 MacBook의 경우 추가 패키지 또는 특정 버전이 필요합니다.
또는 소스에서 설치할 수 있으므로 GIT를 설치해야합니다. 먼저 프로젝트 저장소를 복제하십시오.
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.다시, 누락 된 종속성의 위험을 피하려면 텐서 플로우 또는 Pytorch 빌드를 설치할 수 있습니다.
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]예정인 크레딧 :이 저장소는 무엇보다도 출판 된 연구 논문의 아키텍처를 구현하고 있습니다.
전체 패키지 문서는 자세한 사양을 위해 여기에서 제공됩니다.
최소 데모 앱이 제공됩니다. 엔드 투 엔드 OCR 모델과 함께 플레이 할 수 있습니다!

예의? Hugging Face?, Doctr는 이제 공간에서 사용할 수있는 완전히 배포 된 버전을 가지고 있습니다! 확인하십시오
로컬로 사용하는 것을 선호하는 경우 추가 의존성 (간소)이 필요합니다.
pip install -r demo/tf-requirements.txt그런 다음 기본 브라우저에서 앱을 실행하십시오.
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txt그런 다음 기본 브라우저에서 앱을 실행하십시오.
USE_TORCH=1 streamlit run demo/app.py데모가 실제로 파이썬을 실행하는 대신 웹 브라우저에서 모든 것을 실행하는 것을 선호합니까? 시작하려면 tensorflow.js 데모를 확인하십시오!
쉬운 테스트 및 배포를위한 Docker 컨테이너 지원을 제공합니다. 사용 가능한 Docker 태그는 다음과 같습니다.
교리 도커 이미지는 GPU- 준비이며 Cuda 12.2 기반으로합니다. 호스트가 12.2 이상 인지 확인하십시오. 그렇지 않으면 횃불이나 텐서 플로우가 GPU를 초기화 할 수 없습니다. Docker가 GPU를 사용하도록 구성되어 있는지 확인하십시오.
Docker에 대한 GPU 지원을 확인하고 구성하려면 NVIDIA 컨테이너 툴킷 설치 안내서에 제공된 지침을 따르십시오.
Docker가 GPU를 사용하도록 구성되면 GPU 지원으로 Docker 컨테이너를 실행할 수 있습니다.
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash 교리에 대한 도커 이미지 <deps>-py<python_version>-<doctr_version|YYYY-MM> 특정 태그 명칭을 따릅니다. 태그 구조의 고장은 다음과 같습니다.
<deps> : tf , torch , tf-viz-html-contrib 또는 torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 또는 3.11.8 .<doctr_version> : 태그> = v0.11.0<YYYY-MM> : 예 2014-10다음은 다른 이미지 태그의 예입니다.
| 꼬리표 | 설명 |
|---|---|
tf-py3.10.13-v0.11.0 | 교리 v0.11.0 있는 Tensorflow 버전 3.10.13 . |
torch-viz-html-contrib-py3.11.8-2024-10 | 2024-10 년 main 의 최신 커밋에서 추가 종속성 버전 3.11.8 의 토치. |
torch-py3.11.8-2024-10 | Pytorch 버전 3.11.8 2024-10 년 main 의 최신 커밋. |
컴퓨터에서 로컬로 Docker Images를 구축 할 수도 있습니다.
docker build -t doctr . 빌드 인수를 사용하여 맞춤형 파이썬 버전 및 교리 버전을 지정할 수 있습니다. 예를 들어, Tensorflow, Python 버전 3.9.10 및 Doctr 버전 v0.7.0 을 사용하여 교리 이미지를 작성하려면 다음 명령을 실행하십시오.
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .PDF 또는 이미지 파일의 간단한 문서 분석을 위해 예제 스크립트가 제공됩니다.
python scripts/analyze.py path/to/your/doc.pdf 모든 스크립트 인수는 python scripts/analyze.py --help 사용하여 확인할 수 있습니다.
교리를 API에 통합하려고하십니까? 다음은 멋진 Fastapi 프레임 워크를 사용하여 완전히 작동하는 API로 시작하는 템플릿입니다.
API 템플릿을 실행하려면 특정 종속성이 필요하며 다음과 같이 설치할 수 있습니다.
cd api/
pip install poetry
make lock
pip install -r requirements.txt이제 API를 로컬로 실행할 수 있습니다.
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:app또는 사용하는 것을 선호하는 경우 Docker 컨테이너에서 동일한 서버를 실행할 수 있습니다.
PORT=8002 docker-compose up -d --buildAPI는 이제 포트 8002에서 로컬로 실행해야합니다. http : // localhost : 8002/Redoc에서 자동으로 구축 된 문서에 액세스하고 세 가지 기능 경로 ( "/detection", "/envidition", "/kie", "/kie")를 즐기십시오. 다음은 Python과 함께 OCR 경로에 요청을 보내는 예입니다.
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())교리 특징의 더 많은 삽화를 찾고 계십니까? 더 넓은 개요를 제공하도록 설계된 Jupyter 노트북을 확인할 수 있습니다.
이 프로젝트를 인용하려면이 Bibtex 참조를 자유롭게 사용하십시오.
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}이 섹션으로 스크롤하면 오픈 소스에 감사 할 것입니다. 지원되는 캐릭터의 범위를 확장하고 싶습니까? 아니면 종이 구현을 제출했을까요? 아니면 다른 방법으로 기여합니까?
당신은 운이 좋으며, 우리는 당신이 쉽게 그렇게 할 수 있도록 짧은 가이드 ( CONTRIBUTING )를 편집했습니다!
Apache 2.0 라이센스에 따라 배포되었습니다. 자세한 내용은 LICENSE 참조하십시오.


