doctr
v0.10.0
La reconnaissance optique des caractères rendues transparentes et accessibles à quiconque, alimentées par TensorFlow 2 & Pytorch
Ce que vous pouvez attendre de ce référentiel:

L'OCR de bout en bout est réalisé dans Doctr en utilisant une approche en deux étapes: détection de texte (mots localisants), puis reconnaissance de texte (identifier tous les caractères du mot). En tant que tel, vous pouvez sélectionner l'architecture utilisée pour la détection de texte et celle de la reconnaissance de texte dans la liste des implémentations disponibles.
from doctr . models import ocr_predictor
model = ocr_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )Les documents peuvent être interprétés à partir de PDF ou d'images:
from doctr . io import DocumentFile
# PDF
pdf_doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Image
single_img_doc = DocumentFile . from_images ( "path/to/your/img.jpg" )
# Webpage (requires `weasyprint` to be installed)
webpage_doc = DocumentFile . from_url ( "https://www.yoursite.com" )
# Multiple page images
multi_img_doc = DocumentFile . from_images ([ "path/to/page1.jpg" , "path/to/page2.jpg" ])Utilisons le modèle pré-entraîné par défaut pour un exemple:
from doctr . io import DocumentFile
from doctr . models import ocr_predictor
model = ocr_predictor ( pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )Si vous utilisez Doctr sur des documents qui incluent des pages tournées ou des pages avec plusieurs orientations de boîtes, vous avez plusieurs options pour le gérer:
Si vous n'utilisez que des pages de documents droits avec des mots droits (horizontal, même direction de lecture), envisagez de passer assume_straight_boxes=True à l'OCR_PREDICTOR. Il s'adaptera directement aux boîtes droites de votre page et retournera des boîtes droites, ce qui en fait l'option la plus rapide.
Si vous souhaitez que le prédicteur puisse sortir des boîtes droites (quelle que soit l'orientation de vos pages, les localisations finales seront converties en boîtes droites), vous devez passer export_as_straight_boxes=True dans le prédicteur. Sinon, si assume_straight_pages=False , il renverra les boîtes de délimitation tournées (potentiellement avec un angle de 0 °).
Si les deux options sont définies sur False, le prédicteur s'adaptera toujours et retournera les boîtes tournées.
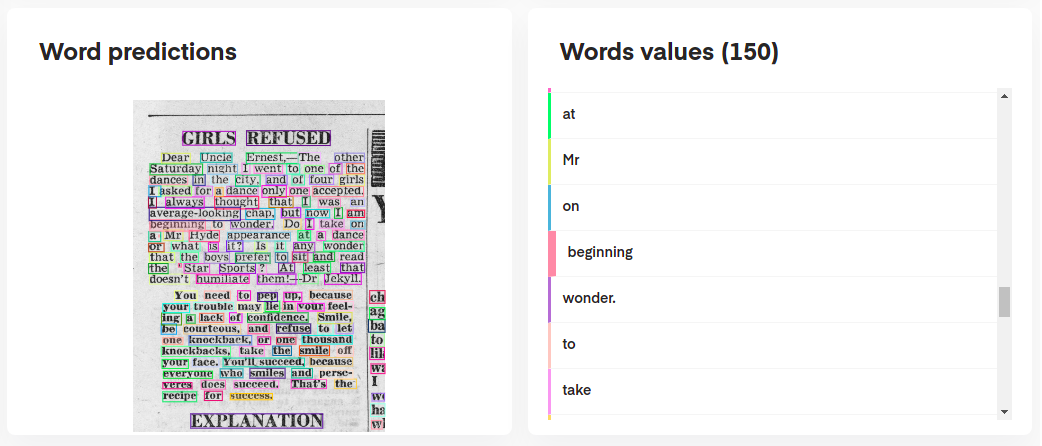
Pour interpréter les prédictions de votre modèle, vous pouvez les visualiser de manière interactive comme suit:
# Display the result (requires matplotlib & mplcursors to be installed)
result . show ()
Ou même reconstruire le document original à partir de ses prédictions:
import matplotlib . pyplot as plt
synthetic_pages = result . synthesize ()
plt . imshow ( synthetic_pages [ 0 ]); plt . axis ( 'off' ); plt . show ()
L' ocr_predictor renvoie un objet Document avec une structure imbriquée (avec Page , Block , Line , Word , Artefact ). Pour mieux comprendre notre modèle de document, consultez notre documentation:
Vous pouvez également les exporter en tant que dict imbriqué, plus approprié pour le format JSON:
json_output = result . export ()Le prédicteur KIE est un prédicteur plus flexible par rapport à l'OCR car votre modèle de détection peut détecter plusieurs classes dans un document. Par exemple, vous pouvez avoir un modèle de détection pour détecter les dates et les adresses, dans un document.
Le prédicteur KIE permet d'utiliser un détecteur avec plusieurs classes avec un modèle de reconnaissance et de faire en sorte que le pipeline entier vous configure déjà.
from doctr . io import DocumentFile
from doctr . models import kie_predictor
# Model
model = kie_predictor ( det_arch = 'db_resnet50' , reco_arch = 'crnn_vgg16_bn' , pretrained = True )
# PDF
doc = DocumentFile . from_pdf ( "path/to/your/doc.pdf" )
# Analyze
result = model ( doc )
predictions = result . pages [ 0 ]. predictions
for class_name in predictions . keys ():
list_predictions = predictions [ class_name ]
for prediction in list_predictions :
print ( f"Prediction for { class_name } : { prediction } " )Les résultats des prédicteurs Kie par page sont dans un format de dictionnaire avec chaque clé représentant un nom de classe et sa valeur est les prédictions de cette classe.

Python 3.10 (ou plus) et PIP sont nécessaires pour installer Doctr.
Vous pouvez ensuite installer la dernière version du package à l'aide de PYPI comme suit:
pip install python-doctr
️ Veuillez noter que l'installation de base n'est pas autonome, car elle ne fournit pas de cadre d'apprentissage en profondeur, qui est requis pour que le package s'exécute.
Nous essayons de maintenir au minimum des dépendances spécifiques au cadre. Vous pouvez installer des versions spécifiques au framework comme suit:
# for TensorFlow
pip install " python-doctr[tf] "
# for PyTorch
pip install " python-doctr[torch] "
# optional dependencies for visualization, html, and contrib modules can be installed as follows:
pip install " python-doctr[torch,viz,html,contib] "Pour les MacBooks avec la puce M1, vous aurez besoin de packages supplémentaires ou de versions spécifiques:
Alternativement, vous pouvez l'installer à partir de Source, qui vous obligera à installer GIT. Clone d'abord le référentiel du projet:
git clone https://github.com/mindee/doctr.git
pip install -e doctr/.Encore une fois, si vous préférez éviter le risque de dépendances manquantes, vous pouvez installer TensorFlow ou la construction de pytorch:
# for TensorFlow
pip install -e doctr/.[tf]
# for PyTorch
pip install -e doctr/.[torch]Crédits où il est dû: ce référentiel met en œuvre, entre autres, des architectures des articles de recherche publiés.
La documentation complète du package est disponible ici pour des spécifications détaillées.
Une application de démonstration minimale est fournie à jouer avec nos modèles OCR de bout en bout!

Avec l'aimable autorisation de? Face étreinte?, Doctr a maintenant une version entièrement déployée disponible sur les espaces! Vérifiez-le
Si vous préférez l'utiliser localement, il y a une dépendance supplémentaire (rationalisation) qui est nécessaire.
pip install -r demo/tf-requirements.txtEnsuite, exécutez votre application dans votre navigateur par défaut:
USE_TF=1 streamlit run demo/app.pypip install -r demo/pt-requirements.txtEnsuite, exécutez votre application dans votre navigateur par défaut:
USE_TORCH=1 streamlit run demo/app.pyAu lieu d'avoir votre démo en cours d'exécution Python, vous préféreriez tout exécuter dans votre navigateur Web? Découvrez notre démo Tensorflow.js pour commencer!
Nous offrons une prise en charge des conteneurs Docker pour des tests et un déploiement faciles. Voici les balises Docker disponibles.
Les images Doctr Docker sont pratiquées par GPU et basées sur CUDA 12.2 . Assurez-vous que votre hôte est au moins 12.2 , sinon la torche ou Tensorflow ne pourra pas initialiser le GPU. Veuillez vous assurer que Docker est configuré pour utiliser votre GPU.
Pour vérifier et configurer la prise en charge du GPU pour Docker, veuillez suivre les instructions fournies dans le Guide d'installation de la boîte à outils Container NVIDIA.
Une fois que Docker est configuré pour utiliser les GPU, vous pouvez exécuter Doctr Docker Contaters avec le support GPU:
docker run -it --gpus all ghcr.io/mindee/doctr:torch-py3.9.18-2024-10 bash Les images Docker pour Doctr suivent une nomenclature spécifique: <deps>-py<python_version>-<doctr_version|YYYY-MM> . Voici une ventilation de la structure de tag:
<deps> : tf , torch , tf-viz-html-contrib ou torch-viz-html-contrib .<python_version> : 3.9.18 , 3.10.13 ou 3.11.8 .<doctr_version> : une balise> = v0.11.0<YYYY-MM> : par exemple 2014-10Voici des exemples de différentes balises d'image:
| Étiqueter | Description |
|---|---|
tf-py3.10.13-v0.11.0 | TENSORFLOW Version 3.10.13 avec Doctr v0.11.0 . |
torch-viz-html-contrib-py3.11.8-2024-10 | Torch avec dépendances supplémentaires version 3.11.8 du dernier engagement sur main en 2024-10 . |
torch-py3.11.8-2024-10 | Pytorch version 3.11.8 de la dernière validation sur main en 2024-10 . |
Vous pouvez également créer des images Doctr Docker localement sur votre ordinateur.
docker build -t doctr . Vous pouvez spécifier des versions Python personnalisées et des versions Doctr à l'aide d'arguments de construction. Par exemple, pour créer une image Doctr avec TensorFlow, Python version 3.9.10 et Doctr Version v0.7.0 , exécutez la commande suivante:
docker build -t doctr --build-arg FRAMEWORK=tf --build-arg PYTHON_VERSION=3.9.10 --build-arg DOCTR_VERSION=v0.7.0 .Un exemple de script est fourni pour une analyse de documentation simple d'un pdf ou d'un fichier image:
python scripts/analyze.py path/to/your/doc.pdf Tous les arguments de script peuvent être vérifiés à l'aide python scripts/analyze.py --help
Vous cherchez à intégrer Doctr dans votre API? Voici un modèle pour vous aider à démarrer avec une API entièrement fonctionnelle en utilisant le merveilleux framework Fastapi.
Des dépendances spécifiques sont nécessaires pour exécuter le modèle API, que vous pouvez installer comme suit:
cd api/
pip install poetry
make lock
pip install -r requirements.txtVous pouvez maintenant exécuter votre API localement:
uvicorn --reload --workers 1 --host 0.0.0.0 --port=8002 --app-dir api/ app.main:appAlternativement, vous pouvez exécuter le même serveur sur un conteneur Docker si vous préférez utiliser:
PORT=8002 docker-compose up -d --buildVotre API devrait maintenant s'exécuter localement sur votre port 8002. Accédez à votre documentation constante automatiquement sur http: // localhost: 8002 / redoc et profitez de vos trois itinéraires fonctionnels ("/ détection", "/ reconnaissance", "/ ocr", "/ kie"). Voici un exemple avec Python pour envoyer une demande à l'itinéraire OCR:
import requests
params = { "det_arch" : "db_resnet50" , "reco_arch" : "crnn_vgg16_bn" }
with open ( '/path/to/your/doc.jpg' , 'rb' ) as f :
files = [ # application/pdf, image/jpeg, image/png supported
( "files" , ( "doc.jpg" , f . read (), "image/jpeg" )),
]
print ( requests . post ( "http://localhost:8080/ocr" , params = params , files = files ). json ())Vous cherchez plus d'illustrations des fonctionnalités Doctr? Vous voudrez peut-être vérifier les ordinateurs portables Jupyter conçus pour vous donner un aperçu plus large.
Si vous souhaitez citer ce projet, n'hésitez pas à utiliser cette référence Bibtex:
@misc { doctr2021 ,
title = { docTR: Document Text Recognition } ,
author = { Mindee } ,
year = { 2021 } ,
publisher = { GitHub } ,
howpublished = { url{https://github.com/mindee/doctr} }
}Si vous avez fait défiler vers le haut de cette section, vous appréciez probablement l'open source. Avez-vous envie d'étendre la gamme de nos personnages pris en charge? Ou peut-être soumettre une mise en œuvre d'un article? Ou contribuer d'une autre manière?
Vous avez de la chance, nous avons compilé un court guide (cf. CONTRIBUTING ) pour que vous le fassiez facilement!
Distribué sous la licence Apache 2.0. Voir LICENSE pour plus d'informations.


