vit explain
1.0.0
该存储库实现了视觉变压器中解释性的方法。
另请参见https://jacobgil.github.io/deeplearning/vision-transformer-ecplainability
注意推出。
特定于类的解释性的梯度注意力推出。这是我们试图进一步建立并改善注意力推广的尝试。
TBD注意力流正在进行中。
包括一些调整和技巧以使其正常工作:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
如果未指定category_index,将使用注意力推广,否则将使用梯度注意力推出。
请注意,默认情况下,这使用了训练数据效率图像变压器的“微小”模型,并通过托管在Torch Hub上的注意力进行蒸馏。
| 图像 | 香草注意推广 | 使用dost_ratio+最大融合 |
|---|---|---|
 |  |  |
 |  |  |
 |  | 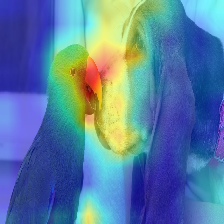 |
 |  |  |
变压器中流动的注意力沿着属于不同类别的信息传递。渐变推出使我们可以看到网络的关注位置,但是它没有告诉我们是否最终使用这些位置进行最终分类。
我们可以将注意力乘以目标类输出的梯度,并在注意力头(同时掩盖负面注意力)中的平均值,以保持对目标类别(或类别)的注意力。




--discard_ratio <value between 0 and 1>
通过保持最强的关注来消除噪音。
不同值的结果:


注意力推广方法表明,将平均注意力吸引到注意力方面,
但是,皇帝看起来像是采用最低值或最大值与 - discard_ratio相结合,效果更好。
--head_fusion <mean, min or max>
| 图像 | 平均融合 | 最小融合 |
|---|---|---|
| |  |
量化变压器的注意力流动
Timm:Pytorch中的大量模型,尤其是Vision Transformer实施
图像值得16x16单词:用于大规模图像识别的变压器
https://github.com/jeonsworld/vit-pytorch的荣誉是一个很好的起点。
pip install timm


