vit explain
1.0.0
هذا المستودع ينفذ طرقًا للشرح في محولات الرؤية.
انظر أيضًا https://jacobgil.github.io/deeplearning/vision-transformer-explainability
انتباه انتباه.
انتباه الانتباه التدرج لتفسير الطبقة المحددة. هذه هي محاولتنا لمزيد من البناء على بدء تشغيل الانتباه وتحسينه.
تدفق الانتباه TBD هو العمل قيد التقدم.
يتضمن بعض التعديلات والحيل لجعلها تعمل:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
إذا لم يتم تحديد الفئة _index ، فسيتم استخدام انتباه الانتباه ، وإلا سيتم استخدام انتباه الانتباه.
لاحظ أنه بشكل افتراضي ، يستخدم هذا النموذج "الصغير" من تدريب محولات الصور الموفرة للبيانات والتقطير من خلال الاهتمام المستضاف على مركز الشعلة.
| صورة | انتباه الفانيليا | مع Discard_ratio+Max Fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  | 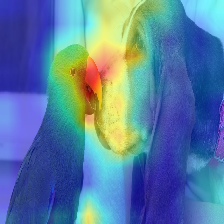 |
 |  |  |
يمر الاهتمام الذي يتدفق في المحول على طول المعلومات التي تنتمي إلى فصول مختلفة. يتيح لنا Rradient Out نرى المواقع التي توليها الشبكة اهتمامًا أيضًا ، لكنها لا تخبرنا شيئًا ما إذا انتهى الأمر باستخدام تلك المواقع للتصنيف النهائي.
يمكننا مضاعفة الانتباه مع التدرج من ناتج الطبقة المستهدفة ، ونأخذ المتوسط بين رؤساء الانتباه (مع إخفاء الاهتمام السلبي) للحفاظ على الاهتمام فقط الذي يساهم في الفئة المستهدفة (أو الفئات).




--discard_ratio <value between 0 and 1>
يزيل الضوضاء عن طريق الحفاظ على أقوى الاهتمام.
نتائج لقيم مختلفة:


تقترح طريقة انتباه الانتباه أخذ متوسط الاهتمام برؤوس الاهتمام ،
لكن يبدو أن أخذ القيمة الدنيا ، أو الحد الأقصى لقيمة -discard_ratio ، يعمل بشكل أفضل.
--head_fusion <mean, min or max>
| صورة | يعني الانصهار | مين اندماج |
|---|---|---|
| |  |
قياس تدفق الانتباه في المحولات
TIMM: مجموعة رائعة من النماذج في Pytorch وخاصة تنفيذ محول الرؤية
الصورة تستحق 16 × 16 كلمة: محولات للتعرف على الصور على نطاق واسع
ائتمان https://github.com/jeonsworld/vit-pytorch لكونه نقطة انطلاق جيدة.
pip install timm


