vit explain
1.0.0
このリポジトリは、視覚変圧器における説明可能性の方法を実装しています。
https://jacobgil.github.io/deeplearning/vision-transformer-explainabilityも参照してください
注意ロールアウト。
クラス固有の説明可能性の勾配注意ロールアウト。これは、注意の展開をさらに構築し、改善する試みです。
TBD注意フローは進行中です。
それを機能させるためのいくつかの微調整とトリックが含まれています:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Category_indexが指定されていない場合、注意ロールアウトが使用されます。
デフォルトでは、これは、トーチハブでホストされている注意を伴うデータ効率の高い画像変圧器と蒸留のトレーニングから「小さな」モデルを使用していることに注意してください。
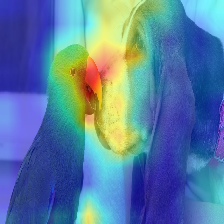
| 画像 | バニラの注意ロールアウト | discard_ratio+max fusionを使用 |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
 |  |  |
トランスに流れる注意は、異なるクラスに属する情報に沿って通過します。 Gradientロールアウトすると、ネットワークがどの場所に注意を払ったかを確認できますが、最終分類のためにそれらの場所を使用することになったかどうかについては何もわかりません。
注意にターゲットクラスの出力の勾配を掛け、注意ヘッドの平均を(否定的な注意を引く一方で)ターゲットカテゴリ(またはカテゴリ)に寄与する注意のみを維持することができます。




--discard_ratio <value between 0 and 1>
最も強い注意を払ってノイズを削除します。
異なる値の結果:


注意の展開方法は、注意を引く平均的な注意を引くことを示唆しています、
しかし、即時は最小値、または-discard_ratioと組み合わされた最大値を取るように見えます。
--head_fusion <mean, min or max>
| 画像 | 平均融合 | Min Fusion |
|---|---|---|
| |  |
トランスの注意の流れを定量化します
TIMM:Pytorchのモデルの素晴らしいコレクション、特にVision Transformerの実装
画像は16x16の価値があります:大規模な画像認識のための変圧器
https://github.com/jeonsworld/vit-pytorchのクレジットは、良い出発点であるためです。
pip install timm


