vit explain
1.0.0
Ce référentiel met en œuvre des méthodes d'explication dans les transformateurs de vision.
Voir aussi https://jacobgil.github.io/deeplearning/vision-transformateur-explainibilité
Déploiement de l'attention.
Déploration de l'attention du gradient pour l'explication spécifique de la classe. Il s'agit de notre tentative de s'appuyer sur et d'améliorer le déploiement de l'attention.
Le flux d'attention TBD est un travail en cours.
Comprend quelques ajustements et astuces pour le faire fonctionner:
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Si category_index n'est pas spécifié, le déploiement de l'attention sera utilisé, sinon le déploiement d'attention du gradient sera utilisé.
Notez que par défaut, cela utilise le modèle «minuscule» de la formation des transformateurs d'image économes en matière de données et de la distillation par l'attention hébergée sur Torch Hub.
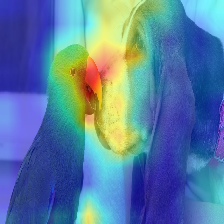
| Image | Déploiement de l'attention de la vanille | Avec Discard_Ratio + Max Fusion |
|---|---|---|
 |  |  |
 |  |  |
 |  |  |
 |  |  |
L'attention qui coule dans le transformateur transmet les informations appartenant à différentes classes. Le déploiement du gradient nous permet de voir quels emplacements le réseau a également prêté attention, mais il ne nous dit rien de s'il a fini par utiliser ces emplacements pour la classification finale.
Nous pouvons multiplier l'attention avec le gradient de la sortie de la classe cible, et prendre la moyenne parmi les têtes d'attention (tout en masquant les attentions négatives) pour ne garder que l'attention qui contribue à la catégorie cible (ou catégories).




--discard_ratio <value between 0 and 1>
Supprime le bruit en gardant les attentions les plus fortes.
Résultats pour différentes valeurs:


La méthode de déploiement de l'attention suggère de prendre l'attention moyenne à l'écart des têtes d'attention,
Mais empiriquement, il semble que prendre la valeur minimale, ou la valeur maximale combinée avec --discard_ratio, fonctionne mieux.
--head_fusion <mean, min or max>
| Image | Fusion moyenne | Fusion min |
|---|---|---|
| |  |
Quantifier le flux d'attention dans les transformateurs
TIMM: Une grande collection de modèles à Pytorch et surtout l'implémentation du transformateur de vision
Une image vaut 16x16 mots: Transformers pour la reconnaissance d'image à grande échelle
Crédit pour https://github.com/jeonsworld/vit-pytorch pour être un bon point de départ.
pip install timm


