vit explain
1.0.0
이 저장소는 Vision Transformers의 설명을위한 방법을 구현합니다.
https://jacobgil.github.io/deeplearning/vision-transformer-explainability도 참조하십시오
주의 롤아웃.
클래스 특정 설명에 대한 그라디언트주의 롤아웃. 이것이 우리의주의 롤아웃을 더욱 구축하고 개선하려는 우리의 시도입니다.
TBD주의 흐름은 진행 중입니다.
작동하기위한 약간의 조정과 트릭이 포함되어 있습니다.
from vit_grad_rollout import VITAttentionGradRollout
model = torch . hub . load ( 'facebookresearch/deit:main' ,
'deit_tiny_patch16_224' , pretrained = True )
grad_rollout = VITAttentionGradRollout ( model , discard_ratio = 0.9 , head_fusion = 'max' )
mask = grad_rollout ( input_tensor , category_index = 243 ) python vit_explain.py --image_path <image path> --head_fusion <mean, min or max> --discard_ratio <number between 0 and 1> --category_index <category_index>
Category_Index가 지정되지 않으면주의 롤아웃이 사용됩니다. 그렇지 않으면 그라디언트주의 롤아웃이 사용됩니다.
기본적으로 이것은 Torch Hub에서 호스팅 된주의를 통해 교육 데이터 효율적인 이미지 변압기 및 증류의 '작은'모델을 사용합니다.
| 영상 | 바닐라주의 롤아웃 | Discard_ratio+Max Fusion과 함께 |
|---|---|---|
 |  |  |
 |  |  |
 |  | 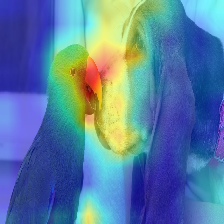 |
 |  |  |
변압기에서 흐르는 관심은 다른 클래스에 속하는 정보를 따라 전달됩니다. 그라디언트 롤아웃을 사용하면 네트워크가 어떤 위치에주의를 기울 였는지 확인할 수 있지만 최종 분류를 위해 해당 위치를 사용하게 된 경우에 대해서는 아무 말도하지 않습니다.
우리는 대상 클래스 출력의 기울기에주의를 곱할 수 있으며, 목표 범주 (또는 카테고리)에 기여하는주의 만 유지하기 위해주의 헤드 (부정적인 관심을 가리는 동안) 중 평균을 취할 수 있습니다.




--discard_ratio <value between 0 and 1>
가장 강력한 관심을 유지하여 소음을 제거합니다.
다른 값에 대한 결과 :


주의 롤아웃 방법은 평균주의를 끌고주의를 끌고 있음을 시사합니다.
그러나 삼각적으로 최소 값을 취하거나 -discard_ratio와 결합 된 최대 값이 더 잘 작동하는 것처럼 보입니다.
--head_fusion <mean, min or max>
| 영상 | 평균 융합 | 최소 퓨전 |
|---|---|---|
| |  |
변압기에서주의 흐름을 정량화합니다
TIMM : Pytorch의 훌륭한 모델, 특히 Vision Transformer 구현 모음
이미지는 16x16의 가치가 있습니다. 단어 : 이미지 인식을위한 변압기 규모
좋은 출발점이 된 것에 대한 https://github.com/jeonsworld/vit-pytorch의 크레딧.
pip install timm


